ЭјТчдРэжЎTCP/IP
ЮФеТФПТМ
здЖЈвхгІгУВуавщ
гІгУВуавщгаЯжГЩЕФ,БШШчhttp,ЕЋЪЧгааЉЪБКђ,ЛЙЪЧашвЊГЬађдБздЖЈвхгІгУВуавщ,здЖЈвхгІгУВуавщ,ОЭЪЧГЬађдБдМЖЈКУПЭЛЇЖЫКЭЗўЮёЦївдЪВУДбљЕФИёЪНДЋЪфЪ§ОнЁЃ
БШШчвдКѓЙЄзїКѓЕФПЊЗЂСїГЬДѓИХЪЧвдЯТМИИіВНжш:
1??ашЧѓЦРЩѓ:ПЊЗЂ,ВтЪд,дЫЮЌ,ВњЦЗОРэ,дквЛЦ№,гЩВњЦЗОРэЬсГіашЧѓ,ШЛКѓЦфЫћШЫЦРЩѓашЧѓ,ПДПДашЧѓЪЧЗёКЯРэ,ФмЗёЪЕЯжЁЃ
2??ЗДРЁХХЦк:ИљОнЙЄзїСП,ОіЖЈМИЬьКѓПЩвдЭъГЩПЊЗЂЙЄзї
3??ЕБашЧѓЩцМАЕНЖрИізщаЭЌПЊЗЂ,гШЦфЪЧЧАКѓЖЫазї,ОЭашвЊдМЖЈКУЧАКѓЖЫ,ИїИіФЃПщжЎМфЕФНЛЛЅНгПк,ABСНИізщаЭЌПЊЗЂ,AИјBЗЂЫЭЪ§Он,BИјAЛиИДЪ§Он,дМЖЈЪ§ОнАДееЪВУДбљЕФИёЪНзщжЏ,етИіЙ§ГЬОЭЪЧздЖЈвхавщЁЃ
4??аДДњТы
5??ЬсВт:ЬсНЛИјВтЪдШЫдБВтЪд
6??СЊЕї:ЖрИіФЃПщЗХдквЛЦ№РДбщжЄ
7??ЗЂВМ/ЩЯЯп
здЖЈвхгІгУВуавщ:
здЖЈвхгІгУВуавщВНжш:ЯШРэЧхНЛЛЅвЊДЋЪфЪВУДаХЯЂ,ШЛКѓОіЖЈаХЯЂАДЪВУДИёЪНРДзщжЏ
БШШчЕуЭтТєЪБЯШЦєЖЏГЬађ,ЦєЖЏГЬађОЭЩцМАЕНвЛДЮЭјТчЭЈаХ:
ЧыЧѓ:гУЛЇаХЯЂ,ЮЛжУаХЯЂ
ЯьгІ::ЩЬМвЕФаХЯЂ(ЩЬМвУћГЦ,ЩЬМвЮЛжУ,ЩЬМвЦРЗж,ЩЬМвдЄРРЭМ)
ФЧПЩвдПДЕНЧыЧѓКЭЯьгІжаАќКЌЕФгаЪБКђПЩВЛЪЧвЛЬѕаХЯЂ,ФЧетаЉаХЯЂашвЊЭЈЙ§вЛЖЈЕФИёЪНРДзщжЏ,ОпЬхЪЙгУЩЖбљЕФИёЪНРДзщжЏ,етЪЧПЩвдздЖЈвхЕФ,етИіЙ§ГЬОЭЪЧздЖЈвхгІгУВуавщЁЃ
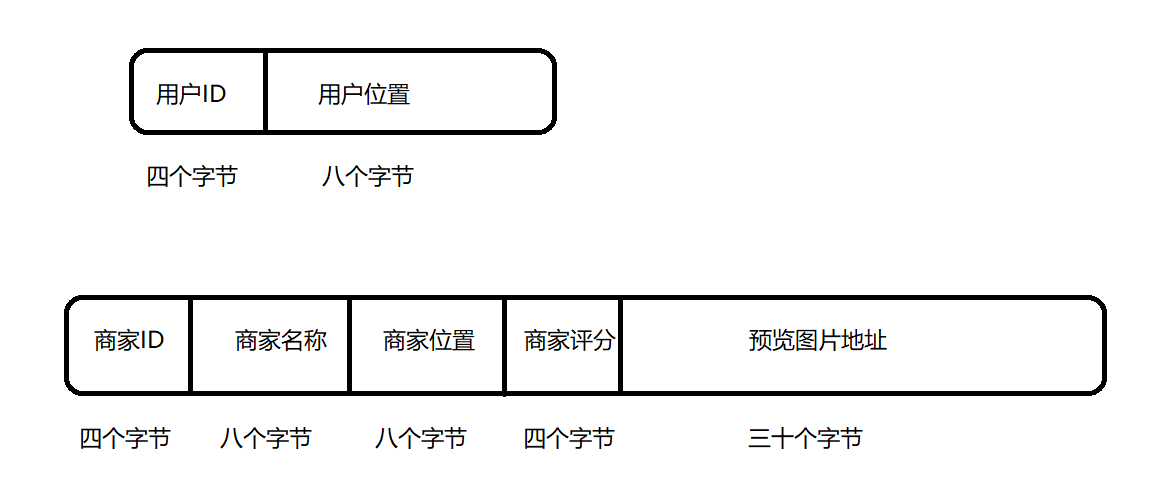
?вЛАуЪЙгУЕФИёЪНгавдЯТМИжж:
1??ЪЙгУЗжИєЗћ:
ЧыЧѓ:гУЛЇID;ЮЛжУаХЯЂ(ЖЋО,ББЮГ)
ЯьгІ:ЩЬМвID;ЩЬМвУћГЦ;ЩЬМвЮЛжУ;ЩЬМвЦРЗж;ЩЬМвдЄРРЭМ
? ЩЬМвID;ЩЬМвУћГЦ;ЩЬМвЮЛжУ;ЩЬМвЦРЗж;ЩЬМвдЄРРЭМ
? Ё
УПДЮЧыЧѓКЭЯьгІжаЕФаХЯЂЪЙгУ;ЗжИє,ЧыЧѓжЎМфЛђЯьгІжЎМфЪЙгУ\nЗжИєЁЃетРяЕФЗжИєЗћвВЪЧПЩвдЬцЛЛЕФЁЃ
2??ЪЙгУЙЬЖЈГЄЖШРДЧјЗжаХЯЂ:
БШШчвЛДЮЧыЧѓ/ЯьгІЙЬЖЈЖрЩйИізжНк,ЧыЧѓЛђЯьгІжааХЯЂЙЬЖЈеМЖрЩйИізжНк,ЪЙгУЙЬЖЈЕФГЄЖШРДЧјЗжаХЯЂЁЃ
3??ЪЙгУЩЯЪіСНжжЗНЪН:ЗжИєЗћКЭЙЬЖЈзжНкЕФЛьДю
4??ЭЈЙ§xmlЕФИёЪНРДзщжЏЪ§Он:
ЧыЧѓ:
<request>
<userId>10<usetId/>
<userPosition>163,245<userPosition/>
<request/>
ЯьгІ:
<response>
<shops>
<shop>
<id>100<id/>
<name>xxx<name/>
<position>xxx<position/>
<rank>xxx<rank/>
<img>xxx<img/>
<shop/>
<shop>
<id>100<id/>
<name>xxx<name/>
<position>xxx<position/>
<rank>xxx<rank/>
<img>xxx<img/>
<shop/>
<shops/>
<response/>
xmlетжжИёЪНЪЧЭЈЙ§БъЧЉРДзщжЏЪ§ОнЕФ,етжжИёЪНЦфЪЕРрЫЦгквЛжжЪїаЮНсЙЙ,вЛМЖвЛМЖЕиЗжМЖЯТШЅ,аЮШч(ПЊЪМБъЧЉ) (НсЪјБъЧЉ),етОЭЪЧБъЧЉ,БъЧЉвЛАуЪЧГЩЖдГіЯжЕФ,ЕЋвВгаЕЅИіЕФБъЧЉ
5??ЪЙгУjsonИёЪНРДзщжЏЪ§Он
ЧыЧѓ:
{
id:xxx,
position:"xxx"
}
ЯьгІ:
{
shops[
{
id:"xxx",
position:"xxx",
name:"xxx"
img:"xxx"
}
{
id:"xxx",
position:"xxx",
name:"xxx"
img:"xxx"
}
]
}
jsonИёЪНЪЧ {} РягавЛаЉМќжЕЖд,ЭЈЙ§МќжЕЖдРДБэЪОЪ§Он ,МќжЛФмЪЧзжЗћДЎ,ЖјжЕПЩвдЪЧЪ§зж,зжЗћДЎ,Ъ§зщ[],ЛЙПЩвдЪЧСэвЛИіjsonИёЪНЕФЪ§Он
ЯёЩЯУцЕФxml,jsonЖМЪЧзщжЏЮФБОЪ§Он,ЛЙгавЛаЉЖўНјжЦЪ§ОнЕФзщжЏИёЪН:protobuffer,thrift
Ыљвд,гІгУВуавщОЭЪЧШЗЖЈЪ§ОнЕФзщжЏИёЪН,вдБЃжЄПЭЛЇЖЫКЭЗўЮёЦїФме§ШЗНтЮіГіЪ§ОнЁЃ
ДЋЪфВуавщ
гІгУВуавщЮвУЧПЩвдздМКздЖЈвхвЛИі,ЕЋЪЧДЋЪфВуавщОЭВЛвЛбљСЫ,ДЋЪфВуавщЪЧВйзїЯЕЭГФкКЫЪЕЯжЕФ,ЮвУЧЪЧЮоЗЈздЖЈвхДЋЪфВуавщЕФ,ДЋЪфВуавщжївЊгЩСНИіTCP/UDP,
UDP:ЮоСЌНг,ВЛПЩППДЋЪф,УцЯђЪ§ОнБЈ,ШЋЫЋЙЄ
TCP:гаСЌНг,ПЩППДЋЪф,УцЯђзжНкСї,ШЋЫЋЙЄ
РэНтЪ§ОнБЈКЭзжНкСї
?зЂвт:TCPКЭUDPУцЯђЪ§ОнБЈКЭУцЯђзжНкСїЪЧеОдкгІгУВуНЧЖШРДПДД§ЕФ,вВОЭЪЧаДгІгУВуДњТыЪБ,ЪЙгУUDPЗЂЫЭЪ§ОнНгЪеЪ§ОнвдЪ§ОнБЈЮЊЕЅЮЛ,ЪЙгУTCPЗЂЫЭНгЪеЪ§ОнвдзжНкЮЊЕЅЮЛЁЃTCP/UDPЖМЛсЖдгІгУВуЪ§ОнзїЗтзА,ЗтзАГЩвЛИіЪ§ОнБЈШЅЗЂЫЭЁЃВЂВЛЪЧЫЕUDPАбгІгУВуЪ§ОнЗтзАГЩвЛИіЪ§ОнБЈ,TCPВЛЛсАбгІгУВуЪ§ОнЗтзАГЩЪ§ОнБЈ,жБНгвдзжНкЮЊЕЅЮЛДЋЪфЁЃетСЉавщЖМЛсАбгІгУВуЪ§ОнЗтзАЮЊЪ§ОнБЈЁЃ
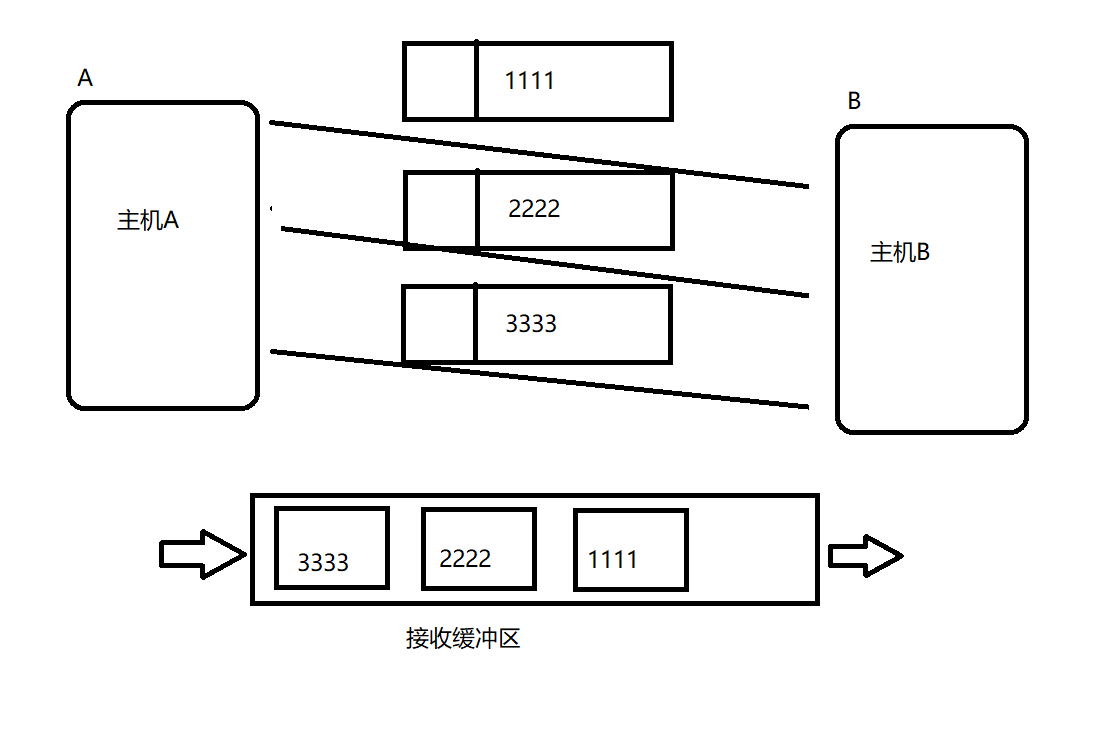
==ЖдгкUDPавщРДЫЕ:==дкгІгУВуУПДЮЕїгУreceive()НгЪеЕНЕФЖМЪЧвЛИіЭъећЕФЪ§ОнАќ(1111Лђ2222Лђ3333),дкФкКЫжаЕФНгЪеЛКГхЧјжаетШ§ИіЪ§ОнАќЪЧгаБпНчЕФ,ЫљвдУПДЮreceive()ЛёШЁЕНЕФЪЧвЛИіЭъећЕФЪ§ОнАќЁЃЖдгкUDPЕФНгЪеЛКГхЧјРДЫЕ,ЫќИќЯёЪЧвЛИіСДБэЁЃУПДЮЗЂРДЕФЪ§ОнЪЧгаБпНчЕФЁЃ
ЖдгкTCPавщРДЫЕ:
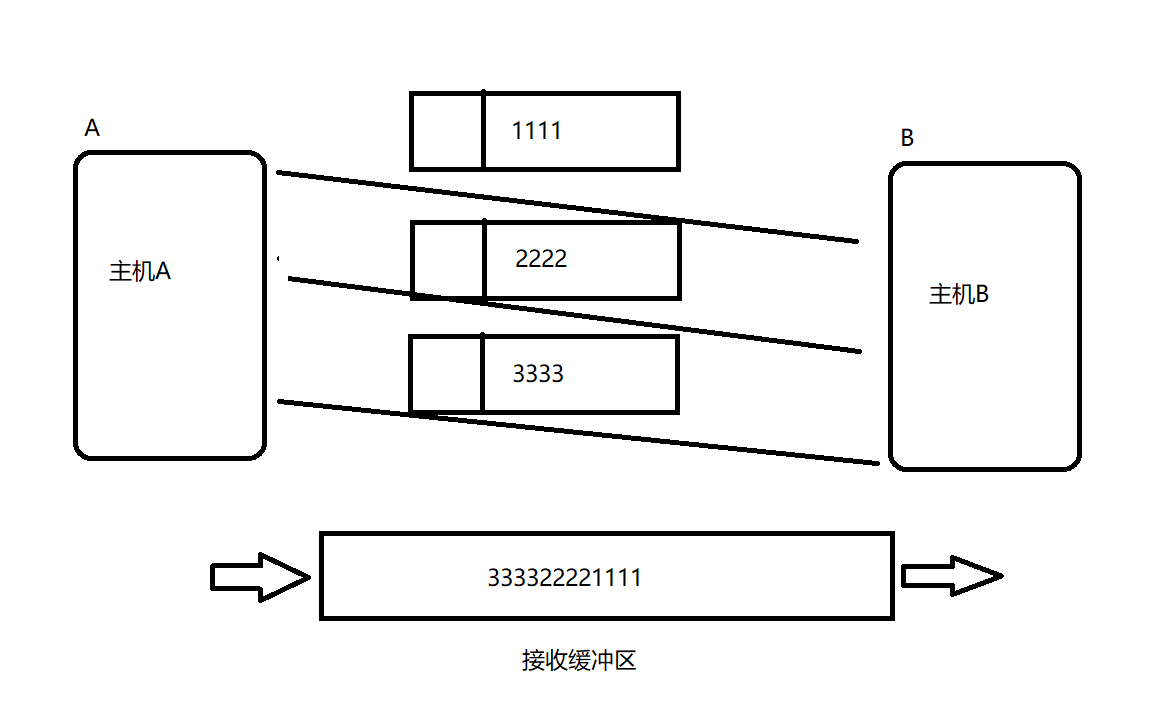
ЖдгкTCPавщРДЫЕ,Ъ§ОндкНгЪеЛКГхЧјжаЪЧУЛгаБпНчЕФ,ЕїгУread(),УПДЮЖСЕНМИИізжНкЕФЪ§ОнЖМЪЧздЖЈвхЕФ,ПЩвдУПДЮЖС1ИізжНк,ПЩвдУПДЮЖС2ИізжНк,вВПЩвдУПДЮЖС3ИізжНк,ЕШЕШЁЃ
TCPЕФНгЪеЛКГхЧјИќЯёЪЧвЛИіЪ§зщ,УПДЮЗЂЫЭЖЫЗЂРДЕФЪ§ОнЖМШкЮЊвЛЬх,УЛгаБпНч
?змНс:ВЛТлTCPЛЙЪЧUDP,ЖМЛсЖдЗЂЫЭЖЫЕФгІгУВуЪ§ОнЗтзАГЩвЛИіЪ§ОнБЈ,НгЪеЖЫНгЪеЕНЪ§ОнЪБ,ЭЌбљЖМЛсЖдЪ§ОнБЈЗжгУ,НтЮіБЈЭЗ,СєЯТгІгУВуЪ§ОнЁЃжЛВЛЙ§дкгІгУВуВЛвЛбљ,ЪЙгУUDPЕФгІгУВу,ЕїгУrecieve()УПДЮНгЪеЪ§ОнЖМжЛФмНгЪеЕНЗЂЫЭЖЫЗЂЫЭЕФвЛИіЭъећЕФЪ§ОнАќ;ЪЙгУTCPавщЕФгІгУВу,ЕїгУread()УПДЮНгЪеЪ§ОнЪБЪЧАДзжНкЮЊЕЅЮЛНгЪеЕФ,ВЛвдЪ§ОнАќЮЊЕЅЮЛЁЃ
??ПЩвдРэНтЮЊUDPЗжгУКѓЕФЪ§ОнЪЧгаБпНчЕФ,TCPЗжгУКѓЕФЪ§ОнЪБУЛгаБпНчЕФЁЃ
ЮвУЧвЊбЇЯАДЋЪфВуавщ,жївЊЪЧбЇЯАвЛИіавщЕФБЈЮФаЮЪН:
РэНтUDPавщ
UDPавщЪЧВйзїЯЕЭГЪЕЯжЕФ,ЬиЕуЪЧ:
ЮоСЌНг,ВЛПЩППДЋЪф,УцЯђЪ§ОнБЈ,ШЋЫЋЙЄ
ВЛПЩППДЋЪф:НгЪеЖЫЪеУЛЪеЕНЪ§ОнЗЂЫЭЖЫВЂВЛЧхГў,РрЫЦЗЂЮЂаХ
УцЯђЪ§ОнБЈ:еОдкгІгУВуЕФНЧЖШ,ЗЂЫЭЕФЪ§ОнЪЧвдЪ§ОнБЈЮЊЕЅЮЛЕФ,НгЪеЪ§ОнЪБвВЪЧвдЪ§ОнБЈЮЊЕЅЮЛЕФ
UDPБЈЮФаЮЪН:
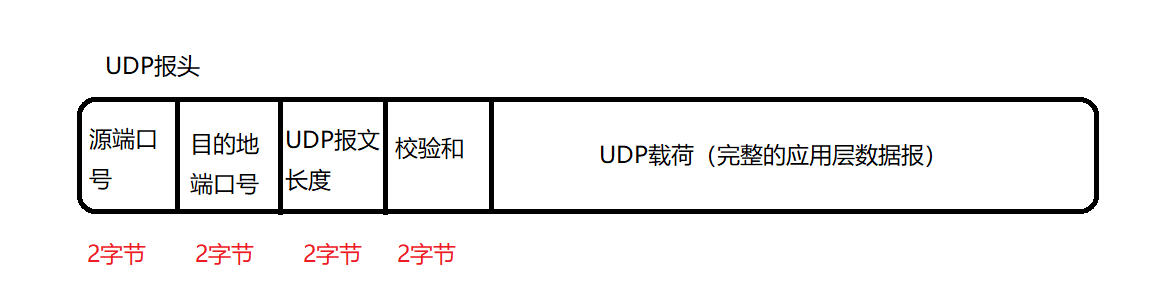
1??дДЖЫПкКХ:ЗЂЫЭЖЫНјГЬЕФЖЫПкКХ
2??ФПЕФЕиЖЫПкКХ:НгЪеЖЫНјГЬЕФЖЫПкКХ
3??UDPБЈЮФГЄЖШ:ЕБЧАБЈЮФЕФГЄЖШ,ЕЅЮЛЪЧзжНк,ДцДЂUDPБЈЮФГЄЖШЪЧЙЬЖЈЕФСНИізжНк,ЖјСНИізжНкДцДЂЕФзюДѓжЕЪЧ65535,65536ИізжНкЪЧ64KB,ЫљвдетОЭгавЛЖЈЕФЯожЦ:==вЛИіUDPЪ§ОнБЈзюДѓВЛФмГЌЙ§64KB,==етдквЛПЊЪМЩшМЦUDPЪБЪЧУЛЩЖЮЪЬтЕФ,ЖдгкФЧИіФъДњРДЫЕ,64KBЪЧЙЛгУЕФ,ЕЋЖдгкЯждкЕФЛЅСЊЭјРДЫЕ,64KBЪЧКмаЁЕФЁЃ
ФЧУДвЊЗЂЫЭвЛИіЧыЧѓЛђвЛИіЯьгІ,ШчЙћЪЧДѓгк64KBЕФ,ИУеІАь?
