�ο�:
����(����!��)https://zhuanlan.zhihu.com/p/341819774
�����鲥�Ϳɿ��鲥 https://blog.csdn.net/fragile98/article/details/113880738
�����鲥 https://www.icode9.com/content-4-872325.html
�������ڡ����塱��,����Լ��Ŀ�������ʦ���Ŀ������ܽ��,������ͬ��һƪ(�������)
may the flame guide thee
������ ������
1.�ֲ�ʽ����ĺ���
-
Ŀ��
-
- ������Ϣ����,ʵ�ֶ��ٽ�����Դ�Ļ������,��ֹ���Ų���֤һ����
-
����
-
- �첽ϵͳ
- ���Ͻ���
- �ɿ�����Ϣ����
-
ִ���ٽ�����Ӧ�ò�Э��
-
- enter():�����ٽ���,��Ҫ����¿�����������
- resourceAccesses():���ٽ������ʹ�����Դ
- exit():�뿪�ٽ���,�������̿��Է����ٽ���
-
����Ҫ��
-
-
��ȫ��(ME1)
-
- ���ٽ�����һ��ֻ��һ������ִ��
-
����(ME2)
-
- ������뿪�ٽ������������ճɹ�ִ��
- ��������Ҳ����
-
˳��(ME3)
-
- ���һ�������ٽ�����������������,������ٽ���ʱ����˳��
- ����Ϊû��ȫ��ʱ��,��ʱʹ�õ�һ�����õĹ�ƽ������,��������������ٽ�������Ϣ֮��ķ�������˳��
-
-
����
-
-
��������,��ÿ��enter��exit�����з��͵���Ϣ��
-
�ͻ��ӳ�,���̽��롢�˳��ٽ����ĵȴ�ʱ��
-
- �� enter �� exit ����������ӳ�
-
ͬ���ӳ�,�����л������ĵ�ʱ��
-
- һ�������뿪�ٽ�������һ�����̽����ٽ���֮����ӳ١�ͬ���ӳٽ϶�ʱ,�������ϴ�
-
2.����ֲ�ʽ����ķ���(4��):����������������鲥+��ʱ�ӡ�MaekawaͶƱ�㷨
1)����������㷨
�ܹ�
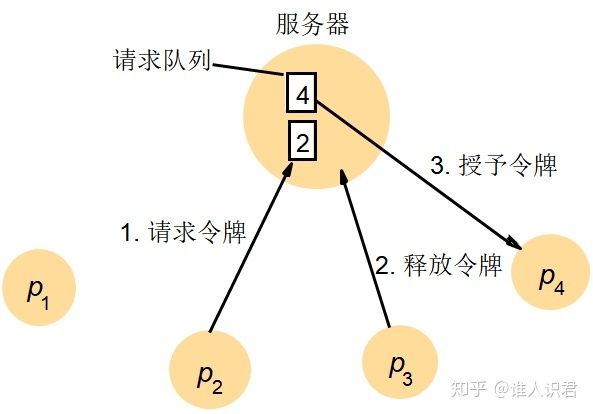
-
������ȫ��������,��������˳��Ҫ��(����������ӳ�)
-
���ܷ���:
-
-
��������
-
- enter():2 ����Ϣ,������Ϣ����Ȩ��Ϣ
- exit():1 ����Ϣ,���ͷ���Ϣ
-
�ͻ��ӳ�,��Ϣ����ʱ�䵼��������̵��ӳ�
-
ͬ���ӳ�,һ����Ϣ������ʱ��
-
�����������ƿ��
-
2)��
- �ܹ�,���̰�����һ��������,ÿ������ Pi �뻷�е���һ������ P(i+1) mod N ��һ��ͨ���ŵ�
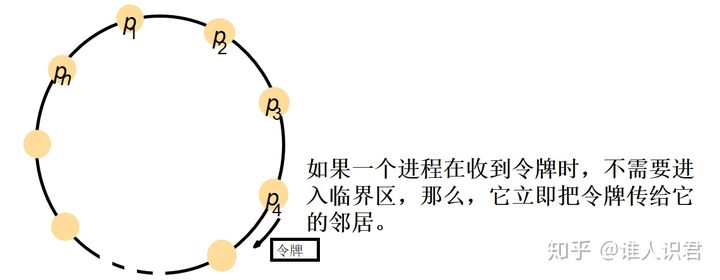
-
������ȫ��������,��������˳����
-
���ܷ���
-
-
��������,�������ƵĴ��ݻ�������Ĵ���
-
�ͻ��ӳ�
-
- Min:0 ����Ϣ,�����յ����Ƶ����
- Max:N ����Ϣ,�ոմ��������Ƶ����
-
ͬ���ӳ�
-
- Min:1 ����Ϣ,�������ν����ٽ���
- Max:N ����Ϣ,��һ�������뿪����һ�����̽����ٽ���֮���ͬ���ӳ�
-
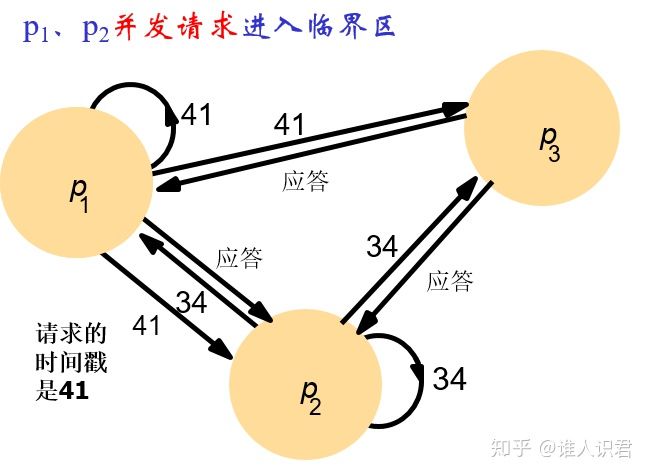
3)�鲥 + ��ʱ�����㷨
-
����˼��
-
-
���̽����ٽ�����Ҫ�����������̵�ͬ��
-
- �鲥+Ӧ��,Ҫ�����ٽ����Ľ����鲥һ��������Ϣ,����ֻ�����������̶��ش��������Ϣʱ���ܽ���
-
��������
-
- ���� Lamport ʱ�����������,����������Ϣ���� <T, pi>
- T �Ƿ����ߵ�ʱ���, pi �Ƿ����ߵı�ʶ����
- ������������ȵ�ʱ���,��ô�����ݽ��̵ı�ʶ������
-
-
α���㷨
-
- RELEASED ��ʾ���ٽ�����, HELD ��ʾ���ٽ�����,WANTED ��ʾϣ�����롣

-
���ܷ���
-
-
��������
-
- enter(),��Ҫ 2(N-1),�� N-1 ������� N-1 ��Ӧ��
-
�ͻ��ӳ�,һ����Ϣ����ʱ��
-
ͬ���ӳ�,һ����Ϣ����ʱ��
-
4)Maekawa ͶƱ�㷨
-
����˼��
-
- ���̽����ٽ�����Ҫ�����������̵�ͬ��,����Ҫ���еĶԵȽ��̶�ͬ����
- ֻҪ����������ʹ�õ��Ӽ����ص�,ֻ��Ҫ����ԵȽ��̵��Ӽ���ý������ɼ���
-
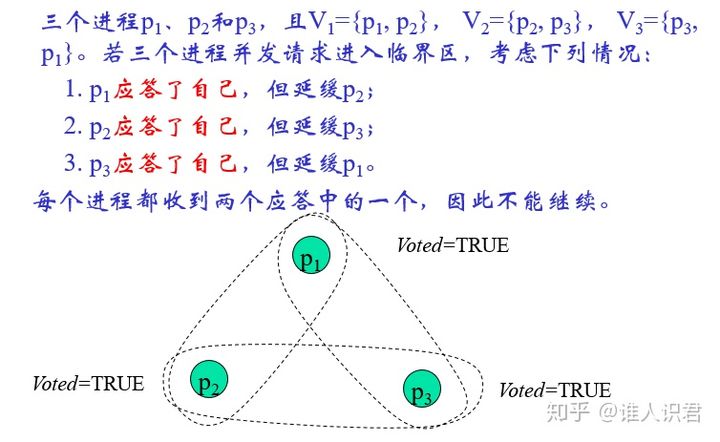
Maekawa ��ÿһ�����̶�������һ��ѡ�ټ� Vi ��
-
- Vi ���� {p1, p2, ��, pn}
- pi ���� Vi
- Vi �� Vj �Ľ�����Ϊ�ըC��������ѡ�ټ�������һ��������Ա
- Vi |= K,��ƽ���, ÿ��������ͬ����С��ѡ�ټ�
- ÿ������ pj ������ѡ�ټ� Vi �е� M ��������,M = K
-
�㷨α��

- ���㷨��������
-
�������㷨��������,���ĺ��㷨������ȫ����������˳����
-
���ܷ���
-
- ��������,3 ������ N
- �ͻ��ӳ�,1 ����Ϣ����ʱ��
- ͬ���ӳ�,1������ʱ��
3. �ֲ�ʽѡ�ٵĺ���
-
��������
-
- ѡ���㷨,ѡ��һ��Ψһ�Ľ��̰����ض��Ľ�ɫ
- �ټ�ѡ��,һ������������ѡ���㷨��һ������,ԭ���� N �����̿��������ټ� N ��ѡ��
- �μ���,���̲μ���ѡ���㷨��ij������
- �Dzμ���,���̵�ǰû�вμ��κ�ѡ���㷨
