示例demo asrt-vue-demo
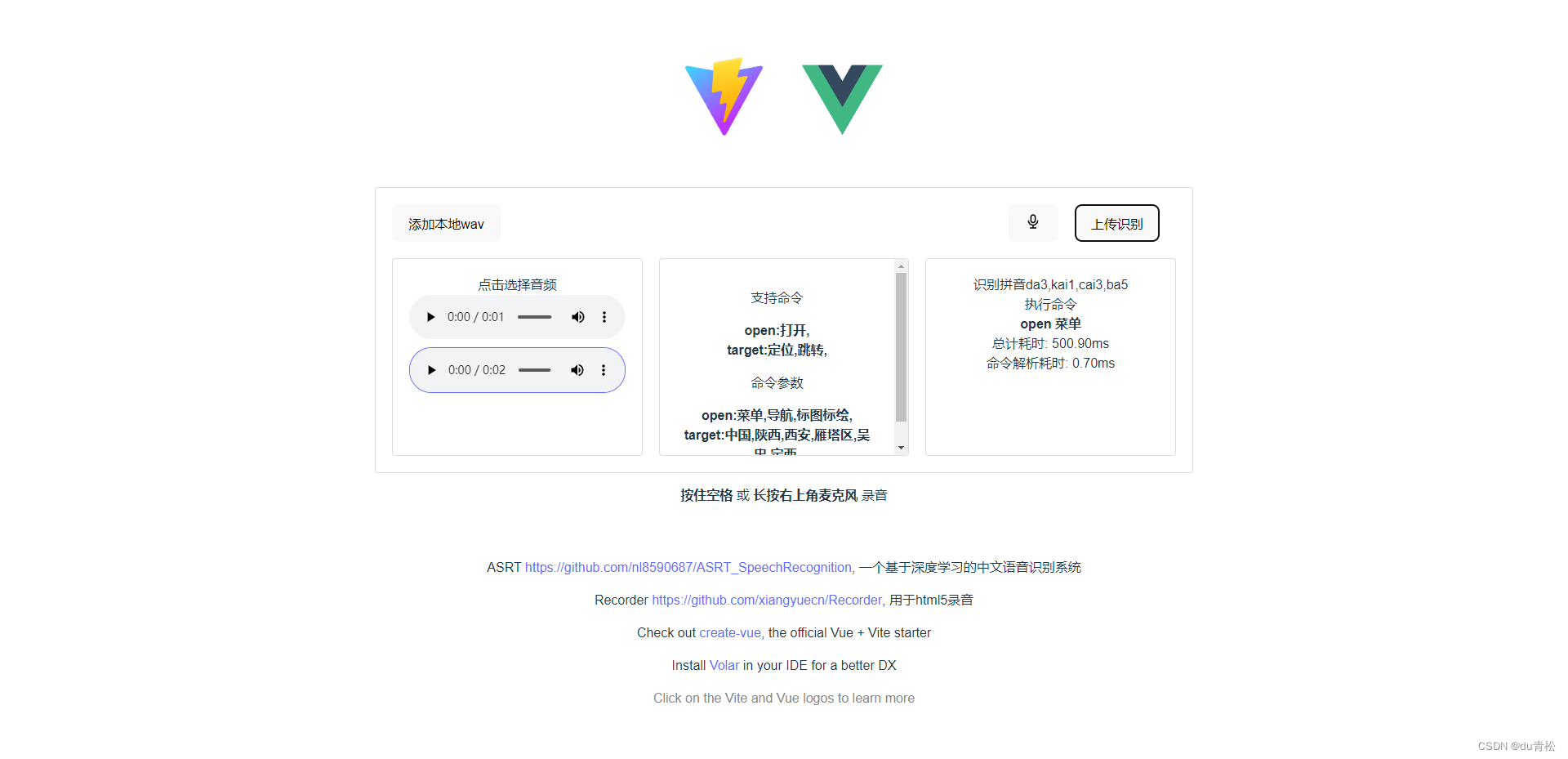
ASRT 环境配置
- 项目地址 https://github.com/nl8590687/ASRT_SpeechRecognition
- 服务端下载地址 https://wiki.ailemon.net/docs/asrt-doc/download
- ASRT语音识别工具文档
用的ASRT提供的http服务,对应文件为 asrserver_http.py, 默认端口20001,没有配置跨域,跨域这边我用nginx跨域代理了还是不行,最后直接用flask-cors 在服务端解决
可以说,最麻烦的就是环境配置这块了,
说一下我两台设备安装的经历吧
设备A windows11 + i5-10200H + GTX 1650
设备B windows11 + i7-12700H + RTX 3060
第一天: 设备A安装,NVIDIA控制面板CUDA驱动版本为11.1.114,我就去安装了11.1版本的CUDA,官网CUDA Toolkit 11.1.1 只有windows10,我试了下,结果安装失败,我就点x了,试了下启动http服务脚本,结果启动成功了,可以正常调用接口识别 (现在想来可能是以cpu模式运行了)
回去以后用设备B安装,CUDA驱动版本为11.7.1,直接安装对应版本的CUDA了,安装成功,但是启动找不到很多东西,于是直接按照柠檬教程走了,vs c++,对应CUDA版本的cuDNN 一套整上,此时离谱的就来了,启动http服务仍然很多dll找不到,但是这些dll确实是存在的,最后看到这篇文章评论区解决https://blog.csdn.net/qq_41112170/article/details/121878288 , 降级到2.8版本的cuDNN成功跑起!
