Kubernetesѧϰ�ʼ� ��������Ա
1. Kubernetes����
1.1 Ӧ�ò���ʽ�ݱ�
�ڲ���Ӧ�ó���ķ�ʽ��,��Ҫ����������ʱ��:
-
��ͳ����:����������,��ֱ�ӽ�Ӧ�ó���������������
�ŵ�:��,����Ҫ���������IJ���
ȱ��:����ΪӦ�ó�������Դʹ�ñ߽�,���Ѻ����ط��������Դ,���ҳ���֮�����ײ���Ӱ��
-
���⻯����:������һ̨�����������ж�������,ÿ����������Ƕ�����һ������
�ŵ�:�������������Ӱ��,�ṩ��һ���̶ȵİ�ȫ��
ȱ��:�����˲���ϵͳ,�˷��˲�����Դ
-
����������:�����⻯����,���ǹ����˲���ϵͳ
�ŵ�:
���Ա�֤ÿ������ӵ���Լ����ļ�ϵͳ��CPU���ڴ桢���̿ռ��
����Ӧ�ó�������Ҫ����Դ����������װ,���͵ײ�����ܹ�����
��������Ӧ�ó�����Կ��Ʒ����̡���Linux����ϵͳ���а���в���
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-ALN3qZSS-1629018950127)(https://i.loli.net/2021/08/15/Ks4WvRhEdGwyk2x.png)]
����������ʽ�������ܶ�ı���,����Ҳ�����һЩ����,����˵:
- һ����������ͣ����,��ô��������һ��������������ȥ�油ͣ��������
- ����������������ʱ��,��ô������������չ��������
��Щ��������������ͳ��Ϊ������������,Ϊ�˽����Щ������������,�Ͳ�����һЩ�������ŵ�����:
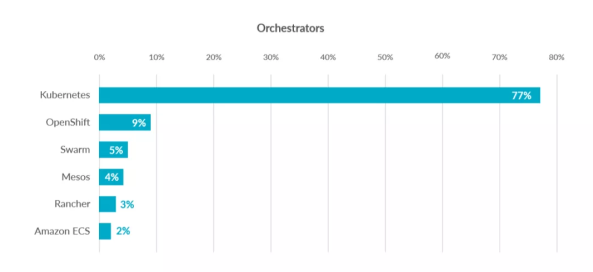
- Swarm:Docker�Լ����������Ź���
- Mesos:Apache��һ����Դͳһ�ܿصĹ���,��Ҫ��Marathon���ʹ��
- Kubernetes:Google��Դ�ĵ��������Ź���
1.2 kubernetes���

kubernetes,��һ��ȫ�µĻ������������ķֲ�ʽ�ܹ����ȷ���,�ǹȸ��ϸ���ʮ�������������----Borgϵͳ��һ����Դ�汾,��2014��9�·�����һ���汾,2015��7�·�����һ����ʽ�汾��
kubernetes�ı�����һ���������Ⱥ,�������ڼ�Ⱥ��ÿ���ڵ��������ض��ij���,���Խڵ��е��������й�����Ŀ����ʵ����Դ�������Զ���,��Ҫ�ṩ�����µ���Ҫ����:
- ������:һ��ijһ����������,�ܹ���1��������Ѹ�������µ�����
- ��������:���Ը�����Ҫ,�Զ��Լ�Ⱥ���������е������������е���
- ������:�������ͨ���Զ����ֵ���ʽ�ҵ����������ķ���
- ���ؾ���:���һ���������˶������,�ܹ��Զ�ʵ������ĸ��ؾ���
- �汾����:��������·����ij���汾������,�����������˵�ԭ���İ汾
- �洢����:���Ը������������������Զ������洢��
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-baDfjwa2-1629018950130)(Kubenetes.assets/image-20200526203726071-1626780706899.png)]
1.3 kubernetes���
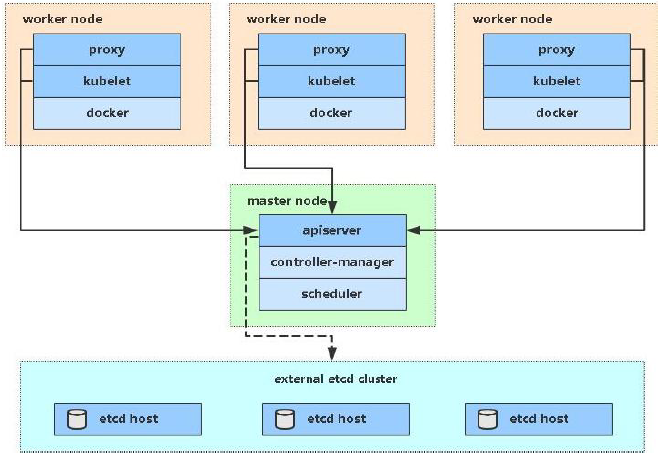
һ��kubernetes��Ⱥ��Ҫ�������ƽڵ�(master)��**�����ڵ�(node)**����,ÿ���ڵ��϶��ᰲװ��ͬ�������
master:��Ⱥ�Ŀ���ƽ��,����Ⱥ�ľ��� ( ���� )
ApiServer : ��Դ������Ψһ���,�����û����������,�ṩ��֤����Ȩ��APIע��ͷ��ֵȻ���
Scheduler : ����Ⱥ��Դ����,����Ԥ���ĵ��Ȳ��Խ�Pod���ȵ���Ӧ��node�ڵ���
ControllerManager : ����ά����Ⱥ��״̬,����������š����ϼ�⡢�Զ���չ���������µ�
Etcd :����洢��Ⱥ�и�����Դ�������Ϣ
node:��Ⱥ������ƽ��,����Ϊ�����ṩ���л��� ( �ɻ� )
Kubelet : ����ά����������������,��ͨ������docker,�����������¡���������
KubeProxy : �����ṩ��Ⱥ�ڲ��ķ����ֺ��ؾ���
Docker : ����ڵ��������ĸ��ֲ���
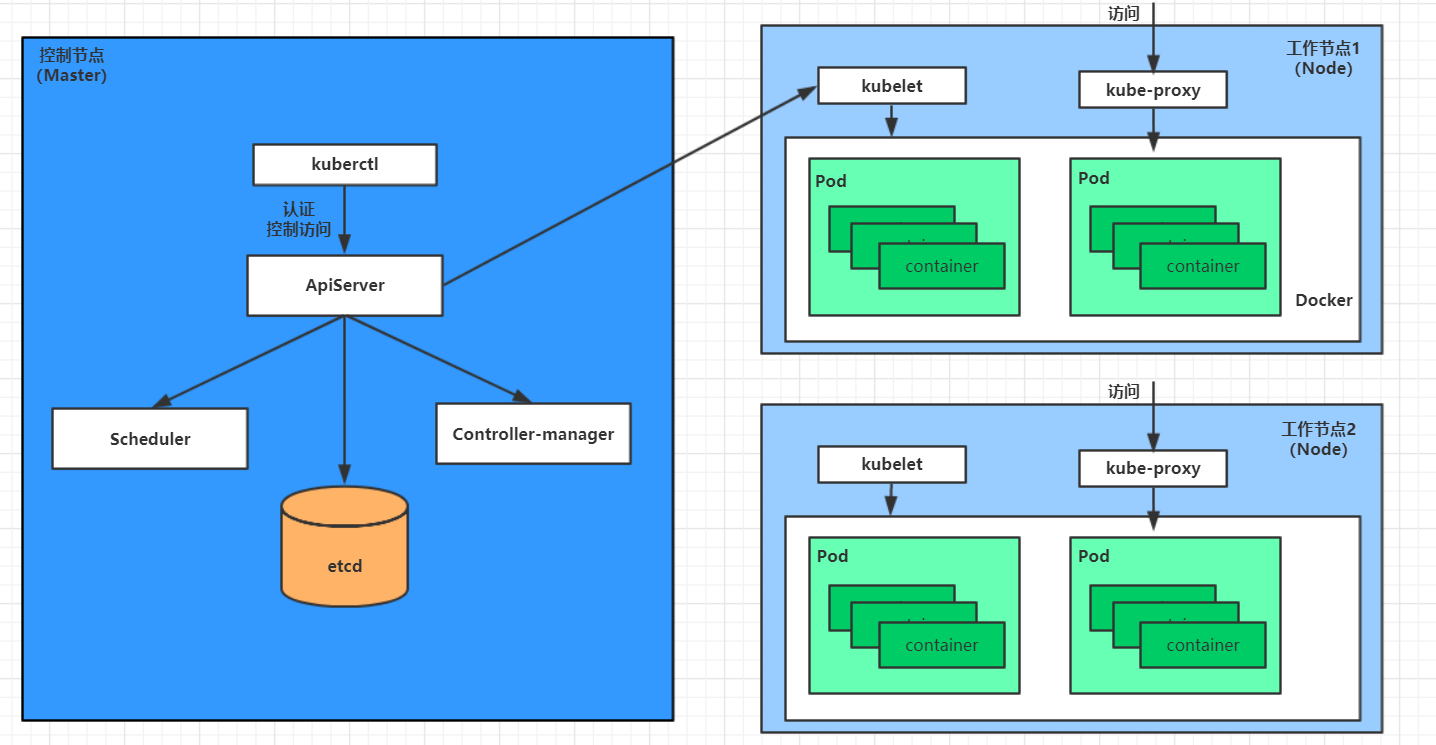
����,�Բ���һ��nginx������˵��kubernetesϵͳ����������ù�ϵ:
-
����Ҫ��ȷ,һ��kubernetes��������֮��,master��node���Ὣ��������Ϣ�洢��etcd���ݿ���
-
һ��nginx����İ�װ��������ȱ����͵�master�ڵ��apiServer���
-
apiServer��������scheduler�������������Ӧ�ð��������װ���ĸ�node�ڵ���
�ڴ�ʱ,�����etcd�ж�ȡ����node�ڵ����Ϣ,Ȼ����һ�����㷨����ѡ��,���������֪apiServer
-
apiServer����controller-managerȥ����Node�ڵ㰲װnginx����
-
kubelet���յ�ָ���,��֪ͨdocker,Ȼ����docker������һ��nginx��pod
pod��kubernetes����С������Ԫ,������������pod������,
-
һ��nginx�����������,�����Ҫ����nginx,����Ҫͨ��kube-proxy����pod�������ʵĴ���
����,����û��Ϳ��Է��ʼ�Ⱥ�е�nginx������
1.4 kubernetes����
Master:��Ⱥ���ƽڵ�,ÿ����Ⱥ��Ҫ����һ��master�ڵ㸺��Ⱥ�Ĺܿ�
Node:�������ؽڵ�,��master������������Щnode�����ڵ���,Ȼ��node�ڵ��ϵ�docker��������������
Pod:kubernetes����С���Ƶ�Ԫ,��������������pod�е�,һ��pod�п�����1�����߶������
Controller:������,ͨ������ʵ�ֶ�pod�Ĺ���,��������pod��ֹͣpod������pod�������ȵ�
Service:pod��������ͳһ���,�������ά����ͬһ��Ķ��pod
Label:��ǩ,���ڶ�pod���з���,ͬһ��pod��ӵ����ͬ�ı�ǩ
NameSpace:�����ռ�,��������pod�����л���
2. kubernetes��Ⱥ�����
2.1 ǰ��֪ʶ��
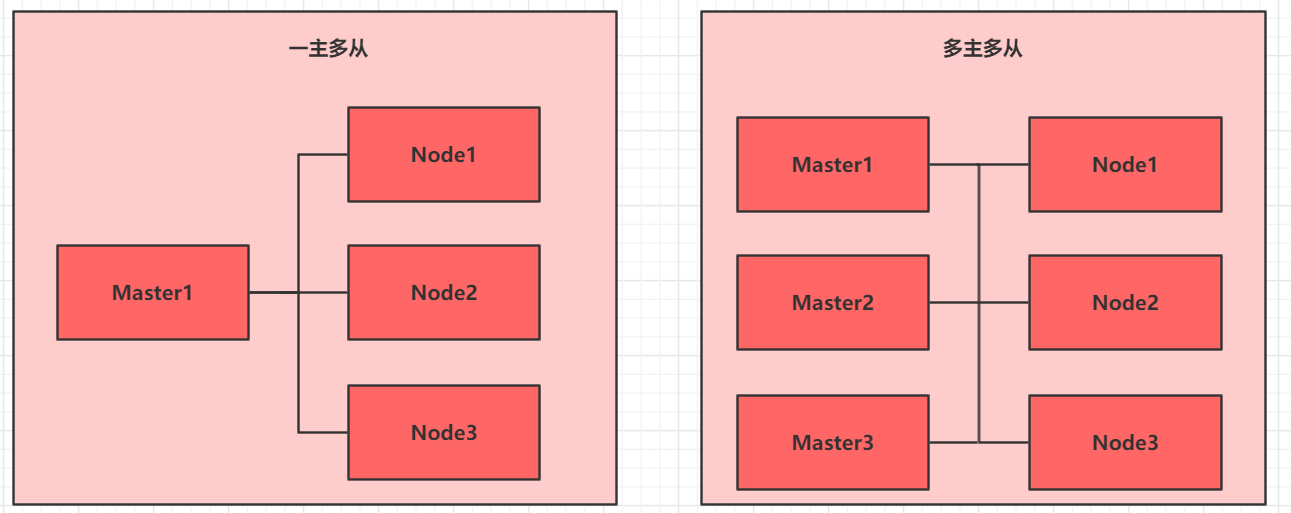
Ŀǰ��������Kubernetes ��Ⱥ��Ҫ�����ַ�ʽ:
kubeadm
Kubeadm ��һ��K8s ����,�ṩkubeadm init ��kubeadm join,���ڿ��ٲ���Kubernetes ��Ⱥ��
�ٷ���ַ:https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm/
�����ư�
��github ���ط��а�Ķ����ư�,�ֶ�����ÿ�����,���Kubernetes ��Ⱥ��
Kubeadm ���Ͳ����ż�,�������˺ܶ�ϸ��,������������Ų顣���������ɿ�,�Ƽ�ʹ�ö����ư�����Kubernetes ��Ⱥ,��Ȼ�ֶ������鷳��,�ڼ����ѧϰ�ܶ��ԭ��,Ҳ���ں���ά����
2.2 kubeadm ����ʽ����
kubeadm �ǹٷ������Ƴ���һ�����ڿ��ٲ���kubernetes ��Ⱥ�Ĺ���,���������ͨ������ָ�����һ��kubernetes ��Ⱥ�IJ���:
- ����һ��Master �ڵ�kubeadm init
- ��Node �ڵ���뵽��ǰ��Ⱥ��$ kubeadm join <Master �ڵ��IP �Ͷ˿�>
2.3 ��װҪ��
�ڿ�ʼ֮ǰ,����Kubernetes ��Ⱥ������Ҫ�������¼�������:
- һ̨���̨����,����ϵͳCentOS7.x-86_x64
- Ӳ������:2GB �����RAM,2 ��CPU �����CPU,Ӳ��30GB �����
- ��Ⱥ�����л���֮�����绥ͨ
- ���Է�������,��Ҫ��ȡ����
- ��ֹswap ����
2.4 ����Ŀ��
- �����нڵ��ϰ�װDocker ��kubeadm
- ����Kubernetes Master
- ��������������
- ����Kubernetes Node,���ڵ����Kubernetes ��Ⱥ��
- ����Dashboard Web ҳ��,���ӻ��鿴Kubernetes ��Դ
2.5 ������
| ��ɫ | IP��ַ | ��� |
|---|---|---|
| k8s-master01 | 192.168.5.3 | docker,kubectl,kubeadm,kubelet |
| k8s-node01 | 192.168.5.4 | docker,kubectl,kubeadm,kubelet |
| k8s-node02 | 192.168.5.5 | docker,kubectl,kubeadm,kubelet |
2.6 ϵͳ��ʼ��
2.6.1 ����ϵͳ�������Լ� Host �ļ��������
hostnamectl set-hostname k8s-master01 && bash
hostnamectl set-hostname k8s-node01 && bash
hostnamectl set-hostname k8s-node02 && bash
cat <<EOF>> /etc/hosts
192.168.5.3 k8s-master01
192.168.5.4 k8s-node01
192.168.5.5 k8s-node02
EOF
scp /etc/hosts root@192.168.5.4:/etc/hosts
scp /etc/hosts root@192.168.5.5:/etc/hosts
2.6.2 ��װ�����ļ�(���нڵ㶼Ҫ����)
yum install -y conntrack ntpdate ntp ipvsadm ipset jq iptables curl sysstat libseccomp wget vim net-tools git
2.6.3 ���÷���ǽΪ Iptables �����ÿչ���(���нڵ㶼Ҫ����)
systemctl stop firewalld && systemctl disable firewalld
yum -y install iptables-services && systemctl start iptables && systemctl enable iptables && iptables -F && service iptables save
2.6.4 �ر� SELINUX(���нڵ㶼Ҫ����)
swapoff -a && sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
setenforce 0 && sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
2.6.5 �����ں˲���,���� K8S(���нڵ㶼Ҫ����)
modprobe br_netfilter
cat <<EOF> kubernetes.conf
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
net.ipv4.tcp_tw_recycle=0
vm.swappiness=0 # ��ֹʹ�� swap �ռ�,ֻ�е�ϵͳ OOM ʱ������ʹ����
vm.overcommit_memory=1 # ����������ڴ��Ƿ���
vm.panic_on_oom=0 # ���� OOM
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963
fs.nr_open=52706963
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
EOF
cp kubernetes.conf /etc/sysctl.d/kubernetes.conf
sysctl -p /etc/sysctl.d/kubernetes.conf
2.6.6 ����ϵͳʱ��(���нڵ㶼Ҫ����)
# ����ϵͳʱ��Ϊ �й�/�Ϻ�
timedatectl set-timezone Asia/Shanghai
# ����ǰ�� UTC ʱ��д��Ӳ��ʱ��
timedatectl set-local-rtc 0
# ����������ϵͳʱ��ķ���
systemctl restart rsyslog
systemctl restart crond
2.6.7 ���� rsyslogd �� systemd journald(���нڵ㶼Ҫ����)
# �־û�������־��Ŀ¼
mkdir /var/log/journal
mkdir /etc/systemd/journald.conf.d
cat > /etc/systemd/journald.conf.d/99-prophet.conf <<EOF
[Journal]
# �־û����浽����
Storage=persistent
# ѹ����ʷ��־
Compress=yes
SyncIntervalSec=5m
RateLimitInterval=30s
RateLimitBurst=1000
# ���ռ�ÿռ� 10G
SystemMaxUse=10G
# ����־�ļ���� 200M
SystemMaxFileSize=200M
# ��־����ʱ�� 2 ��
MaxRetentionSec=2week
# ������־ת���� syslog
ForwardToSyslog=no
EOF
systemctl restart systemd-journald
2.6.8 kube-proxy����ipvs��ǰ������(���нڵ㶼Ҫ����)
cat <<EOF> /etc/sysconfig/modules/ipvs.modules
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
2.6.9 ��װ Docker ����(���нڵ㶼Ҫ����)
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install -y docker-ce
## ���� /etc/docker Ŀ¼
mkdir /etc/docker
cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
}
}
EOF
mkdir -p /etc/systemd/system/docker.service.d
# ����docker����
systemctl daemon-reload && systemctl restart docker && systemctl enable docker
�ϴ��ļ���/etc/yum.repos.d/Ŀ¼��,Ҳ���� ���� yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo����
docker-ce.repo
[docker-ce-stable]
name=Docker CE Stable - $basearch
baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/$releasever/$basearch/stable
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg
[docker-ce-stable-debuginfo]
name=Docker CE Stable - Debuginfo $basearch
baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/$releasever/debug-$basearch/stable
enabled=0
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg
[docker-ce-stable-source]
name=Docker CE Stable - Sources
baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/$releasever/source/stable
enabled=0
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg
[docker-ce-test]
name=Docker CE Test - $basearch
baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/$releasever/$basearch/test
enabled=0
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg
[docker-ce-test-debuginfo]
name=Docker CE Test - Debuginfo $basearch
baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/$releasever/debug-$basearch/test
enabled=0
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg
[docker-ce-test-source]
name=Docker CE Test - Sources
baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/$releasever/source/test
enabled=0
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg
[docker-ce-nightly]
name=Docker CE Nightly - $basearch
baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/$releasever/$basearch/nightly
enabled=0
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg
[docker-ce-nightly-debuginfo]
name=Docker CE Nightly - Debuginfo $basearch
baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/$releasever/debug-$basearch/nightly
enabled=0
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg
[docker-ce-nightly-source]
name=Docker CE Nightly - Sources
baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/$releasever/source/nightly
enabled=0
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg
2.6.10 ��װ Kubeadm (���нڵ㶼Ҫ����)
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
yum install -y kubelet kubeadm kubectl && systemctl enable kubelet
2.7 ����Kubernetes Master
2.7.1 ��ʼ�����ڵ�(���ڵ����)
kubeadm init --apiserver-advertise-address=192.168.5.3 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.21.1 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
2.7.2 �������ڵ��Լ�������ڵ�
kubeadm join 192.168.5.3:6443 --token h0uelc.l46qp29nxscke7f7 \
--discovery-token-ca-cert-hash sha256:abc807778e24bff73362ceeb783cc7f6feec96f20b4fd707c3f8e8312294e28f
2.7.3 ��������
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
�±����ļ�
---
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: psp.flannel.unprivileged
annotations:
seccomp.security.alpha.kubernetes.io/allowedProfileNames: docker/default
seccomp.security.alpha.kubernetes.io/defaultProfileName: docker/default
apparmor.security.beta.kubernetes.io/allowedProfileNames: runtime/default
apparmor.security.beta.kubernetes.io/defaultProfileName: runtime/default
spec:
privileged: false
volumes:
- configMap
- secret
- emptyDir
- hostPath
allowedHostPaths:
- pathPrefix: "/etc/cni/net.d"
- pathPrefix: "/etc/kube-flannel"
- pathPrefix: "/run/flannel"
readOnlyRootFilesystem: false
# Users and groups
runAsUser:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
fsGroup:
rule: RunAsAny
# Privilege Escalation
allowPrivilegeEscalation: false
defaultAllowPrivilegeEscalation: false
# Capabilities
allowedCapabilities: ['NET_ADMIN', 'NET_RAW']
defaultAddCapabilities: []
requiredDropCapabilities: []
# Host namespaces
hostPID: false
hostIPC: false
hostNetwork: true
hostPorts:
- min: 0
max: 65535
# SELinux
seLinux:
# SELinux is unused in CaaSP
rule: 'RunAsAny'
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: flannel
rules:
- apiGroups: ['extensions']
resources: ['podsecuritypolicies']
verbs: ['use']
resourceNames: ['psp.flannel.unprivileged']
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- ""
resources:
- nodes
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: flannel
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: flannel
subjects:
- kind: ServiceAccount
name: flannel
namespace: kube-system
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: flannel
namespace: kube-system
---
kind: ConfigMap
apiVersion: v1
metadata:
name: kube-flannel-cfg
namespace: kube-system
labels:
tier: node
app: flannel
data:
cni-conf.json: |
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: kube-flannel-ds
namespace: kube-system
labels:
tier: node
app: flannel
spec:
selector:
matchLabels:
app: flannel
template:
metadata:
labels:
tier: node
app: flannel
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
hostNetwork: true
priorityClassName: system-node-critical
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni
image: quay.io/coreos/flannel:v0.14.0
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
image: quay.io/coreos/flannel:v0.14.0
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
limits:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: false
capabilities:
add: ["NET_ADMIN", "NET_RAW"]
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: run
mountPath: /run/flannel
- name: flannel-cfg
mountPath: /etc/kube-flannel/
volumes:
- name: run
hostPath:
path: /run/flannel
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg
2.8 ����kubernetes ��Ⱥ
2.8.1 ����nginx ����
kubectl create deployment nginx --image=nginx
kubectl expose deployment nginx --port=80 --type=NodePort
kubectl get pod,svc
3. ��Դ����
3.1 ��Դ��������
��kubernetes��,���е����ݶ�����Ϊ��Դ,�û���Ҫͨ��������Դ������kubernetes��
kubernetes�ı����Ͼ���һ����Ⱥϵͳ,�û������ڼ�Ⱥ�в�����ַ���,��ν�IJ������,��ʵ������kubernetes��Ⱥ������һ����������,����ָ���ij������������С�
kubernetes����С������Ԫ��pod����������,����ֻ�ܽ���������
Pod��,��kubernetesһ��Ҳ����ֱ�ӹ���Pod,����ͨ��Pod������������Pod�ġ�Pod�����ṩ����֮��,��Ҫ������η���Pod�з���,kubernetes�ṩ��
Service��Դʵ��������ܡ���Ȼ,���Pod�г����������Ҫ�־û�,kubernetes���ṩ�˸���
�洢ϵͳ��
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-xscx6rRB-1629018950134)(https://i.loli.net/2021/08/15/vjfxn75pZVHgsaK.png)]
ѧϰkubernetes�ĺ���,����ѧϰ��ζԼ�Ⱥ�ϵ�
Pod��Pod��������Service���洢�ȸ�����Դ���в���
3.2 YAML���Խ���
YAML��һ������ XML��JSON �ı�������ԡ���ǿ��������Ϊ����,�������Ա�ʶ����Ϊ�ص㡣���YAML�����Ķ���Ƚϼ�,�ų�"һ�����Ի������ݸ�ʽ����"��
<heima>
<age>15</age>
<address>Beijing</address>
</heima>
heima:
age: 15
address: Beijing
YAML����Ƚϼ�,��Ҫ�����漸��:
- ��Сд����
- ʹ��������ʾ�㼶��ϵ
- ����������ʹ��tab,ֻ�����ո�( �Ͱ汾���� )
- �����Ŀո�������Ҫ,ֻҪ��ͬ�㼶��Ԫ������뼴��
- '#'��ʾע��
YAML֧�����¼�����������:
- ����:�����ġ������ٷֵ�ֵ
- ����:��ֵ�Եļ���,�ֳ�Ϊӳ��(mapping)/ ��ϣ(hash) / �ֵ�(dictionary)
- ����:һ�鰴�������е�ֵ,�ֳ�Ϊ����(sequence) / �б�(list)
# ����, ����ָ��һ����ֵ,�ַ���������ֵ����������������Null��ʱ�䡢����
# 1 ��������
c1: true (����True)
# 2 ����
c2: 234
# 3 ������
c3: 3.14
# 4 null����
c4: ~ # ʹ��~��ʾnull
# 5 ��������
c5: 2018-02-17 # ���ڱ���ʹ��ISO 8601��ʽ,��yyyy-MM-dd
# 6 ʱ������
c6: 2018-02-17T15:02:31+08:00 # ʱ��ʹ��ISO 8601��ʽ,ʱ�������֮��ʹ��T����,���ʹ��+����ʱ��
# 7 �ַ�������
c7: heima # ��д��,ֱ��дֵ , ����ַ����м��������ַ�,����ʹ��˫���Ż��ߵ����Ű���
c8: line1
line2 # �ַ��������������Բ�ɶ���,ÿһ�лᱻת����һ���ո�
# ����
# ��ʽһ(�Ƽ�):
heima:
age: 15
address: Beijing
# ��ʽ��(�˽�):
heima: {age: 15,address: Beijing}
# ����
# ��ʽһ(�Ƽ�):
address:
- ˳��
- ��ƽ
# ��ʽ��(�˽�):
address: [˳��,��ƽ]
С��ʾ:
1 ��дyaml�м�
:����Ҫ��һ���ո�2 �����Ҫ�����yaml���÷���һ���ļ���,�м�Ҫʹ��
---�ָ�3 ������һ��yamlתjson����վ,����ͨ������֤yaml�Ƿ���д��ȷ
https://www.json2yaml.com/convert-yaml-to-json
3.3 ��Դ������ʽ
-
����ʽ�������:ֱ��ʹ������ȥ����kubernetes��Դ
kubectl run nginx-pod --image=nginx:1.17.1 --port=80 -
����ʽ��������:ͨ���������ú������ļ�ȥ����kubernetes��Դ
kubectl create/patch -f nginx-pod.yaml -
����ʽ��������:ͨ��apply����������ļ�ȥ����kubernetes��Դ
kubectl apply -f nginx-pod.yaml�������� �о���,û�оʹ���
| ���� | �������� | ���û��� | �ŵ� | ȱ�� |
|---|---|---|---|---|
| ����ʽ������� | ���� | ���� | �� | ֻ�ܲ��������,����ơ����� |
| ����ʽ�������� | �ļ� | ���� | ������ơ����� | ��Ŀ��ʱ,�����ļ���,�����鷳 |
| ����ʽ�������� | Ŀ¼ | ���� | ֧��Ŀ¼���� | ������������Ե��� |
3.3.1 ����ʽ�������
kubectl����
kubectl��kubernetes��Ⱥ�������й���,ͨ�����ܹ��Լ�Ⱥ�������й���,���ܹ��ڼ�Ⱥ�Ͻ���������Ӧ�õİ�װ����kubectl����������:
kubectl [command] [type] [name] [flags]
comand:ָ��Ҫ����Դִ�еIJ���,����create��get��delete
type:ָ����Դ����,����deployment��pod��service
name:ָ����Դ������,���ƴ�Сд����
flags:ָ������Ŀ�ѡ����
# �鿴����pod
kubectl get pod
# �鿴ij��pod
kubectl get pod pod_name
# �鿴ij��pod,��yaml��ʽչʾ���
kubectl get pod pod_name -o yaml
��Դ����
kubernetes�����е����ݶ�����Ϊ��Դ,����ͨ�������������в鿴:
kubectl api-resources
����ʹ�õ���Դ��������Щ:
| ��Դ���� | ��Դ���� | ��д | ��Դ���� |
|---|---|---|---|
| ��Ⱥ������Դ | nodes | no | ��Ⱥ��ɲ��� |
| namespaces | ns | ����Pod | |
| pod��Դ | pods | po | װ������ |
| pod��Դ������ | replicationcontrollers | rc | ����pod��Դ |
| replicasets | rs | ����pod��Դ | |
| deployments | deploy | ����pod��Դ | |
| daemonsets | ds | ����pod��Դ | |
| jobs | ����pod��Դ | ||
| cronjobs | cj | ����pod��Դ | |
| horizontalpodautoscalers | hpa | ����pod��Դ | |
| statefulsets | sts | ����pod��Դ | |
| ��������Դ | services | svc | ͳһpod����ӿ� |
| ingress | ing | ͳһpod����ӿ� | |
| �洢��Դ | volumeattachments | �洢 | |
| persistentvolumes | pv | �洢 | |
| persistentvolumeclaims | pvc | �洢 | |
| ������Դ | configmaps | cm | ���� |
| secrets | ���� |
����
kubernetes��������Դ���ж��ֲ���,����ͨ���Chelp�鿴��ϸ�IJ�������
kubectl --help
����ʹ�õIJ�����������Щ:
| ������� | ���� | ���� | �������� |
|---|---|---|---|
| �������� | create | ���� | ����һ����Դ |
| edit | �༭ | �༭һ����Դ | |
| get | ��ȡ | ��ȡһ����Դ | |
| patch | ���� | ����һ����Դ | |
| delete | ɾ�� | ɾ��һ����Դ | |
| explain | ���� | չʾ��Դ�ĵ� | |
| ���к͵��� | run | ���� | �ڼ�Ⱥ������һ��ָ���ľ��� |
| expose | ��¶ | ��¶��ԴΪService | |
| describe | ���� | ��ʾ��Դ�ڲ���Ϣ | |
| logs | ��־��������� pod �е���־ | ��������� pod �е���־ | |
| attach | ���ƽ��������е����� | ���������е����� | |
| exec | ִ�������е�һ������ | ִ�������е�һ������ | |
| cp | ���� | ��Pod���⸴���ļ� | |
| rollout | �״�չʾ | ������Դ�ķ��� | |
| scale | ��ģ | ��(��)��Pod������ | |
| autoscale | �Զ����� | �Զ�����Pod������ | |
| ������ | apply | rc | ͨ���ļ�����Դ�������� |
| label | ��ǩ | ������Դ�ϵı�ǩ | |
| �������� | cluster-info | ��Ⱥ��Ϣ | ��ʾ��Ⱥ��Ϣ |
| version | �汾 | ��ʾ��ǰServer��Client�İ汾 |
������һ��namespace / pod�Ĵ�����ɾ������ʾ�������ʹ��:
# ����һ��namespace
[root@master ~]# kubectl create namespace dev
namespace/dev created
# ��ȡnamespace
[root@master ~]# kubectl get ns
NAME STATUS AGE
default Active 21h
dev Active 21s
kube-node-lease Active 21h
kube-public Active 21h
kube-system Active 21h
# �ڴ�namespace�´���������һ��nginx��Pod
[root@master ~]# kubectl run pod --image=nginx:latest -n dev
kubectl run --generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run --generator=run-pod/v1 or kubectl create instead.
deployment.apps/pod created
# �鿴�´�����pod
[root@master ~]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
pod 1/1 Running 0 21s
# ɾ��ָ����pod
[root@master ~]# kubectl delete pod pod-864f9875b9-pcw7x
pod "pod" deleted
# ɾ��ָ����namespace
[root@master ~]# kubectl delete ns dev
namespace "dev" deleted
3.3.2 ����ʽ��������
����ʽ�������þ���ʹ��������������ļ�һ��������kubernetes��Դ��
1) ����һ��nginxpod.yaml,��������:
apiVersion: v1
kind: Namespace
metadata:
name: dev
---
apiVersion: v1
kind: Pod
metadata:
name: nginxpod
namespace: dev
spec:
containers:
- name: nginx-containers
image: nginx:latest
2)ִ��create����,������Դ:
[root@master ~]# kubectl create -f nginxpod.yaml
namespace/dev created
pod/nginxpod created
��ʱ���ִ�����������Դ����,�ֱ���namespace��pod
3)ִ��get����,�鿴��Դ:
[root@master ~]# kubectl get -f nginxpod.yaml
NAME STATUS AGE
namespace/dev Active 18s
NAME READY STATUS RESTARTS AGE
pod/nginxpod 1/1 Running 0 17s
��������ʾ��������Դ�������Ϣ
4)ִ��delete����,ɾ����Դ:
[root@master ~]# kubectl delete -f nginxpod.yaml
namespace "dev" deleted
pod "nginxpod" deleted
��ʱ����������Դ����ɾ����
�ܽ�:
����ʽ�������õķ�ʽ������Դ,���Լ���Ϊ:���� + yaml�����ļ�(������������Ҫ�ĸ��ֲ���)
3.3.3 ����ʽ��������
����ʽ�������ø�����ʽ�������ú�����,������ֻ��һ������apply��
# ����ִ��һ��kubectl apply -f yaml�ļ�,���ִ�������Դ
[root@master ~]# kubectl apply -f nginxpod.yaml
namespace/dev created
pod/nginxpod created
# �ٴ�ִ��һ��kubectl apply -f yaml�ļ�,����˵��Դû�б䶯
[root@master ~]# kubectl apply -f nginxpod.yaml
namespace/dev unchanged
pod/nginxpod unchanged
�ܽ�:
��ʵ����ʽ�������þ���ʹ��apply����һ����Դ���յ�״̬(��yaml�ж���״̬)
ʹ��apply������Դ:
�����Դ������,�ʹ���,�൱�� kubectl create
�����Դ�Ѵ���,����,�൱�� kubectl patch
��չ:kubectl������node�ڵ��������� ?
kubectl����������Ҫ�������õ�,���������ļ���$HOME/.kube,�����Ҫ��node�ڵ����д�����,��Ҫ��master�ϵ�.kube�ļ����Ƶ�node�ڵ���,����master�ڵ���ִ���������:
scp -r HOME/.kube node1: HOME/
ʹ���Ƽ�: ���ַ�ʽӦ����ô�� ?
