Ŀ��
��snort1.0,1.5�����ϰ汾���з���,�������ݱȽ�����,���������Ƚ�ȷ,��ͼ����ǡ��,�½ڰ��źϺ���
ʵ��ƽ̨
- ����ϵͳ:windows 10��(����������ϵͳΪ)
- ʹ������:
- �ĵ���д����:Typora(markdown��༭��)
- �����������:ʹ�� Git ���д������
- ����鿴����:Sourcetrail
���ڲ���ѧdz,������ȥ�ٶ����˹������̵�ԭ���������Ķ�,

Snort �������̷�Ϊ�����ĸ���Ҫ����:
1��������/��������:����,����libpcap���������������ϵ����ݰ�,Ȼ�����ݰ����������������뵽��·��Э��İ��ṹ����,�Ա�Ը߲�ε�Э����н���,��TCP��UDP�˿ڡ�
2��Ԥ���������:����,���ݰ����͵����ָ�����Ԥ��������,�ڼ�����洦��֮ǰ���м��Ͳ�����ÿ��Ԥ������������ݰ��Ƿ�Ӧ��ע�⡢����������ijЩ������
3����������ͼ������:Ȼ��,�����͵�������档�������ͨ�����ֹ����ļ��еIJ�ͬѡ������ÿ�����������Ͱ���Ϣ���е�һ���ļ�⡣������������ṩ����ļ��ܡ������е�ÿ���ؼ���ѡ���Ӧ�ڼ��������,�ܹ��ṩ��ͬ�ļ��ܡ�
4��������:Snortͨ��������桢Ԥ�������ͽ����������������
��ϸ��������:
һ��������/��������:
1�����ݰ�����:
Snortͨ�����ֻ���������������������Ҫ:����������Ϊ����ģʽ;����libpcap�����������������ݰ���
������Ĭ�Ϲ�����ʽ�Ǻ������в����Լ���MAC��ַΪĿ�ĵ�ַ��������ͨ�����������óɻ���ģʽ,���Լ��������е�����������
���ݰ�����������һ����������������,���ݰ�����⺯����ֱ�Ӵ�������ȡ���ݰ���Snort����ͨ�����øÿ⺯���������豸�ϲ������ݰ�����������OSIģ�͵�������·�㡣�ڲ�ͬ��ƽ̨��ʹ��Snortϵͳ,��Ҫ��װ��ͬ�汾��Libpcap,������Linux��Unixϵͳ����Ҫ��װLibpcap,����Windowsϵ��ϵͳ��,����Ҫ��װWinpcap��
2��������:
���Ѿ������������ұ�lipcap�⺯����������ݰ�,Snort����ý��������������·���ԭʼ���ݰ����н��롣Snort�ܹ�ʶ����̫����802.11(���߾�����Э��)�����ƻ��Լ�����IP��TCP��UDP�ȸ߲�Э�顣Snort����������ݰ�������,�洢���ڴ���ָ��ָ������ݽṹ�С�
����Ԥ������:
SnortԽ���ٶ�Դ�ڼĹ���ƥ��,���ֻ��ÿ�����������ֺ��ַ�����ƥ��,�������ܾ�����Ӧ���ٵĸ߸������硣���ּ��ϵͳ��ȱ����,�������ģʽ�ܳ���,�ͻ�����ܶ������ģʽ��������,�ֻ����©���������Щȱ�ݵ�ԭ�����������Եı�����������IDS��Э��ķ�������,һЩIDSͨ�����ӵķ��������һ���⡣������Щʹ��Э���쳣������Բ�����Э��淶�İ�����,��Щ������״̬,��ֻ�Դ���������TCP�Ự�еİ�������
Snort��ͨ��Ԥ��������ʵ����Щ����,Snort�ж��Ԥ������,����frag2,stream4,http_decode,Telnet_negotiation,portscan,rpc_decode�ȳ��õ�Ԥ����������ЩԤ����������Ҫ����Ϊ:1)������;2) Э�����;3) �쳣���;��
1��������:
���������ļ�⽫�����ݺͶ������õ�ģʽ����ƥ�䡣���Dz��ܶԿ�������ݽ��м�⡣ͨ��frag2�������Ƭ���鵽һ����������,����ȷ�������߲�����IP��Ƭ����ܼ�⡣ͨ��stream4�������������,���ǿ����õ�������������TCP�Ự�п�Խ���������ģʽƥ�䡣���,ͨ��stream4��״̬ά������,����ƥ����Ծ߱�һЩ����,���ж���Щ��Ӧ�ö���,��Щ�����������С���һ�仰�ܽ�,������Ԥ����������Snort���ƥ�����ݷֲ��ڶ�����еĹ�����
2�������:
���ڹ���ļ���ṩ�Ĵ�/λƥ��Ĺ���,�������HTTPЭ���в�ͬ��ʽ��URL,����ʹ������Ĺ��� http_de-codeԤ����������Snort�ڹ���ƥ��ǰ�淶��URL���Ĺ���ƥ�仹������Ϊ�����м�����Э����Ϣ��ʧ�ܡ�Telnet_negoti-ation��rpc_decodeԤ������ȥ�������в�Ӧ�ý���ģʽƥ��IJ���,rpc_decodeԤ�����ϲ�RPC��Ϣ��Ƭ,Telnet_negotiationԤ������ȥ��Telnet��Э��Э�̹��̡���һ�仰�ܽ�,Э�����Ԥ������Э�����ݽ��д���,ʹ��ƥ�书���ڸ���ȷ�������Ϲ�����
3���쳣���:
���ڹ���ļ����������Զ������ɿ������Ĺ��̾�ȷ,���Ժ����ص������ü�����,Ҳ�������Ż�������,��Щ������ͨ������ģʽ����⡣Snort��չ��Э���쳣���:portscanԤ����������Snort������һ��ʱ����ڽ��յ�ɨ�����͵İ�,�Գ�����ֵ��������б���;BackOrificeԤ������ʹSnort���þ�Ĺ��Ϳ��Լ����ܵ�BackOrifice������
������������ͼ������:
Snort�����ǻ����ı���,��ͨ��������Snort����Ŀ¼�л�����Ŀ¼�С���������ʱ��,Snort��ȡ���еĹ����ļ�,���ҽ���һ����ά��������Snortʹ���б�ƥ����ͼ�⡣
1���������:
Snort������Snort���ּ��ϵͳ����Ҫ��ɲ��֡�������snort�Ĺ����ؿ�,ÿ������Ӧһ����������,snortͨ������ʶ����Ϊ��
ÿһ���������������:����ͷ��(RuleHeader)����ѡ��(RuleOption)������ͷ�����������Ϊ��Э�顢Դ��ַ��Ŀ�ĵ�ַ���������롢Դ��Ŀ�Ķ˿���Ϣ������ѡ�����������Ϣ�Լ�����ʱ�ṩ������Ա�IJο���Ϣ������: alerttcpanyany->202.203.112.0/24any(content:��proxy-connection��;msg:��proxyuse��😉 ������������Ϣ��:���κη���202.203.112����,tcp�����к���proxy-connection�����������������������,������ǰ���ǹ���ͷ��Բ�����ڵ������ǹ���ѡ��,�ڹ���ѡ����,content���������Ϊ�ؼ���,����Ҫƥ����ַ���,msg���������Ϊ����ʱ����ʾ����Ϣ��Snort�Ĺ������п���û�й�����,����ֻ���������õض�����Ҫ���е�ij�ִ���(��¼�����������Ե�)�����ݰ����͡�ֻ�е������е�ÿһ��Ԫ�ض�Ϊ��ʱ,���ܴ�����Ӧ�Ĺ�������
2���������:
Snort�Ѿ�����ͬ�����Ĺ������ӵ�һ��������,��RTN�ṹ������;����ѡ���Ӧ�ڹ���ѡ����OTN(OptionalTreeNode),����һЩ�ض��ļ���־��������Ϣ��ƥ�����ݵ�����,ÿ��ѡ���ƥ���Ӻ���(���)�ŵ�FUNC�����С�ֻ�е�����ĸ���������Ϊ��ʱ�Ŵ�����Ӧ�IJ�����
Snort��������ʱ,�ֱ�����TCP��UDP��ICMP��IP��4����ͬ�Ĺ�����,ÿһ��������������������ά����:RTN(����ͷ),OTN(����ѡ��)��FUNC(ָ��ƥ���Ӻ�����ָ��)�� ��Snort����һ�����ݱ�ʱ,���ȶ������,Ȼ�����Ԥ����,�����ù����������ݱ�����ƥ�䡣�ڹ�����ƥ�������:���ݸ����ݱ���IPЭ��������ĸ�����������ƥ��;Ȼ����RTN������ν���ƥ��,����ij������ͷ��ƥ��ʱ,����������OTN������ƥ�䡣ÿ��OTN��㶼������һ�������ȫ��ѡ��,��������һ�麯��ָ���������ʵ�ֶ���Щ������ƥ�������������֪���ݱ���ij��OTN�����������������ʱ,���жϴ����ݱ�Ϊ�������ġ�
Ϊ��߹���ƥ����ٶ�,Snort������Boyer-Moore�ַ���ƥ���㷨����ά�б��ݹ����(RTN��OTN)�Լ�����ָ���б�(��Ϊ����ά�б���)�ȷ�����
����������:
ץ������������ȡ���ݰ�����������ģ��,����������˱�������־�¼�,��ô���ݾͷ�����Ӧ������������������Ԥ��������ץ������ִ����֮�����Snort��������־��ϵͳʱִ�С�
Snort�������Ĺ��ܿ��Է�Ϊ7������:��Ȩ��ͷ��Ϣ;ͷ�ļ���������ϵ��ȫ�ֱ���;�ؼ���ע��;���������ͺ����б���;���ݴ���,��ʽ���ʹ洢;����Ԥ����������;�������˳���������ϸ��������ĸ����ܡ�
1����Ȩ��ͷ��Ϣ�ִ��ÿһ�������������������İ�Ȩ��Ϣ,��Ȩ��Ϣ�����ɲ���������������ӡ������ͷ��ϸ�����˲������;,��Ҫ�IJ���������Լ�����ע�͡�
2��ͷ�ļ�,������ϵ��ȫ�ֱ����;���Ӧ�ö���,�ļ��Լ�����֮���������ϵ�Գ���������Ҫ,����Ҫ�������⡣ȫ�ֱ���������������κβ��ֶ�����ʹ�á�
3���ؼ���ע��������ͨ�������ļ������������ú͵��á��û�����Ϊ�������ؼ��ֲ��Ѹùؼ������ӵ�Snort,�Ա�����ùؼ���ʱ����Ӧ���������
4�����������ͺ����б����ֲ��������ʱ��Ҫ���ݲ���,����б�ҪдһЩ������������Щ���ݡ�����,��ʹ����־����ʱ,������Ҫָ��һ�����ڴ洢��־����־�ļ��������˷�������,�������������Snort�������ڵĺ�����
5�����ݴ�������ʽ���ʹ洢���ݴ�������ʽ���ʹ洢�Dz������Ҫ�Ĺ���,������ô˵,���û�����ݴ�������ʽ���ʹ洢��Щ����,�������Ͳ�����,û���á�
6������Ԥ��������������Ԥ��������������ʱ,����д���ݴ���������������Щ����,�����ڷ�����ʼ֮ǰ,Snort����������������Ԥ��������Ԫ��
7���������˳�,�ھ�����������,��Ҫ�ڲ���а��������ڴ桢Ӧ�������Լ������ֵ��˳���������,�����������Snort��ִ��Ч�ʡ� Snort�ܹ�ʹ�����������㱨�ͱ�ʾ����,Snort֧�ֶ�����־��ʽ,����ֱ�ӵ��ı�ͷ��PCAP��UNIXsyslog��XML�ı����ݿ�Ͷ��ֹ�ϵ���ݿ�,��Щ������ʹ�ñ�������־�Ը������ĸ�ʽ�ͱ�����ʽ���ָ�����Ա�����û�����������������洢��ʽ������,������������������û���κ�����ġ�
��װ��source-insight4.0��ʼ�Ķ�Դ��,arpЭ��ĸ�ϰ
���ȵ�һ��������main���������arguments�����charָ�봫�ݵ�-a��ָ��,���ָ��Ľ����� -a => display ARP packets,
����̫����,һ����������һ����������ֱ��ͨ��,����Ҫ֪��Ŀ��������MAC��ַ�������Ŀ��MAC��ַ����λ�õ���?������ͨ����ַ����Э���õġ���ν����ַ���������������ڷ���֡ǰ��Ŀ��IP��ַת����Ŀ��MAC��ַ�Ĺ��̡�ARPЭ��Ļ������ܾ���ͨ��Ŀ���豸��IP��ַ,��ѯĿ���豸��MAC��ַ,�Ա�֤ͨ�ŵ�˳�����С�
��main����������-a��������Ժ�,���ݵ�ParseCmdLine������,���������һ����ѭ��,
while((ch = getopt(argc, argv, "eh:l:dc:n:i:vV?aso")) != EOF)
case 'a': /* show ARP packets */
#ifdef DEBUG
printf("Show ARP active\n");
#endif
pv.showarp_flag = 1;
break;
�������������,�����pv.showarp_flag������1,˳��һ��,���pvӦ���ǿ��Ʋ���ָ���һ������,��������źܶ�����,Ҫ��ʲô��������������ơ�
snort->openpcap
/* open up our libpcap packet capture interface */
OpenPcap(pv.interface);
�������flag�������Ժ�ʼʹ��openpcap������ץ��,����pv����һ��ָ���IJ�����ָ��ṹ��,interface��ץ���Ľӿڡ������õ���һ�����ģʽ,�����Ժ�ĸ���,�Լ�����Ŀɽ��еIJ���,interface�ӿڴ���������charָ�����͡�
��ʼ���ǿ���openpcap�������
bpf_u_int32 localnet, netmask; /* net addr holders */
struct bpf_program fcode; /* Finite state machine holder */
char errorbuf[PCAP_ERRBUF_SIZE]; /* buffer to put error strings in */
������������������,��һ����bpfu_int32���͵�localnet,����netmask,
����һ��csdn����Ľ���,pcap��ʹ�úͼ��� - ������ - ���� (cnblogs.com)
��������bpf_u_int32ʵ���Ͼ���u_int��һ������,���а�bpf_int32ʵ���Ͼ���int�ı�������Ȼ���int��32λ��,�������ϵͳ��int�Ķ��岻��4�ֽ�,bpf_int32�Ͷ�Ӧ����һ������,��֮,bpf_u_int32����һ��32λ���������͡�
�ؼ�����:
int pcap_lookupnet(const char *device, bpf_u_int32 *netp,bpf_u_int32 *maskp, char *errbuf)���ڻ�ȡ����������ź��������롣����device������������,netp ��maskp��ʾ��Ҫ��õ�����ź���������,�����������ֽ����ŵ�,����һ��IPΪ10.108.20.0,��ônetp�д�ŵ������ַ����:1338378��ת���ɶ����ƾ���:
00000000 00010100 01101100 00001010
bpfu_int32����������Ӧ��ͬϵͳ�ĵ��Ե���,����32λ��int����
����bpf_program������һ������״̬����������ı���?(Ӣ�ﲻ��)
�����errorbuff��һ������Ļ�������
���ڿ�ʼʹ������ĺ���,�����pv�Ľӿڸ�ֵ,pcap_lookupdevݺ����ǵ���c���ԵĿ�,lookupdev����˼�����Ѱ��Ӳ���豸,Ӧ���ǵ��������ı��صĺ�����
��ֵ���Ժ�,��ʹ������������Ӳ���Ľ�����
pd = pcap_open_live(pv.interface, SNAPLEN, PROMISC, READ_TIMEOUT, errorbuf);
pcap_compile(pd, &fcode, pv.pcap_cmd, 0, netmask) < 0
pcap_setfilter(pd, &fcode) < 0
�ж��겻Ϊ���Ժ�Ϳ�ʼʹ��pcap_lookupnet(pv.interface, &localnet, &netmask, errorbuf) < 0�������ж�,���е�С�����dz����˴�������Ӧ����Ӳ���豸û���ҵ�,���������Ҳ�Ǵ�����ж�,�����д��Ͷ�������ջ����,����е���java���쳣�׳�
/* get data link type */
datalink = pcap_datalink(pd);
if (datalink < 0)
{
fprintf(stderr, "ERROR: OpenPcap() datalink grab: \n\t%s\n", pcap_geterr(pd));
exit(1);
}
��һ��Ӧ����openpcap������ؼ���һ��,�����datalink����ָ�������ӵ�������һ����������openpcap��������ˡ�
�ܽ�һ���������,���dz�ʼ��openpcap������,�Ѵ���Ķ�������Ū�ߡ�
snort->setpktprocessor
/* set the packet processor (ethernet, slip or raw)*/
SetPktProcessor();
���ð��Ľ���?(����)
����������᷵��һ��int���͵�����
һ��ʼʹ����һ��switch�ĺ���
switch(datalink)
{
case DLT_EN10MB:
printf("Decoding Ethernet on interface %s\n", pv.interface);
grinder = (pcap_handler) DecodeEthPkt;
break;
case DLT_SLIP:
printf("Decoding Slip on interface %s\n", pv.interface);
if(pv.showeth_flag == 1)
{
printf("Disabling Ethernet header printout (you aren't using Ethernet!\n");
pv.showeth_flag = 0;
}
grinder = (pcap_handler) DecodeSlipPkt;
break;
���datalink����,����·�������,����һ��csdn�����
DLT_EN10MB: ��̫��(10Mb, 100Mb, 1000Mb, ���߸���)��
DLT_SLIP:SLIP��
������һ�µ�һ��DLT_EN10MB������ؼ��ĺ����������DecodeEthPkt,��������Ҿ��þ��ǽ������,�Ҿ�����snort������ؼ��ĺ�����,���е�grinder����Ϊn.��ĥ��е; ĥ����; ĥ��; ĥ��;
���grinder�Ǹ�����ָ��,���������DecodeEthPkt��ֵ,Ȼ��ǿת��pcap_handler����
grinder = (pcap_handler) DecodeEthPkt;
���濪ʼ����decodeEthPkt�������,��decode�ļ�����
void DecodeEthPkt(char *user, struct pcap_pkthdr *pkthdr, u_char *pkt)
���������������������,��һ����user,�ڶ�����
struct pcap_pkthdr {
struct timeval ts; /* time stamp */
bpf_u_int32 caplen; /* length of portion present */
bpf_u_int32 len; /* length this packet (off wire) */
};
���pcap_pkthdr����ṹ��,��һ��ʱ���,���в��ij���,���а��ij��ȡ�csdn����ij���µ�˵���C��Ϊ��ijЩ������㲻�ܱ�֤����İ���������,����һ������1480,�����㲶��1000��ʱ��,������ΪijЩԭ�����ֹ������,����caplen�Ǽ�¼ʵ�ʲ���İ���,Ҳ����1000,��len����1480��
������Ǹ�u_char�����Ǵ���İ�
��������ݸ㶨��,��һ�³�ʼ��������
int pkt_len; /* suprisingly, the length of the packet */
int cap_len; /* caplen value */
int pkt_type; /* type of pkt (ARP, IP, etc) */
EtherHdr *eh; /* ethernet header pointer (thanks Mike!) */
/* set the lengths we need */
pkt_len = pkthdr->len; /* total packet length */
cap_len = pkthdr->caplen; /* captured packet length */
ClearDumpBuf();
bzero((void *) &pip, sizeof(PrintIP));
-
��һ����pkt_len�ǰ��ij���
-
�ڶ�����cap_len�Dz��ij���
-
�������ǰ�������,�ֱ���arp��,ip��,etc��etc��������̫֡
1:�汾�� 4 bit 2:ͷ���� 4 bit 3:�������� 8 bit 4:�ܳ��� 16 bit 5:��ʶ 16 bit 6:��־ 4 bit 7:Ƭ���� 12 bit 8:����ʱ�� 8 bit 9:�ϲ�Э���ʶ 8 bit 10:ͷ��У��� 16 bit 11:Դ��ַ bit 12:Ŀ���ַ 32 bit ����:20�ֽ��е�������Ethernet֡��ʲô����,���ڿ�һ��
��̫֡�л�����Դ��Ŀ��MAC��ַ,�ֱ���������ߵ�MAC�ͽ����ߵ�MAC,�����֡У�������ֶ�,���ڼ��鴫�������֡�������ԡ�
��̫���ڶ�����·��ͨ��MAC��ַ��Ψһ��ʶ�����豸,����ʵ�־������������豸֮���ͨ�š�MAC��ַҲ��������ַ,������������̰�MAC��ַ������������ROM�С����Ͷ�ʹ�ý��ն˵�MAC��ַ��ΪĿ�ĵ�ַ����̫֡��װ��ɺ��ͨ��������ת���ɱ����������������ϴ��䡣
�����豸���ȷ����̫������֡���ϲ�Э��?
��̫��֡�а���һ��Type�ֶ�,��ʾ֡�е�����Ӧ�÷��͵��ϲ��ĸ�Э�鴦��������,IPЭ���Ӧ��TypeֵΪ0x0800,ARPЭ���Ӧ��TypeֵΪ0x0806��
�ն��豸���յ�����֡ʱ,����δ���?
