路由选择的工作及路由选择算法的作用
- 默认路由器:主机通常直接与一台路由器相连接,该路由器称为主机的默认路由器,又称为该主机的第一跳路由器
- 源路由器 :源主机的默认路由器
- 目的路由器 :目的主机的默认路由器
- 路由选择的工作 :路由选择的工作是确定从源主机到目的主机的路径,可以归结为确定从源路由器到目的路由器的路径
- 路由选择算法的作用 :路由选择算法在网络路由器中运行、交换和计算信息,用这些信息配置路由器的转发表
路由选择算法的分类
集中式全局路由选择算法
- 集中式全局路由选择算法:通过让每个结点向网络中所有其他结点广播链路状态分组(每个链路状态分组包含它所连接的链路的特征和费用),这样每个节点都可以获得该网络的等同的、完整的视图。每个节点都可以利用这些完整的网络信息来执行路由选择算法。LS(链路状态)算法便是一种集中式全局路由选择算法。
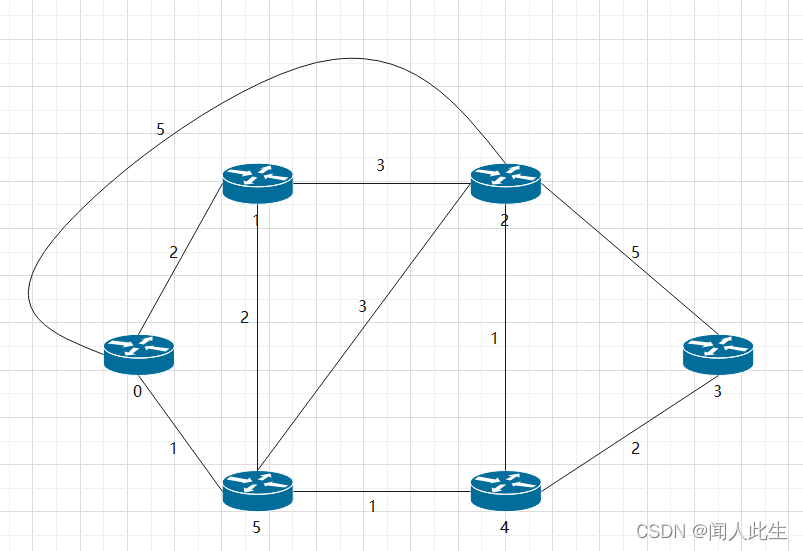
我们用Java来模仿LS算法:如图所示的网络中,路由器0为源路由器,计算从源路由器到该网络中其余所有路由器的最低费用路径
//LS算法实现
import java.util.ArrayList;
//dists[v].dist:到算法的本次迭代,从源路由器到目的路由器v的最低费用路径的费用
//N‘:路由器子集,如果从源路由器到某个路由器的最低费用路径已知,则该路由器在集合N’中
//N:网络中的所有路由器集合
class Node{ //表示一个路由器实体,为了方便表示,我们不将路由器实体的成员变量私有化
int dist; //存放源路由器到这个路由器的最低费用
boolean ifN; //如果这个路由器包含在集合N‘中(即从源路由器到这个路由器的最低费用路径已知),那么ifN为true
ArrayList<Integer> road; //这个列表用于存放源路由器到这个路由器所经过的中间路由器编号(不包括源路由器和这个路由器)
public Node(int dist,boolean ifN,ArrayList<Integer> road){
this.dist = dist;
this.ifN = ifN;
this.road = road;
}
}
public class LS{
public static Node[] LSA(int[][] map){ //该算法以所有路由器之间的连通性(若不连通,则以Integer.MAX_VALUE表示∞)及所有链路的费用为输入,以路由器数组为返回
Node[] dists = new Node[map.length];//将数组的长度初始化为网络中的路由器的个数
for(int i = 0;i < dists.length;i++){
if(i == 0){
dists[i] = new Node(0,true,new ArrayList<Integer>());//将源路由器(源路由器编号为0)的最低费用初始化为0,ifN初始化为true,因为源路由器一开始就在集合N’中