����/������Դ ʹ������ʽ�������� kubectl apply -f XXX.yaml
ɾ����Դ ʹ������ʽ�������� kubectl delete -f XXX.yaml
��ѯ��Դ ʹ������ʽ������� kubectl get(describe) ��Դ����
4. ʵս����
���½ڽ����������kubernetes��Ⱥ�в���һ��nginx����,�����ܹ�������з��ʡ�
4.1 Namespace
Namespace��kubernetesϵͳ�е�һ�ַdz���Ҫ��Դ,������Ҫ����������ʵ������������Դ�����������⻧����Դ������
Ĭ�������,kubernetes��Ⱥ�е����е�Pod���ǿ�������ʵġ�������ʵ����,���ܲ���������Pod֮����л���ķ���,�Ǵ�ʱ�Ϳ��Խ�����Pod���ֵ���ͬ��namespace�¡�kubernetesͨ������Ⱥ�ڲ�����Դ���䵽��ͬ��Namespace��,�����γ����ϵ�"��",�Է��㲻ͬ�������Դ���и���ʹ�ú�����
����ͨ��kubernetes����Ȩ����,����ͬ��namespace������ͬ�⻧���й���,������ʵ���˶��⻧����Դ���롣��ʱ���ܽ��kubernetes����Դ������,����ͬ�⻧��ռ�õ���Դ,����CPUʹ�������ڴ�ʹ�����ȵ�,��ʵ���⻧������Դ�Ĺ�����
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-NC92qPRz-1629018950135)(https://i.loli.net/2021/08/15/EFjqMXJzSfmPidC.png)]
kubernetes�ڼ�Ⱥ����֮��,��Ĭ�ϴ�������namespace
[root@master ~]# kubectl get namespace
NAME STATUS AGE
default Active 45h # ����δָ��Namespace�Ķ��ᱻ������default�����ռ�
kube-node-lease Active 45h # ��Ⱥ�ڵ�֮�������ά��,v1.13��ʼ����
kube-public Active 45h # �������ռ��µ���Դ���Ա������˷���(����δ��֤�û�)
kube-system Active 45h # ������Kubernetesϵͳ��������Դ��������������ռ�
��������namespace��Դ�ľ������:
�鿴
# 1 �鿴���е�ns ����:kubectl get ns
[root@master ~]# kubectl get ns
NAME STATUS AGE
default Active 45h
kube-node-lease Active 45h
kube-public Active 45h
kube-system Active 45h
# 2 �鿴ָ����ns ����:kubectl get ns ns����
[root@master ~]# kubectl get ns default
NAME STATUS AGE
default Active 45h
# 3 ָ�������ʽ ����:kubectl get ns ns���� -o ��ʽ����
# kubernetes֧�ֵĸ�ʽ�кܶ�,�Ƚϳ�������wide��json��yaml
[root@master ~]# kubectl get ns default -o yaml
apiVersion: v1
kind: Namespace
metadata:
creationTimestamp: "2021-05-08T04:44:16Z"
name: default
resourceVersion: "151"
selfLink: /api/v1/namespaces/default
uid: 7405f73a-e486-43d4-9db6-145f1409f090
spec:
finalizers:
- kubernetes
status:
phase: Active
# 4 �鿴ns���� ����:kubectl describe ns ns����
[root@master ~]# kubectl describe ns default
Name: default
Labels: <none>
Annotations: <none>
Status: Active # Active �����ռ�����ʹ���� Terminating ����ɾ�������ռ�
# ResourceQuota ���namespace������Դ����
# LimitRange���namespace�е�ÿ�����������Դ����
No resource quota.
No LimitRange resource.
����
# ����namespace
[root@master ~]# kubectl create ns dev
namespace/dev created
ɾ��
# ɾ��namespace
[root@master ~]# kubectl delete ns dev
namespace "dev" deleted
���÷�ʽ
������һ��yaml�ļ�:ns-dev.yaml
apiVersion: v1
kind: Namespace
metadata:
name: dev
Ȼ��Ϳ���ִ�ж�Ӧ�Ĵ�����ɾ��������:
����:kubectl create -f ns-dev.yaml
ɾ��:kubectl delete -f ns-dev.yaml
4.2 Pod
Pod��kubernetes��Ⱥ���й�������С��Ԫ,����Ҫ���б��벿����������,���������������Pod�С�
Pod������Ϊ�������ķ�װ,һ��Pod�п��Դ���һ�����߶��������
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-bLgunem7-1629018950135)(https://i.loli.net/2021/08/15/f8TDiznsVPa5qoL.png)]
kubernetes�ڼ�Ⱥ����֮��,��Ⱥ�еĸ������Ҳ������Pod��ʽ���еġ�����ͨ����������鿴:
[root@master ~]# kubectl get pod -n kube-system
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-6955765f44-68g6v 1/1 Running 0 2d1h
kube-system coredns-6955765f44-cs5r8 1/1 Running 0 2d1h
kube-system etcd-master 1/1 Running 0 2d1h
kube-system kube-apiserver-master 1/1 Running 0 2d1h
kube-system kube-controller-manager-master 1/1 Running 0 2d1h
kube-system kube-flannel-ds-amd64-47r25 1/1 Running 0 2d1h
kube-system kube-flannel-ds-amd64-ls5lh 1/1 Running 0 2d1h
kube-system kube-proxy-685tk 1/1 Running 0 2d1h
kube-system kube-proxy-87spt 1/1 Running 0 2d1h
kube-system kube-scheduler-master 1/1 Running 0 2d1h
����������
kubernetesû���ṩ��������Pod������,����ͨ��Pod��������ʵ�ֵ�
# �����ʽ: kubectl run (pod����������) [����]
# --image ָ��Pod�ľ���
# --port ָ���˿�
# --namespace ָ��namespace
[root@master ~]# kubectl run nginx --image=nginx:latest --port=80 --namespace dev
deployment.apps/nginx created
�鿴pod��Ϣ
# �鿴Pod������Ϣ
[root@master ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 43s
# �鿴Pod����ϸ��Ϣ
[root@master ~]# kubectl describe pod nginx -n dev
Name: nginx
Namespace: dev
Priority: 0
Node: node1/192.168.5.4
Start Time: Wed, 08 May 2021 09:29:24 +0800
Labels: pod-template-hash=5ff7956ff6
run=nginx
Annotations: <none>
Status: Running
IP: 10.244.1.23
IPs:
IP: 10.244.1.23
Controlled By: ReplicaSet/nginx
Containers:
nginx:
Container ID: docker://4c62b8c0648d2512380f4ffa5da2c99d16e05634979973449c98e9b829f6253c
Image: nginx:latest
Image ID: docker-pullable://nginx@sha256:485b610fefec7ff6c463ced9623314a04ed67e3945b9c08d7e53a47f6d108dc7
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Wed, 08 May 2021 09:30:01 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-hwvvw (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
default-token-hwvvw:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-hwvvw
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned dev/nginx-5ff7956ff6-fg2db to node1
Normal Pulling 4m11s kubelet, node1 Pulling image "nginx:latest"
Normal Pulled 3m36s kubelet, node1 Successfully pulled image "nginx:latest"
Normal Created 3m36s kubelet, node1 Created container nginx
Normal Started 3m36s kubelet, node1 Started container nginx
����Pod
# ��ȡpodIP
[root@master ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ...
nginx 1/1 Running 0 190s 10.244.1.23 node1 ...
#����POD
[root@master ~]# curl http://10.244.1.23:80
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
</head>
<body>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
ɾ��ָ��Pod
# ɾ��ָ��Pod
[root@master ~]# kubectl delete pod nginx -n dev
pod "nginx" deleted
# ��ʱ,��ʾɾ��Pod�ɹ�,�����ٲ�ѯ,�������²�����һ��
[root@master ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 21s
# ������Ϊ��ǰPod����Pod������������,����������Pod״��,һ������Pod����,�������ؽ�
# ��ʱҪ��ɾ��Pod,����ɾ��Pod������
# ������ѯһ�µ�ǰnamespace�µ�Pod������
[root@master ~]# kubectl get deploy -n dev
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 1/1 1 1 9m7s
# ������,ɾ����PodPod������
[root@master ~]# kubectl delete deploy nginx -n dev
deployment.apps "nginx" deleted
# �Ե�Ƭ��,�ٲ�ѯPod,����Pod��ɾ����
[root@master ~]# kubectl get pods -n dev
No resources found in dev namespace.
����
����һ��pod-nginx.yaml,��������:
apiVersion: v1
kind: Pod
metadata:
name: nginx
namespace: dev
spec:
containers:
- image: nginx:latest
name: pod
ports:
- name: nginx-port
containerPort: 80
protocol: TCP
Ȼ��Ϳ���ִ�ж�Ӧ�Ĵ�����ɾ��������:
����:kubectl create -f pod-nginx.yaml
ɾ��:kubectl delete -f pod-nginx.yaml
4.3 Label
Label��kubernetesϵͳ�е�һ����Ҫ����������þ�������Դ�����ӱ�ʶ,���������ǽ������ֺ�ѡ��
Label���ص�:
- һ��Label����key/value��ֵ�Ե���ʽ���ӵ����ֶ�����,��Node��Pod��Service�ȵ�
- һ����Դ������Զ�������������Label ,ͬһ��LabelҲ���Ա����ӵ�������������Դ������ȥ
- Labelͨ������Դ������ʱȷ��,��ȻҲ�����ڶ�����̬���ӻ���ɾ��
����ͨ��Labelʵ����Դ�Ķ�ά�ȷ���,�Ա�������ؽ�����Դ���䡢���ȡ����á�����ȹ���������
һЩ���õ�Label ʾ������:
- �汾��ǩ:��version��:��release��, ��version��:��stable����
- ������ǩ:��environment��:��dev��,��environment��:��test��,��environment��:��pro��
- �ܹ���ǩ:��tier��:��frontend��,��tier��:��backend��
��ǩ�������֮��,��Ҫ���ǵ���ǩ��ѡ��,���Ҫʹ�õ�Label Selector,��:
Label���ڸ�ij����Դ�������ʶ
Label Selector���ڲ�ѯ��ɸѡӵ��ijЩ��ǩ����Դ����
��ǰ������Label Selector:
-
���ڵ�ʽ��Label Selector
name = slave: ѡ�����а���Label��key="name"��value="slave"�Ķ���
env != production: ѡ�����а���Label�е�key="env"��value������"production"�Ķ���
-
���ڼ��ϵ�Label Selector
name in (master, slave): ѡ�����а���Label�е�key="name"��value="master"��"slave"�Ķ���
name not in (frontend): ѡ�����а���Label�е�key="name"��value������"frontend"�Ķ���
��ǩ��ѡ����������ʹ�ö��,��ʱ�����Label Selector�������,ʹ�ö���","���зָ����ɡ�����:
name=slave,env!=production
name not in (frontend),env!=production
���ʽ
# Ϊpod��Դ���ǩ
[root@master ~]# kubectl label pod nginx-pod version=1.0 -n dev
pod/nginx-pod labeled
# Ϊpod��Դ���±�ǩ
[root@master ~]# kubectl label pod nginx-pod version=2.0 -n dev --overwrite
pod/nginx-pod labeled
# �鿴��ǩ
[root@master ~]# kubectl get pod nginx-pod -n dev --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-pod 1/1 Running 0 10m version=2.0
# ɸѡ��ǩ
[root@master ~]# kubectl get pod -n dev -l version=2.0 --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-pod 1/1 Running 0 17m version=2.0
[root@master ~]# kubectl get pod -n dev -l version!=2.0 --show-labels
No resources found in dev namespace.
#ɾ����ǩ
[root@master ~]# kubectl label pod nginx-pod version- -n dev
pod/nginx-pod labeled
���÷�ʽ
apiVersion: v1
kind: Pod
metadata:
name: nginx
namespace: dev
labels:
version: "3.0"
env: "test"
spec:
containers:
- image: nginx:latest
name: pod
ports:
- name: nginx-port
containerPort: 80
protocol: TCP
Ȼ��Ϳ���ִ�ж�Ӧ�ĸ���������:kubectl apply -f pod-nginx.yaml
4.4 Deployment
��kubernetes��,Pod����С�Ŀ��Ƶ�Ԫ,����kubernetes����ֱ�ӿ���Pod,һ�㶼��ͨ��Pod����������ɵġ�Pod����������pod�Ĺ���,ȷ��pod��Դ����Ԥ�ڵ�״̬,��pod����Դ���ֹ���ʱ,�᳢�Խ����������ؽ�pod��
��kubernetes��Pod�������������кܶ�,���½�ֻ����һ��:Deployment��
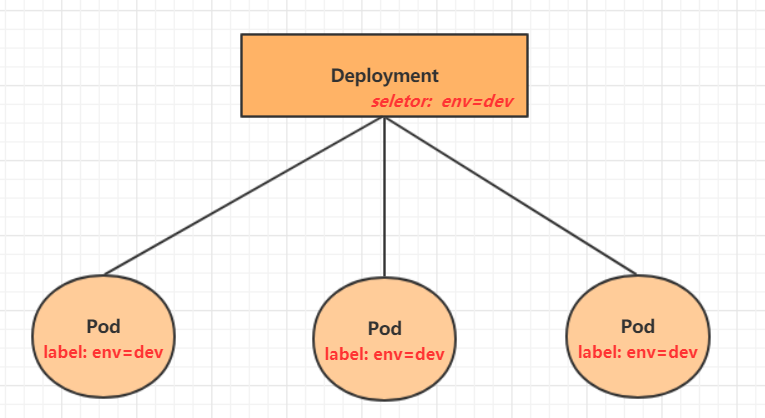
�������
# �����ʽ: kubectl create deployment ���� [����]
# --image ָ��pod�ľ���
# --port ָ���˿�
# --replicas ָ������pod����
# --namespace ָ��namespace
[root@master ~]# kubectl create deploy nginx --image=nginx:latest --port=80 --replicas=3 -n dev
deployment.apps/nginx created
# �鿴������Pod
[root@master ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
nginx-5ff7956ff6-6k8cb 1/1 Running 0 19s
nginx-5ff7956ff6-jxfjt 1/1 Running 0 19s
nginx-5ff7956ff6-v6jqw 1/1 Running 0 19s
# �鿴deployment����Ϣ
[root@master ~]# kubectl get deploy -n dev
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 3/3 3 3 2m42s
# UP-TO-DATE:�ɹ������ĸ�������
# AVAILABLE:���ø���������
[root@master ~]# kubectl get deploy -n dev -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
nginx 3/3 3 3 2m51s nginx nginx:latest run=nginx
# �鿴deployment����ϸ��Ϣ
[root@master ~]# kubectl describe deploy nginx -n dev
Name: nginx
Namespace: dev
CreationTimestamp: Wed, 08 May 2021 11:14:14 +0800
Labels: run=nginx
Annotations: deployment.kubernetes.io/revision: 1
Selector: run=nginx
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: run=nginx
Containers:
nginx:
Image: nginx:latest
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: nginx-5ff7956ff6 (3/3 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 5m43s deployment-controller Scaled up replicaset nginx-5ff7956ff6 to 3
# ɾ��
[root@master ~]# kubectl delete deploy nginx -n dev
deployment.apps "nginx" deleted
����
����һ��deploy-nginx.yaml,��������:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: dev
spec:
replicas: 3
selector:
matchLabels:
run: nginx
template:
metadata:
labels:
run: nginx
spec:
containers:
- image: nginx:latest
name: nginx
ports:
- containerPort: 80
protocol: TCP
Ȼ��Ϳ���ִ�ж�Ӧ�Ĵ�����ɾ��������:
����:kubectl create -f deploy-nginx.yaml
ɾ��:kubectl delete -f deploy-nginx.yaml
4.5 Service
ͨ���Ͻڿε�ѧϰ,�Ѿ��ܹ�����Deployment������һ��Pod���ṩ���и߿����Եķ���
��Ȼÿ��Pod�������һ��������Pod IP,Ȼ��ȴ��������������:
- Pod IP ������Pod���ؽ������仯
- Pod IP �����Ǽ�Ⱥ�ڿɼ�������IP,�ⲿ������
�������ڷ����������������Ѷȡ����,kubernetes�����Service�����������⡣
Service���Կ�����һ��ͬ��Pod����ķ��ʽӿ�������Service,Ӧ�ÿ��Է����ʵ�ַ����ֺ��ؾ��⡣
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-AqcE6IAH-1629018950136)(https://i.loli.net/2021/08/15/oWhETsCk9MUKn1p.png)]
����һ:������Ⱥ�ڲ��ɷ��ʵ�Service
# ��¶Service
[root@master ~]# kubectl expose deploy nginx --name=svc-nginx1 --type=ClusterIP --port=80 --target-port=80 -n dev
service/svc-nginx1 exposed
# �鿴service
[root@master ~]# kubectl get svc svc-nginx1 -n dev -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
svc-nginx1 ClusterIP 10.109.179.231 <none> 80/TCP 3m51s run=nginx
# ���������һ��CLUSTER-IP,�����service��IP,��Service������������,�����ַ�Dz���䶯��
# ����ͨ�����IP���ʵ�ǰservice��Ӧ��POD
[root@master ~]# curl 10.109.179.231:80
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
</head>
<body>
<h1>Welcome to nginx!</h1>
.......
</body>
</html>
������:������Ⱥ�ⲿҲ�ɷ��ʵ�Service
# ���洴����Service��type����ΪClusterIP,���ip��ַֻ�ü�Ⱥ�ڲ��ɷ���
# �����Ҫ�����ⲿҲ���Է��ʵ�Service,��Ҫ��typeΪNodePort
[root@master ~]# kubectl expose deploy nginx --name=svc-nginx2 --type=NodePort --port=80 --target-port=80 -n dev
service/svc-nginx2 exposed
# ��ʱ�鿴,�ᷢ�ֳ�����NodePort���͵�Service,������һ��Port(80:31928/TC)
[root@master ~]# kubectl get svc svc-nginx2 -n dev -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
svc-nginx2 NodePort 10.100.94.0 <none> 80:31928/TCP 9s run=nginx
# �������Ϳ���ͨ����Ⱥ����������� �ڵ�IP:31928���ʷ�����
# �����ڵĵ���������ͨ���������������ĵ�ַ
http://192.168.5.4:31928/
ɾ��Service
[root@master ~]# kubectl delete svc svc-nginx-1 -n dev service "svc-nginx-1" deleted
���÷�ʽ
����һ��svc-nginx.yaml,��������:
apiVersion: v1
kind: Service
metadata:
name: svc-nginx
namespace: dev
spec:
clusterIP: 10.109.179.231 #�̶�svc������ip
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
run: nginx
type: ClusterIP
Ȼ��Ϳ���ִ�ж�Ӧ�Ĵ�����ɾ��������:
����:kubectl create -f svc-nginx.yaml
ɾ��:kubectl delete -f svc-nginx.yaml
��
����,�Ѿ�������Namespace��Pod��Deployment��Service��Դ�Ļ�������,������Щ����,�Ϳ�����kubernetes��Ⱥ��ʵ��һ������ļ���ͷ�����,���������Ҫ���õ�ʹ��kubernetes,����Ҫ����ѧϰ�⼸����Դ��ϸ�ں�ԭ����
5. Pod���
5.1 Pod����
5.1.1 Pod�ṹ
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-O5wZVHCK-1629018950137)(https://i.loli.net/2021/08/15/f8TDiznsVPa5qoL.png)]
ÿ��Pod�ж�������һ�����߶������,��Щ�������Է�Ϊ����:
-
�û��������ڵ�����,�����ɶ����
-
Pause����,����ÿ��Pod�����е�һ��������,��������������:
-
��������Ϊ����,��������Pod�Ľ���״̬
-
�����ڸ�����������Ip��ַ,������������Ip(Pod IP),��ʵ��Pod�ڲ�����·ͨ��
������Pod�ڲ���ͨѶ,Pod��֮���ͨѶ��������������缼����ʵ��,���ǵ�ǰ�����õ���Flannel
-
5.1.2 Pod����
������Pod����Դ�嵥:
apiVersion: v1 #��ѡ,�汾��,����v1
kind: Pod �� #��ѡ,��Դ����,���� Pod
metadata: �� #��ѡ,Ԫ����
name: string #��ѡ,Pod����
namespace: string #Pod�����������ռ�,Ĭ��Ϊ"default"
labels: ���� #�Զ����ǩ�б�
- name: string ��
spec: #��ѡ,Pod����������ϸ����
containers: #��ѡ,Pod�������б�
- name: string #��ѡ,��������
image: string #��ѡ,�����ľ�������
imagePullPolicy: [ Always|Never|IfNotPresent ] #��ȡ����IJ���
command: [string] #���������������б�,�粻ָ��,ʹ�ô��ʱʹ�õ���������
args: [string] #������������������б�
workingDir: string #�����Ĺ���Ŀ¼
volumeMounts: #���ص������ڲ��Ĵ洢������
- name: string #����pod����Ĺ����洢��������,����volumes[]���ֶ���ĵľ���
mountPath: string #�洢����������mount�ľ���·��,Ӧ����512�ַ�
readOnly: boolean #�Ƿ�Ϊֻ��ģʽ
ports: #��Ҫ��¶�Ķ˿ڿ���б�
- name: string #�˿ڵ�����
containerPort: int #������Ҫ�����Ķ˿ں�
hostPort: int #��������������Ҫ�����Ķ˿ں�,Ĭ����Container��ͬ
protocol: string #�˿�Э��,֧��TCP��UDP,Ĭ��TCP
env: #��������ǰ�����õĻ��������б�
- name: string #������������
value: string #����������ֵ
resources: #��Դ���ƺ����������
limits: #��Դ���Ƶ�����
cpu: string #Cpu������,��λΪcore��,������docker run --cpu-shares����
memory: string #�ڴ�����,��λ����ΪMib/Gib,������docker run --memory����
requests: #��Դ���������
cpu: string #Cpu����,���������ij�ʼ��������
memory: string #�ڴ�����,���������ij�ʼ��������
lifecycle: #�������ڹ���
postStart: #��������������ִ�д˹���,���ִ��ʧ��,������������Խ�������
preStop: #������ֹǰִ�д˹���,���۽�����,����������ֹ
livenessProbe: #��Pod�ڸ�����������������,��̽������Ӧ���κ��Զ�����������
exec: �� #��Pod�����ڼ�鷽ʽ����Ϊexec��ʽ
command: [string] #exec��ʽ��Ҫ�ƶ��������ű�
httpGet: #��Pod�ڸ�����������鷽������ΪHttpGet,��Ҫ�ƶ�Path��port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #��Pod�ڸ�����������鷽ʽ����ΪtcpSocket��ʽ
port: number
initialDelaySeconds: 0 #����������ɺ��״�̽���ʱ��,��λΪ��
timeoutSeconds: 0 ���� #�������������̽��ȴ���Ӧ�ij�ʱʱ��,��λ��,Ĭ��1��
periodSeconds: 0 ���� #��������ؼ��Ķ���̽��ʱ������,��λ��,Ĭ��10��һ��
successThreshold: 0
failureThreshold: 0
securityContext:
privileged: false
restartPolicy: [Always | Never | OnFailure] #Pod����������
nodeName: <string> #����NodeName��ʾ����Pod���ȵ�ָ�������Ƶ�node�ڵ���
nodeSelector: obeject #����NodeSelector��ʾ����Pod���ȵ��������label��node��
imagePullSecrets: #Pull����ʱʹ�õ�secret����,��key:secretkey��ʽָ��
- name: string
hostNetwork: false #�Ƿ�ʹ����������ģʽ,Ĭ��Ϊfalse,�������Ϊtrue,��ʾʹ������������
volumes: #�ڸ�pod�϶��干���洢���б�
- name: string #�����洢������ (volumes�����кܶ���)
emptyDir: {} #����ΪemtyDir�Ĵ洢��,��Podͬ�������ڵ�һ����ʱĿ¼��Ϊ��ֵ
hostPath: string #����ΪhostPath�Ĵ洢��,��ʾ����Pod������������Ŀ¼
path: string ���� #Pod������������Ŀ¼,��������ͬ����mount��Ŀ¼
secret: ������#����Ϊsecret�Ĵ洢��,���ؼ�Ⱥ�붨���secret���������ڲ�
scretname: string
items:
- key: string
path: string
configMap: #����ΪconfigMap�Ĵ洢��,����Ԥ�����configMap���������ڲ�
name: string
items:
- key: string
path: string
#С��ʾ:
# ������,��ͨ��һ���������鿴ÿ����Դ�Ŀ�������
# kubectl explain ��Դ���� �鿴ij����Դ�������õ�һ������
# kubectl explain ��Դ����.���� �鿴���Ե�������
[root@k8s-master01 ~]# kubectl explain pod
KIND: Pod
VERSION: v1
FIELDS:
apiVersion <string>
kind <string>
metadata <Object>
spec <Object>
status <Object>
[root@k8s-master01 ~]# kubectl explain pod.metadata
KIND: Pod
VERSION: v1
RESOURCE: metadata <Object>
FIELDS:
annotations <map[string]string>
clusterName <string>
creationTimestamp <string>
deletionGracePeriodSeconds <integer>
deletionTimestamp <string>
finalizers <[]string>
generateName <string>
generation <integer>
labels <map[string]string>
managedFields <[]Object>
name <string>
namespace <string>
ownerReferences <[]Object>
resourceVersion <string>
selfLink <string>
uid <string>
��kubernetes�л���������Դ��һ�����Զ���һ����,��Ҫ����5����:
- apiVersion �汾,��kubernetes�ڲ�����,�汾�ű�������� kubectl api-versions ��ѯ��
- kind ����,��kubernetes�ڲ�����,�汾�ű�������� kubectl api-resources ��ѯ��
- metadata Ԫ����,��Ҫ����Դ��ʶ��˵��,���õ���name��namespace��labels��
- spec ����,��������������Ҫ��һ����,�����ǶԸ�����Դ���õ���ϸ����
- status ״̬��Ϣ,��������ݲ���Ҫ����,��kubernetes�Զ�����
�������������,spec�ǽ������о����ص�,�����������ij���������:
- containers <[]Object> �����б�,���ڶ�����������ϸ��Ϣ
- nodeName ����nodeName��ֵ��pod���ȵ�ָ����Node�ڵ���
- nodeSelector <map[]> ����NodeSelector�ж������Ϣѡ��Pod���ȵ�������Щlabel��Node ��
- hostNetwork �Ƿ�ʹ����������ģʽ,Ĭ��Ϊfalse,�������Ϊtrue,��ʾʹ������������
- volumes <[]Object> �洢��,���ڶ���Pod������ڵĴ洢��Ϣ
- restartPolicy ��������,��ʾPod���������ϵ�ʱ��Ĵ�������
5.2 Pod����
��С����Ҫ���о�pod.spec.containers����,��Ҳ��pod��������Ϊ�ؼ���һ�����á�
[root@k8s-master01 ~]# kubectl explain pod.spec.containers
KIND: Pod
VERSION: v1
RESOURCE: containers <[]Object> # ����,��������������
FIELDS:
name <string> # ��������
image <string> # ������Ҫ�ľ����ַ
imagePullPolicy <string> # ������ȡ����
command <[]string> # ���������������б�,�粻ָ��,ʹ�ô��ʱʹ�õ���������
args <[]string> # ����������������Ҫ�IJ����б�
env <[]Object> # ������������������
ports <[]Object> # ������Ҫ��¶�Ķ˿ں��б�
resources <Object> # ��Դ���ƺ���Դ���������
5.2.1 ��������
����pod-base.yaml�ļ�,��������:
apiVersion: v1
kind: Pod
metadata:
name: pod-base
namespace: dev
labels:
user: heima
spec:
containers:
- name: nginx
image: nginx:1.17.1
- name: busybox
image: busybox:1.30

���涨����һ���Ƚϼ�Pod������,��������������:
- nginx:��1.17.1�汾��nginx����,(nginx��һ��������web����)
- busybox:��1.30�汾��busybox����,(busybox��һ��С�ɵ�linux�����)
# ����Pod
[root@k8s-master01 pod]# kubectl apply -f pod-base.yaml
pod/pod-base created
# �鿴Pod״��
# READY 1/2 : ��ʾ��ǰPod����2������,����1��������,1��δ����
# RESTARTS : ��������,��Ϊ��1������������,Podһֱ��������ͼ�ָ���
[root@k8s-master01 pod]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
pod-base 1/2 Running 4 95s
# ����ͨ��describe�鿴�ڲ�������
# ��ʱ�Ѿ�����������һ��������Pod,��Ȼ����ʱ������
[root@k8s-master01 pod]# kubectl describe pod pod-base -n dev
5.2.2 ������ȡ
����pod-imagepullpolicy.yaml�ļ�,��������:
apiVersion: v1
kind: Pod
metadata:
name: pod-imagepullpolicy
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
imagePullPolicy: Never # �������þ�����ȡ����
- name: busybox
image: busybox:1.30
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-ro2pxNbg-1629018950138)(https://i.loli.net/2021/08/15/PHLergWdBiUXupt.png)]
imagePullPolicy,�������þ�����ȡ����,kubernetes֧������������ȡ����:
- Always:���Ǵ�Զ�ֿ̲���ȡ����(һֱԶ������)
- IfNotPresent:��������ʹ�ñ��ؾ���,����û�����Զ�ֿ̲���ȡ����(�����оͱ��� ����ûԶ������)
- Never:ֻʹ�ñ��ؾ���,�Ӳ�ȥԶ�ֿ̲���ȡ,����û�оͱ��� (һֱʹ�ñ���)
Ĭ��ֵ˵��:
�������tagΪ����汾��, Ĭ�ϲ�����:IfNotPresent
�������tagΪ:latest(���հ汾) ,Ĭ�ϲ�����always
# ����Pod
[root@k8s-master01 pod]# kubectl create -f pod-imagepullpolicy.yaml
pod/pod-imagepullpolicy created
# �鿴Pod����
# ��ʱ���Կ��Կ���nginx������һ��Pulling image "nginx:1.17.1"�Ĺ���
[root@k8s-master01 pod]# kubectl describe pod pod-imagepullpolicy -n dev
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned dev/pod-imagePullPolicy to node1
Normal Pulling 32s kubelet, node1 Pulling image "nginx:1.17.1"
Normal Pulled 26s kubelet, node1 Successfully pulled image "nginx:1.17.1"
Normal Created 26s kubelet, node1 Created container nginx
Normal Started 25s kubelet, node1 Started container nginx
Normal Pulled 7s (x3 over 25s) kubelet, node1 Container image "busybox:1.30" already present on machine
Normal Created 7s (x3 over 25s) kubelet, node1 Created container busybox
Normal Started 7s (x3 over 25s) kubelet, node1 Started container busybox
5.2.3 ��������
��ǰ��İ�����,һֱ��һ������û�н��,���ǵ�busybox����һֱû�гɹ�����,��ô������ʲôԭ������������Ĺ�����?
