计算机网络
基础
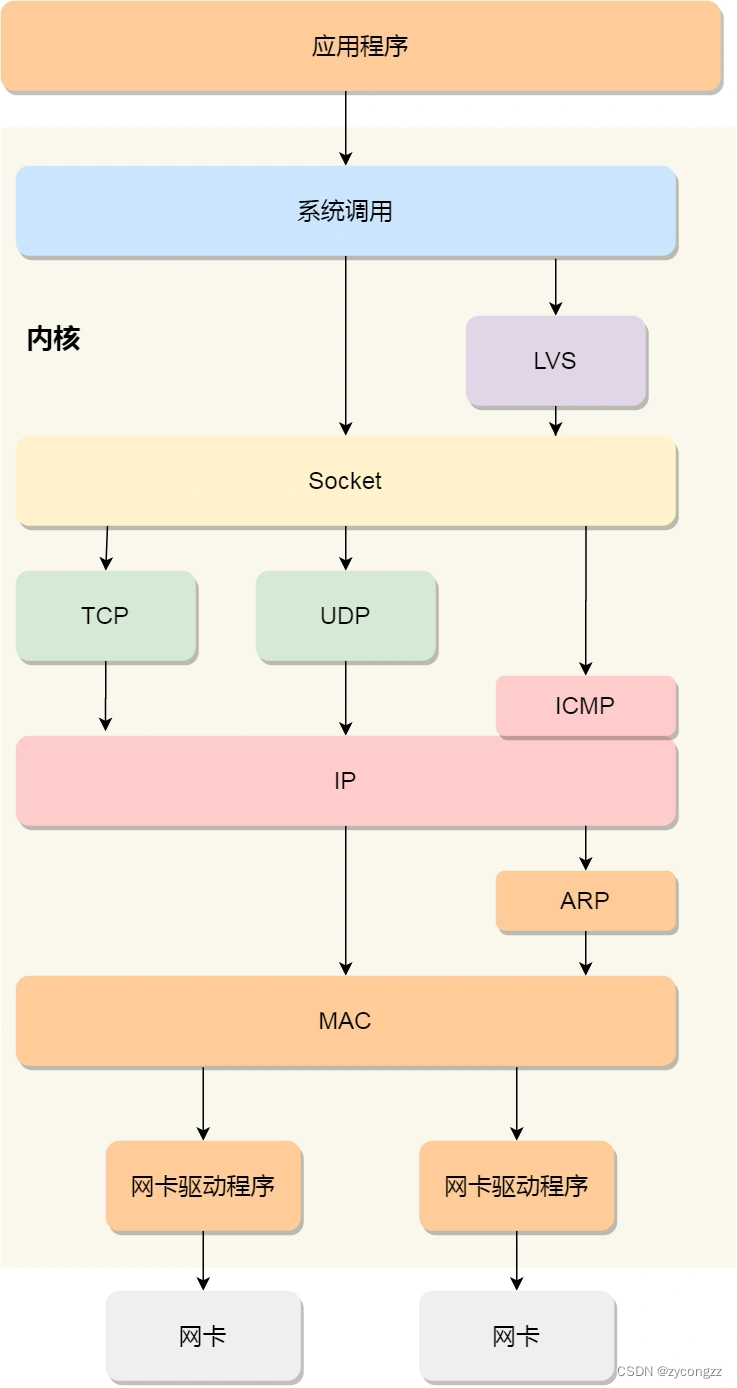
TCP/IP 网络模型
应用层
应用层位于网络模型的最上层,是用户可以直接接触到的,我们电脑和收集使用的应用软件都是在应用层实现,当两个应用层设备需要通信时,应用就会把数据传到下一层――传输层、所以,应用层只需要专注于为用户提供应用功能,比如 HTTP、FTP、Telnet、DNS、SMTP等。
而且应用层是工作在操作系统中的用户态,传输层及以下则工作在内核态。
传输层
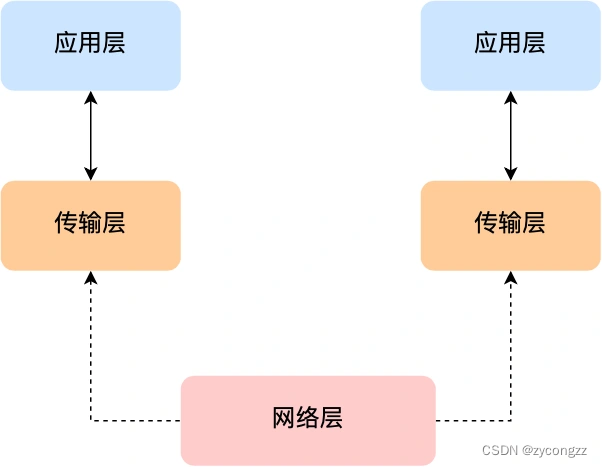
应用层的数据包会传给传输层,传输层(Transport Layer)是为应用层提供网络支持的。
在传输层会有两个传输协议,分别是 TCP 和 UDP。
TCP全称: 传输控制协议(Transmission Control Protocol)大部分应用使用的正是 TCP 传输层协议,比如 HTTP 应用层协议。TCP 相比 UDP 多了很多特性,比如流量控制、超时重传、拥塞控制等,这些都是为了保证数据包能可靠地传输给对方。
UDP UDP 相对来说就很简单,简单到只负责发送数据包,不保证数据包是否能抵达对方,但它实时性相对更好,传输效率也高。当然,UDP 也可以实现可靠传输,把 TCP 的特性在应用层上实现就可以,不过要实现一个商用的可靠 UDP 传输协议,也不是一件简单的事情。
