当前最新版本安装包 apache-druid-0.22.0-bin.tar.gz 百度网盘分享(以下的安装配置使用的也是用的这个文件),也许是我的网络不好,下载很慢 🐌 这里分享一下,有需要的可以使用:
链接:https://pan.baidu.com/s/1893NRqklXY7KGBKU7EMB2g
提取码:2vhj
Druid官网的 Quickstart 从安装到使用还是介绍的比较清晰的。我们跟随官网进行安装使用。
1. Install Druid
Druid官方只支持 Java 8(是不是瞬间明白为啥 JDK1.8 还依然非常活跃 😉)目前,对Java后续主要版本的支持还处于试验阶段。
【环境】 腾讯云服务器 CentOS 7.9 + JKD1.8:
[root@tcloud ~]# cat /etc/redhat-release
CentOS Linux release 7.9.2009 (Core)
[root@tcloud ~]# java -version
java version "1.8.0_251"
Java(TM) SE Runtime Environment (build 1.8.0_251-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.251-b08, mixed mode)
安装过程很简单:
tar -zxvf apache-druid-0.22.0-bin.tar.gz
mv apache-druid-0.22.0 /usr/local/druid
2. Start up Druid services
Druid包含的配置文件范围从最小的 Nano-Quickstart 配置(1 CPU, 4GiB RAM)到 X-Large 配置(64 CPU, 512GiB RAM)。
最小的 Nano-Quickstart 需要 1核 4G内存,我的云服务器是 1核 2G的,启动一下试试:
[root@tcloud druid]# ./bin/start-nano-quickstart
[Tue Nov 9 17:02:39 2021] Running command[zk], logging to[/usr/local/druid/var/sv/zk.log]: bin/run-zk conf
[Tue Nov 9 17:02:39 2021] Running command[coordinator-overlord], logging to[/usr/local/druid/var/sv/coordinator-overlord.log]: bin/run-druid coordinator-overlord conf/druid/single-server/nano-quickstart
[Tue Nov 9 17:02:39 2021] Running command[broker], logging to[/usr/local/druid/var/sv/broker.log]: bin/run-druid broker conf/druid/single-server/nano-quickstart
[Tue Nov 9 17:02:39 2021] Running command[router], logging to[/usr/local/druid/var/sv/router.log]: bin/run-druid router conf/druid/single-server/nano-quickstart
[Tue Nov 9 17:02:39 2021] Running command[historical], logging to[/usr/local/druid/var/sv/historical.log]: bin/run-druid historical conf/druid/single-server/nano-quickstart
[Tue Nov 9 17:02:39 2021] Running command[middleManager], logging to[/usr/local/druid/var/sv/middleManager.log]: bin/run-druid middleManager conf/druid/single-server/nano-quickstart
3. Open the Druid console
After the Druid services finish startup 启动过程是有点儿慢的 🐌 open the Druid console at http://tcloud:8888
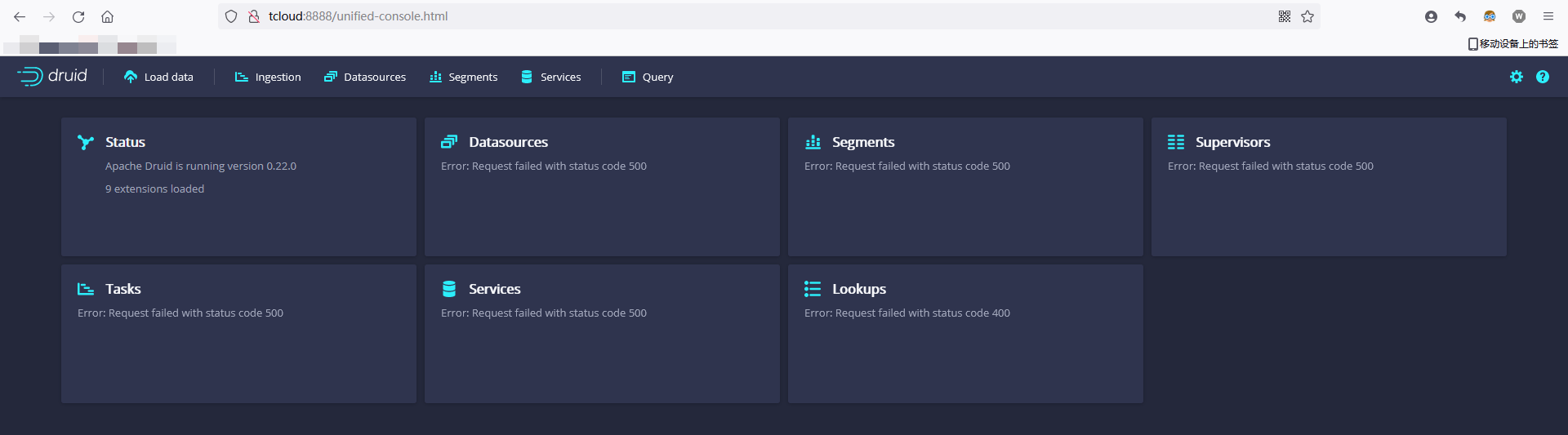
页面显示出来了,实际上启动是失败的,查看报错日志:
Java HotSpot(TM) 64-Bit Server VM warning:
INFO: os::commit_memory(0x00000000e0000000, 536870912, 0) failed;
error='Cannot allocate memory' (errno=12)
3.1 小内存服务器启动JVM参数调整
内存不足!怎么办?试着把每个进程使用的内存调整小一些,我们试试:
# 根据启动脚本用到的配置文件名称 查询一下配置文件的位置
[root@tcloud ~]# find /usr/local/druid/ -name '*nano-*'
/usr/local/druid/conf/supervise/single-server/nano-quickstart.conf
# 查看一下配置文件的内容
cat /usr/local/druid/conf/supervise/single-server/nano-quickstart.conf
# 内容如下
:verify bin/verify-java
:verify bin/verify-default-ports
:kill-timeout 10
