Ŀ¼
1��������װ��ж��
��װ��������:
1.Դ���밲װ
2.rpm��
3.yum������
���� rzsz
����������� windows ������Զ�˵� Linux ����ͨ�� XShell �����ļ�.
��װ���֮�����ͨ����ק�ķ�ʽ���ļ��ϴ���ȥ.
�鿴������
ͨ�� yum list ����������г���ǰһ������Щ������. ���ڰ�����Ŀ���ܷdz�֮��, ����������Ҫʹ�� grep ����ֻɸѡ�����ǹ�ע�İ�
yum list | grep lrzsz
lrzsz.x86_64 0.12.20-36.el7 @base

ע������
����������: ���汾��.�ΰ汾��.Դ�����к�-�������ķ��к�.����ƽ̨.cpu�ܹ�.
��x86_64�� ����ʾ64λϵͳ�İ�װ��, ��i686�� ����ʾ32λϵͳ��װ��. ѡ���ʱҪ��ϵͳƥ��.
��el7�� ��ʾ����ϵͳ���а�İ汾. ��el7�� ��ʾ���� centos7/redhat7. ��el6�� ��ʾ centos6/redhat6.
���һ��, base ��ʾ���� ������Դ�� ������, ������ ��С��Ӧ���̵ꡱ, ����ΪӦ���̵ꡱ �����ĸ���
��ΰ�װ����
ͨ�� yum, ���ǿ���ͨ���ܼ�һ��������� gcc �İ�װ.
����:sudo yum install lrzsz
yum ���Զ��ҵ�������Щ��������Ҫ����, ��ʱ���� ��y�� ȷ�ϰ�װ.
���� ��complete�� ����, ˵����װ���.
ע������:
��װ����ʱ������Ҫ��ϵͳĿ¼��д������, һ����Ҫ sudo �����е� root �˻��²������.
yum��װ����ֻ��һ��װ������װ��һ��. ����yum��װһ�������Ĺ�����, ����ٳ�����yum��װ����һ������, yum�ᱨ��.
��� yum ����, �Ҷ���
��������
����:sudo yum remove lrzsz
2��Linux��������
��Linux�°�װ����, һ��ͨ���İ취�����ص������Դ����, �����б���, �õ���ִ�г���.
��������̫�鷳��, ������Щ�˰�һЩ���õ�������ǰ�����, ����������(���������windows�ϵİ�װ����)����һ����������, ͨ�������������Ժܷ���Ļ�ȡ���������õ�������, ֱ�ӽ��а�װ.
��������������������, �ͺñ� ��App�� �� ��Ӧ���̵ꡱ �����Ĺ�ϵ.
2.1Linux�༭��-vimʹ��
1.����/��ͨ/����ģʽ(Normal mode)
������Ļ�����ƶ�,�ַ����ֻ��е�ɾ��,�ƶ�����ij���μ�����Insert mode��,���ߵ� last line mode
2.����ģʽ(Insert mode)
ֻ����Insert mode��,�ſ�������������,����ESC�����ɻص�������ģʽ����ģʽ�������õ���Ƶ���ı༭ģʽ��
3.ĩ��ģʽ(last line mode)
�ļ�������˳�,Ҳ���Խ����ļ��滻,���ַ���,�г��кŵȲ����� ������ģʽ��,shift+: ���ɽ����ģʽ��Ҫ�鿴�������ģʽ:��vim,����ģʽֱ������:help vim-modes
4.�滻ģʽ
shift+r�ӵ���ת������ģʽ,�ص�����esc
2.1.1vim�Ļ�������
����vim,��ϵͳ��ʾ��������vim���ļ����ƺ�,�ͽ���vimȫ��Ļ�༭����:
$ vim test.c

������һ��Ҫ�ر�ע��,���������vim֮��,�Ǵ���[����ģʽ],��Ҫ�л���**[����ģʽ]���ܹ���������**��
[����ģʽ]�л���[����ģʽ]
����a
����i
����o
[����ģʽ]�л���[����ģʽ]
Ŀǰ����[����ģʽ],��ֻ��һֱ��������,��������������,���ù��������ƶ�,������ɾ��,�����Ȱ�һ�¡�ESC����ת��[����ģʽ]��ɾ�����֡���Ȼ,Ҳ����ֱ��ɾ����
[����ģʽ]�л���[ĩ��ģʽ]
��shift + ;��, ��ʵ�������롸:��
�˳�vim�������ļ�,��[����ģʽ]��,��һ�¡�:��ð�ż����롸Last line mode��,����:
: w (���浱ǰ�ļ�)
: wq (���롸wq��,���̲��˳�vim)
: q! (����q!,������ǿ���˳�vim)
2.1.2vim����ģʽ���
����ģʽ
