????声明: 1. 本文为我的个人复习总结, 并非那种从零基础开始普及知识?内容详细全面, 言辞官方的文章
??????????????2. 由于是个人总结, 所以用最精简的话语来写文章
??????????????3. 若有错误不当之处, 请指出
软硬链接
软链接(快捷方式):
删除原文件时, 软链接则失效
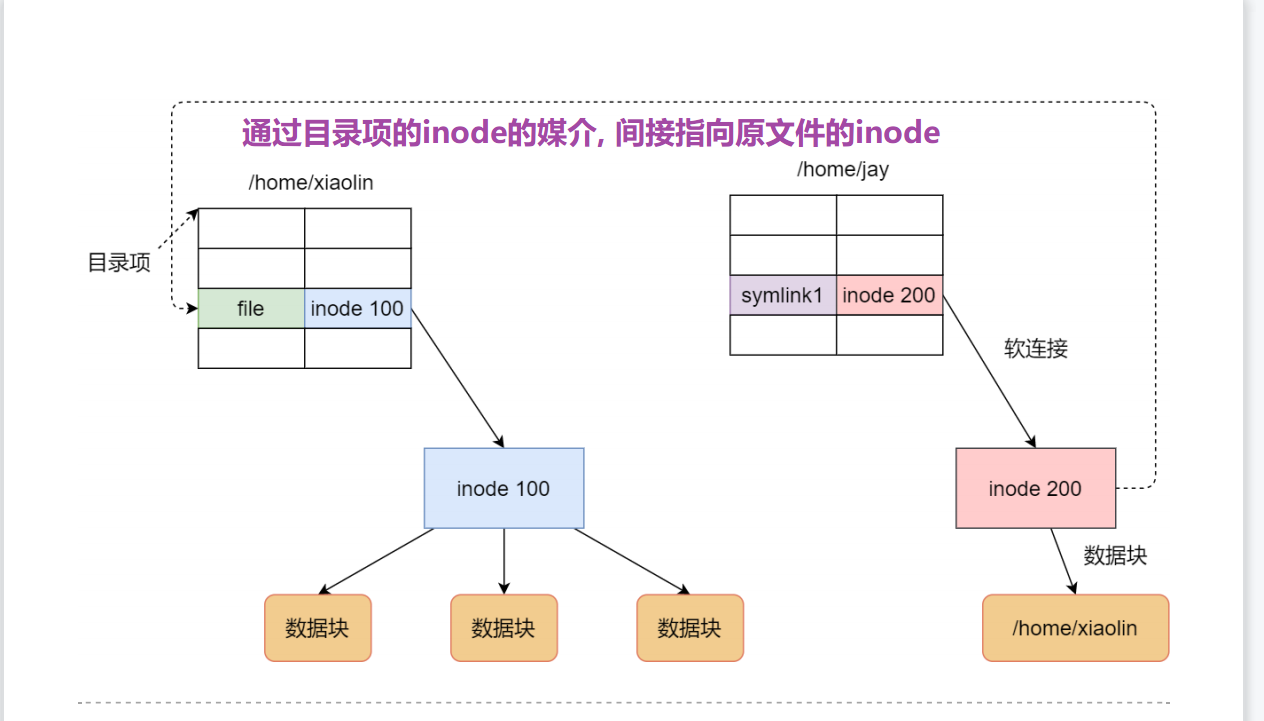
硬链接:
删除硬文件时, 硬链接不会失效
? 硬链接是多个目录项中的「索引节点」指向同一个 inode,但是 inode 是不可能跨越文件系统的,每个文件系统都有各自的 inode 数据结构和列表,所以硬链接不可跨文件系统
? 由于多个目录项都是指向一个 inode, 那么只有删除原文件以及所有硬链接时, 系统才会彻底删除该文件
IO类型
缓冲IO
先访问标准库的缓存, 再访问文件
非缓冲IO
不访问标准库的缓存, 直接去访问文件
直接IO
直接访问磁盘, 不会发生内核态与用户态间的数据拷贝
非直接IO
不直接访问磁盘, 会发生内核态与用户态间的数据拷贝
读操作时, 数据从内核态拷贝到用户态
写操作时, 数据从用户态拷贝到内核态
五种IO模型
-
BIO(同步阻塞)
一个线程只能连接一个Socket连接, 处理一个Socket的请求
accept时阻塞等待有客户端连接, read时阻塞等待有数据输入
-
NIO(同步非阻塞)
一个线程可以连接多个Socket连接, 处理多个Socket的请求; 更好的利用了线程, 避免因一个文件阻塞而导致整个线程啥也不干了
accept时得不到连接 和 read时得不到数据就算了, 直接返回个默认值负数, 不会在那一直阻塞着等待数据输入
-
IO多路复用(同步(半同步), IO多路复用器)
别名: 事件驱动IO
一个线程可以连接多个Socket连接, 处理多个Socket的请求; 更好的利用了线程, 避免因一个文件阻塞而导致整个线程啥也不干了
是对NIO的优化, 是基于Linux内核的select->poll->epoll去实现的
-
AIO(异步IO, 异步回调通知)
基于操作系统去谈:
IO阻塞分为两个阶段
- 数据准备阶段
- 数据从内核态拷贝到用户态的阶段
BIO和AIO在这两阶段, 都是同步的
IO多路复用在第一阶段是异步的, 内核通知应用程序去内核态拷贝数据, 然后第二阶段是同步的
AIO 在这两阶段, 都是异步的, 准备好数据 & 拷贝内核态数据到用户态, 都是内核完成的, 内核完成之后再去通知应用程序
-
信号驱动IO
基础概念:
A线程调用B线程
同步:
? A线程需要等得到B线程的处理结果后才能继续执行下一步任务, B线程处理完成后不会主动通知A线程, A线程需要自己等待着
异步:
- A线程需要等待B线程的处理结果, 但期间A线程可以继续做别的事, 因为B线程处理完后会主动回调通知A线程
- 或是 A线程不依赖于B线程, 各忙各的, 无需等待
阻塞:
? A线程即调用者 一直在等待而且不做别的事情
非阻塞:
? A线程即调用者 等待时可以先做别的事情, 过一会再来继续询问查看
总结:
同步&异步 的讨论对象是B线程即被调用者, 关注的是消息通知机制
阻塞&非阻塞 的讨论对象是A线程即调用者, 关注的是等待得到返回值时的行为, 能否干其他事
Socket连接又被称为Socket描述符/文件描述符(FileDescriptor, fd)
FileDescriptor是指向 打开文件 或 新建文件 的指针
为了安全考虑, 内核态的权限较大, 用户态权限小; 二者间使用系统调用进行切换状态开销较大
BIO:
一个线程只能处理一个Socket连接, 太浪费线程
accept( )阻塞, read( )阻塞
ServerSocket serverSocket = new ServerSocket(8081);
while (true) {
