环境准备:
| 编号 | 主机名 | 类型 | 用户 | 密码 |
|---|---|---|---|---|
| 1 | master1-1 | 主节点 | root | passwd |
| 2 | slave1-1 | 从节点 | root | passwd |
| 3 | slave1-2 | 从节点 | root | passwd |
? ? ? ? 注:提取码均为: 0000
机器检查:
? ? ? ? 1、输入用户名及登录密码进行登录

? ? ? ? 2、?检查内网是否畅通
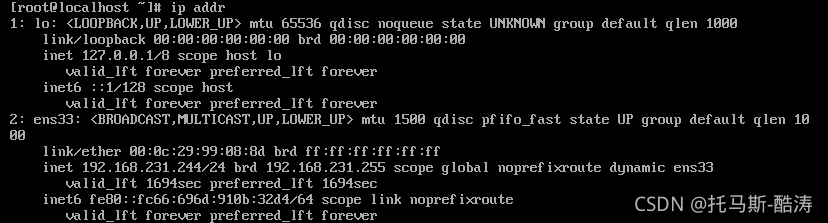
? ? ? ? ? ? ? ? A、查看机器IP地址
ip addr
? ? ? ? 注:通过观察此台机器IP为192.168.231.244?
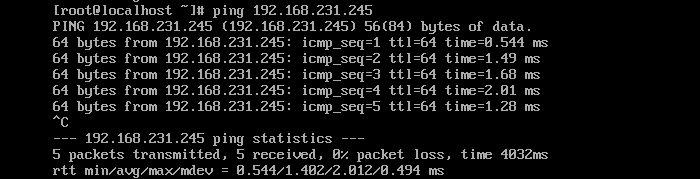
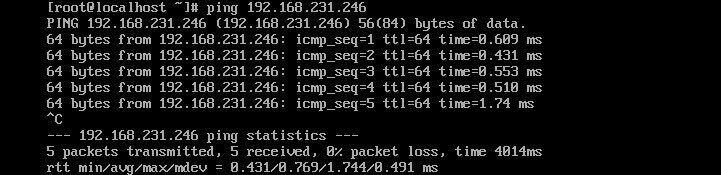
? ? ? ? ? ? ? ? B、测试内网
?
????????注:通过观察机器内网畅通?
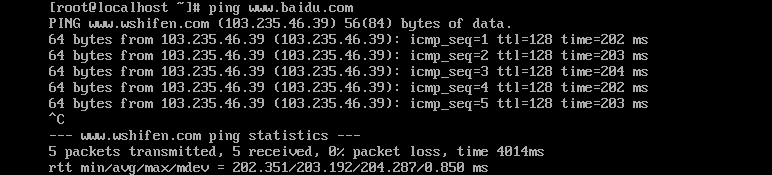
? ? ? ? ? ? ? ? C、测试外网
? ? ? ? 注:通过观察此台机器外网畅通
? ? ? ? 注:三台机器分别进行检查,网络配置无误
静态IP配置:
? ? ? ? 1、查看各台机器IP地址
ip addr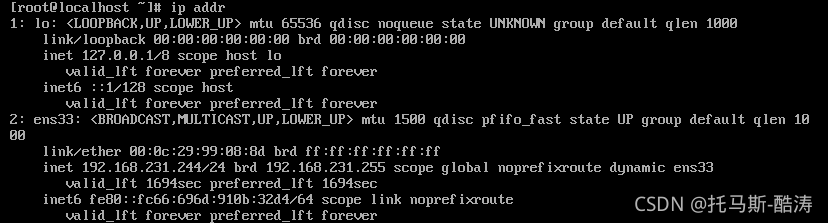
? ? ? ? ?2、编辑ifcfg-ens33网络
vi /etc/sysconfig/network-scripts/ifcfg-ens33
? ? ? ? 注:BOOTPROTO的值更改为static,加入最下面五行内容,分别为:IP,子网掩码,网关,DNS1,DNS2 其余配置勿进行更改
? ? ? ? 提示:IP地址要与网关处于同一网段内,DNS1与网关相同即可,子网掩码,DNS2照搬即可
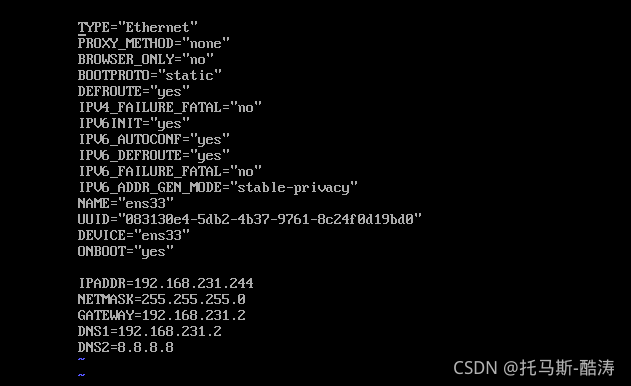
? ? ? ? 3、重启网络
service network restart? ? ? ? 4、进行内网与外网的检查
ping 192.168.231.244ping www.baidu.com????????此处笔者IP为:
| 主机名 | IP |
|---|---|
| master1-1 | 192.168.231.244 |
| slave1-1 | 192.168.231.245 |
| slave1-2 | 192.168.231.246 |
环境部署:
一、解压 JDK 安装包到“/usr/local/src”路径,并配置环境变量;截取环境变量配置文件截图
? ? ? ? 1、进入 /h3cu/ 目录

