���̻�������
�α�����:�����һ��ִ��ʵ��,����ִ�еij����
�ں˹۵�:��������ϵͳ��Դ(CPUʱ��,�ڴ�)��ʵ�塣
��������-PCB
ϵͳ�пɲ����ܴ��ڴ����Ľ��� ?����,
����ϵͳ�������� ? ����ġ�
��ι���������?? ������,����֯
�κν������γ�֮ʱ,����ϵͳҪΪ�ý��̴���PCB,���̿��ƿ�
struct PCB{
//���̵����е�����
}
��OS����,PCB,���̿��ƿ�,����һ���ṹ������
��Linuxϵͳ��,PCB->struct task_struct {//���̵����е�����}
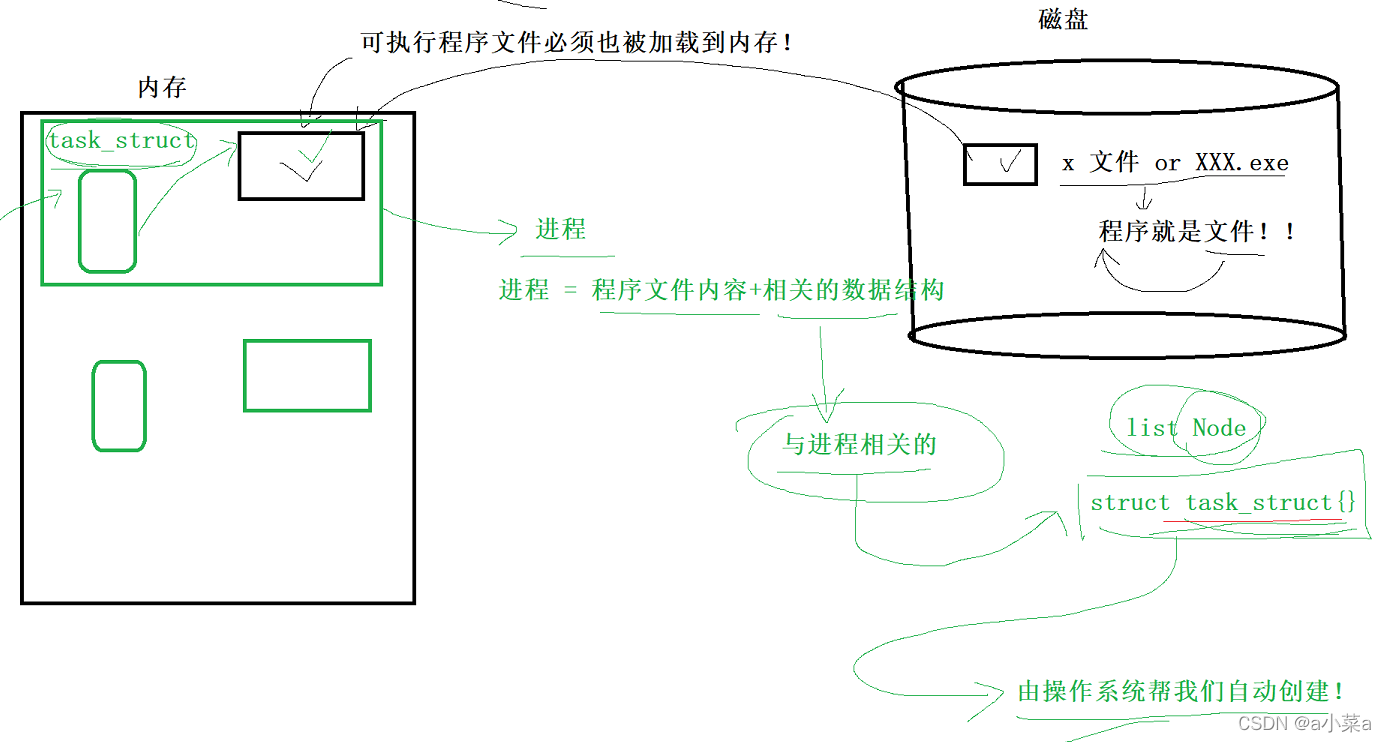
�����ļ�����+��ص����ݽṹ=����

����5������൱�ڴ����еĿ�ִ�г�����ص��ڴ���,�γ�5������,����ϵͳΪ�˹�����5�����̱���������,����֯;Ϊÿһ�����̴���һ��task_struct�Ľṹ��,��������ÿһ�����̵��������
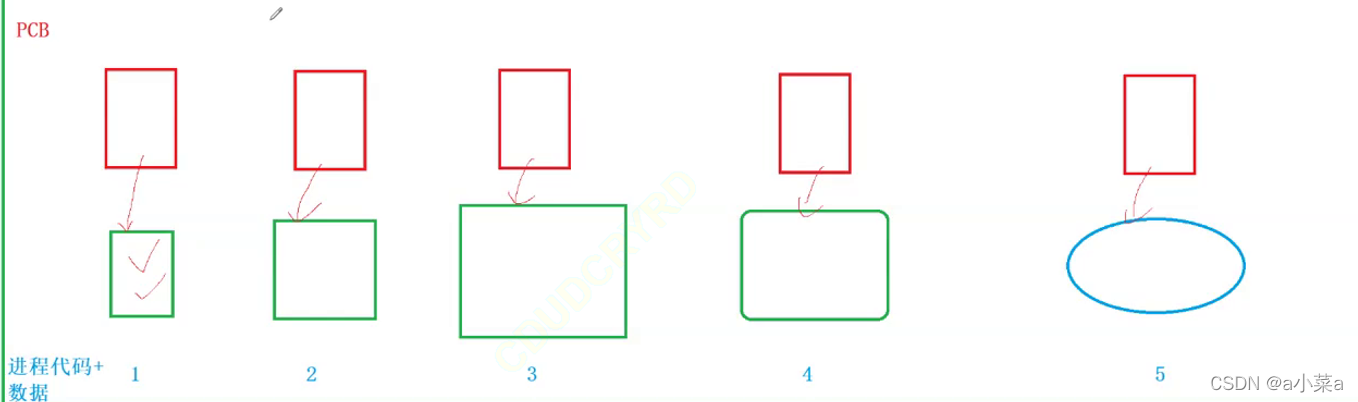
���ҽ��̾����ҽ��̵�task_struct
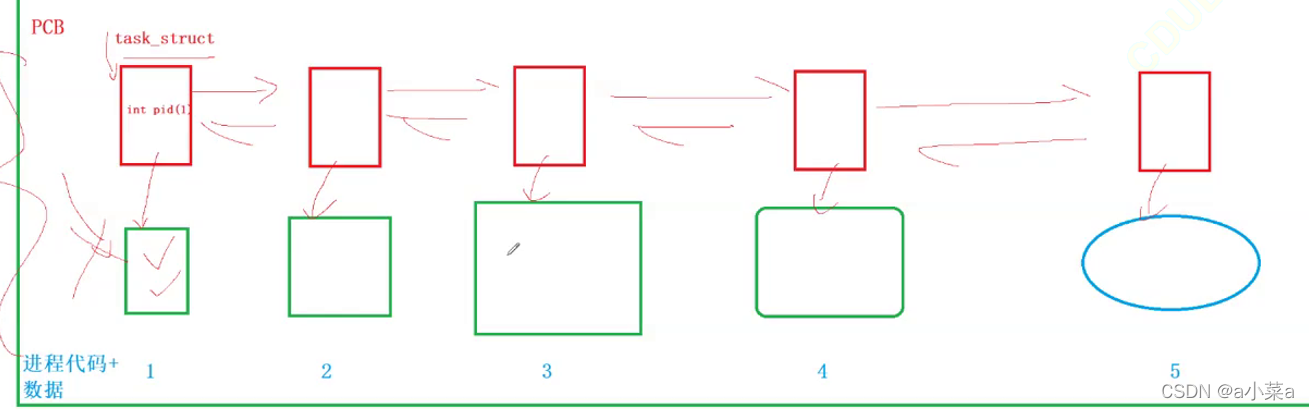
��ͼ����һ�������Ľ���

���˽��̿��ƿ�,���еĽ��̹�����������̶�Ӧ�ij������ϵ!!!,����̶�Ӧ���ں˴����ĸý��̵�PCBǿ���!
