0. 前言
本博客使用的版本是 0.11.0.3
各版本的区别可以自行了解,大致可选 0.11.x 1.x 2.x 三种版本
① 使用的集群是 Docker 搭建的,可参见:
【Docker x Hadoop】使用 Docker 搭建 Hadoop 集群(从零开始保姆级)
② 由于 Docker 搭建的集群有局限性,需要频繁为 Docker 容器动态添加端口映射(下边也会用到),可参见:
【Docker之轨迹】为正在运行中的容器动态添加端口映射(使用 iptables,附删除 iptables 规则)
③ 集群之间的分发脚本 xsync 参照尚硅谷,可参见:
【Linux之轨迹】Linux 各种实用小功能合集(持续补充)
④ 该版本的 kafka 需要用到 zookeeper,简单的搭建流程可参见:
【Zookeeper之轨迹】Zookeeper 入门使用(集群使用 Docker 模拟)
⑤ 由于 Kafka 需要占用较多内存,必要的话需要使用 swap 交换分区(相当于虚拟内存),可参见:
【Linux之轨迹】1核2G 内存不够怎么办?Swap 交换分区解决内存不足问题
1. 安装、启动与关闭
① 下载与配置
下载地址:http://kafka.apache.org/downloads
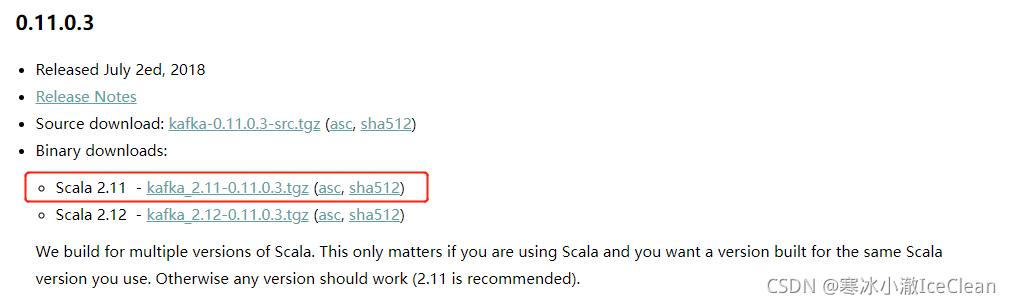
上传压缩包到服务器集群任意一台,解压,然后使用 xsync 分发到集群中的各个容器,再
tar -zxvf kafka_2.11-0.11.0.3.tgz
xsync kafka_2.11-0.11.0.3
rm -rf kafka_2.11-0.11.0.3.tgz
# 这一步改名可选
mv kafka_2.11-0.11.0.3 kafka_0.11.0.3
然后进行配置
1) 在 kafka_0.11.0.3 目录下新建文件夹 data 作为临时存放数据的文件夹
mkdir data
2) 然后进入 config 目录修改 server.properties 文件
vim server.properties
下面是对配置文件的修改
1) 首先修改 broker.id,每台服务器需要唯一,下边是我的配置
`hadoop001:broker.id=1
hadoop002:broker.id=2
hadoop003:broker.id=3`
2) 接着设置主题允许被删除(将注释打开)
`delete.topic.enable=true`
3) 修改数据暂存的目录,默认存放在 tmp 中会被定时删除,需修改为我们刚刚新建的 data 文件夹路径
名字看着像日志文件输出的地方,但实际存放的是真实数据的
`log.dirs=/xxx/kafka_0.11.0.3/data`
4) 修改 zookeeper 连接信息,以下是我的配置供参考(用逗号隔开)
`zookeeper.connect=hadoop001:2181,hadoop002:2181,hadoop003:2181`
5) 然后将配置文件分发到各台服务器上(data 文件夹也顺带分发了)
`xsync data/ config/server.properties`
6) 最后修改每一台服务器的 broker.id,就完事了
② 启动与关闭
首先确保三台服务器的 zookeeper 都已经启动,然后执行:
bin/kafka-server-start.sh config/server.properties
| 》》》 出现问题 Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000c0000000, 1073741824, 0) failed; eory' (errno=12) 原因是内存不足,查了我的服务器,发现 2G 内存剩下不到 1G 然后在 kafka-server-start.sh 中发现了这个东西  参数意思为: -Xmx Java Heap 最大值,默认值为物理内存的 1/4 -Xms java Heap 初始值,Server 端 JVM 最好将 -Xms 和 -Xmx 设为相同值 里边要求 Kafka 启动是必须有 1G 空闲的内存 很明显我没有,况且 2G 内存要启动 3 台显然也不合理 所以这里我们把它改小一点,就 256M 应该可以,修改: 再次启动,就可以了(后边填坑:分发完毕后,记得将 broker.id 修改呀) 此外,如果内存实在不足,可以考虑使用 swap 交换分区作为虚拟内存使用 《《《 问题解决 |
最后上边的程序启动后,都会阻塞窗口,可以加 -daemon 使其以守护进程运行
bin/kafka-server-start.sh -daemon config/server.properties
关闭同样得加上配置文件,如下:
bin/kafka-server-stop.sh config/server.properties
2. 基础使用
① 主题(Topic)的增删查
1) 创建主题
这里指定了 partition 分区数,replication-factor 副本数,下边会详细说明
bin/kafka-topics.sh --zookeeper hadoop001:2181 --create --topic first --partitions 2 --replication-factor 2
2) 查看主题
bin/kafka-topics.sh --zookeeper hadoop001:2181 --list
3) 查看具体主题详情
bin/kafka-topics.sh --zookeeper hadoop001:2181 --describe --topic first
4) 删除主题(需要前边配置有改为 true 才能删除成功)
bin/kafka-topics.sh --zookeeper hadoop001:2181 --delete --topic first
5) 修改主题
bin/kafka-topics.sh --zookeeper hadoop001:2181 --alter --topic first-1 --partition 3
② 模拟发布订阅
1) 在 hadoop001 中,用控制台模拟生产消息
bin/kafka-console-producer.sh --topic first --broker-list hadoop001:9092
2) 在 hadoop002 和 hadoop003 中,用控制台模拟订阅消息,--from-beginning 指从头开始消费信息
bin/kafka-console-consumer.sh --bootstrap-server hadoop001:9092 --topic first [--from-beginning]
旧版:bin/kafka-console-consumer.sh --zookeeper hadoop001:2181 --topic first