? ? ? ? ?2、解压 jdk 到 /usr/local/src
tar -zxvf jdk1.8.0_221.tar.gz -C /usr/local/src/? ? ? ? 3、配置环境变量
vi /etc/profile
二、在指定目录下安装ssh服务,查看ssh进程并截图(安装包统一在“/h3cu/”)
? ? ? ? 1、查看是否已安装ssh服务
rpm -qa | grep ssh
? ? ? ? 注:如有这些包,说明ssh服务已安装?

????????2、使用yum进行安装ssh服务
yum -y install openssh openssh-server? ? ? ? 3、查看ssh进程
ps -ef | grep ssh
三、创建 ssh 密钥,实现主节点与从节点的无密码登录;截取主节点登录其中一个从节点的结果
? ? ? ? 1、在指定目录下生成密钥对
ssh-keygen -t rsa
? ? ? ? 注:依次在系统等待输入时敲入回车键(一共4次回车)后,即可生成密钥对
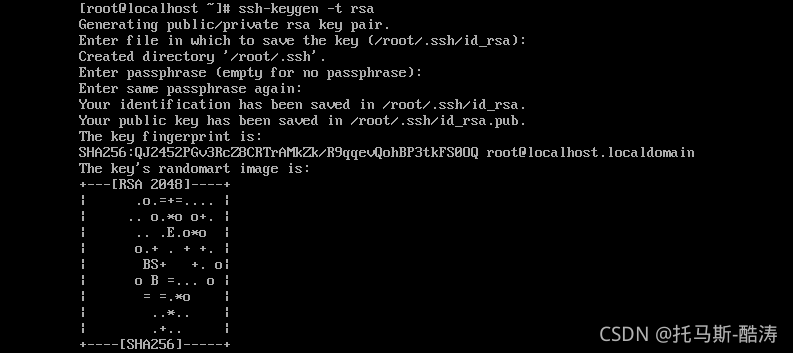
? ? ? ? 2、分发公匙文件
ssh-copy-id 192.168.231.244
ssh-copy-id 192.168.231.245
ssh-copy-id 192.168.231.246
? ? ? ? 注:此为例图,需要免密登录的机器全部都要分发
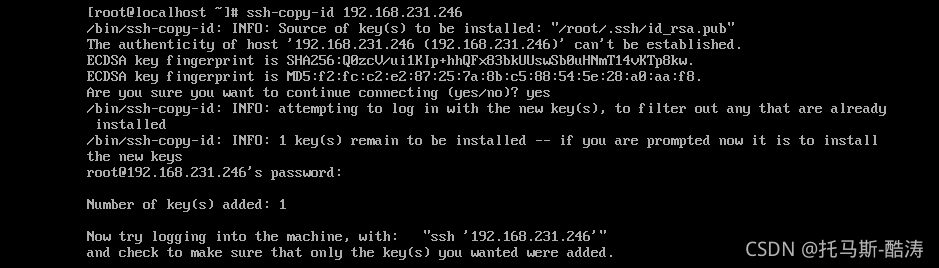
? ? ? ? 3、主节点免密登录从节点