应用需要传输的数据可能会非常大,如果直接传输就不好控制,因此当传输层的数据包大小超过 MSS(TCP 最大报文段长度) ,就要将数据包分块,这样即使中途有一个分块丢失或损坏了,只需要重新发送这一个分块,而不用重新发送整个数据包。在 TCP 协议中,我们把每个分块称为一个 TCP 段(TCP Segment)。
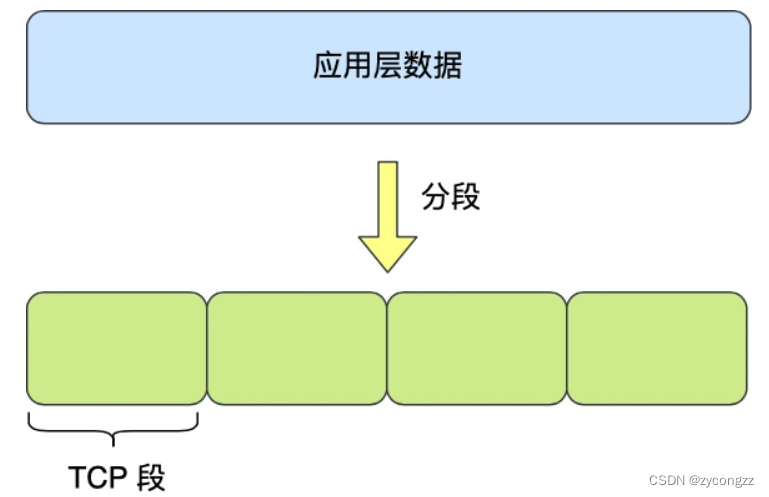
网络层
传输层可能大家刚接触的时候,会认为它负责将数据从一个设备传输到另一个设备,事实上它并不负责。
实际场景中的网络环节是错综复杂的,中间有各种各样的线路和分叉路口,如果一个设备的数据要传输给另一个设备,就需要在各种各样的路径和节点进行选择,而传输层的设计理念是简单、高效、专注,如果传输层还负责这一块功能就有点违背设计原则了。
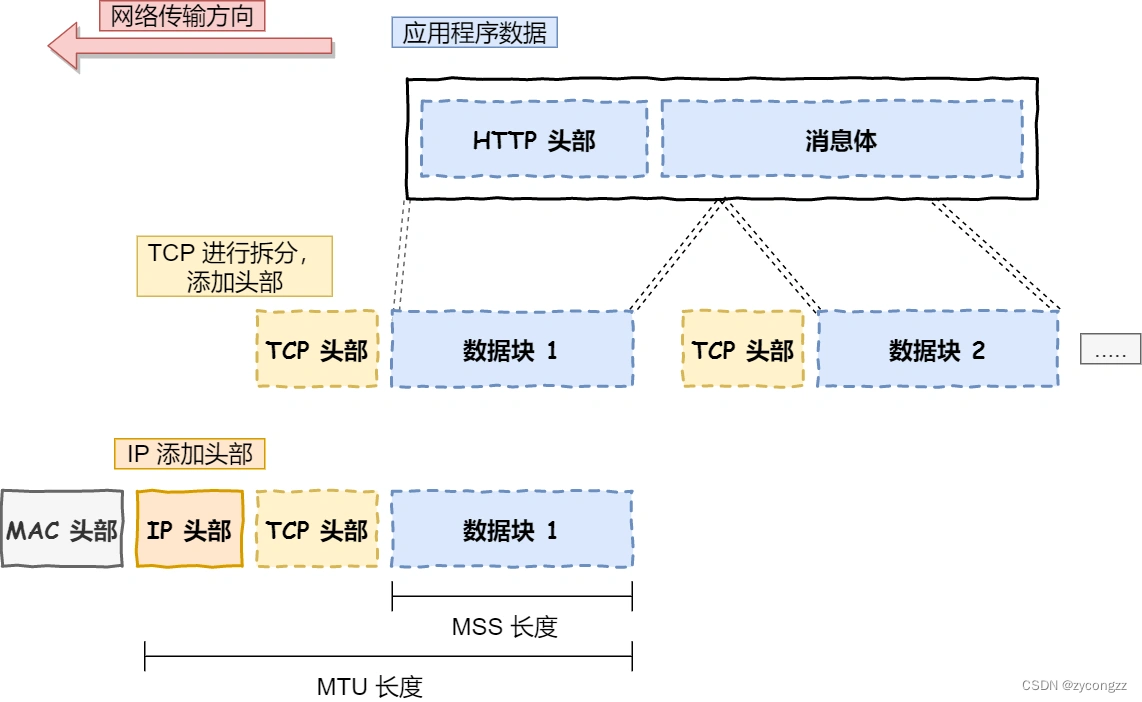
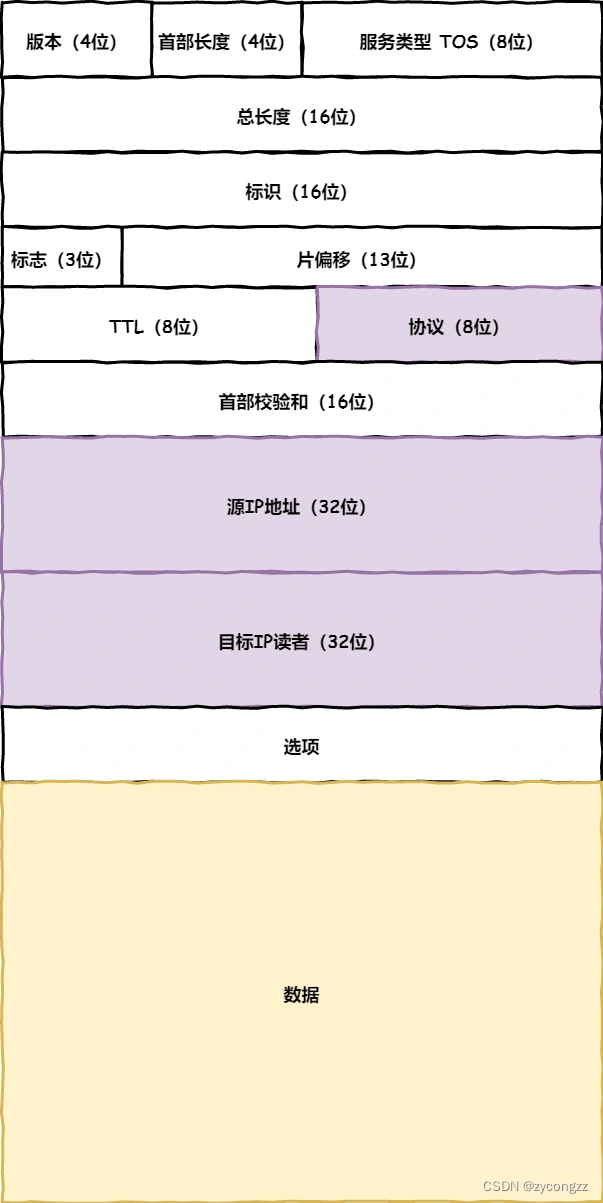
网络层最常使用的是 IP 协议(Internet Protocol),IP 协议会将传输层的报文作为数据部分,再加上 IP 包头组装成 IP 报文,如果 IP 报文大小超过 MTU(以太网中一般为 1500 字节)就会再次进行分片,得到一个即将发送到网络的 IP 报文。
网络层负责将数据从一个设备传输到另一个设备,世界上那么多设备,又该如何找到对方呢?因此,网络层需要有区分设备的编号。
