新手 ansible 入门教程
why ansible?
Ansible作为最受欢迎的自动化配置工具,主要得益于其设计上的优势。
1、无需客户端。与Chef、Puppet以及Saltstack(现在也支持Agentless方式salt-ssh)不同,Ansible是无客户端Agent的,所以无需在客户机上安装或配置任何程序,就可以运行Ansible任务。由于Ansible不会在客户机上安装任何软件或运行监听程序,因此消除了许多管理开销,我们可以在即可上手使用Ansible管理服务器,同时Ansible的更新也不会影响任何客户机。
2、使用SSH进行通讯
默认情况下,Ansible使用SSH协议在管理机和客户机之间进行通信。可以使用SFTP与客户机进行安全的文件传输。
3、并行执行
Ansible与客户机并行通信,可以更快地运行自动化任务。默认情况下,forks值为5,可以按需,在配置文件中增大该值。
安装 ansible
Ansible可以运行在任何机器上,但是对管理机有一定要求。管理机应安装Python 2(2.7)或Python 3(3.5或更高版本),另外,管理机不支持Windows控制节点。我们可以使用Linux发行版包管理器、源码安装或者Python包管理器(PIP)来安装Ansible。
我使用的是 CentOS7。
1、配置EPEL YUM
2、yum install ansible -y #yum安装最新版
3、ansible --version #安装后查看版本以及模块路径等信息
配置证书登录
为了使Ansible与客户端通信,需要使用用户帐户配置管理机和客户机。为了方便快捷安全,一般会配置证书方式连接客户机。
在所有客户机和管理上创建新的ansible用户之后,我们在管理机(ansible用户)生成SSH密钥,然后将SSH公钥复制到所有客户机。
ssh-keygen
三个回车,要是想后面执行一条命令就要输入一次 ssh 密码的话也可以给它个密码。
现在,将SSH公钥复制到所有客户机,这使管理机ansible用户无需输入密码即可登录客户机:
ssh-copy-id -i ~/.ssh/id_rsa.pub 远程主机名@远程主机ip
Ansible 配置文件
1、/etc/ansible/hosts:主机列表清单,也叫Inventory。在大规模的配置管理工作中,特别是云服务提供商或者IDC厂家,需要管理不同业务的不同机器,这些机器的信息都存放在Ansible的inventory组件里面。在我们使用Ansible进行远程主机管理时,必须先将主机信息存放在inventory里面,这样才能使用Ansible对它进行操作。如果不想使用默认清单的话可以用-i选项指定自定义的清单文件,防止多人混合使用一个主机清单。如果没有定义在主机列表文件中,执行命令会提示“No hosts matched”
2、/etc/ansible/ansible.cfg:Ansible服务主配置文件,比如并发数控制等在此文件定义
Inventory 定义方法
方法一:将主机IP、端口、用户名、密码写在配置文件的不同组中,多种写法格式如下
vim /etc/ansible/hosts
[webserver] #组名为webserver
192.168.1.31 ansible_ssh_port=22 ansible_ssh_user=root ansible_ssh_pass="123456"
192.168.1.32 ansible_ssh_port=22 ansible_ssh_user=root ansible_ssh_pass="123456"
192.168.1.33 ansible_ssh_port=22 ansible_ssh_user=root ansible_ssh_pass="123456"
192.168.1.36 ansible_ssh_port=22 ansible_ssh_user=root ansible_ssh_pass="123456"
[dbserver] #组名为dbserver
192.168.1.4[1:3] ansible_ssh_port=22 ansible_ssh_user=root ansible_ssh_pass="123456" #连续IP的简写
[redis]
192.168.1.5[1:3]
[redisserver:vars] #将信息定义为变量
ansible_ssh_pass="123456"
[nginx] #推荐写法
nginx_1 ansible_ssh_host=192.168.1.61 ansible_ssh_port=22 ansible_ssh_user=root ansible_ssh_pass="123456"
nginx_2 ansible_ssh_host=192.168.1.62 ansible_ssh_port=22 ansible_ssh_user=root ansible_ssh_pass="123456"
方法二:基于秘钥管理
#管理端创建秘钥并发送到每个被管理端
ssh-keygen
ssh-copy-id -i $被管理端IP
#管理端清单文件
vim /etc/ansible/hosts
[webserver] #做好秘钥的机器只用写IP即可
192.168.1.31:22
192.168.1.32
192.168.1.33
192.168.1.36
[dbserver] #也可以通过别名方式进行配置
node1 ansible_ssh_host=192.168.1.31 ansible_ssh_port=22
node2 ansible_ssh_host=192.168.1.32 ansible_ssh_port=22
node3 ansible_ssh_host=192.168.1.33 ansible_ssh_port=22
事实证明这就是段费话,照样要 ssh 的密码。推荐用方法一中的推荐写法。
方法三:自定义Inventory清单文件
#创建清单文件
vim /etc/ansible/dockers
[dockers]
192.168.1.31 ansible_ssh_pass='123456'
192.168.1.32
192.168.1.33
#使用-i指定清单文件
ansible dockers -m ping -i /etc/dockers
Inventory内置参数
| 参数名 | 参数含义 | 示例 |
|---|---|---|
| ansible_ssh_host | 定义host ssh地址 | ansible_ssh_host=10.132.42.1.117 |
| ansible_ssh_port | 定义hots ssh端口 | ansible_ssh_port=3009 |
| ansible_ssh_user | 定义hosts ssh 认证用户 | ansible_ssh_user=michael |
| ansible_ssh_pass | 定义hosts ssh认证密码 | ansible_ssh_pass=root123 |
| ansible_sudo | 定义hosts sudo的用户 | ansible_sudo=michael |
| ansible_sudo_pass | 定义hosts sudo密码 | ansible_sudo_pass=“12345” |
| ansible_sudo_exe | 定义hosts sudo 路径 | ansible_sudo_exe=/usr/bin/sudo密码 |
| ansible_ssh_private_key_file | 定义hosts私钥 | ansible_ssh_private_key_file=/root/key |
| ansible_shell_type | 定义hosts shell类型 | ansible_shell_type=bash |
| ansible_python_interpreter | 定义hosts任务执行python的路径 | ansible_python_interpreter=/usr/bin/python2.7 |
| ansible_interpreter | 定义hosts其他语言解析器路径 | ansible_interpreter=/usr/bin/ruby |
动态inventory
上面也说到了,对于那些云服务提供商或者IDC厂家会有大量的主机列表;如果手动维护这些列表将是一个非常繁琐的事情。其实Ansible是支持动态的inventory的,动态inventory就是Ansible所有的inventory文件里面的主机列表和变量信息都是从外部拉取的。比如我们可以从CMDB系统和Zabbix监控系统拉取所有的主机信息,然后使用Ansible进行管理。这样一来我们就可以很方便的将Ansible与其它运维系统结合起来。关于引用动态inventory的功能配置起来是非常简单的;我们只需要把ansible.cfg文件中inventory的定义值改成一个执行脚本即可。这个脚本的内容不受任何编程语言限制,但是这个脚本使用参数时有一定的规范并且对脚本执行的结果也有要求。这个脚本需要支持两个参数:
--list或者-l:这个参数运行后会显示所有的主机以及主机组的信息(JSON格式);--host或者-H:这个参数后面需要指定一个host,运行结果会返回这台主机的所有信息(包括认证信息、主机变量等),也是JSON格式。
来看一个演示脚本:
#!/usr/bin/env python3
# -- coding:utf-8 --
import argparse
import json
def lists():
