Ŀ¼
ǰ��
�����Э����Ҫ������,�ֱ���UDPЭ���TCPЭ�顣
һ���˿ں�
1������
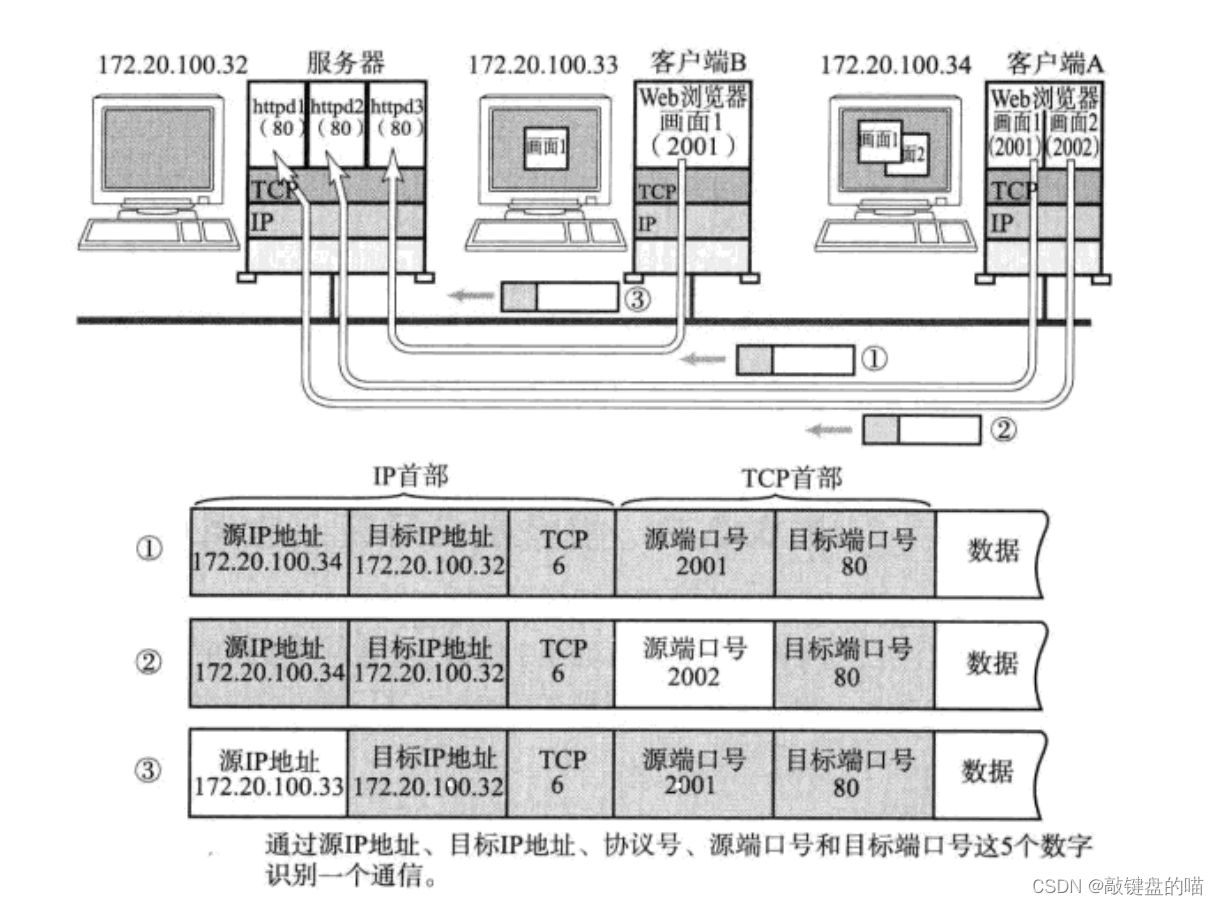
�˿ں�(Port)��ʶ��һ�������Ͻ���ͨ�ŵIJ�ͬ�Ľ��̡���TCP/IPЭ����, �� "ԴIP", "Դ�˿ں�", "Ŀ��IP", "Ŀ�Ķ˿ں�", "Э���" ����һ����Ԫ������ʶһ��ͨ�š�
2���������
netstat:
netstat��һ�������鿴����״̬����Ҫ���ߡ�
�:netstat? ?[ѡ��]
����:�鿴����״̬
����ѡ��:
- n �ܾ���ʾ����,����ʾ���ֵ�ȫ��ת��������
- l ���г����� Listen (����) �ķ���״̬
- p ��ʾ����������ӵij�����
- t (tcp)����ʾtcp���ѡ��
- u (udp)����ʾudp���ѡ��
- a (all)��ʾ����ѡ��,Ĭ�ϲ���ʾLISTEN���
pidof:?
�ڲ鿴�������Ľ���idʱ�dz����㡣
�:pidof [������]
����:ͨ��������, �鿴����id
����UDP��?