- ���̱�ʶ��,Ψһ�ɰ�ȫ��������κ���ֵ
-
����Ҫ��
-
-
��ȫ��
-
- ÿһ�����̶���һ������ elected
- ����Ľ��� pi �� electedi= ���ա�(���̵�һ�γ�Ϊһ��ѡ�ٵIJ�����ʱ,��ֵ��û�ж���) �� electedi = P(P�������н���ʱ��������ʶ���ķDZ�������)
-
����
-
- ���н��� pi ���μӲ��������� electedi�١��ա������ pi ����
- �����л����Dz����ߵĽ��� pj, electedi ��¼���ϴε�ѡ���̵ı�ʶ��
-
-
���ܷ���
-
- ��������,�뷢����Ϣ������������
- ��תʱ��,�������㷨����ֹ�㷨֮�䴮����Ϣ����Ĵ���
4 ����ֲ�ʽѡ�ٵķ���(2��):�����Ե�
1)���ڻ���ѡ���㷨
ÿһ�������е���һ�����̵�ͨ��ͨ��,��˳ʱ�뷢����Ϣ���ھ�
-
Ŀ��
-
- ���첽ϵͳ��ѡ�پ�������ʾ���Ľ�����ΪЭ����
-
����˼��
-
- ���,ÿ�����̱����Ϊѡ���е�һ���Dz����ߡ�
- �κν��̿��Կ�ʼһ��ѡ��,�����Լ����Ϊһ��������,Ȼ����Լ��ı�ʶ���ŵ�һ��ѡ����Ϣ��,������Ϣ˳ʱ�뷢�������ھ�
-
α���㷨

-
���ܷ���
-
-
����
-
- ����ѡ���㷨����ʱ���ھӸպþ�������ʶ��
- ��������,һ����Ҫ 3N-1 ����Ϣ(Ϊʲô??)
- ��תʱ��,3N-1
-
������,2N
-
�Ҳ��߱��ݴ�����
-
2)�Ե��㷨
-
����
-
- ͬ��ϵͳ,ʹ�ó�ʱ������
- ͨ������,���������̱���
- ÿ������֪����Щ���̾��и���ı�ʶ��
- ÿ�����̿��Ժ����и����ʶ���Ľ���ͨ��
-
������Ϣ����
-
- ѡ����Ϣ,��������ѡ��
- Ӧ����Ϣ,�û��ظ�ѡ����Ϣ
- Э������Ϣ,������ѡЭ������Ϣ
-
������������Ľ��̱�ʶ��,��������Լ���Э����,���������������������㷨Ϊ���Ե��㷨��
-
�㷨α��

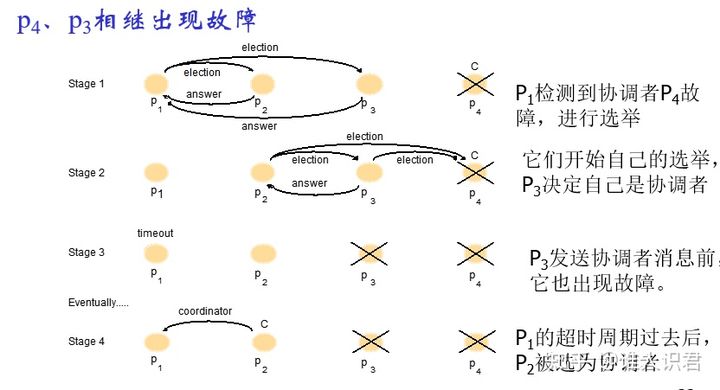
-
���ܷ���
-
- ���,N-2,��ʶ���δ�Ľ��̷���ѡ��,��תʱ��Ϊ 1 ����Ϣ
- �,O(N*N),��ʶ����С�Ľ��̷���ѡ��
5.�����鲥�ɿ��鲥������
-
����һ���鲥���㲥
-
- �鲥,����һ����Ϣ���������ÿһ������
- �㲥,����һ����Ϣ��ϵͳ�����н���
-
�鲥ͨ��ϵͳģ��
-
-
multicast(g,m),���̷�����Ϣ�������� g �����г�Ա
-
deliver(m),�������鲥���͵���Ϣ�����ý���
-
- �鲥��Ϣ�����̽ڵ��յ���,�������DZ��ύ�������ڲ���Ӧ�ò�
-
1)�����鲥
? ���
-
�鲥���̲�����
-
Unicast �ǿɿ���
-
���ͷ�������
������Ϊ��Ϣ�������մ��͵����� -
-
����ԭ��
- Deliver(m):�������鲥���͵���Ϣ�����ý��� ��Ӧ�ò�
- Receive(m):ֻ�ǽ��յ���Ϣ
-
- B-multicast(g,m):��ÿ������ p ���� g,send(p, m)
- ���� p receive(m)ʱ,p ִ�� B-deliver(m)
-
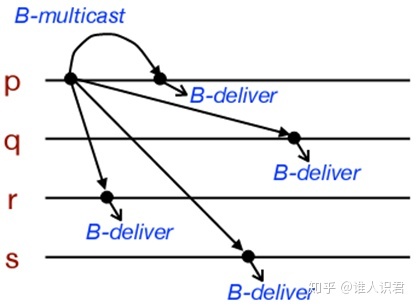
2)�ɿ��鲥
-
-
����(��������һ��ͼ����,����)
-
- ������:һ����ȷ�Ľ��� p ����һ����Ϣ m ����һ��,��Ϣ�ܿ���ͨ��һ���뷢������ص��������
- ��Ч��:���һ����ȷ�Ľ����鲥��Ϣ m,��ô���ս����� m,����������Ӧ�ò�(Liveness for sender)
- Э��:���һ����ȷ�Ľ��̴�����Ϣ m,��ô�� group(m) ��������ȷ�Ľ����ս����� m(Ҫô���ж��ܴ��ݵ�,Ҫô���ж�������)
-
��Ч�Ժ�Э������������Ļ���(overall liveness):���һЩ��ȷ�Ľ����鲥����Ϣm,��������ȷ���̶��ᴫ����Ϣm��
-
����
���һ������B-multicast��һ�������,����һ�����deliver��m,��һ��û�С����ƻ���Э��(Agreement)
-
6.ʵ�ֿɿ��鲥�ķ���(���˵Ҫ�úÿ�)
��������ͶƱ,����һ������ͶƱ,˼·��Ҫ�ֿ�
1)B-multicast ʵ�ֿɿ��鲥

(�Է�����Ϊ��ʼ)��ʼ��Ϊ��(�����������յ���Ϣ��Ҳ��ʼ��������ϢΪ��)
�յ���Ϣ������Ϣm�Ƿ��Ѿ����յ��IJ�����Ϣ,��������������((ȫ����Ϣ)������)����������߲����յ���Ϣ��,�鲥��Ϣ(Э��)�ϴ�������Ϣ��Ӧ�ò�(��Ч��)
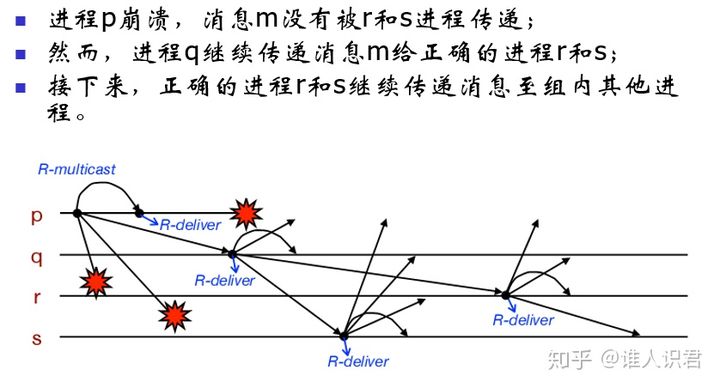
-
�㷨����
- ������Ч�ԡ������ԡ�Э��
- Ч�ʵ�,ÿ����Ϣ�����͵�ÿ������ |g| ��
2)�� IP �鲥ʵ�ֿɿ��鲥
��java���鲥�����Ӻ������Ƚ���һ������ip,Ȼ�����еĶ������ip���ܡ�
����������ֻ��������ip��,�����˶������յ�����
-
�ص�
- ��ʹ�û������ɱ�����,���ɴ�������Ҫ��֮����
- �� IP �鲥���Ӵ�ȷ�Ϸ��ͷ�ȷ������
-
- ���� IP �鲥,IP �鲥ͨ��ͨ���dzɹ���
- �Դ�ȷ��,�ڷ������е���Ϣ���Ӵ�ȷ��
- ����ȷ��,���̼�����©��һ����Ϣʱ,����һ��������Ӧ����Ϣ
