论文标题:An Overview of the HDF5 Technology Suite and Its Applications
作者:Mike Folk, Gerd Heber, Quincey Koziol, Elena Pourmal, Dana Robinson
ACM (2011) 36-47
专业词汇:
RDBMS:关系数据库管理系统。 关系数据库管理系统(Relational Database Management System:RDBMS)是指包括相互联系的逻辑组织和存取这些数据的一套程序 (数据库管理系统软件)。
XLink,即 XML 链接语言,是一种通过 W3C 推荐标准认证的 XML 标记语言,提供一些方法,用于在 XML 文件上创建内部和外部链接,以及与这些链接相关联的元数据。
HDF5 hyperslab:HDF5 hyperslabs are the higher-dimensional analogue of a one-dimensional [start, stride, count, block] pattern.
需要四个参数来描述一个一般的hyperslab。 每个参数是一个与数据空间相同的数组:
start: hyperslab的起始位置。 、stride: 要分离要选择的每个元素或块的元素数。 示例(4,3),每隔4行取一次,每隔3列取一次。 如果stride参数设置为NULL,则每个维度中的步幅大小默认为1。count: 沿着每个维度选择的元素或块的数量。block:从数据空间中选择的块的大小。 如果块参数设置为NULL,则块大小默认为每个维中的单个元素,就像块数组设置为全1。HDF5 point: 数据空间中的独立点
文章目录
Abstract
在本文中,我们概述了 HDF5 技术套件及其一些应用。 我们讨论了 HDF5 数据模型、HDF5 软件架构及其一些性能增强功能。
1. Introduction
-
HDF5技术套件包含一个数据模型,一个库和一个用于存储和管理的文件格式。它支持无限多种数据类型,专为灵活高效的 I/O 以及大容量和复杂数据而设计。
-
HDF5 具有便携性和可扩展性,允许应用程序在使用 HDF5 的过程中不断发展。
-
HDF5 技术套件还包括用于管理、操作、查看和分析 HDF5 格式数据的工具和应用程序。
本文组织如下:在第 2 节中,我们描述了 HDF5 数据模型并讨论了 HDF5 数组变量的细节。 第 3 节包含 HDF5 软件架构的概述。 在第 4 节中,我们将讨论某些性能增强功能,例如支持并行 I/O 和索引。 第 5 节重点介绍了一些使用 HDF5 的应用程序,我们在第 6 节中讨论了 HDF5 与其他技术之间的接口方面的一些挑战。
2. Data Model
HDF5 数据模型并没有关系模型的简单明了,人们对其褒贬不一。
HDF5 数据模型定义了 HDF5 信息集。
-
HDF5 信息集 (infoset) 是数组变量、组和类型的注释关联的容器。
-
在 HDF5 数据模型中,HDF5 信息集的容器方面由具有指定根的 HDF5 文件表示。
-
一个HDF5文件包含数组变量(HDF5 数据集),组(HDF5 groups)和数据类型(HDF5 datatype objects)
HDF5 数据模型定义了用于在 HDF5 信息项之间创建关联的简单和扩展的链接机制。 最后,HDF5 数据模型定义了使用 HDF5 属性注释 HDF5 信息项的工具
