1、TCP概述
1、点对点
一个发送方,一个接收方
2、可靠地,按顺序的字节流
没有报文边界
3、管道化(流水线)
TCP拥塞控制和流量控制设置
窗口大小
4、发送和接收缓存
5、全双工数据
在同一连接中数据流双向流动
MSS:最大报文段大小
6、面向连接:
在数据交换之前,通过握手(交换控制报文)初始化发送方、接收方的状态变量
7、有流量控制
发送方不会淹没接收方
2、TCP报文段的首部格式
1、TCP是面向字节流的,但是TCP传送的数据单元是报文段
2、一个TCP报文段分为首部和数据两部分
3、TCP首部的最小长度是20字节
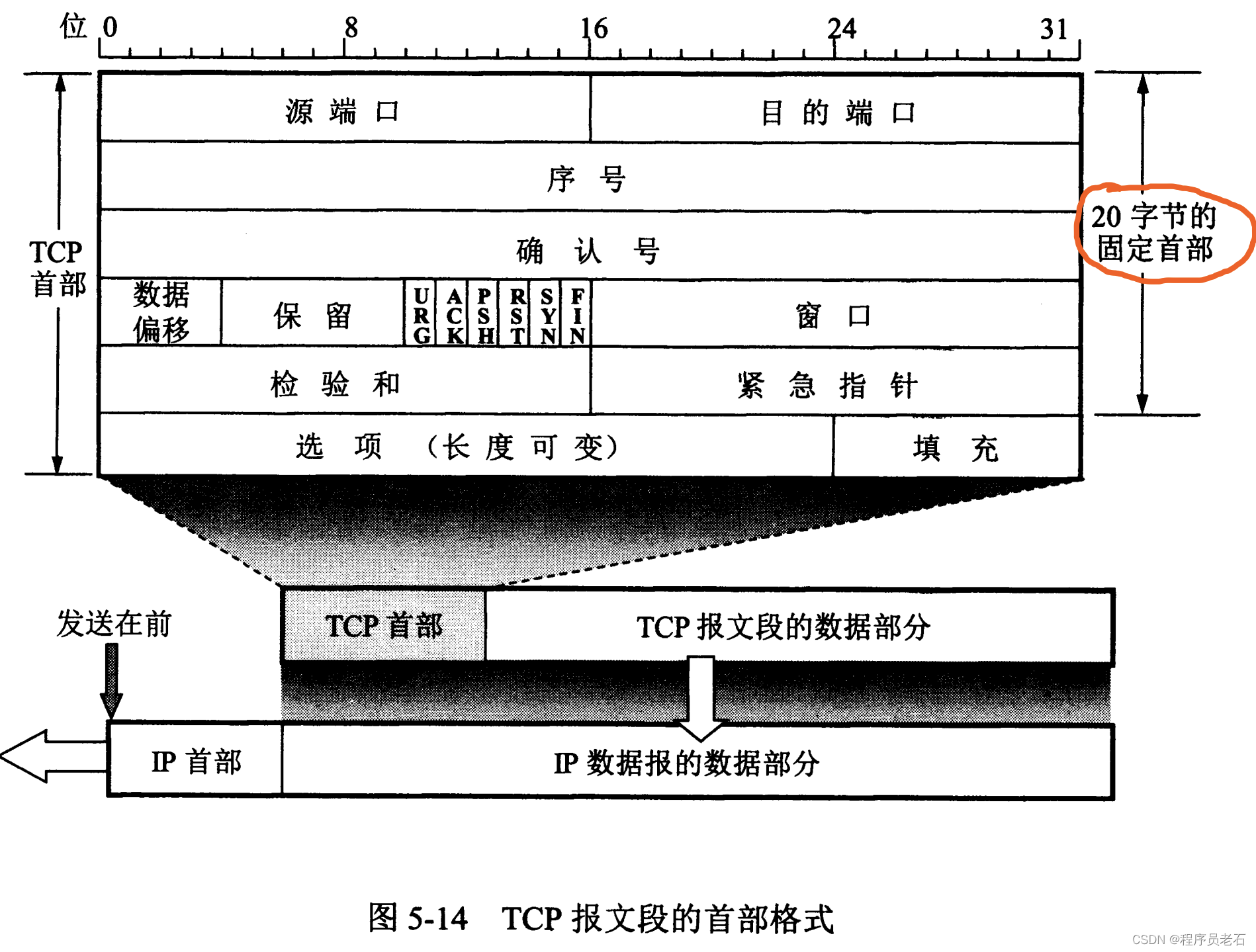
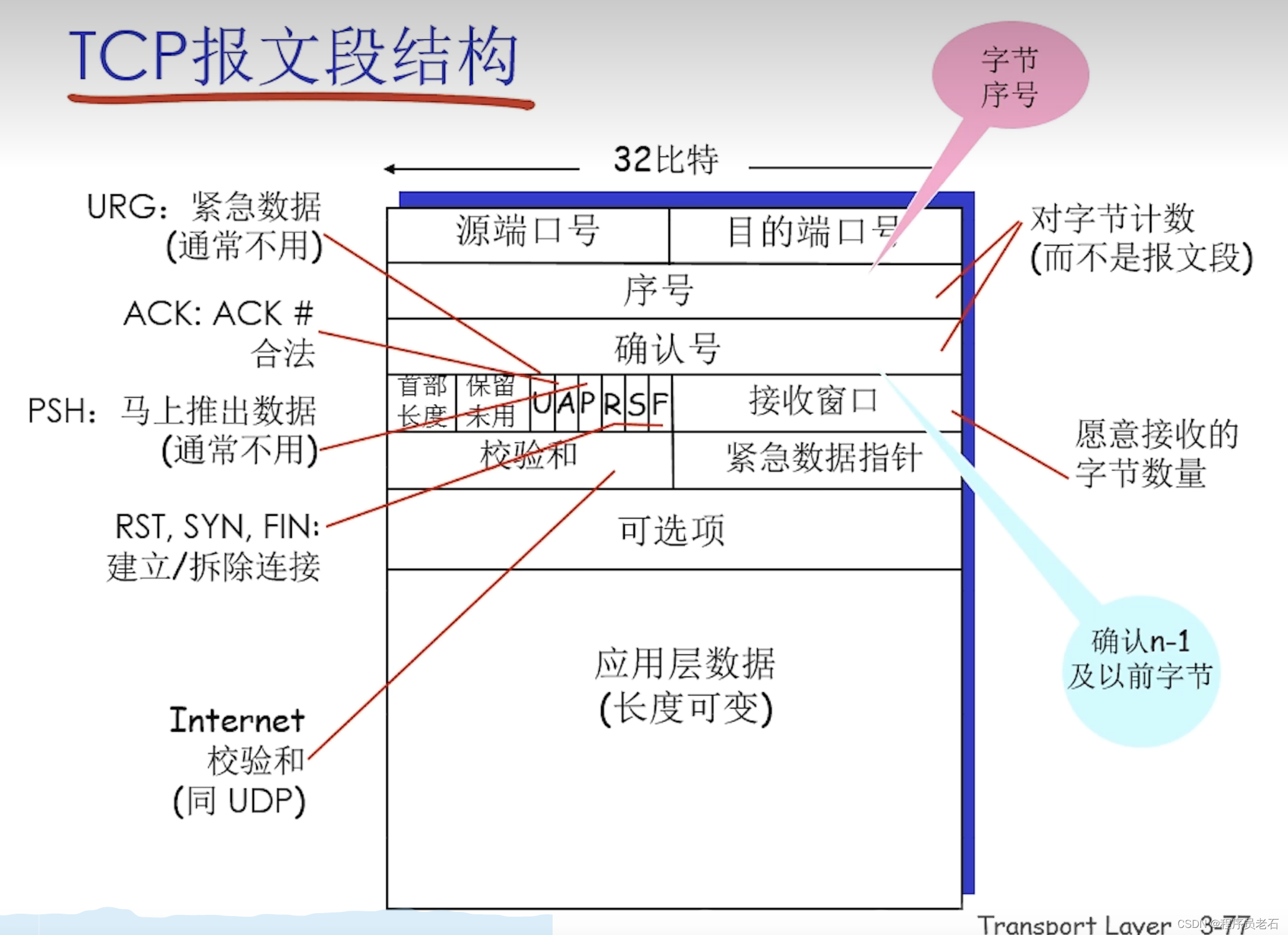
4、首部固定部分各字段的意义如下:
1)源端口和目的端口
各占2个字节(1字节 = 8bit),分别写入源端口号和目的端口号。