-
ʵ��
- �������g,ÿ������p,ά��������Ϣ:
- 1.Sg.p:��Ϊ��һ��Ҫ���͵���Ϣ���(��������,s��Ϊsend,g��Ϊgroup,p�������͵Ľ���,����ָ������g���н���)
- 2.Rg.q:��Ϊ���Խ���q��������Ϣ�����(��������,Rָ��Received(��ȥʽ),qָ��g������һ������Ϣ�Ľ���)
- pҪR-multicastһ����Ϣ����g
- 1.�Ӵ�Sg,p��ȷ��(��<q, Rg,q>)(���뷢��json��ʽ,��һ��Ԫ�ء���š�,������ȫ���˹��ϵ���һ����Ϣ��,��ô�����ǹ�ʶ���Ƶ�����,������趼����˹�ʶ)
- 2.���ؼ���������:Sg,p = Sg,p +1
- �յ�һ������p�Ĺ㲥��Ϣm,��R-deliver:
- �յ���Ϣ�Ľ���q�ȶ��յ���Ϣ�����sg,p=Rg.p+1(1.����ֻ���鲥��Ϣ,�������� +1 ��)
- ��m.S <= Rg,p, �����Ϣ��Ͷ��,ֱ�Ӷ���
- ��m.S > Rg,p +1��������Ӵ�������ȷ��<q, Rq>��Rq > Rg,q, ��©����һ��������Ϣ������Ϣ�ݴ��ڱ���������,�����ͷ���ȷ��NACK,Ҫ�����·��Ͷ�ʧ��Ϣ��
- �������� hold-back queue
- �������в����ǿɿ��Ա����,��������Э��,ʹ������ʹ�������������Ͷ�ݵ���Ϣ����Ҳ�ṩ��Ͷ��˳��֤��
- �������g,ÿ������p,ά��������Ϣ:
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-fRczfNiv-1638620904415)(C:\Users\14182\AppData\Roaming\Typora\typora-user-images\image-20211202171527672.png)]
?�㷨����
? ?������
? ?ͨ������ظ���Ϣ��IP�鲥����ʵ��
? ?����
? ?����IP�鲥������Ч��ʱ����
? ?��
? ?��Ҫ:���������鲥��Ϣ(��֤�л���̽����Ϣ��ʧ,��Ϊ�DZ���NACK)+���ޱ�����Ϣ����ʱ����(һ���յ�NACK,�ط�)�� ����ʵ
? ?ijЩ����Э��ʵ����Э��
3)�����鲥
? ?���һ����ȷ�Ľ��̷���multcast(g, m),Ȼ��multicast(g, m��),��ôÿ��Ͷ��m������ȷ�Ľ��̽���m��ǰͶ��m��
? ?��֤ÿ�����̷��͵���Ϣ�����������еĽ���˳��һ��
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-3fMyk6bG-1638620904416)(https://www.icode9.com/i/ll/?i=20210220132606355.png?,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2ZyYWdpbGU5OA==,size_16,color_FFFFFF,t_70)]
- �������
- Causal Ordering => FIFO Ordering
���һ���鲥Э��ʵʩ�������,�����϶�Ҳ��FIFO ordering
�෴FIFO����֤�����������
- Causal Ordering => FIFO Ordering
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-88ynWzze-1638620904417)(https://www.icode9.com/i/ll/?i=20210220133037431.png?,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2ZyYWdpbGU5OA==,size_16,color_FFFFFF,t_70)]
- ȫ����
- ��֤���н�����ͬ����˳�����е��鲥��
ȫ���������鲥���͵�˳��
���һ����ȷ�Ľ����ڴ���M֮ǰ����M��,��ô�����Ľ���Ҳ�ڴ���M֮ǰ����M���� - �����н�����,����˳����M1:1,M2:1,M3:1,M3:2
- ��֤���н�����ͬ����˳�����е��鲥��
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-w3IRRUzJ-1638620904418)(https://www.icode9.com/i/ll/?i=20210225162800342.png?,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2ZyYWdpbGU5OA==,size_16,color_FFFFFF,t_70)]
? ȫ�����ܱ�֤���
? ���Ҳ���ܱ�֤ȫ����
������������������
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-m0TkkOO5-1638620904419)(https://www.icode9.com/i/ll/?i=20210225163609830.png?,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2ZyYWdpbGU5OA==,size_16,color_FFFFFF,t_70)]
������ͼ������ȫ����,��Ȧ�����������ط���������Ϣ���ݵ�˳��һ����
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-D4K3XP5x-1638620904419)(https://www.icode9.com/i/ll/?i=20210225163657610.png?,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2ZyYWdpbGU5OA==,size_16,color_FFFFFF,t_70)]