HDF5 信息集中的大量信息没有根据数组变量的值显式转换,因此违反了 Codd 的信息原则 [5]。 HDF5 信息集的丰富“上层结构”与关系模型的“扁平”、仅关系变量结构背道而驰。
2.1 HDF5 Datasets
HDF5 数据集是数据元素在逻辑上布局或成形为多维数组的数组变量。
rank: number of dimensionsextent: number of elements
HDF5 数据空间包含它的rank和各个维度上当前以及上限的extent。
HDF5 数据集可以被认为是定位的内容变量 [6]。 它们的值,即某种 HDF5 数据类型的数据元素的总和(参见第 2.3 节),分布在多维(在 HDF5 中最高维数为 32)、直线、整数格的位置。
在图 1 中,HDF5 数据集(数组变量)的值显示为在 HDF5 数据空间上定义的函数的图形,其值采用 HDF5 数据类型。 HDF5 数据集可以被视为关系变量,HDF5 数据空间作为系统定义的候选键空间。
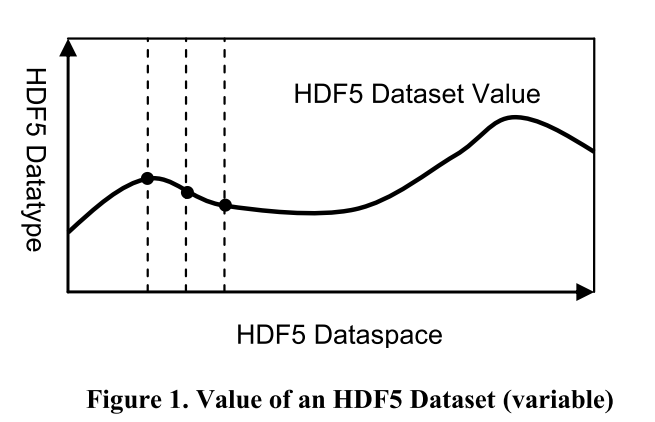
HDF5 数据集可能会在其最大范围内增长和缩小。 根据存储布局策略,最大范围可能是无限的。 目前,支持以下选项:
- 连续(Contiguous)。 阵列元素在 HDF5 阵列数据库中被布置为单个序列。
- 块状(Chunked)。 数组元素被布置为固定大小的常规子数组或块的集合。
- 紧凑(Compact)。 小型 HDF5 数据集(总共小于 64KB)的布局方式是,所有数组元素都可以作为数组变量元数据或标头(HDF5 数据类型、数据空间和其他元数据)检索的一部分读取。
指定存储布局策略为某些操作打开了附加功能和潜在更高性能的大门。 例如,对于具有连续布局策略的 HDF5 数据集,可以确保对数组中任何元素的访问时间几乎恒定,并且可以确保在数据集中定位元素的零开销。 对于具有分块布局策略的 HDF5 数据集,HDF5 支持无、部分或所有维度的无限扩展。
HDF5 还支持过滤器流水线(参见图 4 中的“过滤器流水线”阶段),在 I/O 操作期间提供标准和自定义原始数据处理能力。 HDF5 库与一小组标准过滤器一起分发,例如压缩(gzip、SZIP 和混洗算法)和错误检查(Fletcher32 校验和)。 为了进一步提高灵活性,该库允许应用程序通过创建和注册自定义过滤器来扩展管道,这些过滤器又独立地应用于 HDF5 数据集的每个块。 目前,HDF5 库不支持连续 HDF5 数据集的过滤器,因为难以实现部分 I/O 的随机访问(参见第 3.1 节)。 不支持 HDF5 紧凑数据集过滤器,因为它不会产生显著的结果。
分块HDF5(chunked HDF5)数据集:
- 提供了极大地灵活性,可以显着改善对数组变量切片的访问。当分块与压缩结合使用时,可能会获得额外的性能提升,因为只有引用的块需要解压缩。
- 不是一劳永逸的解决方案:必须仔细选择块大小,并且一方面要在更快(块对齐)I/O 和添加的功能(过滤器)之间进行权衡,另一方面要在访问开销方面进行权衡,并维护一个索引以在 HDF5 文件中定位数组变量的块。
一些 RDBMS 支持某些外部的、非关系的内容接口,例如 Informix 的虚拟表接口。 [7] 同样,HDF5 数据集可能由外部非 HDF5 内容“支持”,这允许与不了解 HDF5 的应用程序共享数据。 这样的数组变量被称为具有外部存储布局的 HDF5 数据集。
2.2 HDF5 Groups
HDF5 组类似文件系统的目录。
/signifies the root group.
