文章目录
通信基本概念
进程通信与进程独立
进程具有独立性,也就是说多个进程运行时独享自己的资源(数据),互不干扰影响。而进程通信则是数据的交互,这与数据独立似乎有所矛盾,但实际上进程独立也是独立的,进程数据也是可以交互的,进程间也会产生协作关系的。(利用管道文件,或者共享内存)
进程间通信的目的
- 数据传输:一个进程需要将它的数据发送给另一个进程
- 资源共享:多个进程之间共享同样的资源。
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
进程间通信的分类
想要让两个进程通信,就要用尽一切方法让他们看见同一份内存空间
当使用fork函数时,子进程会将父进程作为模板,拷贝父进程的数据,所以当父进程打开文件,它就有了自己的files_struct,那么创建子进程之后,就会将其files struct继承下来,这样的话两个进程也就指向了同一份内存空间,也就能通信了
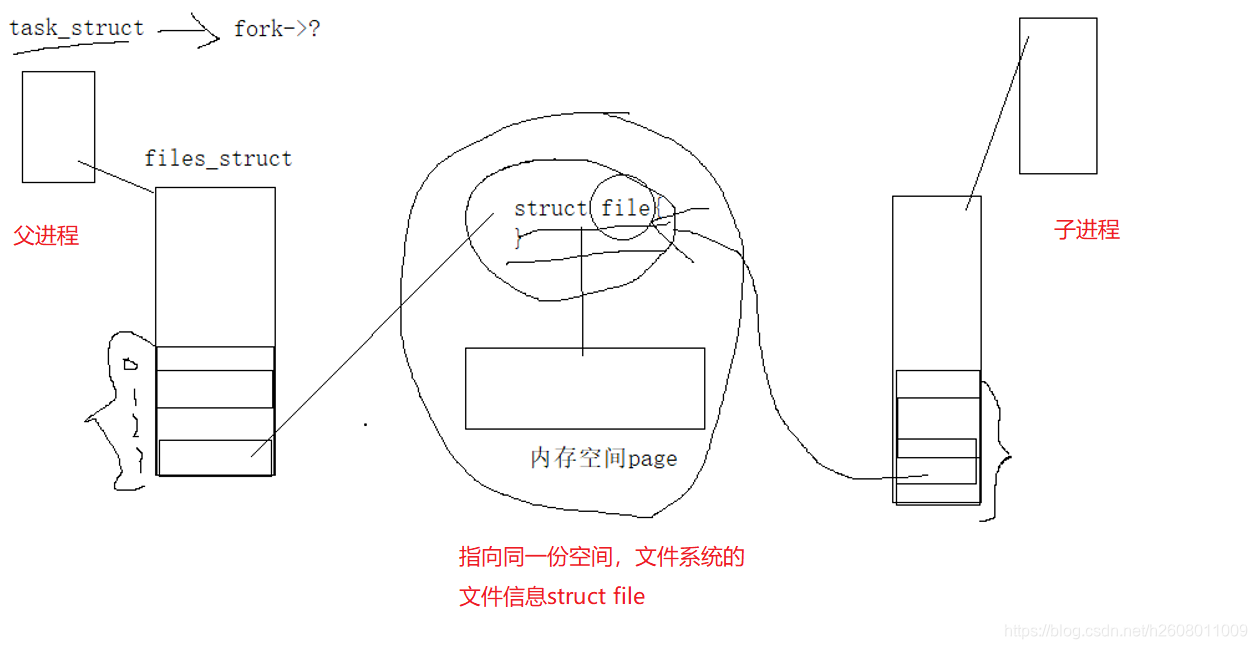
至于这个内存空间是由谁提供的,或者是以什么方式提供的就决定了进程间通信的方式。目前我所了解的是三种方式:
1:管道
- 匿名管道pipe
- 命名管道
2:System V IPC
- System V消息队列
- System V共享内存
- System V信号量
POSIX IPC
- 消息队列
- 共享内存
- 信号量
- 互斥量
- 条件变量
- 读写锁
进程数据交互:管道
什么是管道
管道是Unix中最古老的进程间通信的形式。我们把从一个进程连接到另一个进程的一个数据流称为一个“管道”
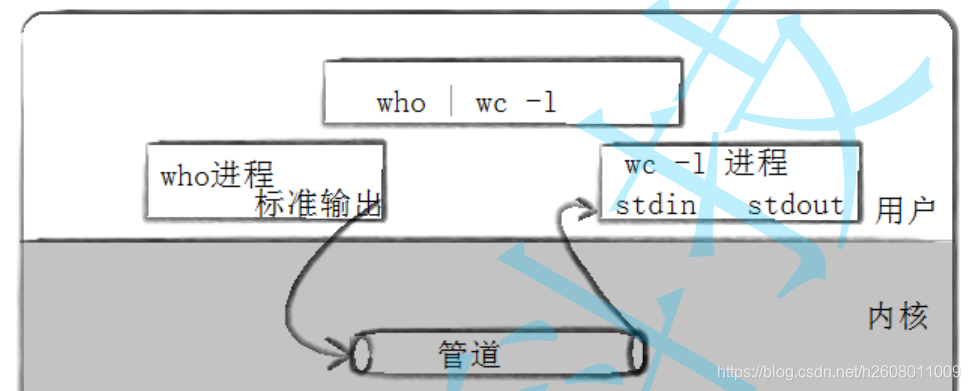
如上,命令行who的标准输出原本是屏幕,但是却输出到了管道文件中,发生了重定向,然后wc命令再从以管道文件作为标准输入,然后输出到屏幕中。上述的who | wc -l就是应用匿名管道进行数据交互。
匿名管道
写端与读端
从who | wc -l可以看出,who作为一个进程是把内容写入管道文件,使用的是管道的写端,wc从管道中读入数据,使用的是管道的读端。
