д��ǰ��
- ѧϰK8s,������������
- ��������Դ��
��KubernetesȨ��ָ��:��Docker��Kubernetesʵ��ȫ�Ӵ�����һ��,����ȤС������֧������һ��
һ���������Լ�����,�����Կ��ֵġ�-------��ë
һ������
Kubernetes�еĴָ�����Node, Pod,Replication Controller, Service�ȶ����Կ���һ�֡���Դ������,�������е���Դ������ͨ��Kubernetes�ṩ��kubect����(����API��̵���)ִ������ɾ���ġ���Ȳ��������䱣����etcd�г־û��洢��������Ƕ�����,Kubernetes��ʵ��һ���߶��Զ�������Դ����ϵͳ,��ͨ��`���ٶԱ�etcd���ﱣ��ġ���Դ����״̬���뵱ǰ�����еġ�ʵ����Դ״̬���IJ�����ʵ���Զ����ƺ��Զ������ĸ����ܡ�
K8s�������Դ:��汾�仯
������[root@vms81.liruilongs.github.io]-[~/ansible/k8s-pod-create]
����$kubectl api-resources
| NAME(����) | SHORTNAMES(���) | APIVERSION(�汾) | NAMESPACED(�����ռ����) | KIND(����) |
|---|---|---|---|---|
| bindings | v1 | true | Binding | |
| componentstatuses | cs | v1 | false | ComponentStatus |
| configmaps | cm | v1 | true | ConfigMap |
| endpoints | ep | v1 | true | Endpoints |
| events | ev | v1 | true | Event |
| limitranges | limits | v1 | true | LimitRange |
| namespaces | ns | v1 | false | Namespace |
| nodes | no | v1 | false | Node |
| persistentvolumeclaims | pvc | v1 | true | PersistentVolumeClaim |
| persistentvolumes | pv | v1 | false | PersistentVolume |
| pods | po | v1 | true | Podpodtemplates |
| replicationcontrollers | rc | v1 | true | ReplicationController |
| resourcequotas | quota | v1 | true | ResourceQuota |
| secrets | v1 | true | Secret | |
| serviceaccounts | sa | v1 | true | ServiceAccount |
| services | svc | v1 | true | Service |
| mutatingwebhookconfigurations | admissionregistration.k8s.io/v1 | false | MutatingWebhookConfiguration | |
| validatingwebhookconfigurations | admissionregistration.k8s.io/v1 | false | ValidatingWebhookConfiguration | |
| customresourcedefinitions | crd,crds | apiextensions.k8s.io/v1 | false | CustomResourceDefinition |
| apiservices | apiregistration.k8s.io/v1 | false | APIService | |
| controllerrevisions | apps/v1 | true | ControllerRevision | |
| daemonsets | ds | apps/v1 | true | DaemonSet |
| deployments | deploy | apps/v1 | true | Deployment |
| replicasets | rs | apps/v1 | true | ReplicaSet |
| statefulsets | sts | apps/v1 | true | StatefulSet |
| tokenreviews | authentication.k8s.io/v1 | false | TokenReview | |
| localsubjectaccessreviews | authorization.k8s.io/v1 | true | LocalSubjectAccessReview | |
| selfsubjectaccessreviews | authorization.k8s.io/v1 | false | SelfSubjectAccessReview | |
| selfsubjectrulesreviews | authorization.k8s.io/v1 | false | SelfSubjectRulesReview | |
| subjectaccessreviews | authorization.k8s.io/v1 | false | SubjectAccessReview | |
| horizontalpodautoscalers | hpa | autoscaling/v1 | true | HorizontalPodAutoscaler |
| cronjobs | cj | batch/v1 | true | CronJob |
| jobs | batch/v1 | true | Jobcertificatesigningrequests | |
| leases | coordination.k8s.io/v1 | true | Lease | |
| bgpconfigurations | crd.projectcalico.org/v1 | false | BGPConfiguration | |
| bgppeers | crd.projectcalico.org/v1 | false | BGPPeer | |
| blockaffinities | crd.projectcalico.org/v1 | false | BlockAffinity | |
| clusterinformations | crd.projectcalico.org/v1 | false | ClusterInformation | |
| felixconfigurations | crd.projectcalico.org/v1 | false | FelixConfiguration | |
| globalnetworkpolicies | crd.projectcalico.org/v1 | false | GlobalNetworkPolicy | |
| globalnetworksets | crd.projectcalico.org/v1 | false | GlobalNetworkSet | |
| hostendpoints | crd.projectcalico.org/v1 | false | HostEndpoint | |
| ipamblocks | crd.projectcalico.org/v1 | false | IPAMBlock | |
| ipamconfigs | crd.projectcalico.org/v1 | false | IPAMConfig | |
| ipamhandles | crd.projectcalico.org/v1 | false | IPAMHandle | |
| ippools | crd.projectcalico.org/v1 | false | IPPool | |
| kubecontrollersconfigurations | crd.projectcalico.org/v1 | false | KubeControllersConfiguration | |
| networkpolicies | crd.projectcalico.org/v1 | true | NetworkPolicy | |
| networksets | crd.projectcalico.org/v1 | true | NetworkSet | |
| endpointslices | discovery.k8s.io/v1 | true | EndpointSlice | |
| events | ev | events.k8s.io/v1 | true | Event |
| flowschemas | flowcontrol.apiserver.k8s.io/v1beta1 | false | FlowSchema | |
| prioritylevelconfigurations | flowcontrol.apiserver.k8s.io/v1beta1 | false | PriorityLevelConfiguration | |
| nodes | metrics.k8s.io/v1beta1 | false | NodeMetrics | |
| pods | metrics.k8s.io/v1beta1 | true | PodMetrics | |
| ingressclasses | networking.k8s.io/v1 | false | IngressClass | |
| ingresses | ing | networking.k8s.io/v1 | true | Ingress |
| networkpolicies | netpol | networking.k8s.io/v1 | true | NetworkPolicy |
| runtimeclasses | node.k8s.io/v1 | false | RuntimeClass | |
