HTTP ��Դ
HTTP ���ɵ�ķ������˹-��(TimBerners��Lee)��1989����ŷ�����о���֯(CERN)������
�������������� 1999 �� 6 �¹����� RFC 2616[1],������ HTTP Э�����ֽ�㷺ʹ�õ�һ���汾����HTTP 1.1

HTTP ��ʲô
ȫ��:���ı�����Э��(HyperText Transfer Protocol)
����:HTTP ��һ���ܹ���ȡ�� HTML��ͼƬ��������Դ��ͨѶЭ��(protocol)�������� web �Ͻ������ݽ����Ļ���,��һ�� client-server Э��
HTTP�����������Ķ�ý����ʹ ������HTTPȨ��ָ�ϡ���HTTP ���������Ľ�ɫ:�䵱һ����ʹ�Ľ�ɫ,�ɵľ���һ�����ȵĻ�,�ڿͻ��˺ͷ����֮�䴫����Ϣ,�������ֲ���ȱ������HTTP Э����Ӧ�ò��Э��,����ǰ�˿�����ϢϢ��ص�Э�顣ƽʱ���������� HTTP ���� HTTP ���桢Cookies���������ʵ���� HTTP ϢϢ���
HTTP �Ļ�������
- ����չЭ�顣
HTTP 1.0���ֵ�HTTP headers��Э����չ��ø��ӵ����ס�ֻҪ����˺Ϳͻ��˾�headers�������һ��,�¹��ܾͿ��Ա����ɵļ������ HTTP����״̬�ġ��лỰ�ġ���ͬһ��������,����ִ�гɹ���HTTP����֮����û�й�ϵ�ġ���ʹ�����һ������,�û�û�а취��ͬһ����վ�н��������Ľ���,������һ��������վ��,�û���ij����Ʒ���뵽���ﳵ,�л�һ��ҳ����ٴ���������Ʒ,������������Ʒ������֮��û�й���,�������֪���û�����ѡ������Щ��Ʒ����ʹ��HTTP��ͷ����չ,HTTP Cookies�Ϳ��Խ��������⡣��Cookies���ӵ�ͷ����,����һ���Ự��ÿ�������ܹ�����ͬ����������Ϣ,�����ͬ��״̬��HTTP�����ӡ�ͨ��TCP,����TLS�������ܵ�TCP����������,�������κοɿ��Ĵ���Э�鶼����ʹ�á������Ǵ������Ƶ�,��Ӹ�������������HTTP�ķ��롣
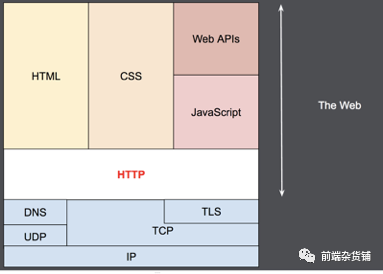
Ҳ����˵,HTTP �������������ӵ� TCP ������Ϣ����,�����Ӳ����DZ���ġ�ֻ��Ҫ���ǿɿ���,��ʧ��Ϣ��(���ٷ��ش���)��
HTTP/1.0 Ĭ��Ϊÿһ�� HTTP ����/��Ӧ����һ�������� TCP ���ӡ�����Ҫ��������������ʱ,����ģʽ�ȶ��������ͬһ�� TCP ���Ӹ���Ч��Ϊ��,HTTP 1.1 �־����ӵĸ���,�ײ� TCP ���ӿ���ͨ�� connection ͷ��ʵ�֡��� HTTP 1.1 ��������Ҳ�Dz�������,�������ǻ��ᵽ��
���� HTTP �����ϵͳ
HTTP �����ϵͳ�����ͻ��ˡ�web �������ʹ���

�ͻ���:user-agent
�����,��������ǹ���ʦʹ�õij���,�Լ� Web ������Ա����Ӧ�ó���
Web�����
�� Web Server �������ṩ�ͻ�����������ĵ���ÿһ�����͵�������������,���ᱻ����������������һ����Ϣ,Ҳ���� response
����(Proxies)
��������ͷ�����֮��,�кܶ������������豸ת���� HTTP ��Ϣ�����ǿ��ܳ����ڴ���㡢��������������,���� HTTP Ӧ�ò���Ծ�������
�����µ�һЩ����
- ����
- ����(�������ɨ�衢�ҳ�����)
- ���ؾ���
- ��֤(�Բ�ͬ����Դ����Ȩ����)
- ��־����
HTTP �������
HTTP ���������͵���Ϣ:
- �����ɿͻ��˷�����������һ���������ϵĶ���
- ��Ӧ�������Է������˵�Ӧ��
HTTP ��Ϣ�ɲ��� ASCII ����Ķ����ı����ɵġ��� HTTP/1.1 �Լ�����İ汾��,��Щ��Ϣͨ�����ӹ����ķ��͡��� HTTP2.0 ��,��Ϣ���ֵ��˶�� HTTP ֡�С�ͨ�������ļ�(���ڴ������������߷�����),API(���������)���������ӿ��ṩ HTTP ��Ϣ
���͵� HTTP �Ự
- �������� �ڿͻ���-������Э����,�������ɿͻ��˷������ġ���
HTTP�д�������ζ���ڵײ㴫�����������,ͨ����TCP��ʹ��TCPʱ,HTTP��������Ĭ�϶˿ں���80,�����8000��8080Ҳ�ܳ��� - ���Ϳͻ�������
- ��������Ӧ����
HTTP �������Ӧ
HTTP �������Ӧ��������ʼ��(start line)������ͷ(HTTP Headers)������(empty line)�Լ� body ����,����ͼ��ʾ:
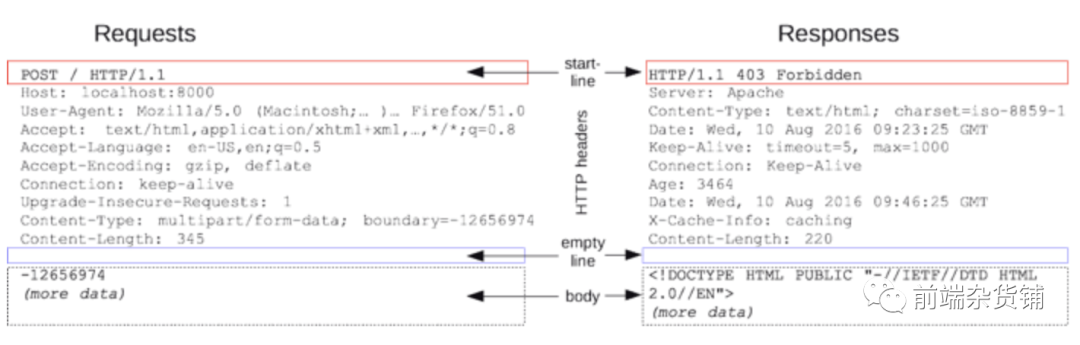
- ��ʼ�С��������ʼ��:����������
Path��HTTP�汾�� ��Ӧ����ʼ��:HTTP�汾�š���Ӧ״̬���Լ�״̬�ı�����
������ϸ˵������ Path,����·��(Path)�����¼���:
1)һ������·��,ĩβ����һ�� �� ? �� �Ͳ�ѯ�ַ����������������ʽ,��Ϊ ԭʼ��ʽ (origin form),�� GET,POST,HEAD �� OPTIONS ������ʹ��
POST / HTTP/1.1
GET /background.png HTTP/1.0
HEAD /test.html?query=alibaba HTTP/1.1
OPTIONS /anypage.html HTTP/1.0
