ʲô�ǹܵ�
����һ��������������������һ������ʱ,����ʹ������ܵ�(pipe)������ͨ���ǰ�һ�����̵����ͨ���ܵ����ӵ���һ�����̵����롣
�����Linux���û�Ӧ�����ѶԽ�shell����������һ��ĸ������Ϥ��,��ʵ���Ͼ��ǰ�һ�����̵����ֱ�Ӵ��ݸ���һ�����̵����롣����shell������˵,�����������ͨ���ܵ����ӵ�,������ʾ
cmd1 | cmd2
shell��������������ı�����ͱ������cmd1�ı����������ն˼��̡�
cmd1�ı�������ݸ�cmd2,��Ϊ���ı����롣cmd2�ı�������ӵ��ն���Ļ��
shell�����Ĺ���ʵ�����ǶԱ�����ͱ��������������������,�Ӷ�ʵ�����������������Ļ��,��ͼ��

�ڱ�ƪ��,���ǽ���������ڳ����л��������Ч��,�����ùܵ������������������,�Ӷ�ʵ��һ���Ŀͻ�/������ϵͳ��
���̹ܵ�
�����������������֮�䴫�����ݵķ�������ʹ��popen��pclose�����ˡ����ǵ�ԭ��������ʾ:
#include <stdio.h>
FILE *popen(const char *command,const char *open_mode) ;
int pclose(FILE*stream to_close);
popen����
popen��������һ��������һ��������Ϊ�½���������,�����Դ������ݸ�������ͨ�����������ݡ�command�ַ�����Ҫ���еij���������Ӧ�IJ�����open_mode������"r"����"w"��
���open_mode��"r",�����ó��������Ϳ��Ա����ó���ʹ��,���ó�������popen�������ص�FILE*�ļ���ָ��,�Ϳ���ͨ�����õ�stdio�⺯��(��fread)����ȡ�����ó������������open_mode��"w",���ó���Ϳ�����fwrite�������ó���������,�������ó���������Լ��ı������϶�ȡ��Щ���ݡ������õij���ͨ��������ʶ���Լ����ڴ���һ�����̶�ȡ����,��ֻ���ڱ��������϶�ȡ����,Ȼ��������Ӧ�IJ�����
ÿ��popen���ö�����ָ��"r"��"w",��popen�����ı�ʵ���в�֧���κ�����ѡ�����ζ�����Dz��ܵ�����һ������ͬʱ�������ж�д������popen������ʧ��ʱ����һ����ָ�롣�����ͨ���ܵ�ʵ��˫��ͨ��,����ͨ�Ľ��������ʹ�������ܵ�,ÿ���ܵ�����һ���������������
pclose����
��popen�����Ľ��̽���ʱ,���ǿ�����pclose�����ر���֮�������ļ�����pclose����ֻ��popen�����Ľ��̽�����ŷ��ء��������pcloseʱ����������,pclose���ý��ȴ��ý��̵Ľ�����
pclose���õķ���ֵͨ���������رյ��ļ������ڽ��̵��˳�����������ý����ڵ���pclose֮ǰִ����һ��wait���,�����ý��̵��˳�״̬�ͻᶪʧ,��Ϊ�����ý����ѽ�������ʱ,pclose������-1������errnoΪECHILD��
ʵ��-��:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
int main()
{
FILE *read_fd;
char buff[128] = {0};
int read_count = 0;
read_fd = popen("uname -a","r");
if(read_fd != NULL)
{
read_count = fread(buff,sizeof(char),127,read_fd);
while(read_count != 0)
{
printf("read : %s",buff);
read_count = fread(buff,sizeof(char),127,read_fd);
}
pclose(read_fd);
exit(EXIT_SUCCESS);
}
exit(EXIT_FAILURE);
}

���������popen������������-aѡ���uname���Ȼ���÷��ص��ļ�����ȡ��������,�������Ǵ�ӡ������ʾ����Ļ�ϡ���Ϊ�������ڳ����ڲ�����uname��������,���Կ��Դ�������
ʵ��-д:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
int main()
{
FILE *write_fd;
char buff[128] = "12 23 34 45 56 67 78 89";
int write_count = 0;
write_fd = popen("cat","w");
if(write_fd != NULL)