/foosignifies a member of the root group calledfoo.
/foo/zoosignifies a member of the groupfoo, which in turn is a member of the root group.
HDF5 组是包含零个或多个 HDF5 对象的结构。一个组有两个部分:
- 组头(header),包含组名和组属性列表。
- 组符号表(symbol table)――属于该组的HDF5对象的列表。
HDF5 数据模型没有定义或认可“HDF5 组 G 表示 HDF5 信息项 A、B、C 等之间的关联”的特定含义。可能的解释包括“G 是 A、B、C 等的父级或上下文。 ’或‘A、B、C等是G的成员’,但这种解释完全取决于应用程序或用户。
由 HDF5 组表示的关联或关系通过指向参与 HDF5 信息项的命名链接集合变得明确。
在每个 HDF5 文件中,恰好有一个 HDF5 组,称为 HDF5 根组。 使用或跟随 HDF5 组中的链接称为遍历。 来自 HDF5 根组的链接遍历生成 HDF5 信息集图,一个有根、有向、连通图。 (严格来说,它是一个多重图,因为允许同一对节点之间有多个边。)从根到每个节点存在一条有向路径。 请注意,允许使用包含循环的图形,并且 HDF5 组、HDF5 数据集或 HDF5 数据类型对象可以链接到多个 HDF5 组。
用户和应用程序可以通过熟悉的(绝对和相对的)HDF5 路径名来引用 HDF5 信息项――由链接名称分隔字符“/”连接散布的链接名称。 例如,考虑一个与时间相关的物理过程的模拟。 在这些情况下,创建一个 HDF5 文件是相当常见的,该文件将在给定逻辑时间步 T 保存某些离散物理场 F 的值的 HDF5 数据集链接到代表该时间步的 HDF 组。 这种排列如图 2 所示,其中椭圆形表示 HDF5 组,矩形表示 HDF5 数据集。 [18]

2.3 HDF5 Datatypes
HDF5 提供了一个几乎无限灵活的类型系统。 正如我们在 2.1 节中看到的,(非标量)HDF5 数组变量类型有两个关键要素:一个描述其形状的 HDF5 数据空间,以及一个描述其数据元素类型的 HDF5 数据类型。
目前支持十个系列或类 HDF5 数据类型:整数、浮点、字符串、位域、opaque、compound(复合类)、引用、枚举、可变长度序列和数组。
在大多数情况下,这些族的类型实例就是族名所暗示的。
除了复合类(可以被认为是元组类型)之外,它们都包含标量类型。
引用族包含两种类型:
- HDF5 对象引用数据类型
- HDF5 区域引用数据类型(参见第 4.2 节)
HDF5 对象引用数据类型类型的变量保存指向 HDF5 信息项的引用或指针。 与作为 HDF5 信息项之间关联的显式表示的 HDF5 组不同,HDF5 数据集或 HDF5 对象引用数据类型类型的属性可以被用户或应用程序视为这种关联的隐式表示。 然而,它不是 HDF5 数据模型意义上的关联。
复合、可变长度序列和数组族的类型生成器具有一个或多个 HDF5 数据类型参数,并且 HDF5 数据类型框架支持 HDF5 数据类型的任意组合/嵌套深度,例如,复合 HDF5 数据类型中的字段可能是 数组 HDF5 数据类型,其元素又是可变长度序列 HDF5 数据类型,依此类推。
除了在 HDF5 数据集和属性的定义中计算之外,HDF5 数据类型项可以链接到 HDF5 组,在这种情况下,它们被称为 HDF5 数据类型对象或 HDF5 命名数据类型。
2.4 HDF5 Links