| poddisruptionbudgets | pdb | policy/v1 | true | PodDisruptionBudget |
| podsecuritypolicies | psp | policy/v1beta1 | false | PodSecurityPolicy |
| clusterrolebindings | rbac.authorization.k8s.io/v1 | false | ClusterRoleBinding | |
| clusterroles | rbac.authorization.k8s.io/v1 | false | ClusterRole | |
| rolebindings | rbac.authorization.k8s.io/v1 | true | RoleBinding | |
| roles | rbac.authorization.k8s.io/v1 | true | Role | |
| priorityclasses | pc | scheduling.k8s.io/v1 | false | PriorityClass |
| csidrivers | storage.k8s.io/v1 | false | CSIDriver | |
| csinodes | storage.k8s.io/v1 | false | CSINode | |
| csistoragecapacities | storage.k8s.io/v1beta1 | true | CSIStorageCapacity | |
| storageclasses | sc | storage.k8s.io/v1 | false | StorageClass |
| volumeattachments | storage.k8s.io/v1 | false | VolumeAttachment |
����Kubernetes��Ⱥ�����ֹ�����ɫ: Master��Node
Master��Node |
|---|
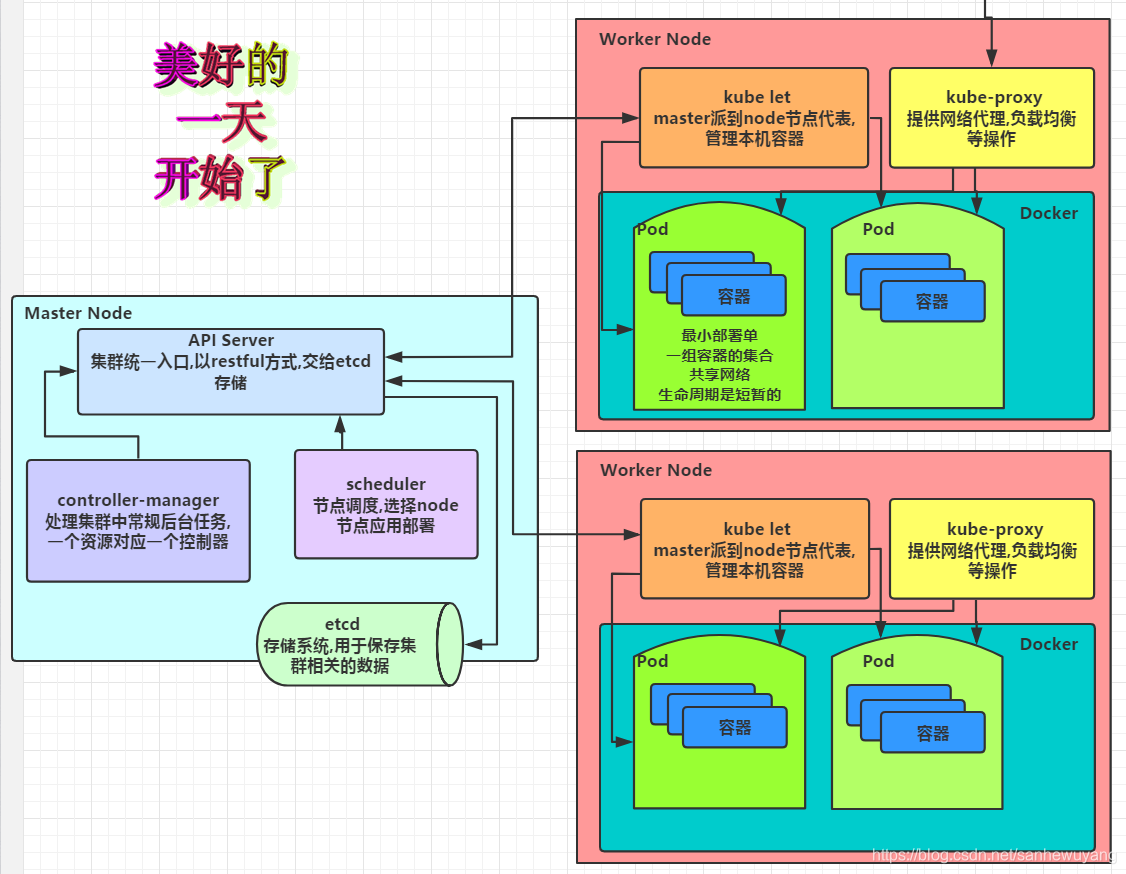 |
1��Master��ɫ
Kubernetes���Masterָ���� ��Ⱥ���ƽڵ�,ÿ��Kubernetes��Ⱥ����Ҫ��һ��Master�ڵ�������������Ⱥ�Ĺ����Ϳ���,������Kubernetes�����п������������,������������ִ�й���,���Ǻ���ִ�е������������������Master�ڵ������еġ�
Master�ڵ�ͨ����ռ��һ�������ķ�����(�߿��ò�������3̨������),����Ҫԭ������̫��Ҫ��,��������Ⱥ�ġ�������,���崻����߲�����,��ô�Լ�Ⱥ������Ӧ�õĹ�������ʧЧ��Master�ڵ�������������һ��ؼ����̡�
| Master�ڵ��Ϲؼ����� | �C |
|---|---|
Kubernetes API Server (kube-apiserver) | �ṩ��HTTP Rest�ӿڵĹؼ��������,��Kubernetes��������Դ������ɾ���ġ���Ȳ�����Ψһ���,Ҳ�Ǽ�Ⱥ���Ƶ���ڽ��̡� |
Kubernetes Controller Manager (kube-controller-manager) | Kubernetes��������Դ������Զ�����������,��������Ϊ��Դ����ġ����ܹܡ��� |
Kubernetes Scheduler (kube-scheduler) | ������Դ����(Pod����)�Ľ���,�൱�ڹ�����˾�ġ������ҡ��� |
etcd | ��Master�ڵ��ϻ���Ҫ����һ��etcd����,��ΪKubernetes���������Դ���������ȫ���DZ�����etcd�еġ� |
����Master, Kubernetes��Ⱥ�е�������������ΪNode�ڵ�
2��Node��ɫ
�ڽ���İ汾��Ҳ����ΪMiniono��Masterһ��, Node�ڵ������һ̨��������,Ҳ������һ̨������� Node�ڵ����Kubermetes��Ⱥ�еĹ������ؽڵ�,ÿ��Node���ᱻMaster����һЩ��������(Docker����),��ij��Node崻�ʱ,���ϵĹ������ػᱻMaster�Զ�ת�Ƶ������ڵ���ȥ��
ÿ��Node�ڵ��϶�����������һ��ؼ����̡�
| ÿ��Node�ڵ��϶����йؼ����� | �C |
|---|---|
kubelet | ����Pod��Ӧ�������Ĵ�������ͣ������,ͬʱ��Master�ڵ�����Э��,ʵ�ּ�Ⱥ�����Ļ������ܡ� |
kube-proxy | ʵ��Kubernetes Service��ͨ���븺�ؾ����������Ҫ�����) |
Docker Engine | (docker): Docker����,���𱾻��������������������� |
Node�ڵ�����������ڼ䶯̬���ӵ�Kubernetes��Ⱥ��,ǰ��������ڵ����Ѿ���ȷ��װ�����ú������������ؼ�����,��Ĭ�������kubelet����Masterע���Լ�,��Ҳ��Kubernetes�Ƽ���Node������ʽ��
һ��Node�����뼯Ⱥ������Χ, kubelet���̾ͻᶨʱ��Master�ڵ�㱨�������鱨,�������ϵͳ��Docker�汾��������CPU���ڴ����,�Լ���ǰ����ЩPod�����е�,����Master���Ի�֪ÿ��Node����Դʹ�����,��ʵ�ָ�Ч�������Դ���Ȳ��ԡ���ij��Node����ָ��ʱ�䲻�ϱ���Ϣʱ,�ᱻMaster�ж�Ϊ��ʧ��", Node��״̬�����Ϊ������(Not Ready),���Master�ᴥ�����������ش�ת�ơ����Զ����̡�
�鿴��Ⱥ�е�Node�ڵ�ͽڵ����ϸ��Ϣ
������[root@vms81.liruilongs.github.io]-[~]
����$kubectl get nodes
NAME STATUS ROLES AGE VERSION
vms81.liruilongs.github.io Ready control-plane,master 47d v1.22.2
vms82.liruilongs.github.io Ready worker1 47d v1.22.2
vms83.liruilongs.github.io NotReady worker2 47d v1.22.2
������[root@vms81.liruilongs.github.io]-[~]
����$kubectl describe node vms82.liruilongs.github.io
# Node������Ϣ:���ơ���ǩ������ʱ��ȡ�
Name: vms82.liruilongs.github.io
Roles: worker1
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
disktype=node1
kubernetes.io/arch=amd64
kubernetes.io/hostname=vms82.liruilongs.github.io
kubernetes.io/os=linux
node-role.kubernetes.io/worker1=
Annotations: dest: ����һ�������ڵ�
kubeadm.alpha.kubernetes.io/cri-socket: /var/run/dockershim.sock
node.alpha.kubernetes.io/ttl: 0
projectcalico.org/IPv4Address: 192.168.26.82/24
projectcalico.org/IPv4IPIPTunnelAddr: 10.244.171.128
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Thu, 07 Oct 2021 01:15:45 +0800
Taints: <none>
Unschedulable: false
Lease:
HolderIdentity: vms82.liruilongs.github.io
AcquireTime: <unset>
RenewTime: Tue, 23 Nov 2021 23:08:16 +0800
# Node��ǰ������״̬, Node�����Ժ����һϵ�е��Լ칤��:
# ��������Ƿ�����,������˾ͱ�עOutODisk=True
# �����������ڴ��Ƿ���(����ڴ治��,�ͱ�עMemoryPressure=True)
# ���һ������,������ΪReady״̬(Ready=True)
# ��״̬��ʾNode���ڽ���״̬, Master�����������ϵ����µ�������(������Pod)
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason
Message
---- ------ ----------------- ------------------ ------
-------
NetworkUnavailable False Tue, 23 Nov 2021 23:02:52 +0800 Tue, 23 Nov 2021 23:02:52 +0800 CalicoIsUp
Calico is running on this node