我们一般用 IP 地址给设备进行编号,对于 IPv4 协议, IP 地址共 32 位,分成了四段(比如,192.168.100.1),每段是 8 位。只有一个单纯的 IP 地址虽然做到了区分设备,但是寻址起来就特别麻烦,全世界那么多台设备,难道一个一个去匹配?这显然不科学。
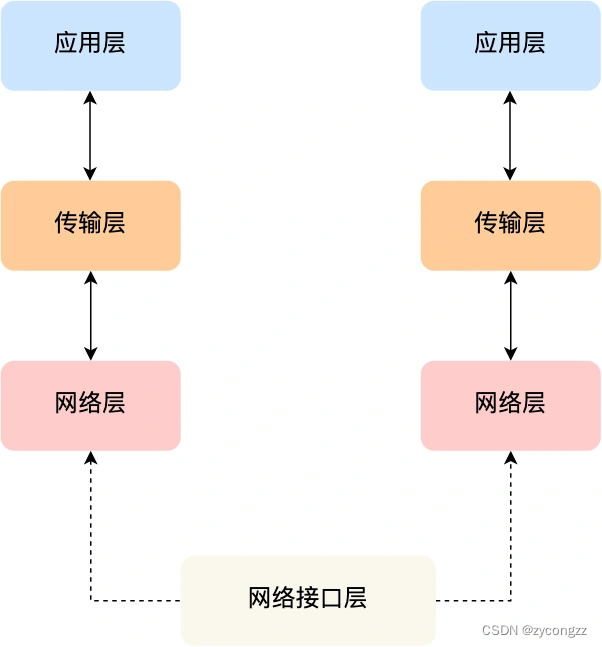
数据接口层
生成了 IP 头部之后,接下来要交给**网络接口层(Link Layer)**在 IP 头部的前面加上 MAC 头部,并封装成数据帧(Data frame)发送到网络上
IP 头部中的接收方 IP 地址表示网络包的目的地,通过这个地址我们就可以判断要将包发到哪里,但在以太网的世界中,这个思路是行不通的。
什么是以太网呢?电脑上的以太网接口,Wi-Fi接口,以太网交换机、路由器上的千兆,万兆以太网口,还有网线,它们都是以太网的组成部分。以太网就是一种在「局域网」内,把附近的设备连接起来,使它们之间可以进行通讯的技术。
以太网在判断网络包目的地时和 IP 的方式不同,因此必须采用相匹配的方式才能在以太网中将包发往目的地,而 MAC 头部就是干这个用的,所以,在以太网进行通讯要用到 MAC 地址。
MAC 头部是以太网使用的头部,它包含了接收方和发送方的 MAC 地址等信息,我们可以通过 ARP 协议获取对方的 MAC 地址。
在输入网址到网页显示,期间发生了什么
