“‘«Α‘Ύ’“ΙΛΉςΒΡ ±ΚρΟφ ‘ΝΥ“Μ–©¥σ≥ß,Τδ÷–‘ΎΟφ ‘Ή÷ΫΎΧχΕ·ΚΆΑΔάοΑΆΑΆΒΡ ±Κρ,Ε‘”ΎK8S’βΩι,ΥϊΟ«Έ ΝΥ“ΜΗωœύΆ§ΒΡΈ Χβ:«κœξœΗΥΒΥΒ,”ΟΜß÷¥––ΝΥ“ΜΗωdeployment.yamlΈΡΦΰ ±,–¬¥¥Ϋ®ΝΥ“ΜΗωPod,’βΗωPodΒΡ¥¥Ϋ®Νς≥Χ «‘θ―υΒΡ, PodΒΡΗϋ–¬Νς≥Χ”÷ «‘θ―υΒΡΓΘΦρΕΧΒΡ“ΜΗωΈ Χβ,“Σ «œκ¥πΒΡœξœΗ,Τδ ΒΜΙ «…φΦΑΝΥK8S÷–ΒΡΚήΕύΕΪΈς,Έ“ΨθΒΡ’β «“ΜΒά±»Ϋœ”–÷ ΝΩΒΡΧβ,Έ“‘Ύœ÷≥Γ¥π≥ωά¥ΝΥ,‘Ύ’βάο,Έ“œκ‘ΌΉήΫα“Μœ¬,≤鬩≤Ι»±,Υψ «Ε‘Οφ ‘ΒΡΉήΫα,Ηϋ «Ε‘K8SΉ‘…μΒΡ―ßœΑΚΆ≥ΝΒμΓΘ
Έ“‘ΎΜΊ¥π’βΗωΈ ΧβΒΡ ±Κρ,Τδ ΒΆΖΡ‘άο¥σΗ≈ «”–“ΜΗωΝς≥ΧΆΦΒΡ,»ΜΚσ‘ΌΑ¥Ή≈¥”ΆΖΒΫΈ≤,÷π≤Ϋ’ΙΩΣΒΡΒΡ‘≠‘ρά¥œξœΗΥΒΟς,œ¬ΟφΨΆ≤Έ’’’βΖυΆΦ,‘Όά¥ΜΙ‘≠“ΜΗωPod±Μ¥¥Ϋ® ±ΒΡΝς≥ΧΓΘ
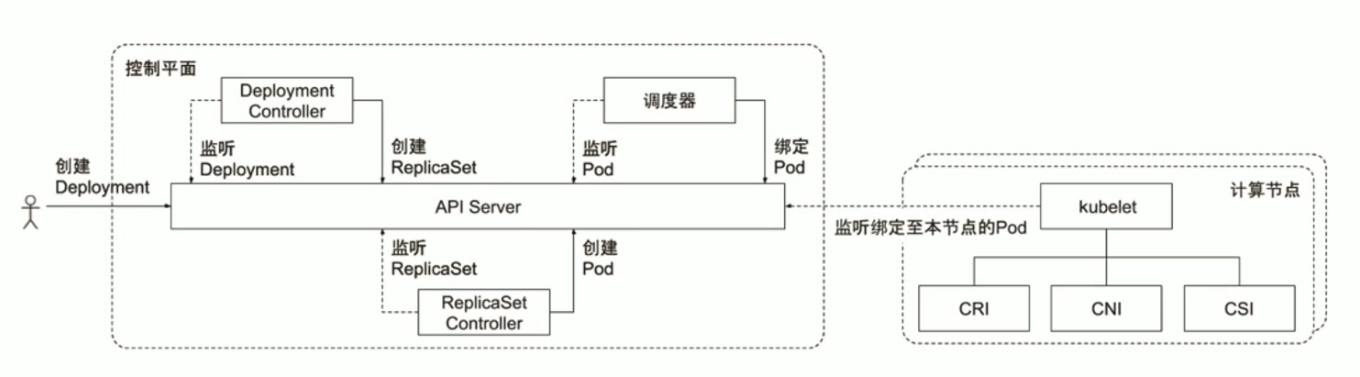
ΒΎ“Μ≤Ϋ:ΦΌ»γΈ“Ο«ΒΡdeployment.yaml÷– Ι”ΟΝΥNginxΨΒœώ,«“replicasΒΡ÷Β…η÷ΟΈΣ1,»ΜΚσ”ΟΜß÷¥––ΝΥkubectl create -f deployment.yamlΟϋΝνΓΘ
ΒΎΕΰ≤Ϋ:kubectl÷¥––yamlΈΡΦΰΚσ,Ε‘api-serverΖΔΤπΝΥ«κ«σ,’β ±api-serverΜαΕ‘¥Υ¥Έ≤ΌΉςΫχ––…μΖί»œ÷Λ,‘ΎΩΆΜßΕΥΒΡ~/.kubeΈΡ
ΦΰΦ–œ¬,“―Ψ≠…η÷ΟΚΟΝΥœύΙΊΒΡ”ΟΜß»œ÷Λ–≈œΔ,’β―υapi-serverΜα÷ΣΒάΈ“ «ΡΡΗω”ΟΜß,≤ΔΕ‘¥Υ”ΟΜßΫχ––Φχ»®,Β±api-server»ΖΕ®Έ“Ο«ΒΡ«κ«σΚœΖ®Κσ,ΨΆΜαΫ” ή±Ψ¥Έ≤ΌΉς,≤ΔΑ―œύΙΊΒΡ–≈œΔ±Θ¥φΒΫetcd÷–ΓΘ