MemoryPressure False Tue, 23 Nov 2021 23:05:32 +0800 Tue, 23 Nov 2021 22:45:03 +0800 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Tue, 23 Nov 2021 23:05:32 +0800 Tue, 23 Nov 2021 22:45:03 +0800 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Tue, 23 Nov 2021 23:05:32 +0800 Tue, 23 Nov 2021 22:45:03 +0800 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Tue, 23 Nov 2021 23:05:32 +0800 Tue, 23 Nov 2021 22:45:03 +0800 KubeletReady
kubelet is posting ready status
# Node��������ַ����������
Addresses:
InternalIP: 192.168.26.82
Hostname: vms82.liruilongs.github.io
# Node�ϵ���Դ����:����Node���õ�ϵͳ��Դ,����CPU���ڴ����������ɵ���Pod������,ע�ĿǰKubernetes�Ѿ�ʵ���Ե�֧��GPU��Դ������(alpha.kubernetes.io/nvidia-gpu=0)
Capacity:
cpu: 2
ephemeral-storage: 153525Mi
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 4030172Ki
pods: 110
# Node�ɷ�����Դ��:����Node��ǰ�����ڷ������Դ����
Allocatable:
cpu: 2
ephemeral-storage: 144884367121
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 3927772Ki
pods: 110
# ����ϵͳ��Ϣ:����������Ψһ��ʶUUID, Linux kernel�汾�š�����ϵͳ������汾��Kubernetes�汾�š�kubelet��kube-proxy�İ汾�ŵȡ�
System Info:
Machine ID: 1ee67b1c4230405a851cf0107d6e89f5
System UUID: C0EA4D56-ED9A-39CF-6942-5B66704F6E6F
Boot ID: b0e42864-9778-4ded-af4c-a88a64f988db
Kernel Version: 3.10.0-693.el7.x86_64
OS Image: CentOS Linux 7 (Core)
Operating System: linux
Architecture: amd64
Container Runtime Version: docker://20.10.9
Kubelet Version: v1.22.2
Kube-Proxy Version: v1.22.2
PodCIDR: 10.244.1.0/24
PodCIDRs: 10.244.1.0/24
# ��ǰ�������е�Pod�б���Ҫ��Ϣ
Non-terminated Pods: (3 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
kube-system calico-node-ntm7v 250m (12%) 0 (0%) 0 (0%) 0 (0%) 47d
kube-system kube-proxy-nzm24 0 (0%) 0 (0%) 0 (0%) 0 (0%) 35d
kube-system metrics-server-bcfb98c76-wxv5l 0 (0%) 0 (0%) 0 (0%) 0 (0%) 27m
# �ѷ������Դʹ�ø�Ҫ��Ϣ,������Դ�������͡��������ʹ����ռϵͳ�����İٷֱȡ�
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 250m (12%) 0 (0%)
memory 0 (0%) 0 (0%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
# Node��ص�Event��Ϣ��
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal NodeHasSufficientMemory 23m (x3 over 3d4h) kubelet Node vms82.liruilongs.github.io status is now: NodeHasSufficientMemory
Normal NodeHasNoDiskPressure 23m (x3 over 3d4h) kubelet Node vms82.liruilongs.github.io status is now: NodeHasNoDiskPressure
Normal NodeHasSufficientPID 23m (x3 over 3d4h) kubelet Node vms82.liruilongs.github.io status is now: NodeHasSufficientPID
Normal NodeReady 23m (x2 over 3d4h) kubelet Node vms82.liruilongs.github.io status is now: NodeReady
������[root@vms81.liruilongs.github.io]-[~]
����$
�ܽ�һ��,����Ҫ����k8s,�ڹ����ڵ���������ô����,����ͨ��kube-apiserver�������û�������,ͨ��kubu-scheduler��������Դ�ĵ���,��ʹ��work1����ڵ�����������ʹ��work2����ڵ�������,Ȼ����ÿ���ڵ���Ҫ����һ����������kubelet,��������ÿ���ڵ�IJ���,����ÿ���ڵ��״̬,�Ƿ����Dz�֪��,����������Ҫkube-controller-manager
3�� Pod��Դ����
Pod��Kubernetes������ҪҲ������ĸ���,
ÿ��Pod����һ������ı���Ϊ������������Pause������Pause������Ӧ�ľ�������Kubernetesƽ̨��һ����,����Pause����,ÿ��Pod������һ������������ص��û�ҵ��������
Pause����
ΪʲôKubernetes����Ƴ�һ��ȫ�µ�Pod�ĸ����Pod�������������ɽṹ? |
|---|
ԭ��֮һ:��һ��������Ϊһ����Ԫ�������,�������Զԡ����塱�ؽ����жϼ���Ч�ؽ����ж�������ҵ���ز��Ҳ���������Pause������ΪPod�ĸ�����,������״̬���������������״̬,�ͼ�����ؽ����������⡣ |
ԭ��֮��: Pod������ҵ����������Pause������IP,����Pause�����ҽӵ�Volume,�����ȼ������й�����ҵ������֮���ͨ������,Ҳ�ܺõؽ��������֮����ļ��������⡣ |
Pod IP
Kubernetes Ϊÿ��Pod��������Ψһ��IP��ַ,��֮ΪPod IP,һ��Pod��Ķ����������Pod IP��ַ�� KuberetesҪ��ײ�����֧�ּ�Ⱥ����������Pod֮���TCP/Pֱ��ͨ��,��ͨ����������������缼����ʵ��(��·������),
��
Kubernetes��,һ��Pod������������������ϵ�Pod�����ܹ�ֱ��ͨ�š�
��ͨ��Pod����̬Pod (Static Pod)
Pod��ʵ����������:��ͨ��Pod����̬Pod (Static Pod),���ʹ��kubeadm�ķ�ʽ����,��̬pod��node�ڵ��master�ڵ㴴�����в�ͬ
| Pod�������� | ���� |
|---|---|
��̬Pod (Static Pod) | �� �������Kubernetes��etcd�洢 ��,���Ǵ����ij�������Node�ϵ�һ�������ļ���,����ֻ�ڴ�Node���������С� |
��ͨ��Pod | һ��������,�ͻᱻ���뵽etcd�д洢,���ᱻKubernetes Masten���ȵ�ij�������Node�ϲ����а�(Binding),����Pod����Ӧ��Node�ϵ�kubelet����ʵ������һ����ص�Docker���������������� |
���������,pod����master��ͳһ������,��ν��̬pod����,��������master�ϴ������ȵ�,������node�����ص�pod,��node��ֻҪ����kubelet֮��,�ͻ��Զ��Ĵ�����pod����������Ļ�,���java��̬��Ϥ,��̬��������,����node�ڵ��ʼ����ʱ����Ҫ������һЩpod
���� kubeadm�İ�װk8s�Ļ�,���Եķ�����ͨ�������ķ�ʽ���еġ���Ƚ϶����Ƶķ�ʽ����ܶ�,����Ļ�,��ô�漰��master�ڵ����������û��k8s����ʱ���������,����master�ڵ��,������漰����̬pod�����⡣
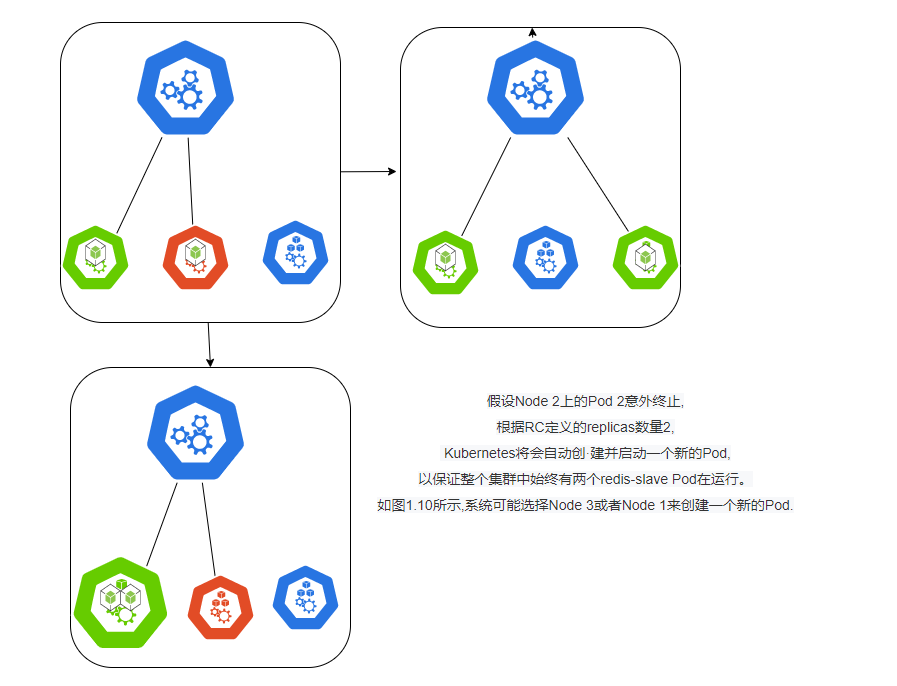
��Ĭ�������,��Pod���ij������ֹͣʱ,Kubernetes���Զ���������Ⲣ�������������Pod(����Pod�����������),���Pod���ڵ�Node崻�,��Ὣ���Node�ϵ�����Pod���µ��ȵ������ڵ���.
