本文介绍使用Vivado中乘法器的使用方法。
Multiplier
首先在IP Catalog中搜索Multiplier,找到后双击打开。
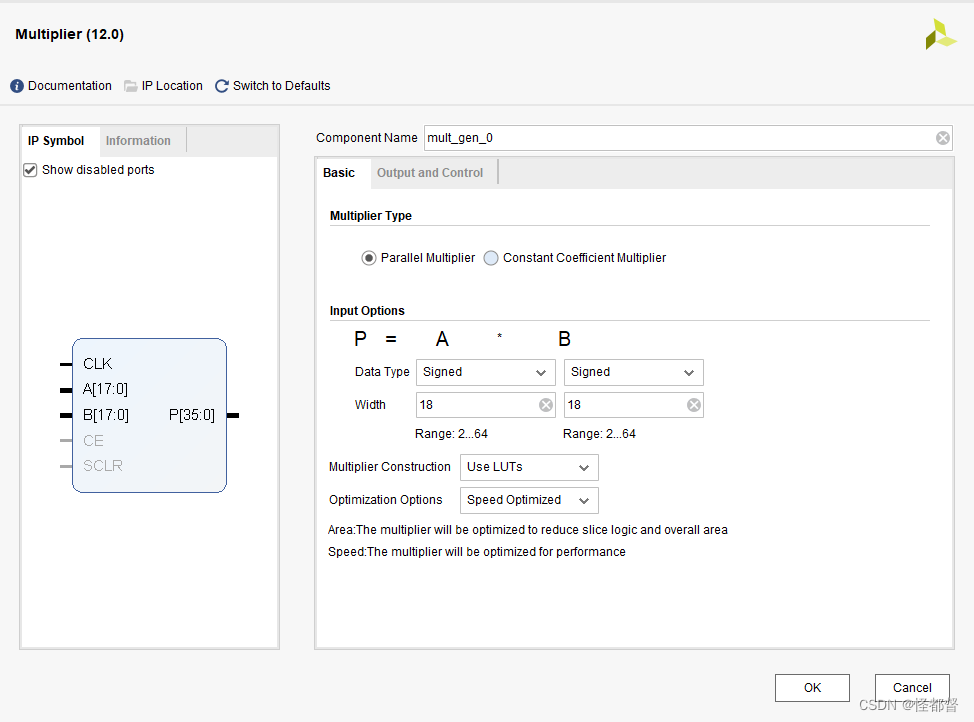
Multiplier Type:
Parallel Multiplier:并行乘法器。
Constant Coefficient Multiplier:恒定系数乘法器。
Input Options:
Data Type:Signed 二进制补码有符号数或 Unsigned二进制无符号数。
Width:操作数位宽。
Multiplier Construction: LUT或乘法器。
Optimization Options:Area Optimized 资源优先或Speed Optimized速度优先。
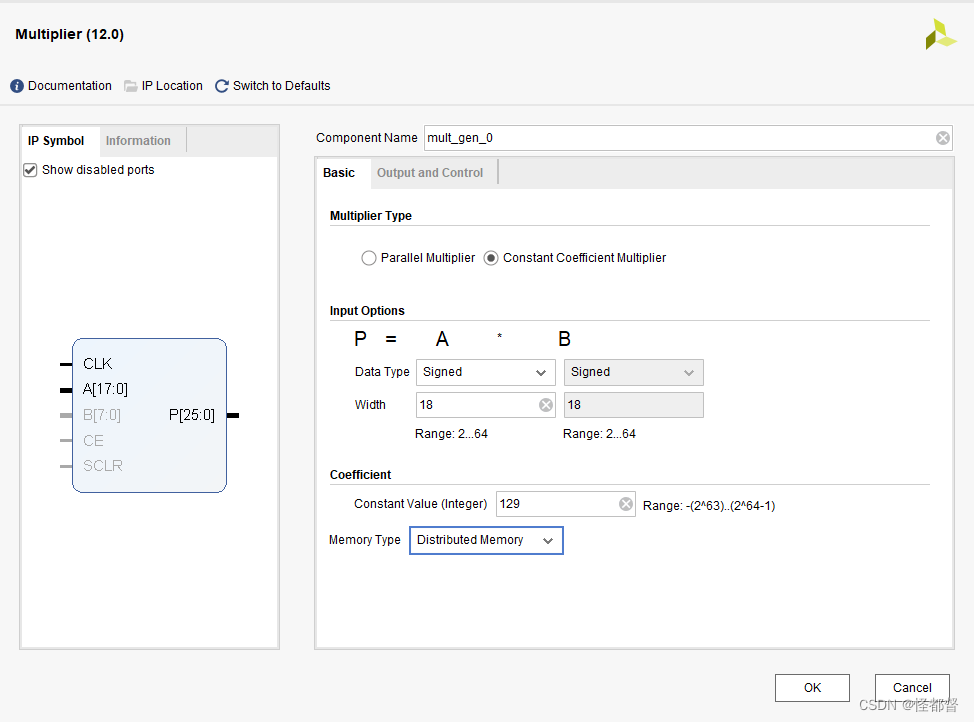
当乘法器类型选择为恒定系数时,
Coefficient:
Constant Value (Integer):输入恒定系数的整数值,支持正负系数。
Memory Type:内存类型,Distributed Memory,Block Memory,Dedicated Multiplier。
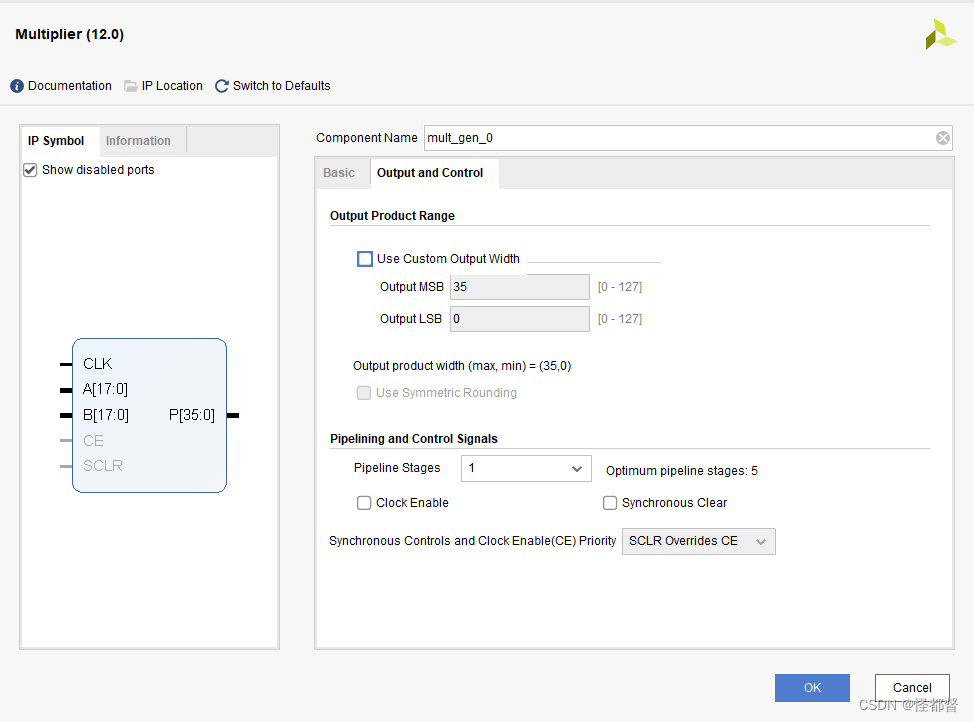
Output Product Range:
Use Custom Output Width:自定义输出宽度。
** Pipelining and Control Signals:**
Pipeline Stages:
Clock Enable:时钟使能。
Synchronous Clear: 同步清除。
SCLR/CE Priority: 设置SCLR引脚和CE引脚的优先级。
仿真
设置输入数据位宽均为16位有符号数,则输出为32位,仿真结果如下。

Complex Multiplier
首先在IP Catalog中搜索Complex Multiplier,找到后双击打开。
