背景
SOFAStack 是蚂蚁集团的商业化金融级云原生架构产品,基于 SOFAStack 可快速搭建云原生微服务体系,快速开发更具可靠性和扩展性、更加易于维护的云原生应用。在宏观架构层面,提供单机房向同城双活、两地三中心、异地多活架构演进路线,使系统容量能在多个数据中心内任意扩展和调度,充分利用服务器资源,提供机房级容灾能力,保证业务连续性。
在应用生命周期管理层面,SOFAStack 提供了一个多模应用 PaaS 平台――SOFAStack CAFE (Cloud Application Fabric Engine) 云应用引擎。它提供应用管理、流程编排、应用部署、集群运维等全生命周期管理的 PaaS 平台能力,满足金融场景中经典和云原生架构的运维需求,帮助传统架构平滑过渡、保障金融技术风险。
在云原生架构运维上,SOFAStack CAFE 通过单元化混合云产品 LHC (LDC Hybrid Cloud) 提供单元化应用的云原生多集群发布运维能力,实现应用的多地域、多机房、多云混合部署。本文将揭开 LHC 的神秘面纱,来详细谈谈我们在其底层 Kubernetes 多集群发布体系中的一些实践。
挑战
在 LHC 产品诞生之初,我们首要面临的问题便是为其选择一个合适的底层 Kubernetes 多集群框架。彼时 Kubernetes 社区刚刚完成了其官方多集群项目 KubeFed,其提供了多集群的纳管、Kubernetes 资源的多集群分发与状态回流等一系列多集群基础能力,自然成为了我们当时的最佳选择。
但正如前面所说,社区的多集群框架提供的仅仅是“基础能力”,这些能力对于我们的单元化混合云产品来说存在着很多不满足甚至有冲突的点。其中,最突出的一个问题就是社区没有“单元化”的概念,其多集群就是纯粹的多 Kubernetes 集群,对任何一个多集群 Kubernetes 资源(在 KubeFed 中我们称其为联邦资源)来说,它的分发拓扑只能是按集群。但在单元化模型中,一个应用服务的资源是分布在多个部署单元中的,而部署单元和集群之间的关系的灵活的――在我们目前的模型中,集群和部署单元之间的关系是 1:n,即一个 Kubernetes 集群可以包含多个部署单元。这时候,我们便遇到了和社区框架的分歧点,也是最大的挑战:上层业务需要按部署单元维度来进行 Kubernetes 资源的治理,底层社区框架则只认集群。
除此之外,KubeFed 自身所涵盖的基础能力也还不足以满足我们的所有需求,比如缺乏集群的租户隔离能力、不支持资源 annotation 的下发、主集群和子集群之间的网络连通性要求高等等。由此,解决冲突并补齐能力便成为了我们在建设 LHC 产品底层多集群能力上的重点课题。
实践
