���ij�����Wireshark����ѧϰTCP���ӡ��Ͽ�ȫ���̡�
һ��ping����
ping��һ��ʮ��ǿ���TCP/IP���ߡ���Ҫ����:
(1)��������������ͨ����ͷ��������ٶ�;
(2)���������õ�������IP;
(3)����ping���ص�TTLֵ���ж϶Է���ʹ�õIJ���ϵͳ�����ݰ�����·����������
��Linux�¿���һ���ն�,����ping�ٶ�,�������ͼ:
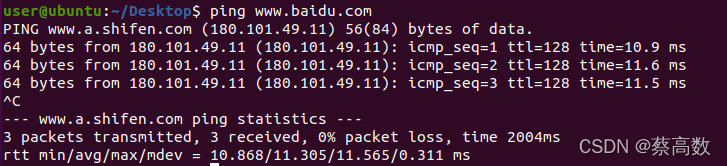
?���Կ�������������
����tcpdump����
���Ǹ����Ը���ʹ���ߵĶ���������ϵ����ݰ����нػ�İ��������ߡ�?tcpdump���Խ������д��͵����ݰ��ġ�ͷ����ȫ�ػ������ṩ��������֧���������㡢Э�顢�����������˿ڵĹ���,���ṩand��or��not�������ȥ�����õ���Ϣ����ͨ�����,ֱ������tcpdump�����ӵ�һ������ӿ����������������ݰ���
���ն��½���root�û�����,����������������:
tcpdump -i any tcp and host 180.101.49.11 -w http.pcap����ͼ:

?ѡ��-iָ������,any��ʾ���нӿ�;tcp��ʾץȡtcp���ݰ�;host��ʾץȡ��ӦIP��ַ�����ݰ�;����-w��ʾ���������ݱ�������,������ļ���Ϊhttp.pcap,��Wireshark������
����curl����
��������������URL�������ݻ����ļ�����,��Ҫ�Ȱ�װ���¿�һ���ն�,ʹ��������ȡǰ��ping�İٶ�IP��ַ����ַ�ı���Ϣ:
curl http://180.101.49.11��ʱ�ص�ԭ���Ǹ��ն�,����ctrl+C��ֹtcpdump����:

?��ʱ���Ŀ¼�����ɵ�pcap�ļ�����windows����Wireshark��
�ġ�Wireshark
����Կ�����������
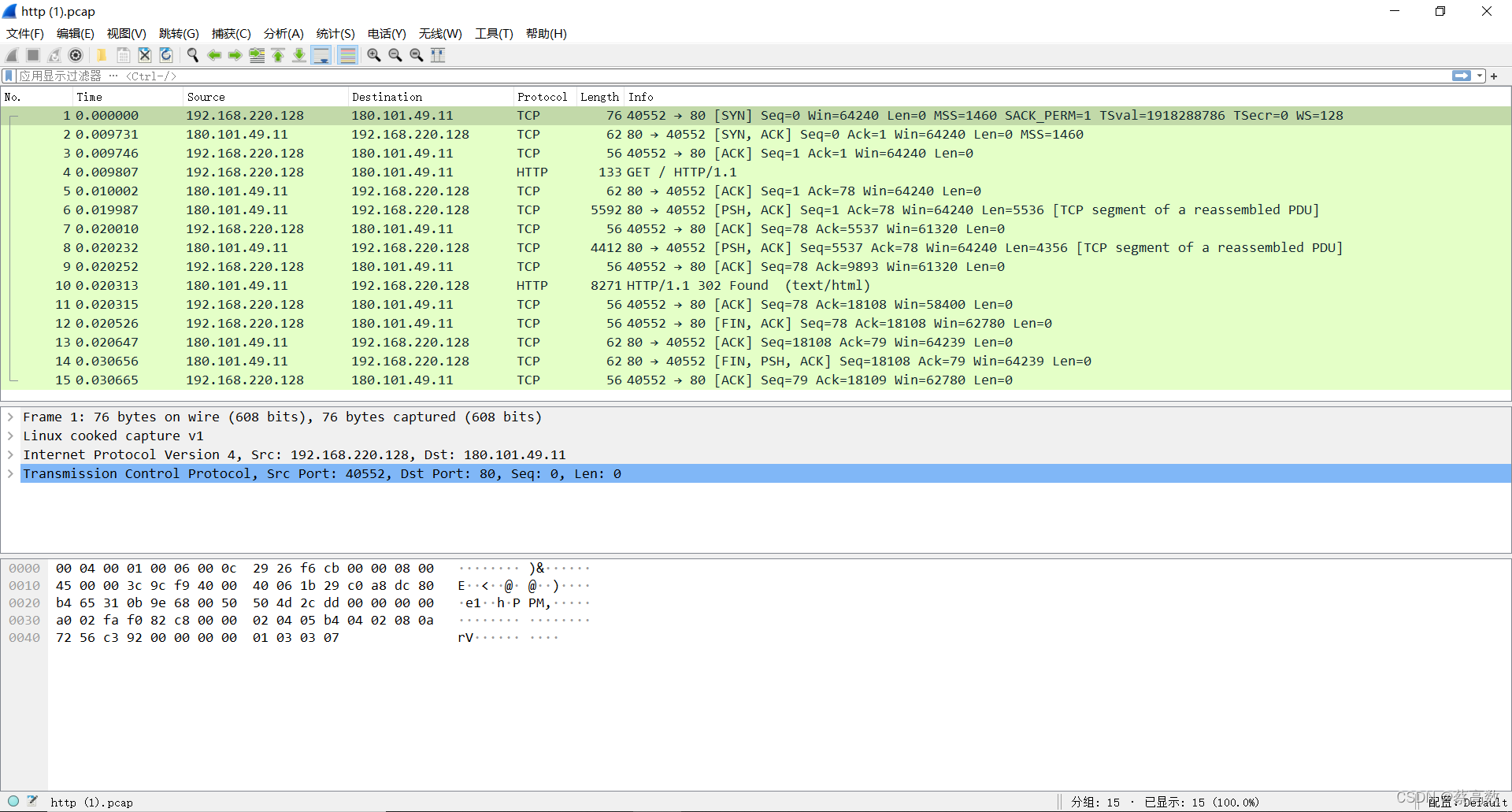
��ͷ����������TCP�������ֽ������ӵİ�,�м��� HTTP �������Ӧ�İ�,����ĸ������Ĵλ��ֶϿ����ӵİ���?
?Wireshark ������ʱ��ͼ�ķ�ʽ��ʾ���ݰ������Ĺ���,�Ӳ˵�����,��� ͳ�� (Statistics) -> ����ͼ (Flow Graph),Ȼ���ڵ����Ľ����еġ��������͡�ѡ�� ��TCP Flows��,���Ը������Ŀ������������� TCP �� ��ִ�й���:

�塢����Linux����
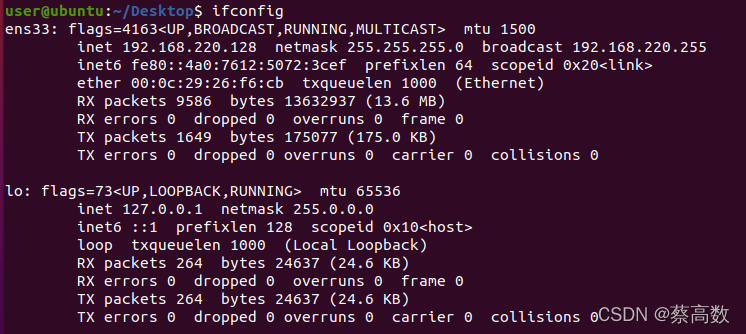
1.ifconfig
������ʾ�����������豸��
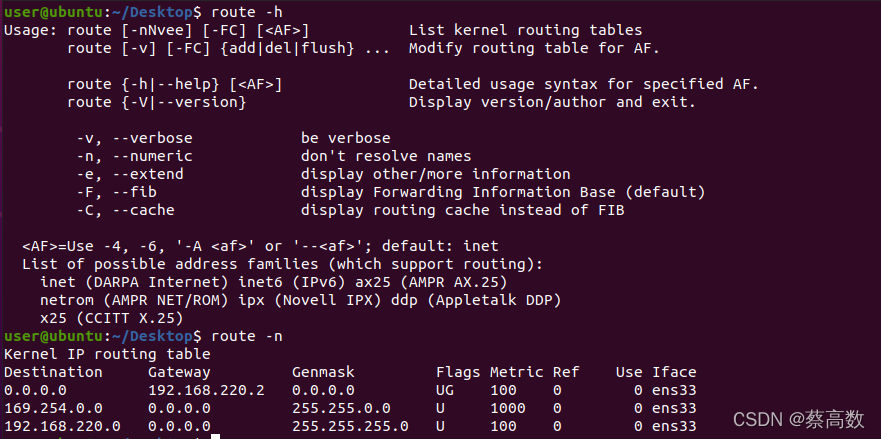
2.route
������ʾ�Ͳ���IP·�ɱ�
ѡ��:
-c?��ʾ������Ϣ
-n?����������(ֱ��ʹ��IP��ַ)
-v?��ʾ��ϸ�Ĵ�����Ϣ
-F?��ʾ������Ϣ
-C?��ʾ·�ɻ���
-f?�������������ڵ�·�ɱ���?
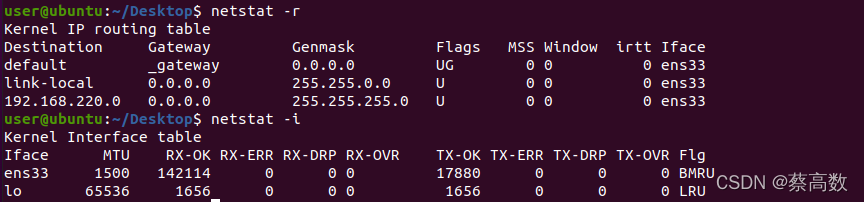
3.netstat
������ʾ����״̬,�˽����� Linux ϵͳ�����������
ѡ��:
- -i��--interfaces ��ʾ���������Ϣ������
- -l��--listening ��ʾ����еķ�������Socket��
- -M��--masquerade ��ʾαװ���������ߡ�
- -n��--numeric ֱ��ʹ��IP��ַ,����ͨ��������������
- -N��--netlink��--symbolic ��ʾ����Ӳ����Χ�豸�ķ����������ơ�
- -o��--timers ��ʾ��ʱ����
- -p��--programs ��ʾ����ʹ��Socket�ij���ʶ����ͳ������ơ�
- -r��--route ��ʾRouting Table��
4.cat
����ļ����ݵ� '>' ������ļ���ѡ��:
-n �� --number:�� 1 ��ʼ�����������������š�
-b �� --number-nonblank:�� -n ����,ֻ�������ڿհ��в���š�
-s �� --squeeze-blank:�������������������ϵĿհ���,�ʹ���Ϊһ�еĿհ��С�
-v �� --show-nonprinting:ʹ�� ^ �� M- ����,���� LFD �� TAB ֮�⡣
-E �� --show-ends?: ��ÿ�н�������ʾ $��
-T �� --show-tabs: �� TAB �ַ���ʾΪ ^I��
5.top
�������linux��ϵͳ״��,�dz��õ����ܷ�������,�ܹ�ʵʱ��ʾϵͳ�и������̵���Դռ�������
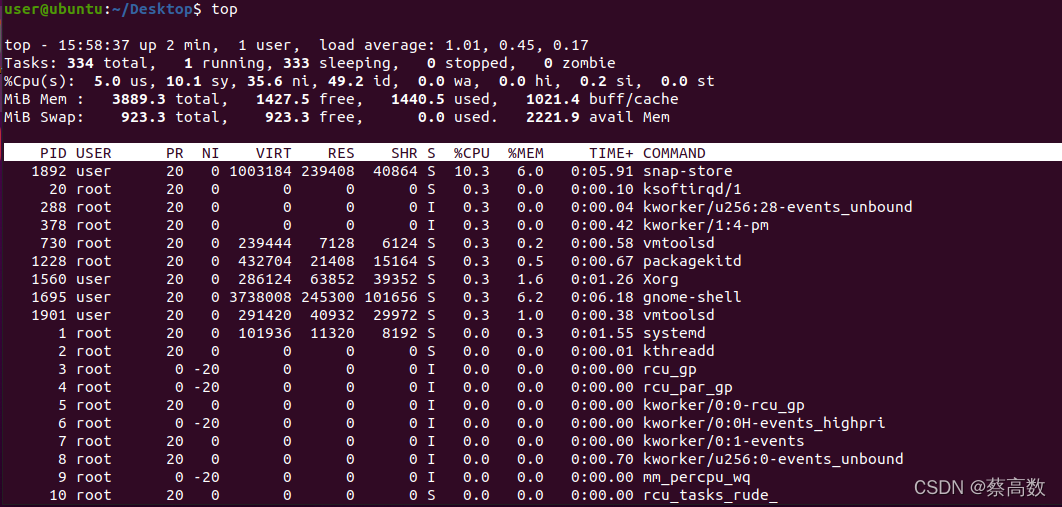
��1�������������Ϣ,���������:
����?? ?????????????????����
15:58:37? ? ? ? ? ? ?��ǰʱ��
up 2min? ? ? ? ? ? ? ϵͳ����ʱ�� ��ʽΪʱ:��
2 users?? ????????????��ǰ��¼�û���
load average: ????1.01, 0.45, 0.17? ? ϵͳ����,��������е�ƽ�����ȡ� ������ֵ�ֱ�Ϊ1���ӡ�5���ӡ�15����ǰ�����ڵ�ƽ��ֵ����������������CPU������,�������5��ʱ��ͱ���ϵͳ�ڳ�������ת�ˡ�?
��2��3��Ϊ���̺�CPU����Ϣ.���ж��CPUʱ,��Щ���ݿ��ܻᳬ������,���������:
����?? ?????????????????����
334total? ? ? ? ? ? ??��������
1 running? ? ? ??????�������еĽ�����
333 sleeping? ? ? ?˯�ߵĽ�����
0 stopped? ? ? ? ???ֹͣ�Ľ�����
0 zombie?? ?????????��ʬ������
5.0 us? ? ? ? ? ? ? ? ?�û��ռ�ռ��CPU�ٷֱ�
10.1 sy?? ????????????�ں˿ռ�ռ��CPU�ٷֱ�
35.6 ni? ? ? ? ? ? ? ? �û����̿ռ��ڸı�����ȼ��Ľ���ռ��CPU�ٷֱ�
49.2 id? ? ? ? ? ? ? ? ����CPU�ٷֱ�
0.0 wa? ? ? ? ? ? ? ? �ȴ����������CPUʱ��ٷֱ�
0.0 hi? ? ? ? ? ? ? ? ? Ӳ�ж�(Hardware IRQ)ռ��CPU�İٷֱ�
0.2?si? ? ? ? ? ? ? ? ? ���ж�(Software Interrupts)ռ��CPU�İٷֱ�
0.0 st?? ??
��4��5��Ϊ�ڴ���Ϣ,���������:
����? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?����
MiB Mem: 3889.3 total?? ?????????�����ڴ�����
1427.5? free? ? ? ? ? ? ? ? ? ? ? ???????�����ڴ�����
1440.5 ?used?? ? ? ? ? ? ? ? ? ????????ʹ�õ������ڴ�����
1021.4 buffers(buff/cache)?�����ں˻�����ڴ���
MiB Swap: 923.3 total? ? ? ? ? ? ?����������
923.3 free?? ?????????????????????????????�����������
0 used? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ʹ�õĽ���������
2221.9 avail Mem? ? ? ? ? ? ? ? ? ? ���������ڽ�����һ�η���������ڴ�����
��������ڴ�����һ�����ƵĹ�ʽ:?
