整理自中国科大李辉老师《数据网络理论基础》课程相关材料。
只有部分要点摘录。方便复习回顾。

文章目录
流量分析
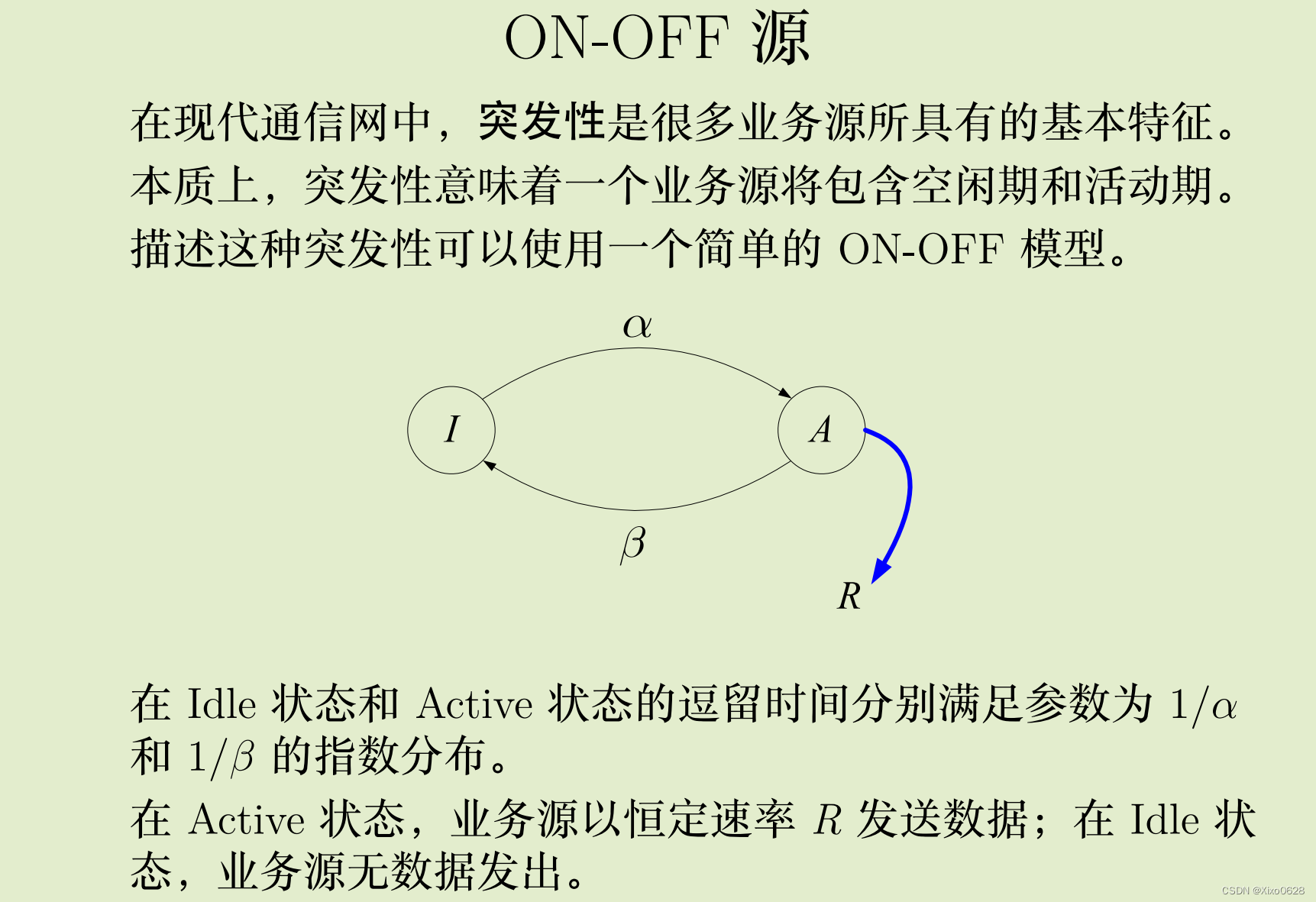
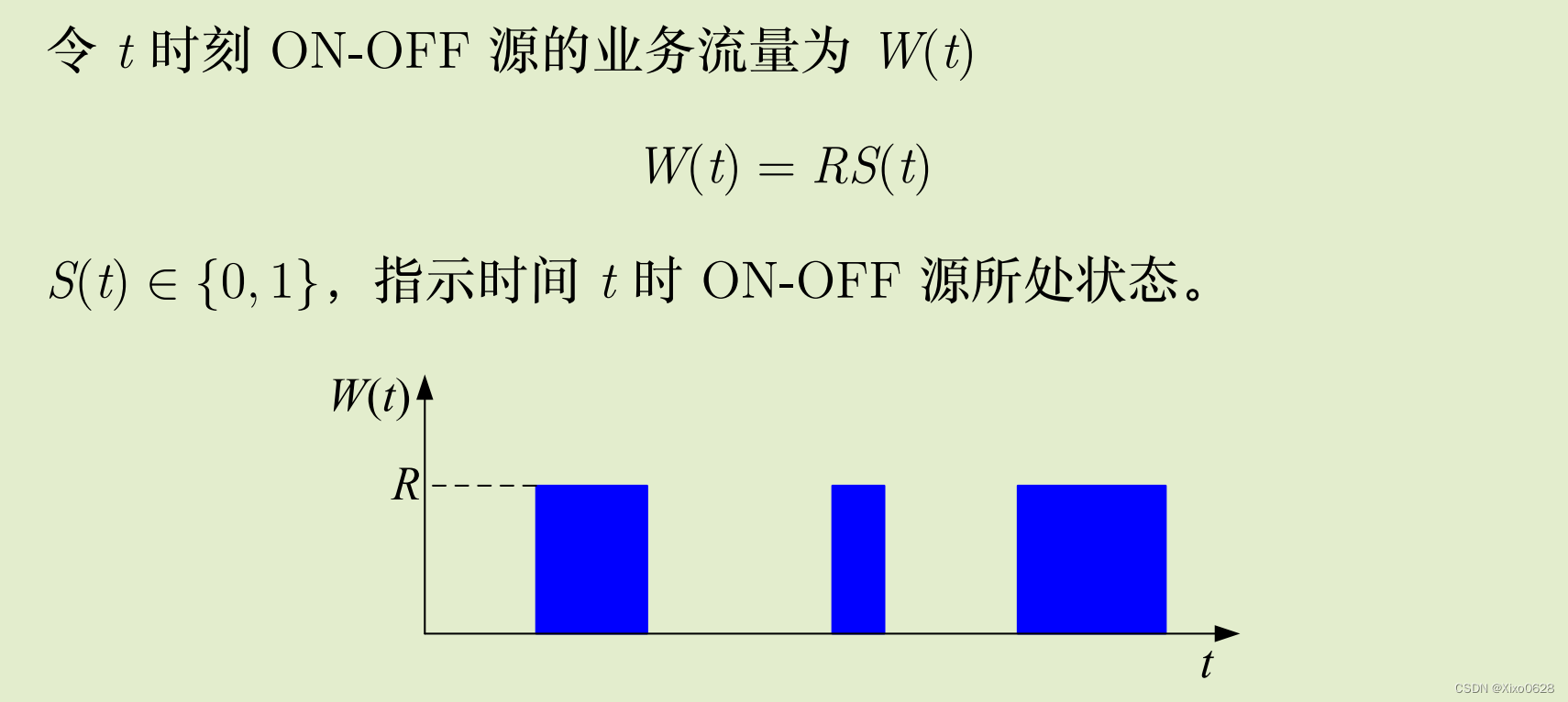
ON-OFF 源可以由最简单的生灭过程来实现,其计数值只能为 0
和 1。不同状态下的生灭速率分别为
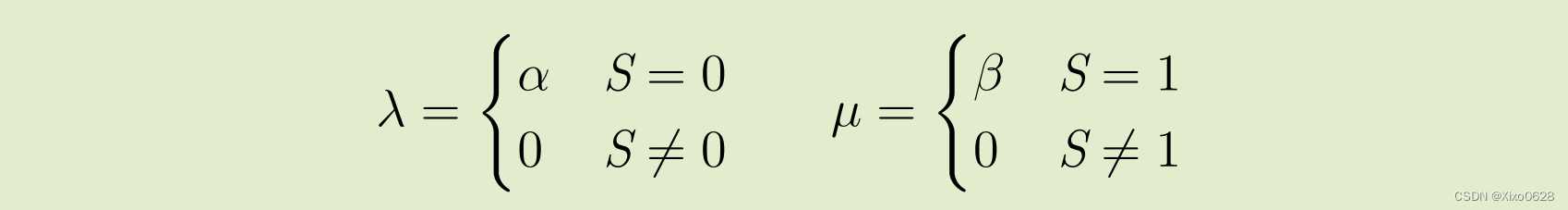
根据该系统的全局平衡方程λP0 = μP1以及 P0 + P1 = 1 可得
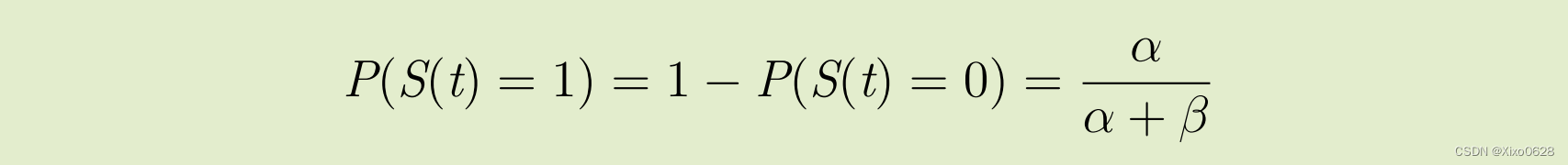

使用 N 个独立的 ON-OFF 源可以用来建模更加复杂的突发源。


拥塞控制理论
拥塞问题的产生
实际通信系统的节点存储容量、处理能力以及每条链路的传输能力都是有限的;