下面我们就来分模块谈谈建设 LHC 产品底层 Kubernetes 多集群能力中的一些具体实践。
多拓扑联邦 CRD
在社区 KubeFed 框架中,我们通过联邦 CR 来进行 Kubernetes 资源的多集群分发。一个典型的联邦 CR 的 spec 如下所示:
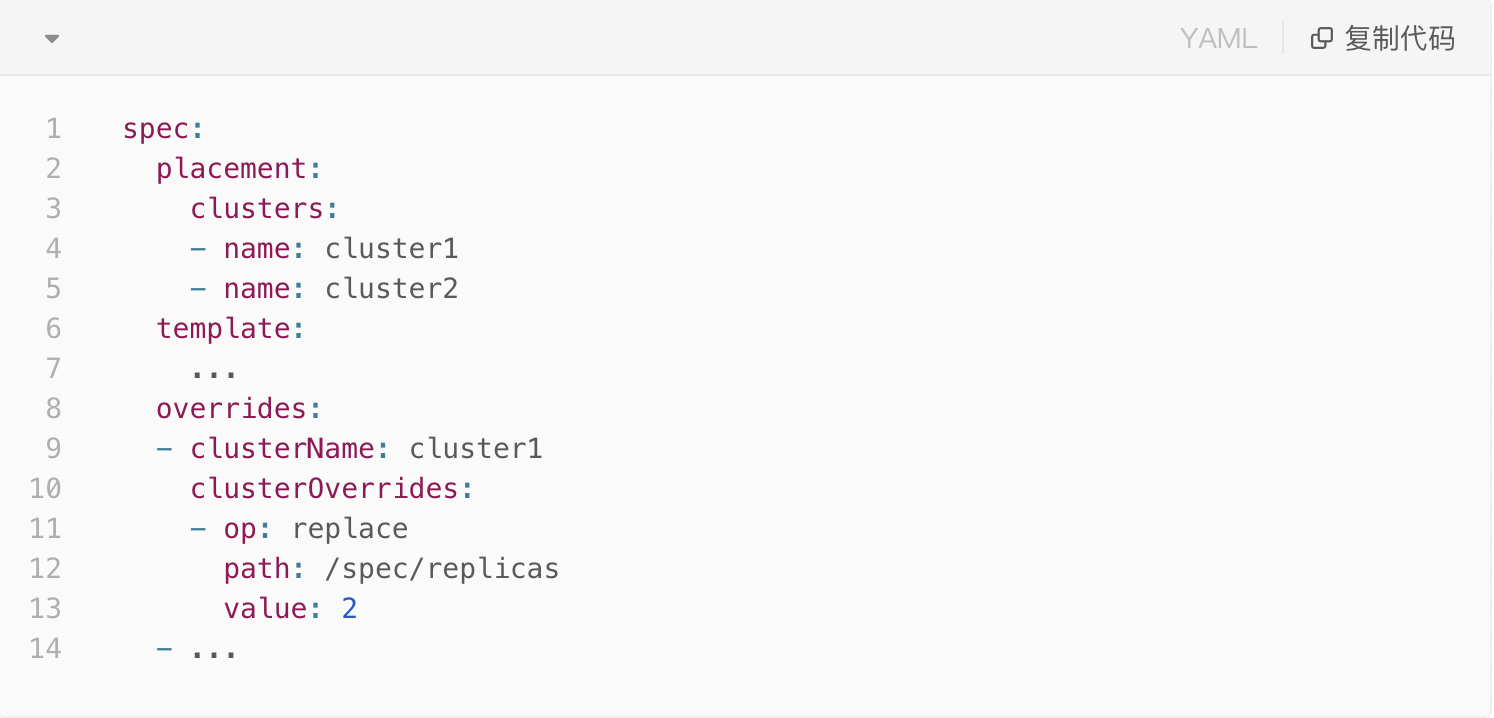
可以看到其主要包含三个字段,其中 placement 用于指定所需分发的集群,template 包含了该联邦资源的单集群资源体,overrides 用于指定每个子集群中对 template 中资源体的自定义部分。
前面我们提到,对于单元化应用的 Kubernetes 资源而言,它需要按部署单元维度而非集群维度进行分发,因此上面的社区 CRD 显然是无法满足要求的,需要对其进行修改。经过修改后,新的联邦 CR 的 spec 如下所示:
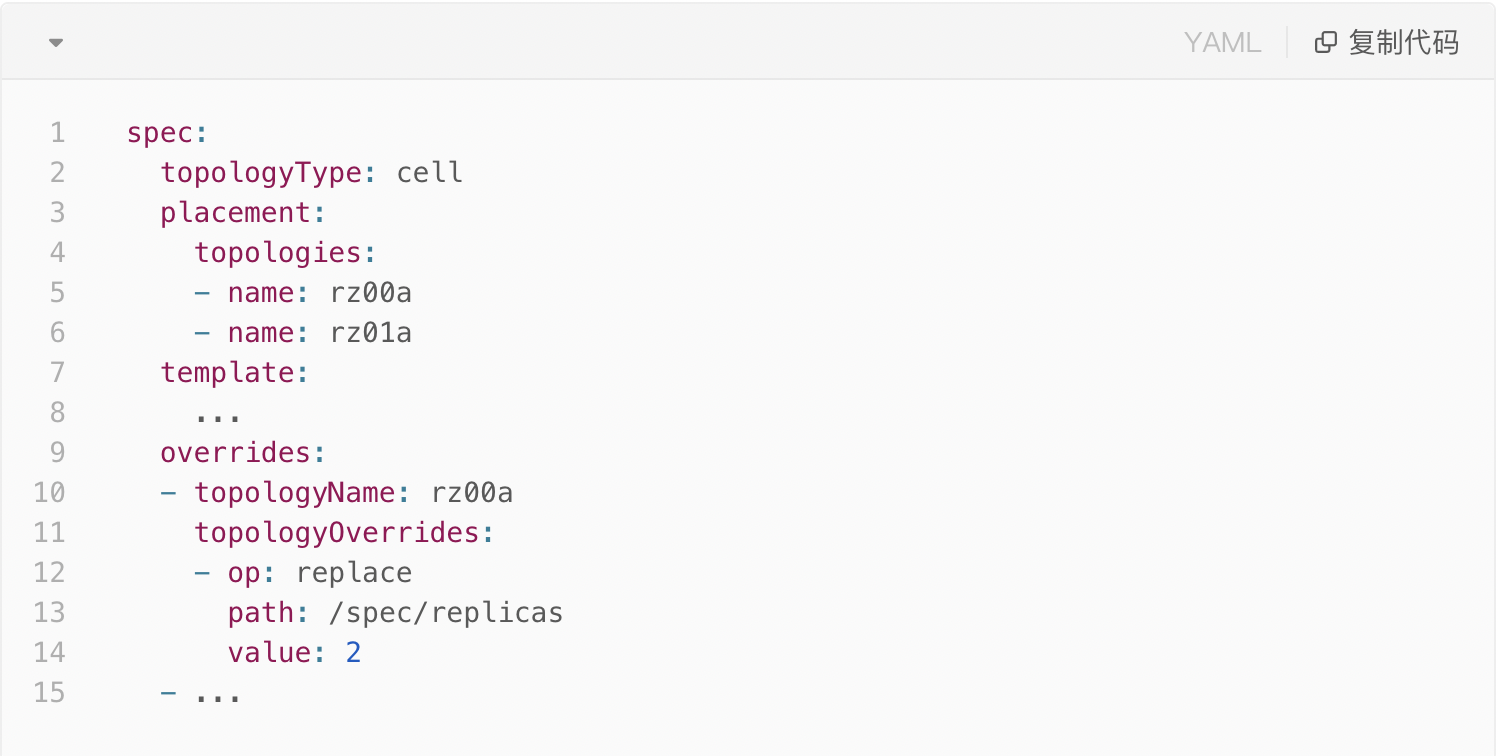
可以看到,我们没有完全摒弃社区的 CRD,而是对其进行了“升级”,通过将具体的“集群”转变为抽象的“拓扑”,将联邦资源的分发拓扑完全自定义化,打破了单一集群维度的限制。如上面的 spec 中我们将 topologyType 设置为 cell 即指定了该资源以部署单元维度进行分发,反之指定为 cluster 则能完全兼容社区原生的集群维度分发模式。
当然,仅仅定义一个新的 CRD 无法解决问题,我们还需要修改其对应的实现,才能让其工作起来。但是,如果要让社区的 KubeFed controller 感知多拓扑模型,势必会对其底层实现进行大量修改,最终很可能就变成了半重写,研发成本高,且无法再继续回流社区上游的修改,带来的维护成本也比较高。我们需要寻求更好方法,把我们的多拓扑模型和 KubeFed 的原生多集群能力解耦开来。
独立并扩展联邦层 ApiServer
既然我们不想对社区 KubeFed controller 进行过多侵入式修改,那么我们必然需要一个转换层,来将上述的多拓扑联邦 CRD 转换成相应的社区 CRD。对于某种特定拓扑来说,其转换逻辑也是确定的,因此最简单高效的转换便是直接通过 Kubernetes ApiServer 来进行处理,而 ApiServer 对于 CRD 的 Conversion Webhook 能力则刚好能够满足这一转换层的实现需求。
因此,我们给 KubeFed controller 搭配了一个专属的 Kubernetes ApiServer 形成了一个独立的 Kubernetes 控制面,我们称其为“联邦层”。这一独立的控制面仅包含联邦多集群相关的数据,确保不会与其他 Kubernetes 资源互相干扰,同时也避免了部署时对外部 Kubernetes 集群的强依赖。