第二天: 设备A再次启动asrt http,启动失败,很多dll找不到… 于是安装 CUDA 11.7.1 + cuDNN 2.8解决
直接安装cpu版本的tensorflow 就不用安装CUDA相关的了,但是速度上差异还是比较大的,下面两图是我在设备A测试的,同一条音频,上 cpu 下 gpu
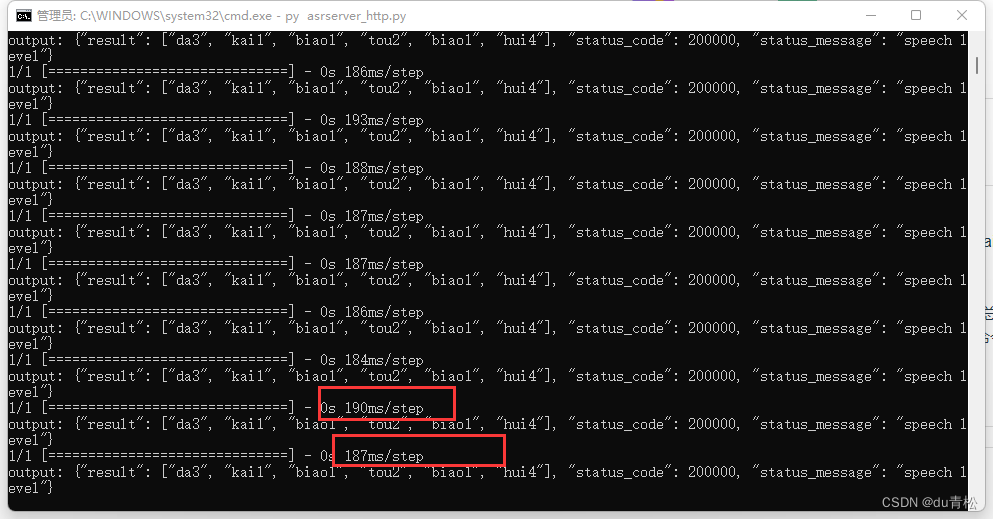
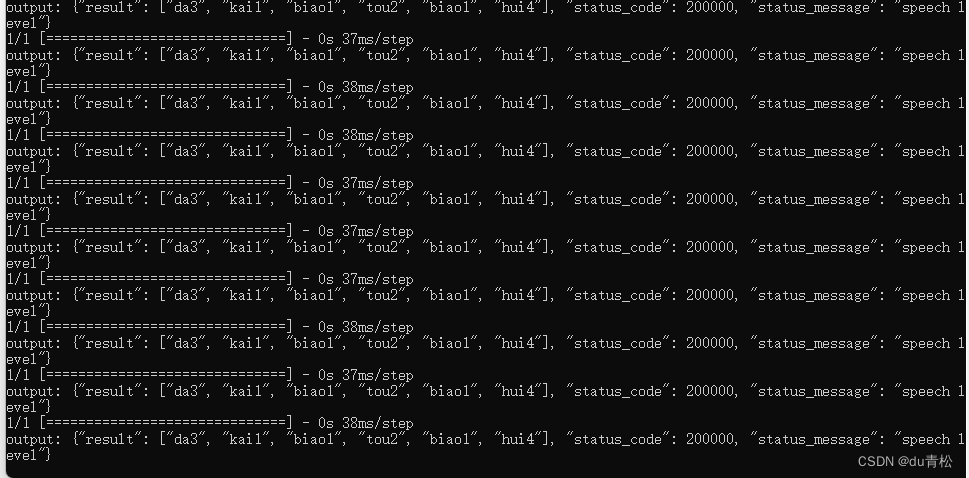
补充参考: 设备三 无NVIDIA 显卡,cpu为 Intel Xeon Silver 4210R, 一次请求平均耗时500ms,接入项目测试延时感知不强
前端音频处理
音频文件格式标准
- 文件格式:wav格式文件,文件名通常以.wav结尾
- 文件头标记:diff文件头 (暂时不理解这个
- 采样频率:16 kHz,对应参数为16000
- 声道数:单声道
- 采样位宽/字节宽度:16 bits的采样位宽, 或2 bytes 样本点的字节宽度(2 bytes * 8 bit/byte = 16 bits), 256 bps 采样比特率 (pcm或raw格式都可以,只要格式正确、能够正常读取到内容即可)
音频采集流程
参考 ASRT语音识别体验Demo
需要引入一个 recorder.wav.min.js 用于录音
注: 非本地环境需要HTTPS才能录音
- 创建 Recorder 实例
rec = Recorder({
// 类型
type: "wav",
// 采样频率
sampleRate: 16000,
// 采样位宽
bitRate: 16
});
- 开始录音
注: open是个异步函数,open后调用start即可录制
rec.open(rec.start)
- 结束录音
// blob: 音频文件
// duration: 时长ms
rec.stop(function(blob, duration) {
// ...