ΒΎ»ΐ≤Ϋ:œ¬Οφcontroller-managerΉιΦΰΨΆΜαΫι»κ,controller-manager «”–ΕύΗωάύ–ΆΒΡ,±»»γDeployment Controller, ΥϋΒΡΉς”ΟΨΆ «ΗΚ‘πΦύΧΐDeployment,¥Υ ±Deployment ControllerΖΔœ÷Έ“Ο«ΒΡdeployment.yamlΈΡΦΰΥΏ«σ «–η“Σ“ΜΗωΗ¥±ΨΦ·«“ ΐΝΩΈΣ1,Ρ«Ο¥ΥϋΨΆΜα»Ξ¥¥Ϋ®“ΜΗωReplicaSet,“ΜΗωReplicaSetΒΡ≤ζ…ζ,”÷±ΜΝμ“ΜΗωΫ–ΉωReplicaSetΒΡControllerΦύΧΐΒΫΝΥ,ΫτΫ”Ή≈ΥϋΨΆΜα»ΞΖ÷ΈωReplicaSetΒΡ”ο“ε,ΥϋΝΥΫβΒΫ «“Σ“ά’’ReplicaSetΒΡtemplate»Ξ¥¥Ϋ®Pod, Υϋ“ΜΩ¥’βΗωPod≤Δ≤Μ¥φ‘Ύ,Ρ«Ο¥ΨΆ–¬Ϋ®¥ΥPod,Β±PodΗ’±Μ¥¥Ϋ® ±,ΥϋΒΡnodeName τ–‘÷ΒΈΣΩ’,¥ζ±μΉ≈¥ΥPodΈ¥±ΜΒςΕ»ΓΘ
ΒΎΥΡ≤Ϋ:ΒςΕ»ΙΛΉςΉ‘»Μ «”…SchedulerΉιΦΰά¥Άξ≥…ΒΡ,Scheduler“Μ÷±ΙΊΉΔPodΦΑNodeΒΡ–≈œΔ,Υυ“‘ΥϋΨΆ“ΣΑ―Έ¥±ΜΒςΕ»ΒΡPod,ΒςΕ»ΒΫΚœ ΒΡNode…œ»ΞΓΘΒΪ «ΥϋΥυΉωΒΡ“≤÷Μ «Α―ΥϋΒΡΒςΕ»ΖΫΑΗ,ΖΒΜΊΗχapi-serverΓΘ
ΒΎΈε≤Ϋ:kubeletΉιΦΰ≤Φ π”ΎNode÷°…œ,Υϋ¥”api-server¥Π÷ΣΒά”–“ΜΗωPod”ΠΗΟ“Σ±ΜΒςΕ»ΒΫΉ‘…μΥυ‘ΎNode…œά¥,ΥϋΜαœ»≈–Εœ±ΨΒΊ «Ζώ‘Ύ¥ΥPod,»γΙϊ≤Μ¥φ‘Ύ,‘ρΜαΫχ»κ¥¥Ϋ®PodΝς≥Χ,¥¥Ϋ®Pod”–Ζ÷ΈΣΦΗ÷÷«ιΩω,ΒΎ“Μ÷÷ «»ίΤς≤Μ–η“ΣΙ“‘ΊΆβ≤Ω¥φ¥Δ,‘ρœύΒ±”Ύ÷±Ϋ”docker runΑ―»ίΤςΤτΕ·,ΒΪ≤ΜΜα÷±Ϋ”Ι“‘ΊdockerΆχ¬γ,Εχ «Ά®ΙΐCNIΒς”ΟΆχ¬γ≤εΦΰ≈δ÷Ο»ίΤςΆχ¬γ,»γΙϊ–η“ΣΙ“‘ΊΆβ≤Ω¥φ¥Δ,‘ρΜΙ“ΣΒς”ΟCSIά¥Ι“‘Ί¥φ¥ΔΓΘ