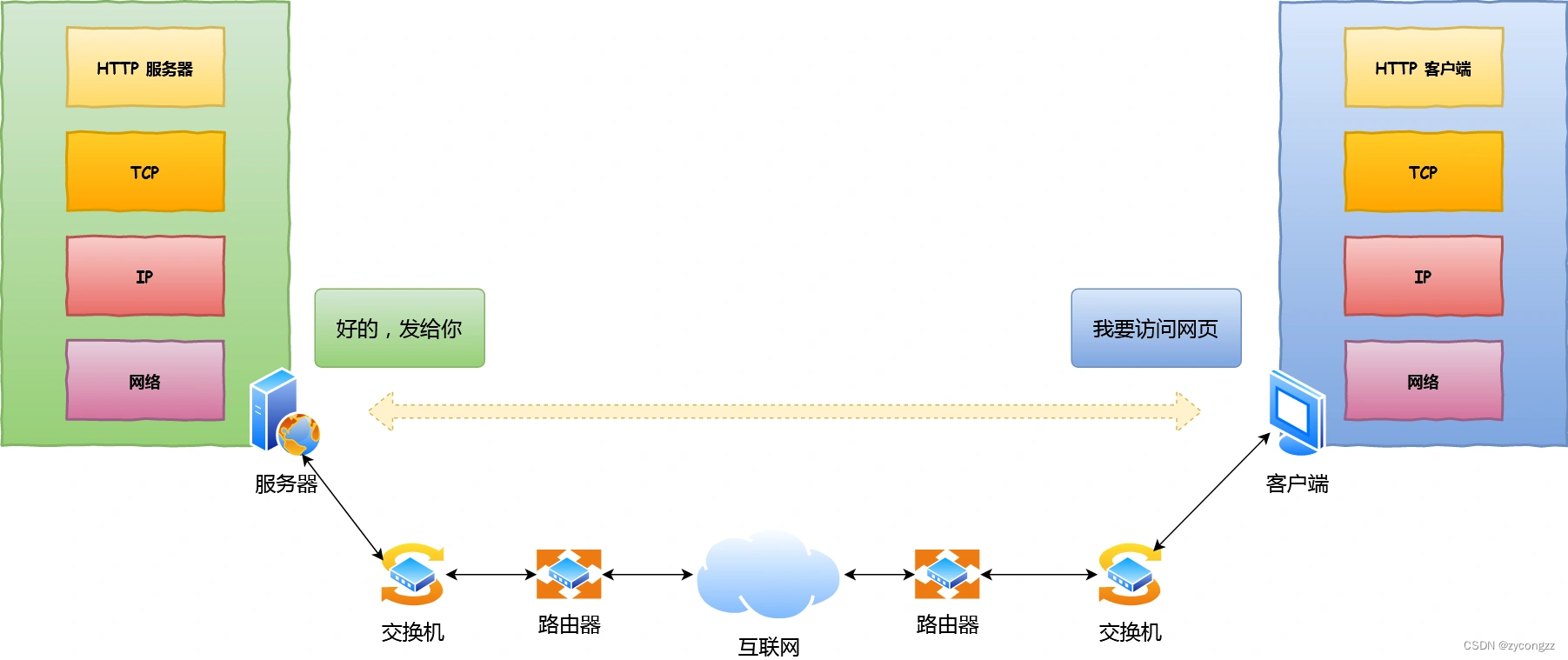
HTTP
当浏览器收到网址,第一步要解析URL
首先浏览器做的第一步工作就是要对 URL 进行解析,从而生成发送给 Web 服务器的请求信息。
DNS 真实地址查询
服务器就专门保存了 Web 服务器域名与 IP 的对应关系,它就是 DNS 服务器。
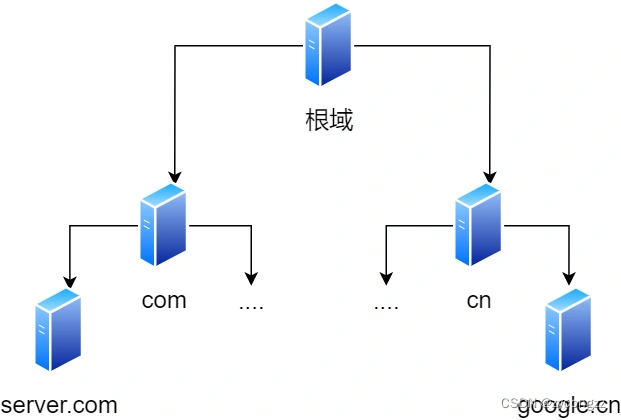
域名解析的工作流程
- 客户端首先会发出一个 DNS 请求,问 www.server.com 的 IP 是啥,并发给本地 DNS 服务器(也就是客户端的 TCP/IP 设置中填写的 DNS 服务器地址)。
- 本地域名服务器收到客户端的请求后,如果缓存里的表格能找到 www.server.com,则它直接返回 IP 地址。如果没有,本地 DNS 会去问它的根域名服务器:“老大, 能告诉我 www.server.com 的 IP 地址吗?” 根域名服务器是最高层次的,它不直接用于域名解析,但能指明一条道路。
- 根 DNS 收到来自本地 DNS 的请求后,发现后置是 .com,说:“www.server.com 这个域名归 .com 区域管理”,我给你 .com 顶级域名服务器地址给你,你去问问它吧。”
- 本地 DNS 收到顶级域名服务器的地址后,发起请求问“老二, 你能告诉我 www.server.com 的 IP 地址吗?”