}else{
dists[i] = new Node(Integer.MAX_VALUE,false,new ArrayList<Integer>());//其他路由器开始都不在集合N‘中,因此ifN都初始化为false,且将最低费用初始化为Integer.MAX_VALUE
}
}
for(int i = 1;i < dists.length;i++){ //遍历除源路由器以外的所有路由器进行初始化
if(map[0][i] < Integer.MAX_VALUE){ //如果这个路由器与源路由器连通,则将dists[i].dist初始化为map[0][i]
dists[i].dist = map[0][i];
}else{ //如果这个路由器与源路由器连通,则将dists[i].dist初始化为Integer.MAX_VALUE
dists[i].dist = Integer.MAX_VALUE;
}
}
for(int i = 1;i < dists.length;i++){ //遍历每一个路由器节点,计算源路由器到其的最低费用和最低费用路径
int min = Integer.MAX_VALUE; //将最小值初始化为Integer.MAX_VALUE
int w = 0; //用来记录不在N’中且dist最小的路由器
for(int v = 0;v < dists.length;v++){ //寻找不在N’中且dist最小的路由器
if(dists[v].ifN == false && dists[v].dist < min){
min = dists[v].dist;
w = v;
}
}
if(min < Integer.MAX_VALUE){ //如果源路由器与网络中其他所有路由器的不连通,那么第一次循环时min = Integer.MAX_VALUE,在dists[k].dist = dists[w].dist + map[w][k]运算中会发生溢出
dists[w].ifN = true; //将路由器w加入集合N‘
dists[w].dist = min;
for (int k = 0;k < dists.length;k++) {
if (dists[k].ifN == false && map[w][k] < Integer.MAX_VALUE && dists[w].dist + map[w][k] < dists[k].dist) { //map[w][k] < Integer.MAX_VALUE也是防止溢出
dists[k].dist = dists[w].dist + map[w][k]; //更新与路由器w连通且不在集合N’中的路由器的dist
