1.OSI �� TCP/IP����ֲ�ģ��
1.1 OSI�߲�ģ��
OSI �߲�ģ�� �ǹ��ʱ�����֯���һ������ֲ�ģ��,�����ṹ�Լ�ÿһ���ṩ�Ĺ�������ͼ��ʾ
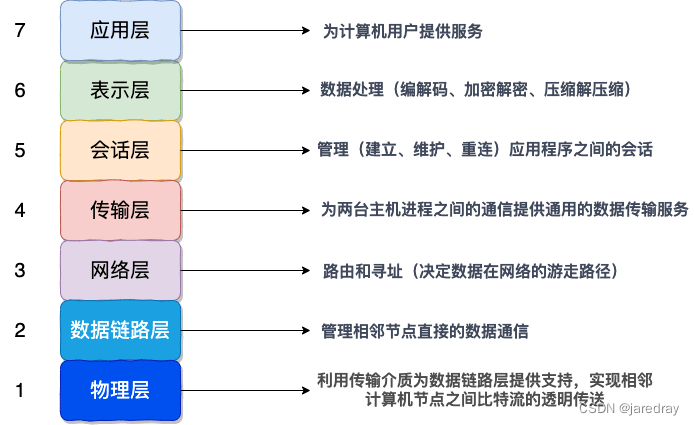
ÿһ�㶼רע��һ������,����ÿһ�㶼��Ҫʹ����һ���ṩ�Ĺ��ܱ��紫�����Ҫʹ��������ṩ��·�ɺ�Ѱַ����,����������֪�������ݴ��䵽����ȥ��
OSI ���߲���ϵ�ṹ�������,����Ҳ������,�������Ƚϸ��Ӷ��Ҳ�ʵ��,������Щ�����ڶ�������ظ����֡�
����������ʵ��ͼ:
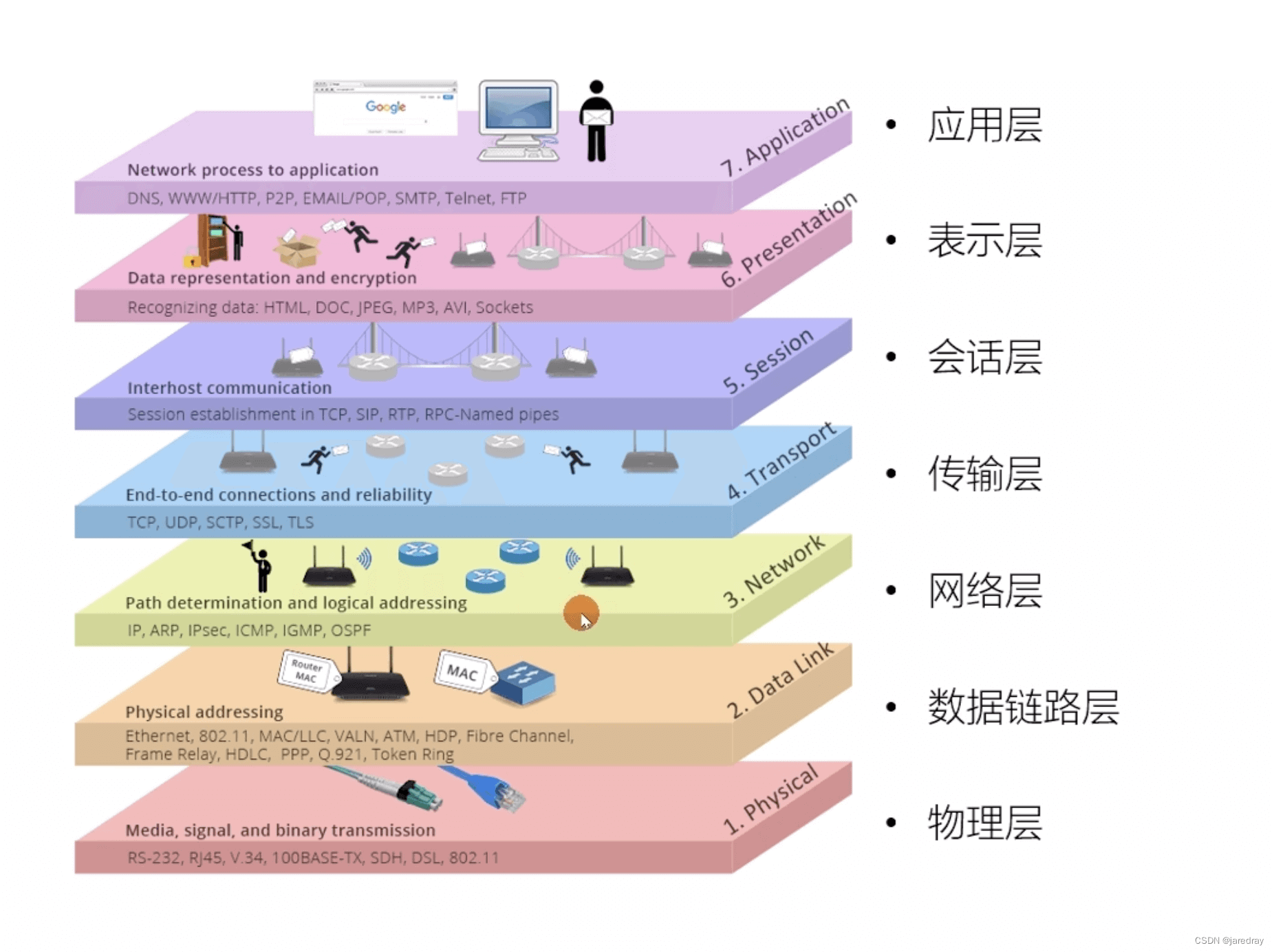
1.2 TCP/IP �IJ�ģ��
TCP/IP �IJ�ģ�� ��Ŀǰ���㷺���õ�һ��ģ��,���ǿ��Խ� TCP / IP ģ�Ϳ����� OSI �߲�ģ�͵ľ���汾,������ 4 �����:
- Ӧ�ò�
- �����
- �����
- ����ӿڲ�
2. Ӧ�ò�
Ӧ�ò�λ�ڴ����֮��,��Ҫ�ṩ�����ն��豸�ϵ�Ӧ�ó���֮����Ϣ�����ķ���,����������Ϣ�����ĸ�ʽ,��Ϣ�ύ����һ�㴫��������䡣 ���ǰ�Ӧ�ò㽻�������ݵ�Ԫ��Ϊ���ġ�

Ӧ�ò�Э�鶨��������ͨ�Ź���,���ڲ�ͬ������Ӧ����Ҫ��ͬ��Ӧ�ò�Э�顣�ڻ�������Ӧ�ò�Э��ܶ�,��֧�� Web Ӧ�õ� HTTP Э��,֧�ֵ����ʼ��� SMTP Э��ȵȡ�

2.1 HTTP:���ı�����Э��
HTTP:���ı�����Э��,��Ҫ��Ϊ Web ������� Web ������֮���ͨ�Ŷ���Ƶġ�������ʹ������������ҳ��ʱ��,������ҳ����ͨ�� HTTP ������м��ص�,������������ͼ��ʾ��

HTTP Э�ǻ��� TCPЭ��,���� HTTP ����֮ǰ����Ҫ���� TCP ����Ҳ����Ҫ���� 3 �����֡�Ŀǰʹ�õ� HTTP Э��ֶ��� 1.1���� 1.1 ��Э������,Ĭ���ǿ����� Keep-Alive ��,�����Ļ����������ӾͿ����ڶ�������б������ˡ�
����, HTTP Э���ǡ���״̬����Э��,������¼�ͻ����û���״̬,һ�����Ƕ���ͨ�� Session ����¼�ͻ����û���״̬��
2.2 SMTP:���ʼ�����(����)Э��
SMTP:���ʼ�����(����)Э��, ���� TCP Э��,�������͵����ʼ���
ע��??:�����ʼ���Э�鲻�� SMTP ���� POP3 Э�顣
�����ʼ��ķ�����?