�����е�free + �����е�buffers + �����е�cached
������Ϣ:
PID?? ?????????????����id
USER?? ?????????���������ߵ��û���
PR?? ??????????????���ȼ�
NI? ? ? ? ? ? ? ? ? ?niceֵ����ֵ��ʾ�����ȼ�,��ֵ��ʾ�����ȼ�
%CPU? ? ? ? ? ?�ϴθ��µ����ڵ�CPUʱ��ռ�ðٷֱ�
TIME? ? ? ? ? ? ?����ʹ�õ�CPUʱ���ܼ�,��λ��
TIME+? ? ? ? ? ?����ʹ�õ�CPUʱ���ܼ�,��λ1/100��
%MEM? ? ? ? ? ����ʹ�õ������ڴ�ٷֱ�
VIRT? ? ? ? ? ? ?����ʹ�õ������ڴ�����,��λkb��VIRT=SWAP+RES
SWAP? ? ? ? ? ?����ʹ�õ������ڴ���,�������Ĵ�С,��λkb
RES? ? ? ? ? ? ? ����ʹ�õġ�δ�������������ڴ��С,��λkb��RES=CODE+DATA
CODE? ? ? ? ? ?��ִ�д���ռ�õ������ڴ��С,��λkb
DATA? ? ? ? ? ? ?��ִ�д�������IJ���(���ݶ�+ջ)ռ�õ������ڴ��С,��λkb
SHR? ? ? ? ? ? ? �����ڴ��С,��λkb
nFLT? ? ? ? ? ? ?ҳ��������
nDRT? ? ? ? ? ? ���һ��д�뵽����,���Ĺ���ҳ������
S? ? ? ? ? ? ? ? ? ?����״̬��D=�����жϵ�˯��״̬ R=���� S=˯�� T=����/ֹͣ Z=��ʬ����
COMMAND?? ?������/������
?����ʹ��ѡ��:?top [-d number] | top [-bnp]
-d:number��������,��ʾtop������ʾ��ҳ�����һ�εļ����Ĭ����5�롣 -b:�����εķ�ʽִ��top�� -n:��-b���ʹ��,��ʾ��Ҫ���м���top������������� -p:ָ���ض���pid���̺Ž��й۲졣
��top������ʾ��ҳ�滹�����������°���ִ����Ӧ�Ĺ���(���ִ�Сд):
?:��ʾ��top���п������������ P:��CPU��ʹ����Դ������ʾ M:���ڴ��ʹ����Դ������ʾ N:��pid������ʾ T:�ɽ���ʹ�õ�ʱ���ۼ�������ʾ k:��ijһ��pidһ���źš���������ɱ������ r:��ij��pid���¶���һ��niceֵ(�����ȼ�) q:�˳�top(��ctrl+cҲ�����˳�top)��
6.sar
�÷�
Usage: sar [ options ] [ <interval> [ <count> ] ]ѡ��:
-A:���б�����ܺ�
-b:��ʾI/O�ʹ������ʵ�ͳ����Ϣ
-B:��ʾ��ҳ״̬
-d:���ÿһ����̵�ʹ����Ϣ
-e:������ʾ����Ľ���ʱ��
-f:���ƶ����ļ���ȡ����
-i:����״̬��Ϣˢ�µļ��ʱ��
-P:����ÿ��CPU��״̬
-R:��ʾ�ڴ�״̬
�Cu:���cpuʹ�������ͳ����Ϣ
�Cv:��ʾ�����ڵ㡢�ļ��������ں˱���״̬
-w:��ʾ����������״̬
-r:�����ڴ������ʵ�ͳ����Ϣ�鿴CPU�������:
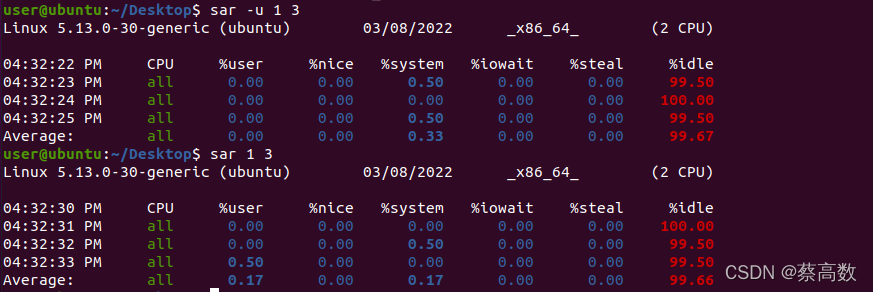
%user ? �û��ռ��CPUʹ����
%nice ? �ı�����ȼ��Ľ��̵�CPUʹ����
%system ? �ں˿ռ��CPUʹ����
%iowait ? CPU�ȴ�IO�İٷֱ�?