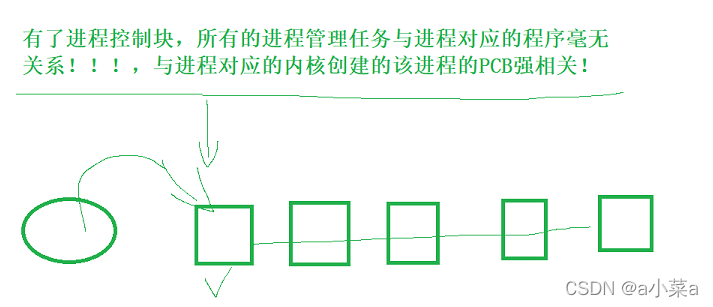
���� vs ����
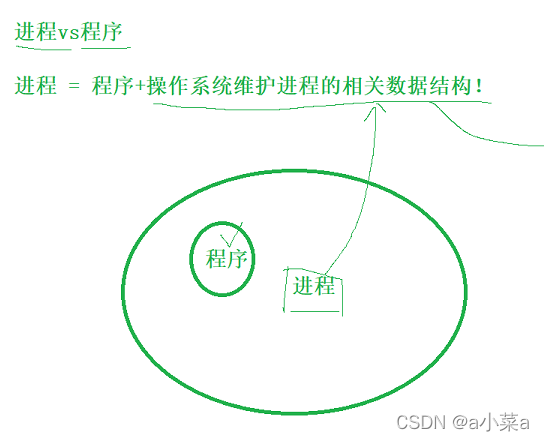
�����������е���������Ĺ���,���ʶ�����ϵͳ���洴������!! !
task_struct-PCB��һ��
��Linux���������̵Ľṹ�����task_struct��
task_struct��Linux�ں˵�һ�����ݽṹ,���ᱻװ�ص�RAM(�ڴ�)�ﲢ�Ұ����Ž��̵���Ϣ��
task_ struct���ݷ���
��ʾ��: ���������̵�Ψһ��ʾ��,���������������̡�
״̬: ����״̬,�˳�����,�˳��źŵȡ�
���ȼ�: ������������̵����ȼ���(�Ⱥ������)
���������: �����м�����ִ�е���һ��ָ��ĵ�ַ��
�ڴ�ָ��: �����������ͽ���������ݵ�ָ��,���к��������̹������ڴ���ָ��
����������: ����ִ��ʱ�������ļĴ����е����� [��ѧ����,Ҫ��ͼCPU,�Ĵ���]��
I/O״̬��Ϣ: ������ʾ��I/O����,��������̵�I/O�豸�ͱ�����ʹ�õ��ļ��б��� ������Ϣ: ���ܰ���������ʱ���ܺ�,ʹ�õ�ʱ�����ܺ�,ʱ������,���˺ŵȡ�
������Ϣ
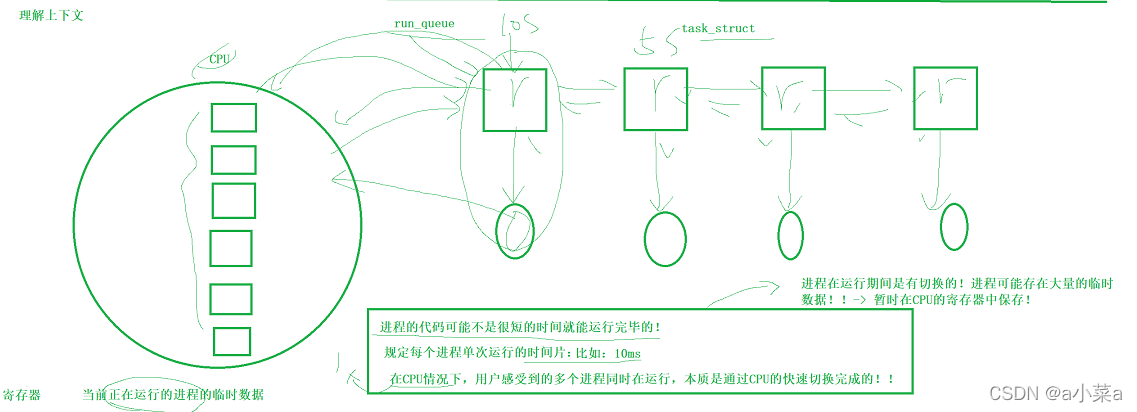
ͨ��������,�����ܸ��ܵ������DZ��л���!!!