1��UDP���ݱ���ʽ
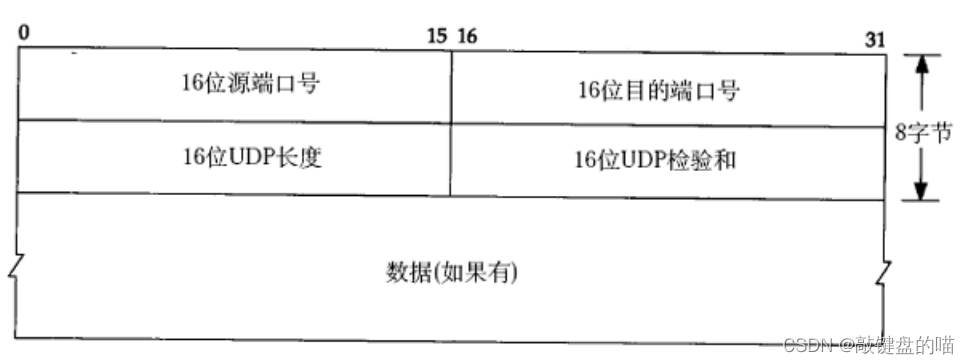
- 16λUDP����, ��ʾ�������ݱ�(UDP��ͷ+UDP����)����ȡ�UDP��ͷ�Ĵ�С�ǹ̶���,����ͨ��UDP���ȾͿ��Ե�֪��ͷ�����ݵĴ�С,�Ӷ�ʵ�ֽ����
- ���У��ͳ���, �ͻ�ֱ�Ӷ�����
- �����Э����Ը��ݱ�ͷ�е�16λ�˿ں��ҵ���Ӧ����,�����ݽ����ϲ�Ӧ��,�����Ӧ�ò�Ľ�����
����ע�, UDPЭ���ײ�����һ��16λ����ȡ�Ҳ����˵һ��UDP�ܴ�������������64K(����UDP�ײ�)��Ȼ��64K�ڵ���Ļ�����������, ��һ���dz�С�����֡����������Ҫ��������ݳ���64K, ����Ҫ��Ӧ�ò��ֶ��ķְ�, ��η���, ���ڽ��ն��ֶ�ƴװ��
2��UDP���ص�
- ������: ֪���Զ˵�IP�Ͷ˿ںž�ֱ�ӽ��д���, ����Ҫ�������ӡ�
- ���ɿ�: û��ȷ�ϻ���, û���ش�����; �����Ϊ������ϸö��������Է�, UDPЭ���Ҳ�����Ӧ�ò㷵���κδ�����Ϣ��
- �������ݱ�,���ܹ����Ŀ��ƶ�д���ݵĴ������������������ݱ�����˼��UDP���Ӧ�ò��������ԭ�ⲻ���Ĵ����ȥ,�Ȳ�����Ҳ����ϲ���������Ͷ˵���һ��sendto, ����100���ֽ�, ��ô���ն�Ҳ������ö�Ӧ��һ��recvfrom, ����100���ֽ�; ������ѭ������10��recvfrom, ÿ�ν���10���ֽڡ��ͺñ�д��һ��,��һ��Է��͵���һ��,�����հ�⡣
3��UDP�Ļ�����?
- UDPû�����������ϵ� ���ͻ�����.������sendto��ֱ�ӽ����ں�, ���ں˽����ݴ��������Э����к����Ĵ��䶯����
- UDP���н��ջ�����������������ջ��������ܱ�֤�յ���UDP����˳��ͷ���UDP����˳��һ��; �������������, �ٵ����UDP���ݾͻᱻ������
UDP��socket���ܶ�, Ҳ��д, ����������ȫ˫����ȫ˫������˼��recvfrom��sendto����ͬʱ�����á�
����TCP��
1��TCP���ݱ���ʽ
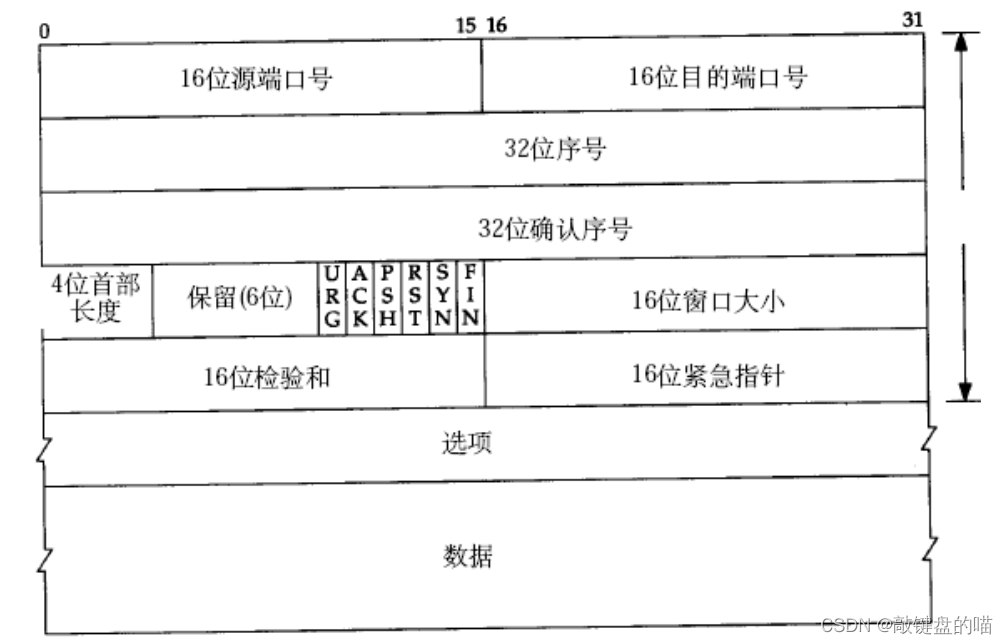
��������;:?