外部输入的业务量大于网络能处理的业务量,使相关链路队长增加,导致:
缓冲区耗尽;分组被丢弃;分组超时;
由于业务量在节点间分布的不平衡性,导致网络某个局部也可能出现分组聚集现象。导致:分组时延增加;丢失率增加;
随着输入业务量的增加,会导致网络的通过量大大下降,时延大大上升,因此必须采用必要的流量和拥塞控制措施,从而保证网络正常运行。
拥塞控制与流量控制的区别
- 拥塞控制
- 寻找对网络资源的要求小于网络可用资源的条件;
- 保证子网能够运载所提交给网络的业务;
- 涉及全网的问题,要保证整个网络有效工作;
- 流量控制
- 仅涉及到给定发送节点到给定接收节点之间的点对点业务流;
- 保证快速发送的节点不会连续发送速率高于接收节点可接收速率的数据。
拥塞控制常常通过流量控制来实现。
控制方式
开环控制:设计网络时事先将有关发生拥塞的因素考虑周到,力求网络在工作时不产生拥塞;
闭环控制:基于反馈环路的概念,采取以下措施:
- 实时检测网络,以便检测到拥塞在何时、何处发生;
- 将拥塞发生的信息传送到可采取行动的地方;
- 调整网络的运行以解决出现的问题。
实现方法
- 呼叫阻止
阻止会话进入网络,拒绝相关的访问请求。完成某种业务的资源(通信速率、优先级、时延要求)无法满足时,拒绝相应会话的建立。 - 数据包丢弃
数据包属于的会话超出公平份额地使用某些资源或可能对高优先级的会话造成阻塞,则即使缓冲区未满也将其丢弃。 - 数据包阻止
阻止数据包进入网络,在进入网络时就丢弃。
数据包调度 通过延迟或加快数据包的传输来进行流量控制。
窗口式流量和拥塞控制



统一窗口拥塞控制

该方法可以限制平均时延的上限,它独立于网络中的 Session数目;
网络的公平性和拥塞情况取决与网络发放多少 permit,如何管理这些 permit。