Ϊ������ȥ����������,��������ǰ,����,�������������ѧϰ��ʱ��,���Խ���֮ǰ���ѧϰ����,����ѧϰ
��֯����
�������ں�Դ�������ҵ���������������ϵͳ��Ľ��̶���task_struct��������ʽ�����ں��
�鿴����
ͨ��ϵͳ���û�ȡ���̱�ʾ��
����id(PID)
������id(PPID)
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main(){
while(1){
printf("hello world! pid: %d\n",getpid());
sleep(1);
}
return 0;
}
������ѭ���Ĵ���,�������Dz鿴
<sys/ypyes.h>��ϵͳͷ�ļ�
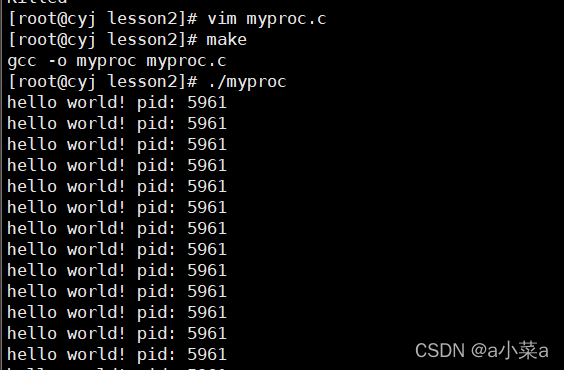
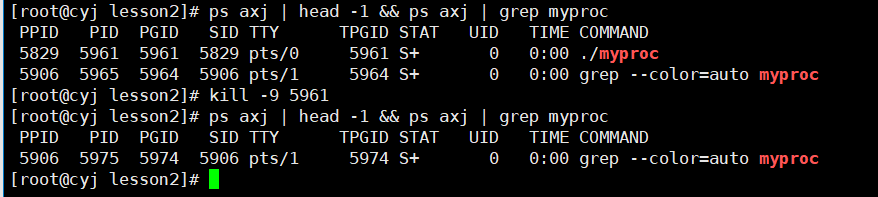
��ͼչʾ�ľ���linux�����´������̺ͽ�������
ͨ��kill -9 ����pid�ɽ�������
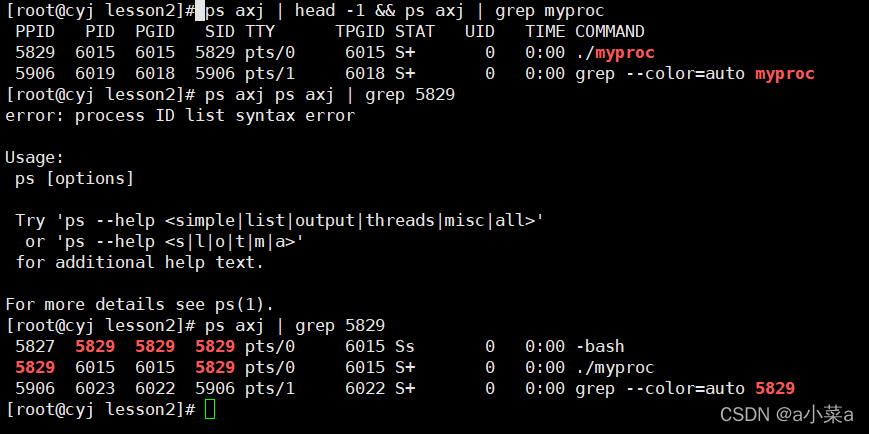
�������������е�����,�����ϸ����̶���bash
�鿴���̵ĵڶ��ַ�ʽ
ͨ��ϵͳ���ô�������-fork��ʶ
���� man fork ��ʶfork
fork����������ֵ
���ӽ��̴�������(����ֻ��һ��,�����Ա���),���ݸ��Կ��ٿռ�,˽��һ��(ͨ����дʱ����"����ɽ������ݵĶ�����)
fork ֮��ͨ��Ҫ�� if ���з���
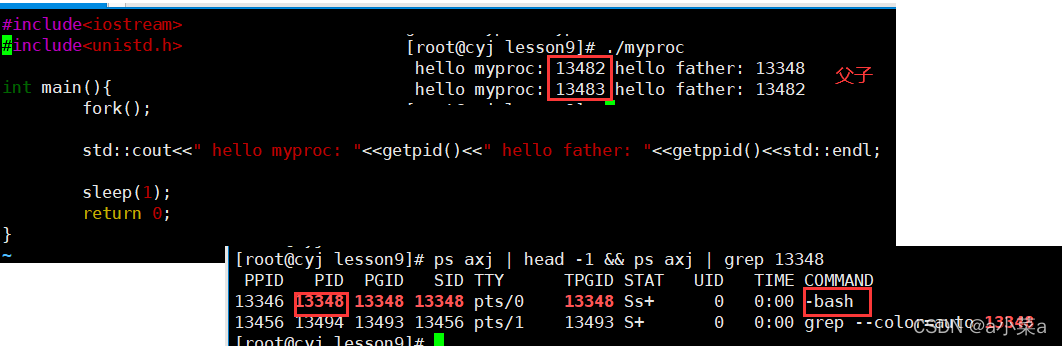
�������fork�����ӽ���
- ./cmd or run command,fork:�ڲ���ϵͳ�Ƕ�,����Ĵ������̵ķ�ʽ,û�в���! ! !
- fork�����Ǵ�������,Ҳ����ϵͳ�����һ������ �������ص��ں����ݽṹ(task_struct)+���̵Ĵ����������ϵͳ�������һ��
����ֻ��fork��,�������ӽ���,�����ӽ��̶�Ӧ�Ĵ����������? ? ?
Ĭ�������,�ᡰ�̳С������̵Ĵ��������
�ں����ݽṹtask_struct ,Ҳ���Ը�����Ϊģ��,��ʼ���ӽ��̵�task struct
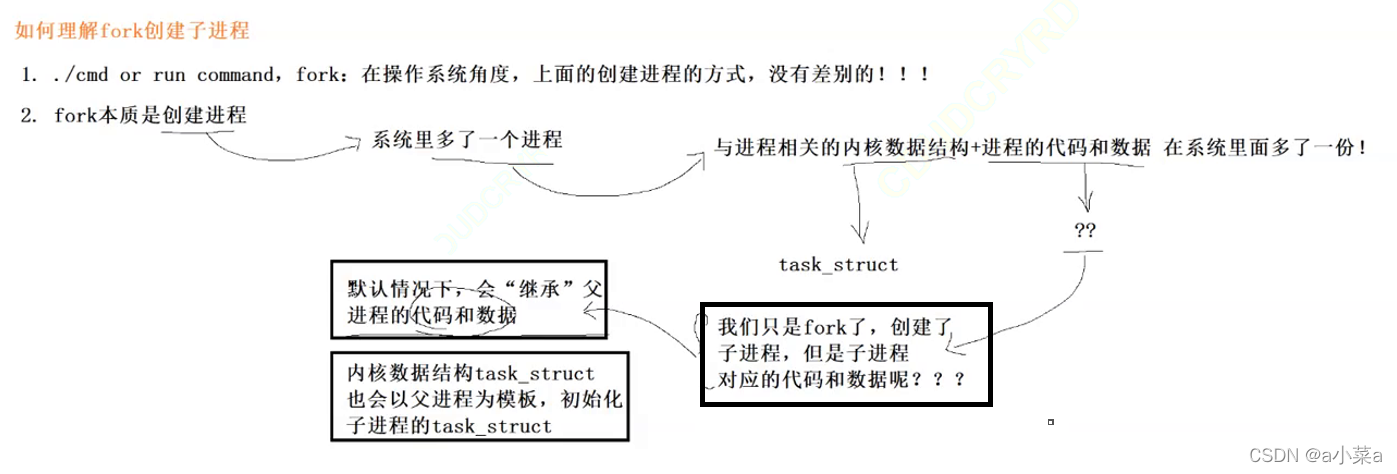
���Ǵ������ӽ���,����Ϊ�˺�������һ��������??? ����һ����û������� ! ! !
ͨ��if else ����,�ø�������һ��������!
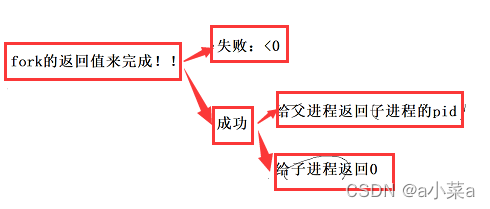
fork�ķ���ֵ�����!!