��˵,FIFO���DZ��ؿ���˭��������˭,���Ҫ����������¼����Կ�������,�����˳���Ⱥ���,ȫ����Ҫ�����нڵ���¼�����һ��
7.��ʶ����ռͥ�������⡢����һ���� ����
1)��ʶ
-
��ʶ����:һ��������������һ��ֵ��,Ӧ���һ�����
?pi: ����i
?vi: ����pi������ֵ(proposed value)
?di: ����pi�ľ�������(decision value)
-
����Ҫ��
-
- ��ֹ��,ÿ����ȷ�Ľ��������������ľ�������di
- Э����,��� Pi �� Pj ����ȷ�����ѽ������״̬,��ô di=dj
- ������,�����ȷ�Ľ��̶�������ͬһ��ֵ,��ô���ھ���״̬���κ���ȷ���̶���ѡ���ֵ
2)��ռͥ����
-
��������
-
- 3 �������Ľ���Э���ǽ������dz���
- 1 �������������ܻ��ѱ�
- ����δ�ѱ�Ľ���ִ����ͬ������
-
�빲ʶ��������
-
- ��ռͥ��һ�������Ľ����ṩһ��ֵ,�������̾����Ƿ��ȡ��ֵ
- ��ʶ��ÿ�����̶�������һ��ֵ
3)����һ����
-
ÿһ�������ṩһ��ֵ,���վ�һ��ֵ�������һ��
-
- ��������:������ÿ��������һ�����̵�ֵ��Ӧ
- ����Ӧ���ڷֲ�ʽ������ȡ�������л�����״̬��Ϣ
-
�㷨Ҫ��
-
- ��ֹ��,ÿ����ȷ���������������ľ�������
- Э����,������ȷ���̵ľ�����������ͬg
- ������,������� Pi ����ȷ��,��ô������ȷ�Ľ��̶��� Vi ��Ϊ���Ǿ��������е� i ������
8.3 ����4 ����ռͥ�����������
1)������ռͥ����
-
��������
-
- ÿ�����ҳϵĽ��������յ���ͬ��ֵ V(i)(�� i ������������)
- ����� i ���������ҳϵ�,��ô�����͵������ÿ���ҳϽ����յ��� V(i) ��ͬ
-
��ģ��
-
-
ʹ��һ���������Ͷ����ξ����ʽ��֤��,��������Ľ�����Ϊ˾��,��������Ľ�����Ϊ��ξ:
-
- �����ҳϵ���ξ������ͬ������
- �����������Ľ������ҳϵ�,��ô�����ҳϵ���ξ����˾�������
-
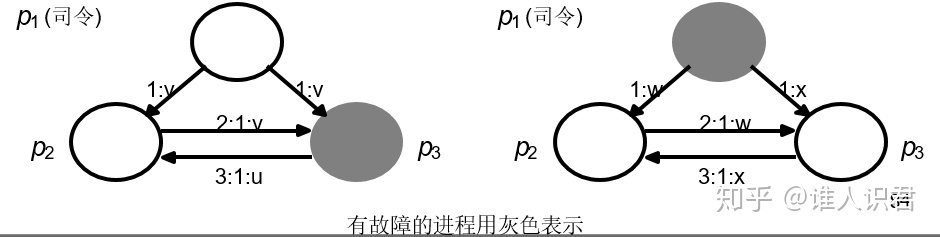
-
�� N <= 3f �IJ������� (������˳���1/3���ҳ����ɴ�ɹ�ʶ)
-
-
n1��n2��n3
-
- �� N �������ֳ�����(����3��),n1+n2+n3=N �� n1��n2��n3<=N/3
-
P1��P2��P3,�ֱ�ģ�� n1��n2��n3������(���ԭ������)
-
2)�ĸ���ռͥ����
-
�������
-
-
��ȷ�Ľ���ͨ��������Ϣȡ��һ��
-
- ��һ��,˾���ÿ����ξ����һ��ֵ
- �ڶ���,ÿ����ξ���Լ���ֵ�����Լ���ͬ��
- ÿ����ξִ�� majority() ����
-

-
��������
-
- ���� f+1 ����Ϣ����
- ������ O(N �� f+1 �η�)
- ��ͼ,����ڵ�С��33%,��Ȼ�õ���ʶ��������Ե�,�ҳ����Եõ���Ϣ;��������,�ҳ��õ���ʶ(�ʵ���ɵ��)
������:����Ͳ�������
1.���еȼ��ĸ����Ҫ������Ӧ��(������û��)
-
���еȼ�
-
- �����������ִ�в�����Ч����ͬ�ڰ�ij�ִ���һ��ִ��һ�������Ч��,��ô���ֽ���ִ����һ�ִ��еȼ۵Ľ���ִ��
- ��ͬЧ��: ������ ����ֵ��ͬ,�����������ͬ
-
���������еȼ۳�Ҫ����
-
- �������������еij�ͻ����������ͬ�Ĵ��������Ƿ��ʵĶ�����ִ��(��T��U *2)
-
Ӧ��
-
-
���еȼۿ���Ϊһ��������������������Э��
-
- ��������Э�����ڽ����ʵIJ��������л�
-
2.��������ֻ������Ʒ���(�����ֹ۷���:��ǰ�����ʱ���)��ԭ����ʵ�֡��Ƚ�
1)��
-
��������һ�ּ������л�����
-
- ������ʶ���ǰ�������
- �������ѱ�����������ס,��������,ֱ��������
-
���μ���,�����ͷ��κ�һ������,���������������µ���
-
- Ϊ�˱�֤������������г�ͻ������������ͬ�Ĵ���ִ��:
- ÿ������ĵ�һ����һ������������,���ϵػ�ȡ����;
- �ڵڶ�����,�����ͷ�������(�������Ρ�)
- (���˼�����ΪҪ������ֱ��������,��ִ��һ�������µ�,�����������䲻�������������ͷ�һ��������һ�����ַ�����������)
������ִ�е��������������������Э��,�����Щ������κβ������Ȳ��Զ����ɴ��л��ġ�
-

-
�ϸ�����μ���
-
- ����������ִ�й����л�ȡ�����������������ύ�����������ͷ�
- Ŀ���Ƿ�ֹ����������µ������ݶ�ȡ������д�������
-
���
-
- Ŀ��:��߲�����
- ֧�ֶ������ͬʱ��ȡij������
- ����һ������д����
-
�����ͻ����
-
- �Ѷ�����д
- ��д���ɶ���д

-
����:������һ��״̬,�ڸ�״̬��һ�������е�ÿһ�������ڵȴ����������ͷ�ij����
-
Ԥ������
-
-
ÿ�������ڿ�ʼ����ʱ��ס��Ҫ���ʵ����ж���(������?)
