����Ŀ¼
- һ�����
- ����Kubernetes��Ⱥ����ʽ
- ������Ⱥ����
- �ġ�Yaml�ļ������
- �塢Pod API�������
- ����Pod����
- �ߡ���������
- �ˡ����̹���
- �š���������
- ʮ��������ȡ����
- ʮһ��pod���������ڹ���
- ʮ����Projected Volume
- ʮ����������ؼ�鼰�ָ�����
- ʮ�ġ�POD �Ļָ�����
- ʮ�塢Deployment ��Դ���
- ʮ����RC��Դ(�˽�)
- ʮ�ߡ�K8S֮��¶IP������
- ʮ�ˡ�������ģʽ����
- ʮ�š���������
- ��ʮ���汾�ع�
- ��ʮһ������DASHBOARDӦ��
һ�����
1����������
kubernetes,��� K8s,���� 8 ���� 8 ���ַ���ubernete�����ɵ���д����һ����Դ ��,���ڹ�����ƽ̨�ж�������ϵ���������Ӧ��,Kubernetes ��Ŀ�����ò�����������Ӧ�ü��Ҹ�Ч,Kubernetes �ṩ��Ӧ�ò���,�滮,����,ά����һ�ֻ��ơ�

1.1 ��ͳ��Ӧ�ò���ʽ
ͨ�������ű�����װӦ�á���������ȱ����Ӧ�õ����С��� �á������������������ڽ��뵱ǰ����ϵͳ��,��������������Ӧ�õ���������/�ع��Ȳ���,��ȻҲ����ͨ������������ķ�ʽ��ʵ��ijЩ����,����������dz���,�������� ����ֲ����
1.2 �µ�Ӧ�ò���ʽ(��������)
ͨ������������ʽʵ��,ÿ������֮�以�����,ÿ���������Լ����ļ�ϵͳ ,����֮����̲����Ӱ��,�����ּ�����Դ������������,�����ܿ��ٲ���, ����������ײ���ʩ�������ļ�ϵͳ�����,���������ڲ�ͬ�ơ���ͬ�汾����ϵͳ�����Ǩ�ơ�
����ռ����Դ�١������,ÿ��Ӧ�ÿ��Ա������һ����������,ÿ��Ӧ�����������һ��һ��ϵҲʹ�����и�������,ʹ������������ build �� release �Ľ�,ΪӦ�ô�����������,��Ϊÿ��Ӧ�ò���Ҫ�������Ӧ�ö�ջ���,Ҳ���������������������ṹ, ��ʹ�ô��з������ԡ��������ṩһ�»��������Ƶ�,�������������������������, ������ڼ�غ�����
1.3 �������Ź����е�ս����--------Kubernetes
Kubernetes �� Google ��Դ��һ��������������,��֧���Զ������𡢴��ģ�������� Ӧ�������������������������в���һ��Ӧ�ó���ʱ,ͨ��Ҫ�����Ӧ�õĶ��ʵ���Ա� ��Ӧ��������и��ؾ��⡣
�� Kubernetes ��,���ǿ��Դ����������,ÿ��������������һ��Ӧ��ʵ��,Ȼ��ͨ�����õĸ��ؾ������,ʵ�ֶ���һ��Ӧ��ʵ���Ĺ��������֡�����,����Щϸ�ڶ�����Ҫ��ά��Աȥ���и��ӵ��ֹ����úʹ�����
2��Kubernetes���ĸ���
2.1 Master
Master��Ҫ������Դ����,���Ƹ���,���ṩͳһ���ʼ�Ⱥ����ڡ����Ľڵ�Ҳ�ǹ����ڵ�
2.2 Node
Node��Kubernetes��Ⱥ�ܹ�������Pod�ķ���ڵ�(���agent��minion)��Node��Kubernetes��Ⱥ�����ĵ�Ԫ,�������ر�����Pod������,��Pod���е�������,��Master����,���㱨����״̬��Master,ͬʱ����MasterҪ����������������ڡ�
Node IP
Node�ڵ��IP��ַ,��Kubernetes��Ⱥ��ÿ���ڵ������������IP��ַ,�����Ǵ��ڵ���������,���������������ķ�����֮�䶼��ͨ���������ֱ��ͨ��;
2.3 Pod
Podֱ���Ƕ���,������������ɶ�����Ķ���,��һ��������ϵ���ܵĶ��Ӱ���һ����Ƕ���(һ��Pod)��
��k8s�����Dz���ֱ�Ӳ�������,���ǰ�������װ��Pod�ٽ��й���
������Node�ڵ���,���������������ϡ�Pod�ڰ���������������ͬһ��������,ʹ����ͬ�����������ռ䡢IP��ַ�Ͷ˿�,�ܹ�ͨ��localhost����ͨ�š�Pod��k8s���д��������Ⱥ�������С��λ,���ṩ�˱��������߲�εij���,ʹ�ò������������һ��Pod������һ���������߶�����������Pod ���� k8s �������"Ӧ��";��һ��Ӧ��,�����ɶ��������ɡ�
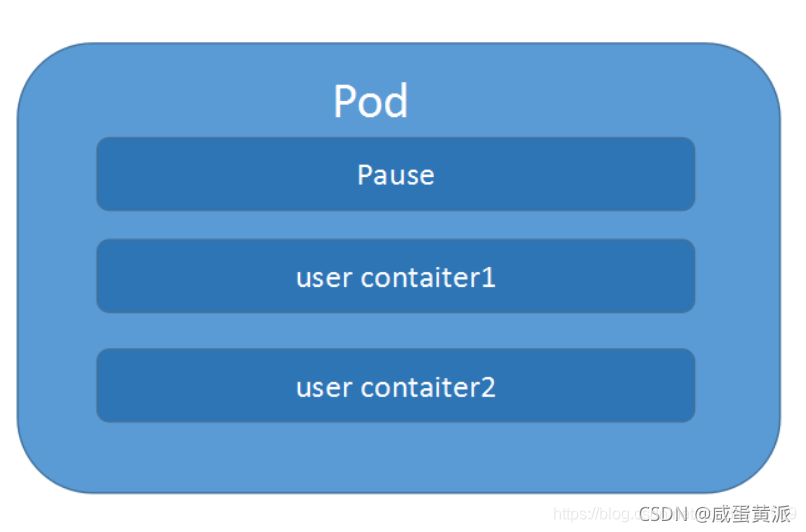
(1)pause����
- ÿ��Pod�ж���һ��pause����,pause������ΪPod����������,Pod��������������ʹ������ӳ��ģʽ���������뵽���pause������
- ����ͬһ��Pod�������������������namespace��
- ���Pod���ڵ�Node崻�,�Ὣ���Node�ϵ�����Pod���µ��ȵ������ڵ���
(2)Pod Volume
Docker Volume��ӦKubernetes�е�Pod Volume;
���ݾ�,�����������ļ���Ŀ¼�����ⲿ�洢��Pod��,ΪӦ�÷����ṩ�洢,Ҳ����Pod������֮�乲�����ݡ�
(3)��Դ����
?
ÿ��Pod����������ļ������Դ��CPU��Memory;


Pod IP
Pod��IP��ַ,��Docker
Engine����docker0���ŵ�IP��ַ�ν��з����,ͨ����һ������Ķ�������,λ�ڲ�ͬNode�ϵ�Pod�ܹ��˴�ͨ��,��Ҫͨ��Pod
IP���ڵ���������������ͨ��,����ʵ��TCP��������ͨ��Node IP���ڵ���������������
2.4 Namespace(�����ռ�)
�����ռ佫��Դ�������Ϸ��䵽��ͬNamespace,�����Dz�ͬ����Ŀ���û������ֹ���,���趨���Ʋ���,�Ӷ�ʵ�ֶ��⻧�������ռ�Ҳ��Ϊ���⼯Ⱥ��
2.5 Label(��ǩ)
Kubernetes�е�����API������ͨ��Label���б�ʶ,Label��ʵ����һϵ�е�K/V��ֵ�ԡ�Label��Replication
Controller��Service���еĻ���,����ͨ��Label�����й���Node�����е�Pod��?
һ��label��һ�������ӵ���Դ�ϵļ�/ֵ��,Ʃ�總�ӵ�һ��Pod��,Ϊ������һ���û��Զ��IJ��ҿ�ʶ�������.Label�����Ա�Ӧ������֯��ѡ�������е���Դ
2.6 RC-Replication Controller
Replication Controller��������Pod�ĸ���,��֤��Ⱥ�д���ָ��������Pod��������Ⱥ�и�������������ָ������,���ָֹͣ������֮��Ķ���pod����,��֮,�����������ָ����������������,��֤�������䡣Replication Controller��ʵ�ֵ�����������̬���ݺ��������ĺ��ġ�
���������Pod,����ij��Pod�ĸ�������������ʱ�̶�����ij��Ԥ��ֵ;
? ? Pod�ڴ��ĸ�����;
? ? ����ɸѡĿ��Pod��Label Selector;
? ? ��Pod��������С��Ԥ��������ʱ��,���ڴ�����Pod��Podģ��(template);
2.7 Deployment
Deployment ���� Pod ��������ϸ�Ϊ�ϲ��һ������,�����Զ���һ�� Pod �ĸ�����Ŀ���Լ���� Pod �İ汾��һ����Deployment ����Ӧ�õ������Ĺ���,�� Pod ����� Deployment ��С�ĵ�Ԫ��
Kubernetes ��ͨ�� kube-controllerȥά�� Deployment �� Pod ����Ŀ,��Ҳ��ȥ���� Deployment �Զ��ָ�ʧ�ܵ� Pod��
����˵�ҿ��Զ���һ�� Deployment,��� Deployment ������Ҫ���� Pod,��һ�� Pod ʧ�ܵ�ʱ��,�������ͻ��,�����°� Deployment �е� Pod ��Ŀ��һ���ָ�������,ͨ����ȥ������һ�� Pod��ͨ��������,����Ҳ�������ɷ����IJ��ԡ�����˵���й�������,�����������ɵ�����,���߽��а汾�Ļع���
2.8 Service
Service������Pod�������Ϻͷ��ʸü��ϵIJ���,����ʵ����ij���Service�ṩ��һ��ͳһ�ķ����������Լ���������ͷ��ֻ���,�û�����Ҫ�˽��̨Pod��������С�
һ��service�����˷���pod�ķ�ʽ,�����̶���IP��ַ���������Ӧ��DNS��֮��Ĺ�ϵ��
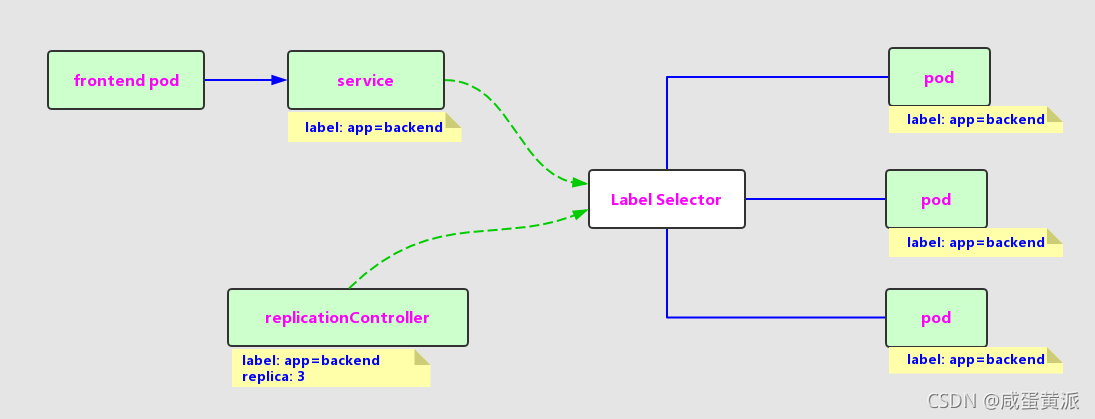
��ͼʾ,ÿ��Pod���ṩ��һ��������Endpoint(Pod IP+ContainerPort)�Ա��ͻ��˷���,���Pod���������һ����Ⱥ���ṩ����,һ��������Dz���һ�����ؾ���������������,Ϊ����Pod����һ������ķ���˿���8000,���ҽ���ЩPod��Endpoint�б�����8000�˿ڵ�ת���б���,�ͻ��˿���ͨ�����ؾ������Ķ���IP��ַ+����˿������ʴ˷���������Node�ϵ�kube-proxy��ʵ����һ�����ܵ��������ؾ�����,������Ѷ�Service������ת������˵�ij��Podʵ����,�������ڲ�ʵ�ַ���ĸ��ؾ�����Ự���ֻ��ơ�Service���ǹ���һ�����ؾ�������IP��ַ,����ÿ��Servcie����һ��ȫ��Ψһ������IP��ַ,�������IP����ΪCluster IP��
(1)Cluster IP
Service��IP��ַ,����:
-
?����������Kubernetes Servcie�������,����Kubernetes�����ͷ���IP��ַ;
-
?����Ping,��Ϊû��һ��"ʵ���������"����Ӧ;
-
?ֻ�ܽ��Service Port���һ�������ͨ�Ŷ˿�;
?Node IP����Pod IP����Cluster IP��֮���ͨ��,���õ���Kubernetes�Լ���Ƶ�һ�ֱ�̷�ʽ�������·�ɹ���,��IP·���кܴ�IJ�ͬ
(2)Endpoint(IP+Port)
��ʶ������̵ķ��ʵ�;
ע:Node��Pod��Replication Controller��Service�ȶ����Կ�����һ��"��Դ����",�������е���Դ������ͨ��Kubernetes�ṩ��kubectl����ִ������ɾ���ġ���Ȳ��������䱣����etcd�г־û��洢��
3��Kubernetes������
Kubernetes��Ҫ����� API Server��Controller Manager��Scheduler��kubelet��kube-proxy,����ǰ���������ڼ�Ⱥ��Master�ڵ�,�����������ڼ�Ⱥ��Slave�ڵ㡣����������һ�����ڴ洢Kubernetes��Ⱥ��Ϣ��Etcd,����һ���߿��á�ǿһ���Եķ����ִ洢�ֿ⡣
- mater�ڵ�: API Server��Controller Manager��Scheduler��etcd
- node�ڵ�: kubelet��kube-proxy
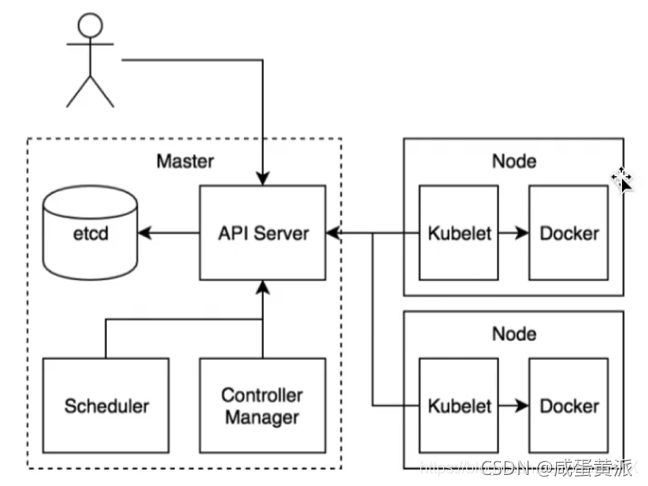
3.1 Master�ڵ�
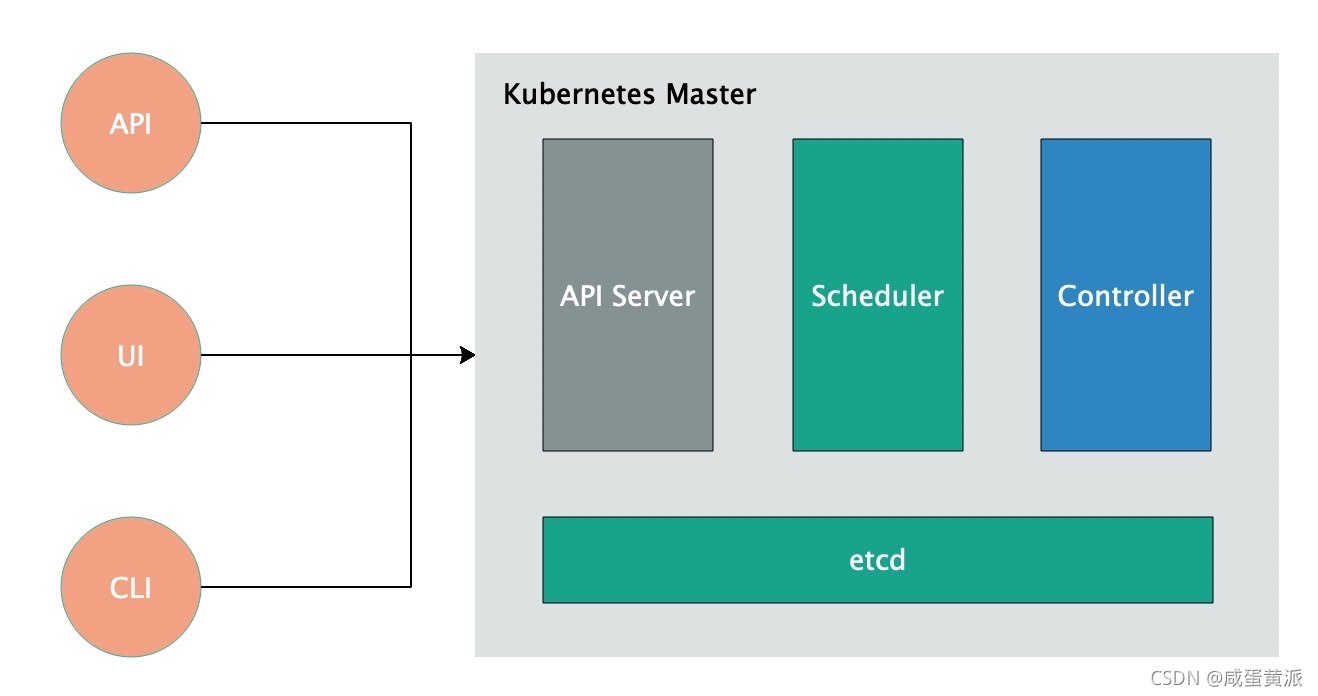
-
etcd:etcd��ŵľ��Ǽ�Ⱥ��״̬,һ������еļ�Ⱥ��Ϣ����ŵ�etcd����,etcd������Kubernetes��ijһ������,���ǵ�����Ⱥ�����,API Server����Ψһ�����,����ֱ�ӷ���etcd��
-
API Server:API Server�ṩ�˲�����Դ��Ψһ���,������֤����Ȩ�����ʿ��ơ�ע����߷���,����ͨ��API Server����ɵġ�
-
Controller Manager:���������Ⱥ������Դ,��֤��Դ����Ԥ�ڵ�״̬��Controller Manager�ɶ���controller���,����replication controller��endpoints controller��namespace controller��serviceaccounts controller�� ���ɿ�������ɵ���Ҫ������Ҫ�����������ڹ��ܺ�APIҵ����,��������:
- �������ڹ���:����Namespace�������������ڡ�Event�������ա�Pod��ֹ��ص��������ա������������ռ�Node�������յȡ�
- APIҵ����:����,��ReplicaSetִ�е�Pod��չ�ȡ�
-
Scheduler:Scheduler���ȿ���������������Ⱥ����Դ����,����Ĭ�ϻ���ָ���ĵ��Ȳ��Խ�Pod���ȵ�����Ҫ���Node�ڵ�������
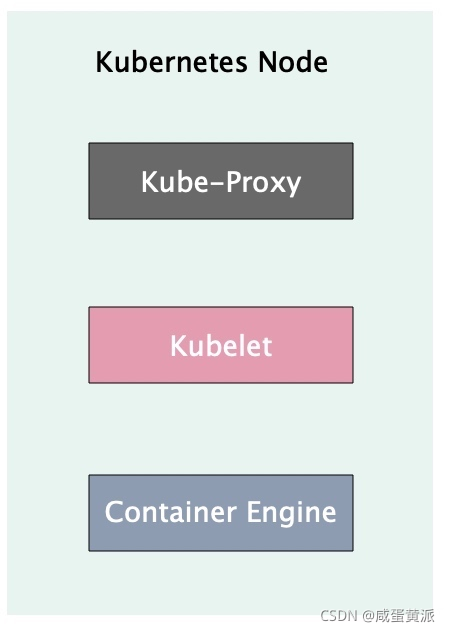
3.2 Node�ڵ�
-
Kubelet:Kubeletά��������������������,API Server����Pod,Scheduler��Pod���ȵ�����Ҫ���Node�ڵ���,�ýڵ��ϵ�Kubelet�ͻ�ȥ����Pod�Լ�Docker,Pod�Ĵ洢�Լ����綼��Kubelet���й�����
-
Docker:Docker������Ĺ���,���羵�����ȡ������������
-
Kube-proxy:Kube-proxy��Ҫ���ṩ������Ⱥ�ڲ�Service�ĸ��ؾ���ͷ�����
3.3 ���֮���ͨ��
API Server��etcd���ʵ�Ψһ���,ֻ��API Server���ܷ��ʺͲ���etcd��Ⱥ;API Server���ںͶ��ⶼ�ṩ��ͳһ��REST API,�����������ͨ��API Server����ͨ�ŵ�
�û�ʹ��kubectl����������API Server�ӿ������Ӧ����
Kubernetes�ڲ��������ͨ��һ��watch����ȥ���API Server�е���Դ�仯,Ȼ�������һЩ��Ӧ�IJ���
����Kubernetes��Ⱥ����ʽ
1�����÷�ʽ
-
��ʽ1. minikube
Minikube��һ������,�����ڱ��ؿ�������һ�������Kubernetes,����Kubernetes���ճ��������û�ʹ�á�������������������
�ٷ���ַ:https://kubernetes.io/docs/setup/minikube/ -
��ʽ2. kubeadm
KubeadmҲ��һ������,�ṩkubeadm init��kubeadm join,���ڿ��ٲ���Kubernetes��Ⱥ��
�ٷ���ַ:https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm/ -
��ʽ3. ֱ��ʹ��epel-release yumԴ,ȱ����ǰ汾�ϵ� 1.5
-
��ʽ4. �����ư�
�ӹٷ����ط��а�Ķ����ư�,�ֶ�����ÿ�����,���Kubernetes��Ⱥ��
�ٷ�Ҳ�ṩ��һ���������Ի�������Ҳ���:https://kubernetes.io/cn/docs/tutorials/kubernetes-basics/cluster-interactive/
2�������Ʒ�ʽ����k8s��Ⱥ
����֮ǰ�ܽ����,����Ͳ����������(�������,���в鿴)
3��kubeadm��ʽ����k8s��Ⱥ
����֮ǰ�ܽ����,����Ͳ����������(�������,���в鿴)
4������Harbor�ֿ�
����һ����Ҫ��ǽ(�õ�1.8.0�汾��harbor)
[root@kub-k8s-master ~]# wget https://storage.googleapis.com/harbor-releases/release-1.8.0/harbor-offline-installer-v1.8.0.tgz
[root@kub-k8s-master ~]# yum -y install lrzsz
[root@kub-k8s-master ~]# curl -L https://github.com/docker/compose/releases/download/1.22.0/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
����ѡ�����ϴ�������������,����Ҫ��������,�ƶ�·��
[root@k8s-master ~]# mv docker-compose-Linux-x86_64 /usr/local/bin/docker-compose
[root@kub-k8s-master ~]# chmod +x /usr/local/bin/docker-compose
[root@kub-k8s-master ~]# tar xf harbor-offline-installer-v1.8.0.tgz
[root@kub-k8s-master ~]# cd harbor
http���ʷ�ʽ������:
[root@kub-k8s-master harbor]# vim harbor.yml #������Ҫ���Խ���(��Ҫ����dns������,��/etc/hosts�ļ�û����),��������Խ���,����ʹ��IP��ַ,��Ҫ�ĵ���������
hostname: 192.168.246.166
[root@kub-k8s-master harbor]# ./install.sh #��Ҫ�ȴ����ؾ���
�����װʧ��,����docker����,���°�װ����;