2)序号(报文段序号):报文段首字节在字节流的编号。
占4个字节,在一个TCP连接中传送的字节流中的每一个字节都按照顺序编号,整个要传送的字节流的起始序号必须在连接建立是设置。首部中的序号字段值则指的是本报文段所发送的数据的第一个字节的序号。
3)确认号
占4个字节,是期望收到对方下一个报文段的第一个数据字节的序号。

总之,确认号 = N,则表明:到序号N-1为止的所有数据都已正确收到。

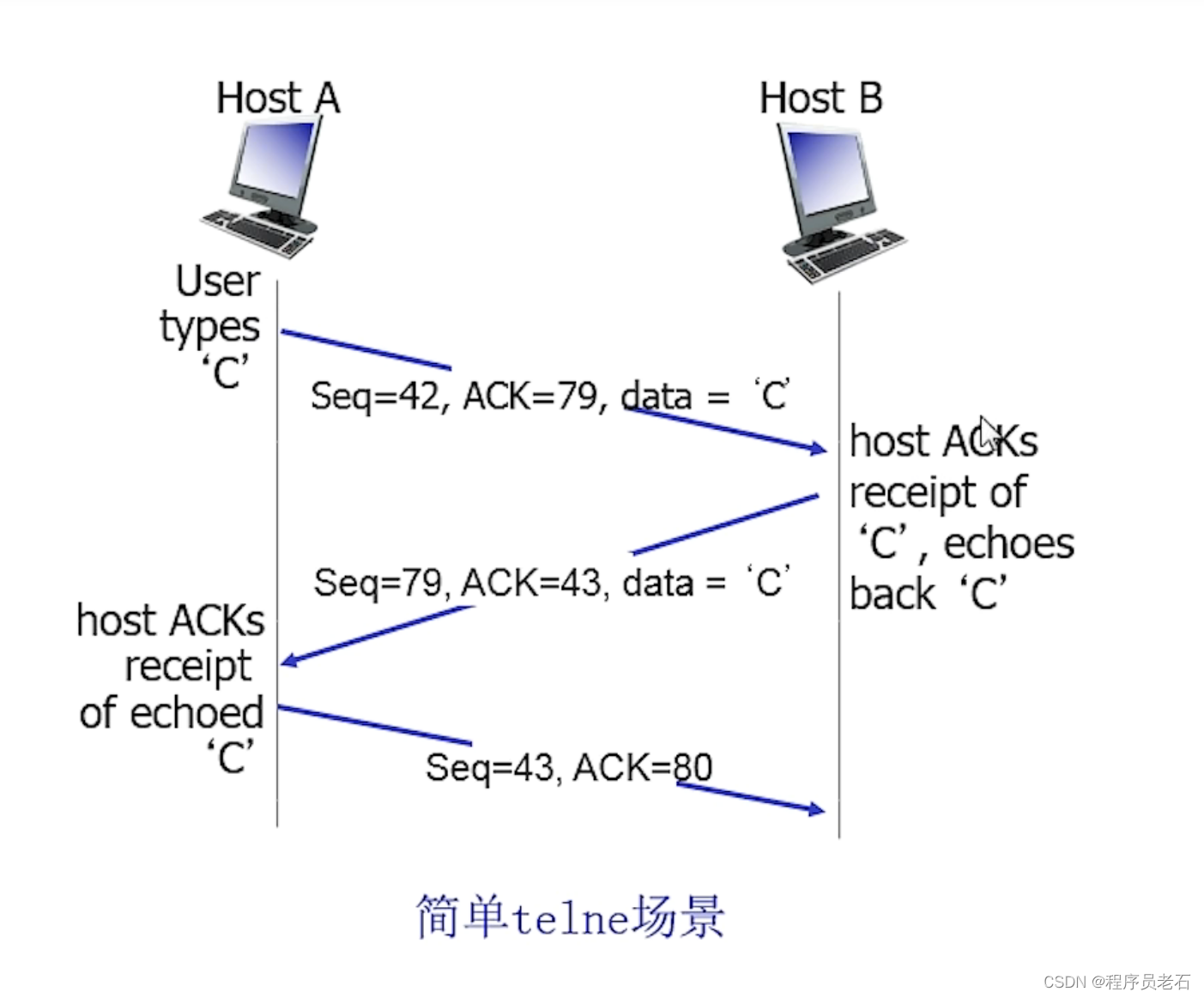
主机A发送X是从42开始,发送一个字节C【报文段中只包含一个字节】,主机B发送的ACK=79,说明78及以前的数据都收到了,告诉主机A希望再从X=79开始传
4)数据偏移
占4位,它指出TCP报文段的数据起始处距离TCP报文段起始处有多远。
5)紧急URG