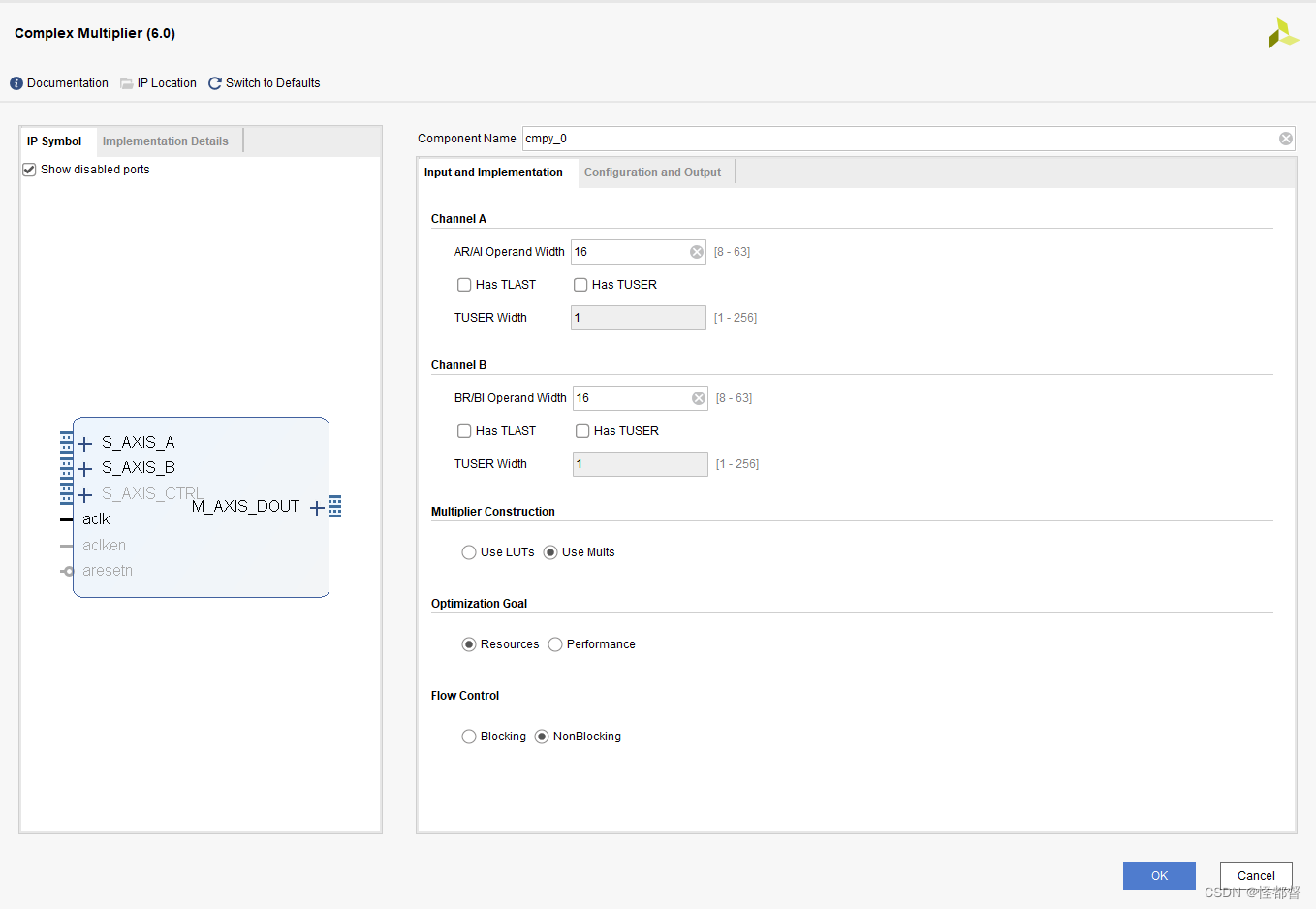
** Input and Implementation:**
Channel A:
AR/AI Operand Width:操作数位宽。
当其设置为11时,输入端口s_axis_a_tdata的结构如下图所示。
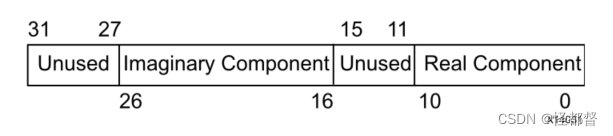
TLAST、TUSER、TUSER Width为AXI4-Stream通道选项。
Multiplier Construction:
选择使用LUT或Multiplier。
Optimization Goal:
选择资源优化或性能优化。
Flow Control Options:
选择阻塞模式或非阻塞模式。
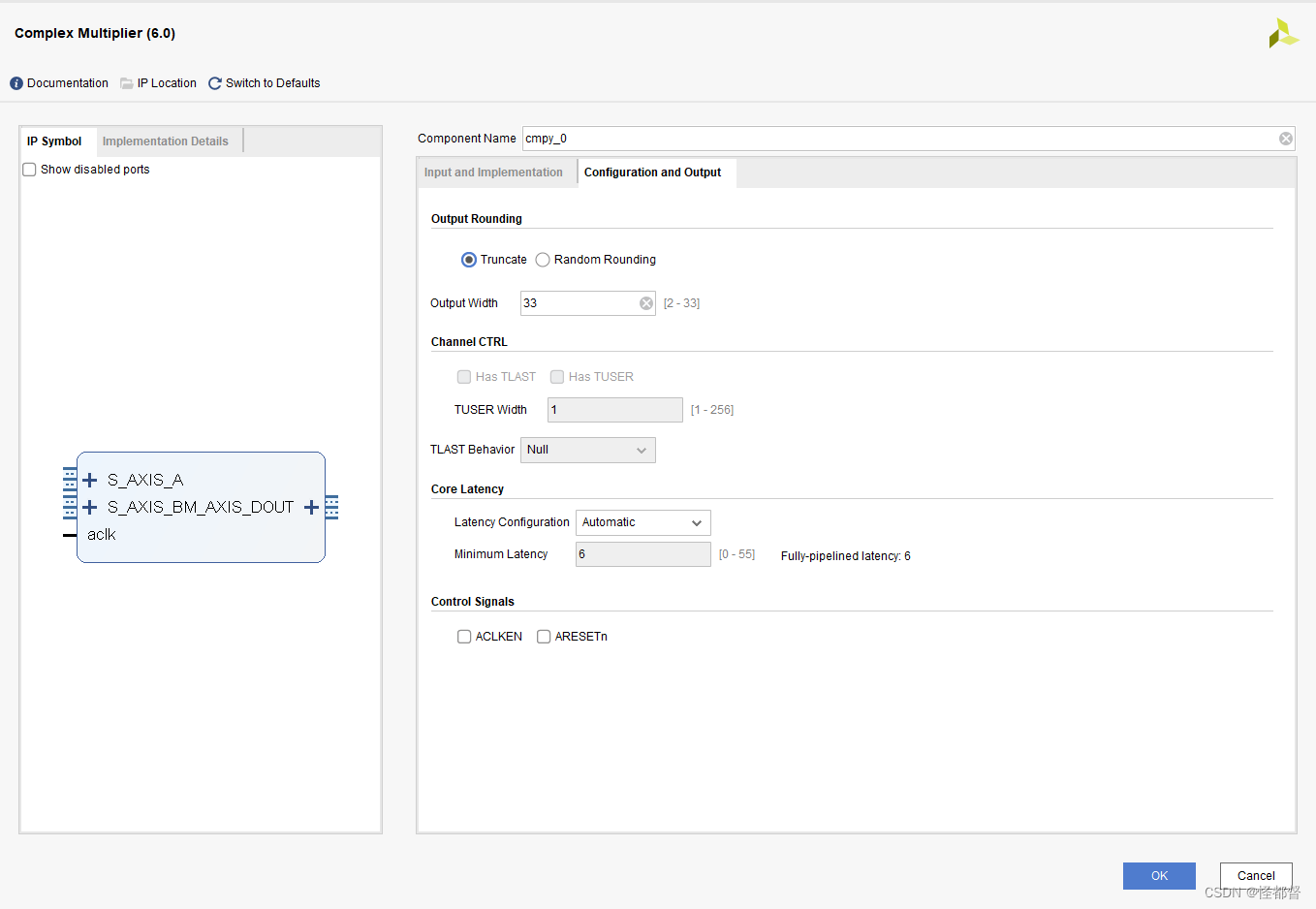
Output Rounding:
Truncate 截断 或 Random Rounding 随机舍入。