所以两个进程利用管道通信时,一个进程要使用管道的写端写入数据,另一个进程则要使用管道的读端读入数据,所以管道文件就要用两个文件描述符进行控制,一个控制读端,一个控制写端
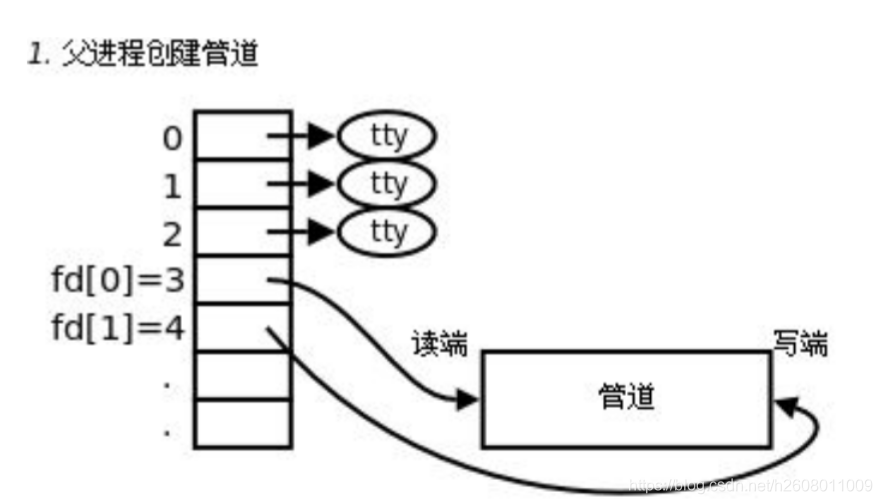
父进程创建了管道
子进程同理
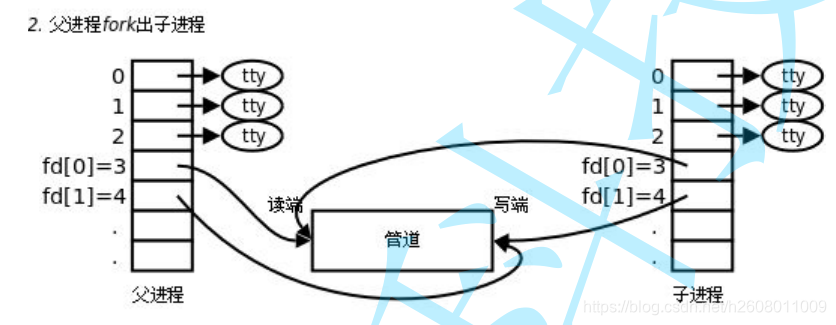
可以发现此时父子进程可以同时对管道进行写入的和读取,但是管道只能一端写入一端读入,所以要进行调整
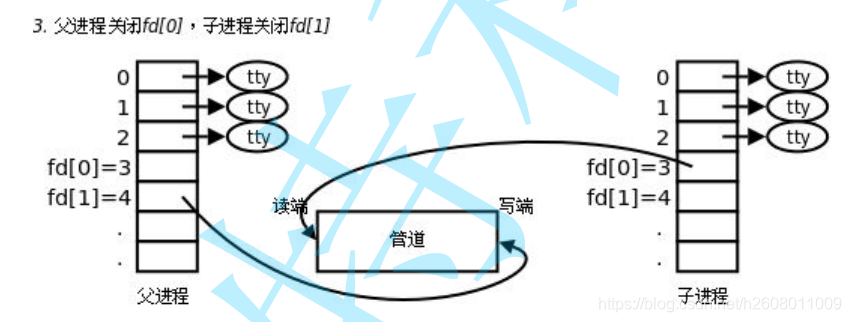
建立匿名管道的函数
其函数原型为int pipe(int fd[2]),头文件是unistd.h,传入函数pipe后在其内部分别以读写的方式打开管道文件,默认情况下,fd[0]和fd[1]会分别获得文件描述符,其中fd[0]表示读端,fd[1]表示写端,返回值:成功返回0,失败返回-1。
其pipe内部函数的模拟实现可能是这样的:
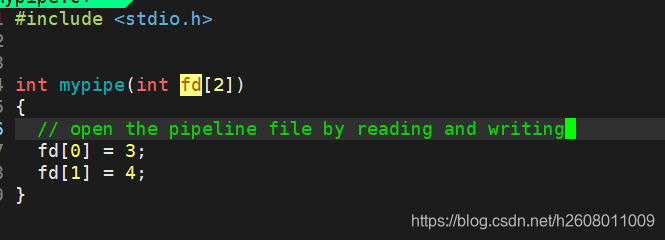
有很多同学在这里会感到疑惑,因为用于进程间通信的管道文件就只有一个,为什么会有两个文件描述符呢?(默认是3和4)
其实这一点在之前的基础IO中我没有表示特别清楚,以读方式的打开一个文件,会分配一个描述符(假设是3),然后再以写方式打开刚才的你文件也会分配一个描述符(假设是4),这里的3和4操作的是一个文件,只不过一个负责读,一个负责写
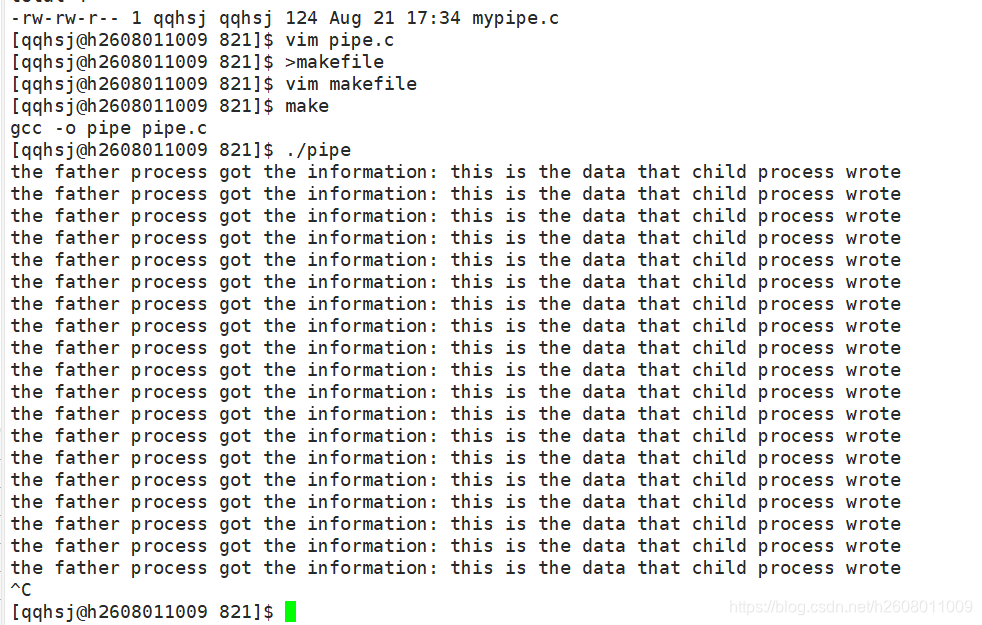
最简单的进程间通信
为了观察方便,对父子进程都是用死循环。子进程每隔一秒读入一段信息this is the data that the child process wrote用来证明子进程写入了数据;对于父进程则取读取数据,一旦读完数据,就输出the father process got the information,用来证明父进程读取到了数据
注意pipe和fork创建后需要关闭一个读端和写端,如下所示。
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