那么,联邦层的 ApiServer 有何特别之处?其实它的主体还是 Kubernetes 原生的 ApiServer,提供 ApiServer 所能提供的所有能力,我们所做的则是对其进行了“包装”,将我们需要扩展到联邦层的能力装了进去。下面具体介绍几项关键扩展能力。
内置多拓扑联邦 CRD 转换能力
正如上文所说,这是联邦层 ApiServer 提供的最重要的能力。借助 Kubernetes CRD 的多版本能力,我们将自己的多拓扑联邦 CRD 和社区 CRD 定义为了同一个 CRD 的两个版本,然后通过在联邦层 ApiServer 中集成针对该 CRD 的 Conversion Webhook,即可自定义二者的转换实现了。这样一来,在联邦层控制面上,任何联邦 CR 都能同时以两种形式进行读取和写入,做到了上层业务仅关心部署单元(或者其他业务拓扑),而底层 KubeFed controller 仍仅关心集群,实现了其对多拓扑联邦 CRD 模型的无感支持。
下面以部署单元拓扑为例,简单介绍下其与集群拓扑之间的转换实现。在 KubeFed 中,我们通过创建包含了子集群访问配置的 KubeFedCluster 对象来使其纳管这一子集群,随后我们就可以在联邦 CRD 的 placement 中通过 KubeFedCluster 对象的名称来指定需要分发的子集群。那么,我们的转换逻辑所要做的就是将多拓扑联邦 CRD 中的部署单元名称转换为其所对应集群的 KubeFedCluster 对象名称。由于集群和部署单元是 1:n 的关系,因此我们只需为每个部署单元额外创建包含其所在集群访问配置的 KubeFedCluster 对象,并通过统一的命名规则为其生成能够通过部署单元所在命名空间(即租户与工作空间组名称)与名称寻址到的名称即可。
以此类推,我们可以通过类似的方式很容易地支持更多拓扑类型,极大地提高了我们在联邦模型使用上的灵活度。
支持直接使用 MySQL/OB 作为 etcd 数据库
对于任何一个 Kubernetes ApiServer 来说,etcd 数据库都是必不可少的依赖。在蚂蚁主站,我们有丰富的物理机资源和强大的 DBA 团队来提供持续高可用的 etcd,但对于 SOFAStack 产品复杂繁多的对外输出场景而言则不是这样。在域外,运维 etcd 的成本要比运维 MySQL 要高得多,此外,SOFAStack 常常会搭配 OceanBase 一起输出,我们也希望能够充分利用 OB 提供的成熟的多机房容灾能力解决数据库高可用的问题。
因此,在一番调研和尝试后,我们将 k3s 社区开源的 etcd on MySQL 适配器 Kine 集成进了联邦层 ApiServer,使其能够直接使用通用的 MySQL 数据库作为 etcd 后端,省去了单独维护一个 etcd 的烦恼。此外,我们也针对 OB 与 MySQL 的一些差异化行为(如切主自增序跳变)进行了适配,使其也能完美兼容 OB,以享受到 OB 带来的数据高可用与强一致性。