选择随机舍入时,启用CTRL通道,此时舍入类型由s_axis_ctrl_tdata的第0位ROUND_CY的值确定。
Core Latency:
Automatic 自动或 Manual 手动。
Control Signals:
ACLKEN 或 ARESETn
仿真
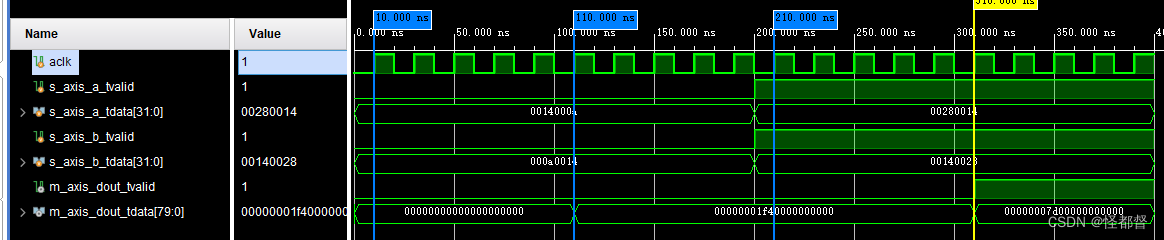
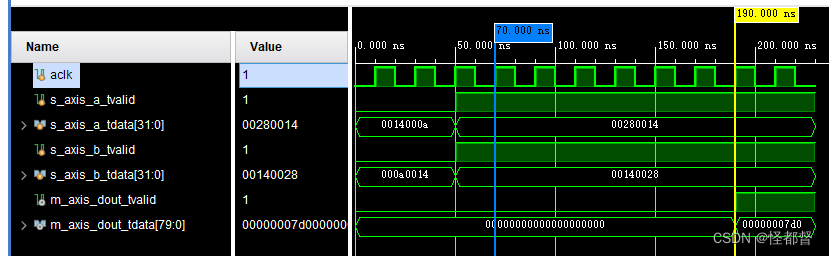
在非阻塞模式下,输入a=10+j20,b=20+j10,dout=ab=j500=j0x1F4 ;a=20+j40,b=40+j20,dout=ab=j2000=j0x7d0。
输入数据实部和虚部位宽16,则输出数据实部和虚部位宽等于16+16+1=33,又因为使用AXI4-Stream接口,需要字节对齐,所以m_axis_dout_tdata位宽80,前5个字节为输出虚部,后5个字节为输出实部。以资源优化为目标时,输出结果会延时5个时钟周期,同时在非阻塞模式下,输出不受输入tvalid影响,若输入通道接受到有效的tvalid时,输出通道才会输出tvalid。