- Դ/Ŀ�Ķ˿ں�: ��ʾ�����Ǵ��ĸ�������, ���ĸ�����ȥ��
- 4λTCP��ͷ����: ��ʾ��TCPͷ���ж��ٸ�4�ֽ�,�����ײ�����Ϊ0101,��ô��ͷ���Ⱦ���4*5=20��ָ����ͷ��С����ܽ��н����
- 16λ���ڴ�С:��Ӧ��ʱ�����Լ��Ľ��ջ�������ʣ��ռ䡣
- 16λУ���:��Ŀ����Ϊ�˷���TCP�ײ��������ڷ��Ͷ˵����ն�֮���Ƿ����Ķ���������շ���У����в��,��TCP�λᱻֱ�Ӷ�����
���ಿ�ֺ�����ϸ���ܡ�
2��ȷ��Ӧ��(ACK)����
TCP�ǿɿ���,���Է�����һ������ǰ����ȷ�϶Է��Ѿ��յ�֮ǰ�����ݡ�����ÿ���ٷ������ݺ�,����Ҫ�Է���������Ӧ��,�������Ѿ��յ����ݡ�

����A�������ݸ�B֮��, ������Ϊ����ӵ�µ�ԭ��, ��������������B���������A��һ���ض�ʱ������û���յ�B������ȷ��Ӧ��, �ͻ�����ط�����Ȼ��������Ӧ��Ҳ���ܶ���,�������¼���B�Ѿ��յ����ݵ�A��֪��,���ɻ��ط�����,Ҫ�ٷ�֮��ȷ��B�յ�����һ�����ݡ��ظ�������OS�����32λ��Ž���ȥ�ز�����
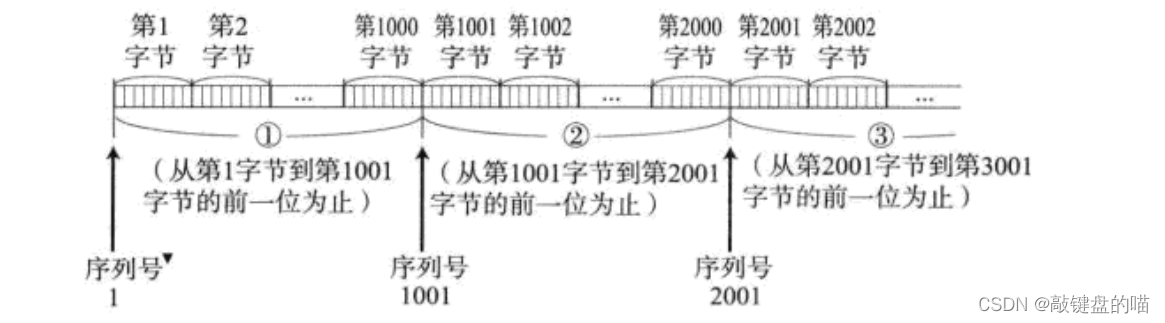
32λ��ź�32λȷ�����:
- ��Ϊ����·��������,��ʱ���ȷ��͵����ݷ������,����Ӧ��˳����ҡ�Ϊ�˶Է������ܹ�ȷ�����Ӧ���Ӧ����Ϣ,ÿ����Ϣ�����һ�����,Ҳ�������ݱ��е�32λ����,�Է�������������кŶ����ݽ�������
- �Է�������Ӧ���ʱ��Ҳ�ᷢ��һ�����,����32λȷ������С�ͬһ�����ݵ�Ӧ�����Ҫ�ȷ�����Ŵ�1��Ҳ����A��B���͵ı������Ϊ3,��B��A���͵ı�����Ӧ����ž�Ӧ��Ϊ4,����A 4֮ǰ�������Ѿ�ȫ���յ���,�´����4��ʼ���͡�
- B��A���͵ı����г�����Ӧ���������Ȼ����������,Ҳ�����з������,Ҳ����˵ȷ��Ӧ���ͬʱҲ���Ը��Է���������,ͬ���Է�Ҳ�����,���ֻ��ƽ����Ӵ�Ӧ����������ʵ����˫��ͨ�š�tcpҲ��һ��ȫ˫��ͨ��Э�顣
tcp�������ֽ�����,TCP��ÿ���ֽڵ����ݶ������˱��,��Ϊ���кš����ǿ����������һ���������ֽ�Ϊ��λ���ԵĴ洢�˻�����������,ÿ���ֽڶ�Ӧһ���±ꡣÿ�������ڷ���ʱ��Я��һ������,������ĵ����Ϊ��һ�����ݶ�Ӧ������±ꡣ������һ������ʱ����ͨ���±�������ʼλ�á�
3��������
TCPЭ�����Դ����ͺͽ��ջ������ġ��û����ڽ���write/send����ʱ,�����ǰ����ݷ���������,���ǿ�����TCPЭ��Ļ������С��û����������ʱͬ��,Ҳ��ֱ�Ӵ�TCPЭ��Ļ����������ٶȡ�
������������:
- ���Ч�ʡ��û�ֻҪ������д��TCPЭ�黺�����м���,���ع��ĶԷ�������û�յ�,֮�������ȫ����TCPЭ�鴦��,�û�����Լ���ȥ���Լ������顣
- ʵ��Ӧ�ò��TCP��Ľ��TCP�Dz���ϵͳ���Э��,ֻ��OS��TCP֪���Է�������״̬,����ֻ��TCP�ܾ���������η�,������,ʲôʱ��ϸ�����⡣����TCPҲ�����������Э��,�û���ֻҪ���İ����ݽ���TCP����,��TCP������,ʵ�����û����TCP��Ľ��
4��TCP���ĵ�6λ��־λ
���κ�һ��ʱ��,�������������յ��ɰ�tcp��ǧ������,ÿ�����ĵ�����Ҫʵ�ֵĹ��ܶ�����ͬ�����Է�����Ҫ����TCP�ı�־λ�����ǽ������֡�
- URG: ����ָ���Ƿ���Ч������TCP����������ŵ�,����һ���ǰ�����д��������ij��������Я���˽�����Ϣ������URG��ʶ,�ᱻ���ȴ�����TCP����еı���ָ�����ָ��������ݵ�,�����������ռһ���ֽ�,������ƻ�TCP�������ԡ�
- ACK: ȷ����š�
- PSH: TCP������������ʱ��,���Ͷ˻ᷢ�ʹ���PSH�ı���,��ʾ���ն�Ӧ�ó������̴�TCP�����������ݶ��ߡ�
- RST: �Է�Ҫ�����½������ӡ����ǰ�Я��RST��ʶ�ij�Ϊ��λ���ĶΡ�
- SYN: ���������ӡ����ǰ�Я��SYN��ʶ�ij�Ϊͬ�����ĶΡ�
- FIN: ֪ͨ�Է�, ����Ҫ�ر��ˡ����dz�Я��FIN��ʶ��Ϊ�������ĶΡ�
5�����ӹ�������
5.1 ״̬�仯

�����״̬ת��:?