ԭ��busybox������һ������,����������һ��������ļ���,kubernetes��Ⱥ����������,�����Զ��رա����������������һֱ������,����õ���command���á�
����pod-command.yaml�ļ�,��������:
apiVersion: v1
kind: Pod
metadata:
name: pod-command
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
- name: busybox
image: busybox:1.30
command: ["/bin/sh","-c","touch /tmp/hello.txt;while true;do /bin/echo $(date +%T) >> /tmp/hello.txt; sleep 3; done;"]
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-8EHVWeLc-1629018950139)(https://i.loli.net/2021/08/15/8vIWeksGANPJrLo.png)]
command,������pod�е�������ʼ�����֮������һ�����
�������������������˼:
��/bin/sh��,"-c", ʹ��shִ������
touch /tmp/hello.txt; ����һ��/tmp/hello.txt �ļ�
while true;do /bin/echo $(date +%T) >> /tmp/hello.txt; sleep 3; done; ÿ��3�����ļ���д�뵱ǰʱ��
# ����Pod
[root@k8s-master01 pod]# kubectl create -f pod-command.yaml
pod/pod-command created
# �鿴Pod״̬
# ��ʱ��������pod������������
[root@k8s-master01 pod]# kubectl get pods pod-command -n dev
NAME READY STATUS RESTARTS AGE
pod-command 2/2 Runing 0 2s
# ����pod�е�busybox����,�鿴�ļ�����
# ����һ������: kubectl exec pod���� -n �����ռ� -it -c �������� /bin/sh �������ڲ�ִ������
# ʹ���������Ϳ��Խ���ij���������ڲ�,Ȼ�������ز�����
# ����,���Բ鿴txt�ļ�������
[root@k8s-master01 pod]# kubectl exec pod-command -n dev -it -c busybox /bin/sh
/ # tail -f /tmp/hello.txt
14:44:19
14:44:22
14:44:25
�ر�˵��:
ͨ�����淢��command�Ѿ����������������ʹ��ݲ����Ĺ���,Ϊʲô���ﻹҪ�ṩһ��argsѡ��,���ڴ��ݲ�����?����ʵ��docker�е��ϵ,kubernetes�е�command��args������ʵ��ʵ�ָ���Dockerfile��ENTRYPOINT�Ĺ��ܡ�
1 ���command��args��û��д,��ô��Dockerfile�����á�
2 ���commandд��,��argsû��д,��ôDockerfileĬ�ϵ����ûᱻ����,ִ�������command
3 ���commandûд,��argsд��,��ôDockerfile�����õ�ENTRYPOINT������ᱻִ��,ʹ�õ�ǰargs�IJ���
4 ���command��args��д��,��ôDockerfile�����ñ�����,ִ��command������args����
5.2.4 ��������
����pod-env.yaml�ļ�,��������:
apiVersion: v1
kind: Pod
metadata:
name: pod-env
namespace: dev
spec:
containers:
- name: busybox
image: busybox:1.30
command: ["/bin/sh","-c","while true;do /bin/echo $(date +%T);sleep 60; done;"]
env: # ���û��������б�
- name: "username"
value: "admin"
- name: "password"
value: "123456"
env,��������,������pod�е��������û���������
# ����Pod
[root@k8s-master01 ~]# kubectl create -f pod-env.yaml
pod/pod-env created
# ��������,�����������
[root@k8s-master01 ~]# kubectl exec pod-env -n dev -c busybox -it /bin/sh
/ # echo $username
admin
/ # echo $password
123456
���ַ�ʽ���Ǻ��Ƽ�,�Ƽ�����Щ���õ����洢�������ļ���,���ַ�ʽ���ں�����ܡ�
5.2.5 �˿�����
��С�������������Ķ˿�����,Ҳ����containers��portsѡ�
���ȿ���ports֧�ֵ���ѡ��:
[root@k8s-master01 ~]# kubectl explain pod.spec.containers.ports
KIND: Pod
VERSION: v1
RESOURCE: ports <[]Object>
FIELDS:
name <string> # �˿�����,���ָ��,���뱣֤name��pod����Ψһ��
containerPort<integer> # ����Ҫ�����Ķ˿�(0<x<65536)
hostPort <integer> # ����Ҫ�������Ϲ����Ķ˿�,�������,������ֻ������������һ������(һ��ʡ��)
hostIP <string> # Ҫ���ⲿ�˿ڰ�������IP(һ��ʡ��)
protocol <string> # �˿�Э�顣������UDP��TCP��SCTP��Ĭ��Ϊ��TCP����
������,��дһ��������,����pod-ports.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-ports
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports: # ����������¶�Ķ˿��б�
- name: nginx-port
containerPort: 80
protocol: TCP
# ����Pod
[root@k8s-master01 ~]# kubectl create -f pod-ports.yaml
pod/pod-ports created
# �鿴pod
# ������������Կ���������Ϣ
[root@k8s-master01 ~]# kubectl get pod pod-ports -n dev -o yaml
......
spec:
containers:
- image: nginx:1.17.1
imagePullPolicy: IfNotPresent
name: nginx
ports:
- containerPort: 80
name: nginx-port
protocol: TCP
......
���������еij�����Ҫʹ�õ���Podip:containerPort
5.2.6 ��Դ���
�����еij���Ҫ����,�϶���Ҫռ��һ����Դ��,����cpu���ڴ��,�������ij����������Դ������,��ô���Ϳ��ܳԵ�������Դ,�����������������С�����������,kubernetes�ṩ�˶��ڴ��cpu����Դ�������Ļ���,���ֻ�����Ҫͨ��resourcesѡ��ʵ��,����������ѡ��:
- limits:������������ʱ���������ռ����Դ,������ռ����Դ����limitsʱ�ᱻ��ֹ,����������
- requests :��������������Ҫ����С��Դ,���������Դ����,������������
����ͨ����������ѡ��������Դ�������ޡ�
������,��дһ��������,����pod-resources.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-resources
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
resources: # ��Դ���
limits: # ������Դ(����)
cpu: "2" # CPU����,���core��
memory: "10Gi" # �ڴ�����
requests: # ������Դ(����)
cpu: "1" # CPU����,���core��
memory: "10Mi" # �ڴ�����
�����cpu��memory�ĵ�λ��һ��˵��:
- cpu:core��,����Ϊ������С��
- memory: �ڴ��С,����ʹ��Gi��Mi��G��M����ʽ
# ����Pod
[root@k8s-master01 ~]# kubectl create -f pod-resources.yaml
pod/pod-resources created
# �鿴����pod��������
[root@k8s-master01 ~]# kubectl get pod pod-resources -n dev
NAME READY STATUS RESTARTS AGE
pod-resources 1/1 Running 0 39s
# ������,ֹͣPod
[root@k8s-master01 ~]# kubectl delete -f pod-resources.yaml
pod "pod-resources" deleted
# �༭pod,��resources.requests.memory��ֵΪ10Gi
[root@k8s-master01 ~]# vim pod-resources.yaml
# �ٴ�����pod
[root@k8s-master01 ~]# kubectl create -f pod-resources.yaml
pod/pod-resources created
# �鿴Pod״̬,����Pod����ʧ��
[root@k8s-master01 ~]# kubectl get pod pod-resources -n dev -o wide
NAME READY STATUS RESTARTS AGE
pod-resources 0/1 Pending 0 20s
# �鿴pod����ᷢ��,������ʾ
[root@k8s-master01 ~]# kubectl describe pod pod-resources -n dev
......
Warning FailedScheduling 35s default-scheduler 0/3 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate, 2 Insufficient memory.(�ڴ治��)
5.3 Pod��������
����һ�㽫pod����Ӵ������յ����ʱ�䷶Χ��Ϊpod����������,����Ҫ��������Ĺ���:
- pod��������
- ���г�ʼ������(init container)����
- ����������(main container)
- ������������(post start)��������ֹǰ����(pre stop)
- �����Ĵ����̽��(liveness probe)��������̽��(readiness probe)
- pod��ֹ����
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-wwnXsfVO-1629018950140)(https://i.loli.net/2021/08/15/nhDBcRAVOpMrj54.png)]
����������������,Pod�����5��״̬(��λ),�ֱ�����:
- ����(Pending):apiserver�Ѿ�������pod��Դ����,������δ��������ɻ����Դ������ؾ���Ĺ�����
- ������(Running):pod�Ѿ���������ij�ڵ�,���������������Ѿ���kubelet�������
- �ɹ�(Succeeded):pod�е������������Ѿ��ɹ���ֹ���Ҳ��ᱻ����
- ʧ��(Failed):�����������Ѿ���ֹ,��������һ��������ֹʧ��,�����������˷�0ֵ���˳�״̬
- δ֪(Unknown):apiserver��������ȡ��pod�����״̬��Ϣ,ͨ��������ͨ��ʧ��������
5.3.1 ��������ֹ
pod�Ĵ�������
-
�û�ͨ��kubectl������api�ͻ����ύ��Ҫ������pod��Ϣ��apiServer
-
apiServer��ʼ����pod�������Ϣ,������Ϣ����etcd,Ȼ��ȷ����Ϣ���ͻ���
-
apiServer��ʼ��ӳetcd�е�pod����ı仯,�������ʹ��watch���������ټ��apiServer�ϵı䶯
-
scheduler�������µ�pod����Ҫ����,��ʼΪPod�����������������Ϣ������apiServer
-
node�ڵ��ϵ�kubelet������pod���ȹ���,���Ե���docker��������,�������������apiServer
-
apiServer�����յ���pod״̬��Ϣ����etcd��
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-zUichOTb-1629018950140)(https://i.loli.net/2021/08/15/BMNKEL7n8fsZS26.png)]
pod����ֹ����
- �û���apiServer����ɾ��pod���������
- apiServcer�е�pod������Ϣ������ʱ������ƶ�����,�ڿ�������(Ĭ��30s),pod����Ϊdead
- ��pod���Ϊterminating״̬
- kubelet�ڼ�ص�pod����תΪterminating״̬��ͬʱ����pod�رչ���
- �˵��������ص�pod����Ĺر���Ϊʱ���������ƥ�䵽�˶˵��service��Դ�Ķ˵��б����Ƴ�
- �����ǰpod��������preStop���Ӵ�����,��������Ϊterminating����ͬ���ķ�ʽ����ִ��
- pod�����е����������յ�ֹͣ�ź�
- �����ڽ�����,��pod�л������������еĽ���,��ôpod������յ�������ֹ���ź�
- kubelet����apiServer����pod��Դ�Ŀ���������Ϊ0�Ӷ����ɾ������,��ʱpod�����û��Ѳ��ɼ�
5.3.2 ��ʼ������
��ʼ����������pod������������֮ǰҪ���е�����,��Ҫ����һЩ��������ǰ�ù���,��������������:
- ��ʼ�����������������ֱ������,��ij��ʼ����������ʧ��,��ôkubernetes��Ҫ������ֱ���ɹ����
- ��ʼ���������밴�ն����˳��ִ��,���ҽ���ǰһ���ɹ�֮��,�����һ����������
��ʼ�������кܶ��Ӧ�ó���,�����г���������ļ���:
- �ṩ�����������в��߱��Ĺ��߳�����Զ������
- ��ʼ������Ҫ����Ӧ�����������������������,��˿������Ӻ�Ӧ������������ֱ���������������õ�����
��������һ������,ģ�������������:
����Ҫ��������������nginx,����Ҫ��������nginx֮ǰ��Ҫ�ܹ�������mysql��redis���ڷ�����
Ϊ�˼���,���ȹ涨��mysql(192.168.5.14)��redis(192.168.5.15)�������ĵ�ַ
����pod-initcontainer.yaml,��������:
apiVersion: v1
kind: Pod
metadata:
name: pod-initcontainer
namespace: dev
spec:
containers:
- name: main-container
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
initContainers:
- name: test-mysql
image: busybox:1.30
command: ['sh', '-c', 'until ping 192.168.5.14 -c 1 ; do echo waiting for mysql...; sleep 2; done;']
- name: test-redis
image: busybox:1.30
command: ['sh', '-c', 'until ping 192.168.5.15 -c 1 ; do echo waiting for reids...; sleep 2; done;']
# ����pod
[root@k8s-master01 ~]# kubectl create -f pod-initcontainer.yaml
pod/pod-initcontainer created
# �鿴pod״̬
# ����pod����������һ����ʼ������������,�����������������
root@k8s-master01 ~]# kubectl describe pod pod-initcontainer -n dev
........
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 49s default-scheduler Successfully assigned dev/pod-initcontainer to node1
Normal Pulled 48s kubelet, node1 Container image "busybox:1.30" already present on machine
Normal Created 48s kubelet, node1 Created container test-mysql
Normal Started 48s kubelet, node1 Started container test-mysql
# ��̬�鿴pod
[root@k8s-master01 ~]# kubectl get pods pod-initcontainer -n dev -w
NAME READY STATUS RESTARTS AGE
pod-initcontainer 0/1 Init:0/2 0 15s
pod-initcontainer 0/1 Init:1/2 0 52s
pod-initcontainer 0/1 Init:1/2 0 53s
pod-initcontainer 0/1 PodInitializing 0 89s
pod-initcontainer 1/1 Running 0 90s
# �������¿�һ��shell,Ϊ��ǰ��������������ip,�۲�pod�ı仯
[root@k8s-master01 ~]# ifconfig ens33:1 192.168.5.14 netmask 255.255.255.0 up
[root@k8s-master01 ~]# ifconfig ens33:2 192.168.5.15 netmask 255.255.255.0 up
5.3.3 ���Ӻ���
���Ӻ����ܹ���֪�������������е��¼�,������Ӧ��ʱ�̵���ʱ�����û�ָ���ij�����롣
kubernetes��������������֮���ֹ֮ͣǰ�ṩ���������Ӻ���:
- post start:��������֮��ִ��,���ʧ���˻���������
- pre stop :������ֹ֮ǰִ��,ִ�����֮���������ɹ���ֹ,�������֮ǰ������ɾ�������IJ���
���Ӵ�����֧��ʹ���������ַ�ʽ���嶯��:
-
Exec����:��������ִ��һ������
���� lifecycle: postStart: exec: command: - cat - /tmp/healthy ���� -
TCPSocket:�ڵ�ǰ�������Է���ָ����socket
���� lifecycle: postStart: tcpSocket: port: 8080 ���� -
HTTPGet:�ڵ�ǰ��������ijurl����http����
���� lifecycle: postStart: httpGet: path: / #URI��ַ port: 80 #�˿ں� host: 192.168.5.3 #������ַ scheme: HTTP #֧�ֵ�Э��,http����https ����
������,��exec��ʽΪ��,��ʾ�¹��Ӻ�����ʹ��,����pod-hook-exec.yaml�ļ�,��������:
apiVersion: v1
kind: Pod
metadata:
name: pod-hook-exec
namespace: dev
spec:
containers:
- name: main-container
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
lifecycle:
postStart:
exec: # ������������ʱ��ִ��һ������,�ĵ�nginx��Ĭ����ҳ����
command: ["/bin/sh", "-c", "echo postStart... > /usr/share/nginx/html/index.html"]
preStop:
exec: # ������ֹ֮ͣǰֹͣnginx����
command: ["/usr/sbin/nginx","-s","quit"]
# ����pod
[root@k8s-master01 ~]# kubectl create -f pod-hook-exec.yaml
pod/pod-hook-exec created
# �鿴pod
[root@k8s-master01 ~]# kubectl get pods pod-hook-exec -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pod-hook-exec 1/1 Running 0 29s 10.244.2.48 node2
# ����pod
[root@k8s-master01 ~]# curl 10.244.2.48
postStart...
5.3.4 ����̽��
����̽�����ڼ�������е�Ӧ��ʵ���Ƿ���������,�DZ���ҵ������Ե�һ�ִ�ͳ���ơ��������̽��,ʵ����״̬������Ԥ��,��ôkubernetes�ͻ�Ѹ�����ʵ��" ժ�� ",���е�ҵ��������kubernetes�ṩ������̽����ʵ������̽��,�ֱ���:
- liveness probes:�����̽��,���ڼ��Ӧ��ʵ����ǰ�Ƿ�����������״̬,�������,k8s����������
- readiness probes:������̽��,���ڼ��Ӧ��ʵ����ǰ�Ƿ���Խ�������,�������,k8s����ת������
livenessProbe �����Ƿ���������,readinessProbe �����Ƿ�����ת����������
��������̽��Ŀǰ��֧������̽�ⷽʽ:
-
Exec����:��������ִ��һ������,�������ִ�е��˳���Ϊ0,����Ϊ��������,��������
���� livenessProbe: exec: command: - cat - /tmp/healthy ���� -
TCPSocket:���᳢�Է���һ���û������Ķ˿�,����ܹ�������������,����Ϊ��������,��������
���� livenessProbe: tcpSocket: port: 8080 ���� -
HTTPGet:����������WebӦ�õ�URL,������ص�״̬����200��399֮��,����Ϊ��������,��������
���� livenessProbe: httpGet: path: / #URI��ַ port: 80 #�˿ں� host: 127.0.0.1 #������ַ scheme: HTTP #֧�ֵ�Э��,http����https ����
������liveness probesΪ��,��������ʾ:
��ʽһ:Exec
����pod-liveness-exec.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-exec
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
exec:
command: ["/bin/cat","/tmp/hello.txt"] # ִ��һ���鿴�ļ�������
����pod,�۲�Ч��
# ����Pod
[root@k8s-master01 ~]# kubectl create -f pod-liveness-exec.yaml
pod/pod-liveness-exec created
# �鿴Pod����
[root@k8s-master01 ~]# kubectl describe pods pod-liveness-exec -n dev
......
Normal Created 20s (x2 over 50s) kubelet, node1 Created container nginx
Normal Started 20s (x2 over 50s) kubelet, node1 Started container nginx
Normal Killing 20s kubelet, node1 Container nginx failed liveness probe, will be restarted
Warning Unhealthy 0s (x5 over 40s) kubelet, node1 Liveness probe failed: cat: can't open '/tmp/hello11.txt': No such file or directory
# �۲��������Ϣ�ͻᷢ��nginx��������֮��ͽ����˽������
# ���ʧ��֮��,������kill��,Ȼ���Խ�������(�����������Ե�����,���潲��)
# �Ե�һ��֮��,�ٹ۲�pod��Ϣ,�Ϳ��Կ���RESTARTS������0,����һֱ����
[root@k8s-master01 ~]# kubectl get pods pod-liveness-exec -n dev
NAME READY STATUS RESTARTS AGE
pod-liveness-exec 0/1 CrashLoopBackOff 2 3m19s
# ��Ȼ������,�����ij�һ�����ڵ��ļ�,����/tmp/hello.txt,����,�����������......
��ʽ��:TCPSocket
����pod-liveness-tcpsocket.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-tcpsocket
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
tcpSocket:
port: 8080 # ���Է���8080�˿�
����pod,�۲�Ч��
# ����Pod
[root@k8s-master01 ~]# kubectl create -f pod-liveness-tcpsocket.yaml
pod/pod-liveness-tcpsocket created
# �鿴Pod����
[root@k8s-master01 ~]# kubectl describe pods pod-liveness-tcpsocket -n dev
......
Normal Scheduled 31s default-scheduler Successfully assigned dev/pod-liveness-tcpsocket to node2
Normal Pulled <invalid> kubelet, node2 Container image "nginx:1.17.1" already present on machine
Normal Created <invalid> kubelet, node2 Created container nginx
Normal Started <invalid> kubelet, node2 Started container nginx
Warning Unhealthy <invalid> (x2 over <invalid>) kubelet, node2 Liveness probe failed: dial tcp 10.244.2.44:8080: connect: connection refused
# �۲��������Ϣ,���ֳ��Է���8080�˿�,����ʧ����
# �Ե�һ��֮��,�ٹ۲�pod��Ϣ,�Ϳ��Կ���RESTARTS������0,����һֱ����
[root@k8s-master01 ~]# kubectl get pods pod-liveness-tcpsocket -n dev
NAME READY STATUS RESTARTS AGE
pod-liveness-tcpsocket 0/1 CrashLoopBackOff 2 3m19s
# ��Ȼ������,�����ij�һ�����Է��ʵĶ˿�,����80,����,�����������......
��ʽ��:HTTPGet
����pod-liveness-httpget.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-httpget
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
httpGet: # ��ʵ���Ƿ���http://127.0.0.1:80/hello
scheme: HTTP #֧�ֵ�Э��,http����https
port: 80 #�˿ں�
path: /hello #URI��ַ
����pod,�۲�Ч��
# ����Pod
[root@k8s-master01 ~]# kubectl create -f pod-liveness-httpget.yaml
pod/pod-liveness-httpget created
# �鿴Pod����
[root@k8s-master01 ~]# kubectl describe pod pod-liveness-httpget -n dev
.......
Normal Pulled 6s (x3 over 64s) kubelet, node1 Container image "nginx:1.17.1" already present on machine
Normal Created 6s (x3 over 64s) kubelet, node1 Created container nginx
Normal Started 6s (x3 over 63s) kubelet, node1 Started container nginx
Warning Unhealthy 6s (x6 over 56s) kubelet, node1 Liveness probe failed: HTTP probe failed with statuscode: 404
Normal Killing 6s (x2 over 36s) kubelet, node1 Container nginx failed liveness probe, will be restarted
# �۲�������Ϣ,���Է���·��,����δ�ҵ�,����404����
# �Ե�һ��֮��,�ٹ۲�pod��Ϣ,�Ϳ��Կ���RESTARTS������0,����һֱ����
[root@k8s-master01 ~]# kubectl get pod pod-liveness-httpget -n dev
NAME READY STATUS RESTARTS AGE
pod-liveness-httpget 1/1 Running 5 3m17s
# ��Ȼ������,�����ij�һ�����Է��ʵ�·��path,����/,����,�����������......
����,�Ѿ�ʹ��liveness Probe��ʾ������̽�ⷽʽ,���Dz鿴livenessProbe��������,�ᷢ�ֳ��������ַ�ʽ,����һЩ����������,������һ��������:
[root@k8s-master01 ~]# kubectl explain pod.spec.containers.livenessProbe
FIELDS:
exec <Object>
tcpSocket <Object>
httpGet <Object>
initialDelaySeconds <integer> # ����������ȴ�������ִ�е�һ��̽��
timeoutSeconds <integer> # ̽�ⳬʱʱ�䡣Ĭ��1��,��С1��
periodSeconds <integer> # ִ��̽���Ƶ�ʡ�Ĭ����10��,��С1��
failureThreshold <integer> # ����̽��ʧ�ܶ��ٴβű��϶�Ϊʧ�ܡ�Ĭ����3����Сֵ��1
successThreshold <integer> # ����̽��ɹ����ٴβű��϶�Ϊ�ɹ���Ĭ����1
��������������,��ʾ��Ч������:
[root@k8s-master01 ~]# more pod-liveness-httpget.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-httpget
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
httpGet:
scheme: HTTP
port: 80
path: /
initialDelaySeconds: 30 # ����������30s��ʼ̽��
timeoutSeconds: 5 # ̽�ⳬʱʱ��Ϊ5s
5.3.5 ��������
����һ����,һ������̽�����������,kubernetes�ͻ���������ڵ�Pod��������,��ʵ������pod���������Ծ�����,pod������������ 3 ��,�ֱ�����:
- Always :����ʧЧʱ,�Զ�����������,��Ҳ��Ĭ��ֵ��
- OnFailure : ������ֹ�������˳��벻Ϊ0ʱ����
- Never : ����״̬Ϊ��,��������������
��������������pod�����е���������,�״���Ҫ����������,��������Ҫʱ������������,����ٴ���Ҫ�����IJ�������kubelet�ӳ�һ��ʱ������,�ҷ����������������ӳ�ʱ���Դ�Ϊ10s��20s��40s��80s��160s��300s,300s������ӳ�ʱ����
����pod-restartpolicy.yaml:
apiVersion: v1
kind: Pod
metadata:
name: pod-restartpolicy
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
httpGet:
scheme: HTTP
port: 80
path: /hello
restartPolicy: Never # ������������ΪNever
����Pod����
# ����Pod
[root@k8s-master01 ~]# kubectl create -f pod-restartpolicy.yaml
pod/pod-restartpolicy created
# �鿴Pod����,����nginx����ʧ��
[root@k8s-master01 ~]# kubectl describe pods pod-restartpolicy -n dev
......
Warning Unhealthy 15s (x3 over 35s) kubelet, node1 Liveness probe failed: HTTP probe failed with statuscode: 404
Normal Killing 15s kubelet, node1 Container nginx failed liveness probe
# ���һ��,�ٹ۲�pod����������,����һֱ��0,��δ����
[root@k8s-master01 ~]# kubectl get pods pod-restartpolicy -n dev
NAME READY STATUS RESTARTS AGE
pod-restartpolicy 0/1 Running 0 5min42s
5.4 Pod����
��Ĭ�������,һ��Pod���ĸ�Node�ڵ�������,����Scheduler���������Ӧ���㷨���������,��������Dz����˹����Ƶġ�������ʵ��ʹ����,�Ⲣ�����������,��Ϊ�ܶ������,���������ijЩPod����ijЩ�ڵ���,��ôӦ����ô����?���Ҫ���˽�kubernetes��Pod�ĵ��ȹ���,kubernetes�ṩ���Ĵ�����ȷ�ʽ:
- �Զ�����:�������ĸ��ڵ�����ȫ��Scheduler����һϵ�е��㷨����ó�
- �������:NodeName��NodeSelector
- ���Ե���:NodeAffinity��PodAffinity��PodAntiAffinity
- �۵�(����)����:Taints��Toleration
5.4.1 �������
�������,ָ����������pod������nodeName����nodeSelector,�Դ˽�Pod���ȵ�������node�ڵ��ϡ�ע��,����ĵ�����ǿ�Ƶ�,�����ζ�ż�ʹҪ���ȵ�Ŀ��Node������,Ҳ����������е���,ֻ����pod����ʧ�ܶ��ѡ�
NodeName
NodeName����ǿ��Լ����Pod���ȵ�ָ����Name��Node�ڵ��ϡ����ַ�ʽ,��ʵ��ֱ������Scheduler�ĵ�����,ֱ�ӽ�Pod���ȵ�ָ�����ƵĽڵ㡣
������,ʵ��һ��:����һ��pod-nodename.yaml�ļ�
apiVersion: v1
kind: Pod
metadata:
name: pod-nodename
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
nodeName: node1 # ָ�����ȵ�node1�ڵ���
#����Pod
[root@k8s-master01 ~]# kubectl create -f pod-nodename.yaml
pod/pod-nodename created
#�鿴Pod���ȵ�NODE����,ȷʵ�ǵ��ȵ���node1�ڵ���
[root@k8s-master01 ~]# kubectl get pods pod-nodename -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodename 1/1 Running 0 56s 10.244.1.87 node1 ......
# ������,ɾ��pod,��nodeName��ֵΪnode3(��û��node3�ڵ�)
[root@k8s-master01 ~]# kubectl delete -f pod-nodename.yaml
pod "pod-nodename" deleted
[root@k8s-master01 ~]# vim pod-nodename.yaml
[root@k8s-master01 ~]# kubectl create -f pod-nodename.yaml
pod/pod-nodename created
#�ٴβ鿴,�����Ѿ���Node3�ڵ����,�������ڲ�����node3�ڵ�,����pod����������
[root@k8s-master01 ~]# kubectl get pods pod-nodename -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodename 0/1 Pending 0 6s <none> node3 ......
NodeSelector
NodeSelector���ڽ�pod���ȵ�������ָ����ǩ��node�ڵ��ϡ�����ͨ��kubernetes��label-selector����ʵ�ֵ�,Ҳ����˵,��pod����֮ǰ,����schedulerʹ��MatchNodeSelector���Ȳ��Խ���labelƥ��,�ҳ�Ŀ��node,Ȼ��pod���ȵ�Ŀ��ڵ�,��ƥ�������ǿ��Լ����
������,ʵ��һ��:
1 ���ȷֱ�Ϊnode�ڵ����ӱ�ǩ
[root@k8s-master01 ~]# kubectl label nodes node1 nodeenv=pro
node/node2 labeled
[root@k8s-master01 ~]# kubectl label nodes node2 nodeenv=test
node/node2 labeled
2 ����һ��pod-nodeselector.yaml�ļ�,��ʹ��������Pod
apiVersion: v1
kind: Pod
metadata:
name: pod-nodeselector
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
nodeSelector:
nodeenv: pro # ָ�����ȵ�����nodeenv=pro��ǩ�Ľڵ���
#����Pod
[root@k8s-master01 ~]# kubectl create -f pod-nodeselector.yaml
pod/pod-nodeselector created
#�鿴Pod���ȵ�NODE����,ȷʵ�ǵ��ȵ���node1�ڵ���
[root@k8s-master01 ~]# kubectl get pods pod-nodeselector -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodeselector 1/1 Running 0 47s 10.244.1.87 node1 ......
# ������,ɾ��pod,��nodeSelector��ֵΪnodeenv: xxxx(�����ڴ��д˱�ǩ�Ľڵ�)
[root@k8s-master01 ~]# kubectl delete -f pod-nodeselector.yaml
pod "pod-nodeselector" deleted
[root@k8s-master01 ~]# vim pod-nodeselector.yaml
[root@k8s-master01 ~]# kubectl create -f pod-nodeselector.yaml
pod/pod-nodeselector created
#�ٴβ鿴,����pod����������,Node��ֵΪnone
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pod-nodeselector 0/1 Pending 0 2m20s <none> <none>
# �鿴����,����node selectorƥ��ʧ�ܵ���ʾ
[root@k8s-master01 ~]# kubectl describe pods pod-nodeselector -n dev
.......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.
5.4.2 ���Ե���
��һ��,���������ֶ�����ȵķ�ʽ,ʹ�������dz�����,����Ҳ��һ��������,�Ǿ������û������������Node,��ôPod�����ᱻ����,��ʹ�ڼ�Ⱥ�л��п���Node�б�Ҳ����,�������������ʹ�ó�����
�������������,kubernetes���ṩ��һ�����Ե���(Affinity)������NodeSelector�Ļ���֮�ϵĽ�������չ,����ͨ�����õ���ʽ,ʵ������ѡ������������Node���е���,���û��,Ҳ���Ե��ȵ������������Ľڵ���,ʹ���ȸ�����
Affinity��Ҫ��Ϊ����:
- nodeAffinity(node����): ��nodeΪĿ��,���pod���Ե��ȵ���Щnode������
- podAffinity(pod����) : ��podΪĿ��,���pod���Ժ���Щ�Ѵ��ڵ�pod������ͬһ���������е�����
- podAntiAffinity(pod������) : ��podΪĿ��,���pod���ܺ���Щ�Ѵ���pod������ͬһ���������е�����
��������(������)ʹ�ó�����˵��:
����:�������Ӧ��Ƶ������,�Ǿ��б�Ҫ��������������Ӧ�õľ����ܵĿ���,�������Լ���������ͨ�Ŷ�������������ġ�
������:��Ӧ�õIJ��öั������ʱ,�б�Ҫ���÷������ø���Ӧ��ʵ����ɢ�ֲ��ڸ���node��,����������߷���ĸ߿����ԡ�
NodeAffinity
��������һ��NodeAffinity�Ŀ�������:
pod.spec.affinity.nodeAffinity
requiredDuringSchedulingIgnoredDuringExecution Node�ڵ��������ָ�������й���ſ���,�൱��Ӳ����
nodeSelectorTerms �ڵ�ѡ���б�
matchFields ���ڵ��ֶ��г��Ľڵ�ѡ����Ҫ���б�
matchExpressions ���ڵ��ǩ�г��Ľڵ�ѡ����Ҫ���б�(�Ƽ�)
key ��
values ֵ
operator ��ϵ�� ֧��Exists, DoesNotExist, In, NotIn, Gt, Lt
preferredDuringSchedulingIgnoredDuringExecution ���ȵ��ȵ�����ָ���Ĺ����Node,�൱�������� (����)
preference һ���ڵ�ѡ������,����Ӧ��Ȩ�������
matchFields ���ڵ��ֶ��г��Ľڵ�ѡ����Ҫ���б�
matchExpressions ���ڵ��ǩ�г��Ľڵ�ѡ����Ҫ���б�(�Ƽ�)
key ��
values ֵ
operator ��ϵ�� ֧��In, NotIn, Exists, DoesNotExist, Gt, Lt
weight ����Ȩ��,�ڷ�Χ1-100��
��ϵ����ʹ��˵��:
- matchExpressions:
- key: nodeenv # ƥ����ڱ�ǩ��keyΪnodeenv�Ľڵ�
operator: Exists
- key: nodeenv # ƥ���ǩ��keyΪnodeenv,��value��"xxx"��"yyy"�Ľڵ�
operator: In
values: ["xxx","yyy"]
- key: nodeenv # ƥ���ǩ��keyΪnodeenv,��value����"xxx"�Ľڵ�
operator: Gt
values: "xxx"
������������ʾһ��requiredDuringSchedulingIgnoredDuringExecution ,
����pod-nodeaffinity-required.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-nodeaffinity-required
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
affinity: #��������
nodeAffinity: #����node����
requiredDuringSchedulingIgnoredDuringExecution: # Ӳ����
nodeSelectorTerms:
- matchExpressions: # ƥ��env��ֵ��["xxx","yyy"]�еı�ǩ
- key: nodeenv
operator: In
values: ["xxx","yyy"]
# ����pod
[root@k8s-master01 ~]# kubectl create -f pod-nodeaffinity-required.yaml
pod/pod-nodeaffinity-required created
# �鿴pod״̬ (����ʧ��)
[root@k8s-master01 ~]# kubectl get pods pod-nodeaffinity-required -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodeaffinity-required 0/1 Pending 0 16s <none> <none> ......