�������֡ͷ�е�Ŀ��MAC��ַ,���Ŀ��MAC��ַ���DZ���MAC��ַ,Ҳ���DZ����������鲥��㲥MAC��ַ,�������ᶪ���յ���֡�����Ŀ��MAC��ַ�DZ���MAC��ַ,����ո�֡,���֡У������(FCS)�ֶ�,���뱾�������ֵ�Ա���ȷ��֡�ڴ���������Ƿ��������ԡ�������ͨ��,�ͻ����֡ͷ��֡β,Ȼ�����֡ͷ�е�Type�ֶ������������ݷ��͵��ĸ��ϲ�Э����к���������
���������
ClearDumpBuf();//�������������
void ClearDumpBuf()
{
if(data_dump_buffer != NULL)
free(data_dump_buffer);
data_dump_buffer = NULL;
dump_ready = 0;
}
bzero((void *) &pip, sizeof(PrintIP));
bzero(&net, sizeof(NetData));//��������0�ij�ʼ��
���е�pip��PrintIP����,Ȼ��net��NetData���͵�
/* do a little validation */
if(cap_len < ETHERNET_HEADER_LEN)//���������Ϸ��Լ���
//������̫��֡�Dz��DZȲ���֡��,��Ļ�����������
/* lay the ethernet structure over the packet data */
pkt_type = ntohs(eh->ether_type);
if(pv.showeth_flag)
{
memcpy(pip.eth_src, eh->ether_src, 6);
memcpy(pip.eth_dst, eh->ether_dst, 6);
pip.eth_len = pkt_len;
pip.eth_type = pkt_type;
}
�������һ�δ����Ǽ�����showethΪ��Ļ�,�Ͱ�6λ��eh->ether_src���Ƶ�pip����
/* set the packet index pointer */
���ð���ָ��
pktidx = pkt;
����һ��ethernet��ͷ���ij���,��Ϊ��������ע�ص��ǰ�������
/* increment the index pointer to the start of the network layer */
pktidx += ETHERNET_HEADER_LEN;
decode����Ӧ��������Ҫ��һ��
switch(pkt_type)
{
case ETHERNET_TYPE_IP:
#ifdef DEBUG
printf("IP Packet\n");
#endif
DecodeIP(pktidx, pkt_len-ETHERNET_HEADER_LEN);
return;
case ETHERNET_TYPE_ARP:
case ETHERNET_TYPE_REVARP:
if(pv.showarp_flag)
DecodeARP(pktidx, pkt_len-ETHERNET_HEADER_LEN, cap_len);
return;
case ETHERNET_TYPE_IPX:
DecodeIPX(pktidx, (pkt_len-ETHERNET_HEADER_LEN));
return;
default:
return;
}
������ɸѡpkt������
1.ETHERNET_TYPE_IP�CDecodeIP(��)
��ʼ�Ķ���
����Ĵ�������ij�- -
�ȿ�����IJ�����
**u_char *pkt, **��>ptr to the packet data
const int len��>length from here to the end of the packet
������
IPHdr *iph; /* ip header ptr ip��ͷָ��*/
u_int ip_len; /* length from the start of the ip hdr to the pkt end ip���ij��� */
u_int hlen; /* ip header length ipͷ�ij���*/
/* lay the IP struct over the raw data */
�����ǽ��ַ����͵�pktǿ��ת��ΪIPHdr�ṹ,raw��"��,δ����"������
iph = (IPHdr *) pkt;
�Ϸ��ԵIJ���
/* do a little validation */
if(len < sizeof(IPHdr))
{
if(pv.verbose_flag)
fprintf(stderr, "Truncated header! (%d bytes)\n", len);
return;
}
��������ĺϷ�����,����İ��DZ�ɾ��������˼(Truncated)ͷ���İ��ĺϷ��Լ��
if(len < ip_len)
{
/*verbose���߳�����˼*/
if(pv.verbose_flag)
{
fprintf(stderr,
"Truncated packet! Header says %d bytes, actually %d bytes\n",
ip_len, len);
PrintNetData(stdout, pkt, len);
}
if(pv.log_flag)
{
OpenLogFile(DUMP);
PrintNetData(log_ptr, pkt, len);
fflush(log_ptr);
fclose(log_ptr);
}
return;
}
����ĺϷ��Լ����,���DZ�ɾ����,���ݰ�ͷ��˵��,���������˵㶫����
��ʽ�Ŀ�ʼ���!
/* set the IP header length */
hlen = iph->ip_hlen * 4;
���������IJ���,��ip_hlen*4��ֵ��hlen
if(hlen > 20)
{
DecodeIPOptions( (pkt + 20), hlen - 20);
}
DecodeIPOptions( (pkt + 20), hlen - 20);
��������������
- Arguments: o_list => ptr to the option list
-
o_len => length of the option list
ip�ײ�����20����Ҫ��ȥ20,�൱��ָ��λ����
���ﴩ��ȥ��o_len��hlen-20,cp�ǰ�
������ϰһ��ip��options
TCPͷ����IPV4ͷ�����˹̶���20�ֽ���,�������� OPTION �ֶ����ڴ洢�Զ��������,��ΪTCPͷ����IPV4�ı��ij����ֶξ�Ϊ4�ֽ�,����ʾ�����ֵΪ15, ��4,����ͷ�����Ϊ60�ֽ�,���Option�ֶ����Ϊ40�ֽ�,�㹻�洢�����ı��Ŀ�����Ϣ��TCP��IPV4 OPTION�ĸ�ʽ��Ϊ(��ʶ�ֶ� - ���� - ����)��ʽ,һ���ȡ4�ֽڶ���洢��
��Ҫ�Ľ���Ĺ���
��һ��,��ȡ��option�ֶ�
**��ѡ��(Options):**����һ���ɱ䳤���ֶΡ����ֶ����ڿ�ѡ��,��Ҫ���ڲ���,����Դ�豸������Ҫ��д����ѡ��Ŀ������������:
? ��ɢԴ·��(Loose source routing):����һ����·�����ӿڵ�IP��ַ��IP������������ЩIP��ַ����,������������̵�����IP��ַ֮���������·������
? �ϸ�Դ·��(Strict source routing):����һ����·�����ӿڵ�IP��ַ��IP������������ЩIP��ַ����,�����һ������IP��ַ�������ʾ��������
? ·�ɼ�¼(Record route):��IP���뿪ÿ��·������ʱ���¼·�����ij�վ�ӿڵ�IP��ַ��
? ʱ���(Timestamps):��IP���뿪ÿ��·������ʱ���¼ʱ�䡣
while (o_len > 0)
{
/* Check for zero length options */
//���ﲻ����,��Ϊ��ip��İ����
opt = *cp++;
if((opt == IPOPT_EOL) ||
(opt == IPOPT_NOP))
{
len = 1;
}
else
{
len = *cp++; /* total including type, len */
if(len < 2 || len > o_len)
{
if(pv.verbose_flag)
{