此外,我们还在联邦层 ApiServer 内集成了一些用于校验与初始化联邦相关资源的 Admission Plugin 等,由于大多和产品业务语义相关,这里不再赘述。
值得一提的是,我们所做的这些扩展都具备拆解为独立的组件与 Webhook 的能力,因此也能适用于社区原生插件化安装的形式,不强依赖独立的 ApiServer。目前我们将 ApiServer 独立出来主要是为了隔离联邦层的数据,同时便于独立部署和维护所需。
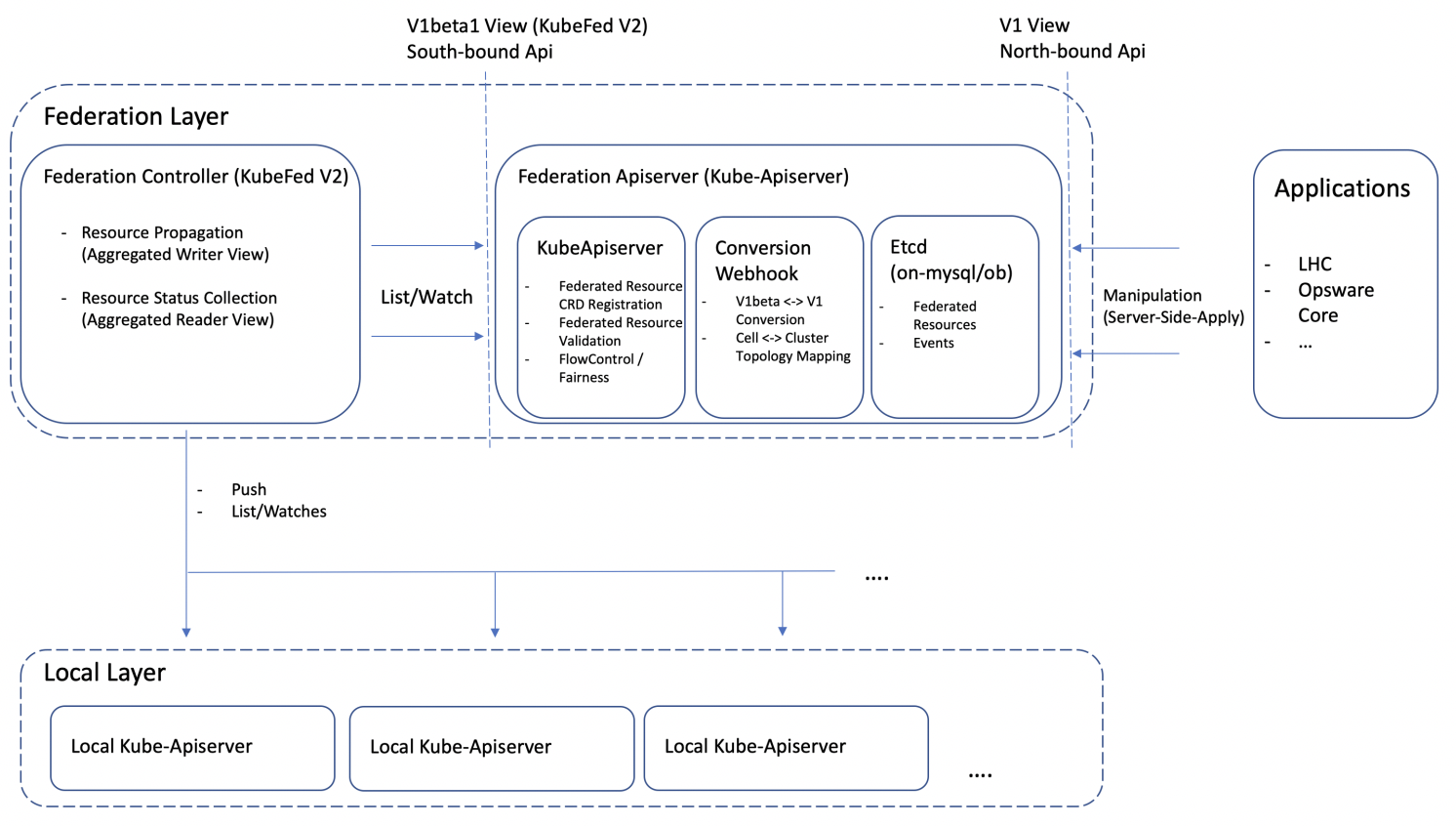
总结一下,从架构层面来讲,联邦层 ApiServer 主要起到了一个联邦资源南北向桥接器的作用,如下图所示,其通过 CRD 多版本的能力,南向为 KubeFed controller 提供了承载社区联邦资源的 ApiServer 能力,北向则为上层业务产品提供了从业务拓扑(部署单元)到集群拓扑的映射转换能力。
KubeFed Controller 能力增强
前面提到,除了联邦模型外,社区 KubeFed controller 在自身底层能力上也无法满足我们的全部需求,因此,我们在产品化过程中对其进行了一些能力增强。其中一些通用的增强我们也贡献给了社区,如支持设置 controller worker 并发数与多集群 informer cache 同步超时、支持 Service 特殊字段保留等。而一些高阶能力我们都通过 Feature Gate 的形式进行了可插拔的增强,做到了与 code base 与社区上游的实时同步。下面我们就来介绍其中几个有代表性的增强能力。
支持子集群多租户隔离
在 SOFAStack 产品中,无论是在公有云还是专有云,所有资源都是按租户与工作空间(组)的粒度进行隔离的,以确保各个用户及其下属的各个环境之间不会互相影响。对于 KubeFed 而言,其所关心的主要资源是 Kubernetes 集群,而社区的实现对其是不做任何隔离的,这一点从联邦资源的删除逻辑上就可看出:在联邦资源被删除时,KubeFed 会检查其控制面中纳管的所有集群以确保该资源在所有子集群中的单集群资源都被删除。在 SOFAStack 产品语义下,这么做显然是不合理的,会产生不同环境之间互相影响的风险。
因此,我们对联邦资源与 KubeFed 中代表纳管子集群的 KubeFedCluster 对象进行了一些无侵入的扩展,通过为其注入一些 well known labels 的方式使其持有了业务层的一些元数据,如租户与工作空间组信息等。借助这些数据,我们在 KubeFed controller 处理联邦资源时对子集群加入了一次预选,使其对联邦资源的任何处理都只会将读写范围限制在其所隶属的租户与工作空间组内,做到了多租户多环境的完全隔离。