当URG设置为1时,发送应用进程就告诉发送方的TCP有紧急数据要传送。于是发送方TCP就把紧急数据插入到本报文段数据的最前面,而在紧急数据后面的数据仍是普通数据。这时要与首部中紧急指针字段配合使用。
6)确认ACK
仅当ACK=1时确认号字段才有效。当ACK=0时,确认号无效。
TCP规定,在连接建立后所有传送的报文段都必须把ACK设置为1
7)窗口

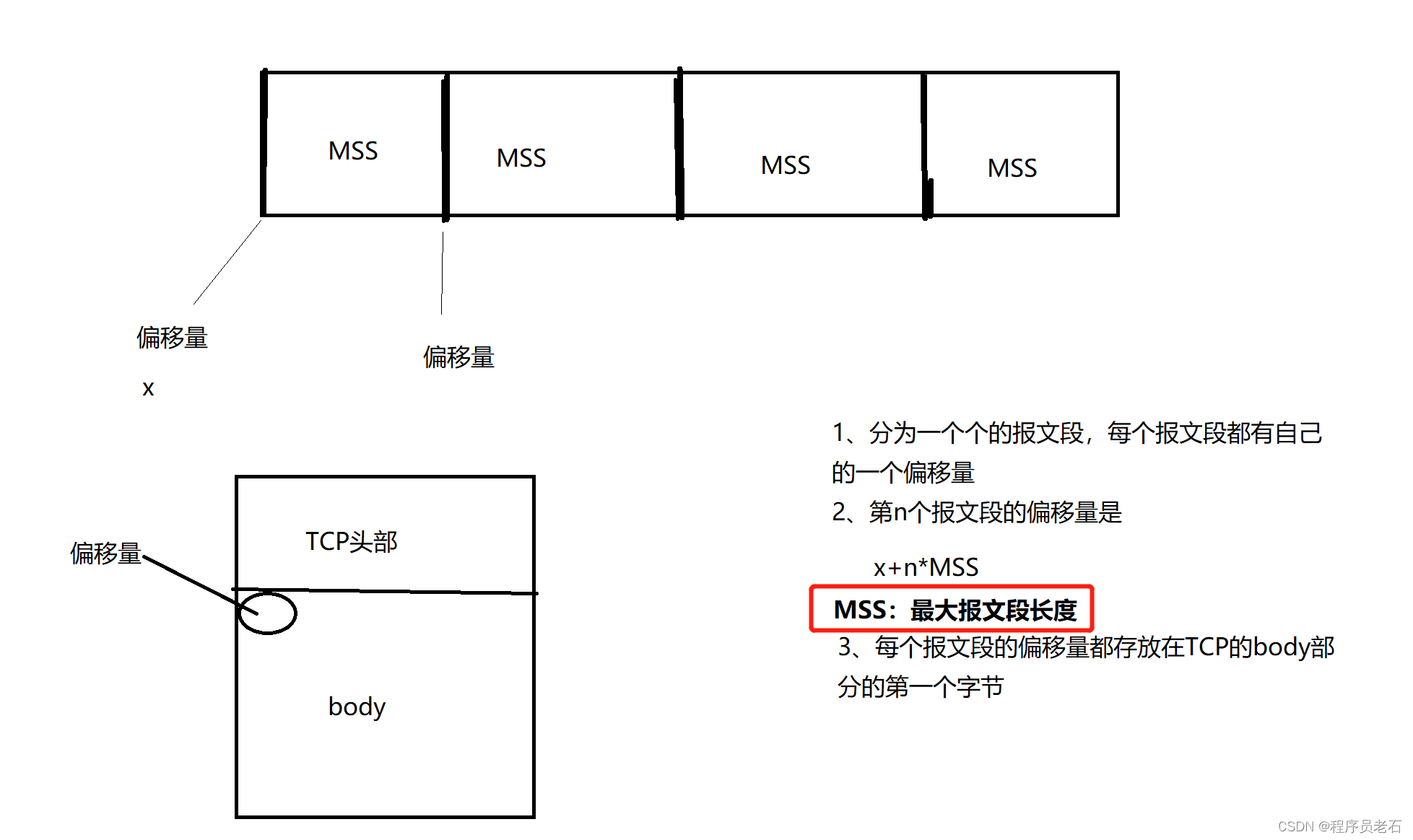
5、MSS:最大报文段长度
MSS是每一个TCP报文段中的数据字段的最大长度。
数据字段加上TCP首部才等于整个的TCP的报文段。所有MSS并不是整个TCP报文段的最大长度。而是TCP报文段长度减去TCP首部长度。
MSS应尽可能大些,只要在IP层传输时不需要再分片就行。对网络的使用率就高一些。如果TCP报文段十分长,那么在IP层传输时就有可能要分解成多个短数据报片。在终点要把收到的各个短数据报片转配成原来的TCP报文段。当传输出错时还要进行重传。这些也都会使开销增大。