ʧ��: <0
�ɹ� �ٸ������̷����ӽ��̵�pid �ڸ��ӽ��̷���0
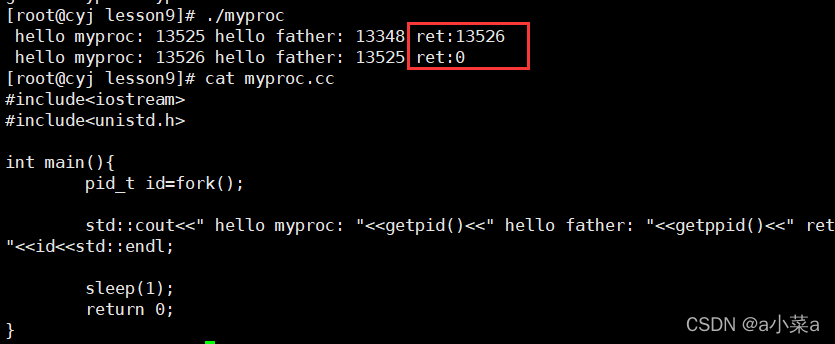
#include<iostream>
#include<unistd.h>
int main(){
pid_t id=fork();
if(id ==0 ){
//child
while(true){
std::cout<<" I am child, pid: "<<getpid()<<",ppid:"<<getppid()<<std::endl;
sleep(1);
}
}else if(id > 0){
//father
while(true){
std::cout<<" I am father, pid: "<<getpid()<<",ppid: "<<getppid()<<std::endl;
sleep(2);
}
}else{
//TODL
}
sleep(1);
return 0;
}
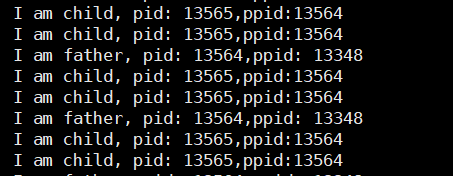

fork֮��,����˭������?? ���Dz�ȷ����,��Ҫ��������
����״̬
����Linux�ں�Դ������ô˵
Ϊ��Ū�����������еĽ�����ʲô��˼,������Ҫ֪�����̵IJ�ͬ״̬��һ�����̿����м���״̬(��Linux�ں���,������ʱ��Ҳ��������)��
�����״̬��kernelԴ�����ﶨ��:
/*
* The task state array is a strange "bitmap" of
* reasons to sleep. Thus "running" is zero, and
* you can test for combinations of others with
* simple bit tests.
*/
static const char * const task_state_array[] = {
"R (running)", /* 0 */
"S (sleeping)", /* 1 */
"D (disk sleep)", /* 2 */
"T (stopped)", /* 4 */
"t (tracing stop)", /* 8 */
"X (dead)", /* 16 */
"Z (zombie)", /* 32 */
};
����R����״̬(running) :������ζ�Ž���һ����������,����������Ҫô����������Ҫô�����ж����
����S˯��״̬(sleeping):��ζ�Ž����ڵȴ��¼����(�����˯����ʱ��Ҳ�������ж�˯����
����D��������״̬(Disksleep):��ʱ��Ҳ�в����ж�˯��״̬(���˯��)(uninterruptible sleep),�����״̬�Ľ���ͨ����ȴ�IO�Ľ�����
����Tֹͣ״̬(stopped): ����ͨ������ SIGSTOP �źŸ�������ֹͣ(T)���̡��������ͣ�Ľ��̿���ͨ������ SIGCONT�ź��ý��̼������С�
����X����״̬(dead):���״ֻ̬��һ������״̬,�㲻���������б�������״̬��
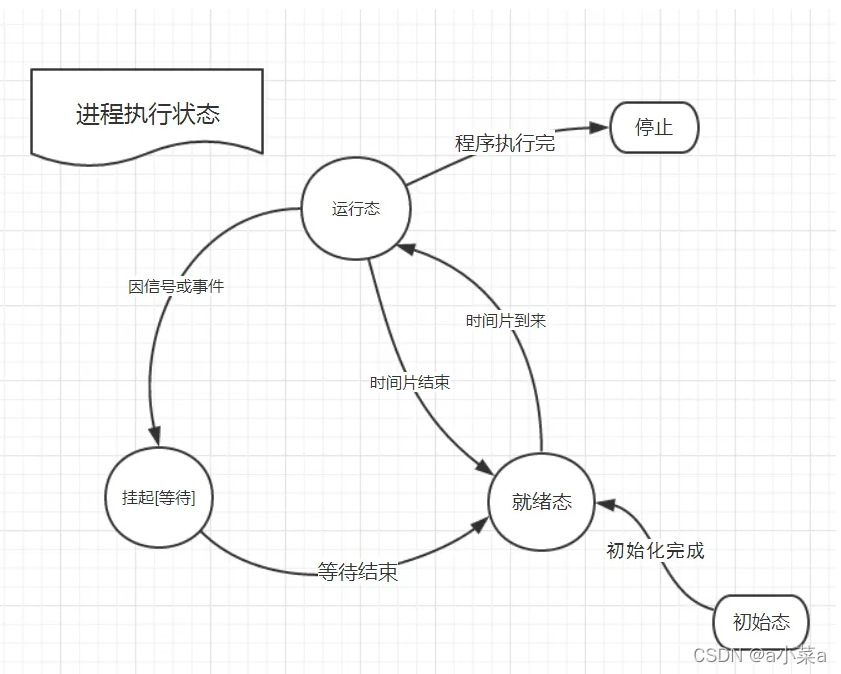
���̵�״̬��Ϣ��������?? --> task_struct (PCB)
����״̬������:����OS�����жϽ���,����ض��Ĺ���,�������,������һ�ַ���!
R����״̬(running)
������״̬ΪRʱ,Ҳ��������״̬,һ������ռ��CPU��?? ��һ��!!!
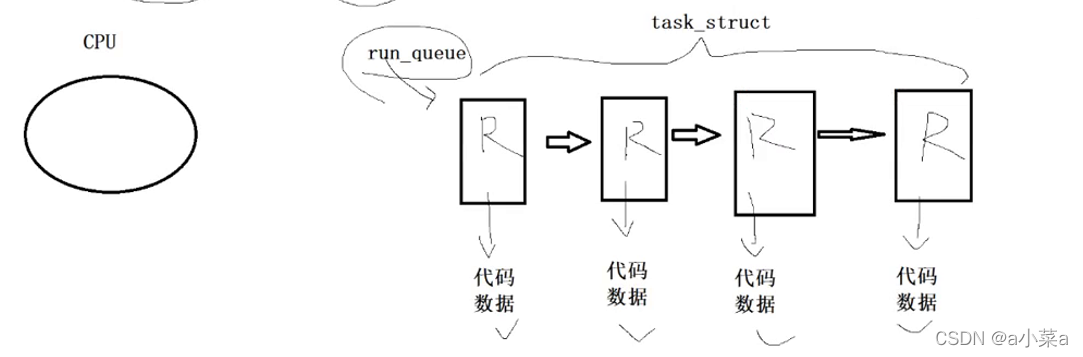
ǧ��Ҫ��Ϊ,����ֻ��ȴ�CPU��Դ!!!����������Դ!!