目前,HDF5 仅支持单向、单源/单目标链接。 此外,源必须是 HDF5 组。 HDF5 链接可以通过它们引用其目的地的方式以及它们是否影响 HDF5 信息项的承诺状态(引用计数)来区分。 在表 1 中,给出了 HDF5 链接类型的概述。
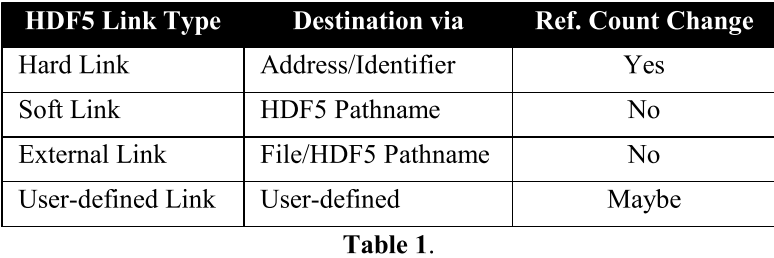
HDF5 数据集、组或数据类型对象通过使用 HDF5 硬链接将其链接到至少一个 HDF5 组来提交到 HDF5 信息集。
- HDF5 硬链接通过 HDF5 信息项的对象标识符指向其目的地。
- HDF5 软链接和外部链接是所谓的符号链接,因为它们通过 HDF5 路径名或文件名/HDF5 路径名组合来引用它们的目的地。与 HDF5 硬链接不同,它们不会影响目的地的承诺状态。 HDF5 符号链接的目标在链接创建时可能不存在,在链接的生命周期内可能会更改甚至不存在。 例如,可以创建一个 HDF5“存根”信息集,其中只包含 HDF5 组、属性和充当目录或查找表的外部链接。
- HDF5 版本 1.8.0 引入了用户定义的链接。 HDF5 用户定义的链接可能是象征性的,它们可能会也可能不会修改其目的地承诺状态(commitment state)。
2.5 HDF5 Attributes
HDF5数据模型定义了一个叫HDF5 属性的机制,可以注释HDF5数据集,组和数据类型对象。
出于逻辑和实现的因素,HDF5 属性的名称在它附加到的 HDF5 项的范围内必须是唯一的。 HDF5 属性可以被认为是键值对(name/value type )。 它们类似于 HDF5 数据集,因为它们的定义需要 HDF5 数据空间和数据类型,但它们在 HDF5 信息集中执行不同的功能 - 注释。 HDF5 属性本身不能具有 HDF5 属性,通常用于小型辅助数据。 (目前,HDF5 属性不支持无限扩展和压缩。)例如,图 2 中的 HDF5 组 /Timestep 10 可能具有物理时间值对应于逻辑步数 10 的 HDF5 属性。
3. HDF5 software architecture
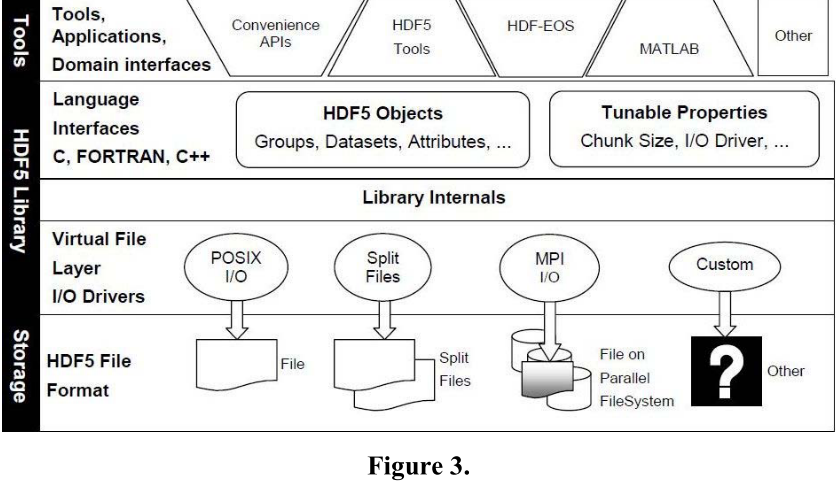
图 3 显示了 HDF5 软件架构的示意图。 通常,应用程序、工具和高级 API 通过 HDF5 库 API 访问 HDF5 文件。 RDBMS 用户可以将此层视为 ODBC 样式的接口。 核心库是用 C 编写的,但也有可用于其他语言的语言绑定,包括 FORTRAN、C++、Java、Python、Perl、Ada 和 .NET Framework。 请注意,并非所有绑定都支持核心 HDF5 库中提供的完整 API。 HDF5 文件以结合了数据和元数据的自描述格式 [8] 存储。 然而,它是“格式和访问库的结合”,“允许人们在不了解数据的实际表示或文件布局的情况下访问数据”。
如第 2.1 节所述,在创建 HDF5 数据集时,必须指定以下参数:
- 数据元素类型
- HDF5 数据类型底层多维数组的形状,包括当前和最大范围、HDF5 数据空间
- 存储布局策略(连续、分块、紧凑)
- 过滤器过滤器(例如,压缩、校验和、加密)
- 外部布局
创建后,HDF5 数据集必须通过将其链接到至少一个 HDF5 组来提交到 HDF5 阵列数据库。 (未提交的变量在底层 HDF5 文件关闭时被放弃。)