НтОіЗНЪН:АбЯьгІЛђЧыЧѓВ№Зж,ШЛКѓЗжЖрДЮЗЂЫЭ,НгЪеЖЫНгЪеЕНжЎКѓ,дйАбВ№ЗжГіРДЕФЪ§ОнБЈећКЯЕНвЛЦ№,ЕЋЪЧОЭгжЛсВњЩњвЛИіЮЪЬт:
ОЭЪЧЗЂЫЭЖЫВ№ГіРДЕФЖрИіЪ§ОнБЈвЛАуЪЧгавЛЖЈЕФЫГађ,ШЛКѓЗЂЫЭЖЫАДетИіЫГађЗЂЫЭ,ЕЋЪЧНгЪеЖЫНгЪеЕНжЎКѓ,ПЩФмЫГађОЭБфСЫ(вЛАуЫГађЪЧВЛЛсБфЕФ,ЕЋЪЧШчЙћгаЭјТчЖЖЖЏ,етИіЫГађПЩФмОЭЛсБф),ФЧЫљвдНгЪеЖЫНгЪеЕНжЎКѓ,ЛЙЕУЖдВ№ЗжГіРДЕФетМИИіЪ§ОнБЈНјааећЖг,ШЗЖЈЪ§ОнБЈЫГађ,ФЧетбљЕФЛАОЭБиШЛЛсВњЩњЖюЭтЕФПЊЯњЁЃ
ФЧЮЊЩЖВЛЖдUDPавщЩ§МЖвЛЯТФи?БШШчАбДцДЂЪ§ОнБЈЕФПеМфЩшЮЊЫФИізжНк?
вђЮЊЯждкШЋЪРНчЕФЕчФдЩЯГЬађЖМгІгУСЫUDPавщ,ФуЕУБЃжЄЫљгаЕчФдЕФЯЕЭГЖМЩ§МЖ,ШчЙћЕчФдЩ§МЖСЫ,вЛИіЕчФдУЛгаЩ§МЖ,ФЧОЭВЛФме§ШЗНтЮіГіЪ§ОнСЫ,етЪЧКмФбАьЕФЁЃЩ§МЖВйзївЊПМТЧМцШнадЁЃ
4??аЃбщКЭ:ШЗБЃДЋЪфЕФЪ§ОнжаЭОУЛгаЗЂЩњИФБфЁЃ
Ъ§ОнДЋЪфЕФБОжЪЪЧЪЙгУЙт/ЕчаХКХ,ИпЕЭЕчЦН,ВЛЭЌЦЕТЪЕФЙтаХКХДњБэ0/1,дкЪ§ОнДЋЪфЕФЙ§ГЬжа,ШчЙћЪмЕНИЩШХ,БШШчДХГЁИЩШХ,ОЭПЩФмВњЩњБШЬиЗДзЊ,0БфГЩ1,1БфЮЊ0ЁЃЫљвдНгЪеЖЫОЭЕУЖдЪ§ОнзіИіаЃбщ,ЗЂЫЭЖЫеыЖдЪ§ОнЧѓГівЛИіаЃбщКЭ,ЕБНгЪеЖЫЪеЕНКѓ,дйЖдЪ§ОнзівЛИіаЃбщКЭ,ШЛКѓБШНЯСНДЮЕФаЃбщКЭ,ШчЙћаЃбщКЭВЛвЛжТ,ЫЕУїЪ§ОндкДЋЪфЙ§ГЬжавЛЖЈВњЩњСЫИФБф,ШчЙћаЃбщКЭвЛжТ,ФЧвВВЛФмЫЕУїЪ§ОнвЛЖЈУЛгаЗЂЩњИФБф,ПЩФмГіЯжСЫЖрДЮБШЬиЗДзЊ,ЕМжТЪ§ОнЗЂЫЭИФБф,ЕЋаЃбщКЭУЛБф,ЕЋетжжЧщПіИХТЪМЋЕЭ,дкЙЄГЬЩЯОЭВЛПМТЧСЫЁЃ
UDPЪЙгУЕФаЃбщКЭЫуЗЈЪЧ:CRCЫуЗЈ(бЛЗШпграЃбщКЭ):АбЪ§ОнЕФУПИізжНкЖММгЕНвЛПщ,ШчЙћГЌЙ§СЫСНИізжНк,вчГіЕФВПЗжОЭВЛвЊСЫ,ЪЃгрЕФВПЗжОЭЪЧаЃбщКЭЁЃ
РэНтTCPавщ
TCPавщЬиЕу
TCPавщвВЪЧВйзїЯЕЭГЪЕЯжЕФ,ЬиЕуЪЧ:
гаСЌНг,ПЩППДЋЪф,УцЯђзжНкСї,ШЋЫЋЙЄ
гаСЌНг:ЯШНЈСЂСЌНгдйДЋЪфЪ§Он
ПЩППДЋЪф:НгЪеЖЫЪЧЗёНгЪеЕНЪ§Он,ЗЂЫЭЖЫаФРягаЪ§ЁЃВЂВЛЪЧЫЕЗЂЫЭЕФЪ§ОнНгЪеЖЫ100%ФмЪеЕНЁЃ
УцЯђзжНкСї:еОдкгІгУВуЕФНЧЖШ,ЗЂЫЭЪ§ОнвдзжНкЮЊЕЅЮЛ,НгЪеЪ§ОнвВЪЧвдзжНкЮЊЕЅЮЛЁЃ
?зЂвт:етРяЕФПЩППадВЂВЛЪЧАВШЋад,АВШЋад:ЕБЪ§ОнБЛНиЛёКѓ,ВЛШнвзБЛРэНтЛђДлИФ(ЭЈЙ§МгУм)
1.ШЗШЯгІД№ЛњжЦ(БЃжЄПЩПП)
ПЩППДЋЪфЪЧTCPЕФГѕаФ:ЖјTCPЪЕЯжПЩППДЋЪфЕФЛњжЦжЎвЛЪЧгІД№ЛњжЦ:
?ЗЂЫЭЖЫЗЂЫЭЙ§РДTCPБЈЮФ(Ъ§ОнБЈЮФ)СЫ,НгЪеЖЫвЊЗЕЛиИјЗЂЫЭЖЫвЛИігІД№БЈЮФ(жЛАќКЌTCPБЈЭЗ)
ЖјдкЭјТчДЋЪфЕФЙ§ГЬжа,ЕБЗЂЫЭЖЫЗЂЫЭЖрЬѕЪ§ОнКѓ,НгЪеЖЫВЛвЛЖЈАДееЗЂЫЭЪ§ОнЕФЫГађНгЪеЕНЪ§Он,етЪЧвђЮЊЭјТчДЋЪфЕФвЛИіЬиад(КѓЗЂЯШжС),гЩгквЛаЉдвђ,БШШчЭјТчЖЖЖЏЕШ,ОЭПЩФмЕМжТTCPБЈЮФКѓЗЂЯШжСЁЃФЧМШШЛвЊгІД№,ОЭвЊФмЙЛШЗЖЈеыЖдФФИіTCPБЈЮФзїГігІД№,гІД№БЈЮФгІД№ЕФЪЧФФЬѕЪ§ОнЁЃетбљЗЂЫЭЖЫОЭФмжЊЕРНгЪеЖЫНгЪеЕНФФИіБЈЮФ,ЛЙУЛгаНгЪеЕНФФИіБЈЮФСЫЁЃФЧОЭашвЊеыЖдTCPБЈЮФНјааБрКХ:
етИіађКХОЭАќКЌдкTCPБЈЭЗжа:

?етИі32ЮЛађКХОЭЪЧЪ§ОнЖдгІЕФБрКХ,ШчЙћЕБЧАБЈЮФЪЧЦеЭЈБЈЮФ(Дјгаеце§Ъ§ОнЕФ),32ЮЛШЗШЯађКХЪЧВЛЩњаЇЕФ,ШчЙћЕБЧАБЈЮФЪЧгІД№БЈЮФ,ШЗШЯађКХОЭДњБэСЫгІД№БЈЮФгІД№ЕФЪЧФФЬѕЦеЭЈБЈЮФЁЃ
?гІД№БЈЮФЪЧУЛгадиКЩЕФ,жЛгавЛИіTCPБЈЭЗЁЃ
ЮвУЧжЊЕР,ашвЊЖдБЈЮФНјааБрКХ,ВХФмУїШЗгІД№БЈЮФгІД№ЕФЪЧФФЬѕБЈЮФ,ФЧШчКЮЖдБЈЮФНјааБрКХ:
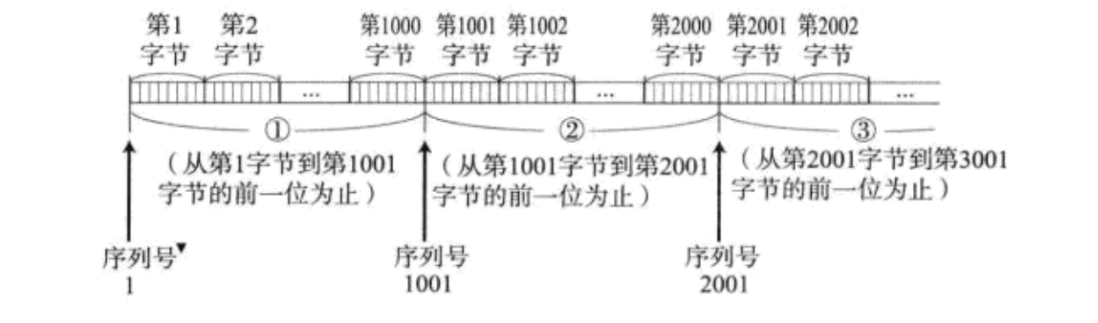
еыЖдБЈЮФНјааБрКХ,ЦфЪЕЪЧеыЖдЗЂЫЭЕФЪ§Он,ЖдУПИізжНкЖМНјааСЫБрКХ,ЕквЛИізжНкЪЧађКХ1,вРДЮРрЭЦ,ађКХДцдкTCPЪ§ОнБЈЭЗжаЁЃБШШчЯТУцетИіР§зг:
жїЛњAЯШИјжїЛњBЗЂЫЭСЫ1~1000ЕФЪ§Он,ДњБэЗЂЫЭСЫађКХ1 ~ 1000ЕФзжНкЁЃФЧдкЗЂЫЭЕФБЈЮФжаЕФ32ЮЛађКХОЭЪЧ1,ЪЧетаЉзжНкЕФЦ№ЪМзжНкађКХ,ШЛКѓжїЛњBЪеЕНжЎКѓ,,ОЭИљОнетИіађКХ1,ЛЙгаБЈЮФЕФГЄЖШ1000,ОЭжЊЕРСЫжїЛњAЗЂЫЭЙ§РДСЫађКХ1~1000ЕФзжНкЁЃШЛКѓжїЛњBЗЂЫЭЕФгІД№БЈЮФ(гІД№БЈЮФжЛгаБЈЭЗ)жаЕФШЗШЯађКХОЭЪЧ1001,ЯрЕБгкИцЫпжїЛњA1001жЎЧАЕФзжНквбОЪеЕНСЫ,НгЯТРДПЊЪМДг1001зжНкЗЂЫЭЪ§ОнЁЃ
ФЧШчКЮЧјЗжвЛИіБЈЮФЪЧЦеЭЈБЈЮФЛЙЪЧгІД№БЈЮФФи?
