BIO
BIO是传统的用于网络传输的一种技术,它是一种阻塞的传输方式,例如Socket就是一种BIO传输方式。
下面给出一个Socket示例
Socket客户端、服务器示例
客户端
public class Client {
private static final int port = 8080;
private static final String host = "localhost";
public static void main(String[] args) {
System.out.println("Client...");
Socket socket = null;
while (true) {
try {
socket = new Socket(host, port);
Client client = new Client();
// 向服务器发送数据
PrintStream out = new PrintStream(socket.getOutputStream());
System.out.print("发送:");
String line = new BufferedReader(new InputStreamReader(System.in)).readLine();
out.println(line);
// 读取服务端数据
BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
String data = reader.readLine();
System.out.println("服务器:" + data);
if ("OK".equals(data)) {
System.out.println("客户端将关闭连接");
Thread.sleep(500);
return;
}
reader.close();
out.close();
} catch (IOException | InterruptedException e) {
System.out.println("客户端异常" + e.getMessage());
} finally {
if (socket != null) {
try {
socket.close();
} catch (IOException e) {
socket = null;
System.out.println("客户端finally异常" + e.getMessage());
}
}
}
}
}
}
简述客户端代码流程:
客户端建立一个Socket,并连接服务器路径和端口号,向服务器端发送数据,并接收服务器端产生的数据。当收到服务器端发送"OK",断开连接。
服务器
public class Server {
private static final int port = 8080;
private static final String host = "localhost";
public static void main(String[] args) {
System.out.println("server...");
Server server = new Server();
server.init();
}
public void init() {
try {
ServerSocket serverSocket = new ServerSocket(port);
while (true) {
Socket socket = serverSocket.accept();
new HandlerThread(socket);
}
} catch (IOException e) {
e.printStackTrace();
}
}
private class HandlerThread implements Runnable {
private Socket socket;
public HandlerThread(Socket socket) {
this.socket = socket;
new Thread(this).start();
}
@Override
public void run() {
try {
// 读取客户端数据
BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
String req = reader.readLine();
System.out.println("客户端:" + req);
// 向客户端回复数据
PrintStream out = new PrintStream(socket.getOutputStream());
System.out.print("回复客户端:");
String line = new BufferedReader(new InputStreamReader(System.in)).readLine();
out.println(line);
out.close();
reader.close();
} catch (IOException e) {
System.out.println("服务器异常" + e.getMessage());
} finally {
if (socket != null) {
try {
socket.close();
} catch (IOException e) {
socket = null;
System.out.println("服务器finally异常" + e.getMessage());
}
}
}
}
}
}
简述服务端代码流程:
建立ServerSocket,绑定地址ip和端口号,通过accept方法监听客户端连接,该方法是阻塞的,也就是只有监听到一个客户端再继续向下执行,每次监听到一个客户端会建立一个新的线程处理该客户端的请求,读取客户端数据,向客户端发送数据,直到处理结束关闭输入输出流,断开连接。
对以上代码整体的理解:
在以上的代码中,客户端部分就是一个不断制造客户端的机器,每一个客户端发送并接收信息后关闭该连接再新建一个客户端。服务端是每次接收并发送数据后关闭该连接并accept一个新的连接。
也就是客户端发送接收一条消息后就换了一个客户端,而服务器监听到客户端请求,接收信息并回复后关闭对这个客户端的连接,监听并重新连接一个客户端。
BIO的缺陷就显现出来了,每次监听一个客户端都会导致新建立一个线程去处理该客户端的请求,如果客户端多了起来,服务器端建立这么多线程会占用很大的栈内存,服务端肯定是吃不消的。与此同时每一个线程处理客户端请求时都是阻塞的,设想一下如果某个客户端迟迟不发送请求,那么服务端该线程一直阻塞在那了。不仅阻塞还会频繁的进行线程创建和销毁以及线程上下文切换,性能下降。
此时能够想到的解决方案就是创建线程池,让线程池去分配线程能在一定程度上限制创建线程的总数,但是当客户端数变多时首先会使核心线程数占满,甚至到达最大线程数,再有新的客户端连接时被放置到阻塞队列中,当阻塞队列也满了就无法满足客户端的需求了,而且其实际上还是阻塞的,问题似乎也没得到什么解决。
----------------------------------------中间插一段-----------------------------------------
线程池为什么能在一定程度上提升性能呢?