| 中途出现了一些问题:使用 --bootstrap-server 无法消费消息? 但 zookeeper 可以,且当 --bootstrap-server 分区为 1 时也可以,其他情况都不行 后来发现是我修改完 server.properties 进行同步分发,将 broker.id 都变成 1 了忘记改回来 所以:broker.id 相同,会出现无法消费消息的情况 |
3. Java API 使用(SpringBoot)
| 前置问题: 这里是使用 Docker 搭建集群的通病,如果是使用虚拟机搭建的话,则可以跳过 但是注意,这里面将三台服务器的 9092 端口分别改成了 19092 19093 19094 当使用 API 访问 Docker 搭建的集群时,最大的问题就是端口问题了 要想让外网访问到 Docker 容器,就必须设置端口映射,然后外网通过访问主机中已经映射的端口,再由主机找到对应的 Docker 容器 但现在我们有 3 个容器(服务器),则有 3 个 9092 端口。很明显一个主机的 9092 端口不能同时映射三个端口 所以就有了如下的修改:将主机的 19092 19093 19094 分别映射到 hadoop001:19092 hadoop002:19093 hadoop003:19094 这样外网通过访问这三个已经映射的端口,就能成功访问到容器啦 这里由于我们的容器已经启动,无法再通过 Docker 进行端口映射,所以我们采用的是动态端口映射,如下: |
准备工作完成,接下来进入正轨
① 首先是导包
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.7.6</version>
</dependency>
② 然后进行配置
spring:
kafka:
bootstrap-servers: <主机地址>:19092,<主机地址>:19093,<主机地址>:19094
producer:
bootstrap-servers: <主机地址>:19092
③ 然后是简单测试
/**
* @author : Ice'Clean
* @date : 2021-10-24
*/
@RestController
public class KafkaController {
@Autowired
private KafkaTemplate<Object, Object> kafkaTemplate;
@GetMapping("/send/{msg}")
public void send(@PathVariable String msg) {
kafkaTemplate.send("first", msg);
}
@KafkaListener(id = "webListener", topics = "first")
public void listen(String msg) {
System.out.println("收到消息:" + msg);
}
}
这样调用 send 接口发送消息,在控制台就能看到对应输出啦
④ API 工具类
以下为简单的工具类:
/**
* @author : Ice'Clean
* @date : 2021-10-25
*/
@Component
public class KafkaUtils {
/** Kafka 操作客户端 */
private static AdminClient adminClient;
/** Kafka 生产模者板 */
private static KafkaTemplate<Object, Object> kafkaTemplate;
@Autowired
public void setKafkaProperties(KafkaProperties kafkaProperties) {
// 通过注入的配置,创建客户端
adminClient = AdminClient.create(kafkaProperties.buildAdminProperties());
}
@Autowired
public void setKafkaTemplate(KafkaTemplate<Object, Object> kafkaTemplate) {
// 注入生产者模板
KafkaUtils.kafkaTemplate = kafkaTemplate;
}
/**
* 生产者发送消息
* @param topic 消息所属主题
* @param message 消息内容
*/
public static void send(String topic, String message) {
kafkaTemplate.send(topic, message).addCallback(success -> {
System.out.println("消息:" + topic + " [" + message + "] 发送成功");
}, failure -> {
System.out.println("消息:" + topic + " [" + message + "] 发送失败");
System.out.println("原因:" + failure.getMessage());
});
}
/**
* 创建主题
* @param topicName 主题名称
* @param numPartitions 主题分区数
* @param replicationFactor 主题副本数
*/
public static void createTopic(String topicName, int numPartitions, short replicationFactor) {
adminClient.createTopics(Collections.singletonList(new NewTopic(topicName, numPartitions, replicationFactor)));
}
/**
* 删除主题
* @param topicName 主题名称
*/
public static void deleteTopic(String topicName) {
adminClient.deleteTopics(Collections.singleton(topicName));
}
/**
* 获取主题详情
* @param topicName 主题名称
*/
public static Map<String, TopicDescription> getTopicDetail(String topicName) throws ExecutionException, InterruptedException {
DescribeTopicsResult result = adminClient.describeTopics(Collections.singleton(topicName));
return result.all().get();
}
}
一石二石,一箭双箭(IceClean)