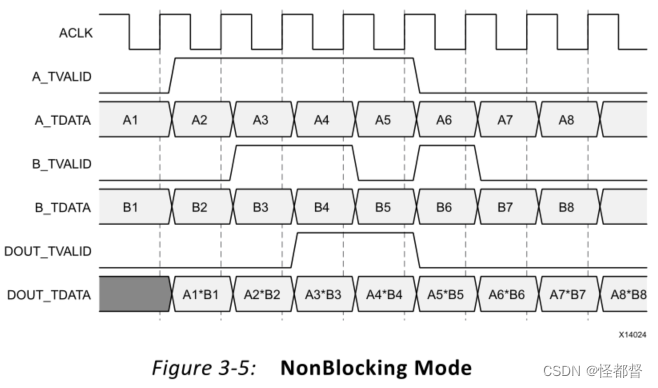
官方手册中,非阻塞模式,时序如下(其输出延迟为一个时钟周期)。
阻塞模式,并且以性能优化时,仿真结果如下。
设为阻塞模式时,内核将启用tready引脚。

官方手册中,阻塞模式下时序如下。
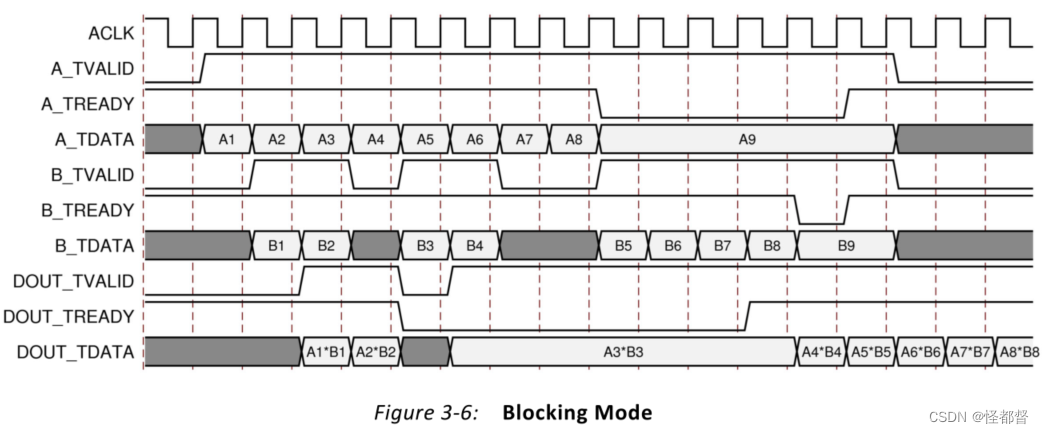
特别注意输入通道和输出通道的tready信号的方向,由此分析阻塞模式与非阻塞模式不同之处。
- 在所有输入通道上都有新数据可用之前不会执行操作,如A1*B1,A3*B3。
- 当DOUT_TREADY无效时,则数据会累积到输出缓冲区中,将不会再更新数据,如A3*B3。此时输入的数据会被存储在通道的输入缓存区中,如A4-A8、B4-B8,直到输入通道的TREADY被拉低。
- 当DOUT_TREADY有效时,输出结果依次为输入缓存区中的数据经操作后的结果,如A4*B4-A8*B8。