支持灰度分发能力
对于 SOFAStack CAFE 这样一个金融生产级发布部署平台而言,灰度发布是一项必不可少的能力。对于任意的应用服务变更,我们都希望其能够以用户可控的方式灰度发布到指定的部署单元中。这就对底层的多集群资源管理框架也提出了相应要求。
从上文联邦 CRD 的介绍中可以看到,我们通过 placement 为联邦资源指定需要分发的部署单元(或其他拓扑)。在初次下发一个联邦资源时,我们可以通过逐步向 placement 中添加欲发布的部署单元来实现灰度发布,但当我们要更新该资源时,就没有办法进行灰度了――此时 placement 中已经包含了所有部署单元,对联邦资源的任何修改都会立刻同步到所有部署单元,同时,我们也不能通过将 placement 重新设置为欲发布的部署单元来做灰度,因为这会导致其他部署单元内的资源被立即删除。此时,为了支持灰度发布,我们就需要一项能力支持我们指定 placement 中的哪些部署单元是要被更新的,其余则需保持不变。
为此,我们引入了 placement mask 的概念。如其名所示,它就像是 placement 的一个掩码一样,当 KubeFed controller 处理联邦资源时,它所更新的拓扑范围就变成了 placement 和 placement mask 的交集。此时,我们只需要在更新联邦资源时同时指定它的 placement mask,即可精细化地控制本次变更影响的部署单元范围,实现了完全自主可控的灰度发布能力。
如下图所示,我们为该联邦资源添加了仅包含部署单元 rz00a 的 placement mask,此时可以看到位于 rz00a 子资源被成功更新(更新后子资源的 generation 为 2),而 rz01a 的资源则不做处理(因而没有产生更新后的 generation),实现了灰度发布的效果。
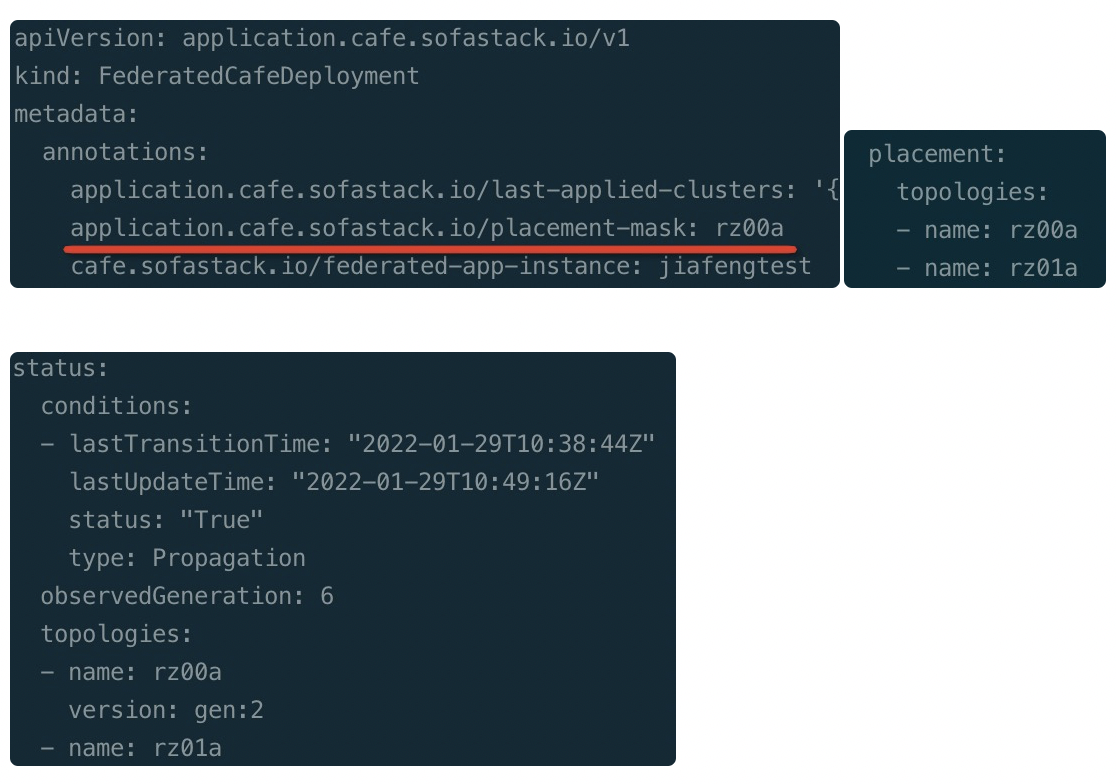
值得一提的是,placement mask 的引入不仅解决了灰度发布的问题,也解决了容灾发布的问题。在因机房灾难导致部分集群(部署单元)不可用的情况下,我们可以通过 placement mask 继续正常发布其他可用的部署单元,不会因局部异常而阻塞整个多集群的发布。而在集群恢复后,placement mask 的存在能够防止对刚恢复部署单元的预期外自动变更,保证了发布变更的强管控性。
支持自定义 Annotation 下发策略