四、?根据要求修改每台主机 host 文件,截取“/etc/hosts”文件截图
????????注:此处需注意,三台机器的hosts文件全部都要修改

五、修 改 每 台 主 机 hostname 文 件 配 置 IP 与 主 机 名 映 射 关 系 ; 截 取 “/etc/hostname”文件截图
? ? ? ? ? ? ? ? 三台电脑分别设置主机名
hostnamectl set-hostname master1-1
hostnamectl set-hostname slave1-1
hostnamectl set-hostname slave1-2


六、在主节点和从节点修改 Hadoop 环境变量,并截取修改内容
? ? ? ? 1、修改Hadoop环境变量
vi /etc/profile
七、需安装 Zookeeper 组件具体要求同 Zookeeper 任务要求,并与 Hadoop HA 环境适配
? ? ? ? 1、解压zookeeper
tar -zxvf /h3cu/zookeeper-3.4.8.tar.gz -C /usr/local/src/? ? ? ? 2、重命名
mv /usr/local/src/zookeeper-3.4.8 /usr/local/src/zookeeper? ? ? ? 3、进入zookeeper/conf目录下
cd /usr/local/src/zookeeper/conf? ? ? ? 4、重命名zoo_sample.cfg为zoo.cfg
mv zoo_sample.cfg zoo.cfg? ? ? ? 5、修改zoo.cfg配置文件
vi zoo.cfgtickTime=2000
initLimit=10
syncLimit=5
clientPort=2181
dataDir=/usr/local/src/zookeeper/data
dataLogDir=/usr/local/src/zookeeper/logs
server.1=master1-1:2888:3888
server.2=slave1-1:2888:3888
server.3=slave1-2:2888:3888? ? ? ? 6、创建ZooKeeper 的数据存储与日志存储目录
mkdir /usr/local/src/zookeeper/data
mkdir /usr/local/src/zookeeper/logs? ? ? ? 7、创建myid文件并写入内容:1
vi /usr/local/src/zookeeper/data/myid? ? ? ? 8、添加zookeeper环境变量
vi /etc/profileexport ZK_HOME=/usr/local/src/zookeeper
export PATH=$PATH:$ZK_HOME/bin????????9、集群分发
scp -r /etc/profile slave1-1:/etc/profilescp -r /etc/profile slave1-2:/etc/profilescp -r /usr/local/src/zookeeper slave1-1:/usr/local/src/scp -r /usr/local/src/zookeeper slave1-2:/usr/local/src/? ? ? ? 10、修改slave1-1 和 slave1-2的myid文件分别为2 ,3
vi /usr/local/src/zookeeper/data/myid? ? ? ? 11、关闭防火墙 和?关闭防火墙自启
systemctl stop firewalld.servicesystemctl disable firewalld.service? ? ? ? 注:三台机器全部都要关闭防火墙 和 自启
八、修改 namenode、datanode、journalnode 等存放数据的公共目录为 /usr/local/hadoop/tmp
? ? ? ? 1、解压安装Hadoop
tar -zxvf /h3cu/hadoop-2.7.1.tar.gz -C /usr/local/? ? ? ? 2、重命名Hadoop
mv /usr/local/hadoop-2.7.1 /usr/local/hadoop? ? ? ? 3、进入hadoop配置文件目录
cd /usr/local/hadoop/etc/hadoop? ? ? ? 4、配置hadoop-env.sh文件