- 顶级域名服务器说:“我给你负责 www.server.com 区域的权威 DNS 服务器的地址,你去问它应该能问到”。
- 本地 DNS 于是转向问权威 DNS 服务器:“老三,www.server.com对应的IP是啥呀?” server.com 的权威 DNS 服务器,它是域 名解析结果的原出处。为啥叫权威呢?就是我的域名我做主。
- 权威 DNS 服务器查询后将对应的 IP 地址 X.X.X.X 告诉本地 DNS。
- 本地 DNS 再将 IP 地址返回客户端,客户端和目标建立连接。
TCP
HTTP 是基于 TCP 协议传输的,所以在这我们先了解下 TCP 协议
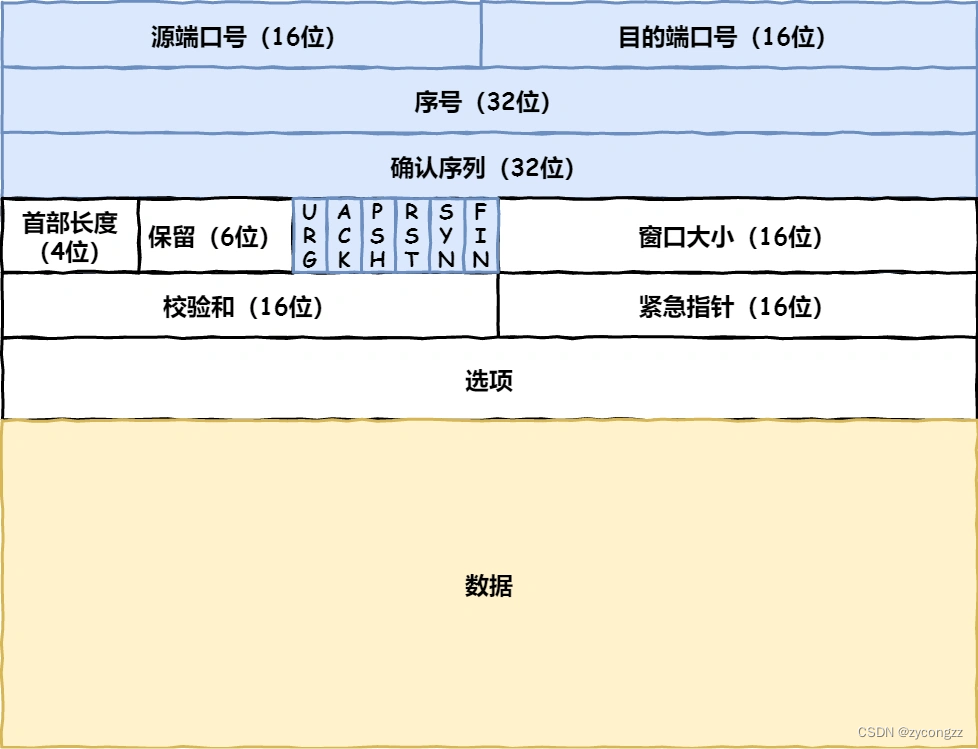
源端口号和目标端口号是不可少的,如果没有这两个端口号,数据就不知道应该发给哪个应用。
接下来有包的序号,这个是为了解决包乱序的问题。
还有应该有的是确认号,目的是确认发出去对方是否有收到。如果没有收到就应该重新发送,直到送达,这个是为了解决不丢包的问题。
接下来还有一些状态位。例如 SYN 是发起一个连接,ACK 是回复,RST 是重新连接,FIN 是结束连接等。TCP 是面向连接的,因而双方要维护连接的状态,这些带状态位的包的发送,会引起双方的状态变更。
还有一个重要的就是窗口大小。TCP 要做流量控制,通信双方各声明一个窗口(缓存大小),标识自己当前能够的处理能力,别发送的太快,撑死我,也别发的太慢,饿死我。
除了做流量控制以外,TCP还会做拥塞控制,对于真正的通路堵车不堵车,它无能为力,唯一能做的就是控制自己,也即控制发送的速度。不能改变世界,就改变自己嘛。
三次握手