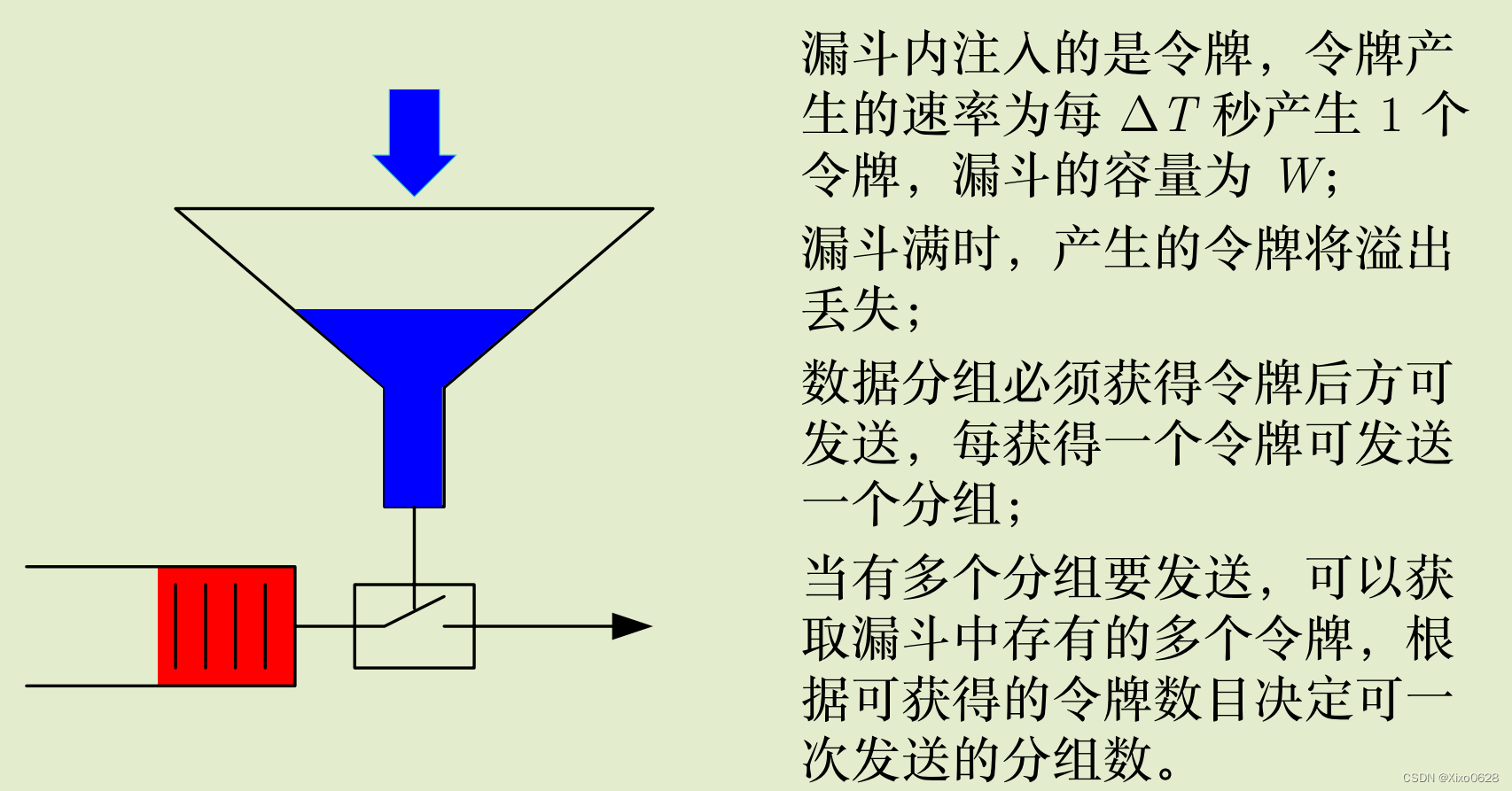
漏斗式速率控制算法
引起拥塞的主要原因之一是业务的突发性,若主机能够以均匀的速率发送,则拥塞发生的频率将大大降低;控制拥塞的一类方法就是使分组以更加可预测的速率进入网络(减少突发性);通过限制进入网络的业务量来进行拥塞控制的方法,广泛用于 ATM 网络,常被称为业务整形 (Traffc Shapping)。
漏斗算法

该方法可以将用户产生的非平稳的分组流变成一个平稳的分组流,从而平滑了用户数据分组的突发性,进而大大降低了拥塞的机会。
该算法就称为漏斗算法( Leaky Bucket Algorithm)。

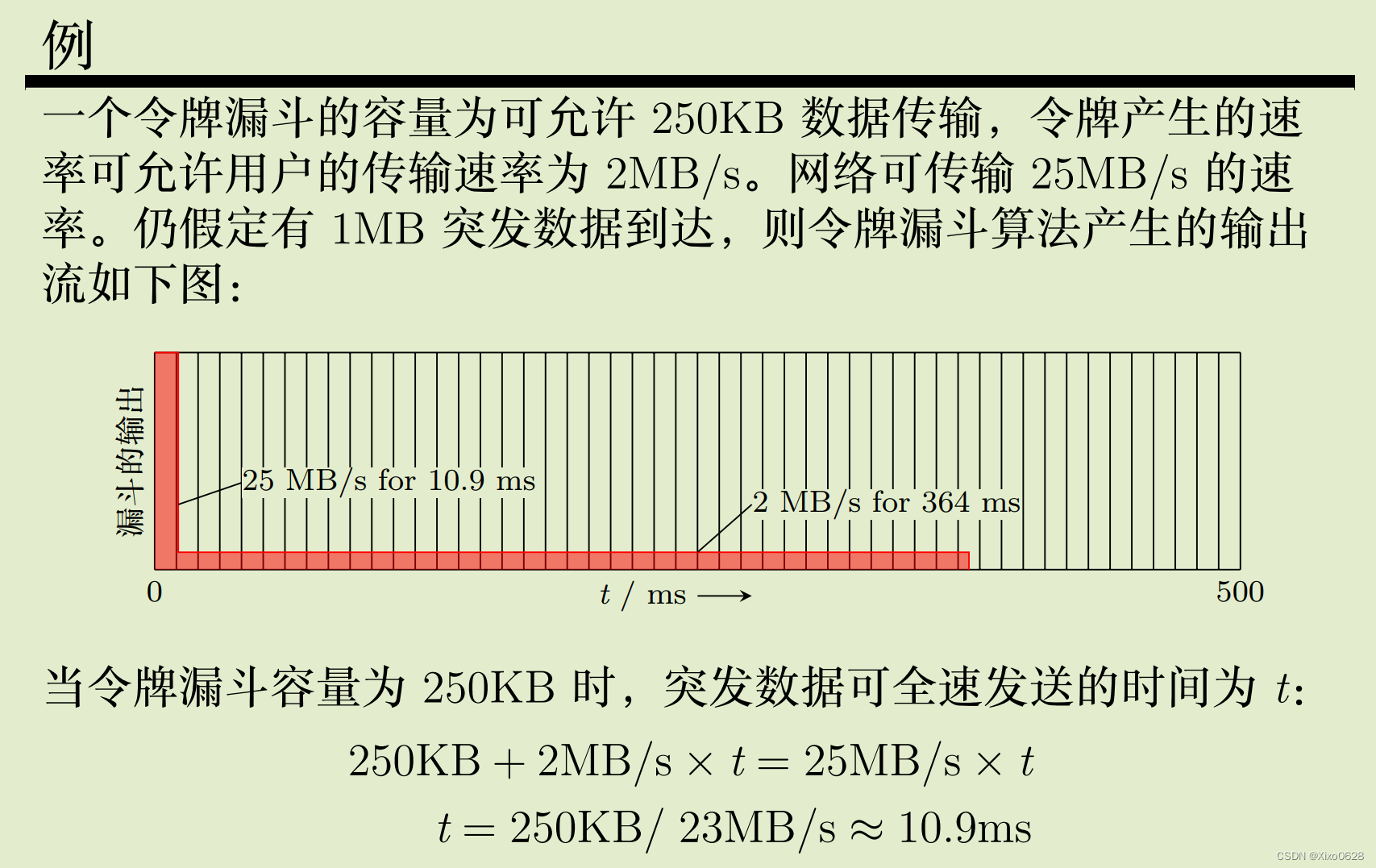
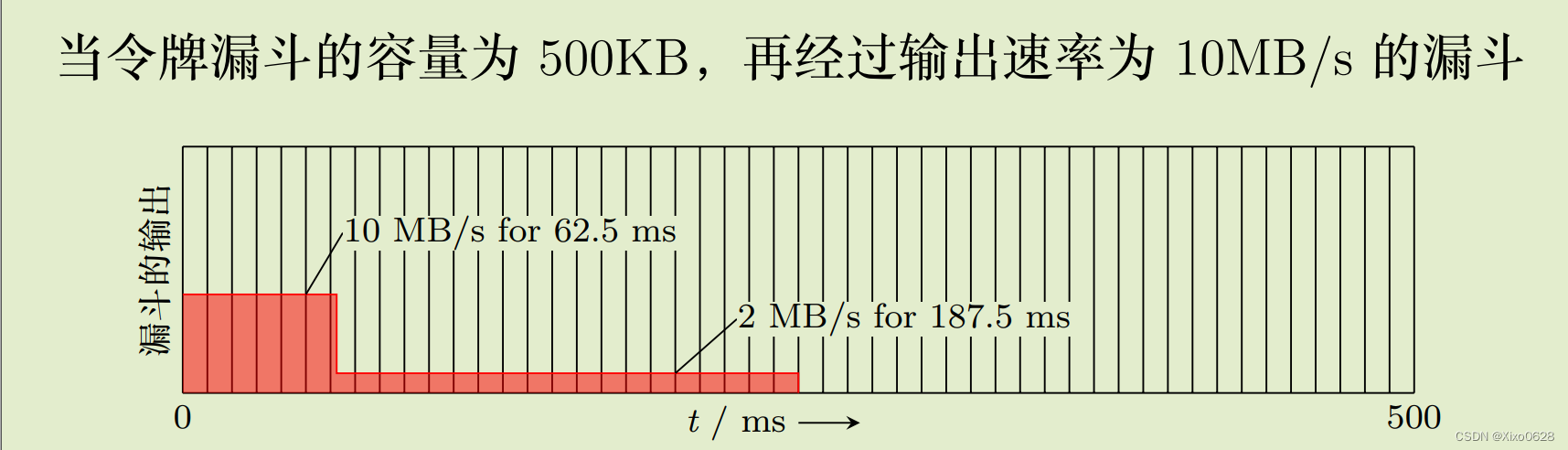
