背景
随着业务规模的发展,需要的kafka集群越来越来,这给部署与管理带来了很大的挑战。我们期望能够利用K8S优秀的扩容能力与快速部署能力,为日常的工作减负。所以就kafka上K8S的可行性方案进行了调研。
像kafka集群这种,涉及到的组件比较多,且都是有状态的集群,业界采用自定义operator的解决方案。目前GitHub上有多个相关的仓库,根据社区活跃度及使用数等综合考虑,此次采用Strimzi Github地址。
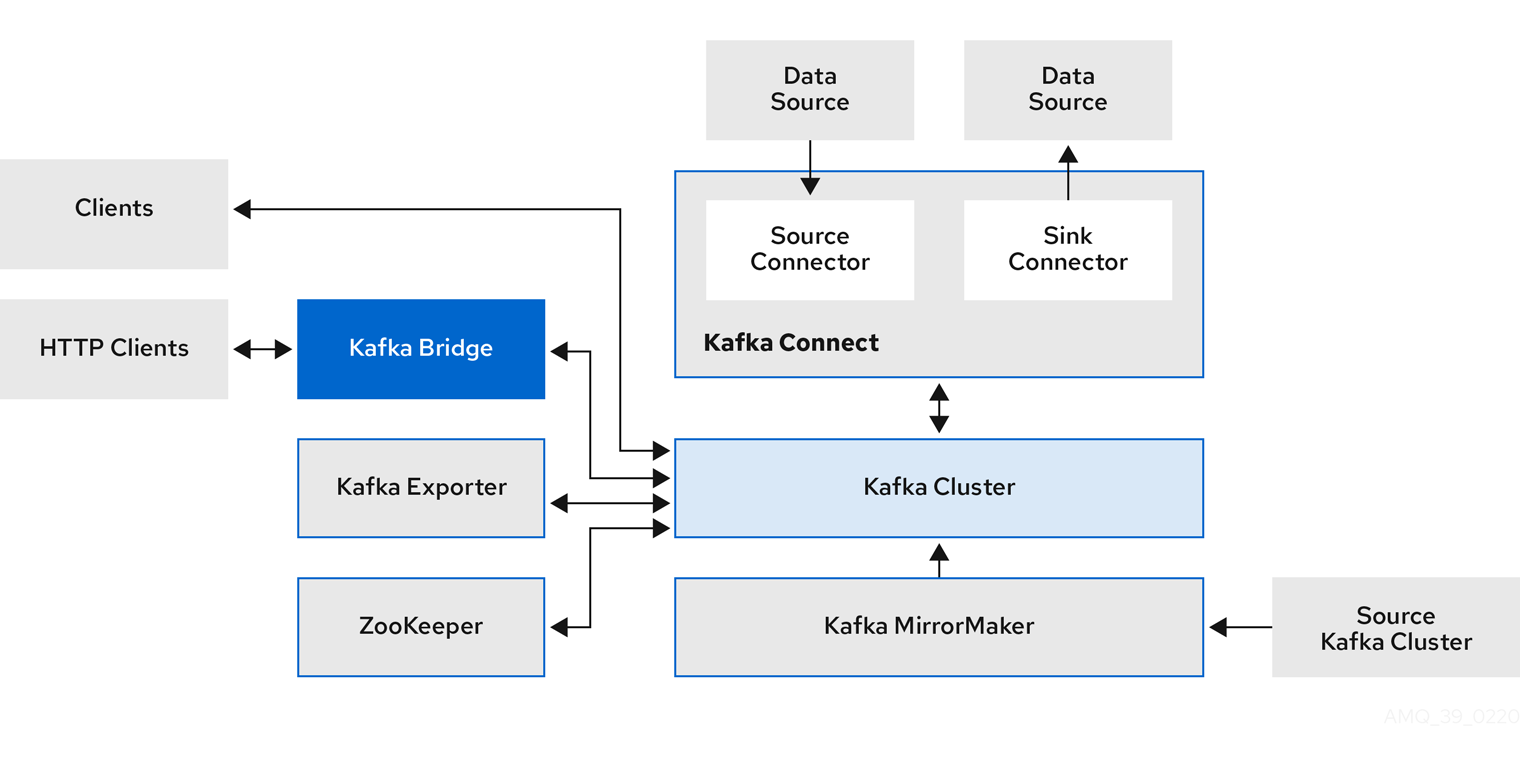
kafka组件交互图
方案
- 使用阿里云K8S集群部署Strimzi
- 由于组内使用的kafka是由开源版本二次开发而来,所以需要维护一个自定义的Strimzi-kafka镜像
- Strimzi管理kafka集群,其中包含kafka、zk、kafka-exporter、
- 使用zoo-entrance 代理集群中的zk GitHub地址
- 部署prometheus,采集kafka和zk的metrics
- 开启服务端口,暴露kafka及zk给K8S集群外部使用
实战过程
构建自定义kafka镜像
- 从公司Git上拉取最新代码 strimzi-kafka-operator (与开源版本有些微的改动,做实验可直接用开源版)
- 在docker-images 文件夹下,有个Makefile文件,执行其中的docker_build, 它会去执行其中的build.sh脚本;此步会从官网拉取kafka的安装包,我们需要将这一步的包修改为我司内部的安装包。
- 构建完镜像,镜像在本地,我们需要将镜像上传到公司内部的harbor服务器上
部署operator
每个K8S集群仅需部署一个operator
- 充分必要条件:一个健康的k8s集群
- 创建namespace, 如已有则跳过,默认使用kafka,kubectl create namespace kafka
- 从公司Git上拉取最新代码(地址在前边)
- 目前文件中默认监听的是名称为 kafka 的namespace,如果需要修改则执行 sed -i 's/namespace: .*/namespace: kafka/' install/cluster-operator/*RoleBinding*.yaml (将命令中的kafka/ 替换掉)
- 然后将所有文件都应用一下 kubectl apply -f install/cluster-operator/ -n kafka
- 此时稍等片刻,就能查看到创建的自定义资源以及operator了 kubectl get pods -nkafka,
- 从阿里云的k8s管控台查看这些资源的创建情况,以及operator的运行情况
部署kafka集群
确保你的operator已经部署成功,且kafka部署的namespace需在上边operator的监控中
- 还是来到最新的代码目录中,其中examples/kafka目录下边就是本次部署所需要的文件了
- 部署 kafka及zk
-
- 查看kafka-persistent.yaml, 该文件就是核心文件了,这个文件部署了kafka与zk及kafka-exporter, 部分内容如下:
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
version: 2.8.1
replicas: 3
resources:
requests:
memory: 16Gi
cpu: 4000m
limits:
memory: 16Gi
cpu: 4000m
image: repository.poizon.com/kafka-operator/poizon/kafka:2.8.4
jvmOptions:
-Xms: 3072m
-Xmx: 3072m
listeners:
- name: external
port: 9092
type: nodeport
tls: false
- name: plain
port: 9093
type: internal
tls: false
config:
offsets.topic.replication.factor: 2
transaction.state.log.replication.factor: 2
transaction.state.log.min.isr: 1
default.replication.factor: 2
***
template:
pod:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: strimzi.io/name
operator: In
values:
- my-cluster-kafka
topologyKey: "kubernetes.io/hostname"
storage:
type: persistent-claim
size: 100Gi
class: rocketmq-storage
deleteClaim: false
metricsConfig:
type: jmxPrometheusExporter
valueFrom:
configMapKeyRef:
name: kafka-metrics
key: kafka-metrics-config.yml
zookeeper:
replicas: 3
resources:
requests:
memory: 3Gi
cpu: 1000m
limits:
memory: 3Gi
cpu: 1000m
jvmOptions:
-Xms: 2048m
-Xmx: 2048m
jmxOptions: {}
template:
pod:
affinity:
podAntiAffinity:
***
storage:
type: persistent-claim
size: 50Gi
class: rocketmq-storage
deleteClaim: false
metricsConfig:
type: jmxPrometheusExporter
valueFrom:
configMapKeyRef:
name: kafka-metrics
key: zookeeper-metrics-config.yml
***
***-
- 可修改kafka集群的名称,在第四行的name属性,目前默认为 my-cluster
- 可修改kafka的Pod个数,即节点数,默认为3
-
- 可修改Pod配置 内存CPU
- 可修改kafka JVM 启动的堆内存大小
-
- 可修改kafka的配置,在36行 config配置
- 可修改磁盘类型及大小,类型为第50行,可修改为其它的存储类,目前可选为高效云盘、SSD、ESSD
-
- zk修改同kafka,可修改的东西类似, 且在同一个文件中
- 文件下边是kafka与zk需要暴露的metrics,可按需求增删改
-
- 修改完配置之后,直接执行 kubect apply -f kafka-persistent.yaml -nkafka 即可创建
- 部署 zk代理
-
- 由于官方不支持外部组件直接访问zk,所以采用代理的方式访问
- 出于安全性 的考虑,官方是故意不支持外部程序访问zk的:?https://github.com/strimzi/strimzi-kafka-operator/issues/1337
-
- 部署完zk的代理,我们需要在k8s控制台上 创建一个loadbalance服务将这个代理暴露给集群外的应用进行连接。具体操作:k8s控制台-->网络-->服务-->创建(选择loadbalance创建,然后找到zoo-entrance这个应用即可)
- 部署 zk-exporter
-
- 官方operator中没有zk-exporter, 我们采用 https://github.com/dabealu/zookeeper-exporter
- 在文件夹中的zk-exporter.yaml 文件中,我们仅需要修改被监听的zk的地址(spec.container.args)
-
- 执行kubectl apply -f zk-exporter.yaml即可部署完成
- 部署 kafka-jmx
-
- 由于ingress不支持tcp连接,而loadbalance的成本又过高,所以kafka 的 jmx 使用nodeport对外暴露
- 可以在阿里云控制台上创建相应的nodeport,也可以使用kafka-jmx.yaml 文件的方式创建
apiVersion: v1
kind: Service
metadata:
labels:
strimzi.io/cluster: my-cluster
strimzi.io/name: my-cluster-kafka-jmx
name: my-cluster-kafka-jmx-0
spec:
ports:
- name: kafka-jmx-nodeport
port: 9999
protocol: TCP
targetPort: 9999
selector:
statefulset.kubernetes.io/pod-name: my-cluster-kafka-0
strimzi.io/cluster: my-cluster
strimzi.io/kind: Kafka
strimzi.io/name: my-cluster-kafka
type: NodePort- 部署 kafka-exporter-service
-
- 前面部署完kafka之后,我们的配置中是开启了exporter的。但是官方开启完exporter之后,并没有自动生成一个相关的service,为了让Prometheus连接更加方便,我们部署了一个service
- 在文件夹中kafka-exporter-service.yaml 文件中
apiVersion: v1
kind: Service
metadata:
labels:
app: kafka-export-service
name: my-cluster-kafka-exporter-service
spec:
ports:
- port: 9404
protocol: TCP
targetPort: 9404