因为线程池中的线程创建及回收成本相对较低,而且线程池可以控制线程数量,避免无休止的创建大量线程。
----------------------------------------中间插一段-----------------------------------------
这个时候NIO出现了
nio就是non-blocking io,非阻塞io。是在jdk1.4出现的,用于实现非阻塞的网络传输。其特点是编程复杂,后来netty就是在其基础上发展出来的,提供了更简单的编程方式。
nio内部的四个组件
- Channel
- Buffer
- Selector
- Selection Key
channel是用来做数据传输的通道,buffer是数据的缓冲区,通过buffer将数据写入通道,将数据从channel读到buffer。
selector是实现非阻塞io的关键,客户端和服务器各自维护一个selector,客户端通过channel与服务器建立连接,将channel的某些事件注册到selector上,(如读写事件、新的连接等,注意这些都是就绪的状态,不会发生阻塞了,就等线程去处理它了),并返回一个selection key,selection key标识了channel和selector的注册关系,可以利用它获取到对应的channel。随后一个线程轮询的访问selector中未被处理的请求并处理,该线程始终是繁忙的状态,因为它处理的都是就绪的请求,不会发生那种连接建立了,客户端却迟迟不发请求(因为服务端确定可以读了才注册到selector上),服务器死等的情况。Selector的select()方法就是从selector中获取事件的方法,如果没有事件它是阻塞的等待的。就如同server阻塞的等待客户端连接一样。
那么这样就可以用一个线程去处理多个客户端的请求了,因为阻塞不见了,过去是等待现在却可以处理别的请求了,这就是非阻塞io/nio的情况。
数据传送时涉及到数据的拷贝
传统IO模型拷贝流程:
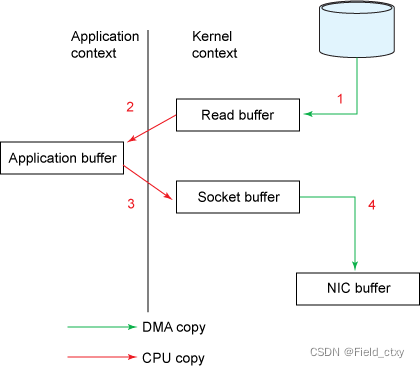
- 从磁盘读取到内核缓冲区- - -DMA引擎拷贝- - -用户态到内核态
- DMA就是直接内存存取,不经过CPU,外部设备和内存直接交换数据。 - 内核缓冲区拷贝到用户缓冲区- - -CPU拷贝- - -内核态切换到用户态- - -拷贝到jvm内存,让用户能够对数据进行操作。
- 用户缓冲区拷贝到socket buffer- - -CPU拷贝- - -用户态切换到内核态- - -调用write()方法将数据写入到socket缓冲区。