��ʾ

S˯��״̬(sleeping) D��������״̬(Disksleep)
���������ij�������ʱ��,�����������߱�,��Ҫ���̽���ij�ֵȴ�(S,D)��
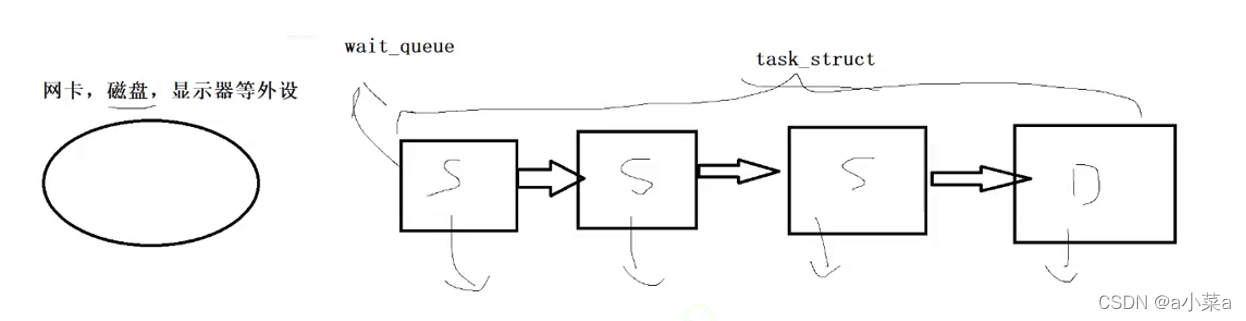
���ǰ�,������״̬��task_struct(run_queue),�ŵ��ȴ�������,�ͽ�������ȴ�(����)�ӵȴ�����,�ŵ����ж���,��CPU���Ⱦͽ������ѽ���!!
��ν�Ľ��������е�ʱ��,�п�����Ϊ������Ҫ,���Ի��ڲ�ͬ�Ķ�����!!!
�ڲ�ͬ�Ķ�����,������״̬�Dz�һ����!!
��ʾ
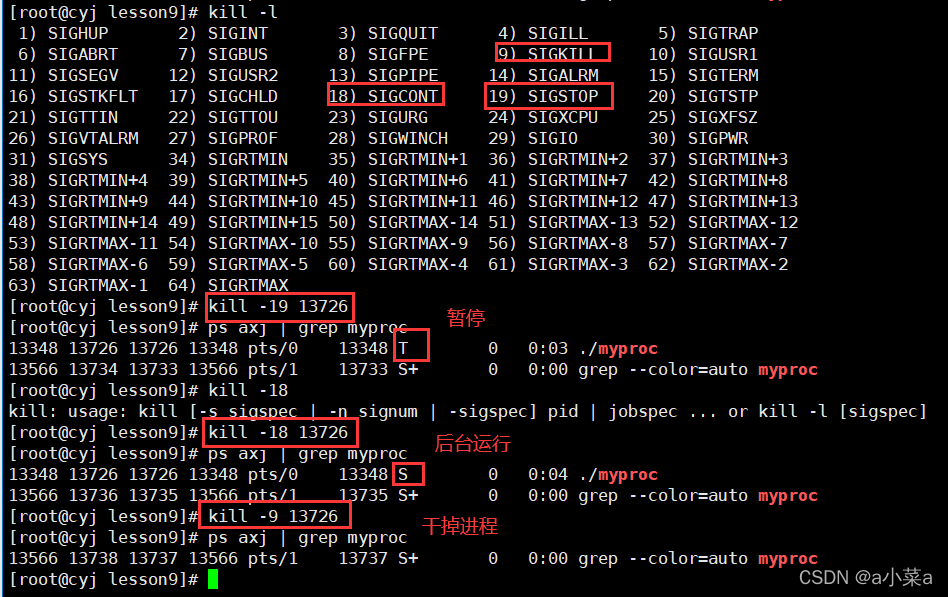
X����״̬(dead)
���� --> ���ս�����Դ = ������ص��ں����ݽṹ + ��Ĵ��������
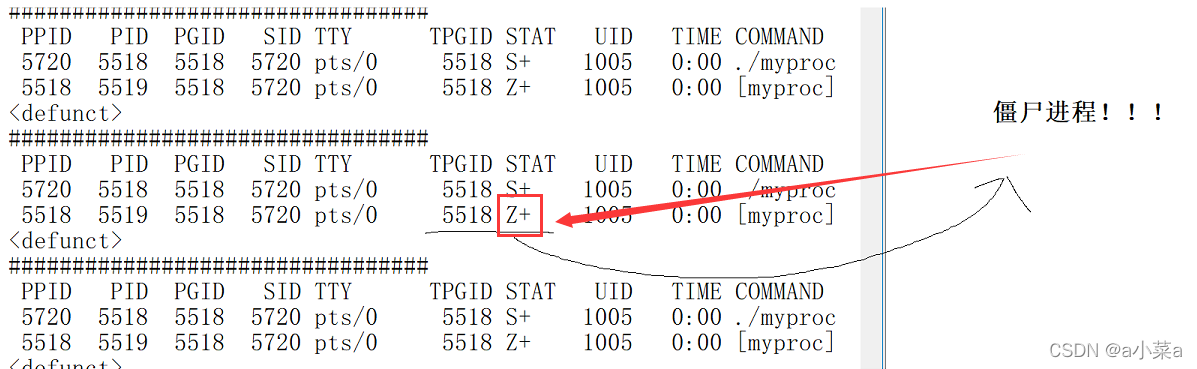
Z(zombie)-��ʬ����
- ����״̬(Zombies)��һ���Ƚ������״̬���������˳����Ҹ�����û�ж�ȡ���ӽ����˳��ķ��ش���ʱ�ͻ��������(ʬ)���̡�
- �������̻�����ֹ״̬�����ڽ��̱���,���һ�һֱ�ڵȴ������̶�ȡ�˳�״̬���롣
- ����,ֻҪ�ӽ����˳�,�����̻�������,��������û�ж�ȡ�ӽ���״̬,�ӽ��̽���Z״̬��
ΪʲôҪ�н�ʬ״̬��??? --> Ϊ�˱������ԭ�� !!�����˳�����Ϣ(����)
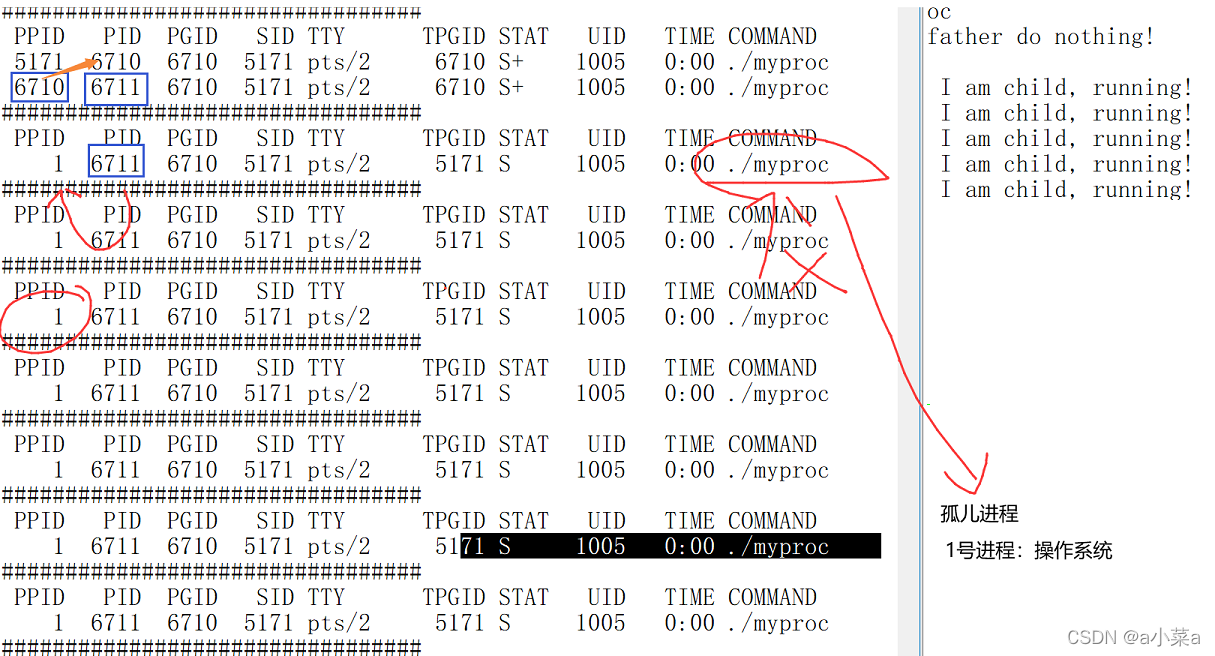
�¶�����
�����������ǰ�˳�,��ô�ӽ��̺��˳�,����Z֮��,�Ǹ���δ�����?