r = {}
h = ['192.168.1.2', '192.168.1.4']
hosts = {'hosts':h}
r['web'] = hosts
return json.dumps(r, indent=4)
def hosts(name):
r = {'ansible_ssh_user':'jelly', 'ansible_ssh_pass':'123456'}
return json.dumps(r)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('-l', '--list', help='hosts list', action='store_true')
parser.add_argument('-H', '--host', help='hosts vars')
args = vars(parser.parse_args())
if args['list']:
print(lists())
elif args['host']:
print(hosts(args['host']))
else:
parser.print_help()
接下来,我们先不修改ansible.cfg中的inventory配置,直接在命令行指定配置文件进行运行:
ansible -i inventoryDemo.py web -m ping
输出结果如下:
192.168.1.2 | SUCCESS => {
"changed": false,
"ping": "pong"
}
192.168.1.4 | SUCCESS => {
"changed": false,
"ping": "pong"
}
在生产环境,我们需要将ansible.cfg中的inventory配置指定为这个python脚本的路径,后续正常执行各个ansible命令即可,比如这样:
ansible web -m ping
ansible.cfg
在Ansible中,它的配置文件是一个名为ansible.cfg的配置文件,ansible.cfg配置文件是以ini格式存储配置数据的。但是ansible.cfg配置文件可以存放在不同的目录,但只有一个可用,在运行Ansible命令时,Ansible将会按照预先设定的顺序查找配置文件,检查到哪个就用哪个。Ansible预先设定的优先级顺序如下:
ANSIBLE_CFG:首先,Ansible命令会先检查环境变量,及这个环境变量将指向的配置文件;./ansible.cfg:其次,将会检查当前目录下的ansible.cfg配置文件;~/.ansible.cfg:再次,将会检查当前用户home目录下的.ansible.cfg配置文件;/etc/ansible/ansible.cfg:最后,将会检查在安装Ansible时自动生产的配置文件。
几乎所有的配置项都可以通过 Ansible 的 playbook 或环境变量来重新赋值,所以当你怎么都不知道这个变量在哪里定义的时候,不妨去看看环境变量里看看。建议使用~/.ansible.cfg作为配置文件使用,这样就可以实现每个用户都有自己独自的配置文件,不污染其它用户正常使用Ansible,同时也方便进行选项配置。
由于Ansible本身没有服务的概念,所以只要配置修改后配置将马上生效。
常用的配置选项
-
defaults配置
配置项 说明 默认值 inventory ansible inventory文件路径 /etc/ansible/hosts library ansible模块文件路径 /usr/share/my_modules/ remote_tmp ansible远程主机脚本临时存放目录 ~/.ansible/tmp local_tmp ansible管理节点脚本临时存放目录 ~/.ansible/tmp forks ansible执行并发数 5 poll_interval ansible异步任务查询间隔 15 sudo_user ansible sudo用户 root ask_sudo_pass 运行ansible是否提示输入sudo密码 True ask_pass 运行ansible是否提示输入密码 True transport ansible远程传输模式 smart remote_port 远程主机SSH端口 22 module_lang ansible模块运行默认语言环境 C gathering facts信息收集开关定义 smart roles_path ansible role存放路径 /etc/ansible/roles timeout ansible SSH连接超时时间 10 remote_user ansible远程认证用户 root log_path ansible日志记录文件 /var/log/ansible.log module_name ansible默认执行模块 command executable ansible命令执行shell /bin/sh hash_behaviour ansible主机变量重复处理方式 replace private_role_vars 默认情况下,角色中的变量将在全局变量范围中可见。 为了防止这种情况,可以启用以下选项,只有tasks的任务和handlers得任务可以看到角色变量 yes vault_password_file 指定vault密码文件路径 无 ansible_managed 定义的一个Jinja2变量,可以插入到Ansible配置模版系统生成的文件中 Ansible managed display_skipped_hosts 开启显示跳过的主机 True error_on_undefined_vars 开启错误,或者没有定义的变量 False action_plugins ansible action插件路径 无 cache_plugins ansible cache插件路径 无 callback_plugins ansible callback插件路径 无 connection_plugins ansible connection插件路径 无 lookup_plugins ansible lookup插件路径 无 inventory_plugins ansible inventory插件路径 无 vars_plugins ansible vars插件路径 无 filter_plugins ansible filter插件路径 无 terminal_plugins ansible terminal插件路径 无 strategy_plugins ansible strategy插件路径 无 fact_caching 定义ansible facts缓存方式 memory fact_caching_connection 定义ansible facts缓存路径 无 -
privilege_escalation配置
配置项 说明 默认值 become 是否开启become模式 True become_method 定义become方式 sudo become_user 定义become方式 root become_ask_pass 是否定义become提示密码 False
Andible 常用模块基本操作
这些常用的模块,就好比基本功,基本招式一样,我们需要掌握这些基本功,掌握这些基本招式。
ping 模块
ping是测试远程节点的SSH连接是否就绪的常用模块,但是它并不像Linux命令那样简单地ping一下远程节点,而是先检查能否通过SSH登陆远程节点,再检查其Python版本能否满足要求,如果都满足则会返回pong,表示成功。使用方式如下:
ansible web -m ping
ping无须任何参数。上述命令输出结果如下所示:
192.168.1.2 | SUCCESS => {
"changed": false,
"ping": "pong"
}
192.168.1.4 | SUCCESS => {
"changed": false,
"ping": "pong"
}
debug模块
打印输出信息,类似Linux上的echo命令。在后续的学习过程中,我们会经常用这个命令来调试我们写的playbook。
对于debug模块有两种用法。下面就对这两种用法都进行详细的总结。
-
通过参数msg定义打印的字符串
msg中可以嵌入变量,比如我先定义了以下的一个playbook。--- - hosts: web vars: name: jellythink tasks: - name: display debug: msg="I am {{name}}" -
通过参数var定义需要打印的变量
变量可以是系统变量,也可以是动态的执行结果,通过关键字register注入变量中。对于变量,我们可以这样玩:
---
- hosts: web
vars:
name: jellythink
tasks:
- name: display
debug:
var: name
对于注入变量,可以这样玩:
---
- hosts: web
tasks:
- name: register var
shell: hostname
register: result
- name: display
debug:
var: result
copy模块
从当前的机器上复制静态文件到远程节点上,并且设置合理的文件权限。copy模块在复制文件的时候,会先比较一下文件的 checksum,如果相同则不会复制,返回状态为 OK;如果不同才会复制,返回状态为 changed。
一般情况的使用,就是这样的:
---
- hosts: server1
tasks:
- name: copyDemo
copy:
src: /home/jelly/nameList.txt
dest: /home/test1/nameList.txt
在实际的工作中,一般会在进行文件分发时,需要备份原文件,这个时候就需要我们加上backup选项:
---
- hosts: server1
tasks:
- name: copyDemo
copy:
src: /home/jelly/nameList.txt
dest: /home/test1/nameList.txt
backup: yes
加上backup: yes后,在目标主机上,就会对原来的文件进行备份,比如这样子的备份文件:
nameList.txt.8648.2019-09-28@06:27:18~
template模块
如果只是复制静态文件,使用copy模块就可以了;但是如果在复制的同时需要根据实际情况修改部分内容,那么就需要用到template模块了。
比如我们在分发配置文件时,每个配置文件需要根据远程主机的一些属性不同而配置不同的值,对于需要替换的部分,我们就可以使用template模块来进行替换。template模块使用的是Python中的Jinja2模板引擎,这里我们不需要过多的去关注这个模板引擎,只需要知道变量的表示法是{{}}就可以了。比如这里就有一个http.conf.j2的模板文件,文件内容如下:
Listen {{ansible_default_ipv4.address}}
Port {{http_port}}
其中{{ansible_default_ipv4.address}}就是需要根据不同的主机,动态变化的。接下来,我们就可以这样使用template模块来完成变量的替换。
---
- hosts: server1
vars:
http_port: 8080
tasks:
- name: Write Config File
template:
src: http.conf.j2
dest: /home/test1/http.conf
在目的主机上,文件内容如下:
Listen 192.168.1.3
Port 8080
和copy模块一样,template模块也可以进行权限设置和文件备份等功能。
file模块
file模块可以用来设置远程主机上的文件、软链接和文件夹的权限,也可以用来创建和删除它们。
我们可以使用mode参数进行权限修改,可以直接赋值数字权限(必须以0开头)。
---
- hosts: server1
tasks:
- name: Modify Mode
file:
path: /home/test1/http.conf
mode: 0777
我们还可以根据state参数的不同,实现不同的行为,比如创建软链接:
---
- hosts: server1
tasks:
- name: Create Soft Link
file:
src: /home/test1/http.conf
dest: /home/test1/conf
state: link
也可以设置state: touch创建一个新文件,比如这样:
---
- hosts: server1
tasks:
- name: Create a new file
file:
path: /home/test1/touchfile
state: touch
mode: 0700
还可以设置state: directory新建一个文件夹,比如这样:
---
- hosts: server1
tasks:
- name: Create directory
file:
path: /home/test1/testDir
state: directory
mode: 0755
user模块
user模块可以对用户进行管理,实现增、删、改Linux远程节点的用户账户。比如增加用户:
---
- hosts: server1
tasks:
- name: Add user
user:
name: test3
删除用户:
---
- hosts: server1
tasks:
- name: Add user
user:
name: test3
state: absent
remove: yes
但是在使用这个user模块时,需要注意权限问题。
shell模块
在远程节点上通过/bin/sh执行命令。如果一个命令可以通过模块yum、copy模块实现时,那么建议不要使用shell或者command这样通用的命令模块。因为通用的命令模块不会根据具体操作的特点进行状态判断,所以当没有必要再重新执行的时候,它还是会重新执行一遍。
-
支持
<、>、|、;和&--- - hosts: server1 tasks: - name: Test shell shell: echo "test1" > ~/testDir/test1 && echo "test2" > ~/testDir/test2 -
调用脚本
--- - hosts: server1 tasks: - shell: ~/test.sh >> somelog.txt在执行命令之前,我们可以改变工作目录,并且仅在文件somelog.txt不存在时执行命令,除此之外,还可以指定用bash运行命令:
--- - hosts: server1 tasks: - shell: ~/test.sh >> somelog.txt args: chdir: ~/testDir creates: somelog.txt executable: /bin/bash
command模块
在远程节点上执行命令。和shell模块类似,但不支持<、>、|、;和&等操作,其它的大抵都是相似的。
service/systemd
管理服务。
- name: 服务管理
service:
name: etcd
state: started
#state: stopped
#state: restarted
#state: reloaded
- name: 设置开机启动
service:
name: httpd
enabled: yes
- name: 服务管理
systemd:
name=etcd
state=restarted
enabled=yes
daemon_reload=yes
unarchive
- name: 解压
unarchive:
src=test.tar.gz
dest=/tmp
Ansible Ad-Hoc命令
虽然Ad-Hoc命令的功能没有playbook剧本那样强大,但是也足以满足我们工作中的很多场景。在Ansible中命令都是并发执行的,我们可以针对目标主机执行任何命令。默认的并发数目由ansible.cfg中的forks值来控制。当然了,我们也可以在运行Ansible命令的时候通过-f指定并发数。通过ansible -h命令就可以列出所有的命令参数,下面列举了常用的一些参数。
-v,--verbose:输出详细执行信息,-vvv可以得到执行过程中的所有信息;-i INVENTORY,--inventory=INVENTORY,--inventory-file=INVENTORY:指定inventory文件,默认使用/etc/ansible/hosts;-f FORKS,--forks=FORKS:执行时并发的线程个数,默认为5;-m MODULE_NAME:指定module,默认为command模块;-a MODULE_ARGS:指定module的参数;-o:精简输出内容;--list-hosts:列出主机列表,并不会执行其他操作。
ansible命令行语法格式:
ansible <host-pattern> [-f forks] [-m module_name] [-a args]
知道了这些选项,接下来我们就通过一些实际的命令操作来熟悉和理解Ansible Ad-Hoc。
ping模块
ping模块是我们经常使用的一个模块,我们经常会这样使用:
ansible server1 -m ping -o
输出内容如下:
192.168.1.3 | SUCCESS => {"changed": false,"ping": "pong"}
copy模块
前面是通过playbook的方式来学习copy模块的,这里通过Ansible Ad-Hoc再来熟悉一下。
ansible server1 -m copy -a 'src=/home/jelly/nameList.txt dest=/home/test1/nameList.txt backup=yes' -o
输出如下:
192.168.1.3 | CHANGED => {"changed": true,"checksum": "2cb17bce3b65b4168ec1472690e6c49028b5b73b","dest": "/home/test1/nameList.txt","gid": 1001,"group": "test1","md5sum": "39e0c6634669ec88003d6d92f50e879e","mode": "0664","owner": "test1","size": 7,"src": "/home/test1/.ansible/tmp/ansible-tmp-1569858467.3466117-143590544702277/source","state": "file","uid": 1001}
command模块
默认模块。让远端主机执行指定的命令,但不支持管道或者重定向。
ansible 192.168.44.130 -a 'date'
shell模块
shell模块是我们使用的最多的模块了。如果学会了Ansible,我想这个命令可能是你今后运维中会经常使用的命令了。为什么这么说呢?就是因为好用!!!