�����ҵ������ǡ�dabai@cszhinan.com��,��Ҫ��xiaoma@qq.com�������ʼ�,�������̿��Լ�Ϊ���漸��:
- ͨ�� SMTP Э��,�ҽ���д�õ��ʼ�����163���������(�ʾ�)��
- 163��������������ҷ��͵�������qq����,Ȼ����ʹ�� SMTPЭ�齫�ҵ��ʼ�ת���� qq�����������
- qq��������������ʼ�֮���֪ͨ����Ϊ��xiaoma@qq.com�����û������ʼ�,Ȼ���û���ͨ�� POP3/IMAP Э�齫�ʼ�ȡ����
����ж��������������ڵ�?
����SMTP�������:
- ��������������Ӧ�� SMTP ��������ַ
- �������������������
- ���ӳɹ���������Ҫ��֤�����䷢���ʼ�
- ���ݷ��ؽ���ж������ַ����ʵ��
2.3 POP3/IMAP:�ʼ����յ�Э��
������Э��û��Ҫ��������,ֻ��Ҫ�˽� POP3 �� IMAP ���߶��Ǹ����ʼ����յ�Э�鼴�ɡ�����,��Ҫע�ⲻҪ�������ߺ� SMTP Э�������ˡ�SMTP Э��ֻ�����ʼ��ķ���,����������յ�Э����POP3/IMAP��
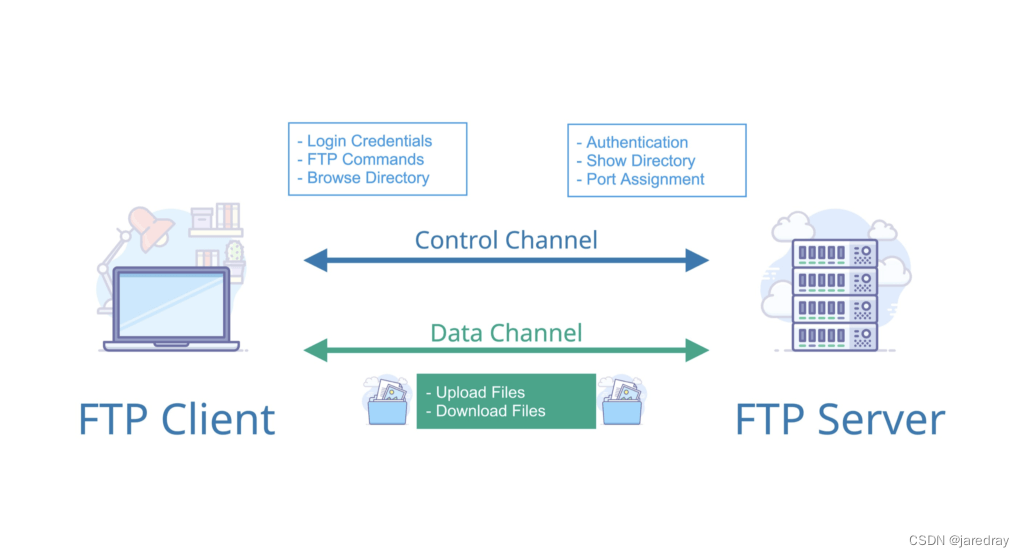
2.4 FTP:�ļ�����Э��
FTP Э�� ��Ҫ�ṩ�ļ��������,���� TCP ʵ�ֿɿ��Ĵ��䡣ʹ�� FTP �����ļ��ĺô��ǿ������β���ϵͳ���ļ��洢��ʽ��
FTP �ǻ��ڿͻ���������(C/S)ģ�Ͷ���Ƶ�,�ڿͻ����� FTP ������֮�佨���������ӡ�FTP �Ķ��ص�����ͬʱҲ���������ͻ��������������IJ�ͬ�������������̨ͨ�ŵ�����֮��ʹ�������� TCP ����(�����ͻ�������Ӧ�ó���һ��ֻ��һ�� TCP ����):
- ��������:���ڴ��Ϳ�����Ϣ(�������Ӧ)
- ��������:�������ݴ���;
���ֽ���������ݷֿ����͵�˼��������� FTP ��Ч�ʡ�
2.5 Telnet:Զ�̵�½Э��
Telnet Э�� ͨ��һ���ն˵�½������������,�����ڿɿ��Ĵ���Э�� TCP ֮�ϡ�Telnet Э������ȱ��֮һ����������(�����û���������)����������ʽ����,����DZ�ڵİ�ȫ���ա������Ϊʲô������ʹ��Telnet����һ�ֳ�ΪSSH�ķdz���ȫ��Э����ȡ������Ҫԭ��
2.6 SSH:��ȫ�����紫��Э��
SSH( Secure Shell) ��Ŀǰ�Ͽɿ�,רΪԶ�̵�¼�Ự��������������ṩ��ȫ�Ե�Э�顣���� SSH Э�������Ч��ֹԶ�̹��������е���Ϣй¶���⡣SSH �����ڿɿ��Ĵ���Э�� TCP ֮�ϡ�
Telnet �� SSH ֮�����Ҫ�������� SSH Э���Դ�������ݽ��м��ܱ�֤���ݰ�ȫ�ԡ�
3. �����
��������Ҫ������Ǹ�������̨�ն��豸����֮���ͨ���ṩͨ�õ����ݴ������ Ӧ�ý������ø÷�����Ӧ�ò㱨�ġ���ͨ�õġ���ָ�������ijһ���ض�������Ӧ��,���Ƕ���Ӧ�ÿ���ʹ��ͬһ����������
�������Ҫ����������Э��:
- �������Э�� TCP(Transmisson Control Protocol)�C�ṩ�������ӵ�,�ɿ������ݴ������
- �û�����Э�� UDP(User Datagram Protocol)�C�ṩ�����ӵ�,�����Ŭ�������ݴ������(����֤���ݴ���Ŀɿ���)

4. �����
����㸺��Ϊ���齻�����ϵIJ�ͬ�����ṩͨ�ŷ��� �ڷ�������ʱ,�����Ѵ��������ı��Ķλ��û����ݱ���װ�ɷ���Ͱ����д��͡��� TCP/IP ��ϵ�ṹ��,���������ʹ�� IP Э��,��˷���Ҳ�� IP ���ݱ�,������ݱ���
�����Ļ���һ���������ѡ����ʵ�·��,ʹԴ������������������ķ���,��ͨ��������е�·�����ҵ�Ŀ��������
���������ɴ������칹(heterogeneous)����ͨ��·����(router)����������ġ�������ʹ�õ������Э���������ӵ�����Э��(Intert Prococol)������·��ѡ��Э��,��˻������������Ҳ�������ʲ��IP �㡣

5. ����ӿڲ�
���ǿ�������ӿڲ㿴����������·���������ĺ��塣
- ������·��(data link layer)ͨ�����Ϊ��·��( ��̨����֮������ݴ���,������һ��һ�ε���·�ϴ��͵�)��������·��������ǽ�����㽻������ IP ���ݱ���װ��֡,���������ڽڵ�����·�ϴ���֡��ÿһ֡�������ݺͱ�Ҫ�Ŀ�����Ϣ(��ͬ����Ϣ,��ַ��Ϣ,������Ƶ�)��
- �������������ʵ�����ڼ�����ڵ�֮���������������,���������ε����崫����ʺ������豸�IJ��졣

6.Ϊʲô������Ҫ�ֲ�?
- ����֮�������:����֮�������,����֮�䲻��Ҫ���������������ʵ�ֵ�,ֻ��Ҫ֪���Լ���ε����²��ṩ�õĹ��ܾͿ�����(���Լ�����Ϊ�ӿڵ���)����������ǶԿ���ʱϵͳ���зֲ���һ��������
- �������������� :ÿһ�㶼����ʹ�����ʺϵļ�����ʵ��,��ֻ��Ҫ��֤���ṩ�Ĺ����Լ���¶�ĽӿڵĹ���û�иı�����ˡ�
- �����⻯С:�ֲ���Խ����ӵ��������ֽ�Ϊ����Ƚ�С�ġ����߱Ƚ�������С�����������ͽ��������ʹ�ø��ӵļ��������ϵͳ����������,ʵ�ֺͱ�����
7. HTTP �� HTTPS
7.1 HTTP ��
HTTP Э��,ȫ�Ƴ��ı�����Э��(Hypertext Transfer Protocol)������˼��,HTTP Э����������淶���ı��Ĵ���,���ı�,Ҳ���������ϵİ����ı����ڵĸ�ʽ��������Ϣ,������˵,��Ҫ�����淶������ͷ������˵���Ϊ�ġ�
����,HTTP ��һ����״̬(stateless)Э��,Ҳ����˵��������ά���κ��йؿͻ��˹�ȥ�����������Ϣ������ʵ��һ������,��״̬Э�����Ӹ���,��Ҫά��״̬(��ʷ��Ϣ),��������ͻ��������ʧЧ,�����״̬�IJ�һ��,������ֲ�һ�µĴ��۸��ߡ�
HTTPЭ���ŵ�:��չ��ǿ���ٶȿ졢��ƽ̨֧���Ժá�
HTTPЭ��ͨ�Ź���:
HTTP ��Ӧ�ò�Э��,���� TCP(�����)��Ϊ�ײ�Э��,Ĭ�϶˿�Ϊ 80. ͨ�Ź�����Ҫ����:
- �������� 80 �˿ڵȴ��ͻ�������
- ��������������� TCP ����(�������� Socket)��
- ��������������������� TCP ���ӡ�
- �����(HTTP �ͻ���)�� Web ������(HTTP ������)���� HTTP ��Ϣ��
- �ر� TCP ���ӡ�
7.2 HTTPS ��
HTTPS Э��(Hyper Text Transfer Protocol Secure),�� HTTP �ļ�ǿ��ȫ�汾��HTTPS �ǻ��� HTTP ��,Ҳ���� TCP ��Ϊ�ײ�Э��,������ʹ�� SSL/TLS Э���������ܺͰ�ȫ��֤��Ĭ�϶˿ں��� 443.