���������˳�,�ӽ��̾ͳ�֮Ϊ���¶����̡�
�¶����̱�1��init��������,��ȻҪ��init���̻���ඡ�
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
pid_t id = fork();
if(id < 0){
perror("fork");
return 1;
}else if(id == 0){//child
printf("I am child, pid : %d\n", getpid());
sleep(10);
}else{//parent
printf("I am parent, pid: %d\n", getpid());
sleep(3);
exit(0);
}
return 0;
}
�������ȼ�
��������
Ϊʲô�������ȼ�? ��Ϊ��Դ̫��! ������һ�ַ�����Դ�ķ�ʽ
cpu��Դ������Ⱥ�˳��,����ָ���̵�����Ȩ(priority)��
����Ȩ�ߵĽ���������ִ��Ȩ�������ý�������Ȩ�Զ�������linux������,���Ը���ϵͳ���ܡ�
�����ѽ������е�ָ����CPU��,����һ��,�Ѳ���Ҫ�Ľ��̰��ŵ�ij��CPU,���Դ�����ϵͳ�������ܡ�
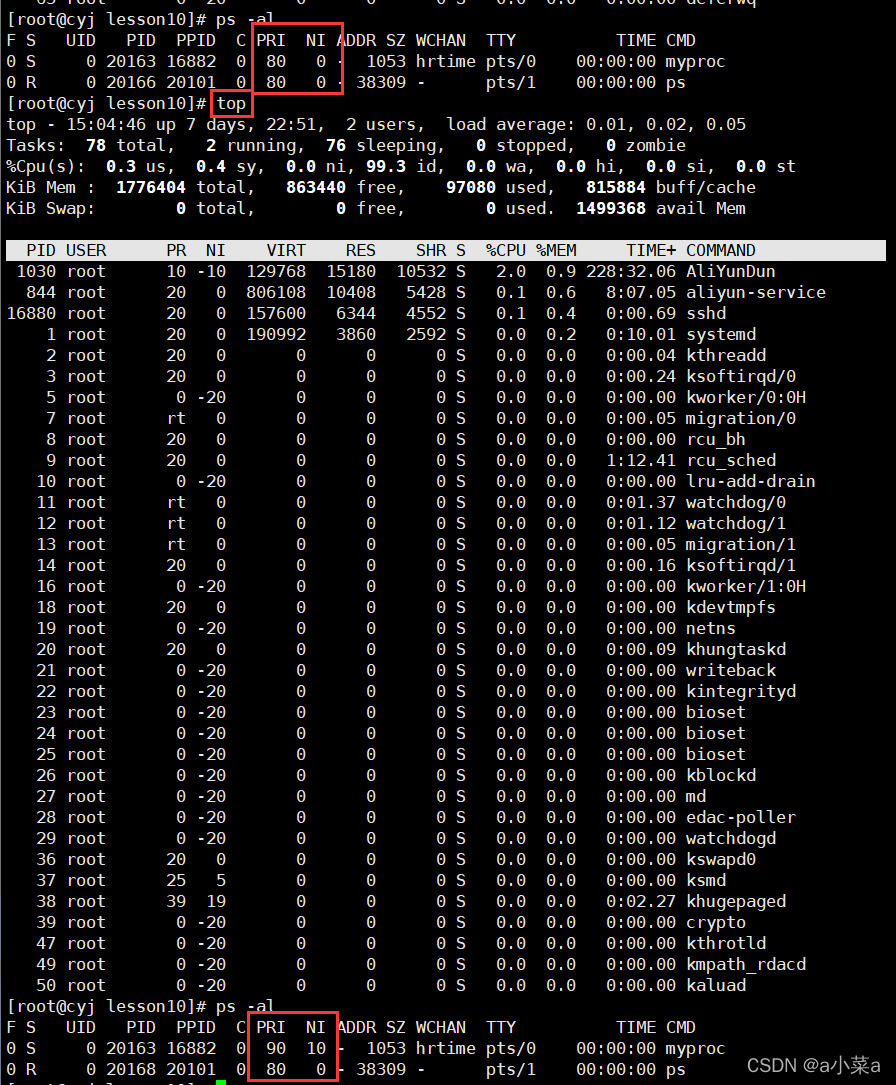
�鿴ϵͳ����
��linux����unixϵͳ��,��ps �Cl�����������������¼�������:

���Ǻ�����ע����еļ�����Ҫ��Ϣ,����:
UID : ����ִ���ߵ�����
PID : ����������̵Ĵ���
PPID :����������������ĸ����̷�չ����������,�༴�����̵Ĵ���
PRI :����������̿ɱ�ִ�е����ȼ�,��ֵԽСԽ�类ִ��
NI :����������̵�nice
PRI and NI
���� PRIҲ���DZȽϺ������,�����̵����ȼ�,����ͨ��˵���dz���CPUִ�е��Ⱥ�˳��,��ֵԽС,���̵����ȼ���Խ��
������NI��?����������Ҫ˵��niceֵ��,���ʾ���̿ɱ�ִ�е����ȼ���������ֵ
���� PRIֵԽСԽ�챻ִ��,��ô����niceֵ��,����ʹ��PRI��Ϊ:PRI(new)=PRI(old)+nice
��������,��niceֵΪ��ֵ��ʱ��,��ô�ó������ȼ�ֵ����С,�������ȼ�����,����Խ�챻ִ��
��������,�����������ȼ�,��Linux��,���ǵ�������niceֵ
PRI vs NI
���� ��Ҫǿ��һ�����,���̵�niceֵ���ǽ��̵����ȼ�,���Dz���һ������,���ǽ���niceֵ��Ӱ�쵽���̵����ȼ��仯��
���� ��������niceֵ�ǽ������ȼ���������������,����ֻ����һ����ԱȽ�С�ķ�Χ,��Ϊ���ȼ�����ô����,Ҳֻ����һ��������ȼ�,���ܳ��־������ȼ�,����������ص�"��������",�����������þ��ǽ�Ϊ�������ÿ���������ܵ�CPU��Դ
�鿴�������ȼ�������
��top��������Ѵ��ڽ��̵�nice:
top
����top��r���C>�������PID�C>����niceֵ
��������
������ : ϵͳ������Ŀ�ڶ�,��CPU��Դֻ������,����1��,���Խ���֮���Ǿ��о������Եġ�Ϊ�˸�Ч�������,���������������Դ,����������ȼ�
������ : ���������,��Ҫ����������Դ,����������ڼ以������
���� : ��������ڶ��CPU���ֱ�,ͬʱ��������,���֮Ϊ����
���� : ���������һ��CPU�²��ý����л��ķ�ʽ,��һ��ʱ��֮��,�ö�����̶������ƽ�,��֮Ϊ����
��������
��Linux��ִ�г�����Ҫ·��./name Ϊ��ϵͳ����ô�·����???��Ϊ��������
��������
��������(environment variables)һ����ָ�ڲ���ϵͳ������ָ������ϵͳ���л�����һЩ����
��:�����ڱ�дC/C++�����ʱ��,�����ӵ�ʱ��,������֪�����ǵ������ӵĶ�̬��̬��������,���������������ӳɹ�,���ɿ�ִ�г���,ԭ���������ػ��������������������в��ҡ�
��������ͨ������ijЩ������;,������ϵͳ����ͨ������ȫ������
�������涨��������������ڴ��п��ٿռ� (������)
��Ҫȥ����OS���ٿռ������ !!
