java数据容器复习
数组
内存上是连续存储的,栈变量指向的数组第一个内存地址
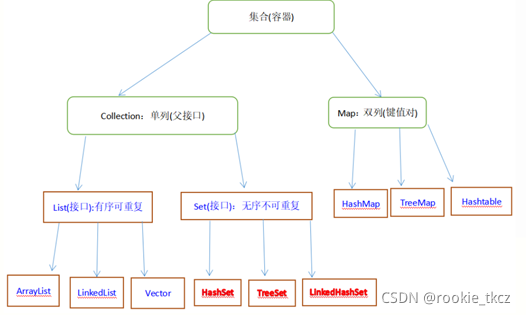
java集合继承结构关系
Iterable与Iterator
三种遍历方法: for 、for Each,Iterator
Iterator
提供了两个方法:
boolean hasNext();
E next(); //返回一后个E的类型
Iterable
是对iterator的封装,继承了Iterable可以使用for each循环

default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
for(Integer i:list){
System.out.print(i);
}
//反编译:
Integer i;
for(Iterator iterator = list.iterator(); iterator.hasNext(); System.out.println(i)){
i = (Integer)iterator.next();
}
for each通过迭代器iterator来进行,其中获取未遍历的元素iterator.hasNext(),输出类型转换后的iterator.next()
Collection
public class CollectionTest01 {
public static void main(String[] args) {
Collection ar = new ArrayList();
ar.add(1);
ar.add(2);
ar.add(3);
ar.add(4);
System.out.println(ar.isEmpty());
System.out.println(ar.size());
System.out.println(ar.contains(3));
System.out.println(ar.hashCode()); //int
System.out.println(ar.remove(new Integer(3)));
System.out.println(Arrays.toString(ar.toArray())); //Object[]
ar.clear(); //清空
// false
// 4
// true
// 955331
// [1, 2, 3, 4]
Collection<A> testA =new ArrayList<A>();
testA.add(new A("bob"));
testA.add(new A("jack"));
A jack = new A("jack");
System.out.println(testA.contains(jack));
}
static class A{
public A(String name) {
this.name = name;
}
public String name;
}
}
- 特点方法
contains和remove
这里面重写了equals方法,对于testA存的是对象地址,基本数据类型可以进行比较行为重写equals,但是对于自定义引用类型,没有重写equals
@Override
public boolean equals(Object obj) {
return this.name.equals(((A)obj).name) ? true:false;
}
重写后为true
LinkedList
底层为双向链表
链表(节点,前后指针,上一个节点的next指针指向下一个节点,pre指向上了节点)
LinkedList可以作为队列(双端队列),

ArrayList

默认初始容量为10,不够就扩容为原来的1.5倍
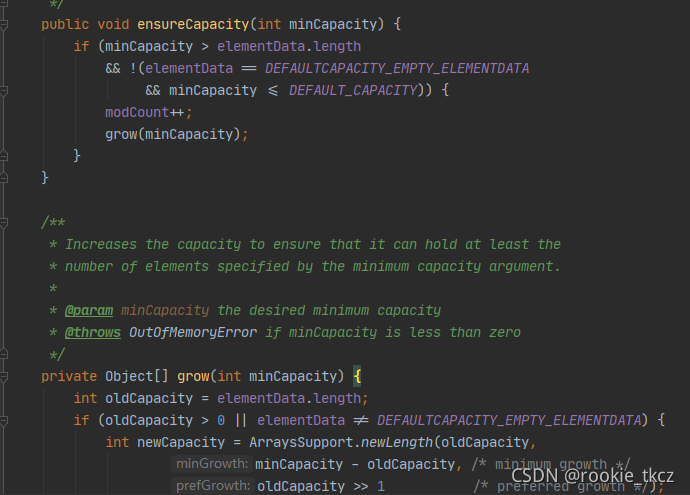
Vector
线程安全的。初始容量为10,每一次扩容都*2,方法里面被synchronized
数组和链表
1、数组内存连续,链表不是
2、数组查询快,内存计算,链表查询需要遍历指针,增删除节点快
Map
1、key-value,底层为Node数组,
2、Map<key,value>存和取对应map.get()与,Map.put()
put(key,value):
- 先封装到Node中
- 计算key的hashcode()得到hash
- hash值计算得到数组下标,没有没有这个下标就添加到下标。有就进行key.equals与链表的每一个值进行比较,没有相等的就添加到末尾,有就替换
get(k): - 先计算hashcode()得到hash值――》数组下标,然后到数组下标下面去和链表的每一个key比较,返回value
3、Map的遍历
(for-each+iterate)(键)+entrySet(底层node)
public class MapTest01 {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<>();
map.put(1,"w");
map.put(2,"m");
map.put(3,"l");
map.put(4,"j");
map.put(5,"k");
Set<Integer> set = map.keySet();
for(Integer key:set){
System.out.println("key=" + key+" ,"+"value="+map.get(key));
}
System.out.println("-------------------------------------------------");
Iterator<Integer> it = set.iterator();
while (it.hasNext()){
Integer key = it.next();
String value = map.get(key);
System.out.println("key=" + key+" ,"+"value="+value);
}
System.out.println("-------------------------------------------------");
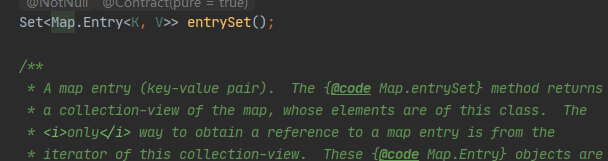
Set<Map.Entry<Integer,String>> set1 = map.entrySet();
//每次取出一个node
Iterator<Map.Entry<Integer,String>> it2 = set1.iterator();
while (it2.hasNext()){
Map.Entry<Integer,String> node = it2.next();
Integer key = node.getKey();
String value = node.getValue();
System.out.println("key=" + key+" ,"+"value="+value);
}
}
}
关于HashSet就是hashMap的键
注意点:
自定义引用对象需要重写equals和Hashcode()
不写equals:计算后成为在链表中添加,应为equals计算得到的key不等
不写hashcode:就是数组,每个对象计算的hashcode不等,就是数组一直加长
背诵:
HashSet中key无序不重复hashmap初始容量2的倍数
Hashmap中key可以为null
Hashtable中key和value都不能为空,线程安全,效率低,不常用
treeSet
1、有序的

可以根据指定的比较器进行比较
2、自定以类型添加需要重写
public class TreeSetTest01 {
public static void main(String[] args) {
TreeSet<Student> ts = new TreeSet<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.id-o2.id;
}
});
ts.add(new Student(10,"python"));
ts.add(new Student(1,"java"));
ts.add(new Student(2,"c")); // cannot be cast to class java.lang.Comparable
ts.add(new Student(5,"c"));
System.out.println(ts.toString());
}
static class Student{
int id;
String name;
public Student(int id, String name) {
this.id = id;
this.name = name;
}
/*
@Override
public int compareTo(Object o) {
return this.id-((Student)o).id;
}
*/
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
/*
@Override
public int compare(Object o1, Object o2) {
return ((Student) o1).id - ((Student) o1).id ;
}
实现comparator接口
*/
}
}
只需要一个比较用comparable(匿名内部类,就只用一次,就在这个类中用下,其他中不需要)
多个切换就用comparator