在读取或更新 HDF5 数组变量时,库会经过我们称为 HDF5 数据管道的某些处理步骤(参见图 4)。 在管道的两端是一个数组变量,可以读取或写入。 在典型场景中,其中一个存储在文件系统(例如 ext3、NTFS、GPFS)中的 HDF5 文件中,另一个映射到应用程序的地址空间(美化的内存缓冲区)。 让 V 和 W 表示数组变量,例如,V 存储在文件系统中,W 存储在内存中。 从 V 到 W 的读或写操作可以被认为是形式的更新(SQL 伪代码)
UPDATE W SET W = T(V)
FROM V JOIN W ON S(V#) = W#
WHERE P(V#) AND Q(W#)
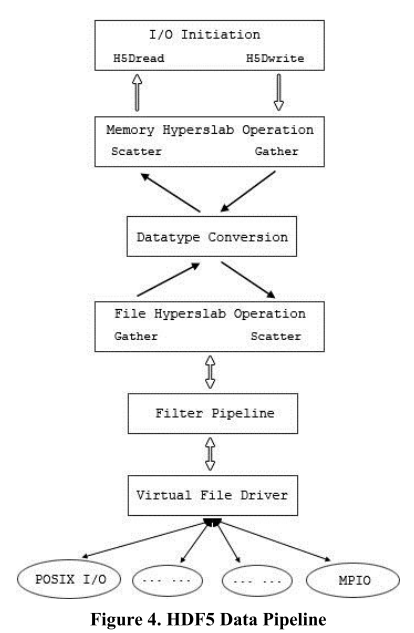
V和W都有分别用V#和W#表示的关联数据空间,我们可以随意对系统定义的键使用相同的符号(见第2.1节)。HDF5库支持部分I/O,即读取或写操作可能只涉及V和W的数据元素的子集。这些子集的选择由谓词P和Q控制,它们定义在V#和W#上。HDF5库假设选择具有相同的基数,即#{P(V#)}=#{Q(W#)},并且在{P(V#)}和{Q(W#)}之间存在一个双射S。最后,可能存在定义的值转换T,例如偏移或缩放。这种转换可能涉及类型提升和较低级的表示变化,如环境。
在实践中,HDF5库支持的谓词没有假代码所建议的那么通用。
HDF5库支持以HDF5超级实验室(hyperslab)和HDF5点集的形式进行的HDF5选择。
HDF5超实验室是一维[开始、步幅、计数、块]模式的高维模拟物。
上面提到的双射S是由HDF5超实验室和点集上的默认遍历顺序给出的。
SQL伪代码没有考虑到图4中的过滤器管道和虚拟文件驱动程序(VFD)阶段。过滤器阶段处理HDF5过滤器。
通过从HDF5组中删除所有链接来删除HDF5数组变量。目前,只要底层HDF5文件保持打开状态,就可以回收释放的空间。
3.2 Tools
一些命令行工具是HDF5发行版的一部分。[11]工具帮助用户在各种活动,包括检查或管理HDF5文件,转换原始数据HDF5和其他特殊格式,移动数据和文件HDF4和HDF5格式,测量HDF5库性能,管理HDF5库和应用程序编译、安装和配置。例如,有一个叫做h5diff的工具,可以用来比较两个HDF5文件和报告差异。
另一个流行的工具是HDFView[12](屏幕截图见图8),这是一个用于浏览和编辑HDF5(和HDF4)文件的GUI工具。使用HDFView,您可以:
- 在树状结构中查看文件层次结构
- 创建一个新的文件,添加或删除组和数据集
- 查看并修改数据集的内容
- 添加、删除和修改属性
- 替换I/O和GUI组件,如表视图、图像视图和元数据视图
3.3 High-Level Interfaces
HDF5HL接口类似于RDBMS中熟悉的数据Blade[33]或数据盒[34]模块。HL接口[17]被设计为:
- 方便和简化对HDF5文件中数组变量的访问
- 为存储实体的标准化表示,包括光栅图像、调色板、表和流数据
例如,HDF5数据包表API[37]被设计为提供高性能的、简化的表功能,用于存储HDF5中的流媒体数据(见图5)。
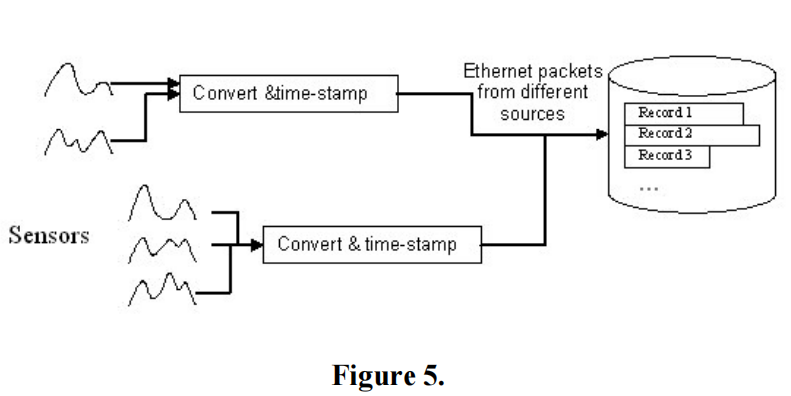
HDF5数据包表可以存储固定大小或可变大小的记录。它由一个一维的HDF5数组变量表示,其中包含描述记录的任何HDF5数据类型的元素(相对于HDF5表API[29]的复合HDF5数据类型)。为了达到目标性能,必须进行某些权衡。HDF5数据包表支持的操作包括表创建、附加和读取记录。不支持删除记录或修改字段的子集。与HDF5表不同,HDF5数据包表中没有附加特殊的HDF5属性。HDF5属性可以通过标准的“低级”HDF5库API添加到HDF5数据包表中。