��������ʲ���:
http://192.168.246.166


4.1����https����
[root@kub-k8s-master ~]# mkdir -pv /data/cert/
[root@kub-k8s-master ~]# openssl genrsa -out /data/cert/server.key 2048
Generating RSA private key, 2048 bit long modulus
............................................+++
............+++
e is 65537 (0x10001)
[root@kub-k8s-master ~]# openssl req -x509 -new -nodes -key /data/cert/server.key -subj "/CN=192.168.246.166" -days 3650 -out /data/cert/server.crt
[root@kub-k8s-master ~]# ll -a /data/cert
[root@kub-k8s-master ~]# cd harbor
[root@kub-k8s-master harbor]# vim harbor.yml #�༭����

����
[root@kub-k8s-master harbor]# ./prepare
prepare base dir is set to /root/harbor
Clearing the configuration file: /config/log/logrotate.conf
Clearing the configuration file: /config/nginx/nginx.conf
Clearing the configuration file: /config/core/env
Clearing the configuration file: /config/core/app.conf
Clearing the configuration file: /config/registry/config.yml
Clearing the configuration file: /config/registry/root.crt
Clearing the configuration file: /config/registryctl/env
Clearing the configuration file: /config/registryctl/config.yml
Clearing the configuration file: /config/db/env
Clearing the configuration file: /config/jobservice/env
Clearing the configuration file: /config/jobservice/config.yml
Generated configuration file: /config/log/logrotate.conf
Generated configuration file: /config/nginx/nginx.conf
Generated configuration file: /config/core/env
Generated configuration file: /config/core/app.conf
Generated configuration file: /config/registry/config.yml
Generated configuration file: /config/registryctl/env
Generated configuration file: /config/db/env
Generated configuration file: /config/jobservice/env
Generated configuration file: /config/jobservice/config.yml
loaded secret from file: /secret/keys/secretkey
Generated configuration file: /compose_location/docker-compose.yml
Clean up the input dir
�������,����Docker����,�ٴ�ִ��./prepare
[root@kub-k8s-master harbor]# docker-compose down
Stopping nginx ... done
Stopping harbor-portal ... done
Stopping harbor-jobservice ... done
Stopping harbor-core ... done
Stopping harbor-db ... done
Stopping redis ... done
Stopping registryctl ... done
Stopping registry ... done
Stopping harbor-log ... done
Removing nginx ... done
Removing harbor-portal ... done
Removing harbor-jobservice ... done
Removing harbor-core ... done
Removing harbor-db ... done
Removing redis ... done
Removing registryctl ... done
Removing registry ... done
Removing harbor-log ... done
Removing network harbor_harbor
[root@kub-k8s-master harbor]# docker-compose up -d #�ź�̨
����:


�ͻ�������(ÿ������harbor�Ļ����϶�Ҫ����)
��node�������:
[root@kub-k8s-node1 ~]# vim /etc/docker/daemon.json #�༭�ļ�
{
"insecure-registries": ["192.168.246.166"] #��ipΪ����ֿ������ip
}
[root@kub-k8s-node1 ~]# systemctl restart docker
�����ֿ�



�����˺�



��Ŀ��Ȩ




����
1.��¼
[root@kub-k8s-node1 ~]# docker login 192.168.246.166
Username: soso
Password:
Login Succeeded
2.����һ�����Եľ���
[root@kub-k8s-node1 ~]# docker pull daocloud.io/library/nginx
3.�鿴
[root@kub-k8s-node1 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
daocloud.io/library/nginx latest 98ebf73aba75 3 months ago 109MB
4.���tag
[root@kub-k8s-node1 ~]# docker tag daocloud.io/library/nginx:latest 192.168.246.166/jenkins/nginx
5.�ϴ����ֿ�
[root@kub-k8s-node1 ~]# docker push 192.168.246.166/jenkins/nginx:latest
The push refers to repository [192.168.246.166/jenkins/nginx]
589561a3ffb4: Pushed
ef7dbb0cfc81: Pushed
d56055da3352: Pushed
latest: digest: sha256:f83b2ffd963ac911f9e638184c8d580cc1f3139d5c8c33c87c3fb90aebdebf76 size: 948
��web�����в鿴�����Ƿ��ϴ����ֿ���

������Ⱥ����
1���鿴��Ⱥ��Ϣ
1.�鿴��Ⱥ��Ϣ:
[root@kub-k8s-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
kub-k8s-master Ready master 16h v1.16.1
kub-k8s-node1 Ready <none> 15h v1.16.1
kub-k8s-node2 Ready <none> 15h v1.16.1
2.ɾ���ڵ�(��Ч����ʾ��Ҳ����ɾ��)
[root@kub-k8s-master ~]# kubectl delete node kub-k8s-node1
3.�鿴ijһ���ڵ�(�ڵ����ƿ����ÿո����д���)
[root@kub-k8s-master ~]# kubectl get node kub-k8s-node1
NAME STATUS ROLES AGE VERSION
kub-k8s-node1 Ready <none> 15h v1.16.1
4.�鿴һ�� API �����ϸ��
[root@kub-k8s-master ~]# kubectl describe
ע��:Events(�¼�) ֵ�����ر��ע
�� Kubernetes ִ�еĹ�����,�� API �����������Ҫ����,���ᱻ��¼���������� Events ��,������ʾ�� kubectl describe ָ��صĽ���С�
����,������� Pod,���ǿ��Կ�����������֮��,������������(Successfully assigned)���� node-1,��ȡ��ָ���ľ���(pulling image),Ȼ�������� Pod �ﶨ�������(Started container)��
��������������ǽ������� Debug ����Ҫ���ݡ�������쳣����,һ��Ҫ��һʱ��鿴��Щ Events,�������Կ����dz���ϸ�Ĵ�����Ϣ��
�鿴node����ϸ��Ϣ
[root@kub-k8s-master ~]# kubectl describe node kub-k8s-node1 #Ҳ���Բ鿴pod����Ϣ
Name: kub-k8s-node1
Roles: <none>
...
-------- -------- ------
cpu 100m (2%) 100m (2%)
memory 50Mi (1%) 50Mi (1%)
ephemeral-storage 0 (0%) 0 (0%)
Events: <none>
#ע��:��鿴�Ľڵ�����ֻ����get nodes����鵽��name!
�鿴�������Ϣ:
�鿴service����Ϣ:
[root@kub-k8s-master ~]# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 22h
�ڲ�ͬ��namespace����鿴service:
[root@kub-k8s-master ~]# kubectl get service -n kube-system
-n:namespace���ƿռ�
�鿴�������ƿռ��ڵ���Դ:
[root@kub-k8s-master ~]# kubectl get pods --all-namespaces
ͬʱ�鿴������Դ��Ϣ:
[root@kub-k8s-master ~]# kubectl get pod,svc -n kube-system
�鿴���ڵ�:
[root@k8s-master prome]# kubectl cluster-info
api��ѯ:
[root@kub-k8s-master ~]# kubectl api-versions
2���������ƿռ�
1. ��дyaml�ļ�
[root@kub-k8s-master ~]# mkdir prome
[root@kub-k8s-master ~]# cd prome/
[root@kub-k8s-master prome]# vim namespace.yml
---
apiVersion: v1 #api�汾
kind: Namespace #����---�̶���
metadata: #Ԫ����
name: ns-monitor #�������
labels:
name: ns-monitor
2. ������Դ
[root@kub-k8s-master prome]# kubectl apply -f namespace.yml
namespace/ns-monitor created
3. �鿴��Դ
[root@kub-k8s-master prome]# kubectl get namespace
NAME STATUS AGE
default Active 22h
kube-node-lease Active 22h
kube-public Active 22h
kube-system Active 22h
ns-monitor Active 34s
4.�鿴ijһ��namespace
[root@kub-k8s-master prome]# kubectl get namespace ns-monitor
5.�鿴ij��namespace����ϸ��Ϣ
[root@kub-k8s-master prome]# kubectl describe namespace ns-monitor
6.ɾ�����ƿռ�
[root@kub-k8s-master prome]# kubectl delete -f namespace.yml
namespace "ns-monitor" deleted
[root@k8s-master prome]# kubectl delete namespace ns-monitor
namespace "ns-monitor" deleted
3��������һ��������Ӧ��
ʲô���� Kubernetes ��Ŀ��"��ʶ"�ķ�ʽ?
����ʹ�� Kubernetes �ıر�����:��д�����ļ���
��Щ�����ļ������� YAML ���� JSON ��ʽ�ġ�
Kubernetes �� Docker �Ⱥܶ���Ŀ���IJ�ͬ,�����������Ƽ���ʹ�������еķ�ʽֱ����������(��Ȼ Kubernetes ��ĿҲ֧�����ַ�ʽ,����:kubectl run),����ϣ������ YAML �ļ��ķ�ʽ,��:�������Ķ��塢����������,ͳͳ��¼��һ�� YAML �ļ���,Ȼ��������һ��ָ�������������:
# kubectl create/apply -f �ҵ������ļ�
�ô�:
- �����һ���ļ��ܼ�¼�� Kubernetes ����"run"��ʲô,���������Ժ�鿴��¼
ʹ��YAML����Pod
- YAML�ļ�,��Ӧ��k8s��,����һ��API Object(API ����)������Ϊ�������ĸ����ֶ����ֵ���ύ��k8s֮��,k8s�ͻḺ������Щ��������������������������͵�API��Դ��
��дyaml�ļ���������:
[root@kub-k8s-master prome]# vim pod.yml
---
apiVersion: v1 #api�汾,֧��pod�İ汾
kind: Pod #Pod,��������ע�����ͷ��д
metadata: #Ԫ����
name: website #����pod������
labels:
app: website #�Զ���,���Dz����Ǵ�����
spec: #ָ������˼
containers: #��������
- name: test-website #����������,�����Զ���
image: daocloud.io/library/nginx #����
ports:
- containerPort: 80 #������¶�Ķ˿�
����pod
[root@kub-k8s-master prome]# kubectl apply -f pod.yml
pod/website created
�鿴pod
[root@kub-k8s-master prome]# kubectl get pods
NAME READY STATUS RESTARTS AGE
website 1/1 Running 0 74s
=============================================================================
���ֶκ���:
NAME: Pod������
READY: Pod����״��,�ұߵ����ֱ�ʾPod��������������Ŀ,��ߵ����ֱ�ʾ��������������Ŀ
STATUS: Pod��״̬
RESTARTS: Pod����������
AGE: Pod������ʱ��
pod����״��ָ����Pod�Ƿ��������Խ�������,Pod����״��ȡ��������,��������������������,Pod������������ʱ��kubernetes�Ĵ�������Ż�����Pod��Ϊ�ַ����,��һ��Pod����״����Ϊfalse(����һ����������״��Ϊfalse),kubernetes�ὫPod�Ӵ�������ķַ�����Ƴ�,������ַ��������Pod��
һ��pod�ձ�������ʱ���Dz��ᱻ���ȵ�,��Ϊû���κνڵ㱻ѡ�������������pod�����ȵĹ��̷����ڴ������֮��,�����������һ��ܿ�,������ͨ��������pod�Ǵ���unscheduler״̬�ij��Ǵ����Ĺ������������⡣
pod������֮��,���䵽ָ���Ľڵ�������,��ʱ��,����ýڵ�û������Ҫ��image,��ô�����Զ���Ĭ�ϵ�Docker Hub��pullָ����image,һ�о���֮��,����pod�Ǵ���running״̬��
3.1 �鿴pod��Ϣ
�鿴pod��������̨������
[root@kub-k8s-master prome]# kubectl get pods -o wide