为了达到平均速率为 2MB/s,则设定漏斗的输出速率 ρ = 2MB/s,漏斗的容量 C = 1MB,则该突发经过漏斗算法处理后将产生一个持续时间为 500ms 的分组流。
漏斗算法无论在什么样的突发业务下都力图维持一个不变的输出业务流,但在很多应用场合,当一个突发到达时,希望能够加速传输,即允许输出业务流有一定的突发性。
一个典型的算法就是令牌漏斗算法 (Token Buket Algorithm),该算法不限制漏斗的流出速度,但限制令牌注入漏斗的速度。

主动队列管理
丢包
由于网络业务的突发性,正常情况下设置的缓冲区总会因为突发流量而被耗尽;
针对突发流量设置缓冲区大小,在大部分时间里会造成存储资源的浪费;
过大的缓冲区会潜在地增大分组延迟。
观察分组延迟和分组丢失是源节点检测拥塞的重要手段;
在路由器中策略性地丢弃分组可以使源节点及时地检测到拥塞出现,进而采取措施降低流量避免拥塞。
不同的丢包策略会导致不同的效率。
主动队列管理(AQN)
互联网中的路由器会为每一个接口维护一个队列;
在早期的路由器设计中,当队列满或溢出时丢弃新到分组;
主动队列管理就是在队列尚未满时,就对新到分组以某种概率采取丢弃或标记拥塞的处理。
- AQM 的优点
避免了 Drop tail 方式下的全局同步现象;
通过在队列满之前向端节点提示拥塞,可以避免拥塞,减小队长,减小网络延迟。 - AQM 的缺点
AQM 算法中的相关参数的设计对网络性能影响很大;在队列未满时就丢弃分组,造成浪费。
Random Early Detection (RED) 算法

丢弃分组在时间上分布不均,在 Pa 较大时,算法将倾向于连续地丢弃分组,由于一般流量都具有具有短时的突发性,这种模式容易连续丢弃同一个会话的多个分组,从而导致收发双方无法及时地根据窗口流控协议降低流量。