!p10 zk bin/run-zk conf
coordinator-overlord bin/run-druid coordinator-overlord conf/druid/single-server/nano-quickstart
broker bin/run-druid broker conf/druid/single-server/nano-quickstart
router bin/run-druid router conf/druid/single-server/nano-quickstart
historical bin/run-druid historical conf/druid/single-server/nano-quickstart
!p90 middleManager bin/run-druid middleManager conf/druid/single-server/nano-quickstart
实际上在 /usr/local/druid/conf/druid/single-server/nano-quickstart 文件夹下一共有 6?? 个文件夹:

每个文件夹下都有运行和配置参数,以 coordinator-overlord 服务为例,查询 jvm.config 配置,顺便看一下 runtime.properties 当前组件占用的端口号 :
[root@tcloud coordinator-overlord]# cat ./jvm.config
-server
-Xms256m
-Xmx256m
-XX:+ExitOnOutOfMemoryError
-XX:+UseG1GC
-Duser.timezone=UTC
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
-Dderby.stream.error.file=var/druid/derby.log
[root@tcloud coordinator-overlord]# cat ./runtime.properties
druid.service=druid/coordinator
druid.plaintextPort=8081
查询启动脚本里的 5?? 个组件,实际上还有 zookeeper 和 derby 数据库,一共 7?? 个:
| 组件 | 使用内存 | 占用端口号 |
|---|---|---|
| router | 128m | 8888 |
| coordinator-overlord | 256m | 8081 |
| broker | 512m | 8082 |
| historical | 512m | 8083 |
| middleManager | 64m | 8091 |
| zookeeper | 128m | 2181 |
| derby | 未标出 | 1527 |
进行一波调整【也不能调整的过小 太小组件本身就无法启动】:
| 组件 | 调整后内存 | 占用端口号 |
|---|---|---|
| router | (减半)64m | 8888 |
| coordinator-overlord | (减半)128m | 8081 |
| broker | (减半)256m | 8082 |
| historical | (减半)256m | 8083 |
| middleManager | (不调整)64m | 8091 |
| zookeeper | (减半)64m | 2181 |
| derby | (不调整)未标出 | 1527 |
3.2 系统初始化及需要开放端口
官网有这么两段话:
??All persistent state, such as the cluster metadata store and segments for the services, are kept in the var directory under the Druid root directory, apache-druid-0.22.0. Each service writes to a log file under var/sv, as noted in the startup script output above.
??At any time, you can revert Druid to its original, post-installation state by deleting the entire var directory. You may want to do this, for example, between Druid tutorials or after experimentation, to start with a fresh instance.
??大概是说元数据都保存在 var 文件夹下,各个服务的日志文件都在 var/sv 文件夹下,如果想初始化程序,那么删除 var 文件夹下的数据即可。
??如果是云服务器,需要在安全组里释放相关端口【8888、1527、2181、8081、8082、8083、8091】,内存后调整好后,我们删掉 var 文件夹下的文件,然后重新启动:

似乎改观并不大,唯一的区别是Lookups的状态从400变为uninitiated,查看日志并没有发现内存不足的情况,我们继续 Quickstart 的下一步,遇到问题再进行解决。
4. Load data
不得不说 Druid 的 Quickstart 还是很贴心的,提供了测试文件:
The Druid distribution bundles sample data we can use. The sample data located in quickstart/tutorial/wikiticker-2015-09-12-sampled.json.gz in the Druid root directory represents Wikipedia page edits for a given day.