���Բ��Է���:
[root@kub-k8s-master prome]# curl 10.244.1.3 #����pod��ip

�ܷ��ʵ�!!
�鿴pods�������ϸ��Ϣ
�鿴pod����ϸ��Ϣ----ָ��pod����
[root@kub-k8s-master prome]# kubectl get pod website -o yaml
-o:output
yaml:yaml��ʽҲ������json��ʽ
�鿴kubectl describe ֧�ֲ�ѯPod��״̬�����������¼�
[root@kub-k8s-master prome]# kubectl describe pod website
Name: website
Namespace: default
Priority: 0
Node: kub-k8s-node1/192.168.246.167
Start Time: Thu, 17 Oct 2019 22:31:16 +0800
Labels: app=website
...
1.���ֶκ���:
Name: Pod������
Namespace: Pod��Namespace��
Image(s): Podʹ�õľ���
Node: Pod���ڵ�Node��
Start Time: Pod����ʼʱ��
Labels: Pod��Label��
Status: Pod��״̬��
Reason: Pod���ڵ�ǰ״̬��ԭ��
Message: Pod���ڵ�ǰ״̬����Ϣ��
IP: Pod��PodIP
Replication Controllers: Pod��Ӧ��Replication Controller��
===============================
2.Containers:Pod����������Ϣ
Container ID: ������ID
Image: �����ľ���
Image ID:�����ID
State: ������״̬
Ready: ��������״��(true��ʾ������)��
Restart Count: ��������������ͳ��
Environment Variables: �����Ļ�������
Conditions: Pod������,����Pod��״��(true��ʾ������)
Volumes: Pod�����ݾ�
Events: ��Pod��ص��¼��б�
=====
��������:ָ����statusͨ��# kubectl get pod
�������ڰ���:running��Pending��completed��
3.2 �������ڵĽ���
-
Pending:��״̬��ʾPod �� YAML �ļ��Ѿ��ύ���� Kubernetes,API �����Ѿ��������������� Etcd ����(��״̬)������� Pod ����Щ������Ϊij��ԭ������ܱ�˳������������,���Ȳ��ɹ���
-
Running:��״̬��ʾPod �Ѿ����ȳɹ�,��һ������Ľڵ�����������������Ѿ������ɹ�,����������һ�����������С�
-
Succeeded:��״̬��ʾ Pod ������������������������,�����Ѿ��˳��ˡ��������������һ��������ʱ��Ϊ������
-
Failed:��״̬��ʾ Pod ��������һ�������Բ�������״̬(�� 0 �ķ�����)�˳������״̬�ij���,��ζ�������취 Debug ���������Ӧ��,����鿴 Pod �� Events ����־��
-
Unknown:����һ���쳣״̬(δ֪״̬),��ʾ Pod ��״̬���ܳ����ر� kubelet �㱨�� kube-apiserver����п��������ӽڵ�(Master �� Kubelet)���ͨ�ų���������
����״̬
CrashLoopBackOff: �����˳�,kubelet���ڽ�������
InvalidImageName: ��������������
ImageInspectError: ��У�龵��
ErrImageNeverPull: ���Խ�ֹ��ȡ����
ImagePullBackOff: ����������ȡ
RegistryUnavailable: ���Ӳ�����������
ErrImagePull: ͨ�õ���ȡ�������
CreateContainerConfigError: ���ܴ���kubeletʹ�õ���������
CreateContainerError: ��������ʧ��
m.internalLifecycle.PreStartContainer ִ��hook����
RunContainerError: ��������ʧ��
PostStartHookError: ִ��hook����
ContainersNotInitialized: ����û�г�ʼ�����
ContainersNotReady: ����û�������
ContainerCreating:����������
PodInitializing:pod ��ʼ����
DockerDaemonNotReady:docker��û����ȫ����
NetworkPluginNotReady: ��������û����ȫ����
3.3 ����Pod��Ӧ�������ڲ�
ͨ��pod����
[root@kub-k8s-master prome]# kubectl exec -it website /bin/bash
root@website:/#
3.4 ɾ��pod
[root@kub-k8s-master prome]# kubectl delete pod pod��1 pod��2 //��������ɾ��
[root@kub-k8s-master prome]# kubectl delete pod --all //����ɾ��
����:
[root@kub-k8s-master prome]# kubectl delete pod website
pod "website" deleted
[root@kub-k8s-master prome]# kubectl delete -f pod.yaml
pod "website" deleted
3.5 ����pod
[root@kub-k8s-master prome]# kubectl apply -f pod.yaml #ָ������pod��yml�ļ���
[root@k8s-master prome]# kubectl apply -f pod.yaml --validate �뿴������Ϣ,����--validate����
������������yaml�ļ���Ӧ��(���ﲢ����������������)
# kubectl delete -f XXX.yaml #ɾ��
# kubectl apply -f XXX.yaml #����
��չ
create��apply������:
create������Ӧ�������Ҫ��yml�ļ�,������ָ��yml�ļ�ɾ��,�ڴ����µ�pod��
�����apply������Ӧ�ÿ���ֱ����yml�ļ�,����apply����,������ɾ����
�ġ�Yaml�ļ������

����ijЩǿ���Ե�����,��:kubectl run����expose��,k8s������ͨ�������ļ��ķ�ʽ��������Щ��������
ͨ��,ʹ�������ļ��ķ�ʽ���ֱ��ʹ�������и���ȡ,��Ϊ��Щ�ļ����Խ��а汾����,�����ļ��ı仯������Ҳ���Խ������,��ʹ�ü��临�ӵ��������ṩһ���Ƚ����ɿ�����ά����ϵͳʱ,��Щ����Ե÷dz���Ҫ��
���������������ļ���ʱ��,���е������ļ����洢��YAML����JSON��ʽ���ļ��в�����ѭk8s����Դ���÷�ʽ��
YAML��ר������д�����ļ�������,�dz�����ǿ��,ʹ�ñ�json�����㡣��ʵ������һ��ͨ�õ����ݴ��л���ʽ��
kubernetes����������YAML�ļ�����Pod�ʹ���Deployment����Դ��
ʹ��YAML����K8s�Ķ���ĺô�:
�����:�������Ӵ����IJ�������������ִ������
��ά����:YAML�ļ�����ͨ��Դͷ����,����ÿ�β���
�����:YAML���Դ����������и��Ӹ��ӵĽṹ
YAML�����:
1. ��Сд����
2. ʹ��������ʾ�㼶��ϵ
3. ����ʱ������ʹ��Tab��,ֻ����ʹ�ÿո�
4. �����Ŀո�������Ҫ,ֻҪ��ͬ�㼶��Ԫ�������뼴��
5. " ��ʾע��,������ַ�һֱ����β,���ᱻ����������
�� k8s ��,ֻ��Ҫ֪�����ֽṹ����:
1.Lists
2.Maps
�ֵ�
a={key:value, key1:{key2:{value2}}, key3:{key4:[1,{key5:value5},3,4,5]}}
key: value
key1:
key2: value2
key3:
key4:
- 1
- key5: value5
- 3
- 4
- 5
YAML Maps
Mapָ�����ֵ�,��һ��Key:Value �ļ�ֵ����Ϣ��
����:
---
apiVersion: v1
kind: Pod
ע:--- Ϊ��ѡ�ķָ��� ,����Ҫ��һ���ļ��ж������ṹ��ʱ����Ҫʹ�á��������ݱ�ʾ��������apiVersion��kind,�ֱ��Ӧ��ֵΪv1��Pod��
Maps��value���ܹ���Ӧ�ַ���Ҳ�ܹ���Ӧһ��Maps��
����:
---
apiVersion: v1
kind: Pod
metadata:
name: kube100-site
labels:
app: web
{apiVersion:v1,kind:Pod,Metadata:{name:kube100-site,labels:{app:web}}}
ע:������YAML�ļ���,metadata���KEY��Ӧ��ֵΪһ��Maps,��Ƕ��labels���KEY��ֵ����һ��Map��ʵ��ʹ���п���������ж��Ƕ�ס�
YAML������������������֪������֮��Ĺ���������������,ʹ�������ո���Ϊ����,���ո��������������Ҫ,ֻ������Ҫ��һ���ո���������������һ�µĿո��� ������,name��labels����ͬ��������,���YAML������֪����������ͬһmap;��֪��app��lables��ֵ��Ϊapp����������
ע��:��YAML�ļ��о��Բ�Ҫʹ��tab��
YAML Lists
List���б�,��������
����:
args:
- beijing
- shanghai
- shenzhen
- guangzhou
����ָ���κ������������б���,ÿ����Ķ��������ַ�(-)��ͷ,�����븸Ԫ��֮�����������
��JSON��ʽ��,��ʾ����:
{
"args": ["beijing", "shanghai", "shenzhen", "guangzhou"]
}
�塢Pod API�������
Pod API ����
Pod�� k8s ��Ŀ�е���С���ŵ�λ������������ʵ�� API ������,����(Container)�ͳ��� Pod ������һ����ͨ���ֶΡ�
����:
? ͨ��yaml�ļ�����pod��ʱ������������,����ļ����浽����Щ�������� Pod ����,��Щ�������� Container?
���:
Pod ���ݵ��Ǵ�ͳ������"�����"�Ľ�ɫ����Ϊ��ʹ�û��Ӵ�ͳ����(���������)�� k8s(��������)��Ǩ��,����ƽ����
�� Pod ���ɴ�ͳ�������"����"�����������������������"����"���"�û�����",��ô�ܶ���� Pod �������ƾͷdz����������ˡ�
���ǵ��ȡ����硢�洢,�Լ���ȫ��ص�����,�������� Pod �����
? ��ͬ������,������������"����"�������,�������������е�"����"��
����:
�������"����"������(��:Pod �����綨��)
�������"����"�Ĵ���(��:Pod �Ĵ洢����)
�������"����"�ķ���ǽ(��:Pod �İ�ȫ����)
��̨"����"�������ĸ�������֮��(��:Pod �ĵ���)
kind:ָ������� API ���������(Type),��һ�� Pod,����ʵ�����,�˴���Դ���Ϳ�����Deployment��Job��Ingress��Service�ȡ�
metadata:����Pod��һЩmeta��Ϣ,�������ơ�namespace����ǩ����Ϣ.
spec:specification of the resource content ָ������Դ������,����һЩcontainer,storage,volume�Լ�����Kubernetes��Ҫ�IJ���,�Լ������Ƿ�������ʧ��ʱ�����������������ԡ������ض�Kubernetes API�ҵ�������Kubernetes Pod�����ԡ�
specification----->[spes?f??ke??n]
������ѡ����������:
���������Ļ���������,���ܹ�ָ�����ӵ�����,���������������е����ʹ�õIJ���������Ŀ¼�Լ�ÿ��ʵ�����Ƿ���ȡ�µĸ����� ������ָ�����������Ϣ,�����������˳���־��λ�á�
������ѡ������������:
"name"��"image"��"command"��"args"��"workingDir"��"ports"��"env"��resource��"volumeMounts"��livenessProbe��readinessProbe��livecycle��terminationMessagePath��"imagePullPolicy"��securityContext��stdin��stdinOnce��tty
��"����"��ص�����
[root@kub-k8s-master ~]# cd prome/
[root@kub-k8s-master prome]# kubectl get pods
NAME READY STATUS RESTARTS AGE
website 1/1 Running 0 2d23h
[root@kub-k8s-master prome]# kubectl get pod -o wide #�鿴pod��������̨��������

����Pod����
nodeSelector
nodeName
���������ԵĹ�����һ���Ķ��������˹���Ԥ������
1��ָ��node�ڵ������(nodeName)
��node1�����podɾ����
[root@kub-k8s-master prome]# kubectl delete -f pod.yml
pod "website" deleted
===========================================
nodeName:��һ�����û��� Pod �� Node ���а��ֶ�,�÷�:
����ָ����pod����node2����:
[root@kub-k8s-master prome]# vim pod.yml
---
apiVersion: v1
kind: Pod
metadata:
name: website
labels:
app: website
spec:
containers:
- name: test-website
image: daocloud.io/library/nginx
ports:
- containerPort: 80
nodeName: kub-k8s-node2 #ָ��node�ڵ������
����
[root@kub-k8s-master prome]# kubectl apply -f pod.yml
pod/website created

NodeName:
- һ�� Pod ������ֶα���ֵ,k8s�ͻᱻ��Ϊ��� Pod �Ѿ������˵���,���ȵĽ�����Ǹ�ֵ�Ľڵ����֡�����ֶ�һ���ɵ�������������,�û�Ҳ������������"ƭ��"������,�������һ�����ڲ��Ի��ߵ��Ե�ʱ��Ż��õ���
2��ָ��node��ǩ(nodeSelector)
����������Ҫ֪��node2������ı�ǩ����Щ?
1.�鿴node2����ı�ǩ
[root@kub-k8s-master prome]# kubectl describe node kub-k8s-node2

1.���´���һ���µ�pod
"nodeSelector:��һ�����û��� Pod �� Node ���а��ֶ�",,ͨ��ָ����ǩ��ָ��
[root@kub-k8s-master prome]# vim tomcat.yml
---
apiVersion: v1
kind: Pod
metadata:
name: tomcat
labels:
app: tomcat
spec:
containers:
- name: test-tomcat
image: daocloud.io/library/tomcat:8
ports:
- containerPort: 8080
nodeSelector: #ָ����ǩ
kubernetes.io/hostname: kub-k8s-node2
2.����pod
[root@kub-k8s-master prome]# kubectl apply -f tomcat.yml
pod/tomcat created

ע:��ʾ��� Pod ��Զֻ��������Я����"kubernetes.io/hostname: kub-k8s-node2"��ǩ(Label)�Ľڵ���;����,��������ʧ�ܡ�
�ߡ���������
����pod���������hosts�ļ�����,Ҳ�������ؽ���
HostAliases:���� Pod �� hosts �ļ�(���� /etc/hosts)�������,�÷�:

1.�����Ƚ��մ�����podɾ����
[root@kub-k8s-master prome]# kubectl delete -f tomcat.yml
pod "tomcat" deleted
[root@kub-k8s-master prome]# vim tomcat.yml
---
apiVersion: v1
kind: Pod
metadata:
name: tomcat
labels:
app: tomcat
spec:
hostAliases:
- ip: "192.168.246.113" #���ĸ�ip��������ʵ�黷�������ip�Զ����
hostnames:
- "foo.remote" #���������֡�����������������д���
- "bar.remote"
containers:
- name: test-tomcat
image: daocloud.io/library/tomcat:8
ports:
- containerPort: 8080
2.����pod
[root@kub-k8s-master prome]# kubectl apply -f tomcat.yml
pod/tomcat created
3.����pod
[root@kub-k8s-master prome]# kubectl exec -it tomcat /bin/bash
root@tomcat:/usr/local/tomcat# cat /etc/hosts #�鿴hosts�ļ�

ע��:
- �� k8s ��,���Ҫ���� hosts �ļ��������,һ��Ҫͨ�����ַ���������,���ֱ������ hosts �ļ�,�� Pod ��ɾ���ؽ�֮��,kubelet ���Զ����ǵ����ĵ����ݡ�
�ˡ����̹���
���Ǹ������� Linux Namespace ��ص�����,Ҳһ���� Pod �����
ԭ��:Pod �����,����Ҫ������������������ܶ�ع��� Linux Namespace,��������Ҫ�ĸ������������������,Pod ģ�����Ч��,�������������Ĺ�ϵ�dz������ˡ�
����,һ�� Pod ���� yaml �ļ�����:
[root@kub-k8s-master prome]# kubectl delete -f pod.yml
pod "website" deleted
[root@kub-k8s-master prome]# vim pod.yml #�����¡��������ǰ������pull������
---
apiVersion: v1
kind: Pod
metadata:
name: website
labels:
app: website
spec:
shareProcessNamespace: true #�����������ƿռ�
containers:
- name: test-web
image: daocloud.io/library/nginx
ports:
- containerPort: 80
- name: busybos
image: daocloud.io/library/busybox
stdin: true
tty: true
2.����
[root@kub-k8s-master prome]# kubectl apply -f pod.yml
pod/website created
1. ������ shareProcessNamespace=true
��ʾ��� Pod �������Ҫ��������(PID Namespace)�����false��Ϊ��������
2. ��������������:
һ�� nginx ����
һ�������� tty �� stdin �� busybos ����
�� Pod �� YAML �ļ�����������������,��ͬ�������� docker run ��� -it(-i �� stdin,-t �� tty)������
����ֱ����Ϊ tty ���� Linux ���û��ṩ��һ����פС����,���ڽ����û��ı�����,���ز���ϵͳ�ı������Ϊ���ܹ��� tty ��������Ϣ,��Ҫͬʱ���� stdin(��������)��
�� Pod ��������,�Ϳ���ʹ�� shell ������ tty ������������н����ˡ�
�鿴��������̨��������:

���ǵ�¼node1�Ļ�������busybox������

[root@kub-k8s-node1 ~]# docker exec -it f684bd1d05b5 /bin/sh

�������ﲻ�����Կ����������� ps ָ��,�����Կ��� nginx �����Ľ���,�Լ� Infra ������ /pause ���̡�Ҳ����˵���� Pod ���ÿ�������Ľ���,��������������˵���ǿɼ���:���ǹ�����ͬһ�� PID Namespace��
[root@kub-k8s-master prome]# kubectl delete -f pod.yml
[root@kub-k8s-master prome]# vim pod.yml
��shareProcessNamespace=true��Ϊfalse
[root@kub-k8s-master prome]# kubectl apply -f pod.yml
pod/website created

��֤:

���� Pod �е�����Ҫ������������ Namespace,Ҳһ���� Pod ����Ķ��塣
�ղŵĶ���pod����������Namespace,��û�кͱ�����Namespace������,���������ǿ������뱾����Namespace����,�������������濴�������Ľ��̡�
[root@kub-k8s-master prome]# kubectl delete -f pod.yml
pod "website" deleted
[root@kub-k8s-master prome]# vim pod.yml #������
---
apiVersion: v1
kind: Pod
metadata:
name: website
labels:
app: website
spec:
hostNetwork: true #��������������
hostIPC: true #����ipcͨ��
hostPID: true #������������pid
containers:
- name: test-web
image: daocloud.io/library/nginx
ports:
- containerPort: 80
- name: busybos
image: daocloud.io/library/busybox
stdin: true
tty: true
����pod
[root@kub-k8s-master prome]# kubectl apply -f pod.yml
pod/website created

��֤:

�����˹����������� Network��IPC �� PID Namespace������,�� Pod �����������,��ֱ��ʹ�������������硢ֱ�������������� IPC ͨ�š��������������������е����н��̡�
�š���������
Pod ������Ҫ���ֶ�"Containers":
- "Containers"��"Init Containers"�������ֶζ����� Pod �������Ķ���,����Ҳ��ȫ��ͬ,ֻ�� Init Containers ����������,���������е� Containers,�����ϸ��ն����˳��ִ��.
k8s �� Container �Ķ���,�� Docker ��Ȳ�û��ʲô̫������
- Docker��Image(����)��Command(��������)��workingDir(�����Ĺ���Ŀ¼)��Ports(����Ҫ�����Ķ˿�),�Լ� volumeMounts(����Ҫ���ص� Volume)���ǹ��� k8s �� Container ����Ҫ�ֶΡ�
ʮ��������ȡ����
ImagePullPolicy :���徵�����ȡ���ԡ�֮������һ�� Container ���������,����Ϊ�������������� Container �����е�һ���֡�
| ���� | ���� |
|---|---|
| Never | ֻʹ�ñ���image |
| Always | ÿ�ζ����ؾ��� |
| IfNotPresent | ����ʹ�ñ���image,����û����ȥ���� |
Ĭ��ֵ: Always:��ʾÿ�δ��� Pod ��������ȡһ�ξ���
- ������ڶ����Ѿ������°汾�Ͳ�����ȡ����
- ������������ؾ���
- ���������ڵ��ǰ汾�����°汾Ҳ�����ؾ���
����:����latest,���ؾ����ʱ��ֱ��ָ���汾
ע:������bug,�������ľ����������� nginx ���� nginx:latest ����������ʱ,ImagePullPolicy Ҳ�ᱻ��Ϊ Always��
ʮһ��pod���������ڹ���
1�����
Lifecycle :���� Container Lifecycle Hooks��������������״̬�����仯ʱ����һϵ��"����"��
lifecycle�����ֻص�����:
- PostStart:���������ɹ���,����ǰ������,������Դ���𡢻������ȡ�
- PreStop:����������ֹǰ������,�������Źر�Ӧ�ó���֪ͨ����ϵͳ�ȵȡ�
postStart:��������������,����ִ��һ��ָ���IJ�����
ע��:postStart ����IJ���,��Ȼ���� Docker ���� ENTRYPOINT ִ��֮��,���������ϸ�֤˳��Ҳ����˵,�� postStart ����ʱ,ENTRYPOINT �п��ܻ�û�н�����
��� postStartִ�г�ʱ���ߴ���,k8s ���ڸ� Pod �� Events �б�������������ʧ�ܵĴ�����Ϣ,���� Pod Ҳ����ʧ�ܵ�״̬��
preStop:��������ɱ��֮ǰ(����,�յ��� SIGKILL �ź�)��
ע��:preStop ������ִ��,��ͬ���ġ�
����,����������ǰ������ɱ������,ֱ����� Hook ����������֮��,������������ɱ��,��� postStart ��һ����
2����������
һ��Pod ������ Kubernetes �е���������:Pod �������ڵı仯,��Ҫ������ Pod API �����Status ����,���dz��� Metadata �� Spec ֮��ĵ�������Ҫ�ֶΡ�
����,phase��ʾһ��Pod�������������ڵ��ĸ���,һ��������5�����ܵ�ȡֵ
-
Pending:��״̬��ʾPod �� YAML �ļ��Ѿ��ύ���� Kubernetes,API �����Ѿ��������������� Etcd ����(��״̬)������� Pod ����Щ������Ϊij��ԭ������ܱ�˳������������,���Ȳ��ɹ���
-
Running:��״̬��ʾPod �Ѿ����ȳɹ�,��һ������Ľڵ�����������������Ѿ������ɹ�,����������һ�����������С�
-
Succeeded:��״̬��ʾ Pod ������������������������,�����Ѿ��˳��ˡ��������������һ��������ʱ��Ϊ������
-
Failed:��״̬��ʾ Pod ��������һ�������Բ�������״̬(�� 0 �ķ�����)�˳������״̬�ij���,��ζ�������취 Debug ���������Ӧ��,����鿴 Pod �� Events ����־��
-
Unknown:����һ���쳣״̬(δ֪״̬),��ʾ Pod ��״̬���ܳ����ر� kubelet �㱨�� kube-apiserver
����п��������ӽڵ�(Master �� Kubelet)���ͨ�ų���������
3������
���� k8s �ٷ��ĵ���һ�� Pod YAML �ļ�
�����������,�����ɹ�����֮��,�� /usr/share/message ��д����һ��"��ӭ��Ϣ"(�� postStart ����IJ���)���������������ɾ��֮ǰ,�������ȵ����� nginx ���˳�ָ��(�� preStop ����IJ���),�Ӷ�ʵ����������"�����˳�"��
����:
- ������һ�� nginx ���������
- ������һ�� postStart �� preStop ����
[root@kub-k8s-master prome]# kubectl delete -f pod.yml
pod "website" deleted
[root@kub-k8s-master prome]# cp pod.yml pod.yml.bak
[root@kub-k8s-master prome]# vim pod.yml
---
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: daocloud.io/library/nginx
lifecycle:
postStart: #��������֮��
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
preStop: #�����ر�֮ǰ
exec:
command: ["/usr/sbin/nginx","-s","quit"]