- [CLOSED -> LISTEN] �������˵���listen�����LISTEN״̬, �ȴ��ͻ������ӡ�
- [LISTEN -> SYN_RCVD] һ����������������(ͬ�����Ķ�), �ͽ������ӷ����ں˵ȴ�������, ����ͻ��˷���SYNȷ�ϱ��ġ�
- [SYN_RCVD -> ESTABLISHED] �����һ���յ��ͻ��˵�ȷ�ϱ���, �ͽ���ESTABLISHED״̬, ���Խ��ж�д�����ˡ�
- [ESTABLISHED -> CLOSE_WAIT] ���ͻ��������ر�����(����close), ���������յ��������Ķ�, ����������ȷ�ϱ��Ķβ�����CLOSE_WAIT��
- [CLOSE_WAIT -> LAST_ACK] ����CLOSE_WAIT��˵�����������ر�����(��Ҫ������֮ǰ������); ����������������close�ر�����ʱ, ����ͻ��˷���FIN, ��ʱ����������LAST_ACK״̬, �ȴ����һ��ACK����(���ACK�ǿͻ���ȷ���յ���FIN)��
- [LAST_ACK -> CLOSED] �������յ��˶�FIN��ACK, ���ر����ӡ�
�ͻ���״̬ת��:?
- [CLOSED -> SYN_SENT] �ͻ��˵���connect, ����ͬ�����ĶΡ�
- [SYN_SENT -> ESTABLISHED] connect���óɹ�, �����ESTABLISHED״̬, ��ʼ��д���ݡ�
- [ESTABLISHED -> FIN_WAIT_1] �ͻ�����������closeʱ, ����������ͽ������Ķ�, ͬʱ����FIN_WAIT_1��
- [FIN_WAIT_1 -> FIN_WAIT_2] �ͻ����յ��������Խ������Ķε�ȷ��, �����FIN_WAIT_2, ��ʼ�ȴ��������Ľ������ĶΡ�
- [FIN_WAIT_2 -> TIME_WAIT] �ͻ����յ������������Ľ������Ķ�, ����TIME_WAIT, ������LAST_ACK��
- [TIME_WAIT -> CLOSED] �ͻ���Ҫ�ȴ�һ��2MSL(Max Segment Life, �����������ʱ��)��ʱ��, �Ż����CLOSED״̬��
TIME_WAIT״̬:
������һ������,��������server,Ȼ������client,Ȼ����Ctrl-Cʹserver��ֹ,��ʱ����������server, �����:

?������Ϊserver��Ӧ����Ȼ��ֹ��,����tcp��Э�鲢û����ȫ�Ͽ�,��˲����ٴμ���ͬ����server�˿ڡ�
- TCPЭ��涨,�����ر����ӵ�һ��Ҫ����TIME_ WAIT״̬,�ȴ�����MSL(maximum segment lifetime)��ʱ�����ܻص�CLOSED״̬��
- ����ʹ��Ctrl-C��ֹ��server, ����server�������ر����ӵ�һ��, ��TIME_WAIT�ڼ���Ȼ�����ٴμ���ͬ����server�˿ڡ�
- MSL��RFC1122�й涨Ϊ������,���Ǹ�����ϵͳ��ʵ�ֲ�ͬ, ��Centos7��Ĭ�����õ�ֵ��60s��
TIME_WAIT��ʱ��ΪΪʲô��2MSL?
- MSL��TCP���Ĵ������ʱ��,һ�����������MSLʱ��,���ͼ���Ӧ���������Ҫ2MSL,2MSL�Ļ����Ա�֤���������������ڴ���ı��Ķ���ʧ��(��������رպ����������Ļ��п����յ���һ���������ӳٵ�����)��
- ͬʱҲ�DZ�֤�����һ�����ĵĿɿ�����,�������һ��ACK��ʧ, ��ô�����������ط�һ��FIN���˿���Ȼ�ͻ����Ѿ�������,����TCP���ӻ���,��Ȼ�����ط�LAST_ACK��
���TIME_WAIT״̬�����bindʧ�ܵķ���:
��server��TCP����û����ȫ�Ͽ�֮ǰ���������¼���, ijЩ����¿����Dz�������:
- ��������Ҫ�����dz������Ŀͻ��˵�����(ÿ�����ӵ�����ʱ����ܺܶ�, ����ÿ�붼�кܴ������Ŀͻ���������)��
- ����ɷ������������ر�����(����ijЩ�ͻ��˲���Ծ, ����Ҫ��������������������), �ͻ��������TIME_WAIT���ӡ�
- �������ǵ��������ܴ�, �Ϳ��ܵ���TIME_WAIT���������ܶ�, ÿ�����Ӷ���ռ��һ��ͨ����Ԫ��(Դip,Դ�˿�, Ŀ��ip, Ŀ�Ķ˿�, Э��). ���з�������ip�Ͷ˿ں�Э���ǹ̶���.����������Ŀͻ������ӵ�ip�Ͷ˿ںź�TIME_WAITռ�õ������ظ���, �ͻ�������⡣
����취:ʹ��setsockopt()����socket�������� ѡ��SO_REUSEADDRΪ1, ��ʾ���������˿ں���ͬ��IP��ַ��ͬ�Ķ��socket��������

CLOSE_WAIT ״̬:
������������ǵ���close�ر�socket,�Ĵλ���û����ȷ���,����ʹ��������һ�ߵ����ӿ���CLOSE_WAIT״̬,������ȷ�˳���
5.1 ��������
tcpЭ�����������ӵ�,tcp socket��ͨ�ŵ�ʱ��Ҫ�Ƚ���connect�����������ӡ��ڽ������ӵĹ�������Ҫ�����������֡�
�������ֹ���:
- �ͻ�������������ʹ���SYH��ʶ�ı����������ӡ�
- ��������ͻ��˷��ʹ���SYH��ACK�ı��ı�ʾ�յ���Ϣ��ͬ�����ӡ�
- �ͻ�������������ʹ���ACK�ı��ı�ʾ�յ���
�ڿͻ��˿���,�ڵ����������������ACK�����Ӿ��Ѿ���������ˡ����ڷ��������������յ�ACK�����������ɡ����ǵ��������͵Ĵ���ACK�ı��Ŀ�������;Ū��,��ʱ��ͻ���������ʧ�ܡ����û���ȷ��Ϊ���ӳɹ���,���ǿ��ܾͻῪʼ���������������,�������������ڽ�������ǰ��û�н���������,�ͻ���˫�������쳣��,�Ӷ���ͻ��˷��ʹ���RST��ʶ�ı���,Ҫ��Է����½������ӡ�
����˵��һ��ʲô������:�ڷ������д��ڴ���������,��Щ������Ҫ��������,�����ı��ʾ�������������֯������������������ɺ�,˫����OS��Ϊ������Ӵ�����Ӧ�����ݽṹ���������Ϣ������ά��,����Ȼ,ά���������гɱ��ġ�
Ϊʲô��������?