-
- һ����ԭ�Ӳ���
- ����Ҫ����Դ��������
- ��Ԥ�ƽ�Ҫ���ʵĶ���
-
�������
-
- �������
- ���ٲ�����
-
-
�������
-
- ά���ȴ�ͼ
- ���ȴ�ͼ���Ƿ���ڻ�·
- �����ڻ�·,��ѡ�����һ������
-
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-UKLruCuu-1638620904422)(C:\Users\14182\AppData\Roaming\Typora\typora-user-images\image-20211202213322564.png)]
-
����ʱ,���������õķ�ʽ
-
- ÿ��������һ��ʱ������
- ����ʱ����������Ϊ�ɰ�����
- �����ڵȴ��ɰ����������Ķ���,��������
2)�ֹ۲�������
-
�ֹ۲���
-
-
������ʵ,�����Ӧ����,�����ͻ���������ͬһ������ĸ��ʺܵ�
-
����
-
- ���ʶ���ʱ����������
- �����ύʱ����ͻ
- �����ڳ�ͻ,�����һЩ����
-
-
��������
-
-
������(������������(ָ��д),����������)
-
- ÿ������ӵ�������������ʱ�汾
- ����ʱû�и�����
- ��ʱֵ(д����)���������ɼ�
- ÿ������ά�����ʶ������������:�����Ϻ�д����
-
��֤��(�û���ʾ����,ϵͳ����ͻû)
-
- ���յ�closeTransaction����ʱ,�ж��Ƿ�������������ڳ�ͻ
- �ɹ������ύ
- ʧ�ܷ�����ǰ������߷�����ͻ������
-
���½�(����ͻ����)
- ֻ������ͨ����֤�����ύ
- д�����ڶ������ʱ�汾��¼���־ô洢�����ύ
-
-
�������֤
- nͨ����-д��ͻ����ȷ��ij�������ִ�ж������ص����������Ǵ��еȼ۵�
- �ص�������ָ����������ʱ��û���ύ���κ�����
-
-
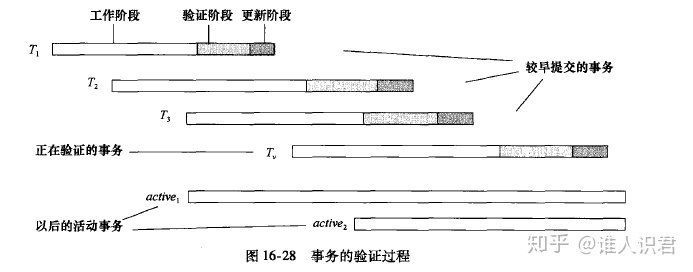
�����
-
- ÿ�������ڽ�����֤��ǰ������һ�������
- �����������,������������
- ���������˳�������֤��
- ����������ύ
-
��ͻ����
-
- ���� Tv ����֤����
- Ti �� Tv ֮����ڳ�ͻ
- ���� Tv ������ Ti �����ǿɴ��л���
- ÿ��ֻ����һ����������֤���½�
-

-
������֤���뱣֤����Ķ���֮����ص���ѭ���� 1 ���� 2����������֤��ʽ
-
- �����֤,��鵱ǰ����ͽ����ص�����֮��ij�ͻ
- ��ǰ��֤,��鵱ǰ�����������������֮��ij�ͻ
�����֤
-
���:������ص�����
-
���Tv�Ķ����Ƿ�����������ص�(Tv�����ύ��ʼ֮ǰ��ʼ��������(�����Ѿ��Ƚ���))�����д���Ƿ��ص�
-
-
�㷨
-
- startTn: Tv ����������ʱ�ѷ��������������
- finishTn: Tv ������֤��ʱ�ѷ��������������
- ���ڼ������������һ�����ȶ�,���Tv�Ķ�������Tiд�����ص�,��ͻ,��֤ʧ��
-
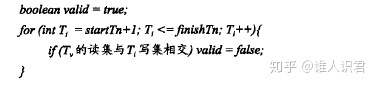
-
-
- ����֤ʧ��,������ǰ��֤������
-
? startTn+1=T2,finishTn=T3(��Ѱ˼�����TvӦ����ָͼ��T1)
��ǰ��֤
-
��ǰ:�ص��Ļ����(�����ε�����)
-
-
�㷨
-
- avtive1~activeN,������
-
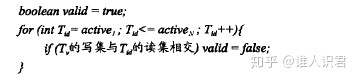
-
n��֤ʧ�ܺ�,��ͻ�������
- ������ǰ������֤����
- �Ƴ���֤
- �������г�ͻ�Ļ����,�ύ����֤����
-
��ǰ��֤�������֤�ıȽ�
-
- ��ǰ��֤�ڴ�����ͻʱ�Ƚ����
- �����֤���ϴ�Ķ����Ϻͽ��������д���Ͻ��бȽ�
- ��ǰ��֤����С��д���Ϻͻ����Ķ����Ͻ��бȽ�
- �����֤��Ҫ�洢���ύ�����д����
- ��ǰ��֤����������֤�����п�ʼ������
������֪,������д;��������,��д�Ҷ�
����
? һ�����������ᱻ����,�����ܱ�֤����������ͨ����֤���
? �����ź���,ʵ����Դ�Ļ������,��������
3) ʱ�������
-
ʱ���
-
- ÿ������������ʱ������һ��Ψһ��ʱ���
- ʱ��������˸�����������ʱ�������е�λ��
- ������������
-
����˼��
- ������ÿ��������ִ��ǰ������֤
-
��ͻ����
-
-
д������Ч
-
- ��������һ�������ʻ�д������һ�����������ִ�е������
-
��������Ч
-
- ��������һ��д������һ����������ִ�е������
-
-
����ʱ����IJ�������
-
-
��ʱ�汾
-
- д������¼�ڶ������ʱ�汾��(��˵,������ʱ�汾��������д�汾�ĸ���)