4. Performance
HDF5库允许用户利用CPU和文件系统级别的并行性来实现更好的I/O性能。用户也或多或少实现了普遍适用的索引HDF5数据集的方案。HDF5库使用单个全局信号量来保护内部数据结构不被多个执行线程修改。虽然这提供了线程安全性,但它不允许对HDF5文件进行并发访问。未来的工作将把这种锁定机制移动到库中的单个数据结构上,允许多个线程并发访问。
4.1 Parallel File I/O
在基于MPI的[35]并行应用程序中,HDF5库可用于并行访问HDF5文件。
首要目标是在大型HDF5数据集上,通过一个标准的并行I/O接口,MPI-IO,并利用并行文件系统,如GPFS和Lustre 支持 快速并行I/0,
并行访问可以是独立的,也可以是集体的。
- 在独立模式下,单个MPI进程执行独立于访问相同HDF5文件的同一应用程序中的I/O操作,且不受其他MPI进程的影响。
- 在集体模式中,并行访问是一种高度协调、协作的工作,涉及一个应用程序中的所有MPI进程。
这两种模式在编程复杂性上有所不同,具有不同的性能影响,并且受到当前并行HDF5实现的不同方式的限制(但不是HDF5数据模型或格式!)。例如,当前需要以集体模式在HDF5文件中创建、修改或删除对象。这样,就可以确保一个HDF5文件内容的全局一致视图。
独立模式下的一种常见策略是预先创建HDF5文件的总体结构,然后根据需要执行读取和/或写操作,而无需在MPI进程之间进行任何进一步的同步或协调。避免竞争条件的负担落在了程序员身上。由于缺乏显式的I/O模式,在目标文件系统上的动态优化是有限的,并且在最坏的情况下,可能会加剧资源争用。
当集体执行I/O时,有一个全局视角,因此有更好的机会利用并行文件系统的缓冲和缓存机制。另一方面,增加的通信和同步开销可能会降低性能和可伸缩性。
4.2 Indexing
在本节中,我们将重点关注索引单个数组变量。目前,HDF5库还没有提供用于索引HDF5数据集的标准化API。这并不是由于人们对HDF5用户社区缺乏兴趣。事实上,已经有一些努力来创建或多或少普遍适用的解决方案。
企业RDBMS中高度开发的索引支持为比较关系变量和HDF5数据集之间的索引需求提供了一些参考点。
将HDF5数据集视为关系变量(第2.1节中,我们提到了可行性――由底层的HDF5数据空间提供了一个系统定义的候选码),有两个关系属性的子集,HDF5数据空间感知属性的子集A(例如,整数格坐标)及其补集 B。 A中针对属性的简单查询可以利用准随机访问或HDF5区域引用,而传统的索引技术可以很好地用于B中针对属性的查询。 对于同时针对A和B的组合查询,应该有一类HDF5数据空间感知索引,它在高维设置中也表现良好。
在关系数据库中,索引是通过用户可见的成分来定义的。主要原因是Codd的信息原则[5]:“在任何给定的时间,数据库中的所有信息都必须明确地转换为关系中的值,而不是以其他方式。”
这在类型和关系变量之间产生了一定的紧张关系,并确定了什么可以被索引。标量HDF5数据类型提供的巨大灵活性是一个滑坡,它可能会吸引用户创建只是“封装的集合”的数据集,因此无法用于查询索引。
以下建议适用于HDF5信息集同样的方式关系数据库设计:“总的来说,我们怀疑最合适的设计选择将出现如果仔细考虑以下两点的区别(a)人类语言中的陈述性句和(b)在构建这些句子中使用的词汇。“
域(类型)给我们一些代表我们可能希望提及的事物的价值观;关系给了我们提及这些事物的方式。”