比如:
ansible server1 -m shell -a 'uname -ra' -o
输出如下:
192.168.1.3 | CHANGED | rc=0 | (stdout) Linux localhost.localdomain 3.10.0-957.el7.x86_64 #1 SMP Thu Nov 8 23:39:32 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
总而言之,言而总之,当你想在多台机器上执行某个命令时,不妨试一试这里说的这个方法哦!
cron模块
设置定时任务,其中有个state选项包含present、absent两个参数,分别代表增加和移除
ansible webserver -m cron -a 'minute="*/10" job="/bin/echo test" name="test cron job" '
ansible webserver -m cron -a 'hour="*/1" job="/usr/sbin/ntpdate 10.254.1.10" name="crontab from ansible" state=present'
user模块
管理用户,还有一个group模块用于管理组
ansible webserver -m user -a "name=mysql system=yes"
yum模块
安装程序包,远端主机需要先配置好正确的yum源
ansible -m yum -a 'name=httpd state=present'
name:指明要安装的程序包,可以带版本号,否则默认最新版本,多个安装包用逗号分隔
state:present代表安装,也是默认操作;absent是卸载;latest最新版本安装
copy模块
实现文件复制
ansible all -m copy -a 'src=/etc/fstab dest=/etc/fstab owner=root mode=640'
ansible all -m copy -a 'content="hello world" dest=/etc/fstab owner=root mode=640 backup=yes'
src=:定义本地源文件的路径
dset=:定义目标文件路径
content=:用该选项直接生成内容,替代src
backup=:如果目标路径存在同名文件,将自动备份该文件
这些模块在 ansible 中是通用的,所以有些在上一 part 写了这一 part 不一定写,不代表没有。
查看 ansible 模块帮助信息
1、通过ansible-doc -l命令可以显示当前版本所支持的模块信息

2、通过ansible-doc -s modulename显示指定模块的详细用法
ansible-doc -s yum


Ansible playbook
如果基于AD-Hoc去执行多任务(如安装Nginx、修改配置文件、启动服务),需要先使用yum或command模块安装程序,再使用copy模块复制配置文件,最后使用service模块启动服务。为了解决这种多任务繁琐的情况,可以使用Ansible的playbook(剧本)功能。
playbook 的构成
Inventory:主机列表,表示剧本中的任务要应用在哪些主机上
Tasks:具体任务,即调用哪些模块完成操作,可以配置多个任务
Variables:变量,包含内置变量和自定义变量
Templates:模板,即使用模板语法来灵活变更的配置文件
Handlers与notify:触发器,由某事件触发执行的操作,比如修改配置文件后自动重启服务
playbook本质是包含了一个或多个play的YAML配置文件,通常以.yaml或者.yml结尾。在单一的一个playbook文件中,使用连续的三个中横线(―)作为每个play的区分。
执行playbook命令
我们都是按照yaml语法规则来编写playbook。
Ansible提供了一个单独的命令:ansible-playbook命令,我们可以通过这个命令来执行yaml脚本。常见的ansible-playbook的使用方法如下:
最简单的使用方法:
ansible-playbook copyDemo.yaml
我们还可以使用以下命令查看输出的细节:
ansible-playbook copyDemo.yaml --verbose
我们也可以使用以下命令查看该yaml脚本将影响的主机列表:
ansible-playbook copyDemo.yaml --list-hosts
还可以使用以下命令检查yaml脚本语法是否正确:
ansible-playbook copyDemo.yaml --syntax-check
上面的几种使用方法基本就涵盖了我们日常工作中80%的场景了,剩余的20%场景,比如并行、异步等,很少用到,等真正用到的时候再去查阅相关资料也来的及。而工作中,更多的时候,我们不是在编写playbook,就是在编写playbook的路上。所以,接下来我重点说说如何写这个playbook,也就是playbook的基本语法。
任务控制
如果你有一个大的剧本,那么能够在不运行整个剧本的情况下运行特定部分可能会很有用。
tasks:
- name: 安装nginx最新版
yum: pkg=nginx state=latest
tags: install
- name: 写入nginx配置文件
template: src=/srv/httpd.j2 dest=/etc/nginx/nginx.conf
tags: config
使用:
ansible-playbook example.yml --tags "install"
ansible-playbook example.yml --tags "install,config"
ansible-playbook example.yml --skip-tags "install"
playbook基本语法
最基本的playbook脚本分为三个部分:
- 在哪些机器上以什么身份执行
- 执行的任务有哪些
- 善后任务有哪些
我们在编写playbook脚本的时候,总是离不开上面的三个部分的。下面先来一个稍微有点复杂的playbook脚本,让大家先有一个整体的认识。
---
- hosts: server1
user: root
vars:
http_port: 80
max_clients: 200
tasks:
- name: Write apache config file
template: src=/home/test1/httpd.j2 dest=/home/test2/httpd.conf
notify:
- restart apache
- name: Ensure apache is running
service: name=httpd state=started
handlers:
- name: restart apache
service: name=httpd state=restarted
现在就对上述三部分稍作详细总结。
主机和用户
上面的yaml脚本,我们一开始就会看到hosts、user和vars,其中vars在后面的文章进行专门总结。而这里的hosts和user就是表示我们这个yaml将要在哪些主机上用哪个用户身份去操作。而这里的深一层次的关系如下表所示:
| key | 含义 |
|---|---|
| hosts | 为主机的IP,或者主机组名,或者关键字all |
| user | 在远程以哪个身份执行 |
| become | 切换成其他用户身份执行,值为yes或者no |
| become_method | 与become一起使用,值可以为sudo/su等 |
| become_user | 与become一起使用,可以是root或者其它用户名 |
在实际工作中,如果我们不指定user时,则默认使用连接远程主机的用户进行操作,如果指定了执行用户而与ansible_ssh_user指定用户不一致时,则需要开启become操作,这里的become配置与ansible.cfg中配置将相互配合完成工作,yaml中的become优先级高于ansible.cfg中配置中的优先级。
任务列表
任务列表是整个playbook的核心,对于任务列表,我们首先需要知道以下三点内容:
- 任务是从上到下顺序执行的,如果中间发生错误,那么整个playbook会中止;
- 每一个任务都是对模块的一次调用,只是使用不同的参数和变量而已;
- 每一个任务最好有一个name属性,这样在执行yaml脚本时,可以看到执行进度信息。
对于任务的参数有两种不同的写法,我们在编写yaml脚本时,可以按照自己的喜好进行选择。
写法一:
- name: Write apache config file
template: src=/home/test1/httpd.j2 dest=/home/test2/httpd.conf
写法二:
- name: Write apache config file
template:
src: /home/test1/httpd.j2
dest: /home/test2/httpd.conf
这两种写法都是OK的,我一般喜欢第二种写法。
最后,对于任务我们还需要特别一个点,那就是任务的执行状态。我们在执行Ansible Ad-Hoc或者ansible-playbook的时候,在输出中都会有一个changed字段,比如:
192.168.1.3 : ok=2 changed=0 unreachable=0 failed=0
或者
192.168.1.3 : ok=2 changed=1 unreachable=0 failed=0
这里的这个changed就是任务的执行状态,但是它为什么一会是0,一会有是1呢?这就要说到Ansible中一个叫做“幂等性”的概念。
幂等性
幂等性是数学和计算机科学上一个常见的概念,多次执行产生的结果不会发生改变,这样的特性就被成为幂等性。
大多数的Ansible模块在设计时保证了幂等性,幂等性保证了Ansible脚本多次执行情况下的相同结果,尽可能的避免使用那些不能满足幂等性的模块。比如我们经常使用的
shell模块就是非幂等性的。
我们要明白Ansible是以“结果为导向的”,我们指定了一个“目标状态”,Ansible会自动判断“当前状态”是否与“目标状态”一致,如果一致,则不进行任何操作;如果不一致,那么就将“当前状态”变成“目标状态”,这就是“幂等性”,“幂等性”可以保证我们重复的执行同一项操作时,得到的结果是一样的。
那这个幂等性与上面的changed又有什么关系呢?且听我下面慢慢道来!
