?网站如何检测网络爬虫?

网络爬取和网络抓取相辅相成,对于公共数据收集来说至关重要。电子商务企业会使用网络抓取工具从各个网站收集新数据。然后,将抓取到的信息用于改进业务和营销策略。
对于那些不知道如何避免抓取网站时被封IP的人来说,在抓取数据时被列入黑名单是一个常见的问题。我们整理了一个方法清单,用来防止在抓取和爬取网站时被列入黑名单。
Q:网站是如何检测网络爬虫?
A:网页通过检查其IP地址、用户代理、浏览器参数和一般行为来检测网络爬取工具和网络抓取工具。如果网站发现可疑情况,您将会收到验证码,在不输入验证码的情况下就会被网站检测到爬取程序,最终您的请求也会被阻止。
检查网络爬虫排除协议
在爬取或抓取任何网站之前,请确保您的目标网站允许从其页面收集数据。检查网络爬虫排除协议(robots.txt)文件,并遵守网站规则。
即使网页允许爬取,也要对网站持尊重态度,不要做任何破坏网页的行为。请遵循网络爬虫排除协议中概述的规则,在非高峰时段进行爬取,限制来自一个IP地址的请求数,并在请求之间设置延迟值。
但是,即使该网站允许进行网页抓取,您仍然可能会被封锁,因此也必须执行其他必要步骤,这点很重要。
轮换您的IP地址以减少被封锁的风险
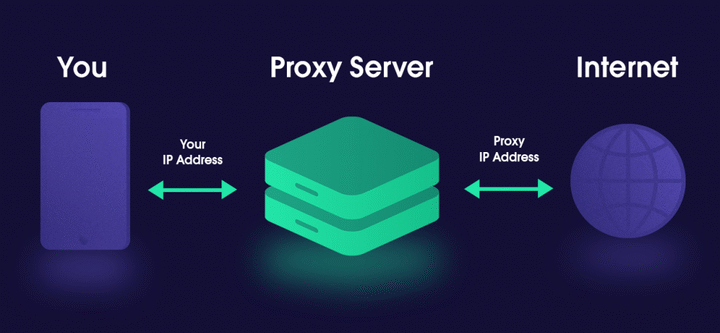
使用代理服务器
没有代理服务器,几乎不可能进行网络爬取。选择一个可靠的代理服务提供商,并根据您的任务在数据中心代理和住宅代理之间进行选择。
在设备和目标网站之间使用中介可以减少IP地址被封的风险,确保匿名,并允许您访问您所在地区不可用的网站。例如,如果您的总部位于德国,则可能需要使用美国代理才能访问美国的网页内容。
为了获得最佳结果,请选择能够提供大量IP和大量位置的代理提供商。
轮换IP地址
使用代理池时,轮换IP地址很有必要。
如果您从同一IP地址发送太多请求,目标网站将很快把您标识为威胁并封锁您的IP地址。代理轮换使您看起来像许多不同的网络用户,减少了被封锁IP的概率。
所有Oxylabs住宅代理都在轮换IP,但是如果您使用的是数据中心代理,则应使用代理轮换服务。我们还轮换IPv4和IPv6代理。如果您对IPv4与IPv6之间的差异感兴趣,请点击前方链接查看我们同事Iveta撰写的文章。
轮换您的IP地址以减少被封锁的风险
使用真实用户代理
托管网站的大多数服务器都可以分析爬虫发出的HTTP请求header。这个HTTP请求header(称为用户代理)包含从操作系统和软件到应用程序类型及其版本的各种信息。
服务器可以轻松检测可疑的用户代理。实际用户代理包含由有机访问者提交的流行的HTTP请求配置。为避免被封锁,请确保自定义用户代理,使其看起来像是一个有机代理。
由于网络浏览器发出的每个请求都包含一个用户代理,因此您应该经常切换该用户代理。
使用最新的和最常用的用户代理也很重要。如果您使用Firefox浏览器的旧版本,而这个旧版本不再提供技术支持,用该浏览器发出用户代理请求后,则会引发很多危险信号。您可以在互联网上找到公共数据库,这些数据库向您显示哪些用户代理是当今最受欢迎的用户代理。我们还拥有自己的定期更新的数据库,如果您需要访问它,请与我们联系。
正确设置指纹
反抓取机制变得越来越复杂,一些网站使用传输控制协议(TCP)或IP指纹来检测僵尸程序。
抓取网页时,TCP会留下各种参数。这些参数由最终用户的操作系统或设备设置。如果您想知道如何防止在抓取时被列入黑名单,请确保您的参数一致。
如果您有兴趣,请详细了解指纹及其对网络抓取的影响。
当心蜜罐陷阱
蜜罐是HTML代码中的链接。这些链接对于自然用户不可见,但是网络爬虫可以检测到它们。蜜罐用于识别和阻止网络爬取程序,因为只有爬虫才能跟踪该链接。
由于设置蜜罐需要相对大的工作量,因此该技术并未得到广泛使用。但是,如果您的请求被阻止并且检测到爬取程序,请注意您的目标可能正在使用蜜罐陷阱。
使用验证码解决服务