# �鿴Pod������
# ���ֵ���ʧ��,��ʾnodeѡ��ʧ��
[root@k8s-master01 ~]# kubectl describe pod pod-nodeaffinity-required -n dev
......
Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.
Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.
#������,ֹͣpod
[root@k8s-master01 ~]# kubectl delete -f pod-nodeaffinity-required.yaml
pod "pod-nodeaffinity-required" deleted
# ���ļ�,��values: ["xxx","yyy"]------> ["pro","yyy"]
[root@k8s-master01 ~]# vim pod-nodeaffinity-required.yaml
# �ٴ�����
[root@k8s-master01 ~]# kubectl create -f pod-nodeaffinity-required.yaml
pod/pod-nodeaffinity-required created
# ��ʱ�鿴,���ֵ��ȳɹ�,�Ѿ���pod���ȵ���node1��
[root@k8s-master01 ~]# kubectl get pods pod-nodeaffinity-required -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodeaffinity-required 1/1 Running 0 11s 10.244.1.89 node1 ......
����������ʾһ��requiredDuringSchedulingIgnoredDuringExecution ,
����pod-nodeaffinity-preferred.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-nodeaffinity-preferred
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
affinity: #��������
nodeAffinity: #����node����
preferredDuringSchedulingIgnoredDuringExecution: # ������
- weight: 1
preference:
matchExpressions: # ƥ��env��ֵ��["xxx","yyy"]�еı�ǩ(��ǰ����û��)
- key: nodeenv
operator: In
values: ["xxx","yyy"]
# ����pod
[root@k8s-master01 ~]# kubectl create -f pod-nodeaffinity-preferred.yaml
pod/pod-nodeaffinity-preferred created
# �鿴pod״̬ (���гɹ�)
[root@k8s-master01 ~]# kubectl get pod pod-nodeaffinity-preferred -n dev
NAME READY STATUS RESTARTS AGE
pod-nodeaffinity-preferred 1/1 Running 0 40s
NodeAffinity�������õ�ע������:
1 ���ͬʱ������nodeSelector��nodeAffinity,��ô���������������õ�����,Pod����������ָ����Node��
2 ���nodeAffinityָ���˶��nodeSelectorTerms,��ôֻ��Ҫ����һ���ܹ�ƥ��ɹ�����
3 ���һ��nodeSelectorTerms���ж��matchExpressions ,��һ���ڵ�����������еIJ���ƥ��ɹ�
4 ���һ��pod���ڵ�Node��Pod�����ڼ����ǩ�����˸ı�,���ٷ��ϸ�Pod�Ľڵ���������,��ϵͳ�����Դ˱仯
PodAffinity
PodAffinity��Ҫʵ�������е�PodΪ����,ʵ�����´�����Pod������pod��һ������Ĺ��ܡ�
��������һ��PodAffinity�Ŀ�������:
pod.spec.affinity.podAffinity
requiredDuringSchedulingIgnoredDuringExecution Ӳ����
namespaces ָ������pod��namespace
topologyKey ָ������������
labelSelector ��ǩѡ����
matchExpressions ���ڵ��ǩ�г��Ľڵ�ѡ����Ҫ���б�(�Ƽ�)
key ��
values ֵ
operator ��ϵ�� ֧��In, NotIn, Exists, DoesNotExist.
matchLabels ָ���matchExpressionsӳ�������
preferredDuringSchedulingIgnoredDuringExecution ������
podAffinityTerm ѡ��
namespaces
topologyKey
labelSelector
matchExpressions
key ��
values ֵ
operator
matchLabels
weight ����Ȩ��,�ڷ�Χ1-100
topologyKey����ָ������ʱ������,����:
���ָ��Ϊkubernetes.io/hostname,�Ǿ�����Node�ڵ�Ϊ���ַ�Χ
���ָ��Ϊbeta.kubernetes.io/os,����Node�ڵ�IJ���ϵͳ����������
������,��ʾ��requiredDuringSchedulingIgnoredDuringExecution,
1)���ȴ���һ������Pod,pod-podaffinity-target.yaml:
apiVersion: v1
kind: Pod
metadata:
name: pod-podaffinity-target
namespace: dev
labels:
podenv: pro #���ñ�ǩ
spec:
containers:
- name: nginx
image: nginx:1.17.1
nodeName: node1 # ��Ŀ��pod��ȷָ����node1��
# ����Ŀ��pod
[root@k8s-master01 ~]# kubectl create -f pod-podaffinity-target.yaml
pod/pod-podaffinity-target created
# �鿴pod״��
[root@k8s-master01 ~]# kubectl get pods pod-podaffinity-target -n dev
NAME READY STATUS RESTARTS AGE
pod-podaffinity-target 1/1 Running 0 4s
2)����pod-podaffinity-required.yaml,��������:
apiVersion: v1
kind: Pod
metadata:
name: pod-podaffinity-required
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
affinity: #��������
podAffinity: #����pod����
requiredDuringSchedulingIgnoredDuringExecution: # Ӳ����
- labelSelector:
matchExpressions: # ƥ��env��ֵ��["xxx","yyy"]�еı�ǩ
- key: podenv
operator: In
values: ["xxx","yyy"]
topologyKey: kubernetes.io/hostname
�������ñ������˼��:��Pod����Ҫ��ӵ�б�ǩnodeenv=xxx����nodeenv=yyy��pod��ͬһNode��,��Ȼ����û������pod,������,���в���һ�¡�
# ����pod
[root@k8s-master01 ~]# kubectl create -f pod-podaffinity-required.yaml
pod/pod-podaffinity-required created
# �鿴pod״̬,����δ����
[root@k8s-master01 ~]# kubectl get pods pod-podaffinity-required -n dev
NAME READY STATUS RESTARTS AGE
pod-podaffinity-required 0/1 Pending 0 9s
# �鿴��ϸ��Ϣ
[root@k8s-master01 ~]# kubectl describe pods pod-podaffinity-required -n dev
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 2 node(s) didn't match pod affinity rules, 1 node(s) had taints that the pod didn't tolerate.
# �������� values: ["xxx","yyy"]----->values:["pro","yyy"]
# ��˼��:��Pod����Ҫ��ӵ�б�ǩnodeenv=xxx����nodeenv=yyy��pod��ͬһNode��
[root@k8s-master01 ~]# vim pod-podaffinity-required.yaml
# Ȼ�����´���pod,�鿴Ч��
[root@k8s-master01 ~]# kubectl delete -f pod-podaffinity-required.yaml
pod "pod-podaffinity-required" deleted
[root@k8s-master01 ~]# kubectl create -f pod-podaffinity-required.yaml
pod/pod-podaffinity-required created
# ���ִ�ʱPod��������
[root@k8s-master01 ~]# kubectl get pods pod-podaffinity-required -n dev
NAME READY STATUS RESTARTS AGE LABELS
pod-podaffinity-required 1/1 Running 0 6s <none>
����PodAffinity�� preferredDuringSchedulingIgnoredDuringExecution,���ﲻ����ʾ��
PodAntiAffinity
PodAntiAffinity��Ҫʵ�������е�PodΪ����,���´�����Pod������pod����һ�������еĹ��ܡ�
�������÷�ʽ��ѡ���PodAffinty��һ����,���ﲻ������ϸ����,ֱ����һ����������
1)����ʹ���ϸ�������Ŀ��pod
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide --show-labels
NAME READY STATUS RESTARTS AGE IP NODE LABELS
pod-podaffinity-required 1/1 Running 0 3m29s 10.244.1.38 node1 <none>
pod-podaffinity-target 1/1 Running 0 9m25s 10.244.1.37 node1 podenv=pro
2)����pod-podantiaffinity-required.yaml,��������:
apiVersion: v1
kind: Pod
metadata:
name: pod-podantiaffinity-required
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
affinity: #��������
podAntiAffinity: #����pod����
requiredDuringSchedulingIgnoredDuringExecution: # Ӳ����
- labelSelector:
matchExpressions: # ƥ��podenv��ֵ��["pro"]�еı�ǩ
- key: podenv
operator: In
values: ["pro"]
topologyKey: kubernetes.io/hostname
�������ñ������˼��:��Pod����Ҫ��ӵ�б�ǩnodeenv=pro��pod����ͬһNode��,���в���һ�¡�
# ����pod
[root@k8s-master01 ~]# kubectl create -f pod-podantiaffinity-required.yaml
pod/pod-podantiaffinity-required created
# �鿴pod
# ���ֵ��ȵ���node2��
[root@k8s-master01 ~]# kubectl get pods pod-podantiaffinity-required -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ..
pod-podantiaffinity-required 1/1 Running 0 30s 10.244.1.96 node2 ..
5.4.3 �۵������
�۵�(Taints)
ǰ��ĵ��ȷ�ʽ����վ��Pod�ĽǶ���,ͨ����Pod����������,��ȷ��Pod�Ƿ�Ҫ���ȵ�ָ����Node��,��ʵ����Ҳ����վ��Node�ĽǶ���,ͨ����Node�������۵�����,�������Ƿ�����Pod���ȹ�����
Node���������۵�֮��ͺ�Pod֮�������һ�����Ĺ�ϵ,�����ܾ�Pod���Ƚ���,�������Խ��Ѿ����ڵ�Pod�����ȥ��
�۵�ĸ�ʽΪ:key=value:effect, key��value���۵�ı�ǩ,effect�����۵������,֧����������ѡ��:
- PreferNoSchedule:kubernetes�����������Pod���ȵ����и��۵��Node��,����û�������ڵ�ɵ���
- NoSchedule:kubernetes�������Pod���ȵ����и��۵��Node��,������Ӱ�쵱ǰNode���Ѵ��ڵ�Pod
- NoExecute:kubernetes�������Pod���ȵ����и��۵��Node��,ͬʱҲ�ὫNode���Ѵ��ڵ�Pod����

ʹ��kubectl���ú�ȥ���۵������ʾ������:
# �����۵�
kubectl taint nodes node1 key=value:effect
# ȥ���۵�
kubectl taint nodes node1 key:effect-
# ȥ�������۵�
kubectl taint nodes node1 key-
������,��ʾ���۵��Ч��:
- ���ڵ�node1(Ϊ����ʾЧ����������,��ʱֹͣnode2�ڵ�)
- Ϊnode1�ڵ�����һ���۵�:
tag=heima:PreferNoSchedule;Ȼ��pod1( pod1 ���� ) - ��Ϊnode1�ڵ�����һ���۵�:
tag=heima:NoSchedule;Ȼ��pod2( pod1 ���� pod2 ʧ�� ) - ��Ϊnode1�ڵ�����һ���۵�:
tag=heima:NoExecute;Ȼ��pod3 ( 3��pod��ʧ�� )
# Ϊnode1�����۵�(PreferNoSchedule)
[root@k8s-master01 ~]# kubectl taint nodes node1 tag=heima:PreferNoSchedule
# ����pod1
[root@k8s-master01 ~]# kubectl run taint1 --image=nginx:1.17.1 -n dev
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
taint1-7665f7fd85-574h4 1/1 Running 0 2m24s 10.244.1.59 node1
# Ϊnode1�����۵�(ȡ��PreferNoSchedule,����NoSchedule)
[root@k8s-master01 ~]# kubectl taint nodes node1 tag:PreferNoSchedule-
[root@k8s-master01 ~]# kubectl taint nodes node1 tag=heima:NoSchedule
# ����pod2
[root@k8s-master01 ~]# kubectl run taint2 --image=nginx:1.17.1 -n dev
[root@k8s-master01 ~]# kubectl get pods taint2 -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
taint1-7665f7fd85-574h4 1/1 Running 0 2m24s 10.244.1.59 node1
taint2-544694789-6zmlf 0/1 Pending 0 21s <none> <none>
# Ϊnode1�����۵�(ȡ��NoSchedule,����NoExecute)
[root@k8s-master01 ~]# kubectl taint nodes node1 tag:NoSchedule-
[root@k8s-master01 ~]# kubectl taint nodes node1 tag=heima:NoExecute
# ����pod3
[root@k8s-master01 ~]# kubectl run taint3 --image=nginx:1.17.1 -n dev
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED
taint1-7665f7fd85-htkmp 0/1 Pending 0 35s <none> <none> <none>
taint2-544694789-bn7wb 0/1 Pending 0 35s <none> <none> <none>
taint3-6d78dbd749-tktkq 0/1 Pending 0 6s <none> <none> <none>
С��ʾ:
ʹ��kubeadm��ļ�Ⱥ,Ĭ�Ͼͻ��master�ڵ�����һ���۵���,����pod�Ͳ�����ȵ�master�ڵ���.
����(Toleration)
����������۵������,���ǿ�����node�������۵����ھܾ�pod��������,������������뽫һ��pod���ȵ�һ�����۵��node��ȥ,��ʱ��Ӧ����ô����?���Ҫʹ�õ�������
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-GC8Z356r-1629018950142)(https://i.loli.net/2021/08/15/oz4D2yXYLgACsFB.png)]
�۵���Ǿܾ�,���̾��Ǻ���,Nodeͨ���۵�ܾ�pod������ȥ,Podͨ�����̺��Ծܾ�
������ͨ��һ����������Ч��:
- ��һС��,�Ѿ���node1�ڵ��ϴ�����
NoExecute���۵�,��ʱpod�ǵ��Ȳ���ȥ�� - ��С��,����ͨ����pod��������,Ȼ���������ȥ
����pod-toleration.yaml,��������
apiVersion: v1
kind: Pod
metadata:
name: pod-toleration
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
tolerations: # ��������
- key: "tag" # Ҫ���̵��۵��key
operator: "Equal" # ������
value: "heima" # ���̵��۵��value
effect: "NoExecute" # �������̵Ĺ���,�������ͱ�ǵ��۵������ͬ
# ��������֮ǰ��pod
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED
pod-toleration 0/1 Pending 0 3s <none> <none> <none>
# ��������֮���pod
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED
pod-toleration 1/1 Running 0 3s 10.244.1.62 node1 <none>
���濴һ�����̵���ϸ����:
[root@k8s-master01 ~]# kubectl explain pod.spec.tolerations
......
FIELDS:
key # ��Ӧ��Ҫ���̵��۵�ļ�,����ζ��ƥ�����еļ�
value # ��Ӧ��Ҫ���̵��۵��ֵ
operator # key-value�������,֧��Equal��Exists(Ĭ��)
effect # ��Ӧ�۵��effect,����ζ��ƥ������Ӱ��
tolerationSeconds # ����ʱ��, ��effectΪNoExecuteʱ��Ч,��ʾpod��Node�ϵ�ͣ��ʱ��
6. Pod���������
6.1 Pod����������
Pod��kubernetes����С������Ԫ,��kubernetes��,����pod�Ĵ�����ʽ���Խ����Ϊ����:
- ����ʽpod:kubernetesֱ�Ӵ���������Pod,����podɾ�����û����,Ҳ�����ؽ�
- ������������pod:kubernetesͨ��������������pod,����podɾ����֮���Զ��ؽ�
ʲô��Pod������Pod�������ǹ���pod���м��,ʹ��Pod������֮��,ֻ��Ҫ����Pod������,��Ҫ���ٸ�ʲô����Pod�Ϳ�����,���ᴴ��������������Pod��ȷ��ÿһ��Pod��Դ�����û�������Ŀ��״̬�����Pod��Դ�������г��ֹ���,�������ָ���������±���Pod��
��kubernetes��,�кܶ����͵�pod������,ÿ�ֶ����Լ����ʺϵij���,��������������Щ:
- ReplicationController:�Ƚ�ԭʼ��pod������,�Ѿ�������,��ReplicaSet��� RS
- ReplicaSet:��֤��������һֱά��������ֵ,��֧��pod����������,����汾����
- Deployment:ͨ������ReplicaSet������Pod,��֧�ֹ������������˰汾
- Horizontal Pod Autoscaler:���Ը��ݼ�Ⱥ�����Զ�ˮƽ����Pod������,ʵ���������
- DaemonSet:�ڼ�Ⱥ�е�ָ��Node�������ҽ�����һ������,һ�������ػ������������
- Job:������������podֻҪ�������������˳�,����Ҫ�������ؽ�,����ִ��һ��������
- Cronjob:��������Pod�����������������,����Ҫ������̨����
- StatefulSet:������״̬Ӧ��
6.2 ReplicaSet(RS)
ReplicaSet����Ҫ��������֤һ��������pod��������,�������������ЩPod������״̬,һ��Pod��������,�ͻ��������ؽ���ͬʱ����֧�ֶ�pod�������������;���汾����������
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-hvTipfoZ-1629018950143)(https://i.loli.net/2021/08/15/kMbWd8SUIXo1Kjq.png)]
ReplicaSet����Դ�嵥�ļ� pc-replicaset.:
apiVersion: apps/v1 # �汾��
kind: ReplicaSet # ����
metadata: # Ԫ����
name: # rs����
namespace: # ���������ռ�
labels: #��ǩ
controller: rs
spec: # ��������
replicas: 3 # ��������
selector: # ѡ����,ͨ����ָ���ÿ�����������Щpod
matchLabels: # Labelsƥ�����
app: nginx-pod
matchExpressions: # Expressionsƥ�����
- {key: app, operator: In, values: [nginx-pod]}
template: # ģ��,��������������ʱ,����������ģ�崴��pod����
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
��������,��Ҫ���˽�����������spec���漸��ѡ��:
-
replicas:ָ����������,��ʵ���ǵ�ǰrs����������pod������,Ĭ��Ϊ1
-
selector:ѡ����,���������ǽ���pod��������pod֮��Ĺ�����ϵ,���õ�Label Selector����
��podģ���϶���label,�ڿ������϶���ѡ����,�Ϳ��Ա�����ǰ�������ܹ�����Щpod��
-
template:ģ��,���ǵ�ǰ����������pod��ʹ�õ�ģ���,������ʵ����ǰһ��ѧ����pod�Ķ���
����ReplicaSet
����pc-replicaset.yaml�ļ�,��������:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: pc-replicaset
namespace: dev
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
# ����rs
[root@k8s-master01 ~]# kubectl create -f pc-replicaset.yaml
replicaset.apps/pc-replicaset created
# �鿴rs
# DESIRED:������������
# CURRENT:��ǰ��������
# READY:�Ѿ������ṩ����ĸ�������
[root@k8s-master01 ~]# kubectl get rs pc-replicaset -n dev -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
pc-replicaset 3 3 3 22s nginx nginx:1.17.1 app=nginx-pod
# �鿴��ǰ����������������pod
# ����ֿ���������������pod���������ڿ��������ƺ���ƴ����-xxxxx�����
[root@k8s-master01 ~]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
pc-replicaset-6vmvt 1/1 Running 0 54s
pc-replicaset-fmb8f 1/1 Running 0 54s
pc-replicaset-snrk2 1/1 Running 0 54s
������
# �༭rs�ĸ�������,��spec:replicas: 6����
[root@k8s-master01 ~]# kubectl edit rs pc-replicaset -n dev
replicaset.apps/pc-replicaset edited
# �鿴pod
[root@k8s-master01 ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
pc-replicaset-6vmvt 1/1 Running 0 114m
pc-replicaset-cftnp 1/1 Running 0 10s
pc-replicaset-fjlm6 1/1 Running 0 10s
pc-replicaset-fmb8f 1/1 Running 0 114m
pc-replicaset-s2whj 1/1 Running 0 10s
pc-replicaset-snrk2 1/1 Running 0 114m
# ��ȻҲ����ֱ��ʹ������ʵ��
# ʹ��scale����ʵ��������, ����--replicas=nֱ��ָ��Ŀ����������
[root@k8s-master01 ~]# kubectl scale rs pc-replicaset --replicas=2 -n dev
replicaset.apps/pc-replicaset scaled
# �����������,�����鿴,�����Ѿ���4����ʼ���˳���
[root@k8s-master01 ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
pc-replicaset-6vmvt 0/1 Terminating 0 118m
pc-replicaset-cftnp 0/1 Terminating 0 4m17s
pc-replicaset-fjlm6 0/1 Terminating 0 4m17s
pc-replicaset-fmb8f 1/1 Running 0 118m
pc-replicaset-s2whj 0/1 Terminating 0 4m17s
pc-replicaset-snrk2 1/1 Running 0 118m
#�Ե�Ƭ��,��ֻʣ��2����
[root@k8s-master01 ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
pc-replicaset-fmb8f 1/1 Running 0 119m
pc-replicaset-snrk2 1/1 Running 0 119m
��������
# �༭rs���������� - image: nginx:1.17.2
[root@k8s-master01 ~]# kubectl edit rs pc-replicaset -n dev
replicaset.apps/pc-replicaset edited
# �ٴβ鿴,���־���汾�Ѿ������
[root@k8s-master01 ~]# kubectl get rs -n dev -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES ...
pc-replicaset 2 2 2 140m nginx nginx:1.17.2 ...
# ͬ���ĵ���,Ҳ����ʹ����������������
# kubectl set image rs rs���� ����=����汾 -n namespace
[root@k8s-master01 ~]# kubectl set image rs pc-replicaset nginx=nginx:1.17.1 -n dev
replicaset.apps/pc-replicaset image updated
# �ٴβ鿴,���־���汾�Ѿ������
[root@k8s-master01 ~]# kubectl get rs -n dev -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES ...
pc-replicaset 2 2 2 145m nginx nginx:1.17.1 ...
ɾ��ReplicaSet
# ʹ��kubectl delete�����ɾ����RS�Լ���������Pod
# ��kubernetesɾ��RSǰ,�ὫRS��replicasclear����Ϊ0,�ȴ����е�Pod��ɾ����,��ִ��RS�����ɾ��
[root@k8s-master01 ~]# kubectl delete rs pc-replicaset -n dev
replicaset.apps "pc-replicaset" deleted
[root@k8s-master01 ~]# kubectl get pod -n dev -o wide
No resources found in dev namespace.
# ���ϣ������ɾ��RS����(����Pod),����ʹ��kubectl delete����ʱ����--cascade=falseѡ��(���Ƽ�)��
[root@k8s-master01 ~]# kubectl delete rs pc-replicaset -n dev --cascade=false
replicaset.apps "pc-replicaset" deleted
[root@k8s-master01 ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
pc-replicaset-cl82j 1/1 Running 0 75s
pc-replicaset-dslhb 1/1 Running 0 75s
# Ҳ����ʹ��yamlֱ��ɾ��(�Ƽ�)
[root@k8s-master01 ~]# kubectl delete -f pc-replicaset.yaml
replicaset.apps "pc-replicaset" deleted
6.3 Deployment(Deploy)
Ϊ�˸��õĽ��������ŵ�����,kubernetes��V1.2�汾��ʼ,������Deployment��������ֵ��һ�����,���ֿ���������ֱ�ӹ���pod,����ͨ������ReplicaSet��������Pod,��:Deployment����ReplicaSet,ReplicaSet����Pod������Deployment��ReplicaSet���ܸ���ǿ��

Deployment��Ҫ���������漸��:
- ֧��ReplicaSet�����й���
- ֧�ַ�����ֹͣ������
- ֧�ֹ��������ͻع��汾
Deployment����Դ�嵥�ļ�:
apiVersion: apps/v1 # �汾��
kind: Deployment # ����
metadata: # Ԫ����
name: # rs����
namespace: # ���������ռ�
labels: #��ǩ
controller: deploy
spec: # ��������
replicas: 3 # ��������
revisionHistoryLimit: 3 # ������ʷ�汾
paused: false # ��ͣ����,Ĭ����false
progressDeadlineSeconds: 600 # ����ʱʱ��(s),Ĭ����600
strategy: # ����
type: RollingUpdate # �������²���
rollingUpdate: # ��������
maxSurge: 30% # ��������Դ��ڵĸ�����,����Ϊ�ٷֱ�,Ҳ����Ϊ����
maxUnavailable: 30% # �����״̬�� Pod �����ֵ,����Ϊ�ٷֱ�,Ҳ����Ϊ����
selector: # ѡ����,ͨ����ָ���ÿ�����������Щpod
matchLabels: # Labelsƥ�����
app: nginx-pod
matchExpressions: # Expressionsƥ�����
- {key: app, operator: In, values: [nginx-pod]}
template: # ģ��,��������������ʱ,����������ģ�崴��pod����
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
����deployment
����pc-deployment.yaml,��������:
apiVersion: apps/v1
kind: Deployment
metadata:
name: pc-deployment
namespace: dev
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
# ����deployment
[root@k8s-master01 ~]# kubectl create -f pc-deployment.yaml --record=true
deployment.apps/pc-deployment created
# �鿴deployment
# UP-TO-DATE ���°汾��pod������
# AVAILABLE ��ǰ���õ�pod������
[root@k8s-master01 ~]# kubectl get deploy pc-deployment -n dev
NAME READY UP-TO-DATE AVAILABLE AGE
pc-deployment 3/3 3 3 15s
# �鿴rs
# ����rs����������ԭ��deployment�����ֺ���������һ��10λ���������
[root@k8s-master01 ~]# kubectl get rs -n dev
NAME DESIRED CURRENT READY AGE
pc-deployment-6696798b78 3 3 3 23s
# �鿴pod
[root@k8s-master01 ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
pc-deployment-6696798b78-d2c8n 1/1 Running 0 107s
pc-deployment-6696798b78-smpvp 1/1 Running 0 107s
pc-deployment-6696798b78-wvjd8 1/1 Running 0 107s
������
# �����������Ϊ5��
[root@k8s-master01 ~]# kubectl scale deploy pc-deployment --replicas=5 -n dev
deployment.apps/pc-deployment scaled
# �鿴deployment
[root@k8s-master01 ~]# kubectl get deploy pc-deployment -n dev
NAME READY UP-TO-DATE AVAILABLE AGE
pc-deployment 5/5 5 5 2m
# �鿴pod
[root@k8s-master01 ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
pc-deployment-6696798b78-d2c8n 1/1 Running 0 4m19s
pc-deployment-6696798b78-jxmdq 1/1 Running 0 94s
pc-deployment-6696798b78-mktqv 1/1 Running 0 93s
pc-deployment-6696798b78-smpvp 1/1 Running 0 4m19s
pc-deployment-6696798b78-wvjd8 1/1 Running 0 4m19s
# �༭deployment�ĸ�������,��spec:replicas: 4����
[root@k8s-master01 ~]# kubectl edit deploy pc-deployment -n dev
deployment.apps/pc-deployment edited
# �鿴pod
[root@k8s-master01 ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
pc-deployment-6696798b78-d2c8n 1/1 Running 0 5m23s
pc-deployment-6696798b78-jxmdq 1/1 Running 0 2m38s
pc-deployment-6696798b78-smpvp 1/1 Running 0 5m23s
pc-deployment-6696798b78-wvjd8 1/1 Running 0 5m23s
�������
deployment֧�����ָ��²���:�ؽ���������������,����ͨ��strategyָ����������,֧����������:
strategy:ָ���µ�Pod�滻�ɵ�Pod�IJ���, ֧����������:
type:ָ����������,֧�����ֲ���
Recreate:�ڴ������µ�Pod֮ǰ����ɱ�������Ѵ��ڵ�Pod
RollingUpdate:��������,����ɱ��һ����,������һ����,�ڸ��¹�����,���������汾Pod
rollingUpdate:��typeΪRollingUpdateʱ��Ч,����ΪRollingUpdate���ò���,֧����������:
maxUnavailable:����ָ�������������в�����Pod���������,Ĭ��Ϊ25%��
maxSurge: ����ָ�������������п��Գ���������Pod���������,Ĭ��Ϊ25%��
�ؽ�����
- �༭pc-deployment.yaml,��spec�ڵ������Ӹ��²���
spec:
strategy: # ����
type: Recreate # �ؽ�����
- ����deploy������֤
# �������
[root@k8s-master01 ~]# kubectl set image deployment pc-deployment nginx=nginx:1.17.2 -n dev
deployment.apps/pc-deployment image updated
# �۲���������
[root@k8s-master01 ~]# kubectl get pods -n dev -w
NAME READY STATUS RESTARTS AGE
pc-deployment-5d89bdfbf9-65qcw 1/1 Running 0 31s
pc-deployment-5d89bdfbf9-w5nzv 1/1 Running 0 31s
pc-deployment-5d89bdfbf9-xpt7w 1/1 Running 0 31s
pc-deployment-5d89bdfbf9-xpt7w 1/1 Terminating 0 41s
pc-deployment-5d89bdfbf9-65qcw 1/1 Terminating 0 41s
pc-deployment-5d89bdfbf9-w5nzv 1/1 Terminating 0 41s
pc-deployment-675d469f8b-grn8z 0/1 Pending 0 0s
pc-deployment-675d469f8b-hbl4v 0/1 Pending 0 0s
pc-deployment-675d469f8b-67nz2 0/1 Pending 0 0s
pc-deployment-675d469f8b-grn8z 0/1 ContainerCreating 0 0s
pc-deployment-675d469f8b-hbl4v 0/1 ContainerCreating 0 0s
pc-deployment-675d469f8b-67nz2 0/1 ContainerCreating 0 0s
pc-deployment-675d469f8b-grn8z 1/1 Running 0 1s
pc-deployment-675d469f8b-67nz2 1/1 Running 0 1s
pc-deployment-675d469f8b-hbl4v 1/1 Running 0 2s
��������
- �༭pc-deployment.yaml,��spec�ڵ������Ӹ��²���
spec:
strategy: # ����
type: RollingUpdate # �������²���
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
- ����deploy������֤
# �������
[root@k8s-master01 ~]# kubectl set image deployment pc-deployment nginx=nginx:1.17.3 -n dev
deployment.apps/pc-deployment image updated
# �۲���������
[root@k8s-master01 ~]# kubectl get pods -n dev -w
NAME READY STATUS RESTARTS AGE
pc-deployment-c848d767-8rbzt 1/1 Running 0 31m
pc-deployment-c848d767-h4p68 1/1 Running 0 31m
pc-deployment-c848d767-hlmz4 1/1 Running 0 31m
pc-deployment-c848d767-rrqcn 1/1 Running 0 31m
pc-deployment-966bf7f44-226rx 0/1 Pending 0 0s
pc-deployment-966bf7f44-226rx 0/1 ContainerCreating 0 0s
pc-deployment-966bf7f44-226rx 1/1 Running 0 1s
pc-deployment-c848d767-h4p68 0/1 Terminating 0 34m
pc-deployment-966bf7f44-cnd44 0/1 Pending 0 0s
pc-deployment-966bf7f44-cnd44 0/1 ContainerCreating 0 0s
pc-deployment-966bf7f44-cnd44 1/1 Running 0 2s
pc-deployment-c848d767-hlmz4 0/1 Terminating 0 34m
pc-deployment-966bf7f44-px48p 0/1 Pending 0 0s
pc-deployment-966bf7f44-px48p 0/1 ContainerCreating 0 0s
pc-deployment-966bf7f44-px48p 1/1 Running 0 0s
pc-deployment-c848d767-8rbzt 0/1 Terminating 0 34m
pc-deployment-966bf7f44-dkmqp 0/1 Pending 0 0s
pc-deployment-966bf7f44-dkmqp 0/1 ContainerCreating 0 0s
pc-deployment-966bf7f44-dkmqp 1/1 Running 0 2s
pc-deployment-c848d767-rrqcn 0/1 Terminating 0 34m
# ����,�°汾��pod�������,�Ͱ汾��pod�������
# �м�����ǹ������е�,Ҳ���DZ����ٱߴ���
�������µĹ���:
���������rs�ı仯
# �鿴rs,����ԭ����rs�����ɴ���,ֻ��pod������Ϊ��0,�������²�����һ��rs,pod����Ϊ4
# ��ʵ�����deployment�ܹ����а汾���˵İ�������,�������ϸ����
[root@k8s-master01 ~]# kubectl get rs -n dev
NAME DESIRED CURRENT READY AGE
pc-deployment-6696798b78 0 0 0 7m37s
pc-deployment-6696798b11 0 0 0 5m37s
pc-deployment-c848d76789 4 4 4 72s
�汾����
deployment֧�ְ汾���������е���ͣ�����������Լ��汾���˵�����,�����������.
kubectl rollout: �汾������ع���,֧�������ѡ��:
- status ��ʾ��ǰ����״̬
- history ��ʾ ������ʷ��¼
- pause ��ͣ�汾��������
- resume �����Ѿ���ͣ�İ汾��������
- restart �����汾��������
- undo �ع�����һ���汾(����ʹ�èCto-revision�ع���ָ���汾)
# �鿴��ǰ�����汾��״̬
[root@k8s-master01 ~]# kubectl rollout status deploy pc-deployment -n dev
deployment "pc-deployment" successfully rolled out
# �鿴������ʷ��¼
[root@k8s-master01 ~]# kubectl rollout history deploy pc-deployment -n dev
deployment.apps/pc-deployment
REVISION CHANGE-CAUSE
1 kubectl create --filename=pc-deployment.yaml --record=true
2 kubectl create --filename=pc-deployment.yaml --record=true
3 kubectl create --filename=pc-deployment.yaml --record=true
# ���Է��������ΰ汾��¼,˵����ɹ���������
# �汾�ع�
# ����ֱ��ʹ��--to-revision=1�ع�����1�汾, ���ʡ�����ѡ��,���ǻ��˵��ϸ��汾,����2�汾
[root@k8s-master01 ~]# kubectl rollout undo deployment pc-deployment --to-revision=1 -n dev
deployment.apps/pc-deployment rolled back
# �鿴����,ͨ��nginx����汾���Է��ֵ��˵�һ��
[root@k8s-master01 ~]# kubectl get deploy -n dev -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES
pc-deployment 4/4 4 4 74m nginx nginx:1.17.1
# �鿴rs,���ֵ�һ��rs����4��pod����,���������汾��rs��podΪ����
# ��ʵdeployment֮���Կ���ʵ�ְ汾�Ļع�,����ͨ����¼����ʷrs��ʵ�ֵ�,
# һ����ع����ĸ��汾,ֻ��Ҫ����ǰ�汾pod������Ϊ0,Ȼ�ع��汾��pod����ΪĿ�������Ϳ�����
[root@k8s-master01 ~]# kubectl get rs -n dev
NAME DESIRED CURRENT READY AGE
pc-deployment-6696798b78 4 4 4 78m
pc-deployment-966bf7f44 0 0 0 37m
pc-deployment-c848d767 0 0 0 71m
��˿ȸ����
Deployment������֧�ֿ��Ƹ��¹����еĿ���,�硰��ͣ(pause)������(resume)�����²�����
������һ���µ�Pod��Դ������ɺ�������ͣ���¹���,��ʱ,������һ�����°汾��Ӧ��,���岿�ֻ��Ǿɵİ汾��Ȼ��,��ɸѡһС���ֵ��û�����·�ɵ��°汾��PodӦ��,�����۲��ܷ��ȶ��ذ������ķ�ʽ���С�ȷ��û����֮���ټ���������µ�Pod��Դ��������,���������ع����²������������ν�Ľ�˿ȸ������
# ����deployment�İ汾,��������ͣdeployment
[root@k8s-master01 ~]# kubectl set image deploy pc-deployment nginx=nginx:1.17.4 -n dev && kubectl rollout pause deployment pc-deployment -n dev
deployment.apps/pc-deployment image updated
deployment.apps/pc-deployment paused
#�۲����״̬
[root@k8s-master01 ~]# kubectl rollout status deploy pc-deployment -n dev��
Waiting for deployment "pc-deployment" rollout to finish: 2 out of 4 new replicas have been updated...