| �C |
|---|
 |
Kubernetes���������Դ�����Բ���yaml����JSON��ʽ���ļ������������,������������֮ǰHello World�������õ���myweb���Pod����Դ�����ļ�:
apiVersion: v1
kind: Pod # Pod ����
metadata:
name: myweb # Pod ����
lables:
name: myweb
spec: # ������������
containers:
- name: myweb
image: kubeguide/tomcat-app:v1
ports:
- containerPort: 8080
env:
- name: MYSQL_SERVICE_HOST
value: 'mysql'
- name: MYSQL_SERVICE_PORT
value: '3306'
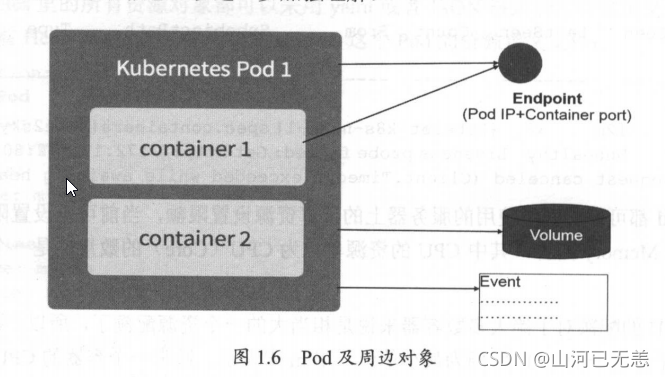
Kubernetes��Event����, Event��һ���¼��ļ�¼,��¼���¼����������ʱ�䡢�������ʱ�䡢�ظ������������ߡ�����,�Լ����´��¼���ԭ����ڶ���Ϣ��Eventͨ���������ij���������Դ������,���Ų���ϵ���Ҫ�ο���Ϣ,
Podͬ����Event��¼,�����Ƿ���ij��Pod�ٳ�������ʱ,������kubectl describe pod xxxx���鿴����������Ϣ,������λ�����ԭ��
��Kubernetes��,һ��������Դ�����������Ҫ�趨��������������
| ������Դ��������� |
|---|
| Requests:����Դ����С������,ϵͳ��������Ҫ�� |
| Limits:����Դ�������ʹ�õ���,���ܱ�ͻ��,��������ͼʹ�ó������������Դʱ,���ܻᱻKubernetes Kill�������� |
ͨ�����ǻ��Request����Ϊһ���Ƚ�С����ֵ,��������ƽʱ�Ĺ�����������µ���Դ����,����Limit����Ϊ��ֵ�����������Դռ�õ��������
����������ζ���,����MysQL������������0.25��CPU��64MiB�ڴ�,�����й�����MySQL��������ʹ�õ���Դ���Ϊ0.5��CPU��128MiB�ڴ�:
....
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
...
Pod Pod �ܱ߶����ʾ��ͼ
4 ��Lable ��ǩ
Label��Kubernetesϵͳ������һ�����ĸ��һ��Label��һ��key-value�ļ�ֵ��������key��value���û��Լ�ָ����
Label���Ը��ӵ�������Դ������,����Node��Pod��Service��RC��,һ����Դ������Զ�������������Label,ͬһ��LabelҲ���Ա����ӵ�������������Դ������ȥ, Labelͨ������Դ������ʱȷ��,Ҳ�����ڶ�����̬����,����ɾ����
����ͨ����ָ������Դ��������һ��������ͬ��Label��ʵ�ֶ�ά�ȵ���Դ�����������,�Ա���������ؽ�����Դ���䡢���ȡ����á�����ȹ���������
����:����ͬ�汾��Ӧ�õ���ͬ�Ļ�����;����غͷ���Ӧ��(��־��¼����ء��澯)�ȡ�һЩ���õ�Labelʾ�����¡�
�汾��ǩ: "release" : "stable", "release":"canary"....
������ǩ: "environment":"dev", "environment":"ga","environment":"production"��
�ܹ���ǩ: "ier":"frontend," "tier":"backend", "tier":"midleware"
������ǩ: "artition":"customerA", "partition": "customerB".
�����ܿر�ǩ: "track": "daily","track":"weeky"
����ͨ�����Label Selector����ʽ�����ʵ�ָ��ӵ�����ѡ��,�������ʽ֮���á�,�����зָ�����,��������֮���ǡ�AND"�Ĺ�ϵ,��ͬʱ����������,�������������:
name=��ǩ��
env != ��ǩ��
name in (��ǩ1,��ǩ2)
name not in(��ǩ1)
name in (redis-master, redis-slave):ƥ�����о��б�ǩ`name=redis-master`����`name=redis-slave`����Դ����
name not in (phn-frontend):ƥ�����в����б�ǩname=php-frontend����Դ����
name=redis-slave, env!=production
name notin (php-frontend),env!=production
apiVersion: v1
kind: Pod
metadata:
name: myweb
lables:
app: myweb
# ��������RC��Service �� spec ���Selector �� Pod �������
apiVersion: v1
kind: ReplicationController
metadata:
name: myweb
spec:
replicas: 1
selector:
app: myweb
template:
...��...
apiVersion" v1
kind: Service
metadata:
name: myweb
spec:
selector:
app: myweb
ports:
port: 8080
�³��ֵĹ���������Deployment, ReplicaSet, DaemonSet��Job�������Selector��ʹ�û��ڼ��ϵ�ɸѡ��������,����:
selector:
matchLabels:
app: myweb
matchExpressions:
- {key: tire,operator: In,values: [frontend]}
- {key: environment, operator: NotIn, values: [dev]}
matchLabels���ڶ���һ��Label,��ֱ��д��Selector��������ͬ; matchExpressions���ڶ���һ����ڼ��ϵ�ɸѡ����,���õ��������������: In, NotIn, Exists��DoesNotExist.
���ͬʱ������matchLabels��matchExpressions,����������Ϊ"AND"��ϵ,������������Ҫͬʱ����������Selector��ɸѡ��
Label Selector��Kubernetes�е���Ҫʹ�ó��������¼���:
kube-controller����ͨ����Դ����RC�϶����Label Selector��ɸѡҪ��ص�Pod����������,�Ӷ�ʵ��Pod����������ʼ�շ���Ԥ���趨��ȫ�Զ���������
kube-proxy����ͨ��Service��Label Selector��ѡ���Ӧ��Pod, �Զ�������ÿ��Service����ӦPod������ת��·�ɱ�,�Ӷ�ʵ��Service�����ܸ��ؾ������
ͨ����ijЩNode�����ض���Label,������Pod�����ļ���ʹ��NodeSelector���ֱ�ǩ���Ȳ���, kube-scheduler���̿���ʵ��Pod ��������ȡ���������
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: podnodea
name: podnodea
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: podnodea
resources: {}
affinity:
nodeAffinity: #��������
requiredDuringSchedulingIgnoredDuringExecution: #Ӳ����
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- vms85.liruilongs.github.io
- vms84.liruilongs.github.io
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
5�� Replication Controller
RC��Kubernetesϵͳ�еĺ��ĸ���֮һ,����˵,����ʵ��������һ�������ij���,������ij��Pod�ĸ�������������ʱ�̶�����ij��Ԥ��ֵ,����RC�Ķ���������¼������֡�
| RC�Ķ��� |
|---|
Pod�ڴ��ĸ�����(replicas) |
����ɸѡĿ��Pod��Label Selector |
��Pod�ĸ�������С��Ԥ������ʱ,���ڴ�����Pod��Podģ��(template)�� |
������һ��������RC���������,��ȷ��ӵ��tier-frontend��ǩ�����Pod (����Tomcat����)������Kubernetes��Ⱥ��ʼ��ֻ��һ������:
apiVersion: v1
kind: ReplicationController
metadata:
name: frontend
spec:
replicas: 1
selector:
tier: frontend
template:
metadata:
labels:
app: app-demo
tier: frontend
spec:
containers:
- name: tomcat-demo
image: tomcat
imagePullPolicy: IfNotPresent
env:
- name: GET_HOSTS_FROM
value: dns
ports:
- containerPort: 80