KubeFed 对于资源的下发有一项原则,即只下发 spec 类的属性,不下发 status 类的属性。这一原则的出发点很简单:我们需要保证子集群资源的 spec 被联邦层强管控,但又要保持其 status 各自独立。对于任何 Kubernetes 对象而言,其绝大多数属性都是非 spec 即 status 的――spec 和 status 属性本身就不用说了,像 metadata 中的 name、labels 等就属于 spec,而 creationTimestamp、resourceVersion 之流则属于 status。但是,凡事皆有例外,这其中有一个属性是既能充当 spec 又能充当 status 的,它就是 annotations。
很多时候,我们无法把一个 Kubernetes 对象的所有 spec 和 status 都收敛在真正的 spec 和 status 属性内,一个最典型的例子就是 Service。对 Service 应用有所了解的同学应该知道,我们可以使用 LoadBalancer 类型的 Service 并搭配不同云厂商提供的 CCM(Cloud Controller Manager)来实现不同云平台下负载均衡的管理。由于 Service 是 Kubernetes 内置对象,其 spec 和 status 都是固定不可扩展的,而不同云厂商 CCM 支持的参数都各不相同,因此 Service 的 annotations 便自然地承载起了这些配置,起到了 spec 的作用。与此同时,部分 CCM 还支持回流负载均衡的一些具体状态到 annotations,比如创建负载均衡过程中的一些中间状态包括错误信息等,这时候 Service 的 annotations 又起到了 status 的作用。这时候 KubeFed 就面临了一个问题――究竟要不要下发 annotations 字段?社区选择了完全不下发,这固然不会影响 annotations 作为 status 的能力,但也失去了 annotations 作为 spec 时对其的管控能力。
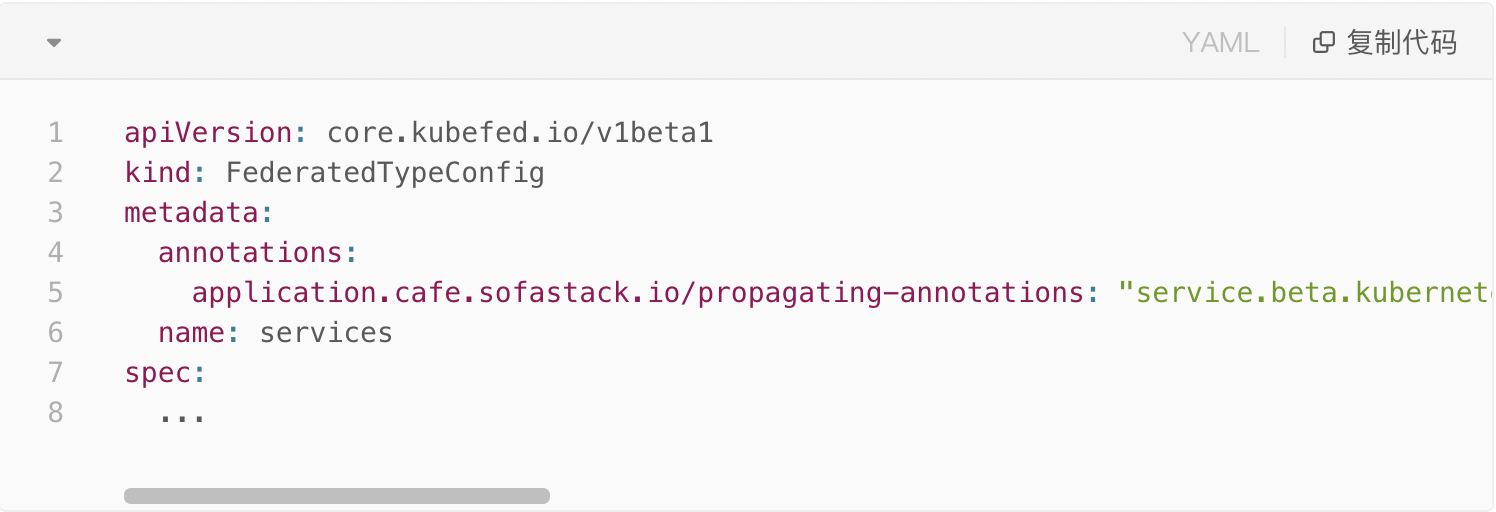
那么,有没有可能做到两者兼得呢?答案自然是有的。在 KubeFed 中,对于每一种需要多集群化的 Kubernetes 资源类型,都需要在联邦层为其创建一个 FederatedTypeConfig 对象,用于指定联邦类型与单集群类型的 GVK 等信息。既然 annotations 字段的 spec/status 特性也是和具体资源类型有关的,那么我们便可以在这个对象中做文章,为其加入了一项 propagating annotations 的配置。在该配置中,我们可以显式地指定(支持通配符)该资源类型的 annotations 中,哪些 key 是用作 spec 的,对这些 key,KubeFed controller 会进行下发和管控,而其余的 key 则作为 status 对待,不会对子集群资源上的值进行覆盖。借助这项扩展能力,我们便能灵活地自定义任意 Kubernetes 资源类型的 annotation 下发策略,实现完整的多集群资源 spec 管控能力。