# ��ظ��µĹ���,���Կ����Ѿ�������һ����Դ,���Dz�δ����Ԥ�ڵ�״̬ȥɾ��һ���ɵ���Դ,������Ϊʹ����pause��ͣ����
[root@k8s-master01 ~]# kubectl get rs -n dev -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES
pc-deployment-5d89bdfbf9 3 3 3 19m nginx nginx:1.17.1
pc-deployment-675d469f8b 0 0 0 14m nginx nginx:1.17.2
pc-deployment-6c9f56fcfb 2 2 2 3m16s nginx nginx:1.17.4
[root@k8s-master01 ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
pc-deployment-5d89bdfbf9-rj8sq 1/1 Running 0 7m33s
pc-deployment-5d89bdfbf9-ttwgg 1/1 Running 0 7m35s
pc-deployment-5d89bdfbf9-v4wvc 1/1 Running 0 7m34s
pc-deployment-6c9f56fcfb-996rt 1/1 Running 0 3m31s
pc-deployment-6c9f56fcfb-j2gtj 1/1 Running 0 3m31s
# ȷ�����µ�podû������,��������
[root@k8s-master01 ~]# kubectl rollout resume deploy pc-deployment -n dev
deployment.apps/pc-deployment resumed
# �鿴���ĸ������
[root@k8s-master01 ~]# kubectl get rs -n dev -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES
pc-deployment-5d89bdfbf9 0 0 0 21m nginx nginx:1.17.1
pc-deployment-675d469f8b 0 0 0 16m nginx nginx:1.17.2
pc-deployment-6c9f56fcfb 4 4 4 5m11s nginx nginx:1.17.4
[root@k8s-master01 ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
pc-deployment-6c9f56fcfb-7bfwh 1/1 Running 0 37s
pc-deployment-6c9f56fcfb-996rt 1/1 Running 0 5m27s
pc-deployment-6c9f56fcfb-j2gtj 1/1 Running 0 5m27s
pc-deployment-6c9f56fcfb-rf84v 1/1 Running 0 37s
ɾ��Deployment
# ɾ��deployment,���µ�rs��podҲ����ɾ��
[root@k8s-master01 ~]# kubectl delete -f pc-deployment.yaml
deployment.apps "pc-deployment" deleted
6.4 Horizontal Pod Autoscaler(HPA)
��ǰ��Ŀγ���,�����Ѿ�����ʵ��ͨ���ֹ�ִ��kubectl scale����ʵ��Pod���ݻ�����,��������Ȼ������Kubernetes�Ķ�λĿ��C�Զ��������ܻ��� Kubernetes��������ʵ��ͨ�����Pod��ʹ�����,ʵ��pod�������Զ�����,���ǾͲ�����Horizontal Pod Autoscaler(HPA)���ֿ�������
HPA���Ի�ȡÿ��Pod������,Ȼ���HPA�ж����ָ����жԱ�,ͬʱ�������Ҫ�����ľ���ֵ,���ʵ��Pod�������ĵ�������ʵHPA��֮ǰ��Deploymentһ��,Ҳ����һ��Kubernetes��Դ����,��ͨ���ٷ���RC���Ƶ�����Ŀ��Pod�ĸ��ر仯���,��ȷ���Ƿ���Ҫ����Եص���Ŀ��Pod�ĸ�����,����HPA��ʵ��ԭ����
������,��������һ��ʵ��
1 ��װmetrics-server
metrics-server���������ռ���Ⱥ�е���Դʹ�����
# ��װgit
[root@k8s-master01 ~]# yum install git -y
# ��ȡmetrics-server, ע��ʹ�õİ汾
[root@k8s-master01 ~]# git clone -b v0.3.6 https://github.com/kubernetes-incubator/metrics-server
# ��deployment, ע���ĵ��Ǿ���ͳ�ʼ������
[root@k8s-master01 ~]# cd /root/metrics-server/deploy/1.8+/
[root@k8s-master01 1.8+]# vim metrics-server-deployment.yaml
��ͼ����������ѡ��
hostNetwork: true
image: registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server-amd64:v0.3.6
args:
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP
# ��װmetrics-server
[root@k8s-master01 1.8+]# kubectl apply -f ./
# �鿴pod�������
[root@k8s-master01 1.8+]# kubectl get pod -n kube-system
metrics-server-6b976979db-2xwbj 1/1 Running 0 90s
# ʹ��kubectl top node �鿴��Դʹ�����
[root@k8s-master01 1.8+]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master01 289m 14% 1582Mi 54%
k8s-node01 81m 4% 1195Mi 40%
k8s-node02 72m 3% 1211Mi 41%
[root@k8s-master01 1.8+]# kubectl top pod -n kube-system
NAME CPU(cores) MEMORY(bytes)
coredns-6955765f44-7ptsb 3m 9Mi
coredns-6955765f44-vcwr5 3m 8Mi
etcd-master 14m 145Mi
...
# ����,metrics-server��װ���
2 ��deployment��servie
����pc-hpa-pod.yaml�ļ�,��������:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: dev
spec:
strategy: # ����
type: RollingUpdate # �������²���
replicas: 1
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
resources: # ��Դ���
limits: # ������Դ(����)
cpu: "1" # CPU����,���core��
requests: # ������Դ(����)
cpu: "100m" # CPU����,���core��
# ����service
[root@k8s-master01 1.8+]# kubectl expose deployment nginx --type=NodePort --port=80 -n dev
# �鿴
[root@k8s-master01 1.8+]# kubectl get deployment,pod,svc -n dev
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nginx 1/1 1 1 47s
NAME READY STATUS RESTARTS AGE
pod/nginx-7df9756ccc-bh8dr 1/1 Running 0 47s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/nginx NodePort 10.101.18.29 <none> 80:31830/TCP 35s
3 ����HPA
����pc-hpa.yaml�ļ�,��������:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: pc-hpa
namespace: dev
spec:
minReplicas: 1 #��Сpod����
maxReplicas: 10 #���pod����
targetCPUUtilizationPercentage: 3 # CPUʹ����ָ��
scaleTargetRef: # ָ��Ҫ���Ƶ�nginx��Ϣ
apiVersion: apps/v1
kind: Deployment
name: nginx
# ����hpa
[root@k8s-master01 1.8+]# kubectl create -f pc-hpa.yaml
horizontalpodautoscaler.autoscaling/pc-hpa created
# �鿴hpa
[root@k8s-master01 1.8+]# kubectl get hpa -n dev
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
pc-hpa Deployment/nginx 0%/3% 1 10 1 62s
4 ����
ʹ��ѹ��߶�service��ַ192.168.5.4:31830����ѹ��,Ȼ��ͨ������̨�鿴hpa��pod�ı仯
hpa�仯
[root@k8s-master01 ~]# kubectl get hpa -n dev -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
pc-hpa Deployment/nginx 0%/3% 1 10 1 4m11s
pc-hpa Deployment/nginx 0%/3% 1 10 1 5m19s
pc-hpa Deployment/nginx 22%/3% 1 10 1 6m50s
pc-hpa Deployment/nginx 22%/3% 1 10 4 7m5s
pc-hpa Deployment/nginx 22%/3% 1 10 8 7m21s
pc-hpa Deployment/nginx 6%/3% 1 10 8 7m51s
pc-hpa Deployment/nginx 0%/3% 1 10 8 9m6s
pc-hpa Deployment/nginx 0%/3% 1 10 8 13m
pc-hpa Deployment/nginx 0%/3% 1 10 1 14m
deployment�仯
[root@k8s-master01 ~]# kubectl get deployment -n dev -w
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 1/1 1 1 11m
nginx 1/4 1 1 13m
nginx 1/4 1 1 13m
nginx 1/4 1 1 13m
nginx 1/4 4 1 13m
nginx 1/8 4 1 14m
nginx 1/8 4 1 14m
nginx 1/8 4 1 14m
nginx 1/8 8 1 14m
nginx 2/8 8 2 14m
nginx 3/8 8 3 14m
nginx 4/8 8 4 14m
nginx 5/8 8 5 14m
nginx 6/8 8 6 14m
nginx 7/8 8 7 14m
nginx 8/8 8 8 15m
nginx 8/1 8 8 20m
nginx 8/1 8 8 20m
nginx 1/1 1 1 20m
pod�仯
[root@k8s-master01 ~]# kubectl get pods -n dev -w
NAME READY STATUS RESTARTS AGE
nginx-7df9756ccc-bh8dr 1/1 Running 0 11m
nginx-7df9756ccc-cpgrv 0/1 Pending 0 0s
nginx-7df9756ccc-8zhwk 0/1 Pending 0 0s
nginx-7df9756ccc-rr9bn 0/1 Pending 0 0s
nginx-7df9756ccc-cpgrv 0/1 ContainerCreating 0 0s
nginx-7df9756ccc-8zhwk 0/1 ContainerCreating 0 0s
nginx-7df9756ccc-rr9bn 0/1 ContainerCreating 0 0s
nginx-7df9756ccc-m9gsj 0/1 Pending 0 0s
nginx-7df9756ccc-g56qb 0/1 Pending 0 0s
nginx-7df9756ccc-sl9c6 0/1 Pending 0 0s
nginx-7df9756ccc-fgst7 0/1 Pending 0 0s
nginx-7df9756ccc-g56qb 0/1 ContainerCreating 0 0s
nginx-7df9756ccc-m9gsj 0/1 ContainerCreating 0 0s
nginx-7df9756ccc-sl9c6 0/1 ContainerCreating 0 0s
nginx-7df9756ccc-fgst7 0/1 ContainerCreating 0 0s
nginx-7df9756ccc-8zhwk 1/1 Running 0 19s
nginx-7df9756ccc-rr9bn 1/1 Running 0 30s
nginx-7df9756ccc-m9gsj 1/1 Running 0 21s
nginx-7df9756ccc-cpgrv 1/1 Running 0 47s
nginx-7df9756ccc-sl9c6 1/1 Running 0 33s
nginx-7df9756ccc-g56qb 1/1 Running 0 48s
nginx-7df9756ccc-fgst7 1/1 Running 0 66s
nginx-7df9756ccc-fgst7 1/1 Terminating 0 6m50s
nginx-7df9756ccc-8zhwk 1/1 Terminating 0 7m5s
nginx-7df9756ccc-cpgrv 1/1 Terminating 0 7m5s
nginx-7df9756ccc-g56qb 1/1 Terminating 0 6m50s
nginx-7df9756ccc-rr9bn 1/1 Terminating 0 7m5s
nginx-7df9756ccc-m9gsj 1/1 Terminating 0 6m50s
nginx-7df9756ccc-sl9c6 1/1 Terminating 0 6m50s
6.5 DaemonSet(DS)
DaemonSet���͵Ŀ��������Ա�֤�ڼ�Ⱥ�е�ÿһ̨(��ָ��)�ڵ��϶�����һ��������һ����������־�ռ����ڵ��صȳ�����Ҳ����˵,���һ��Pod�ṩ�Ĺ����ǽڵ㼶���(ÿ���ڵ㶼��Ҫ��ֻ��Ҫһ��),��ô����Pod���ʺ�ʹ��DaemonSet���͵Ŀ�����������

DaemonSet���������ص�:
- ÿ����Ⱥ������һ���ڵ�ʱ,ָ���� Pod ����Ҳ�����ӵ��ýڵ���
- ���ڵ�Ӽ�Ⱥ���Ƴ�ʱ,Pod Ҳ�ͱ�����������
������������DaemonSet����Դ�嵥�ļ�
apiVersion: apps/v1 # �汾��
kind: DaemonSet # ����
metadata: # Ԫ����
name: # rs����
namespace: # ���������ռ�
labels: #��ǩ
controller: daemonset
spec: # ��������
revisionHistoryLimit: 3 # ������ʷ�汾
updateStrategy: # ���²���
type: RollingUpdate # �������²���
rollingUpdate: # ��������
maxUnavailable: 1 # �����״̬�� Pod �����ֵ,����Ϊ�ٷֱ�,Ҳ����Ϊ����
selector: # ѡ����,ͨ����ָ���ÿ�����������Щpod
matchLabels: # Labelsƥ�����
app: nginx-pod
matchExpressions: # Expressionsƥ�����
- {key: app, operator: In, values: [nginx-pod]}
template: # ģ��,��������������ʱ,����������ģ�崴��pod����
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
����pc-daemonset.yaml,��������:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: pc-daemonset
namespace: dev
spec:
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
# ����daemonset
[root@k8s-master01 ~]# kubectl create -f pc-daemonset.yaml
daemonset.apps/pc-daemonset created
# �鿴daemonset
[root@k8s-master01 ~]# kubectl get ds -n dev -o wide
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES
pc-daemonset 2 2 2 2 2 24s nginx nginx:1.17.1
# �鿴pod,������ÿ��Node�϶�����һ��pod
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pc-daemonset-9bck8 1/1 Running 0 37s 10.244.1.43 node1
pc-daemonset-k224w 1/1 Running 0 37s 10.244.2.74 node2
# ɾ��daemonset
[root@k8s-master01 ~]# kubectl delete -f pc-daemonset.yaml
daemonset.apps "pc-daemonset" deleted
6.6 Job
Job,��Ҫ���ڸ���**��������(һ��Ҫ����ָ����������)���ݵ�һ����(ÿ�����������һ�ξͽ���)**����Job�ص�����:
- ��Job������podִ�гɹ�����ʱ,Job����¼�ɹ�������pod����
- ���ɹ�������pod�ﵽָ��������ʱ,Job�����ִ��

Job����Դ�嵥�ļ�:
apiVersion: batch/v1 # �汾��
kind: Job # ����
metadata: # Ԫ����
name: # rs����
namespace: # ���������ռ�
labels: #��ǩ
controller: job
spec: # ��������
completions: 1 # ָ��job��Ҫ�ɹ�����Pods�Ĵ�����Ĭ��ֵ: 1
parallelism: 1 # ָ��job����һʱ��Ӧ�ò�������Pods��������Ĭ��ֵ: 1
activeDeadlineSeconds: 30 # ָ��job�����е�ʱ������,����ʱ�仹δ����,ϵͳ���᳢�Խ�����ֹ��
backoffLimit: 6 # ָ��jobʧ�ܺ�������ԵĴ�����Ĭ����6
manualSelector: true # �Ƿ����ʹ��selectorѡ����ѡ��pod,Ĭ����false
selector: # ѡ����,ͨ����ָ���ÿ�����������Щpod
matchLabels: # Labelsƥ�����
app: counter-pod
matchExpressions: # Expressionsƥ�����
- {key: app, operator: In, values: [counter-pod]}
template: # ģ��,��������������ʱ,����������ģ�崴��pod����
metadata:
labels:
app: counter-pod
spec:
restartPolicy: Never # ��������ֻ������ΪNever����OnFailure
containers:
- name: counter
image: busybox:1.30
command: ["bin/sh","-c","for i in 9 8 7 6 5 4 3 2 1; do echo $i;sleep 2;done"]
���������������õ�˵��:
���ָ��ΪOnFailure,��job����pod���ֹ���ʱ��������,�����Ǵ���pod,failed��������
���ָ��ΪNever,��job����pod���ֹ���ʱ�����µ�pod,���ҹ���pod������ʧ,Ҳ��������,failed������1
���ָ��ΪAlways�Ļ�,����ζ��һֱ����,��ζ��job������ظ�ȥִ����,��Ȼ����,���Բ�������ΪAlways
����pc-job.yaml,��������:
apiVersion: batch/v1
kind: Job
metadata:
name: pc-job
namespace: dev
spec:
manualSelector: true
selector:
matchLabels:
app: counter-pod
template:
metadata:
labels:
app: counter-pod
spec:
restartPolicy: Never
containers:
- name: counter
image: busybox:1.30
command: ["bin/sh","-c","for i in 9 8 7 6 5 4 3 2 1; do echo $i;sleep 3;done"]
# ����job
[root@k8s-master01 ~]# kubectl create -f pc-job.yaml
job.batch/pc-job created
# �鿴job
[root@k8s-master01 ~]# kubectl get job -n dev -o wide -w
NAME COMPLETIONS DURATION AGE CONTAINERS IMAGES SELECTOR
pc-job 0/1 21s 21s counter busybox:1.30 app=counter-pod
pc-job 1/1 31s 79s counter busybox:1.30 app=counter-pod
# ͨ���۲�pod״̬���Կ���,pod��������������,�ͻ���Completed״̬
[root@k8s-master01 ~]# kubectl get pods -n dev -w
NAME READY STATUS RESTARTS AGE
pc-job-rxg96 1/1 Running 0 29s
pc-job-rxg96 0/1 Completed 0 33s
# ������,������pod���е��������Ͳ������� ��:��spec��������������ѡ��
# completions: 6 # ָ��job��Ҫ�ɹ�����Pods�Ĵ���Ϊ6
# parallelism: 3 # ָ��job��������Pods������Ϊ3
# Ȼ����������job,�۲�Ч��,��ʱ�ᷢ��,job��ÿ������3��pod,�ܹ�ִ����6��pod
[root@k8s-master01 ~]# kubectl get pods -n dev -w
NAME READY STATUS RESTARTS AGE
pc-job-684ft 1/1 Running 0 5s
pc-job-jhj49 1/1 Running 0 5s
pc-job-pfcvh 1/1 Running 0 5s
pc-job-684ft 0/1 Completed 0 11s
pc-job-v7rhr 0/1 Pending 0 0s
pc-job-v7rhr 0/1 Pending 0 0s
pc-job-v7rhr 0/1 ContainerCreating 0 0s
pc-job-jhj49 0/1 Completed 0 11s
pc-job-fhwf7 0/1 Pending 0 0s
pc-job-fhwf7 0/1 Pending 0 0s
pc-job-pfcvh 0/1 Completed 0 11s
pc-job-5vg2j 0/1 Pending 0 0s
pc-job-fhwf7 0/1 ContainerCreating 0 0s
pc-job-5vg2j 0/1 Pending 0 0s
pc-job-5vg2j 0/1 ContainerCreating 0 0s
pc-job-fhwf7 1/1 Running 0 2s
pc-job-v7rhr 1/1 Running 0 2s
pc-job-5vg2j 1/1 Running 0 3s
pc-job-fhwf7 0/1 Completed 0 12s
pc-job-v7rhr 0/1 Completed 0 12s
pc-job-5vg2j 0/1 Completed 0 12s
# ɾ��job
[root@k8s-master01 ~]# kubectl delete -f pc-job.yaml
job.batch "pc-job" deleted
6.7 CronJob(CJ)
CronJob��������Job��������ԴΪ��ܿض���,������������pod��Դ����,Job�������������ҵ���������������Դ����֮��������ִ��,��CronJob������������Linux����ϵͳ��������������ҵ�ƻ��ķ�ʽ����������ʱ������ظ������ķ�ʽ��Ҳ����˵,CronJob�������ض���ʱ���(������)ȥ����job������
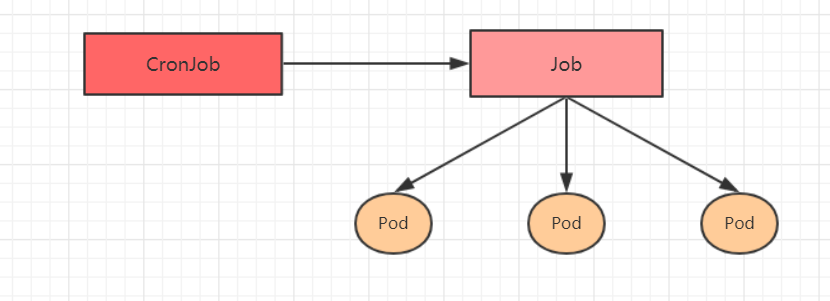
CronJob����Դ�嵥�ļ�:
apiVersion: batch/v1beta1 # �汾��
kind: CronJob # ����
metadata: # Ԫ����
name: # rs����
namespace: # ���������ռ�
labels: #��ǩ
controller: cronjob
spec: # ��������
schedule: # cron��ʽ����ҵ��������ʱ���,���ڿ���������ʲôʱ��ִ��
concurrencyPolicy: # ����ִ�в���,���ڶ���ǰһ����ҵ������δ���ʱ�Ƿ��Լ�������к�һ�ε���ҵ
failedJobHistoryLimit: # Ϊʧ�ܵ�����ִ�б�������ʷ��¼��,Ĭ��Ϊ1
successfulJobHistoryLimit: # Ϊ�ɹ�������ִ�б�������ʷ��¼��,Ĭ��Ϊ3
startingDeadlineSeconds: # ������ҵ����ij�ʱʱ��
jobTemplate: # job������ģ��,����Ϊcronjob����������job����;������ʵ����job�Ķ���
metadata:
spec:
completions: 1
parallelism: 1
activeDeadlineSeconds: 30
backoffLimit: 6
manualSelector: true
selector:
matchLabels:
app: counter-pod
matchExpressions: ����
- {key: app, operator: In, values: [counter-pod]}
template:
metadata:
labels:
app: counter-pod
spec:
restartPolicy: Never
containers:
- name: counter
image: busybox:1.30
command: ["bin/sh","-c","for i in 9 8 7 6 5 4 3 2 1; do echo $i;sleep 20;done"]
��Ҫ�ص���͵ļ���ѡ��:
schedule: cron����ʽ,����ָ�������ִ��ʱ��
*/1 * * * *
<����> <Сʱ> <��> <�·�> <����>
���� ֵ�� 0 �� 59.
Сʱ ֵ�� 0 �� 23.
�� ֵ�� 1 �� 31.
�� ֵ�� 1 �� 12.
���� ֵ�� 0 �� 6, 0 ����������
���ʱ������ö��Ÿ���; ��Χ���������ַ�����;*������Ϊͨ���; /��ʾÿ...