int pipefd[2] = {0};
pipe(pipefd);
//pipefi[0] write, else read
pid_t id = fork();
if(id == 0)
{
//child
close(pipefd[0]);
const char* msg = "this is the data that child process wrote";
while(1)
{
write(pipefd[1], msg, strlen(msg));
sleep(1);
}
}
else{
//father
close(pipefd[1]);
char buffer[64] = {0};
while(1)
{
ssize_t ret = read(pipefd[0], buffer, sizeof(buffer) - 1);
//judge whether to read in
if(ret > 0)
{
buffer[ret] = '\0';
printf("the father process got the information: %s\n",buffer);
}
sleep(0);
}
}
return 0;
}
管道的四大特性
特性一:如果写端(这里是子进程)不关闭文件描述符,且不写入(简称为读端条件不就绪),那么读端可能会长时间阻塞(当管道有历史数据时会先读完,管道为空,且写端不写入会长时间堵塞),也就是读端快,写端慢
将写端子进程睡眠时间提升至5秒,观察现象,可以的到读端被阻塞,读写同步,均变为5s。
特性二:当写端在写入时,写端条件不就绪(比如管道已经满了),写端就要被阻塞,也就是写端快,读端慢
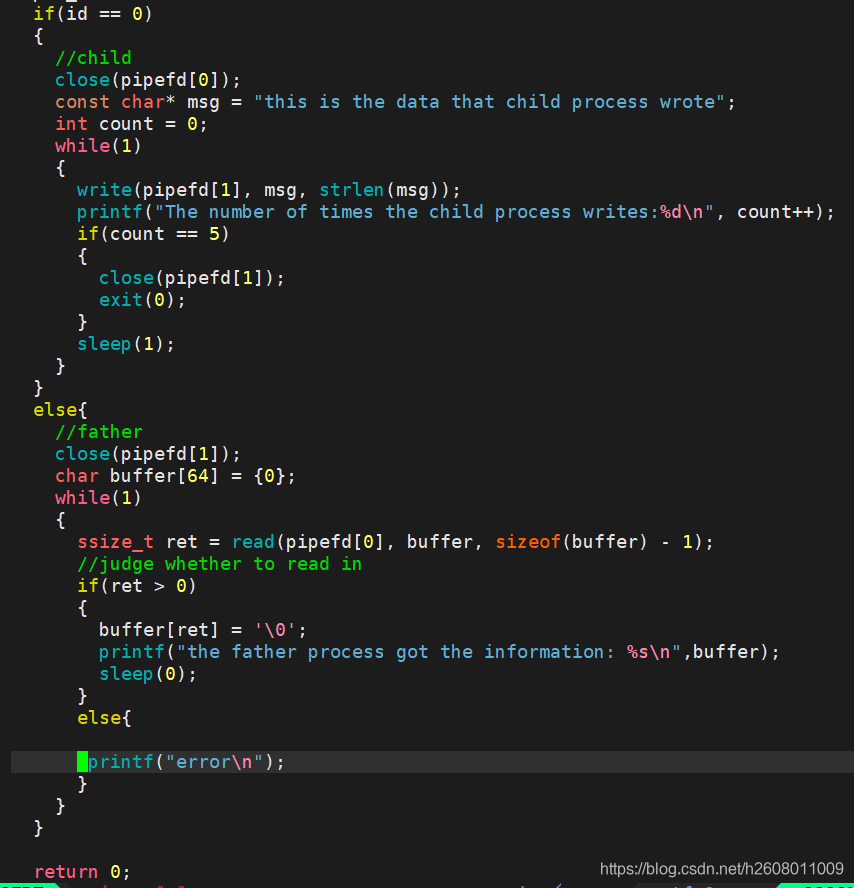
子进程代码改动如下:
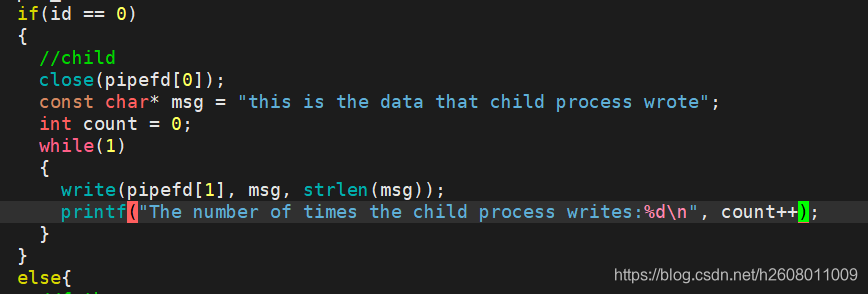
结果如下:写端瞬间将管道充满,然后读端慢慢的从管道中读数据
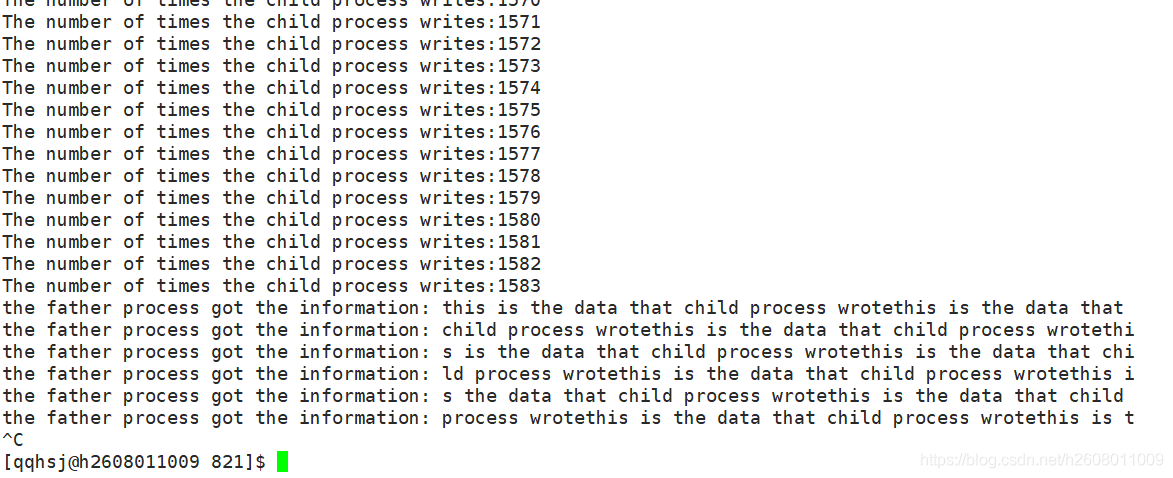
特性三:如果写端关闭文件描述符,那么读端当读完管道内容后,或读到文件结尾(此时read的返回值是0)