��������������OS���ڴ�/�����ļ��п��ٵĿռ�,��������ϵͳ��ص����� !!
������������
PATH : ָ�����������·��
HOME : ָ���û���������Ŀ¼(���û���½��Linuxϵͳ��ʱ,Ĭ�ϵ�Ŀ¼)
SHELL :��ǰShell,����ֵͨ����/bin/bash��
�鿴������������
echo $NAME //NAME:��Ļ�����������

�ͻ���������ص�����
- echo: ��ʾij����������ֵ
- export: ����һ���µĻ�������
- env: ��ʾ���л�������
- unset: �����������
- set: ��ʾ���ض����shell�����ͻ�������
������������֯��ʽ
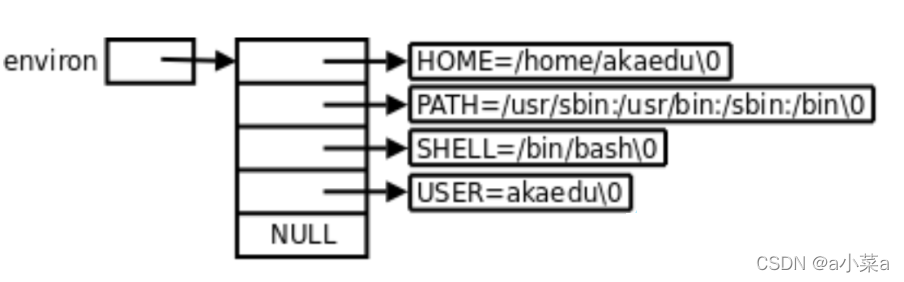
ÿ�������յ�һ�Ż�����,��������һ���ַ�ָ������,ÿ��ָ��ָ��һ���ԡ�\0����β�Ļ����ַ���
ͨ��������λ�ȡ��������
�������������
#include <stdio.h>
int main(int argc, char *argv[], char *env[])
{
int i = 0;
for(; env[i]; i++){
printf("%s\n", env[i]);
}
return 0;
}
ͨ������������environ��ȡ
#include <stdio.h>
int main(int argc, char *argv[])
{
extern char **environ;
int i = 0;
for(; environ[i]; i++){
printf("%s\n", environ[i]);
}
return 0;
}
libc�ж����ȫ�ֱ���environָ��������,environû�а������κ�ͷ�ļ���,������ʹ��ʱ Ҫ��extern����
ͨ��ϵͳ���û�ȡ�����û�������
int main(){
printf("PATH: %s\n",getenv("PATH"));
printf("HOME: %s\n",getenv("HOME"));
printf("SHEEL: %s\n",getenv("SHEEL"));
}
��������ͨ������ȫ������,���Ա��ӽ��̼̳���ȥ
�����ַ�ռ�
�о����� kernel 2.6.32 (32λƽ̨)
�����ַ�ռ�ع�
�����ڽ�C���Ե�ʱ��,���������Ŀռ䲼��ͼ
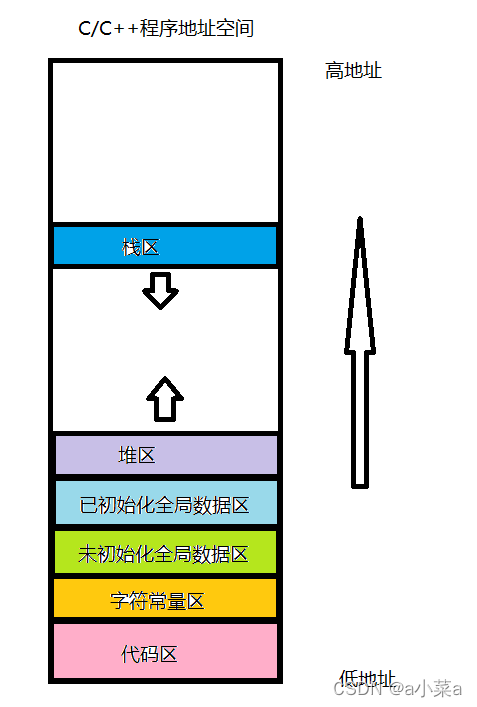
���δ������һ��
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
int g_unval;
int g_val =100;
int main(){
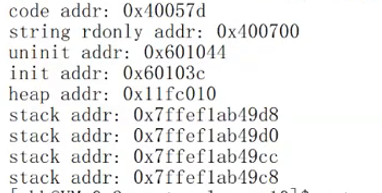
const char *s ="hello world";
printf("code addr: %p\n", main);
printf("string rdonly addr: %p\n", s);
printf("uninit addr: %p\n", &g_unval);
printf("init addr:%pln" , &g_val);
char *heap = (char*)ma1loc(10);
printf("heap addr: %p\n", heap);