������Ϊ���ж������������Ƿ�����,��������֤ȫ˫��˫�������շ�����С������A��B��������,��һ������A��B����SYN,�ڶ�������A�յ���B������ȷ����Ӧ,��ʱ�����ж�A�����շ����ݵ�����,����A�յ���B����������֤�����������ݵ�����,���B����A��Ӧ֤����A�ɹ���B����������,���з����ݵ�����������ʱֻ���ж�B�������ݵ�����,��ΪB���ж��Ƿ�ɹ�����������,��ҪA��B���з���,Ҳ���ǵ���������,B����֪���Լ��ɹ����������ݡ�
���������ڰ�ȫ����Ҳ��һ��������:֮ǰ�ᵽ����������Ҫά����,�����һ�����־������ӳɹ�,��ô��Ҫ����ij��������ֻ��Ҫ�������ʹ�����SYN����������ĵ����dz���Ŀռ�,�Ӷ�ʹ��������������ֺ�һ������һ��,��Ϊ���еڶ�������ʱ���ж϶Է���û���յ�,���Ա����ϻ�����Ҫ�յ�SYN�ͽ�������ά����������������ֵĻ�,��������Ҫ���ij����������������,��Ҫ�ڷ���SYN��ѷ������������Ϣά������,��ΪҪ�ȴ��������������ֺ��ٶԷ���������ACK��������̶Թ�������˵�ɱ�Ҳ�Ƿdz����,ͬ����Ҫά���ܶ���Դ,һ���̶��ϱ����˹�������һ̨���Ծ������ɵĸ��ij����������
5.2 �Ĵλ���
һ�����,���������ӵ��ǿͻ���,����ֹ������˫�������顣����ֹ����ʱҪ�����Ĵλ��֡�
�Ĵλ��ֹ���:
- ��������ͻ���(��ȻҲ���Է�����)����FIN��ʾҪ��ֹ���ӡ�
- �ͻ��������������ACK��ʾ�յ���
- �ͻ����������������FIN��ʾҪ��ֹ���ӡ�
- �ͻ����������������ACK��ʾ�յ���
6����ʱ�ش�����
ǰ���ᵽ��,������A���͵������ղ�������B��Ӧ��ʱ�ͻ�����ش���������������, �ҵ�һ����С��ʱ��, ��֤ "ȷ��Ӧ��һ���������ʱ���ڷ���"���������ʱ��ij���, �������绷���IJ�ͬ, ���в����:
- �����ʱʱ�����̫��, ��Ӱ��������ش�Ч�ʡ�
- �����ʱʱ�����̫��, �п��ܻ�Ƶ�������ظ��İ���
TCPΪ�˱�֤�������κλ����¶��ܱȽϸ����ܵ�ͨ��, ��˻ᶯ̬����������ʱʱ��:
- Linux��(BSD Unix��WindowsҲ�����), ��ʱ��500msΪһ����λ���п���, ÿ���ж���ʱ�ط��ij�ʱʱ�䶼��500ms����������
- ����ط�һ��֮��, ��Ȼ�ò���Ӧ��, �ȴ� 2*500ms ���ٽ����ش�����������,ÿ���ش�����ָ����ʽ���ӡ�
- �ۼƵ�һ�����ش�����, TCP��Ϊ������߶Զ����������쳣, ǿ�ƹر����ӡ�
7����������
�ղ�����������ȷ��Ӧ�����, ��ÿһ�����͵����ݶ�, ��Ҫ��һ��ACKȷ��Ӧ���յ�ACK���ٷ�����һ�����ݶ�,��������һ���Ƚϴ��ȱ��,?�������ܽϲ?����������������ʱ��ϳ���ʱ��Ȼ����һ��һ�յķ�ʽ���ܽϵ�, ��ô����һ�η��Ͷ�������, �Ϳ��Դ����������(��ʵ�ǽ�����εĵȴ�ʱ���ص���һ����)��
 ?�������ڴ�С:�������ڴ�Сָ��������ȴ�ȷ��Ӧ��Ϳ��Լ����������ݵ����ֵ������ͼΪ��,�������ڵĴ�СΪ4000,�ٷ���ǰ�ĸ��ε�����ʱ����ȴ���
?�������ڴ�С:�������ڴ�Сָ��������ȴ�ȷ��Ӧ��Ϳ��Լ����������ݵ����ֵ������ͼΪ��,�������ڵĴ�СΪ4000,�ٷ���ǰ�ĸ��ε�����ʱ����ȴ���
���������Ǵ��ڷ��ͻ������е�,���ͻ������е����ݿ��Էֳ�������,�ֱ����Ѿ����͵�����,���������е�����(Ҳ�������ڷ��ͺ������͵�����),��û�з��͵����ݡ�

?���յ�ȷ��Ӧ���,�������ڻ�����������ƶ�����Ҫ���ݾ����������:
���һ: ���ݰ��Ѿ��ִ�, ACK�����ˡ�
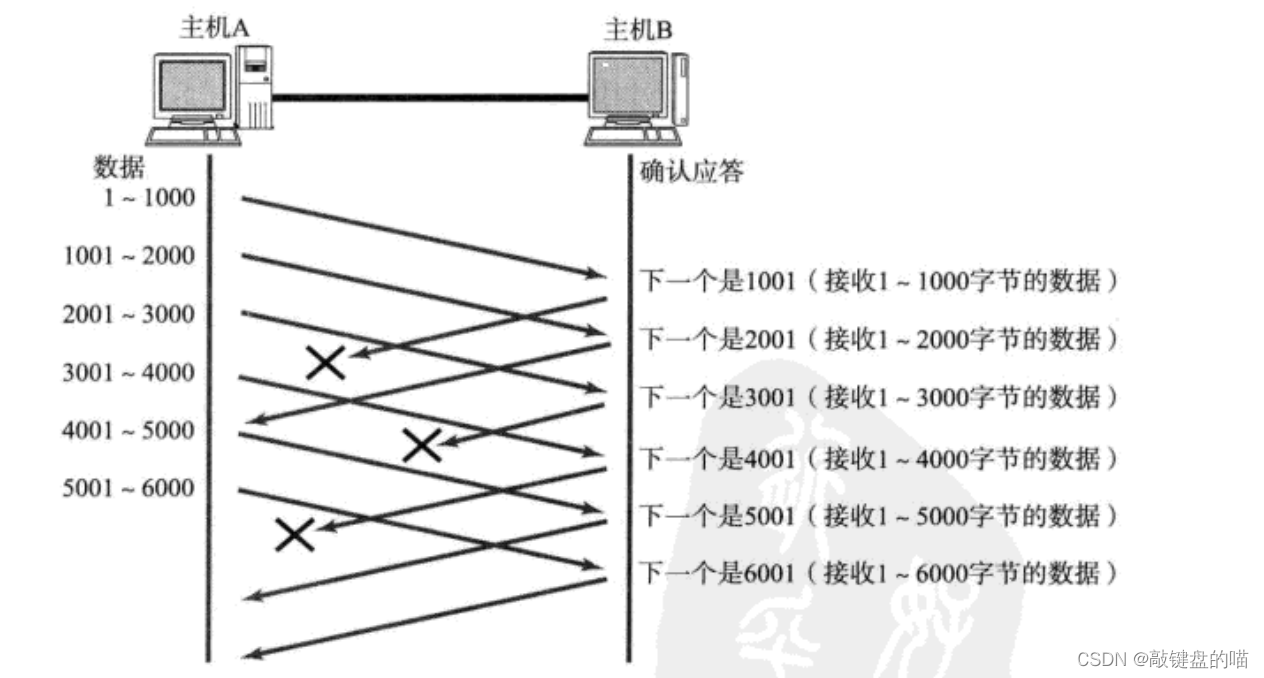
����ͼ��ʾ,�м��ACK����,����������κ�Ӱ�졣��ΪTCP�����Ե��DZ����е�ȷ����Ŵ����������ǰ������ȫ���յ���ͨ��ȷ�����Ϊ6001��Ӧ���ͷ��Ϳ����жϳ�ǰ�淢�͵������Ѿ������յ������Ի���������ʼ��ֱ���ƶ���6001��λ�á����������ĩβ��ACK����,���緢�ͷ������յ�5001��Ӧ��,��6001����,��ô���ͷ���Ҫ�ط�5000��6000�����ݡ�
�����:���ݰ���ֱ�Ӷ���
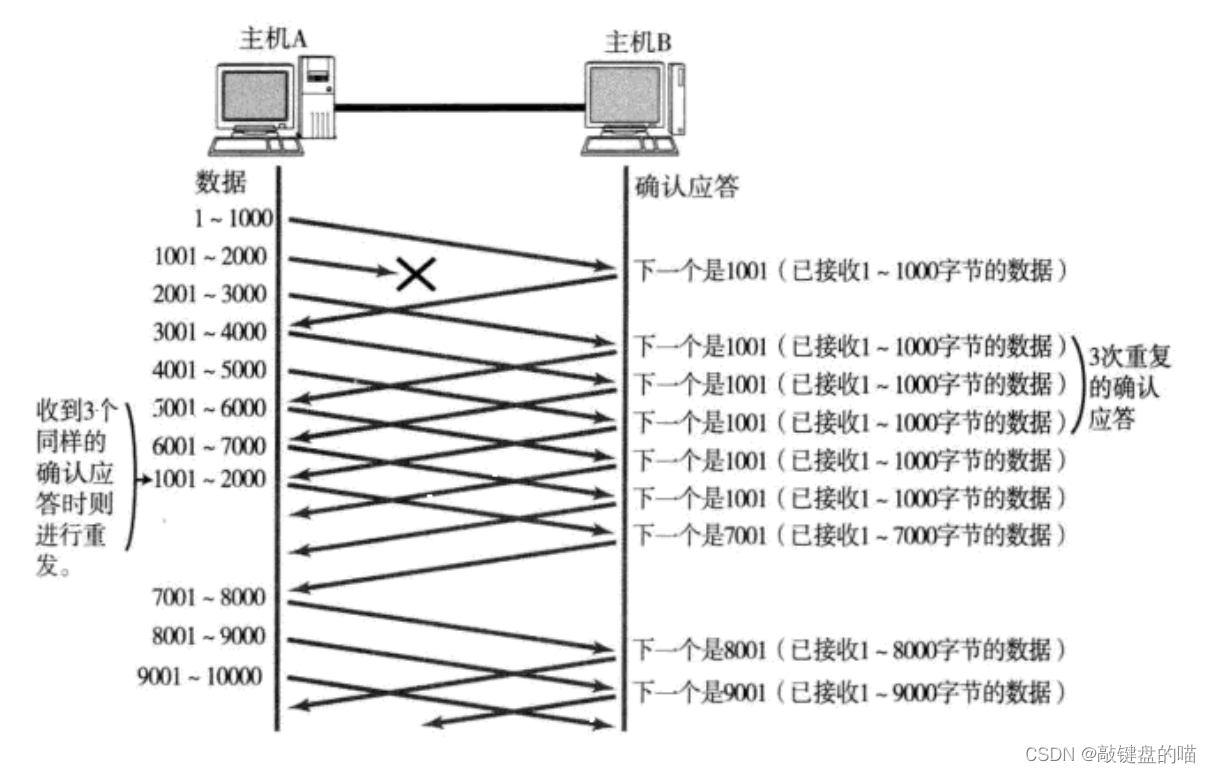
��ijһ�����ݷ������ж�ʧ��,���ն˻��ظ�������ͬ��ACK,�������1000��2000ȱʧ,��ô���շ�֮���յ��κ����ݶ��ᷢ��ȷ�����Ϊ1001��ACK,���ѷ��Ͷ�1001��������ȱʧ���ڷ��Ͷ��յ�������ͬ��ŵ�ȷ��Ӧ��ʱ��Ӵ���Ŵ��ط���������,һ�����շ��յ�ȱʧ���ݺ�Ӧ���ȷ����žͻ����ϻָ�����,���ͷ��յ���Ϳ�ʼ����������ź���������ݡ�?