- 用户对HDF5文件的操作集中在读取上――主要是具有复杂的特殊查询(即涉及列值的数学表达式)。与事务处理系统中的表不同,HDF5数据集及其关联索引通常在创建后不会更改。这为索引技术打开了大门,否则在删除、插入和/或更新下维护成本很高。
一个有索引辅助的HDF5数据集读取操作的高级处理结构非常类似于在一个RDBMS中执行一个选择。
该查询被表示为一个真值表达式,根据用户可见的成分(components),如(energy > 105)and (70 < pressure < 90).
优化器决定是否有索引(一个或多个),以便可以设计出一个有效的数据访问路径。扫描索引的某些薄片(thin slices),会得到一个在实际HDF5数据集读取操作中使用的HDF5选择块(hyperslab,point)。
HDF5提供了一种方便的机制,即HDF5区域引用,用于持久化HDF5数据空间的选择,请参见下图。D1和D2是二维HDF5数据集,R1是一个一维HDF5数据集或属性,包含四个HDF5区域引用,在D1和D2中的HDF5数据空间选择。HDF5区域引用可以被取消引用,并用于读取所选的数据元素。
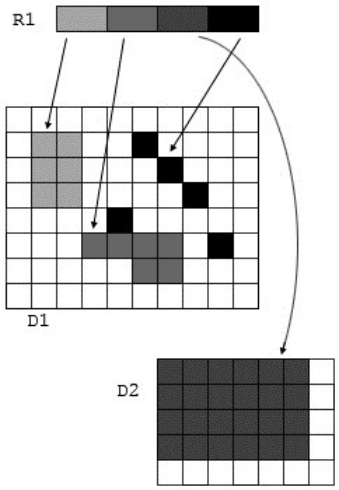
- 对于HDF5数据集没有一刀切的索引解决方案:
(1)对高低维数据和各种查询有效
(2)可以用合理的资源及时创建
(3)规模是合理的
在参考[22]中,描述了一个基于R*树的索引库,其中是存储为HDF4和HDF5格式的HDF-EOS数据(见5.2节)。在参考文献[18]中,提出了一种基于位图索引的HDF5数据集的查询加速技术。作者演示了位图索引对大型HDF5数据集上的复杂的临时查询的有效性,证实了来自RDBMS社区[25]的类似结果。[23]的作者对他们优化的部分排序指标(OPSI)的适用性得出了类似的结论,这是基于一个完全不同的方法。如果OPSI提供了在RDBMS中不常见的HDF5数据集索引的第一个示例,那么基于嵌套包含列表(NCList)的索引[26]是另一个例子。(BioHDF项目[27]已经实现了NCList索引的变体。)
“我们的最终目标是自动化为各种自我描述的科学数据集生成索引结构的过程,使用可以从数据集中的元数据中自动提取的元信息,以及由科学数据文件格式的开发人员或用户提供的语义信息。”[22]从用户的角度来看,这是索引事务的理想状态。对于HDF5的维护者来说,“最小公分母问题”的挑战仍然存在:识别为大多数HDF5用户带来最大利益的领域独立机制和设施的挑战。
5. Application
应用程序和库开发人员选择HDF5的原因有很多,可能包括以下一种或多种:
- 其数据模型的简单和实用,接近他们自己的数据模型
- 稳定、开放、自描述、平台独立、二进制格式的使用寿命
- 串行和并行计算的性能增强
- 与已经使用HDF5的应用程序的互操作性方面的益处
- 通过标准化和共享面向非问题的代码以及消除冗余开发来提高生产力
- 商业和免费的可视化和高性能数据分析工具,包括MATLAB,IDL,Paraview…
- 许多组织和科学和工程界采用的事实上标准的优势
- 可通过HDF组的帮助台、邮件列表和用户论坛提供支持
- 支持高级语言如Python和R
与其他一些技术一样,HDF5已经显示出了它通过激发或改变数据管理实践来改变研究社区或小型行业的潜力。下面我们将看看HDF-EOS/netCDF4和BioHDF的两个应用程序。HDF-EOS是一种成熟的格式,并在地球科学界广泛使用。BioHDF是一种新生的格式,旨在解决生物信息学数据泛滥的问题。在讨论应用程序之前,我们将简要描述一种HDF5许多应用程序中常见的分析技术。