printf("stack addr: %p\n", &s);
printf("stack addr:%pln", &heap);
int a = 10;
int b = 30;
printf("stack addr: %p\n", &a);
printf("stack addr: %p\n", &b);
return 0;
}
����Զ���
�ٿ�������δ���
int g_val = 100;
int main(){
if(fork() == o){
//child
int cnt = 5;
while(cnt){
printf("I am child, times: %d, g_val = %d,&g val = %p\n ", cnt,g val,&g_val);
cnt--;
sleep(1);
}
}else{
//parent
while(1){
printf("I am child,g_val = %d,&g_val = %p\n", g_val,&g_val);sleep(1);
}
}
return 0;
}

���Ƿ���,��������ı���ֵ�͵�ַ��һģһ����,�ܺ�����ѽ,��Ϊ�ӽ��̰��ո�����Ϊģ��,���Ӳ�û�жԱ������н����κ��ġ����ǽ������ԼӸĶ�:
int g_val = 100;
int main(){
//�����Ǹ���˽��һ��
if(fork() == o){
//child
int cnt = 5;
while(cnt){
printf("I am child, times: %d, g_val = %d,&g val = %p\n ", cnt,g val,&g_val);
cnt--;
sleep(1);
if(cnt == 3){
printf("##################child���ݸ���##################\n");
g_val = 200;
printf("##################child���ݸ������#######################\n");
}
}
}else{
//parent
while(1){
printf("I am father,g_val = %d,&g_val = %p\n", g_val,&g_val);sleep(1);
}
}
return 0;
}

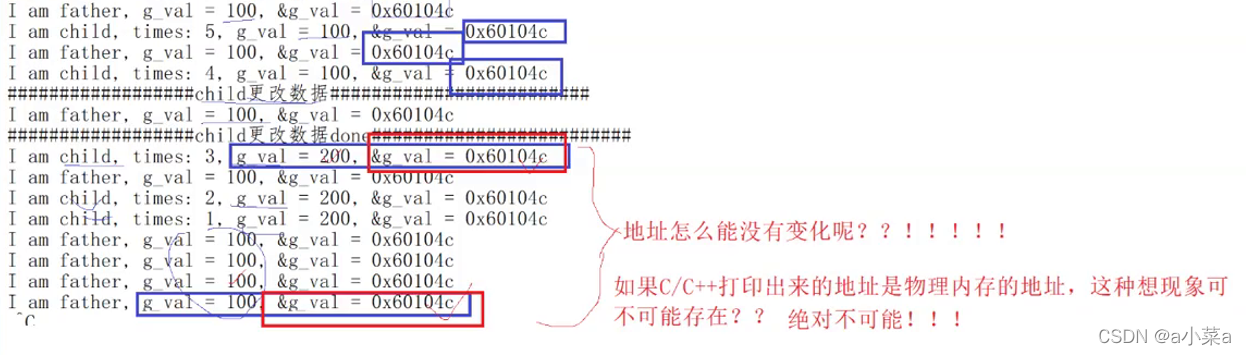
���Ƿ���,���ӽ���,�����ַ��һ�µ�,���DZ������ݲ�һ��!�ܵó����½���:
�����������ݲ�һ��,���Ը��ӽ�������ı������Բ���ͬһ������
��������ֵַ��һ����,˵��,�õ�ַ���Բ���������ַ!
������Linux��ַ��,���ֵ�ַ���������ַ
������������C/C++�����������ĵ�ַ,ȫ�����������ַ!������ַ,�û�һ�ſ�����,��OSͳһ����,OS���븺�� �����ַ ת�� ��������ַ ��
���̵�ַ�ռ�
����֮ǰ˵������ĵ�ַ�ռ䡯�Dz�ȷ��,ȷ��Ӧ��˵�� ���̵�ַ�ռ� ,�Ǹ����������?��ͼ:
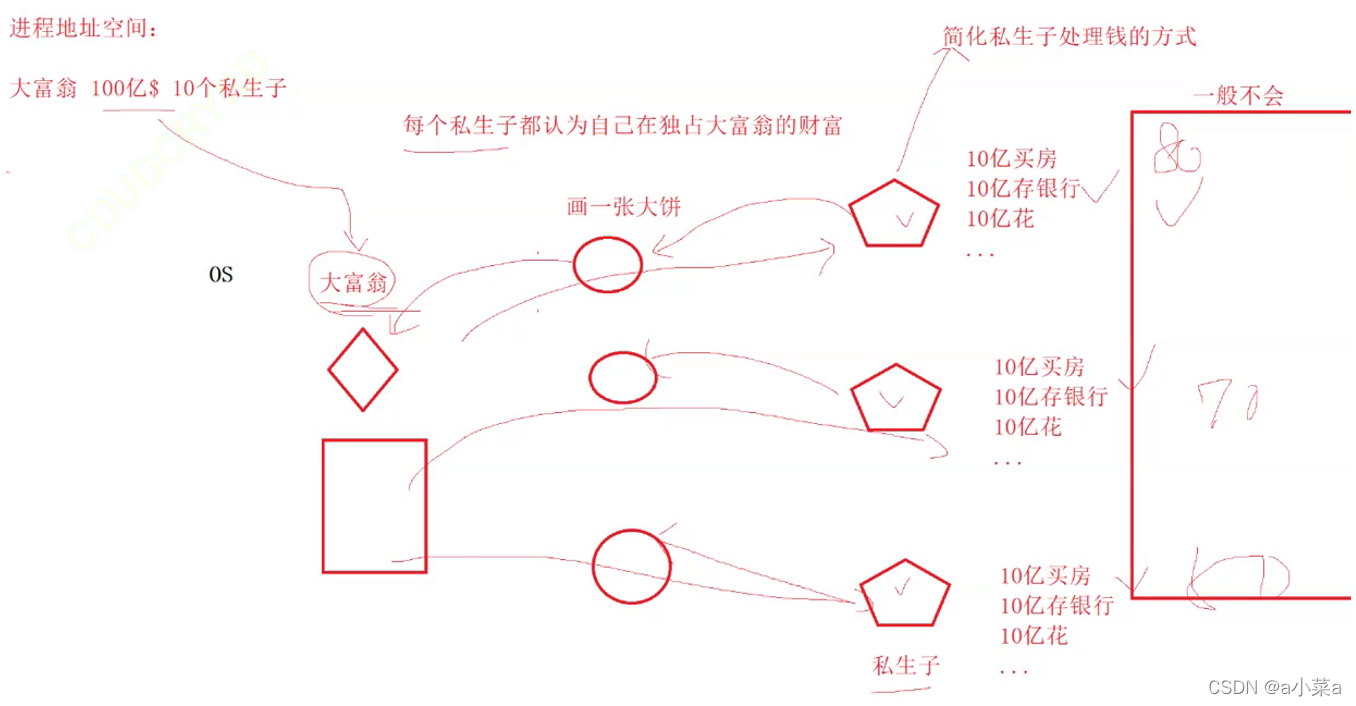
ÿ��˽���Ӷ�������һ�Ŵ��,����Ϊ�Լ���100��
ÿ�����̶���һ�����̿ռ�,����Ϊ�Լ��ڶ�ռ�����ڴ�!!
�����ͼ������˵������,ͬһ������,��ַ��ͬ,��ʵ�������ַ��ͬ,���ݲ�ͬ��ʵ�DZ�ӳ�䵽�˲�ͬ��������ַ!