�����������п��Կ���,�������ڵ����һ��������յ���ȷ����Ŷ��ƶ�,��֤�������ݶԷ�ȫ���յ������Ҳ���ƶ����Ǹ���Ӧ���ĵĴ��ڴ�СҲ���ǽ��ջ������Ĵ�С���ı�,ȷ�����ᷢ�ͳ����Է�������ʣ��ռ�����ݡ�����˵�������ڲ���λ�û�ı�,��СҲ��ı䡣�����������ڼ�,���շ���Ӧ������û�����ݵ�,�����Ѿ������˴��ڴ�С,���ͷ��ͻ���ݶԷ����ڴ�С���û������ڳ�ʼֵ��?
���ֻ��Ʊ���Ϊ "�����ط�����"(Ҳ�� "���ش�")�����ش����ƺͳ�ʱ�ش�������TCP��Эͬ���е�,���ش����Ʊ�֤���ش����ٶ�,����Ϊ�����յ������ظ�Ӧ���Żᴥ��,ijЩ����¿��������������㡣����ʱ�ش�����ȷ���Է�û���յ�������һ�����ش������仰˵��ʱ�ش������������ش����ġ�
8����������
��ǰ����ܴ��ڴ�С��ʱ���ᵽ��,���ն˴������ݵ��ٶ�������,������Ͷ˷���̫��, ���½��ն˵Ļ�����������, ���ʱ��������Ͷ˼�������,�ͻ���ɶ���, �̶������ش��ȵ�һϵ��������Ӧ�����TCP֧�ָ��ݽ��ն˵Ĵ�������, ���������Ͷ˵ķ����ٶȡ�������ƾͽ����������ơ�
- ���ն˽��Լ����Խ��յĻ�������С���� TCP �ײ��е� "���ڴ�С" �ֶ�, ͨ��ACK��֪ͨ���Ͷ�;
- ���ڴ�С�ֶ�Խ��, ˵�������������Խ�ߡ�
- ���ն�һ�������Լ��Ļ�����������, �ͻὫ���ڴ�С���ó�һ����С��ֵ֪ͨ�����Ͷˡ����Ͷ˽��ܵ��������֮��, �ͻ�����Լ��ķ����ٶȡ�
- ������ն˻���������, �ͻὫ������Ϊ0����ʱ���ͷ����ٷ�������, ������Ҫ���ڷ���һ������̽�����ݶ�, ʹ���ն˰Ѵ��ڴ�С���߷��Ͷˡ�
9��ӵ������
TCP���˻������������ɱ��, �ܹ���Ч�ɿ��ķ��ʹ���������,����������Կ��ƵĻ����ݹ���ܿ��ܳ������⡣����������Ҫ���ǵ��ǶԷ������Ľ�������������֮��,����ij�����Ҳ�����ġ���Ϊ�����д��ںܶ�������������,�����ǰ����״̬�Ѿ��Ƚ�ӵ��,���´������ݵ��ﻺ����,��ʱ����������ش��������·��ʹ������ݺܿ��ܻ�ʹ����״̬ѩ�ϼ�˪�����,TCP��������������, �ȷ�����������, ̽̽·, ���嵱ǰ������ӵ��״̬, �پ������ն����ٶȴ������ݡ�
�˴�����һ�������Ϊӵ������:
- �������ݿ�ʼ��ʱ��,ӵ������Ϊ1,ÿ���յ�һ��ACKӦ��,ӵ�����ڵ�ֵ���ӱ���
- �������ڵĴ�СΪӵ�����ںͶԷ�Ӧ�����д��ڴ�С����Сֵ��
������������ӵ�����������ٶ�, ��ָ�������. "������" ֻ��ָ��ʹʱ��, ���������ٶȷdz��졣Ϊ�˲���������ô��, ��˲���ʹӵ�����ڵ����ļӱ�.,�˴�����һ����������������ֵ,��ӵ�����ڳ��������ֵ��ʱ��, ���ٰ���ָ����ʽ����, ���ǰ������Է�ʽ����������������ӵ��ʱ,���細�ڵ�ֵ�ήΪԭ����һ��,

?�ڷ�������ӵ����,ssthresh��ֵ��Ϊӵ�����ڵ�һ��,ӵ���������´�1��ʼ�����������Ķ���, ���ǽ����Ǵ�����ʱ�ش�; �����Ķ���, ���Ǿ���Ϊ����ӵ������TCPͨ�ſ�ʼ��, ������������������; �������緢��ӵ��, �������������½���ӵ������, ��������TCPЭ���뾡���ܿ�İ����ݴ�����Է�, ������Ҫ������������̫��ѹ�������з�����
10���ӳ�Ӧ��
����������ݵ��������̷���ACKӦ��, ��ʱ�صĴ��ڿ��ܱȽ�С��
������ն˻�����Ϊ1M. һ���յ���500K������,�������Ӧ��, ���صĴ��ھ���500K����ʵ���Ͽ��ܴ����˴������ٶȺܿ�, 10ms֮�ھͰ�500K���ݴӻ��������ѵ��ˡ������������, ���ն˴�����Զû�дﵽ�Լ��ļ���, ��ʹ�����ٷŴ�һЩ, Ҳ�ܴ���������������ն�����һ����Ӧ��, ����ȴ�200ms��Ӧ��, ��ô���ʱ�صĴ��ڴ�С����1M��
һ��Ҫ�ǵ�, ����Խ��, ������������Խ��, ����Ч�ʾ�Խ�ߡ����ǵ�Ŀ�����ڱ�֤���粻ӵ��������¾�����ߴ���Ч�ʡ�
11��ճ������
����Ҫ��ȷ, ճ�������е� "��" , ��ָ��Ӧ�ò�����ݰ���
- ��TCP��Э��ͷ��, û����ͬUDPһ���� "���ij���" �������ֶ�, ������һ������������ֶΡ�
- վ�ڴ����ĽǶ�, TCP��һ��һ�����Ĺ�����,?��������ź�����ڻ������С�վ��Ӧ�ò�ĽǶ�, ������ֻ��һ���������ֽ����ݡ�
- ��ôӦ�ó�������ôһ�������ֽ�����, �Ͳ�֪�����ĸ����ֿ�ʼ���ĸ�����, ��һ��������Ӧ�ò����ݰ���
��ô��α���ճ��������? ��������һ�仰, ��ȷ������֮��ı߽硣���ڶ����İ�, ��֤ÿ�ζ����̶���С��ȡ����,���ڱ䳤�İ�, �������ڰ��Ͱ�֮��ʹ����ȷ�ķָ���(Ӧ�ò�Э��, �dz���Գ�Լ�������, ֻҪ��֤�ָ����������ij�ͻ����)��
12��TCP�쳣���
������ֹ:�ļ�����������������̵�,������ֹ���ͷ��ļ�������,����FIN,�������ر�û��ʲô����
��������:�ͽ�����ֹ��ͬ,��Ϊ�����ڹػ�ǰ���Ȱ����н��̹ص���
��������/���߶Ͽ�:��������Ϊ���ӻ���,һ����������д������ͻᷢ�������Ѿ�������,�ͻ����reset����ʹû��д�����, TCP�Լ�Ҳ������һ�����ʱ��, �ᶨ��ѯ�ʶԷ��Ƿ��ڡ�����Է�����, Ҳ��������ͷš�
13������TCPӦ�ò��Э��
- HTTP
- HTTPS
- SSH
- Telnet
- FTP
- SMTP
�ġ��ܽ�
1��TCP/UDP�Ա�
����˵��TCP�ǿɿ�����, ��ô�Dz���TCPһ��������UDP��? TCP��UDP֮����ŵ��ȱ��, ���ܼ�, ���ԵĽ��бȽϡ�������, TCP��UDP���dz���Ա�Ĺ���, ʲôʱ����, ������ô��, ����Ҫ���ݾ��������ȥ�ж���
2����UDPʵ�ֿɿ�����(����������)
�ܶ�С����ٵ�һ�μ���������ʱ���е���,ʵ������õĿɿ�����Э���Ѿ�����������ǰ��,�Ǿ���TCPЭ�顣������UDP�Ŀɿ���,ֻҪ�ο�TCP�Ŀɿ��Ի���, ��Ӧ�ò�ʵ�����Ƶ�������:
- �������к�,��֤����˳��
- ����ȷ��Ӧ��,���շ��յ����ݺ�Ҫ�����ͷ�Ӧ��
- ���볬ʱ�ش�,������ͷ��������ݺ�һ��ʱ����û���յ�Ӧ�����ط����ݡ�
- ����
3������ listen �ĵڶ�������
Linux�ں�Э��ջΪһ��tcp���ӹ���ʹ����������:
- �����Ӷ���:�������洦��SYN_SENT��SYN_RECV״̬������
- ȫ���Ӷ���(accept����):�������洦��established״̬,����Ӧ�ò�û�е���acceptȡ�ߵ�����
��д���ֵ�ʱ��,���ǽӴ���һ��listen�ӿ�,���еĵڶ�����������Ϊ����ȫ���Ӷ��еij���,ȫ���Ӷ��еij��ȵ���listen�ڶ���������1���ڵ���cannect�����,���û�б����շ�accept����,��ô������ӻᴦ��EATABLISHED״̬����ȫ���Ӷ����еȴ�������,ȫ����������ӱ������Ѿ���������ˡ����ȫ���Ӷ�������ʱ,��ô֮���յ�������������һ�λ��ֺ���ͣ,����SYN_RECV״̬���ڰ����Ӷ����С�
Ϊʲôȫ����һ��Ҫ������������?�ٸ�����,һ������𱬵ķ���(���纣����)�������ſڷż�������,����ڵ�������ʱ���п��������������������ϵȴ������û���⼸������,�����ڵ���Ա��ʱ���ֱ���ߵ�,����ȵ����п��˳���ʱǡ����û���¿�����,��ô������ͻ������ӿճ���,�����Դ�˷ѡ��������Ӽ�������ʹ��������һЩ�ȴ��Ŀ���,����ʹ��Դ������������������̫��Ҳû������,��Ϊ���ڲ�����ͬʱӿ����������,���������ϵ��˾��㹻�����ȱ��ȫ�ȴ�����Ҳ�����,ȫ���Ӷ��е���������Ӧ�ò����ʱ�������̰ѽ��õ����Ӽӵ�Ӧ�ò���,�ѳ�����Ĺ�����û��̫�������,����ȫ���Ӷ����е�����Ҳ��Ҫ��Դȥά��,������ȹ����Ļ�,��ά�������з������˷ѵ��ܶ���Դ��
�ܽ�
������Ҫ��TCP/IPЭ���еĴ��������˽���,ϣ���ܸ���Ҵ�������������·Զ,���շ���,�����´μ���