结果如下:
对比特性一,特性一中是写端不关闭文件描述符还写的特别慢,因此读端也被牵制住,造成读端堵塞。而当写端文件描述符关闭之后,这个管道文件唯一的输入来源就切断了,因此如果不给其结束标记,那么就会造成读端永久阻塞
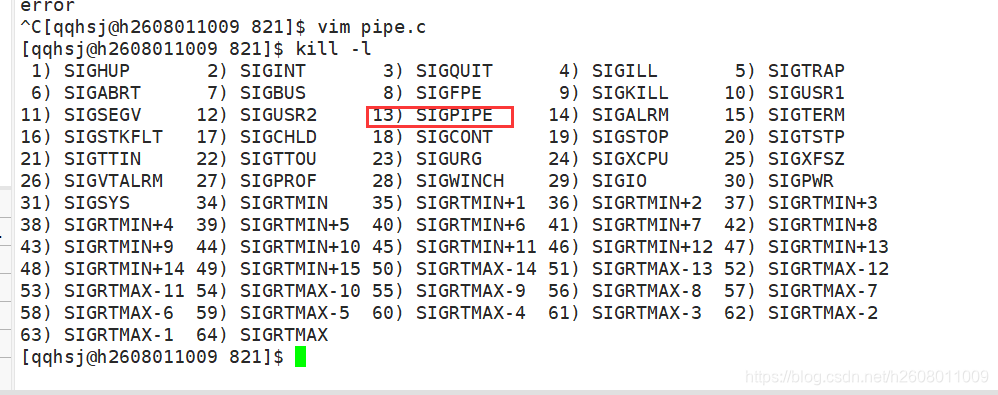
特性四:如果读端关闭文件描述符,那么写端有可能被操作系统结束掉
脚本观察:
while :; do ps axj | grep pipe | grep -v grep; echo "#######################";sleep 1;done
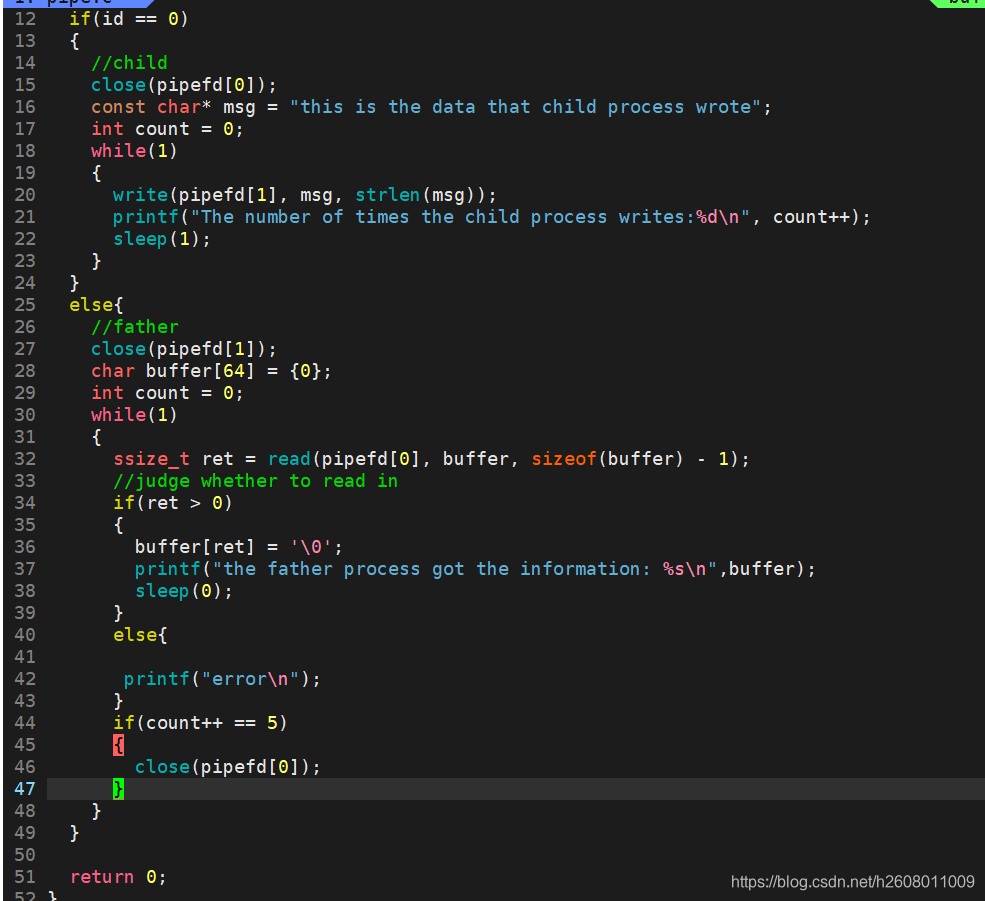
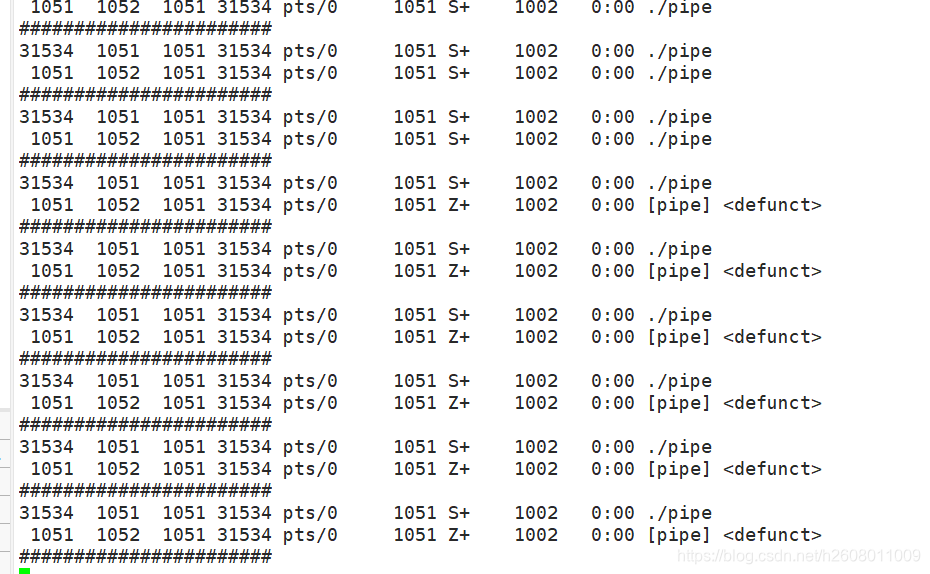
当读端关闭之后,就没有进程读取数据了,那么写入的操作就变成了一种无用操作,所以操作系统发现了这种浪费资源的行为后,就发送了13号信号,结束了子进程
管道的特点
- 只能用于具有共同祖先的进程(具有亲缘关系的进程)之间进行通信。通常,一个管道由一个进程创建,然后该进程调用fork,此后父子进程之间就可使用该管道
- 管道提供流式服务。所谓流式服务就是读端在读取时可以任意读取,想读多少就读多少,就像水龙头一样,你想开多大完全取决于你
- 一般而言,进程退出,管道释放,所以管道的生命周期跟随进程
- 由特性1,2可知,管道之间具有同步和互斥的机制
- 管道是半双工的,数据只能向一个方向流动
内核角度理解管道
Linux下一切皆文件
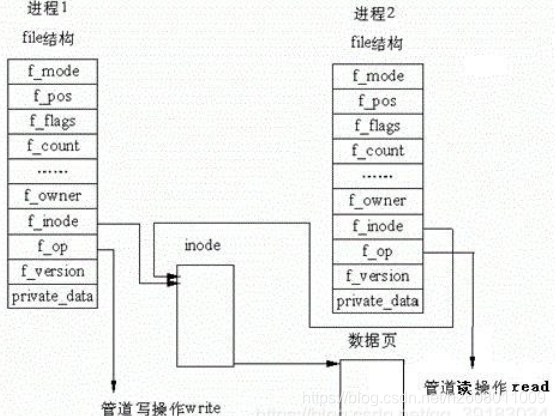
如下便是进程打开的文件的file结构体,其中有一个结构体path,跳转过去,当找到其所在的目录后,其结构体内就存储了目录的inode
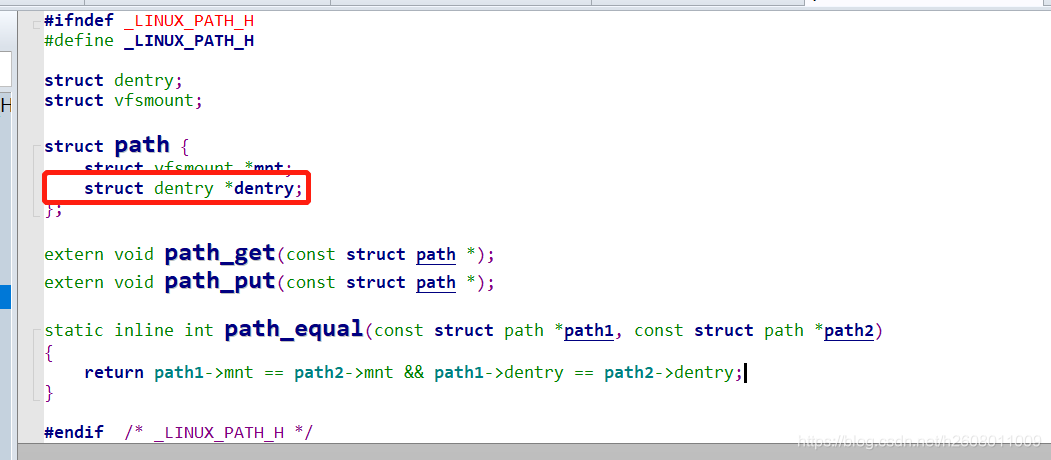
根据目录的inode可以找到目录的数据块,而之前说过目录中存储的就是文件名和inodei・映射关系,于是就可找到该文件file的inode,如下
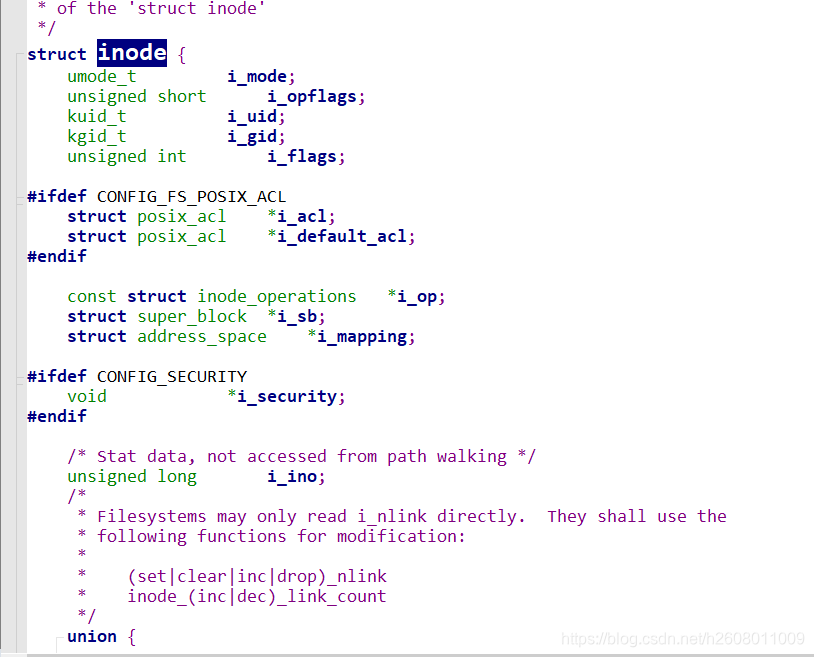