������������һ��RC���ύ��Kubernetes��Ⱥ���Ժ�, Master�ڵ��ϵ�Controller Manager����͵õ�֪ͨ,����Ѳ��ϵͳ�е�ǰ����Ŀ��Pod,��ȷ��Ŀ��Podʵ���������պõ��ڴ�RC������ֵ,����й����Pod����������,ϵͳ�ͻ�ͣ��һЩPod,����ϵͳ�ͻ����Զ�����һЩPod
ͨ��RC, Kubernetesʵ�����û�Ӧ�ü�Ⱥ�ĸ߿�����,���Ҵ�������ϵͳ����Ա�ڴ�ͳIT��������Ҫ��ɵ������ֹ���ά����(��������ؽű���Ӧ�ü�ؽű������ϻָ��ű���)
����������3��Node�ڵ�ļ�ȺΪ��,˵��Kubernetes���ͨ��RC��ʵ��Pod���������Զ����ƵĻ������������ǵ�RC�ﶨ��redis-slave���Pod��Ҫ����3������,ϵͳ�����������е�����Node�ϴ���Pod��
������ʱ,���ǿ���ͨ�� ��RC�ĸ�������,��ʵ��Pod�Ķ�̬����(Scaling)����,�����ͨ��ִ��kubectl scale������һ�����:
kubectl scale rc redsi-slave --replicas=3
��Ҫע�����,ɾ��RC������Ӱ��ͨ����RC�Ѵ����õ�Pod,Ϊ��ɾ������Pod,��������replicas��ֵΪ0,Ȼ����¸�RC������, kubectl�ṩ��stop��delete������һ����ɾ��RC��RC���Ƶ�ȫ��Pod��
Ӧ������ʱ,ͨ����ͨ��Buildһ���µ�Docker����,�����µľ���汾������ɵİ汾�ķ�ʽ�ﵽĿ�ġ���ϵͳ�����Ĺ�����,����ϣ����ƽ���ķ�ʽ,���統ǰϵͳ��10����Ӧ�ľɰ汾��Pod,��ѵķ�ʽ�Ǿɰ汾��Podÿ��ֹͣһ��,ͬʱ����һ���°汾��Pod,����������������,�����˳�,�������е�Pod����ʼ����10��,ͨ��RC�Ļ���, Kubernetes������ʵ�������ָ�ʵ�õ�����,����Ϊ������������ (Rolling Update)
6�� Deployment
Deployment��Kubernetes v1.2������¸���,�����Ŀ����Ϊ�˸��õؽ��Pod�ı������⡣
Deployment�����RC��һ��������������ǿ�����ʱ֪����ǰPod �����𡱵Ľ�����ʵ��������һ��Pod�Ĵ��������ȡ��ڵ㼰��Ŀ��Node��������Ӧ��������һ����������Ҫһ����ʱ��,���������ڴ�ϵͳ����N��Pod������Ŀ��״̬,ʵ������һ�������仯�ġ��������"���µ�����״̬��
Deployment�ĵ���ʹ�ó��������¼�����
| Deployment�ĵ���ʹ�ó��� |
|---|
| ����һ��Deployment���������ɶ�Ӧ��Replica Set�����Pod�����Ĵ������̡� |
| ���Deployment��״̬�����������Ƿ����(Pod�����������Ƿ�ﵽԤ�ڵ�ֵ) |
| ����Deployment�Դ����µ�Pod (���羵������)�� |
| �����ǰDeployment���ȶ�,��ع���һ�����ȵ�Deployment�汾�� |
| ��ͣDeployment�Ա���һ�����Ķ��PodTemplateSpec��������,֮���ٻָ�Deployment,�����µķ����� |
| ��չDeployment��Ӧ�Ը߸��ء� |
| �鿴Deployment��״̬,�Դ���Ϊ�����Ƿ�ɹ���ָ�ꡣ |
| ����������Ҫ�ľɰ汾ReplicaSets�� |
Deployment�Ķ�����Replica Set�Ķ��������,����API������Kind���͵���������:
apiversion: extensions/vlbetal apiversion: v1
kind: Deployment kind: ReplicaSet
metadata: metadata:
name: nginx-deployment name: nginx-repset
����һ�� tomcat-deployment.yaml Deployment �����ļ�:
apiVersion: extensions/v1betal
kind: Deployment
metadata:
name: frontend
spec:
replicas: 1
selector:
matchLabels:
tier: frontend
matchExpressions:
- {key: tier, operator: In,value: [frontend]}
template:
metadata:
labels:
app: app-demo
tier: frontend
spec:
containers:
- name: tomcat-demo
images: tomcat
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
������������� Deployment:
kubectl create -f tomcat-deploment.yaml
������������漰�������������¡�
| ���� | ���� |
|---|---|
DESIRED | Pod��������������ֵ,��Deployment�ﶨ���Replica. |
CURRENT | ��ǰReplica��ֵ,ʵ������Deployment��������Replica Set���Replicaֵ,���ֵ��������,ֱ���ﵽDESIREDΪֹ,�����������������ɡ� |
UP-TO-DATE | ���°汾��Pod�ĸ�������,����ָʾ�ڹ��������Ĺ�����,�ж��ٸ�Pod�����Ѿ��ɹ������� |
AVAILABLE | ��ǰ��Ⱥ�п��õ�Pod��������,����Ⱥ�е�ǰ����Pod������ |
������������鿴��Ӧ��Replica Set,���ǿ�������������Deployment�������й�ϵ:
������[root@vms81.liruilongs.github.io]-[~/ansible]
����$kubectl get rs -A
NAMESPACE NAME DESIRED CURRENT READY AGE
kube-system calico-kube-controllers-78d6f96c7b 1 1 1 47d
kube-system coredns-545d6fc579 0 0 0 47d
kube-system coredns-7f6cbbb7b8 2 2 2 36d
kube-system kuboard-78dccb7d9f 1 1 1 11d
kube-system metrics-server-bcfb98c76
7�� Horizontal Pod Autoscaler
HPA��֮ǰ��RC�� Deploymentһ��,Ҳ����һ��Kubernetes��Դ������ͨ�� �ٷ���RC���Ƶ�����Ŀ��Pod�ĸ��ر仯���,��ȷ���Ƿ���Ҫ����Եص���Ŀ��Pod�ĸ�����,����HPA��ʵ��ԭ�� ����ǰ, HPA�������������ַ�ʽ��ΪPod���صĶ���ָ�ꡣ
| Horizontal Pod Autoscaler |
|---|
| CPUUtilizationPercentage. |
| Ӧ�ó����Զ���Ķ���ָ��,���������ÿ���ڵ���Ӧ��������(TPS��QPS) |
apiversion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: default
spec
maxReplicas: 10
minReplicas: 1
scaleTargetRef:
kind: Deployment
name: php-apache
targetcpuutilizationPercentage: 90
CPUUtilizationPercentage��һ������ƽ��ֵ,��Ŀ��Pod���и���������CPU��������ƽ��ֵ��һ��Pod������CPU�������Ǹ�Pod��ǰCPU��ʹ������������Pod Request��ֵ,��,�����Ƕ���һ��Pod��Pod RequestΪ0.4,����ǰPod��CPUʹ����Ϊ0.2,������CPUʹ����Ϊ50%
��������Ķ���,���ǿ���֪�����HPA���Ƶ�Ŀ�����Ϊһ������php-apache Deployment���Pod����,����ЩPod������CPUUtilizationPercentage��ֵ����90%ʱ�ᴥ���Զ���̬������Ϊ,���ݻ�����ʱ���������һ��Լ��������Pod�ĸ�����Ҫ����1��10֮����
���˿���ͨ��ֱ�Ӷ���yaml�ļ����ҵ���kubectrl create������������һ��HPA��Դ����ķ�ʽ,���ǻ���ͨ������ļ�������ֱ�Ӵ����ȼ۵�HPA����:
kubectl autoscale deployment php-apache --cpu-percent=90--min-1 --max=10
8�� StatefulSet
��Kubernetesϵͳ��, Pod�Ĺ�������RC, Deployment, DaemonSet��Job����������״̬�ķ��� ����ʵ���кܶ��������״̬��,�ر���һЩ���ӵ��м����Ⱥ,����MysQL����Ⱥ��MongoDB��Ⱥ��ZooKeeper��Ⱥ��,��ЩӦ�ü�Ⱥ������һЩ��ͬ��:
| ��ͬ�c |
|---|
| ÿ���ڵ㶼�й̶�������ID,ͨ�����ID,��Ⱥ�еij�Ա��������ֲ���ͨ�š� |
| ��Ⱥ�Ĺ�ģ�DZȽϹ̶���,��Ⱥ��ģ��������䶯�� |
| ��Ⱥ���ÿ���ڵ㶼����״̬��,ͨ����־û����ݵ����ô洢�С� |
| ���������,��Ⱥ���ij���ڵ�����������,��Ⱥ�������� |
�����
RC/Deployment����Pod�������ķ�ʽ��ʵ��������״̬�ļ�Ⱥ,�����ǻᷢ�ֵ�1�����������,��ΪPod�����������������,Pod��IP��ַҲ���������ڲ�ȷ���ҿ����б䶯��,����������Ϊÿ��Podȷ��Ψһ�����ID,
Ϊ���ܹ��������ڵ��ϻָ�ij��ʧ�ܵĽڵ�,���ּ�Ⱥ�е�Pod��Ҫ�ҽ�ij�ֹ����洢,Ϊ�˽���������, Kubernetes��v1.4�汾��ʼ������PetSet����µ���Դ����,������v1.5�汾ʱ����ΪStatefulSet, StatefulSet�ӱ�������˵,���Կ���DeploymentRC��һ���������,��������һЩ���ԡ�)
| ���� |
|---|
StatefulSet���ÿ��Pod�����ȶ���Ψһ�������ʶ,�����������ּ�Ⱥ�ڵ�������Ա������StatefulSet�����ֽ�kafka,��ô��1��Pod �� kafka-0,��2����kafk-1,�Դ����ơ�) |
StatefulSet���Ƶ�Pod��������ͣ˳�����ܿص�,������n��Podʱ,ǰn-1��Pod�Ѿ������������õ�״̬) |
StatefulSet���Pod�����ȶ��ij־û��洢��,ͨ��PV/PVC��ʵ��,ɾ��PodʱĬ�ϲ���ɾ����StatefulSet��صĴ洢��(Ϊ�˱�֤���ݵİ�ȫ)�� |
statefulSet����Ҫ��PV������ʹ���Դ洢Pod��״̬����,��Ҫ��Headless Service���ʹ��,����ÿ��StatefulSet�Ķ�����Ҫ�����������ĸ�Headless Service. Headless Service����ͨService�Ĺؼ���������,��û��Cluster IP,�������Headless Service��DNS����,�ص��Ǹ�Service��Ӧ��ȫ��Pod��Endpoint�б���StatefulSet��Headless Service�Ļ�������ΪStatefulSet���Ƶ�ÿ��Podʵ��������һ��DNS����,��������ĸ�ʽΪ:
$(podname).$(headless service name)
9�� Service (����)
ServiceҲ��Kubernetes�������ĵ���Դ����֮һ, Kubernetes���ÿ��Service��ʵ�������Ǿ������������ܹ��е�һ��������,֮ǰ������˵��Pod, RC����Դ������ʵ����Ϊ�����˵�ġ�����-Kubernetes Service�������¡�����Pod,RC��Service������ϵ��
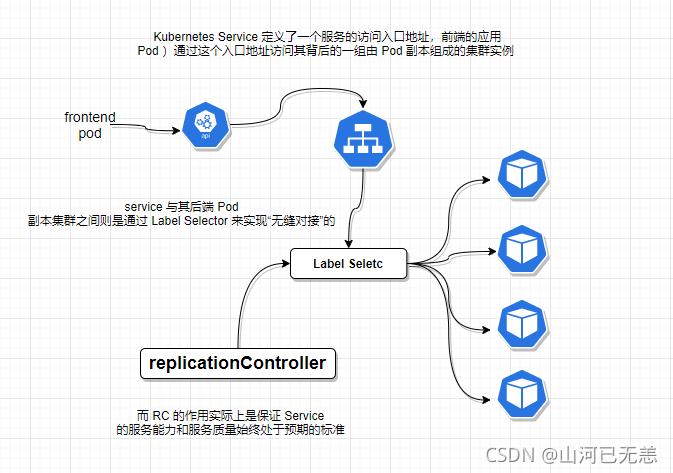
Kubernetes��Service������һ������ķ�����ڵ�ַ,ǰ�˵�Ӧ��(Pod)ͨ�������ڵ�ַ�����䱳���һ����Pod������ɵļ�Ⱥʵ��, Service������Pod������Ⱥ֮������ͨ��Label Selector��ʵ�֡���Խӡ��ġ���RC������ʵ�����DZ�֤Service�ķ��������ͷ�������ʼ�մ���Ԥ�ڵı���
ÿ��Pod���ᱻ����һ��������IP��ַ,����ÿ��Pod���ṩ��һ��������Endpoint(Pod IP+ContainerPort)�Ա��ͻ��˷���,���ڶ��Pod���������һ����Ⱥ���ṩ����.�ͻ������������������?һ��������Dz���һ�����ؾ�����(������Ӳ��),
Kubernetes��������ÿ��Node�ϵ�kube-proxy������ʵ����һ�����ܵ��������ؾ�����,������Ѷ�Service������ת������˵�ij��Podʵ����,�����ڲ�ʵ�ַ���ĸ��ؾ�����Ự���ֻ�����
Kubernetes������һ�ֺ�������Ӱ����Զ�����:
Service���ǹ���һ�����ؾ�������IP��ַ,����ÿ��Service������һ��ȫ��Ψһ������IP��ַ,�������IP����ΪCluster IP,����һ��,ÿ������ͱ���˾߱�ΨһIP��ַ�ġ�ͨ�Žڵ㡱,������þͱ�����������TCP����ͨ��������
����֪��, Pod��Endpoint��ַ������Pod�����ٺ����´����������ı�,��Ϊ��Pod��IP��ַ��֮ǰ��Pod�IJ�ͬ���� Serviceһ��������, Kubernetes�ͻ��Զ�Ϊ������һ�����õ�Cluster IP,������Service����������������,����Cluster IP���ᷢ���ı�������,������������ֵ�������Kubernetes�ļܹ���Ҳ�������ɽ��:ֻҪ��Service��Name��Service��Cluster IP��ַ��һ��DNS����ӳ�伴������������⡣
������[root@vms81.liruilongs.github.io]-[~/ansible/k8s-pod-create]
����$kubectl get svc myweb -o yaml
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2021-10-16T14:25:08Z"
name: myweb
namespace: liruilong-pod-create
resourceVersion: "339816"
uid: 695aa461-166c-4937-89ed-7b16ac49c96b
spec:
clusterIP: 10.109.233.35
clusterIPs:
- 10.109.233.35
externalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- nodePort: 30001
port: 8080
protocol: TCP
targetPort: 8080
selector:
app: myweb
sessionAffinity: None
type: NodePort
status:
loadBalancer: {}
Kubernetes Service֧�ֶ��Endpoint(�˿�),�ڴ��ڶ��Endpoint�������,Ҫ��ÿ��Endpoint����һ��������������������Tomcat��˿ڵ�Service��������:
spec:
ports:
- port: 8080
name: service-port
- port: 8005
name: shutdown-port
��˿�Ϊʲô��Ҫ��ÿ���˿�������?����漰Kubernetes�ķ����ֻ�����
Kubernetes �ķ����ֻ���
| Kubernetes �ķ����ֻ��� |
|---|
| ����ʱKubernetes������Linux���������ķ�ʽ����������,��ÿ��Service����һЩ��Ӧ��Linux��������(ENV),����ÿ��Pod������������ʱ,�Զ�ע����Щ�������� |
| ����Kubernetesͨ��Add-On��ֵ���ķ�ʽ������DNSϵͳ,�ѷ�������ΪDNS����,����һ��,����Ϳ���ֱ��ʹ�÷�����������ͨ�������ˡ�ĿǰKubernetes�ϵĴ�Ӧ�ö��Ѿ�������DNS��Щ���˵ķ����ֻ��� |
�ⲿϵͳ���� Service ������
| Kubernetes��ġ�����IP" | ���� |
|---|---|
| Node IP | Node �ڵ��IP��ַ,Node IP��Kubernetes��Ⱥ��ÿ���ڵ������������IP��ַ,����һ����ʵ���ڵ���������,���������������ķ�����֮�䶼��ͨ���������ֱ��ͨ��,�����������Ƿ��в��ֽڵ㲻�������Kubernetes��Ⱥ����Ҳ������Kubernetes��Ⱥ֮��Ľڵ����Kubernetes��Ⱥ֮�ڵ�ij���ڵ����TCP/IP����ʱ,����Ҫͨ��Node IP����ͨ���� |
| Pod IP | Pod �� IP ��ַ:Pod IP��ÿ��Pod��IP��ַ,����Docker Engine����dockero���ŵ�IP��ַ�ν��з����,ͨ����һ������Ķ�������,ǰ������˵��, KubernetesҪ��λ�ڲ�ͬNode�ϵ�Pod�ܹ��˴�ֱ��ͨ��,����Kubernetes��һ��Pod���������������һ��Pod�������,����ͨ��Pod IP���ڵ���������������ͨ�ŵ�,����ʵ��TCP/IP��������ͨ��Node IP���ڵ��������������ġ� |
| Cluster IP | Service ��IP��ַ,Cluster IP����������Kubernetes Service�������,����Kubernetes�����ͷ���IP��ַ(��Դ��Cluster IP��ַ��)��Cluster IP����Ping,��Ϊû��һ����ʵ�������������Ӧ��Cluster IPֻ�ܽ��Service Port���һ�������ͨ�Ŷ˿�,������Cluster IP���߱�TCPIPͨ�ŵĻ���,������������Kubernetes��Ⱥ����һ����յĿռ�,��Ⱥ֮��Ľڵ����Ҫ�������ͨ�Ŷ˿�,����Ҫ��һЩ����Ĺ�������Kubernetes��Ⱥ֮��, Node IP����Pod IP����Cluster IP��֮���ͨ��,���õ���Kubermetes�Լ���Ƶ�һ�ֱ�̷�ʽ�������·�ɹ���,����������֪��IP·���кܴ�IJ�ͬ�� |
�ⲿϵͳ���� Service,����NodePort�ǽ�������������ֱ�ӡ�����Ч����õ�������������������,��tomcat-serviceΪ��,������Service�Ķ�������������չ����:
...
spec:
type: NodePort
posts:
- port: 8080
nodePort: 31002
selector:
tier: frontend
...