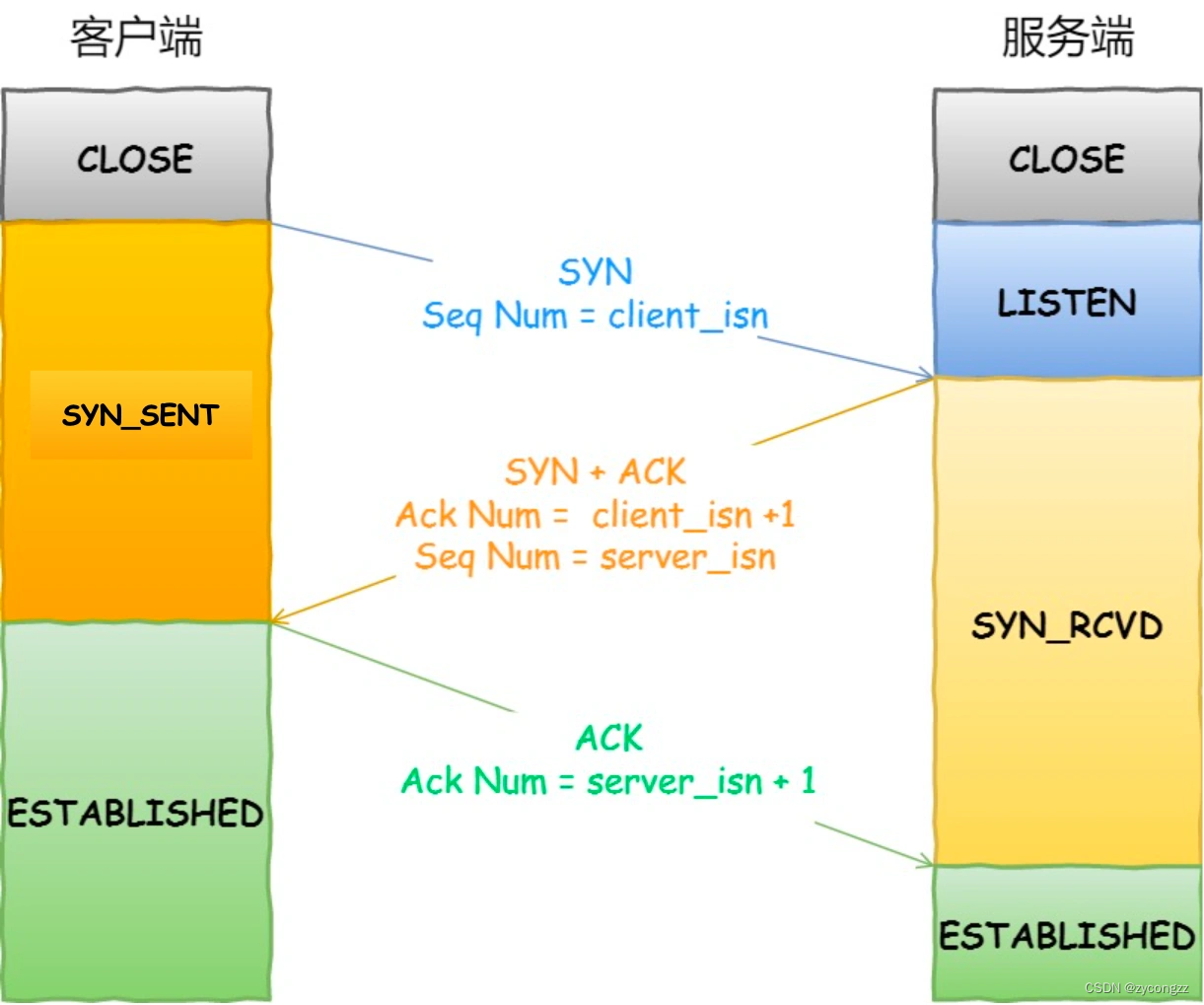
- 一开始,客户端和服务端都处于 CLOSED 状态。先是服务端主动监听某个端口,处于 LISTEN 状态。
- 然后客户端主动发起连接 SYN,之后处于 SYN-SENT 状态。
- 服务端收到发起的连接,返回 SYN,并且 ACK 客户端的 SYN,之后处于 SYN-RCVD 状态。
- 客户端收到服务端发送的 SYN 和 ACK 之后,发送对 SYN 确认的 ACK,之后处于 ESTABLISHED 状态,因为它一发一收成功了。
- 服务端收到 ACK 的 ACK 之后,处于 ESTABLISHED 状态,因为它也一发一收了。
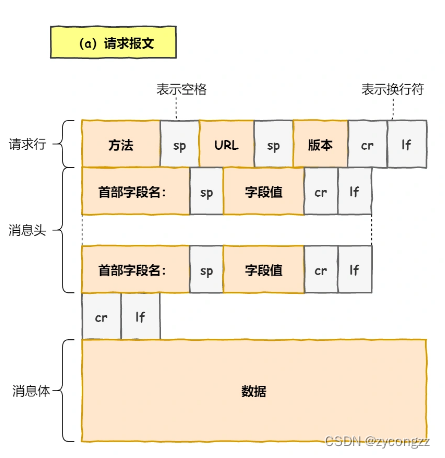
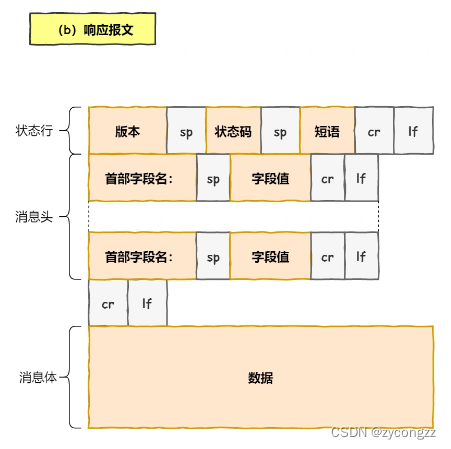
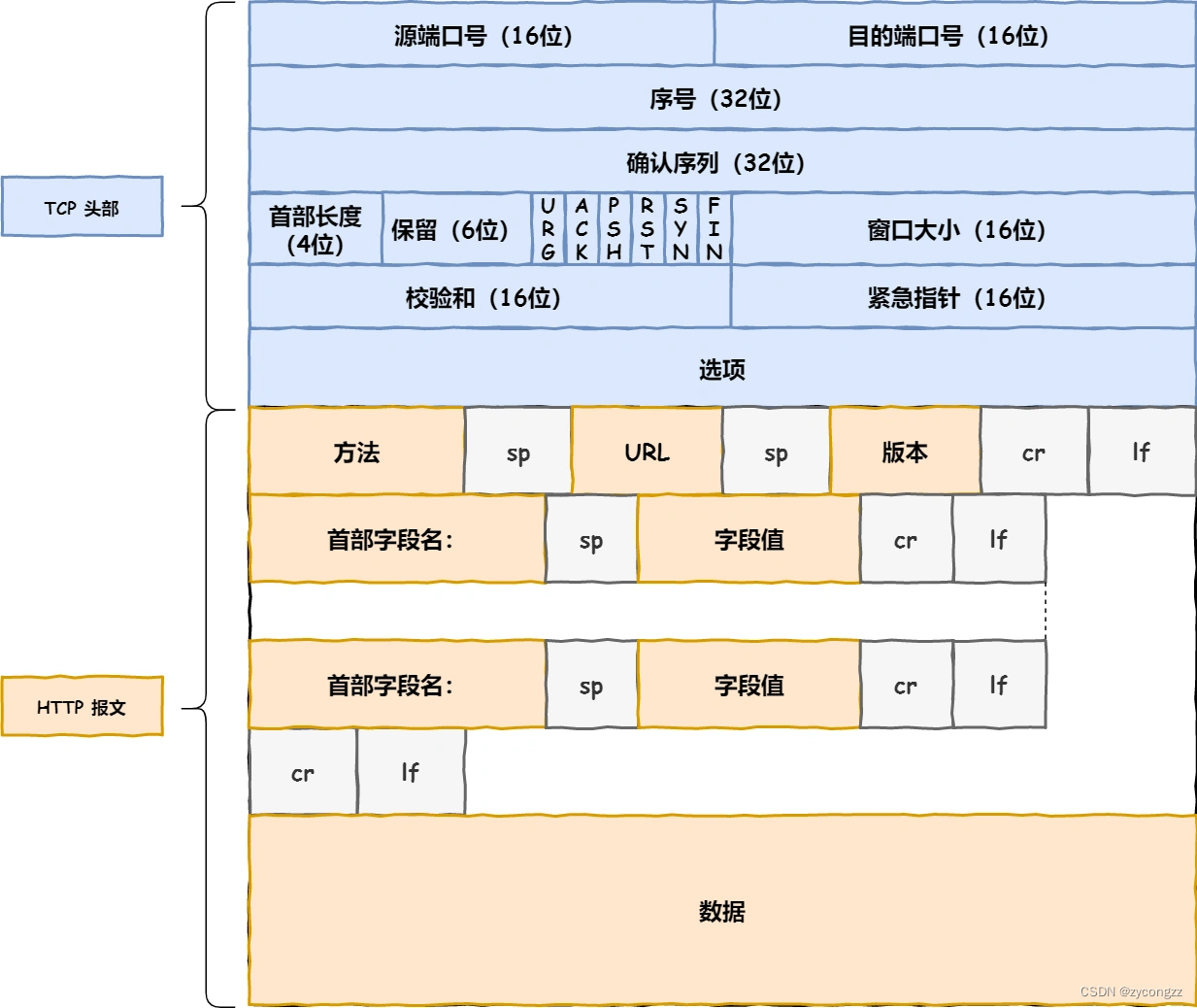
在双方建立了连接后,TCP 报文中的数据部分就是存放 HTTP 头部 + 数据,组装好 TCP 报文之后,就需交给下面的网络层处理。
至此,网络包的报文如下图
远程定位 ―― IP
MAC
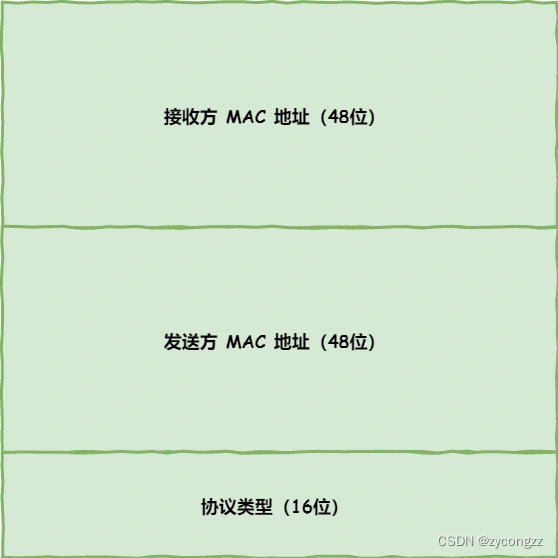
发送方的 MAC 地址获取就比较简单了,MAC 地址是在网卡生产时写入到 ROM 里的,只要将这个值读取出来写入到 MAC 头部就可以了。
接收方的 MAC 地址就有点复杂了,只要告诉以太网对方的 MAC 的地址,以太网就会帮我们把包发送过去,那么很显然这里应该填写对方的 MAC 地址。
不知道对方 MAC 地址?不知道就喊呗。