从这个页面开始,官网的教程界面跟最新版本的开始有不同了,Web页面大家随便点击,又不会坏 😊 步骤名称用官网的,配图用最新版本的:
- Click Load data from the Druid console header (Load data).
- Select the Local disk tile and then click Connect data.
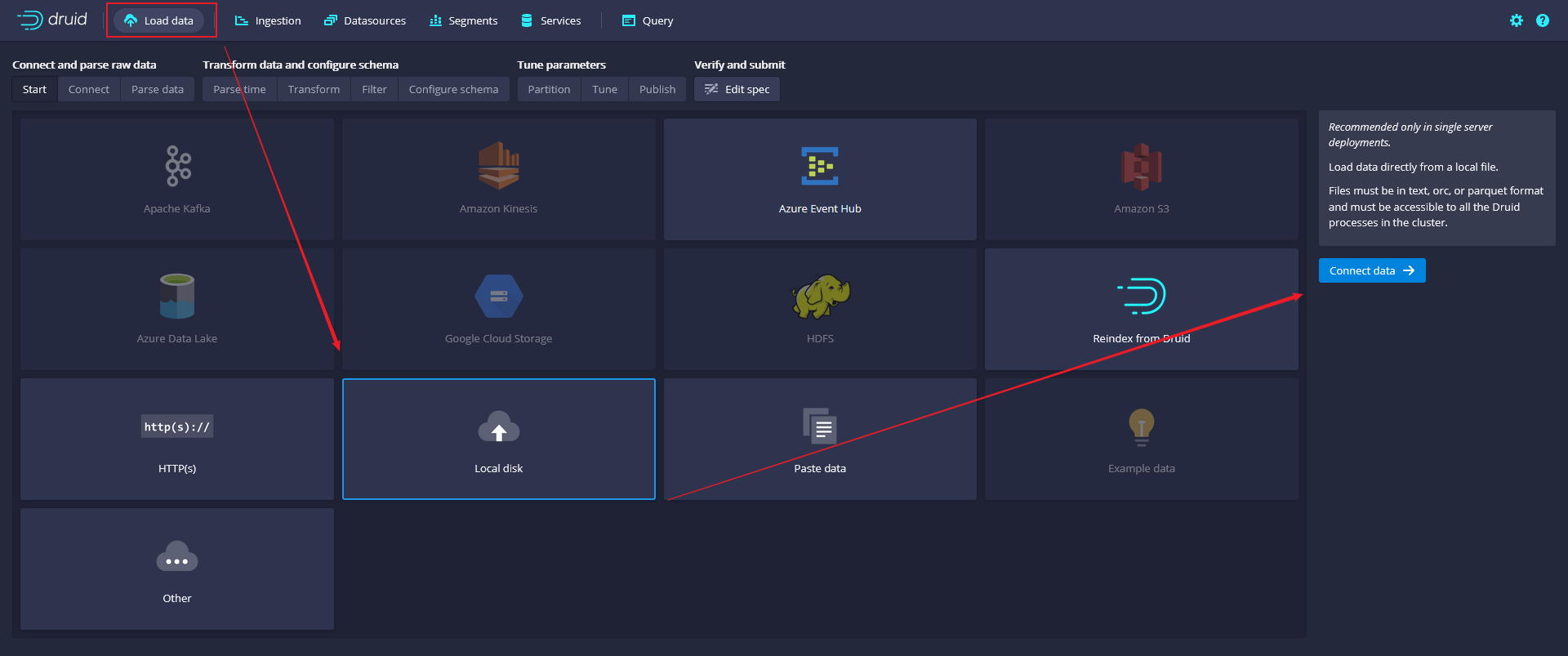
- Enter the following values.
- Base directory:
quickstart/tutorial/- File filter:
wikiticker-2015-09-12-sampled.json.gz
- Click Apply.
The data loader displays the raw data, giving you a chance to verify that the data appears as expected.
数据加后会显示原始数据,可以验证数据是否如预期的那样显示。

官网特别提示:在加载数据的步骤序列(当前是Connect)中,显示在控制台的顶部,如下所示。可以随时单击其他步骤,按顺序向前或向后移动。

- Click Next: Parse data.