���������ǿ���ͨ��nodePort:31002 ������Service,NodePort��ʵ�ַ�ʽ����Kubernetes��Ⱥ���ÿ��Node��Ϊ��Ҫ�ⲿ���ʵ�Service��������Ӧ��TCP�����˿�,�ⲿϵͳֻҪ������һ��Node��IP��ַ+�����NodePort�˿ڼ��ɷ��ʴ˷���,������Node������netstat����,���ǾͿ��Կ�����NodePort�˿ڱ�����:
Service ���ؾ�������
��NodePort��û����ȫ����ⲿ����Service����������,�������ؾ�������,�������ǵ���Ⱥ����10��Node,���ʱ�����һ�����ؾ�����,�ⲿ������ֻ����ʴ����ؾ�������IP��ַ,�ɸ��ؾ���������ת������������ij��Node��NodePort�ϡ���ͼ
| NodePort�ĸ��ؾ��� |
|---|
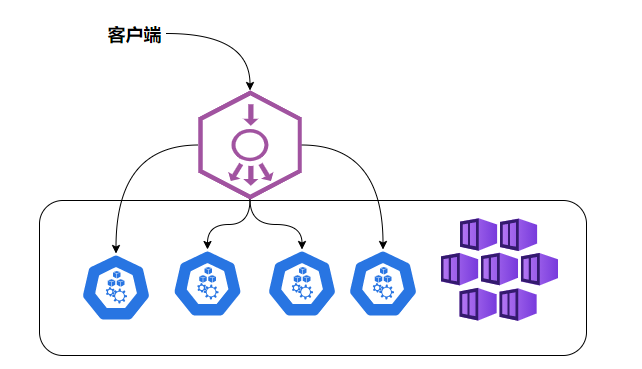 |
Load balancer���������Kubernetes��Ⱥ֮��,ͨ����һ��Ӳ���ĸ��ؾ�����,��������������ʽʵ����,����HAProxy����Nginx������ÿ��Service,����ͨ����Ҫ����һ����Ӧ��Load balancerʵ����ת����������˵�Node�� |
Kubernetes�ṩ���Զ����Ľ������,������ǵļ�Ⱥ�������ȸ��GCE��������,��ôֻҪ���ǰ�Service��type-NodePort��Ϊtype-LoadBalancer,��ʱKubernetes���Զ�����һ����Ӧ��Load balancerʵ������������IP��ַ���ⲿ�ͻ���ʹ���� |
10�� Volume (�洢��)
Volume��Pod���ܹ�������������ʵĹ���Ŀ¼��Kuberetes��Volume�����;��Ŀ����Docker��Volume�Ƚ�����,�����߲��ܵȼ���
| Volume (�洢��) |
|---|
Kubernetes�е�Volume������Pod��,Ȼ��һ��Pod��Ķ���������ص�������ļ�Ŀ¼��; |
Kubernetes�е�Volume��Pod������������ͬ,�����������������ڲ����,��������ֹ��������ʱ, Volume�е�����Ҳ���ᶪʧ�� |
Kubernetes֧���������͵�Volume,����GlusterFS, Ceph���Ƚ����ֲ�ʽ�ļ�ϵͳ�� |
Volume��ʹ��Ҳ�Ƚϼ�,�ڴ���������,��������Pod������һ��Volume,Ȼ�������������ø�Volume��Mount���������ij��Ŀ¼�ϡ�������˵,����Ҫ��֮ǰ��Tomcat Pod����һ������Ϊdatavol��Volume,����Mount��������/mydata-dataĿ¼��,��ֻҪ��Pod�Ķ����ļ���������������(ע������ֲ���):
template:
metadata:
labels:
app: app-demo
tier: frontend
spec:
volumes:
- name: datavol
emptyDir: {}
containers:
- name: tomcat-demo
image: tomcat
volumeMounts:
- mountPath: /myddata-data
name: datavol
imagePullPolicy: IfNotPresent
���˿�����һ��
Pod���������������ļ���������������д���������Ĵ����ϻ���д�ļ�������洢��,Kubernetes��Volume����չ����һ�ַdz���ʵ�ü�ֵ�Ĺ���,��
���������ļ����л����������,����ͨ��ConfigMap����µ���Դ������ʵ�ֵ�.
Kubernetes�ṩ�˷dz��ḻ��Volume����,������һ����˵����
1. emptyDir
һ��emptyDir Volume����Pod���䵽Nodeʱ�����������������ƾͿ��Կ���,������ʼ����Ϊ��,��������ָ���������϶�Ӧ��Ŀ¼�ļ�,��Ϊ���� Kubernetes�Զ������һ��Ŀ¼,��Pod��Node���Ƴ�ʱ, emptyDir�е�����Ҳ�ᱻ����ɾ����emptyDir��һЩ��;���¡�
| emptyDir��һЩ��; |
|---|
| ��ʱ�ռ�,��������ijЩӦ�ó�������ʱ�������ʱĿ¼,���������ñ����� |
| ��ʱ��������м����CheckPoint����ʱ����Ŀ¼�� |
| һ��������Ҫ����һ�������л�ȡ���ݵ�Ŀ¼(����������Ŀ¼) |
2. hostPath
hostPathΪ��Pod�Ϲ����������ϵ��ļ���Ŀ¼,��ͨ�������������¼����档
|����Ӧ�ó������ɵ���־�ļ���Ҫ���ñ���ʱ,����ʹ���������ĸ����ļ�ϵͳ���д洢��|
��Ҫ������������Docker�����ڲ����ݽṹ������Ӧ��ʱ,����ͨ������hostPathΪ������/var/lib/dockerĿ¼,ʹ�����ڲ�Ӧ�ÿ���ֱ�ӷ���Docker���ļ�ϵͳ��
��ʹ���������͵�Volumeʱ,��Ҫע�����¼��㡣
�ڲ�ͬ��Node�Ͼ�����ͬ���õ�Pod���ܻ���Ϊ�������ϵ�Ŀ¼���ļ���ͬ�����¶�Volume��Ŀ¼���ļ��ķ��ʽ����һ�¡�)
���ʹ������Դ������,��Kubernetes����hostPath����������ʹ�õ���Դ����������������������ʹ����������/dataĿ¼������һ��hostPath���͵�Volume:
volumes:
- name: "persistent-storage"
hostPath:
path: "/data"
3. gcePersistentDisk
ʹ���������͵�Volume��ʾʹ�ùȸ蹫�����ṩ�����ô���(PersistentDisk, PD)���Volume������,����emptyDir��ͬ, PD�ϵ����ݻᱻ���ô�,��Pod��ɾ��ʱ, PDֻ�DZ�ж��(Unmount),�����ᱻɾ������Ҫע����,����Ҫ�ȴ���һ�����ô���(PD),����ʹ��gcePersistentDisk.
4. awsElasticBlockStore
��GCE����,�����͵�Volumeʹ������ѷ�������ṩ��EBS Volume�洢����,��Ҫ�ȴ���һ��EBS Volume����ʹ��awsElasticBlockStore.
5. NFS
ʹ��NFS�����ļ�ϵͳ�ṩ�Ĺ���Ŀ¼�洢����ʱ,������Ҫ��ϵͳ�в���һ��NFSServer,����NES���͵�Volume��ʾ������
yum -y install nfs-utils
...
volumes:
- name: test-volume
nfs:
server: nfs.server.locathost
path: "/"
....