%steal ? ������������CPUʹ�õ�CPU
%idle ? ���е�CPU%iowait���߱�ʾ����I/Oƿ��,������IO������ҵ������,���%idle���ͱ�ʾCPUʹ���ʱȽ�����,��Ҫ����ڴ�ʹ�õ�����ж�CPU�Ƿ�ƿ����
7.ps
ps?������?Process Status?����д,�����г�ϵͳ�е�ǰ�������е���Щ���̡�

ps ������÷�(����鿴ϵͳ����)
1)ps a ��ʾ�����ն˻��µ����г���,���������û��ij���
2)ps -A ��ʾ���н��̡�
3)ps c �г�����ʱ,��ʾÿ������������ָ������,��������·��,������פ����ı�ʾ��
4)ps -e �˲�����Ч����ָ��"A"������ͬ��
5)ps e �г�����ʱ,��ʾÿ��������ʹ�õĻ���������
6)ps f �� ASCII �ַ���ʾ��״�ṹ,������������ϵ��
7)ps -H ��ʾ��״�ṹ,��ʾ���������ϵ��
8)ps -N ��ʾ���еij���,����ִ��psָ���ն˻��µij���֮�⡣
9)ps s ���ó����źŵĸ�ʽ��ʾ����״����
10)ps S �г�����ʱ,�������жϵ��ӳ������ϡ�
11)ps -t<�ն˻����> ��ָ���ն˻����,���г����ڸ��ն˻��ij����״����
12)ps -u root ����ʾroot�û���Ϣ
13)ps x �� ��ʾ���г���,�����ն˻������֡�8.grep
grep�����Dz���,��һ��ǿ����ı���������,����ʹ���������ʽ�����ı�,����ƥ����д�ӡ������ȫ����Global Regular Expression Print,��ʾȫ���������ʽ�汾����ʱ��psһ��ʹ�á�
�÷�:
Usage: grep [OPTION]... PATTERNS [FILE]...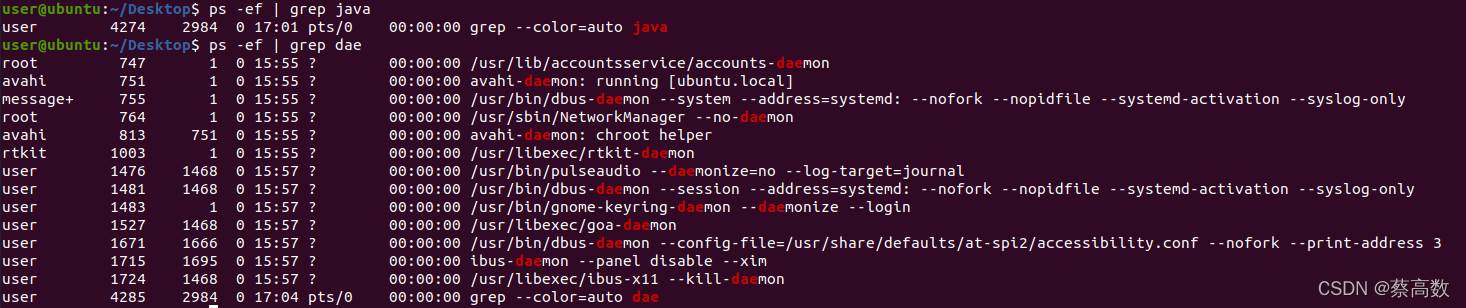
����ѡ��:
--help
-V, --version
-G, --basic-regexp BRE ģʽ,Ҳ��Ĭ�ϵ�ģʽ
-E, --extended-regexp ERE ģʽ
-P, --perl-regexp PRE ģʽ
-F, --fixed-strings ָ����ģʽ������Ϊ�ַ���
-i ���Դ�Сд
-o ֻ���ƥ�䵽�IJ���(������������)
-v ����ѡ��,�����û��û��ƥ�����
-c �����ҵ��ķ����еĴ���
-n ˳������к�?9.sed
sed �����սű���ָ�����������༭�ı��ļ�����Ҫ�����Զ��༭һ�������ļ������ļ��ķ�����������дת������ȡ��÷�:
Usage: sed [OPTION]... {script-only-if-no-other-script} [input-file]...����:?