这一步是对数据进行格式化,我们可以自由选择其他输入格式选项,以了解它们的配置设置以及Druid如何解析其他类型的数据。
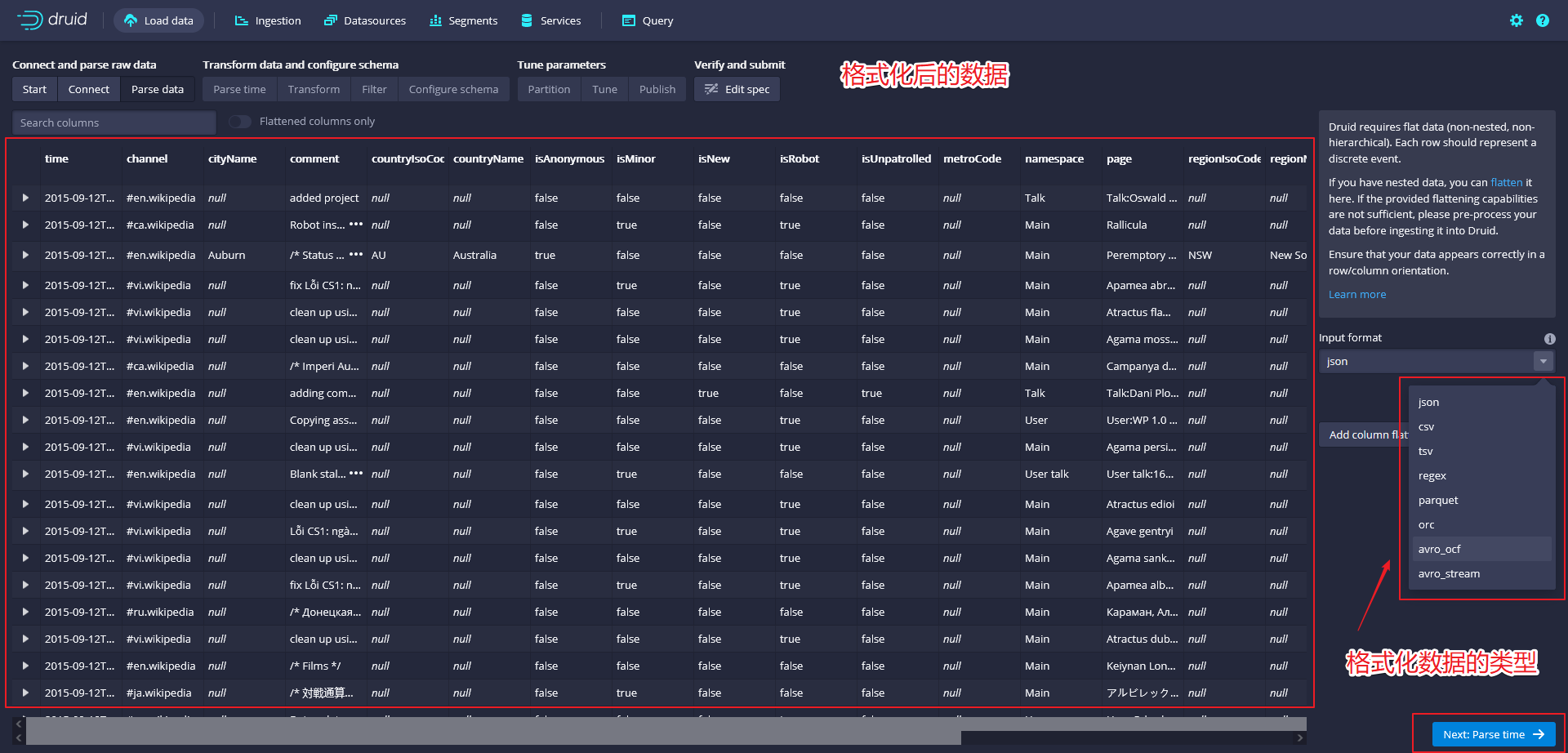
- With the JSON parser selected, click Next: Parse time. The Parse time settings are where you view and adjust the primary timestamp column for the data.
这一步是对时间字段的格式化,
Druid 要求数据有一个主时间戳列(内部存储在一个名为 __time 的列中)。如果数据中没有时间戳,需要选择常量值。示例中,数据加载程序确定时间列是唯一可以用作主时间列的候选项。

没有修改 Format 的类型,所以 _time 和 time 的格式其实是一样的。
- Click Next: Transform, Next: Filter, and then Next: Configure schema, skipping a few steps.
这一步跳过了调整转换或筛选设置。
- 配置模式设置是您配置所摄取的维度和指标的地方。这个配置的结果准确地表示了数据在摄入后将如何在Druid中出现。
- 数据集小的可以通过取消rollup开关,并在提示时确认更改来关闭rollup。
- Click Next: Partition to configure how the data will be split into segments. In this case, choose DAY as the Segment granularity.
这一步是对数据进行分区,选择分区的字段。