? ? ? ? 5、配置core-site.xml文件
<configuration>
<!-- 指定 hdfs 的 nameservice 为 mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<!-- 指定 zookeeper 地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>master1-1:2181,slave1-1:2181,slave1-2:2181</value>
</property>
<!-- hadoop 链接 zookeeper 的超时时长设置 -->
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>30000</value>
<description>ms</description>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration> ? ? ? ? ?6、配置hdfs-site.xml文件
<configuration>
<!-- journalnode 集群之间通信的超时时间 -->
<property>
<name>dfs.qjournal.start-segment.timeout.ms</name>
<value>60000</value>
</property>
<!--指定 hdfs 的 nameservice 为 mycluster,需要和 core-site.xml 中的保持一致
dfs.ha.namenodes.[nameservice id]为在 nameservice 中的每一个 NameNode 设置唯一标示
符。配置一个逗号分隔的NameNode ID列表。这将是被DataNode识别为所有的NameNode。
如果使用"mycluster"作为 nameservice ID,并且使用"master"和"slave1"作为 NameNodes 标
示符 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- mycluster 下面有两个 NameNode,分别是 master,slave1 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>master1-1,slave1-1</value>
</property>
<!-- master 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.master1-1</name>
<value>master1-1:9000</value>
</property>
<!-- slave1 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.slave1-1</name>
<value>slave1-1:9000</value>
</property>
<!-- master 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.master1-1</name>
<value>master1-1:50070</value>
</property>
<!-- slave1 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.slave1-1</name>
<value>slave1-1:50070</value>
</property>
<!-- 指定 NameNode 的 edits 元数据的共享存储位置。也就是 JournalNode 列表
该 url 的配置格式:qjournal://host1:port1;host2:port2;host3:port3/journalId
journalId 推荐使用 nameservice,默认端口号是:8485 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master1-1:8485;slave1-1:8485;slave1-2:8485/mycluster</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
<!-- 使用 sshfence 隔离机制时需要 ssh 免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 指定副本数 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<!-- 指定 JournalNode 在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<!-- 开启 NameNode 失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 启用 webhdfs -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!-- 配置 sshfence 隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
<value>60000</value>
</property>
</configuration> ? ? ? ? 7、配置mapred-site.xml文件
? ? ? ? ? ? ? ? A、拷贝mapred-site.xml.template重命名为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml? ? ? ? ? ? ? ? B、编辑文件
vi mapred-site.xml<configuration>
<!-- 指定 mr 框架为 yarn 方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 指定 mapreduce jobhistory 地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master1-1:10020</value>
</property>
<!-- 任务历史服务器的 web 地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master1-1:19888</value>
</property>
</configuration> ? ? ? ? 8、配置yarn-site.xml文件
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 开启 RM 高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定 RM 的 cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定 RM 的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定 RM 的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master1-1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave1-1</value>
</property>
<!-- 指定 zk 集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master1-1:2181,slave1-1:2181,slave1-2:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 制定 resourcemanager 的状态信息存储在 zookeeper 集群上 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration> ? ? ? ? 9、创建tmp , logs目录
mkdir /usr/local/hadoop/tmp
mkdir /usr/local/hadoop/logs? ? ? ? 10、配置hadoop/etc/hadoop/slaves文件
master1-1
slave1-1
slave1-2? ? ? ? 11、分发jdk和hadoop文件
scp -r /usr/local/src/jdk1.8.0_221/ slave1-1:/usr/local/src/
scp -r /usr/local/src/jdk1.8.0_221/ slave1-2:/usr/local/src/
scp -r /usr/local/hadoop slave1-1:/usr/local/
scp -r /usr/local/hadoop slave1-2:/usr/local/
? ? ? ? 12、确保3台机器的环境变量已经生效
source /etc/profile? ? ? ? 注:三台机器全部进行source即时生效
九、根据要求修改 Hadoop 相关文件,并初始化 Hadoop,截图初始化结果
? ? ? ? 1、启动zookeeper集群并查看状态
进入zookeeper安装目录下
bin/zkServer.sh startbin/zkServer.sh status? ? ? ? 注:三台机器都要启动
? ? ? ? 2、初始化HA在zookeeper中的状态
进入hadoop安装目录下
bin/hdfs zkfc -formatZK? ? ? ? 3、启动全部机器的 journalnode 服务
进入/usr/local/hadoop安装目录下
sbin/hadoop-daemon.sh start journalnode? ? ? ? 注:三台机器全部启动journalnode进程
? ? ? ? 4、初始化namenode
进入hadoop/bin目录下
hdfs namenode -format
? ? ? ? ?注:观察是否有报错信息,status是否为0,0即为初始化成功,1则报错,检查配置文件是否有误

