网络安全――linux文本三剑客
awk、grep、sed是linux操作文本的三大利器,合称文本三剑客,也是必须掌握的linux命令之一。三者的功能都是处理文本,但侧重点各不相同,其中属awk功能最强大,但也最复杂。grep更适合单纯的查找或匹配文本,sed更适合编辑匹配到的文本,awk更适合格式化文本,对文本进行较复杂格式处理。
1.grep
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来(匹配到的标红)。
命令参数(可使用grep --help寻求帮助)
[root@localhost ~]# cat grepdemo.txt
aaa
bbbbb
AAAAaaa
BBBBBASDABBBDA
#-A显示行数:除了显示符合范本样式的那一列之外,还显示该行之后的所有内容
[root@localhost ~]# grep -A2 b grepdemo.txt
bbbbb
AAAAaaa
BBBBBASDABBBDA
#-B显示行数:除了显示符合范本样式的那一列之外,还显示该行之前的所有内容
[root@localhost ~]# grep -B3 a grepdemo.txt
aaa
bbbbb
AAAAaaa
#-C显示行数:除了显示符合范本样式的那一列之外,还显示该行之前和之后的所有内容
[root@localhost ~]# grep -C3 A grepdemo.txt
aaa
bbbbb
AAAAaaa
BBBBBASDABBBDA
#-c:显示单词匹配出现的行数
[root@localhost ~]# grep -c bbbbb grepdemo.txt
1
#-e:实现多个选项间的逻辑or关系
[root@localhost ~]# grep -e aaa -e bbbbb grepdemo.txt
aaa
bbbbb
AAAAaaa
#-i:ignore 忽略大小写匹配
[root@localhost ~]# grep -i a grepdemo.txt
aaa
AAAAaaa
BBBBBASDABBBDA
#-n:number 显示匹配到的行号
[root@localhost ~]# grep -n b grepdemo.txt
2:bbbbb
#-in:连用 显示忽略大小写的匹配以及相应的行号
[root@localhost ~]# grep -in b grepdemo.txt
2:bbbbb
4:BBBBBASDABBBDA
#-o:只显示匹配到的字符串
[root@localhost ~]# grep -o ASDA grepdemo.txt
ASDA
#-q:静默模式,不输出任何信息
[root@localhost ~]# grep -q aaa grepdemo.txt
#-v:显示不被匹配到的行,相当于[^]反向匹配
[root@localhost ~]# grep -v bbbbb grepdemo.txt
aaa
AAAAaaa
BBBBBASDABBBDA
#-w:匹配整个单词
[root@localhost ~]# grep -w aaaa grepdemo.txt
#无输出,无完整的单词匹配
[root@localhost ~]# grep -w aaa grepdemo.txt
aaa
#-f:从file文件获取PATTERN匹配
[root@localhost ~]# touch grep.txt
#使用vim编辑
[root@localhost ~]# cat grep.txt
aaa
bbb
[root@localhost ~]# grep -f grep.txt grepdemo.txt
aaa
bbbbb
AAAAaaa
2.正则表达式
2.1 匹配字符
[root@localhost ~]# cat test1
abc
123
//[
. 匹配任意单个字符,不能匹配空行
[root@localhost ~]# grep . test1
abc
123
//[
[]匹配指定范围的任意单个字符
[root@localhost ~]# grep [a] test1
abc
[root@localhost ~]# grep [a1] test1
abc
123
[root@localhost ~]# grep [1] test1
123
[^]取反
[root@localhost ~]# grep [^a] test1
abc
123
//[
[root@localhost ~]# grep [^abc] test1
123
//[
[:alnum:] 或 [0-9a-zA-Z],匹配数字和字母
[root@localhost ~]# grep [[:alnum:]] test1
abc
123
[:alpha:] 或 [a-zA-Z],匹配字母
[root@localhost ~]# grep [[:alpha:]] test1
abc
[:upper:] 或 [A-Z],匹配大写字母
[root@localhost ~]# grep [[:upper:]] test1
[:lower:] 或 [a-z],匹配小写字母
[root@localhost ~]# grep [[:lower:]] test1
abc
[:blank:] 空白字符(空格和制表符)
[root@localhost ~]# grep [[:blank:]] test1
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[root@localhost ~]# grep [[:space:]] test1
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[root@localhost ~]# grep [[:cntrl:]] test1