- 当
changed为false或者0时,表示Ansible没有进行任何操作,没有“改变什么”; - 当
changed为true或者大于0时,表示Ansible执行了操作,“当前状态”已经被Ansible改变成了“目标状态”。
拿copy这个模块来举例子说明,当我们准备将一个文件通过Ansible拷贝到远程主机时,copy模块首先检查远程是否已经存在了该文件,如果不存在,则把文件拷贝过去,返回changed为大于0;如果存在时,则开始比对两个文件的md5值,如果md5值一致,则说明两个文件是一样的,则不需要拷贝,此时copy模块则什么都不干,返回changed为0。
使用ansible-vault加密Playbook
ansible-vault encrypt hello.yml #加密playbook,加密否的文件无法直接执行和查看
ansible-vault view hello.yml #查看加密后的文件
ansible-vault edit hello.yml #查看加密后的文件
ansible-vault decrypt hello.yml #解密playbook
playbook的handlers与notify
一、Ansible handlers的作用
handlers是一种触发器,它可以对task进行监控,如果task所指定的任务状态发生变化,则进行notify通知,然后触发额外的一系列操作,看一个示例来帮助理解:
cat apache.yml
- hosts: webservers
remote_user: root
tasks:
- name: install apache
yum: name=httpd state=latest
- name: install configure file for httpd
copy: src=/root/conf/httpd.conf dest=/etc/httpd/conf/httpd.conf
- name: start httpd service
service: enabled=true name=httpd state=started
上面的YAML文件存在三个task任务,分别是安装httpd、复制配置文件到远端主机、启动httpd服务。但是当第二个task中的配置文件发生了改变后再次执行playbook的话,会发现新的配置文件虽然会正确的复制到远端主机去,但是却没有重启httpd服务。因为Ansible在执行playbook时发现第三个任务与现在状态是一致的,就不会再次执行任务。为了解决这种问题,就需要使用ansible的handlers功能。handlers是用于监控一个任务的执行状态,如果一个tasks任务最后是changed状态则会触发handlers指定的操作。
二、如何配置handlers
Ansible中通过notify这个模块来实现handlers,将示例1修改后:
cat apache.yml
- hosts: webservers
remote_user: root
tasks:
- name: install apache
yum: name=httpd state=latest
- name: install configure file for httpd
copy: src=/root/conf/httpd.conf dest=/etc/httpd/conf/httpd.conf
notify:
- restart httpd #通知restart httpd这个触发器
- check httpd #可以定义多个触发器
- name: start httpd service
service: enabled=true name=httpd state=started
handlers: #定义触发器,和tasks同级
- name: restart httpd #触发器名字,被notify引用,两边要一致
service: name=httpd state=restart
- name: check httpd
shell: netstat -ntulp | grep 80
当httpd.conf的源文件发生修改后,只需重新执行playbook就会自动重启httpd服务,因为配置文件状态是changed而非ok。
playbook的变量定义与调用
一、Ansible变量的作用
在Ansible中支持设置主机变量、组变量,变量支持嵌套使用,定义好了的变量可以在playbook中引用。由于Ansible是在每个主机上单独运行命令,所以不同的主机去调用同样的变量,也可以取到不同的值,这样进行一些配置就更灵活合理。
二、Ansible变量定义与调用
方法1:在/etc/ansible/hosts文件中定义变量
# 定义变量
vim /etc/ansible/hosts
[apache]
192.168.1.36 webdir=/opt/test #定义单个主机的变量
192.168.1.33
[apache:vars] #定义整个组的统一变量
webdir=/web/test
[nginx] 192.168.1.3[1:2]
[nginx:vars]
webdir=/opt/web
# playbook调用变量
cat variables.yml
---
- hosts: all
remote_user: root
tasks:
- name: create webdir
file: name={{ webdir }} state=directory #引用变量
# 执行playbook
[root@ansible PlayBook]# ansible-playbook variables.yml
方法2:在playbook中定义和调用变量
cat apache.yml
- hosts: webservers
remote_user: root
vars: #开始声明变量
- package: httpd #变量名与变量值
- service: httpd
tasks:
- name: install apache
yum: name={{ package }} state=latest #要引用的变量用"{{ }}"囊括
- name: install configure file for httpd
copy: src=/root/conf/httpd.conf dest=/etc/httpd/conf/httpd.conf
- name: start httpd service
service: enabled=true name={{ service }} state=started
# 这个好像就缺了点意思吧
方法3:使用ansible-playbook -e选项定义变量,命令行变量优先级高于配置文件中的变量
cat app.yml
---
- hosts: all
remote_user: root
tasks:
- name: install httpd
yum: name="{{ package }}" #配置文件声明需要引用的变量名
ansible-playbook -e 'package=httpd' app.yml #通过-e给变量赋值,在app.yml文件全局生效
方法4:调用setup模块获取变量
setup模块主要用于获取主机信息并保存在变量中,如IPv4、IPv6、MAC地址、磁盘分区等。该模块获取到的变量是可以直接调用的,无需定义
ansible webserver -m setup
红框处每个引号内的就是默认变量名,使用双花括号可以直接引用。对于一些包含多个层级的变量(比如磁盘分区会存在sda、sdb、sdc…),可以通过从上级书写的形式,比如{{ansible_devices.sda.partitions.sda.size}}
- hosts: webservers
remote_user: root
tasks:
- name: copy file
copy: content='{{ ansible_default_ipv4.address }}' dest=/tmp/vars.ans

方法5:使用独立的YAML文件定义变量
为了方便管理将所有的变量统一放在一个独立的变量YAML文件中,laybook文件直接引用文件调用变量即可
# 定义存放变量的文件
cat var.yml
var1: vsftpd
var2: httpd
# 编写playbook
cat variables.yml
---
- hosts: all
remote_user: root
vars_files: #引用变量文件
- ./var.yml #指定变量文件的path(这里可以是绝对路径,也可以是相对路径)
tasks:
- name: install package
yum: name={{ var1 }} #引用变量
- name: create file
file: name=/tmp/{{ var2 }}.log state=touch #引用变量
# 执行playbook
[root@ansible PlayBook]# ansible-playbook variables.yml
流程控制
条件:
tasks:
- name: 只在192.168.1.100运行任务
debug: msg="{{ansible_default_ipv4.address}}"