printf("Illegal IP options: option says %d, IP header says %d\n", len, o_len);
PrintNetData(stdout, o_list, o_len);
}
if(pv.log_flag)
{
OpenLogFile(BOGUS);
fprintf(log_ptr, "Illegal IP options: option says %d, IP header says %d\n", len, o_len);
PrintNetData(log_ptr, o_list, o_len);
fclose(log_ptr);
}
break;
}
/* account for length byte */
o_len--;
}
/* account for type byte */
o_len--;
/* Handle the rest of the options */
datalen = 0;
switch (opt)
{
case IPOPT_RR:
datalen = len - 2;
strncat(pip.IPO_Str, "RR ", 3);
break;
case IPOPT_EOL:
strncat(pip.IPO_Str, "EOL ", 4);
break;
case IPOPT_NOP:
strncat(pip.IPO_Str, "NOP ", 4);
break;
case IPOPT_TS:
datalen = len - 2;
strncat(pip.TO_Str, "TS ", 3);
break;
case IPOPT_SECURITY:
datalen = len - 2;
strncat(pip.TO_Str, "SEC ", 4);
break;
case IPOPT_LSRR:
case IPOPT_LSRR_E:
datalen = len - 2;
strncat(pip.TO_Str, "LSRR ", 5);
break;
case IPOPT_SATID:
datalen = len - 2;
strncat(pip.TO_Str, "SID ", 4);
break;
case IPOPT_SSRR:
datalen = len - 2;
strncat(pip.TO_Str, "SSRR ", 5);
break;
default:
datalen = len - 2;
sprintf(tmpbuf, "Opt %d:", opt);
strncat(pip.TO_Str, tmpbuf, strlen(tmpbuf));
for(i = 0; i < datalen; ++i)
{
sprintf(tmpbuf, " %02x ", cp[i]);
strncat(pip.TO_Str, tmpbuf, strlen(tmpbuf));
}
break;
}
/*
* Account for data printed
*/
cp += datalen;
o_len -= datalen;
}
������ݶ�ȡ�Ķ���,֪����ip��option�ֶ���ʲô��
��ʼ�������ֵ
/* generate a timestamp */
/*GetTime(pip.timestamp);*/
/* start filling in the printout data structures */
strncpy(pip.saddr, inet_ntoa(iph->ip_src), 15);//���︴����15λΪʲô��15λ��,��Ϊ
//���һλ������,�㶨Ϊ0 IP���ܳ�(Total Length):����16����
strncpy(pip.daddr, inet_ntoa(iph->ip_dst), 15);
net.sip = iph->ip_src.s_addr;//Դ��ַ
net.dip = iph->ip_dst.s_addr;//Ŀ�ĵ�
pip.ttl = iph->ip_ttl;//����ʱ��
pip.tos = iph->ip_tos;//������|||||
|||||
vvvv
/* check for fragmented packets */
ip_len -= hlen;
pip.frag_off = ntohs(iph->ip_off);
TOS
ToS��Ϊ��������,ֻ�е������豸�ܹ�֧��(�ܹ�ʶ��IP�ײ��е�ToS�ֶ�)ʶ��ToS�ֶ�ʱ,����ֶ����ò������塣�����ǿ�̸��
��˵�����ֶε�����:
Tos�ֶγ���Ϊ8bit
pip.ip_df = (pip.frag_off & 0x4000) >> 14;df���Ƿ����÷�Ƭ//��������0x4000����������14λ,
pip.ip_mf = (pip.frag_off & 0x2000) >> 13;
/** more fragment,��IP���ݱ���FLAGS�еķ�Ƭ��־λ,λ��IP���ݱ��еĵ�50����λ,��ΪMF��DF(DFΪ��49λ,��48λ��δʹ��,��ʵ������),MF��ʾmore fragment�����з�Ƭ,DF��ʾdon't fragment��û�з�Ƭ��
more fragment,��IP���ݱ���FLAGS�еķ�Ƭ��־λ,��ΪMF��DF,MF��ʾmore fragment�����з�Ƭ,DF��ʾdont't fragment��û�з�Ƭ��*/
pip.frag_off &= 0x1FFF;12+1�����
pip.frag_id = ntohs(iph->ip_id);
if(pip.frag_off == 0)
//����û�з�Ƭ
{
#ifdef DEBUG
printf("IP header length: %d\n", hlen);
#endif
/* move the packet index to point to the transport layer */
pktidx = pktidx + hlen;
switch(iph->ip_proto)
{
//������
case IPPROTO_TCP:
net.proto = IPPROTO_TCP;
strncpy(pip.proto, "TCP", 3);
DecodeTCP(pktidx, len-hlen);
return;
case IPPROTO_UDP:
net.proto = IPPROTO_UDP;
strncpy(pip.proto, "UDP", 3);
DecodeUDP(pktidx, len-hlen);
return;
case IPPROTO_ICMP:
net.proto = IPPROTO_ICMP;
strncpy(pip.proto, "ICMP", 4);
DecodeICMP(pktidx, len-hlen);
return;
default:
return;
}
}
else
{
switch(iph->ip_proto)
{
case IPPROTO_TCP:
net.proto = IPPROTO_TCP;
strncpy(pip.proto, "TCP", 3);
break;
case IPPROTO_UDP:
net.proto = IPPROTO_UDP;
strncpy(pip.proto, "UDP", 3);
break;
case IPPROTO_ICMP:
net.proto = IPPROTO_ICMP;
strncpy(pip.proto, "ICMP", 4);
break;
default:
net.proto = IPPROTO_ICMP;
strncpy(pip.proto, "UNK", 3);
break;
}
/* move the packet index to point to the transport layer */
pktidx = pktidx + hlen;
pip.data = pktidx;
pip.dsize = len - hlen;
if(pv.verbose_flag)
{
PrintIPPkt(stdout, net.proto);
}
if(pv.log_flag)
{
OpenLogFile(0);
PrintIPPkt(log_ptr, net.proto);
fclose(log_ptr);
}
}
ip�����IJ����,��ʼ��udp,tcp,icmp��ump�Ľ�����,���������ip��ͷ
С��,ѧϰ��ip��Э��,��ipͷ�������˽��ˡ�
���濪ʼ1.5����
ps:����source insign�Ѿ�������������ѡ�����µ�Դ��忨������,�����õ���sourcetrail
���ȿ϶��Ǵ�snort.c�ļ���ʼ����
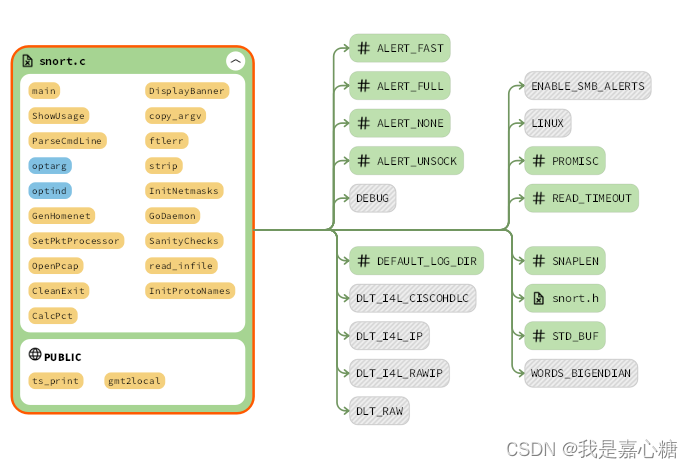
snort.c�Ľṹ��������,���Ǿʹ�main������ʼ��
��һ���dz�ʼ�����ֲ���,������������ĵ���,����netmask protonames��
signal(SIGKILL, CleanExit);
signal(SIGTERM, CleanExit);