- -e<script>��--expression=<script> ��ѡ����ָ����script������������ı��ļ���
- -f<script�ļ�>��--file=<script�ļ�> ��ѡ����ָ����script�ļ�������������ı��ļ���
- -h��--help ��ʾ������
- -n��--quiet��--silent ����ʾscript������Ľ����
- -V��--version ��ʾ�汾��Ϣ��
10.tail
���ڲ鿴�ļ�������,�����ʽ:
tail [����] [�ļ�]����:
- -f ѭ����ȡ
- -q ����ʾ������Ϣ
- -v ��ʾ��ϸ�Ĵ�����Ϣ
- -c<��Ŀ> ��ʾ���ֽ���
- -n<����> ��ʾ�ļ���β�� n ������
- --pid=PID ��-f����,��ʾ�ڽ���ID,PID����֮�����
- -q, --quiet, --silent �Ӳ���������ļ������ײ�
- -s, --sleep-interval=S ��-f����,��ʾ��ÿ�η����ļ������S��
11.kill
����̷����ź�,�÷�:
kill: kill [-s sigspec | -n signum | -sigspec] pid | jobspec ... or kill -l [sigspec]-l�����г������ź�?
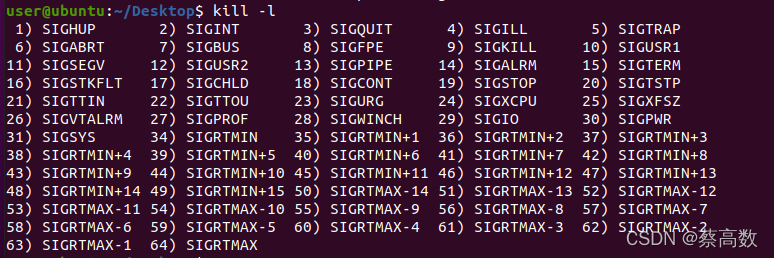
12.awk
awk ��һ�ֱ������,������linux/unix�¶��ı������ݽ��д��������ݿ������Ա����롢һ�������ļ�,��������������(���ܵ�)����֧���û��Զ��庯����?��̬�������ʽ���Ƚ�����,��linux/unix�µ�һ��ǿ���̹��ߡ�������������ʹ��,����������Ϊ�ű���ʹ�á�
awk�Ĵ����ı������ݵķ�ʽ���� ����,������ɨ���ļ�,�ӵ�һ�е����һ��,Ѱ��ƥ����ض�ģʽ����,������Щ���Ͻ�������Ҫ�IJ��������û��ָ����������,���ƥ�������ʾ������� (��Ļ),��Ĭ�ϴ���������print;���û��ָ��ģʽ,�����б�������ָ�����ж�������,��Ĭ��ָ��ģʽ��ȫ����awk�ֱ�������������ϵĵ�һ����ĸ����Ϊ����������������,�ֱ���Alfred Aho��Brian Kernighan��Peter Weinberger��gawk��awk��GNU�汾,���ṩ��Bellʵ���Һ�GNU��һЩ��չ��
��shellһ��,awkҲ�кü���,��������awk��nawk��mawk��gawk���÷�:
Usage: mawk [Options] [Program] [file ...]ѡ�����:
- -F fs or --field-separator fs
ָ�������ļ��۷ָ���,fs��һ���ַ���������һ���������ʽ,��-F:��- -v var=value or --asign var=value
��ֵһ���û����������- -f scripfile or --file scriptfile
�ӽű��ļ��ж�ȡawk���
13.�鿴��־��������
? ? tail: ?