5.1 HDF5 Profiles
使用HDF5可以被比作一个翻译项目。它是关于将应用程序概念映射到HDF5数据模型上的。这个过程必然充满了模糊性,如果有的话,只有在相当简单的场景中才能实现自动化。尝试回答几个问题可能有助于指导不同概念框架之间的翻译:
- 我们试图代表的基本事实是什么?
- 必须施加什么约束来排除非语法和荒谬的陈述?
- 翻译如何促进新事实的衍生和发现?
大规模使用HDF5的应用程序倾向于以高级库和工具的形式编码和实现其特定领域的映射或翻译。附带的文档将列出结构性(HDF5组、链接)需求、“magic”HDF5属性(见第3.3节)、HDF5数据类型和链接命名约定,以及能够使和应用程序能够识别HDF5文件的结构符合域标准的其他指标。综合这些假设和规定,构成了一个所谓的HDF5配置文件。这种配置文件的一个简单例子是HDF5图像和调色板规范。不出所料,考虑到领域的多样性和定义的模糊性,没有规范或标准来管理HDF5配置文件的创建和遵从性检查。
XML模式验证可能是寻找要模拟模型时想到的第一个也是最成熟的候选对象。XML模式提供的词汇表和语法通常不足以表达基本事实的结构和结构约束。当然,我们希望为此使用高度开发的XML机制,这种情况可以通过利用XQuery来形式化HDF5约束来补救。对HDF5约束的有效性检查是高度机械化的,并且可以完全自动化。在图7中,显示了这个HDF5约束(满意度)验证管道的高级结构。域知识被包装到一个测试模块中,表示为布尔XQuery函数(Constraints.xquery)
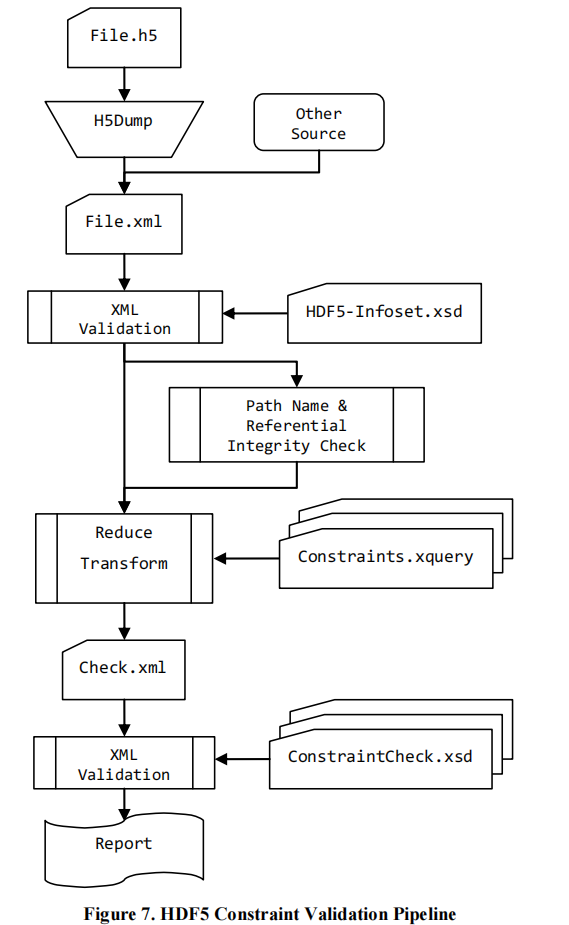
它提出了一个框架来定义和验证HDF5约束,该约束可用于完成大多数处于有点难以捉摸的HDF5概要文件的核心任务。
6. Beyond HDF5
6.1 HDF5 as a DBMS Back-End
DBMS提供了一种标准的查询语言和大量的前端客户端。
将HDF5文件安排为表的集合,允许使用最小的HDF5应用程序,然后用户可以发出查询,将存储在HDF5文件中的数据与已经存储在传统数据库表中的数据组合起来。
巴罗代尔计算服务(BCS)开发了一个名为通用文件接口(UFI)的插件,允许信息DBMS─通过其虚拟表接口─透明地访问HDF5文件,就像它们是RDBMS中的传统表一样;BCS目前正在扩展UFI与大多数其他DBMS(Oracle,DB2,SQL-Server,…)。UFI的体系结构如图9所示。
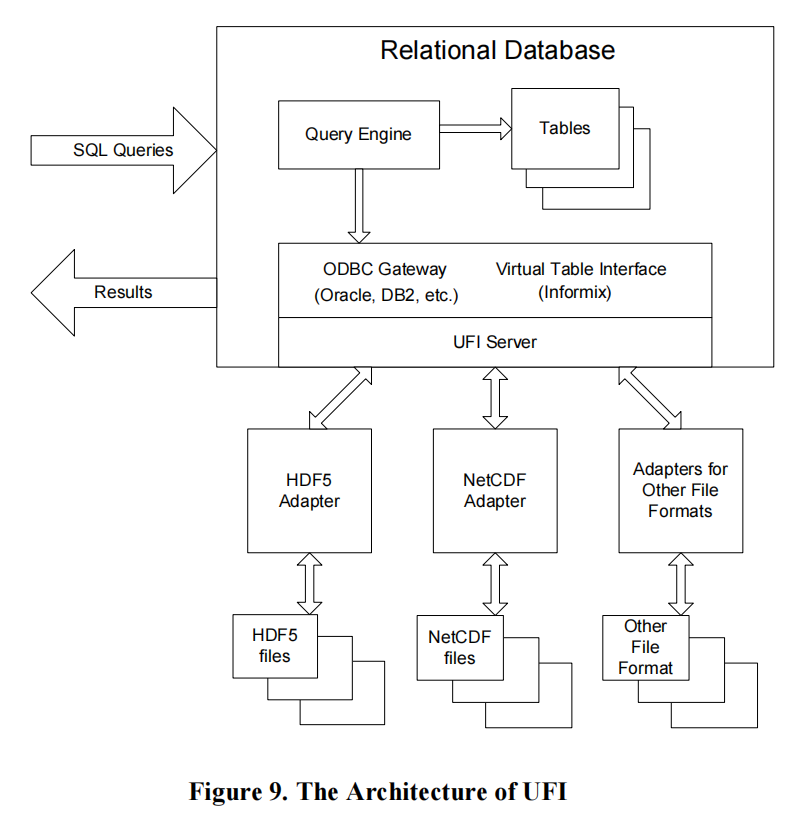
在HDF5文件中使用UFI是一个分两步进行的过程:
- 定义一个虚拟表(表名、列名和列类型),并为每个列定义该列与HDF5文件对象(组、数据集、属性等)之间的关联。此关联使用HDF5路径名定义,可能包括通配符。
- 将该表与一个或多个HDF5文件相关联。
7. Conclusion
在本文中,我们概述了HDF5技术套件及其一些应用。HDF5解决了以下主要的数据挑战:
- 它使应用程序开发人员能够组织复杂的数据集合。
- 它为高效和可扩展的数据存储和访问提供了手段。
- 它满足了对集成各种类型的数据和数据源的日益增长的需求。
- 它利用了不断发展的数据技术,但也保护了用户和应用程序。
- 它保证了数据的长期保存。
除了HDF5的核心能力之外,还有很多数据挑战。然而,对于处理数据交付、搜索和查询的一个重要问题子集,HDF5――与其他技术相结合――能够提供具有高度竞争力的解决方案。