signal(SIGINT, CleanExit);
signal(SIGQUIT, CleanExit);
signal(SIGHUP, CleanExit);
/* set a global ptr to the program name so other functions can tell
what the program name is */
progname = argv[0];
InitNetmasks();
InitProtoNames();
/*
InitPreprocessors();
DumpPreprocessors();
InitPlugIns();
DumpPlugIns();
*/
/* initialize the packet counter to loop forever */
pv.pkt_cnt = -1;
/* set the default alert mode */
pv.alert_mode = ALERT_FULL;
/* set the timezone (ripped from tcpdump) */
thiszone = gmt2local(0);
�ڶ������Ǵ���ָ���ParseCmdLine(argc, argv);
�������������1.0��ʱ���Ѿ�������,���ǰѴ������IJ������д���,Ȼ���ɸ�ʽ���IJ�������������ʹ��,���������������snort.c���洴����,���Կ��ԽӴ��������ȫ�ֱ���,�����Ļ���Ϊ�����Ĵ����ṩ����
ͬʱ������������Դ�һ��ѭ��,������������ָֹ���ʱ���һֱ����
�ڴ�����ָ���Ժ����һ����ĺϷ��Լ��鰡ʲô��
if(pv.use_rules || pv.log_flag)
{
/* perform some sanity checks on the output directory, etc*/
SanityChecks();
}
if(!pv.logbin_flag)
{
if(!pv.nolog_flag)
LogFunc = LogPkt;
else
LogFunc = NoLog;
}
if(pv.use_rules && pv.rules_order_flag)
{
printf("Rule application order changed to Pass->Alert->Log\n");
}
if(!pv.use_rules && !pv.verbose_flag && !pv.log_flag)
{
printf("\n\nUh, you need to tell me to do something....\n\n");
ShowUsage(progname);
exit(0);
}
if(pv.syslog_flag)
{
AlertFunc = SyslogAlert;
}
else if(pv.smbmsg_flag)
{
#ifdef ENABLE_SMB_ALERTS
AlertFunc = SmbAlert;
#else
fprintf(stderr, "ERROR: SMB support not compiled into program, exiting...\n");
exit(1);
#endif
}
else
/* Tell 'em who wrote it, and what "it" is */
DisplayBanner();
���ﻹ��һ����ɵ�Ĵ���,������github�����ĸ����ˮ�����д��hhh,�ص�д�˸�ֻ��һ�еĺ���
���������ǿ�ʼ�����ոմ����ָ���ˡ�int OpenPcap(char *intf)
if(!pv.readmode_flag)
{
/* open up our libpcap packet capture interface */
OpenPcap(pv.interface);
}
else
{
OpenPcap(pv.readfile);
}
�����pv���Ѿ�������������,������������ɵ�ģʽ,���openpcap��1.0�汾��Ӧ���Ǵ�ͬС��,���ǿ�ʼץ��,��������ѡ������ĸ��ӿ�
libpcap

libpcapʹ�����̽���csdn
��������һ���ӿڽ�����̽,��eth0������Ҳ������һ���ַ�������������豸��
��ʼ��pcap��ʹ���ļ����������Ҫ��̽���豸��ͬʱ֧�ֶ���豸����̽��
����BPF. ����һ������,���벢��ʹ������������̷�Ϊ������:
1.���ϱ�����һ���ַ�����,���ұ�ת�����ܱ�pcap���ĸ�ʽ��
2.����ù���(���ǵ���һ�������ⲿ����ʹ�õĺ���)��
3.����pcapʹ�������������ݰ���
pcap����������ѭ�������������pcapһֱ������������������������Ҫ�İ�Ϊֹ��ÿ�����յ�һ����(���߶�����ݰ�)�͵�����һ���Ѿ�����õĺ���,�������������������Ҫ���κι���,�������������������ϲ�Э����Ϣ�����û���ӡ�����,�����Խ��������Ϊһ���ļ�,����ʲôҲ������
����̽����������ݺ�,����Ҫ�رջỰ��������
���IJ����� SetPktProcessor();
��һ����������Ϣ�������� һ�������ֵ���̬
DLT_EN10MB
grinder = (pcap_handler) DecodeEthPkt;
DLT_IEEE802
grinder = (pcap_handler) DecodeTRPkt;
DLT_SLIP
grinder = (pcap_handler) DecodeSlipPkt;
DLT_PPP
grinder = (pcap_handler) DecodePppPkt;
DLT_NULL
grinder = (pcap_handler) DecodeNullPkt;
����һ����������̬,grinder����˼����ĥ��е; ĥ����; ĥ��; ĥ��;,��������Ǵ�������ʹ�õķ���,Ȼ������ǿ������ת��,�ټ�����Ҫ������,����е�����������̵ķ���,(pcap_handler)��һ���ӿ�,Ȼ���ڵ��������ʱ��,ʵ�ʵ��õ���ʵ��������ʵ�ʷ���
�����Ͳ�ϸ˵��,�����еķ����Ѿ���1.0�ʹ����ˡ�
���岽����pcap_loop
if(pcap_loop(pd, pv.pkt_cnt, grinder, NULL) < 0)
{
if(pv.daemon_flag)
syslog(LOG_CONS|LOG_DAEMON,"pcap_loop: %s", pcap_geterr(pd));
else
fprintf(stderr, "pcap_loop: %s", pcap_geterr(pd))
CleanExit();
}
������һ��c����ԭ����һ��������ķ���
��������:int pcap_loop(pcap_t * p,int cnt, pcap_handler callback, uchar * user);
��������:�������ݰ�,������Ӧpcap_open_live()�������õij�ʱʱ��
����˵��:p ����pcap_open_live()���ص������������ָ��;cnt�����������������ݰ��ĸ���;pcap_handler ����void packet_handler()ʹ�õ�һ������,���ص�����������;userֵһ��ΪNULL
pcap_loopԭ����pcap_loop(pcap_t *p,int cnt,pcap_handler callback,u_char *user)
���е�һ��������winpcap�ľ��,�ڶ�����ָ����������ݰ�����,���Ϊ-1������ѭ�������ĸ�����user�������û�ʹ�õġ��������ǻص�������ԭ������:
pcap_callback(u_char* argument,const struct pcap_pkthdr* packet_header,const u_char* packet_content)
���в���packet_content��ʾ�IJ������ݰ������ݲ���argument�ǴӺ���pcap_loop()���ݹ����ġ�
ע��:����IJ�������ָ pcap_loop�е� *user ��������
pcap_pkthdr ��ʾ�������ݰ�������Ϣ,����ʱ��,���ȵ���Ϣ.