- 将数据异步的拷贝到网卡buffer- - -DMA拷贝- - -write()方法返回后由内核态切换到用户态。
传统的IO拷贝涉及4次拷贝,4次上下文切换(用-内-用-内)。
NIO零拷贝之mmap优化
mmap也叫直接内存。流程如下。
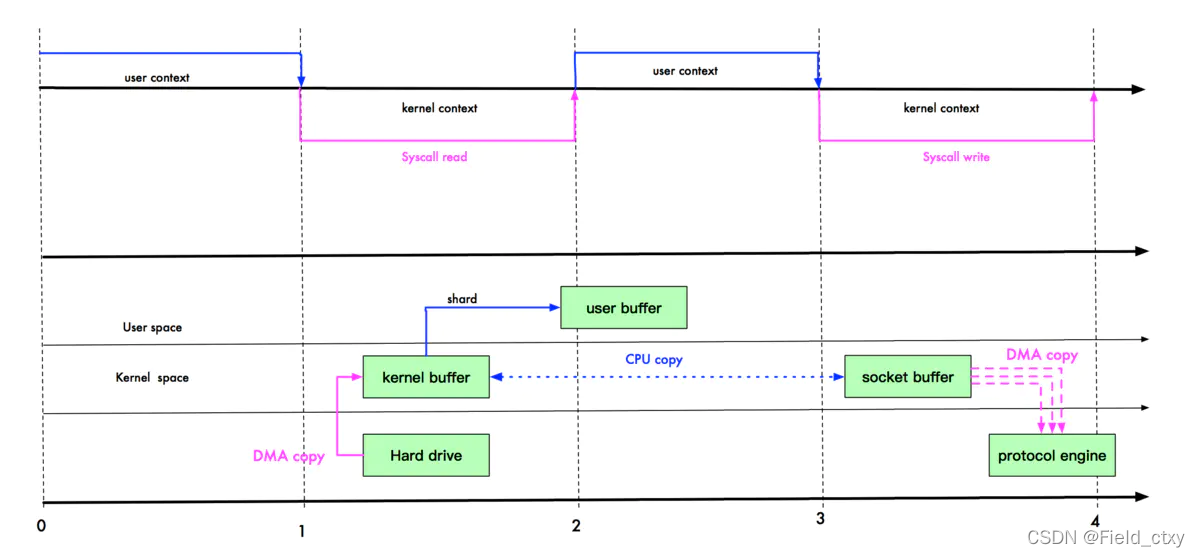
- 磁盘拷贝到内核缓冲区- - -DMA拷贝- - -用户态切换到内核态
- 用户共享内核数据- - -不发生拷贝- - -内核态切换到用户态- - -怎么不复制,用户还能获取到数据呢?一会细说。
- 内核缓冲区直接拷贝到socket缓冲区- - -CPU拷贝- - -用户态切换到内核态
- socket缓冲区拷贝到网卡缓存- - -DMA- - -write()方法返回后由内核态切换到用户态。
过程涉及3次拷贝(2次DMA,一次CPU),以及4次上下文切换(用-内-用-内)。
现在说说第二步说的要细说的部分:对比mmap和传统io拷贝模式,其实是减少了从内核缓冲区复制到用户缓冲区的步骤,但是用户还是可以共享内核数据,它是如何做到的呢?NIO的mmap优化方式是由MappedByteBuffer类实现的,它的map() 方法实现将内核缓冲区数据复制到用户内存并返回内存地址,用户获取到这个地址,通过这个地址构造MappedByteBuffer类,以暴露各种操作文件的api。MappedByteBuffer申请的是堆外内存,因此不受MinorGC控制,只能在FullGC时回收。
DirectByteBuffer改善了这一情况,它是MappedByteBuffer的子类,实现了DirectBuffer接口,维护了一个Cleaner对象完成对象的回收,这样既可以用FullGC,又可以用clean()方法回收。
还有HeatByteBuffer,它直接申请堆内存,可受GC管控,易于回收。
NIO零拷贝之sendFile优化
linux2.1 优化
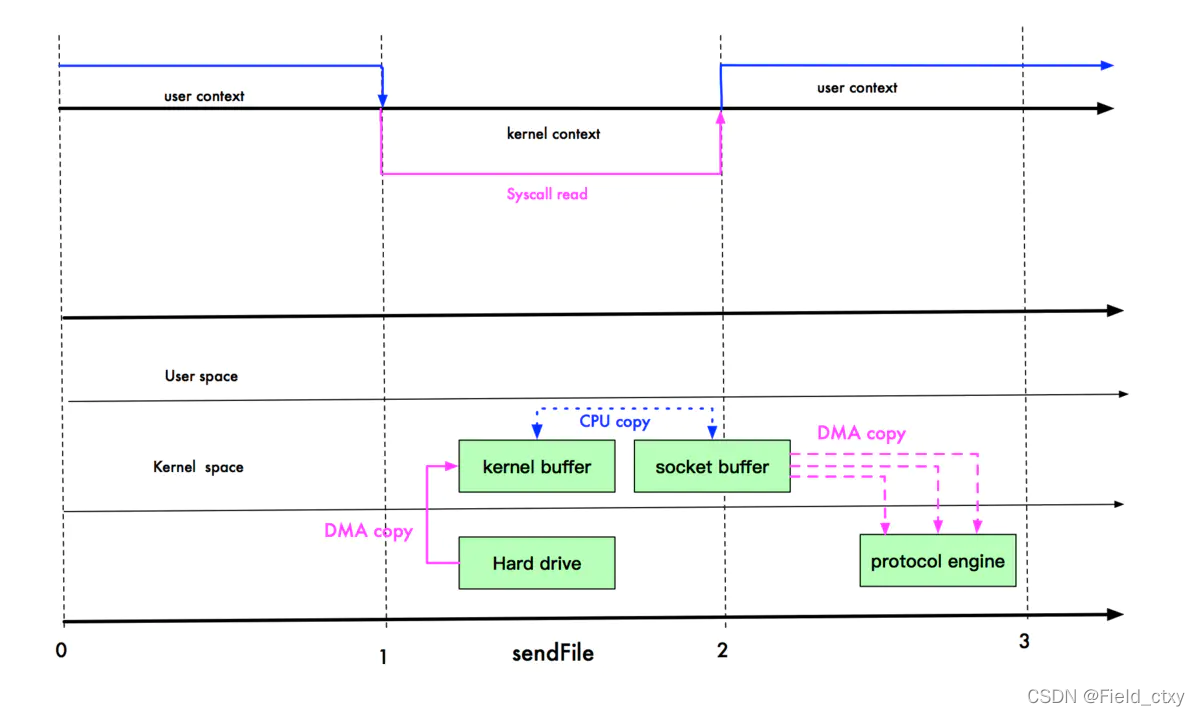
- 磁盘拷贝到内核缓冲区- - -DMA拷贝- - -用户态切换到内核态
- 内核缓冲区直接拷贝到socket缓冲区- - -CPU拷贝- - -内核态保持不变
- socket缓冲区拷贝到网卡缓存- - -DMA- - -write()方法返回后由内核态切换到用户态。
涉及3次拷贝,3次上下文切换(用-内-用)。相比于mmap少了一次上下文切换。
linux2.4优化
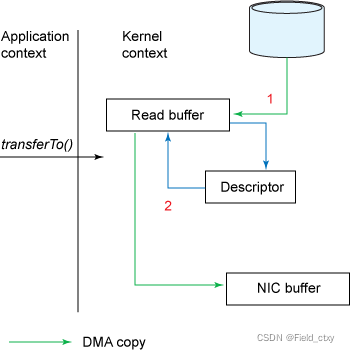
在2.1的基础上减少了内核缓冲区拷贝到socket缓冲区的步骤。
- 磁盘拷贝到内核缓冲区- - -DMA拷贝- - -用户态切换到内核态