})
4.封装请求数据
const reader = new FileReader();
reader.onloadend = function() {e
const data = {
'channels': 1,
'sample_rate': 16000,
'byte_width': 2,
'samples': (/.+;\s*base64\s*,\s*(.+)$/i.exec(reader.result)||[])[1]
}
// fetch ajax...
}
reader.readAsDataURL(blob)
命令关键字识别
首先定义, 一条完整的命令 = 命令 + 参数
如 打开菜单, 打开即命令,菜单即参数
因此,只要识别出语句中含有的命令+参数就就可以知道执行什么命令了,
帮我打开菜单,我要打开菜单都是打开菜单
当然这也有个问题,就是三秒后打开菜单也会被识别成打开菜单,这样的话一条完整的命令应该 = 执行条件 + 命令 + 参数 了,目前还不考虑这种情况!
主要有三部分
- 字典: 定义拼音所有可识别的文字
export const dict = {}
dict['an'] = '安'
dict['cai'] = '菜才采'
// ...
- 命令: 定义命令及其对应的关键字
这里考虑的是一个命令可能对应多个关键字
export const commands = new Map()
commands.set('open', ['打开'])
commands.set('target', ['定位', '跳转'])
- 参数: 定义命令对应的参数(这里参数即关键字,关键字即参数)
export const commandsParam = new Map()
commandsParam.set('open', ['菜单', '导航', '标图标绘'])
commandsParam.set('target', ['中国', '陕西', '西安', '雁塔区', '吴忠', '定西'])
大概流程
-
ASRT 使用 /speech 接口获取语音的拼音,如 [‘da3’,‘kai1’,‘cai4’,‘dan1’]
这步有时候拼音对了声调不对,所以处理词典的时候不考虑音调以提高准确率 -
前端通过自定义的词典获取可能存在的文字 如 [‘打’, ‘大’, ‘开’, ‘楷’, ‘菜’, ‘才’, ‘单’, ‘跳’, ‘转’]
// speechs 接口返回的拼音集合
export const resolveWords = function(speechs) {
let result = ''
speechs.forEach(item => {
result += dict[item.substring(0, item.length - 1)] || ''
})
return result
}
- 根据解析出来的文字 对 命令相关的关键词进行权重分析得到权重最高的命令 如 open
export const resolveCommand = function(words) {
// { 命令 => 权重 }
const weightMap = new Map()
commands.forEach((_, key) => weightMap.set(key, 0))
let result = null
Array.from(words).forEach((word, key) => {
for (const item of weightMap) {
const commandKeywords = commands.get(item[0]).join('')
if(commandKeywords.includes(word)) {
const w = item[1] + 1
weightMap.set(item[0], w)
if(!result || result[1] < w) {
result = [item[0], w]
if(w >= (words.length / 2)) {
break
}
}
}
}
})
return result ? result[0] : ''
}
- 如果有命令,就通过解析出来的文字对命令参数进行权重分析得到参数
跟命令权重分析差不多, 这里遍历文字的时候从后往前,因为一般都是命令+参数,从后往前减小命令关键字对权重计算的影响
export const resolveCommandParams = function(command, words) {
const params = commandParams.get(command)
if(!params) return
// { 命令参数 => 权重 }
const weightMap = new Map()
params.forEach(item => weightMap.set(item, 0))
let result = null
// 从后往前,减小命令关键字对参数计算的影响
Array.from(words).reverse().forEach((word, key) => {
for (const key of weightMap) {
if(key[0].includes(word)) {
const w = key[1]+1
weightMap.set(key[0], w)
if(!result || result[1] < w) {
result = [key[0], w]
if(w >= (words.length / 2)) {
break
}
}
}
}
})
return result ? result[0] : ''
}
- 执行命令
const executeCommand = function(command, params) {
switch(command) {
case 'open':
console.log('执行命令: 打开' + params);
break;
case 'target':
console.log('执行命令: 定位' + params);
break;
default:
console.warn(`命令${command}不存在`)
}
}
目前总的字典数和关键字越少精确度就越高,欢迎大佬给这个算法指点一二啊!!!