concurrencyPolicy:
Allow: ����Jobs��������(Ĭ��)
Forbid: ��ֹ��������,�����һ��������δ���,��������һ������
Replace: �滻,ȡ����ǰ�������е���ҵ��������ҵ�滻��
����pc-cronjob.yaml,��������:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: pc-cronjob
namespace: dev
labels:
controller: cronjob
spec:
schedule: "*/1 * * * *"
jobTemplate:
metadata:
spec:
template:
spec:
restartPolicy: Never
containers:
- name: counter
image: busybox:1.30
command: ["bin/sh","-c","for i in 9 8 7 6 5 4 3 2 1; do echo $i;sleep 3;done"]
# ����cronjob
[root@k8s-master01 ~]# kubectl create -f pc-cronjob.yaml
cronjob.batch/pc-cronjob created
# �鿴cronjob
[root@k8s-master01 ~]# kubectl get cronjobs -n dev
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
pc-cronjob */1 * * * * False 0 <none> 6s
# �鿴job
[root@k8s-master01 ~]# kubectl get jobs -n dev
NAME COMPLETIONS DURATION AGE
pc-cronjob-1592587800 1/1 28s 3m26s
pc-cronjob-1592587860 1/1 28s 2m26s
pc-cronjob-1592587920 1/1 28s 86s
# �鿴pod
[root@k8s-master01 ~]# kubectl get pods -n dev
pc-cronjob-1592587800-x4tsm 0/1 Completed 0 2m24s
pc-cronjob-1592587860-r5gv4 0/1 Completed 0 84s
pc-cronjob-1592587920-9dxxq 1/1 Running 0 24s
# ɾ��cronjob
[root@k8s-master01 ~]# kubectl delete -f pc-cronjob.yaml
cronjob.batch "pc-cronjob" deleted
7. Service���
7.1 Service����
��kubernetes��,pod��Ӧ�ó��������,���ǿ���ͨ��pod��ip������Ӧ�ó���,����pod��ip��ַ���ǹ̶���,��Ҳ����ζ�Ų�����ֱ�Ӳ���pod��ip�Է�����з��ʡ�
Ϊ�˽���������,kubernetes�ṩ��Service��Դ,Service����ṩͬһ������Ķ��pod���оۺ�,�����ṩһ��ͳһ����ڵ�ַ��ͨ������Service����ڵ�ַ���ܷ��ʵ������pod����
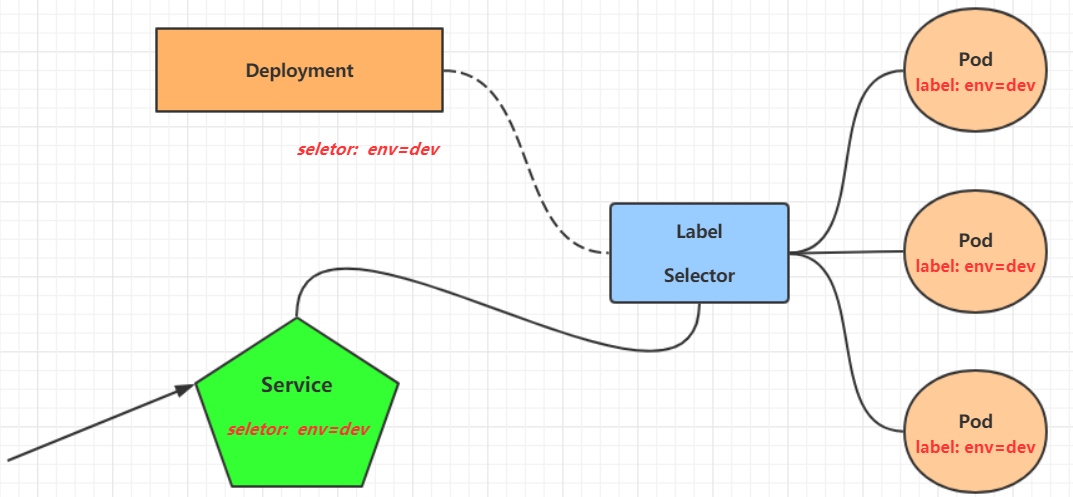
Service�ںܶ������ֻ��һ������,���������õ���ʵ��kube-proxy�������,ÿ��Node�ڵ��϶�������һ��kube-proxy������̡�������Service��ʱ���ͨ��api-server��etcdд�봴����service����Ϣ,��kube-proxy����ڼ����Ļ��Ʒ�������Service�ı䶯,Ȼ�����Ὣ���µ�Service��Ϣת���ɶ�Ӧ�ķ��ʹ�����

# 10.97.97.97:80 ��service�ṩ�ķ������
# �����������ڵ�ʱ��,���Է��ֺ���������pod�ķ����ڵȴ�����,
# kube-proxy�����rr(��ѯ)�IJ���,������ַ�������һ��pod��ȥ
# ��������ͬʱ�ڼ�Ⱥ�ڵ����нڵ��϶�����,�������κ�һ���ڵ��Ϸ��ʶ����ԡ�
[root@node1 ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.97.97.97:80 rr
-> 10.244.1.39:80 Masq 1 0 0
-> 10.244.1.40:80 Masq 1 0 0
-> 10.244.2.33:80 Masq 1 0 0
kube-proxyĿǰ֧�����ֹ���ģʽ:
userspace ģʽ
userspaceģʽ��,kube-proxy��Ϊÿһ��Service����һ�������˿�,����Cluster IP������Iptables�����ض���kube-proxy�����Ķ˿���,kube-proxy����LB�㷨ѡ��һ���ṩ�����Pod�����佨������,�Խ�����ת����Pod�ϡ� ��ģʽ��,kube-proxy�䵱��һ���IJ㸺��������Ľ�ɫ������kube-proxy������userspace��,�ڽ���ת������ʱ�������ں˺��û��ռ�֮������ݿ���,��Ȼ�Ƚ��ȶ�,����Ч�ʱȽϵ͡�
iptables ģʽ
iptablesģʽ��,kube-proxyΪservice��˵�ÿ��Pod������Ӧ��iptables����,ֱ�ӽ�����Cluster IP�������ض���һ��Pod IP�� ��ģʽ��kube-proxy���е��IJ㸺��������Ľ�ɫ,ֻ����iptables����ģʽ���ŵ��ǽ�userspaceģʽЧ�ʸ���,�������ṩ����LB����,�����Pod������ʱҲ���������ԡ�
ipvs ģʽ
ipvsģʽ��iptables����,kube-proxy���Pod�ı仯��������Ӧ��ipvs����ipvs���iptablesת��Ч�ʸ��ߡ���������,ipvs֧�ָ����LB�㷨��
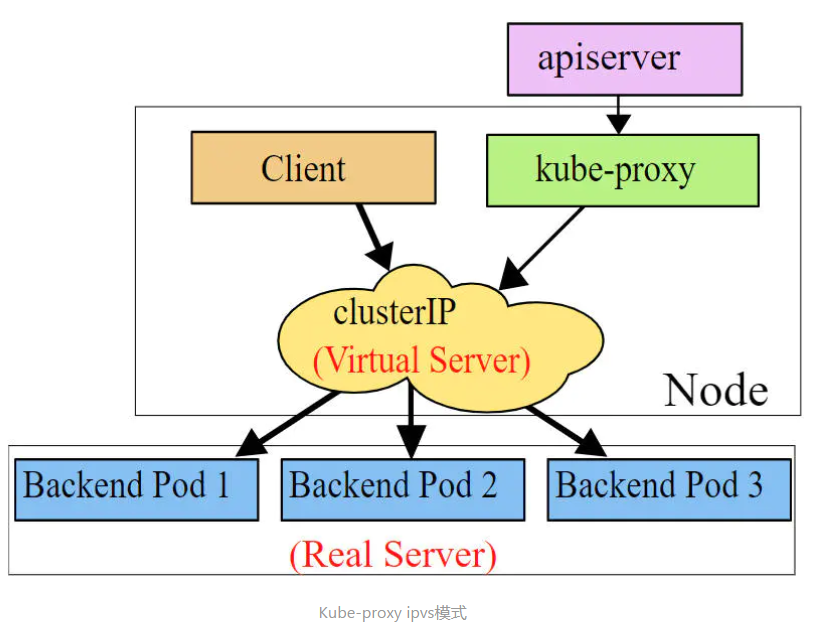
# ��ģʽ���밲װipvs�ں�ģ��,����ή��Ϊiptables
# ����ipvs
[root@k8s-master01 ~]# kubectl edit cm kube-proxy -n kube-system
# ��mode: "ipvs"
[root@k8s-master01 ~]# kubectl delete pod -l k8s-app=kube-proxy -n kube-system
[root@node1 ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.97.97.97:80 rr
-> 10.244.1.39:80 Masq 1 0 0
-> 10.244.1.40:80 Masq 1 0 0
-> 10.244.2.33:80 Masq 1 0 0
7.2 Service����
Service����Դ�嵥�ļ�:
kind: Service # ��Դ����
apiVersion: v1 # ��Դ�汾
metadata: # Ԫ����
name: service # ��Դ����
namespace: dev # �����ռ�
spec: # ����
selector: # ��ǩѡ����,����ȷ����ǰservice������Щpod
app: nginx
type: # Service����,ָ��service�ķ��ʷ�ʽ
clusterIP: # ��������ip��ַ
sessionAffinity: # session����,֧��ClientIP��None����ѡ��
ports: # �˿���Ϣ
- protocol: TCP
port: 3017 # service�˿�
targetPort: 5003 # pod�˿�
nodePort: 31122 # �����˿�
- ClusterIP:Ĭ��ֵ,����Kubernetesϵͳ�Զ����������IP,ֻ���ڼ�Ⱥ�ڲ�����
- NodePort:��Serviceͨ��ָ����Node�ϵĶ˿ڱ�¶���ⲿ,ͨ���˷���,�Ϳ����ڼ�Ⱥ�ⲿ���ʷ���
- LoadBalancer:ʹ����Ӹ��ؾ�������ɵ�����ĸ��طַ�,ע���ģʽ��Ҫ�ⲿ�ƻ���֧��
- ExternalName: �Ѽ�Ⱥ�ⲿ�ķ������뼯Ⱥ�ڲ�,ֱ��ʹ��
7.3 Serviceʹ��
7.3.1 ʵ�黷����
��ʹ��service֮ǰ,��������Deployment������3��pod,ע��ҪΪpod����app=nginx-pod�ı�ǩ
����deployment.yaml,��������:
apiVersion: apps/v1
kind: Deployment
metadata:
name: pc-deployment
namespace: dev
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
[root@k8s-master01 ~]# kubectl create -f deployment.yaml
deployment.apps/pc-deployment created
# �鿴pod����
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide --show-labels
NAME READY STATUS IP NODE LABELS
pc-deployment-66cb59b984-8p84h 1/1 Running 10.244.1.39 node1 app=nginx-pod
pc-deployment-66cb59b984-vx8vx 1/1 Running 10.244.2.33 node2 app=nginx-pod
pc-deployment-66cb59b984-wnncx 1/1 Running 10.244.1.40 node1 app=nginx-pod
# Ϊ�˷������IJ���,������̨nginx��index.htmlҳ��(��̨�ĵ�IP��ַ��һ��)
# kubectl exec -it pc-deployment-66cb59b984-8p84h -n dev /bin/sh
# echo "10.244.1.39" > /usr/share/nginx/html/index.html
echo "10.244.1.40" > /usr/share/nginx/html/index.html
echo "10.244.1.49" > /usr/share/nginx/html/index.html
#�����֮��,���ʲ���
[root@k8s-master01 ~]# curl 10.244.1.39
10.244.1.39
[root@k8s-master01 ~]# curl 10.244.2.33
10.244.2.33
[root@k8s-master01 ~]# curl 10.244.1.40
10.244.1.40
7.3.2 ClusterIP���͵�Service
����service-clusterip.yaml�ļ�
apiVersion: v1
kind: Service
metadata:
name: service-clusterip
namespace: dev
spec:
selector:
app: nginx-pod
clusterIP: 10.97.97.97 # service��ip��ַ,�����д,Ĭ�ϻ�����һ��
type: ClusterIP
ports:
- port: 80 # Service�˿�
targetPort: 80 # pod�˿�
# ����service
[root@k8s-master01 ~]# kubectl create -f service-clusterip.yaml
service/service-clusterip created
# �鿴service
[root@k8s-master01 ~]# kubectl get svc -n dev -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service-clusterip ClusterIP 10.97.97.97 <none> 80/TCP 13s app=nginx-pod
# �鿴service����ϸ��Ϣ
# ��������һ��Endpoints�б�,������ǵ�ǰservice���Ը��ص��ķ������
[root@k8s-master01 ~]# kubectl describe svc service-clusterip -n dev
Name: service-clusterip
Namespace: dev
Labels: <none>
Annotations: <none>
Selector: app=nginx-pod
Type: ClusterIP
IP: 10.97.97.97
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 10.244.1.39:80,10.244.1.40:80,10.244.2.33:80
Session Affinity: None
Events: <none>
# �鿴ipvs��ӳ�����
[root@k8s-master01 ~]# ipvsadm -Ln
TCP 10.97.97.97:80 rr
-> 10.244.1.39:80 Masq 1 0 0
-> 10.244.1.40:80 Masq 1 0 0
-> 10.244.2.33:80 Masq 1 0 0
# ����10.97.97.97:80�۲�Ч��
[root@k8s-master01 ~]# curl 10.97.97.97:80
10.244.2.33
Endpoint
Endpoint��kubernetes�е�һ����Դ����,�洢��etcd��,������¼һ��service��Ӧ������pod�ķ��ʵ�ַ,���Ǹ���service�����ļ���selector���������ġ�
һ��Service��һ��Pod���,��ЩPodͨ��Endpoints��¶����,Endpoints��ʵ��ʵ�ʷ���Ķ˵㼯�������仰˵,service��pod֮�����ϵ��ͨ��endpointsʵ�ֵġ�
���طַ�����
��Service�ķ��ʱ��ַ����˺�˵�Pod��ȥ,Ŀǰkubernetes�ṩ�����ָ��طַ�����:
-
���������,Ĭ��ʹ��kube-proxy�IJ���,�����������ѯ
-
���ڿͻ��˵�ַ�ĻỰ����ģʽ,������ͬһ���ͻ��˷������������ת�����̶���һ��Pod��
��ģʽ����ʹ��spec������
sessionAffinity:ClientIPѡ��
# �鿴ipvs��ӳ�����rr ��ѯ��
[root@k8s-master01 ~]# ipvsadm -Ln
TCP 10.97.97.97:80 rr
-> 10.244.1.39:80 Masq 1 0 0
-> 10.244.1.40:80 Masq 1 0 0
-> 10.244.2.33:80 Masq 1 0 0
# ѭ�����ʲ���
[root@k8s-master01 ~]# while true;do curl 10.97.97.97:80; sleep 5; done;
10.244.1.40
10.244.1.39
10.244.2.33
10.244.1.40
10.244.1.39
10.244.2.33
# �ķַ�����----sessionAffinity:ClientIP
# �鿴ipvs����persistent �����־á�
[root@k8s-master01 ~]# ipvsadm -Ln
TCP 10.97.97.97:80 rr persistent 10800
-> 10.244.1.39:80 Masq 1 0 0
-> 10.244.1.40:80 Masq 1 0 0
-> 10.244.2.33:80 Masq 1 0 0
# ѭ�����ʲ���
[root@k8s-master01 ~]# while true;do curl 10.97.97.97; sleep 5; done;
10.244.2.33
10.244.2.33
10.244.2.33
# ɾ��service
[root@k8s-master01 ~]# kubectl delete -f service-clusterip.yaml
service "service-clusterip" deleted
7.3.3 HeadLiness���͵�Service
��ijЩ������,������Ա���ܲ���ʹ��Service�ṩ�ĸ��ؾ����,��ϣ���Լ������Ƹ��ؾ������,����������,kubernetes�ṩ��HeadLiness Service,����Service�������Cluster IP,�����Ҫ����service,ֻ��ͨ��service���������в�ѯ��
����service-headliness.yaml
apiVersion: v1
kind: Service
metadata:
name: service-headliness
namespace: dev
spec:
selector:
app: nginx-pod
clusterIP: None # ��clusterIP����ΪNone,���ɴ���headliness Service
type: ClusterIP
ports:
- port: 80
targetPort: 80
# ����service
[root@k8s-master01 ~]# kubectl create -f service-headliness.yaml
service/service-headliness created
# ��ȡservice, ����CLUSTER-IPδ����
[root@k8s-master01 ~]# kubectl get svc service-headliness -n dev -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service-headliness ClusterIP None <none> 80/TCP 11s app=nginx-pod
# �鿴service����
[root@k8s-master01 ~]# kubectl describe svc service-headliness -n dev
Name: service-headliness
Namespace: dev
Labels: <none>
Annotations: <none>
Selector: app=nginx-pod
Type: ClusterIP
IP: None
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 10.244.1.39:80,10.244.1.40:80,10.244.2.33:80
Session Affinity: None
Events: <none>
# �鿴�����Ľ������
[root@k8s-master01 ~]# kubectl exec -it pc-deployment-66cb59b984-8p84h -n dev /bin/sh
/ # cat /etc/resolv.conf
nameserver 10.96.0.10
search dev.svc.cluster.local svc.cluster.local cluster.local
[root@k8s-master01 ~]# dig @10.96.0.10 service-headliness.dev.svc.cluster.local
service-headliness.dev.svc.cluster.local. 30 IN A 10.244.1.40
service-headliness.dev.svc.cluster.local. 30 IN A 10.244.1.39
service-headliness.dev.svc.cluster.local. 30 IN A 10.244.2.33
7.3.4 NodePort���͵�Service
��֮ǰ��������,������Service��ip��ַֻ�м�Ⱥ�ڲ��ſ��Է���,���ϣ����Service��¶����Ⱥ�ⲿʹ��,��ô��Ҫʹ�õ�����һ�����͵�Service,��ΪNodePort���͡�NodePort�Ĺ���ԭ����ʵ������service�Ķ˿�ӳ�䵽Node��һ���˿���,Ȼ��Ϳ���ͨ��NodeIp:NodePort������service�ˡ�
����service-nodeport.yaml
apiVersion: v1
kind: Service
metadata:
name: service-nodeport
namespace: dev
spec:
selector:
app: nginx-pod
type: NodePort # service����
ports:
- port: 80
nodePort: 30002 # ָ����node�Ķ˿�(Ĭ�ϵ�ȡֵ��Χ��:30000-32767), �����ָ��,��Ĭ�Ϸ���
targetPort: 80
# ����service
[root@k8s-master01 ~]# kubectl create -f service-nodeport.yaml
service/service-nodeport created
# �鿴service
[root@k8s-master01 ~]# kubectl get svc -n dev -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) SELECTOR
service-nodeport NodePort 10.105.64.191 <none> 80:30002/TCP app=nginx-pod
# ����������ͨ�����������������ȥ���ʼ�Ⱥ������һ��nodeip��30002�˿�,���ɷ��ʵ�pod
7.3.5 LoadBalancer���͵�Service
LoadBalancer��NodePort������,Ŀ�Ķ������ⲿ��¶һ���˿�,��������LoadBalancer���ڼ�Ⱥ���ⲿ������һ�����ؾ����豸,������豸��Ҫ�ⲿ����֧�ֵ�,�ⲿ�����͵�����豸�ϵ�����,�ᱻ�豸����֮��ת������Ⱥ�С�
7.3.6 ExternalName���͵�Service
ExternalName���͵�Service�������뼯Ⱥ�ⲿ�ķ���,��ͨ��externalName����ָ���ⲿһ������ĵ�ַ,Ȼ���ڼ�Ⱥ�ڲ����ʴ�service�Ϳ��Է��ʵ��ⲿ�ķ����ˡ�
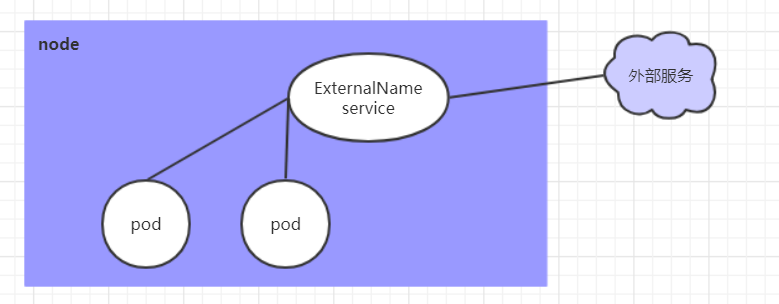
apiVersion: v1
kind: Service
metadata:
name: service-externalname
namespace: dev
spec:
type: ExternalName # service����
externalName: www.baidu.com #�ij�ip��ַҲ����
# ����service
[root@k8s-master01 ~]# kubectl create -f service-externalname.yaml
service/service-externalname created
# ��������
[root@k8s-master01 ~]# dig @10.96.0.10 service-externalname.dev.svc.cluster.local
service-externalname.dev.svc.cluster.local. 30 IN CNAME www.baidu.com.
www.baidu.com. 30 IN CNAME www.a.shifen.com.
www.a.shifen.com. 30 IN A 39.156.66.18
www.a.shifen.com. 30 IN A 39.156.66.14
7.4 Ingress����
��ǰ��γ����Ѿ��ᵽ,Service�Լ�Ⱥ֮�Ⱪ¶�������Ҫ��ʽ������:NotePort��LoadBalancer,���������ַ�ʽ,����һ����ȱ��:
- NodePort��ʽ��ȱ���ǻ�ռ�úܶ༯Ⱥ�����Ķ˿�,��ô����Ⱥ�������ʱ��,���ȱ�����������
- LB��ʽ��ȱ����ÿ��service��Ҫһ��LB,�˷ѡ��鷳,������Ҫkubernetes֮���豸��֧��
����������״,kubernetes�ṩ��Ingress��Դ����,Ingressֻ��Ҫһ��NodePort����һ��LB�Ϳ������㱩¶���Service�����������ƴ�������ͼ��ʾ:

ʵ����,Ingress�൱��һ��7��ĸ��ؾ�����,��kubernetes�Է��������һ������,���Ĺ���ԭ��������Nginx,�����������Ingress�ィ�����ӳ�����,Ingress Controllerͨ��������Щ���ù���ת����Nginx�ķ���������� , Ȼ����ⲿ�ṩ���������������������ĸ���:
- ingress:kubernetes�е�һ������,�����Ƕ����������ת����service�Ĺ���
- ingress controller:����ʵ�ַ�����������ؾ���ij���,��ingress����Ĺ�����н���,�������õĹ�����ʵ������ת��,ʵ�ַ�ʽ�кܶ�,����Nginx, Contour, Haproxy�ȵ�
Ingress(��NginxΪ��)�Ĺ���ԭ������:
- �û���дIngress����,˵���ĸ�������Ӧkubernetes��Ⱥ�е��ĸ�Service
- Ingress��������̬��֪Ingress�������ı仯,Ȼ������һ�ζ�Ӧ��Nginx�����������
- Ingress�������Ὣ���ɵ�Nginx����д�뵽һ�������ŵ�Nginx������,����̬����
- ����Ϊֹ,��ʵ�����ڹ����ľ���һ��Nginx��,�ڲ��������û����������ת������
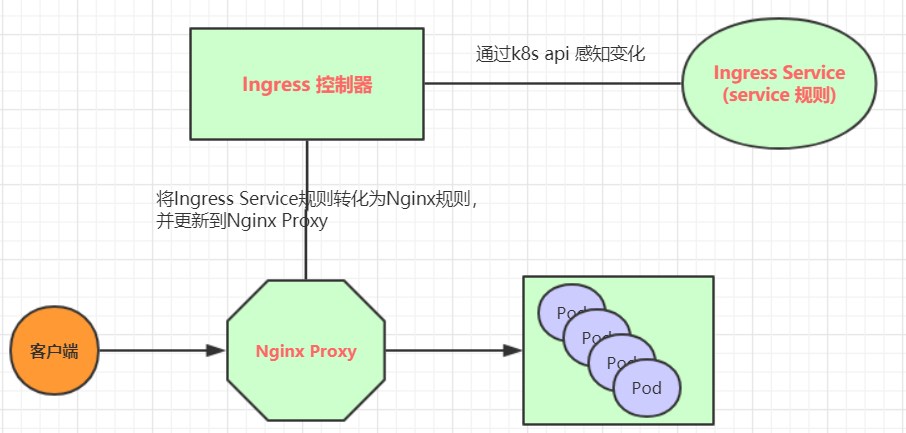
7.5 Ingressʹ��
7.5.1 ������
�ingress����
# �����ļ���
[root@k8s-master01 ~]# mkdir ingress-controller
[root@k8s-master01 ~]# cd ingress-controller/
# ��ȡingress-nginx,���ΰ���ʹ�õ���0.30�汾
[root@k8s-master01 ingress-controller]# wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.30.0/deploy/static/mandatory.yaml
[root@k8s-master01 ingress-controller]# wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.30.0/deploy/static/provider/baremetal/service-nodeport.yaml
# ��mandatory.yaml�ļ��еIJֿ�
# ��quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.30.0
# Ϊquay-mirror.qiniu.com/kubernetes-ingress-controller/nginx-ingress-controller:0.30.0
quay-mirror.qiniu.com/kubernetes-ingress-controller/nginx-ingress-controller:0.30.0
# ����ingress-nginx
[root@k8s-master01 ingress-controller]# kubectl apply -f ./
# �鿴ingress-nginx
[root@k8s-master01 ingress-controller]# kubectl get pod -n ingress-nginx
NAME READY STATUS RESTARTS AGE
pod/nginx-ingress-controller-fbf967dd5-4qpbp 1/1 Running 0 12h
# �鿴service
[root@k8s-master01 ingress-controller]# kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx NodePort 10.98.75.163 <none> 80:32240/TCP,443:31335/TCP 11h
��service��pod
Ϊ�˺����ʵ��ȽϷ���,��������ͼ��ʾ��ģ��
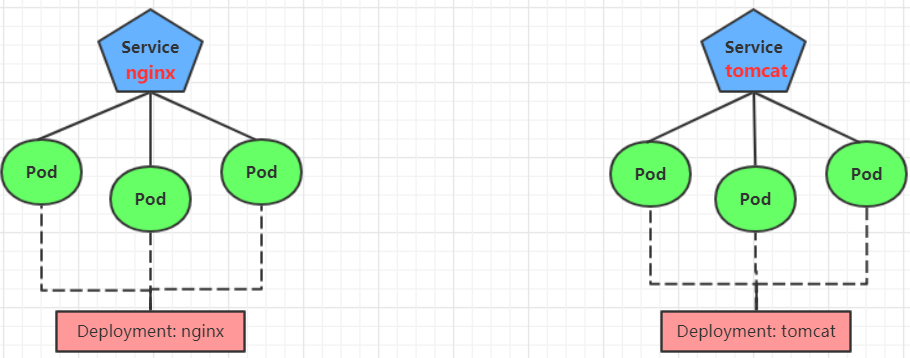
����tomcat-nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: dev
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: tomcat-deployment
namespace: dev
spec:
replicas: 3
selector:
matchLabels:
app: tomcat-pod
template:
metadata:
labels:
app: tomcat-pod
spec:
containers:
- name: tomcat
image: tomcat:8.5-jre10-slim
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
namespace: dev
spec:
selector:
app: nginx-pod
clusterIP: None
type: ClusterIP
ports:
- port: 80
targetPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: tomcat-service
namespace: dev
spec:
selector:
app: tomcat-pod
clusterIP: None
type: ClusterIP
ports:
- port: 8080
targetPort: 8080
# ����
[root@k8s-master01 ~]# kubectl create -f tomcat-nginx.yaml
# �鿴
[root@k8s-master01 ~]# kubectl get svc -n dev
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-service ClusterIP None <none> 80/TCP 48s
tomcat-service ClusterIP None <none> 8080/TCP 48s
7.5.2 Http����
����ingress-http.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-http
namespace: dev
spec:
rules:
- host: nginx.itheima.com
http:
paths:
- path: /
backend:
serviceName: nginx-service
servicePort: 80
- host: tomcat.itheima.com
http:
paths:
- path: /
backend:
serviceName: tomcat-service
servicePort: 8080
# ����
[root@k8s-master01 ~]# kubectl create -f ingress-http.yaml
ingress.extensions/ingress-http created
# �鿴
[root@k8s-master01 ~]# kubectl get ing ingress-http -n dev
NAME HOSTS ADDRESS PORTS AGE
ingress-http nginx.itheima.com,tomcat.itheima.com 80 22s
# �鿴����
[root@k8s-master01 ~]# kubectl describe ing ingress-http -n dev
...
Rules:
Host Path Backends
---- ---- --------
nginx.itheima.com / nginx-service:80 (10.244.1.96:80,10.244.1.97:80,10.244.2.112:80)
tomcat.itheima.com / tomcat-service:8080(10.244.1.94:8080,10.244.1.95:8080,10.244.2.111:8080)
...
# ������,�ڱ��ص���������host�ļ�,�������������������192.168.109.100(master)��
# Ȼ��,�Ϳ��Էֱ����tomcat.itheima.com:32240 �� nginx.itheima.com:32240 �鿴Ч����
7.5.3 Https����
����֤��
# ����֤��
openssl req -x509 -sha256 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/C=CN/ST=BJ/L=BJ/O=nginx/CN=itheima.com"
# ������Կ
kubectl create secret tls tls-secret --key tls.key --cert tls.crt
����ingress-https.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-https
namespace: dev
spec:
tls:
- hosts:
- nginx.itheima.com
- tomcat.itheima.com
secretName: tls-secret # ָ����Կ
rules:
- host: nginx.itheima.com
http:
paths:
- path: /
backend:
serviceName: nginx-service
servicePort: 80
- host: tomcat.itheima.com
http:
paths:
- path: /
backend:
serviceName: tomcat-service
servicePort: 8080
# ����
[root@k8s-master01 ~]# kubectl create -f ingress-https.yaml
ingress.extensions/ingress-https created
# �鿴
[root@k8s-master01 ~]# kubectl get ing ingress-https -n dev
NAME HOSTS ADDRESS PORTS AGE
ingress-https nginx.itheima.com,tomcat.itheima.com 10.104.184.38 80, 443 2m42s
# �鿴����
[root@k8s-master01 ~]# kubectl describe ing ingress-https -n dev
...
TLS:
tls-secret terminates nginx.itheima.com,tomcat.itheima.com
Rules:
Host Path Backends
---- ---- --------
nginx.itheima.com / nginx-service:80 (10.244.1.97:80,10.244.1.98:80,10.244.2.119:80)
tomcat.itheima.com / tomcat-service:8080(10.244.1.99:8080,10.244.2.117:8080,10.244.2.120:8080)
...
# �������ͨ�����������https://nginx.itheima.com:31335 �� https://tomcat.itheima.com:31335���鿴��
8. ���ݴ洢
��ǰ���Ѿ��ᵽ,�������������ڿ��ܺܶ�,�ᱻƵ���ش��������١���ô����������ʱ,�����������е�����Ҳ�ᱻ��������ֽ�����û���˵,��ijЩ������Dz����⿴���ġ�Ϊ�˳־û���������������,kubernetes������Volume�ĸ��
Volume��Pod���ܹ�������������ʵĹ���Ŀ¼,����������Pod��,Ȼ��һ��Pod��Ķ���������ص�������ļ�Ŀ¼��,kubernetesͨ��Volumeʵ��ͬһ��Pod�в�ͬ����֮������ݹ����Լ����ݵij־û��洢��Volume��������������Pod�е��������������������,��������ֹ��������ʱ,Volume�е�����Ҳ���ᶪʧ��
kubernetes��Volume֧�ֶ�������,�Ƚϳ����������漸��:
- �洢:EmptyDir��HostPath��NFS
- ���洢:PV��PVC
- ���ô洢:ConfigMap��Secret
8.1 �����洢
8.1.1 EmptyDir
EmptyDir���������Volume����,һ��EmptyDir����Host�ϵ�һ����Ŀ¼��
EmptyDir����Pod�����䵽Nodeʱ������,���ij�ʼ����Ϊ��,��������ָ���������϶�Ӧ��Ŀ¼�ļ�,��Ϊkubernetes���Զ�����һ��Ŀ¼,��Pod����ʱ, EmptyDir�е�����Ҳ�ᱻ����ɾ���� EmptyDir��;����:
- ��ʱ�ռ�,��������ijЩӦ�ó�������ʱ�������ʱĿ¼,���������ñ���
- һ��������Ҫ����һ�������л�ȡ���ݵ�Ŀ¼(����������Ŀ¼)
������,ͨ��һ������֮���ļ������İ�����ʹ��һ��EmptyDir��
��һ��Pod������������nginx��busybox,Ȼ������һ��Volume�ֱ���ڵ�����������Ŀ¼��,Ȼ��nginx����������Volume��д��־,busybox��ͨ�������־���ݶ�������̨��
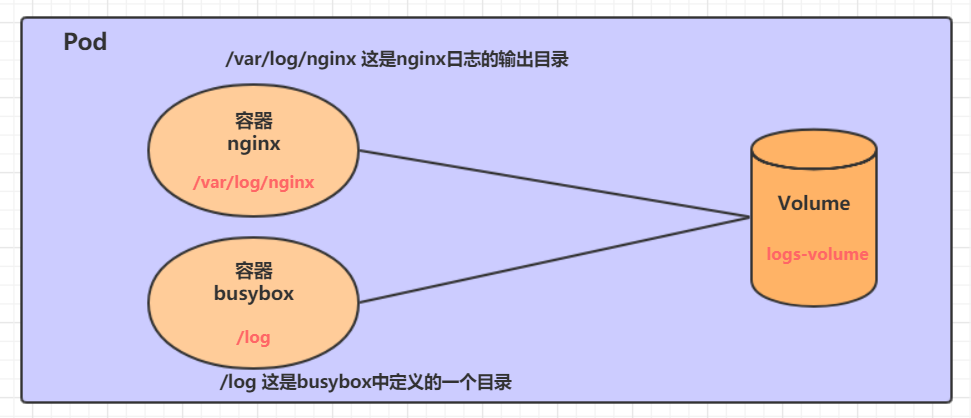
����һ��volume-emptydir.yaml
apiVersion: v1
kind: Pod
metadata:
name: volume-emptydir
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
volumeMounts: # ��logs-volume���ڵ�nginx������,��Ӧ��Ŀ¼Ϊ /var/log/nginx
- name: logs-volume
mountPath: /var/log/nginx
- name: busybox
image: busybox:1.30
command: ["/bin/sh","-c","tail -f /logs/access.log"] # ��ʼ����,��̬��ȡָ���ļ�������
volumeMounts: # ��logs-volume ���ڵ�busybox������,��Ӧ��Ŀ¼Ϊ /logs
- name: logs-volume
mountPath: /logs
volumes: # ����volume, nameΪlogs-volume,����ΪemptyDir
- name: logs-volume
emptyDir: {}
# ����Pod
[root@k8s-master01 ~]# kubectl create -f volume-emptydir.yaml
pod/volume-emptydir created
# �鿴pod
[root@k8s-master01 ~]# kubectl get pods volume-emptydir -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
volume-emptydir 2/2 Running 0 97s 10.42.2.9 node1 ......
# ͨ��podIp����nginx
[root@k8s-master01 ~]# curl 10.42.2.9
......
# ͨ��kubectl logs����鿴ָ�������ı����
[root@k8s-master01 ~]# kubectl logs -f volume-emptydir -n dev -c busybox
10.42.1.0 - - [27/Jun/2021:15:08:54 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.29.0" "-"
8.1.2 HostPath
�Ͻڿ��ᵽ,EmptyDir�����ݲ��ᱻ�־û�,��������Pod�Ľ���������,�����Ľ����ݳ־û���������,����ѡ��HostPath��
HostPath���ǽ�Node������һ��ʵ��Ŀ¼���ڵ�Pod��,�Թ�����ʹ��,��������ƾͿ��Ա�֤Pod������,�����������ݿ��Դ�����Node�����ϡ�
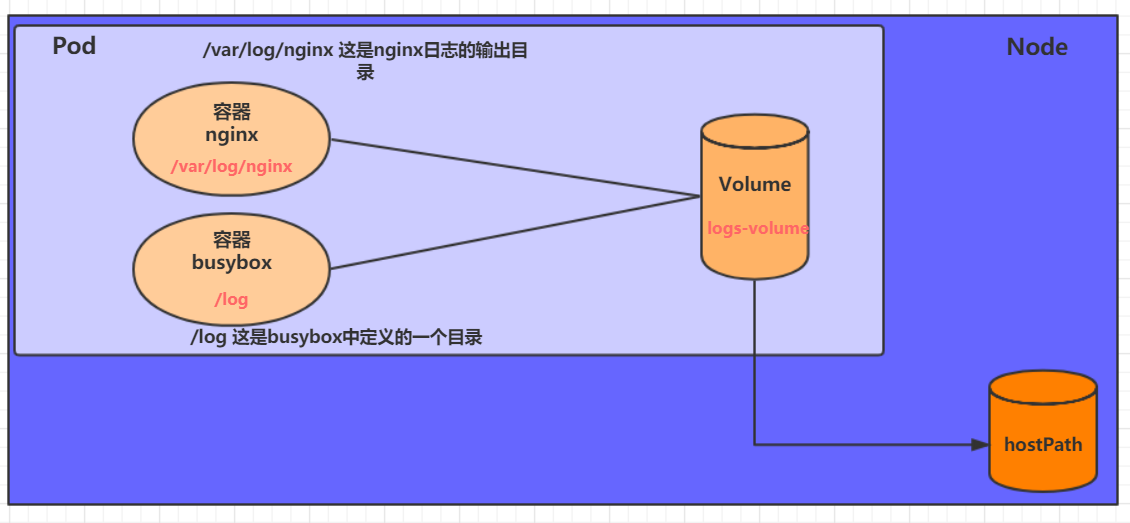
����һ��volume-hostpath.yaml:
apiVersion: v1
kind: Pod
metadata:
name: volume-hostpath
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
volumeMounts:
- name: logs-volume
mountPath: /var/log/nginx
- name: busybox
image: busybox:1.30
command: ["/bin/sh","-c","tail -f /logs/access.log"]
volumeMounts:
- name: logs-volume
mountPath: /logs
volumes:
- name: logs-volume
hostPath:
path: /root/logs
type: DirectoryOrCreate # Ŀ¼���ھ�ʹ��,�����ھ��ȴ�����ʹ��
����type��ֵ��һ��˵��:
DirectoryOrCreate Ŀ¼���ھ�ʹ��,�����ھ��ȴ�����ʹ��
Directory Ŀ¼�������
FileOrCreate �ļ����ھ�ʹ��,�����ھ��ȴ�����ʹ��
File �ļ��������
Socket unix���ֱ������
CharDevice �ַ��豸�������
BlockDevice ���豸�������
# ����Pod
[root@k8s-master01 ~]# kubectl create -f volume-hostpath.yaml
pod/volume-hostpath created
# �鿴Pod
[root@k8s-master01 ~]# kubectl get pods volume-hostpath -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-volume-hostpath 2/2 Running 0 16s 10.42.2.10 node1 ......