����i���������ģʽ��insert mode��,����i���������ģʽ���Ǵӹ�굱ǰλ�ÿ�ʼ�����ļ�;
����a���������ģʽ��,�Ǵ�Ŀǰ�������λ�õ���һ��λ�ÿ�ʼ��������;
����o���������ģʽ��,�Dz����µ�һ��,������ʼ�������֡�
�Ӳ���ģʽ�л�Ϊ����ģʽ����ESC������
�ƶ����
vim����ֱ���ü����ϵĹ�������������ƶ�,�������vim����СдӢ����ĸ��h������j������k������l��,�ֱ���ƹ�����¡��ϡ�����һ��
����G��:�ƶ������µ����
���� $ ��:�ƶ�����������еġ���β��
����^��:�ƶ�����������еġ����ס�
����w��:��������¸��ֵĿ�ͷ
����e��:��������¸��ֵ���β
����b��:���ص��ϸ��ֵĿ�ͷ
����#l��:����Ƶ����еĵ�#��λ��,��:5l,56l
��[gg]:���뵽�ı���ʼ
��[shift+g]:�����ı�ĩ��
��[n+shift+g]: ��λ���������һ��
����ctrl��+��b��:��Ļ�������ƶ�һҳ
����ctrl��+��f��:��Ļ����ǰ���ƶ�һҳ
����ctrl��+��u��:��Ļ�������ƶ���ҳ
����ctrl��+��d��:��Ļ����ǰ���ƶ���ҳ
ɾ������
��x��:ÿ��һ��,ɾ���������λ�õ�һ���ַ�
��#x��:����,��6x����ʾɾ���������λ�õġ�����(�����Լ�����)��6���ַ�
��X��:��д��X,ÿ��һ��,ɾ���������λ�õġ�ǰ�桱һ���ַ�
��#X��:����,��20X����ʾɾ���������λ�õġ�ǰ�桱20���ַ�
��dd��:ɾ�����������/����
��#dd��:�ӹ�������п�ʼɾ��#��
����
��yw��:���������֮������β���ַ����Ƶ��������С�
��#yw��:����#���ֵ�������
��yy��:���ƹ�������е���������
��#yy��:����,��6yy����ʾ�����ӹ�����ڵĸ��С���������6�����֡�
��p��:���������ڵ��ַ������������λ�á�ע��:�����롰y���йصĸ�����������롰p����ϲ�����ɸ�����ճ�����ܡ�
�滻
��r��:�滻������ڴ����ַ�,֧��nr��
��R��:�����ı��滻,ֱ�����¡�ESC����Ϊֹ��������һ�β���
[~] :��Сд,С��д�滻
��u��:�������ִ��һ������,�������ϰ��¡�u��,�ص���һ������������Ρ�u������ִ�ж�λظ���
��ctrl + r��: �����Ļָ�����
��cw��:���Ĺ�����ڴ����ֵ���β��
��c#w��:����,��c3w����ʾ����3��������ָ������
��ctrl��+��g���г���������е��кš�
��#G��:����,��15G��,��ʾ�ƶ���������µĵ�15������
2.1.3vim����(ĩ��)ģʽ���
��ʹ�õ���ģʽ֮ǰ,���ס�Ȱ���ESC����ȷ�����Ѿ���������ģʽ,�ٰ���:��ð�ż��ɽ���ĩ��ģʽ��
�г��к�
��set nu��: ���롸set nu����,�����ļ��е�ÿһ��ǰ���г��кš�
�����ļ��е�ijһ��
��#��:��#���ű�ʾһ������,��ð�ź�����һ������,�ٰ��س����ͻ�����������,����������15,�ٻس�,�ͻ��������µĵ�15�С�
�����ַ�
��/�ؼ��֡�: �Ȱ���/����,����������Ѱ�ҵ��ַ�,�����һ���ҵĹؼ��ֲ�������Ҫ��,����һֱ����n��������Ѱ�ҵ���Ҫ�Ĺؼ���Ϊֹ��
��?�ؼ��֡�:�Ȱ���?����,����������Ѱ�ҵ��ַ�,�����һ���ҵĹؼ��ֲ�������Ҫ��,����һֱ����n������ǰѰ�ҵ���Ҫ�Ĺؼ���Ϊֹ��
����:/ (���ҵ������ı���һ�γ��ֵ��Ǹ��ַ���λ��)�Ͷ�?(���ҵ������ı����һ�γ����Ǹ��ؼ��ֵ�λ��)
�����ļ�
��w��: ��ð��������ĸ��w���Ϳ��Խ��ļ���������
�뿪vim
��q��:����q�������˳�,������뿪vim,�����ڡ�q�����һ����!��ǿ���뿪vim�� ��wq��:һ�㽨���뿪ʱ,���䡸w��һ��ʹ��,�������˳���ʱ���Ա����ļ�
�������滻
:%s/��Ҫ�滻������/�滻�������/g
����ִ��bash����
:!
