Redis主从复制
概念
?主从复制,是指将一台Redis服务器的数据复制到其他的Redis服务器。
前者称为主节点(Master/Leader),后者称为从节点(Slave/Follower), 数据的复制是单向的!只能由主节点复制到从节点(主节点以写为主、从节点以读为主)。
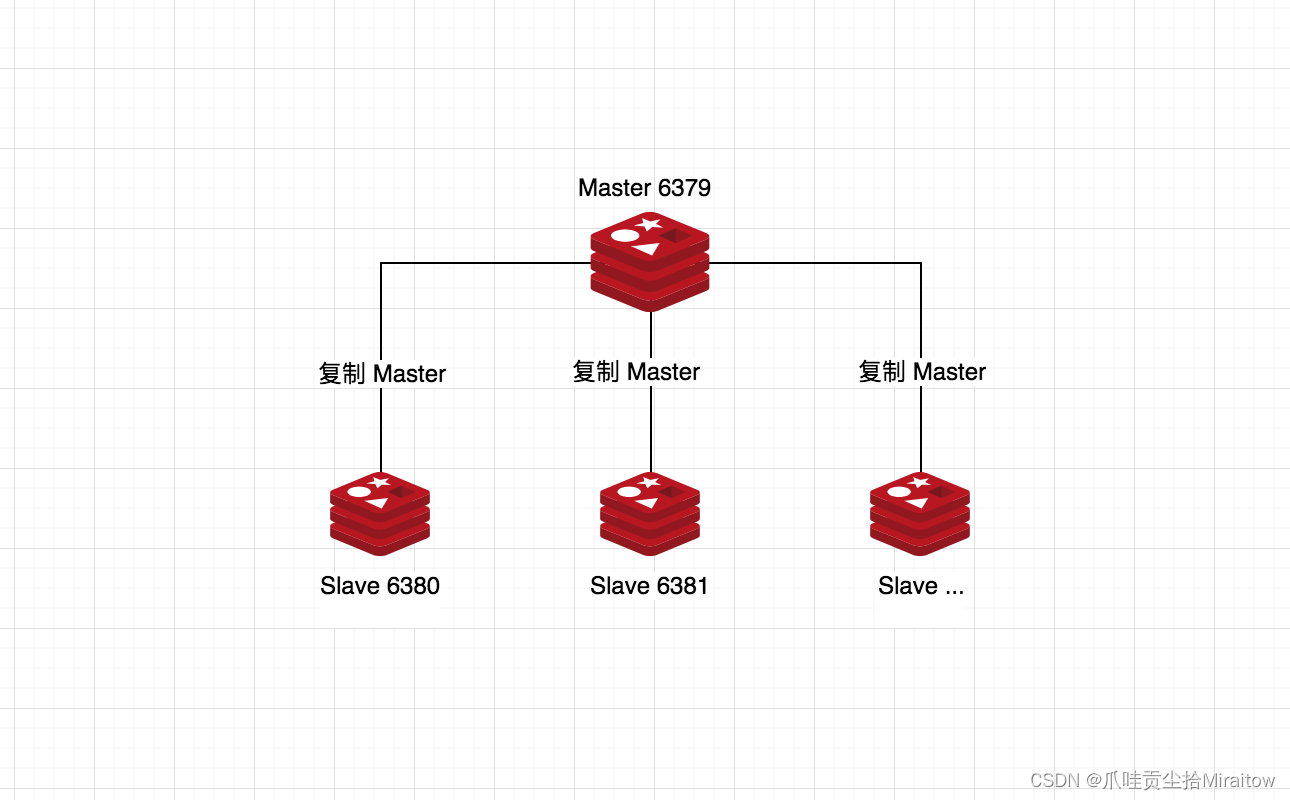
默认情况下,每台Redis服务器都是主节点,一个主节点可以有0个或者多个从节点,但每个从节点只能有一个主节点。
主从复制,读写分离!80%的情况都是在进行读操作!减缓服务器的压力!架构中经常使用!一主二从
从服务器会向主服务器发出SYNC指令,当主服务器接到此命令后,就会调用BGSAVE指令来创建一个子进程专门进行数据持久化工作,也就是将主服务器的数据写入RDB文件中。在数据持久化期间,主服务器将执行的写指令都缓存在内存中。
在BGSAVE指令执行完成后,主服务器会将持久化好的RDB文件发送给从服务器,从服务器接到此文件后会将其存储到磁盘上,然后再将其读取到内存中。这个动作完成后,主服务器会将这段时间缓存的写指令再以redis协议的格式发送给从服务器。
另外,要说的一点是,即使有多个从服务器同时发来SYNC指令,主服务器也只会执行一次BGSAVE,然后把持久化好的RDB文件发给多个下游。在redis2.8版本之前,如果从服务器与主服务器因某些原因断开连接的话,都会进行一次主从之间的全量的数据同步;而在2.8版本之后,redis支持了效率更高的增量同步策略,这大大降低了连接断开的恢复成本。
主服务器会在内存中维护一个缓冲区,缓冲区中存储着将要发给从服务器的内容。从服务器在与主服务器出现网络瞬断之后,从服务器会尝试再次与主服务器连接,一旦连接成功,从服务器就会把“希望同步的主服务器ID”和“希望请求的数据的偏移位置(replication offset)”发送出去。主服务器接收到这样的同步请求后,首先会验证主服务器ID是否和自己的ID匹配,其次会检查“请求的偏移位置”是否存在于自己的缓冲区中,如果两者都满足的话,主服务器就会向从服务器发送增量内容。
增量同步功能,需要服务器端支持全新的PSYNC指令。这个指令,只有在redis-2.8之后才具有。
主从复制作用
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余的方式。
- 故障恢复:当主节点故障时,从节点可以暂时替代主节点提供服务,是一种服务冗余的方式
- 负载均衡:在主从复制的基础上,配合读写分离,由主节点进行写操作,从节点进行读操作,分担服务器的负载;尤其是在多读少写的场景下,通过多个从节点分担负载,提高并发量。
- 高可用基石:主从复制还是哨兵和集群能够实施的基础。
为什么使用集群
- 单台服务器难以负载大量的请求
- 单台服务器故障率高,系统崩坏概率大
- 单台服务器内存容量有限。
模仿集群
我们在讲解配置文件的时候,注意到有一个replication模块
查看当前库的信息:info replication
127.0.0.1:6379> info replication
#Replication
role:master # 角色
connected_slaves:0 # 从机数量
master_replid:3b54deef5b7b7b7f7dd8acefa23be48879b4fcff
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
既然需要启动多个服务,就需要多个配置文件(复制三个 redis.conf就可以了)。每个配置文件对应修改以下信息:
- 端口号 #
为了模拟不同的主机 - pid文件名 #
为了区分文件是那个产生的 - 日志文件名 #
也是为了区分文件产生对象 - rdb文件名 #