此时就需要 ARP 协议帮我们找到路由器的 MAC 地址。
ARP 协议会在以太网中以广播的形式,对以太网所有的设备喊出:“这个 IP 地址是谁的?请把你的 MAC 地址告诉我”。
然后就会有人回答:“这个 IP 地址是我的,我的 MAC 地址是 XXXX”。
如果对方和自己处于同一个子网中,那么通过上面的操作就可以得到对方的 MAC 地址。然后,我们将这个 MAC 地址写入 MAC 头部,MAC 头部就完成了。
网卡
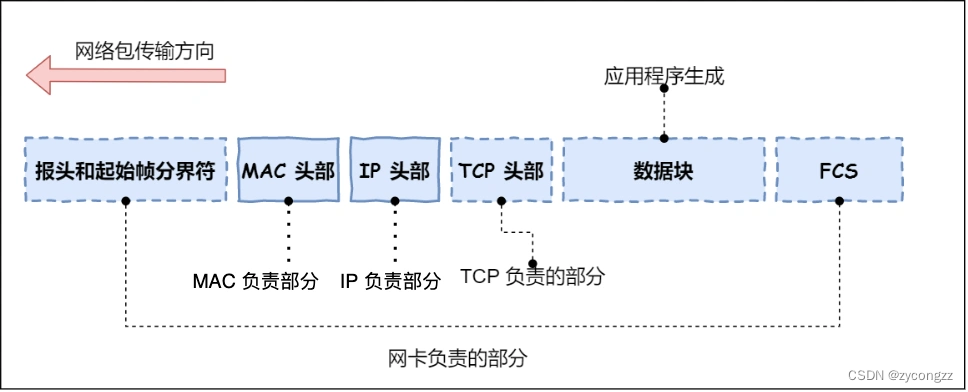
linux 网络协议栈
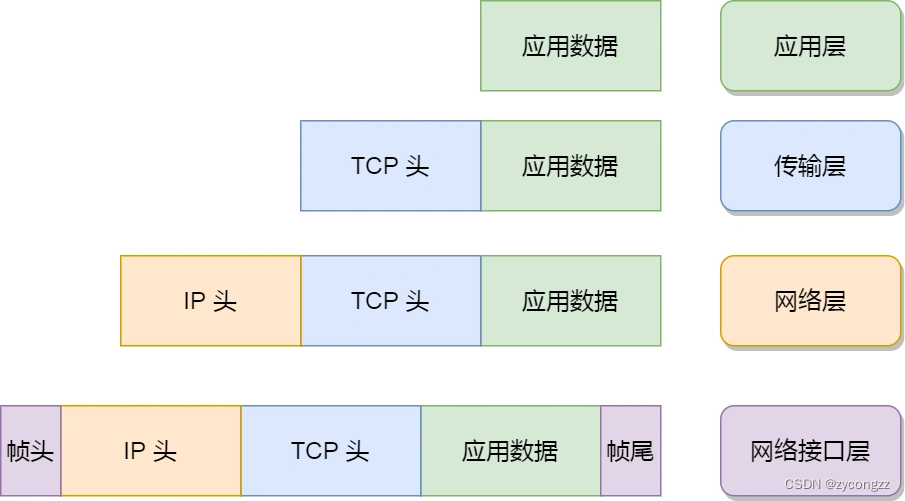
这些新增的头部和尾部,都有各自的作用,也都是按照特定的协议格式填充,这每一层都增加了各自的协议头,那自然网络包的大小就增大了,但物理链路并不能传输任意大小的数据包,所以在以太网中,规定了最大传输单元(MTU)是 1500 字节,也就是规定了单次传输的最大 IP 包大小。
当网络包超过 MTU 的大小,就会在网络层分片,以确保分片后的 IP 包不会超过 MTU 大小,如果 MTU 越小,需要的分包就越多,那么网络吞吐能力就越差,相反的,如果 MTU 越大,需要的分包就越小,那么网络吞吐能力就越好
HTTP常见面试题
http是什么?
HTTP 是超文本传输协议,也就是HyperText Transfer Protocol。HTTP 是一个在计算机世界里专门在「两点」之间「传输」文字、图片、音频、视频等「超文本」数据的「约定和规范」。
http常见的状态码

GET 与 POST