#����nginx
[root@k8s-master01 ~]# curl 10.42.2.10
# �������Ϳ���ȥhost��/root/logsĿ¼�²鿴�洢���ļ���
### ע��: ����IJ�����Ҫ��Pod���ڵĽڵ�����(��������node1)
[root@node1 ~]# ls /root/logs/
access.log error.log
# ͬ���ĵ���,����ڴ�Ŀ¼�´���һ���ļ�,��������Ҳ�ǿ��Կ�����
8.1.3 NFS
HostPath���Խ�����ݳ־û�������,����һ��Node�ڵ������,Pod���ת�Ƶ��˱�Ľڵ�,�ֻ����������,��ʱ��Ҫ������������洢ϵͳ,�Ƚϳ��õ���NFS��CIFS��
NFS��һ�������ļ��洢ϵͳ,���Դһ̨NFS������,Ȼ��Pod�еĴ洢ֱ�����ӵ�NFSϵͳ��,�����Ļ�,����Pod�ڽڵ�����ôת��,ֻҪNode��NFS�ĶԽ�û����,���ݾͿ��Գɹ����ʡ�
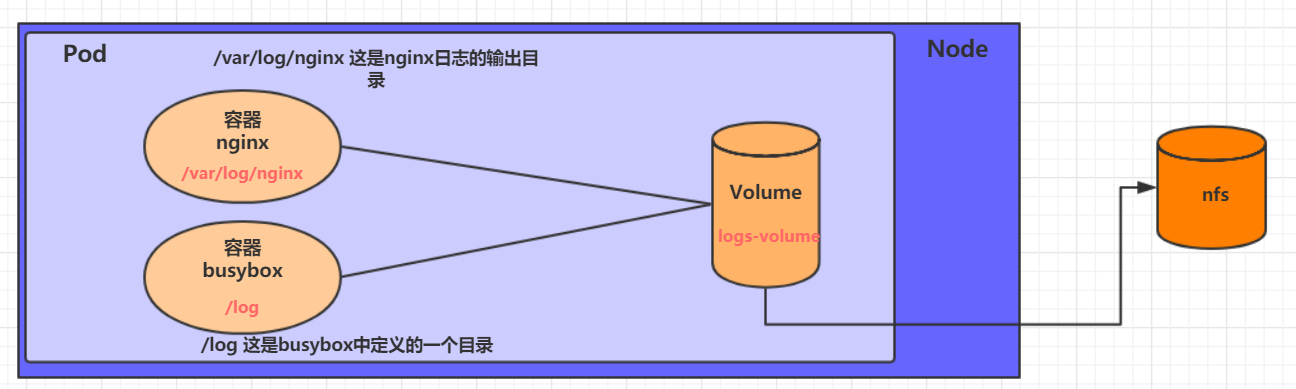
1)����Ҫ��nfs�ķ�����,����Ϊ�˼�,ֱ����master�ڵ���nfs������
# ��nfs�ϰ�װnfs����
[root@nfs ~]# yum install nfs-utils -y
# ��һ������Ŀ¼
[root@nfs ~]# mkdir /root/data/nfs -pv
# ������Ŀ¼�Զ�дȨ�ޱ�¶��192.168.5.0/24�����е���������
[root@nfs ~]# vim /etc/exports
[root@nfs ~]# more /etc/exports
/root/data/nfs 192.168.5.0/24(rw,no_root_squash)
# ����nfs����
[root@nfs ~]# systemctl restart nfs
2)������,Ҫ�ڵ�ÿ��node�ڵ��϶���װ��nfs,������Ŀ����Ϊ��node�ڵ��������nfs�豸
# ��node�ϰ�װnfs����,ע�ⲻ��Ҫ����
[root@k8s-master01 ~]# yum install nfs-utils -y
3)������,�Ϳ��Ա�дpod�������ļ���,����volume-nfs.yaml
apiVersion: v1
kind: Pod
metadata:
name: volume-nfs
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
volumeMounts:
- name: logs-volume
mountPath: /var/log/nginx
- name: busybox
image: busybox:1.30
command: ["/bin/sh","-c","tail -f /logs/access.log"]
volumeMounts:
- name: logs-volume
mountPath: /logs
volumes:
- name: logs-volume
nfs:
server: 192.168.5.6 #nfs��������ַ
path: /root/data/nfs #�����ļ�·��
4)���,������pod,�۲���
# ����pod
[root@k8s-master01 ~]# kubectl create -f volume-nfs.yaml
pod/volume-nfs created
# �鿴pod
[root@k8s-master01 ~]# kubectl get pods volume-nfs -n dev
NAME READY STATUS RESTARTS AGE
volume-nfs 2/2 Running 0 2m9s
# �鿴nfs�������ϵĹ���Ŀ¼,�����Ѿ����ļ���
[root@k8s-master01 ~]# ls /root/data/
access.log error.log
8.2 ���洢
ǰ���Ѿ�ѧϰ��ʹ��NFS�ṩ�洢,��ʱ��Ҫ���û���NFSϵͳ,���һ���yaml����nfs������kubernetes֧�ֵĴ洢ϵͳ�кܶ�,Ҫ��ͻ�ȫ������,��Ȼ����ʵ��Ϊ���ܹ����εײ�洢ʵ�ֵ�ϸ��,�����û�ʹ��, kubernetes����PV��PVC������Դ����
PV(Persistent Volume)�dz־û�������˼,�ǶԵײ�Ĺ����洢��һ�ֳ���һ�������PV��kubernetes����Ա���д���������,����ײ����Ĺ����洢�����й�,��ͨ���������빲���洢�ĶԽӡ�
PVC(Persistent Volume Claim)�dz־þ���������˼,���û����ڴ洢�����һ�����������仰˵,PVC��ʵ�����û���kubernetesϵͳ������һ����Դ�������롣
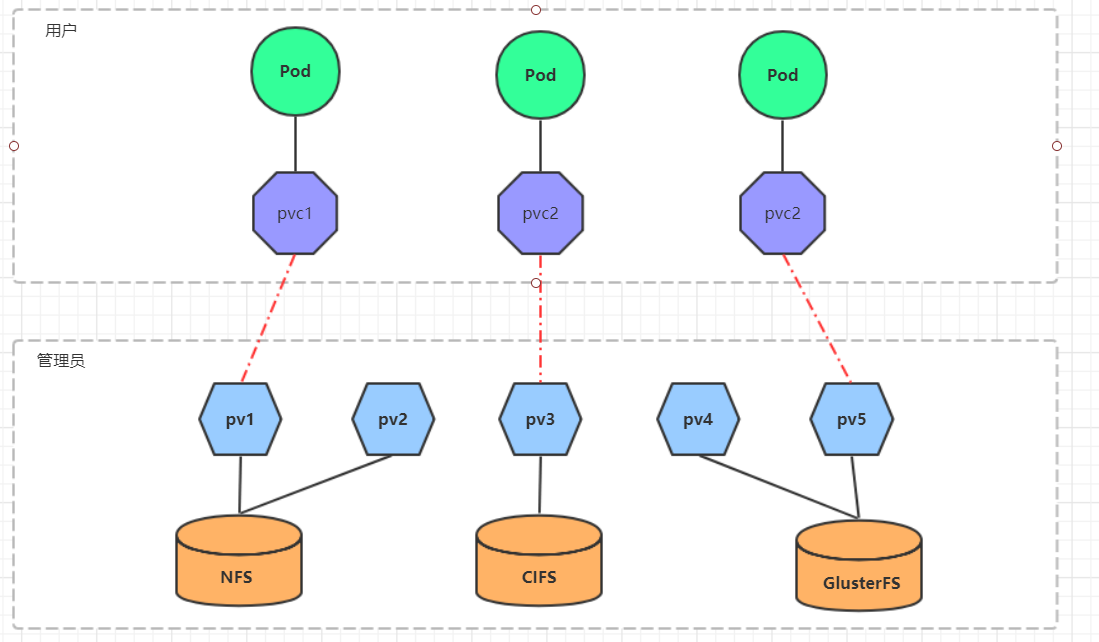
ʹ����PV��PVC֮��,�������Եõ���һ����ϸ��:
- �洢:�洢����ʦά��
- PV: kubernetes����Աά��
- PVC:kubernetes�û�ά��
8.2.1 PV
PV�Ǵ洢��Դ�ij���,��������Դ�嵥�ļ�:
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv2
spec:
nfs: # �洢����,��ײ������洢��Ӧ
capacity: # �洢����,Ŀǰֻ֧�ִ洢�ռ������
storage: 2Gi
accessModes: # ����ģʽ
storageClassName: # �洢���
persistentVolumeReclaimPolicy: # ���ղ���
PV �Ĺؼ����ò���˵��:
-
�洢����
�ײ�ʵ�ʴ洢������,kubernetes֧�ֶ��ִ洢����,ÿ�ִ洢���͵����ö���������
-
�洢����(capacity)
Ŀǰֻ֧�ִ洢�ռ������( storage=1Gi ),����δ�����ܻ����IOPS����������ָ�������
-
����ģʽ(accessModes)
���������û�Ӧ�öԴ洢��Դ�ķ���Ȩ��,����Ȩ�ް������漸�ַ�ʽ:
- ReadWriteOnce(RWO):��дȨ��,����ֻ�ܱ������ڵ����
- ReadOnlyMany(ROX): ֻ��Ȩ��,���Ա�����ڵ����
- ReadWriteMany(RWX):��дȨ��,���Ա�����ڵ����
��Ҫע�����,�ײ㲻ͬ�Ĵ洢���Ϳ���֧�ֵķ���ģʽ��ͬ -
���ղ���(persistentVolumeReclaimPolicy)
��PV���ٱ�ʹ����֮��,����Ĵ�����ʽ��Ŀǰ֧�����ֲ���:
- Retain (����) ��������,��Ҫ����Ա�ֹ���������
- Recycle(����) ��� PV �е�����,Ч���൱��ִ�� rm -rf /thevolume/*
- Delete (ɾ��) �� PV �����ĺ�˴洢��� volume ��ɾ������,��Ȼ�ⳣ�����Ʒ����̵Ĵ洢����
��Ҫע�����,�ײ㲻ͬ�Ĵ洢���Ϳ���֧�ֵĻ��ղ��Բ�ͬ -
�洢���
PV����ͨ��storageClassName����ָ��һ���洢���
- �����ض�����PVֻ���������˸�����PVC���а�
- δ�趨����PV��ֻ���벻�����κ�����PVC���а�
-
״̬(status)
һ�� PV ������������,���ܻᴦ��4�в�ͬ�Ľ�:
- Available(����): ��ʾ����״̬,��δ���κ� PVC ��
- Bound(�Ѱ�): ��ʾ PV �Ѿ��� PVC ��
- Released(���ͷ�): ��ʾ PVC ��ɾ��,������Դ��δ����Ⱥ��������
- Failed(ʧ��): ��ʾ�� PV ���Զ�����ʧ��
ʵ��
ʹ��NFS��Ϊ�洢,����ʾPV��ʹ��,����3��PV,��ӦNFS�е�3����¶��·����
- ��NFS����
# ����Ŀ¼
[root@nfs ~]# mkdir /root/data/{pv1,pv2,pv3} -pv
# ��¶����
[root@nfs ~]# more /etc/exports
/root/data/pv1 192.168.5.0/24(rw,no_root_squash)
/root/data/pv2 192.168.5.0/24(rw,no_root_squash)
/root/data/pv3 192.168.5.0/24(rw,no_root_squash)
# ��������
[root@nfs ~]# systemctl restart nfs
- ����pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv1
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
nfs:
path: /root/data/pv1
server: 192.168.5.6
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv2
spec:
capacity:
storage: 2Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
nfs:
path: /root/data/pv2
server: 192.168.5.6
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv3
spec:
capacity:
storage: 3Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
nfs:
path: /root/data/pv3
server: 192.168.5.6
# ���� pv
[root@k8s-master01 ~]# kubectl create -f pv.yaml
persistentvolume/pv1 created
persistentvolume/pv2 created
persistentvolume/pv3 created
# �鿴pv
[root@k8s-master01 ~]# kubectl get pv -o wide
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS AGE VOLUMEMODE
pv1 1Gi RWX Retain Available 10s Filesystem
pv2 2Gi RWX Retain Available 10s Filesystem
pv3 3Gi RWX Retain Available 9s Filesystem
8.2.2 PVC
PVC����Դ������,���������Դ洢�ռ䡢����ģʽ���洢���������Ϣ����������Դ�嵥�ļ�:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc
namespace: dev
spec:
accessModes: # ����ģʽ
selector: # ���ñ�ǩ��PVѡ��
storageClassName: # �洢���
resources: # ����ռ�
requests:
storage: 5Gi
PVC �Ĺؼ����ò���˵��:
- ����ģʽ(accessModes)
���������û�Ӧ�öԴ洢��Դ�ķ���Ȩ��
-
ѡ������(selector)
ͨ��Label Selector������,��ʹPVC����ϵͳ�м����ڵ�PV����ɸѡ
-
�洢���(storageClassName)
PVC�ڶ���ʱ�����趨��Ҫ�ĺ�˴洢�����,ֻ�������˸�class��pv���ܱ�ϵͳѡ��
-
��Դ����(Resources )
�����Դ洢��Դ������
ʵ��
- ����pvc.yaml,����pv
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc1
namespace: dev
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc2
namespace: dev
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc3
namespace: dev
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
# ����pvc
[root@k8s-master01 ~]# kubectl create -f pvc.yaml
persistentvolumeclaim/pvc1 created
persistentvolumeclaim/pvc2 created
persistentvolumeclaim/pvc3 created
# �鿴pvc
[root@k8s-master01 ~]# kubectl get pvc -n dev -o wide
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE VOLUMEMODE
pvc1 Bound pv1 1Gi RWX 15s Filesystem
pvc2 Bound pv2 2Gi RWX 15s Filesystem
pvc3 Bound pv3 3Gi RWX 15s Filesystem
# �鿴pv
[root@k8s-master01 ~]# kubectl get pv -o wide
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM AGE VOLUMEMODE
pv1 1Gi RWx Retain Bound dev/pvc1 3h37m Filesystem
pv2 2Gi RWX Retain Bound dev/pvc2 3h37m Filesystem
pv3 3Gi RWX Retain Bound dev/pvc3 3h37m Filesystem
- ����pods.yaml, ʹ��pv
apiVersion: v1
kind: Pod
metadata:
name: pod1
namespace: dev
spec:
containers:
- name: busybox
image: busybox:1.30
command: ["/bin/sh","-c","while true;do echo pod1 >> /root/out.txt; sleep 10; done;"]
volumeMounts:
- name: volume
mountPath: /root/
volumes:
- name: volume
persistentVolumeClaim:
claimName: pvc1
readOnly: false
---
apiVersion: v1
kind: Pod
metadata:
name: pod2
namespace: dev
spec:
containers:
- name: busybox
image: busybox:1.30
command: ["/bin/sh","-c","while true;do echo pod2 >> /root/out.txt; sleep 10; done;"]
volumeMounts:
- name: volume
mountPath: /root/
volumes:
- name: volume
persistentVolumeClaim:
claimName: pvc2
readOnly: false
# ����pod
[root@k8s-master01 ~]# kubectl create -f pods.yaml
pod/pod1 created
pod/pod2 created
# �鿴pod
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pod1 1/1 Running 0 14s 10.244.1.69 node1
pod2 1/1 Running 0 14s 10.244.1.70 node1
# �鿴pvc
[root@k8s-master01 ~]# kubectl get pvc -n dev -o wide
NAME STATUS VOLUME CAPACITY ACCESS MODES AGE VOLUMEMODE
pvc1 Bound pv1 1Gi RWX 94m Filesystem
pvc2 Bound pv2 2Gi RWX 94m Filesystem
pvc3 Bound pv3 3Gi RWX 94m Filesystem
# �鿴pv
[root@k8s-master01 ~]# kubectl get pv -n dev -o wide
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM AGE VOLUMEMODE
pv1 1Gi RWX Retain Bound dev/pvc1 5h11m Filesystem
pv2 2Gi RWX Retain Bound dev/pvc2 5h11m Filesystem
pv3 3Gi RWX Retain Bound dev/pvc3 5h11m Filesystem
# �鿴nfs�е��ļ��洢
[root@nfs ~]# more /root/data/pv1/out.txt
node1
node1
[root@nfs ~]# more /root/data/pv2/out.txt
node2
node2
8.2.3 ��������
PVC��PV��һһ��Ӧ��,PV��PVC֮����������ѭ������������:
-
��Դ��Ӧ:����Ա�ֶ������ײ�洢��PV
-
��Դ��:�û�����PVC,kubernetes�������PVC������ȥѰ��PV,����
���û������PVC֮��,ϵͳ������PVC�Դ洢��Դ���������Ѵ��ڵ�PV��ѡ��һ������������
- һ���ҵ�,�ͽ���PV���û������PVC���а�,�û���Ӧ�þͿ���ʹ�����PVC��
- ����Ҳ���,PVC��������ڴ���Pending״̬,ֱ���ȵ�ϵͳ����Ա������һ��������Ҫ���PV
PVһ����ij��PVC��,�ͻᱻ���PVC��ռ,������������PVC���а���
-
��Դʹ��:�û�����pod����volumeһ��ʹ��pvc
Podʹ��Volume�Ķ���,��PVC���ص������ڵ�ij��·������ʹ�á�
-
��Դ�ͷ�:�û�ɾ��pvc���ͷ�pv
���洢��Դʹ����Ϻ�,�û�����ɾ��PVC,���PVC��PV���ᱻ���Ϊ�����ͷš�,������������������PVC���а�ͨ��֮ǰPVCд������ݿ��ܻ������ڴ洢�豸��,ֻ�������֮���PV�����ٴ�ʹ�á�
-
��Դ����:kubernetes����pv���õĻ��ղ��Խ�����Դ�Ļ���
����PV,����Ա�����趨���ղ���,����������֮��PVC�ͷ���Դ֮����δ����������ݵ����⡣ֻ��PV�Ĵ洢�ռ���ɻ���,���ܹ��µ�PVC��ʹ��
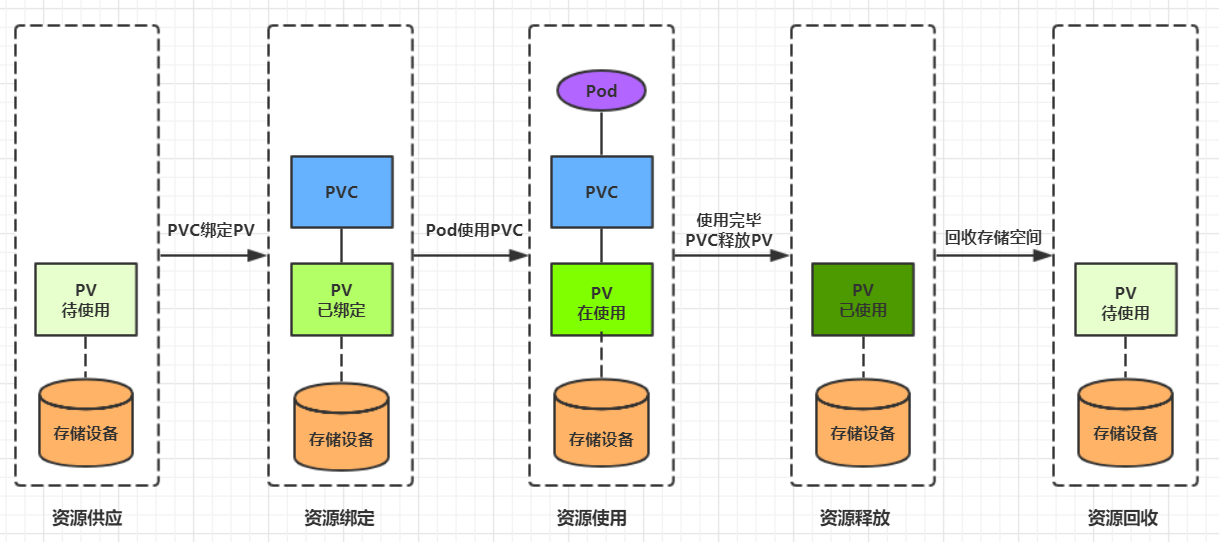
8.3 ���ô洢
8.3.1 ConfigMap
ConfigMap��һ�ֱȽ�����Ĵ洢��,������Ҫ�����������洢������Ϣ�ġ�
����configmap.yaml,��������:
apiVersion: v1
kind: ConfigMap
metadata:
name: configmap
namespace: dev
data:
info: |
username:admin
password:123456
������,ʹ�ô������ļ�����configmap
# ����configmap
[root@k8s-master01 ~]# kubectl create -f configmap.yaml
configmap/configmap created
# �鿴configmap����
[root@k8s-master01 ~]# kubectl describe cm configmap -n dev
Name: configmap
Namespace: dev
Labels: <none>
Annotations: <none>
Data
====
info:
----
username:admin
password:123456
Events: <none>
����������һ��pod-configmap.yaml,�����洴����configmap���ؽ�ȥ
apiVersion: v1
kind: Pod
metadata:
name: pod-configmap
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
volumeMounts: # ��configmap���ص�Ŀ¼
- name: config
mountPath: /configmap/config
volumes: # ����configmap
- name: config
configMap:
name: configmap
# ����pod
[root@k8s-master01 ~]# kubectl create -f pod-configmap.yaml
pod/pod-configmap created
# �鿴pod
[root@k8s-master01 ~]# kubectl get pod pod-configmap -n dev
NAME READY STATUS RESTARTS AGE
pod-configmap 1/1 Running 0 6s
#��������
[root@k8s-master01 ~]# kubectl exec -it pod-configmap -n dev /bin/sh
# cd /configmap/config/
# ls
info
# more info
username:admin
password:123456
# ���Կ���ӳ���Ѿ��ɹ�,ÿ��configmap��ӳ�����һ��Ŀ¼
# key--->�ļ� value---->�ļ��е�����
# ��ʱ�������configmap������, �����е�ֵҲ�ᶯ̬����
8.3.2 Secret
��kubernetes��,������һ�ֺ�ConfigMap�dz����ƵĶ���,��ΪSecret��������Ҫ���ڴ洢������Ϣ,�������롢��Կ��֤��ȵȡ�
- ����ʹ��base64�����ݽ��б���
[root@k8s-master01 ~]# echo -n 'admin' | base64 #��username
YWRtaW4=
[root@k8s-master01 ~]# echo -n '123456' | base64 #��password
MTIzNDU2
- ��������дsecret.yaml,������Secret
apiVersion: v1
kind: Secret
metadata:
name: secret
namespace: dev
type: Opaque
data:
username: YWRtaW4=
password: MTIzNDU2
# ����secret
[root@k8s-master01 ~]# kubectl create -f secret.yaml
secret/secret created
# �鿴secret����
[root@k8s-master01 ~]# kubectl describe secret secret -n dev
Name: secret
Namespace: dev
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password: 6 bytes
username: 5 bytes
- ����pod-secret.yaml,�����洴����secret���ؽ�ȥ:
apiVersion: v1
kind: Pod
metadata:
name: pod-secret
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
volumeMounts: # ��secret���ص�Ŀ¼
- name: config
mountPath: /secret/config
volumes:
- name: config
secret:
secretName: secret
# ����pod
[root@k8s-master01 ~]# kubectl create -f pod-secret.yaml
pod/pod-secret created
# �鿴pod
[root@k8s-master01 ~]# kubectl get pod pod-secret -n dev
NAME READY STATUS RESTARTS AGE
pod-secret 1/1 Running 0 2m28s
# ��������,�鿴secret��Ϣ,�����Ѿ��Զ�������
[root@k8s-master01 ~]# kubectl exec -it pod-secret /bin/sh -n dev
/ # ls /secret/config/
password username
/ # more /secret/config/username
admin
/ # more /secret/config/password
123456
����,�Ѿ�ʵ��������secretʵ������Ϣ�ı��롣
9. ��ȫ��֤
9.1 ���ʿ��Ƹ���
Kubernetes��Ϊһ���ֲ�ʽ��Ⱥ�Ĺ�������,��֤��Ⱥ�İ�ȫ������һ����Ҫ��������ν�İ�ȫ����ʵ���DZ�֤��Kubernetes�ĸ����ͻ���������֤�ͼ�Ȩ������
�ͻ���
��Kubernetes��Ⱥ��,�ͻ���ͨ��������:
- User Account:һ���Ƕ�����kubernetes֮�����������������û��˺š�
- Service Account:kubernetes�������˺�,����ΪPod�еķ�������ڷ���Kubernetesʱ�ṩ���ݱ�ʶ��
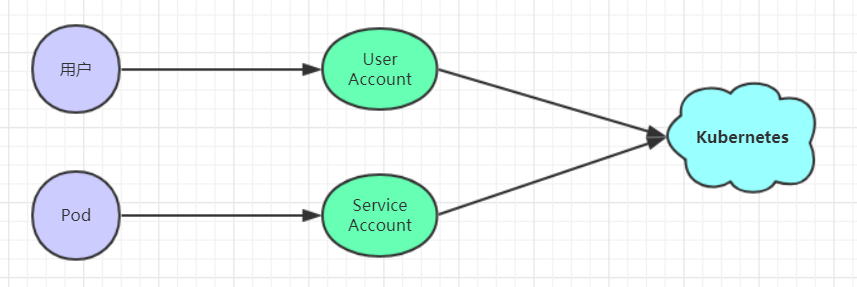
��֤����Ȩ�������
ApiServer�Ƿ��ʼ�������Դ�����Ψһ��ڡ��κ�һ���������ApiServer,��Ҫ����������������:
- Authentication(��֤):���ݼ���,ֻ����ȷ���˺Ų��ܹ�ͨ����֤
- Authorization(��Ȩ): �ж��û��Ƿ���Ȩ�Է��ʵ���Դִ���ض��Ķ���
- Admission Control(�����):���ڲ�����Ȩ������ʵ�ָ��Ӿ�ϸ�ķ��ʿ��ƹ��ܡ�
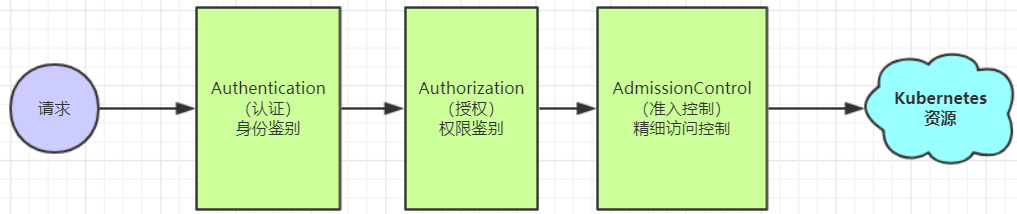
9.2 ��֤����
Kubernetes��Ⱥ��ȫ����ؼ����������ʶ����֤�ͻ�������,���ṩ��3�ֿͻ���������֤��ʽ:
-
HTTP Base��֤:ͨ���û���+����ķ�ʽ��֤
������֤��ʽ�ǰѡ��û���:���롱��BASE64�㷨���б������ַ�������HTTP�����е�Header Authorization���������ˡ�������յ�����н���,��ȡ�û���������,Ȼ������û�������֤�Ĺ��̡� -
HTTP Token��֤:ͨ��һ��Token��ʶ��Ϸ��û�
������֤��ʽ����һ���ܳ������Ա�ģ�µ��ַ���--Token�������ͻ����ݵ�һ�ַ�ʽ��ÿ��Token��Ӧһ���û���,���ͻ��˷���API��������ʱ,��Ҫ��HTTP Header�����Token,API Server�ӵ�Token�����������б����token���бȶ�,Ȼ������û�������֤�Ĺ��̡� -
HTTPS֤����֤:����CA��֤��ǩ����˫������֤����֤��ʽ
������֤��ʽ�ǰ�ȫ����ߵ�һ�ַ�ʽ,����ͬʱҲ�Dz����������鷳��һ�ַ�ʽ��
HTTPS��֤�����Ϊ3������:
-
֤��������·�
HTTPSͨ��˫���ķ�������CA��������֤��,CA�����·���֤�顢�����֤�鼰˽Կ�������� -
�ͻ��˺ͷ���˵�˫����֤
1> �ͻ�����������˷�������,������·��Լ���֤����ͻ���, �ͻ��˽��յ�֤���,ͨ��˽Կ����֤��,��֤���л�÷���˵Ĺ�Կ, �ͻ������÷������˵Ĺ�Կ��֤֤���е���Ϣ,���һ��,���Ͽ���������� 2> �ͻ��˷����Լ���֤�����������,����˽��յ�֤���,ͨ��˽Կ����֤��, ��֤���л�ÿͻ��˵Ĺ�Կ,���øù�Կ��֤֤����Ϣ,ȷ�Ͽͻ����Ƿ�Ϸ� -
�������˺Ϳͻ��˽���ͨ��
�������˺Ϳͻ���Э�̺ü��ܷ�����,�ͻ��˻����һ���������Կ������,Ȼ���͵��������ˡ� �������˽��������Կ��,˫��������ͨ�ŵ��������ݶ�ͨ���������Կ����
ע��: Kubernetes����ͬʱ���ö�����֤��ʽ,ֻҪ��������һ����ʽ��֤ͨ������
9.3 ��Ȩ����
��Ȩ��������֤�ɹ�֮��,ͨ����֤�Ϳ���֪�������û���˭, Ȼ��Kubernetes��������ȶ������Ȩ�����������û��Ƿ���Ȩ����,������̾ͳ�Ϊ��Ȩ��
ÿ�����͵�ApiServer�����������û�����Դ����Ϣ:���緢��������û��������·��������Ķ�����,��Ȩ���Ǹ�����Щ��Ϣ����Ȩ���Խ��бȽ�,������ϲ���,����Ϊ��Ȩͨ��,����᷵�ش���
API ServerĿǰ֧�����¼�����Ȩ����:
- AlwaysDeny:��ʾ�ܾ���������,һ�����ڲ���
- AlwaysAllow:����������������,�൱�ڼ�Ⱥ����Ҫ��Ȩ����(KubernetesĬ�ϵIJ���)
- ABAC:�������Եķ��ʿ���,��ʾʹ���û����õ���Ȩ������û��������ƥ��Ϳ���
- Webhook:ͨ�������ⲿREST������û�������Ȩ
- Node:��һ��ר��ģʽ,���ڶ�kubelet������������з��ʿ���
- RBAC:���ڽ�ɫ�ķ��ʿ���(kubeadm��װ��ʽ�µ�Ĭ��ѡ��)
RBAC(Role-Based Access Control) ���ڽ�ɫ�ķ��ʿ���,��Ҫ��������һ������:����Щ������������ЩȨ��
�����漰�������漸������:
- ����:User��Groups��ServiceAccount
- ��ɫ:������һ�鶨������Դ�ϵĿɲ�������(Ȩ��)�ļ���
- ��:������õĽ�ɫ���û�����һ��
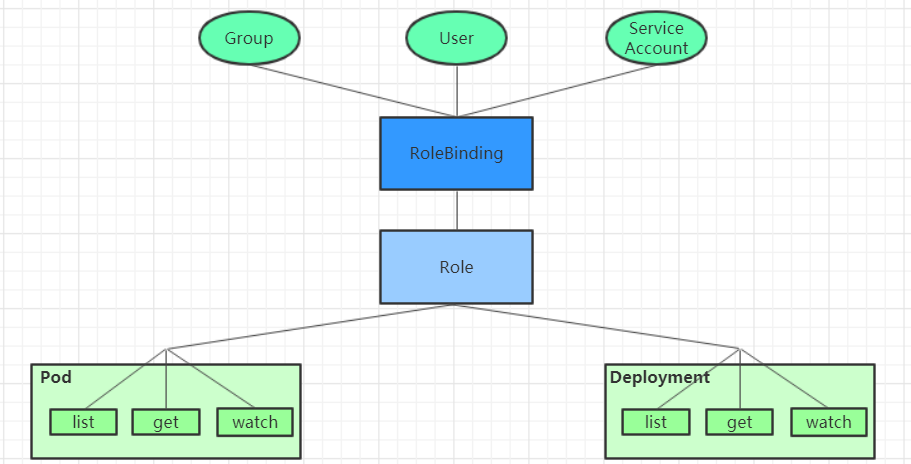
RBAC������4��������Դ����:
- Role��ClusterRole:��ɫ,����ָ��һ��Ȩ��
- RoleBinding��ClusterRoleBinding:��ɫ��,���ڽ���ɫ(Ȩ��)���������
Role��ClusterRole
һ����ɫ����һ��Ȩ�ļ���,�����Ȩ����������ʽ��(������)��
# Roleֻ�ܶ������ռ��ڵ���Դ������Ȩ,��Ҫָ��nameapce
kind: Role
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
namespace: dev
name: authorization-role
rules:
- apiGroups: [""] # ֧�ֵ�API���б�,"" ���ַ���,��ʾ����APIȺ
resources: ["pods"] # ֧�ֵ���Դ�����б�
verbs: ["get", "watch", "list"] # �����Ķ���Դ����IJ��������б�
# ClusterRole���ԶԼ�Ⱥ��Χ����Դ����namespaces�ķ�Χ��Դ������Դ���ͽ�����Ȩ
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: authorization-clusterrole
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list"]
��Ҫ��ϸ˵������,rules�еIJ���:
-
apiGroups: ֧�ֵ�API���б�
"","apps", "autoscaling", "batch" -
resources:֧�ֵ���Դ�����б�
"services", "endpoints", "pods","secrets","configmaps","crontabs","deployments","jobs", "nodes","rolebindings","clusterroles","daemonsets","replicasets","statefulsets", "horizontalpodautoscalers","replicationcontrollers","cronjobs" -
verbs:����Դ����IJ��������б�
"get", "list", "watch", "create", "update", "patch", "delete", "exec"
RoleBinding��ClusterRoleBinding
��ɫ��������һ����ɫ��һ��Ŀ�������,��Ŀ�������User��Group����ServiceAccount��
# RoleBinding���Խ�ͬһnamespace�е�subject��ij��Role��,���subject�����и�Role�����Ȩ��
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: authorization-role-binding
namespace: dev
subjects:
- kind: User
name: heima
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: authorization-role
apiGroup: rbac.authorization.k8s.io
# ClusterRoleBinding��������Ⱥ���������namespaces���ض���subject��ClusterRole��,����Ȩ��
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: authorization-clusterrole-binding
subjects:
- kind: User
name: heima
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: authorization-clusterrole
apiGroup: rbac.authorization.k8s.io
RoleBinding����ClusterRole������Ȩ
RoleBinding��������ClusterRole,������ͬһ�����ռ���ClusterRole�������Դ���������Ȩ��
һ�ֺܳ��õ���������,��Ⱥ����ԱΪ��Ⱥ��ΧԤ�����һ���ɫ(ClusterRole),Ȼ���ڶ�������ռ����ظ�ʹ����ЩClusterRole���������Դ�������Ȩ��������Ч��,Ҳʹ�ø��������ռ��µĻ�������Ȩ������ʹ�����鱣��һ�¡�
# ��Ȼauthorization-clusterrole��һ����Ⱥ��ɫ,������Ϊʹ����RoleBinding
# ����heimaֻ�ܶ�ȡdev�����ռ��е���Դ
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: authorization-role-binding-ns
namespace: dev
subjects:
- kind: User
name: heima
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: authorization-clusterrole
apiGroup: rbac.authorization.k8s.io
ʵս:����һ��ֻ�ܹ���dev�ռ���Pods��Դ���˺�
- �����˺�
# 1) ����֤��
[root@k8s-master01 pki]# cd /etc/kubernetes/pki/
[root@k8s-master01 pki]# (umask 077;openssl genrsa -out devman.key 2048)
# 2) ��apiserver��֤��ȥǩ��
# 2-1) ǩ������,������û���devman,����devgroup
[root@k8s-master01 pki]# openssl req -new -key devman.key -out devman.csr -subj "/CN=devman/O=devgroup"
# 2-2) ǩ��֤��
[root@k8s-master01 pki]# openssl x509 -req -in devman.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out devman.crt -days 3650
# 3) ���ü�Ⱥ���û�����������Ϣ
[root@k8s-master01 pki]# kubectl config set-cluster kubernetes --embed-certs=true --certificate-authority=/etc/kubernetes/pki/ca.crt --server=https://192.168.109.100:6443
[root@k8s-master01 pki]# kubectl config set-credentials devman --embed-certs=true --client-certificate=/etc/kubernetes/pki/devman.crt --client-key=/etc/kubernetes/pki/devman.key
[root@k8s-master01 pki]# kubectl config set-context devman@kubernetes --cluster=kubernetes --user=devman
# �л��˻���devman
[root@k8s-master01 pki]# kubectl config use-context devman@kubernetes
Switched to context "devman@kubernetes".