������ʾ
:vs ��ʾ���ı�,����������л�:ctrl ww
2.2Linux������-gcc/g++ʹ��
����֪ʶ
- Ԥ����(���к��滻)
- ����(���ɻ��)
- ���(���ɻ�����ʶ�����)
- ����(���ɿ�ִ���ļ�����ļ�)
gcc������
��ʽ gcc [ѡ��] Ҫ������ļ� [ѡ��] [Ŀ���ļ�]
Ԥ����(1.ͷ�ļ�չ�� 2.���滻 3.�������� 4.ȥע��)
Ԥ����ָ������#�ſ�ͷ�Ĵ����С�
ʵ��: gcc �CE test.c �Co test.i
ѡ�-E��,��ѡ����������� gcc ��Ԥ����������ֹͣ������̡�
ѡ�-o����ָĿ���ļ�,��.i���ļ�Ϊ�Ѿ���Ԥ������Cԭʼ����
����(��C���Է������ɻ��)
���������,gcc ����Ҫ������Ĺ淶�ԡ��Ƿ���������,��ȷ�������ʵ��Ҫ���Ĺ���,�ڼ�������,gcc �Ѵ��뷭��ɻ�����ԡ�
�û�����ʹ�á�-S��ѡ�������в鿴,��ѡ��ֻ���б���������л��,���ɻ����롣
ʵ��: gcc �CS test.i �Co test.s
���(������������ɻ�����ʶ������ƴ���)
�����ǰѱ�������ɵġ�.s���ļ�ת��Ŀ���ļ�
��ʹ��ѡ�-c���Ϳɿ�����������ת��Ϊ��.o���Ķ�����Ŀ�������
ʵ��: gcc �Cc test.s �Co test.o
����(���ɿ�ִ���ļ�����ļ�)
�ڳɹ�����֮��,�ͽ��������ӽ�(�γɿ�ִ�г���)��
ʵ��: gcc test.o �Co test
ʲô��������?
���ǵ�C������,��û�ж��塰printf���ĺ���ʵ��,����Ԥ�����а����ġ�stdio.h����Ҳֻ�иú���������,��û�ж��庯����ʵ��,��ô,��������ʵ��printf����������?
����:ϵͳ����Щ����ʵ�ֶ���������Ϊ libc.so.6 �Ŀ��ļ���ȥ��,��û���ر�ָ��ʱ,gcc �ᵽϵͳĬ�ϵ�����·����/usr/lib���½��в���,Ҳ�������ӵ� libc.so.6 �⺯����ȥ,��������ʵ�ֺ�����printf����,����Ҳ�������ӵ�����
������һ���Ϊ��̬��Ͷ�̬�����֡�
��̬��(�����ǽ���ؿ�Ĵ��뿽�����Լ��Ŀ�ִ�г�����ȥ)��ָ��������ʱ,�ѿ��ļ��Ĵ���ȫ�����뵽��ִ���ļ���,������ɵ��ļ��Ƚϴ�,��������ʱҲ�Ͳ�����Ҫ���ļ��ˡ������һ��Ϊ��.a��
��̬����֮�෴,�ڱ�������ʱ��û�аѿ��ļ��Ĵ�����뵽��ִ���ļ���,�����ڳ���ִ��ʱ������ʱ�����ļ����ؿ�,����������ʡϵͳ�Ŀ�������̬��һ�����Ϊ**��.so��**,��ǰ�������� libc.so.6 ���Ƕ�̬�⡣gcc �ڱ���ʱĬ��ʹ�ö�̬�������������֮��,gcc �Ϳ������ɿ�ִ���ļ�,������ʾ��
gcc test.o �Co test
gccĬ�����ɵĶ����Ƴ���,�Ƕ�̬���ӵ�,������ͨ�� file ������֤��
gccѡ��
-E ֻ����Ԥ����,����������ļ�,����Ҫ�����ض���һ������ļ�����
-S ���뵽������Բ����л�������
-c ���뵽Ŀ�����
-o �ļ������ �ļ�
-static ��ѡ������ɵ��ļ����þ�̬����
-g ���ɵ�����Ϣ��GNU �����������ø���Ϣ��
-shared ��ѡ�����ʹ�ö�̬��,���������ļ��Ƚ�С,������Ҫϵͳ�ɶ�̬��.
-O0��-O1��-O2��-O3 ���������Ż�ѡ���4������,-O0��ʾû���Ż�,-O1Ϊȱʡֵ,-O3�Ż��������
-w �������κξ�����Ϣ��
-Wall �������о�����Ϣ��
2.3Linux������-gdbʹ��
һ��ʹ�ñ���
����������˵��,Linux��,Ĭ�ϳ�������ʱ��,�Ƕ�̬����,�õĶ�̬�⡣����Ĭ�����ɵĿ�ִ�г�������release�汾��,�ڴ˰汾���Dz����Ե��Եġ�����Ҫ��������Ҫ���� -g ѡ��,����debugģʽ
debug vs release
1.һ�����Ե���,һ������
2.debug�����ɳ����ʱ�����������Ϣ,release��
������ʼʹ��
��������:
list/l �к�:��ʾ�ļ�Դ����,�����ϴε�λ��������,ÿ����10�С�
list/l ������:�г�ij��������Դ���롣
r��run:�����
n �� next:����ִ�С�
s��step:���뺯������
break(b) �к�:��ijһ�����öϵ�
break ������:��ij��������ͷ���öϵ�
info break :�鿴�ϵ���Ϣ��
finish:ִ�е���ǰ��������,Ȼ��ͦ�����ȴ�����
print��:��ӡ����ʽ��ֵ,ͨ������ʽ�����ı�����ֵ���ߵ��ú���
p ����:��ӡ����ֵ��
set var:�ı�����ֵ
continue(��c):�ӵ�ǰλ�ÿ�ʼ�������ǵ���ִ�г���
run(��r):�ӿ�ʼ�������ǵ���ִ�г���
delete breakpoints:ɾ�����жϵ�
delete breakpoints n:ɾ�����Ϊn�Ķϵ�
disable breakpoints:���öϵ�
enable breakpoints:���öϵ�
info(��i) breakpoints:�ο���ǰ��������Щ�ϵ�
display ������:���ٲ鿴һ������,ÿ��ͣ��������ʾ����ֵ
undisplay:ȡ������ǰ���õ���Щ�����ĸ���
until X�к�:����X��
breaktrace(��bt):�鿴�����������ü�����
info(i) locals:�鿴��ǰջ֡�ֲ�������ֵ
quit:�˳�gdb
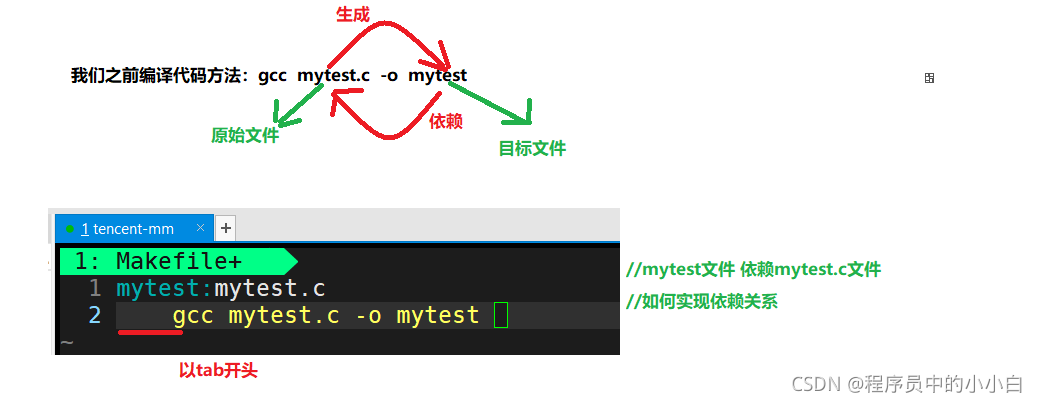
3��Linux��Ŀ�Զ�����������-make/Makefile
���:
1��makefile�����ĺô����ǡ������Զ������롱,һ��д��,ֻ��Ҫһ��make����,����������ȫ�Զ�����,��������������������Ч�ʡ�
2��make��һ�������,��һ������makefile��ָ��������,һ����˵,�������IDE(���ɿ�������)�����������,����:Delphi��make,Visual C++��nmake,Linux��GNU��make��makefile��Ϊ��һ���ڹ��̷���ı��뷽����
3��make��һ������,makefile��һ���ļ�,��������ʹ��,�����Ŀ�Զ���������
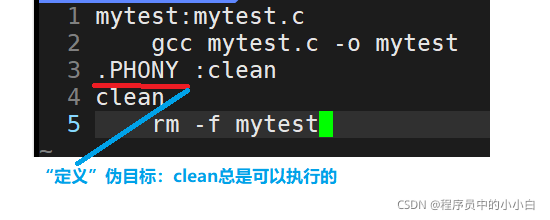
���Ŀ���ļ�:make clean ,Ҳ������.PHONY�ķ�ʽд��Makefile�ļ���
4��������
��������һ���ڴ�ռ�,�ݴ���ʱ����,�ٺ��ʵ�ʱ��ˢ�³�ȥ
ˢ�²���:
1��ֱ��ˢ��,������
2��������д��,��ˢ��,ȫ����
3������\n��ˢ��,��ˢ��(ˢ�µ���ʾ����)
4��ǿ��ˢ��(������������д����̡��ļ�����ʾ����������豸�����ļ���)