若主机没有填写这一项,则MSS的默认值是536字节长。因此,所有在互联网上的主机都应能接受的报文段长度是536+20(固定首部长度) = 556字节。
6、往返时间RTT
第一,用来计算往返时间RTT。发送方在发送报文段时把当前时钟的时间值放入时间戳字段,接收不方在确认该报文段时把时间戳字段值复制到时间戳回送回答字段。因此,发送方在收到确认服文后,可以准确地计算出 RTT来。
第二,用于处理TCP序号超过232的情况,这又称为防止序号绕回PAWS S(Protect Against Wrapped Sequence numbers)。我们知道,TCP 报文段的序号只有32位,而每增加2的32次方个序号就会重复使用原来用过的序号。当使用高速网络时,在一次 TCP连接的数据传送。为了使接收方能够把新的报文段和迟到很久的报文段区分开,可以再报文段中加上这种时间戳。
3、超时重传时间的选择
1、TCP的发送方在规定的时间内没有收到确认就要重传已发送的报文段。

2、TCP采用了一种自适应算法
RTT:报文段的往返时间

3、超时重传时间RTO

4、TCP:可靠数据传输
1、TCP在IP不可靠服务的基础上建立了rdt
1)管道化的报文段
2)累计确认
3)单个重传定时器
定时器只和最老的报文段相关联
4)是否可以接收乱序的,没有规范
接收方收到一个乱序的报文段怎么处理,接收方可以进行缓存也可以抛弃掉
2、TCP发送方事件
从应用层接收数据:
1)用nextseq创建报文段
2)序号nextseq为报文段首字节的字节流编号
3)如果还没有运行,启动定时器
* 定时器与最早未确认的报文段关联
* 过期间隔:TimeOutInterval
4)超时
* 重传后延最老的报文段
* 重启定时器
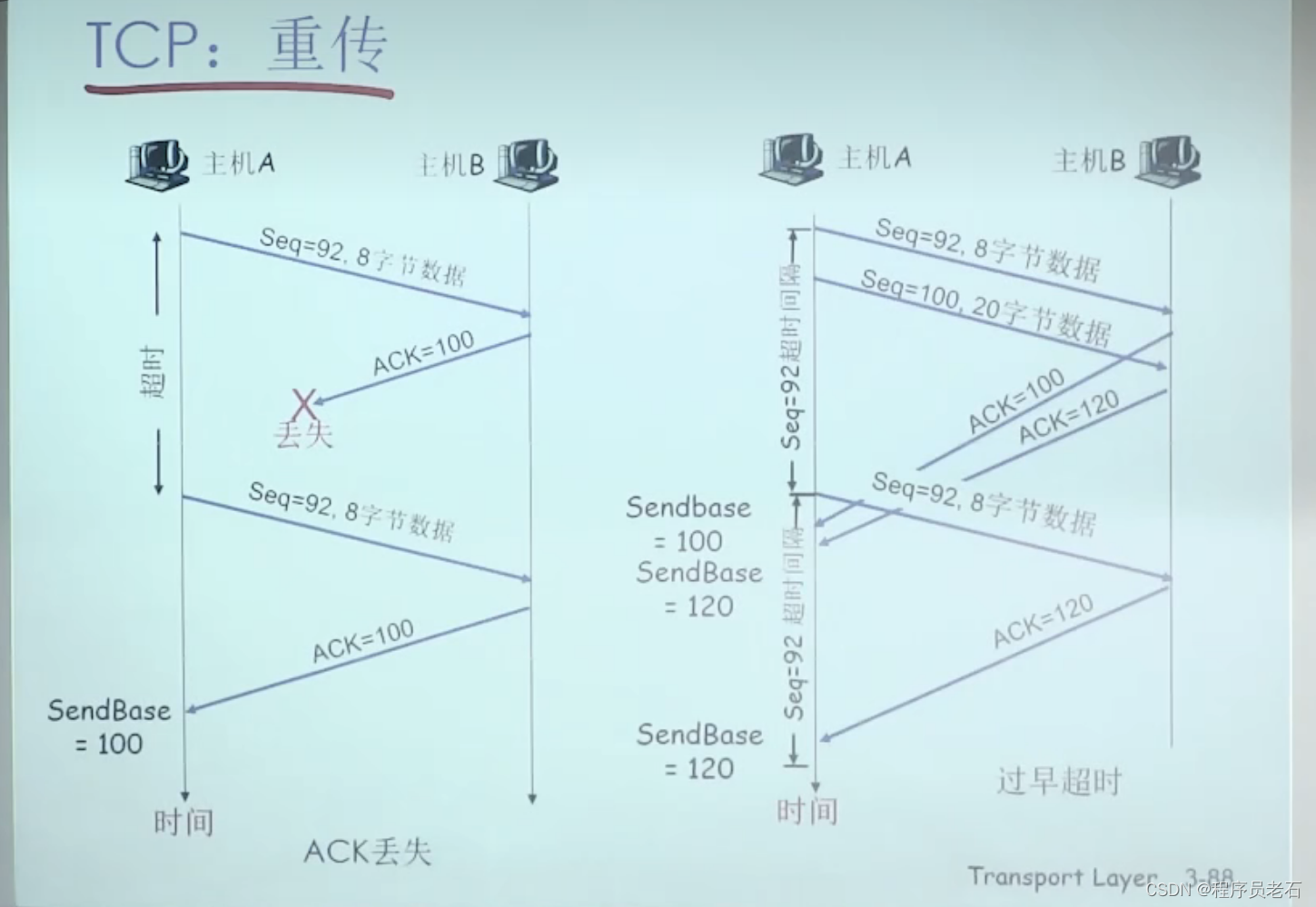