дкTCPБЈЮФжагаСљИіЗЧГЃживЊЕФbitЮЛ,ЦфжаЕкЖўЮЛACK(acknowledge)ОЭФмБэЪОЕБЧАБЈЮФЪЧЦеЭЈБЈЮФЛЙЪЧгІД№БЈЮФ,ACKЮЊ0БэЪОВЛЪЧгІД№БЈЮФ,ACKЮЊ1БэЪОЪЧгІД№БЈЮФЁЃгІД№БЈЮФвВБЛГЦЮЊACKБЈЮФЁЃ
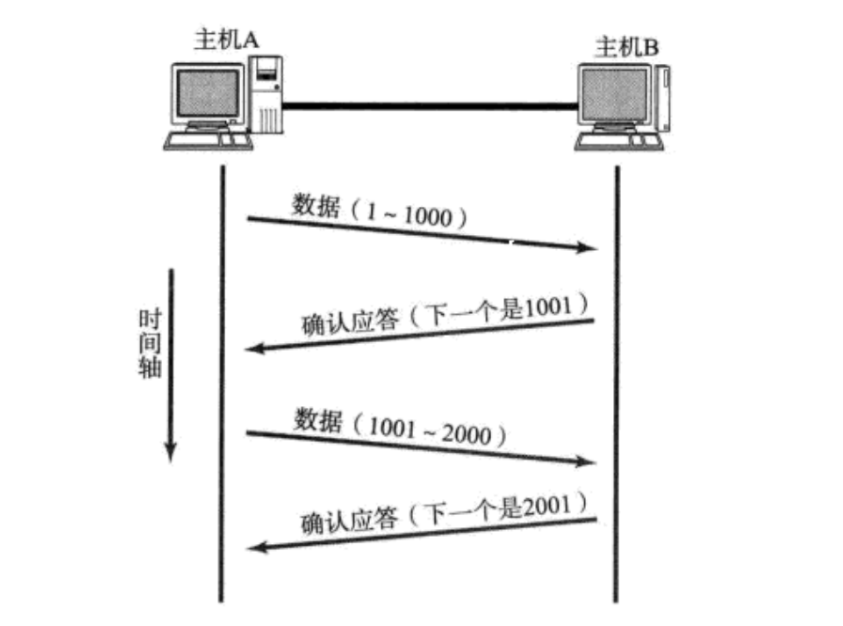
2.ГЌЪБжиДЋЛњжЦ(БЃжЄПЩПП)
гІД№ЛњжЦЪЧдкЭјТче§ГЃЧщПіЯТ,ЗЂЫЭЖЫЗЂЫЭСЫЪ§Он,НгЪеЖЫЪеЕНЪ§ОнКѓ,ЗЕЛиACKЁЃЕЋЪЧецЪЕЕФЭјТчЧщПіЪЧБШНЯИДдгЕФ,гаПЩФмЛсГіЯжЭјТчгЕЖТЕФЧщПі,ЭјТчгЕЖТОЭгаПЩФмЕМжТЭјТчбгЪББШНЯДѓ(Ъ§ОнБЈДгЗЂЫЭЖЫЕННгЪеЖЫКФЪББШНЯГЄ),ЛђепЖЊАќ(ЗЂЫЭЕФЪ§ОнБЈдкжаЭОЖЊСЫ,етбљНгЪеЖЫЪЧВЛПЩФмНгЪеЕНЪ§ОнСЫ)ЁЃ
ФЧУДдкЩЯУцЕФЭјТЗгЕЖТЕФЧщПіЯТ,ОЭЛсЕМжТЖЊАќ,НјЖјЕМжТЗЂЫЭЖЫЗЂЫЭСЫЪ§Он,ЕЋЪЧГйГйНгЪеВЛЕНACKЁЃФЧНгЪеВЛЕНACK,гаСНжждвђ:ПЩФмЪЧЗЂЫЭЖЫЗЂЫЭЕФЪ§ОнБЈЖЊЪЇСЫ,НгЪеЖЫИљБОУЛгаЪеЕНЪ§Он;вВПЩФмЪЧНгЪеЖЫНгЪеЕНЪ§ОнСЫ,ЕЋЪЧЗЕЛиЕФACKЖЊСЫЁЃФЧЫљвдНгЯТРДПМТЧетСНжжЧщПі:
1??вЕЮёЪ§ОнЖЊСЫ:

етжжЧщПіНгЪеЖЫНгЪеВЛЕНЪ§ОнБЈ,ФЧздШЛВЛЛсЗЕЛиACK,ФЧЗЂЫЭЖЫУЛгаНгЪеЕНACK,Й§СЫЬиЖЈЪБМфжЎКѓ,ОЭЛсДЅЗЂГЌЪБжиДЋ,дйжиаТЗЂвЛЗнЪ§Он
2??ACKБЈЮФЖЊСЫ:

етжжЧщПіЯТ,НгЪеЖЫНгЪеЕНСЫЪ§Он,ЕЋЪЧЗЕЛиЕФACKБЈЮФЖЊСЫ,ФЧЗЂЫЭЖЫжЛЪЧжЊЕРУЛгаЪеЕНACK,ВЛЙмНгЪеЖЫЪЧЗёНгЪеЕНСЫЪ§Он,ЫљвдЙ§СЫЬиЖЈЪБМфжЎКѓ,ЗЂЫЭЖЫОЭЛсжиаТЗЂвЛЗнЪ§ОнЁЃ
ЗЂЫЭЖЫЪЧЮоЗЈЧјЗжЪЧвЕЮёЪ§ОнЖЊСЫЛЙЪЧACKЖЊСЫ,жЛЙмвЛЖЈЪБМфФкУЛгаЪеЕНACKОЭжиДЋЁЃ
ШЅжи:
ФЧЕкЖўжжЧщПіЯТ,жїЛњBЛсЪеЕНСНЗнЪ§ОнЛђЖрЗнжиИДЕФЪ§Он,ЕЋЪЧдкжїЛњBЕФгІгУВуЕїгУread()ЖСШЁЪ§ОнЪБ,АДРэРДЫЕЖСЕНвЛЗнЪ§ОнВХЪЧе§ШЗЕФ,ЫљвдTCPдкНгЪеЕНЪ§ОнЪБЛсИљОнађКХШЅжи,ЕквЛДЮЪеЕНађКХЮЊ1~1000ЕФЪ§Он,ШЛКѓЕкЖўДЮШчЙћгжЪеЕН1 ~ 1000ЕФЪ§Он,ОЭЛсШЅжи,жЛБЃСєвЛЗнЪ§Он,БЃжЄгІгУВуЖСЪ§ОнЪБ,ВЛЛсЖСЕНжиИДЪ§ОнЁЃ
Ъ§ОндкДЋЪфЙ§ГЬжаЗЂЩњ ИФБф:
ЗЂЫЭЕФЪ§ОнБОРДЪЧ1~1000,ЕЋЪЧдкДЋЪфЙ§ГЬжаЗЂЩњИФБфСЫ,НгЪеЖЫНгЪеЕНЕФЪ§ОнПЩФмЪЧ:
1~500 1~2000 1~1000(ФкШнБфСЫ),ФЧНгЪеЖЫШчКЮХаЖЯЪ§ОндкДЋЪфЙ§ГЬжаЪЧЗёЗЂЩњСЫИФБфФи?етОЭвРРЕаЃбщКЭСЫЁЃЮвУЧжЊЕРжїЛњAЗЂЫЭИјжїЛњBЕФЙ§ГЬжаЛсОЙ§КмЖрНкЕу(ТЗгЩЦїКЭНЛЛЛЛњ),ЕБЪ§ОнОЙ§НкЕуЪБОЭЛсжиаТМЦЫуаЃбщКЭ,ШчЙћЗЂЯжМЦЫуЕФаЃбщКЭКЭЗЂЫЭЖЫЗЂЫЭЕФаЃбщКЭВЛвЛжТ,ОЭЛсжїЖЏЖЊАќ,МйШчЪ§ОнЕНДяжїЛњB,вВЛсМЦЫуаЃбщКЭ,ШчЙћВЛвЛжТ,ОЭжїЖЏЖЊАќЁЃЖЊАќжЎКѓ,ЕШжїЛњAДЅЗЂГЌЪБжиДЋКѓжиДЋЪ§ОнЁЃ
СЌајЖЊАќ:
дкГЌЪБжиДЋЕФЛњжЦЯТ,ЖЊАќжЎКѓжиДЋ,ФЧжиДЋЕФАќвВЪЧгаПЩФмдйЖЊЕФ,ЕЋЪЧСЌајЖЊАќЕФИХТЪЪЧБШНЯаЁЕФ,МйШчУПДЮЖЊАќЕФИХТЪЪЧ10%,ФЧСЌајСНДЮЖЊАќЕФИХТЪЪЧ1%,СЌајШ§ДЮЖЊАќЕФИХТЪЪЧ0.1%ЁЃЫљвдГЌЪБжиДЋЫќШЗЪЕФмНтОіЖЊАќЕФЮЪЬтЁЃ
ГЌЪБЪБМф:
МйШчЕквЛДЮЖЊАќЕФГЌЪБЪБМфЪЧt1,ЕкЖўДЮЖЊАќЕФГЌЪБЪБМфЪЧt2ЁЃФЧt1<t2
втЫМОЭЪЧЕкЖўДЮЕШД§ACKЕФЪБМфБШЕквЛДЮГЄ,вђЮЊШчЙћЗЂЩњЖЊАќ,НЯДѓПЩФмЪЧЭјТчЮЪЬт(БШШчЭјТчгЕЖТ),ЭјТчЮЪЬтЖЬЪБМфФкПЩФмЛжИДВЛСЫ,ЫљвдЕкЖўДЮЕФЕШД§ЪБМфОЭБШЕквЛДЮГЄ,ЕкШ§ДЮЕФЪБМфЛсБШЕкЖўДЮИќГЄ,вРДЮРрЭЦЁЃ
TCPЮЊСЫБЃжЄШЮКЮЛЗОГЯТЖМФмИќИпаЇЭЈаХ,ЛсЖЏЬЌМЦЫуГЌЪБЪБМф,вђЮЊШчЙћЪБМфЬЋГЄ,ЛсгАЯьЭЈаХаЇТЪ,ШчЙћЪБМфЬЋЖЬ,ОЭЯрЕБгкЦЕЗБжиДЋ,МгжиЭјТчгЕЖТЁЃЕквЛДЮЕФГЌЪБЪБМфЪЧ500ms,ЕкЖўДЮЪЧ2*500ms,ЕкШ§ДЮЪЧ4 * 500ms,жИЪ§ЕндіЁЃвђЮЊШчЙћСЌајЖЊАќДЮЪ§дНЖр,ЫЕУїЖЊАќИХТЪдНДѓ,ЗЂЫЭЕФЦЕЗБвВУЛЩЖгУ,ЫљвдЕШД§ACKЕФЪБМфОЭЛсдНОУЁЃБмУтЦЕЗБЗЂЫЭжиИДЕФАќЁЃШчЙћСЌајМИДЮжиДЋЖМЪЇАм,ОЭЛсЗХЦњжиДЋ,ЖЯПЊСЌНгЁЃ
?ШЗШЯгІД№КЭГЌЪБжиДЋЪЧБЃжЄTCPПЩППадЕФзюКЫаФЛњжЦЁЃ
3.НЈСЂСЌНг(БЃжЄПЩПП)
TCPавщзїЮЊгаСЌНгЕФавщ,ЪЙгУTCPавщдке§ЪНЗЂЫЭЪ§ОнжЎЧА,ЛЙвЊЯШНЈСЂСЌНг,НЈСЂСЌНгвВЪЧЮЊСЫБЃжЄПЩППадЁЃНЈСЂСЌНгЕФЙ§ГЬГЦЮЊШ§ДЮЮеЪж:
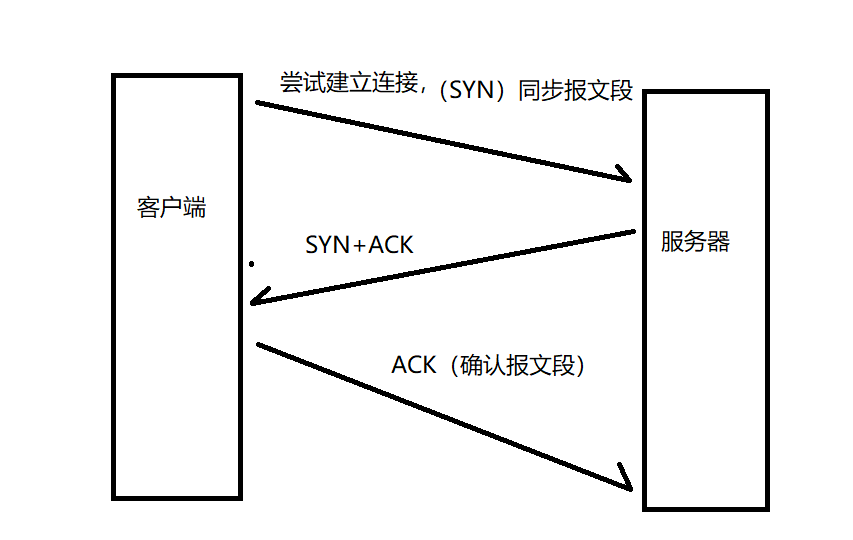
Ш§ДЮЮеЪжЙ§ГЬ:
1??ЯШЪЧПЭЛЇЖЫИјЗўЮёЦїЗЂЫЭЭЌВНБЈЮФЖЮ(SYN)
2??ЗўЮёЦїНгЪеЕНSYNжЎКѓ,ЗЕЛивЛИіБЈЮФЖЮ(SYN+ACK)
3??ПЭЛЇЖЫНгЪеЕНSYNКЭACKжЎКѓ,ЗЕЛиИјЗўЮёЦївЛИіACK(ШЗШЯБЈЮФЖЮ)
Ыљвд,ПЭЛЇЖЫКЭЗўЮёЦїЛЅЯрИјЖдЗНЗЂЫЭСЫвЛИіSYNКЭвЛИіACKЁЃ
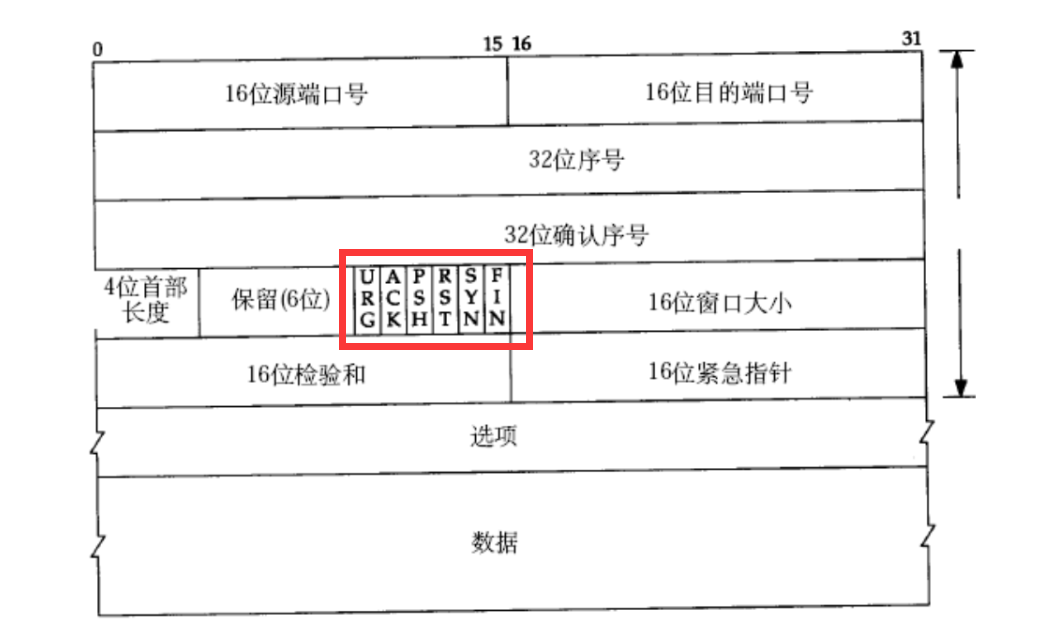
SYNКЭACKЖМЪЧTCPЪ§ОнБЈЕФБЈЭЗжаЕФБъжОЮЛ:
SYNЮЊ1ДњБэЕБЧАБЈЮФЪЧЭЌВНБЈЮФ,ACKЮЊ1ДњБэЕБЧАБЈЮФЪЧШЗШЯБЈЮФЁЃSYN (synchronize)
ЫљвдЕквЛЬѕБЈЮФжаSYNЮЊ1,ЕкЖўЬѕБЈЮФжаACKКЭSYNЖМЪЧ1,ЕкШ§ЬѕБЈЮФжаACKЮЊ1
ЮЊЩЖдке§ЪНЗЂЫЭвЕЮёЪ§ОнЧА,вЊЯШШ§ДЮЮеЪж?
1??Ш§ДЮЮеЪжЕФвтвхвЛ:
Ш§ДЮЮеЪжШЯЮЊБЃжЄПЩППадЕФвЛИіЛњжЦ,Ш§ДЮЮеЪжЯрЕБгкЭЖЪЏЮЪТЗ,дке§ЪНЗЂЫЭвЕЮёЪ§ОнЧА,ЯШбщжЄвЛЯТЭЈаХСДТЗЪЧЗёГЉЭЈЁЃФЧдѕУДбљЭЈаХСДТЗВХЫуГЉЭЈФи?
ФЧОЭЪЧЭЈаХЫЋЗНЕФЗЂЫЭЪ§ОнКЭНгЪеЪ§ОнЕФФмСІЖМЪЧOKЕФ,Ш§ДЮЮеЪжОЭЪЧдкбщжЄЫЋЗНЕФЗЂЫЭФмСІКЭНгЪеФмСІЪЧЗёе§ГЃЁЃ
- ПЭЛЇЖЫЗЂЫЭSYNИјЗўЮёЦї,ЕБЗўЮёЦїНгЪеЕНSYNжЎКѓ,ЗўЮёЦїОЭжЊЕРздМКЕФНгЪеФмСІok,ПЭЛЇЖЫЕФЗЂЫЭФмСІok
- ШЛКѓЕБЗўЮёЦїНгЪеЕНSYNжЎКѓ,ЗўЮёЦїЗЂЫЭACKКЭSYNИјПЭЛЇЖЫ,ЕБПЭЛЇЖЫНгЪеЕНACKКЭSYNжЎКѓ,ПЭЛЇЖЫОЭжЊЕРздМКЕФЗЂЫЭФмСІКЭНгЪеФмСІЪЧOKЕФ,ЛЙжЊЕРЗўЮёЦїЕФЗЂЫЭФмСІКЭНгЪеФмСІЪЧokЕФЁЃ
- зюКѓПЭЛЇЖЫЗЕЛиACK,ЕБЗўЮёЦїНгЪеЕНжЎКѓ,ЗўЮёЦїОЭжЊЕРздМКЕФЗЂЫЭФмСІЪЧokЕФ,ПЭЛЇЖЫЕФНгЪеФмСІЪЧokЕФЁЃ
?ШчЙћШ§ДЮЮеЪжФмдВТњЭъГЩ,ОЭЫЕУїПЭЛЇЖЫКЭЗўЮёЦїЖМЧхГўздМКвдМАЖдЗНЕФЗЂЫЭФмСІКЭНгЪеФмСІЪЧokЕФЁЃ
2??Ш§ДЮЮеЪжЕФвтвхЖў:
ФмЙЛШУЭЈаХЫЋЗНаЩЬвЛаЉживЊВЮЪ§ЁЃБШШчађКХвЊДгМИПЊЪМ,ЪЕМЪЩЯађКХВЛвЛЖЈЪЧДгвЛПЊЪМЕФЁЃвдМАMSS
3.ЖЯПЊСЌНг:
ЕБвЕЮёЪ§ОнЗЂЫЭЭъСЫ,ОЭвЊЖЯПЊСЌНг,зюПЊЪМНЈСЂСЌНгЕФЙ§ГЬЪЧПЭЛЇЖЫЯШЗЂЦ№ЕФ,ЕЋЪЧЖЯПЊСЌНгМШПЩвдЪЧПЭЛЇЖЫЯШЗЂЦ№,вВПЩвдЪЧЗўЮёЖЫЯШЗЂЦ№ЁЃ
ЖЯПЊСЌНгетИіЙ§ГЬГЦЮЊЫФДЮЛгЪж:
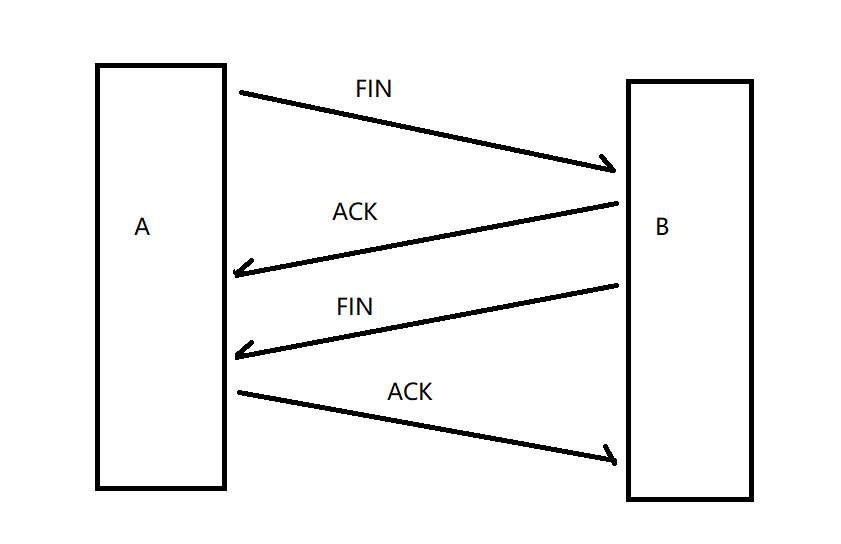
?ЫФДЮЛгЪжЕФЙ§ГЬ:жїЖЏЖЯПЊСЌНгЕФвЛЗНЯШЗЂЫЭFIN(БэЪОвЊЖЯПЊСЌНг),ШЛКѓЖдЗНЪеЕНКѓЯШЗЂЫЭвЛИіACK(ДњБэНгЪеЕНЖЯПЊСЌНгЕФЧыЧѓ),ШЛКѓдйЗЂЫЭвЛИіFIN(ДњБэПЩвдЖЯПЊСЌНгСЫ),ШЛКѓЖдЗНЪеЕНКѓЗЕЛивЛИіACK(ДњБэЖдЗННгЪеЕНСЫ)ЁЃ
етРяПДЦ№РДКЭШ§ДЮЮеЪжЕФЙ§ГЬВюВЛЖр,ЕЋЪЧВЛЭЌЕФЪЧ,етРяЛсЗЂЫЭЫФЬѕЪ§Он,Ш§ДЮЮеЪжФЧРяЗЂЫЭЕФЪЧШ§ЬѕЪ§Он,вђЮЊетРяЕФжаМфСНЬѕЪ§ОнВЛвЛЖЈФмвЛДЮадЗЂЫЭ,ЯёШ§ДЮЮеЪжФЧРяОЭЪЧSYNКЭACKПЩвдвЛДЮадЗЂЫЭ
етРяЕФACKКЭFINВЛвЛЖЈФмвЛДЮадЗЂЫЭЕФдвђЪЧ:ЗЕЛиACKЪЧДПФкКЫЕФВйзї,НгЪеЕНЖдЗНЗЂЫЭЕФFINжЎКѓ,ФкКЫЛсСЂМДЗЕЛиACK,ЕЋЪЧЗЂЫЭFINЪЧгУЛЇЬЌДњТыЕФааЮЊЁЃдкгІгУВуДњТыжаЕїгУsocket.close(),ЛсДЅЗЂЗЂЫЭFIN,ЕБвЛЗННгЪеЕНFINКѓ,ЛсСЂМДЗЕЛиACK,ЕЋЪЧВЛвЛЖЈЩЖЪБКђЗЕЛиFIN,ЕУПДЩЖЪБКђЕїгУsocket.close(),ЫљвдетСНДЮЗЕЛиЪЧгаЪБМфМфИєЕФ,ФЧЫљвдвЛАуЧщПіЯТетСНИіЪ§ОнЪЧЗжСНДЮЗЕЛиЕФЁЃ
==Ш§ДЮЮеЪжЪБ,SYNКЭACKПЩвдКЯВЂЪЧвђЮЊ:==ЗЕЛиЕФSYNКЭACKПЩвдКЯВЂЪЧвђЮЊетСНИіВйзїЖМЪЧФкКЫжБНгВйзїЕФ,ЕБЗўЮёЦїНгЪеЕНПЭЛЇЖЫЗЂРДЕФSYNКѓ,ОЭСЂМДЗЕЛиSYNКЭACKСЫЁЃ
??ЕЋЪЧвВВЛЪЧетСНДЮЗЕЛиЕФЪ§ОнвЛЖЈВЛФмКЯВЂ,гаЪБКђвВЪЧПЩвдКЯВЂЕФ,вђЮЊTCPЛЙгавЛИібгЪБгІД№КЭЩгДјгІД№ЛњжЦЁЃ
ЖЯПЊСЌНгЪБ,КмПЩФмA->B ЗЂЫЭFINЪБ,BЛЙгаЪ§ОнУЛгаЖСЭъ,вЛАуВЛЛсЖЯПЊСЌНг,ЕШЪ§ОнЖСЭъжЎКѓ,ПЩФмВХЛсЕїгУsocke.close(),ШЛКѓЗЕЛиFIN,ЫљвдBЩЖЪБКђЗЕЛиFINЪЧгІгУВуДњТыЕФЪТЧщЁЃ
ЖјЕБДДНЈSocketЪЕР§ЪБ,ОЭЪЧдкНЈСЂСЌНг,ЕБЪЕР§ДДНЈКУжЎКѓ,СЌНгвВОЭНЈСЂКУСЫЁЃ
ЭЈЙ§ДњТыдйРДРэНтНЈСЂСЌНгКЭЖЯПЊСЌНгЁЃ
TCPЕФзДЬЌ
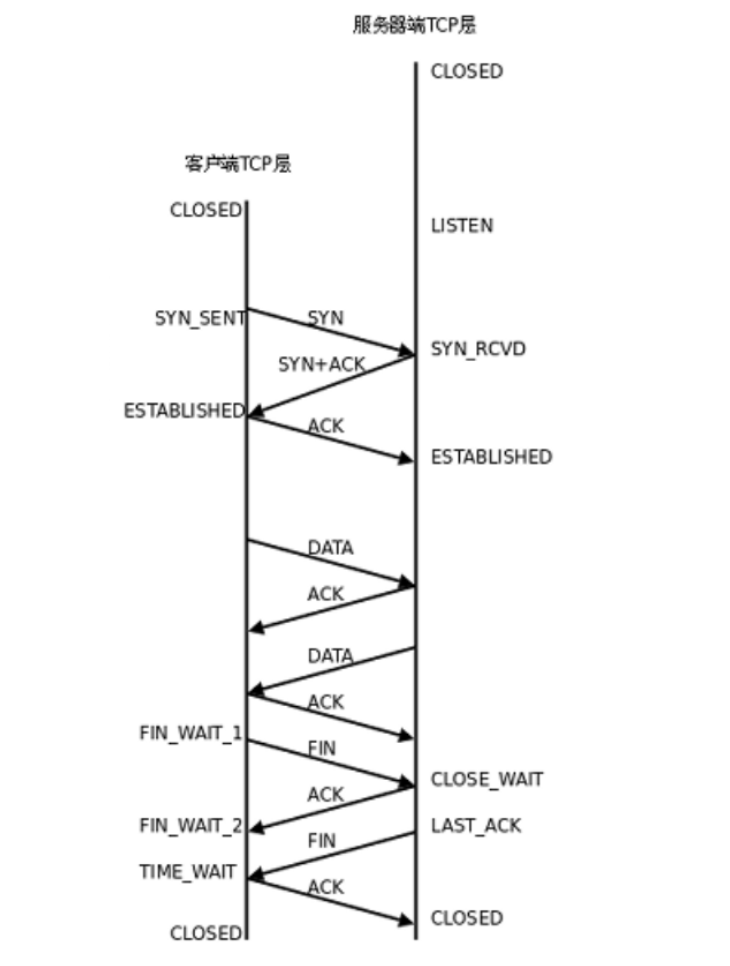
?ЩЯЭМЪЧПЭЛЇЖЫКЭЗўЮёЦїЫЋЗНдкЭЈаХЙ§ГЬжаЕФTCPЕФзДЬЌ,жївЊгаЯТУцетМИжжзДЬЌ:
1??LISTEN:етЪЧЗўЮёЦїАѓЖЈЖЫПкГЩЙІ,ЦєЖЏЭъБЯЕФзДЬЌ,ОЭЪЧServerSocketДДНЈКУЪЕР§КѓЕФзДЬЌ
2??ESTABLISHED:етЪЧСЌНгНЈСЂКУжЎКѓЕФзДЬЌ,ОЭЪЧШ§ДЮЮеЪжжЎКѓЕФзДЬЌЁЃПЭЛЇЖЫnew Socket()жЎКѓЕФзДЬЌЁЃ
3??CLOSE_WAIT:дкЫФДЮЛгЪжЙ§ГЬжа,БЛЖЏНгЪеFINЕФвЛЗНЕФзДЬЌ,ОЭЪЧдкНгЪеЕНFIN,ВЂЧвЗЕЛиСЫACK,дкздМКЗЂЫЭFINжЎЧАЕФзДЬЌ,вВОЭЪЧдкЗЕЛиACK,ВЂЧвЕїгУsocket.close()жЎЧАЕФзДЬЌЁЃ
4??TIME_WAIT:етИізДЬЌЪЧПЭЛЇЖЫНгЪеЕНЗўЮёЦїЗЕЛиЕФFIN,ВЂЗЕЛивЛИіACKжЎКѓЕФзДЬЌ,дкетИізДЬЌЯТЕШД§вЛЖЮЪБМф,ВХЛсНјШыCLOSEDзДЬЌ,еце§ЪЭЗХСЌНгЁЃ
ЕБНјГЬжБНгЭЫГіЛђепЕїгУsocket.close()(етСЉВйзїЖМЛсЙиБеЮФМў)ЛсДЅЗЂПЭЛЇЖЫЗЂЫЭFIN,ЕБЗўЮёЖЫНгЪеЕНFINжЎКѓ,ЛсСЂМДЗЕЛиACK,ШЛКѓЕШЕїгУsocket.close()жЎКѓЛсЗЕЛиFIN
дкЗЕЛиACKжЎКѓВЂУЛгаСЂМДЪЭЗХСЌНг,ЖјЪЧЕШД§вЛЖЮЪБМфВХЪЭЗХСЌНгЕФвтвхЪЧ:ЗЕЛиЕФACKгаПЩФмЖЊАќ,ШчЙћЖЊАќ,ЗўЮёЦїФЧБпОЭЛсДЅЗЂГЌЪБжиДЋ,дйИјПЭЛЇЖЫЗЂЫЭвЛДЮFIN,ШчЙћПЭЛЇЖЫЗЕЛиACKжЎКѓСЂМДЪЭЗХСЌНг,ФЧжиДЋЙ§РДЕФFINОЭУЛШЫДІРэ,здШЛвВВЛЛсЗЕЛиACK,ФЧЗўЮёЦїФЧБпОЭЛсНјааЖрДЮГЌЪБжиДЋЁЃЫљвддкTIME_WAITзДЬЌЯТ,МйШчACKЖЊАќСЫ,ФЧОЭФмДІРэГЌЪБжиДЋЙ§РДЕФFIN,дйЗЕЛивЛИіACKЁЃШчЙћЙ§СЫвЛЖЮЪБМфУЛгаЗЂЩњжиДЋ,ФЧОЭЫЕУїACKУЛгаЖЊ,ФЧПЭЛЇЖЫдйНјШыCLOSEDзДЬЌ,ЪЭЗХСЌНгЁЃ
ВщПДTCPзДЬЌ:

4.ЛЌЖЏДАПк(ЬсИпаЇТЪ)
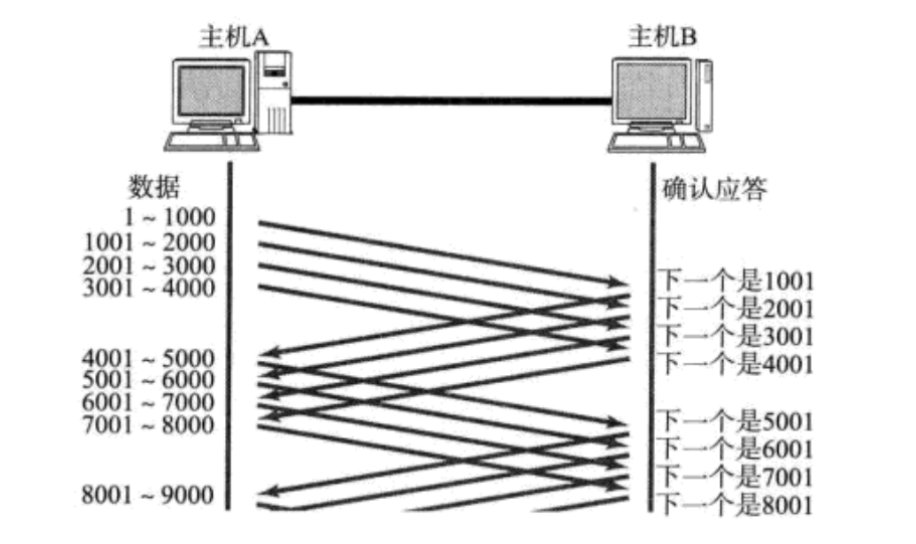
дкШЗШЯгІД№ЛњжЦжа,ЗЂЫЭвЛДЮЪ§Он,ЕШД§вЛИігІД№,ШЛКѓВХФмЗЂЫЭЯТвЛДЮЪ§Он,етбљЕФаЇТЪЪЧБШНЯЕЭЕФ,ЖјЛЌЖЏДАПкЛњжЦОЭПЩвдЯрЖдЕФЬсИпвЛЯТаЇТЪ,жЎЧАЭЌвЛЪБПЬжЛФмЕШД§вЛИіACK,ЯждкЭЌвЛЪБПЬПЩвдЕШД§ЖрИіACK,вВОЭЯрЕБгквЛЗнЪБМфЕШД§ЖрЗнACK,етбљећЬхРДЫЕ,ЕШД§ACKЕФЪБМфОЭЛсМѕЩйЁЃЬсИпСЫаЇТЪ
?ЛЌЖЏДАПкЪЧTCPЕФвЛИіЬсИпаЇТЪЕФЛњжЦ,ЛЌЖЏДАПкЕФБОжЪЪЧАбЕШД§ACKЕФЪБМфжиЕўЦ№РД,вВОЭЪЧвЛЗнЪБМф,ЕШД§ЖрЗнACKЁЃЛЌЖЏДАПкЕФБОжЪЪЧвЛДЮЗЂЫЭвЛХњЪ§Он,ЕШД§вЛХњACKЁЃ
?дке§ГЃЧщПіЯТ(УЛгаЖЊАќ),ХњСПЗЂЫЭЪ§ОнОЭЪЧвЛПЊЪМВЛгУЕШД§ACK,зюЖрСЌајЗЂЫЭNЬѕЪ§Он,ШЛКѓШчЙћвЊМЬајЗЂЫЭЪ§Он,ОЭашвЊЕШД§ACKСЫ,ШЛКѓЕШД§вЛИіACK,дйЗЂЫЭвЛЬѕЪ§Он,ЕШД§вЛИіACK,дйЗЂЫЭвЛЬѕЪ§ОнЁЃетбљвРДЮНјааЁЃ(етРяЕФNГЦЮЊДАПкДѓаЁ)
??гЩгкКѓЗЂЯШжСЕФЧщПі,дкTCPЛсдкНгЪеЛКГхЧјжаИљОнЪ§ОнБЈжаЕФађКХЖдЪ§ОнНјааХХЖгЁЃ
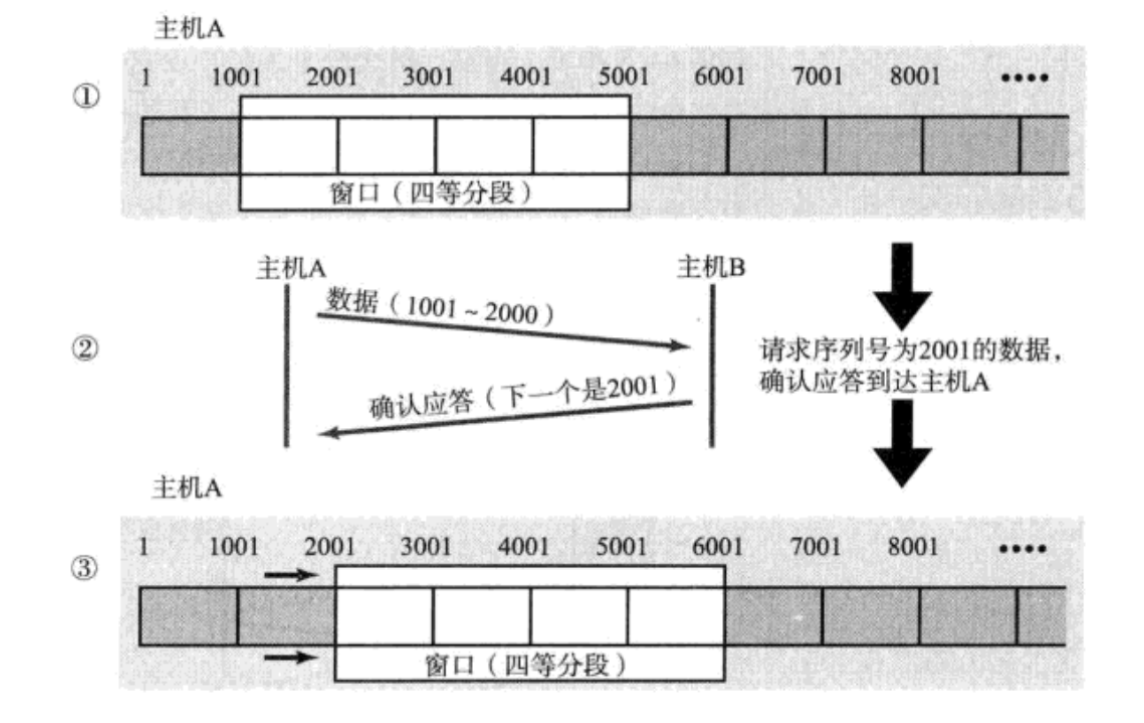
ЩЯЭМбнЪОСЫЛЌЖЏДАПкЪЧдѕУДЛЌЖЏЕФ,ЪзЯШЗЂЫЭСЫ1001~5000етаЉЪ§Он,етЪЧЗжЫФДЮЗЂЫЭЕФ,ЖдгІСЫЫФИіЪ§ОнБЈ,ШЛКѓЕШД§ACK,ЕБШЗШЯађКХЮЊ2001ЕФACKЗЕЛижЎКѓ,ОЭПЩвдМЬајЗЂЫЭЯТвЛЬѕЪ§Он(5001 ~ 6000),ЯрЕБгкДАПкЯђКѓЛЌЖЏСЫвЛИёЁЃДАПкОЭДњБэЗЂЫЭЗНЗЂЫЭЕФЪ§Он,ШЛКѓетаЉЪ§ОндкЕШД§ACKЁЃ
ЛЌЖЏДАПкПЩвдЬсИпаЇТЪ,ФЧЛЌЖЏДАПкЛсВЛЛсгАЯьПЩППадФи?
дкЛЌЖЏДАПкЛњжЦЯТ,ПЩвдПДЕНШЗШЯгІД№ЪЧВЛЪмгАЯьЕФ,ФЧГЌЪБжиДЋЛсВЛЛсЪмгАЯьФи?вВОЭЪЧЖЊАќСЫ,ЛсВЛЛсгАЯьПЩППад?
ЖЊАќЗжСНжжЧщПі,вЕЮёЪ§ОнЖЊСЫ,ACKЖЊСЫ,ЯТУцЗжСНжжЧщПіПМТЧ:
1??ЧщПівЛ:ACKЖЊСЫ
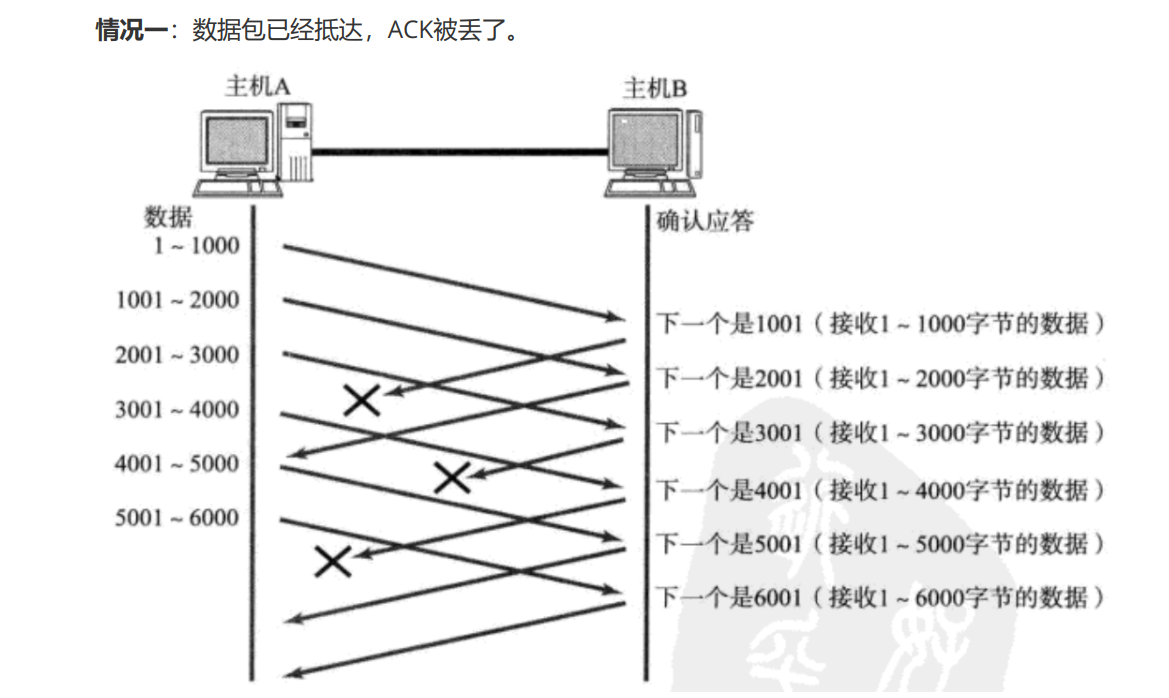
дкетжжЧщПіЯТ,МйШчШЗШЯађКХЪЧ1001ЕФACKЖЊСЫ,2001ЗЕЛиСЫ,ФЧОЭЫЕУїНгЪеЗНвбОНгЪеЕН2001жЎЧАЕФЫљгаЪ§ОнСЫ,ЕБЗЂЫЭЗННгЪеЕН2001жЎКѓ,ЗЂЫЭЗНвВОЭжЊЕРНгЪмЗНвбОГЩЙІНгЪеЕН2001жЎЧАЕФЪ§ОнСЫ,МДЪЙУЛгаЪеЕН1001,вВВЛгУжиДЋ1 ~ 1000ЕФЪ§Он(вђЮЊШЗШЯађКХ2001ОЭДњБэСЫ2001жЎЧАЕФЫљгаЪ§ОнЖМвбОГЩЙІНгЪеЕНСЫ,жЛгаНгЪеЗНГЩЙІНгЪеЕН2001жЎЧАЕФЫљгаЪ§Он,ВХЛсЗЕЛиШЗШЯађКХЮЊ2001ЕФACK)ЁЃФЧетжжЧщПіЯТ,ЛЌЖЏДАПкЛсЯђКѓвЦЖЏСНВНЁЃ
дкжЎЧАЕФЧщПіЯТ,ВЛЙмвЕЮёЪ§ОнЖЊСЫ,ЛЙЪЧACKЖЊСЫ,ЖМашвЊГЌЪБжиДЋ,ЕЋЪЧдкЛЌЖЏДАПкЛњжЦЯТ,ACKЖЊСЫВЂВЛашвЊжиДЋ,ПЩвдЭЈЙ§КѓајЕФACKШЗЖЈНгЪеЗННгЪеЕНСЫЪ§ОнЁЃЕЋЪЧШчЙћЪЧзюКѓЕФвЛИіACKЖЊСЫ,етЛЙЪЧЛсДЅЗЂГЌЪБжиДЋЕФЁЃ
2??ЧщПіЖў:вЕЮёЪ§ОнЖЊСЫ
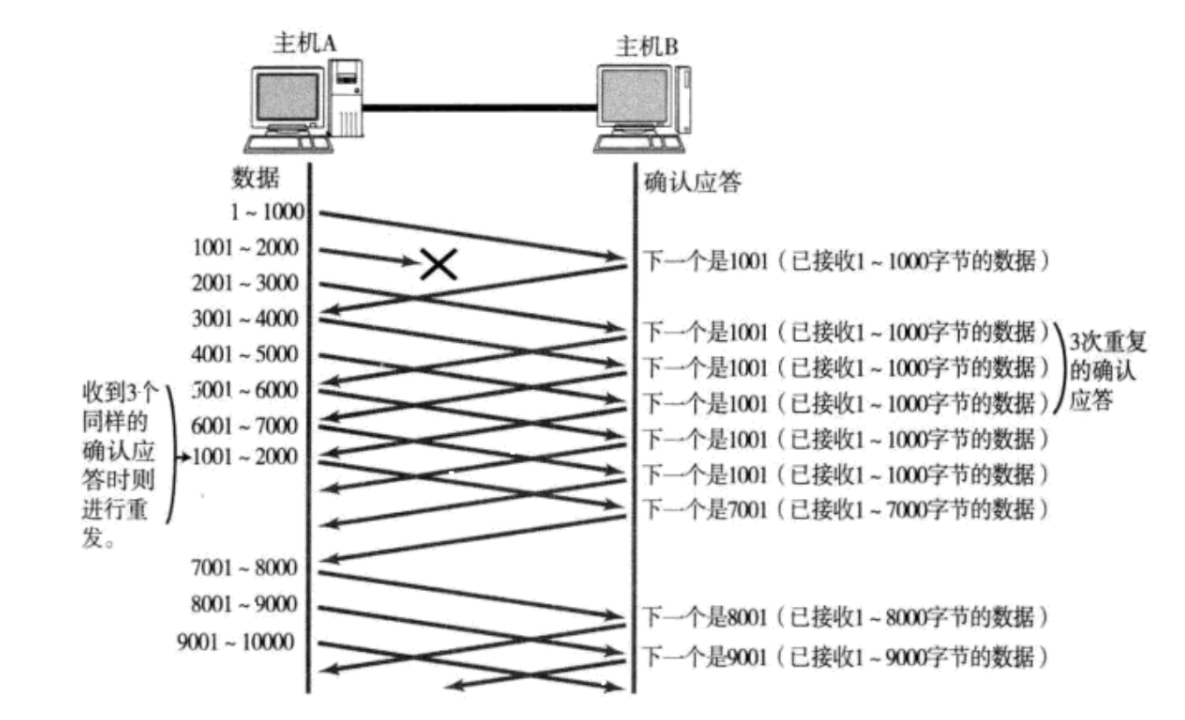
етжжЧщПі,ЪЧЪ§ОнБЈЖЊСЫ,ФЧетжжЧщПіПЯЖЈвЊжиДЋЕФ
БШШчдкЗЂЫЭЙ§ГЬжа1001~2000етИіЪ§ОнБЈЖЊСЫ,дђЕБНгЪеЗННгЪеЕН2000вдКѓЕФЪ§ОнБЈ,ЛЙЪЧЛсЗЕЛи1001ЁЃОЭЪЧНгЪеЕН2001 ~ 3000,3001 ~ 4000ЕШ,ЫќЖМЛсЗЕЛи1001,ФЧЕБЗЂЫЭЖЫНгЪеЕНЖрИі1001ACK,ЗЂЫЭЖЫОЭЛсУїАз,1001 ~ 2000етИіЪ§ОнЖЊСЫ,ОЭЛсДЅЗЂжиДЋЁЃЕШжиДЋЙ§РДжЎКѓ,ДгЩЯЭМжаПЩвдПДЕНжБНгЗЕЛиЕФЪЧ7001ЕФACK,ЫЕУї2001 ~ 7000ЕФЪ§ОнвбОНгЪеЕНСЫЁЃЯТвЛДЮИУДг7001ЗЂЫЭСЫЁЃ
змНс:МйШчвЕЮёЪ§ОнЖЊЪЇСЫ,ФЧШчЙћНгЪеЖЫУПДЮНгЪеЕНИУвЕЮёЪ§ОнКѓУцЕФЪ§Он,ОЭЛсЗЕЛиЖЊЪЇЕФвЕЮёЪ§ОнЖдгІЕФACK,ОЭЪЧИцжЊЗЂЫЭЗНжиДЋЪ§Он,ЕШЗЂЫЭЖЫСЌајНгЪеЕНШ§ДЮвЛбљЕФACK,ОЭЛсДЅЗЂжиДЋ,ЕБНгЪеЕНжиДЋЕФЪ§ОнКѓ,ОЭЛсЗЕЛивЛИівбОНгЪеЕНЕФЫљгаЪ§ОнКѓУцЕФФЧИіађКХЕФACKЁЃ
ЫљвддкЛЌЖЏДАПкЛњжЦЯТЕФжиДЋЪЧгЩШ§ДЮвЛбљЕФACKДЅЗЂЕФ,ВЛЪЧгЩГЌЙ§ЪБМфжиДЋЕФЁЃе§ГЃЧщПіЯТЪЧИУЗЕЛивЛДЮACKЕФ,ЕЋЪЧСЌајЗЕЛиШ§ДЮвЛбљЕФACK,ФЧОЭПЩвдЫЕУїетИіЪ§ОнБЈДѓИХТЪЪЧЖЊЪЇСЫЁЃ
етвВГЦжЎЮЊПьЫйжиДЋЁЃ
5.СїСППижЦ(БЃжЄПЩПП)
==СїСППижЦ:==ИљОнНгЪеЗНЕФНгЪеФмСІПижЦЗЂЫЭЗНЕФЛЌЖЏДАПкЕФДѓаЁ
СїСППижЦЕФБГОА:
ЮЊСЫЬсИпДЋЪфЫйТЪЮвУЧв§ШыСЫЛЌЖЏДАПкЛњжЦ,ЬсИпСЫЗЂЫЭЫйТЪ,ЕЋЪЧетИіЗЂЫЭЫйТЪВЂВЛЪЧдНИпдНКУ,ЛЙЕУПМТЧжаМфДЋЪфЙ§ГЬТЗгЩЦїНЛЛЛЛњЕШКмЖрЩшБИЕФЪ§ОнзЊЗЂФмСІвдМАЭјТчЛЗОГЪЧЗёгЕМЗЛђГЉЭЈ,вдМАНгЪеЗНЕФНгЪеФмСІ,вђЮЊДЋЪфЫйТЪЪЧгЩетШ§епЙВЭЌОіЖЈЕФЁЃ
МйШчЮоЯожЦЕФЬсИпЗЂЫЭЫйТЪ,ЖјНгЪеЗНЕФНгЪеЫйТЪВЂВЛИп,ОЭПЩФмЛсвђЮЊНгЪеЗНЖЊАќ,ДЅЗЂжиДЋ,ОЭгаПЩФмНЕЕЭЫйТЪЁЃМйШчЭјТчЛЗОГВЂВЛКУ,ЖјЗЂЫЭЗНЕФЗЂЫЭЫйТЪвРШЛКмИп,ОЭЛсЪЙЭјТчЛЗОГбЉЩЯМгЫЊЁЃВЂВЛФмеце§ЬсИпДЋЪфЫйТЪЁЃ
ФЧв§ШыСїСППижЦКЭгЕШћПижЦОЭФмИљОнНгЪеЗНЕФНгЪеЫйТЪКЭжаМфЕФЭјТчЛЗОГПижЦЗЂЫЭЫйТЪЁЃ
ЖјСїСППижЦ,ОЭЪЧШУЗЂЫЭЫйТЪКЭНгЪеЫйТЪВНЕївЛжТЁЃБОжЪЩЯЪЧЖдЛЌЖЏДАПкЕФжЦдМ,БмУтДАПкЙ§ДѓЁЃ
МШШЛСїСППижЦЪЧЦНКтЗЂЫЭЫйТЪКЭНгЪеЫйТЪ,ФЧдѕУДКтСПЗЂЫЭЫйТЪКЭНгЪеЫйТЪФи?
ЗЂЫЭЫйТЪгУЛЌЖЏДАПкОЭПЩвдКтСП,ДАПкдНДѓ,ЗЂЫЭЫйТЪдНДѓ,ДАПкдНаЁ,ЗЂЫЭЫйТЪдНаЁЁЃФЧНгЪеЫйТЪШчКЮКтСП?
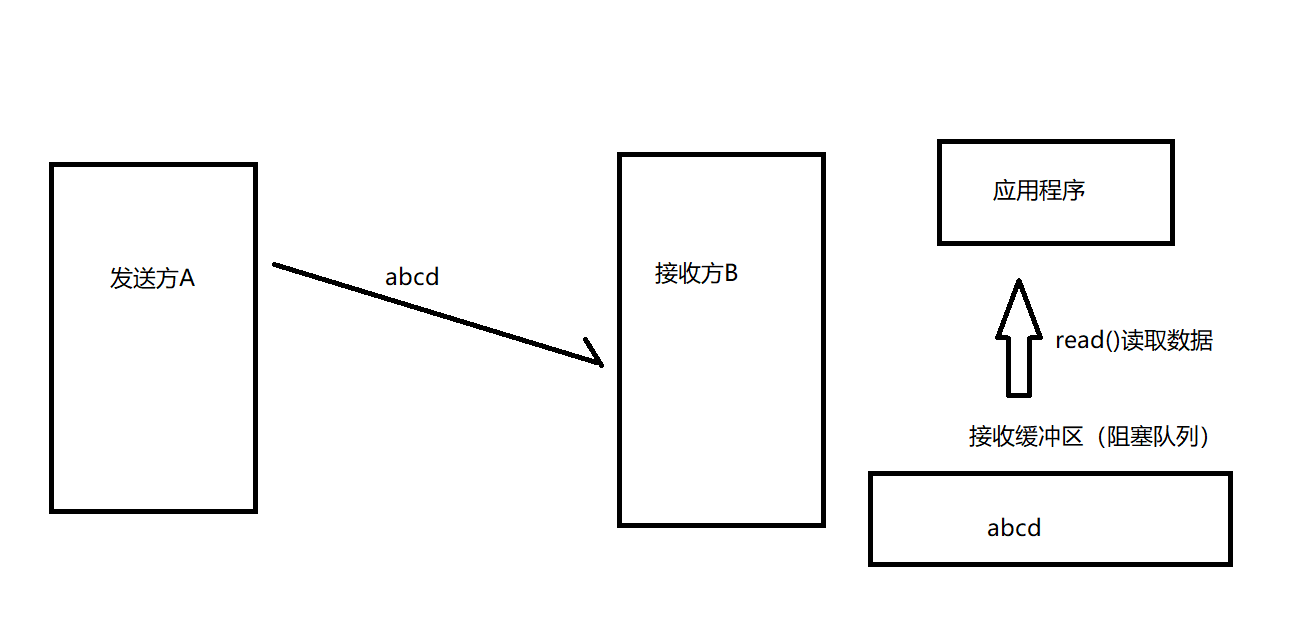
?КтСПНгЪеЫйТЪ:ЕБЗЂЫЭЗНАбЪ§ОнЗЂЫЭИјBЪБ,ОЭЛсЭЈЙ§ЭјПЈЗЂЫЭИјBЕФНгЪеЛКГхЧј,ШЛКѓBЕФгІгУГЬађДгЛКГхЧјжаШЁзпЪ§Он,ЫљвдНгЪеЫйТЪОЭЪЧгІгУГЬађЕФЖСШЁЫйТЪ,етИіЫйТЪШЁОігкгІгУВуДњТыЕФЪЕЯжЁЃЕЋЪЧжБНгКтСПгІгУГЬађЕФЖСШЁЫйТЪЪЧВЛЗНБуКтСПЕФ,ЫљвдПЩвдЭЈЙ§КтСПНгЪеЛКГхЧјЪЃгрПеМфДѓаЁ,ДњЬцЖСШЁЫйТЪ,НгЪеЛКГхЧјДѓ,ФЧЫЕУїПЩвдЪЪЕБЬсЩ§ЗЂЫЭЫйТЪ,НгЪеЛКГхЧјаЁ,ФЧОЭЕУЪЪЕБНЕЕЭЗЂЫЭЫйТЪЁЃ
ФЧНгЪеЗНШчКЮАбЪЃгрПеМфДѓаЁИцжЊИјЗЂЫЭЖЫФи?
етИіаХЯЂОЭДцгкACKБЈЮФЕФБЈЭЗжа:
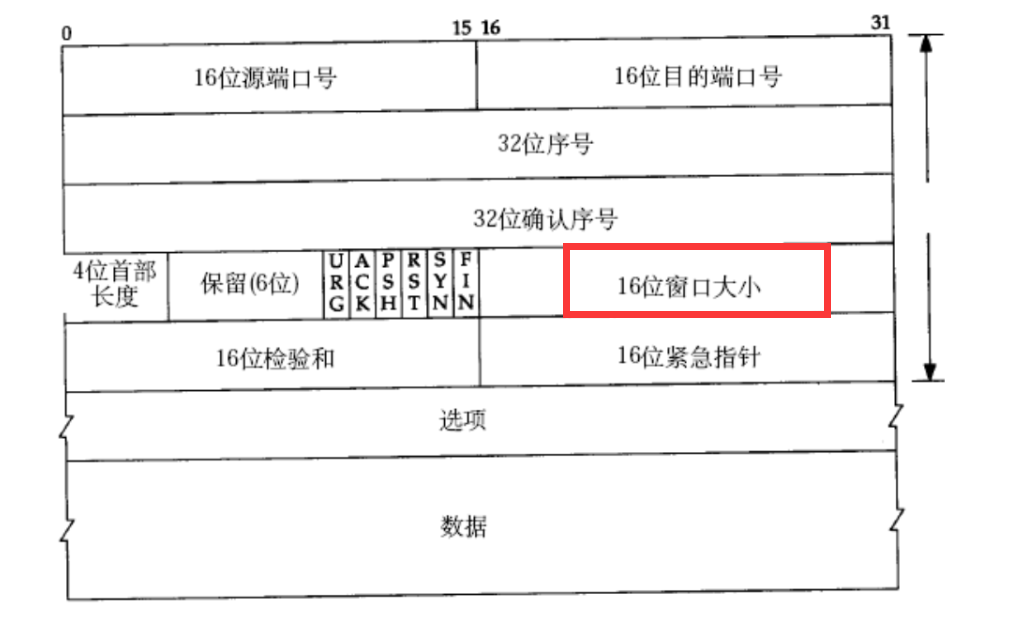
етИі16ЮЛДАПкДѓаЁОЭДњБэСЫНгЪеЛКГхЧјДѓаЁ,ДцгкACKБЈЮФЕФБЈЭЗЁЃЕБACKЗЕЛиИјНгЪеЖЫКѓ,НгЪеЖЫОЭФмИљОнЕБЧАНгЪеЛКГхЧјЕФДѓаЁРДЕїећЗЂЫЭЫйТЪЁЃЕЋЪЧетИі16ЮЛДАПкДѓаЁБэЪОЕФПеМфЗЖЮЇВЂВЛЪЧзюДѓ64kb,вђЮЊбЁЯюРягаИіЬиЪтзжЖЮ:ДАПкРЉДѓвђзг,етИівђзгГЫвд16ЮЛДАПкДѓаЁОЭДњБэСЫецЪЕЕФЛКГхЧјПеМфДѓаЁЁЃ

ЕБНгЪеЛКГхЧјДѓаЁЮЊ0Кѓ,ЗЂЫЭЗНОЭЛсднЭЃЗЂЫЭЪ§Он,ЕЋЪЧЗЂЫЭЗНВЂВЛЪЧецЕФднЭЃЗЂЫЭЪ§ОнСЫ,ЖјЪЧЙ§вЛЛсЗЂЫЭвЛИіДАПкЬНВтЕФАќЁЃетИіАќВЂУЛгавЕЮёЪ§Он,жЛЪЧЗЂИіАќДЅЗЂвЛЯТACK,жЊЕРЛКГхЧјЯждкЪЧЗёгаЪЃгрПеМфЁЃЕБДАПкДг0БфЮЊгаЪЃгрПеМфСЫ,НгЪеЗНвВЛсЗЕЛивЛИіДАПкИќаТЭЈжЊ,ИцЫпЗЂЫЭЗНПЩвдМЬајЗЂЫЭЪ§ОнСЫ,ЕЋЪЧетИіЭЈжЊЕФЪ§ОнАќгаПЩФмЖЊЪЇ,ФЧЫљвдЗЂЫЭЗНВЛЪБЕФЗЂЫЭвЛИіДАПкЬНВтЕФАќОЭЯдЕУгШЮЊживЊЁЃ
6.гЕШћПижЦ(БЃжЄПЩПП)
ЩЯУцЕФСїСППижЦЪЧИљОнНгЪеЗНЕФНгЪеЫйТЪПижЦЗЂЫЭЫйТЪ,ЖјЯждкЕФгЕШћПижЦЪЧИљОнЭјТчЛЗОГ(жаМфЩшБИзЊЗЂЪ§ОнЕФЫйТЪ)РДПижЦЗЂЫЭЫйТЪЁЃ
КтСПНгЪеЗНЕФНгЪеФмСІЪЧИљОнНгЪеЛКГхЧјЕФДѓаЁРДКтСПЕФ,ЖјКтСПжаМфЩшБИЕФзЊЗЂФмСІЪЧВЛКУКтСПЕФ,ЕЋЪЧПЩвдИљОнЪЕМЪЧщПіРДЖЏЬЌКтСПжаМфЩшБИЕФзЊЗЂФмСІ,ВЂжЦдМЗЂЫЭЫйТЪЁЃ
ОпЬхзіЗЈ:
- ИеПЊЪМАДееаЁДАПкЗЂЫЭ
- ШчЙћВЛЖЊАќ,ЫЕУїЭјТчЛЗОГЪЧБШНЯЭЈГЉЕФ,етЪБКђОЭПЩвдж№НЅРЉДѓДАПкЁЃ
- ЕБЗХДѓЕНвЛЖЈГЬЖШ,ЫйТЪЩЯШЅСЫ,ЭјТчЩЯОЭШнвзГіЯжгЕЖТ,ПЊЪМГіЯжЖЊАќЁЃетЪБКђдйЫѕаЁДАПкЁЃ
дк2КЭ3жЎМфЗДИДбЛЗ,ДяЕНвЛИіЖЏЬЌЦНКт:ЗЂЫЭЫйТЪВЛТ§,НгНќСЫФмГадиЕФМЋЯо,ЛЙФмБмУтЖЊАќЁЃ
СїСППижЦКЭгЕШћПижЦЖМФмПижЦДАПкДѓаЁ,ФЧШЁФФИізїЮЊЪЕМЪДАПкДѓаЁФи?
гЕШћПижЦШЗЖЈЕФДАПкДѓаЁЪЧЗЂЫЭЗНздМКЭЈЙ§вЛДЮДЮЕФГЂЪдЪЕбщГіРДЕФ,ЖјСїСППижЦШЗЖЈЕФДАПкДѓаЁЪЧИљОнНгЪеЗНЗЕЛиЛиРДЕФвЛИіЪ§ОнШЗЖЈЕФДАПкДѓаЁЁЃЖјзюжеЗЂЫЭЗНЕФДАПкДѓаЁЪЧгЩетСНепЕФНЯаЁжЕРДШЗЖЈЕФЁЃвВОЭЪЧбЁвЛИіНЯаЁжЕРДзїЮЊЯТвЛДЮЛЌЖЏДАПкЕФДѓаЁЁЃЫљвдЛЌЖЏДАПкЕФДѓаЁЪЧИљОнЭјТЗЛЗОГКЭНгЪеЗНЕФНгЪеФмСІдкЖЏЬЌБфЛЏЕФЁЃ
ЩЯУцжЛЪЧЖЈадЕФЗжЮіЗЂЫЭЖЫШчКЮзіЪЕбщШЗЖЈДАПкДѓаЁ,ЯТУцПДTCPЪЧШчКЮЖЈСПЗжЮіЕФ:
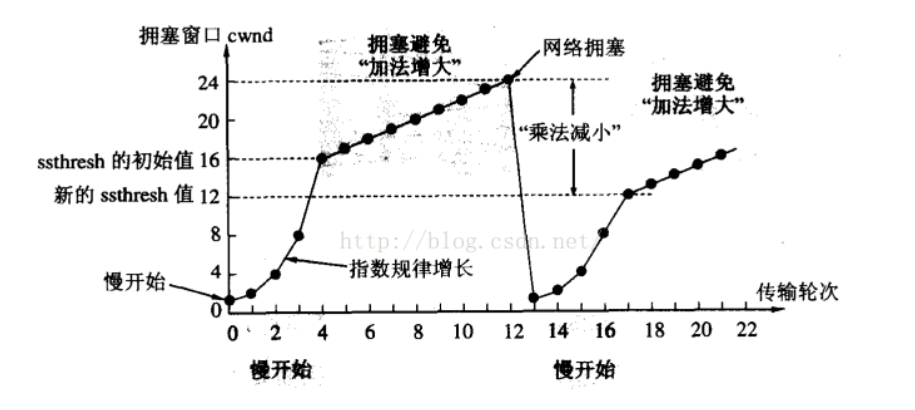
гЕШћДАПк:ЭЈЙ§гЕШћПижЦШЗЖЈЕФДАПкДѓаЁ;ДЋЪфТжДЮ:ЕкМИДЮЗЂЫЭЪ§Он
ИеПЊЪМгЕШћДАПкДгвЛИіаЁжЕПЊЪМ,ШЛКѓжИЪ§діГЄ(Т§ПЊЪМ),вђЮЊВЛжЊЕРЕБЧАЭјТчЛЗОГШчКЮ,БмУтвђЮЊЕБЧАЭјТчЛЗОГВЛКУ,ЕМжТЭјТчЛЗОГбЉЩЯМгЫЊЁЃЕБжИЪ§діГЄМИТжДяЕНвЛИіуажЕжЎКѓ,ОЭзЊЮЊЯпаддіГЄЁЃШЛКѓжИЪ§діГЄдіГЄПЊЪМГіЯжЖЊАќСЫ,ШЛКѓАбуажЕИФЮЊЕБЧАДАПкЕФвЛАы,ВЂЧвАбДАПкИФЮЊвЛИіКмаЁЕФжЕ,ШЛКѓдйжИЪ§діГЄ,жиИДЩЯЪіВйзїЁЃ
7.бгЪБгІД№(ЬсИпаЇТЪ)
бгЪБгІД№вВЪЧвЛИіЬсИпаЇТЪЕФЛњжЦ,ЭЈЙ§ШУЗЂЫЭЖЫЕФЛЌЖЏДАПкРЉДѓвЛаЉЬсИпаЇТЪЁЃдкСїСППижЦжа,НгЪеЗНЗЕЛиЕФACKБЈЮФРяУцАќКЌЕФ16ЮЛДАПкДѓаЁОЭДњБэСЫЕБЧАНгЪеЛКГхЧјЪЃгрПеМфЕФДѓаЁЁЃЗЂЫЭЗНОЭЛсИљОнЪЃгрПеМфЕФДѓаЁЖЏЬЌЦНКтДАПкДѓаЁЁЃ
бгЪБгІД№ЦфЪЕНгЪеЗННгЪеЕНЪ§ОнКѓ,ВЛСЂМДЗЕЛиACK,ЖјЪЧЩдЕШвЛЛсЗЕЛиACK,дкетбљЩдЕШвЛЛсЕФЪБМфРя,гІгУГЬађОЭдкВЛЭЃЕФДгНгЪеЛКГхЧјжаШЁЪ§ОнЁЃетбљЕФЛАЩдЕШвЛЛсЗЕЛиЕФACKБЈЮФжаНгЪеЛКГхЧјЪЃгрЕФПеМфПЩФмОЭЛсБфДѓ,ШЛКѓЗЂЫЭЗНПДЕНЪЃгрПеМфБфДѓ,ОЭЛсдіДѓДАПкДѓаЁ,вВОЭЛсЬсИпЗЂЫЭЪ§ОнЕФаЇТЪЁЃ
ЕЋЪЧвВВЛЪЧЫљгаЕФACKЖМбгЪБгІД№:
бгГйЕФЙцдђ:
Ъ§СПЯожЦ:УПИєNИіАќОЭгІД№вЛДЮ
ЪБМфЯожЦ:ГЌЙ§зюДѓбгГйЪБМфОЭгІД№вЛДЮ
вЛАуNШЁ2,зюДѓбгГйЪБМфШЁ200ms,ОпЬхЕФбгГйЙцдђЕУПДВйзїЯЕЭГ,ВЛЭЌЕФЯЕЭГЙцдђВЛвЛбљЁЃ
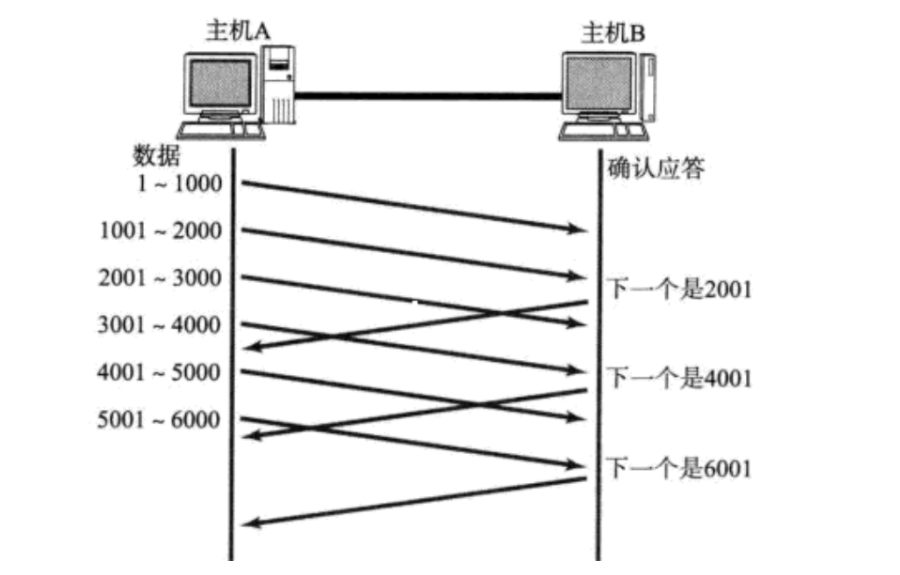
ЩЯЭМжаПЩвдПДЕНУПИєСНИіАќОЭгІД№вЛДЮ,1001УЛгаЗЕЛи,ЗЕЛиЕФЪЧ2001,ШЛКѓЗЕЛи4001,ШЛКѓЪЧ6001,ЫфШЛУЛгаЗЕЛи1001вГУЛгаЙиЯЕ,вђЮЊ2001ОЭДњБэСЫ2001жЎЧАЕФЫљгаЪ§ОнЖМНгЪеЕНСЫЁЃЫљвдетвВЪЧбгЪБгІД№ДјРДЕФвЛИіЖюЭтЕФгХЪЦ:СНИіACKКЯВЂЮЊвЛЬѕACK,ЬсИпСЫаЇТЪЁЃ
СїСППижЦЪЧПижЦДАПкВЛФмЬЋДѓ,ЖјбгЪБгІД№гжЪЧШУСїСППижЦБ№ЯожЦЕФЬЋКнЁЃ
8.ЩгДјгІД№(ЬсИпаЇТЪ)
ЩгДјгІД№ЪЧЛљгкбгЪБгІД№ЕФвЛИіВпТд,вВЪЧЮЊСЫЬсИпаЇТЪЁЃ
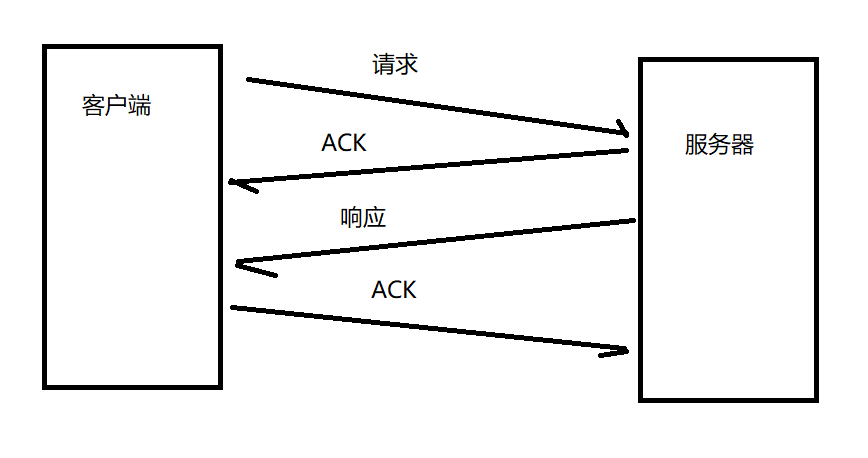
ЕБПЭЛЇЖЫЗЂРДвЛИіЧыЧѓКѓ,ФкКЫЛсСЂМДЗЕЛиACK,ЖјЯьгІЪБгІгУВуДњТыМЦЫуКУСЫЯьгІВХЗЕЛиЕФ,етСНИіЗЕЛиВЛЪЧЭЌвЛЪБМфЕФ,ЕЋЪЧдкбгЪБгІД№ЛњжЦЯТ,ЗЕЛиЕФACKЛсЩдЕШвЛЛсВХЗЕЛи,ФЧетбљЯьгІКЭACKОЭгаПЩФмКЯВЂЮЊвЛИіАќЗЕЛиЁЃЕЋЪЧвВВЛвЛЖЈФмКЯВЂЮЊвЛИіАќ,ЕУПДЯьгІЩЖЪБКђМЦЫуКУЁЃ
СНИіАќКЯВЂЮЊвЛИіАќетбљвВОЭЬсИпСЫДЋЪфаЇТЪЁЃ
ЛиЙЫЫФДЮЛгЪж:
ПЭЛЇЖЫЯШЗЂЫЭFIN,ЗўЮёЦїЗЕЛивЛИіACK(етЪЧгЩФкКЫСЂМДжБНгЗЕЛиЕФ),ШЛКѓдйЗЕЛивЛИіFIN(етЪЧгІгУВуЕїгУsocket.close()ВХДЅЗЂЗЕЛиFINЕФ),вЛАуЧщПіЯТетСНИіЗЕЛиЪЧЗжСНДЮЕФ,вђЮЊЫћУЧВЂВЛЪЧЭЌвЛЪБМфЗЕЛиЕФ,ЕЋЪЧдкбгЪБгІД№ЕФЛњжЦЯТ,ACKЩдЕШвЛЛсдйЗЕЛи,ОЭгаПЩФмКЭFINИЯЕНвЛПщ,ШЛКѓКЯВЂЮЊвЛИіАќЗЕЛиЁЃетбљЫФДЮЛгЪжвВОЭБфЮЊСЫШ§ДЮЛгЪжЁЃ
9.УцЯђзжНкСї
УцЯђзжНкСїжИЕФЪЧдкЖСаДдиКЩЪ§ОнЕФЪБКђ,ЪЧАДеевЛИізжНквЛИізжНкЖСШЁЕФ,ВЂВЛЪЧАДзжНкДЋЪфЕФ,ДЋЪфЕФЪБКђвРШЛЪЧвдЪ§ОнАќЮЊЕЅЮЛЁЃдкгІгУГЬађЪЧИажЊВЛЕНЪ§ОнАќЕФ,етРяКЭUDPЪЧгаВюБ№ЕФ,UDPавщдкгІгУВуЪЧФмИажЊЕНЪ§ОнАќЕФЁЃ
УцЯђзжНкСїЕФзюДѓЮЪЬт:еГАќЮЪЬт
ШчЙћвЛИіTCPСЌНгРяжЛДЋвЛИіЪ§ОнБЈ,етЪЧВЛЛсВњЩњеГАќЮЪЬтЕФ(ЖЬСЌНг)
ШчЙћвЛИіTCPСЌНгДЋСЫКмЖрЪ§ОнАќ,етУДЖрЕФЪ§ОнБЈЕФдиКЩЖМДцгкНгЪеЛКГхЧјСЫ,гІгУГЬађЧјЗжВЛЧхДгФФЕНФФЪЧвЛИіЭъећЕФЪ§ОнАќ,МДеГАќЮЪЬтЁЃ(ГЄСЌНг)
НтОіеГАќЮЪЬт:
дкгІгУГЬађДњТыжаУїШЗАќжЎМфЕФБпНч,МДЪЙгУЗжИєЗћ,ЛђШЗЖЈАќЕФЙЬЖЈДѓаЁЁЃетбљдкНгЪеЪБ,ОЭАДЗжИєЗћШЁЪ§Он,ЛђАДЙЬЖЈЕФГЄЖШШЁЪ§ОнЁЃетвВОЭЪЧздЖЈвхгІгУВуавщЁЃ
10.TCPСЌНгГіЯжвьГЃЪБШчКЮДІРэ
TCPСЌНгГіЯжвьГЃПЩФмЪЧвдЯТМИжжЧщПіЕМжТЕФЁЃ
1??жїЛњЙиЛњ(АДГЬађЙиЛњ)
АДееГЬађЙиЛњ,ЙиЛњЧАЛсЯШЩБЫРЫљгагУЛЇНјГЬ,АќРЈTCPГЬађ,ЩБЫРНјГЬ =ЁЗЪЭЗХPCB =ЁЗЪЭЗХЮФМўУшЪіЗћБэЁЃжЎЧАгабЇЙ§ДђПЊвЛИіЮФМў,ОЭЛсдкЮФМўУшЪіЗћБэжаеМгУвЛИіЪ§зщПеМф,гУРДУшЪіетИіЮФМў,ЖјЯждкЪЭЗХЮФМўУшЪіЗћБэФЧвВОЭДњБэзХЮФМўЙиБе,вВОЭЪЧsocketЮФМўЙиБеЁЃЯрЕБгкЕїгУСЫsocket.close(),ЕїгУСЫsocket.close()вВОЭЪЧЙиБеsocketЮФМўЁЃжЛВЛЙ§е§ГЃЧщПіЯТЪЧгІгУВуГЬађЕїгУclose()ЙиБеЕФЮФМў,етДЮЪЧЯЕЭГжБНгАбЮФМўЙиБеСЫЁЃ
?ЗЂЫЭFINПЩвдгЩгІгУВуГЬађЕїгУsocket.close()ЗЂЫЭ(ЕїгУетИіЗНЗЈЛсЙиБеЮФМў),вВПЩвдгЩФкКЫжБНгЗЂЫЭ(МйШчНјГЬБРРЃСЫ)
вЛЕЉЙиБеЮФМўжЎКѓ,ОЭЛсгЩФкКЫЗЂЫЭFIN,НгЯТРДжДаае§ГЃЕФЫФДЮЛгЪжСїГЬЁЃ
ШчЙћЫФДЮЛгЪжЛЙУЛгаЭъФиОЭЙиЛњСЫ,ФЧвВУЛгаЙиЯЕ,ФЧЖдЖЫ(УЛгаЙиЛњЕФФЧвЛЖЫ)ГЌЪБжиДЋМИДЮFINУЛгаЯьгІОЭЗХЦњСЫЁЃ
2??ГЬађБРРЃ
ШчЙћГЬађе§ГЃЭЫГі,дкгІгУВуГЬађжДааЭъжЎЧАЕїгУСЫsocket.close(),ФЧОЭЛсЗЂЫЭFIN,ШЛКѓгЩФкКЫМЬајжДааЫФДЮЛгЪж,МйШчГЬађБРРЃСЫ,ФЧОЭжБНггЩФкКЫЗЂЫЭFIN,ШЛКѓФкКЫМЬајжДааЭъЫФДЮЛгЪжЁЃ
ЩЯУцСНжжЧщПіЪЧвЛЗНвбОЗЂЫЭСЫFINСЫ,ЫФДЮЛгЪжвЛАуЪЧПЩвде§ГЃжДааЭъЕФ,ЯТУцЕФжїЛњЕєЕчКЭЭјЯпЖЯПЊ,етИљБОУЛгаЛњЛсЗЂЫЭFINЁЃ
3??жїЛњЕєЕч(ЭЛШЛАЮЕчдД)
жБНгЙиЕчдД,ФЧПЯЖЈЪЧРДВЛМАЛгЪжСЫ
- НгЪеЗНЕєЕч:
ШчЙћНгЪеЗНЕєЕч,ФЧACKОЭЮоЗЈЗЕЛи,ФЧЗЂЫЭЗНОЭЛсГЌЪБжиДЋ,жиДЋМИДЮЛЙЪЧУЛгаACK,ФЧОЭГЂЪджиаТНЈСЂСЌНг,ШчЙћСЌНгВЛЩЯ,ФЧОЭЗХЦњСЌНгСЫЁЃ
- ЗЂЫЭЗНЕєЕч:
ШчЙћЗЂЫЭЗНЕєЕч,ФЧНгЪеЖЫЪЧПЯЖЈНгЪеВЛЕНЪ§ОнСЫ,ЕЋЪЧНгЪеЗНВЛжЊЕРЪЧЗЂЫЭЗНЛЙУЛгаЗЂЪ§ОнФи,ЛЙЪЧЗЂЫЭЗНФЧБпГіЮЪЬтСЫ,вбОЙвСЫЁЃЫљвдНгЪеЗНШчЙћвЛЖЮЪБМфФквЛжБУЛгаЪеЕНЗЂЫЭЗНЗЂРДЕФЪ§Он,ФЧУДОЭЛсЖЈЦкЗЕЛивЛИіЁАаФЬјАќЁБ,ЪЕМЪЪЧЗЕЛивЛИіЬиЪтЕФБЈЮФ:ЁАpingЁБ,ШчЙћЖдЗНЗЕЛиСЫвЛИіЬиЪтБЈЮФ:ЁАpongЁБ,ФЧЫЕУїЖдУцЛЙЪЧДцЛюЕФ,жЛВЛЙ§УЛгаЗЂЧыЧѓЖјвб,ШчЙћУЛгаЗЕЛи"pong",ФЧЫЕУїЖдУцвбОУЛСЫ,ЙвСЫ,ВЛДцдкСЫ
ШчЙћВЛЗЂЫЭетИіаФЬјАќ,ЖдУцвВВЛЗЂЪ§Он,ФЧОЭИЩЕШзХТ№,етвВВЛКУ,АзАзРЫЗбСЫзЪдДЁЃ
4??ЭјЯпЖЯПЊ
ЭјЯпЖЯПЊКЭжїЛњЕєЕчЧщПівЛбљЁЃвВЪЧЗжЗЂЫЭЗНЭјЯпЖЯПЊКЭНгЪеЗНЭјЯпЖЯПЊЁЃ
TCPКЭUDPЖдБШ
- ШчЙћашвЊПЩППДЋЪф,гХЯШПМТЧTCP
- ШчЙћДЋЪфЕФЕЅИіЪ§ОнБЈБШНЯДѓ,гХЯШПМТЧTCP(UDPЪ§ОнБЈзюДѓЪЧ64KB),вђЮЊЪЙгУTCPЕФЛАдкгІгУВуУЛгаЪ§ОнБЈДѓаЁЕФЯожЦ,дкгІгУВуПЩвдвЛДЮЗЂЫЭКмДѓЕФЪ§Он,дкIPавщЛсздЖЏВ№Аќ,зщАќЁЃЕЋЪЧШчЙћЪЙгУUDPЕФЛА,гавЛИізюДѓБЈЮФГЄЖШЕФЯожЦ(64KB),ЫљвддкгІгУВуДђАќЕФЪ§ОнАќВЛФмГЌЙ§64KB,ЫљвдШчЙћЯывЊДЋЪфвЛИіКмДѓЕФЪ§Он,ЕУдкгІгУВуздМКЪЕЯжВ№ЗжЪ§Он,зщзАЪ§ОнЁЃ
- ШчЙћЖдПЩППадвЊЧѓВЛИп,ЕЋЖдДЋЪфЫйТЪвЊЧѓИп,ПЩвдЪЙгУUDP
- ШчЙћЖдПЩППадвЊЧѓИп,ЖдДЋЪфЫйТЪвЊЧѓвВИп,ЛЙгаЦфЫћЕФДЋЪфВуавщПЩвдгУ,БШШчKCP
ШчКЮЪЙгУUDPЪЕЯжПЩППДЋЪф?
дкгІгУВуДњТыВЮПМTCPЕФВпТдРДЪЕЯжПЩППДЋЪфЁЃ
ЭјТчВуавщ
ЭјТчВуавщЕФжївЊЙЄзї:
1??ЕижЗЙмРэ:АбЭјТчЩЯжїЛњЕФЕижЗгУЭГвЛЕФЙцдђЙмРэЦ№РД
2??ТЗгЩбЁдё(ЙцЛЎТЗОЖ):
ЭјТчВуавщзюжївЊЕФавщ:IPавщ
IPавщБЈЭЗНсЙЙ:
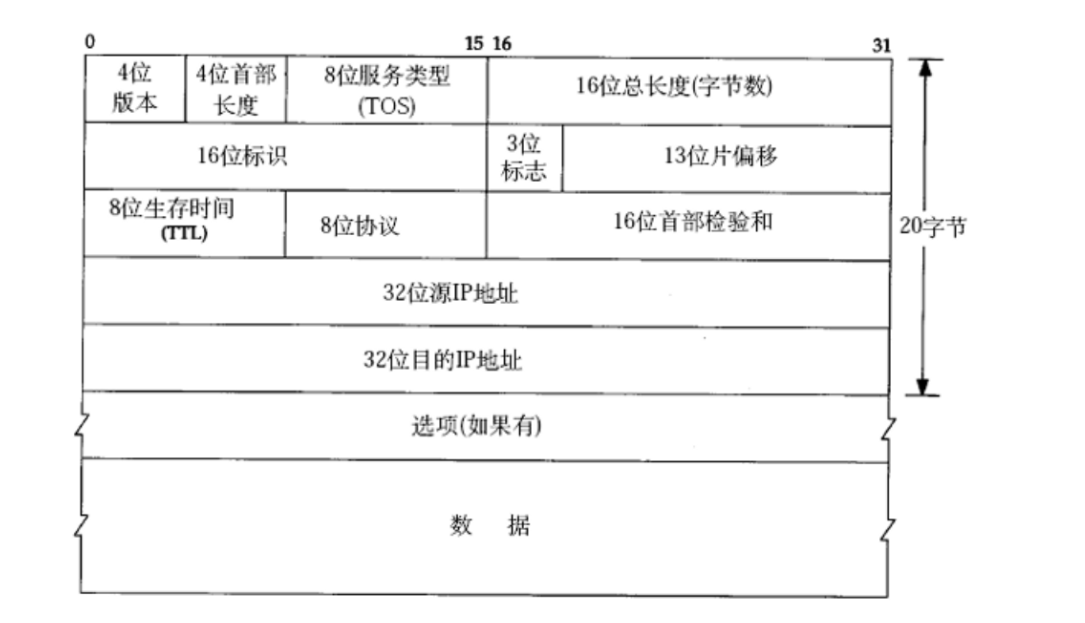
- 4ЮЛАцБОКХ:ЕБЧАIPавщЕФАцБО:4КЭ6,IPv4КЭIPv6ЁЃ
- 4ЮЛЪзВПГЄЖШ:IPавщБЈЭЗЕФГЄЖШ,ЕЅЮЛЪЧ4зжНк,ЫљвдБэЪОЕФЗЖЮЇЪЧ0~60зжНкЁЃIPавщЕФБЈЭЗжСЩйЪЧ20зжНк,ШчЙћгабЁЯю(бЁЯюПЩвдга,вВПЩвдУЛга,ПЩвдгаЖрИі,вВПЩвдга1Иі),дђБЈЭЗЕФГЄЖШЛсИќГЄ,ЕЋжСЖрВЛЛсГЌЙ§60зжНк
- 8ЮЛЗўЮёРраЭ:type of service ет8ЮЛжажЛга4ЮЛгааЇ,ЦфгрЫФЮЛЪЧБЃСєЮЛ(ЯждкВЛгУ,НЋРДПЩФмЛсгУ),етЫФИіbitЮЛЪЧЛЅГтЕФ,вВОЭЪЧжЛгаЦфжа1ЮЛЮЊ1,ЦфгрЮЊ0ЁЃгУРДБэЪОЕБЧАЕФЗўЮёРраЭЁЃетРяЕФЗўЮёРраЭга:зюаЁбгЪБ,зюДѓЭЬЭТСП,зюИпПЩППад,зюаЁГЩБО
- 16ЮЛзмГЄЖШ:IPавщБЈЮФЕФзмГЄЖШ(БЈЭЗ+диКЩ),диКЩОЭЪЧвЛИіДЋЪфВуЪ§ОнБЈ(вЛИіTCPЪ§ОнБЈ),16ЮЛ,ЕЅЮЛЪЧзжНквВОЭДњБэСЫвЛИіIPЪ§ОнБЈзюДѓЪЧ64kb,ФЧШчЙћдиКЩЪЧвЛИіTCPЪ§ОнБЈЕФЛА,гЩгкTCPВЂУЛгаЯожЦвЛИіTCPЪ§ОнБЈЕФзюДѓГЄЖШ,ЫљвдвЛИіTCPЪ§ОнБЈПЩФмКмГЄ,ФЧвВОЭвтЮЖзХвЛИіIPЪ§ОнБЈЕФГЄЖШПЩФмЛсГЌЙ§64KB,ФЧШчЙћГЌЙ§64KBЕФЛА,ОЭЛсЖдетИіIPЪ§ОнБЈНјааВ№АќЁЃ
- ФЧБЈЭЗжаЕФ16ЮЛБъЪЖКЭ3ЮЛБъжОКЭ13ЮЛЦЌЦЋвЦОЭЪЧгУРДИЈжњВ№АќзщАќЕФЁЃ==16ЮЛБъЪЖ:==ЭЌвЛИіАќВ№ГіРДЕФШєИЩаЁАќЪЧвВвЛбљЕФ,ВЛЭЌЕФАќВ№ГіРДЕФаЁАќжЎМфЪЧВЛвЛбљЕФЁЃ==3ЮЛБъжОЮЛ:==ЦфжагавЛЮЛЪЧзюЙиМќЕФ,ШчЙћетвЛЮЛЪЧ1ОЭБэЪОКѓУцЛЙгааЁАќ,ШчЙћЪЧ0ОЭБэЪОКѓУцУЛгааЁАќСЫ,ЕБЧААќОЭЪЧВ№ЗжГіРДЕФАќжаЕФзюКѓвЛИіАќЁЃЛЙгавЛЮЛЪЧБЃСєЮЛ,ЛЙгавЛЮЛБэЪОЕБЧААќЪЧЗёЗжАќСЫЁЃ13ЮЛЦЌЦЋвЦУшЪіСЫВ№ГіРДЕФАќЕФЯШКѓЫГађЁЃ
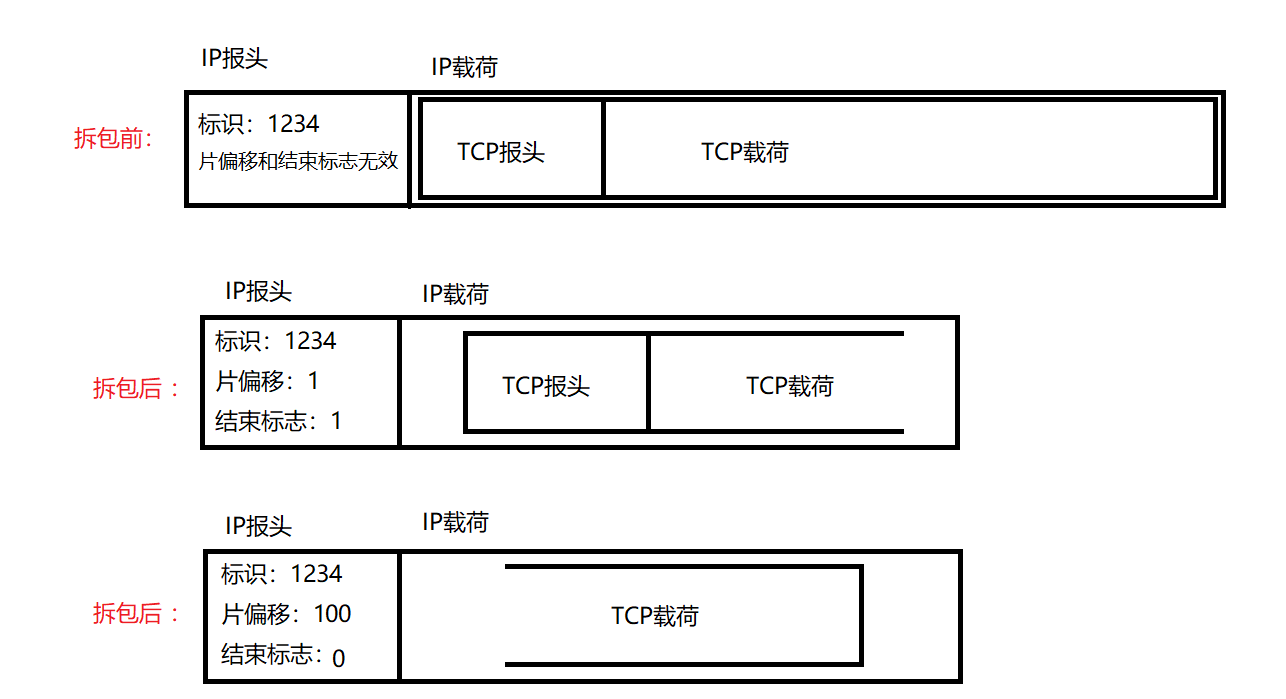
АбећЬхЕФTCPЪ§ОнБЈЗжГЩШєИЩВПЗж,ЗжБ№ЗХЕНIPЪ§ОнБЈжа,ЕЋЪЧетРяЕФTCPЪ§ОнБЈжЛгавЛИі,ВЂВЛЪЧвЛИіIPЪ§ОнБЈжагавЛИіЁЃ
- 8ЮЛЩњДцЪБМф(TTL),УшЪіСЫетИіЪ§ОнАќЛЙФмБЛзЊЗЂЕФДЮЪ§ЁЃБШШчAИјBЗЂЫЭСЫвЛИіЪ§ОнБЈ,ЕЋЪЧBетИіЕижЗПЩФмЪЧВЛДцдкЕФ,ФЧетИіЪ§ОнБЈЕФзЊЗЂДЮЪ§УЛСЫжЎКѓ,ОЭЛсБЛЖЊЦњ,ВЛЛсвЛжБДцдкЭјТчжаЁЃБШШчИјTTLвЛИіГѕЪМжЕ(64,128ЕШ),ШЛКѓУПОЙ§вЛИіТЗгЩЦїTTLОЭЛсМѕ1,ЕБTTLЮЊ0етИіЪ§ОнБЈОЭЛсБЛЖЊЦњ
- 8ЮЛавщ:жИЕФЪЧДЋЪфВуЪЙгУЕФФФИіавщ,ДЋЪфВуавщгаВЛЭЌЕФБрКХЁЃБШШчДюХфЕФЪЧTCPЪ§ОнБЈОЭЕУНЛИјTCPНтЮі,ВЛФмНЛИјUDPНтЮі
- 16ЮЛЪзВПаЃбщКЭ:жЛаЃбщIPЪ§ОнБЈБЈЭЗ,диКЩВПЗжЕФаЃбщгЩДЋЪфВуавщИКд№,ЫљвдетИіаЃбщКЭжЛаЃбщIPавщБЈЭЗЁЃ
- 32ЮЛдДIPКЭ32ЮЛФПЕФIP:УшЪіСЫЪ§ОнДгФФИіжїЛњРДЕНФФИіжїЛњШЅ,жЎЧАЕФUDPавщКЭTCPавщБЈЭЗжаЛЙгадДЖЫПкКХКЭФПЕФЖЫПкКХ(ЖЫПкКХБъЪЖЕФЪЧНјГЬ)ЁЃетЫФИіаХЯЂдйМгЩЯавщРраЭ,ОЭЙЙГЩСЫвЛИіЮхдЊзщ
IPЕижЗЦфЪЕЪЧвЛИі32ЮЛЕФЖўНјжЦЪ§зж,ЮЊСЫИќКУЪЖБ№,в§ШыСЫЕуЗжЪЎНјжЦДњБэетИі32ЮЛЕФЪ§зж,гУШ§ИіЕуАб32ЮЛЪ§зжЗжГЩ4ВПЗж,УПвЛВПЗж8Иіbit,УПвЛВПЗжЕФШЁжЕЗЖЮЇЪЧ0~255,БШШч183.197.199.136
IPЕижЗЪЧ32ЮЛ,ФЧетИі32ЮЛЪ§зжзюДѓЪЧ42вкЖр,ЖјУПИіжїЛњЕУгавЛИіЮЈвЛЕФIPЕижЗВХФмБЃжЄЪ§ОнВЛЛсЗЂДэ,ЕЋЪЧЪЕМЪЩЯЯждкЕФжїЛњ,ЪжЛњ,ЦфЫћЩшБИЕФЪ§СПдЖГЌСЫ42вк,ФЧIPЕижЗВЛЙЛЗжСЫ,ФЧеІАь?
🆗ЖЏЬЌЗжХфIPЕижЗ(DHCP),вЛИіЩшБИЩЯЭјОЭЗжХф,ВЛЩЯЭјОЭВЛЗжХф
🆗IPЕижЗзЊЛЛ(NAT),ЯШАбIPЗжЮЊСНДѓРр:
ФкЭјIP:ОжгђЭјФкВПЕФIP,вЛИіОжгђЭјФкВПЕФIPвЊБЃГжЮЈвЛ,ЖрИіОжгђЭјжЎМфЕФIPПЩвджиИД
ЭтЭјIP:ЙугђЭјжаЪЙгУЕФIP,ЙугђЭјжаЕФIPЕУБЃГжЮЈвЛ
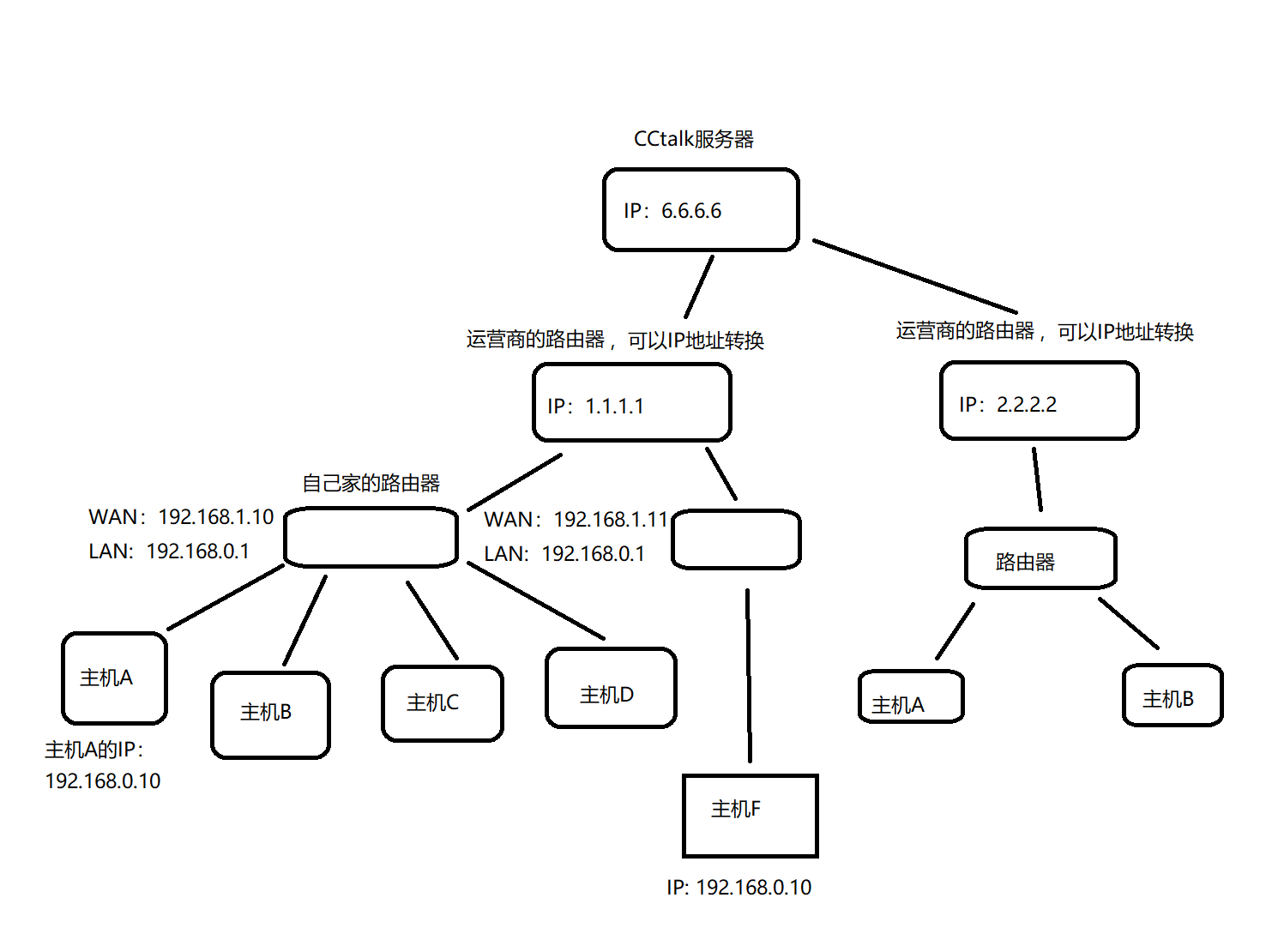
NATЯТЕФЪ§ОнДЋЪфСїГЬ:
БШШчжїЛњAИјCCtalkЗЂЫЭЪ§Он,дђЪ§ОнБЈжаЕФдДIPЮЊ:192.168.0.10,ФПЕФIPЮЊ:6.6.6.6,ОздМКМвЕФТЗгЩЦїзЊЗЂ,ШЛКѓЕНдЫгЊЩЬЕФТЗгЩЦїДІ,дЫгЊЩЬЕФТЗгЩЦїОЭЛсАбдДIP:192.168.0.10ЬцЛЛЮЊТЗгЩЦїздМКЕФIP:1.1.1.1,ШЛКѓдйзЊЗЂГіШЅ,(дЫгЊЩЬЕФТЗгЩЦїетРяЛсМЧзЁФФИіIPЬцЛЛЮЊздМКЕФIPСЫ),МйШчжБНгзЊЗЂИјCCtalkЕФЗўЮёЦїСЫ,ЗўЮёЦїЪеЕНЕФЪ§ОнАќжаЕФдДIPЪЧ:1.1.1.1,ФПЕФIPЪЧ:6.6.6.6ЁЃCCtalkжЛжЊЕРЪ§ОнРДздФФИі1.1.1.1,ВЂВЛжЊЕРЪ§Онеце§РДзд192.168.0.10ЁЃ
ЩЯУцЪЧМђЛЏСЫЕФСїГЬ,ШчЙћЯИЛЏвЛЕуФЧжїЛњAЗЂЫЭЕФЪ§ОнЕНздМКМвЕФТЗгЩЦїЛсНЋдДIPЬцЛЛЮЊздМКМвТЗгЩЦїЕФWANПкIP,ШЛКѓдйзЊЗЂГіШЅ,ЯьгІЗЕЛиЛиРДЕФЪБКђОЭЪЧвЛИіФцЙ§ГЬСЫЁЃШЛКѓздМКМвЕФТЗгЩЦїКЭCCtalkЗўЮёЦїжЎМфИєЕФЪЧЖрИіТЗгЩЦїЁЃ
ШЛКѓCCtalkЗЕЛиЕФЯьгІБЈЮФжаЕФдДIPЮЊ6.6.6.6,ФПЕФIPЮЊ1.1.1.1,АбетИіЪ§ОнБЈЗЕЛиИјдЫгЊЩЬТЗгЩЦї,ШЛКѓдЫгЊЩЬТЗгЩЦїдйАбФПЕФIPЬцЛЛЮЊ192.168.0.10ЗЕЛиЕНжїЛњA
ЫљвджЛвЊгаЕчФдНгШыетвЛИідЫгЊЩЬТЗгЩЦї,ФЧетаЉЕчФдЗУЮЪЭтЭј,ОЭЕУЪЙгУдЫгЊЩЬТЗгЩЦїЕФЭтЭјIPЁЃвВОЭЪЧгУвЛИіЭтЭјIPДњБэФкЭјЕФКмЖрЩшБИЁЃ
ФкЭјIPгаШ§Рр:10.xxx,172.16.x.xжС172.31.x.x КЭ192.168.x.x (етаЉЪЧБЃСєIP,ФкЭјIPЖМЪЧетШ§РржаЕФвЛИі),ЭтЭјIPЖМЪЧБЃСєIPжЎЭтЕФIPЁЃ
🆗ЪЙгУIPv6авщДњЬцIPv4авщ,етЪЧНтОіIPЕижЗВЛЙЛгУЕФжеМЋЗНАИ
IPv6ЪЧСэвЛИіЭјТчВуавщ,ВЂВЛЪЧIPv4ЕФЩ§МЖАцЁЃIPv6ЪЙгУ128ЮЛ(16ИізжНк)РДБэЪОIPЕижЗ,етбљвЛРДЕФЛА,IPЕижЗЪЧЭъШЋЙЛгУСЫЁЃ
ЩЯУцЫЕСЫЕижЗЙмРэ,ЯТУцЫЕвЛЯТТЗгЩбЁдё:
ТЗгЩбЁдё:ОЭЪЧЪ§ОнБЈдкДЋЪфЕФЙ§ГЬжаОЙ§вЛаЉТЗгЩЦї,ТЗгЩЦївЊАбДЋРДЕФЪ§ОнЗЂИјФФИіЩшБИЁЃ
дкАйЖШЕиЭМЛђ ИпЕТЕиЭМжаЛсАбЫљгаЮЛжУаХЯЂЖМБЃДцЦ№РД,етбљЕФЛА,жЊЕРЦ№ЕуКЭжеЕуСЫ,бЁФФИіТЗОЖетвВБШНЯШнвзЙцЛЎГіРД,ВЂЧвжаМфОЙ§ФФаЉНкЕуЖМЛсжЊЕРЁЃЕЋЪЧТЗгЩЦїВЛвЛбљ,ТЗгЩЦїЕФгВМўХфжУБШНЯЕЭ,ЫќВЛПЩФмАбЫљгаЕФЮЛжУаХЯЂЖМБЃДцЦ№РД,ФЧТЗгЩЦїетРяШчКЮДЋЪфЪ§ОнЕФФи?
ТЗгЩЦїжЛжЊЕРЮЛжУаХЯЂЕФвЛВПЗж:МДжЊЕРгыЫћЯрСкЕФЩшБИдѕУДзп,ЛђгыЫћЯрСкЩшБИЕФЯрСкЩшБИдѕУДзп,УПИіТЗгЩЦїЖМжЊЕРвЛВПЗжЮЛжУаХЯЂ(ДцгкТЗгЩБэжа),ЕБЪ§ОнБЈЗЂЫЭЕНТЗгЩЦїетРяКѓ,ТЗгЩЦїОЭФУIPЪ§ОнБЈжаЕФФПЕФIPКЭТЗгЩБэжаЕФЮЛжУаХЯЂНјааЦЅХф(АДееЭјЖЮНјааЦЅХф),ШчЙћЦЅХфЕН,ОЭЗЂЫЭЕНжИЖЈЗНЯђ,ШчЙћУЛгаЦЅХфЕН,ОЭЗЂЫЭЕНФЌШЯЗНЯђЁЃ
ТЗгЩзЊЗЂЕФЙ§ГЬОЭРрЫЦгкЮЪТЗ,вЛЬјвЛЬјЕФзЊЗЂЁЃ
Ъ§ОнСДТЗВуавщ
Ъ§ОнСДТЗВуавщжївЊЪЧвдЬЋЭјавщ(ВхЭјЯпЕФавщ),ЛЙгавЛИіЮоЯпЭјавщ(802.11),ЦНЪБВхЕФЭјЯпвВНавдЬЋЭјЯпЁЃ
вдЬЋЭјжЁНсЙЙ:

ПЊЪМЪЧ6ЮЛЕФФПЕФЕижЗКЭдДЕижЗ,етЪЧЮяРэЕижЗ,вВОЭЪЧЭјПЈЕижЗ(MACЕижЗ),УПИіЭјПЈдкЩњВњЪБЖМЛсАВХХвЛИіЕижЗЁЃУПИіЭјПЈЕижЗЮЈвЛЁЃ
РраЭДњБэЪЙгУЕФЪЧФФИіЭјТчВуавщЁЃ
РраЭШчЙћЪЙгУЕФIPавщЕФЛА,Ъ§ОнОЭДњБэвЛИіЭъећЕФIPЪ§ОнБЈЁЃетИіЪ§ОнзюаЁЪЧ46зжНк,зюДѓЪЧ1500зжНкЁЃетИізюДѓГЄЖШГЦЮЊMTUЁЃФЧМШШЛЪ§ОнзюДѓГЄЖШЪЧ1500зжНк,ФЧШчЙћIPЪ§ОнБЈЕФГЄЖШГЌЙ§1500зжНкСЫ,ОЭвЊЯёIPавщФЧРяЗжАќЁЃ
ЕБЪ§ОндкЙЋЭјДЋЪфЪБ,MACЕижЗКЭIPЕижЗЕФЧјБ№:
ЕБЪ§ОндкЙЋЭјДЋЪфЪБ,УЛгаNATзЊЛЛIPЕижЗ,ЫљвддДIPЕижЗКЭФПЕФIPЕижЗЪЧвЛжБВЛБфЕФЁЃ
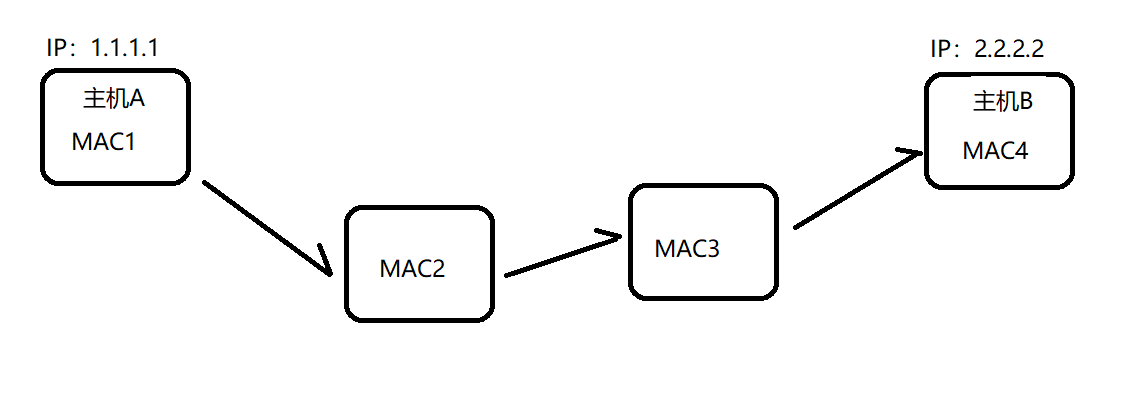
МйЩшдкЙЋЭјЩЯЕФЪ§ОнДЋЪфТЗЯпЪЧЩЯУцетЬѕТЗЯпЁЃЕБЪ§ОнгЩжїЛњAЗЂЫЭИјжїЛњBЕФЙ§ГЬжадДIPКЭФПЕФIPЪЧвЛжБВЛБфЕФ(дДIPЪЧ1.1.1.1,ФПЕФIPЪЧ2.2.2.2)ЁЃЕЋЪЧMACЕижЗЪЧвЛжББфЛЏЕФ,ЕБЪ§ОнгЩжїЛњAЗЂЫЭИјжїЛњBЪБ,дДMACЪЧMAC1,ФПЕФMACЪЧMAC2,ЕБЪ§ОнЗЂЫЭИјMACЕижЗЪЧMAC2ЕФжїЛњЪБ,дДMACЕижЗзЊЛЛЮЊMAC2,ФПЕФMACзЊЛЛЮЊMAC3,ШЛКѓдйЗЂЫЭИјЕкШ§ЬЈЛњЦїЁЃвРДЮзЊЗЂ,ЫљвддкЪ§ОнДЋЪфЙ§ГЬжа,ОЙ§вЛИіНкЕуMACЕижЗКЭФПЕФЕижЗЪЧЛсЗЂЩњБфЛЏЕФЁЃ
IPЪ§ОнБЈжаЕФIPЕижЗМЧТМЕФЪЧЦ№ЕуКЭжеЕу,ЖјвдЬЋЭјЪ§ОнжЁжаЕФMACЕижЗМЧТМЕФЪЧСНИіЯрСкНкЕуЕФЕижЗаХЯЂЁЃЫљвдгаСНЬзЕижЗМШПЩвдМЧТМШЋОж,гжПЩвдМЧТМжаМфЙ§ГЬаХЯЂЁЃ
DNSавщ
етЪЧвЛИігІгУВуавщ,гУЭОЪЧ:гђУћНтЮі
==гђУћ:==ЦфЪЕОЭЪЧЭјжЗЁЃБШШчsougou.comОЭЪЧЫбЙЗЭјеОЕФгђУћ
==гђУћНтЮі:==АбгђУћзЊЛЛЮЊЖдгІЕФIPЕижЗЁЃ
гђУћКЭIPЕижЗЪЧвЛвЛЖдгІЕФЙиЯЕ,гђУћЪЧЮЊСЫЗНБуIPЕижЗЕФЪЖМЧЁЃСэЭтгђУћЛЙгавЛИіКУДІ,ОЭЪЧгђУћПЩвдЭЈЙ§DNSЯЕЭГзЊЛЛЮЊЖдгІЕФIPЕижЗ,МйШчЗўЮёЦїЧЈвЦЕНБ№ЕФЩшБИСЫ,ФЧЖдгІЕФIPЕижЗвВОЭБфСЫ,ФЧгУЛЇвЊЯыЗУЮЪЗўЮёЦїОЭЕУАбаТЕФIPЕижЗЭЈжЊИјгУЛЇ,ЕЋЪЧгаСЫDNSОЭВЛгУСЫ,жЛвЊгУЛЇЛЙЪЧЪЙгУжЎЧАЕФгђУћРДЗУЮЪОЭааСЫ,вђЮЊПЩвддкDNSЯЕЭГРяАбгђУћЖдгІЕФIPЕижЗзЊЛЛЮЊаТЕФIPЕижЗЁЃ
зюдчЕФгђУћЯЕЭГЪЙгУвЛИіЮФМўДцДЂгђУћЖдгІЕФIPЕижЗЕФ,ПЩвдАбгђУћЖдгІЕФIPЕижЗБЃДцНјЮФМўжа,гУРДзЊЛЛгђУћ,ЕЋЪЧетжжЗНЪНВЛПЦбЇ,вђЮЊЭјеОЬЋЖрСЫЁЃ
БШНЯПЦбЇЕФЗНЗЈЪЧИувЛИіDNSЗўЮёЦї,гУЗўЮёЦїАбгђУћКЭIPЕижЗЕФгГЩфЙиЯЕБЃДцЦ№РД,ЕБгУЛЇЯыЗУЮЪвЛИіЭјеОЪБЯШЗУЮЪDNSЗўЮёЦї,АбгђУћНтЮіГЩIPЕижЗдйЗУЮЪЁЃ
ЕЋЪЧШЋЪРНчвЊЩЯЭјЕФЩшБИКмЖр,ЪЧЪ§вдвкМЦЕФ,ФЧШЋЪРНчЫљгаЕФЩшБИЖМРДЗУЮЪетИіЗўЮёЦїЯдШЛЗўЮёЦїЪЧжЇГХВЛСЫЕФЁЃФЧдѕУДНтОіЗўЮёЦїЗУЮЪСПЬЋДѓЕФЮЪЬтФи?
==НтОіЗНАИ1:==ЕБгУЛЇЕквЛДЮЗУЮЪDNSЗўЮёЦїЕФЪБКђОЭЛсЖдгГЩфЙиЯЕНјааБОЕиЛКДц,АбгГЩфЙиЯЕДцгкБОЕиЕчФдЁЃКѓајдйЗУЮЪЯрЭЌЭјеОЪБОЭВЛгУдйЗУЮЪDNSЗўЮёЦїСЫЁЃжБНгИљОнБОЕиЕФгГЩфЙиЯЕНјаазЊЛЛОЭКУСЫ
==НтОіЗНАИ2:==дкШЋЪРНчМмЩшКмЖрЕФОЕЯёЗўЮёЦїЁЃзюГѕЕФDNSЗўЮёЦїГЦЮЊИљЗўЮёЦї,ЦфЫћЕФЗўЮёЦїДгИљЗўЮёЦїЩЯЭЌВНЪ§Он,ГЦЮЊОЕЯёЗўЮёЦїЁЃетИіОЕЯёЗўЮёЦїашвЊМмЩшКмЖрЁЃ
ЩшБИвЊЯыЕЧТМЭјеО,ОЭашвЊХфжУКУЪЙгУФФИіDNSЗўЮёЦї,ЕЋЪЧЩшБИвЛАуЪЧздЖЏЛёШЁЕНDNSЗўЮёЦїЕФЕижЗЕФ,ЕЋЪЧвВПЩвдздМКХфжУЪЙгУФФИіDNSЗўЮёЦїЁЃ
?дкетРяПЩвдХфжУздМКЕчФдЕФIPЕижЗКЭDNSЗўЮёЦїЁЃ