dists[k].road = (ArrayList<Integer>) dists[w].road.clone(); //更新路由器k的中间路径,这两行代码的含义是,在满足if语句中条件的情况下,路由器k的中间路径是路由器w的中间路径再追加上路由器w
dists[k].road.add(w);
}
}
}
}
return dists; //返回路由器数组
}
}
//测试LS算法
public class Demo {
public static void main(String[] args) {
int[][] map = {{0, 2, Integer.MAX_VALUE, Integer.MAX_VALUE, Integer.MAX_VALUE, 1}, {2, 0, 3, Integer.MAX_VALUE, Integer.MAX_VALUE, 2}, {Integer.MAX_VALUE, 3, 0, 5, 1, 3}, {Integer.MAX_VALUE, Integer.MAX_VALUE, 5, 0, 2, Integer.MAX_VALUE}, {Integer.MAX_VALUE, Integer.MAX_VALUE, 1, 2, 0, 1}, {1, 2, 3, Integer.MAX_VALUE, 1, 0}};
Node[] dists = LS.LSA(map);
for (int i = 1; i < dists.length; i++) {
if (dists[i].ifN == true) {
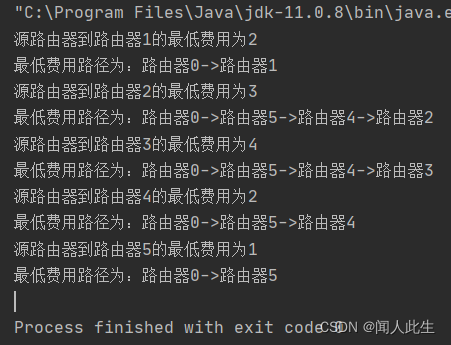
System.out.println("源路由器到路由器" + i + "的最低费用为" + dists[i].dist);
System.out.print("最低费用路径为:");
System.out.print("路由器0->");
for (int j = 0; j < dists[i].road.size(); j++) {
System.out.print("路由器"+dists[i].road.get(j)+"->");
}
System.out.println("路由器"+i);
}else{
System.out.println("路由器"+i+"与源路由器不连通");
}
}
}
}
测试结果
分散式路由选择算法
- 分散式路由选择算法 :分布式计算,没有结点拥有关于所有网络链路费用的完整信息,而每个结点仅有与其直接相连链路的费用知识即可开始工作。
- DV(距离向量)算法是一种分散式路由选择算法
- DV算法的特点
①分布式:每个结点都要从一个或多个直接相连邻居接收某些信息,执行计算,然后将其计算结果分发给邻居
②迭代性:此过程一直要持续到邻居之间无更多信息要交换为止 (此算法是自我终止的,即没有计算应该停止的信号,它就停止了)
③异步性:它不要求所有结点相互之间步伐一致地操作
DV算法的原理