? ? ? ?-n ?����ʾ�к�;�൱��nl����;��������:
? ? ? ? ? ??tail -100f syslog.log ? ? ?ʵʱ���100����־
? ? ? ? ? ? tail? -n? 10? syslog.log ? ��ѯ��־β�����10�е���־;
? ? ? ? ? ? tail -n +10 syslog.log??? ��ѯ10��֮���������־;
? ? head: ?
? ? ? ? ��tail���෴��,tail�ǿ����������־;��������:
? ? ? ? ? ? head -n 10? syslog.log ? ��ѯ��־�ļ��е�ͷ10����־;
? ? ? ? ? ? head -n -10? syslog.log ? ��ѯ��־�ļ��������10�е�����������־;
? ? cat:?
? ? ? ? tac�ǵ���鿴,��cat���ʷ�д;��������:
? ??? ? ? ? cat -n syslog.log |grep "debug" ? ��ѯ�ؼ��ֵ���־ʾ��:
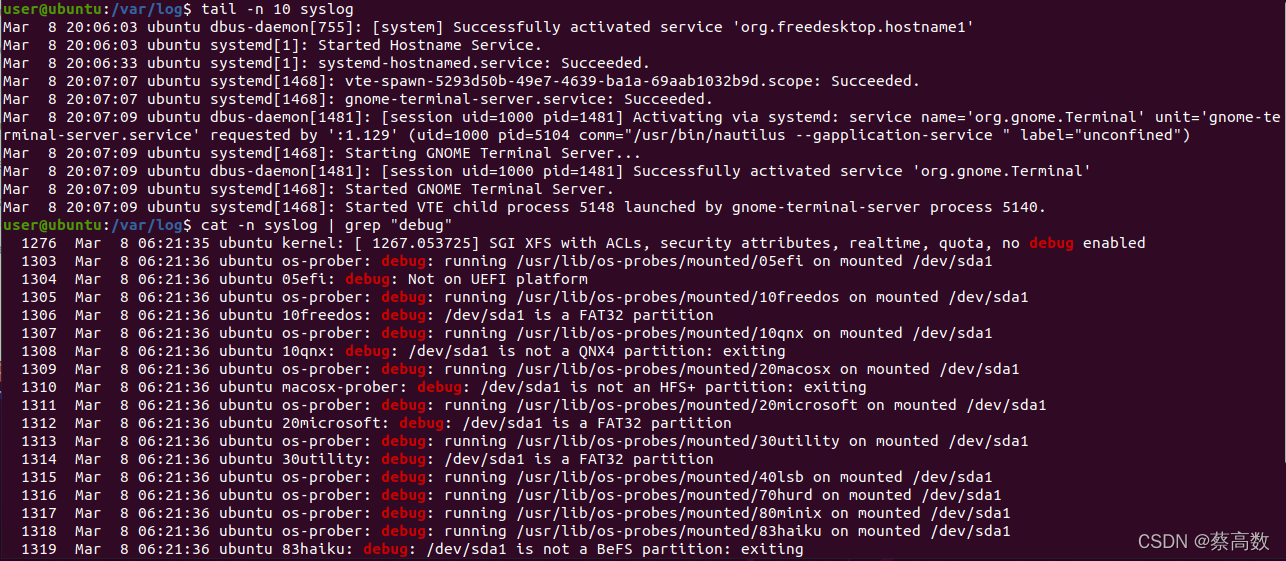
?