以 Service 为例,我们对该类型的 FederatedTypeConfig 对象进行了如下配置:
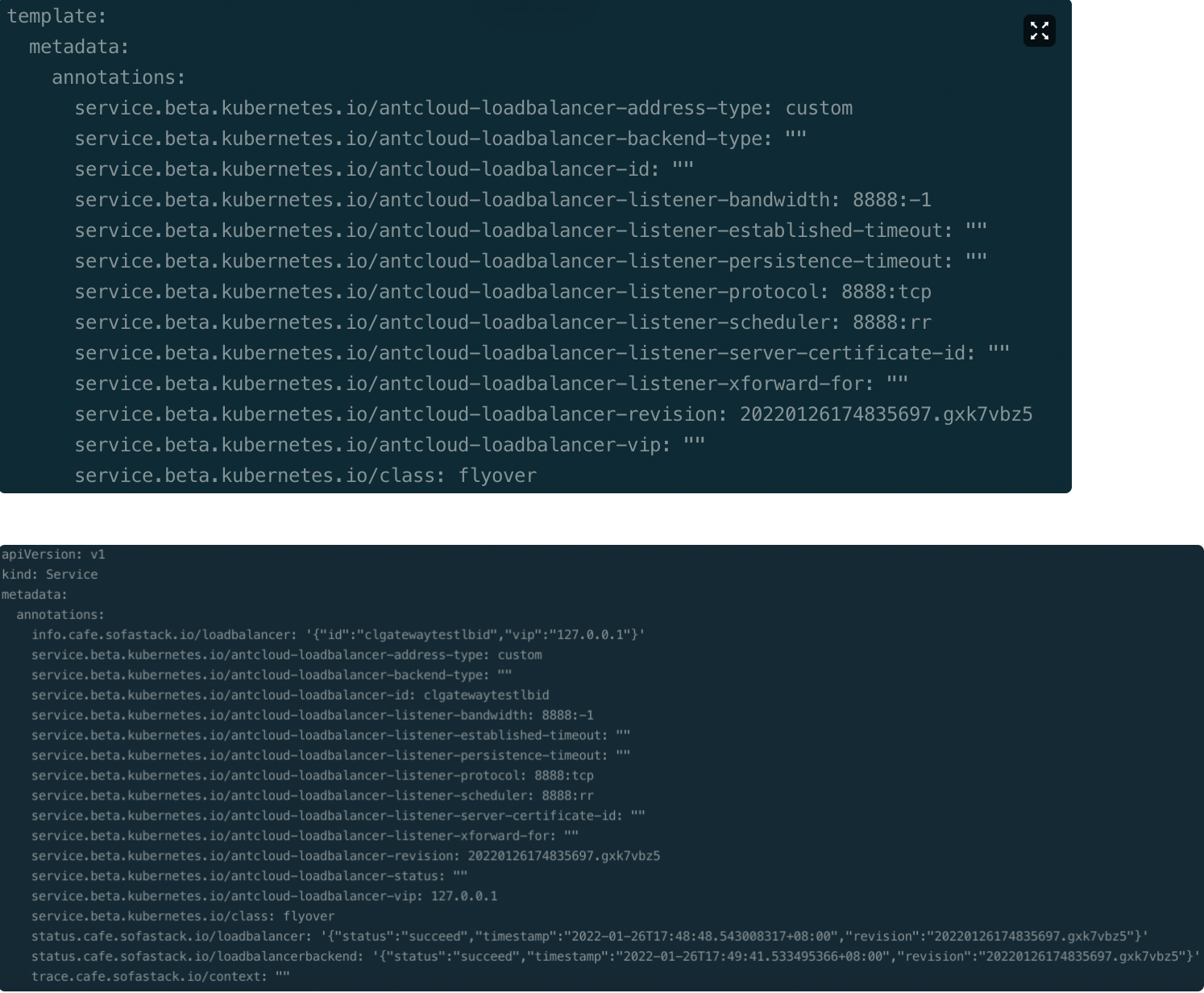
下面第一张图为 FederatedService 的 template 所指定的下发模板,第二张图为实际子集群中被管控 Service 的情况。可以看到,我们在联邦资源中指定的 spec 类 annotation(如 service.beta.kubernetes.io/antcloud-loadbalancer-listener-protocol)被成功下发到了子资源上,而属于子资源自身的 status 类 annotation(如 status.cafe.sofastack.io/loadbalancer)则被正常保留,没有因 annotations 字段的强管控而被删去或覆盖。
此外,我们还增强了 KubeFed controller 的状态回流能力,使其能够实时回流所有联邦资源类型的 status 类字段;支持了联邦层子集群访问配置的 KMS 加密存储以满足金融级安全合规需求等等,受篇幅所限不再一一展开介绍。
到这里,联邦层已经满足了上层单元化应用发布运维产品的绝大多数需求,但正如前文所提到的,我们做的是一款“混合云”的产品,在混合云场景下,异构集群与网络连通性的限制是我们运维 Kubernetes 集群会遇到的最典型的问题。对联邦层而言,由于其主要关注 Kubernetes 应用资源管理,因此集群的异构性不会带来太多影响,只要是符合一定版本范围内 Kubernetes 规范的集群理论上都能直接纳管;而网络连通性的限制则是致命的:由于 KubeFed 采用推模式进行子集群管控,它要求 KubeFed controller 需要能直接访问到每个子集群的 ApiServer,这对于网络连通性的要求是相当高的,很多情况下的网络环境都无法满足这样的要求,就算有办法满足也需要很高的成本(比如打通中枢集群与所有用户集群之间的网络)。因此,我们势必要寻求一种解法来降低联邦层对集群间网络连通性的要求,以使我们的产品能够兼容更多的网络拓扑。
集成 ApiServer Network Proxy
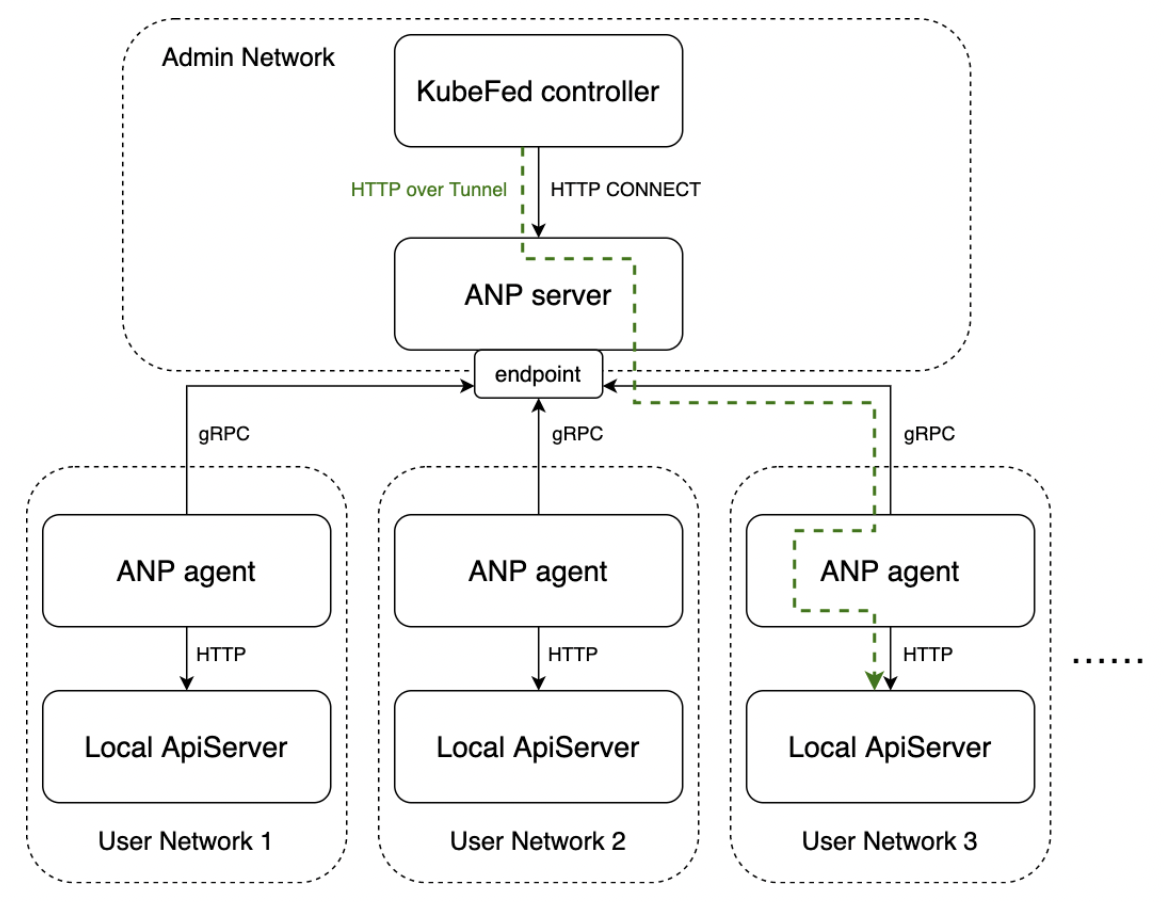