{
fwrite(buff,sizeof(char),strlen(buff),write_fd);
pclose(write_fd);
exit(EXIT_SUCCESS);
}
exit(EXIT_FAILURE);
}

����ʹ�ô��в���"w"��popen����cat����,�����Ϳ����������������ˡ�Ȼ������cat�����һ���ַ���,��������ղ�������,���Ѵ��������ӡ���Լ��ı�����ϡ�
����������,���ǿ��������������õ�ͬ����������:

pipe����
�ڿ�������popen����֮��,�������������ײ��pipe������ͨ�������������������֮�䴫�����ݲ���Ҫ����һ��shell����������������ͬʱ���ṩ�˶Զ�д���ݵĸ�����ơ�
pipe������ԭ��������ʾ:
#include <unistd.h>
int pipe(int fi1e_descriptor[2]);
pipe�����IJ�����һ���������������͵��ļ���������ɵ������ָ�롣�ú��������������������µ��ļ���������0,���ʧ����-1������errno������ʧ�ܵ�ԭ����Linux�ֲ�ҳ(�ֲ�ĵڶ�����)�ж���������һЩ����
FEMFILE: ����ʹ�õ��ļ����������ࡣ
ENFILE: ϵͳ���ļ���������
EFAULT: �ļ���������Ч��
�������ص��ļ���������һ������ķ�ʽ����������д��file_descriptor[1]���������ݶ����Դ�file_descriptor[0]�����������ݻ����Ƚ��ȳ���ԭ��(ͨ����дΪFIFO)���д���,����ζ���������ֽ�1,2,3д��file_descriptor[1],��file_descriptor [0]��ȡ��������Ҳ����1,2,3��
�ر�Ҫע��,����ʹ�õ����ļ��������������ļ���,�������DZ����õײ��read��write��������������,���������ļ����⺯��fread��fwrite��
pipe����ʹ��
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
int main()
{
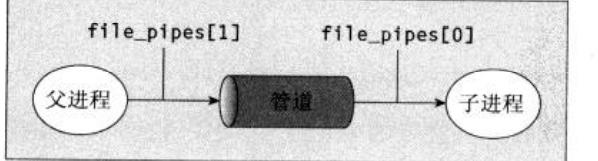
int file_pipe[2] = {0};
const char send_data[] = "Hello , world \n";
char recv_buff[128] = {0};
if(pipe(file_pipe) == 0)
{
write(file_pipe[1],send_data,strlen(send_data));
int read_num = read(file_pipe[0],recv_buff,127);
write(STDOUT_FILENO,recv_buff,read_num);
close(file_pipe[0]);
close(file_pipe[1]);
exit(EXIT_SUCCESS);
}
exit(EXIT_FAILURE);
}

�������������file_pipes[]�е������ļ�����������һ���ܵ���Ȼ�������ļ�������file pipes[1]��ܵ���д����,�ٴ�file_pipes[0]�������ݡ�ע��,�ܵ���һЩ���õĻ�����,����write��read����֮�䱣�����ݡ�
����㳢����file_descriptor[0]д���ݻ���file_descriptor[1]������,������δ���ĵ�����ȷ����,��������Ϊ���ܻ�dz����,��������ϵͳ�IJ�ͬ,����Ϊ���ܻᷢ���仯�����ҵ�ϵͳ��,�����ĵ��ý�ʧ�ܲ�����-1,�������ܹ�˵�����ִ���Ƚ������֡�
է������,���ʹ�ùܵ������Ӳ����ر�֮��,�����Ĺ���Ҳ������һ�����ļ���ɡ��ܵ�����������������,����������������֮�䴫�����ݵ�ʱ��������fork���ô����½���ʱ,ԭ�ȴ��ļ��������Խ����ִ�״̬�������ԭ�ȵĽ����д���һ���ܵ�,Ȼ���ٵ���fork�����½���,���Ǽ���ͨ���ܵ�����������֮�䴫�����ݡ�
pipe��fork
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
int main()
{
int file_pipe[2] = {0};
if(pipe(file_pipe) == 0)
{
pid_t pid = fork();
if(pid == 0)
{
const char send_data[] = "Hello , world \n";
write(file_pipe[1],send_data,strlen(send_data));
close(file_pipe[1]);
}
else
{
char recv_buff[128] = {0};