HTTPS Э����,SSL ͨ��ͨ��ʹ�û�����Կ�ļ����㷨,��Կ����ͨ���� 40 ���ػ� 128 ���ء�
HTTPSЭ���ŵ�:�����Ժá����ζȸߡ�
7.3 HTTPS �ĺ��ġ�SSL/TLSЭ�鼰�乤��ԭ��
SSL��TLSЭ�������:SSL3.0�汾������ΪTLS,����û��̫�������
1.�ǶԳƼ���
SSL/TLS �ĺ���Ҫ���ǷǶԳƼ��ܡ��ǶԳƼ��ܲ���������Կ����һ����Կ,һ��˽Կ����ͨ��ʱ,˽Կ���ɽ����߱���,��Կ���κ�һ�����������ͨ�ŵķ�����(������)��֪��
2.�ԳƼ���
ʹ�� SSL/TLS ����ͨ�ŵ�˫����Ҫʹ�÷ǶԳƼ��ܷ�����ͨ��,���ǷǶԳƼ�������˽�Ϊ���ӵ���ѧ�㷨,��ʵ��ͨ�Ź�����,����Ĵ��۽ϸ�,Ч��̫��,���,SSL/TLS ʵ�ʶ���Ϣ�ļ���ʹ�õ��ǶԳƼ��ܡ�
�ԳƼ��ܵ���Կ���ɴ��۱ȹ�˽Կ�Ե����ɴ��۵͵ö�,��ô�е��˻�����,Ϊʲô SSL/TLS ����Ҫʹ�÷ǶԳƼ�����?��Ϊ�ԳƼ��ܵı�������ȫ��������Կ�ı����ԡ���˫��ͨ��֮ǰ,��Ҫ����һ�����ڶԳƼ��ܵ���Կ������֪������ͨ�ŵ��ŵ��Dz���ȫ��,���䱨�Ķ��κ����ǿɼ���,��Կ�Ľ����϶�����ֱ���������ŵ��д��䡣���,ʹ�÷ǶԳƼ���,�ԶԳƼ��ܵ���Կ���м���,��������Կ���������ŵ��б�����������,ͨ��˫��ֻ��Ҫһ�ηǶԳƼ���,�����ԳƼ��ܵ���Կ,��֮�����Ϣͨ����,ʹ�þ���ȫ����Կ,����Ϣ���жԳƼ���,���ɱ�֤������Ϣ�ı����ԡ�
8.HTTP/1.0 �� HTTP/1.1
8.1 ���ӷ�ʽ�Ա�
**HTTP/1.0 Ĭ��ʹ�ö����� **,Ҳ����˵,�ͻ��˺ͷ�����ÿ����һ�� HTTP ����,�ͽ���һ������,����������ж����ӡ����ͻ�����������ʵ�ij�� HTML ���������͵� Web ҳ�а����������� Web ��Դ(�� JavaScript �ļ���ͼ���ļ���CSS �ļ���),ÿ��������һ�� Web ��Դ,������ͻ����½���һ��TCP����,�����ͻᵼ���д����ġ����ֱ��ġ��͡����ֱ��ġ�ռ���˴�����
Ϊ�˽�� HTTP/1.0 ���ڵ���Դ�˷ѵ�����, HTTP/1.1 �Ż�ΪĬ�ϳ�����ģʽ �� ���ó�����ģʽ�������Ļ�֪ͨ�����:����������������,�������ӳɹ�������,�벻Ҫ�رա������,��TCP���ӽ�������,Ϊ�����Ŀͻ���-����˵����ݽ�������Ҳ����˵��ʹ�ó����ӵ������,��һ����ҳ����ɺ�,�ͻ��˺ͷ�����֮�����ڴ��� HTTP ���ݵ� TCP ���Ӳ���ر�,�ͻ����ٴη������������ʱ,�����ʹ����һ���Ѿ����������ӡ�
HTTP Э��ij����ӺͶ�����,ʵ������ TCP Э��ij����ӺͶ����ӡ�
ʵ�ֳ�������Ҫ�ͻ��˺ͷ���˶�֧�ֳ����ӡ�
8.2 Hostͷ����
����ϵͳ(DNS)���������������ͬһ��IP��ַ��,����HTTP/1.0��û�п����������,����������һ����ԴURL��http://example1.org/home.html,HTTP/1.0����������,�����������GET /home.html HTTP/1.0.Ҳ���Dz�������������������ı����͵���������,�����������ⲻ�˿ͻ����������������ַ��
���,HTTP/1.1������ͷ�м�����Host�ֶΡ�����Host�ֶεı���ͷ��������:
GET /home.html HTTP/1.1
Host: example1.org
8.3 �����Ż�
HTTP/1.1�����˷�Χ����(range request)����,�Ա���������˷ѡ����ͻ���������һ���ļ���һ����,������Ҫ��������һ���Ѿ������˲��ֵ�����ֹ���ļ�,HTTP/1.1�����������м���Rangeͷ��,������(��ֻ�������ֽ�������)���ݵ�һ���֡��������˿��Ժ���Rangeͷ��,Ҳ���Է�������Range��Ӧ��
���һ����Ӧ�����������ݵĻ�,��ô������206 (Partial Content)״̬�롣��״̬����������ڱ�����HTTP/1.0�����������ذѸ���Ӧ��Ϊ��һ��������������Ӧ,�Ӷ���������Ϊһ���������Ӧ���档
8.4 ״̬��100
HTTP/1.1���¼�����״̬��100����״̬���ʹ�ó���Ϊ,����ijЩ�ϴ���ļ�����,���������ܲ�Ը����Ӧ��������,��ʱ״̬��100������Ϊָʾ�����Ƿ�ᱻ������Ӧ,��������ͼ:


8.5 ѹ��
�����ʽ�������ڴ���ʱ������Ԥѹ�����������ݵ�ѹ�����Դ���Ż����������á�Ȼ��,HTTP/1.0������ѹ����ѡ���ṩ�IJ���,��֧��ѹ��ϸ�ڵ�ѡ��,Ҳ�����ֶ˵���(end-to-end)ѹ������������(hop-by-hop)ѹ����
HTTP/1.1������ݱ���(content-codings)�ʹ������(transfer-codings)�������֡����ݱ������Ƕ˵��˵�,����������������ġ�
HTTP/1.0������Content-Encodingͷ��,����Ϣ���ж˵��˱��롣HTTP/1.1������Transfer-Encodingͷ��,���Զ���Ϣ��������������롣HTTP/1.1��������Accept-Encodingͷ��,�ǿͻ�������ָʾ���ܴ���ʲô�������ݱ���
8.6 �ܽ�
- ���ӷ�ʽ : HTTP 1.0 Ϊ������,HTTP 1.1 ֧�ֳ����ӡ�
- ״̬��Ӧ�� : HTTP/1.1���¼����˴�����״̬��,���Ǵ�����Ӧ״̬���������24�֡�����˵,100 (Continue)�������������Դǰ��Ԥ������,206 (Partial Content)������Χ����ı�ʶ��,409 (Conflict)���������뵱ǰ��Դ�Ĺ涨��ͻ,410 (Gone)������Դ�ѱ�����ת��,����û���κ���֪��ת����ַ��
- ���洦�� : �� HTTP1.0 ����Ҫʹ�� header ��� If-Modified-Since,Expires ����Ϊ�����жϵı�,HTTP1.1 �������˸���Ļ�����Ʋ������� Entity tag,If-Unmodified-Since, If-Match, If-None-Match �ȸ���ɹ�ѡ��Ļ���ͷ�����ƻ�����ԡ�
- �����Ż����������ӵ�ʹ�� :HTTP1.0 ��,����һЩ�˷Ѵ���������,����ͻ���ֻ����Ҫij�������һ����,��������ȴ����������������,���Ҳ�֧�ֶϵ���������,HTTP1.1 ��������ͷ������ range ͷ��,������ֻ������Դ��ij������,���������� 206(Partial Content),�����ͷ����˿��������ɵ�ѡ���Ա��ڳ�����ô��������ӡ�
- Hostͷ���� : HTTP/1.1������ͷ�м�����Host�ֶ�
9. TCP�������ֺ��Ĵλ��ֵĹ���
9.1 ��������
Ϊ��ȷ����ذ������ʹ�Ŀ�괦,TCP Э��������������ֲ��ԡ�


- �ͻ��˨C���ʹ��� SYN ��־�����ݰ��Cһ�����֨C�����
- ����˨C���ʹ��� SYN/ACK ��־�����ݰ��C�������֨C�ͻ���
- �ͻ��˨C���ʹ��д��� ACK ��־�����ݰ��C�������֨C�����
�������ֵ�Ŀ���ǽ����ɿ���ͨ���ŵ�,˵��ͨѶ,����˵�������ݵķ��������,��������������Ҫ��Ŀ�ľ���˫��ȷ���Լ���Է��ķ���������������ġ�
ΪʲôҪ���е���������?