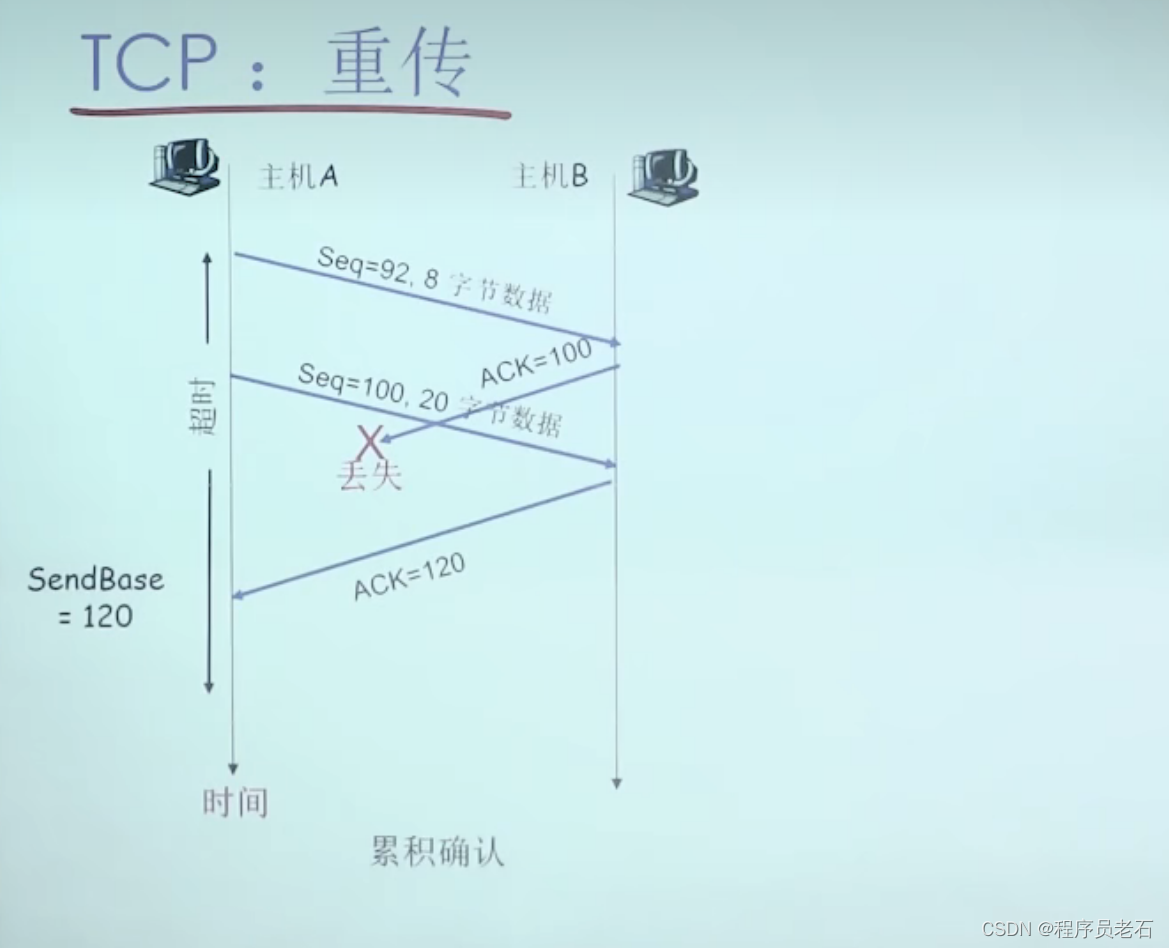

TCP快速重传是在超时重传时间到来之前,发送方连续收到3个ACK,发送方快速重传。
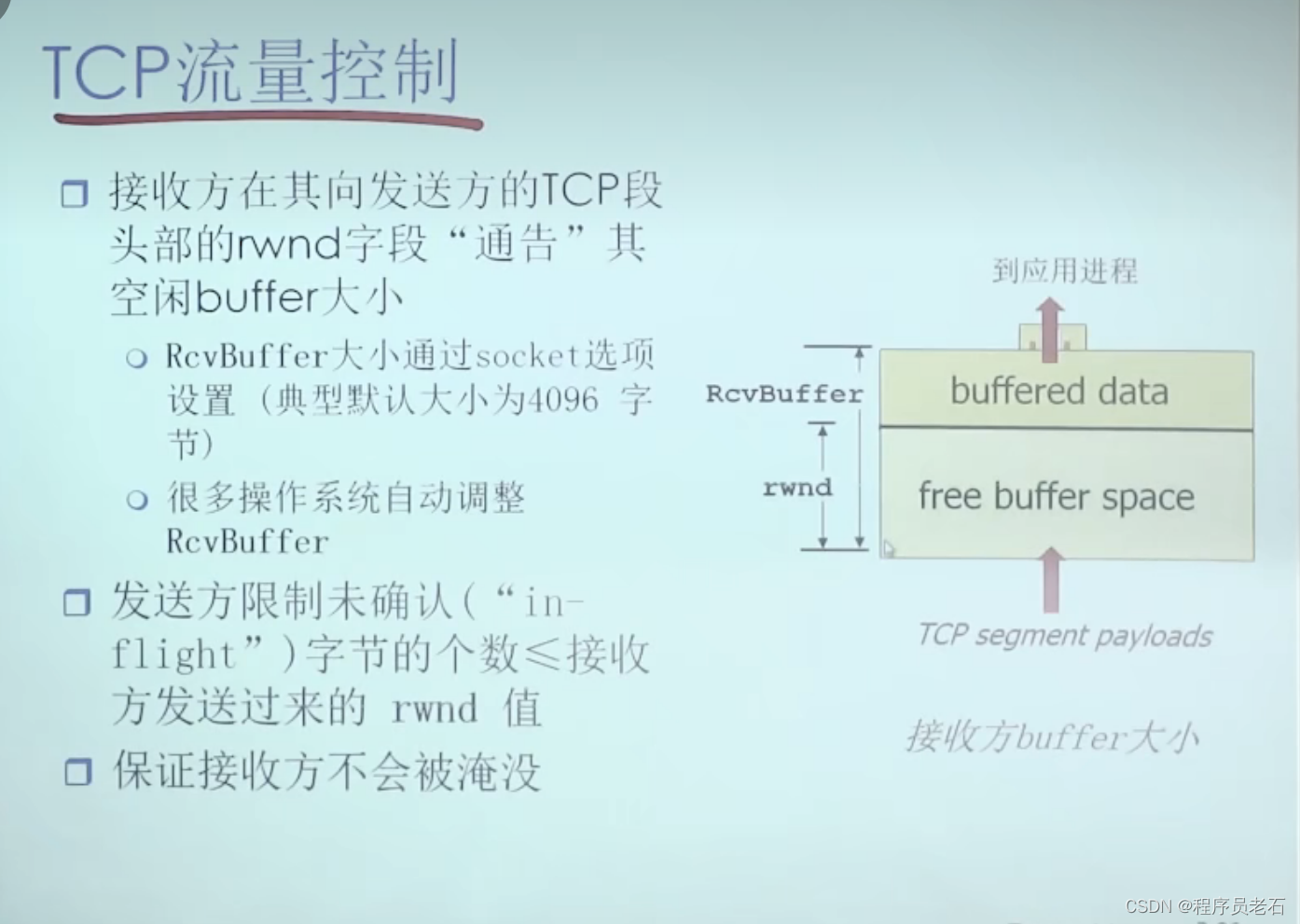
5、TCP:流量控制
1、接收方控制发送方,不让发送方发送太多,太快以至于让接收方的缓冲区溢出
6、TCP连接管理

7、拥塞控制原理
拥塞:
1、非正式的定义:“太多的数据需要网络传输,超过了网络的处理能力”
2、与流量控制不同
3、拥塞的表现
1)分组丢失(路由器缓冲区溢出)
2)分组经历比较长的延迟(在路由器的队列中排队)
4、网络中前10位问题
7.1 导致网络拥塞的原因
1、当某个节点缓存的容量太小时,到达该节点的分组因无存储空间暂存而不得不被丢弃。
2、简单的对节点缓存扩容也解决不了网络拥塞的问题,原因是由于链路的容量和处理机的速度并没有提高,在队列中的绝大多数分组的排队等待时间会大大增加,结果上层软件只好把他们进行重传(超过重传时间)。