- Dx(y)=min{c(x,v)+Dv(y)}表示从路由器x到路由器y的最低费用路径的费用
c(x,v)表示路由器x到与其直接连接的邻居路由器v的路径费用
min表示路由器x的所有邻居路由器(即与路由器x直接连通的所有路由器)- Dx[Dx(y):y∈N](距离向量)表示从路由器x到在N中的所有其他路由器y的费用估计的向量
Dx(y)表示从路由器x到路由器y的最低费用路径的费用
N表示给定网络中的路由器集合- 在DV算法中,对于每个路由器x,它需要维护以下几条信息
①c(x,v)
②路由器x的距离向量Dx[Dx(y):y∈N]
③路由器x的每个邻居v的距离向量Dv[Dv(y):y∈N]- 算法流程
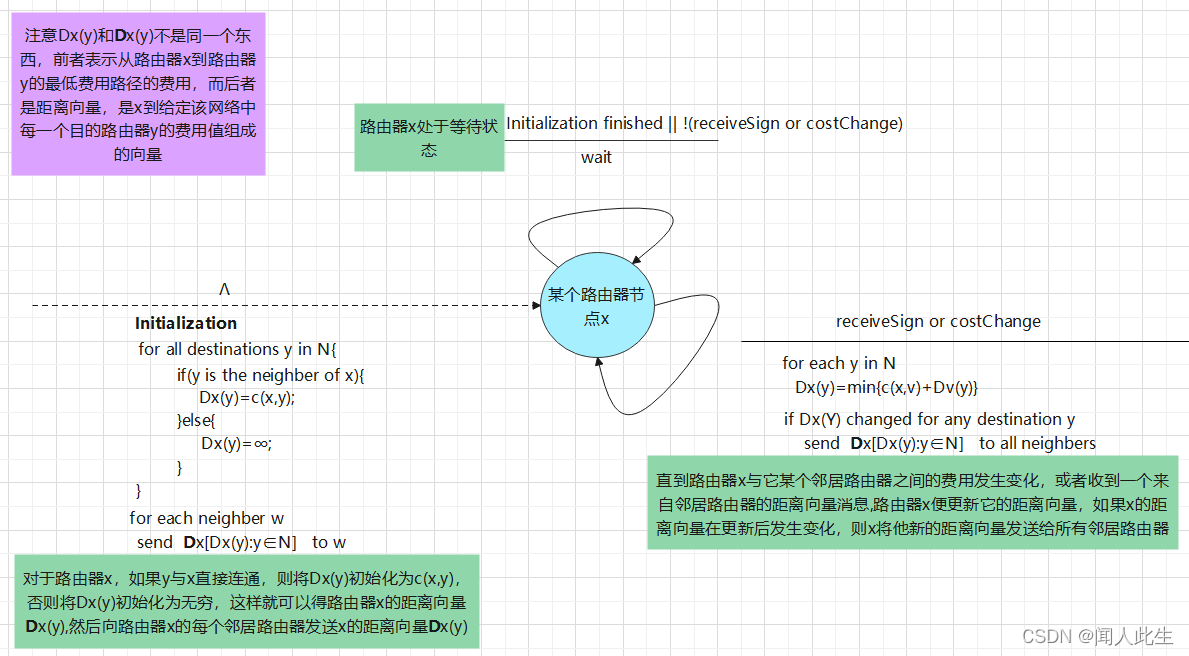
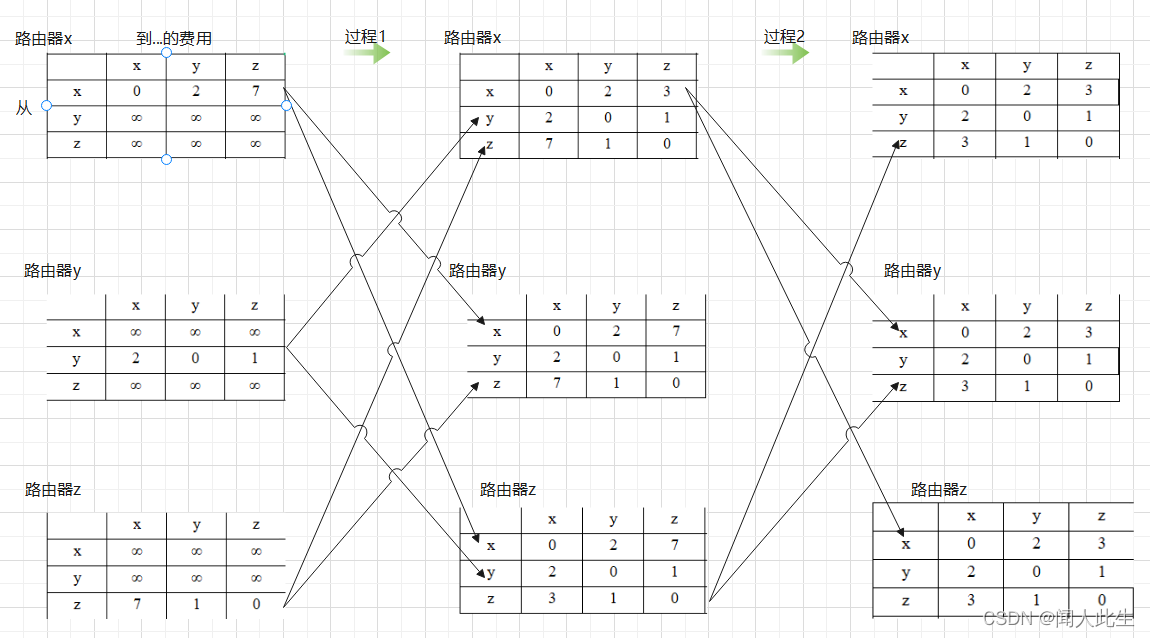
- 我们结合一个例子分析上面的算法流程
从算法流程图中可以看出,在初始化阶段,对于路由器x,如果y与x直接连通,则将Dx(y)初始化为c(x,y),否则将Dx(y)初始化为无穷,这样就可以得路由器x的距离向量D x(y),然后向路由器x的每个邻居路由器发送x的距离向量 D x(y),因此便有了上图中的 第一列和过程1
从算法流程图中可以看出,一旦路由器x与它某个邻居路由器之间的费用发生变化,或者收到一个来自邻居路由器的距离向量消息,路由器x便更新它的距离向量,如果x的距离向量在更新后发生变化,则x将他新的距离向量发送给所有邻居路由器。于是便有了上图中的第二列和过程2
到达第三列后,经重新计算,路由器x、y和z的距离向量均没有发生变化,算法处于稳定状态- 需要特别注意的是,路由器与它某个邻居路由器之间的费用发生变化,或者收到一个来自邻居路由器的距离向量消息时会更新它自身的向量表,上图中的过程2是由于收到一个来自邻居路由器的距离向量消息,那么路由器与它某个邻居路由器之间的费用发生变化时会是什么样子呢? 我们分别从费用变小和变大两个方向来看这个问题
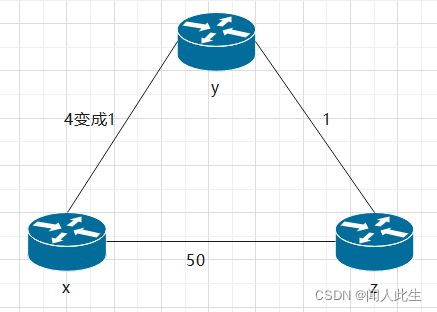
- 路由器和它某个邻居路由器之间的费用变小时(在此只关注y与z到目的地x的距离表中的有关表项)
- t0时刻,路由器y检测到链路费用变化(费用从4变为1) ,更新其距离向量,并通知其邻居这个变化
- t1时刻,z收到来自y的更新报文并更新了其距离表。它计算出到x的新最低费用(从费用5减为费用2) ,它向其邻居发送了它的新距离向量
- t2时刻,y收到来自z的更新并更新其距离表。y的最低费用未变,因此y不发送任何报文给z。该算法进入稳定状态
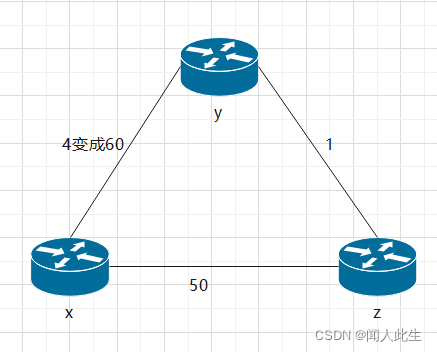
- 路由器和它某个邻居路由器之间的费用变大时(在此只关注y与z到目的地x的距离表中的有关表项)
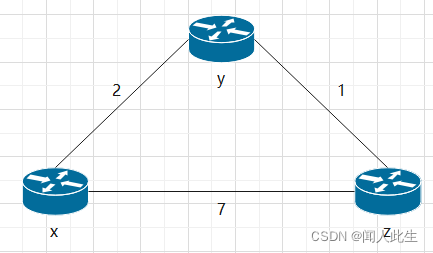