selector:
strimzi.io/cluster: my-cluster
strimzi.io/kind: Kafka
strimzi.io/name: my-cluster-kafka-exporter
type: ClusterIP-
- 执行kubectl apply -f kafka-exporter-service.yaml即可部署完成
- 部署 kafka-prometheus
-
- 如果将Prometheus部署在k8s集群外,数据采集会比较麻烦,所以我们直接将Prometheus部署到集群内
- 在文件夹中kafka-prometheus.yaml文件中,可以选择性的修改其中prometheus的配置,比如需要的内存CPU的大小,比如监控数据保存时间,外挂的云盘大小,以及需要监听的kafka与zk地址
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: kafka-prometheus
labels:
app: kafka-prometheus
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: kafka-prometheus
serviceName: kafka-prometheus
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
app: kafka-prometheus
spec:
containers:
- args:
- '--query.max-concurrency=800'
- '--query.max-samples=800000000'
***
command:
- /bin/prometheus
image: 'repository.poizon.com/prometheus/prometheus:v2.28.1'
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 10
httpGet:
path: /status
port: web
scheme: HTTP
initialDelaySeconds: 300
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 3
name: kafka-prometheus
resources:
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 200m
memory: 128Mi
volumeMounts:
- mountPath: /etc/localtime
name: volume-localtime
- mountPath: /data/prometheus/
name: kafka-prometheus-config
- mountPath: /data/database/prometheus
name: kafka-prometheus-db
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
terminationGracePeriodSeconds: 30
restartPolicy: Always
schedulerName: default-scheduler
securityContext:
fsGroup: 0
volumes:
- hostPath:
path: /etc/localtime
type: ''
name: volume-localtime
- configMap:
defaultMode: 420
name: kafka-prometheus-config
name: kafka-prometheus-config
volumeClaimTemplates:
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: kafka-prometheus-db
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
storageClassName: rocketmq-storage
volumeMode: Filesystem
status:
phase: Pending-
- 执行kubectl apply -f kafka-prometheus.yaml即可部署完成
- 部署完成后将prometheus暴露给监控组的grafana,可以直连pod IP做验证,然后在k8s管控台的 网络-->路由-->创建, 创建一个ingress,选择刚刚部署的这个Prometheus的service,然后找运维申请域名,即可。
总结
- 优点
-
- 快速部署集群(分钟级),快速集群扩容(秒级),快速灾难恢复(秒级)
- 支持滚动更新,支持备份以及还原
- 缺点
-
- 引入较多组件,复杂度升高
- 对K8S集群外的访问不太友好
-
文/ZUOQI
-
关注得物技术,做最潮技术人?