when: ansible_default_ipv4.address == '192.168.1.100'
循环:
tasks:
- name: 批量创建用户
user: name={{ item }} state=present groups=wheel
with_items:
- testuser1
- testuser2
- name: 解压
copy: src={{ item }} dest=/tmp
with_fileglob:
- "*.txt"
常用循环语句:
| 语句 | 描述 |
|---|---|
| with_items | 标准循环 |
| with_fileglob | 遍历目录文件 |
| with_dict | 遍历字典 |
模板
vars:
domain: "www.ctnrs.com"
tasks:
- name: 写入nginx配置文件
template: src=/srv/server.j2 dest=/etc/nginx/conf.d/server.conf
# server.j2
{% set domain_name = domain %}
server {
listen 80;
server_name {{ domain_name }};
location / {
root /usr/share/html;
}
}
在jinja里使用ansible变量直接 {{ }}引用。使用ansible变量赋值jinja变量不用{{ }}引用。
定义变量:
{% set local_ip = inventory_hostname %}
条件和循环:
{% set list=['one', 'two', 'three'] %}
{% for i in list %}
{% if i == 'two' %}
-> two
{% elif loop.index == 3 %}
-> 3
{% else %}
{{i}}
{% endif %}
{% endfor %}
例如:生成连接etcd字符串
{% for host in groups['etcd'] %}
https://{{ hostvars[host].inventory_hostname }}:2379
{% if not loop.last %},{% endif %}
{% endfor %}
里面也可以用ansible的变量。
使用template实现灵活配置
一、Ansible template 作用
在实际的工作中由于每台服务器的环境配置都可能不同,但是往往很多服务的配置文件都需要根据服务器环境进行不同的配置,比如Nginx最大进程数、Redis最大内存等。为了解决这个问题可以使用Ansible的template模块,该模块和copy模块作用基本一样,都是把管理端的文件复制到客户端主机上,但是区别在于template模块可以通过变量来获取配置值,支持多种判断、循环、逻辑运算等,而copy只能原封不动的把文件内容复制过去。需要注意的是template只能在playbook中运行,不能使用命令行方式。
二、Ansible template使用方法
1、多数情况下都会建立一个templates目录并和playbook同级,这样playbook可以直接引用和寻找这个模板文件,如果在别的路径需要单独指定。模板文件后缀名为.j2
mkdir templates
cp /etc/conf/httpd.conf templates/httpd.conf.jinja2 #复制一个原始配置文件进行修改
2、创建playbook并使用template模板
cat test.yml
---
- hosts: all
remote_user: root
vars:
- listen_port: 88 #定义变量
tasks:
- name: Install Httpd
yum: name=httpd state=installed
- name: Config Httpd
template: src=httpd.conf.j2 dest=/etc/httpd/conf/httpd.conf #使用模板
notify: Restart Httpd
- name: Start Httpd
service: name=httpd state=started
handlers:
- name: Restart Httpd
service: name=httpd state=restarted
3、修改模板文件,配置文件中需要针对端口做不同设置,找到Listen一项做以下修改
vi templates/httpd.conf.jinja2
Listen {{ listen_port }} #这里的端口用变量替代
4、由于调用了listen_port这个变量,所以需要在主机列表文件中给每个主机定义这样一个变量(也可以将变量写在playbook中):
vi /etc/ansible/hosts
192.168.100.110 listen_port=80
192.168.100.120 listen_port=8080
192.168.100.130 listen_port=808
192.168.100.140 listen_port=8000
5、运行ansible-playbook test.yml即可
template中的with循环与when条件判断
一、Ansible with循环
在Ansible中使用with_items进行循环迭代,适用于需要重复执行的任务。对需要进行循环时,使用固定变量名{{ itme }},然后在task中使用with_items给定要迭代的元素列表。
示例1,通过with_items安装多个软件
vi /etc/ansible/with.yml
---
- hosts: 192.168.1.100
remote_user: root
tasks:
- name: Install Package
yum: name={{ item }} state=installed #引用item获取值
with_items: #定义with_items
- redis
- nginx
ansible-playbook while.yml
二、Ansible when条件判断
示例1:判断客户端系统判断,然后选择对应的配置文件
vi /etc/ansible/when.yml #加入如下内容
- hosts: dbservers
user: root
vars:
- http_port: 8080
tasks:
- name: install nginx
yum: name=nginx
- name: copy conf for centos7
template: src=nginx.conf7.j2 dest=/etc/nginx/nginx.conf
when: ansible_distribution_major_version == "7" #这里的变量是取facts信息
notify: restart service
- name: copy conf for centos6
template: src=nginx.conf6.j2 dest=/etc/nginx/nginx.conf
when: ansible_distribution_major_version == "6"
notify: restart service
- name: start service
service: name=nginx state=started enabled=yes
handlers:
- name: restart service
service: name=nginx state=restarted
示例2:当远程主机FQDN名为test时,给该主机添加一个用户user10
vi test.yml
- hosts: all
remote_user: root
vars:
- username: user10
tasks:
- name: create {{ username }} user
user: name={{ username }}
when: ansible_fqdn == "test"
YAML 语法入门
YAML就和XML、JSON一样,专门用来写配置文件的语言,非常简洁和强大。
下面就通过一段简单的YAML脚本来感受它的简介与强大:
---
- hosts: server1
user: root
vars:
http_port: 80
max_clients: 200
tasks:
- name: Write apache config file
template: src=/home/test1/httpd.j2 dest=/home/test2/httpd.conf
notify:
- restart apache
- name: Ensure apache is running
service: name=httpd state=started
handlers:
- name: restart apache
service: name=httpd state=restarted
我们可以看到,最开始是---,---它是一个特殊的符号,表示一个文档的开始。接下来的-代表一个数组项,后面的user: root这种key: value格式,代表一个对象。具体的接下来继续细说!