既然 KubeFed controller 到子集群 ApiServer 的直接正向连接可能受限,那么我们就需要在这两者之间架设一个能够反向建连的代理,通过该代理建立的长连接通道进行正向访问。ApiServer Network Proxy(ANP)是社区为了解决 Kubernetes 集群内部网络隔离问题而开发的 ApiServer 代理,它刚好提供了我们所需要的反向长连接代理的能力,使得我们无需正向的网络打通也能正常访问到子集群的 ApiServer。
但是,ANP 主要解决的是单集群内部访问 ApiServer 的问题,其连接模型是多个 client 访问一个 ApiServer,但对于联邦层这样的多集群管控而言,它的连接模型是一个 client 访问多个 ApiServer。为此,我们对 ANP 的后端连接模型进行了扩展,使其支持了按集群名称进行动态选址――通过在于 ANP 服务端进行建连时告知本次连接需要访问的集群,ANP 服务端就会将后续请求路由到其与上报了该集群名称的 agent 所建立的长连接通道上。最终的架构如下图所示,通过集成这一“多集群扩展版”的 ANP,我们就能够在更为严苛的网络环境下轻松地进行多集群管理了。
总结
最后,让我们通过具体产品能力来进行总结,以简要地体现 SOFAStack CAFE 多集群产品相较于社区版 KubeFed 的一些亮点:
● 借助可扩展的多拓扑联邦模型原生支持了 LDC 部署单元维度的多集群应用发布,屏蔽了底层 Kubernetes 基础设施
● 支持多租户,能够在底层对 Kubernetes 集群等资源进行租户、工作空间级别的隔离
● 打破声明式的掣肘,支持精细化的多集群灰度发布,同时支持容灾发布
● 支持自定义 annotation 下发、完整状态回流、集群访问凭证 KMS 加密等高级能力
● 借助 ANP 支持在异构混合云等网络连通性受限的情况下继续以推模式管理所有用户集群
● 多集群控制面可不依赖 Kubernetes 集群独立部署,且支持直接使用 MySQL/OB 作为后端数据库
目前,SOFAStack 已经应用在国内外 50 多家金融机构,其中浙江农信、四川农信等企业正是借助 CAFE 的单元化混合云架构来进行容器应用的全生命周期管理,构建多地域、高可用的多集群管理平台。
未来规划
从上文的实践部分中可以看出,目前我们对于底层多集群框架的应用主要还是集中在 Kubernetes 集群纳管和多集群资源治理上,但多集群的应用还有着更广阔的可能性。未来,我们也会逐步演进包括但不限于如下的能力:
● 多集群资源动态调度能力
● 多集群 HPA 能力
● 多集群 Kubernetes API 代理能力
● 直接使用单集群原生资源作为模板的轻 CRD 能力
后续,我们也会继续分享对这些能力的思考与实践,欢迎大家持续关注我们的多集群产品,也随时期盼任何意见与交流。