- 内核缓冲区直接拷贝到网卡缓存(协议栈)- - -DMA拷贝- - -内核态切换到用户态
涉及2次拷贝,3次上下文切换(用-内-用)。
mmap和sendFile的区别:
- mmap3次拷贝,4次上下文切换;sendFile涉及3或2次拷贝,3次上下文切换。
- mmap适合小文件传输,sendFile适合大文件。
- mmap涉及CPU拷贝,sendFile可以不涉及。
- 在消息队列中间件中,rocketMQ消费消息采用mmap,kafka采用sendFile。
IO多路复用
IO多路复用的思想就是在通信的两端都维护用于监听的文件描述符和用于通信的文件描述符,每个文件描述符对应一块读缓冲区和一块写缓冲区。监听的文件描述符用于和对方建立连接,当建立连接后,通过通信的文件描述符来进行数据传输,服务器端有一个用于监听的文件描述符,有n个用于通信的文件描述符,用来和n个客户端通信。IO的多路复用其实就是来检测这些文件描述符的。实现方式主要有以下三种,select、poll和epoll,select支持跨平台,poll和epoll只支持linux,select检测文件描述符上限1024,poll和epoll无限制,epoll文件描述符存储底层是红黑树。一般不选择poll。
实现之select函数
如果是检测读缓冲区,select的方式需要扫描fd_set,去对应的缓冲区查看是否可读,若是则置为1,否则为0,更新好fd_set后,遍历fd_set,找到标记为1的文件描述符,如果是监听的文件描述符则进行连接,如果是通信的文件描述符则读取数据。写也类似。最大文件描述符数量为1024。
实现之poll函数
和select类似,文件描述符检测数量无上限。
实现之epoll函数
采用回调机制,维护了一系列事件处理机制,当一个文件描述符可以读了,将触发事件处理机制,一个事件处理函数被调用,性能好。
打个比方,就是养猪户小王,他养的每只猪猪都有一个猪圈,每个猪圈有2块区域,一块是猪猪上厕所区,一块是猪猪吃饭区。当上厕所区有东西小王就要对其清理,当吃饭区不满了,小王就往里添加食物。(对应文件描述符的读缓冲区和写缓冲区)。select方式相当于他要先依次遍历每个猪圈,去记录每个猪圈的情况,写到一张纸上,写完后,看着这张纸去对应的猪圈清理或者添食。而epoll方式是每个猪圈有一个按铃,当猪猪上厕所了或者饭不够吃了都会按铃,小王听见铃声过去就好了。显而易见epoll的性能会更高。
以上是我看了一些博客后对io做的一些总结和思考,有不对的地方欢迎大家指正。有些写的很简略只是简述一下原理,因为目前我还没有实践到如此深度,希望以后有机会对其补充。