3、如果一个路由器没有足够的缓存空间,它就会丢弃一些新到的分组。但是当分组被丢弃,发送这一分组的源点就会重传这一分组,甚至可能还要重传多次,这样会引起更多的分组流入网络和被网络中的路由器丢弃。反而会加剧网络的拥塞。

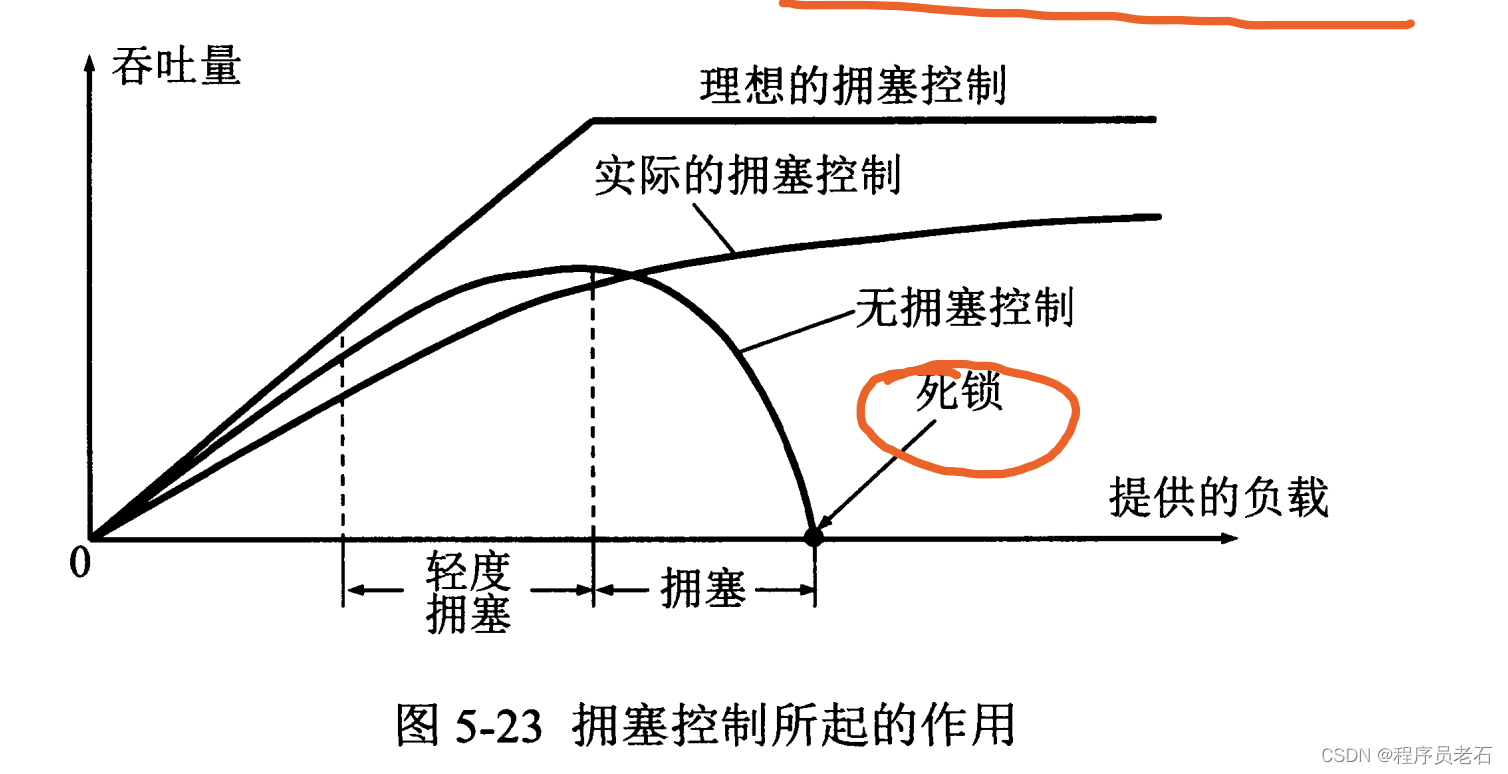
1、理想的拥塞控制作用下,网络的吞吐量仍然维持在其所能达到的最大值。
2、实际的拥塞控制情况下,随着提供的负载的增大,网络吞吐量的增长速率逐渐减少。当提供的负载达到某一数值时,网络的吞吐量反而会随着提供的负载的增大而降低。当提供的负载继续增大到某一数值时,网络的吞吐量就下降到零,网络已无法工作,这就是所谓的死锁。
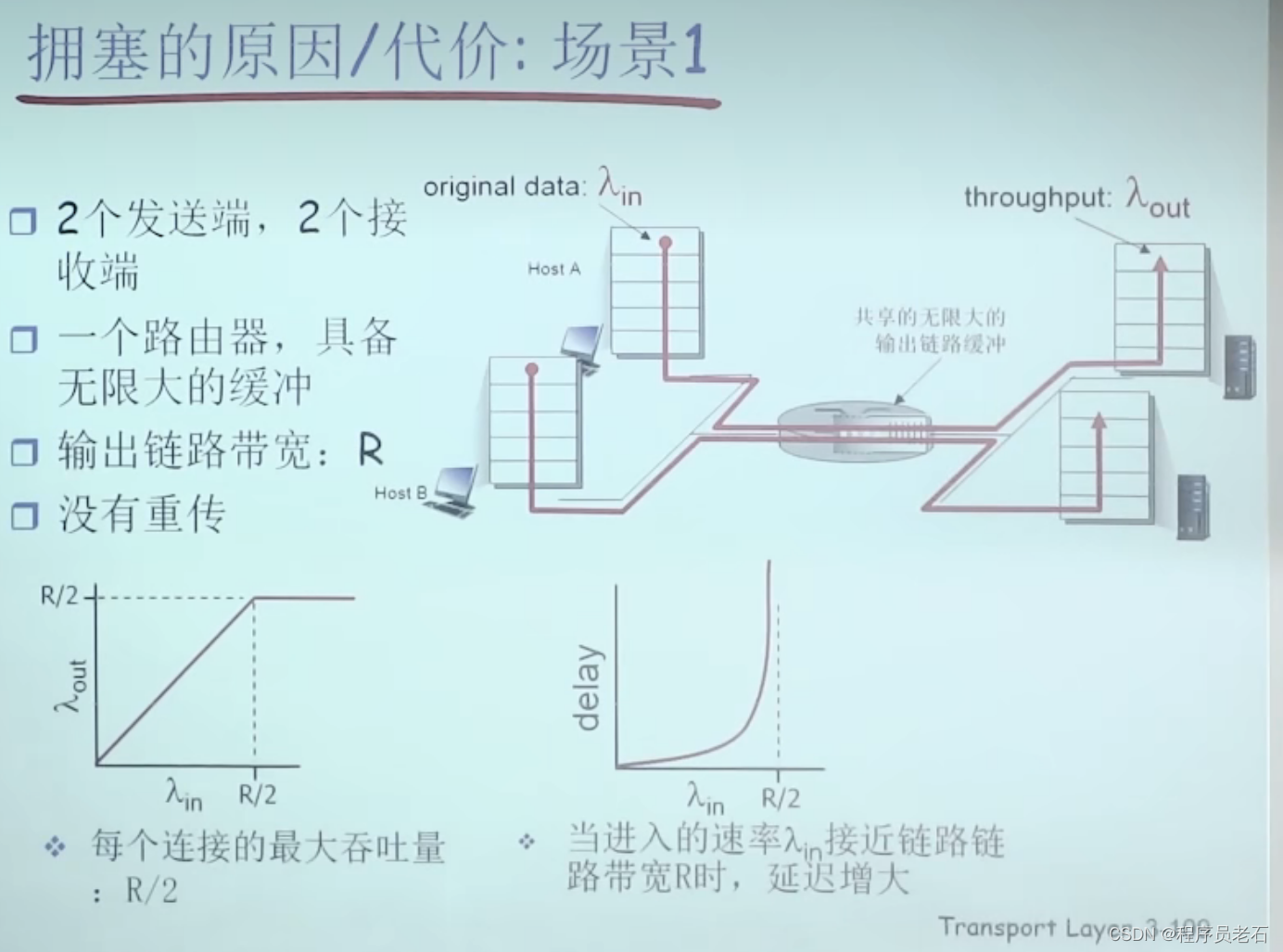
网络拥塞的原因:
1、为了达到有效的输出,需要输入更多的数据。在网络拥塞的时候需要重传很多没有不必要的数据,从而加速了网络拥塞的程度,使得网络变得更拥塞。

8、TCP拥塞控制




8.1 TCP的拥塞控制方法
1、慢开始算法:当主机开始发送数据时,由于并不清楚网络的负荷情况,所以如果立即把大量数据字节注入到网络,那么就有可能引起网络发生拥塞。经验证明,较好的方法是先探测一下,及由小到大逐渐增大发送窗口,也就是说,由小到大逐渐增大拥塞窗口数值。
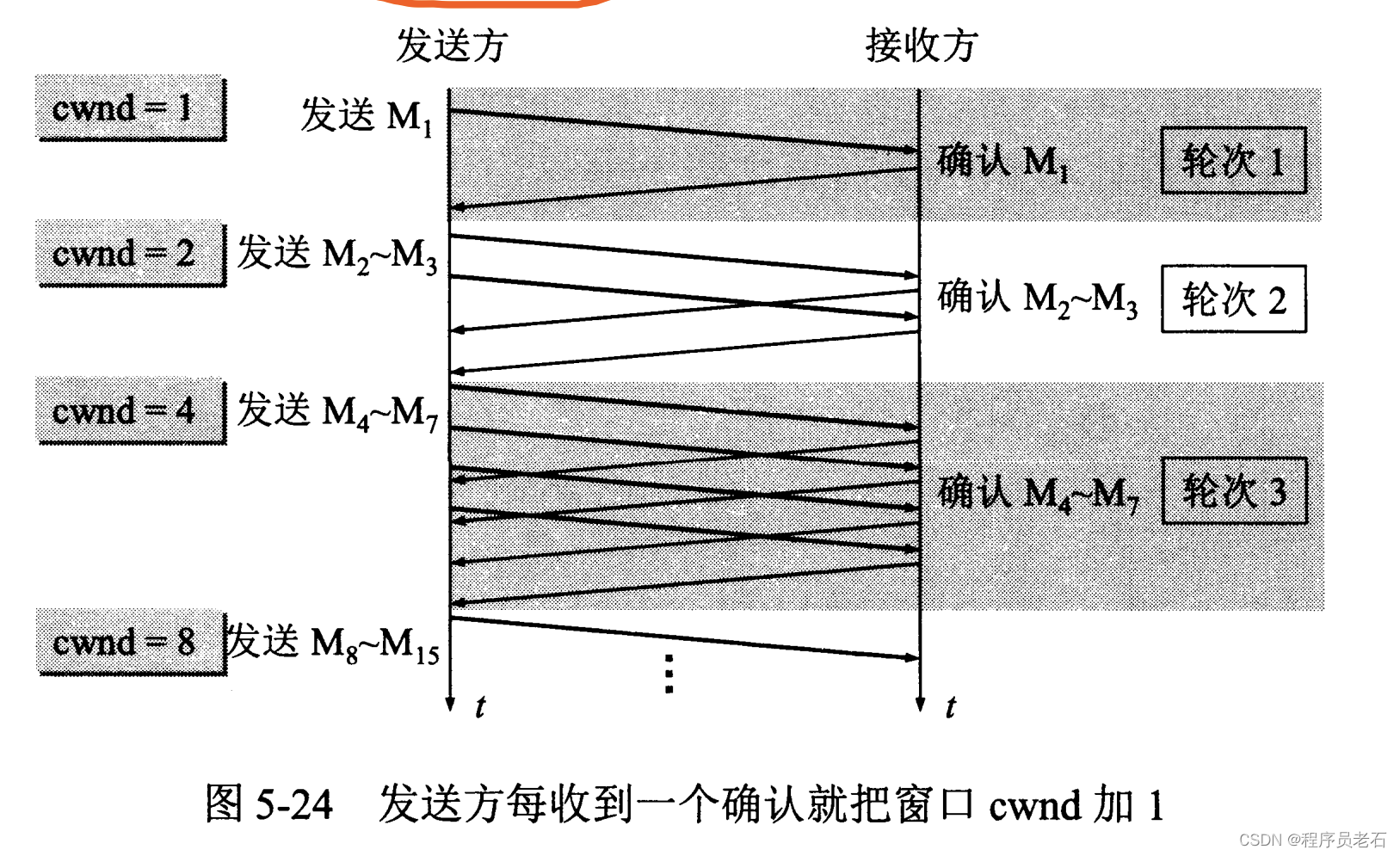
拥塞窗口cwnd是按倍数增加的。
2、拥塞避免算法:是让拥塞窗口cwnd缓慢地增大,即每经过一个往返时间RTT就把发送方的拥塞窗口cwnd加1,而不是像慢开始阶段那样加倍增长。因此在拥塞避免阶段就有“加法增大”的特点。这表明在拥塞避免阶段,拥塞窗帘cwnd按线性规律缓慢增长,比慢开始算法的拥塞窗口增大速率缓慢得多。
3、快重传