2)һ�������� URL����Ҫ��ʹ�� GET �������ӵ�������ʱ��ʹ��
GET http://developer.mozilla.org/en-US/docs/Web/HTTP/Messages HTTP/1.1
3)�������Ϳ�ѡ�˿�(�ԡ�:'Ϊǰ)��ɵ� URL �� authority component,��Ϊ authority form������ʹ�� CONNECT ���� HTTP ����ʱ��ʹ��
CONNECT developer.mozilla.org:80 HTTP/1.1
4)�Ǻ���ʽ (asterisk form),һ�����Ǻ�(��*��),��� OPTIONS ����ʹ��,����������������
OPTIONS * HTTP/1.1
Headers����ͷ������Ӧͷ�����������ײ��������ִ�Сд���ַ���,�����ŵ�ð�� (��:��) ��һ���ṹȡ����header��ֵ- ���С��ܶ���������
Body
���� Body ����:��Щ�������ݷ��͵��������Ա��������:�����ĵ������ POST ����(���� HTML ��������)�������ĵ� Body һ��Ϊ���ࡣһ����ͨ�� Content-Type �� Content-Length ����ĵ��ļ� body������һ�����ɶ� Body ���,ͨ���Ǻ� HTML Form ��ϵ��һ��ġ����ߵIJ�ͬ�������� Content-Type��ֵ��
1)Content-Type ���� application/x-www-form-urlencoded���� application/x-www-form-urlencoded ��ʽ�ı�������,�������ص�:
I.���е����ݻᱻ�������&�ָ��ļ�ֵ��
II.�ַ���URL���뷽ʽ���롣
// ת������: {a: 1, b: 2} -> a=1&b=2 -> ����(������ʽ)
"a%3D1%26b%3D2"
2)Content-Type ���� multipart/form-data
����ͷ�е� Content-Type �ֶλ���� boundary,�� boundary ��ֵ�������Ĭ��ָ������: Content-Type: multipart/form-data;boundary=----WebkitFormBoundaryRRJKeWfHPGrS4LKe��
���ݻ��Ϊ�������,ÿ��������֮��ͨ���ָ������ָ�,ÿ���ֱ������� HTTP ͷ�������Ӱ���,��Content-Type,�����ķָ�������ϨC��ʾ������
Content-Disposition: form-data;name="data1";
Content-Type: text/plain
data1
----WebkitFormBoundaryRRJKeWfHPGrS4LKe
Content-Disposition: form-data;name="data2";
Content-Type: text/plain
data2
----WebkitFormBoundaryRRJKeWfHPGrS4LKe--
��Ӧ Body ����:
1)����֪���ȵĵ����ļ���ɡ������� body ������ header ����:Content-Type �� Content-Length
2)��δ֪���ȵĵ����ļ����,ͨ���� Transfer-Encoding ����Ϊ chunked ��ʹ�� chunks ���롣
���� Content-Length ������ HTTP 1.0 �л��ᵽ,����� HTTP 1.0 �������ķdz���Ҫ��ͷ����
����
��ȫ����:HTTP ������һ�鱻��Ϊ��ȫ�����ķ�����GET ������ HEAD ����������Ϊ�ǰ�ȫ��,����ζ�� GET ������ HEAD �������������ʲô���� ���� HTTP �����ٷ���˲���ʲô���,���Ⲣ����ζ��ʲô������û����,��ʵ�������� web �����߾�����
GET:�������������ij����ԴHEAD:��GET��������,������������Ӧ��ֻ�������ײ������᷵��ʵ������岿�֡�PUT:���������д���ĵ�������:����������岿��������һ�����������URL���������ĵ�POST:��������������������ݵġ�ͨ�������ύ�������ݸ�����������POST�������������������,PUT����������������ϵ���Դ(�����ļ�)�д洢���ݡ�TRACE:��Ҫ������ϡ�ʵ����ͨ��Ŀ����Դ��·������Ϣ����(loop-back)���� ,�ṩ��һ��ʵ�õ�debug���ơ�OPTIONS:����WEB��������֪��֧�ֵĸ��ֹ��ܡ�����ѯ�ʷ�����֧����Щ�������������ijЩ������Դ֧����Щ������DELETE:���������ɾ������URL��ָ���ĵ���Դ
GET �� POST ������
����Ҫ�˽��¸����ú��ݵȵĸ���,������ָ���ǶԷ���������Դ���ġ��ݵ�ָ���� M �� N ������(���߲���ͬ�Ҷ����� 1),����������Դ��״̬һ�¡�Ӧ�ó�����,get�������õ�,�ݵȵġ�post ��Ҫ���и����õ�,���ݵȵ����
�����������µ�����:
- ����:
Get�����ܻ���,Post������ - ��ȫ:
Get����û��Post������ô��ȫ,��Ϊ������URL�С��һᱻ�����������ʷ��¼��POST������������,���Ӱ�ȫ - ����:
URL�г�������,���ԤGet����,���������������� - ����:
GET����ֻ�ܽ���URL����,ֻ�ܽ���ASCII�ַ�,��POSTû�����ơ�POST֧�ָ���ı�������,���Ҳ����������������� - ��
TCP�ĽǶ�,GET������������һ���Է���ȥ,��POST���Ϊ����TCP���ݰ�,���ȷ�header����,�����������Ӧ100(continue), Ȼ��body���֡�(������������,����POST����ֻ��һ��TCP��)
״̬��
-
100~199������Ϣ��״̬��
101 Switching Protocols����HTTP����ΪWebSocket��ʱ��,���������ͬ����,�ͻᷢ��״̬�� 101��
-
200~299�����ɹ�״̬��
200 OK,��ʾ�ӿͻ��˷����������ڷ������˱���ȷ����
204 No content,��ʾ����ɹ�,����Ӧ���IJ���ʵ������岿��
205 Reset Content,��ʾ����ɹ�,����Ӧ���IJ���ʵ������岿��,������ 204 ��Ӧ��ͬ����Ҫ��������������
206 Partial Content,���з�Χ����
-
300~399�����ض���״̬��
301 moved permanently,�������ض���,��ʾ��Դ�ѱ��������µ� URL
302 found,��ʱ���ض���,��ʾ��Դ��ʱ���������µ� URL
303 see other,��ʾ��Դ��������һ�� URL,Ӧʹ�� GET ������ȡ��Դ
304 not modified,��ʾ����������������Դ,����������δ�������������
307 temporary redirect,��ʱ�ض���,��302��������,���������ͻ��˱��������������µĵ�ַ��������
-
400~499�����ͻ��˴���״̬��
400 bad request,�����Ĵ��������
401 unauthorized,��ʾ���͵�������Ҫ��ͨ�� HTTP ��֤����֤��Ϣ
403 forbidden,��ʾ��������Դ�ķ��ʱ��������ܾ�
404 not found,��ʾ�ڷ�������û���ҵ��������Դ
-
500~599��������������״̬��
500 internal sever error,��ʾ����������ִ������ʱ�����˴���
501 Not Implemented,��ʾ��������֧�ֵ�ǰ��������Ҫ��ij������
503 service unavailable,������������ʱ���ڳ����ػ�����ͣ��ά��,����������
�ײ�
HTTP Headers
1.ͨ���ײ�(General headers)ͬʱ�������������Ӧ��Ϣ,����������Ϣ�����д���������ص���Ϣͷ���� Date
2.�����ײ�(Request headers)���������й�Ҫ��ȡ����Դ��ͻ��˱�����Ϣ����Ϣͷ���� User-Agent
3.��Ӧ�ײ�(Response headers)�����й���Ӧ�IJ�����Ϣ
4.ʵ���ײ�(Entity headers)���й�ʵ������ĸ�����Ϣ,�������峤(Content-Length)�Ȼ��� MIME ���͡��� Accept-Ranges
��ϸ�� Header �� HTTP Headers ����[2]
HTTP ��ǰ������
HTTP(HyperText Transfer Protocol)����ά��(World Wide Web)�Ļ���Э�顣Tim Berners-Lee ��ʿ�������Ŷ���1989-1991��䴴���������HTTP���������������������
�� 1991 �귢���� HTTP 0.9 ��,�� 1996 �귢�� 1.0 ��,1997 ���� 1.1 ��,1.1 ��Ҳ�ǵ�����Ϊֹ������㷺�İ汾��2015 �귢���� 2.0 ��,�伫����Ż��� HTTP/1.1 �����ܺͰ�ȫ��,�� 2018 �귢���� 3.0 ��,�����Ż� HTTP/2,������ʹ�� UDP ȡ�� TCP Э��,Ŀǰ,HTTP/3 �� 2019 �� 9 �� 26 �� �� Chrome,Firefox,�� Cloudflare ֧��
HTTP 0.9
����Э��,�����ɵ���ָ��ɡ���Ψһ���õķ��� GET ��ͷ�����������Ŀ����Դ��·��
GET /mypage.html
��Ӧ:ֻ������Ӧ�ĵ�����
<HTML>
����һ���dz���HTMLҳ��
</HTML>
- û����Ӧͷ,ֻ����
HTML�ļ� - û��״̬��
HTTP 1.0
RFC 1945[3] ����� HTTP1.0,�������ÿ���չ��
- Э��汾��Ϣ������ÿ��������
- ��Ӧ״̬��
- ������
HTTPͷ�ĸ���,��������������չ,��������Ԫ���ݡ�ʹЭ�������,���Ӿ�����չ�� Content-Type����ͷ,�߱��˴�������ı�HTML�ļ��������������ĵ������� ����Ӧ��,Content-Type��ͷ���߿ͻ���ʵ�ʷ��ص����ݵ���������
ý��������һ�ֱ���������ʾ�ĵ����ļ������ֽ��������ʺ�ʽ�������ͨ��ʹ�� MIME (Multipurpose Internet Mail Extensions )������ȷ����δ��� URL,��� Web ����������Ӧͷ��������ȷ�� MIME ���ͻ�dz�����Ҫ��������ò���ȷ,���ܻᵼ����վ�������Ĺ�����MIME ����ɽṹ�dz���;�������������������ַ����м��á�/'�ָ�����ɡ�
HTTP �� MIME type ȡ��һ��������DZ��� body ���ֵ���������,��Щ����������Content-Type ����ֶ�,��Ȼ��������ڷ��Ͷ˶���,���ն���Ҫ�յ��ض����͵�����,Ҳ������ Accept �ֶΡ�
�������ֶε�ȡֵ���Է�Ϊ���漸��:
- text:text/html, text/plain, text/css ��
- image: image/gif, image/jpeg, image/png ��
- audio/video: audio/mpeg, video/mp4 ��
- application: application/json, application/javascript, application/pdf, application/octet-stream
ͬʱΪ��Լ����������ݺ���Ӧ���ݵ�ѹ����ʽ��֧�����ԡ��ַ�����,����������µ� Header
1.ѹ����ʽ:���Ͷ�:Content-Encoding(����˸�֪�ͻ���,��������ʵ������岿�ֵı��뷽ʽ) �� ���ն�:Accept-Encoding(�û�����֧�ֵı��뷽ʽ),ֵ�� gzip: ���������е�ѹ����ʽ;deflate: ����һ��������ѹ����ʽ;br: һ��ר��Ϊ HTTP ������ѹ���㷨
2.֧������:Content-Language �� Accept-Language(�û�����֧�ֵ���Ȼ���Լ�)
3.�ַ���:���Ͷ�:Content-Type ��,�� charset ����ָ�������ն�:Accept-Charset(�û�����֧�ֵ��ַ���)��
// ���Ͷ�
Content-Encoding: gzip
Content-Language: zh-CN, zh, en
Content-Type: text/html; charset=utf-8
// ���ն�
Accept-Encoding: gzip
Accept-Language: zh-CN, zh, en
Accept-Charset: charset=utf-8
��Ȼ HTTP1.0 �� HTTP 0.9 �Ļ����ϸĽ��˺ܶ�,�����Ǵ����ⲻ�ٵ�ȱ��
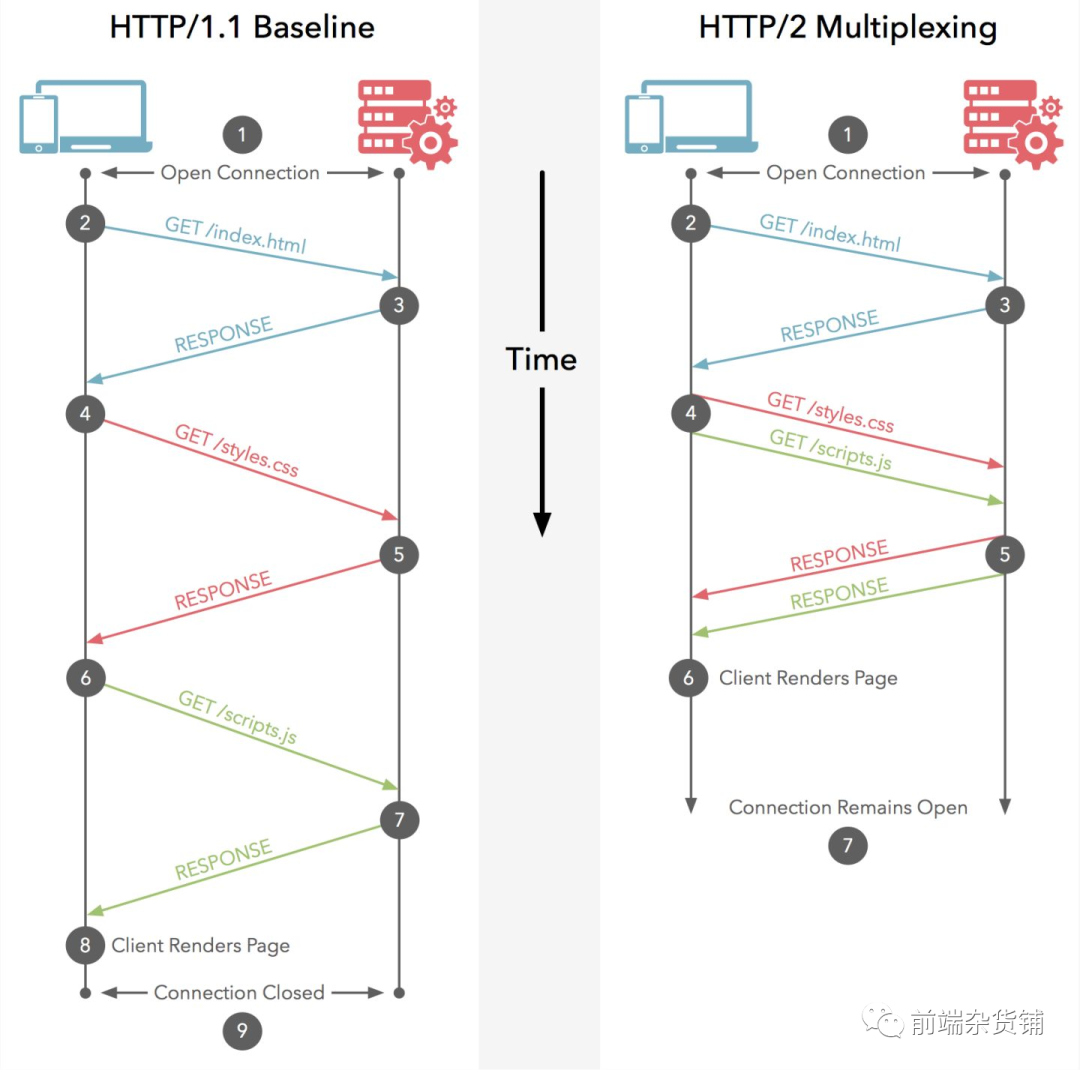
HTTP/1.0 �����Ҫȱ����,ÿ�� TCP ����ֻ�ܷ���һ���������������,���Ӿر�,�����Ҫ����������Դ,�ͱ������½�һ�����ӡ�TCP ���ӵ��½��ɱ��ܸ�,��Ϊ��Ҫ�ͻ��˺ͷ�������������,���ҿ�ʼʱ�������ʽ���(slow start)��
HTTP �����ڵ�ģ��,Ҳ�� HTTP/1.0 ��Ĭ��ģ��,�Ƕ����ӡ�ÿһ�� HTTP ���������Լ��������������;����ζ�ŷ���ÿһ�� HTTP ����֮ǰ������һ�� TCP ����,�������������ϵġ�
HTTP 1.1
HTTP/1.1 ��1997��1���� RFC 2068[4] �ļ�������
HTTP 1.1 �����˴����������ݲ������˶����
- ���ӿ��Ը��á�������:
connection: keep-alive��HTTP 1.1֧�ֳ�����(PersistentConnection),��һ��TCP�����Ͽ��Դ��Ͷ��HTTP�������Ӧ,�����˽����ر����ӵ����ĺ��ӳ�,��HTTP1.1��Ĭ�Ͽ���Connection:keep-alive,һ���̶����ֲ���HTTP1.0ÿ������Ҫ�������ӵ�ȱ�㡣 - �����˹ܵ�������(
HTTP Pipelinling),�����ڵ�һ��Ӧ����ȫ�������֮ǰ�ͷ��͵ڶ�������,�Խ���ͨ���ӳ١�����ͬһ��TCP�����ڼ�,������ͨ���ܵ�ͬʱ�����˶������,�����Ҳ�ǰ������˳�����θ�����Ӧ��;���ͻ�����δ�յ�֮ǰ�����������������Ӧ֮ǰ,�����������������(�Ŷӵȴ�),���Ϊ"��ͷ����"(Head-of-line blocking)�� - ֧����Ӧ�ֿ�,�ֿ���봫��:
Transfer-Encoding: chunked``Content-length����������Ӧ�����ݳ��ȡ�keep-alive���ӿ����Ⱥ��Ͷ����Ӧ,�����Content-length���������ݰ���������һ����Ӧ��ʹ��Content-Length�ֶε�ǰ��������,������������Ӧ֮ǰ,����֪����Ӧ�����ݳ��ȡ�����һЩ�ܺ�ʱ�Ķ�̬������˵,����ζ��,������Ҫ�ȵ����в������,���ܷ�������,��Ȼ������Ч�ʲ��ߡ����õĴ���������,����һ������,�ͷ���һ��,����"��ģʽ"(Stream)ȡ��"����ģʽ"(Buffer)�����,HTTP 1.1�涨���Բ�ʹ��Content-Length�ֶ�,��ʹ��"�ֿ鴫�����"(Chunked Transfer Encoding)��ֻҪ�������Ӧ��ͷ��Ϣ��Transfer-Encoding: chunked�ֶ�,�ͱ���body������������δ���Ķ�����ݿ���ɡ�ÿ�����ݿ�֮ǰ����һ�а���һ�� 16 ������ֵ,��ʾ�����ij���;���һ����СΪ 0 �Ŀ�,�ͱ�ʾ������Ӧ�����ݷ������ˡ� - �������Ļ�����ƻ��ơ���
HTTP1.0����Ҫʹ��header���If-Modified-Since,Expires������Ϊ�����жϵı�,HTTP1.1�������˸���Ļ�����Ʋ�������Entity tag,If-None-Match,Cache-Control�ȸ���ɹ�ѡ��Ļ���ͷ�����ƻ�����ԡ� Hostͷ����ͬ����������ͬһ��IP��ַ�ķ�������Host��HTTP 1.1Э����������һ������ͷ,��Ҫ����ʵ����������������
��������(virtual hosting)����������(shared web hosting),�����������⼼����һ̨�����ķ������ֳ����ɸ�����,��˿����ڵ�һ���������ж����վ�����
�ٸ�����,��һ̨ ip ��ַΪ 61.135.169.125 �ķ�����,����̨�������ϲ����Źȸ衢�ٶȡ��Ա�����վ��Ϊʲô���Ƿ��� https://www.google.com ʱ,�������� Google ����ҳ�����ǰٶȻ����Ա�����ҳ?ԭ����� Host ����ͷ�����ŷ����ĸ�����������
HTTP 2.0