����:�ص�����������ȫ�ֺ�����̬����,�����Ĭ��,
�����ĸ������ĸ�ֵ�����
pd->winpcap�ľ��
/* get the device file descriptor,�������ӿ� */
pd = pcap_open_live(pv.interface, snaplen,
pv.promisc_flag ? PROMISC : 0, READ_TIMEOUT, errorbuf);
����
/* open the file,���ļ� */
pd = pcap_open_offline(intf, errorbuf);
cnt->���ĸ���
/* initialize the packet counter to loop forever */
pv.pkt_cnt = -1;
������������������Ҫ���İ���������ǰ��ParseCmdLine(����������)�����ĵ�����,��������n,�����趨pv.pkt_cnt��ֵ��ParseCmdLine������������:
case 'n': /* grab x packets and exit */
pv.pkt_cnt = atoi(optarg);
�ܽ�:�ں����,main���������Ϻ�1.0ûʲô����
�������й���snort�Ĺ��������

�������ȷ���snort.h�����и�ȫ�ֱ�����use_rules,������6����������,��������Ǹ�int���͵ı���,Ҳ����˵��������϶����Ƿ�ʹ�ù����й�,��ô��ͼ����,���Դ������6�����õĵط���֪��������йص���ϸ�����á�


����DecodeIcmp(decode.c)
�������DecodeIcmp�����õ�ʱ��Ӧ����֮ǰ��grinder����ķ���,���Զ�����loop���汻����
�����ǹؼ�����
����ֱ�ӿ�������ifelse���,pv.use_rules�����,Ϊ1�Ļ��ͻ�ִ��Preprocess������
���������Ԥ������
if(!pv.use_rules)
{
if(pv.log_flag)
{
if(pv.logbin_flag)
LogBin(p);
else
LogPkt(p);
}
}else
{
Preprocess(p);
}
����Preprocess����

void Preprocess(Packet *p)
{
PreprocessFuncNode *idx;
do_detect = 1;
idx = PreprocessList;
while(idx != NULL)
{
idx->func(p);
idx = idx->next;
}
if(!p->frag_flag && do_detect)
{
Detect(p);
}
}
��������һ��ɨ��ȥ�и�->�ķ���,���һ�������next,Node�������,��ô�Զ�������һ��������������,�������˼·�����ٶ�PreprocessFuncNode������͵ķ����ͻ���ͷ����,
��������һ������,Ϊʲô��ʹ��������,����Ϊ����Ϊ����������һ����ˮ��һ���IJ���,���������Խṹ��,Ϊ�˷�����ɾ,�����ڴ������,����ʽ�������DZȽϺõķ���,�������������������,,
������idx���ָ��,����������ʹ�õ�,������¼��ǰָ��ĵط�������,��ָ���preprocesslist�����һ��ȫ�ֱ���,�ڱ�ĵط�����ֵ,���澭���ŵ���һ�������ı���,ÿ�ζ������һ��func�������,��packet p �����в���,����������func��ô��
��preprocessList�����
�����������Ǹ�funcNode�Ľṹ������
typedef struct _PreprocessFuncNode
{
void (*func)(Packet *);
struct _PreprocessFuncNode *next;
} PreprocessFuncNode;
��������ŷ���ֵΪvoid��һ����func����Packet������һ������,������һ���ڵ㡣
������;��������洢�����ڵ�ġ�
����������������������ﱻ����

һ����addFuncToPreprocList�ķ���,һ����Preprocess����,��һ��������,�ڶ�����ʵʩ��
����������������
�������һ������ͨͨ���������ӵķ�����,�����ǿյĻ��ʹ���ͷ,calloc��һ�ο���,֮ǰ������malloc��,malloc��calloc��������:
��Ҫ�IJ�ͬ��malloc����ʼ��������ڴ�,calloc��ʼ���ѷ�����ڴ�Ϊ0��
��Ҫ�IJ�ͬ��calloc���ص���һ������,��malloc���ص���һ������
calloc����malloc����memset�ܿ���calloc�ڲ�����һ��malloc����һ��memset��0��
����malloc��calloc����Ч.
void AddFuncToPreprocList(void (*func)(Packet *))
{
PreprocessFuncNode *idx;
idx = PreprocessList;
if(idx == NULL)
{
PreprocessList = (PreprocessFuncNode *) calloc(sizeof(PreprocessFuncNode), sizeof(char));
PreprocessList->func = func;
}
else
{
while(idx->next != NULL)
idx = idx->next;
idx->next = (PreprocessFuncNode *) calloc(sizeof(PreprocessFuncNode), sizeof(char));
idx = idx->next;
idx->func = func;
}
return;
}

������������������ط�����
HttpDecodeInit(u_char *args)�ķ��� ������spp_http_decode.c
�����������һ���ַ���
�ܽ�
Snort�����ǻ����ı���,��ͨ��������Snort����Ŀ¼�л�����Ŀ¼�С���������ʱ��,Snort��ȡ���еĹ����ļ�,���ҽ���һ����ά��������Snortʹ���б�ƥ����ͼ�⡣
1���������:
Snort������Snort���ּ��ϵͳ����Ҫ��ɲ��֡�������snort�Ĺ����ؿ�,ÿ������Ӧһ����������,snortͨ������ʶ����Ϊ��
ÿһ���������������:����ͷ��(RuleHeader)����ѡ��(RuleOption)������ͷ�����������Ϊ��Э�顢Դ��ַ��Ŀ�ĵ�ַ���������롢Դ��Ŀ�Ķ˿���Ϣ������ѡ�����������Ϣ�Լ�����ʱ�ṩ������Ա�IJο���Ϣ������: alerttcpanyany->202.203.112.0/24any(content:��proxy-connection��;msg:��proxyuse��😉 ������������Ϣ��:���κη���202.203.112����,tcp�����к���proxy-connection�����������������������,������ǰ���ǹ���ͷ��Բ�����ڵ������ǹ���ѡ��,�ڹ���ѡ����,content���������Ϊ�ؼ���,����Ҫƥ����ַ���,msg���������Ϊ����ʱ����ʾ����Ϣ��Snort�Ĺ������п���û�й�����,����ֻ���������õض�����Ҫ���е�ij�ִ���(��¼�����������Ե�)�����ݰ����͡�ֻ�е������е�ÿһ��Ԫ�ض�Ϊ��ʱ,���ܴ�����Ӧ�Ĺ�������
2���������:
Snort�Ѿ�����ͬ�����Ĺ������ӵ�һ��������,��RTN�ṹ������;����ѡ���Ӧ�ڹ���ѡ����OTN(OptionalTreeNode),����һЩ�ض��ļ���־��������Ϣ��ƥ�����ݵ�����,ÿ��ѡ���ƥ���Ӻ���(���)�ŵ�FUNC�����С�ֻ�е�����ĸ���������Ϊ��ʱ�Ŵ�����Ӧ�IJ�����
Snort��������ʱ,�ֱ�����TCP��UDP��ICMP��IP��4����ͬ�Ĺ�����,ÿһ��������������������ά����:RTN(����ͷ),OTN(����ѡ��)��FUNC(ָ��ƥ���Ӻ�����ָ��)�� ��Snort����һ�����ݱ�ʱ,���ȶ������,Ȼ�����Ԥ����,�����ù����������ݱ�����ƥ�䡣�ڹ�����ƥ�������:���ݸ����ݱ���IPЭ��������ĸ�����������ƥ��;Ȼ����RTN������ν���ƥ��,����ij������ͷ��ƥ��ʱ,����������OTN������ƥ�䡣ÿ��OTN��㶼������һ�������ȫ��ѡ��,��������һ�麯��ָ���������ʵ�ֶ���Щ������ƥ�������������֪���ݱ���ij��OTN�����������������ʱ,���жϴ����ݱ�Ϊ�������ġ�
Ϊ��߹���ƥ����ٶ�,Snort������Boyer-Moore�ַ���ƥ���㷨����ά�б��ݹ����(RTN��OTN)�Լ�����ָ���б�(��Ϊ����ά�б���)�ȷ�����
snort��������

������:
ץ������������ȡ���ݰ�����������ģ��,����������˱�������־�¼�,��ô���ݾͷ�����Ӧ������������������Ԥ��������ץ������ִ����֮�����Snort��������־��ϵͳʱִ�С�
Snort�������Ĺ��ܿ��Է�Ϊ7������:��Ȩ��ͷ��Ϣ;ͷ�ļ���������ϵ��ȫ�ֱ���;�ؼ���ע��;���������ͺ����б���;���ݴ���,��ʽ���ʹ洢;����Ԥ����������;�������˳���������ϸ��������ĸ����ܡ�
1����Ȩ��ͷ��Ϣ�ִ��ÿһ�������������������İ�Ȩ��Ϣ,��Ȩ��Ϣ�����ɲ���������������ӡ������ͷ��ϸ�����˲������;,��Ҫ�IJ���������Լ�����ע�͡�
2��ͷ�ļ�,������ϵ��ȫ�ֱ����;���Ӧ�ö���,�ļ��Լ�����֮���������ϵ�Գ���������Ҫ,����Ҫ�������⡣ȫ�ֱ���������������κβ��ֶ�����ʹ�á�
3���ؼ���ע��������ͨ�������ļ������������ú͵��á��û�����Ϊ�������ؼ��ֲ��Ѹùؼ������ӵ�Snort,�Ա�����ùؼ���ʱ����Ӧ���������
4�����������ͺ����б����ֲ��������ʱ��Ҫ���ݲ���,����б�ҪдһЩ������������Щ���ݡ�����,��ʹ����־����ʱ,������Ҫָ��һ�����ڴ洢��־����־�ļ��������˷�������,�������������Snort�������ڵĺ�����
5�����ݴ�������ʽ���ʹ洢���ݴ�������ʽ���ʹ洢�Dz������Ҫ�Ĺ���,������ô˵,���û�����ݴ�������ʽ���ʹ洢��Щ����,�������Ͳ�����,û���á�
6������Ԥ��������������Ԥ��������������ʱ,����д���ݴ���������������Щ����,�����ڷ�����ʼ֮ǰ,Snort����������������Ԥ��������Ԫ��
7���������˳�,�ھ�����������,��Ҫ�ڲ���а��������ڴ桢Ӧ�������Լ������ֵ��˳���������,�����������Snort��ִ��Ч�ʡ� Snort�ܹ�ʹ�����������㱨�ͱ�ʾ����,Snort֧�ֶ�����־��ʽ,����ֱ�ӵ��ı�ͷ��PCAP��UNIXsyslog��XML�ı����ݿ�Ͷ��ֹ�ϵ���ݿ�,��Щ������ʹ�ñ�������־�Ը������ĸ�ʽ�ͱ�����ʽ���ָ�����Ա�����û�����������������洢��ʽ������,������������������û���κ�����ġ�
������ʹ��Snort�����û��ṩ��ʽ�����ʱ��������������Snort�ı����ͼ�¼��ϵͳ������ʱ����,��Ԥ������̽������֮�����ļ���ָ��ĸ�ʽ�dz�������Ԥ��������
��ʽ:
output:
����:
output alert_syslog:LOG_AUTHLOG_ALERT
�ܽ�
1.5�汾�����1.0�汾�����������,��һ����Ԥ���������,�ڶ����Ǵ��������
������������÷ֱ���:
Ԥ���������ģ��
�����ݰ�����������֮ǰ, �������ȱ�����Ԥ������ , ��Ҫ�������ݰ����� Snort���������ǰ�ṩһ���������������ݰ��������ݰ��ĵط���Ԥ��������ɵĹ�����Ҫ��:�ٰ�����, ��ɽ�������е����ݽ��кϲ��Ĺ���, �� TCP�������� (stream4)�� IP ��Ƭ������ (frag2);��Э�����淶��, Snort��������Э����뼰�淶�����, �ֱ�� Telne t��HTTP�� RPC Э����д���;���쳣���, ������һ��Ĺ����ֵĹ������м��, ���߽���Э���쳣���, ��˿�ɨ������Back Orifice�������;�� Snort.conf�ļ��м���preprocessor �Ϳ������������Ԥ��������
�������ģ��
�����ӡ������ͷ��ϸ�����˲������;,��Ҫ�IJ���������Լ�����ע�͡�
2��ͷ�ļ�,������ϵ��ȫ�ֱ����;���Ӧ�ö���,�ļ��Լ�����֮���������ϵ�Գ���������Ҫ,����Ҫ�������⡣ȫ�ֱ���������������κβ��ֶ�����ʹ�á�
3���ؼ���ע��������ͨ�������ļ������������ú͵��á��û�����Ϊ�������ؼ��ֲ��Ѹùؼ������ӵ�Snort,�Ա�����ùؼ���ʱ����Ӧ���������
4�����������ͺ����б����ֲ��������ʱ��Ҫ���ݲ���,����б�ҪдһЩ������������Щ���ݡ�����,��ʹ����־����ʱ,������Ҫָ��һ�����ڴ洢��־����־�ļ��������˷�������,�������������Snort�������ڵĺ�����
5�����ݴ�������ʽ���ʹ洢���ݴ�������ʽ���ʹ洢�Dz������Ҫ�Ĺ���,������ô˵,���û�����ݴ�������ʽ���ʹ洢��Щ����,�������Ͳ�����,û���á�
6������Ԥ��������������Ԥ��������������ʱ,����д���ݴ���������������Щ����,�����ڷ�����ʼ֮ǰ,Snort����������������Ԥ��������Ԫ��
7���������˳�,�ھ�����������,��Ҫ�ڲ���а��������ڴ桢Ӧ�������Լ������ֵ��˳���������,�����������Snort��ִ��Ч�ʡ� Snort�ܹ�ʹ�����������㱨�ͱ�ʾ����,Snort֧�ֶ�����־��ʽ,����ֱ�ӵ��ı�ͷ��PCAP��UNIXsyslog��XML�ı����ݿ�Ͷ��ֹ�ϵ���ݿ�,��Щ������ʹ�ñ�������־�Ը������ĸ�ʽ�ͱ�����ʽ���ָ�����Ա�����û�����������������洢��ʽ������,������������������û���κ�����ġ�
������ʹ��Snort�����û��ṩ��ʽ�����ʱ��������������Snort�ı����ͼ�¼��ϵͳ������ʱ����,��Ԥ������̽������֮�����ļ���ָ��ĸ�ʽ�dz�������Ԥ��������
��ʽ:
output:
����:
output alert_syslog:LOG_AUTHLOG_ALERT
�ܽ�
1.5�汾�����1.0�汾�����������,��һ����Ԥ���������,�ڶ����Ǵ��������
������������÷ֱ���:
Ԥ���������ģ��
�����ݰ�����������֮ǰ, �������ȱ�����Ԥ������ , ��Ҫ�������ݰ����� Snort���������ǰ�ṩһ���������������ݰ��������ݰ��ĵط���Ԥ��������ɵĹ�����Ҫ��:�ٰ�����, ��ɽ�������е����ݽ��кϲ��Ĺ���, �� TCP�������� (stream4)�� IP ��Ƭ������ (frag2);��Э�����淶��, Snort��������Э����뼰�淶�����, �ֱ�� Telne t��HTTP�� RPC Э����д���;���쳣���, ������һ��Ĺ����ֵĹ������м��, ���߽���Э���쳣���, ��˿�ɨ������Back Orifice�������;�� Snort.conf�ļ��м���preprocessor �Ϳ������������Ԥ��������
�������ģ��
��������ڹ���ƥ��ε� ParseRleOptions����(�� rule. c��)�б�����, ������ɻ��ڹ����ƥ����̡� ÿ������������ͨ����Ӧ����ѡ���е�һ���ؼ���, ʵ�ֶ�����ؼ��ֵĽ���, ��Ҫ����Ϊ:�ټ��Э����ֶ�,��TCPF lag�� ICMPType�� IPId ��;�ڸ�������, ��Ự��¼��������Ӧ���ر����ӵȡ