[:digit:] 十进制数字 或[0-9]
[root@localhost ~]# grep [[:digit:]] test1
123
[:xdigit:]十六进制数字
[root@localhost ~]# grep [[:xdigit:]] test1
abc
123
[:graph:] 可打印的非空白字符
[root@localhost ~]# grep [[:graph:]] test1
abc
123
//[
[:print:] 可打印字符
[root@localhost ~]# grep [[:print:]] test1
abc
123
//[
[:punct:] 标点符号
[root@localhost ~]# grep [[:punct:]] test1
//[

2.2 配置次数
[root@localhost ~]# cat test2
ggle
gogle
google
goooooooooooooogle
gagle
* 匹配0次或者多次
[root@localhost ~]# grep "g[o]*gle" test2
ggle
gogle
google
goooooooooooooogle
.* 匹配多次(不包括0次)
[root@localhost ~]# grep "g[o].*gle" test2
gogle
google
goooooooooooooogle
\? 匹配0次或者1次
[root@localhost ~]# grep "g[o]\?gle" test2
ggle
gogle
+ 匹配1次或者多次
[root@localhost ~]# grep "g[o]\+gle" test2
gogle
google
goooooooooooooogle
{n} 匹配前面的字符n次
{m,n} 匹配前面的字符至少m次,最多n次
{,n} 匹配前面的字符最多n次
{n,} 匹配前面的字符最少n次
[root@localhost ~]# grep "g[o]\{1,2\}gle" test2
gogle
google
[root@localhost ~]# grep -E "g[o]{5,}gle" test2
goooooooooooooogle
[root@localhost ~]# egrep "g[o]{,5}gle" test2
ggle
gogle
google
2.3 位置锚定
[root@localhost ~]# cat test3
aaa
bbbbbb
acdkjshfjkshk
^ 行首锚定,用于模式的最左侧
[root@localhost ~]# grep ^a test3
aaa
acdkjshfjkshk
$ 行尾锚定,用于模式的最右侧
[root@localhost ~]# grep b$ test3
bbbbbb
^$ 匹配空行
[root@localhost ~]# grep ^$ test3
^[[:space:]].*$ 匹配空白行
[root@localhost ~]# grep ^[[:space:]].*$ test3
\< 或 \b 词首锚定,用于单词模式的左侧
\> 或 \b 词尾锚定;用于单词模式的右侧
[root@localhost ~]# grep "\<a.*k\>" test3
acdkjshfjkshk

2.4 分组和后向引用
格式
① 分组:() 将一个或多个字符捆绑在一起,当作一个整体进行处理
分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名方式为: \1, \2, \3, …
② 后向引用
引用前面的分组括号中的模式所匹配字符,而非模式本身
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
\2 表示从左侧起第2个左括号以及与之匹配右括号之间的模式所匹配到的字符,以此类推
& 表示前面的分组中所有字符
[root@localhost ~]# cat test4
Hello world Hello world
Hiiii world Hiiii world
Hello world Heiii wwwww
匹配“He”字符
[root@localhost ~]# grep "\(He\)" test4
Hello world Hello world
Hello world Heiii wwwww
第一个匹配He .*匹配中间字符 \1引用第一个分组
[root@localhost ~]# grep "\(He\).*\1" test4
Hello world Hello world
Hello world Heiii wwwww
第一个匹配He .*匹配中间字符 第二个匹配wo .*匹配中间字符 \2引用第二个分组wo
[root@localhost ~]# grep "\(He\).*\(wo\).*\2" test4
Hello world Hello world

2.5 断言
断言有很多种叫法,比如环视、巡视,断言又分为4种:
x(?=y) 匹配x 匹配模式:仅仅当x后面跟着y,这种叫做先行肯定断言
(?<=y)x 匹配x 匹配模式:仅仅当x前面是y,这种叫做后行肯定断言
x(?!y) 匹配x 匹配模式:仅仅当x后面不跟着y,这种叫做先行否定断言
(?<!y) 匹配x 匹配模式:仅仅当x前面不是y,这种叫做后行否定断言
3.sed