在费用变化之前,Dy(x)=4,Dy(z)=1,Dz(y)=1,Dz(x)=5;
费用变化之后,y检测到费用的变化,开始更新自己的距离向量Dy(x)=min{c(y,x)+Dx(x),c(y,z)+Dz(x)}=min{60+0,1+5}=6,并且向z通知这个变化。如果y需要向x发送一条消息,y会选择通过z路由到x(因为在y看来,y->x的费用是60,而y->z->x的费用是6),当消息到达z时,z又会选择通过y路由到x(因为此时在z看来,z->x的费用是50,而z->y->x的费用是c(z,y)+Dy(x)=1+6=7),如此往复,经过44次迭代(z发现z->y->x的费用大于50)后,z会直接将这个消息发送到x。
可见关于链路费用增加的坏消息传播得很慢!这个问题有时被称为无穷计数问题- 解决无穷计数问题的方法:增加毒性逆转
其思想较为简单:如果z通过y路由选择到目的地x,则z将通告y,z到x的距离是无穷大,即z将向y通告Dz(x)=∞(z实际上知道 Dz(x) =5), 只要z经过y路由选择至x, 就持续地向y讲述这个善意的谎言。因为y相信z没有到x的路径,故只要z继续经y路由选择到x并这样去撒谎),y将永远不会试图经由z路由选择到x。
涉及3个或更多结点(而不只是两个直接相连的邻居结点)的环路将无法用毒性逆转技术检测
集中式全局路由选择算法和分散式路由选择算法的对比
- 报文复杂性。LS算法要求每个结点都知道网络中每条链路的费用。这就要求要发送 O(|N| |E|)个报文(N表示路由器个数,E表示链路个数),并且无论何时一条链路的费用改变时,必须向所有结点发送新的链路费用。当链路费用改变时, DV 算法仅当在新的链路费用导致与该链路相连结点的最低费用路径发生改变时,才传播己改变的链路费用。
- 收敛速度(算法趋于稳定的速度):LS算法的时间复杂度为O(N2)(N表示路由器个数),而DV算法收敛速度较慢,可能还会遭遇无穷计数问题
- 健壮性:LS算法的计算在一定程度上是分离的,因此提供了一定的健壮性。在DV算法中,一个结点可向任意或所有目的结点通告其不正确的最低费用路径
层次路由选择
- 为什么要引入层次路由选择?
① 如果将网络中所有路由器等同看待,随着路由器数目的增多,路由器间类似于传播费用变化这样的开销将非常高,导致没有多余的带宽来发送数据分组
②一个组织应当能够按自己的愿望运行和管理其网络,还要能将其网络与其他外部网络相连接- 可以通过将路由器组织进自治系统(AS)来解决这两个问题
自治系统内部路由选择协议:在相同的AS中的路由器都全部运行同样的路由选择算法(如 LS或DV算法) ,且拥有彼此的信息。在一个自治系统内运行的路由选择算法叫做自治系统内部路由选择协议
网关路由器:负责向在本 AS 之外的目的地转发分组的路由器
自治系统间路由选择协议:从相邻 AS 获取可达性信息和向该AS中所有路由器传播可达性信息是两项由自治系统间路由选择协议处理的任务