��֤:
[root@kub-k8s-node1 ~]# docker exec -it 3d404e658 /bin/bash
root@lifecycle-demo:~# cat /usr/share/message
Hello from the postStart handler
4����չ:
Pod ����� Status �ֶ�,��������ϸ�ֳ�һ�� Conditions:
��Щϸ��״̬��ֵ����:
- PodScheduled
- Ready
- Initialized
- Unschedulable
������Ҫ����������ɵ�ǰ Status �ľ���ԭ����ʲô��
-
����, Pod ��ǰ�� Status �� Pending,��Ӧ�� Condition �� Unschedulable,���ʾ���ĵ��ȳ��������⡣
-
����, Ready ���ϸ��״̬��ʾ Pod �����Ѿ���������(Running ״̬),�����Ѿ����Զ����ṩ�����ˡ�������֮��(Running �� Ready)���������,��ϸ˼��һ�¡�
Pod ����Щ״̬��Ϣ,���ж�Ӧ�������������Ҫ��,������ Pod �����˷�"Running"״̬��,һ��Ҫ��Ѹ��������Ӧ,���������������쳣�����ʼ���ٺͶ�λ,������ȥ��æ���ҵز����ĵ���
ʮ����Projected Volume
1��ʲô��Projected Volume
�� k8s ��,�м�������� Volume,���ǵ����岻��Ϊ�˴�������������,Ҳ������������������������֮������ݽ���������Ϊ�����ṩԤ�ȶ���õ����ݡ�
�������ĽǶ�����,��Щ Volume �����Ϣ�·��DZ� k8s ��Ͷ�䡱(Project)�����������еġ�
k8s ֧�ֵ� Projected Volume һ��������:
- Secret
- ConfigMap
- Downward API
- ServiceAccount Token
2��Secret���
secret��������СƬ�������ݵ�k8s��Դ,��������,token,������Կ���������ݵ�ȻҲ���Դ����Pod���߾�����,���Ƿ���Secret����Ϊ�˸�����Ŀ������ʹ������,�����ٱ�¶�ķ��ա�
Pod��2�ַ�ʽ��ʹ��secret:
- ��Ϊvolume��һ����һ��������������
- ����ȡ�����ʱ��kubelet���á�
�û����Դ����Լ���secret,ϵͳҲ�����Լ���secret�� Pod��Ҫ�����ò���ʹ��ij��secret��
-
�Ƚ���Secrets:��ServiceAccount������API֤�鸽�ӵ���Կk8s�Զ����ɵ���������apiserver��Secret,����Pod��Ĭ��ʹ�����Secret��apiserverͨ��
-
�����Լ���Secret:
- ��ʽ1:ʹ��kubectl create secret����
- ��ʽ2:yaml�ļ�����Secret
2.1 ���ʽ����secret
����ij��PodҪ�������ݿ�,��Ҫ�û�������,�ֱ�����2���ļ���:username.txt,password.txt
����:
[root@kub-k8s-master ~]# echo -n 'admin' > ./username.txt
[root@kub-k8s-master ~]# echo -n '1f2d1e2e67df' > ./password.txt
kubectl create secret ָ��û�������д��secret��,����apiserver����Secret
[root@kub-k8s-master ~]# kubectl create secret generic db-user-pass --from-file=./username.txt --from-file=./password.txt
secret/db-user-pass created
�鿴�������:
[root@kub-k8s-master ~]# kubectl get secrets
NAME TYPE DATA AGE
db-user-pass Opaque 2 54s
default-token-6svwp kubernetes.io/service-account-token 3 4d11h
ע: opaque:Ӣ[???pe?k] ��[o??pe?k] ģ��
�鿴��ϸ��Ϣ:
[root@kub-k8s-master ~]# kubectl describe secret db-user-pass
Name: db-user-pass
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password.txt: 12 bytes
username.txt: 5 bytes
get��describeָ�����չʾsecret��ʵ������,���dz��ڶ����ݵı����Ŀ���,�����鿴ʵ������ʹ������:
[root@kub-k8s-master ~]# kubectl get secret db-user-pass -o json
base64����:
[root@kub-k8s-master ~]# echo 'MWYyZDFlMmU2N2Rm' | base64 --decode
1f2d1e2e67df
2.2 yaml��ʽ����Secret
����һ��secret.yaml�ļ�,������base64����:������ʾ���ױ����˷���,������ת�롣
[root@kub-k8s-master ~]# echo -n 'admin' | base64
YWRtaW4=
[root@kub-k8s-master ~]# echo -n '1f2d1e2e67df' | base64
MWYyZDFlMmU2N2Rm
����һ��secret.yaml�ļ�,������base64����
[root@kub-k8s-master prome]# vim secret.yml
---
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque #ģ��
data:
username: YWRtaW4=
password: MWYyZDFlMmU2N2Rm
����:
[root@kub-k8s-master prome]# kubectl apply -f secret.yml
secret/mysecret created
����Secret������,���Ǿ�������ġ���Ҫ����
[root@kub-k8s-master ~]# kubectl get secrets
NAME TYPE DATA AGE
default-token-7vc82 kubernetes.io/service-account-token 3 30h
mysecret Opaque 2 6s
[root@kub-k8s-master prome]# kubectl get secret mysecret -o yaml
apiVersion: v1
data:
password: MWYyZDFlMmU2N2Rm
username: YWRtaW4=
kind: Secret
metadata:
creationTimestamp: "2019-10-21T03:07:56Z"
name: mysecret
namespace: default
resourceVersion: "162855"
selfLink: /api/v1/namespaces/default/secrets/mysecret
uid: 36bcd07d-92eb-4755-ac0a-a5843ed986dd
type: Opaque
2.3 ʹ��Secret
һ��Pod������Secret������:
[root@kub-k8s-master prome]# vim pod_use_secret.yaml
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: testredis
image: daocloud.io/library/redis
volumeMounts: #����һ����
- name: foo #���������Ҫ�붨��ľ�������һ��
mountPath: "/etc/foo" #���ص��������ĸ�Ŀ¼��,���д
readOnly: true
volumes: #���ݾ��Ķ���
- name: foo #����������������Զ���
secret: #����ֱ��ʹ�õ�secret��
secretName: mysecret #���øղŶ����secret
����:
[root@kub-k8s-master prome]# kubectl apply -f pod_use_secret.yaml
pod/mypod created
[root@kub-k8s-master prome]# kubectl exec -it mypod /bin/bash
root@mypod:/data# cd /etc/foo/
root@mypod:/etc/foo# ls
password username
root@mypod:/etc/foo# cat password
1f2d1e2e67df
ע:
- ÿһ�������õ�Secret��Ҫ��
spec.volumes�ж��� - ���Pod�еĶ��������Ҫ�������Secret��ôÿһ�����������ж�Ҫָ���Լ���volumeMounts,����Pod����������һ��spec.volumes�ͺ��ˡ�
2.4 ӳ��secret key��ָ����·��
[root@kub-k8s-master prome]# kubectl delete -f pod_use_secret.yaml
pod "mypod" deleted
[root@kub-k8s-master prome]# vim pod_use_secret.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: testredis
image: daocloud.io/library/redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
volumes:
- name: foo
secret:
secretName: mysecret
items: #����һ��items
- key: username #���Ǹ�key���¶��嵽�Ǹ�Ŀ¼��
path: my-group/my-username #���·��,�����/etc/foo��·��
2.����
[root@kub-k8s-master prome]# kubectl apply -f pod_use_secret.yaml
pod/mypod created
3.��volume�ж�ȡsecret��ֵ
[root@kub-k8s-master prome]# kubectl exec -it mypod /bin/bash
root@mypod:/data# cd /etc/foo/my-group
root@mypod:/etc/foo/my-group# ls
my-username
root@mypod:/etc/foo/my-group# cat my-username
admin
root@mypod:/etc/foo/my-group#
ע:
- username��ӳ�䵽���ļ�
/etc/foo/my-group/my-username������/etc/foo/username
�����ص�secret�����Զ�����
Ҳ���������һ��Secret������,��ô�����˸�Secret��������Ҳ����ȡ�����º��ֵ,�������ʱ��������kubelet��ͬ��ʱ������ġ�
1.����base64����
[root@kub-k8s-master prome]# echo qianfeng | base64
cWlhbmZlbmcK
2.��admin�滻��qianfeng
[root@kub-k8s-master prome]# vim secret.yml
---
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: cWlhbmZlbmcK #��Ϊqianfeng��base64���ܺ��
password: MWYyZDFlMmU2N2Rm
1.����
[root@kub-k8s-master prome]# kubectl apply -f secret.yml
Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply
secret/mysecret configured
2.����pod����
[root@kub-k8s-master prome]# kubectl exec -it mypod /bin/bash
root@mypod:/data# cd /etc/foo/my-group
root@mypod:/etc/foo/my-group# ls
my-username
root@mypod:/etc/foo/my-group# cat my-username
qianfeng
2.5 �Ի�����������ʽʹ��Secret
[root@kub-k8s-master prome]# kubectl delete -f pod_use_secret.yaml
pod "mypod" deleted
[root@kub-k8s-master prome]# vim pod_use_secret.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: testredis
image: daocloud.io/library/redis
env: #���廷������
- name: SECRET_USERNAME #�����µĻ�����������
valueFrom:
secretKeyRef: #���õ�key��ʲô
name: mysecret #������ֵ������mysecret
key: username #username�����ֵ
2.����ʹ��secret��pod����
[root@kub-k8s-master prome]# kubectl apply -f pod_use_secret.yaml
pod/mypod created
3.����
[root@kub-k8s-master prome]# kubectl exec -it mypod /bin/bash
root@mypod:/data# echo $SECRET_USERNAME #��ӡһ�¶���ı���
qianfeng
2.6 ʵ��
1. ͨ����д YAML �ļ��ķ�ʽ��������� Secret ����
Secret ����Ҫ����Щ���ݱ����Ǿ��� Base64 ת���,���������������İ�ȫ������
ת�����:
[root@kub-k8s-master ~]# echo -n 'admin' | base64
YWRtaW4=
[root@kub-k8s-master ~]# echo -n '1f2d1e2e67df' | base64
MWYyZDFlMmU2N2Rm
ע��:������������ Secret ����,����������ݽ����Ǿ�����ת��,��û�б����ܡ�����������,��Ҫ�� Kubernetes �п��� Secret �ļ��ܲ��,��ǿ���ݵİ�ȫ�ԡ�
[root@kub-k8s-master prome]# vim create_secret.yml
---
apiVersion: v1
kind: Secret
metadata:
name: mysecret-01
type: Opaque
data:
user: YWRtaW4=
pass: MWYyZDFlMmU2N2Rm
[root@kub-k8s-master prome]# kubectl apply -f create_secret.yml
secret/mysecret-01 created
[root@kub-k8s-master prome]# kubectl get secret
��yaml��ʽ������secret���÷�������:
[root@kub-k8s-master prome]# vim test-projected-volume.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: test-projected-volume
spec:
containers:
- name: test-secret-volume
image: daocloud.io/library/nginx
volumeMounts:
- name: mysql-cred
mountPath: "/projected-volume"
readOnly: true
volumes:
- name: mysql-cred
secret:
secretName: mysecret-01
������� Pod:
[root@kub-k8s-master prome]# kubectl apply -f test-projected-volume.yaml
pod/test-projected-volume1 created
��֤��Щ Secret �����Dz����Ѿ�����������:
[root@kub-k8s-master prome]# kubectl exec -it test-projected-volume /bin/bash
root@test-projected-volume:/# ls
bin dev home lib64 mnt proc root sbin sys usr
boot etc lib media opt projected-volume run srv tmp var
root@test-projected-volume:/# ls projected-volume/
pass user
root@test-projected-volume:/# cat projected-volume/pass
1f2d1e2e67df
root@test-projected-volume:/# cat projected-volume/user
admin
root@test-projected-volume:/#
ע��:
�������:������������ᱨ������
# kubectl exec -it test-projected-volume /bin/sh
error: unable to upgrade connection: Forbidden (user=system:anonymous, verb=create, resource=nodes, subresource=proxy)
���:��һ��cluster-admin��Ȩ��
# kubectl create clusterrolebinding system:anonymous --clusterrole=cluster-admin --user=system:anonymous
clusterrolebinding.rbac.authorization.k8s.io/system:anonymous created
����п���,������ Etcd ����û�����������Ϣ,�Ѿ����ļ�����ʽ�������������� Volume Ŀ¼�������ļ�������,���� kubectl create secret ָ���� Key,����˵�� Secret ����� data �ֶ�ָ���� Key��
2��ConfigMap���
ConfigMap �� Secret ����,�����洢�����ļ���kubernetes��Դ����,���е��������ݶ��洢��etcd�С�
�� Secret ������:
-
ConfigMap ������Dz���Ҫ���ܵġ�Ӧ�������������Ϣ��
-
ConfigMap ���÷������� Secret ��ȫ��ͬ:����ʹ�� kubectl create configmap ���ļ�����Ŀ¼���� ConfigMap,Ҳ����ֱ�ӱ�д ConfigMap ����� YAML �ļ���
2.1 ����ConfigMap�ķ�ʽ
����ConfigMap�ķ�ʽ��4��:
�����з�ʽ
- ��ʽ1:ͨ��ֱ������������ָ��configmap��������,���Cfrom-literal
- ��ʽ2:ͨ��ָ���ļ�����,����һ�������ļ�����Ϊһ��ConfigMap,�Cfrom-file=<�ļ�>
- ��ʽ3:ͨ��ָ��Ŀ¼����,����һ��Ŀ¼�µ����������ļ�����Ϊһ��ConfigMap,�Cfrom-file=<Ŀ¼>
- ��ʽ4:����д�ñ���configmap��yaml�ļ�,Ȼ��kubectl create -f ����
2.1.1 ͨ�������в����Cfrom-literal����
��������:
[root@kub-k8s-master prome]# kubectl create configmap test-configmap --from-literal=user=admin --from-literal=pass=1122334
configmap/test-configmap created
����������data������ʾ:
[root@kub-k8s-master prome]# kubectl get configmap test-configmap -o yaml
apiVersion: v1
data:
pass: "1122334"
user: admin
kind: ConfigMap
metadata:
creationTimestamp: "2019-10-21T07:48:15Z"
name: test-configmap
namespace: default
resourceVersion: "187590"
selfLink: /api/v1/namespaces/default/configmaps/test-configmap
uid: 62a8a0d0-fab9-4159-86f4-a06aa213f4b1
2.1.2 ͨ��ָ���ļ�����
�༭�����ļ�app.properties��������:
[root@kub-k8s-master prome]# vim app.properties
property.1 = value-1
property.2 = value-2
property.3 = value-3
property.4 = value-4
[mysqld]
!include /home/wing/mysql/etc/mysqld.cnf
port = 3306
socket = /home/wing/mysql/tmp/mysql.sock
pid-file = /wing/mysql/mysql/var/mysql.pid
basedir = /home/mysql/mysql
datadir = /wing/mysql/mysql/var
����(�������Cfrom-file):
[root@kub-k8s-master prome]# kubectl create configmap test-config2 --from-file=app.properties
configmap/test-config2 created
���������data������ʾ:
[root@kub-k8s-master prome]# kubectl get configmap test-config2 -o yaml
apiVersion: v1
data:
app.properties: |
property.1 = value-1
property.2 = value-2
property.3 = value-3
property.4 = value-4
[mysqld]
!include /home/wing/mysql/etc/mysqld.cnf
port = 3306
socket = /home/wing/mysql/tmp/mysql.sock
pid-file = /wing/mysql/mysql/var/mysql.pid
basedir = /home/mysql/mysql
datadir = /wing/mysql/mysql/var
kind: ConfigMap
metadata:
creationTimestamp: "2019-10-21T08:01:43Z"
name: test-config2
namespace: default
resourceVersion: "188765"
selfLink: /api/v1/namespaces/default/configmaps/test-config2
uid: 790fca12-3900-4bf3-a017-5af1070792e5
ͨ��ָ���ļ�����ʱ,configmap�ᴴ��һ��key/value��,key���ļ���,value���ļ����ݡ�
2.1.3 ָ��Ŀ¼����
configs Ŀ¼�µ�config-1��config-2����������ʾ:
[root@kub-k8s-master prome]# mkdir config
[root@kub-k8s-master prome]# cd config/
[root@kub-k8s-master config]# vim config1
aaa
bbb
c=d
[root@kub-k8s-master config]# vim config2
eee
fff
h=k
����:
[root@kub-k8s-master config]# cd ..
[root@kub-k8s-master prome]# kubectl create configmap test-config3 --from-file=./config
configmap/test-config3 created
�������data������ʾ:
[root@kub-k8s-master prome]# kubectl get configmap test-config3 -o yaml
apiVersion: v1
data:
config1: |
aaa
bbb
c=d
config2: |
eee
fff
h=k
kind: ConfigMap
metadata:
creationTimestamp: "2019-10-21T08:20:42Z"
name: test-config3
namespace: default
resourceVersion: "190420"
selfLink: /api/v1/namespaces/default/configmaps/test-config3
uid: 6e00fded-80a8-4297-aeb3-4c48795e6eb9
ָ��Ŀ¼����ʱ,configmap�����еĸ����ļ��ᴴ��һ��key/value��,key���ļ���,value���ļ����ݡ�
2.1.4 ͨ����yaml�ļ�����
yaml�ļ���������: ע������һ��key��value�ж�������ʱ��д��
[root@kub-k8s-master prome]# vim configmap.yaml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: test-config4
namespace: default
data:
cache_host: memcached-gcxt
cache_port: "11211"
cache_prefix: gcxt
my.cnf: |
[mysqld]
log-bin = mysql-bin
haha = hehe
����:
[root@kub-k8s-master prome]# kubectl apply -f configmap.yaml
configmap/test-config4 created
���������data������ʾ:
[root@kub-k8s-master prome]# kubectl get configmap test-config4 -o yaml
apiVersion: v1
data:
cache_host: memcached-gcxt
cache_port: "11211"
cache_prefix: gcxt
my.cnf: |
[mysqld]
log-bin = mysql-bin
haha = hehe
kind: ConfigMap
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","data":{"cache_host":"memcached-gcxt","cache_port":"11211","cache_prefix":"gcxt","my.cnf":"[mysqld]\nlog-bin = mysql-bin\nhaha = hehe\n"},"kind":"ConfigMap","metadata":{"annotations":{},"name":"test-config4","namespace":"default"}}
creationTimestamp: "2019-10-21T08:30:24Z"
name: test-config4
namespace: default
resourceVersion: "191270"
selfLink: /api/v1/namespaces/default/configmaps/test-config4
uid: 2a8cd6e7-db2c-4781-b005-e0b76d26394b
�鿴configmap����ϸ��Ϣ:
[root@kub-k8s-master prome]# kubectl describe configmap
2.2 ʹ��ConfigMap
ʹ��ConfigMap�����ַ�ʽ,
- ͨ�����������ķ�ʽ,ֱ�Ӵ���pod
- ͨ����pod�������������еķ�ʽ,
- ʹ��volume�ķ�ʽ�����뵽pod��
ʾ��ConfigMap�ļ�:
[root@kub-k8s-master prome]# vim config-map.yml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: config-map
namespace: default
data:
special.how: very
special.type: charm
����
[root@kub-k8s-master prome]# kubectl apply -f config-map.yml
configmap/config-map created
2.2.1 ͨ����������ʹ��
(1) ʹ��valueFrom��configMapKeyRef��name��keyָ��Ҫ�õ�key:
[root@kub-k8s-master prome]# vim testpod.yml
---
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: daocloud.io/library/nginx
env: #ר���������������ñ����Ĺؼ���
- name: SPECIAL_LEVEL_KEY #�����-name,�����������õ��±���������
valueFrom:
configMapKeyRef:
name: config-map #��������Դ���ĸ�configMap
key: special.how #configMap���key
- name: SPECIAL_TYPE_KEY
valueFrom:
configMapKeyRef:
name: config-map
key: special.type
restartPolicy: Never
����pod
[root@kub-k8s-master prome]# kubectl apply -f testpod.yml
pod/dapi-test-pod created
����:
[root@kub-k8s-master prome]# kubectl exec -it dapi-test-pod /bin/bash
root@dapi-test-pod:/# echo $SPECIAL_TYPE_KEY
charm
(2) ͨ��envFrom��configMapRef��nameʹ��configmap�е�����key/value�Զ� ���Զ���ɻ�������:
[root@kub-k8s-master prome]# kubectl delete -f testpod.yml
pod "dapi-test-pod" deleted
[root@kub-k8s-master prome]# cp testpod.yml testpod.yml.bak
[root@kub-k8s-master prome]# vim testpod.yml
---
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: daocloud.io/library/nginx
envFrom:
- configMapRef:
name: config-map
restartPolicy: Never
����������ı�������ֱ��ʹ��configMap���key��:
[root@kub-k8s-master prome]# kubectl apply -f testpod.yml
pod/dapi-test-pod created.
[root@kub-k8s-master prome]# kubectl exec -it dapi-test-pod /bin/bash
root@dapi-test-pod:/# env
HOSTNAME=dapi-test-pod
NJS_VERSION=0.3.3
NGINX_VERSION=1.17.1
KUBERNETES_PORT_443_TCP_PROTO=tcp
KUBERNETES_PORT_443_TCP_ADDR=10.96.0.1
PKG_RELEASE=1~stretch
KUBERNETES_PORT=tcp://10.96.0.1:443
PWD=/
special.how=very
HOME=/root
KUBERNETES_SERVICE_PORT_HTTPS=443
KUBERNETES_PORT_443_TCP_PORT=443
KUBERNETES_PORT_443_TCP=tcp://10.96.0.1:443
TERM=xterm
SHLVL=1
KUBERNETES_SERVICE_PORT=443
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
special.type=charm
KUBERNETES_SERVICE_HOST=10.96.0.1
_=/usr/bin/env
2.2.2 ��Ϊvolume����ʹ��
(1) ��1.4��test-config4����key/value���ؽ���:
[root@kub-k8s-master prome]# kubectl delete -f testpod.yml
pod "dapi-test-pod" deleted
[root@kub-k8s-master prome]# vim volupod.yml
---
apiVersion: v1
kind: Pod
metadata:
name: nginx-configmap
spec:
containers:
- name: nginx-configmap
image: daocloud.io/library/nginx
volumeMounts:
- name: config-volume4
mountPath: "/tmp/config4"
volumes:
- name: config-volume4
configMap:
name: test-config4
����pod
[root@kub-k8s-master prome]# kubectl apply -f volupod.yml
pod/nginx-configmap created
����������/tmp/config4�鿴:
[root@kub-k8s-master prome]# kubectl exec -it nginx-configmap /bin/bash
root@nginx-configmap:/# ls /tmp/config4/
cache_host cache_port cache_prefix my.cnf
root@nginx-configmap:/# cat /tmp/config4/cache_host
memcached-gcxt
root@nginx-configmap:/#
���Կ���,��config4�ļ�������ÿһ��keyΪ�ļ���valueΪֵ�����˶���ļ���
3��Downward API
Downward API �����������л�ȡ POD �Ļ�����Ϣ,kubernetesԭ��֧��
Downward API�ṩ�����ַ�ʽ���ڽ� POD ����Ϣע�뵽�����ڲ�:
- ��������:���ڵ�������,���Խ� POD ��Ϣ��������Ϣֱ��ע�������ڲ���
- Volume����:�� POD ��Ϣ����Ϊ�ļ�,ֱ�ӹ��ص������ڲ���ȥ��
3.1 ���������ķ�ʽ
ͨ��Downward API���� POD �� IP�������Լ�����Ӧ�� namespace ע�뵽�����Ļ���������ȥ,Ȼ���������д�ӡȫ���Ļ���������������֤
ʹ��fieldRef��ȡ POD �Ļ�����Ϣ:
[root@kub-k8s-master prome]# vim test-env-pod.yml
---
apiVersion: v1
kind: Pod
metadata:
name: test-env-pod
namespace: kube-system
spec:
containers:
- name: test-env-pod
image: daocloud.io/library/nginx
env:
- name: POD_NAME #��һ����������������
valueFrom: #ʹ��valueFrom��ʽ����
fieldRef: #����һ���ֶ�metadata.name
fieldPath: metadata.name #����ֶδӵ�ǰ���е�pod��ϸ��Ϣ�鿴
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
ע��: POD �� name �� namespace ����Ԫ����,���� POD ����֮ǰ���Ѿ��������˵�,����ʹ�� metadata ��ȡ�Ϳ�����,���Ƕ��� POD �� IP ��һ��,��ΪPOD IP �Dz��̶���,POD �ؽ��˾ͱ���,������״̬����,����ʹ�� status ȥ��ȡ:
���л�����Ϣ����ʹ������ķ�ʽȥ�鿴(describe��ʽ��������):
# kubectl get pod first-pod -o yaml
��������� POD:
[root@kub-k8s-master prome]# kubectl apply -f test-env-pod.yml
pod/test-env-pod created
POD �����ɹ���,�鿴:
[root@kub-k8s-master prome]# kubectl exec -it test-env-pod /bin/bash -n kube-system
root@test-env-pod:/# env | grep POD
POD_NAME=test-env-pod
POD_NAMESPACE=kube-system
POD_IP=10.244.1.35
root@test-env-pod:/#
3.2 Volume����
ͨ��Downward API�� POD �� Label��Annotation ����Ϣͨ�� Volume ���ص�������ij���ļ���ȥ,Ȼ���������д�ӡ�����ļ���ֵ����֤��
[root@kub-k8s-master prome]# vim test-volume-pod.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: test-volume-pod
namespace: kube-system
labels:
k8s-app: test-volume
node-env: test
spec:
containers:
- name: test-volume-pod-container
image: daocloud.io/library/nginx
volumeMounts:
- name: podinfo
mountPath: /etc/podinfo
volumes:
- name: podinfo
downwardAPI:
items:
- path: "labels"
fieldRef:
fieldPath: metadata.labels
��Ԫ���� labels �� annotaions ���ļ�����ʽ���ص���/etc/podinfoĿ¼��,��������� POD :
[root@kub-k8s-master prome]# kubectl apply -f test-volume-pod.yaml
pod/test-volume-pod created
[root@kub-k8s-master prome]# kubectl get pod -n kube-system
[root@k8s-master prome]# kubectl exec -it test-volume-pod /bin/bash -n kube-system
root@test-volume-pod:/# cd /etc/podinfo/
root@test-volume-pod:/etc/podinfo# ls
labels
root@test-volume-pod:/etc/podinfo# cat labels
k8s-app="test-volume"
node-env="test"
��ʵ��Ӧ����,������Ӧ���л�ȡ POD �Ļ�����Ϣ������,�Ϳ�������Downward API����ȡ������Ϣ,Ȼ���дһ�������ű���������initContainer�� POD ����Ϣע�뵽������ȥ,Ȼ�����Լ���Ӧ���оͿ��������Ĵ���������ˡ�
Ŀǰ Downward API ֧�ֵ��ֶ�:
1. ʹ�� fieldRef ��������ʹ��:
spec.nodeName - ����������
status.hostIP - ������ IP
metadata.name - Pod ������
metadata.namespace - Pod �� Namespace
status.podIP - Pod �� IP
spec.serviceAccountName - Pod �� Service Account ������
metadata.uid - Pod �� UID
metadata.labels['<KEY>'] - ָ�� <KEY> �� Label ֵ
metadata.annotations['<KEY>'] - ָ�� <KEY> �� Annotation ֵ
metadata.labels - Pod ������ Label
metadata.annotations - Pod ������ Annotation
��������б�������,���� Kubernetes ��Ŀ�ķ�չ�϶���������ӡ����������г�������Ϣ�����ο�,��ʹ�� Downward API ʱ,����Ҫ�ǵ�ȥ����һ�¹ٷ��ĵ���
Secret��ConfigMap,�Լ� Downward API ������ Projected Volume �������Ϣ,������ͨ�����������ķ�ʽ���������������,ͨ������������ȡ��Щ��Ϣ�ķ�ʽ,���߱��Զ����µ�������һ�������,����ʹ�� Volume �ļ��ķ�ʽ��ȡ��Щ��Ϣ��
4��ServiceAccount
�ٷ��ĵ���ַ:https://kubernetes.io/docs/tasks/configure-pod-container/configure-service-account/
k8s���ṩ�����õĶ��⻧��֤��������,��RBAC��ServiceAccount���и���Policy�ȡ�
4.1 ʲô�� Service Account
���û����ʼ�Ⱥ(����ʹ��kubectl����)ʱ,apiserver �Ὣ�û���֤Ϊһ���ض��� User Account(Ŀǰͨ����admin,����ϵͳ����Ա�Զ����˼�Ⱥ����)��
Pod �����еĽ���Ҳ������ apiserver ��ϵ�� ����������ϵ apiserver ��ʱ��,���ǻᱻ��֤Ϊһ���ض���Service Account(����default)��
ʹ�ó���:
- Service Account�������Ǹ�kubernetes��Ⱥ���û�ʹ�õ�,���Ǹ�pod����Ľ���ʹ�õ�,��Ϊpod�ṩ��Ҫ��������֤��----ר��Ϊpod����Ľ��̺�apiserverͨ���ṩ��֤�ġ�
4.2 Service account��User account����
1. User account��Ϊ�û���Ƶ�,��service account����ΪPod�еĽ��̵���Kubernetes API�������ⲿ�������Ƶ�
2. User account�ǿ�namespace��,��service account���ǽ����������ڵ�namespace;
3. ÿ��namespace�����Զ�����һ��default service account
4. Token controller���service account�Ĵ���,��Ϊ���Ǵ���secret
5. ����ServiceAccount Admission Controller��:
5.1 ÿ��Pod�ڴ������Զ�����spec.serviceAccountΪdefault(����ָ��������ServiceAccout)
5.2 ��֤Pod���õ�service account�Ѿ�����,����ܾ�����
5.3 ���Podû��ָ��ImagePullSecrets,���service account��ImagePullSecrets�ӵ�Pod��
5.4 ÿ��container��������ظ�service account��token��ca.crt��/run/secrets/kubernetes.io/serviceaccount/
ÿһ��pod����֮����һ������֤��صĶ�������pod����,,���ڵ�������?
�鿴ϵͳ��config����:
�����õ���token���DZ���Ȩ����SeviceAccount�˻���token,��Ⱥ����token��ʹ��ServiceAccount�˻�
[root@kub-k8s-master prome]# cat /root/.kube/config
4.3 Service AccountӦ��ʾ��
Service Account(�����˺�)����ʾ��
��Ϊƽʱϵͳ��ʹ��Ĭ��service account,���Dz���Ҫ�Լ�����,�о�����service account�Ĵ���,��ʵ����ʹ���Լ��ֶ�������service account
1������serviceaccount
[root@kub-k8s-master ~]# kubectl create serviceaccount mysa
serviceaccount/mysa created
2���鿴mysa
[root@kub-k8s-master ~]# kubectl describe sa mysa
Name: mysa
Namespace: default
Labels: <none>
Annotations: <none>
Image pull secrets: <none>
Mountable secrets: mysa-token-cknwf
Tokens: mysa-token-cknwf
Events: <none>
3���鿴mysa�Զ�������secret
[root@kub-k8s-master ~]# kubectl get secret
NAME TYPE DATA AGE
db-user-pass Opaque 2 11h
default-token-6svwp kubernetes.io/service-account-token 3 4d23h
mysa-token-cknwf kubernetes.io/service-account-token 3 76s
mysecret Opaque 2 11h
mysecret-01 Opaque 2 6h58m
pass Opaque 1 7h6m
user Opaque 1 7h7m
4��ʹ��mysa��sa��Դ����pod
[root@kub-k8s-master ~]# cd prome/
[root@kub-k8s-master prome]# vim mysa-pod.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
labels:
app: my-pod
spec:
containers:
- name: my-pod
image: daocloud.io/library/nginx
ports:
- name: http
containerPort: 80
serviceAccountName: mysa #ָ��serviceaccount������
5������
[root@kub-k8s-master prome]# kubectl apply -f mysa-pod.yaml
pod/nginx-pod created
6���鿴
[root@kub-k8s-master prome]# kubectl describe pod nginx-pod
7���鿴ʹ�õ�token��secret(ʹ�õ���mysa��token)
[root@kub-k8s-master prome]# kubectl get pod nginx-pod -o jsonpath={".spec.volumes"}
[map[name:mysa-token-cknwf secret:map[defaultMode:420 secretName:mysa-token-cknwf]]]
[root@kub-k8s-master prome]#
4.4 RBAC ���(���ڽ�ɫ�ķ��ʿ���)
4.4.1 ʲô��RBAC
Service AccountΪ�����ṩ��һ�ַ������֤����,������������Ȩ�����⡣�������RBAC��ΪService Account��Ȩ
��Kubernetes��,��Ȩ��ABAC(�������Եķ��ʿ���)��RBAC(���ڽ�ɫ�ķ��ʿ���)��Webhook��Node��AlwaysDeny(һֱ�ܾ�)��AlwaysAllow(һֱ����)��6��ģʽ��
��RBAC API��,ͨ�����µIJ��������Ȩ:
- �����ɫ:�ڶ����ɫʱ��ָ���˽�ɫ������Դ�ķ��ʿ��ƵĹ���;
- ��ɫ:���������ɫ���а�,���û����з�����Ȩ��
4.4.2 Role��ClusterRole
- Role:��ɫ�����������ռ��ڵ�Role������,һ��Role����ֻ�����������ijһ��һ�����ռ�����Դ�ķ���Ȩ�ޡ�
- ClusterRole:����Kubernetes��Ⱥ��Χ����Ч�Ľ�ɫ��ͨ��ClusterRole����ʵ�֡�
���
role:
1�������IJ���,��get,list��
2�����������Ķ���,��pod,service��
rolebinding:
���ĸ��û����ĸ�role��clusterrole��
clusterrole:(��Ⱥ��ɫ)
clusterrolebinding:(��s��Ⱥ)
���ʹ��rolebinding��clusterrole��,��ʾ���û�ֻ�����ڵ�ǰnamespace��Ȩ��
4.4.3 ʵ��һ:role
����k8s�˺���RBAC��Ȩʹ��
�����˺�/�û�
1������˽Կ
[root@kub-k8s-master ~]# (umask 077; openssl genrsa -out soso.key 2048)
Generating RSA private key, 2048 bit long modulus
...............................+++
..........................+++
e is 65537 (0x10001)
�ô�˽Կ����һ��csr(֤��ǩ������)�ļ�
[root@kub-k8s-master ~]# openssl req -new -key soso.key -out soso.csr -subj "/CN=soso"
����˽Կ�������ļ�����֤��
[root@kub-k8s-master ~]# openssl x509 -req -in soso.csr -CA /etc/kubernetes/pki/ca.crt -CAkey /etc/kubernetes/pki/ca.key -CAcreateserial -out soso.crt -days 365
Signature ok
subject=/CN=soso
Getting CA Private Key
2���鿴֤������
[root@kub-k8s-master ~]# openssl x509 -in soso.crt -text -noout
�����˺�
[root@kub-k8s-master ~]# kubectl config set-credentials soso --client-certificate=soso.crt --client-key=soso.key --embed-certs=true
User "soso" set.
3�����������Ļ���--ָ��������˺�ֻ������������в�����
[root@kub-k8s-master ~]# kubectl config set-context soso@kubernetes --cluster=kubernetes --user=soso
Context "soso@kubernetes" created.
�鿴��ǰ�Ĺ���������
[root@kub-k8s-master ~]# kubectl config view
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: DATA+OMITTED
server: https://192.168.246.166:6443
....
4���л��û�(�л�������)
[root@kub-k8s-master ~]# kubectl config use-context soso@kubernetes
Switched to context "soso@kubernetes".
��֤�Ƿ��Ѿ��л������µ�������
[root@kub-k8s-master ~]# kubectl config current-context
soso@kubernetes
5.����(��δ����Ȩ��)
[root@kub-k8s-master ~]# kubectl get pod
Error from server (Forbidden): pods is forbidden: User "soso" cannot list resource "pods" in API group "" in the namespace "default"
����һ����ɫ(role)---Ȩ��
1.�лع����ʺ���
[root@kub-k8s-master ~]# kubectl config use-context kubernetes-admin@kubernetes
Switched to context "kubernetes-admin@kubernetes".
������ɫ:
[root@kub-k8s-master ~]# kubectl create role myrole --verb=get,list,watch --resource=pod,svc
role.rbac.authorization.k8s.io/myrole created
--verb: �൱����Ȩ��
--resource:��ʲô��Դʹ��
2.���û�soso(���洴�����û�),��roleΪmyrole
[root@kub-k8s-master ~]# kubectl create rolebinding myrole-binding --role=myrole --user=soso
rolebinding.rbac.authorization.k8s.io/myrole-binding created
3.�л��û�
[root@kub-k8s-master ~]# kubectl config use-context soso@kubernetes
Switched to context "soso@kubernetes".
4.�鿴Ȩ��(ֻ��Ȩ��default���ƿռ�pod��svc��get,list,watchȨ��)
[root@kub-k8s-master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
lifecycle-demo 1/1 Running 1 22h
mypod 1/1 Running 0 8h
nginx-configmap 1/1 Running 0 4h29m
nginx-pod 1/1 Running 0 39m
[root@kub-k8s-master ~]# kubectl get pod -n kube-system #��Ȩ����kube-system
Error from server (Forbidden): pods is forbidden: User "soso" cannot list resource "pods" in API group "" in the namespace "kube-system"
[root@kub-k8s-master ~]# kubectl delete pod nginx-pod #��Ȩ��ɾ��
Error from server (Forbidden): pods "nginx-pod" is forbidden: User "soso" cannot delete resource "pods" in API group "" in the namespace "default"
5.�л��û�
[root@kub-k8s-master ~]# kubectl config use-context kubernetes-admin@kubernetes
Switched to context "kubernetes-admin@kubernetes".
...
4.4.4 ʵ���:clusterrole
6.ɾ��soso�˺�֮ǰ��rolebinding
[root@kub-k8s-master ~]# kubectl delete rolebinding myrole-binding
rolebinding.rbac.authorization.k8s.io "myrole-binding" deleted
7.����clusterrole #���Է���ȫ����namespace
[root@kub-k8s-master ~]# kubectl create clusterrole myclusterrole --verb=get,list,watch --resource=pod,svc
clusterrole.rbac.authorization.k8s.io/myclusterrole created
8.��Ⱥ��ɫ���û�soso
[root@kub-k8s-master ~]# kubectl create clusterrolebinding my-cluster-rolebinding --clusterrole=myclusterrole --user=soso
clusterrolebinding.rbac.authorization.k8s.io/my-cluster-rolebinding created
8.�л��˺�
[root@kub-k8s-master ~]# kubectl config use-context soso@kubernetes
Switched to context "soso@kubernetes".
9.�鿴Ȩ�� �鿴kube-system�ռ��pod
[root@kub-k8s-master ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-5644d7b6d9-sm8hs 1/1 Running 0 5d
coredns-5644d7b6d9-vddll 1/1 Running 0 5d
etcd-kub-k8s-master 1/1 Running 0 5d
ע��:10.�л�Ϊ����Ա�û�
[root@kub-k8s-master ~]# kubectl config use-context kubernetes-admin@kubernetes
4.4.5 ���������ĺ��˻��л�
���ù���������(ǰ������û�)
[root@kub-k8s-master ~]# kubectl config set-context soso@kubernetes --cluster=kubernetes --user=soso
Context "soso@kubernetes" created.
�鿴��ǰ�Ĺ���������
[root@kub-k8s-master ~]# kubectl config view
apiVersion: v1
clusters:
- cluster:
....
�л�������(�л��û�)
[root@kub-k8s-master ~]# kubectl config use-context soso@kubernetes
Switched to context "soso@kubernetes".
�л�Ϊ����Ա�û�
[root@kub-k8s-master prome]# kubectl config use-context kubernetes-admin@kubernetes
Switched to context "kubernetes-admin@kubernetes".
ʮ����������ؼ�鼰�ָ�����
? �� k8s ��,����Ϊ Pod �����������һ���������"̽��"(Probe)��kubelet �ͻ������� Probe �ķ���ֵ�������������״̬,������ֱ���������Ƿ�����(���� Docker ���ص���Ϣ)��Ϊ���ݡ����ֻ���,�����������б�֤Ӧ�ý���������Ҫ�ֶΡ�
ע:
- k8s �в�û�� Docker �� Stop ���塣�������������̽���������,�鿴״̬��Ȼ�������� Restart,��ʵ��ȴ�����´�����������
1������ģʽ̽��
Kubernetes �ĵ��е�����:
[root@kub-k8s-master ~]# cd prome/
[root@kub-k8s-master prome]# vim test-liveness-exec.yaml
---
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: test-liveness-exec
spec:
containers:
- name: liveness
image: daocloud.io/library/nginx
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 50
livenessProbe: #̽��,�������
exec: #����
command: #����
- cat
- /tmp/healthy
initialDelaySeconds: 5 #�������,���������� 5 s ��ʼִ��
periodSeconds: 5 #ÿ 5 s ִ��һ��
�ļ����ݽ���:
-
��������֮�����ĵ�һ�������� /tmp Ŀ¼�´�����һ�� healthy �ļ�,�Դ���Ϊ�Լ��Ѿ��������еı�־���� 30 s ����,���������ļ�ɾ������
-
���ͬʱ,������һ�������� livenessProbe(�������)������������ exec,����������������,����������ִ��һ������ָ��������,����:��cat /tmp/healthy������ʱ,�������ļ�����,��������ķ���ֵ���� 0,Pod �ͻ���Ϊ������������Ѿ�����,�����ǽ����ġ�
-
����������,���������� 5 s ��ʼִ��(initialDelaySeconds: 5),ÿ 5 s ִ��һ��(periodSeconds: 5)��
����Pod:
[root@kub-k8s-master prome]# kubectl apply -f test-liveness-exec.yaml
pod/test-liveness-exec created
�鿴 Pod ��״̬:
[root@kub-k8s-master prome]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-configmap 1/1 Running 0 16h
nginx-pod 1/1 Running 0 12h
test-liveness-exec 1/1 Running 0 75s
�����Ѿ�ͨ���˽������,��� Pod �ͽ����� Running ״̬��
Ȼ��30 s ֮��,�ٲ鿴һ�� Pod �� Events:
[root@kub-k8s-master prome]# kubectl describe pod test-liveness-exec
����,��� Pod �� Events ������һ���쳣:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning Unhealthy 54s (x9 over 3m34s) kubelet, kub-k8s-node1 Liveness probe failed: cat: /tmp/healthy: No such file or directory
����������̽�鵽 /tmp/healthy �Ѿ���������,���������������Dz������ġ���ô�������ᷢ��ʲô��?
�ٴβ鿴һ����� Pod ��״̬:
[root@kub-k8s-master prome]# kubectl get pod test-liveness-exec
NAME READY STATUS RESTARTS AGE
test-liveness-exec 1/1 Running 4 5m19s
��ʱ����,Pod ��û�н��� Failed ״̬,���DZ����� Running ״̬������Ϊʲô��?
-
RESTARTS �ֶδ� 0 �� 1 �ı仯,������ԭ����:����쳣�������Ѿ��� Kubernetes �����ˡ������������,Pod ���� Running ״̬���䡣
-
ע��:Kubernetes �в�û�� Docker �� Stop ���塣������Ȼ�� Restart(����),��ʵ��ȴ�����´�����������
-
������ܾ��� Kubernetes ���Pod �ָ�����,Ҳ�� restartPolicy������ Pod �� Spec ���ֵ�һ�����ֶ�(pod.spec.restartPolicy),Ĭ��ֵ�� Always,��:�κ�ʱ����������������쳣,��һ���ᱻ���´�����
С��ʾ:
Pod �Ļָ�����,��Զ���Ƿ����ڵ�ǰ�ڵ���,�������ܵ���Ľڵ���ȥ����ʵ��,һ��һ�� Pod ��һ���ڵ�(Node)��,������������˱仯(pod.spec.node �ֶα���),��������Զ�������뿪����ڵ㡣��Ҳ����ζ��,������������崻���,��� Pod Ҳ��������Ǩ�Ƶ������ڵ���ȥ��
2��http get��ʽ̽��
[root@kub-k8s-master prome]# vim liveness-httpget.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: liveness-httpget-pod
namespace: default
spec:
containers:
- name: liveness-exec-container
image: daocloud.io/library/nginx
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
livenessProbe: #̽��,�������
httpGet:
port: http
path: /index.html
initialDelaySeconds: 1
periodSeconds: 3
������pod
[root@kub-k8s-master prome]# kubectl create -f liveness-httpget.yaml
pod/liveness-httpget-pod created
�鿴��ǰpod��״̬
[root@kub-k8s-master prome]# kubectl describe pod liveness-httpget-pod
...
Liveness: http-get http://:http/index.html delay=1s timeout=1s period=3s #success=1 #failure=3
...
���Խ������ڵ�index.htmlɾ����
��½����
[root@kub-k8s-master prome]# kubectl exec -it liveness-httpget-pod /bin/bash
root@liveness-httpget-pod:/# mv /usr/share/nginx/html/index.html index.html
root@liveness-httpget-pod:/# command terminated with exit code 137
���Կ���,����index.html���ߺ�,��������������˳��ˡ�
��ʱ,�鿴pod����Ϣ
[root@kub-k8s-master prome]# kubectl describe pod liveness-httpget-pod
...
Normal Killing 49s kubelet, kub-k8s-node2 Container liveness-exec-container failed liveness probe, will be restarted
Normal Pulled 49s kubelet, kub-k8s-node2 Container image "daocloud.io/library/nginx" already present on machine
...
�����,�������ڽ������δͨ��,pod�ᱻɱ��,�����´���
[root@kub-k8s-master prome]# kubectl get pods
NAME READY STATUS RESTARTS AGE
lifecycle-demo 1/1 Running 1 34h
liveness-httpget-pod 1/1 Running 1 5m42s
restarts Ϊ 1
���µ�½�����鿴
���µ�½����,����index.html�ֳ�����,֤�������DZ������ˡ�
[root@kub-k8s-master prome]# kubectl exec -it liveness-httpget-pod /bin/bash
root@liveness-httpget-pod:/# cat /usr/share/nginx/html/index.html
ʮ�ġ�POD �Ļָ�����
Pod �Ļָ�����:
����ͨ������ restartPolicy,�ı� Pod �Ļָ����ԡ�һ����3��:
1. Always: ���κ������,ֻҪ������������״̬,���Զ���������;
2. OnFailure: ֻ�������쳣ʱ���Զ���������;
3. Never: ����������������
ʵ��ʹ��ʱ,��Ҫ����Ӧ�����е�����,�������������ָֻ����ԡ�
ʮ�塢Deployment ��Դ���
ʹ��yaml����Deployment
k8s deployment��Դ��������:
1. �û�ͨ�� kubectl ���� Deployment��
2. Deployment ���� ReplicaSet��
3. ReplicaSet ���� Pod��
Deployment��һ�����弰�����ั��Ӧ��(��������� Pod)����һ������,��Replication Controller���,���ṩ�˸������ƵĹ���,ʹ���������Ӽ��㡣
�����������ʽ��:�Ӷ�������� = ���������� + ����ַ���������

1��Ϊʲôʹ��Deployment
���Pod���ֹ���,��Ӧ�ķ���Ҳ��ҵ�,����Kubernetes�ṩ��һ��Deployment�ĸ��� ,Ŀ������Kubernetesȥ����һ��Pod�ĸ���,Ҳ���Ǹ����� ,�������ܹ���֤һ�������ĸ���һֱ����,������Ϊijһ��Pod�ҵ�������������ҵ���
Deployment �������� Pod ���巢���仯ʱ,��ÿ���������й�������(Rolling Update)��
����ʹ��һ�� API ����(Deployment)������һ�� API ����(Pod)�ķ���,�� k8s ��,����"������"ģʽ(controller pattern)��Deployment ���ݵ����� Pod �Ŀ������Ľ�ɫ��
2������Deployment
��1:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
��2:������yaml�Ļ�����������volume
[root@kub-k8s-master prome]# vim deployment.yaml
apiVersion: apps/v1 #ע��汾��
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector: #����,ѡ����
matchLabels:
app: nginx
replicas: 2 #�����ĸ�������
template: #ģ������
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: daocloud.io/library/nginx
ports:
- containerPort: 80
volumeMounts: #������ؾ�
- mountPath: "/usr/share/nginx/html"
name: nginx-vol
volumes: #���干����
- name: nginx-vol
emptyDir: {}
����Deployment:
��������YAML�ļ�����Ϊdeployment.yaml,Ȼ��Deployment:
[root@kub-k8s-master prome]# kubectl apply -f deployment.yaml
deployment.apps/nginx-deployment created
���Deployment���б�:����֮����Ҫ����ʱ��Ƚϳ�
ͨ�� kubectl get ��������� YAML ����������״̬:
[root@kub-k8s-master prome]# kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 2/2 2 2 2m22s
[root@kub-k8s-master prome]# kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
nginx-deployment-59c4b86474-2llrt 1/1 Running 0 2m51s
nginx-deployment-59c4b86474-n2r2m 1/1 Running 0 2m51s
�����������һ�� -l ����,����ȡ����ƥ�� app: nginx ��ǩ�� Pod����Ҫע�����,����������,���� key-value ��ʽ�IJ���,��ʹ��"="����":"��ʾ��
ɾ��Deployment:
[root@k8s-master ~]# kubectl delete deployments nginx-deployment
deployment "nginx-deployment" deleted
����
[root@k8s-master ~]# kubectl delete -f deployment.yaml
apiVersion:ע������apiVersion��Ӧ��ֵ��extensions/v1beta1����apps/v1.����汾����Ҫ���ݰ�װ��Kubernetes�汾����Դ���ͽ��б仯,��ס����д���ġ���ֵ������kubectl apiversion��
[root@kub-k8s-master prome]# kubectl api-versions
apps/v1beta1
authentication.k8s.io/v1beta1
authorization.k8s.io/v1beta1
autoscaling/v1
batch/v1
certificates.k8s.io/v1alpha1
extensions/v1beta1
policy/v1beta1
rbac.authorization.k8s.io/v1alpha1
storage.k8s.io/v1beta1
v1
kind:��Դ����:����ָ��ΪDeployment��
metadata:ָ��һЩmeta��Ϣ,�������ֻ��ǩ֮��ġ�ÿһ�� API ������һ������ Metadata ���ֶ�,����ֶ��� API �����"��ʶ",��Ԫ����,Ҳ�����Ǵ� Kubernetes ���ҵ�����������Ҫ���ݡ�
labels:Labels������Ҫ���ֶ�,��һ�� key-value ��ʽ�ı�ǩ,k8s�е�������Դ��֧��Я��label,Ĭ�������,pod��label�Ḵ��rc��label
k8sʹ���û��Զ����key-value��ֵ�������ֺͱ�ʶ��Դ����(����rc��pod����Դ),���ּ�ֵ�Գ�Ϊlabel��
�� Deployment �����Ŀ���������,�Ϳ���ͨ����� Labels �ֶδ� Kubernetes �й��˳��������ĵı����ƶ���
����Annotations:�� Metadata ��,����һ���� Labels ��ʽ���㼶��ȫ��ͬ���ֶν� Annotations,��ר������Я�� key-value ��ʽ���ڲ���Ϣ����ν�ڲ���Ϣ,ָ���Ƕ���Щ��Ϣ����Ȥ��,�� Kubernetes �������,�������û������Դ���� Annotations,������ Kubernetes ���й�����,���Զ�������� API �����ϡ�
selector:���˹���Ķ���,���� Deployment ��"spec.selector.matchLabels"�ֶΡ�һ���֮Ϊ:Label Selector��
pod��label�ᱻ��������һ��selector,����ƥ�����Я����Щlabel��pods��
ʹ��labels��λpods
[root@kub-k8s-master prome]# kubectl get pods -l app=nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx-deployment-59c4b86474-2llrt 1/1 Running 0 16m 10.244.2.15 kub-k8s-node2
nginx-deployment-59c4b86474-n2r2m 1/1 Running 0 16m 10.244.1.39 kub-k8s-node1
������Pod��IPs:
[root@kub-k8s-master prome]# kubectl get pods -l app=nginx -o json | grep podIP
"podIP": "10.244.2.15",
"podIPs": [
"podIP": "10.244.1.39",
"podIPs": [
spec : һ�� k8s �� API ����Ķ���,�����Է�Ϊ Metadata �� Spec �������֡�ǰ�ߴ�ŵ�����������Ԫ����,������ API ������˵,��һ���ֵ��ֶκ�ʽ��������һ����;�����ߴ�ŵ�,�����������������еĶ���,������������Ҫ����Ĺ��ܡ�
���ﶨ����Ҫ��������,�˴��������úܶ�����,��Ҫ���ܴ�DeploymentӰ���Pod��ѡ����
replicas:����� Pod �������� (spec.replicas) ��:2
template:������һ�� Pod ģ��(spec.template),���ģ����������Ҫ������ Pod ��ϸ�ڡ�������,��� Pod ��ֻ��һ������,��������ľ���(spec.containers.image)�� nginx:latest,������������˿�(containerPort)�� 80��
volumes:������ Pod �����һ���֡���Ҫ�� template.spec �ֶ�
��2��,�� Deployment �� Pod ģ�岿��������һ�� volumes �ֶ�,��������� Pod ���������� Volume���������ֽ��� nginx-vol,������ emptyDir��
����emptyDir ����:��ͬ�� Docker ����ʽ Volume ����,��:����ʽ����������Ŀ¼�� Volume������,Kubernetes Ҳ�����������ϴ���һ����ʱĿ¼,���Ŀ¼�����ͻᱻ���ص������������� Volume Ŀ¼�ϡ�
k8s �� emptyDir ����,ֻ�ǰ� k8s ��������ʱĿ¼��Ϊ Volume ��������Ŀ¼,������ Docker����ô����ԭ��,�� k8s �������� Docker �Լ��������Ǹ� _data Ŀ¼��
volumeMounts:Pod �е�����,ʹ�õ��� volumeMounts �ֶ��������Լ�Ҫ�����ĸ� Volume,��ͨ�� mountPath �ֶ������������ڵ� Volume Ŀ¼,����:/usr/share/nginx/html��
hostPath:k8s Ҳ�ṩ����ʽ�� Volume ����,������ hostPath�������������� YAML �ļ�:
...
volumes:
- name: nginx-vol
hostPath:
path: /var/data
����,���� Volume ���ص�������Ŀ¼,�ͱ���� /var/data
3������SERVICE
��̨��װiptables:
[root@kub-k8s-master prome]# yum install -y iptables iptables-services
1.����һ��depl
[root@kub-k8s-master prome]# kubectl delete -f deployment.yaml
[root@kub-k8s-master prome]# vim nginx-depl.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: dep01
spec:
selector:
matchLabels: #�����趨��
app: web
replicas: 2
template:
metadata:
name: testnginx9
labels:
app: web
spec:
containers:
- name: testnginx9
image: daocloud.io/library/nginx
ports:
- containerPort: 80
[root@kub-k8s-master prome]# kubectl apply -f nginx-depl.yml
deployment.apps/nginx-deployment created
2. ����service������nodePort�ķ�ʽ��¶�˿ڸ�����:
[root@kub-k8s-master prome]# vim nginx_svc.yaml
apiVersion: v1
kind: Service
metadata:
name: mysvc
spec:
type: NodePort #����
ports:
- port: 8080
nodePort: 30001
targetPort: 80
selector: #ѡ����
app: web
[root@kub-k8s-master prome]# kubectl apply -f nginx_svc.yaml
service/mysvc created
3.����
[root@kub-k8s-master prome]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 5d18h
mysvc NodePort 10.100.166.208 <none> 8080:30001/TCP 21s
4���˿����
��װiptables(������Ҫ�ر�iptables),����service֮��k8s���Զ����ӹ���Iptables����,���һ���Ч(��Ȼiptables���ڹر�״̬)
�����е�3���˿�����
�⼸��port�ĸ����������,���紴������service:
apiVersion: v1
kind: Service
metadata:
name: mysvc
spec:
type: NodePort
ports:
- port: 8080
nodePort: 30001
targetPort: 80
selector:
app: web
port
- �����port��ʾ:service��¶��cluster ip�ϵĶ˿�,cluster ip:port ���ṩ����Ⱥ�ڲ��ͻ�����service����ڡ�
nodePort
- ����,nodePort��kubernetes�ṩ����Ⱥ�ⲿ�ͻ�����service��ڵ�һ�ַ�ʽ(��һ�ַ�ʽ��LoadBalancer),����,:nodePort ���ṩ����Ⱥ�ⲿ�ͻ�����service����ڡ�
targetPort
- targetPort�ܺ�����,targetPort��pod�ϵĶ˿�,��port��nodePort�ϵ������������վ���kube-proxy���뵽���pod��targetPort�Ͻ���������
�ܽ�
�ܵ���˵,port��nodePort����service�Ķ˿�,ǰ�߱�¶����Ⱥ�ڿͻ����ʷ���,���߱�¶����Ⱥ��ͻ����ʷ����������˿ڵ��������ݶ���Ҫ�����������kube-proxy������pod��targetPod,�Ӷ�����pod�ϵ������ڡ�
5��kube-proxy��iptables�Ĺ�ϵ
��service����port��nodePort֮��,�Ϳ��Զ���/���ṩ������ô�������ͨ��ʲôԭ����ʵ�ֵ���?ԭ�����kube-proxy�ڱ���node�ϴ�����iptables����
Kube-Proxy ͨ������ DNAT ����(�����������ķ���,�ӱ������������ķ���������),������������ַ�ķ���ӳ�䵽���ص�kube-proxy�˿�(����˿�)��Ȼ�� Kube-Proxy ������ڱ��صĶ�Ӧ�˿�,��������˿ڵķ��ʸ�������Զ����ʵ�� pod ��ַ��ȥ��
������ͨ����Ⱥ�ڲ��������:port����ͨ����Ⱥ�ⲿ�������:nodePort�������ض�����kube-proxy�˿�(����˿�)��ӳ��,Ȼ�����kube-proxy�˿ڵķ��ʸ�������Զ����ʵ�� pod ��ַ��ȥ��
ʮ����RC��Դ(�˽�)
1��ʲô��RC
Replication Controller(���rc)��������Pod�ĸ���,��֤��Ⱥ�д���ָ��������Pod��������Ⱥ�и�������������ָ������,���ָֹͣ������֮��Ķ�����������,��֮,�����������ָ����������������,��֤�������䡣Replication Controller��ʵ�ֵ�����������̬���ݺ��������ĺ��ġ�
RC ����Ҫ���ܵ�:
- ȷ��pod����:ָ��ij��������Kubernetes������Ӧ������Pod������;
- ȷ��pod����:��pod������,���г����������ṩ����ʱ,��ɱ��������pod�����´���,����pod����һ��;
- ��������:��ҵ��߷��ڵ�ʱ�������������pod����,��ϼ�ؾͿ������Զ�������;
- ��������:Ҳ�������̷���,��һ��podʹ�õľ������,���ù�������ģʽ,RC���Զ�һ����pod�Ľ�������,�ر�һ��pod��ͬʱ��������,����ԭ��������ϴ���һ����pod,��һ��pod��������ٹر�һ���ɾ���pod��
2������RC
1.ʹ��yaml����������replicas����
k8sͨ��Replication Controller����������������ͬ���ظ���������(ʵ�������ظ���pods)��
Replication Controller��ȷ��pod�����������е�ʱ���һֱ������һ�����������,��replicas�����á�
[root@kub-k8s-master ~]# cd prome/
[root@kub-k8s-master prome]# vim nginx-rc.yml
---
apiVersion: v1
kind: ReplicationController
metadata:
name: my-nginx
spec:
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: daocloud.io/library/nginx
ports:
- containerPort: 80
�Ͷ���һ��pod��YAML�ļ����,��ͬ��ֻ��kind��ֵΪReplicationController,replicas��ֵ��Ҫָ��,pod����ض�����template��,pod�����ֲ���Ҫ��ʽ��ָ��,��Ϊ���ǻ���rc�д�������������
����rc:
[root@kub-k8s-master prome]# kubectl apply -f nginx-rc.yml
replicationcontroller/my-nginx created
��ֱ�Ӵ���pod��һ��,rc�����滻��Ϊ�κ�ԭ�����ɾ������ֹͣ���е�Pod,����˵pod�����Ľڵ���ˡ����������Ƽ�ʹ��rc��������������Ӧ��,��ʹ���Ӧ��ֻҪʹ�õ�һ��pod,�������ļ��к���replicas�ֶε����ü���
2���鿴Replication Controller��״̬
[root@kub-k8s-master prome]# kubectl get rc
NAME DESIRED CURRENT READY AGE
my-nginx 2 2 2 11
���״̬��ʾ,�㴴����rc����ȷ����һֱ������nginx�ĸ�����
Ҳ���Ժ�ֱ�Ӵ���Podһ���鿴������Pod״̬��Ϣ:
[root@kub-k8s-master prome]# kubectl get pods
NAME READY STATUS RESTARTS AGE
dep01-58f6d4d4cb-g6vtg 1/1 Running 0 3h8m
dep01-58f6d4d4cb-k6z47 1/1 Running 0 3h8m
my-nginx-7kbwz 1/1 Running 0 2m49s
my-nginx-jkn8l 1/1 Running 0 2m49s
3��ɾ��Replication Controller
������ֹͣ���Ӧ��,ɾ�����rc,����ʹ��:
[root@kub-k8s-master prome]# kubectl delete rc my-nginx
replicationcontroller "my-nginx" deleted
Ĭ�ϵ�,�⽫��ɾ�����б����rc������pod,���pod�������ܴ�,���ỨһЩʱ�����������ɾ������,�������ʹ��Щpodֹͣ����,��ָ���Ccascade=false��
�������ɾ��rc֮ǰ����ɾ��pod,rc�������������µ�pod���滻��ɾ����pod
3������TOMCATʵ��
ע��:�����к������е�NodePortû����ȫ����ⲿ����Service����������,���縺�ؾ���,����������10��Node,���ʱ�����һ�����ؾ�����,�ⲿ������ֻ����ʴ˸��ؾ�������IP��ַ,�ɸ��ؾֺ�������ת������������ij��Node��NodePort�ϡ�������ؾ�����������Ӳ��,Ҳ������������ʽ,����HAProxy����Nginx;
Java WebӦ��
ע:Tomcat�п�������������,ԭ����������ڴ��CPU���ù�С,���������!
���ؾ���
[root@kub-k8s-node1 ~]# docker pull daocloud.io/library/tomcat
����Tomcat RC�����ļ�
[root@kub-k8s-master prome]# vim myweb.rc.yml
---
apiVersion: v1
kind: ReplicationController
metadata:
name: myweb
spec:
replicas: 2
selector:
app: myweb
template:
metadata:
labels:
app: myweb
spec:
containers:
- name: myweb
image: daocloud.io/library/tomcat:7
ports:
- containerPort: 8080 #��8080�˿���������������,PodIP�������˿����Endpoint,������һ��������̶���ͨ�ŵĵ�ַ
������Kubernetes��Ⱥ
����RC
[root@kub-k8s-master prome]# kubectl apply -f myweb.rc.yml
replicationcontroller/myweb created
�鿴RC
[root@kub-k8s-master prome]# kubectl get rc
NAME DESIRED CURRENT READY AGE
myweb 1 1 1 20s
�鿴Pod
[root@kub-k8s-master prome]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myweb-shjfn 1/1 Running 0 52s
����Tomcat Kubernetes Service�����ļ�
[root@kub-k8s-master prome]# vim myweb-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: myweb
spec:
type: NodePort
ports:
- port: 8081
nodePort: 30009
targetPort: 8080
selector:
app: myweb
����
[root@kub-k8s-master prome]# kubectl apply -f myweb-svc.yaml
service/myweb created
�鿴SVC
[root@kub-k8s-master prome]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 5d22h
mysvc NodePort 10.110.160.108 <none> 8080:30001/TCP 3h37m
myweb NodePort 10.96.19.61 <none> 8081:30009/TCP 33s
����
�����������http://�����IP:30009���ɳ�����������:

ע���ڽڵ�(node)�з���,����master
[root@kub-k8s-node1 ~]# curl 192.168.246.166:30009
���ϲ���,Ӧ���Ǿ��������:
����nginx����,����rc:
����rc
[root@k8s-master prome]# cat nginx-rc.yml
---
apiVersion: v1
kind: ReplicationController
metadata:
name: my-nginx
spec:
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: daocloud.io/library/nginx
ports:
- containerPort: 80
[root@k8s-master prome]# kubectl apply -f nginx-rc.yml
ͨ������service��¶�˿�
[root@k8s-master prome]# cat nginx-svc.yml
apiVersion: v1
kind: Service
metadata:
name: mynginx
spec:
type: NodePort
ports:
- port: 8082
nodePort: 30010
targetPort: 80
selector:
app: nginx
[root@k8s-master prome]# kubectl apply -f nginx-svc.yml
���ʲ���:


��һ��Tomcat�������
��������tomcat��rc
[root@k8s-master prome]# cat myweb.rc.yml
---
apiVersion: v1
kind: ReplicationController
metadata:
name: myweb
spec:
replicas: 2
selector:
app: myweb
template:
metadata:
labels:
app: myweb
spec:
containers:
- name: myweb
image: hub.c.163.com/public/tomcat:7.0.28
ports:
- containerPort: 8080
[root@k8s-master prome]# kubectl apply -f myweb.rc.yml
����serviceͨ��NodePort�ķ�ʽ��¶tomcat�����Ķ˿ڵ�����
[root@k8s-master prome]# cat myweb-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: myweb
spec:
type: NodePort
ports:
- port: 8081
nodePort: 30009
targetPort: 8080
selector:
app: myweb
[root@k8s-master prome]# kubectl apply -f myweb-svc.yml
���ʲ���,�ɹ�:


ʮ�ߡ�K8S֮��¶IP������
ת��K8S��˷�������ַ�ʽ
1��ClusterIP
�����ͻ��ṩһ����Ⱥ�ڲ�������IP(��Pod����ͬһ����),�Թ���Ⱥ�ڲ���pod֮��ͨ��ʹ�á�ClusterIPҲ��Kubernetes service��Ĭ�����͡�
2��NodePort(����)
����client��>nodeIP+nodePort��>podIP+PodPort
Ϊÿ���ڵ㱩¶һ���˿�,ͨ��nodeip + nodeport���Է����������,ͬʱ������Ȼ����cluster���͵�ip+port���ڲ�ͨ��clusterip��ʽ����,�ⲿͨ��nodeport��ʽ���ʡ�
3��loadbalance
LoadBalancer��NodePort������,K8S��������ײ���ƽ̨����һ�����ؾ�����,��ÿ��Node��Ϊ���,���з���ַ���
4��Ingress
Ingress��һ��HTTP��ʽ��·��ת������,ΪK8S��������HTTP���ؾ�����,ͨ���Ὣ����¶��K8SȺ����Ŀͻ��ˡ�
ʮ�ˡ�������ģʽ����
1��ʲô�ǿ��Ƽ�Ⱥģʽ
k8s ��Ŀͨ��һ������"������ģʽ"(controller pattern)����Ʒ���,��ͳһ��ʵ�ֶԸ��ֲ�ͬ�Ķ��������Դ���еı��Ų�����
k8s���ľ�����һ������ȥ������һ������,���е����ݶ��DZ����Ƶ�,����������Ȼ����,������������һ��"ɳ��"�ĸ���,��������Ӧ����˵̫�����ñ�,��װ���Ȼ����,��������涼��ͺͺ��,��������ô�������װ����������ڷź���?
����,Pod ����,��ʵ���������������档�����������������,�����˸�������Ժ��ֶΡ���ͺñȸ���װ�����氲װ�˵���,ʹ�� Kubernetes ���"����",���Ը����ɵز�������
�� k8s ������Щ"��װ��"����,���ɿ�����(Controller)���
�ع� Deployment ���������Ŀ���������֮ǰ����һ�� nginx-deployment ������:
��1:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
��� Deployment ����ı��Ŷ���Ϊ:
- ȷ��Я���� app=nginx ��ǩ�� Pod �ĸ���,��Զ���� spec.replicas ָ���ĸ���,�� 2 ����
- ����������Ⱥ��,Я�� app=nginx ��ǩ�� Pod �ĸ������� 2 ��ʱ��,�ͻ��оɵ� Pod ��ɾ��;��֮,�ͻ����µ� Pod ��������
������ Kubernetes ��Ŀ�е��ĸ����,��ִ����Щ������?
kube-controller-manager ���:������,����һϵ�п������ļ���
2������������
�������:
deployment job podautoscaler
cloud disruption namespace
replicaset serviceaccount volume
cronjob garbagecollector nodelifecycle replication statefulset daemon
�����ÿһ��������,���Զ��еķ�ʽ����ij�ֱ��Ź��ܡ���Deployment,������Щ�������е�һ�֡�
�������ƶ���Ķ���,��������һ��"ģ��"������,Deployment ��� template �ֶΡ�
Deployment ��� template �ֶ��������,��һ������ Pod ����� API ����,˿����������б���� Deployment ������ Pod ʵ��,���Ǹ������ template �ֶε����ݴ��������ġ�
�� Deployment �Լ��������ƵĿ�����,��һ���ܽ�:
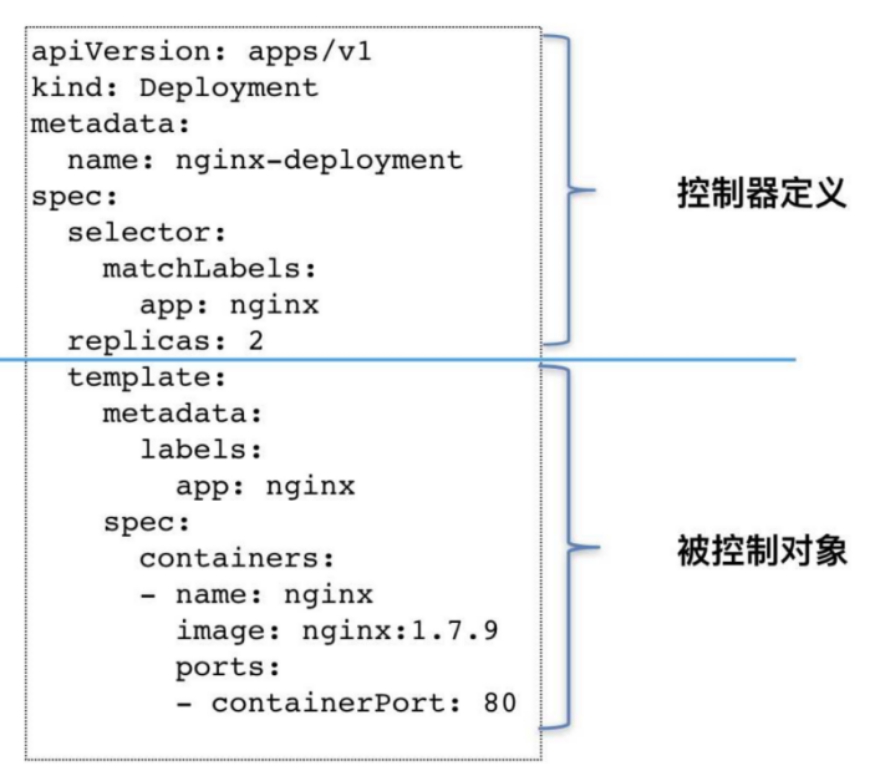
��ͼ,���� Deployment ��һ��������,���������������:
- �ϰ벿�ֵĿ���������(��������״̬)
- �°벿�ֵı����ƶ����ģ����ɵġ�
Ҳ���������ͳһ�ı��ſ����,��ͬ�Ŀ����������ھ���ִ�й�����,��Ʋ�ͬ��ҵ����,�Ӷ��ﵽ��ͬ�ı���Ч����
���ʵ��˼·,���� k8s �����������ŵĺ���ԭ����
ʮ�š���������
����:
��һ����Ⱥ���������еĶ�� Pod �汾,�������һ�����Ĺ���,����"��������"��
ʵ��:
[root@kub-k8s-master prome]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
dep01 2/2 2 2 4h41m
nginx-deployment 2/2 2 2 5h13m
���ǽ�nginx-deploument�ĸ����������4��,����2��
[root@kub-k8s-master prome]# vim deployment.yaml #����������
��replicas: 2
��Ϊ:
replicas: 4
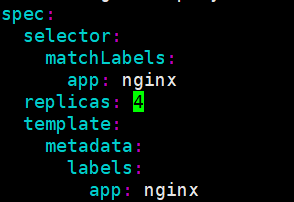
�����Ͻڶ���:nginx-deployment
[root@kub-k8s-master prome]# kubectl apply -f deployment.yaml --record
deployment.apps/nginx-deployment configured
--record ��¼��ÿ�β�����ִ�е�����,�Է������鿴
���nginx-deployment �������״̬��Ϣ:
[root@kub-k8s-master prome]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
dep01 2/2 2 2 4h53m
nginx-deployment 4/4 4 4 5h25m
���ؽ�����ĸ�״̬�ֶκ���:
DESIRED:
����оͱ�ʾ�û������� Pod ��������(spec.replicas ��ֵ);
CURRENT:
��ǰ���� Running ״̬�� Pod �ĸ���;
UP-TO-DATE:
��ǰ�������°汾�� Pod �ĸ���,��ν���°汾ָ���� Pod �� Spec ������ Deployment �� Pod ģ���ﶨ�����ȫһ��;
AVAILABLE:
��ǰ�Ѿ����õ� Pod �ĸ���,��:���� Running ״̬,�������°汾,�����Ѿ����� Ready(���������ȷ)״̬�� Pod �ĸ�����ֻ������ֶ�,�����IJ����û�������������״̬��
�� Deployment:
[root@kub-k8s-master prome]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
dep01 2/2 2 2 4h59m
nginx-deployment 4/4 4 4 5h32m
��dep01�ĸ�����2��Ϊ3��
[root@kub-k8s-master prome]# kubectl edit deployment/dep01
# reopened with the relevant failures.
#
apiVersion: apps/v1
...
spec:
progressDeadlineSeconds: 600
replicas: 3 #������ԭ����2��Ϊ3
revisionHistoryLimit: 10
selector:
matchLabels:
...
�����˳�,vim�ķ�ʽ
[root@kub-k8s-master prome]# kubectl edit deployment/dep01
deployment.apps/dep01 edited
[root@kub-k8s-master prome]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
dep01 3/3 3 3 5h16m
nginx-deployment 4/4 4 4 5h48m
���а汾������
����һ���µ�deploy
[root@kub-k8s-master prome]# cp nginx-depl.yml nginx-depl02.yml
[root@kub-k8s-master prome]# vim nginx-depl02.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: dep02 #ע����
spec:
selector:
matchLabels:
app: web1
replicas: 2
template:
metadata:
name: testnginx9
labels:
app: web1
spec:
containers:
- name: testnginx9
image: daocloud.io/library/nginx:1.14 #ע����
ports:
- containerPort: 80
[root@kub-k8s-master prome]# kubectl apply -f nginx-depl02.yml
deployment.apps/dep02 created
[root@kub-k8s-master prome]# kubectl get pods
NAME READY STATUS RESTARTS AGE
dep01-58f6d4d4cb-997jw 1/1 Running 0 16m
dep01-58f6d4d4cb-g6vtg 1/1 Running 0 5h32m
dep02-78dbd944fc-47czr 1/1 Running 0 44s
dep02-78dbd944fc-4snsj 1/1 Running 0 25s
[root@k8s-node1 ~]# docker exec -it 7e491bb33dcd /bin/bash
root@dep02-8594cd6447-z5mzs:/# nginx -v
nginx version: nginx/1.14.2
��nginx�İ汾��1.14������1.16
[root@kub-k8s-master prome]# kubectl edit deployment/dep02
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
...
spec:
containers:
- image: daocloud.io/library/nginx:1.16 #������ԭ����nginx:1.14��Ϊnginx:1.16
imagePullPolicy: Always
name: testnginx9
ports:
- containerPort: 80
...
�����˳�,vim�ķ�ʽ
[root@kub-k8s-master prome]# kubectl edit deployment/dep01
deployment.apps/dep01 edited
��ʱ����ͨ���鿴 Deployment �� Events,�������"��������"������:
[root@kub-k8s-master prome]# kubectl describe deployment dep02
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 50s deployment-controller Scaled up replica set dep02-846bf8775b to 2
Normal ScalingReplicaSet 9s deployment-controller Scaled up replica set dep02-58f8d5678 to 1
Normal ScalingReplicaSet 8s deployment-controller Scaled down replica set dep02-846bf8775b to 1
Normal ScalingReplicaSet 8s deployment-controller Scaled up replica set dep02-58f8d5678 to 2
Normal ScalingReplicaSet 5s deployment-controller Scaled down replica set dep02-846bf8775b to 0
��˽������,�� ReplicaSet ������ Pod ������,�� 0 ����� 1 ��,�ٱ�� 2 ��,����� 3 �������ɵ� ReplicaSet ������ Pod ��������� 3 ����� 2 ��,�ٱ�� 1 ��,����� 0 ��������,���������һ�� Pod �İ汾�������̡�
��֤
[root@kub-k8s-master prome]# kubectl get pods
NAME READY STATUS RESTARTS AGE
dep02-78dbd944fc-69t8x 1/1 Running 0 11h
dep02-78dbd944fc-7cn86 1/1 Running 0 11h
[root@kub-k8s-master prome]# kubectl exec -it dep02-78dbd944fc-69t8x /bin/bash
root@dep02-78dbd944fc-69t8x:/# nginx -v
nginx version: nginx/1.16.1
root@dep02-78dbd944fc-69t8x:/# exit
�������ĺô�:
- �������տ�ʼ��ʱ��,��Ⱥ��ֻ�� 1 ���°汾�� Pod�������ʱ,�°汾 Pod ����������������,��ô"��������"�ͻ�ֹͣ,�Ӷ�������������ά��Ա���롣
- �������������,����Ӧ�ñ������������ɰ汾�� Pod ����,���Է������ܵ�̫���Ӱ�졣
��ʮ���汾�ع�
1���鿴�汾��ʷ
[root@kub-k8s-master prome]# kubectl rollout history deployment/dep02
deployment.apps/dep02
REVISION CHANGE-CAUSE
1 <none>
2 <none>
2���ع�����ǰ�ľɰ汾
? ������ Deployment �ع�����һ���汾:
[root@kub-k8s-master prome]# kubectl rollout undo deployment/dep02
deployment.apps/dep02 rolled back
�鿴�ع�״̬
[root@kub-k8s-master prome]# kubectl rollout status deployment/dep02
deployment "dep02" successfully rolled out
��֤:
[root@kub-k8s-master prome]# kubectl get pods
NAME READY STATUS RESTARTS AGE
dep02-8594cd6447-pqtxk 1/1 Running 0 55s
dep02-8594cd6447-tt4h4 1/1 Running 0 51s
[root@kub-k8s-master prome]# kubectl exec -it dep02-8594cd6447-tt4h4 /bin/bash
root@dep02-8594cd6447-tt4h4:/# nginx -v
nginx version: nginx/1.14.2
3���ع�������֮ǰ�İ汾
(1)ʹ�� kubectl rollout history ����鿴ÿ�� Deployment �����Ӧ�İ汾��
[root@kub-k8s-master prome]# kubectl rollout history deployment/dep02
deployment.apps/dep02
REVISION CHANGE-CAUSE
2 <none>
3 <none>
�����ڴ������ Deployment ��ʱ��,ָ���˨Crecord ����,���Դ�����Щ�汾ʱִ�е� kubectl ����,���ᱻ��¼������
? �鿴ÿ���汾��Ӧ�� Deployment �� API �����ϸ��:
[root@kub-k8s-master prome]# kubectl rollout history deployment/dep02 --revision=3
deployment.apps/dep02 with revision #3
Pod Template:
Labels: app=web1
pod-template-hash=8594cd6447
Containers:
testnginx9:
Image: daocloud.io/library/nginx:1.14
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
(2)�� kubectl rollout undo ���������,����Ҫ�ع�����ָ���汾�İ汾��,�Ϳ��Իع���ָ���汾�ˡ�
[root@kub-k8s-master prome]# kubectl rollout undo deployment/dep02 --to-revision=2
deployment.apps/dep02 rolled back
��֤:
[root@kub-k8s-master prome]# kubectl get pods
NAME READY STATUS RESTARTS AGE
dep02-78dbd944fc-8nvxl 1/1 Running 0 86s
dep02-78dbd944fc-sb9sj 1/1 Running 0 88s
[root@kub-k8s-master prome]# kubectl exec -it dep02-78dbd944fc-8nvxl /bin/bash
root@dep02-78dbd944fc-8nvxl:/# nginx -v
nginx version: nginx/1.16.1
��ʮһ������DASHBOARDӦ��
ע��:�����ɹ�֮��,��Ϊ��5�ַ�ʽ����dashboard:��������ֻʹ��Nodport��ʽ����
1. Nodport��ʽ����dashboard,service����ΪNodePort
2. loadbalacer��ʽ,service����Ϊloadbalacer
3. Ingress��ʽ����dashboard
4. API server��ʽ���� dashboard
5. kubectl proxy��ʽ����dashboard
1������yaml�ļ�
�����Լ�����,Ҳ����ʹ����Ŀ¼�е������Լ�����
[root@kub-k8s-master ~]# wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0-beta8/aio/deploy/recommended.yaml
�����ƿռ���ΪĬ��system
[root@kub-k8s-master ~]# sed -i '/namespace/ s/kubernetes-dashboard/kube-system/g' recommended.yaml
2�����ؾ���
����yaml�����ļ���ָ���ľ���
��̨����������
[root@kub-k8s-master ~]# docker pull kubernetesui/dashboard:v2.0.0-beta8
[root@kub-k8s-master ~]# docker pull kubernetesui/metrics-scraper:v1.0.1
3����yaml�ļ�
NodePort��ʽ:Ϊ�˱��ڱ��ط���,��yaml�ļ�,��service��ΪNodePort ����:
[root@kub-k8s-master ~]# vim recommended.yaml
...
30 ---
31
32 kind: Service
33 apiVersion: v1
34 metadata:
35 labels:
36 k8s-app: kubernetes-dashboard
37 name: kubernetes-dashboard
38 namespace: kube-system
39 spec:
40 type: NodePort #����type: NodePort
41 ports:
42 - port: 443
43 targetPort: 8443
44 nodePort: 31260 #����nodePort: 31260
45 selector:
46 k8s-app: kubernetes-dashboard
47
48 ---

4������Ӧ��
[root@kub-k8s-master ~]# kubectl apply -f recommended.yaml
namespace/kubernetes-dashboard created
serviceaccount/kubernetes-dashboard created
service/kubernetes-dashboard created
secret/kubernetes-dashboard-certs created
secret/kubernetes-dashboard-csrf created
secret/kubernetes-dashboard-key-holder created
configmap/kubernetes-dashboard-settings created
role.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrole.rbac.authorization.k8s.io/kubernetes-dashboard created
rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
deployment.apps/kubernetes-dashboard created
service/dashboard-metrics-scraper created
deployment.apps/dashboard-metrics-scraper created
�鿴Pod ��״̬Ϊrunning˵��dashboard�Ѿ�����ɹ�:
[root@kub-k8s-master ~]# kubectl get pod -n kube-system -o wide | grep dashboard
dashboard-metrics-scraper-76585494d8-z7n2h 1/1 Running 0 34s 10.244.1.6 k8s-node2 <none> <none>
kubernetes-dashboard-594b99b6f4-s9q2h 1/1 Running 0 34s 10.244.2.8 k8s-node1 <none> <none>
Dashboard ���� kube-system namespace �д����Լ��� Deployment �� Service:
[root@kub-k8s-master ~]# kubectl get deployment kubernetes-dashboard -n kube-system
NAME READY UP-TO-DATE AVAILABLE AGE
kubernetes-dashboard 1/1 1 1 72s
[root@kub-k8s-master ~]# kubectl get service kubernetes-dashboard -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes-dashboard NodePort 10.108.97.179 <none> 443:31260/TCP 49s
5������dashboard
�ٷ��ο��ĵ�:
�鿴service,TYPE�����Ѿ���ΪNodePort,�˿�Ϊ31260
[root@kub-k8s-master ~]# kubectl get service -n kube-system | grep dashboard
kubernetes-dashboard NodePort 10.108.97.179 <none> 443:31260/TCP 101s
�鿴dashboard��������̨��������
[root@kub-k8s-master ~]# kubectl get pods -n kube-system -o wide
ͨ�����������:https://master:31260
��Ϊ�ҵ�Ӧ��������master��,����NodePort��ʽ,����ֱ�ӷ���master�ĵ�ַ
��¼��������(�û��,���ùȸ�):


Dashboard ֧�� Kubeconfig �� Token ������֤��ʽ,����ѡ��Token��֤��ʽ��¼:
�����Token�ȿ���,��Ҫ���µ�,����������token,�����˺�
6������token
�ٷ��ο��ĵ�:
https://github.com/kubernetes/dashboard/wiki/Creating-sample-user
����dashboard-adminuser.yaml:
[root@kub-k8s-master ~]# vim dashboard-adminuser.yaml
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kube-system
ִ��yaml�ļ�:
[root@kub-k8s-master ~]# kubectl create -f dashboard-adminuser.yaml
serviceaccount/admin-user created
clusterrolebinding.rbac.authorization.k8s.io/admin-user created
˵��:���洴����һ����admin-user�ķ����˺�,������kube-system�����ռ���,����cluster-admin��ɫ��admin-user�˻�,����admin-user�˻������˹���Ա��Ȩ�ޡ�Ĭ�������,kubeadm������Ⱥʱ�Ѿ�������cluster-admin��ɫ,ֱ�Ӱ��ɡ�
�鿴admin-user�˻���token
[root@kub-k8s-master ~]# kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}')
Name: admin-user-token-d2hnw
Namespace: kube-system
Labels: <none>
Annotations: kubernetes.io/service-account.name: admin-user
kubernetes.io/service-account.uid: f2a2fb2d-fa04-4535-ac62-2d8779716175
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1025 bytes
namespace: 11 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IjBUc19ucm9qbW1zOHJzajhJd2M2bndpWENQSDRrcHRYY3RpWGlMcEhncEUifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLWQyaG53Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiJmMmEyZmIyZC1mYTA0LTQ1MzUtYWM2Mi0yZDg3Nzk3MTYxNzUiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZS1zeXN0ZW06YWRtaW4tdXNlciJ9.f-nhR31D2yMXRvjfM7ZzaKcwOEg_3HYNyxQFioqTO3rKcD6cfLZeOZfZlqrxcrHbcclCsNvIR5ReccKE8GqBJcAcAHZZVSpY9pivtfaU08_VlyQxU4ir3wcCZeeJyAeqEjGhxWJVuouQ-zoofImbaa7wKvSIoEr1jnlOP1rQb51vbekZvDCZue03QBcBRB_ZMfObfLDGI8cuVkYZef9cWFQlI4mEL4kNqHAbmSdJBAVS_6MmF0C1ryIXbe_qM_usm6bsawDsBK8mpuDrXJUU5FBI-rW8qUuZ8QrE_vjRuJkjp5iNCrNd_TyBxWX2jBziMmrWKqofZnGN6ZiqvTAJ8w
�ѻ�ȡ����Token���Ƶ���¼�����Token�������:

�ɹ���½dashboard:

7��ʹ��Dashboard
Dashboard ����ṹ��Ϊ�����������:
-
����������,�������û�����������Ⱥ�е���Դ��������Դ���˳���
-
��ߵ����˵�,ͨ�������˵����Բ鿴������Ⱥ�еĸ�����Դ���˵������Դ�IJ㼶��Ϊ����:Cluster �������Դ ,Namespace �������Դ ,Ĭ����ʾ���� default Namespace,���Խ����л�
-
�м�������,�ڵ����˵��е����ij����Դ,�м��������ͻ���ʾ����Դ����ʵ��,������ Pods��