从上面的一小段代码,可以看到它的基本语法规则超级简单:
- 大小写敏感;
- 使用缩进表示层级关系;
- 缩进时不允许使用Tab键,只允许使用空格;
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可;
#表示注释,只支持单行注释,不支持多行注释。
说完语法规则,再来看它支持的数据结构:
- 对象:键值对的集合,又称为映射(mapping)/ 哈希(hashes) / 字典(dictionary);
- 数组:一组按次序排列的值,又称为序列(sequence) / 列表(list);
- 标量(scalars):单个的、不可再分的值
再复杂的YAML脚本,基本上也都是上述这三种数据结构组成的。所以,掌握了这三种结构,剩下的就是语法糖了。下面就分别对这三种语法结构展开说明。
对象
对象的一组键值对,使用冒号结构表示,格式为key: value(冒号后面一定要记住加一个空格)。
key: value
也可以使用缩进表示层级关系:
vars:
http_port: 80
max_clients: 200
YAML也允许另一种写法,将所有键值对写成一个行内对象。比如这样:
vars: {http_port: 80, max_clients: 200}
数组
使用-代表一个数组项,比如可以这样子定义一个数组:
- 192.168.1.2
- 192.168.1.3
- 192.168.1.4
如果数据结构的子成员是一个数组,则可以在该项下面缩进一个空格,比如这样:
-
- 192.168.1.2
- 192.168.1.3
- 192.168.1.4
数组也可以采用行内表示法,就像这样子:
- servers: [192.168.1.2, 192.168.1.3, 192.168.1.4]
标量
YAML中提供了以下常量结构:
- 字符串
- 布尔值
- 整数
- 浮点数
- Null
- 时间
- 日期
---
boolean:
- TRUE # true,True都可以
- FALSE # false,False都可以
float:
- 3.14
- 6.8523015e+5 # 可以使用科学计数法
int:
- 123 # 整数
null:
nodeName: 'node'
parent: ~ # 使用~表示null
string:
- 哈哈
- 'Hello world' # 可以使用双引号或者单引号包裹特殊字符
- newline
newline2 # 字符串可以拆成多行,每一行会被转化成一个空格
date:
- 2018-02-17 # 日期必须使用ISO 8601格式,即yyyy-MM-dd
datetime:
- 2018-02-17T15:02:31+08:00 # 时间使用ISO 8601格式,时间和日期之间使用T连接,最后使用+代表时区
复合结构&特殊语法
在YAML中,任何一个复杂的脚本文件都是上面的这三种数据结构再加上一些语法组成的。如果手里有一个复杂的YAML脚本,挠破头皮都看不懂,没关系,我们可以将看不懂的YAML通过工具转成我们可以看懂的JSON格式。
对于还有一些特殊的语法,比如引用、锚点、别名等,这些特殊语法,我们在遇到的时候,再去查询资料即可!这里不做详细的总结!
Ansible facts
如果你跟着前面的文章在自己的测试环境进行了操作的话,你会发现在Ansible执行完成后,在输出内容中都包含以下这么一项:
TASK [Gathering Facts] ****************************************
ok: [192.168.1.3]
从内容来看,这是执行了一个名为Gathering Facts的TASK,但是即使在我们的命令中或者YAML中没有定义这个TASK,也会执行这个任务,这是什么道理?下面我就带着大家对Ansible中的facts一探究竟。
Ansible facts简介
facts组件是Ansible用于采集被管理机器设备信息的一个功能,采集的机器设备信息主要包含IP地址,操作系统,以太网设备,mac 地址,时间/日期相关数据,硬件信息等。
那话又说回来了,采集这些信息有什么用呢?有的时候我们需要根据远程主机的信息作为执行条件操作,例如,根据远程服务器使用的操作系统版本,可以安装不同版本的软件包;或者也可以显示与每台远程计算机相关的一些信息,例如每台设备上有多少RAM可用。
所以,在一些业务场景中,facts对我们是很有帮助的,省去了我们好多工作,大大提高了工作效率。
Ansible facts用法
我们可以使用setup模块获取被管理机器的所有 facts 信息,可以使用filter来查看指定的信息。setup模块获取的整个 facts 信息被包装在一个 JSON 格式的数据结构中,ansible_facts是最外层的值。我们可以通过以下Ansible Ad-Hoc命令查看facts信息:
ansible server1 -m setup
由于输出内容实在太多,这里只贴出部分内容:
192.168.1.3 | SUCCESS => {
"ansible_facts": {
"ansible_all_ipv4_addresses": [
"192.168.1.3"
],
"ansible_all_ipv6_addresses": [
"2409:8a10:72:1c10:c59e:af39:7c72:6afb",
"fe80::7107:62de:8cf8:db00"
],
"ansible_apparmor": {
"status": "disabled"
},
"ansible_architecture": "x86_64",
"ansible_bios_date": "12/01/2006",
"ansible_bios_version": "VirtualBox",
"ansible_cmdline": {
"BOOT_IMAGE": "/vmlinuz-3.10.0-957.el7.x86_64",
"LANG": "en_US.UTF-8",
"crashkernel": "auto",
"quiet": true,
"rd.lvm.lv": "centos/swap",
"rhgb": true,
"ro": true,
"root": "/dev/mapper/centos-root"
},
......
由于输出的内容实在是太多了,我们可以使用filter参数来查看指定的信息,比如这样:
ansible server1 -m setup -a 'filter=ansible_all_ipv4_addresses'
输出内容如下:
192.168.1.3 | SUCCESS => {
"ansible_facts": {
"ansible_all_ipv4_addresses": [
"192.168.1.3"
]
},
"changed": false
}
到这里,话又说回来!我们没有配置Gathering Facts的TASK,但是依然自动的就执行了这个任务,这个默认是在哪里配置的呢?
Ansible facts配置
在Ansible的配置文件中,关于facts的重要配置项有以下几个:
gathering:facts的开关,默认是开启的;有以下三个取值:smart:开启facts信息收集,但是会优先使用facts缓存信息,可以使用gather_facts: False禁用facts收集;implicit:开启facts信息收集,要禁止收集,必须使用gather_facts: False;explicit:关闭facts信息收集,要显式收集,必须使用gather_facts: Ture。
fact_caching:缓存facts信息的方式;可以配置成jsonfile或者redis;fact_caching_connection:缓存插件的配置,针对不同的fact_caching方式,取值含义则不同:- 如果
fact_caching为jsonfile,则此处应配置存储缓存文件的目录; - 如果
fact_caching为redis,则此处应按照host:port:database的格式配置redis的信息。
- 如果
gather_timeout:收集超时时间,默认为86400;fact_caching_timeout:设置facts缓存的过期时间,默认是86400秒。
Ansible 之 roles 使用
role 的作用
主要作用是重用playbook,例如我们无论安装什么软件都会安装时间同步服务,那么每个playbook都要编写ntp task。我们可以将ntp task写好,等到用的时候再调用就行了。ansible中将其组织成role,他有着固定的组织格式。以便playbook调用。
假如我们现在有3个被管理主机,第一个要配置成httpd,第二个要配置成php服务器,第三个要配置成MySQL服务器。我们如何来定义playbook?