2015��,HTTP2.0 ������rfc7540[5]
-
HTTP/2�Ƕ�����Э��������ı�Э�顣��������������: -
- ֡:�ͻ����������ͨ������֡��ͨ��,֡�ǻ��������Э��ͨ�ŵ���С��λ��
- ��Ϣ:��ָ���ϵ� HTTP ��Ϣ,����������Ӧ��,��һ����֡��ɡ�
- ��:���������е�һ�������ŵ�,���Գ���˫�����Ϣ;ÿ��������һ��Ψһ��������ʶ��
HTTP 2.0 �е�֡�� HTTP/1.x ��Ϣ�ֳ�֡��Ƕ�뵽�� (stream) �С�����֡�ͱ�ͷ֡����,�⽫������ͷѹ��������������,����һ������Ϊ��·���� (multiplexing) �Ĺ���,����������Ч�ĵײ� TCP ���ӡ�
Ҳ����˵,������������Ϣ,��Ϣ������һ������֡��ɡ������ƴ���ķ�ʽ���������˴������ܡ�ÿ��������������Ϣ����ʽ����,����Ϣ����һ������֡��ɡ�֡�����е����ݵ�λ��
HTTP ֡���ڶ� Web ������Ա�����ġ��� HTTP/2 ��,����һ���� HTTP/1.1 �͵ײ㴫��Э��֮�丽�ӵIJ��衣Web ������Ա����Ҫ����ʹ�õ� API �����κθ��������� HTTP ֡;��������ͷ�����������ʱ,HTTP/2 ������ʹ�á�
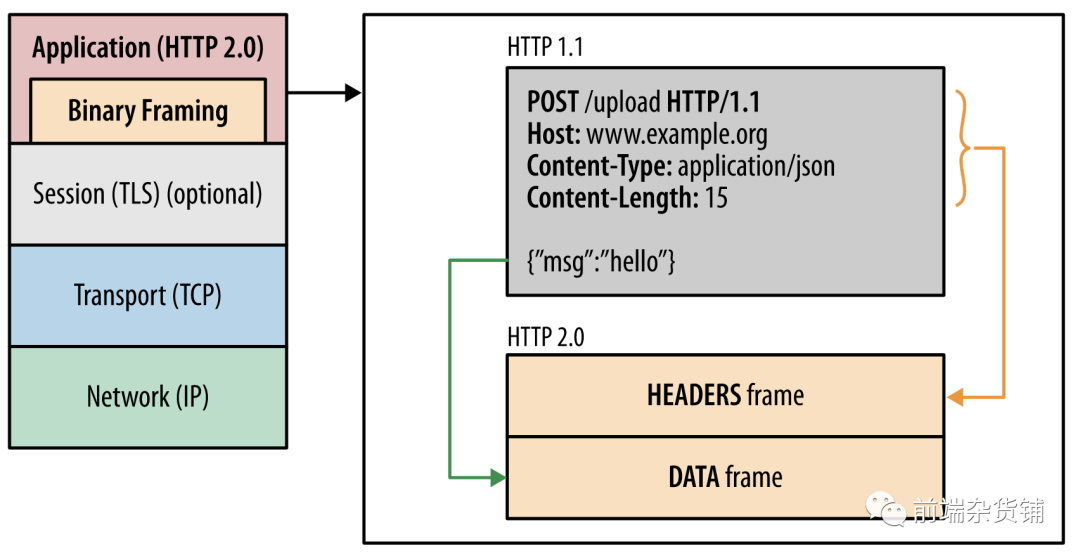
- ����һ������Э�顣���е���������ͬһ�������д���,�Ƴ���
HTTP/1.x��˳���������Լ������·��������ͬʱͨ����һ��HTTP/2���ӷ�����ص�����-��Ӧ��Ϣ
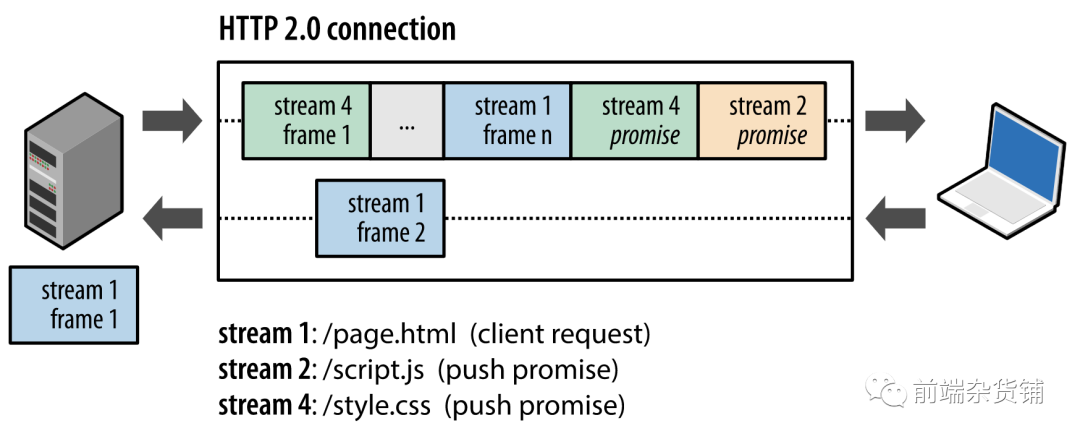
֮ǰ�����ᵽ,��Ȼ HTTP 1.1 ���˳����Ӻܵ����ļ���,���ǻ��ǻ���� ��ͷ�������� HTTP 2.0 �ͽ�����������HTTP/2 ���µĶ����Ʒ�֡��ͻ������Щ����,ʵ�����������������Ӧ����:�ͻ��˺ͷ��������Խ� HTTP ��Ϣ�ֽ�Ϊ����������֡,Ȼ������,���������һ�˰�����������װ������
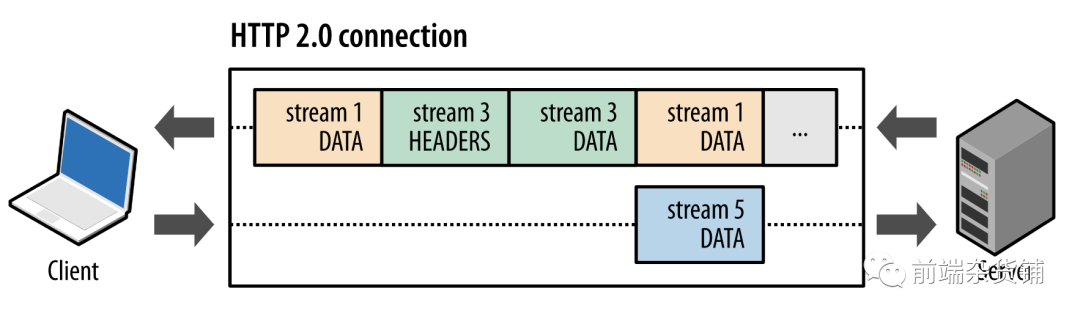
����ͼ��ʾ,���ղ���ͬһ�������ڲ��еĶ�����������ͻ������������������һ�� DATA ֡(������ 5),���ͬʱ,����������ͻ��˽������������� 1 �������� 3 ��һϵ��֡�����,һ��������ͬʱ������������������
�� HTTP ��Ϣ�ֽ�Ϊ������֡,��������,Ȼ������һ��������װ�� HTTP 2 ����Ҫ��һ����ǿ����ʵ��,������ƻ����������缼��ջ������һϵ��������Ӧ,�Ӷ����������������,�����ǿ���:1.���н����ط��Ͷ������,����֮�以��Ӱ�졣2.���н����ط��Ͷ����Ӧ,��Ӧ֮�以�����š�3.ʹ��һ�����Ӳ��з��Ͷ���������Ӧ��4.��������Ҫ���ӳٺ������������������������,�Ӷ�����ҳ�����ʱ�䡣5.������Ϊ�ƹ� HTTP/1.x ���ƶ����ܶ��(���羫��ͼ) ��
���ӹ���,��ÿһ�� request �������������ӹ������Ƶġ�һ�� request ��Ӧһ�� id,����һ�������Ͽ����ж�� request,ÿ�����ӵ� request ��������Ļ�����һ��,���շ����Ը��� request �� id �� request �ٹ��������Բ�ͬ�ķ�����������档
HTTP 1.1 �� HTTP 2.0 �ĶԱ�,���Բο���� ��վ demo ��ʾ[6]
HTTP 1.1 ��ʾ����: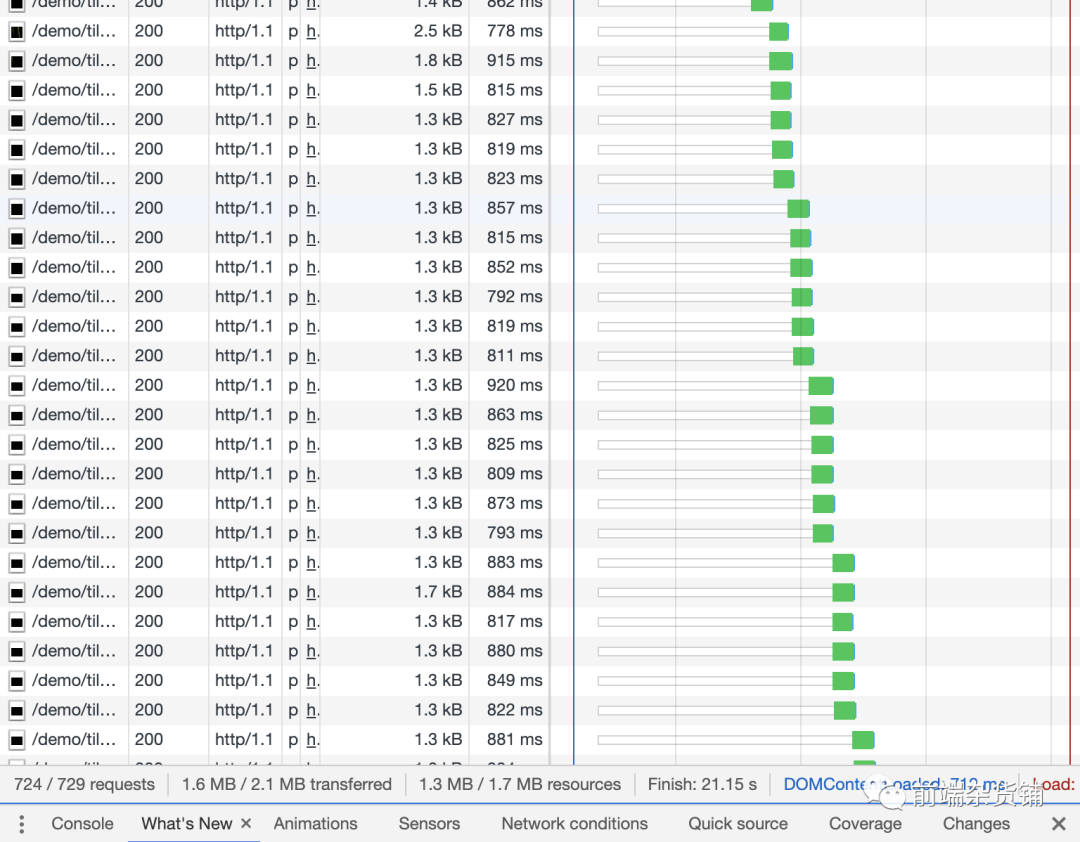
HTTP2.0 ��ʾ����:
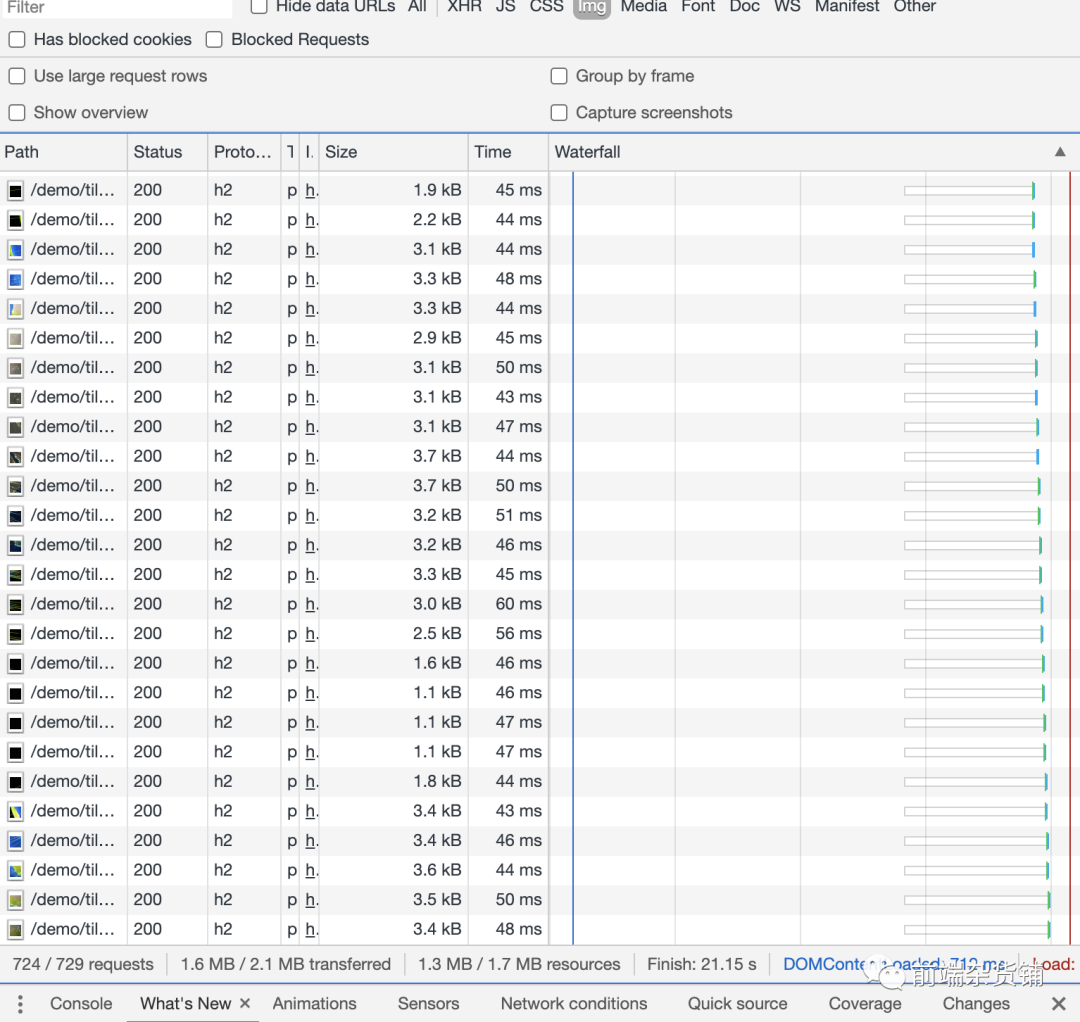
- ѹ����
headers��HTTP1.x��header���д�����Ϣ,����ÿ�ζ�Ҫ�ظ�����,����������ܵ���ġ�Ϊ�˼��ٴ˿�������������,HTTP/2ʹ��HPACKѹ����ʽѹ���������Ӧ��ͷԪ����,���ָ�ʽ�������ּ���ǿ��ļ���:���ָ�ʽ֧��ͨ����̬����������Դ���ı�ͷ�ֶν��б���,�Ӷ���С�˸�������Ĵ�С�����ָ�ʽҪ��ͻ��˺ͷ�����ͬʱά������һ������֮ǰ�����ı�ͷ�ֶε������б�(���仰˵,�����Խ���һ��������ѹ��������),���б����������ο�,��֮ǰ�����ֵ������Ч���롣
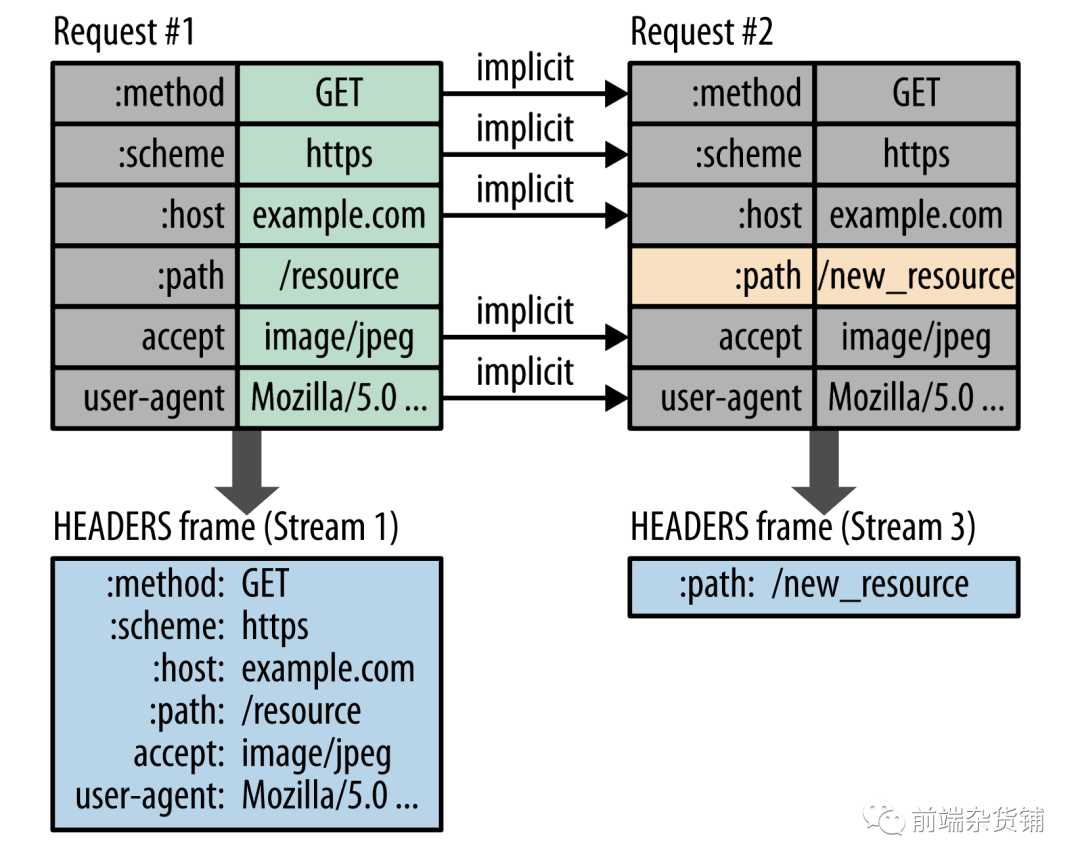
- ��������͡��������������ڿͻ��˻������������,ͨ��һ���з��������͵Ļ�������ǰ����������ͻ���������Դ����ͻ�����ȷ������,����˿�����ǰ���ͻ������ͱ�Ҫ����Դ,�������Լ��������ӳ�ʱ��,�������˿���������
JS��CSS�ļ������ͻ���,�����ǵȵ�HTML��������Դʱ��������,�������Լ����ӳ�ʱ����¹�������ͼ��ʾ:
���������� HTTP �汾
ʹ�� HTTP/1.1 �� HTTP/2 ����վ���Ӧ����˵�����ġ�ӵ��һ�����µķ��������µ����������н������㹻�ˡ�ֻ��һС����Ⱥ����Ҫ�����ı�,�������ų¾ɵ�������ͷ������ĸ���,������ Web ��������ʲô,�õ�����Ȼ��������
HTTPS
HTTPS Ҳ��ͨ�� HTTP Э����д�����Ϣ,���Dz����� TLS Э������˼���
�ԳƼ��ܺͷǶԳƼ���
�ԳƼ��ܾ�������ӵ����ͬ����Կ,���߶�֪����ν����ļ��ܽ��ܡ�������Ϊ�������ݶ����ߵ�����,�������Կͨ������ķ�ʽ���ݵĻ�,һ����Կ���ػ��û�м��ܵ������
�ǶԳƼ���
��Կ��Ҷ�֪��,�����ù�Կ�������ݡ����������ݱ���ʹ��˽Կ,˽Կ�����ڰ䷢��Կ��һ�������ȷ���˽���Կ������ȥ,��ô�ͻ�����֪����Կ�ġ�Ȼ��ͻ��˴���һ����Կ,��ʹ�ù�Կ����,��������ˡ�����˽��յ������Ժ�ͨ��˽Կ���ܳ���ȷ����Կ
TLS ���ֹ���
TLS ���ֵĹ��̲��õ��ǷǶԳƼ���
Client Hello: �ͻ��˷���һ�����ֵ(Random1)�Լ���Ҫ��Э��ͼ��ܷ�ʽ��Server Hello�Լ�Certificate: ������յ��ͻ��˵����ֵ,�Լ�Ҳ����һ�����ֵ(Random2),�����ݿͻ��������Э��ͼ��ܷ�ʽ��ʹ�ö�Ӧ�ķ�ʽ,���ҷ����Լ���֤��(�����Ҫ��֤�ͻ���֤����Ҫ˵��)Certificate Verify: �ͻ����յ�����˵�֤�鲢��֤�Ƿ���Ч,��֤ͨ����������һ�����ֵ(Random3),ͨ�������֤��Ĺ�Կȥ����������ֵ�����������,����������Ҫ��֤�ͻ���֤��Ļ��ḽ��֤��Server ���� secret: ������յ����ܹ������ֵ��ʹ��˽Կ���ܻ�õ��������ֵ(Random3),��ʱ�����˶�ӵ�����������ֵ,����ͨ�����������ֵ����֮ǰԼ���ļ��ܷ�ʽ������Կ,��������ͨ�žͿ���ͨ������Կ�����ܽ���
HTTP ����
ǿ����
ǿ������Ҫ���� Cache-control �� Expires ���� Header ������
Expires ��ֵ��ͷ����� Date ���Ե�ֵ���ж��Ƿ滹��Ч��Expires �� Web ��������Ӧ��Ϣͷ�ֶ�,����Ӧ http ����ʱ����������ڹ���ʱ��ǰ���������ֱ�Ӵ����������ȡ����,�������ٴ�����Expires ��һ��ȱ�����,���صĵ���ʱ���Ƿ������˵�ʱ��,����һ�����Ե�ʱ��,��������һ������,����ͻ��˵�ʱ�����������ʱ�����ܴ�(����ʱ�Ӳ�ͬ��,���߿�ʱ��),��ô���ͺܴ�
Cache-Control ָ����ǰ��Դ����Ч��,����������Ƿ�ֱ�Ӵ����������ȡ���ݻ������·���������ȡ���ݡ����������õ���һ�����ʱ�䡣
ָ������ʱ��:max-age �Ǿ����������ʱ�������,��������ָ���Ǿ��뷢������ 31536000S �ڶ���������ǿ����
Cache-Control: max-age=31536000
��ʾû�л���
Cache-Control: no-store
�л��浫Ҫ������֤
Cache-Control: no-cache
˽�к�������
public ��ʾ��Ӧ���Ա��κ��м���(�����м������CDN �Ȼ���) �� private ���ʾ����Ӧ��ר����ij�����û���,�м��˲��ܻ������Ӧ,����Ӧֻ��Ӧ���������˽�л����С�
Cache-Control: private
Cache-Control: public
��֤��ʽ:���±�ʾһ����Դ����(�����Ѿ����� max-age),�ڳɹ���ԭʼ��������֤֮ǰ,���治���ø���Դ��Ӧ��������
Cache-Control: must-revalidate
Cache-control ���ȼ��� Expires ���ȼ���
������һ�� Cache-Control ǿ����Ĺ���:
- �״�����,ֱ�Ӵ� server �л�ȡ�����л�����
max-age=100 - �ڶ�������,
age=10,С�� 100,������Cache,ֱ�ӷ��� - ����������,
age=110,���� 110��ǿ����ʧЧ,����Ҫ�ٴ�����Server

Э�̻���
If-Modified-Since����Last-Modified
Last-Modified ��ʾ�����ļ����������,��������� request header ���� If-Modified-Since(�ϴη��ص� Last-Modified ��ֵ),ѯ�ʷ������ڸ����ں���Դ�Ƿ��и���,�и��µĻ��ͻὫ�µ���Դ���ͻ���
��������ڱ��ش����ļ�,�ͻ���� Last-Modified ����,������ HTTP / 1.1 ������ ETag
If-none-match����ETags
Etag ����һ��ָ��,��Դ�仯���ᵼ�� ETag �仯,�������ʱ��û�й�ϵ,ETag ���Ա�֤ÿһ����Դ��Ψһ�ġ�If-None-Match �� header �Ὣ�ϴη��ص� Etag ����������,ѯ�ʸ���Դ�� Etag �Ƿ��и���,�б䶯�ͻᷢ���µ���Դ����
If-none-match`��`ETags` ���ȼ����� `If-Modified-Since��Last-Modified
��һ������:

�ڶ���������ͬ��ҳ:

Э�̻���,����û�иĶ��Ļ�,���� 304 ,�Ķ��˷��� 200 ��Դ
- 200:ǿ����
Expires/Cache-ControlʧЧʱ,�����µ���Դ�ļ� - 200
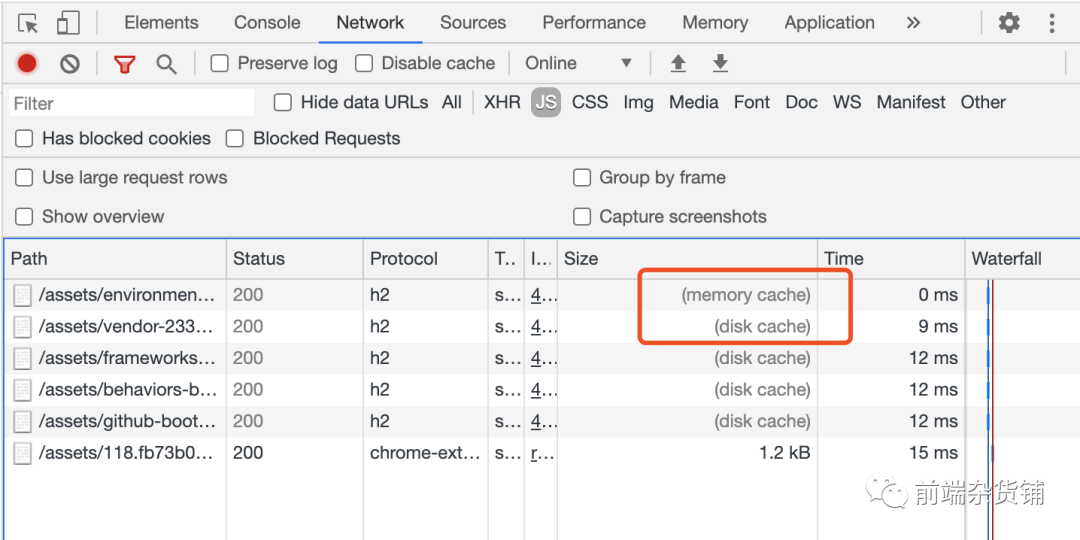
(from cache): ǿ��Expires/Cache-Control���߶�����,δ����,Cache-Control����Expiresʱ,������ӱ��ػ�ȡ��Դ�ɹ� - 304
(Not Modified):Э�̻���Last-modified/Etagû�й���ʱ,����˷���״̬��304
���ڵ�200(from cache)�Ѿ������ disk cache(���̻���)�� memory cache(�ڴ滺��)����
revving ����
�����ᵽ HTTP �������,���Ǻܶ���ʱ��,����ϣ������֮����Ҫ����������Դ��
web �����߷�����һ�ֱ� Steve Souders ��֮Ϊ revving �ļ�������Ƶ�����µ��ļ���ʹ���ض���������ʽ:�� URL ����(ͨ�����ļ�������)����ϰ汾�š�
��:�����˰汾��,����������Щ����Դ�ĵط��İ汾�Ŷ�Ҫ�ı�
web ��������ͨ��������Զ�������������ʵ�ʹ����������Щ����Ĺ���������Ƶ���µ���Դ(js/css)�䶯��,ֻ���ڸ�Ƶ�䶯����Դ�ļ�(html)������ڵĸĶ���
Cookies
HTTP Cookie(Ҳ�� Web Cookie ������� Cookie)�Ƿ��������͵��û�������������ڱ��ص�һС������,������������´���ͬһ�������ٷ�������ʱ��Я�������͵��������ϡ�
���� cookie
Set-Cookie ��Ӧͷ���� Cookie ����ͷ��
Set-Cookie: <cookie��>=<cookieֵ>
�Ự��Cookie
�Ự��Cookie����� Cookie:������ر�֮�����ᱻ�Զ�ɾ��,Ҳ����˵�����ڻỰ������Ч���Ự�� Cookie ����Ҫָ������ʱ��(Expires)������Ч��(Max-Age)����Ҫע�����,��Щ������ṩ�˻Ự�ָ�����,��������¼�ʹ�ر��������,�Ự�� Cookie Ҳ�ᱻ��������,�ͺ������������û�йر�һ��
�־���Cookie
�ر��������ʧЧ�ĻỰ�� Cookie ��ͬ,�־��� Cookie ����ָ��һ���ض��Ĺ���ʱ��(Expires)����Ч��(Max-Age)��
Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07:28:00 GMT;
Cookie��Secure��HttpOnly ���
���Ϊ Secure �� Cookie ֻӦͨ���� HTTPS Э����ܹ�������������ˡ�
���Ϊ Secure �� Cookie ֻӦͨ���� HTTPS Э����ܹ�������������ˡ������������� Secure ���,������ϢҲ��Ӧ��ͨ�� Cookie ����,��Ϊ Cookie ������еIJ���ȫ��,Secure ���Ҳ���ṩȷʵ�İ�ȫ����
ͨ�� JavaScript �� Document.cookie API �������ʴ��� HttpOnly ��ǵ� cookie����ô����Ϊ�˱������ű�����(XSS)
Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07:28:00 GMT; Secure; HttpOnly
Cookie��������
Domain �� Path ��ʶ������ Cookie ��������:�� Cookie Ӧ�÷�����Щ URL��
Domain ��ʶָ������Щ�������Խ��� Cookie�������ָ��,Ĭ��Ϊ��ǰ������(������������)�����ָ���� Domain,��һ�������������
����,������� Domain=mozilla.org,�� Cookie Ҳ��������������(��developer.mozilla.org)��
Path ��ʶָ���������µ���Щ·�����Խ��� Cookie(�� URL ·��������������� URL ��)�����ַ� %x2F (��/��) ��Ϊ·���ָ���,��·��Ҳ�ᱻƥ�䡣
����,���� Path=/docs,�����µ�ַ����ƥ��:
/docs
/docs/Web/
/docs/Web/HTTP
SameSite Cookies
SameSite Cookie ����������Ҫ��ij�� cookie �ڿ�վ����ʱ���ᱻ����,�Ӷ�������ֹ��վ����α�칥��
None���������ͬվ����վ�����¼�������cookies,�����ִ�Сд�����ɰ汾chromeĬ��Chrome 80�汾֮ǰ��Strict�������ֻ�ڷ�����ͬվ��ʱ����cookie��Lax����ΪһЩ��վ��������,��ͼƬ���ػ���frames�ĵ���,��ֻ�е��û����ⲿվ�㵼����URLʱ�Żᷢ�͡���link����
Set-Cookie: key=value; SameSite=Strict
None Strict Lax
���°汾�������(Chrome 80 ֮��)��,SameSite ��Ĭ�������� SameSite=Lax�����仰˵,�� Cookie û������ SameSite ����ʱ,�������� SameSite ���Ա�����Ϊ Lax ���� ����ζ�� Cookies �������ڵ�ǰ�û�ʹ��ʱ���Զ����͡������Ҫָ�� Cookies ��ͬվ����վ��������,��ô��Ҫ��ȷָ��SameSite Ϊ None����Ϊ��һ��,������Ҫ�ú��Ų��ϵͳ�Ƿ���ȷָ�� SameSite,�Լ��Ƽ���ϵͳ��ȷָ�� SameSite,�Լ����¾ɰ汾 Chrome
���� cookie ���,���Բ鿴��֮ǰ�ܽ��һƪ���� cookie ������ ǰ����֪�� Cookie ֪ʶС��[7]
HTTP���ʿ���(CORS)
������Դ����(CORS)��һ�ֻ���,��ʹ�ö���� HTTP ͷ���������,��������һ�� origin (domain) �ϵ� web Ӧ�ñ����������Բ�ͬԴ�������ϵ�ָ������Դ
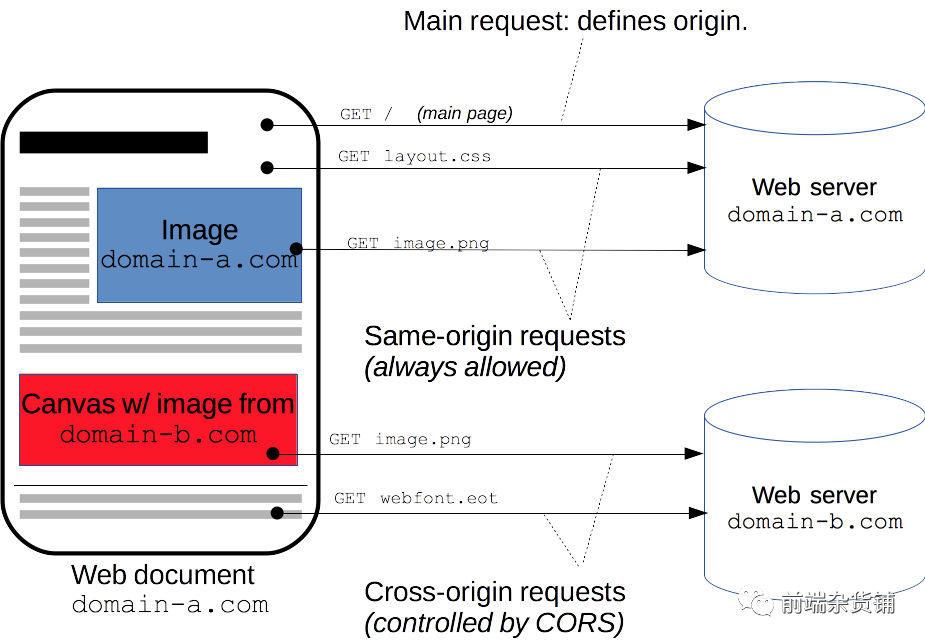
������Դ������������һ�� HTTP �ײ��ֶ�,����������������ЩԴվͨ���������Ȩ������Щ��Դ��
������
������(���ᴥ�� CORS ��Ԥ������)��Ҫͬʱ������������:
- ������
GET/HEAD/POST֮һ Content-Type��ֵ����text/plain��multipart/form-data��application/x-www-form-urlencoded����֮һHTTPͷ�����ܳ��������ֶ�:Accept��Accept-Language��Content-Language``Content-Type(��Ҫע����������)DPR��Downlink��Save-Data��Viewport-Width��Width
����Ϊһ����������������Լ���Ӧ����
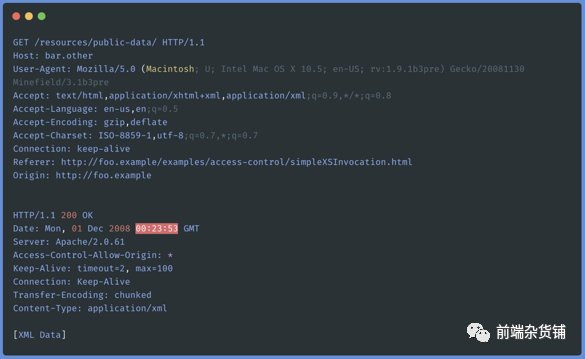
������:
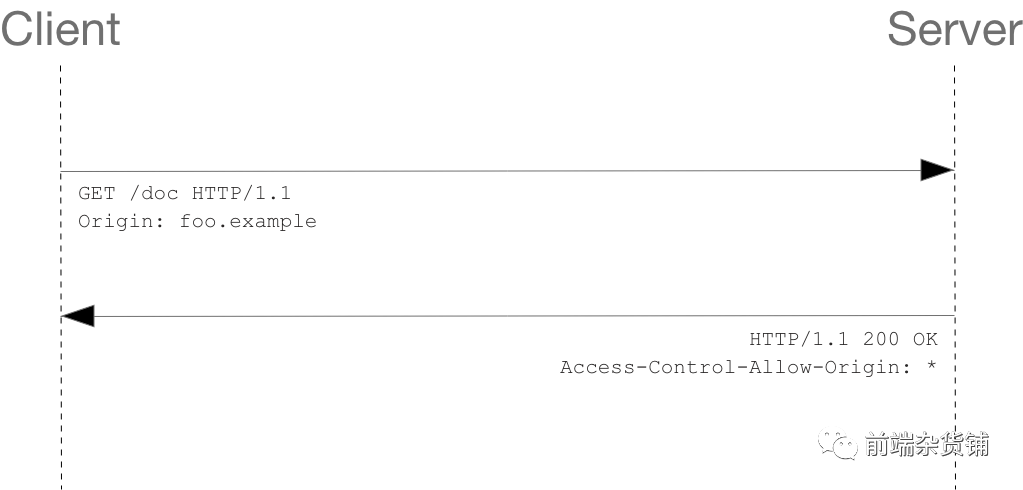
�����ײ��ֶ� Origin ������������Դ�� http://foo.example
������,����˷��ص� Access-Control-Allow-Origin: * ����,����Դ���Ա�����������ʡ��������˽��������� http://foo.example �ķ���,���ײ��ֶε���������:
Access-Control-Allow-Origin: http://foo.example
Access-Control-Allow-Origin Ӧ��Ϊ * ���߰����� Origin �ײ��ֶ���ָ����������
Ԥ������
�淶Ҫ��,����Щ���ܶԷ��������ݲ��������õ� HTTP �������������������ʹ�� OPTIONS ��������һ��Ԥ������(preflight request),�Ӷ���֪������Ƿ������ÿ�������
������ȷ������֮��,�ŷ���ʵ�ʵ� HTTP ������Ԥ������ķ�����,��������Ҳ����֪ͨ�ͻ���,�Ƿ���ҪЯ������ƾ֤(���� Cookies �� HTTP ��֤�������)
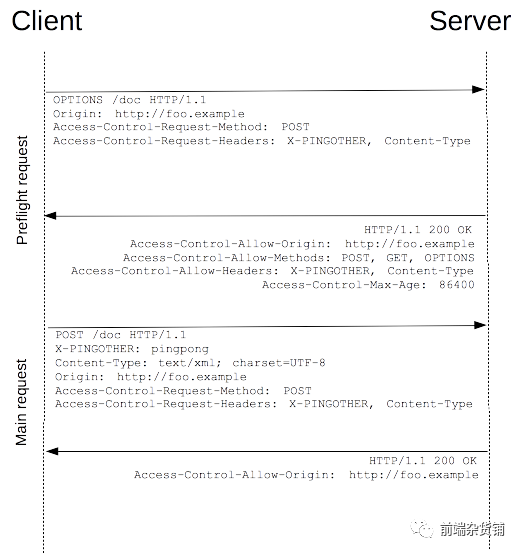
Ԥ��������ͬʱЯ�������������ײ��ֶ�:
Access-Control-Request-Method: POST
Access-Control-Request-Headers: X-PINGOTHER, Content-Type
�ײ��ֶ� Access-Control-Request-Method ��֪������,ʵ������ʹ�� POST �������ײ��ֶ� Access-Control-Request-Headers ��֪������,ʵ������Я�������Զ��������ײ��ֶ�:X-PINGOTHER �� Content-Type���������ݴ˾���,��ʵ�������Ƿ�������
Ԥ���������Ӧ��,���������¼����ֶ�
Access-Control-Allow-Origin: http://foo.example
// ���������������ͻ���ʹ�� POST, GET �� OPTIONS ������������
Access-Control-Allow-Methods: POST, GET, OPTIONS
// ��������������������Я���ֶ� X-PINGOTHER �� Content-Type
Access-Control-Allow-Headers: X-PINGOTHER, Content-Type
// ��������Ӧ����Чʱ��Ϊ 86400 ��,Ҳ���� 24 Сʱ������Чʱ����,���������Ϊͬһ�����ٴη���Ԥ������
Access-Control-Max-Age: 86400
HTTP �������Ӧ һ�����,���ڿ��� XMLHttpRequest �� Fetch ����,��������ᷢ������ƾ֤��Ϣ�����Ҫ����ƾ֤��Ϣ,��Ҫ���� XMLHttpRequest ��ij�������־λ������˵ XMLHttpRequest �� withCredentials ��־����Ϊ true,����Է��� cookie ������ˡ�
���ڸ�������ƾ֤������,�������������� Access-Control-Allow-Origin ��ֵΪ������������Ϊ������ײ���Я���� Cookie ��Ϣ,��� Access-Control-Allow-Origin ��ֵΪ����,����ʧ�ܡ����� Access-Control-Allow-Origin ��ֵ����Ϊ http://foo.example,�����ɹ�ִ�С�
CORS �漰�����������Ӧͷ����:HTTP ��Ӧ�ײ��ֶ�
Access-Control-Allow-Origin�������ʸ���Դ������URI�����ڲ���ҪЯ������ƾ֤������,����������ָ�����ֶε�ֵΪͨ���,��ʾ�������������������Access-Control-Expose-Headersͷ�÷�������������������ʵ�ͷ���������Access-Control-Max-Ageͷָ����preflight����Ľ���ܹ���������Access-Control-Allow-Credentialsͷָ���˵��������credentials����Ϊtrueʱ�Ƿ������������ȡresponse�����ݡ�Access-Control-Allow-Methods�ײ��ֶ�����Ԥ���������Ӧ����ָ����ʵ������������ʹ�õ�HTTP������Access-Control-Allow-Headers�ײ��ֶ�����Ԥ���������Ӧ����ָ����ʵ������������Я�����ײ��ֶΡ�
HTTP �����ײ��ֶ�
Origin�ײ��ֶα���Ԥ�������ʵ�������ԴվAccess-Control-Request-Method�ײ��ֶ�����Ԥ��������������,��ʵ��������ʹ�õ� HTTP �������߷�������Access-Control-Request-Headers�ײ��ֶ�����Ԥ��������������,��ʵ��������Я�����ײ��ֶθ��߷�������