而inode中有一个union,它是迎来标识文件类型的,可以发现第一个便是管道文件
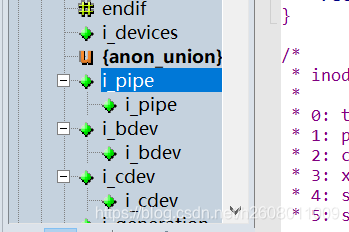
总结:
- 至此我们便可以从更深的层次中理解管道的本质。sleep 1000 | sleep 2000,分别是两个进程,它们的父进程均是bash,所以bash创建了管道,然后关闭了它对管道的通信,这两个sleep命令则利用管道进行通信
- who | wc -l,bash创建了管道,who和wc利用管道通信,who发生输出了重定向,将输出重定向的管道文件中,wc发生了输入重定向,将输入来源从键盘更改为管道文件,Linux一切皆文件,这就管道的本质
命名管道
命名管道和匿名管道的区别
前面说过,匿名管道的限制就是只能在具有共同祖先(具有亲缘关系)的进程间通信,而不适合与毫无相干的两个进程
如果我们想在两个不相干的进程之间进行通信,可以使用FIFO文件完成,也被称为命名管道,命名管道实际是一种类型为“p”的文件
如何创建命名管道
匿名管道由pipe函数创建并打开,命名管道则有mkfifo函数创建
命名管道可以从命令行上创建
mkfifo filename
也可以从程序汇总创建,其函数为
int mkfifo(const char* filename,modet_t mode);
//filename是创建管道文件的路径+文件名
//mode是权限值
管道实现服务端和客户端的通信
服务端:
客户端:
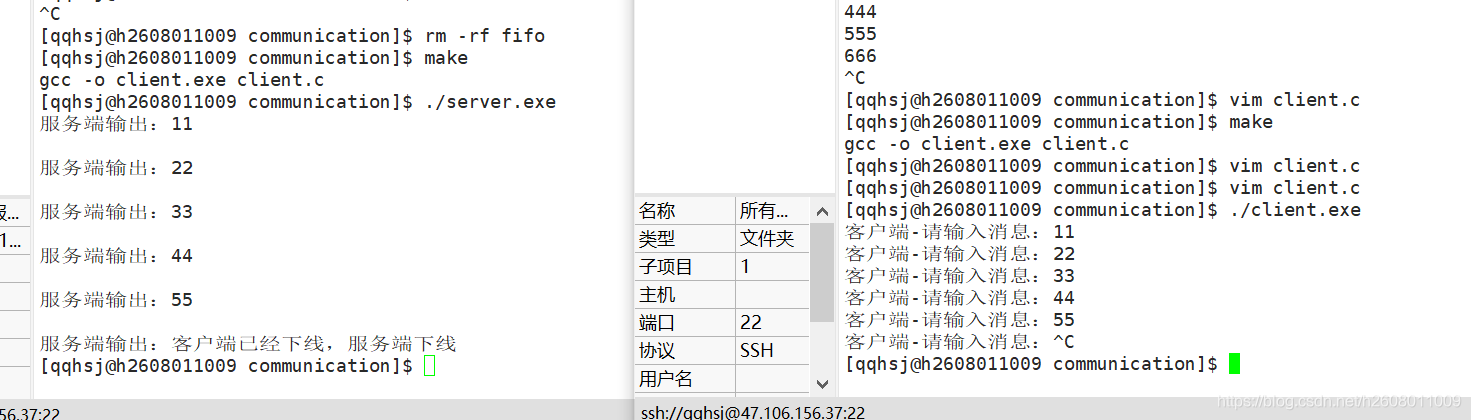
这里还有一个非常有趣的点:那个fifo文件是0个字节,自始至终它都是一个字节
这表明它们之间通信时,并没有直接在这个文件上进行IO操作,因为如果进行IO操作其实代价就太大了。这里的fifo其实仅仅起到了一种标志的作用,它的底层其实和匿名管道是差不多的。
管道和共享内存的区别
前面讲到了管道,不管是匿名管道也好,还是命名管道也罢,它都是文件,也就是两个进程之间通信时还要借助文件系统。但是,文件系统也是帮助我们最终回到相同的内存空间, 所以如果能跳过文件系统,直接让进程看到相同的内存空间,是否通信的效率就会提高呢?