ed 是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(patternspace ),接着用sed 命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。然后读入下行,执行下一个循环。如果没有使诸如‘D’ 的特殊命令,那会在两个循环之间清空模式空间,但不会清空保留空间。这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出或-i。
功能:主要用来自动编辑一个或多个文件, 简化对文件的反复操作
3.1 常用选项
[root@localhost ~]# cat demo
aaa
bbbbb
AABBCCDD
p 打印全部(默认输出+模式空间内容)
[root@localhost ~]# sed "/aaa/p" demo
aaa
aaa
bbbbb
AABBCCDD
-n 不输出模式空间内容,只打印匹配到的行
[root@localhost ~]# sed -n "/aaa/p" demo
aaa
-e 多点编辑,单个匹配(全局匹配加/g)
[root@localhost ~]# sed -e "s/a/A/" -e "s/b/B/" demo
Aaa
Bbbbb
AABBCCDD
-f 把Script写到文件当中,在执行sed时-f 指定文件路径(如果是多个Script,换行写)
[root@localhost ~]# cat sedscript.txt
s/A/a/g
[root@localhost ~]# sed -f sedscript.txt demo
aaa
bbbbb
aaBBCCDD
-i 直接将处理的结果写入文件,修改原始文件,不加就不会修改原始文件
-i.bak 在将处理的结果写入文件之前备份一份
[root@localhost ~]# sed -i.bak "s/a/A/g" demo
直接对文件进行处理,不建议直接-i对原文件进行处理
[root@localhost ~]# cat demo
AAA
bbbbb
AABBCCDD
[root@localhost ~]# cat demo.bak
aaa
bbbbb
AABBCCDD
3.2 地址界定演示
[root@localhost ~]# cat demo
AAA
bbbbb
AABBCCDD
不给地址,对全文进行处理
[root@localhost ~]# sed -n "p" demo
AAA
bbbbb
AABBCCDD
单地址:#指定的行
/pattern/:被此模式所能够匹配到的每一行
将第二行的b替换为B
[root@localhost ~]# sed "2s/b/B/g" demo
AAA
BBBBB
AABBCCDD
地址范围:#,#
#,+#
/pat1/,/pat2/
#,/pat1/
只打印1 2行
[root@localhost ~]# sed -n "1,2p" demo
AAA
bbbbb
打印AAA到DD匹配到的行
[root@localhost ~]# sed -n "/AAA/,/DD/p" demo
AAA
bbbbb
AABBCCDD
打印第二行到DD匹配到的
[root@localhost ~]# sed -n "2,/DD/p" demo
bbbbb
AABBCCDD
将奇数行(偶数行的话,将1更改为2)的a或A替换为E,从第一行开始匹配,跳两行匹配
[root@localhost ~]# sed "1~2s/[aA]/E/g" demo
EEE
bbbbb
EEBBCCDD
3.3 编辑命令command
[root@localhost ~]# cat demo
AAA
bbbbb
AABBCCDD
d:删除模式空间匹配到的行
删除第二行
[root@localhost ~]# sed "2d" demo
AAA
AABBCCDD
在第二行后面追加(a-append)一行123
[root@localhost ~]# sed "2a123" demo
AAA
bbbbb
123
AABBCCDD
在第一行前面插入(i-insert)一行123
[root@localhost ~]# sed "1i123" demo
123
AAA
bbbbb
AABBCCDD
将第三行更换(c-change)为123\n456
[root@localhost ~]# sed "3c123\n456" demo
AAA
bbbbb
123
456
w:保存模式匹配到的行至指定文件
保存第三行的内容到文件demo6中
[root@localhost ~]# sed -n "3w/root/demo6" demo
[root@localhost ~]# cat demo6
AABBCCDD
r:读取指定文件的文本至模式空间中匹配到的行后
将demo6的内容读取到第一行后
[root@localhost ~]# sed "1r/root/demo6" demo
AAA
AABBCCDD
bbbbb
AABBCCDD
= 为模式空间中的行打印行号
[root@localhost ~]# sed -n "=" demo
1
2
3
!:模式空间中匹配进行取反处理
打印除了第二行之外的所有行
[root@localhost ~]# sed -n '2!p' demo
AAA
AABBCCDD
s///
:
查找替换
,支持使用其它分隔符,如:
s@@@
,
s###
;
加g表示行内全局替换;
\l:把下个字符转换成小写
\L:把replacement字母转换成小写,直到\U或\E出现
\u:把下个字符转换成大写
\U:把replacement字母转换成大写,直到\L或\E出现
\E:停止以\L或\U开始的大小写转换
将全文的小写字母替换为大写字母
[root@localhost ~]# sed 's@[a-z]@\u&@g' demo
AAA
BBBBB