同样为了区分 - 启动单机多服务集群:
一主二从配置
默认情况下,每台Redis服务器都是主节点;我们一般情况下只用配置从机就好了!
认老大!一主(6379)二从(6380,6381)
主机79,从机分别为80,81
使用SLAVEOF host port就可以为从机配置主机了。
127.0.6.1:6380> SLAVEOF 127.0.0.1 6379
OK
127.0.0.1:6380> info replication
# Replication
roLe SLave
haster host:127.0.0.1
naster port:6379
naster Link status:up
aster_Last_ io seconds_ ago:o
naster sync . in_ progress:o
sLave_ repL offset:28
sLave priority:100
lave_ read_ onLy :1
connected_ sLaves:o
127 .0.0.1:6381> SL AVEOF 127 .0.0.1 6379
0K
127.0.0.1:6381> info replication
# Replication
roleslave
master_ host:127.0.0.1
master port :6379
master. Link_ status: up
master_Last_ io_ seconds_ ago:4
master sync_ in_ progress:o
slave_ repl_ offset:56
slave_ priority: 100
sLave read only :1
connected_ sLaves: 0
然后主机上也能看到从机的状态:
127.0.0.1:6379> info replication
# RepLication
roLe :master
connected_ slavesS2
# salve指的就是从机
slave0:ip=127.0.0.1, port=6380, state=ontine , offset=252, Lag=1
slave1:ip=127.0.0.1.port=6381, state=ontine, offset=252, Lag=1
master. replid: 8f 615b36b4b44ad2dae3cfac90045f 7 ab9ce4b5e I
master repLid2 : 0000000000000000000000000000000000000000
master rep_ offset:252
second_ rep_ offset:-1
repl_ backlog_ active:1
repl_ backlog_ size: 1048576
repl_ backlog_first_ byte_ offset:1
repl_ backLog histlen:252
htps://blog.csdn.netweixin_ 43873227
我们这里是使用命令搭建,是暂时的,真实开发中应该在从机的配置文件中进行配置这样的话是永久的。
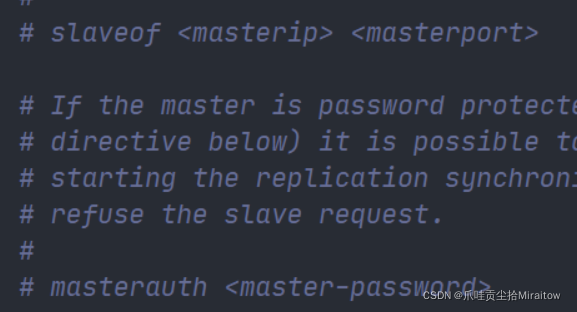
可以把#去掉然后设置maserip和masterprot把配置写死
使用规则
- 从机只能读,不能写,主机可读可写但是多用于写
- 主机的所有信息和数据,都会被从机保存
主机写,从机写
--------------------从机6381------------------------------
127.0.0.1:6381> set name gql # 从机6381写入失败
(error) READONLY You can't write against a read only replica.