read(file_pipe[0],recv_buff,127);
printf("read : %s",recv_buff);
close(file_pipe[0]);
}
exit(EXIT_SUCCESS);
}
exit(EXIT_FAILURE);
}

�������������pipe���ô���һ���ܵ�,������fork���ô���һ���½��̡����fork���óɹ�,�ӽ��̾�д���ݵ��ܵ���,�������̴ӹܵ��ж�ȡ���ݡ����ӽ��̶���ֻ������һ��write��read֮����˳���
��Ȼ�ӱ����Ͽ�,�������͵�һ��ʹ�ùܵ������Ӻ�����,��ʵ���������������������ǰ�����һ��,���ǿ����ڲ�ͬ�Ľ���֮����ж�д������,��ͼ��ʾ��
pipe��exec
�ڽ������Ķ�pipe���õ��о���,���ǽ�ѧϰ������ӽ���������һ�����丸������ȫ��ͬ������һ������,�����ǽ�������һ����ͬ����������exec�����������һ�����������һ���ѵ���,ͨ��exec���õĽ�����Ҫ֪��Ӧ�÷����ĸ��ļ�����������ǰ���������,��Ϊ�ӽ��̱�����file_pipes���ݵ�һ�ݸ���,�����Ⲣ����Ϊ���⡣������exec���ú�,����Ͳ�һ����,��Ϊԭ�ȵĽ����Ѿ����µ��ӽ����滻�ˡ�Ϊ����������,���ǿ��Խ��ļ�������(��ʵ����ֻ��һ������)��Ϊһ���������ݸ���exec�����ij���
Ϊ����ʾ������ι�����,������Ҫʹ����������һ������������������,�������ܵ��������ӽ���,�����������������ߡ�
������:
#include<stdlib.h>
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<sys/wait.h>
int main()
{
int file_pipe[2] = {0};
if(pipe(file_pipe) == 0)
{
int pid = fork();
if(pid == 0)
{
char buff[5] = {0};
sprintf(buff,"%d",file_pipe[0]);
execl("consumer","consumer",buff,NULL);
}
else
{
char send_data[] = "12 23 45 56 78 \n";
write(file_pipe[1],send_data,strlen(send_data));
wait(NULL);
}
exit(EXIT_SUCCESS);
}
exit(EXIT_FAILURE);
}
������:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
int main(int argc,void *argv[])
{
int file_pipe = 0;
sscanf((char*)argv[1],"%d",&file_pipe);
char buff[128] = {0};
read(file_pipe,buff,127);
printf("read : %s",buff);
exit(EXIT_SUCCESS);
}
���:

�����߳���Ŀ�ʼ���ֺ�ǰ�������һ��,��pipe���ô���һ���ܵ�,Ȼ����fork���ô���һ���½��̡�������,����sprintf�Ѷ�ȡ�ܵ����ݵ��ļ����������浽һ����������,�û������е����ݽ����������߳����һ��������
����ͨ��execl����������pipe4����,execl�IJ���������ʾ��
Ҫ�����ij���
argv[0]:��������
argv[1]:�����������ñ����ó���ȥ��ȡ���ļ���������
NULL:�����������������ֹ�����ó���IJ����б���
�����߳���Ӳ����ַ�������ȡ���ļ�����������,Ȼ���ȡ���ļ�����������ȡ���ݡ�
�ܵ��رպ�Ķ�����
�ڼ���ѧϰ֮ǰ,����������ϸ�о�һ�´��ļ�������������,����һֱ��ȡ�����ö����̶�ȡһЩ����Ȼ��ֱ���˳��ķ�ʽ,������Linux��������ļ��������ڽ��̽���ʱӦ�����Ĺ�����һ���֡�
��������ӱ������ȡ���ݵij�����õ�ȴ�������ǵ�ĿǰΪֹ���������ӷdz���ͬ������һ��������ͨ�����Dz���֪���ж���������Ҫ��ȡ,������������ѭ���ķ���,��ȡ���ݡ����������ݡ�����ȡ���������,ֱ��û�����ݿɶ�Ϊֹ��
��û�����ݿɶ�ʱ,read����ͨ��������,��������ͣ�������ȴ�ֱ�������ݵ���Ϊֹ������ܵ�����һ���ѱ��ر�,Ҳ����˵,û�н��̴�����ܵ�������д������,��ʱread���þͻ����������������������Ǻ�����,��˶�һ���ѹر�д���ݵĹܵ���read���ý�����0���������������ʹ�������ܹ������ļ�����һ��,�Թܵ����м�Ⲣ������Ӧ�Ķ�����ע��,�����ȡһ����Ч���ļ���������ͬ,read����Ч���ļ�����������һ��������-1��
�����Խfork����ʹ�ùܵ�,�ͻ���������ͬ���ļ�����������������ܵ�д����,һ���ڸ�������,һ�����ӽ����С�ֻ�аѸ��ӽ����е���Թܵ���д�ļ����������ر�,�ܵ��Żᱻ��Ϊ�ǹر���,�Թܵ���read���òŻ�ʧ�ܡ�
�����ܵ�:FIFO
����,���ǻ�ֻ������صij���֮�䴫������,����Щ��������һ����ͬ�����Ƚ�����������������������ڲ���صĽ���֮�佻������,����Ǻܷ��㡣
���ǿ�����FIFO�ļ�����������,��ͨ��Ҳ����Ϊ�����ܵ�(named pipe)�������ܵ���һ���������͵��ļ�(������Linux�е��������ﶼ���ļ�),�����ļ�ϵͳ�����ļ�������ʽ����,��������Ϊȴ�������Ѿ�������û�����ֵĹܵ����ơ�
���ǿ������������ϴ��������ܵ�,Ҳ�����ڳ����д����������������������������ܵ��ij�����mkfifo,������ʾ:
mkfifo filename #�ϰ汾������mknod filename p
�ڳ�����,���ǿ���ʹ��������ͬ�ĺ�������,������ʾ;
#include <sys/types.h>
#include <sys/stat.h>
int mkfifo(const char *filename,mode_t mode);
int mknod(const char *filename,mode_t mode | S_IFIFO,(dev_t) 0);
���������������,����ʹ�ý�Ϊ��mkfifo
���������ܵ�
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
int res = mkfifo("my_fifo",0600);
if( res == 0 ) printf("FIFO Created \n");
exit(EXIT_SUCCESS);
}
����FIFO�ļ�
���������ǽ���ϸ����FIFO�ı�̽ӿ�,�������������ڷ���FIFO�ļ�ʱ����ؿ������д��Ϊ��
��ͨ��pipe���ô����ܵ���ͬ,FIFO���������ļ�����ʽ����,�����Ǵ��ļ�������,�����ڶ������ж�д����֮ǰ�����ȴ����� FIFOҲ��open��close�����ر�,��������ǰ�濴���Ķ��ļ��IJ���һ��,��������һЩ�����Ĺ���.��FIFO��˵,���ݸ�open���õ���FIFO��·����,������һ���������ļ���
ʹ��open��FIFO�ļ�
��FIFO��һ����Ҫ������,��������O_RDWRģʽ��FIFO�ļ����ж�д����,�������ĺ����δ��ȷ������������������е�����,��Ϊ����ͨ��ʹ��FIFOֻ��Ϊ�˵�������,����û�б�Ҫʹ��O_RDWRģʽ�����һ���ܵ��Զ�/д��ʽ��,���̾ͻ������ܵ��������Լ��������
���ȷʵ��Ҫ�ڳ���֮��˫������,���ʹ��һ��FIFO��ܵ�,һ������ʹ��һ��,����(����������)�����ȹر������´�FIFO�ķ�������ȷ�ظı��������ķ�����
��FIFO�ļ��ʹ���ͨ�ļ�����һ��������,��open_flag (open�����ĵڶ�������)��O_NONBLOCKѡ����÷���ʹ�����ѡ����ı�open���õĴ�����ʽ,����ı�����open���÷��ص��ļ����������еĶ�д����Ĵ�����ʽ��
O_RDONLY��O_WRONLY��O_NONBLOCK��־����4�ֺϷ�����Ϸ�ʽ,���ǽ�����������ǡ�
open(const char *path,O_RDONLY);
�����������,open���ý�����,������һ��������д��ʽ��ͬһ��FIFO,���������᷵�ء�
open(const char *path, O__RDONLY | O_NONBLOCK);
��ʹû������������д��ʽ��FIFO,���open����Ҳ���ɹ������̷��ء�
open (const char *path, O_WRONLY);
�����������,open���ý�����,ֱ����һ�������Զ���ʽ��ͬһ��FIFOΪֹ��
open(const char *path, O_WRONLY | O_NONBLOCK);