答案是的,这一种方式就是System V,它是一种标准,这里重点介绍的是System V共享内存
前面在进程地址空间的时候,我们知道了每个进程看到的都是虚拟内存,页表则负责将虚拟内存映射到真实的物理内存处
既然页表是负责映射的,那么是否可以在物理内存上开辟一片空间,然后通过页表让他们都映射到一片内存空间,这样就符合“看到同一片内存空间”的规则呢?
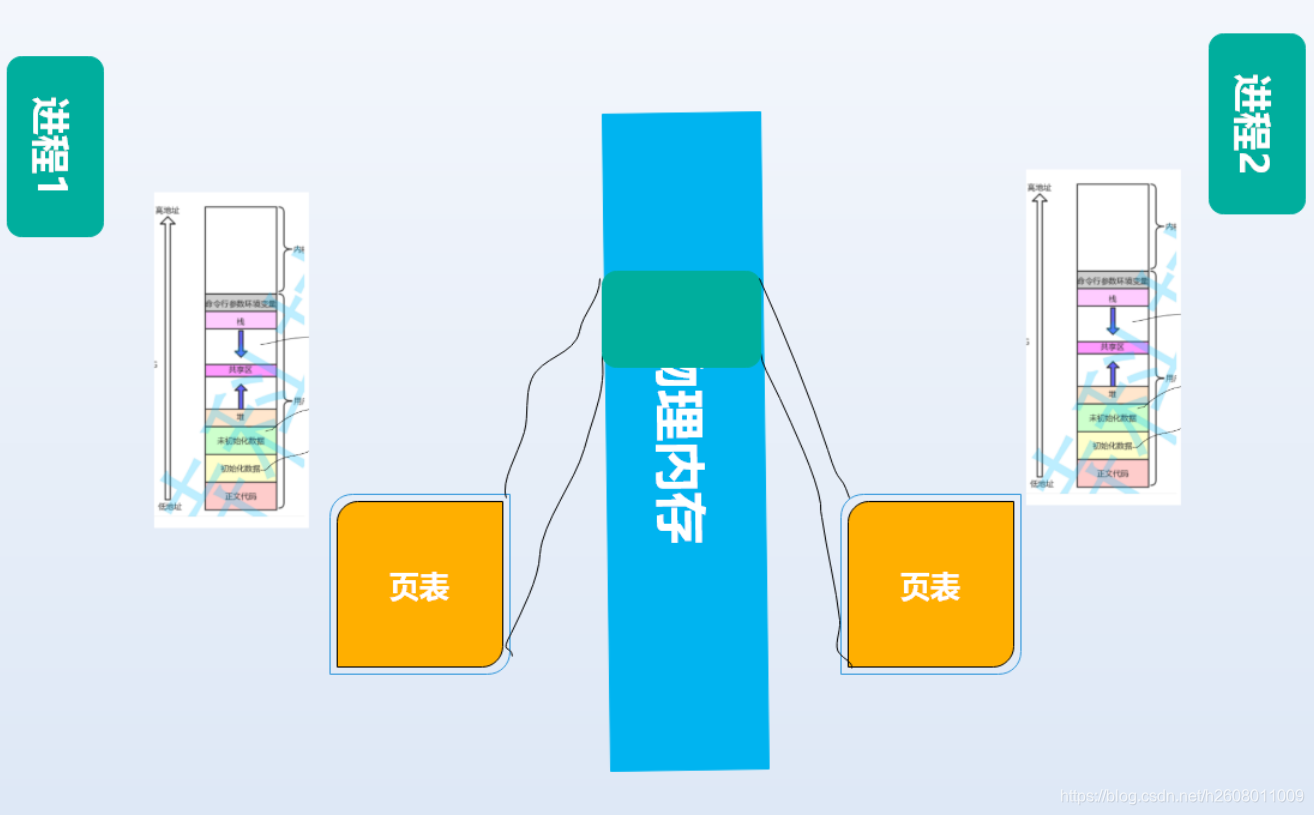
答案是可以的。这样的话,两个进程在进行读写时实际操纵的是同一片内存,进程1的读写操作就可以让进程2看到了。
大家可以回忆刚才管道的操作,在写端写入时,首先从标准输入中输入,拷贝至buffer中,然后再从buffer拷贝到管道文件中,这实则经过了两次拷贝,同时读取时从管道中读取,这算拷贝一次,接着再输出到标准输出中,还算一次拷贝,总共经过了4次拷贝。而通过咋们刚才的页表映射时,直接写入,只需要拷贝一次,对于另一个进程,它是可以直接看到,感知到这块内存的,所以总共只需要进行一次拷贝。所以共享内存要实现进程通信要比管道快很多。
所以,共享区除了放咋们前面说过的动态库外,还可以放共享内存,也是专门处理通信的区域
先组织,再描述
不管是管道,还是共享内存,进程间通信的本质就是让他们看见相同的内存资源。大家需要明白的一点是,进程间通信不是嘴上说说那么简单,想要实现两个进程看见同一份内存资源,以及看见资源后如何写入,读取,同时对于这份内存如何把不同进程关联上去,如何保证关联的稳定等等 ,这都是需要去管理的,况且操作系统会存在大量的进程通信,所以对于操作系统,想要管理好进程间通信,一定是先组织,再描述,也就是底层会存在大量与此相关的数据结构
正如描述进程时的task_strct,描述文件时的file struct,描述进程间通信的结构体则是shmid_ds
进程间通信相关接口
- 创建共享内存
- 删除共享内存
- 关联共享内存
- 取消共享内存的关联
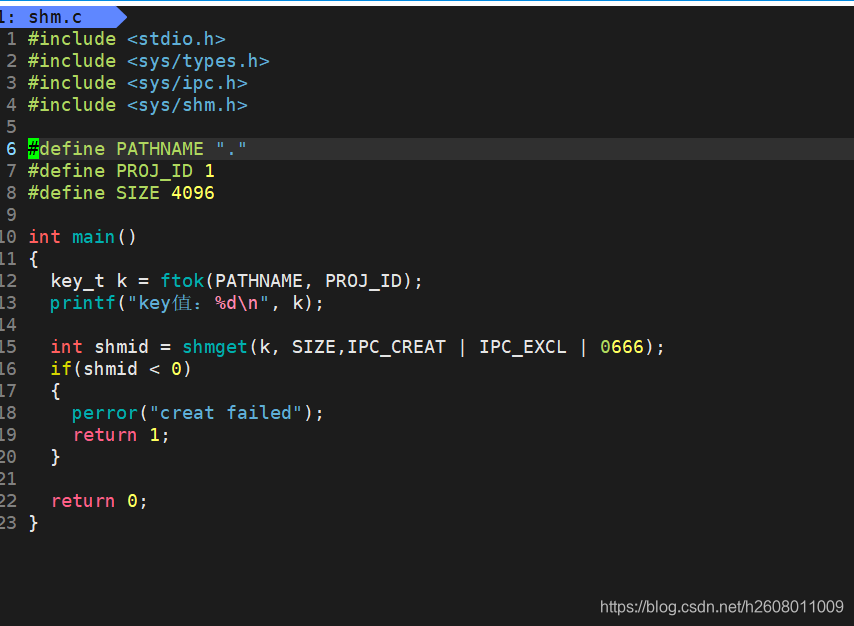
ftok(获取唯一标识码)
#include <sys/type.h>
#include <sys/ipc.h>
key _t ftok(const char* pathname,int proj_id);
pathname:可以是目录或者是文件的绝对路径,可以随便设置
proj_id:设置权限
共享内存有很多,你既然申请了一块内存,那么操作系统总要能区分出来,所以它的作用就类似于身份证号一样,生成一个唯一的数字,来标识你申请的那块内存
shmid_ds结构体中有一个叫做ipc perm,系统为每一个共享内存保存一个ipc_perm结构体,该结构说明了共享内存的权限和所有者
struct ipc_perm
{
key_t key; //调用shmget()时给出的关键字
uid_t uid; /*共享内存所有者的有效用户ID */
gid_t gid; /* 共享内存所有者所属组的有效组ID*/
uid_t cuid; /* 共享内存创建 者的有效用户ID*/
gid_t cgid; /* 共享内存创建者所属组的有效组ID*/
unsigned short mode; /* Permissions + SHM_DEST和SHM_LOCKED标志*/
unsignedshort seq; /* 序列号*/
};
shmget(创建共享内存)
#include <sys/ipc.h>
#include <sys/shm.h>
int shmget(key_t key, size_t size,int shmflg);
key:ftok的返回值
size:共享内存创建的大小,最好是页的整数倍
shmflg:一些标志选项
IPC_CREAT:如果内核中不存在键值与传入的key值相等的共享内存,则会新建一个共享内存;如果内核中存在键值与传入的key值相等的共享内存,则返回此共享内存的标识符。如果按照从文件的角度理解就是:打开一个目标名字为key的文件,没有的话就创建,有的话就返回key