十、启动 Hadoop,使用相关命令查看所有节点 Hadoop 进程并截图
? ? ? ? 1、启动hadoop所有进程
进入hadoop安装目录下
sbin/start-all.sh
?
?
? ? ? ? 注:三台机器使用 ps -ef 命令查看进程

十一、本题要求配置完成后在 Hadoop 平台上运行查看进程命令,要求运行结果的截屏保存
?
?
? ? ? ? ?注:三台机器使用 jps 命令查看hadoop 进程


十二、格式化主从节点
? ? ? ? 1、复制 namenode 元数据到其它节点
scp -r /usr/local/hadoop/tmp/* slave1-1:/usr/local/hadoop/tmp/scp -r /usr/local/hadoop/tmp/* slave1-2:/usr/local/hadoop/tmp/
? ? ? ? ?注:由于之前namenode,datanode,journalnode的数据全部存放在hdaoop/tmp目录下,所以直接复制 tmp 目录至从节点


十三、启动两个 resourcemanager 和 namenode
? ? ? ? 1、在slave1-1节点启动namenode和resourcemanager进程
进入hadoop安装目录
sbin/yarn-daemon.sh start resourcemanagersbin/hadoop-daemon.sh start namenode十四、使用查看进程命令查看进程,并截图(要求截取主机名称),访问两个 namenode 和 resourcemanager web 界面.并截图保存(要求截到 url 状态)