- ��ʱ�汾�е�д�������������ɼ�
-
����дʱ���
-
- ���ύ�����дʱ�����������ʱ�汾��Ҫ��
- ��ʱ������ü��������ֵ����ʾ
- ����Ķ�����������ʱ���С�ڸ�����ʱ��������дʱ����Ķ���汾��
-

[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-O7p7H36D-1638620904425)(C:\Users\14182\AppData\Roaming\Typora\typora-user-images\image-20211203153300522.png)]
ʱ��������д����
-
- �����������1,2,�����Ƿ�������� Tc �Զ��� D ִ��д����
if (Tc �� D������ʱ��� && Tc > D���ύ�汾�ϵ�дʱ���)
��D����ʱ�汾��ִ��д����,дʱ�����Ϊ Tc
else /* д����̫���� */
�������� Tc
-
-
����
-
- ���� T3 ��д����ִ�����
-
-
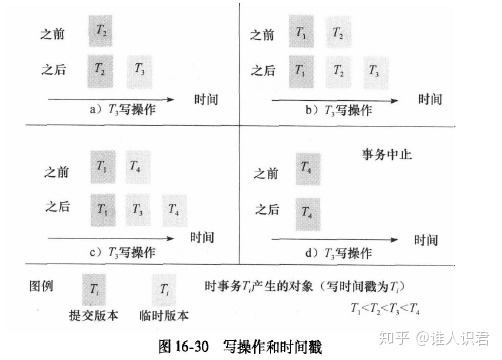
abc��T3�����ύ�汾T1��ʱ���,����ͼ����T3,��ʾ�����ܡ�������һ���Ƿ��ǽ���������(b),������û���������µ�����(�Ƚ���3�ٽ���4,ע������4����ʱ�汾!)
d��4����ʱ��Ϊ�ύ�汾,��û��Ҫ��3��,T3����,���ڼ�¼(ͼ�г���)
ʱ�������Ķ�����
����3,�����Ƿ��������Tc�Զ���Dִ�еĶ�����
if (Tc > D�ύ�汾��дʱ���)
��Dselected��D�ľ������дʱ����İ汾��Tc;
if (Dselected���ύ)
��Dselected�汾����ɶ�����
else
�ȴ�ֱ���γ�Dselected�汾�������ύ�����,Ȼ������Ӧ�ö�����;
}else
�������� Tc
����

[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-cjZvecAL-1638620904426)(C:\Users\14182\AppData\Roaming\Typora\typora-user-images\image-20211203155919962.png)]
�ҷ���ʱ���T3����,��������a���и��ύ��T2,b����Ȼ��T4,����Ϊ����ʱ�汾��Ӱ��,C�������ʱ�汾���(��ѡ��),�Ǿ�ֻ�ܵ���ʱ�汾д��,d��T4>T3,���Ƹ�����˵Ҫ��10.1�ı�ֽ��̯λֻ��10.2�ı�ֽ,��ȡʧ��
ʱ���Ӧ�þ���
��ʼʱ����ABC�����˻�(����)�ձ�(�༭�û�S)��ʼ��д��
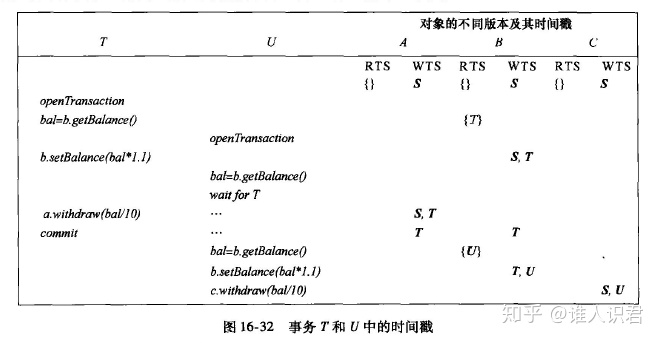
���TҪB���˻�ת�˸�A,�����������,Bά���Ķ��������м���T,Ȼ��д����B,д����A,�ڼ�U�༭����༭B,������B��һ��ʱ����¼�������ʱ״̬,����ϵͳ�ܾ�U��B�Ķ����ȴ�TתΪ�ύ��B,�ύ��UgetB�Ķ�ȡ��,B�Ķ�ȡ����Ҳ����U
3.��˵��˵�İ�
���±ȽϷ�(Ҳ�������Ƕ�ʱ�䲡��ȫ���Լ�����),�������Ʒ�����Ӧ�öԱ�,ppt����ܶ�����д�����,���鿴һ��
������:����
1.���Ƶĸ������������Ҫ��
-
����
-
- �ڶ��������н������ݸ�����ά��
-
���ƵĶ���:��ǿ����
-
-
��ǿ����
-
- ������� WEB ��Դ�Ļ���
- �����ڶ��������֮���������
-
��߿�����
- 1-p��n��,nΪ����������,pΪ��ը����
-
- Ӧ�Է���������
- ��������Ͷ�������:Ԥ�ȸ���(n�˻��û�,����������ܻ��ж�(�����������߶�������))
-
��ǿ�ݴ�����(��ȷ��)
-
- ����һ�����������͵Ĺ���
- (������Ӳ��������)
- f+1�ű���,2f+1����ռͥ(51%???)
- ����ͳһ
- ����һ�����������͵Ĺ���
-
-
����Ҫ��
-
-
��������
-
- �Կͻ����ζ�����������Ĵ���
- �ͻ�����һ����������в���
-
һ����
-
- �ڲ�ͬӦ�����в�ͬǿ�ȵ�һ��������
- ���ƶ��ϵIJ�����������Ӧ������
-
2 ���Ƶ�ϵͳģ��:�������ơ���������
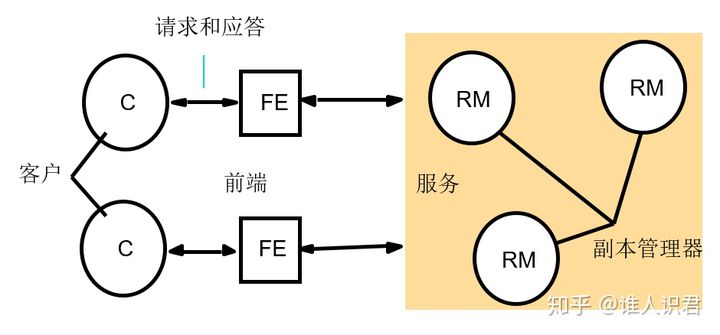
1)ϵͳģ��
-
��������������,�����ڸ�ģ��,�������ڿͻ�����������������������ʽ
-
���
-
-
ǰ��
-
- ���տͻ�������
- ͨ����Ϣ�������������������ͨ��
- Ϊʲô���ÿͻ�ֱ�ӽ���ͨ��?(��֤���Ƶ�����)
-
����������
- һ��ӵ�����ݿ����Ľڵ��Ϊ����������
-
- ����ǰ������
- �Ը���ִ��ԭ���Բ���
-
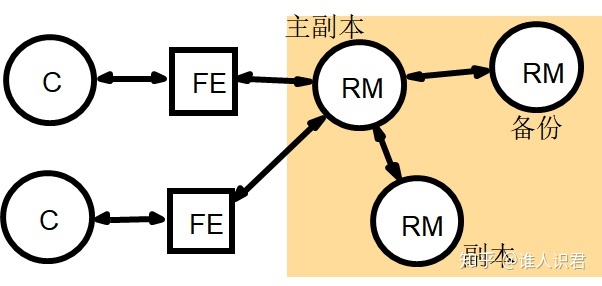
2)��������
- ģ��
-
-
һ������������ + ����θ���������
-
- �����������������ֹ���,��ij�����ݸ���������������Ϊ������������
- Raft?