ΒΎΝυ≤Ϋ:PodΫ®ΝΔ≥…ΙΠΚσ,ReplicaSet ControllerΜαΕ‘Τδ≥÷–χΫχ––ΙΊΉΔ,»γΙϊNginx Pod“ρ“βΆβΜρ±ΜΈ“Ο« ÷Ε·ΆΥ≥ω,ReplicaSet ControllerΜα÷ΣΒά,≤Δ¥¥Ϋ®–¬ΒΡPod,“‘±Θ≥÷replicas ΐΝΩΤΎΆϊ÷ΒΓΘ
ΒΎΤΏ≤Ϋ:Ηϋ–¬Pod, ≤Ο¥ ±ΚρΜαΗϋ–¬Pod? Β±deployment.yamlΈΡΦΰ÷–templateΒΡ≤ΩΖ÷±ΜΗϋ–¬,ΨΆΜα¥ΞΖΔPodΗϋ–¬,“ρΈΣDeployment Controller ΜαΑ―template≤ΩΖ÷ΈΡ±ΨΦΤΥψ“ΜΗωhash÷Β,ΗυΨί’βΗωhash÷Β≈–ΕœΈΡ±Ψ±δΜ·ΓΘ
ΒΎΑΥ≤Ϋ:Φ»»Μ¥ΞΖΔΝΥΗϋ–¬,Ρ«Ο¥ReplicaSet ControllerΨΆΜα–¬Ϋ®“ΜΗωReplicaSet≤Δ‘ΎΤδ÷–ΤτΕ·–¬ΒΡPod,‘ΎάœΒΡReplicaSetάοΙΊ±’Pod,÷±ΒΫ–¬ΒΡReplicaSetΫ”ΧφάœΒΡReplicaSetΓΘ
ΉήΫα:
Ω…“‘Ω¥ΒΫ,Ε‘”Ύ“ΜΗωΦρΒΞΒΡΈ Χβ,Ω…“‘ΜΊ¥πΒΡΡΎ»ίΜΙ «ΚήΕύ,Έ“œύ–≈…œ ωΡΎ»ί,»γΙϊΟφ ‘ΙΌ≤Μ «“Σ«σΡψΕ‘‘¥¬κ…œ λœΛ”κΩΣΖΔ,“―Ψ≠ΜΊ¥πΒΡ±»ΫœœξΨΓΝΥΓΘΈ“Ϋ®“ι‘ΎΟφ ‘ΒΡ ±Κρ,»γΙϊΟφ ‘ΙΌΈ ΝΥ“ΜΗωΡψ±»Ϋœ λΜρΨΪΆ®ΒΡΈ Χβ,Ρ«Ο¥Ρψ”ΠΗΟΉΞΉΓΜζΜαΨΓΩ…ΡήΒΡΑ―’βΗωΈ ΧβΫ≤…ν,Ϋ≤Ιψ,»γΙϊΟφ ‘ΙΌ≤ΜΫ–ΆΘ,…θ÷ΝΩ…“‘Α―”κ¥ΥœύΙΊΒΡΕΪΈςΥΒ≥ωά¥ΓΘΡψ÷ΣΒά’β―υΉωΒΡΡΩΒΡ¬π?Ω…“‘‘ΎΤά¬έ¥Π”κ“ΜΧ÷¬έ : )
?