当目标识别出可疑行为时,它会要求输入验证码
验证码是网络爬网最大挑战之一。网站要求访问者解决各种难题,以确认他们是人而不是爬虫。现有的验证码通常包含计算机几乎无法读取的图像。
抓取时如何绕过验证码?为了解决验证码问题,请使用专用的验证解决服务或即用型爬网工具。例如,Oxylabs的数据爬取工具可以为您解决验证码问题,并提供可立即使用的结果。
更改抓取模式
该模式指的是如何配置您的爬虫以浏览网站。如果您始终使用相同的基本爬取模式,那么被封锁只是时间问题。
您可以添加随机的单击,滚动和鼠标移动,以使您的爬取变得难以预测。但是,该行为不应完全随机。开发爬取模式时的最佳做法之一是考虑普通用户如何浏览网站,然后将这些原理应用于工具本身。例如,首先访问主页,然后才访问内页,这样会显得比较正常。

数据抓取通常用于电子商务业务
降低抓取速度
为了减轻被封锁的风险,您应该放慢抓取速度。例如:您可以在请求之间添加随机间隔,或者在执行特定操作之前启动等待命令。
Q:如果由于速率限制而无法抓取该网址怎么办?
A:IP地址速率限制意味着在特定时间网站上可执行的操作数有限。为避免请求受到限制,请尊重网站并降低抓取速度。
在非高峰时段爬取
大多数爬虫在页面上的浏览速度比普通用户要快得多,因为它们实际上并不读取内容。因此,一个不受限制的网络爬取工具将比任何普通的互联网用户对服务器负载的影响都更大。反过来,由于服务速度变慢,在高负载时间进行爬取可能会对用户体验产生负面影响。
寻找最佳时间爬取网站会因情况而异,但是在午夜之后(仅针对服务)选择非高峰时间是一个不错的开始。
避免爬取图像
图像是数据量大的对象,通常可以受到版权保护。这不仅会占用额外的带宽和存储空间,而且还存在侵犯他人权利的风险。
此外,由于图像数据量很大,因此它们通常隐藏在JavaScript元素中(例如,在延迟加载之后),这将大大增加数据采集过程的复杂性并减慢网络爬虫的速度。为了从JS元素中获取图像,必须编写并采用更复杂的抓取程序(某些方法会迫使网站加载所有内容)。
避免使用JavaScript
嵌套在JavaScript元素中的数据很难获取。网站使用许多不同的JavaScript功能来根据特定的用户操作显示内容。一种常见的做法是仅在用户输入一些内容后才在搜索栏中显示产品图像。
JavaScript还可能导致许多其他问题――内存泄漏,应用程序不稳定或有时完全崩溃。动态功能通常会成为负担。除非绝对必要,否则避免使用JavaScript。
使用无头浏览器
反封锁网页抓取的其它工具之一就是无头浏览器。无头浏览器除了没有图形用户界面(GUI),它与任何其它浏览器一样工作。
无头浏览器还允许抓取通过呈现JavaScript元素加载的内容。使用最广泛的网络浏览器Chrome和Firefox均具有无头模式。
总结
爬取公共数据,做好各类防封措施,例如正确设置浏览器参数,注意指纹识别,并当心蜜罐陷阱等,就再也不用担心在抓取时被列入黑名单了。但最重要的大前提是,使用可靠的代理并尊重网站。这些措施都到位后,您所有的公共数据收集工作将顺利进行,您将能够使用新抓取到的信息来改善您的业务。
如果您仍然怀疑爬取和抓取网站是否合法,请查看我们的博客文章网络抓取合法吗。