����Ŀ¼
ǰ��
���̵��йصĸ�����������һ���Ѿ��Ƚ�������,��ô��һ�����Ǿ�����ε��ö�Ӧ��ϵͳ�ӿڽ��н��̵Ĵ���,�Լ����������������̡�
һ�����̴���
fork��ʲô
fork�������ӽ���,�Ը�����Ϊģ��,�ܶ�����,���붼�̳и�����,���еĽ���PCB,���̵�ַ�ռ�,ҳ����ÿ�����̶��е�,�������е���������(pid),�ӽ��̵ĵ���ʱ��,pid,ppid,�ֵ�id,���������̵����ӹ�ϵ��Ҫ��������,������������Ϣ�����Ը���Ϊģ��ġ�
ʾ��ͼ:
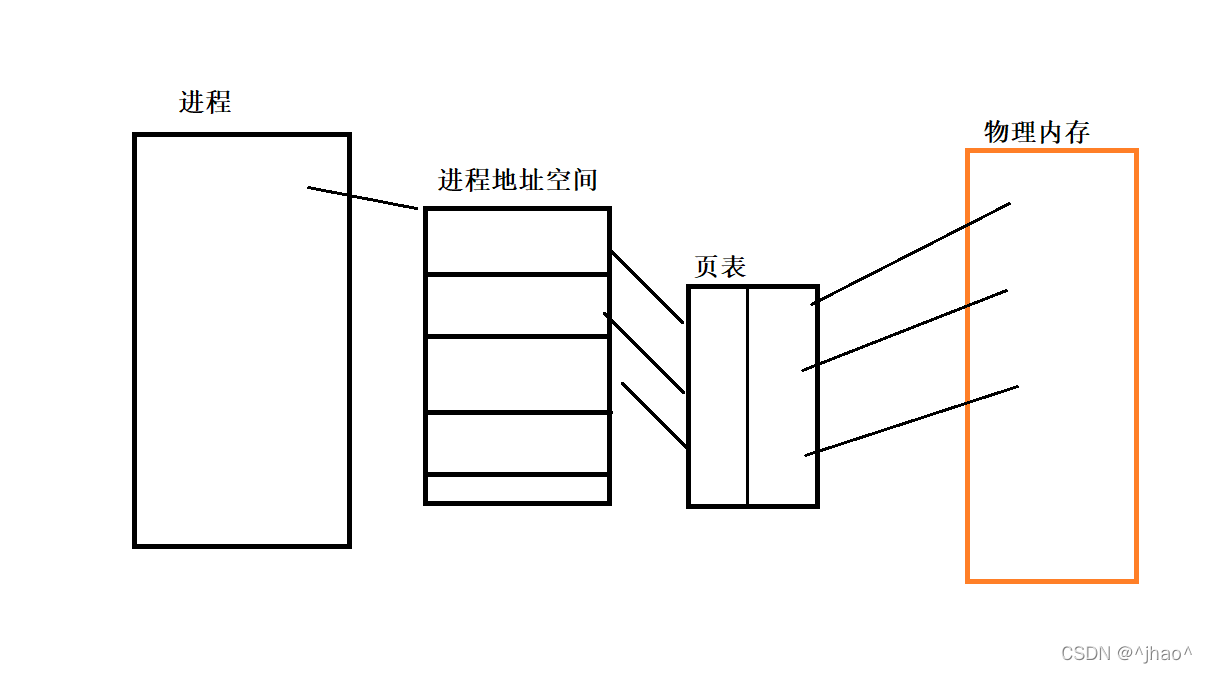
����fork��:�����ӽ���,����ϵͳ����һ������,����һ���������ص����ݽṹ��
����fork���ϵͳ����:
- �����µ��ڴ����ں����ݽṹ���ӽ���
- �������̲������ݽṹ�����������ӽ���
- �����ӽ��̵�ϵͳ�����б�����
- fork����,��ʼ����������
Ϊʲô����������ֵ
��������pid_t pid = fork();��ʱ��,Ϊʲô����벻ͬ��������,һ��������λ���������ͬ�ķ���ֵ,�Ӷ��ø��ӽ��벻ͬ��ҵ��������������������:
��һ������:
fork��һ������,��fork��������嵱��,һ���д���pcb,�������̵�ַ�ռ�,����ҳ��,����pcb֮��Ĺ�ϵ(���ӹ�ϵ),��pcb������ȶ����еȵȡ���return֮ǰ�ӽ����Ѿ�����������,������Щ�Ķ������ɸ�����ִ��,����ֵpid�������ɸ����̴�����,���ﲻ����˭������,���ڸ��ӽ��̶�����������ǹ�����,�����ص�ʱ���൱���ǶԱ�����д��,���ʱ��ͻᷢ��дʵ����,�ɴ˸��ӽ��̵��ж����Լ���pid!!����һ��������,���ݾ��Dz�ͬ��,���ʾ��Ǹ���ҳ��ӳ�����ݵ��˲�ͬ�������ڴ�����!
��ʱfork����֮ǰ�ӽ����Ѿ������ɹ�,����pid��д��ͻᷢ��дʵ�����ˡ�
�ڶ�������:
�������ⲻһ����ȷ,���DZ�������,��fork������returnʱ,�ӽ����Ѿ�������������,return����,pid�ͻ������ݡ�
ΪʲôҪ��дʱ����
ʲô��дʱ����:
����/�ӽ�����ҳ������Ϊֻ��(����ϵͳ����֪��)��������ʱ,�ͻᷢ��дʱ�������ķ�дʱ���ִ���,����ϵͳ���ز��Ұ����ǿ������ݵ��µ��ڴ��,����������ҳ���ϵ����ӹ�ϵ,��ҳ���е���дȨ��Ϊ�ɶ���д,��ʱ�Ͳ��ᱨ��������û��㡣- -��һ������OS�������!
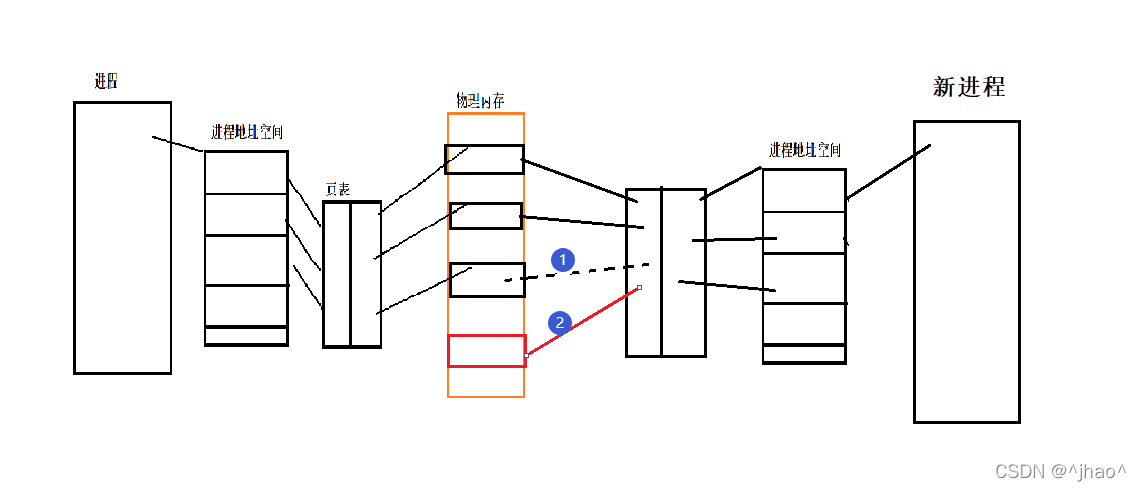
ΪʲôҪ��ʱ����:
��ΪҪ��֤���ӽ��̵�������,��Ϊʲô����һ��ʼ��ʱ��Ͱ��ӽ��̴������Լ��Ĵ����������?������ʱ��������Ϊʲô�������?
����ѧϰ���Բ��дʱ����ʱ,�����ڸ��ӽ��̴�����ʱ��ֱ�ӽ����ݸ��Կ���һ��,Ҳ�ܴﵽ���ӽ��̵Ķ����ԡ�
�����������ȱ��:
- ����fork��Ч��: forkʱ,������Ӧ�����ݽṹ,�����н����ݿ���һ��,һ�������fork����Ч�ʵĽ���,���ҵ��ڴ���ŵ�ʱ���п���ʧ��!
- ���п����ı�Ҫ��: ���е�����,�����Ǹ����Ӷ������д��,����������10G����,���ӽ���ѹ�����Ը��������ݽ�����,��ʱ����Ҫд��(Ҳ����ֻ����),��ʱ������û������,����ռ�������ڴ�ռ��,�˷�ϵͳ��Դ(cpu��Դ)! --fork��
- ���óɹ��ĸ���: fork����������ϵͳҪ�������Դ,Ҫ�������Դ���ٵ���Դ,��ȻҪ���ٵ���Դ����������forkʧ��!
�������̵ij���:
1.��������������(����ָ���)��
2.ͨ����������,fork�������ӽ��̡�
�����dz���Ҫ����һ��Ҫ�����½���!
ע��: дʵ��������������ǿ���������ݵ�дʱ����,������Ȼ��������,����Ҳ�ǻᷢ������дʱ����������,��execϵ�к���������������
����������ֹ
�������������ֹ:
��main����return������ֹ,�����⺯����exit�������ֹ��
return������:
����return���صĽ���Ǹ�ϵͳ����,ȷ�Ͻ���ִ���Ƿ���ȷ��
���ǿ���ͨ������echo $?,���鿴�������һ��ִ�еij�����˳���Ϣ,��������������ɹ���,�����������ִ��������Ϊһ������,���ɹ���ֵҲ��0,����echoһ��ֻ���ĵ�һ�Ρ�
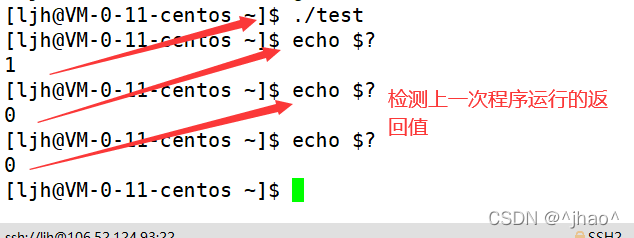
main���з���ֵ��ѧϰ����ʱ�������ó�0,������Ϊ����Ĭ����Ϊ����ֵ��0��ʾ����ִ�гɹ���
return����ȷ����:
ʵ���������ڱ�д�����ʱ������ڲ�ͬ�ط�,�ɲ�ͬ�ķ�֧return��ֵͬ��������ͬ�Ľ���������ִ���ʱ�������Ƕ�λ���⡣
�����˳����������:
1.��������,�����ȷ�� �C �˳���0
2.��������,�������ȷ�� �C �˳�������Լ�����,һ������Ϊ!0��Ҳ����ʹ��ϵͳ�Ĵ�����list��
3.���뱻�ź�ɱ����(�������,ָ��Խ�����)�� �˳����ʱ����Ҫ��,����Ҳ��һ��ȷ��
���ڼ��������������,�����Ƕ��ַ�����Ϣ����,���Դ�����ͨ�����Ǹ���һ������ת����һ���ַ�����
����ҿ�һ�´�����:��135��,ʹ��strerror����ѭ��������ӡ��

���Dz��������еĸ����̶������ӽ��̵��˳���,�������ǻ�ѧϰ������ص�ϵͳ�������ӽ����������Զ�������
�쳣������:
�쳣��ָ���������з�����ͻ��,������Ӧ������״̬�е�ijЩ�仯,��CPU��ִ��ij��ָ���ʱ��,CPU�ڲ���״̬������Ϊ��ͬ��λ���źš�����״̬�ı仯�����¼�,�¼��ķ����������������ִ�е�ָ���й�(Ұָ��,����,Խ��),Ҳ�п������ⲿϵͳ��ʱ���������źŻ���һ��IO�������ɡ�
exit��_exit������
exit��_exit���κεط���ʾֱ����ֹ����,����exit�����_exit,���ǵ�����֮ǰ�����һЩ������
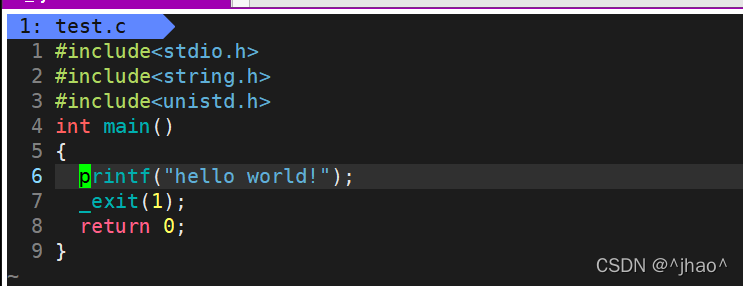
_exit����ˢ�»�����,���Բ����ӡhello world,��exit��ִ���û�ͨ��atexit��on_exit�������������,�ر����д���,���л������ݾ���д��,��exit��������_exit��
վ�ڲ���ϵͳ�ĽǶ�,������������ֹ?
����˼��:�黹��Դ
- 1.���ͷš�����Ϊ�ι���������ά�����������ݽṹ����
- 2.���ͷš�������������ռ�õ��ڴ�ռ�
- 3.ȡ�������ý��̵����ӹ�ϵ
����:
1."�ͷ�"�������˫��������Ϊ����ϵͳ������ֱ�ӽ���Դ�ͷŵ�,���ǽ���Դ����һ������,��Ҫ��Դ����Slab����������Ч�ʾ��ˡ�
2.�ͷų�����������ʵ����ֻҪ�Ѷ�Ӧ���ڴ����ó���Ч�Ϳ���,����ij������ֱ�Ӹ���ʽ��ʹ������Ϊ��Ч���ڴ�,���������ͷŵ�Ч�ʡ�
3.ȡ�����ӹ�ϵʵ���Ͼ��Dz���ָ��,����֮�����֯��ʽ����˫������ɵ�,ȡ�����ߵ����ӹ�ϵʵ���Ͼ��Ƕ�ָ��IJ�����
�������̵ȴ�
���̵ȴ��ı�Ҫ��:
1.���ս�ʬ����(kill����ɱ����),����ڴ�й©���ӽ���û�и����̵ĵȴ��ᱣ���������ݽṹ��
2.��Ҫ����ӽ��̵����н���״̬����������DZ����!
3.����������Ҫ�����ӽ����˳�,���Թ淶��������Դ���ա�����һ�������ϵ�ϰ�ߡ�
���̵ȴ��ķ���:
wait,�ȴ�����һ���ӽ���,���ӽ����˳�wait����,��һ������ʽ�ĵȴ���
���չ����ɲ���ϵͳ���,�Ǹ����̵���wait�ӿ��ɲ���ϵͳ��ɡ�
wait:
wait���ԵĴ���:
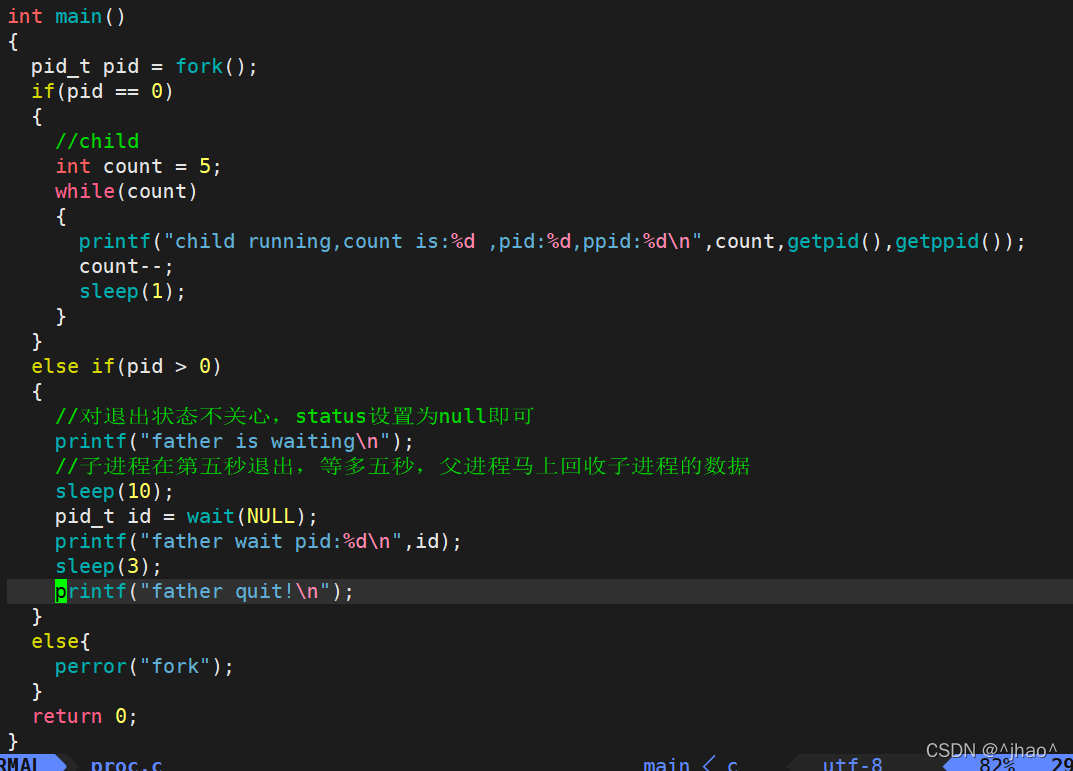
���Խ��:
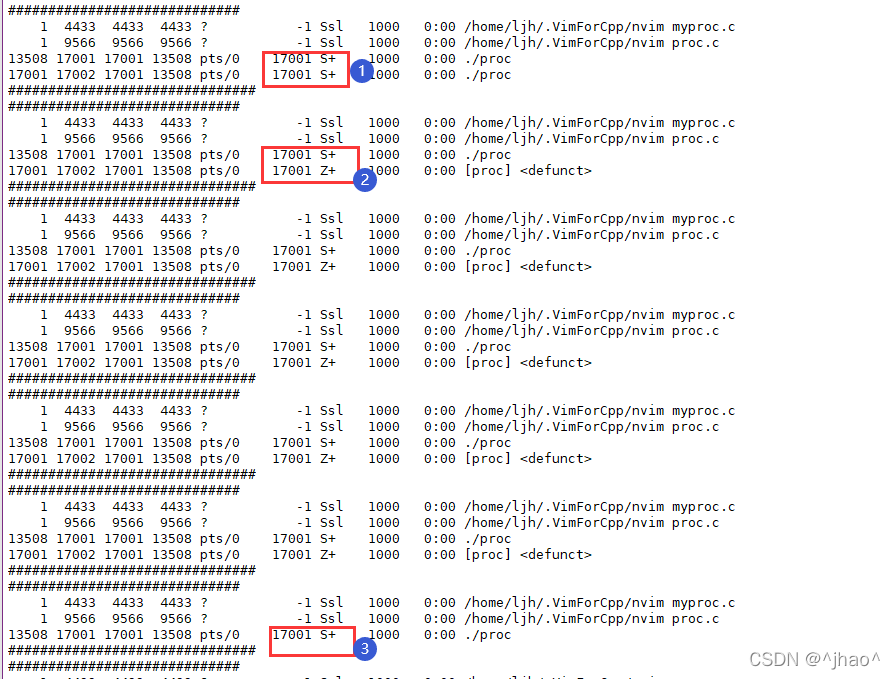
������ijɶ����,���Dz���ѭ���ȴ���
���:
���2:
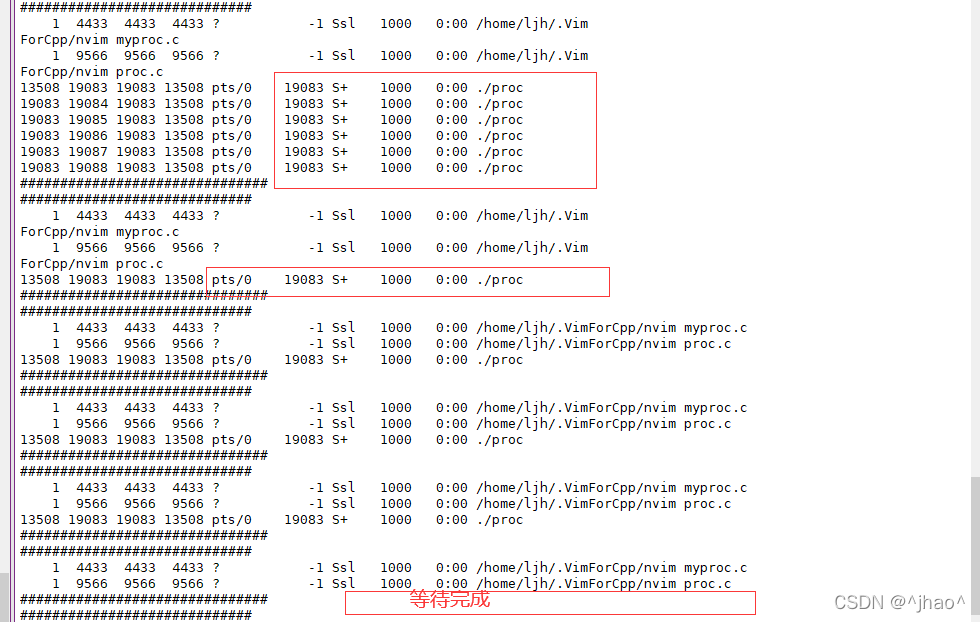
ע��: ���ӽ��̽�ʬ��,���������˳���,�ӽ��̻���һ�Ž�������,��ʱps axj���һ���ܿ����ý���,��Ϊ�ý��̿����Ѿ���һ�Ž����ͷ��ˡ�
waitpid:
waitpid�ĵ�һ������,������Ϊ-1���ʾ�ȴ������ӽ���,��wait��Ч,����>0��ֵʱ�ȴ��þ����pid(���ȴ�ָ���Ľ���)���ȴ��ɸ����̵��ò���ϵͳ,�ɲ���ϵͳ��ɡ�
fork�ķ���ֵ,�������̷��ص����ӽ��̵�pid,��ôǡ�ø����̾Ϳ����������pidȥ�ȴ����ˡ��ȴ�,����Ҳ�ǹ�����һ�ַ�ʽ��
waitpid�ĵ������������ó�0Ĭ�Ͼ�������ʽ�ȴ������ַ�ʽ���
�Եȴ�һ������Ϊ��,waitpidҲ�DZȽϼ�,��һ��������д��Ӧ��id���ɡ�

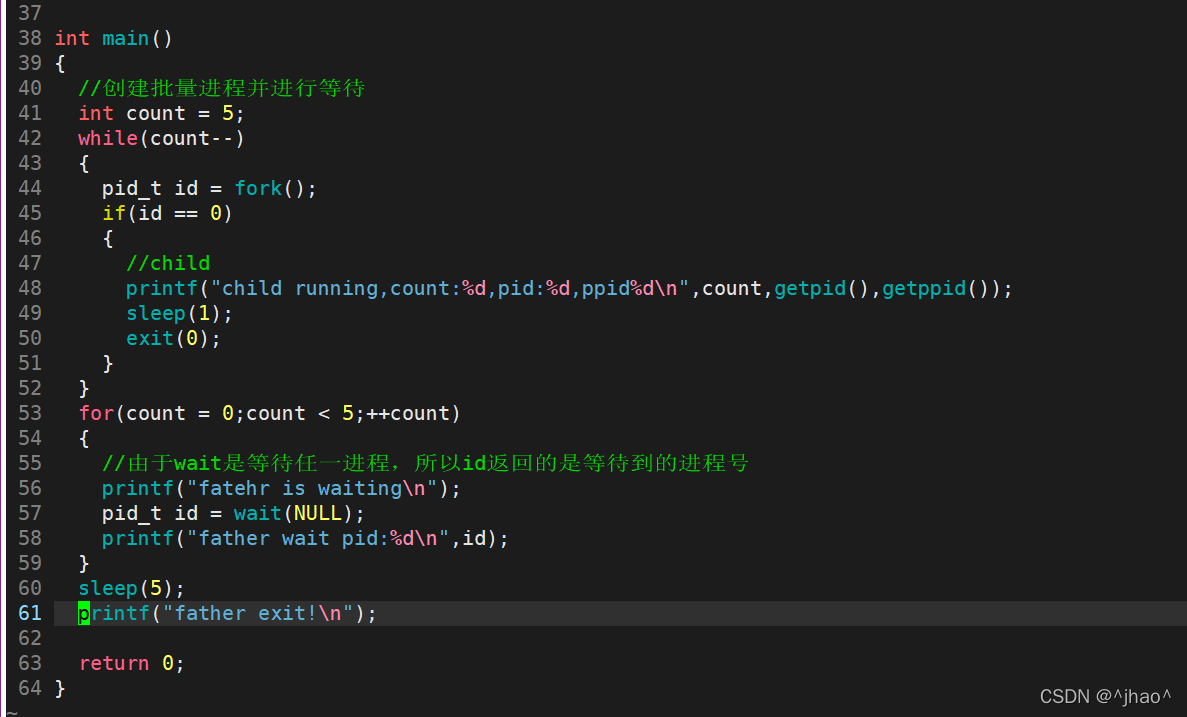
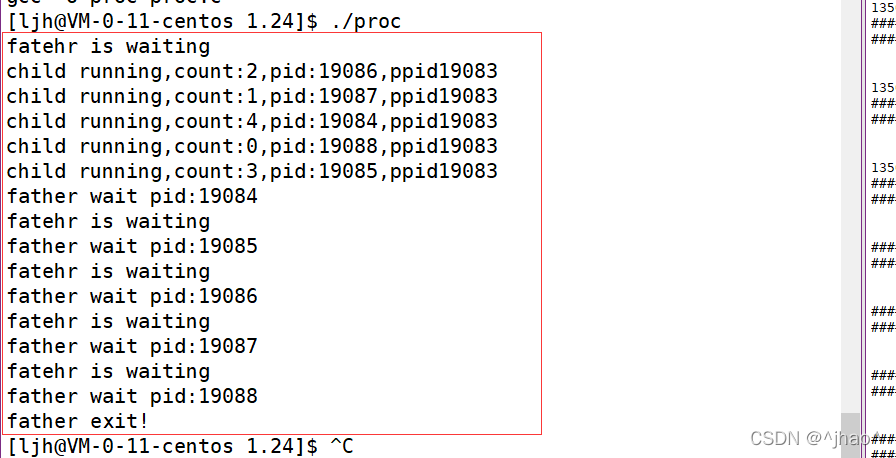
��Ҫ�ȴ����,����������齫Ҫ�ȴ���pid������,Ȼ��������鼴�ɡ�����ֻ��һ�������ڽ��еȴ�,���Բ��ü������ķ�ʽ,���ȴ��Ľ�������¼,���������ѭ�����ɡ�
����: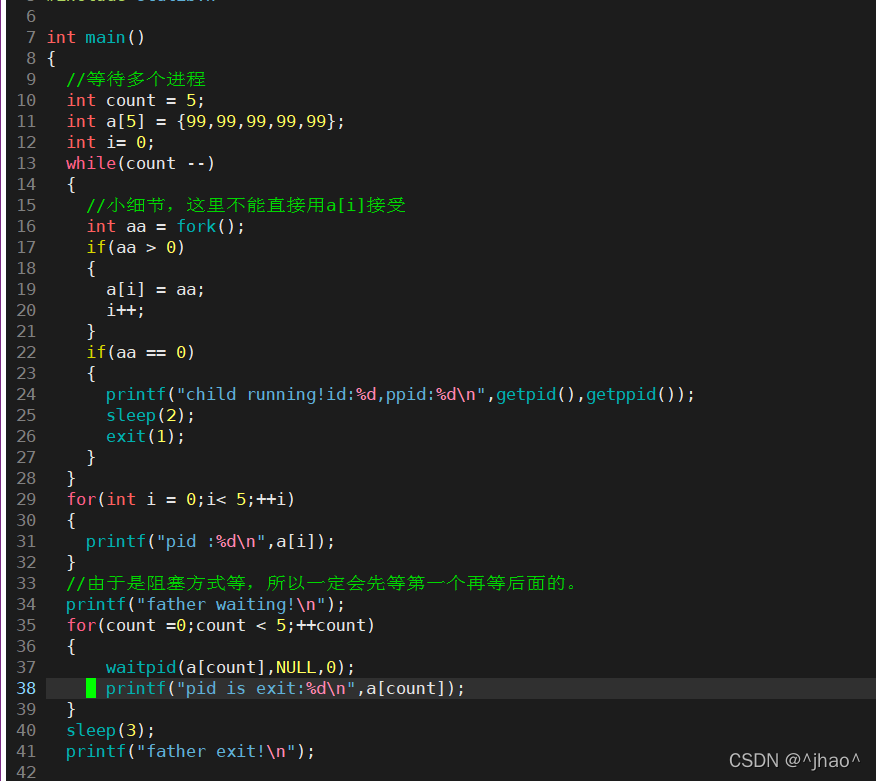
���:
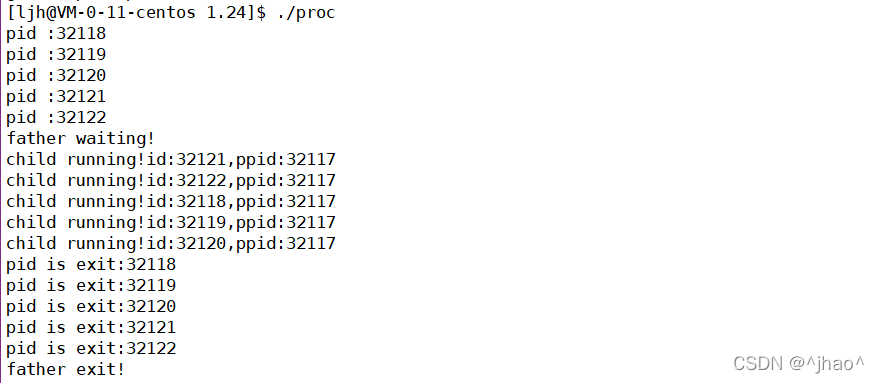
status������:
������ֹ�Ĵε�8λ�����˳�ʱ���˳���!
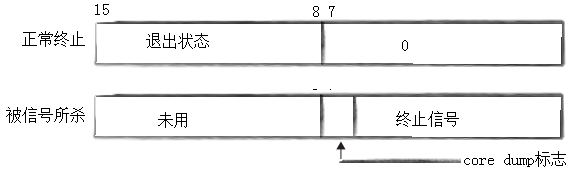
�Զ���ȫ�ֱ����ķ�ʽ�ø����̿����ӽ��̵��˳���ķ�ʽ����ȡ��
����(status>>8) & 0xFF,��status�Ĵΰ�λ����ȫ1,�õ��ľ������ǵ��˳����ˡ����ַ�ʽ��Ϊ����֤����stauts�Ĺ��ɡ�
����: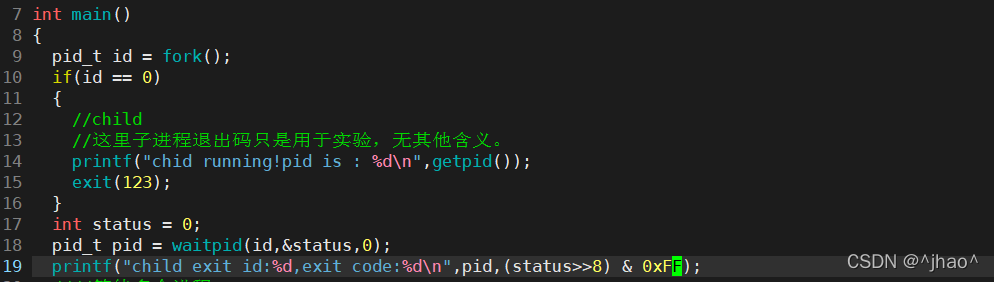
���:

������ͨ���õ��˳����������һЩ������waitpid�õ���status�Ǵ��ӽ��̵���δ�ͷŵ���Դ�õ���,��ʬ״̬ʱ���в�����Դ�����ͷŵ�,ͨ������waitpid���Խ���ʬ���̵��˳���Ϣ��������
�쳣�˳������:
һ�������ǰ��ֹ,�����Ǹý����յ���os���͵��źš��õ���λ��ʾ��ֹ�ź�,���м�һλ��ʾ�Ƿ�core
dump(�ñ�־λ֮������)�����ǵ���kill
-l���Է���������ͨ�źŵ��в�û��0���ź�,���Ե����Ǽ���˳���ĵ���λȫ0ʱ,���ǾͿ��Ա���Ƿ���������ֹ�ˡ�
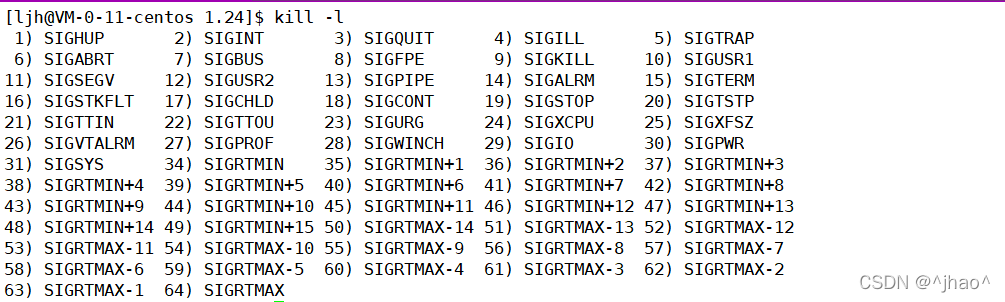
�����˳�ʱ,signalΪ0,��δ�յ��źš�

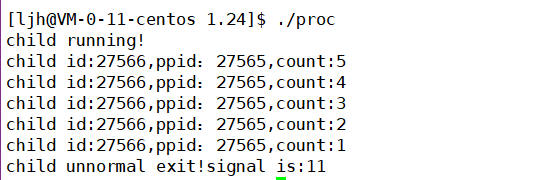
���������ӽ��̱�д��ѭ��,��kill����ɱ���ӽ���,���signal������Ϊ9,�˳�����ʱ��0����Ҳ˵�����ź���ɱʱ���ǿ��Բ��ù����˳�����,�����塣�������ⲿ�źŵ��µġ�


�ڲ�ָ��Խ�����,�������,���ǹ۲����λ�仯��
����ʱsignalΪ8
ָ��Խ����ʵ��ź�Ϊ11��Խ�粻��ָ��ָ��������������˳�!
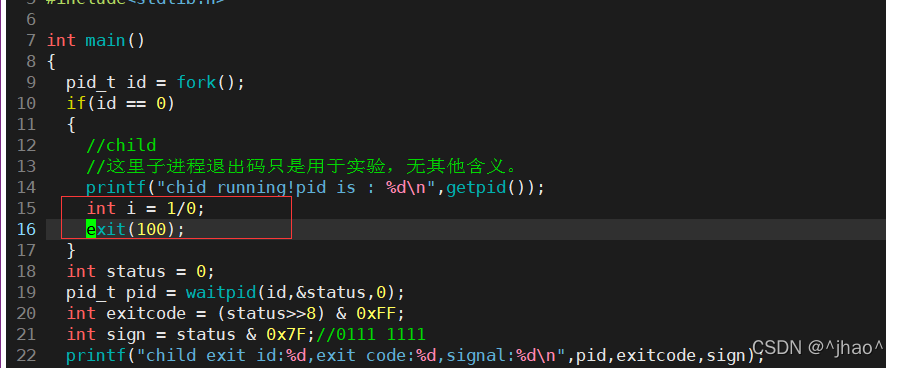