1、配置windows中的hosts文件
? ? ? ? A、进入C:\Windows\System32\drivers\etc目录下找到hosts文件
? ? ? ? B、更改hosts文件的属性,使其可以修改内容
? ? ? ? C、最后加入
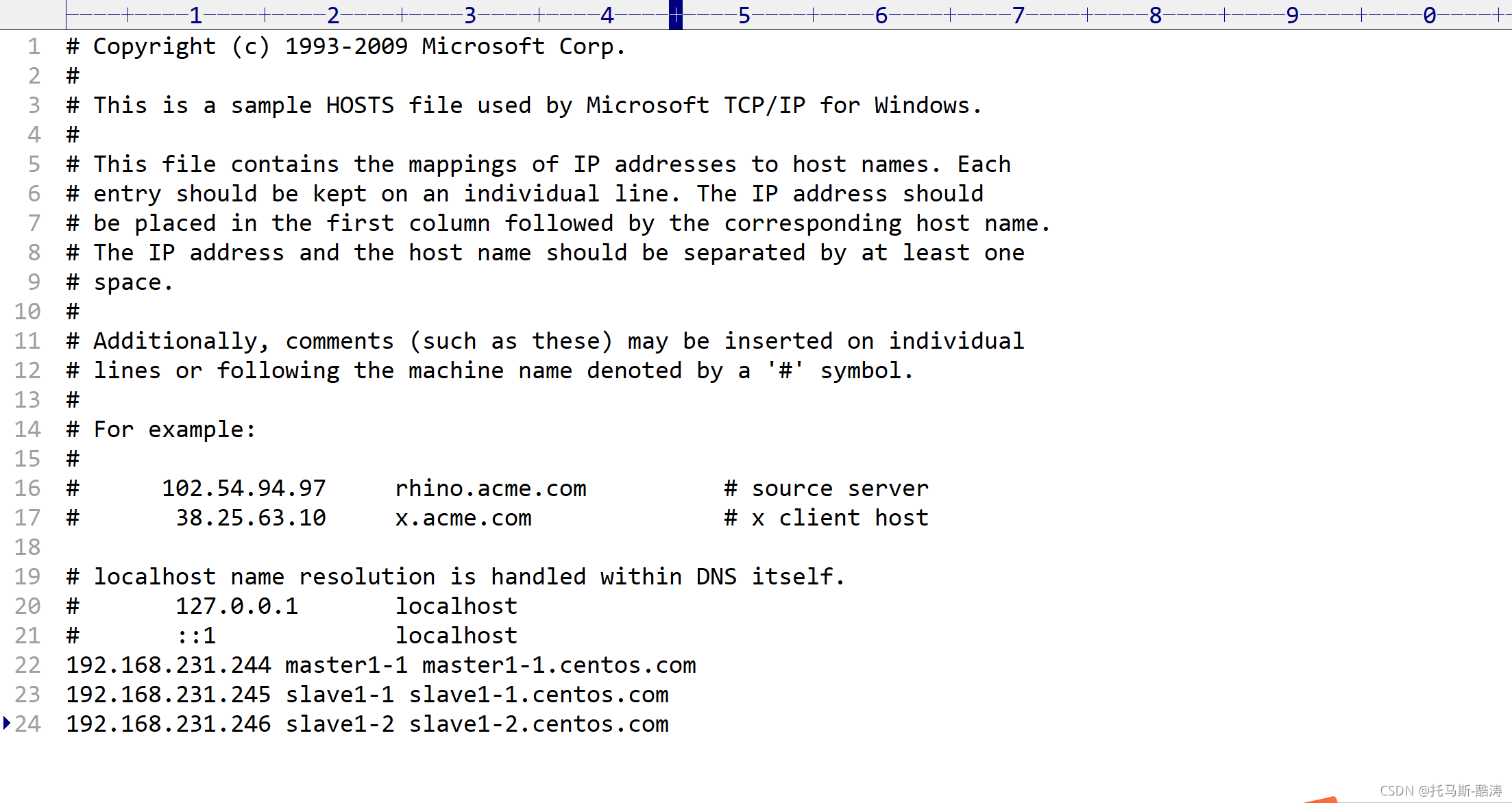
192.168.231.244 master1-1 master1-1.centos.com 192.168.231.245 slave1-1 slave1-1.centos.com 192.168.231.246 slave1-2 slave1-2.centos.com更改前