���ն˴��ط��Ͷ������͵� ACK ��Ϊ�˸��߿ͻ���,�ҽ��յ�����Ϣȷʵ�����������͵��ź���,������ӿͻ��˵�����˵�ͨ���������ġ����ش� SYN ����Ϊ�˽�����ȷ�ϴӷ���˵��ͻ��˵�ͨ�š�
9.2 �Ĵλ���

�Ͽ�һ�� TCP ��������Ҫ���Ĵλ��֡�:
- �ͻ���-����һ�� FIN,�����رտͻ��˵������������ݴ���
- ������-�յ���� FIN,������һ �� ACK,ȷ�����Ϊ�յ�����ż� 1 ���� SYN һ��,һ�� FIN ��ռ��һ�����
- ������-�ر���ͻ��˵�����,����һ�� FIN ���ͻ���
- �ͻ���-���� ACK ����ȷ��,����ȷ���������Ϊ�յ���ż� 1
�κ�һ�������������ݴ��ͽ����������ͷŵ�֪ͨ,���Է�ȷ�Ϻ�����ر�״̬������һ��Ҳû�������ٷ��͵�ʱ��,�������ͷ�֪ͨ,�Է�ȷ�Ϻ����ȫ�ر��� TCP ���ӡ�
�ٸ�����:A �� B ��绰,ͨ������������,A ˵����ûɶҪ˵���ˡ�,B �ش���֪���ˡ�,���� B ���ܻ�����Ҫ˵�Ļ�,A ����Ҫ�� B �����Լ��Ľ������ͨ��,���� B �����ְ�������˵��һͨ,��� B ˵����˵���ˡ�,A �ش�֪���ˡ�,����ͨ�����������
10.TCP��UDP�������
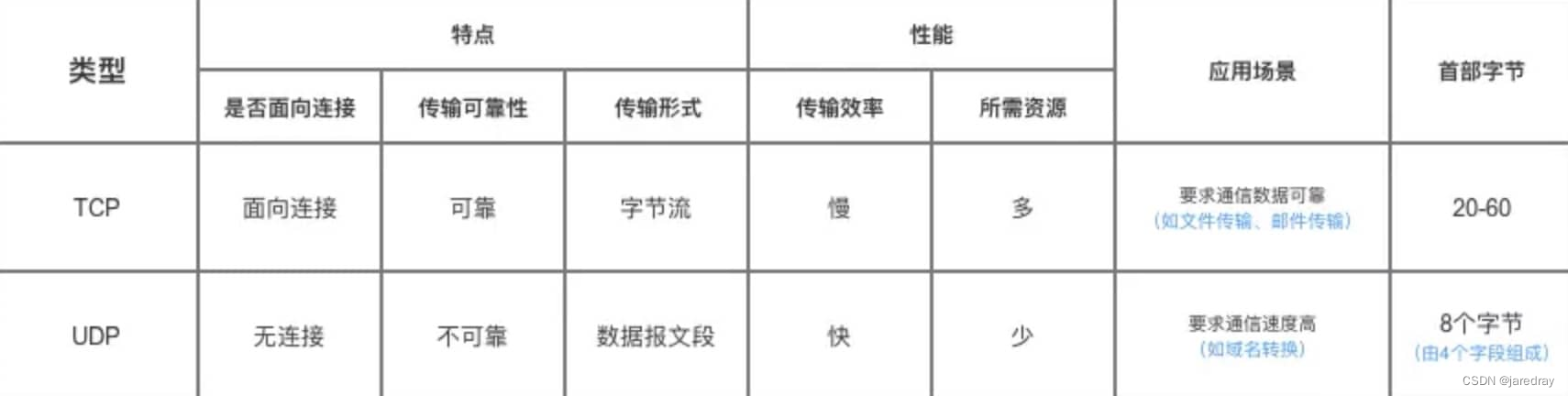
UDP �ڴ�������֮ǰ����Ҫ�Ƚ�������,Զ���������յ� UDP ���ĺ�,����Ҫ�����κ�ȷ�ϡ���Ȼ UDP ���ṩ�ɿ�����,����ijЩ����� UDP ȴ��һ������Ч�Ĺ�����ʽ(һ�����ڼ�ʱͨ��),����: QQ ������ QQ ��Ƶ ��ֱ���ȵȡ�
TCP �ṩ�������ӵķ����ڴ�������֮ǰ�����Ƚ�������,���ݴ��ͽ�����Ҫ�ͷ����ӡ� TCP ���ṩ�㲥��ಥ�������� TCP Ҫ�ṩ�ɿ���,�������ӵĴ������(TCP �Ŀɿ������� TCP �ڴ�������֮ǰ,����������������������,���������ݴ���ʱ,��ȷ�ϡ����ڡ��ش���ӵ�����ƻ���,�����ݴ����,����Ͽ�����������Լϵͳ��Դ),�����Ա��������������,��ȷ��,��������,��ʱ���Լ����ӹ����ȡ��ⲻ��ʹЭ�����ݵ�Ԫ���ײ�����ܶ�,��Ҫռ�����ദ������Դ��TCP һ�������ļ����䡢���ͺͽ����ʼ���Զ�̵�¼�ȳ�����
11.TCPЭ����α�֤�ɿ�����
- Ӧ�����ݱ��ָ�� TCP ��Ϊ���ʺϷ��͵����ݿ顣
- TCP �����͵�ÿһ�������б��,���շ������ݰ���������,���������ݴ���Ӧ�ò㡣
- У���: TCP ���������ײ������ݵļ���͡�����һ���˵��˵ļ����,Ŀ���Ǽ�������ڴ�������е��κα仯������յ��εļ�����в��,TCP ������������ĶκͲ�ȷ���յ��˱��ĶΡ�
- TCP �Ľ��ն˻ᶪ���ظ������ݡ�
- ��������: TCP ���ӵ�ÿһ�����й̶���С�Ļ���ռ�,TCP �Ľ��ն�ֻ�������Ͷ˷��ͽ��ն˻������ܽ��ɵ����ݡ������շ��������������ͷ�������,����ʾ���ͷ����ͷ��͵�����,��ֹ����ʧ��TCP ʹ�õ���������Э���ǿɱ��С�Ļ�������Э�顣 (TCP ���û�������ʵ����������)
- ӵ������: ������ӵ��ʱ,�������ݵķ��͡�
- ARQ Э��: Ҳ��Ϊ��ʵ�ֿɿ������,���Ļ���ԭ������ÿ����һ�������ֹͣ����,�ȴ��Է�ȷ�ϡ����յ�ȷ�Ϻ��ٷ���һ�����顣
- ��ʱ�ش�: �� TCP ����һ���κ�,������һ����ʱ��,�ȴ�Ŀ�Ķ�ȷ���յ�������ĶΡ�������ܼ�ʱ�յ�һ��ȷ��,���ط�������ĶΡ�
11.1 ARQЭ��(�Զ��ش�Э��)
�Զ��ش�����(Automatic Repeat-reQuest,ARQ)�� OSI ģ����������·��ʹ����Ĵ������Э��֮һ����ͨ��ʹ��ȷ�Ϻͳ�ʱ����������,�ڲ��ɿ�����Ļ�����ʵ�ֿɿ�����Ϣ���䡣������ͷ��ڷ��ͺ�һ��ʱ��֮��û���յ�ȷ��֡,��ͨ�������·��͡�ARQ ����ֹͣ�ȴ� ARQ Э������� ARQ Э�顣
11.1.1ֹͣ�ȴ� ARQ Э��
ֹͣ�ȴ�Э����Ϊ��ʵ�ֿɿ������,���Ļ���ԭ������ÿ����һ�������ֹͣ����,�ȴ��Է�ȷ��(�ظ� ACK)���������һ��ʱ��(��ʱʱ���),����û���յ� ACK ȷ��,˵��û�з��ͳɹ�,��Ҫ���·���,ֱ���յ�ȷ�Ϻ��ٷ���һ�����顣
��ֹͣ�ȴ�Э����,�����շ��յ��ظ�����,�Ͷ����÷���,��ͬʱ��Ҫ����ȷ�ϡ�
�ŵ�:��;ȱ��:�ŵ������ʵ�,�ȴ�ʱ�䳤��
(1)������:
���ͷ����ͷ���, ���շ��ڹ涨ʱ�����յ�, ���һظ�ȷ��. ���ͷ��ٴη��͡�
(2)���ֲ�����(��ʱ�ش�):
ֹͣ�ȴ�Э���г�ʱ�ش���ָֻҪ����һ��ʱ����Ȼû���յ�ȷ��,���ش�ǰ�淢���ķ���(��Ϊ�ղŷ����ķ��鶪ʧ��)�����ÿ������һ��������Ҫ����һ����ʱ��ʱ��,���ش�ʱ��Ӧ�������ڷ��鴫���ƽ������ʱ�����һЩ�������Զ��ش���ʽ����Ϊ �Զ��ش����� ARQ ��������ֹͣ�ȴ�Э�������յ��ظ�����,�Ͷ����÷���,��ͬʱ��Ҫ����ȷ�ϡ����� ARQ Э�� ������ŵ������ʡ�����ά��һ�����ʹ���,��λ�ڷ��ʹ����ڵķ�����������ͳ�ȥ,������Ҫ�ȴ��Է�ȷ�ϡ����շ�һ������ۻ�ȷ��,��������һ�����鷢��ȷ��,�������������λ�õ����з��鶼�Ѿ���ȷ�յ��ˡ�
(3)ȷ�϶�ʧ��ȷ�ϳٵ�
- ȷ�϶�ʧ :ȷ����Ϣ�ڴ�����̶�ʧ���� A ���� M1 ��Ϣ,B �յ���,B �� A ������һ�� M1 ȷ����Ϣ,��ȴ�ڴ�������ж�ʧ���� A ����֪��,�ڳ�ʱ��ʱ����,A �ش� M1 ��Ϣ,B �ٴ��յ�����Ϣ���ȡ���������ʩ:1. ��������ظ��� M1 ��Ϣ,�����ϲ㽻���� 2. �� A ����ȷ����Ϣ��(������Ϊ�Ѿ�������,�Ͳ��ٷ��͡�A ���ش�,��֤�� B ��ȷ����Ϣ��ʧ)��
- ȷ�ϳٵ� :ȷ����Ϣ�ڴ�������гٵ���A ���� M1 ��Ϣ,B �յ�������ȷ�ϡ��ڳ�ʱʱ����û���յ�ȷ����Ϣ,A �ش� M1 ��Ϣ,B ��Ȼ�յ�����������ȷ����Ϣ(B �յ��� 2 �� M1)����ʱ A �յ��� B �ڶ��η��͵�ȷ����Ϣ�����ŷ����������ݡ�����һ��,A �յ��� B ��һ�η��͵Ķ� M1 ��ȷ����Ϣ(A Ҳ�յ��� 2 ��ȷ����Ϣ)����������:1. A �յ��ظ���ȷ�Ϻ�,ֱ�Ӷ�����2. B �յ��ظ��� M1 ��,Ҳֱ�Ӷ����ظ��� M1��
11.1.2 ���� ARQ ��
���� ARQ Э�������ŵ������ʡ����ͷ�ά��һ�����ʹ���,��λ�ڷ��ʹ����ڵķ�������������ͳ�ȥ,������Ҫ�ȴ��Է�ȷ�ϡ����շ�һ������ۻ�ȷ��,��������һ�����鷢��ȷ��,�������������Ϊֹ�����з��鶼�Ѿ���ȷ�յ��ˡ�
�ŵ�:�ŵ������ʸ�,����ʵ��,��ʹȷ�϶�ʧ,Ҳ�����ش�;
ȱ��: �������ͷ���ӳ�����շ��Ѿ���ȷ�յ������з������Ϣ�� ����:���ͷ������� 5 �� ��Ϣ,�м��������ʧ(3 ��),��ʱ���շ�ֻ�ܶ�ǰ��������ȷ�ϡ����ͷ���֪�����������������,��ֻ�ðѺ�����ȫ���ش�һ�Ρ���Ҳ�� Go-Back-N(���� N),��ʾ��Ҫ�˻����ش��Ѿ������� N ����Ϣ��
11.2 �������ں���������
**TCP ���û�������ʵ���������ơ�**����������Ϊ�˿��Ʒ��ͷ���������,��֤���շ����ü����ա� ���շ����͵�ȷ�ϱ����еĴ����ֶο����������Ʒ��ͷ����ڴ�С,�Ӷ�Ӱ�췢�ͷ��ķ������ʡ��������ֶ�����Ϊ 0,���ͷ����ܷ������ݡ�
11.3 ӵ������
��ij��ʱ��,����������ijһ��Դ�������˸���Դ�����ṩ�Ŀ��ò���,��������ܾ�Ҫ�仵����������ͽ�ӵ����ӵ�����ƾ���Ϊ�˷�ֹ���������ע�뵽������,�����Ϳ���ʹ�����е�·��������·���¹��ء�ӵ��������Ҫ���Ķ���һ��ǰ��,���������ܹ��������е����縺�ɡ�ӵ��������һ��ȫ���ԵĹ���,�漰�����е�����,���е�·����,�Լ��뽵�����紫�������йص��������ء��෴,�������������ǵ�Ե�ͨ�����Ŀ���,�Ǹ��˵��˵����⡣����������Ҫ�����ľ������Ʒ��Ͷ˷������ݵ�����,�Ա�ʹ���ն����ü����ա�
Ϊ�˽���ӵ������,TCP ���ͷ�Ҫά��һ�� ӵ������(cwnd) ��״̬������ӵ�����ƴ��ڵĴ�Сȡ���������ӵ���̶�,���Ҷ�̬�仯�����ͷ����Լ��ķ��ʹ���ȡΪӵ�����ںͽ��շ��Ľ��ܴ����н�С��һ����
TCP ��ӵ�����Ʋ����������㷨,������ʼ �� ӵ������ �����ش� �� ��ָ����������Ҳ����ʹ·���������ʵ��ķ��鶪������(���������й��� AQM),�Լ�������ӵ���ķ�����
- ����ʼ: ����ʼ�㷨��˼·�ǵ�������ʼ��������ʱ,��������Ѵ��������ֽ�ע�뵽����,��ô���ܻ�������������,��Ϊ���ڻ���֪������ķ���������������,�Ϻõķ�������̽��һ��,����С�����������ʹ���,Ҳ������С����������ӵ��������ֵ��cwnd ��ʼֵΪ 1,ÿ����һ�������ִ�,cwnd �ӱ���
- ӵ������: ӵ�������㷨��˼·����ӵ������ cwnd ��������,��ÿ����һ������ʱ�� RTT �Ͱѷ��ͷŵ� cwnd �� 1��
- ���ش����ָ�: �� TCP/IP ��,�����ش��ͻָ�(fast retransmit and recovery,FRR)��һ��ӵ�������㷨,���ܿ��ٻָ���ʧ�����ݰ���û�� FRR,������ݰ���ʧ��,TCP ����ʹ�ö�ʱ����Ҫ������ͣ������ͣ�����ʱ����,û���µĻ��Ƶ����ݰ������͡����� FRR,������ջ����յ�һ������˳������ݶ�,�������������ͻ�����һ���ظ�ȷ�ϡ�������ͻ����յ������ظ�ȷ��,����ٶ�ȷ�ϼ�ָ�������ݶζ�ʧ��,�������ش���Щ��ʧ�����ݶΡ����� FRR,�Ͳ�����Ϊ�ش�ʱҪ�����ͣ������ �����е��������ݰ���ʧʱ,�����ش��ͻָ�(FRR)������Ч�ع��������ж��������Ϣ����ijһ�κ̵ܶ�ʱ���ڶ�ʧʱ,�����ܺ���Ч�ع�����
12. ������������� url ��ַ ->> ��ʾ��ҳ�Ĺ���
��һ����ҳ,�������̻�ʹ����ЩЭ��?
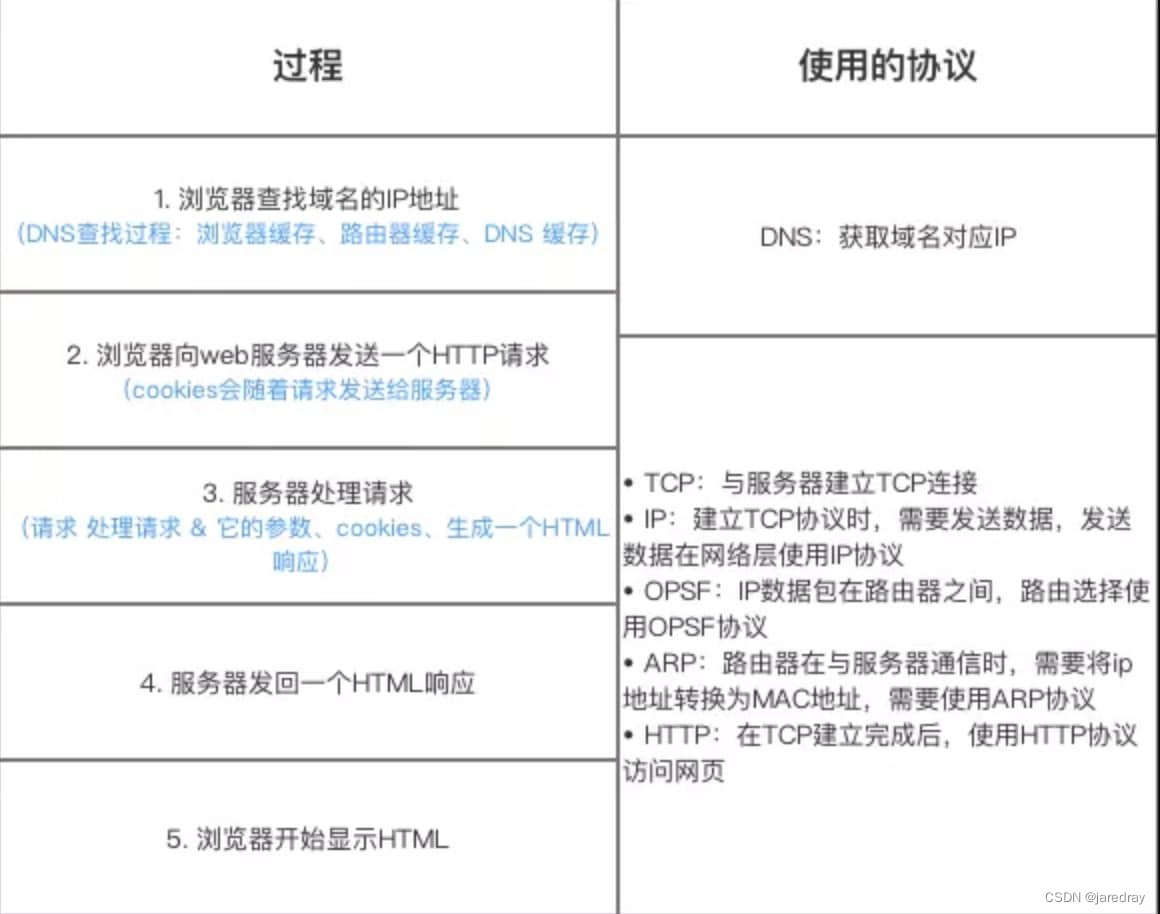
������˵��Ϊ���¼�������:
- DNS ����
- TCP ����
- ���� HTTP ����
- ���������������� HTTP ����
- �����������Ⱦҳ��
- ���ӽ���
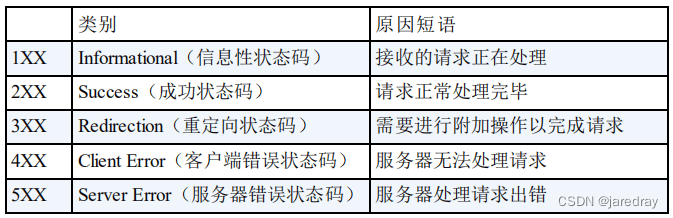
13. ״̬��
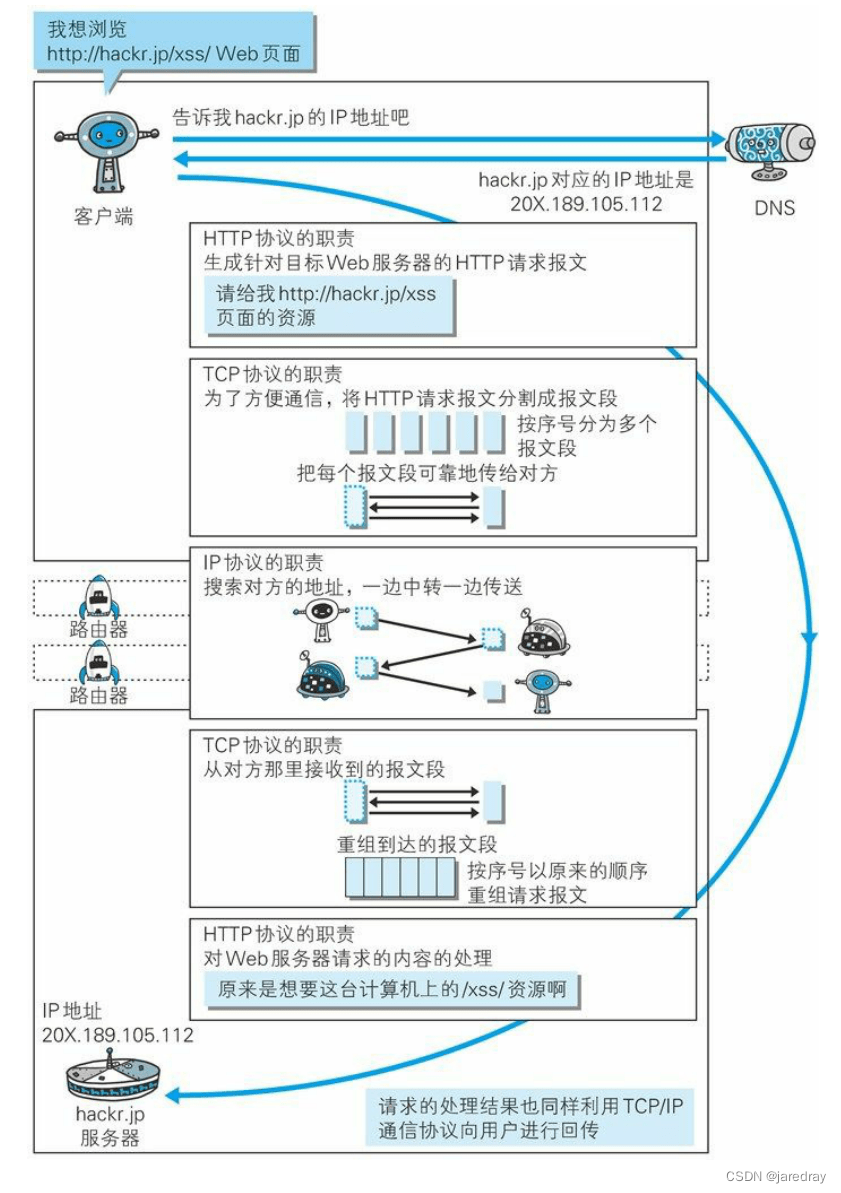
14.����Э���� HTTP Э��֮��Ĺ�ϵ
15. HTTP��α����û���״̬?
HTTP ��һ�ֲ�����״̬,����״̬(stateless)Э�顣Ҳ����˵ HTTP Э�����������������Ӧ֮���ͨ��״̬���б��档��ô���DZ����û�״̬��?Session ���ƵĴ��ھ���Ϊ�˽���������,Session ����Ҫ���þ���ͨ������˼�¼�û���״̬��
�ڷ���˱��� Session �ķ����ܶ�,��õľ����ڴ�����ݿ�(������ʹ���ڴ����ݿ� redis ����)����Ȼ Session ����ڷ�������,��ô�������ʵ�� Session ������?�������,���Ƕ���ͨ���� Cookie �и���һ�� Session ID ����ʽ�����١�
Cookie�����������
��õľ������� URL ��д�� Session ID ֱ�Ӹ����� URL ·���ĺ��档
16.Cookie ��������ʲô? �� Session ��ʲô����?
Cookie �� Session ������������������û����ݵĻỰ��ʽ,�������ߵ�Ӧ�ó�����̫һ����
Cookie һ�����������û���Ϣ�� ���� �� ������ Cookie �б����Ѿ���¼�����û���Ϣ,�´η�����վ��ʱ��ҳ������Զ�����ѵ�¼��һЩ������Ϣ������;�� һ�����վ�����б��ֵ�¼,Ҳ����˵�´����ٷ�����վ��ʱ��Ͳ���Ҫ���µ�¼��,������Ϊ�û���¼��ʱ�����ǿ��Դ����һ�� Token �� Cookie ��,�´ε�¼��ʱ��ֻ��Ҫ���� Token ֵ�������û�����(Ϊ�˰�ȫ����,���µ�¼һ��Ҫ�� Token ��д);�� ��¼һ����վ�������վ����ҳ�治��Ҫ���µ�¼��
Session ����Ҫ���þ���ͨ������˼�¼�û���״̬�� ���͵ij����ǹ��ﳵ,����Ҫ������Ʒ�����ﳵ��ʱ��,ϵͳ��֪�����ĸ��û�������,��Ϊ HTTP Э������״̬�ġ�����˸��ض����û������ض��� Session ֮��Ϳ��Ա�ʶ����û����Ҹ�������û��ˡ�
Cookie ���ݱ����ڿͻ���(�������),Session ���ݱ����ڷ������ˡ�
17. URI �� URL ��������ʲô?
- URI(Uniform Resource Identifier) ��ͳһ��Դ��־��,����Ψһ��ʶһ����Դ��
- URL(Uniform Resource Locator) ��ͳһ��Դ��λ��,�����ṩ����Դ��·��������һ�־���� URI,�� URL ����������ʶһ����Դ,���һ�ָ������� locate �����Դ��
URI ������������֤��һ��,URL �����ø����ͥסַһ����URL ��һ�־���� URI,������Ψһ��ʶ��Դ,���һ��ṩ�˶�λ����Դ����Ϣ��

