����Ŀ¼
1.TCP
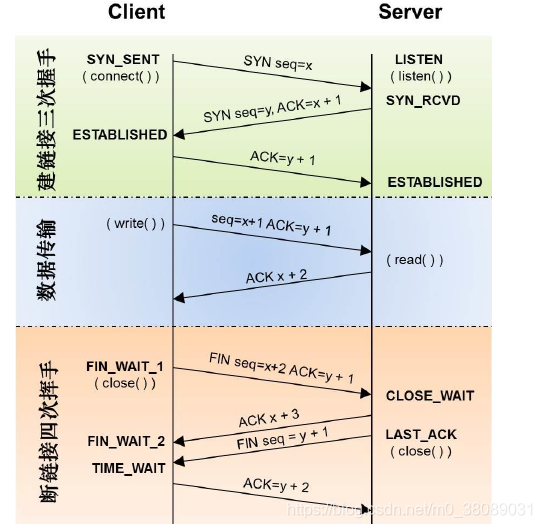
�������� ��֤˫�����н��պͷ��͵�������
�ͻ���:��������?
������:����,��������?
�ͻ���:����
�Ĵλ��� �ͻ��������ر�����
�ͻ���:�����ݴ�����,��Ҫ������
������:֪����,�һ��е�����,�����
һ��ʱ���:
������:�����ݷ�����,�����������
�ͻ���:�õ�
3.TCP Ϊɶ����Ҫ�����ֶ�һ��?
(1)��Ϊ������ LISTEN ״̬�ķ��������յ����Կͻ��˵� SYN ����(�ͻ���ϣ���½�һ��TCP ����)ʱ,������ ACK(ȷ��Ӧ��)�� SYN(ͬ�����)����ͬһ���������������ͻ��ˡ�
(2)���ڹر� TCP ����ʱ,���յ��Է��� FIN ����ʱ,�Է�������ʾ�Է��Ѿ�û�����ݷ�������,�������Լ����ܻ���������Ҫ�����Է�,����㷢����ʣ������ݸ��Է�֮��,�ٷ��� FIN ���ĸ��Է�����ʾ�������Ѿ��������,������ر�����,����ͨ�������,����� ACK ������ FIN �������Ƿֿ����͵ġ�
TCPճ����ָ���ͷ����͵����ɰ����ݵ����շ�����ʱճ��һ��,�ӽ��ջ�������,��һ�����ݵ�ͷ������ǰһ�����ݵ�β��
TCP���������ӵ�,��UDP�����������ӵġ�
TCP��֧�ֵ�������,UDP �ṩ�˵���,�ಥ,�㲥�Ĺ��ܡ�
TCP���������ֱ�֤�����ӵĿɿ���; UDP�������ӵġ����ɿ���һ�����ݴ���Э��,���Ȳ��ɿ�����������������,ͨ�Ŷ�����Ҫ��������,�Խ��յ�������Ҳ������ȷ���ź�,���Ͷ˲�֪�������Ƿ����ȷ���ա�
UDP��ͷ��������TCP�ĸ�С,���ݴ������ʸ���,ʵʱ�Ը��á�
��˵,TCPע�����ݿɿ���,��UDP���ݴ�����,����ȫ��һ�㡣
��������
��������:�ǽ��ն˽��е��������ơ�����������Ϊ�˿��Ʒ��ͷ��ķ�������,��֤���շ����ü�������Ϣ�����ͷ��ͽ��շ�����һ���������,���շ�����ȷ�ϱ��ĵ�ʱ��Я����Ҫ���ͷ����������ڴ�С�������շ��Ļ�������Ѿ�����ʱ��,���շ��ڷ���ȷ�ϱ��ĵ�ʱ��,���С���ڴ�С,�Ƿ��ͷ���һ�η����ٵ����ݡ���Ϊ�������ʱ��̬�ı��С��,���Խл������ڡ�
ӵ������
ӵ������:Ҳ�Ƕ������Ŀ���,�Ƿ��ͷ���������ġ�ӵ��������Ҫ����������е�����������������Դ�������õIJ���,�����е�������·���� ���Ӱ�졣����һ�����̵�·�ڵij�������ͻ����ӵ��,���ʱ�����Ҫ�����������������������ݴ������ʡ�
TCP��ӵ�����Ʋ����������㷨:����ʼ��ӵ�����⡢���ش��Ϳ�ָ�
2.HTTP �����������
HTTPS ��ʲô?
HTTPS ���� HTTP �� TCP ֮�佨����һ����ȫ��,HTTP �� TCP ͨ�ŵ�ʱ��,�����Ƚ���һ����ȫ��,�����ݰ����м���,Ȼ���ܺ�����ݰ����� TCP,��Ӧ�� TCP ���뽫���ݰ�����,���ܴ�������� HTTP��
�����ԭ��
����,��ָ���������ִ��������վ�Ľű����������������ͬԴ������ɵġ�
ͬԴ����,��������� JavaScript ʵʩ�İ�ȫ����,ֻҪЭ�顢�������˿����κ�һ����ͬ,���������Dz�ͬ����
����ԭ��,����ͨ�����ַ�ʽ,�ܿ�������İ�ȫ���ơ�
HTTP����
�� HTTP/1.0 ��Ĭ��ʹ����������Ҳ����˵,�ͻ��˺ͷ�����ÿ����һ�� HTTP ����,�ͽ���һ������,����������ж����ӡ����ͻ�����������ʵ�ij�� HTML ���������͵� Web ҳ�а����������� Web ��Դ(��:JavaScript �ļ���ͼ���ļ���CSS �ļ���),ÿ��������һ�� Web ��Դ,������ͻ����½���һ�� HTTP �Ự��
���� HTTP/1.1 ��,Ĭ��ʹ�ó�����,���Ա����������ԡ�ʹ�ó����ӵ� HTTP Э��,������Ӧͷ�������д���:Connection:keep-alive
��ʹ�ó����ӵ������,��һ����ҳ����ɺ�,�ͻ��˺ͷ�����֮�����ڴ��� HTTP ���ݵ� TCP ���Ӳ���ر�,�ͻ����ٴη������������ʱ,�����ʹ����һ���Ѿ����������ӡ�
Keep-Alive �������ñ�������,����һ������ʱ��,�����ڲ�ͬ�ķ���������(��:Apache)���趨���ʱ�䡣ʵ�ֳ�������Ҫ�ͻ��˺ͷ���˶�֧�ֳ����ӡ�
���ʵ�ֳ�����?��ʲôʱ��ᳬʱ?
ͨ����ͷ��(�������Ӧͷ)���� Connection: keep-alive,HTTP1.0Э��֧��,����Ĭ�Ϲر�,��HTTP1.1Э���Ժ�,����Ĭ�϶��dz�����
HTTP һ����� httpd �ػ�����,����������� keep-alive timeout,�� tcp �������ó������ʱ��ͻ�ر�,Ҳ������ HTTP �� header �������ó�ʱʱ��
TCP �� keep-alive ������������,֧����ϵͳ�ں˵� net.ipv4 ��������:�� TCP ����֮��,������ tcp_keepalive_time,��ᷢ������,���û���յ��Է��� ACK,��ô��ÿ�� tcp_keepalive_intvl �ٷ�һ��,ֱ�������� tcp_keepalive_probes,�ͻᶪ�������ӡ�
tcp_keepalive_intvl = 15
tcp_keepalive_probes = 5
tcp_keepalive_time = 1800
ʵ���� HTTP û�г�������,ֻ�� TCP ��,TCP �����ӿ��Ը���һ�� TCP ������������ HTTP ����,�������Լ�����Դ����,����һ������ HTML,���ܻ���Ҫ��������� JS/CSS/ͼƬ��
3.������URL��ҳ����ص�ȫ����
- �����������������URL
- ���һ���:������Ȳ鿴���������-ϵͳ����-·�ɻ������Ƿ��иõ�ַҳ��,���������ʾҳ�����ݡ����û���������һ����
- DNS��������:�������DNS��������������,������URL�е�������Ӧ��IP��ַ��DNS������������UDP��,��˻��õ�UDPЭ�顣
- ����TCP����:������IP��ַ��,����IP��ַ��Ĭ��80�˿�,�ͷ���������TCP����
- ����HTTP����:����������ȡ�ļ���HTTP����,����������ΪTCP�������ֵĵ��������ݷ���������
- ��������Ӧ�����ؽ��:�����������������������Ӧ,���Ѷ�Ӧ��html�ļ����������
- �ر�TCP����:ͨ���Ĵλ����ͷ�TCP����
- �������Ⱦ:�ͻ���(�����)����HTML���ݲ���Ⱦ����,��������յ����ݰ���Ľ�������Ϊ:
- ����DOM��:�ʷ�����Ȼ�������DOM��(dom tree),����domԪ�ؼ����Խڵ����,���ĸ���document����
- ����CSS������:����CSS������(CSS Rule Tree)
- ����render��:Web�������DOM��CSSOM���,����������Ⱦ��(render tree)
- ����(Layout):�����ÿ���ڵ�����Ļ�е�λ��
- ����(Painting):������render��,��ʹ��UI��˲����ÿ���ڵ㡣
- JS�����������:����JS����ִ��JS����(JS�Ľ��ͽ�,Ԥ������,ִ�н�����ִ��������,VO,�������������ջ��Ƶȵ�)
- ����window����:window����Ҳ��ȫ��ִ�л���,��ҳ�����ʱ�ͱ�����,���е�ȫ�ֱ����ͺ���������window�����Ժͷ���,��DOM TreeҲ��ӳ����window��doucment�����ϡ����ر���ҳ���߹ر������ʱ,ȫ��ִ�л����ᱻ���١�
- �����ļ�:���js��������������ʷ��Ƿ�Ϸ�,����Ϸ�����Ԥ����
- Ԥ����:��Ԥ����Ĺ�����,�������Ѱ��ȫ�ֱ�������,������Ϊwindow�����Լ��뵽window������,����������ֵΪ**��undefined��**;Ѱ��ȫ�ֺ�������,������Ϊwindow�ķ������뵽window������,���������帳ֵ����(���������Dz�����Ԥ�����,��Ϊ���DZ���)��������������Ϊ�������ĵط���ES6���Ѿ������,�������������ڡ�
- ����ִ��:ִ�е�������ֵ,�������û�б�����,Ҳ��û�б�Ԥ����ֱ�Ӹ�ֵ,��ES5���ϸ�ģʽ������������Ϊwindow��һ������,Ҳ���dz�Ϊȫ�ֱ�����string��int������ֵ����ֱ�Ӱ�ֵ���ڱ����Ĵ洢�ռ���,object������ǰ�ָ��ָ������Ĵ洢�ռ䡣����ִ��,�ͽ������Ļ�������һ��������ջ��,ִ����ɺ��ٵ���,����Ȩ������֮ǰ�Ļ�����JS��������ʵ����������ִ��������ʵ�ֵġ�
4.������Ļ������ ǿ�ƻ��� && Э�̻���
������������ͨ�ŵķ�ʽΪӦ��ģʽ,����:���������HTTP���� �C ��������Ӧ������
��ô�������һ��������������������õ�������,�������Ӧ������HTTPͷ�Ļ����ʶ,�����Ƿ���,�����������ͻ����ʶ���������������,�Ĺ�������ͼ: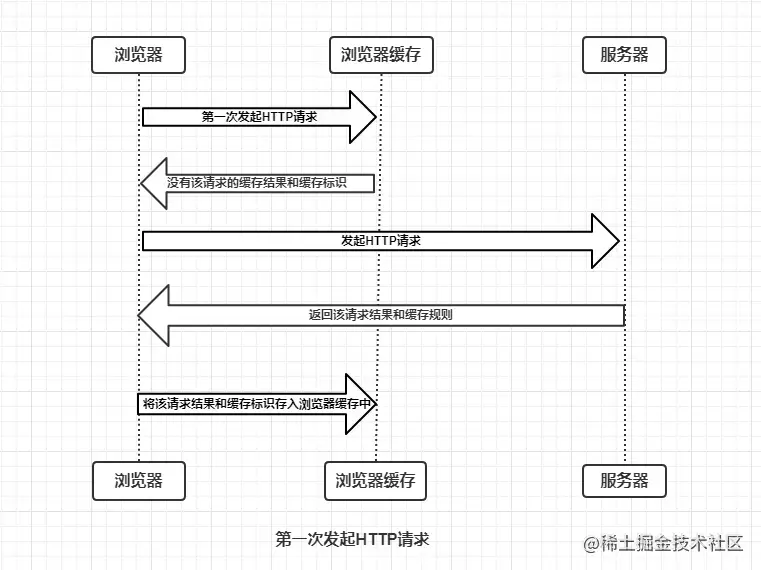
����ͼ���ǿ���֪��:
�����ÿ�η�������,������������������в��Ҹ�����Ľ���Լ������ʶ
�����ÿ���õ����ص����������Ὣ������ͻ����ʶ���������������
��������Ƿ���Ҫ����������·���HTTP��������̷�Ϊ��������,�ֱ���ǿ�ƻ�����Э�̻�����
ǿ�ƻ���
ǿ�ƻ�������������������Ҹ�������,�����ݸý���Ļ�������������Ƿ�ʹ�øû������Ĺ���������������������������ʱ,�������Ὣ����������HTTP��Ӧ���ĵ�HTTPͷ�к�������һ�ظ������,����ǿ�ƻ�����ֶηֱ��� Expires �� Cache-Control,����Cache-Control���ȼ���Expires�ߡ�
ǿ�ƻ���������Ҫ������(�ݲ�����Э�̻������),����:
�����ڸû������ͻ����ʶ,ǿ�ƻ���ʧЧ,��ֱ�����������������(����һ�η�������һ��)��
���ڸû������ͻ����ʶ,���ý����ʧЧ,ǿ�ƻ���ʧЧ,��ʹ��Э�̻��档
���ڸû������ͻ����ʶ,�Ҹý����δʧЧ,ǿ�ƻ�����Ч,ֱ�ӷ��ظý��
Э�̻���
Э�̻������ǿ�ƻ���ʧЧ��,�����Я�������ʶ���������������,�ɷ��������ݻ����ʶ�����Ƿ�ʹ�û���Ĺ���,ͬ��,Э�̻���ı�ʶҲ������Ӧ���ĵ�HTTPͷ�к�������һ�ظ��������,����Э�̻�����ֶηֱ���:Last-Modified / If-Modified-Since �� Etag / If-None-Match,����Etag / If-None-Match�����ȼ���Last-Modified / If-Modified-Since�ߡ�Э�̻�����Ҫ�������������:
Э�̻�����Ч,����304
Э�̻���ʧЧ,����200�����������
������������
1.�������һ�μ�����Դ,����������200,���������Դ�ļ��ӷ�������������������,����response header��������ķ���ʱ��һ������;
2.��һ�μ�����Դʱ,�ȱȽϵ�ǰʱ�����һ�η���200ʱ��ʱ���,���û�г���cache-control���õ�max-age,��û�й���,����ǿ����,��������ֱ�Ӵӱ��ػ����ȡ���ļ�(����������֧��HTTP1.1,����expires�ж��Ƿ����);���ʱ�����,�������������header����If-None-Match��If-Modified-Since������
3.�������յ������,���ȸ���Etag��ֵ�жϱ�������ļ���û������,Etagֵһ����û����,����Э�̻���,����304;�����һ�����иĶ�,ֱ�ӷ����µ���Դ�ļ������µ�Etagֵ������200;;
4.����������յ�������û��Etagֵ,��If-Modified-Since�ͱ������ļ��������ʱ�����ȶ�,һ��������Э�̻���,����304;��һ�����µ�last-modified���ļ�������200;
5.HTTP����֪ʶ��
1xx:��ʾĿǰ��Э����м�״̬,����Ҫ��������
2xx:��ʾ����ɹ�
3xx:��ʾ�ض���״̬,��Ҫ��������
4xx:��ʾ�����Ĵ���
5xx:�������˴���
����״̬��:
101 �������,�� HTTP ��� WebSocket
200 ����ɹ�,����Ӧ��
301 �����ض���:�Ỻ��
302 ��ʱ�ض���:���Ỻ��
304 Э�̻�������
403 ��������ֹ����
404 ��Դδ�ҵ�
400 �������
500 �������˴���
503 ��������æ
״̬��302
��֪�� 302 ״̬����ʲô��?��ƽʱ�����ҳ�Ĺ�������������Щ 302 �ij���?
- 302 ��ʾ��ʱ�ض���,�����Դֻ����ʱ���ܱ�������,����֮���һ��ʱ�仹�ǿ��Լ�������,һ���Ƿ���ij����վ����Դ��ҪȨ��ʱ,����Ҫ�û�ȥ��¼,��ת����¼ҳ��֮���¼֮��,�����Լ������ʡ�
״̬��301
-
301 ����,������ת��һ���µ���վ,���� 301 �������ʵĵ�ַ����Դ�������Ƴ���,�Ժ�Ӧ�÷��������ַ,��������ץȡ��ʱ��Ҳ�����µĵ�ַ�滻����ϵġ������ڷ��ص���Ӧ�� location �ײ�ȥ��ȡ�����صĵ�ַ��301 �ij�������:
-
����� baidu.com,��ת�� baidu.com
-
��������
��:HTTP ���õ�����ʽ,�������;?
http/1.1 �涨��������:
GET:ͨ�û�ȡ����
HEAD:��ȡ��Դ��Ԫ��Ϣ
POST:�ύ����
PUT:������
DELETE:ɾ������
CONNECT:������������,���ڴ���������
OPTIONS:�г��ɶ���Դʵ�е�����,�����ڿ���
TRACE:������-��Ӧ�Ĵ���·��
6.OSI�߲�ģ�ͺ�TCP/IP�IJ�ģ��
Ӧ�ò�
��ʾ��
�Ự��
�����
�����
������·��
������
TCP/IP �IJ����:
Ӧ�ò�:Ӧ�ò㡢��ʾ�㡢�Ự��:HTTP
�����:�����:TCP/UDP
�����:�����:IP
������·��:������·�㡢������
7.�ڴ�������ڴ�й¶�Ĺ�ϵ�Լ�����
1.��ϵ:�ڴ�й¶���ջᵼ���ڴ����,����ϵͳ�е��ڴ�������,�������ռ����Դ������ʱ�ͷ�,���ᵼ���ڴ治��,�Ӷ���������Ҫ�洢�������ṩ�㹻���ڴ�,�Ӷ������ڴ�����������ڴ����Ҳ�����������ڸ����ݷ����Сʱû�и���ʵ��Ҫ�����,����·�����ڴ����������ݵ�����,�Ӷ������ڴ������
2.����:
�ڴ�й¶������GC(Garbage Collection,����������)����ʱ������ʶ����Ի��յ����ݽ��м�ʱ�Ļ���,�����ڴ���˷�;
�ڴ������������������Ҫ���ڴ����õ�����,���������������洢���ڴ��С�
�ڴ�й¶�Ķ�α��־��ǻᵼ���ڴ������