更改后?
修改hosts文件拒绝访问参考:
2、在浏览访问两个 namenode 和 resourcemanager web 界面
namenode web界面:
地址栏输入master1-1:50070 如图所示
??
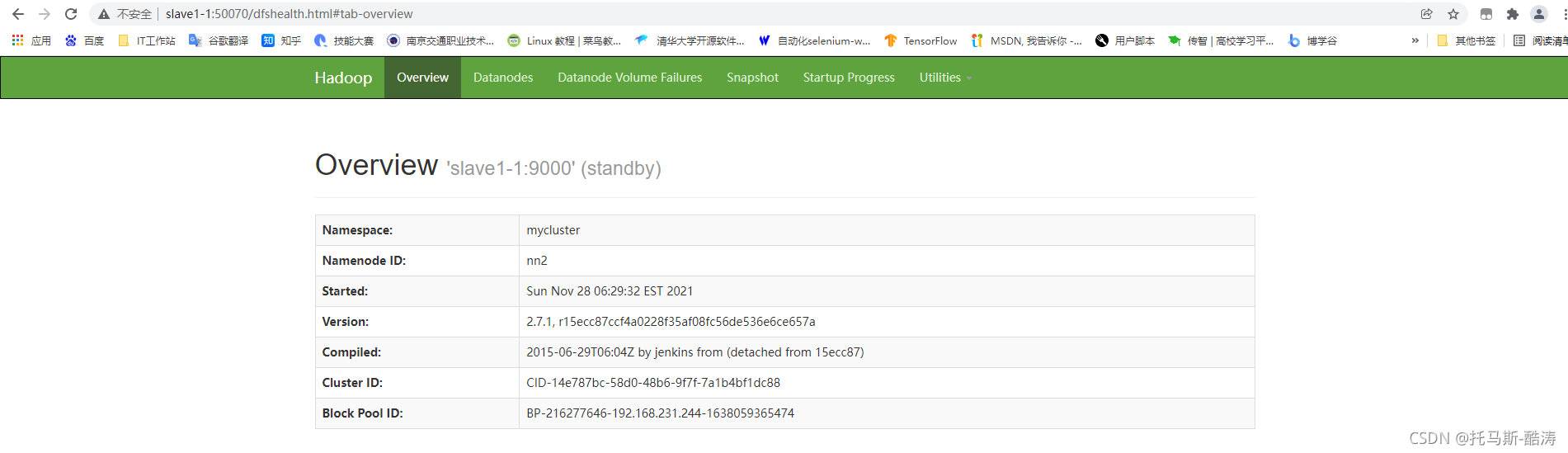
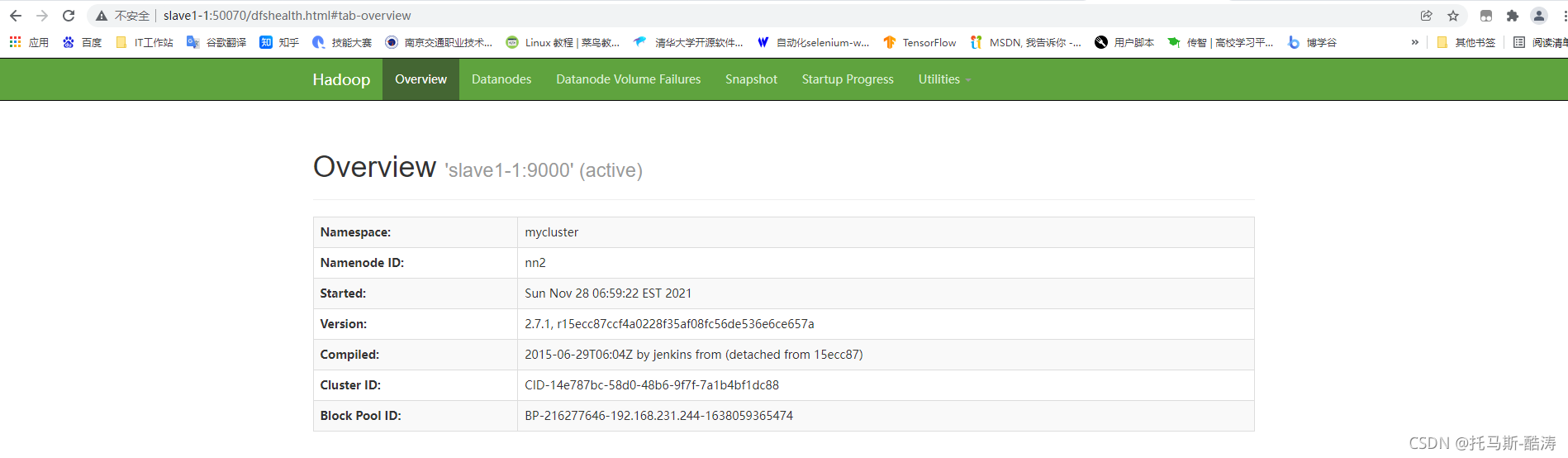
地址栏输入slave1-1:50070 如图所示
resourcemanager web 界面:
? ? ? ? 注:点击左方Nodes可以看到当前存在的节点