11�� Persistent Volume
Volume�Ƕ�����Pod�ϵ�,���ڡ�������Դ����һ����,��ʵ����, ������洢������Զ����ڡ�������Դ�������ڵ�һ��ʵ����Դ��������ʹ��������������,����ͨ�����ȶ���һ������洢,Ȼ����л���һ�������̡����ҽӵ��������
Persistent Volume(���PV)����֮�������Persistent Volume Claim (���PVC)Ҳ�������Ƶ����á�PV��������� Kubernetes��Ⱥ�е�ij������洢�ж�Ӧ��һ��洢,����Volume������,������������
| Persistent Volume��Volume������ |
|---|
| PVֻ��������洢,�������κ�Node,��������ÿ��Node�Ϸ��ʡ� |
| PV�����Ƕ�����Pod�ϵ�,���Ƕ�����Pod֮�ⶨ�塣 |
| PVĿǰ֧�ֵ����Ͱ���: gcePersistentDisk�� AWSElasticBlockStore, AzureFileAzureDisk, FC (Fibre Channel). Flocker, NFS, isCSI, RBD (Rados Block Device)CephFS. Cinder, GlusterFS. VsphereVolume. Quobyte Volumes, VMware Photon.PortworxVolumes, ScalelO Volumes��HostPath (������������)�� |
apiversion: v1
kind: PersistentVolume
metadata:
name: pv0003
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
nfs:
path: /somepath
server: 172.17.0.2
PV��accessModes����, Ŀǰ����������:
- ReadWriteOnce:��дȨ�ޡ�����ֻ�ܱ�����Node���ء�
- ReadOnlyMany:ֻ��Ȩ�ޡ����������Node���ء�
- ReadWriteMany:��дȨ�ޡ����������Node���ء�
���ij��Pod������ij�����͵�PV,��������Ҫ����һ��PersistentVolumeClaim (PVC)����:
kind: Persistentvolumeclaim
apiversion: v1
metadata:
name: myclaim
spec:
accessModes:
- Readwriteonce
resources:
requests:
storage: BGi
����PVC
volumes:
- name: mypd
persistentvolumeclaim:
claimName: myclaim
PV����״̬�Ķ���,�������¼���״̬�� |
|---|
Available:����״̬�� |
Bound:�Ѿ���ij��Pvc�ϡ� |
Released:��Ӧ��PVC�Ѿ�ɾ��,����Դ��û�б���Ⱥ�ջء� |
Failed: PV�Զ�����ʧ�ܡ� |
12�� Namespace (�����ռ�)
Namespace (�����ռ�)��Kubernetesϵͳ�зdz���Ҫ�ĸ���, Namespace�ںܶ����������ʵ�� ���⻧����Դ������Namespaceͨ������Ⱥ�ڲ�����Դ�����䡱����ͬ��Namespace ��,�γ����Ϸ���IJ�ͬ��Ŀ��С����û���,���ڲ�ͬ�ķ����ڹ���ʹ��������Ⱥ����Դ��ͬʱ���ܱ��ֱ������Kubernetes��Ⱥ��������,�ᴴ��һ����Ϊ"default"��Namespace,ͨ��kubectl���Բ鿴��:
| ��ͬ��namespace֮�以����� |
|---|
| �鿴���������ռ� |
| �鿴��ǰ�����ռ� |
| ���������ռ� |
kub-system �����ĸ��� pod,��kubamdĬ�ϵĿռ䡣podʹ�������ռ������
������[root@vms81.liruilongs.github.io]-[~/ansible]
����$kubectl get namespaces
NAME STATUS AGE
default Active 13h
kube-node-lease Active 13h
kube-public Active 13h
kube-system Active 13h
������[root@vms81.liruilongs.github.io]-[~/ansible]
����$kubectl get ns
NAME STATUS AGE
default Active 13h
kube-node-lease Active 13h
kube-public Active 13h
kube-system Active 13h
������[root@vms81.liruilongs.github.io]-[~/ansible]
����$
�����ռ��������
������[root@vms81.liruilongs.github.io]-[~/ansible]
����$kubectl create ns liruilong
namespace/liruilong created
������[root@vms81.liruilongs.github.io]-[~/ansible]
����$kubectl get ns
NAME STATUS AGE
default Active 13h
kube-node-lease Active 13h
kube-public Active 13h
kube-system Active 13h
liruilong Active 4s
������[root@vms81.liruilongs.github.io]-[~/ansible]
����$kubectl create ns k8s-demo
namespace/k8s-demo created
������[root@vms81.liruilongs.github.io]-[~/ansible]
����$kubectl get ns
NAME STATUS AGE
default Active 13h
k8s-demo Active 3s
kube-node-lease Active 13h
kube-public Active 13h
kube-system Active 13h
liruilong Active 20s
������[root@vms81.liruilongs.github.io]-[~/ansible]
����$kubectl delete ns k8s-demo
namespace "k8s-demo" deleted
������[root@vms81.liruilongs.github.io]-[~/ansible]
����$kubectl get ns
NAME STATUS AGE
default Active 13h
kube-node-lease Active 13h
kube-public Active 13h
kube-system Active 13h
liruilong Active 54s
������[root@vms81.liruilongs.github.io]-[~/ansible]
����$
�����ռ��л�
������[root@vms81.liruilongs.github.io]-[~/.kube]
����$vim config
������[root@vms81.liruilongs.github.io]-[~/.kube]
����$kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* context1 cluster1 kubernetes-admin1
context2 cluster2 kubernetes-admin2
������[root@vms81.liruilongs.github.io]-[~/.kube]
����$kubectl config set-context context2 --namespace=kube-system
Context "context2" modified.
������[root@vms81.liruilongs.github.io]-[~/.kube]
����$kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* context1 cluster1 kubernetes-admin1
context2 cluster2 kubernetes-admin2 kube-system
������[root@vms81.liruilongs.github.io]-[~/.kube]
����$kubectl config set-context context1 --namespace=kube-public
Context "context1" modified.
���߿��������л����ƿռ�
kubectl config set-context $(kubectl config current-context) --namespace=<namespace>
kubectl config view | grep namespace
kubectl get pods
����podʱָ�������ռ�
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: pod-static
name: pod-static
namespeace: default
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: pod-demo
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
�����Ǹ�ÿ���⻧����һ��Namespace��ʵ�ֶ��⻧����Դ����ʱ,�������Kubernetes"����Դ������,����ͬ�⻧��ռ�õ���Դ,����CPUʹ�������ڴ�ʹ�����ȡ�
13�� Annotation (ע��)
Annotation��Label����,Ҳʹ��key/value��ֵ�Ե���ʽ���ж��塣
��ͬ����Label�����ϸ����������,���������Kubernetes�����Ԫ����(Metadata),��������Label Selector.
Annotation�����û����ⶨ��ġ����ӡ���Ϣ,�Ա����ⲿ���߽��в���, Kubernetes��ģ��������ͨ��Annotation�ķ�ʽ�����Դ�����һЩ������Ϣ��
������[root@vms81.liruilongs.github.io]-[~/ansible/k8s-pod-create]
����$kubectl annotate nodes vms82.liruilongs.github.io "dest=����һ�������ڵ�"
node/vms82.liruilongs.github.io annotated
������[root@vms81.liruilongs.github.io]-[~/ansible/k8s-pod-create]
����$kubectl describe nodes vms82.liruilongs.github.io
Name: vms82.liruilongs.github.io
Roles: worker1
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
disktype=node1
kubernetes.io/arch=amd64
kubernetes.io/hostname=vms82.liruilongs.github.io
kubernetes.io/os=linux
node-role.kubernetes.io/worker1=
Annotations: dest: ����һ�������ڵ�
kubeadm.alpha.kubernetes.io/cri-socket: /var/run/dockershim.sock
node.alpha.kubernetes.io/ttl: 0
projectcalico.org/IPv4Address: 192.168.26.82/24
projectcalico.org/IPv4IPIPTunnelAddr: 10.244.171.128
volumes.kubernetes.io/controller-managed-attach-detach: true
.....................
| ͨ����˵,��Annotation����¼����Ϣ���� |
|---|
| build��Ϣ�� release��Ϣ��Docker������Ϣ��,����ʱ�����release id�š�PR�š�����hashֵ�� docker registry��ַ�ȡ� |
| ��־�⡢��ؿ⡢���������Դ��ĵ�ַ��Ϣ�� |
| ������Թ�����Ϣ,���繤�����ơ��汾�ŵȡ� |
| �Ŷӵ���ϵ��Ϣ,����绰���롢���������ơ���ַ�ȡ� |