AABBCCDD
3.4 sed高级编辑命令
- h:把模式空间中的内容覆盖至保持空间中
- H:把模式空间中的内容追加至保持空间中
- g:从保持空间取出数据覆盖至模式空间
- G:从保持空间取出内容追加至模式空间
- x:把模式空间中的内容与保持空间中的内容进行互换
- n:读取匹配到的行的下一行覆盖 至模式空间
- N:读取匹配到的行的下一行追加 至模式空间
- d:删除模式空间中的行
- D:删除 当前模式空间开端至\n 的内容(不再传 至标准输出),放弃之后的命令,但是对剩余模式空间重新执行sed
倒序输出文本内容
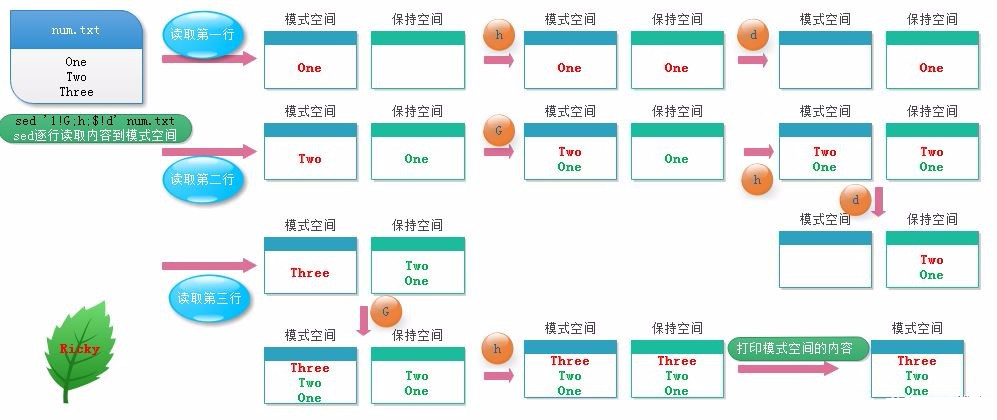
[root@localhost ~]# cat num.txt
One
Two
Three
[root@localhost ~]# sed '1!G;h;$!d' num.txt ##sort -nr也可以实现倒序
Three
Two
One
1!G 第一行不执行G命令,从第二行开始执行
$!d 最后一行不删除
显示偶数行:
第一种
[root@localhost ~]# seq 9 |sed -n 'n;p' #n:读取匹配到的行的下一行覆盖至模式空间
2
4
6
8
第二种
seq 9 | sed -n "2~2p" 打印偶数行(将第一个2换为1打印奇数行)
显示奇数行
[root@localhost ~]# seq 9 |sed 'H;n;d'
1
3
5
7
9
显示最后一行
[root@localhost ~]# seq 9| sed 'N;D'
9
每行之间加空格
[root@localhost ~]# seq 9 |sed 'G'
1
2
3
4
5
6
7
8
9
每行内容替换为空行
[root@localhost ~]# seq 9 |sed "g"
每一行下面都有一个空行
[root@localhost ~]# seq 9 |sed '/^$/d;G'
1
2
3
4
5
6
7
8
9
4.awk
awk是一种编程语言,用于在linux/unix下对文本和数据进行处理。数据可以来自标准输入(stdin)、一个或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,是linux/unix下的一个强大编程工具。它在命令行中使用,但更多是作为脚本来使用。awk有很多内建的功能,比如数组、函数等,这是它和C语言的相同之处,灵活性是awk最大的优势。
[root@along ~]# cat awkdemo
hello:world
linux:redhat:lalala:hahaha
along:love:youou
FS指定输入分隔符(默认为空白字符),打印第一列 第二列
-v FS=':' 可以用 -F: 替换
[root@along ~]# awk -v FS=':' '{print $1,$2}' awkdemo
hello world
linux redhat
along love
OFS指定输出分隔符
[root@along ~]# awk -v FS=':' -v OFS='---' '{print $1,$2}' awkdemo
hello---world
linux---redhat
along---love
RS :输入记录分隔符,指定输入时的换行符,原换行符仍有效
[root@along ~]# awk -v RS=':' '{print $1,$2}' awkdemo
hello
world linux
redhat
lalala
hahaha along
love
you
[root@along ~]# awk -v FS=':' -v ORS='---' '{print $1,$2}' awkdemo
hello world---linux redhat---along love---
[root@along ~]# awk -F: '{print NF}' awkdemo #-F 指定分隔符
2
4
3
NF:字段数量,共有多少字段,$NF引用最后一列
[root@along ~]# awk -F: '{print $(NF-1)}' awkdemo #显示倒数第2列
hello #$NF显示最后一列,相当于python的切片
lalala
love
NR:行号,后可跟多个文件,第二个文件行号继续从第一个文件最后行号开始
[root@along ~]# awk '{print NR}' awkdemo awkdemo1
1
2
3
4
5
[root@along ~]# awk END'{print NR}' awkdemo awkdemo1
5
FNR :各文件分别计数, 行号,后跟一个文件和NR一样,跟多个文件,第二个文件行号从1开始
[root@along ~]# awk '{print FNR}' awkdemo awkdemo1
1
2
3
1
2
FILENAME :当前文件名
[root@along ~]# awk '{print FILENAME}' awkdemo
awkdemo
awkdemo
awkdemo
[root@along ~]# awk 'BEGIN {print ARGC}' awkdemo awkdemo1
3
[root@along ~]# awk 'BEGIN {print ARGV[0]}' awkdemo awkdemo1
awk
[root@along ~]# awk 'BEGIN {print ARGV[1]}' awkdemo awkdemo1
awkdemo
[root@along ~]# awk 'BEGIN {print ARGV[2]}' awkdemo awkdemo1
awkdemo1