十五、终止 active 的 namenode 进程,并使用 Jps 查看各个节点进程,(截上主机名称),访问两个 namenode 和 resourcemanager web 界面.并截图保存 (要求截到 url 和状态)
? ? ? ? 1、终止活跃状态的namenode
kill -9 (namenode进程号)

??


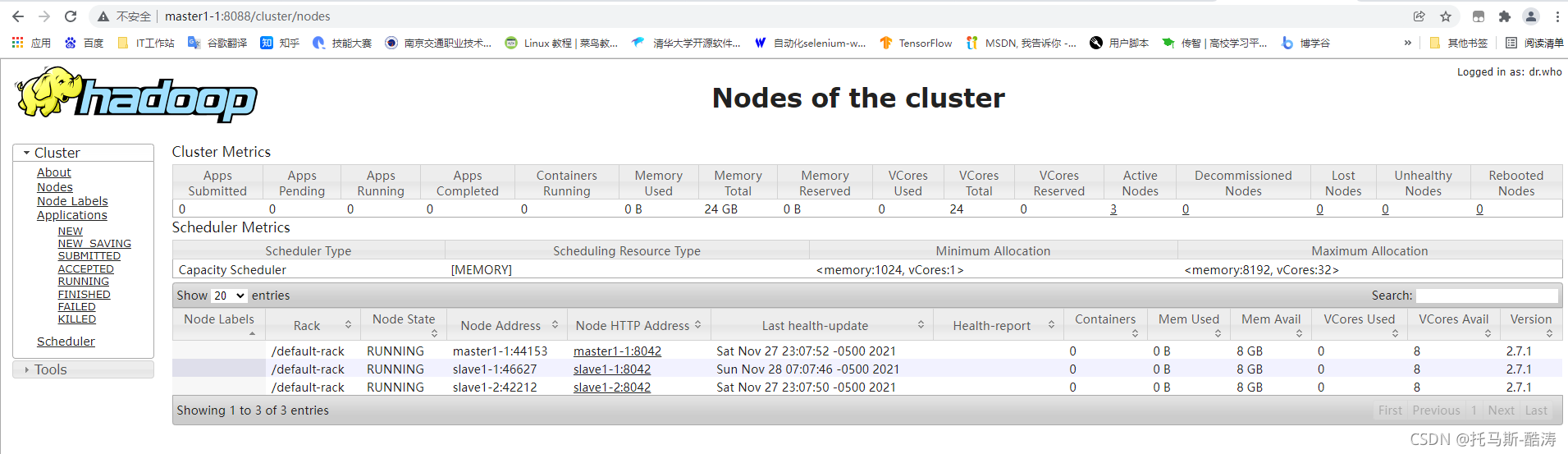
十六、重启刚才终止的 namenode,并查看 jps 进程,截图访问两个 namenode 的 web 界面,并截图保存
sbin/hadoop-daemon.sh start namenode
?
??
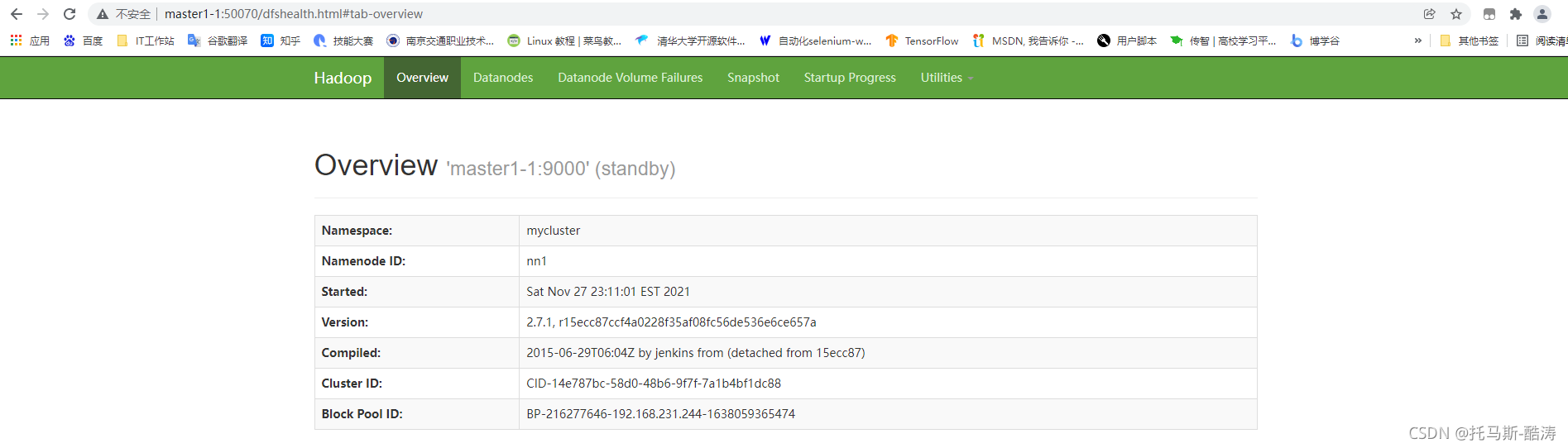
Hadoop HA部署(MINI版)完成
不能打败你的必将使你愈发强大!