第一个play用到第一个主机上,用来构建httpd,第二个play用到第二个主机上,用来构建php,第三个play用到第三个主机上,用来构建MySQL。这些个play定义在playbook中比较麻烦,将来也不利于模块化调用,不利于多次调。比如说后来又加进来一个主机,这个第4个主机既是httpd服务器,又是php服务器,我们只能写第4个play,上面写上安装httpd和php。这样playbook中的代码就重复了。
为了避免代码重复,roles能够实现代码重复被调用。定义一个角色叫websrvs,第二个角色叫phpappsrvs,第三个角色叫dbsrvs。那么调用时如下来调用:
hosts: host1
role:
- websrvs
hosts: host2
role:
- phpappsrvs
hosts: host3
role:
- dbsrvs
hosts: host4
role:
- websrvs
- phpappsrvs
这样代码就可以重复利用了,每个角色可以被独立重复调用。
二、roles示例
假设有3台主机,172.16.7.151主机上安装MySQL,172.16.7.152上安装httpd,172.16.7.153上安装MySQL和httpd。我们建立两个角色websrvs和dbsrvs,然后应用到这几个主机上。
1. 创建roles的必需目录
[root@node1 opt]# mkdir -pv ansible_playbooks/roles/{websrvs,dbsrvs}/{tasks,files,templates,meta,handlers,vars}
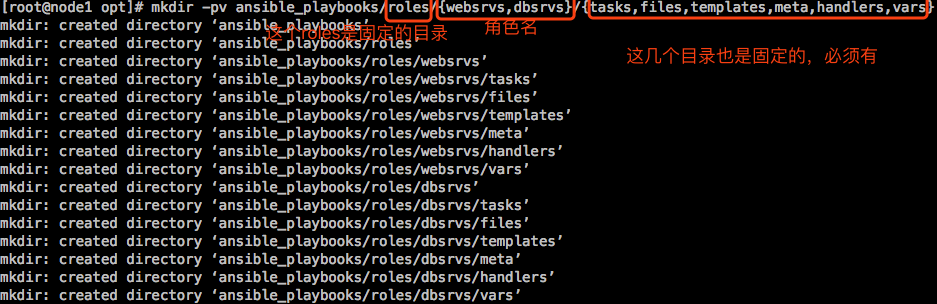
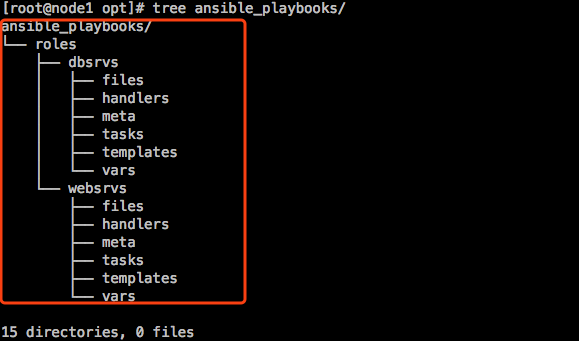
每个role下面有个目录叫meta,在里面可以新建文件main.yml,在文件中可以设置该role和其它role之前的关联关系。

2. 配置角色
(1)配置角色websrvs
[root@node1 opt]# cd ansible_playbooks/roles/
[root@node1 roles]# cd websrvs/
[root@node1 websrvs]# ls
files handlers meta tasks templates vars
a. 将httpd配置文件上传到files目录下,我这里假设httpd.conf每台主机都是一样的,实际上应该用模板,先用一样的配置文件举例
[root@node1 websrvs]# cp /etc/httpd/conf/httpd.conf files/
直接复制的静态文件都放在files目录下。打算用模板文件的都放在templates目录下。
b.编写任务列表tasks
[root@node1 websrvs]# vim tasks/main.yml
- name: install httpd package
yum: name=httpd
- name: install configuration file
copy: src=httpd.conf dest=/etc/httpd/conf
tags:
- conf
notify:
- restart httpd
- name: start httpd
service: name=httpd state=started
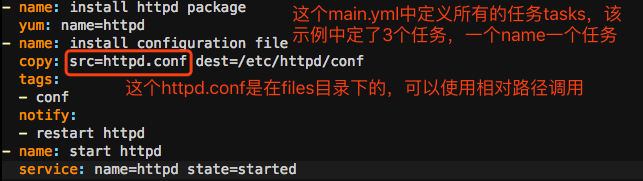
c.由于上面的tasks中定义了notify,所以要定义handlers
[root@node1 websrvs]# vim handlers/main.yml
- name: restart httpd
service: name=httpd state=restarted
如果需要定义变量,则在vars目录下创建main.yml文件,在文件中写入变量,以key:value的形式定义,比如:
http_port: 8080
(2)配置角色dbsrvs
[root@node1 roles]# cd dbsrvs/
[root@node1 dbsrvs]# ls
files handlers meta tasks templates vars
a.将MySQL配置文件上传到files目录下。
[root@node1 dbsrvs]# vim tasks/main.yml
- name: install mysql-server package
yum: name=mysql-server state=latest
- name: install configuration file
copy: src=my.cnf dest/etc/my.cnf
tags:
- conf
notify:
- restart mysqld
- name:
service: name=mysqld enabled=true state=started
c.定义handlers
[root@node1 dbsrvs]# vim handlers/main.yml
- name: restart mysqld
service: name=mysqld state=restarted
(3)定义playbook
【注意】:要在roles目录同级创建playbook。
[root@node1 ansible_playbooks]# vim web.yml
- hosts: 172.16.7.152
roles:
- websrvs
[root@node1 ansible_playbooks]# vim db.yml
- hosts: 172.16.7.151
roles:
- dbsrvs
[root@node1 ansible_playbooks]# vim site.yml
- hosts: 172.16.7.153
roles:
- websrvs
- dbsrvs
[ ](javascript:void(0)😉
](javascript:void(0)😉
运行:
[root@node1 ansible_playbooks]# ansible-playbook web.yml
[root@node1 ansible_playbooks]# ansible-playbook db.yml
[root@node1 ansible_playbooks]# ansible-playbook site.yml
当然也可以把这些内容写入同一个playbook中。playbook的名字可以自定义。