# �鿴dev��pod,����û��Ȩ��
[root@k8s-master01 pki]# kubectl get pods -n dev
Error from server (Forbidden): pods is forbidden: User "devman" cannot list resource "pods" in API group "" in the namespace "dev"
# �л���admin�˻�
[root@k8s-master01 pki]# kubectl config use-context kubernetes-admin@kubernetes
Switched to context "kubernetes-admin@kubernetes".
2) ����Role��RoleBinding,Ϊdevman�û���Ȩ
kind: Role
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
namespace: dev
name: dev-role
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: authorization-role-binding
namespace: dev
subjects:
- kind: User
name: devman
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: dev-role
apiGroup: rbac.authorization.k8s.io
[root@k8s-master01 pki]# kubectl create -f dev-role.yaml
role.rbac.authorization.k8s.io/dev-role created
rolebinding.rbac.authorization.k8s.io/authorization-role-binding created
- �л��˻�,�ٴ���֤
# �л��˻���devman
[root@k8s-master01 pki]# kubectl config use-context devman@kubernetes
Switched to context "devman@kubernetes".
# �ٴβ鿴
[root@k8s-master01 pki]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
nginx-deployment-66cb59b984-8wp2k 1/1 Running 0 4d1h
nginx-deployment-66cb59b984-dc46j 1/1 Running 0 4d1h
nginx-deployment-66cb59b984-thfck 1/1 Running 0 4d1h
# Ϊ�˲�Ӱ������ѧϰ,�л�admin�˻�
[root@k8s-master01 pki]# kubectl config use-context kubernetes-admin@kubernetes
Switched to context "kubernetes-admin@kubernetes".
9.4 �����
ͨ����ǰ�����֤����Ȩ֮��,����Ҫ��������ƴ���ͨ��֮��,apiserver�Żᴦ���������
�������һ�������õĿ������б�,����ͨ����Api-Server��ͨ������������ѡ��ִ����Щ�������:
--admission-control=NamespaceLifecycle,LimitRanger,ServiceAccount,PersistentVolumeLabel,
DefaultStorageClass,ResourceQuota,DefaultTolerationSeconds
ֻ�е����е�������������ͨ��֮��,apiserver��ִ�и�����,���ؾܾ���
��ǰ�����õ�Admission Control���������:
- AlwaysAdmit:������������
- AlwaysDeny:��ֹ��������,һ�����ڲ���
- AlwaysPullImages:����������֮ǰ��ȥ���ؾ���
- DenyExecOnPrivileged:����������������Privileged Container��ִ�����������
- ImagePolicyWebhook:��������������˵�һ��Webhook���������admission controller�Ĺ��ܡ�
- Service Account:ʵ��ServiceAccountʵ�����Զ���
- SecurityContextDeny:��������ʹ��SecurityContext��Pod�еĶ���ȫ��ʧЧ
- ResourceQuota:������Դ������Ŀ��,�۲���������,ȷ����namespace�ϵ����ᳬ��
- LimitRanger:������Դ���ƹ���,������namespace��,ȷ����Pod������Դ����
- InitialResources:Ϊδ������Դ���������Ƶ�Pod,�����侵�����ʷ��Դ��ʹ�������������
- NamespaceLifecycle:���������һ�������ڵ�namespace�д�����Դ����,��ô��������ܾ�����ɾ��һ��namespaceʱ,ϵͳ����ɾ����namespace�����ж���
- DefaultStorageClass:Ϊ��ʵ�ֹ����洢�Ķ�̬��Ӧ,Ϊδָ��StorageClass��PV��PVC����ƥ��Ĭ�ϵ�StorageClass,�����ܼ����û�������PVCʱ�����˽�ĺ�˴洢ϸ��
- DefaultTolerationSeconds:������Ϊ��Щû������forgiveness tolerations������notready:NoExecute��unreachable:NoExecute����taints��Pod����Ĭ�ϵġ����̡�ʱ��,Ϊ5min
- PodSecurityPolicy:�����������ڴ�������Podʱ�����Ƿ����Pod��security context�Ϳ��õ�PodSecurityPolicy��Pod�İ�ȫ���Խ��п���
10. DashBoard
֮ǰ��kubernetes����ɵ����в�������ͨ�������й���kubectl��ɵġ���ʵ,Ϊ���ṩ���ḻ���û�����,kubernetes��������һ������web���û�����(Dashboard)���û�����ʹ��Dashboard������������Ӧ��,�����Լ��Ӧ�õ�״̬,ִ�й����Ų��Լ�����kubernetes�и�����Դ��
10.1 ����Dashboard
- ����yaml,������Dashboard
# ����yaml
[root@k8s-master01 ~]# wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0/aio/deploy/recommended.yaml
# ��kubernetes-dashboard��Service����
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
type: NodePort # ����
ports:
- port: 443
targetPort: 8443
nodePort: 30009 # ����
selector:
k8s-app: kubernetes-dashboard
# ����
[root@k8s-master01 ~]# kubectl create -f recommended.yaml
# �鿴namespace�µ�kubernetes-dashboard�µ���Դ
[root@k8s-master01 ~]# kubectl get pod,svc -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
pod/dashboard-metrics-scraper-c79c65bb7-zwfvw 1/1 Running 0 111s
pod/kubernetes-dashboard-56484d4c5-z95z5 1/1 Running 0 111s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/dashboard-metrics-scraper ClusterIP 10.96.89.218 <none> 8000/TCP 111s
service/kubernetes-dashboard NodePort 10.104.178.171 <none> 443:30009/TCP 111s
2)���������˻�,��ȡtoken
# �����˺�
[root@k8s-master01-1 ~]# kubectl create serviceaccount dashboard-admin -n kubernetes-dashboard
# ��Ȩ
[root@k8s-master01-1 ~]# kubectl create clusterrolebinding dashboard-admin-rb --clusterrole=cluster-admin --serviceaccount=kubernetes-dashboard:dashboard-admin
# ��ȡ�˺�token
[root@k8s-master01 ~]# kubectl get secrets -n kubernetes-dashboard | grep dashboard-admin
dashboard-admin-token-xbqhh kubernetes.io/service-account-token 3 2m35s
[root@k8s-master01 ~]# kubectl describe secrets dashboard-admin-token-xbqhh -n kubernetes-dashboard
Name: dashboard-admin-token-xbqhh
Namespace: kubernetes-dashboard
Labels: <none>
Annotations: kubernetes.io/service-account.name: dashboard-admin
kubernetes.io/service-account.uid: 95d84d80-be7a-4d10-a2e0-68f90222d039
Type: kubernetes.io/service-account-token
Data
====
namespace: 20 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6ImJrYkF4bW5XcDhWcmNGUGJtek5NODFuSXl1aWptMmU2M3o4LTY5a2FKS2cifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4teGJxaGgiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiOTVkODRkODAtYmU3YS00ZDEwLWEyZTAtNjhmOTAyMjJkMDM5Iiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmVybmV0ZXMtZGFzaGJvYXJkOmRhc2hib2FyZC1hZG1pbiJ9.NAl7e8ZfWWdDoPxkqzJzTB46sK9E8iuJYnUI9vnBaY3Jts7T1g1msjsBnbxzQSYgAG--cV0WYxjndzJY_UWCwaGPrQrt_GunxmOK9AUnzURqm55GR2RXIZtjsWVP2EBatsDgHRmuUbQvTFOvdJB4x3nXcYLN2opAaMqg3rnU2rr-A8zCrIuX_eca12wIp_QiuP3SF-tzpdLpsyRfegTJZl6YnSGyaVkC9id-cxZRb307qdCfXPfCHR_2rt5FVfxARgg_C0e3eFHaaYQO7CitxsnIoIXpOFNAR8aUrmopJyODQIPqBWUehb7FhlU1DCduHnIIXVC_UICZ-MKYewBDLw
ca.crt: 1025 bytes
3)ͨ�����������Dashboard��UI
�ڵ�¼ҳ�������������token
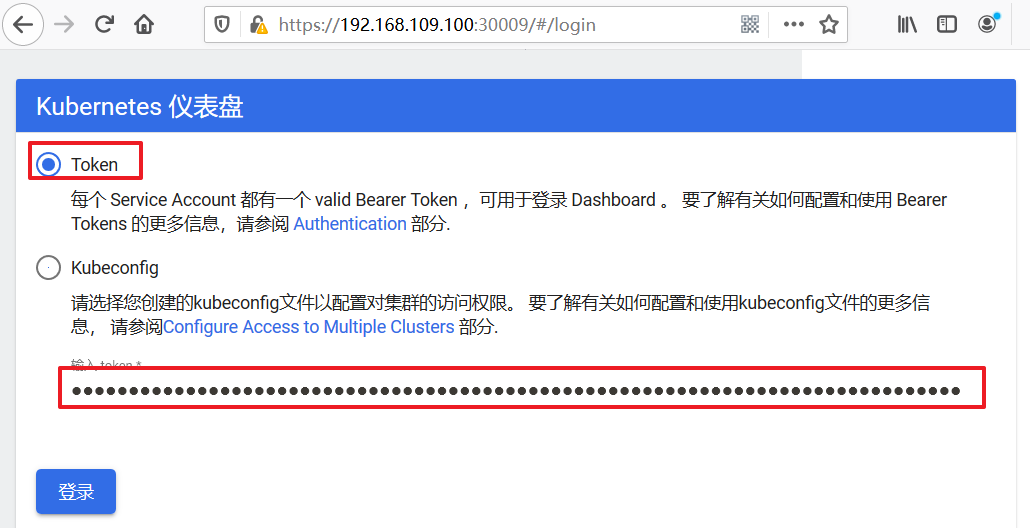
���������ҳ������ɹ�
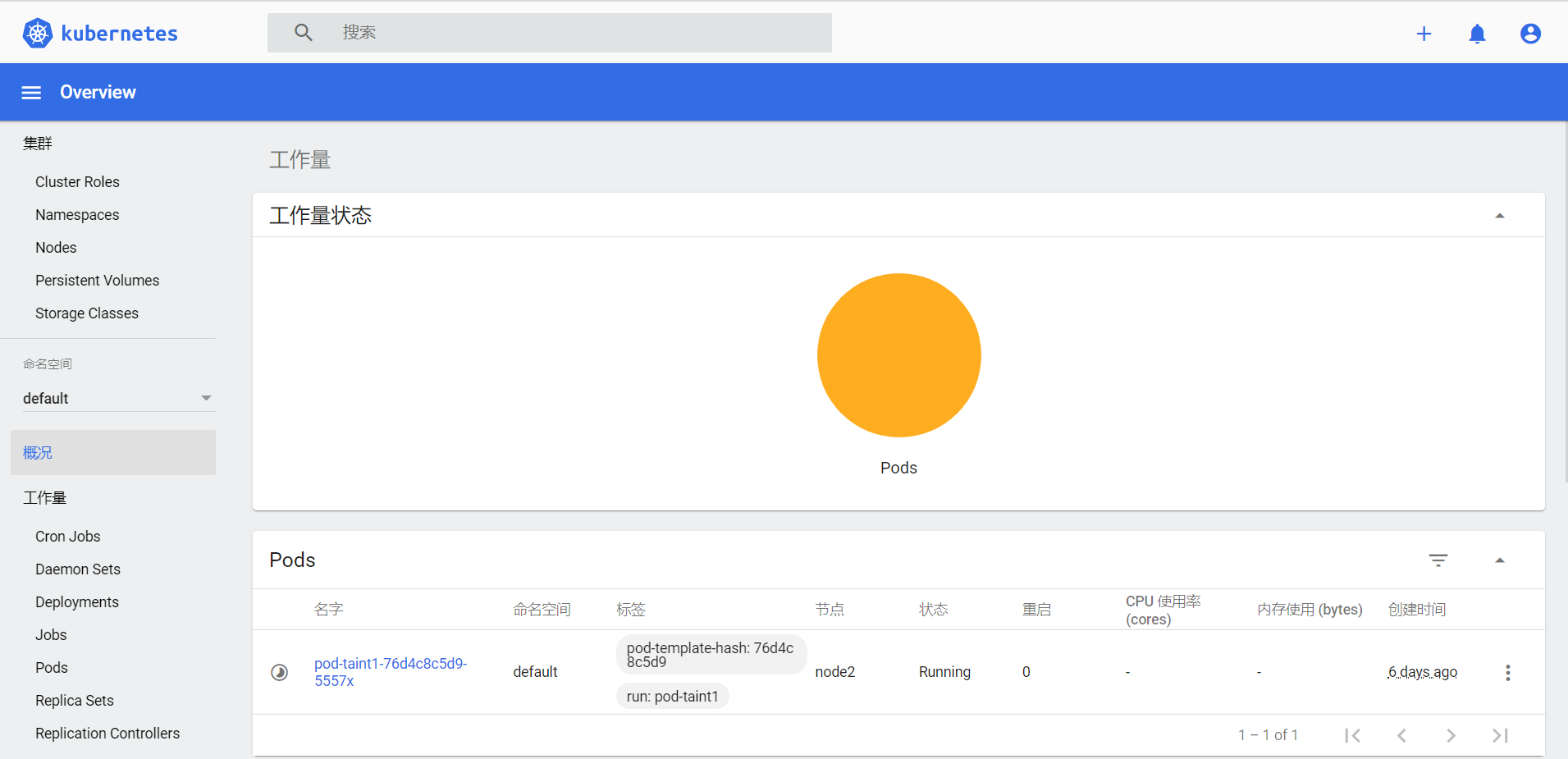
10.2 ʹ��DashBoard
���½���DeploymentΪ����ʾDashBoard��ʹ��
�鿴
ѡ��ָ���������ռ�dev,Ȼ����Deployments,�鿴dev�ռ��µ�����deployment
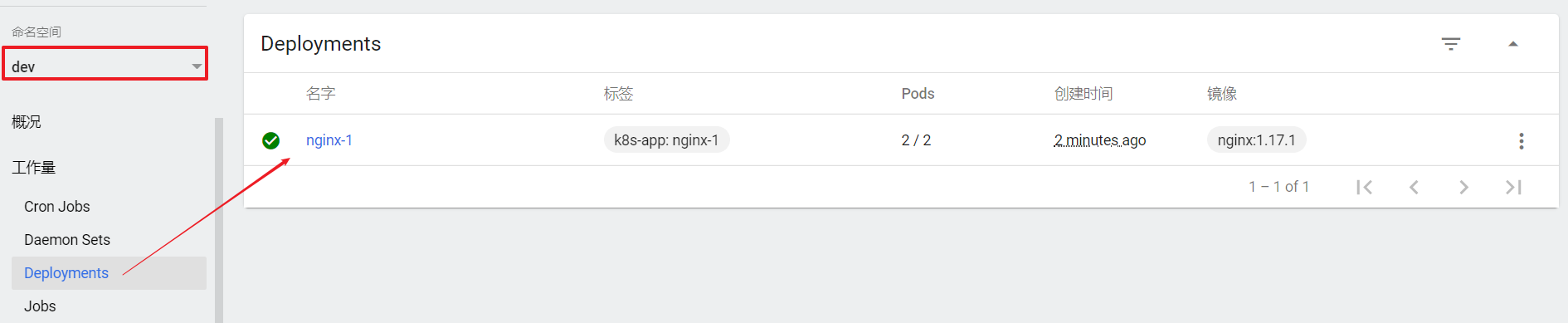
������
��Deployment�ϵ����ģ,Ȼ��ָ��Ŀ�긱������,���ȷ��
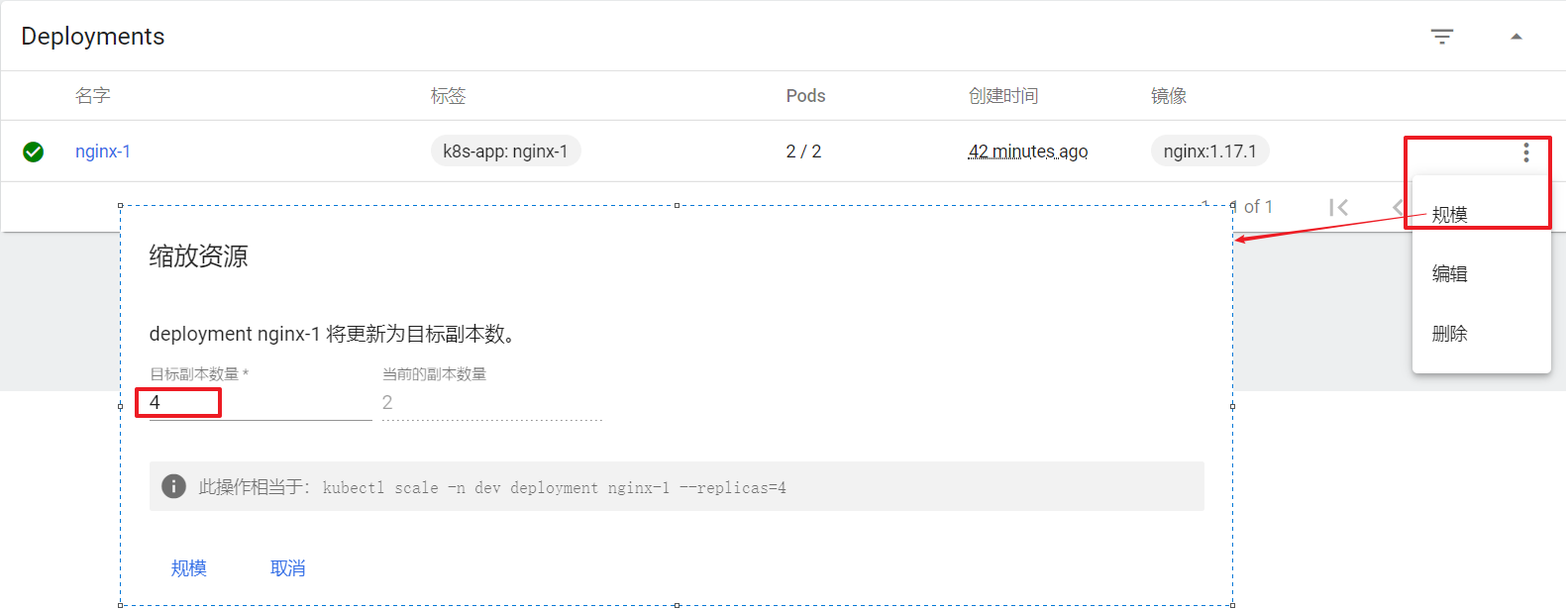
�༭
��Deployment�ϵ���༭,Ȼ����yaml�ļ�,���ȷ��
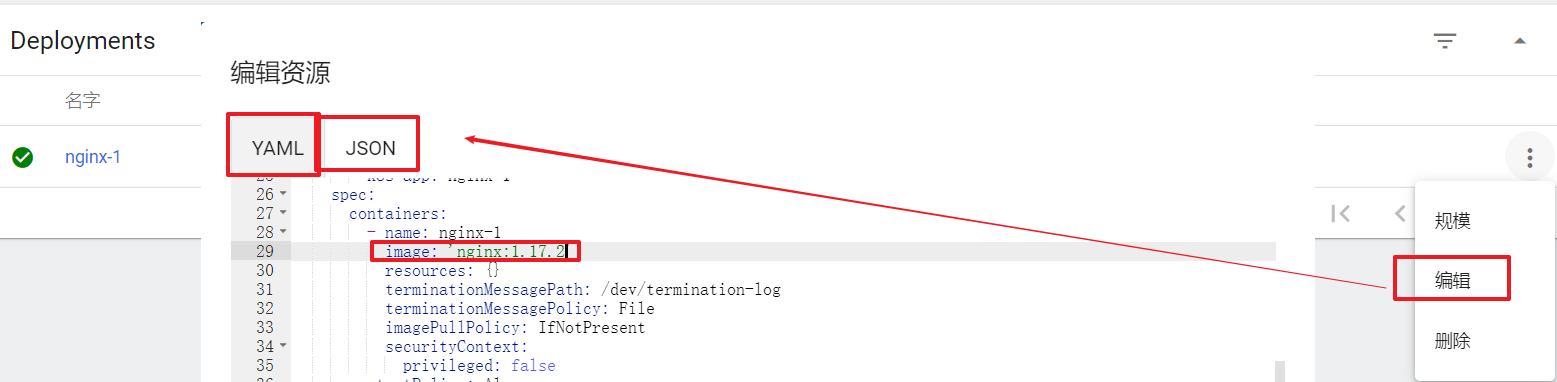
�鿴Pod
���Pods, �鿴pods�б�
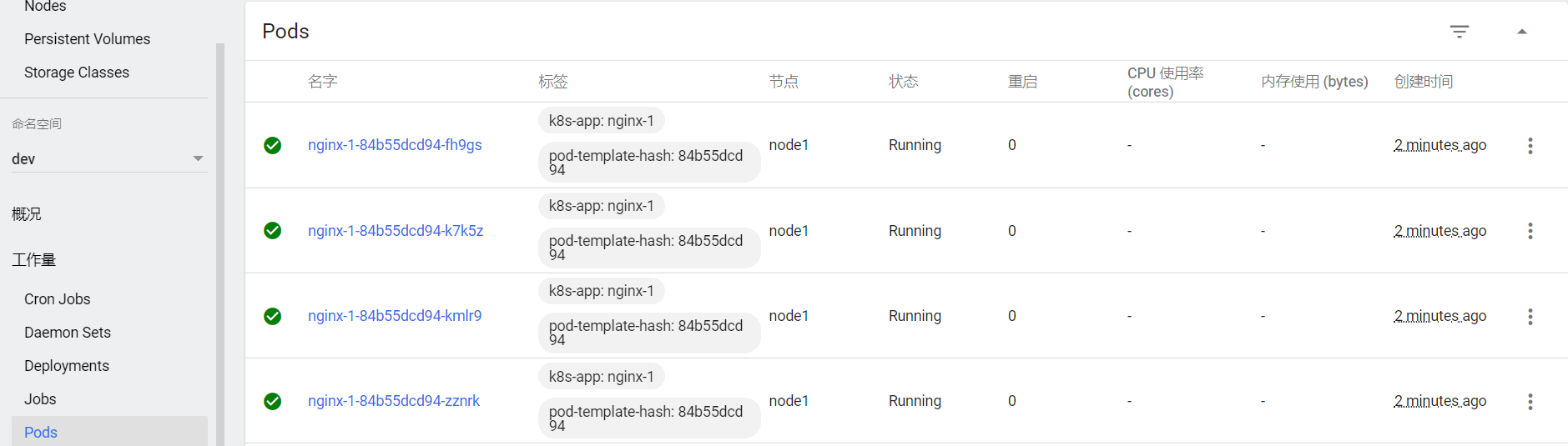
����Pod
ѡ��ij��Pod,���Զ���ִ����־(logs)������ִ��(exec)���༭��ɾ������
Dashboard�ṩ��kubectl�ľ��ֹ���,���ﲻ��һһ��ʾ
le.rbac.authorization.k8s.io/dev-role created
rolebinding.rbac.authorization.k8s.io/authorization-role-binding created
3) �л��˻�,�ٴ���֤
```shell
# �л��˻���devman
[root@k8s-master01 pki]# kubectl config use-context devman@kubernetes
Switched to context "devman@kubernetes".
# �ٴβ鿴
[root@k8s-master01 pki]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
nginx-deployment-66cb59b984-8wp2k 1/1 Running 0 4d1h
nginx-deployment-66cb59b984-dc46j 1/1 Running 0 4d1h
nginx-deployment-66cb59b984-thfck 1/1 Running 0 4d1h
# Ϊ�˲�Ӱ������ѧϰ,�л�admin�˻�
[root@k8s-master01 pki]# kubectl config use-context kubernetes-admin@kubernetes
Switched to context "kubernetes-admin@kubernetes".
9.4 �����
ͨ����ǰ�����֤����Ȩ֮��,����Ҫ��������ƴ���ͨ��֮��,apiserver�Żᴦ���������
�������һ�������õĿ������б�,����ͨ����Api-Server��ͨ������������ѡ��ִ����Щ�������:
--admission-control=NamespaceLifecycle,LimitRanger,ServiceAccount,PersistentVolumeLabel,
DefaultStorageClass,ResourceQuota,DefaultTolerationSeconds
ֻ�е����е�������������ͨ��֮��,apiserver��ִ�и�����,���ؾܾ���
��ǰ�����õ�Admission Control���������:
- AlwaysAdmit:������������
- AlwaysDeny:��ֹ��������,һ�����ڲ���
- AlwaysPullImages:����������֮ǰ��ȥ���ؾ���
- DenyExecOnPrivileged:����������������Privileged Container��ִ�����������
- ImagePolicyWebhook:��������������˵�һ��Webhook���������admission controller�Ĺ��ܡ�
- Service Account:ʵ��ServiceAccountʵ�����Զ���
- SecurityContextDeny:��������ʹ��SecurityContext��Pod�еĶ���ȫ��ʧЧ
- ResourceQuota:������Դ������Ŀ��,�۲���������,ȷ����namespace�ϵ����ᳬ��
- LimitRanger:������Դ���ƹ���,������namespace��,ȷ����Pod������Դ����
- InitialResources:Ϊδ������Դ���������Ƶ�Pod,�����侵�����ʷ��Դ��ʹ�������������
- NamespaceLifecycle:���������һ�������ڵ�namespace�д�����Դ����,��ô��������ܾ�����ɾ��һ��namespaceʱ,ϵͳ����ɾ����namespace�����ж���
- DefaultStorageClass:Ϊ��ʵ�ֹ����洢�Ķ�̬��Ӧ,Ϊδָ��StorageClass��PV��PVC����ƥ��Ĭ�ϵ�StorageClass,�����ܼ����û�������PVCʱ�����˽�ĺ�˴洢ϸ��
- DefaultTolerationSeconds:������Ϊ��Щû������forgiveness tolerations������notready:NoExecute��unreachable:NoExecute����taints��Pod����Ĭ�ϵġ����̡�ʱ��,Ϊ5min
- PodSecurityPolicy:�����������ڴ�������Podʱ�����Ƿ����Pod��security context�Ϳ��õ�PodSecurityPolicy��Pod�İ�ȫ���Խ��п���
10. DashBoard
֮ǰ��kubernetes����ɵ����в�������ͨ�������й���kubectl��ɵġ���ʵ,Ϊ���ṩ���ḻ���û�����,kubernetes��������һ������web���û�����(Dashboard)���û�����ʹ��Dashboard������������Ӧ��,�����Լ��Ӧ�õ�״̬,ִ�й����Ų��Լ�����kubernetes�и�����Դ��
10.1 ����Dashboard
- ����yaml,������Dashboard
# ����yaml
[root@k8s-master01 ~]# wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0/aio/deploy/recommended.yaml
# ��kubernetes-dashboard��Service����
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
type: NodePort # ����
ports:
- port: 443
targetPort: 8443
nodePort: 30009 # ����
selector:
k8s-app: kubernetes-dashboard
# ����
[root@k8s-master01 ~]# kubectl create -f recommended.yaml
# �鿴namespace�µ�kubernetes-dashboard�µ���Դ
[root@k8s-master01 ~]# kubectl get pod,svc -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
pod/dashboard-metrics-scraper-c79c65bb7-zwfvw 1/1 Running 0 111s
pod/kubernetes-dashboard-56484d4c5-z95z5 1/1 Running 0 111s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/dashboard-metrics-scraper ClusterIP 10.96.89.218 <none> 8000/TCP 111s
service/kubernetes-dashboard NodePort 10.104.178.171 <none> 443:30009/TCP 111s
2)���������˻�,��ȡtoken
# �����˺�
[root@k8s-master01-1 ~]# kubectl create serviceaccount dashboard-admin -n kubernetes-dashboard
# ��Ȩ
[root@k8s-master01-1 ~]# kubectl create clusterrolebinding dashboard-admin-rb --clusterrole=cluster-admin --serviceaccount=kubernetes-dashboard:dashboard-admin
# ��ȡ�˺�token
[root@k8s-master01 ~]# kubectl get secrets -n kubernetes-dashboard | grep dashboard-admin
dashboard-admin-token-xbqhh kubernetes.io/service-account-token 3 2m35s
[root@k8s-master01 ~]# kubectl describe secrets dashboard-admin-token-xbqhh -n kubernetes-dashboard
Name: dashboard-admin-token-xbqhh
Namespace: kubernetes-dashboard
Labels: <none>
Annotations: kubernetes.io/service-account.name: dashboard-admin
kubernetes.io/service-account.uid: 95d84d80-be7a-4d10-a2e0-68f90222d039
Type: kubernetes.io/service-account-token
Data
====
namespace: 20 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6ImJrYkF4bW5XcDhWcmNGUGJtek5NODFuSXl1aWptMmU2M3o4LTY5a2FKS2cifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4teGJxaGgiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiOTVkODRkODAtYmU3YS00ZDEwLWEyZTAtNjhmOTAyMjJkMDM5Iiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmVybmV0ZXMtZGFzaGJvYXJkOmRhc2hib2FyZC1hZG1pbiJ9.NAl7e8ZfWWdDoPxkqzJzTB46sK9E8iuJYnUI9vnBaY3Jts7T1g1msjsBnbxzQSYgAG--cV0WYxjndzJY_UWCwaGPrQrt_GunxmOK9AUnzURqm55GR2RXIZtjsWVP2EBatsDgHRmuUbQvTFOvdJB4x3nXcYLN2opAaMqg3rnU2rr-A8zCrIuX_eca12wIp_QiuP3SF-tzpdLpsyRfegTJZl6YnSGyaVkC9id-cxZRb307qdCfXPfCHR_2rt5FVfxARgg_C0e3eFHaaYQO7CitxsnIoIXpOFNAR8aUrmopJyODQIPqBWUehb7FhlU1DCduHnIIXVC_UICZ-MKYewBDLw
ca.crt: 1025 bytes
3)ͨ�����������Dashboard��UI
�ڵ�¼ҳ�������������token
[����ͼƬת���С�(img-PW7jlG9t-1629018950162)]
���������ҳ������ɹ�
[����ͼƬת���С�(img-TLW14APL-1629018950163)]
10.2 ʹ��DashBoard
���½���DeploymentΪ����ʾDashBoard��ʹ��
�鿴
ѡ��ָ���������ռ�dev,Ȼ����Deployments,�鿴dev�ռ��µ�����deployment
[����ͼƬת���С�(img-pB3m2oFO-1629018950163)]
������
��Deployment�ϵ����ģ,Ȼ��ָ��Ŀ�긱������,���ȷ��
[����ͼƬת���С�(img-00UGOuRZ-1629018950164)]
�༭
��Deployment�ϵ���༭,Ȼ����yaml�ļ�,���ȷ��
[����ͼƬת���С�(img-YbmPQgfH-1629018950165)]
�鿴Pod
���Pods, �鿴pods�б�
[����ͼƬת���С�(img-PWTNQ2jd-1629018950165)]
����Pod
ѡ��ij��Pod,���Զ���ִ����־(logs)������ִ��(exec)���༭��ɾ������
[����ͼƬת���С�(img-sz0TvefE-1629018950166)]
Dashboard�ṩ��kubectl�ľ��ֹ���,���ﲻ��һһ��ʾ
�ο���ƵKubernetes(K8S)�����ŵ���ͨȫ�̳�
https://www.bilibili.com/video/BV1Qv41167ck?p=71&spm_id_from=pageDriver