根据 RFC 规范,GET 的语义是从服务器获取指定的资源,这个资源可以是静态的文本、页面、图片视频等。GET 请求的参数位置一般是写在 URL 中,URL 规定只能支持 ASCII,所以 GET 请求的参数只允许 ASCII 字符 ,而且浏览器会对 URL 的长度有限制(HTTP协议本身对 URL长度并没有做任何规定)。
根据 RFC 规范,POST 的语义是根据请求负荷(报文body)对指定的资源做出处理,具体的处理方式视资源类型而不同。POST 请求携带数据的位置一般是写在报文 body 中, body 中的数据可以是任意格式的数据,只要客户端与服务端协商好即可,而且浏览器不会对 body 大小做限制。
GET 和 POST 方法都是安全和幂等的吗?
- GET 方法就是安全且幂等的,因为它是「只读」操作,无论操作多少次,服务器上的数据都是安全的,且每次的结果都是相同的。所以,可以对 GET 请求的数据做缓存,这个缓存可以做到浏览器本身上(彻底避免浏览器发请求),也可以做到代理上(如nginx),而且在浏览器中 GET 请求可以保存为书签。
- POST 因为是「新增或提交数据」的操作,会修改服务器上的资源,所以是不安全的,且多次提交数据就会创建多个资源,所以不是幂等的。所以,浏览器一般不会缓存 POST 请求,也不能把 POST 请求保存为书签。
但是实际过程中,开发者不一定会按照 RFC 规范定义的语义来实现 GET 和 POST 方法。比如:
可以用 GET 方法实现新增或删除数据的请求,这样实现的 GET 方法自然就不是安全和幂等。
可以用 POST 方法实现查询数据的请求,这样实现的 POST 方法自然就是安全和幂等。
HTTP缓存技术
HTTP 缓存有两种实现方式,分别是强制缓存和协商缓存。