-
-
�����¼�����
-
����:ǰ�˽�������������������
-
Э��(����):�����������������մ������������(FIFO,���,ȫ����)
-
ִ��:������������ִ�����洢��Ӧ
- ������̽��ִ��,��ִ��Ч������ȥ��
-
Э��(��ʶ)
-
- ������Ϊ���²���,����������������ÿ�����ݸ��������������º��״̬����Ӧ��Ψһ��ʶ��(������֤�ʶ)
- ���ݸ�������������ȷ��
-
��Ӧ
-
- ����������������Ӧ����ǰ��(Ҳ���Զ��,��֮���ص�һ�������Ӧ��)
- ǰ�˽���Ӧ�����ͻ�
-
�����Ի�һ����
-
�����Ĵ�����ʱ�����
��ʽ���ƿ����ṩ�����Ի�
��������(������)�����ṩ�����Ի�
-
3)��������
-
ģ��
-
- ������������λ���,ǰ���鲥��Ϣ��������������
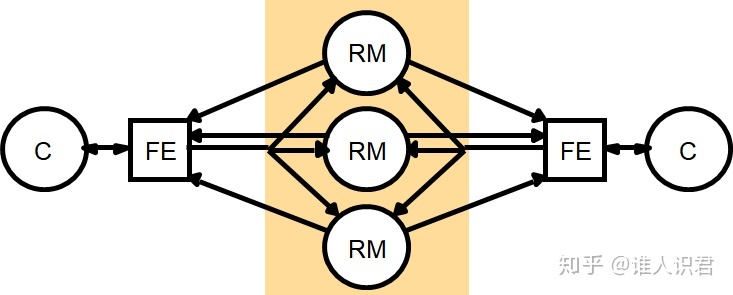
- �¼�����
-
����:ǰ��ʹ��ȫ�ɿ����鲥ԭ�ォ�����鲥��������������
-
Э��:��ͨ��ϵͳ��ͬ���Ĵ���(ȫ��)�����ݵ�ÿ������������
-
ִ��:ÿ����������������ͬ�ķ�ʽִ������
-
Э��:�����鲥�Ĵ�������,����Ҫ�ý�(��Ϊ�鲥,�Ѿ�������������״̬�Ѿ����˹�ʶ)
-
��Ӧ
-
- ÿ����������������Ӧ����ǰ��
- ǰ�˽���Ӧ�����ͻ�
- һ����:˳��һ��
- ÿ���ͻ���������Ĵ���
4)���Ƶ�һ����
- �����Ի���˳��һ����
- ������һ����(���������ĵ��������Ĵ���)
- ���һ����(��ȷ���������ص�д����)
- �����ϵ:A����Bд������;Ȼ��B��д������
- ���н��̱�������ͬ�Ĵ��������ص�д����
- ��ͬ���̿��ܻ��Բ�ͬ�Ĵ���������д����
- ����һ���� (ֻҪ���еĸ������ն�������ͬһ������)
- ���������һ���������������Ϊ��������������
- һ������ij�Ա���ͨ��,��ͬ����ij�Ա����ͨ��
- ���û�з�������,���ͻ����������֮һ������
- ����������ʱ,��ͻ�����Ѿ��������ڲ�ͬ�������ύ
3.���������л��ĸ��� + ��һ��д���з���ԭ������������(�ڵ㲻ʧЧ����)��������֤����
Ŀ��:���������ϵ�����
-
���������л�
-
- �ͻ��ڸ��ƶ�����ִ�е������Ч��Ӧ����������һ���������һִ����ͬ(��ÿ������ 1 ������)
- �൱�ڽ�ϴ��еȼ�+��������/һ����
- ���������л�����ͨ������һ��/д���С�ʵ�ָ��Ʒ�����
-
��һ��д����
-
- ÿһ��д�����������κ�һ��������������ִ��,�Ҹ�����������ÿһ�����������һ��д��
- ÿ���������ɵ�������������ִ��,�ø����������ڲ��������ϼ�һ������
- ��������:����������(��Ҫ����IJ�������ʵ�ִ��еȼ�)
-
������֤(����)
-
-
������֤����ȷ���κι��ϻ�ָ��¼������������ִ�й����з���
-
��������:ͨ���û����¼����̿����ƶϹ���˳��,����ִ�,��һ��Ϊ��,�����ÿ����㷨���ع���ԭ
-
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-wd3r3ON8-1638620904428)(C:\Users\14182\AppData\Roaming\Typora\typora-user-images\image-20211204183045198.png)]
-
N ������ ->T �� X �϶����� A;T �� M �� P ��д���� B ->T �ύ ->X ������
-
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-Mka9D8uV-1638620904429)(C:\Users\14182\AppData\Roaming\Typora\typora-user-images\image-20211204183104404.png)]
-
X ������ ->U �� N �϶����� B;U �� Y ��д���� A ->U �ύ ->N ������
-
X��������T��֤֮��,U��֤֮ǰ-> U��֤��T��֤֮�� ->�������в�����
-
��� T ��� N ������,�� X��M��P ����,T �ύ
-
- ����ζ�� T ��֤֮��,U ��֤֮ǰ X ���ֹ���,�� U ��֤�� T ��֤֮��,U ��֤ʧ����Ϊ N �ѳ�����
-
-
�����������ĸ������������ܺ�����ĸ���������ͨ��ʱ,���ÿ����㷨����ʹ��
4.gossip ��ϵ�ṹ����������
-