IPC_CREAT|IPC_EXCL:承接上面,如果内核中存在键值与传入的key值相等的共享内存,则报错。如果从文件的角度理解就是:打开一个目标名字为key的文件,没有的话就创建,有的话直接报错,说key已经存在了
返回值
成功:返回共享内存的标识符
错误:返回-1
演示:
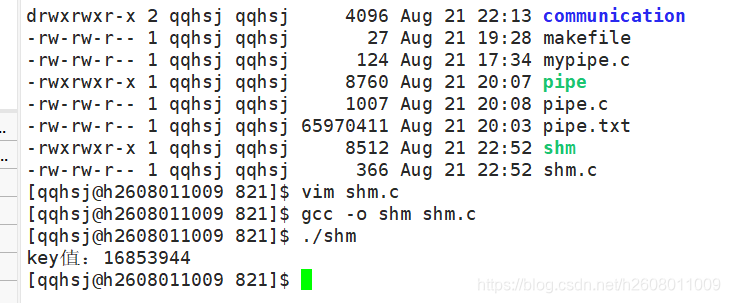
ipcs命令是关于共享内存的
其中ipcs -m表示查看共享内存,可以发现其中id=30的便是我创建的共享内存
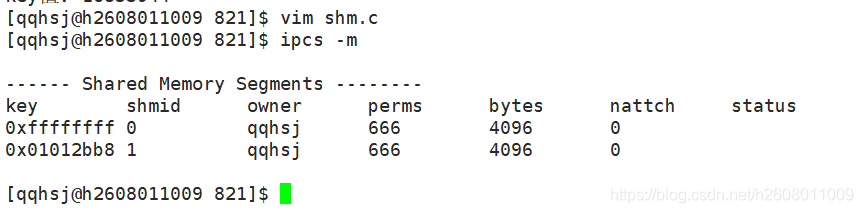
0x01012bb8就是我们需要创建的共享内存。
删除共享内存的命令是ipcrm
ipcrm -m 1来进行删除。
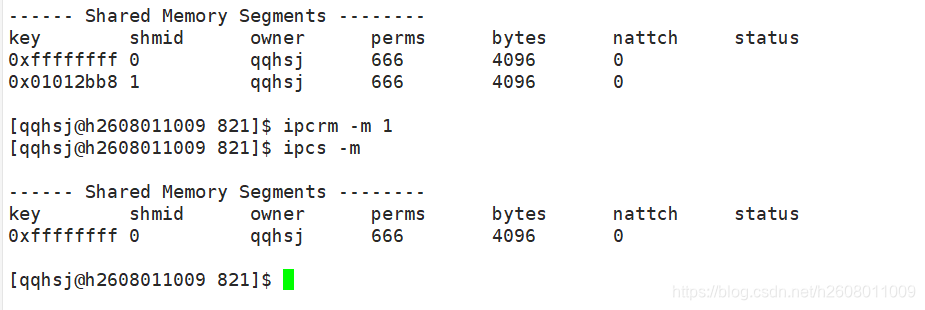
shmctl(控制共享内存)
#include <sys/ipc.h>
#include <sys/shm.h>
int shmctl(int shmid,int cmd,struct shmid_ds* buf);
shmid:共享内存的id
cmd:将要采取的动作,有三个选项‘
IPC_RMID:删除共享内存(主要使用)
IPC_STAT:将shmid_ds结构体中的数据设置为共享内存的当前关联值
IPC_SET:在进程有足够权限的前提下,把共享内存的当前关联值设置为shmid_ds结构中给出的值
buf:这是一个结构指针,指向的就是shmd_ds结构体,不使用就传入NULL
shmat(将共享内存段与当前进程挂接)
#include <sys/ipc.h>
#include <sys/shm.h>
void* shmat(int shmid,const void* shmaddr,int shmflag);
shmid:共享内存标识符
shmaddr:指定的连接地址,设置为NULL即可
shmflag:设置为0(默认值)即可
shmdt(将共享内存段与当前进程脱离)
#include <sys/ipc.h>
#include <sys/shm.h>
int shmdt(const void* shmaddr);
shmaddr:就是shmat的返回值
演示
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <unistd.h>
#include <sys/shm.h>
#define PATHNAME "tmp"
#define PROJ_ID 88
#define SIZE 4096
int main()
{
key_t k=ftok(PATHNAME,PROJ_ID);
printf("key值:%#X\n",k);
int shmid=shmget(k,SIZE,IPC_CREAT | IPC_EXCL|0666);
if(shmid<0)
{
perror("creat failed");
return 1;
}
sleep(5);//5s后与共享内存进行挂接
void* shmaddr=shmat(shmid,NULL,0);
sleep(3);//挂接3s后将本进程与共享内存脱离
shmdt(shmaddr);
sleep(3);//脱离后3s释放共享内存
shmctl(shmid,IPC_RMID,NULL);
sleep(3);//释放后结束进程
return 0;
}
上面只是挂接了本进程(server.c),现在将另外一个进程也挂接上(client.c)。需要注意,下一个进程在挂接时,对于shmget最后一个参数可以传入0,表示接受到主进程创建的那个共享内存,并且释放共享内存不需要它进行
client.c的代码如下
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <unistd.h>
#include <sys/shm.h>
#define PATHNAME "tmp"