������������������̷���,�����û�н����Զ���ʽ��FIFO�ļ�,open���ý�����һ������-1����FIFOҲ���ᱻ�����ȷʵ��һ�������Զ���ʽ��FIFO�ļ�,��ô���ǾͿ���ͨ�������ص��ļ������������FIFO�ļ�����д������
��ҿ���дһ��С������֤һ��;
��ע��O_NONBLOCK�ֱ����O_RDONLY��O_WRONLY��Ч���ϵIJ�ͬ,���û�н����Զ���ʽ�ܵ�,������д��ʽ��open���ý�ʧ��,������������ʽ��open�������dzɹ���close���õ���Ϊ������O_NONBLOCK��־��Ӱ�졣
��FIFO���ж�д����
ʹ��O_NONBLOCKģʽ��Ӱ�쵽��FIFO��read��write���á�
��һ���յġ�������FIFO(��û����O_NONBLOCK��־��)��read���ý��ȴ�,ֱ�������ݿ��Զ�ʱ�ż���ִ�С�����෴,��һ���յġ���������FIFO��read���ý����̷���0�ֽڡ�
��һ����ȫ����FIFO��write���ý��ȴ�,ֱ�����ݿ��Ա�д��ʱ�ż���ִ�С����FIFO���ܽ�������д�������,����������Ĺ���ִ�С�
�������д������ݵij���С�ڵ���PIPE_BUF�ֽ�,����ʧ��,���ݲ���д�롣
�������д������ݵij��ȴ���PIPE_BUF�ֽ�,��д�벿������,����ʵ��д����ֽ���,����ֵҲ������0��
FIFO�ij�������Ҫ���ǵ�һ������Ҫ�����ء�ϵͳ����һʱ����һ��FIFO�п��Դ��ڵ����ݳ����������Ƶġ�����#define PIPE_BUF��䶨��,ͨ��������ͷ�ļ�limits.h���ҵ�������Linux������������UNIXϵͳ��,����ֵͨ����4 096�ֽ�,����ijЩϵͳ�������ܻ�С��512�ֽڡ�ϵͳ�涨:��һ����O_WRONLY��ʽ(��������ʽ)��FIFO��,���д������ݳ���С�ڵ���PIPE_BUF,��ô����д��ȫ���ֽ�,����һ���ֽڶ���д�롣
��Ȼ,��ֻ��һ��FIFOд���̺�һ��FIFO�����̵ļ������˵,������Ʋ����Ƿdz���Ҫ,��ֻʹ��һ��FIFO�����������ͬ�ij�����һ��FIFO�����̷������������Ǻܳ�����,���������ͬ�ij�����ͬʱ��FIFOд����,�ܷ�֤���Բ�ͬ��������ݿ鲻������ͷdz��ؼ�����Ҳ����˵,ÿ��д�����������ǡ�ԭ�ӻ����ġ���������������һ����?
������ܱ�֤���е�д�����Ƿ���һ��������FIFO��,����ÿ��д��������ݳ���С�ڵ���PIPE_BUF�ֽ�,ϵͳ�Ϳ���ȷ�����ݾ����ύ����һ��ͨ����ÿ��ͨ��FIFO���ݵ����ݳ�������ΪPIPE_BUF�ֽ��Ǹ��÷���,������ֻʹ��һ��д���̺�һ�������̡�
ʹ��FIFOʵ�ֽ��̼�ͨ��
��һ���Ƿ��ͳ���:
ע��,������ʾ��Ŀ��,���Dz�������д�����ݵ��ڿ�,�������Dz�δ�Ի��������г�ʼ����(��10M������)
#include<stdio.h>
#include<unistd.h>
#include<fcntl.h>
#include<stdlib.h>
int main()
{
int fd = open("./fifo",O_WRONLY);
char buff[128];
int send_num = 1024*1024*10;
while(send_num > 0)
{
write(fd,buff,128);
send_num-=128;
}
close(fd);
exit(EXIT_SUCCESS);
}
�ڶ����ǽ��ճ���:���ըC>����
#include<stdio.h>
#include<unistd.h>
#include<fcntl.h>
#include<stdlib.h>
int main()
{
int fd = open("./fifo",O_RDONLY);
char buff[128] = {0};
int recv_num = 0;
while(read(fd,buff,128))
{
recv_num+=128;
}
printf("I recv %d byte\n",recv_num);
close(fd);
exit(EXIT_SUCCESS);
}
��������������֮ʱ,������time�����¼�����е�ʱ��,����������

��������ʹ�õĶ�������ģʽ��FIFO��������������д����,���������Եȴ������̴����FIFO�������������Ժ�,д���̽����������ʼ��ܵ�д���ݡ�ͬʱ,������Ҳ��ʼ�ӹܵ��ж�ȡ���ݡ�
Linux�ᰲ�ź�����������֮��ĵ���,ʹ�����ڿ������е�ʱ������,�ڲ������е�ʱ�����������,д���̽��ڹܵ���ʱ����,�����̽��ڹܵ���ʱ������
�ܵ��ڳ���֮�䴫�������Ǻ���Ч�ʵġ