--------------------从机6380------------------------------
127.0.0.1:6380> set name gql # 从机6380写入失败
(error) READONLY You can't write against a read only replica.
--------------------主机6379------------------------------
127.0.0.1:6379> set name gql # 主机6379写入成功
OK
127.0.0.1:6379> get name # 主机6379读取成功
"gql"
主机写,从机读
--------------------主机6379------------------------------
127.0.0.1:6379> set name ljk # 主机6379写入成功
OK
--------------------从机6381------------------------------
127.0.0.1:6381> get name # 从机6381读取成功
"ljk"
--------------------从机6380------------------------------
127.0.0.1:6380> get name # 从机6380读取成功
"ljk"
重点!!!
a. 当主机断电宕机后,默认情况下从机的角色不会发生变化(虽然老大不见了,但是还是尊重他不慌乱,甘心作下属,等着老大回来) ,集群中只是失去了写操作,当主机恢复以后(老大回来了),又会连接上从机恢复原状。
注意: 不管老大有没有回来,我都可以得到老大之前给我的东西,也就是我保存到从机的东西
b. 当从机断电宕机后,如果是使用命令行,来配置的主从机,这个时候如果重启就会变成主机了(可以使用info replication 会发现自己变成主机了),所以若不是使用配置文件配置的从机,再次启动后作为主机是无法获取之前主机的数据的,若此时重新配置这个重启后的主机为从机,又可以获取到主机的所有数据。这里就要提到一个同步原理。
b中提到,默认情况下,主机故障后,不会出现新的主机,有两种方式可以产生新的主机:
简单来说
你只要是我的小弟,我有的东西你就可以得到,但是你想要和我平起平坐,那么我们将再无瓜葛,我的东西你想都别想
那么就有人想问为什么会这样那?
复制原理
Slave(从机)启动成功连接到master(主机)后会发送一个sync同步命令
Master接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后, master将传送
整个数据文件到slave ,并完成一次完全同步。
- 全量复制:slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
- 增量复制: Master继续将新的所有收集到的修改命令依次传给slave ,完成同步
但是只要是重新连接master , 一次完全同步(全量复制)将被自动执行
另一种主从复制(
毛毛虫模式)
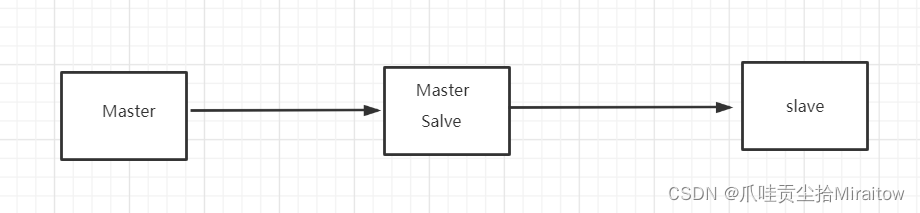
这样也可以完成主从复制
这个模式如果没有老大了(主机断了)这个时候能不能选个老大出来那?
其实当主机没了以后,我们第二个里面输入info replication我们role依然为salve但是我们可以不用一直做小弟,只需要命令行输入
这时候第二个就可以执行下面的命令
slaveof no one # 没有主机了
这样自己就变成主机了,这样别的节点就可以手动连接
这个新的主机谋权篡位这个时候前老大回来(恕瑞玛你们的皇帝回来了)以后,天都变了,变成光杆司令了!!!回来也没用了,需要从新开始了。