#define PROJ_ID 88
#define SIZE 4096
int main()
{
key_t k=ftok(PATHNAME,PROJ_ID);
printf("key值:%#X\n",k);
int shmid=shmget(k,SIZE,0);//服务端已经申请了,写成0直接获取
if(shmid<0)
{
perror("creat failed");
return 1;
}
sleep(5);//5s后与共享内存进行挂接
void* shmaddr=shmat(shmid,NULL,0);
sleep(3);//挂接3s后将本进程与共享内存脱离
shmdt(shmaddr);
sleep(3);//脱离后3s释放共享内存
return 0;
}
共享内存实现客户端和服务端的通信
介绍完如上接口后,现在我们使用共享内存完成客户端和服务端之间的通信,为了说明一些情况,我们让客户端每隔5s向内存中依次序输入小写字母,而服务端每隔1s读取一次。其中注意,shmat的返回值是一个void类型的,所以要打印字符,就要强转为char*
server.c代码
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <unistd.h>
#include <sys/shm.h>
#define PATHNAME "tmp"
#define PROJ_ID 88
#define SIZE 4096
int main()
{
key_t k=ftok(PATHNAME,PROJ_ID);
printf("key值:%#X\n",k);
int shmid=shmget(k,SIZE,IPC_CREAT | IPC_EXCL|0666);
if(shmid<0)
{
perror("creat failed");
return 1;
}
char* shmaddr=shmat(shmid,NULL,0);//挂接,注意强转
while(1)//每1s打印一次
{
sleep(1);
printf("%s\n",shmaddr);
}
shmdt(shmaddr);//脱离
shmctl(shmid,IPC_RMID,NULL);//释放
return 0;
}
client.c代码
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <unistd.h>
#include <sys/shm.h>
#define PATHNAME "tmp"
#define PROJ_ID 88
#define SIZE 4096
int main()
{
key_t k=ftok(PATHNAME,PROJ_ID);
printf("key值:%#X\n",k);
int shmid=shmget(k,SIZE,0);//服务端已经申请了,写成0直接获取
if(shmid<0)
{
perror("creat failed");
return 1;
}
char* shmaddr=shmat(shmid,NULL,0);//挂接,注意强转
int i=0;
while(i<26)
{
shmaddr[i]=97+i;每隔5s依次输入a,b,c...........................
i++;
sleep(5);
}
shmdt(shmaddr);//脱离
return 0;
}
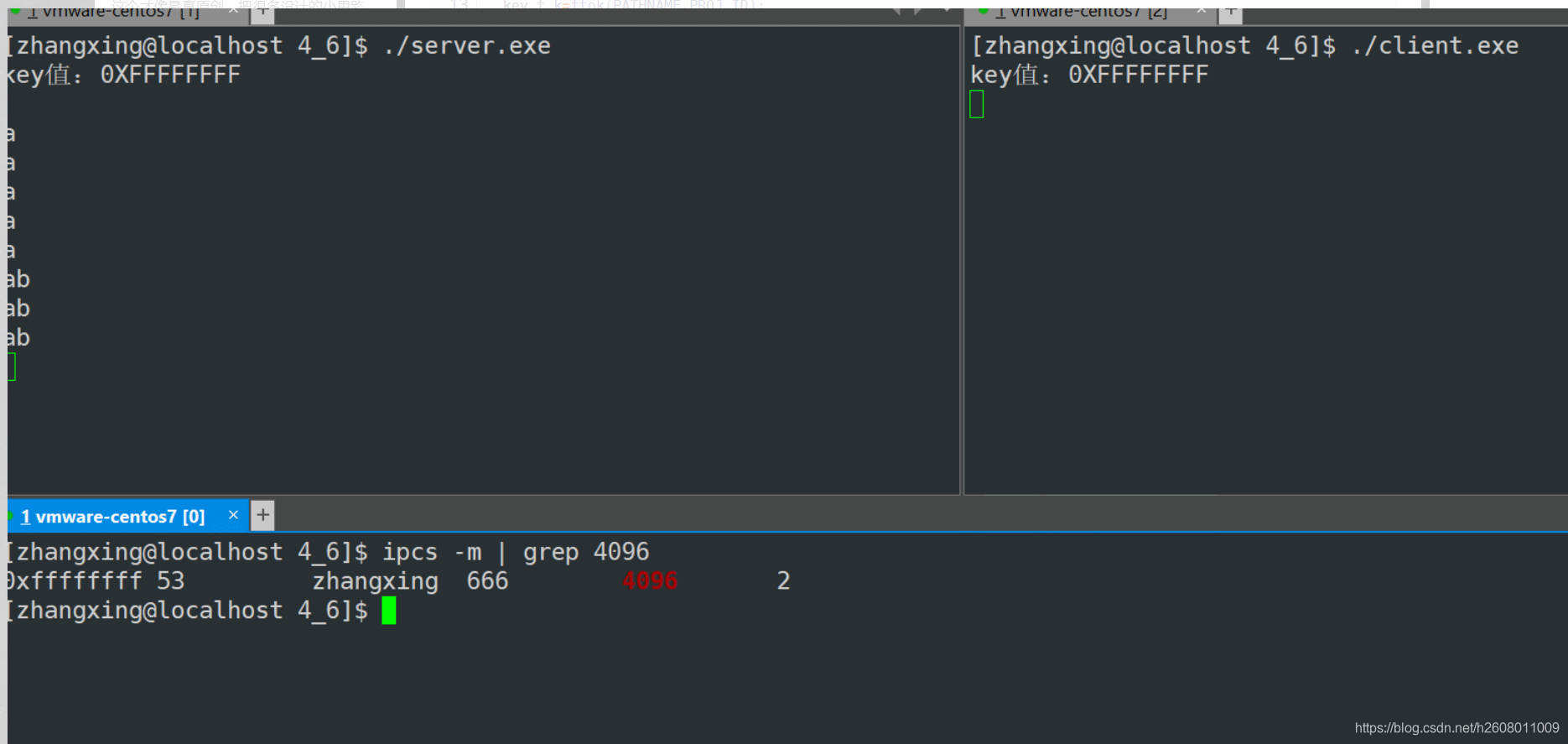
从上面的图中可以看出,服务端是每隔1s的读取的,而客户端是每隔5s输入一次。也就是写端慢,读端快,按照管道中的逻辑,读端将会发生阻塞,但是在共享内存这里并没有出现读端堵塞的情况,这是因为共享内存底层不提供任何同步和互斥的机制。 这说明两个进程根本就不知道对方的存在
所以服务端一旦写入数据,客户端立马就可以看到,而不存在管道中的那种缓冲区导致发生发生多次拷贝的现象,所以共享内存也是最快的进程间通信的方式