输入页数开始爬取
可设定是否无头浏览
有一个坑就是在翻页时无法直接click该元素
要写一个执行js
预览图:
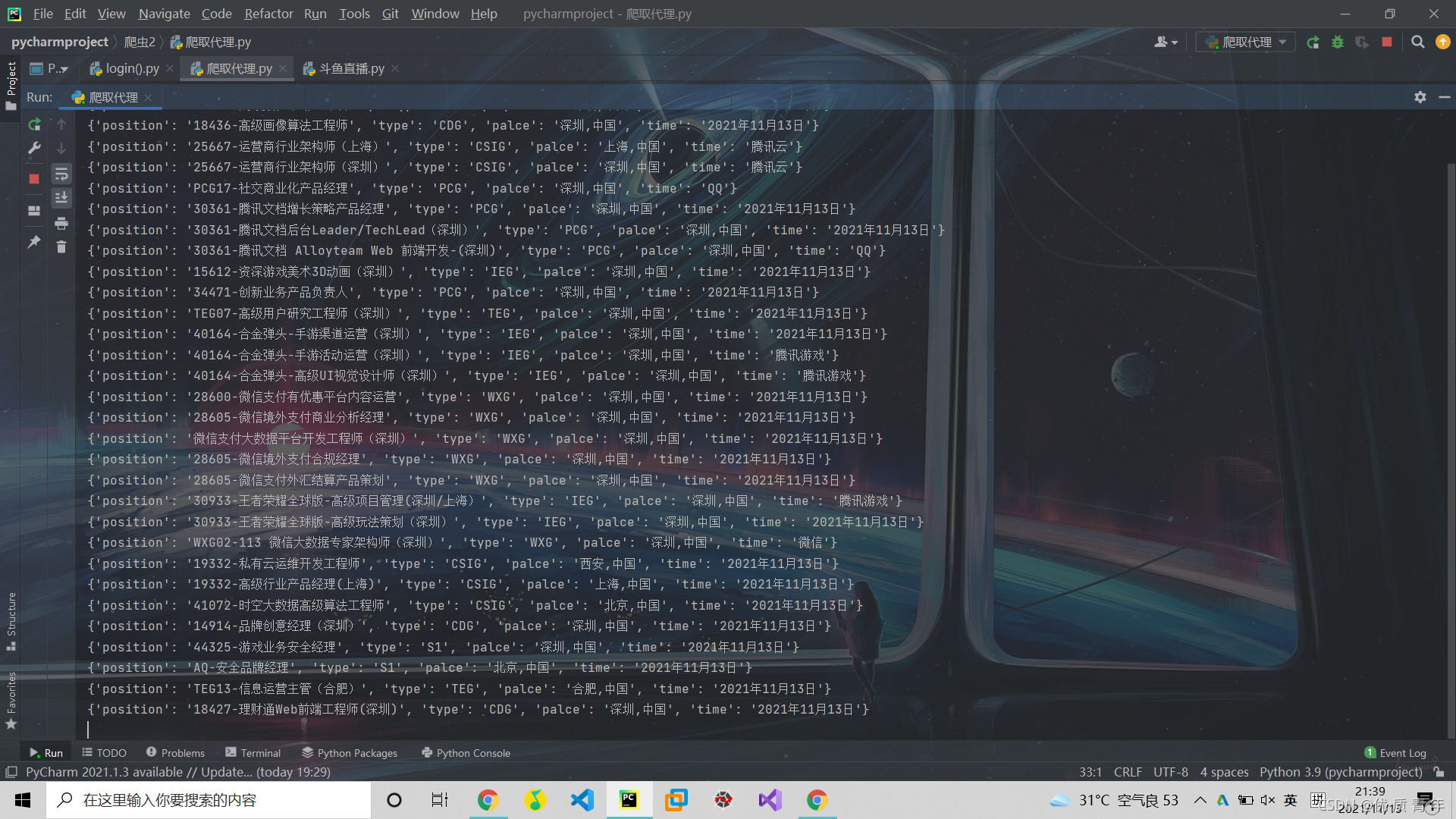
?上代码
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
class Tencent():
def __init__(self, page):
self.page = page+1
self.url = "https://careers.tencent.com/search.html"
self.opt = webdriver.ChromeOptions() # 配置
# opt.add_argument("--headless")
# opt.add_argument("--disable-gpu")
# self.opt.add_argument("--referer=https://careers.tencent.com/search.html?index=3")
self.opt.add_argument("--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36")
self.driver = webdriver.Chrome(options=self.opt)
def parse(self):
time.sleep(1)
pos_list = self.driver.find_elements(By.XPATH, "/html/body/div/div[4]/div[3]/div[2]/div[2]/div/div")
time.sleep(0.2)
csv = []
for info in pos_list:
time.sleep(0.1)
dict = {}
dict['position'] = info.find_element(By.XPATH, "./a/h4").text
dict['type'] = info.find_element(By.XPATH, "./a/p[1]/span[1]").text
dict['palce'] = info.find_element(By.XPATH, "./a/p[1]/span[2]").text
dict['time'] = info.find_element(By.XPATH, "./a/p[1]/span[4]").text
csv.append(dict)
return csv
def show(self, csv):
for i in csv:
print(i)
def run(self):
self.driver.get(url=self.url)
self.driver.implicitly_wait(10)
while True:
self.page -= 1
if self.page == 0:
break
ans = self.parse()
self.show(ans)
time.sleep(1)
try:
button = self.driver.find_element(By.XPATH, "/html/body/div/div[4]/div[3]/div[2]/div[3]/ul/li[10]")
self.driver.execute_script("$(arguments[0]).click()", button)
except:
break
if __name__ == '__main__':
p = int(input("请输入要爬取的页数"))
obj = Tencent(p)
obj.run()