Gossip ����:�ֳ�����,��ʾ������������Ѱ��һ��
-
�ص�:
-
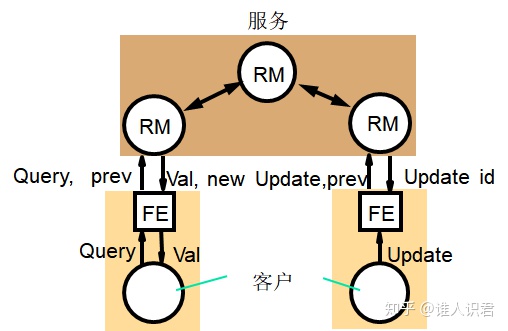
��ϵ�ṹ
-
- ǰ�˿���ѡ�����⸱��������
- �ṩ���ָ���������:��ѯ + ����
- ��������������ͨ�� gossip ��Ϣ�����ݿͻ��ĸ���
-
-
ϵͳ��������֤
-
-
����ʱ�������,ÿ���û����ܻ��һ�·���
-
- �����������ṩ�������ܷ�ӳ����Ϊֹ�ͻ��Ѿ��۲�ĸ���
-
����֮���ɳڵ�һ����
-
- ���и������������ս��յ����и���(����һ����)
- �����ͻ����ܻ�۲쵽��ͬ�ĸ���
- �ͻ����ܹ۲쵽��ʱ����
-
-
��ѯ��������
-
-
����(�����æ):ǰ�˽�������������������
-
- ��ѯ:�ͻ���������;
- ����:Ĭ����������,Ϊ��߿ɿ���,�ͻ����Ա��������Ѿ�����f+1�����������������ִ��
-
������Ӧ(���յ���):��������������Ӧ���յ��ĸ�������
-
Э��(�ո�˭��˵��?):�յ�����ĸ���������������������,ֱ�����ܸ�����Ҫ��Ĵ���Լ����������Ϊֹ
-
ִ��(�ҼǸ���):����������ִ������
-
��ѯ��Ӧ:�����������Բ�ѯ������������Ӧ��
-
Э��:����������ͨ������ gossip ��Ϣ���������
-
- gossip ��Ϣ�Ľ�����ż����
- ������Ϣ��ʧ��,�ź��ض��ĸ���������������Ϣ
-
-
ǰ�˵İ汾ʱ���
-
- Ϊ�˿��Ʋ�����������,ÿ��ǰ��ά����һ������ʱ���,������ӳǰ�˷��ʵ���������ֵ�İ汾
- �ͻ�ͨ��������ͬ�� gossip ������ֱ��ͨ������������
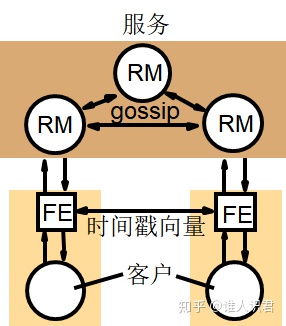
-
ÿ��ǰ��ά��һ������ʱ���
-
- ÿ��������������һ����Ӧ�ļ�¼
- ���»��ѯ��Ϣ�а���ʱ���
- �ϲ��������ص�ʱ�����ǰ��ʱ���
-
����ʱ���������
-
- ��ӳǰ�˷��ʵ���������ֵ
����������״̬
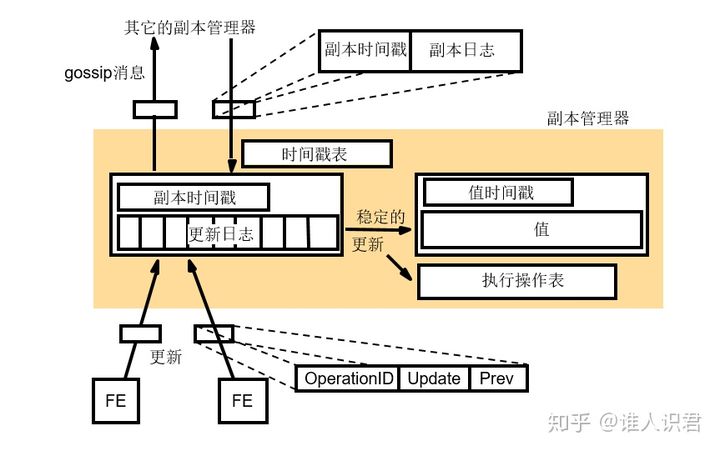
- ֵ:����������ά����Ӧ��״̬��ֵ
- ֵ��ʱ���:���µ�����ʱ���
- ������־:��¼���²���
- ������ʱ���:�Ѿ����������������յ��ĸ���
- ��ִ�в�����:��¼�Ѿ�ִ�еĸ��µ�Ψһ��ʶ��,��ֹ�ظ�ִ��
- ʱ�����:ȷ����ʱһ�������Ѿ�Ӧ�������еĸ���������
5.Coda ��ϵ�ṹ�����Ʋ���(�Թ�Bayou��AFS)
-
Coda Ŀ��:
- �ṩһ���������ļ�ϵͳ
- �ڴ洢ȫ���ֲ��ɷ���ʱ����ȫ����������Դ�������������
-
��չ(���AFS����):
- �����ļ������Ƽ���������������ʺ��ݴ���
- �ڿͻ�������ϻ����ļ�����������������
-
��ϵ�ṹ
-
-
Venus/Vice ����
-
- Venus:ǰ�˺����������Ļ����
- Vice:����������
-
���洢��(VSG)
-
- ����һ���ļ�������������������
-
���õľ��洢��(AVSG)
-
- ��һ���ļ��Ŀͻ��ܷ��� VSG ��ij���Ӽ�
-
�ļ����ʹ���
-
- ��ǰ AVSG �κ�һ���������ṩ�ļ�����,�������ڿͻ��������
- ��ÿ�������������������·ֲ�
-
�ر��ļ�
-
- �Ĺ��Ŀ��� ���� �㲥�� AVSG �е����з�������
-
-
���Ʋ���
-
-
�ֹ۲���
-
- ����������Ͷ��������ڼ�,��Ȼ���Խ����ļ�����
-
Coda �汾����(CVV,Code Version Vector )
-
-
��Ϊʱ���������ÿ���汾���ļ���
-
CVV ��ÿ��Ԫ����һ������ֵ,��ʾ���������ļ��Ĵ����Ĺ���
-
Ŀ��:�ṩ�㹻�Ĺ���ÿ���ļ������ĸ�����ʷ,�Լ���DZ�ڵij�ͻ,�����ֹ���Ԥ���Զ�����
-
���� CVV = (2,2,1)
-
- �ļ��ڷ����� 1 ��,�յ� 2 ������
- �ļ��ڷ����� 2 ��,�յ� 2 ������
- �ļ��ڷ����� 3 ��,�յ� 1 ������
-
-
��ͻ���
-
- ��һ��վ��� CVV ���ڻ������������վ��� CVV,���ڳ�ͻ���Զ�����
- ���������� CVV ����,V1 >= V2 �� V2 >= V1 ��������,����ڳ�ͻ���ֹ���Ԥ
-
�ļ��ر�
-
- Venus ���̷���������Ϣ(���� CVV ���ļ�������)�� AVSG
- AVSG ��ÿ�������������ļ�,������ȷ��
- Venus �����µ� CVV,������Ӧ�������Ĵ���,���ַ��µ� C
-