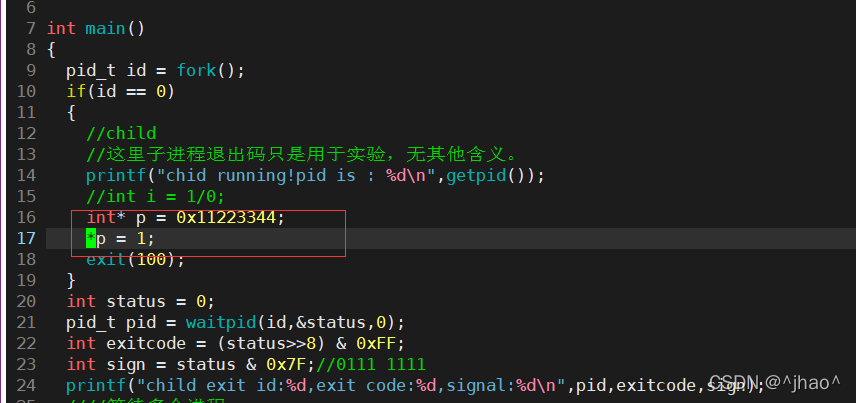
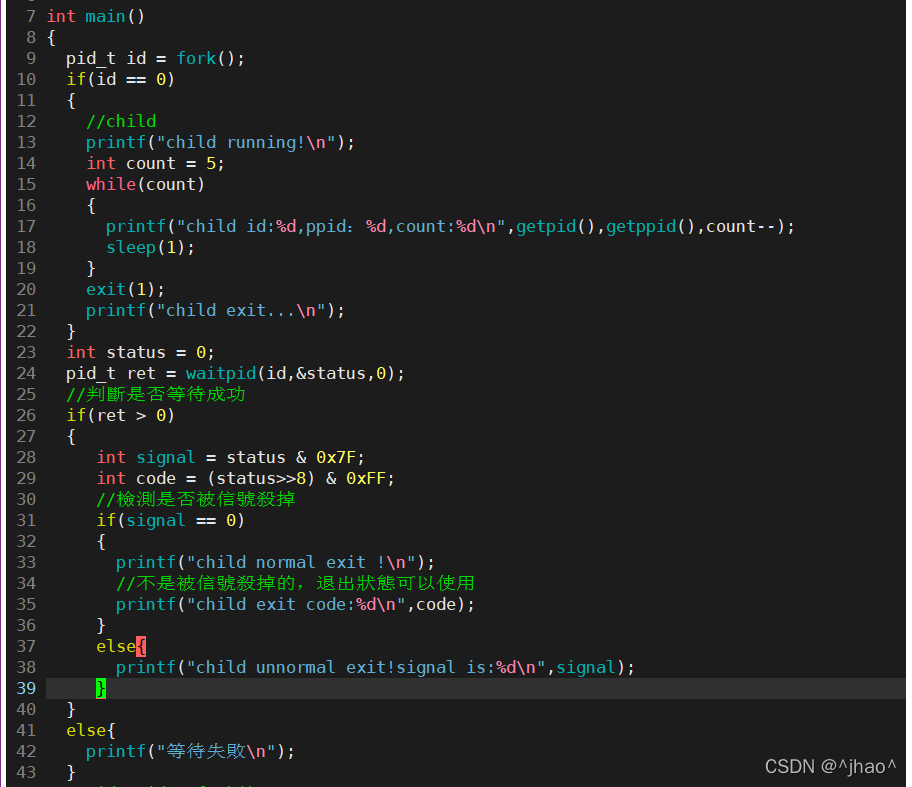
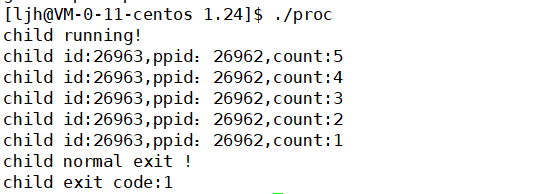
�����Ľ��̴�������:
����:
���н��:��������ʱ
����Ұָ��ʱ:
�йغ������:
ϵͳ�ṩ�˺�,���ж��˳�����˳�״̬!���ǿ���ֱ���á�
���õĺ�:
WIFEXITED(status): ��Ϊ������ֹ�ӽ��̷��ص�״̬,��Ϊ�档(�鿴�����Ƿ��������˳�)
WEXITSTATUS(status): ��WIFEXITED����,��ȡ�ӽ����˳��롣(�鿴���̵��˳���)

option����������:
����:
������ʽ��,���õij���Ҳ�ܶ�,̸���������ò�˵cpu���л��еȴ����еĸ���,�������̵���waitpid��ʱ��,����ϵͳ���ĸ����̵�״̬RΪ!R,Ȼ�����̴����ж��е���ȡ��,�ŵ��ȴ����е��С����ӽ������н���ʱ,����ϵͳ�����waitpid���½������̻���,������״̬��ΪR,�������ж��е��С�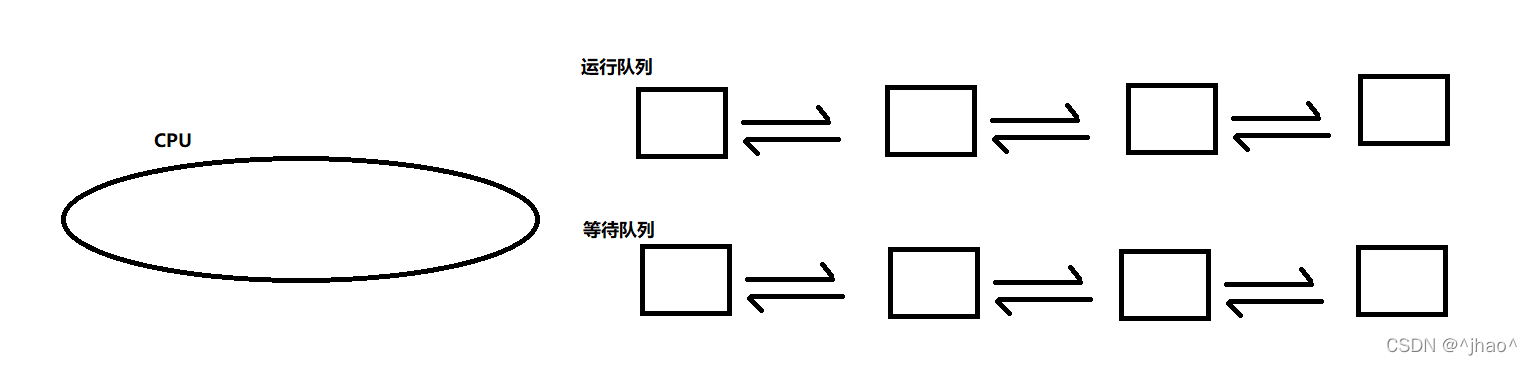
������:
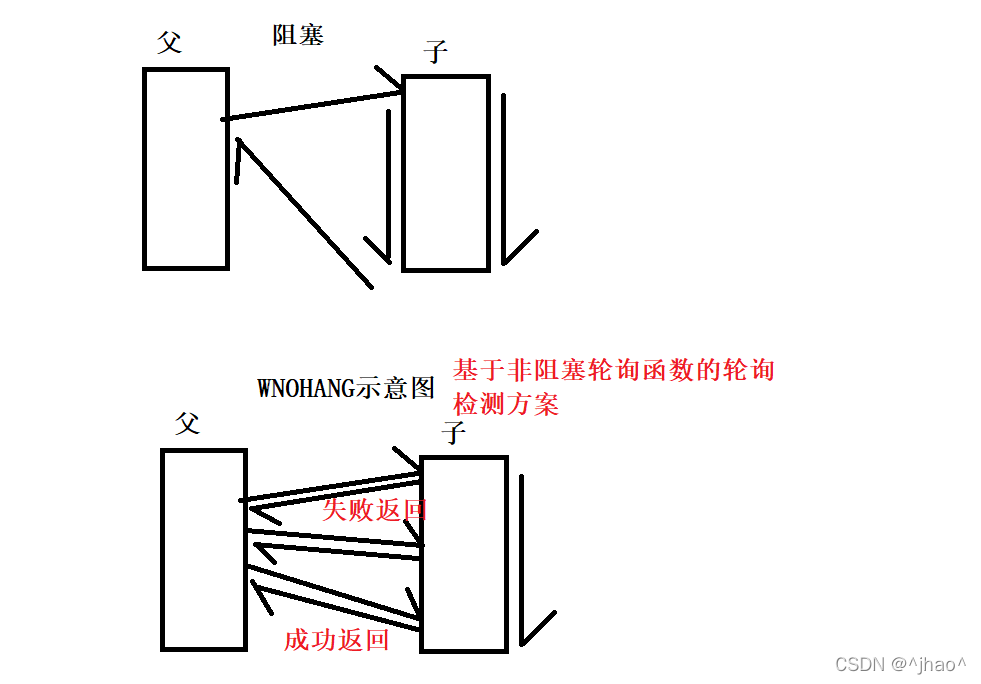
������������ѯ����,���DZ��������Ῠס,���Dz��ϼ��״̬,�����ȡ����Զ�Ҳ��һ�������;������C��������ѯ�����������������Ե��÷�����Ч�������ڵ�ִ��������,������Ƚϼ�,�õ�Ҳ��Ƚ϶ࡣ
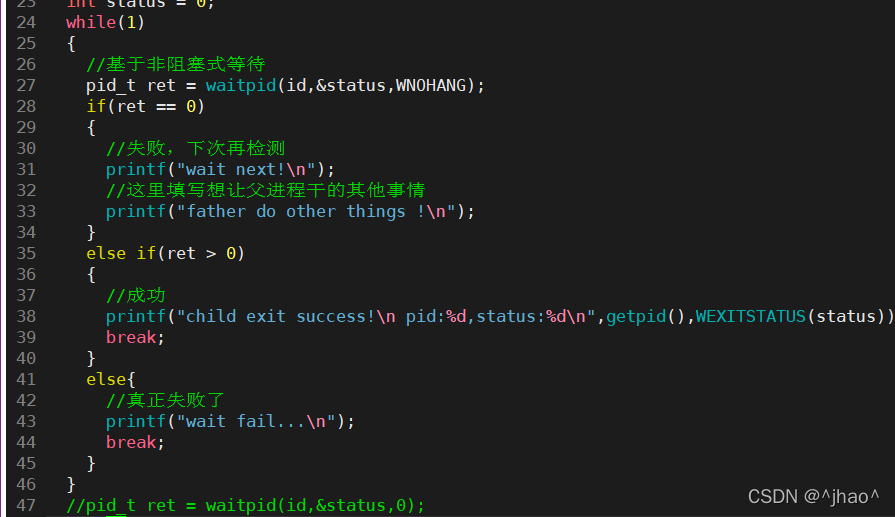
WNOHANG(��hangס,��崻�):��pidָ�����ӽ���û�н���,��waitpid()��������0,�����Եȴ�������������,�ظ��ӽ��̵�ID��
�˴�ʧ�����㺬��:
1.���������ʧ��,�����ǶԷ���״̬û�дﵽԤ��,�´μ������С�
2.���ʧ����,���ء�
waitpid��WNOHANG�����ַ��ط�ʽ1.ʧ��,�´��ټ��,2.�ɹ�:�Ѿ�����,3.ʧ��:����ʧ��
�������ķ���ֵ�����֡�
����:
����:
����vs������
����,���������ڵ�,�ӽ�������,�ȴ��ǽ�R״̬Ū�ɷ�R״̬,����ȴ�����,�ӽ������н��������ϵͳ��Ѹ����̻��ѵȴ�,���·ŵ����ж���,���������״̬ΪR����Щ��������OS���𡣷�������ѯ�൱��һ����ѭ���ڲ�����Ŀ����̽���ѯ��,��ռ��CPU��Դ������
����ϵͳ���֪���ý��̶�Ӧ�ĸ������ڵȴ�����?
���������ǵĸ����̵���wait/waitpid���˵ȴ�����,����ϵͳ�ܹ���֪Ҫ�ȴ��Ľ�����˭,�����������������ȴ����еĽ��̻��ѵġ�
���Ե������ϲ㿴�����Խ��̿�ס��,���ǿ��ܷŵ��˵ȴ�����,Ȼ�����ϵͳ��������Ӧ�Ĵ���Ȼ��Űѵȴ����еĽ���Ū������
�ں��˳����ֶ�:
/* task state */
int exit_state;
int exit_code, exit_signal;//�˳���,�˳��ź�
int pdeath_signal; /* The signal sent when the parent dies */
��������,�������ĸ����˽�:���еIJ���
�ġ����̳����滻
���̳����滻��ʲô:
�����ý��̲���ִ�и����̵Ĵ��������,�����ý���ִ���µĴ�������ݡ�
������linux�µ�ls,pwd�ȶ��dz���,����ͨ��exec*,���ض������ػ����ȥ���ش����е���������,�ﵽ���е�Ŀ��,�ڼ䲻�����µĽ��̡�
�����ӽ��̵�Ŀ��,ΪʲôҪ���г����滻:
1.ִ�и����̵IJ��ִ���
2.ִ����������Ĵ��� --�����滻
�ӳ��������µij�������������統��ͨ����һ�����̵ȴ�,���ɸ�����ִ�С�
�Լ�shell������ԭ��!!!
������Ĵ���ʵ����Ҳ�ᷢ��������дʱ���������г����滻!!
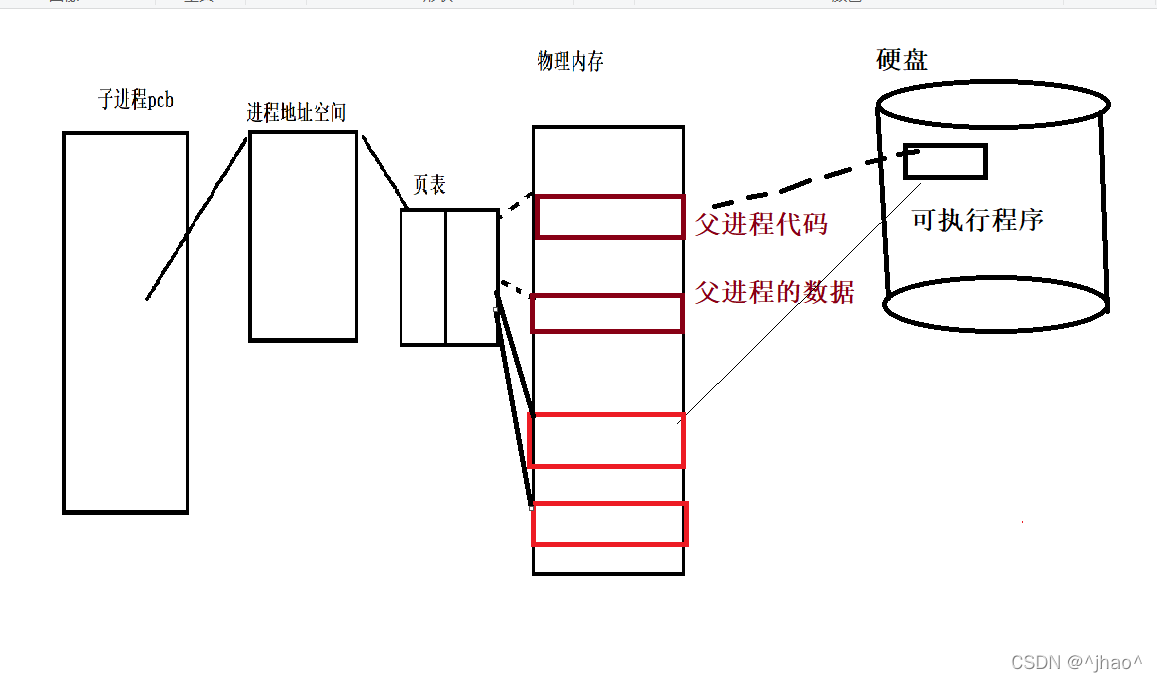
ϵͳ����������½���ӳ��?
����Ҫ���ص�ʱ��,���ӽ��̶��ڴ�Ĵ�������ݽ���д��,�ӽ��̾ͻ�ʹ��дʱ����,���ڴ��п����ڴ������,�������еĿ�ִ���ļ����ص��µ��ڴ�ռ��
�����õ�Ҳ��дʱ������һ������
�ڽ��г����滻��ʱ��,��û�д����µĽ���?
û��,��Ϊ���Dz���Ҫ��������PCB,��ַ�ռ�,ҳ����
�������ǵ��ӽ��̵�pidҲû�䡣
����Ҫ��������,һ��Ҫ���ص��ڴ�!
��������ص��ڴ�,��һ������һ���µĽ���!
ϵͳ����������½���ӳ��?
exec*������
����ִ��ʧ�ܾͻ�ִ�к���Ĵ��롣����������ǰҪ�ȱ����ؽ��ڴ�,exec��������������ļ�����������Ҫ��������Ҫ���γɽ���,��ִ��exec����!
#include <unistd.h>`
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ...,char *const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
------
ϵͳ���ýӿ�:
int execve(const char *path, char *const argv[], char *const envp[]);
��������:
- ��Щ����������óɹ�������µij�����������뿪ʼִ��,���ٷ��ء�
- ���������-1
- ����exec����ֻ�г����ķ���ֵ��û�гɹ��ķ���ֵ��
���䷽ʽ:
- l(list) : ��ʾ���������б�
- v(vector) : ����������
- p(path) : ��p�Զ�������������PATH
- e(env) : ��ʾ�Լ�ά����������
ע��:���������б������������Ҫ��NULL
�������ڼ�ʹ��һ��execl,��һ�������Ǿ��Ի������·�����ǿ��Եġ�
lΪlist��ʽ,�ڶ����������������������ôд,������д,һ���������б�����ʽ���뺯����

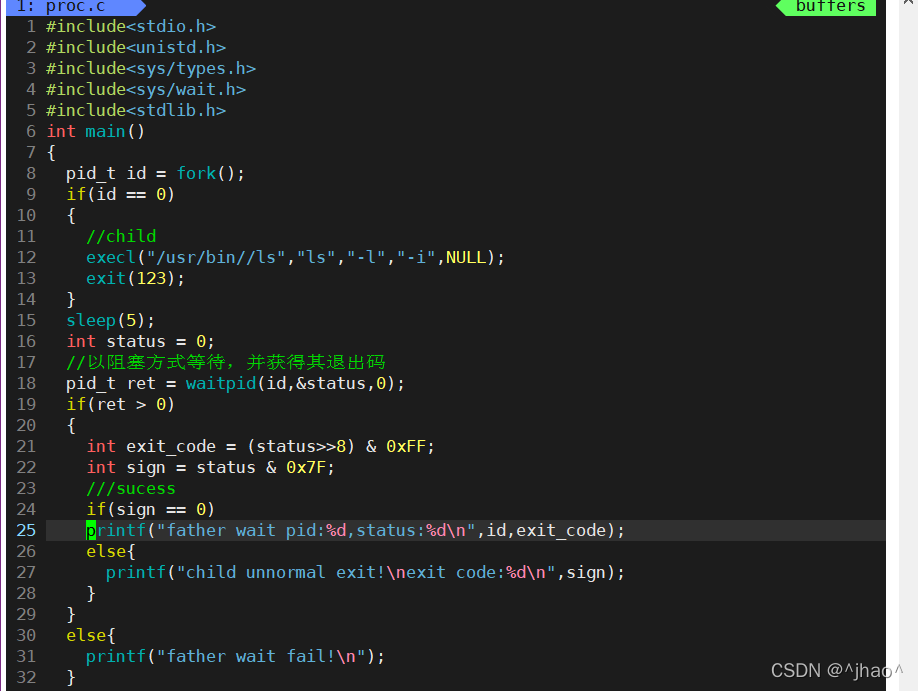
������û�д����ӽ��̵�ʱ�����ǿ��Է�������ĵ�һ���͵ڶ������붼��ȷִ����,���ǵ����д���ȴû�д�ӡ����,����ʵ������Ϊ�����滻��֮�����2����Ĵ��붼�Ѿ���������,���ʱ��ķ���ֵ��û�������,execl��������ʧ�ܷ��ص���-1,������wait/waitpid���н��̵ȴ���ʱ��,�õ����˳���Ϣ�DZ��滻�Ľ��̵��˳���Ϣ��

����ֱ���������̽��г����滻û������,������������������������,����һ�������Ǵ����ӽ���,���ӽ��̽��г����滻,�������̽��еȴ�������������
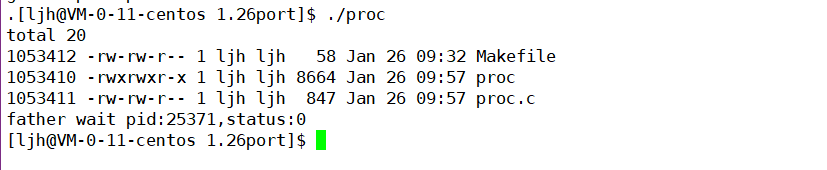
����:�˴���֤��execl�ɹ���ִ����һ������,���ո����̻�õ��˳����DZ��滻�����ݺʹ����ִ�н����
���Խ��:
�����ǹ����������ʱ,���ͻ�ִ�к������,���ʱ��������ʧ��ʱִ�к������,������execl�ķ���ֵ�������ж�,execlʧ�ܷ���-1��

��execv��main������һ������ ����֪��main����ʵ��������������(int argc,char* argv[],char* env[]); ���ĵڶ�������ʵ���Ͼ���ϵͳ��������ʱͨ���ú�������������,������Ҳ��֤��������˵��exec*�Ǽ�����,�ܹ����µij������С�
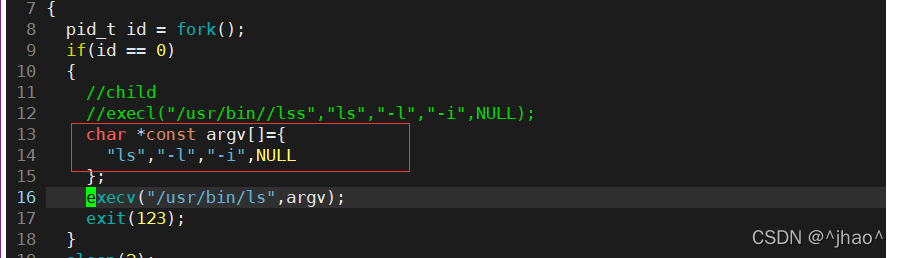
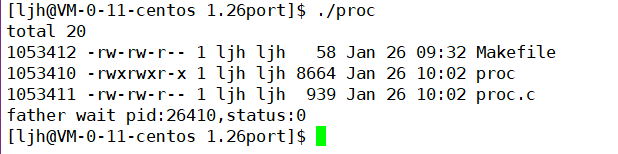
execv�IJ��� ����:�����execl���ǰ��б�չʾ�IJ���,�������鵱��Ȼ�Ρ�
���Խ��
execlp�IJ��� ����:��������Ĵ���,��ͬѧ���ܻ������ls�Ƚ����,����������ظ���?
������,��һ�������Ǹ���ϵͳȥִ��˭,�ڶ��������Ǹ���ϵͳ��������ִ�С�
���Բ���p��execϵ�к�����һ������Ҫ���ȥ����,��˭������ ��p�Ļ�ȥϵͳ�Ļ�������������,����ֻ��Ҫ�ṩ��˭�����⡣
������������Ҫ,���ǿ����Լ���·�����뻷���б�����,�Ϳ���ʹ��execlpָ����,���Dz��Ƽ���������
�ڶ������������������Ҫִ�еIJ����б�
���:

execvp����
����:ʵ�������ʱ���ٿ���������ͻ���ñȽϼ��ˡ�
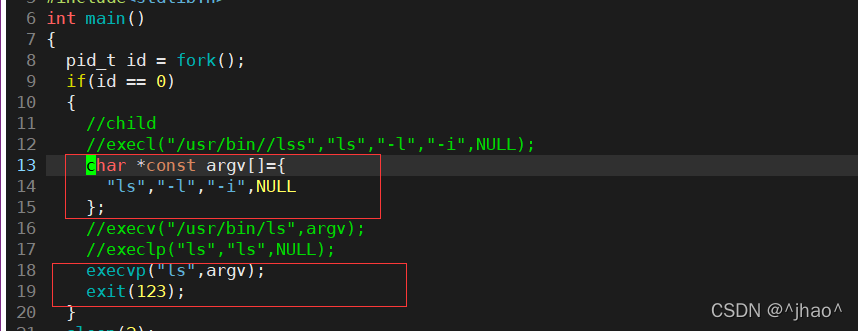

execle������:
e:���ѻ����������ݸ����滻�����ij���
���Լ�д������ȥ���ñ�ij���
������������execl������������,����ĵڶ����������Բ�������·����,��Ϊ��һ�������Ѿ�ָ����·����
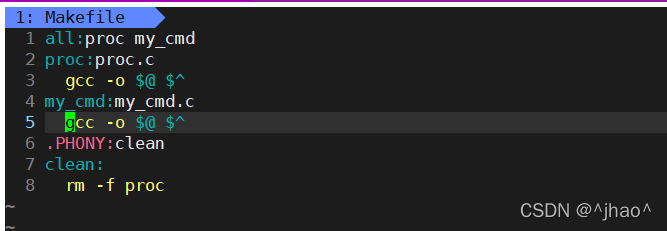
proc.c:
mycmd.c:
���:
Makefile�����γ����ɸ���ִ�г���ķ���
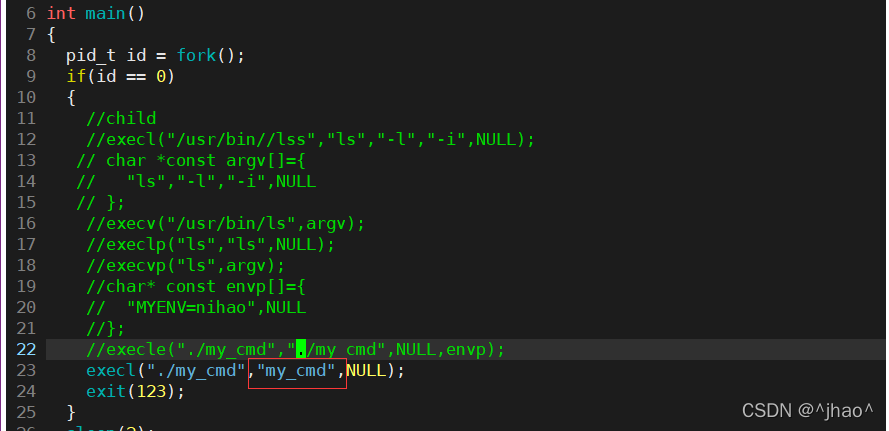
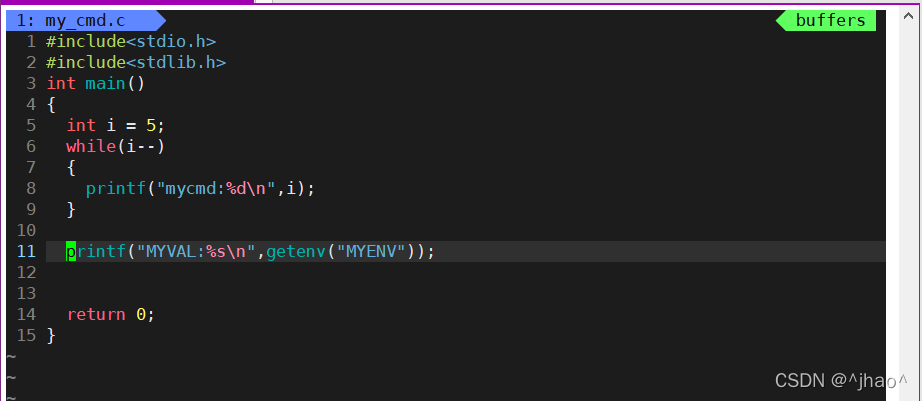
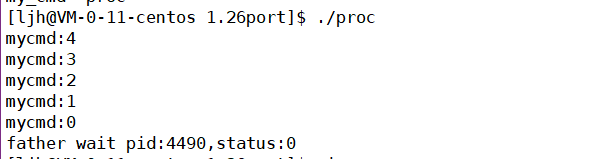
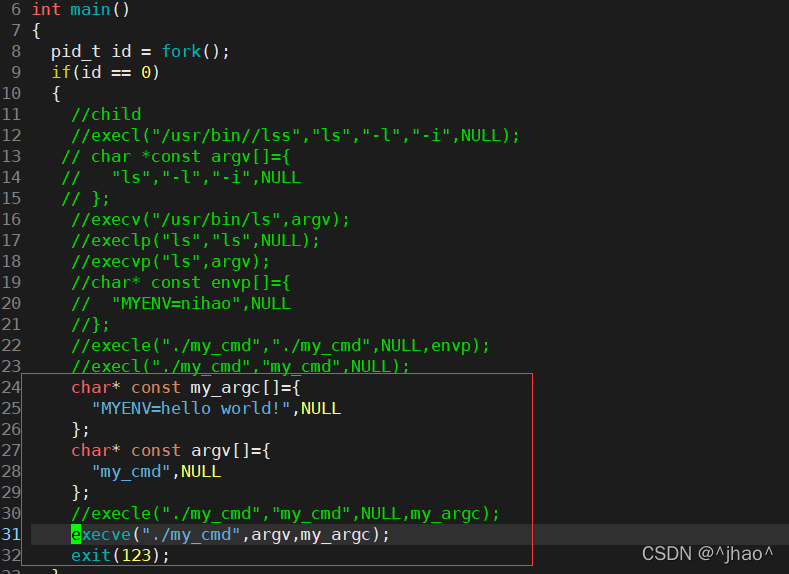
execle��ʹ��:
���ݻ������������滻�Ľ���,���ǿ���ʹ�����Ǻ������ڶ���Ļ����������ݸ��ӽ���,Ҳ����ʹ��main�������env�Ļ���������
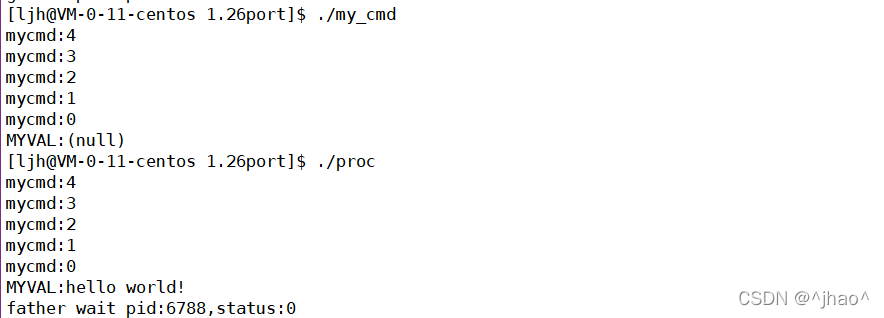
���:ֱ������mycmd��û�иû�������,����proc������滻��my_cmd,����my_cmd�õ��˻�������,���������������н��̴��ݸ����滻�������Ľ��̡�
����e��exec�����ǿ��Դ�Ĭ�ϻ����Զ���Ļ���������Ŀ���ִ�г���!
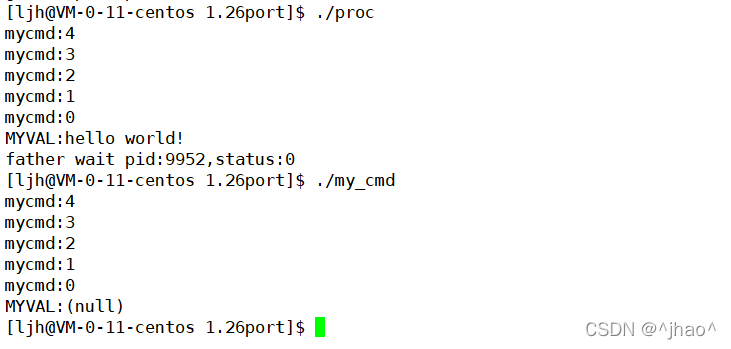
ϵͳ���ýӿ�execve��ʹ��:
�Ա���execle����,���ǰѲ����������鴫�뼴��
����:
���:
�����Dz�ʹ���Լ�д�Ļ�������,����ϵͳ�����ǵĻ���������
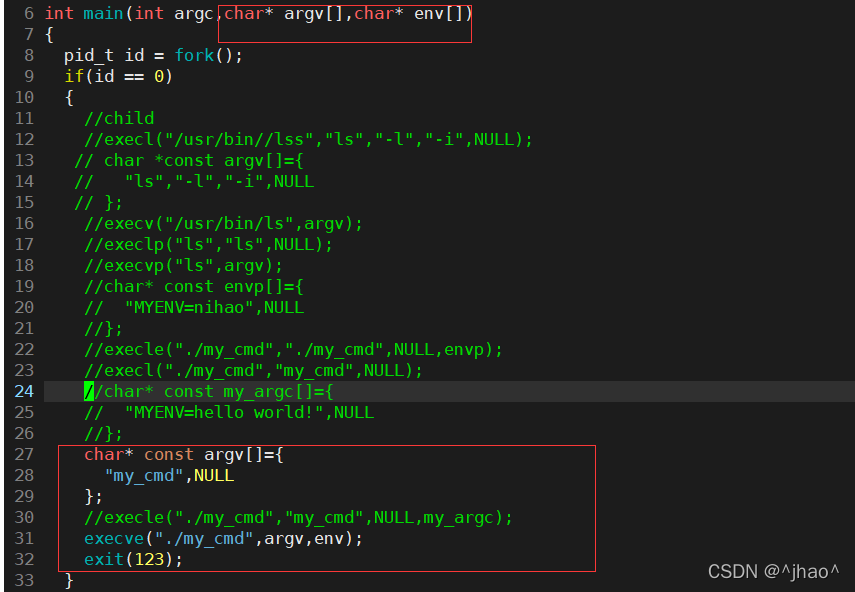
����:
����ϵͳ��������:export MYENV=hello world
���Է������ս���滻�Ľ������õ�MYENV,ֻ�������˺����world,������Ϊ�������е���Ĭ�ϵĻ�������ͨ����·��ɶ��,�Dz����пո�ġ�
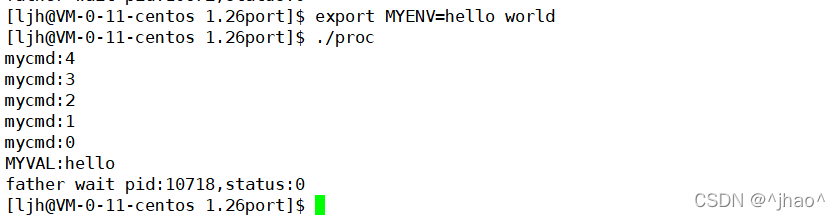
execvpe:�������������my_cmd����ϵͳ������������,˵��������ʹ��pwd��ȡ���ǵĿ�ִ���ļ���·��,Ȼ��PATH=$PATH:·�����ķ�ʽ��
����:
���:

ʵ��������ʹ�ô��������������ĺ���,��������������ȫ�����Ե�ԭ��,�����ӽ��̶���̳м������ӽ���ͨ��exec*ִ���³����ʱ��ѻ����������ݸ�����!!
execve������exec*�����²�Ĺ�ϵ,�������ն������execve��ִ�С�
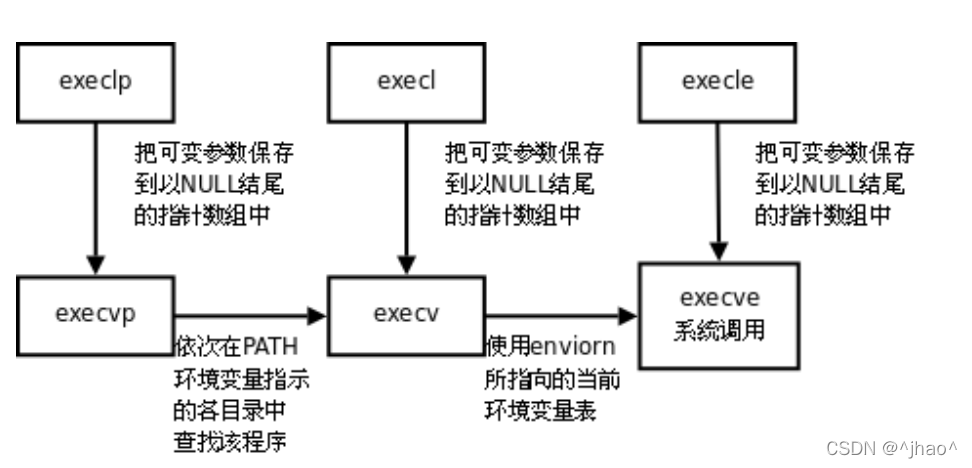
shell������ԭ��
�в��ֳ���ֻ����shell�Լ�ִ��,���Ƕ�Ӧ���ڽ����
������Ǵ����ӽ���,�ӽ���ִ������,����ٷ��ظ�os,shell������,�ٵ��û�
top,ls,pwd�ȵ�����,shell�����ӽ���,�ӽ��̵���exec*Ȼ��ִ�ж�Ӧ�ĺ�����
Ԥ��֪ʶ:
1.�û���,������,��ǰ·��,��ʾ��,�����ж�Ӧ�ĺ�����ȡ��Ӧ������,������������Ϊ�˼��,ֱ�Ӵ�ӡ��ʾ�����
��gethostname�ܻ�������������ͨ��ƴ�ӾͿ����û���,������,��ǰ·������ʾ������ʾ������getcwd�ܻ�ȡ��ǰ�Ĺ���Ŀ¼��
2.strtok��Ĭ�ϰ�ǰ���ո������,ֻҪ�����������Ч�ַ���
3.��������д�����shell��ʱ��֧���ض���ܵ�,����������º��������в��䡣
4.x=100�������ر���,�ӽ��̻�ȡ�Ļ��ǻ�ȡ�����ġ�
5.�ӽ��̵�ijЩ���Ӱ�츸���̴Ӷ�Ӱ������,����������pwd����ǰ·��,��cd ����������·����û�иı�!!!����ͨ��ls/proc/minishell�Ľ��̺ŵ��п��Կ���cwd���з��ŵ�ǰ�Ľ��̵�һ��·����
ԭ��:
������Ϊ������cd �� ���������ĸ��ĵ��Ǹ����̵ĵ�ǰ·��,������ȥ�����ӽ��̵�·�����ӽ���ִ��cd ���������˳���,�Ը����̲����Ӱ�졣
�������:�ø����̵���ϵͳ�ӿ�ȥִ��cd,�������ν����������,����ʱҪʹ�ö�Ӧ��ϵͳ�ӿ������"����"��ִ�С������Dz��ܰѸ�����shell�Ĵ����滻��cd�Ĵ���,��Ȼ�����̾��������������������ˡ�
����������ϵͳ���������,���ǵ���ϵͳ�ӿڼ��ɡ�
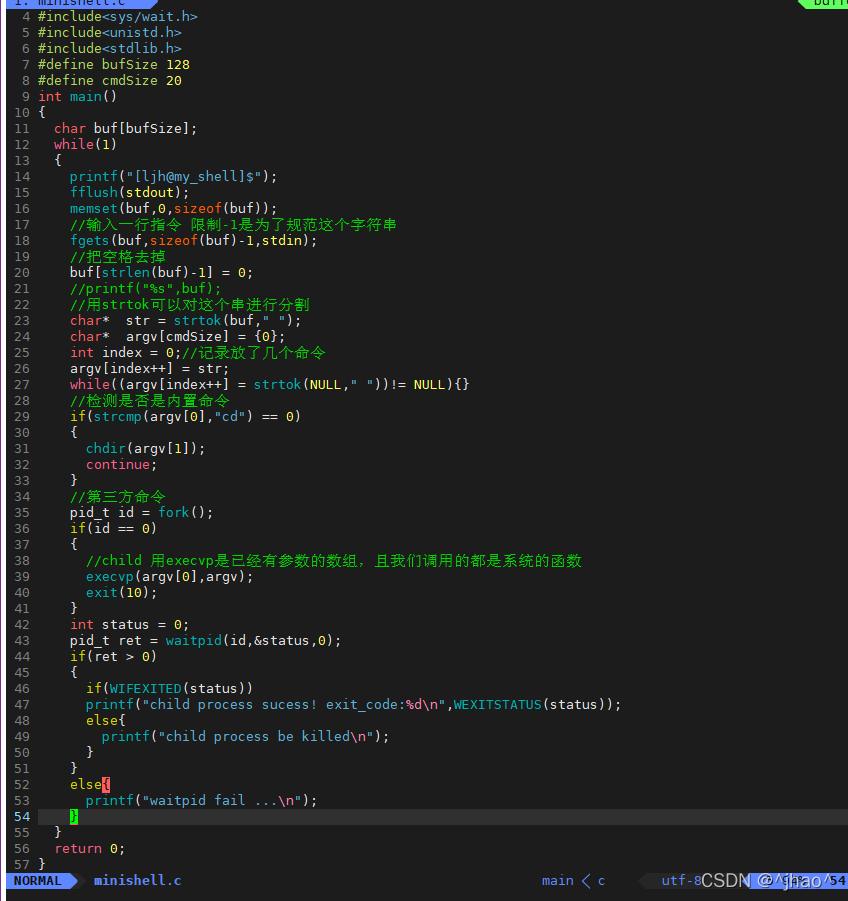
���������õ���chdir!!


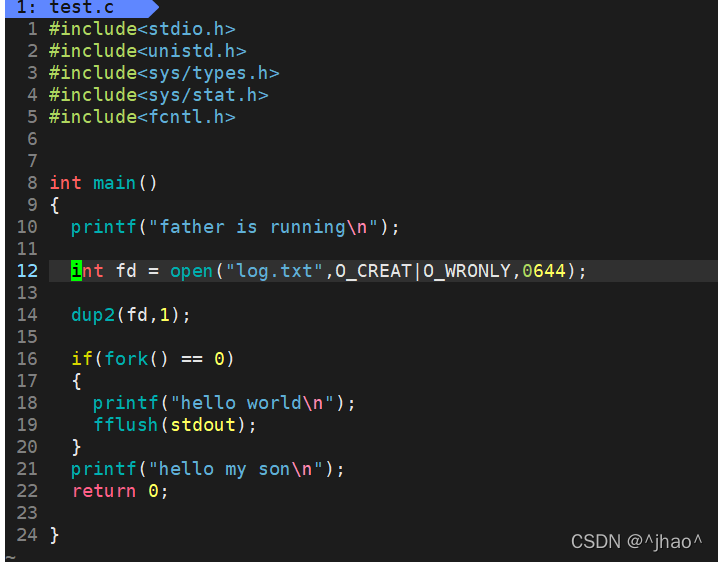
�ӽ��̻�����˸��������κδ��ļ���������ͬ�ĸ���,�������̵���forkʱ,�ӽ��̿��Զ�д�������д��κ��ļ���
����:
���:

С�ܽ�:����������Ǹ����̵���ϵͳ���ýӿ���ɵĺ���,��quit֮���Ҳ�����������
�塢PCB����֯��ʽ
���ô��в��ͽ���:http://www.cnblogs.com/skywang12345/p/3562146.html
�����и�Ԥ��֪ʶ��Ҫ�̵档
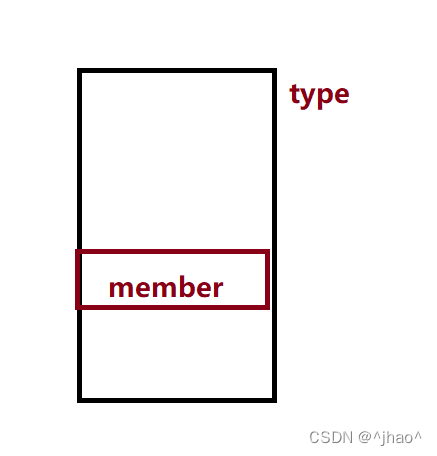
1.offsetof
#define offsetof(TYPE, MEMBER) \
((size_t) &((TYPE *)0)->MEMBER)
�����c���Ե��г����ĺ꺯��,��;�Խ�type������member���е�λ�ü��������
2.container_of
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
�������ǿ���ͨ��ptr֪��member��type���е�λ��,Ȼ�����ǿ���ͨ��offsetof���member��ָ��typeͷָ���λ��,����ptr��ȥ���ƫ���������ҵ��ṹ��ͷ��λ�á�
PCB���оͿ�����������дһ���ֶ�
struct task_struct
{
//struct files_struct;
//struct mm_struct;
struct list_head list;
}
˼��
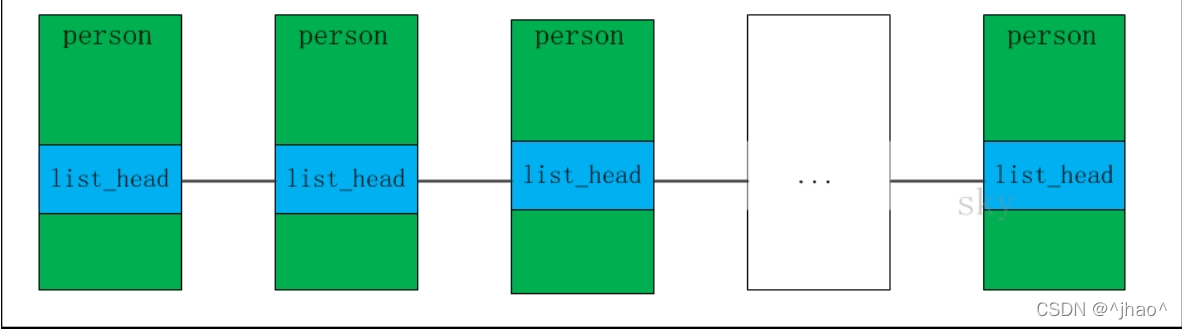
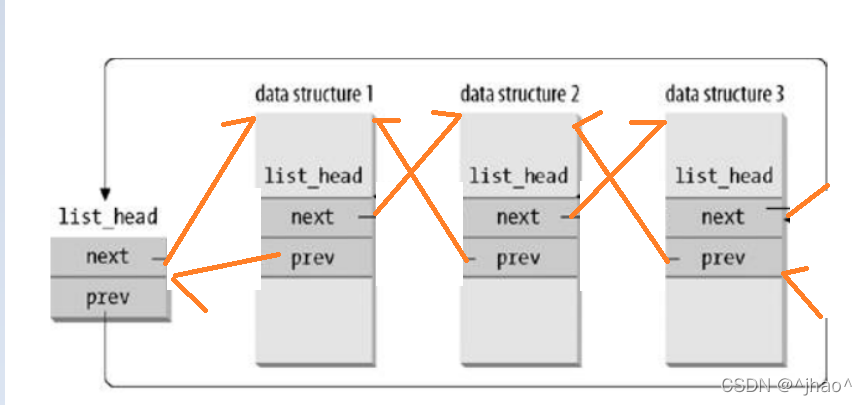
Ϊʲô�������list_head��ǰ��ָ��ָ��PCB��,��������һ������PCB��ֱ��ͨ�������ṹ�ҾͿ���,��Ҫ���ʵ�ǰ�Ľ����õ�list_head����ֶζ�Ӧ�Ĵ�ṹ��,����ֱ��list_head->prev->next�����õ�������PCB�ṹ������?ʾ��ͼ����:
��:
ʵ����������ȷʵ����,���������������,�������еĽڵ��ľ���struct task_struct*,��ô���ǵ�list_head���Ҫ����ϵͳ���е��ڴ����,��������,�ļ������Ͷ���Ҫ����ƶ�һ��Ӧ��list_head,���ṹ��ָ��ָ������Ͳ���list_head��ʹ��һ����Ƶĸ��Ӹ��ӡ�
����linux�µIJ��õ�������һ����,��ͨ��ָ��ǿת�ķ�ʽ�Ϳ��Ը�ֵ�������Ľṹ�塣
linux�½���1.�ڵ�Ķ���:ǰ��ָ�롣
struct list_head {
struct list_head *next, *prev;
};
2.��ʼ���ڵ�:�ýڵ��ǰ��ָ���Լ�,����Ĵ�ͷѭ��˫��������
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}
�������һ��LIST_NAME��LIST_HEAD_INIT���÷�,�����Ǵ�һ������,������Ϊ����,����ͨ��Ԥ��������������֪�õ��Ǵ����ŶԱ������˳�ʼ����
LIST_HEAD(list);
���: ������һ��list�ı�������ʼ����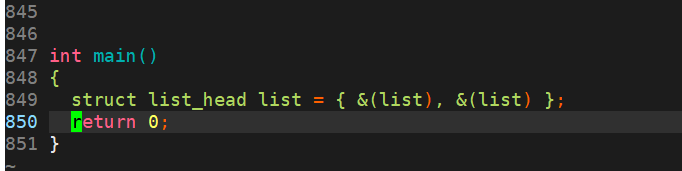
3.���ӽڵ�:
����������ʽ:list_add������ͷ���ĺ��档
list_add_tail ���뵽β�͡�
ע��:һ��ǰ��_��ʾ���ڲ�ʹ��,���ṩ���ⲿ��
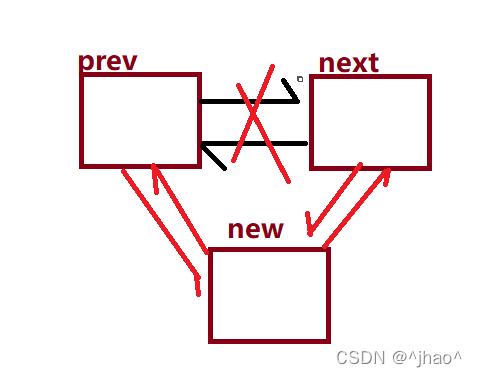
static inline void __list_add(struct list_head *new, struct list_head *prev, struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
4.ɾ���ڵ�:
list_delɾ���ڵ�ʵ����ʵ����û���ͷ�ָ��Ľڵ�,ֻ�ǰ�����˫�����ṹ�ó�����
list_del_init,���dz��˰�����ڵ��˫�����ṹ�ó���,���������Լ�ָ���Լ���
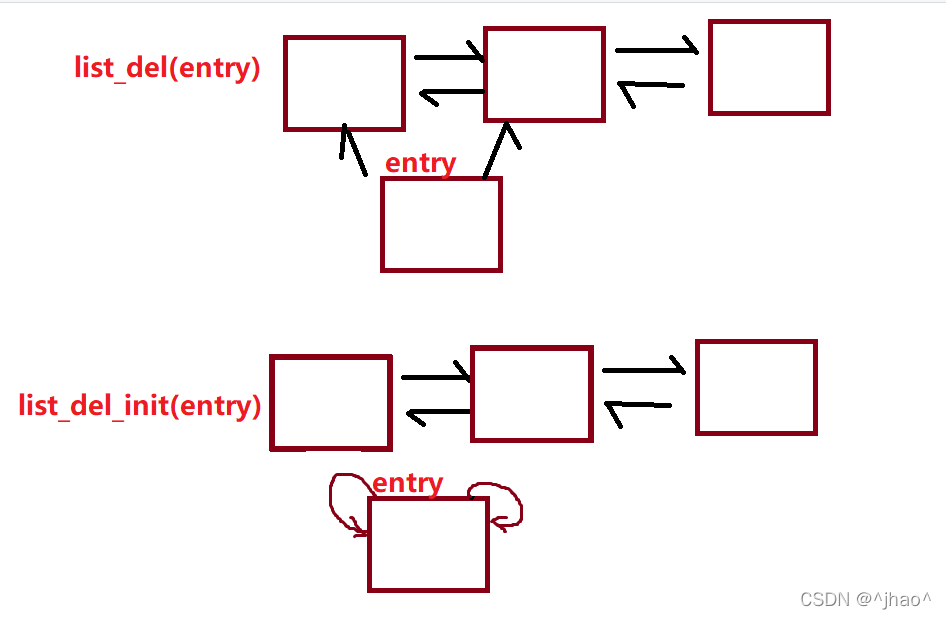
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
}
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
}
static inline void __list_del_entry(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
}
static inline void list_del_init(struct list_head *entry)
{
__list_del_entry(entry);
INIT_LIST_HEAD(entry);
}
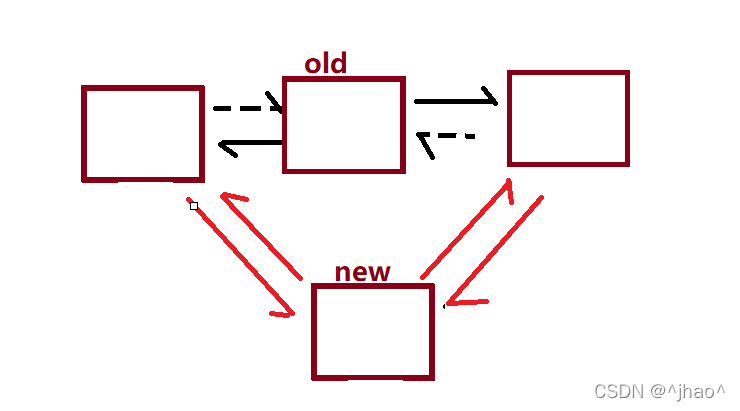
5.�滻�ڵ�:
��ָ���ָ��û�иı䡣
static inline void list_replace(struct list_head *old,
struct list_head *new)
{
new->next = old->next;
new->next->prev = new;
new->prev = old->prev;
new->prev->next = new;
}
6.˫�����п�:
static inline int list_empty(const struct list_head *head)
{
return head->next == head;
}
7.��ȡ�ڵ�:
��ȡ�ڵ��ʾ��ȡ�������ṹ��ָ�롣
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
8.�����ڵ�:
list_for_eachͨ�����ڻ�ȡ�ڵ�,��������ɾ��,��Ϊɾ���ᵼ���Ҳ�����ǰ�ڵ����һ���ڵ㡣
list_for_each_safeͨ������ɾ���ڵ�ij���,����posָ��ǰ�ڵ�,��nָ��pos�ĺ�̽ڵ�,ɾ���ڵ��ʱ��ɾ��pos�Ϳ��ԡ�
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
#define list_for_each_safe(pos, n, head) \
for (pos = (head)->next, n = pos->next; pos != (head); \
pos = n, n = pos->next)
�����һ��������β:
˫����list.h����:
#ifndef _LIST_HEAD_H
#define _LIST_HEAD_H
// ˫�������ڵ�
struct list_head {
struct list_head *next, *prev;
};
// ��ʼ���ڵ�:����name�ڵ��ǰ�̽ڵ�ͺ�̽ڵ㶼��ָ��name������
#define LIST_HEAD_INIT(name) { &(name), &(name) }
// �����ͷ(�ڵ�):�½�˫��������ͷname,������name��ǰ�̽ڵ�ͺ�̽ڵ㶼��ָ��name������
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
// ��ʼ���ڵ�:��list�ڵ��ǰ�̽ڵ�ͺ�̽ڵ㶼��ָ��list������
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}
// ���ӽڵ�:��new���뵽prev��next֮�䡣
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
// ����new�ڵ�:��new���ӵ�head֮��,��new��Ϊhead�ĺ�̽ڵ㡣
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
// ����new�ڵ�:��new���ӵ�head֮ǰ,����new���ӵ�˫������ĩβ��
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
// ��˫������ɾ��entry�ڵ㡣
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
}
// ��˫������ɾ��entry�ڵ㡣
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
}
// ��˫������ɾ��entry�ڵ㡣
static inline void __list_del_entry(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
}
// ��˫������ɾ��entry�ڵ�,����entry�ڵ��ǰ�̽ڵ�ͺ�̽ڵ㶼ָ��entry������
static inline void list_del_init(struct list_head *entry)
{
__list_del_entry(entry);
INIT_LIST_HEAD(entry);
}
// ��new�ڵ�ȡ��old�ڵ�
static inline void list_replace(struct list_head *old,
struct list_head *new)
{
new->next = old->next;
new->next->prev = new;
new->prev = old->prev;
new->prev->next = new;
}
// ˫�����Ƿ�Ϊ��
static inline int list_empty(const struct list_head *head)
{
return head->next == head;
}
// ��ȡ"MEMBER��Ա"��"�ṹ��TYPE"�е�λ��ƫ��
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
// ����"�ṹ��(type)����"�е�"���Ա����(member)��ָ��(ptr)"����ȡָ�������ṹ�������ָ��
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
// ����˫������
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
#define list_for_each_safe(pos, n, head) \
for (pos = (head)->next, n = pos->next; pos != (head); \
pos = n, n = pos->next)
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
#endif
test.c:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "list.h"
struct person
{
int age;
char name[20];
struct list_head list;
};
void main(int argc, char* argv[])
{
struct person *pperson;
struct person person_head;
struct list_head *pos, *next;
int i;
// ��ʼ��˫�����ı�ͷ
INIT_LIST_HEAD(&person_head.list);
// ���ӽڵ�
for (i=0; i<5; i++)
{
pperson = (struct person*)malloc(sizeof(struct person));
pperson->age = (i+1)*10;
sprintf(pperson->name, "%d", i+1);
// ���ڵ����ӵ�������ĩβ
// �����ѽڵ����ӵ������ı�ͷ����,��ʹ�� list_add
list_add_tail(&(pperson->list), &(person_head.list));
}
// ��������
printf("==== 1st iterator d-link ====\n");
list_for_each(pos, &person_head.list)
{
pperson = list_entry(pos, struct person, list);
printf("name:%-2s, age:%d\n", pperson->name, pperson->age);
}
// ɾ���ڵ�ageΪ20�Ľڵ�
printf("==== delete node(age:20) ====\n");
list_for_each_safe(pos, next, &person_head.list)
{
pperson = list_entry(pos, struct person, list);
if(pperson->age == 20)
{
list_del_init(pos);
free(pperson);
}
}
// �ٴα�������
printf("==== 2nd iterator d-link ====\n");
list_for_each(pos, &person_head.list)
{
pperson = list_entry(pos, struct person, list);
printf("name:%-2s, age:%d\n", pperson->name, pperson->age);
}
// �ͷ���Դ
list_for_each_safe(pos, next, &person_head.list)
{
pperson = list_entry(pos, struct person, list);
list_del_init(pos);//ɾ��pos�ڵ�
free(pperson);//free�����ṹ��
}
}
����:
==== 1st iterator d-link ====
name:1 , age:10
name:2 , age:20
name:3 , age:30
name:4 , age:40
name:5 , age:50
==== delete node(age:20) ====
==== 2nd iterator d-link ====
name:1 , age:10
name:3 , age:30
name:4 , age:40
name:5 , age:50
�����:
https://blog.csdn.net/qq_28992301/article/details/53142826
http://www.cnblogs.com/skywang12345/p/3562146.html
�ܽ�
���̵Ľ�����ȸ�һ������,�������ὲ������IO,�ļ�������һ���֪ʶ,������ò���д�Ļ����Ե�,��һ��һ��������,ף������µ�һ���������,����˳�ġ