//阻塞1 ,等待客户端连接
Socket socket = serverSocket.accept();
new Thread(() -> {
//阻塞2 ,等待客户端发送数据
while ((length = inputStream.read(bytes)) != -1) {
System.out.println("-----444 成功读取" + new String(bytes, 0, length));
}).start( );
}
}
如果要是单线程, 那么被Client1阻塞着时, Client2的请求就得不到处理
如果是多线程, 太浪费线程资源
NIO:
一个线程可以连接多个Socket连接, 处理多个Socket的请求; 更好的利用了线程, 避免因一个文件阻塞而导致整个线程啥也不干了
accept( )方法是非阻塞的, 如果没有客户端连接就返回error默认值数据
read( )方法是非阻塞的, 如果读取不到数据就返回error默认值数据
while (true) {
SocketChannel socketChannel = serverSocket.accept();
if (socketChannel != null) {
socketChannel.configureBlocking(false);
// 添加socket连接到List中
socketList.add(socketChannel);
}
for (SocketChannel element : socketList) {
int read = element.read(byteBuffer);
// 读不到数据就返回负数了, 这里做判断是否读到实际数据了
if (read > 0) {
System.out.println("-----读取实际数据: " + read);
}
}
}
如果要是单线程, 那么就不会被Client1阻塞着, Client2的请求便可以得到处理
依然存在的问题:
- 在客户端少的时候十分好用,但是如果客户端很多, 比如有1万个客户端进行连接,那么每次循环就要遍历1万个socket; 如果一万个socket中只有10个socket有数据,也会遍历一万个socket,就会做很多无用功
- 遍历过程是在用户态进行的, 调用内核的read( )方法涉及了用户态和内核态的切换, 每遍历一个就要切换一次开销很大
IO多路复用:
别名: 事件驱动IO
"多路"是指多个Socket连接, “复用” 指的是复用同一个线程
一个线程可以连接多个Socket连接, 处理多个Socket的请求; 更好的利用了线程, 避免因一个文件阻塞而导致整个线程啥也不干了
基于Linux内核实现, 操作系统会在Socket连接有数据时 通知应用程序,进行业务处理
select:
? 其实就是把NIO中用户态要遍历的fd数组(List集合)拷贝到了内核态, 外加select能感知到有事件发生(只是不清楚具体是哪一个socket有数据), 让内核态来遍历(处于内核态时调用内核的read( )判断是否有数据, 就不用切换用户态和内核态了)
存在的问题:
- 一个进程最多只能处理1024个客户端
- 每一次调用select( ), fd数组都会被从用户态拷贝到内核态, 仍具有很大开销
- select只是感知到了有事件发生, 并没有通知用户态具体是哪一个socket有数据, 仍需要O(n)的遍历
数据结构: 固定大小的BitMap, 因此有1024个客户端的数量上限
poll:
? 基于select进行改进, 一个进程最多可以处理的客户端数量没上限
存在的问题:
- 每一次调用select( ), fd数组都会被从用户态拷贝到内核态, 仍具有很大开销
- select只是感知到了有事件发生, 并没有通知用户态具体是哪一个socket有数据, 仍需要O(n)的遍历
数据结构: 动态数组(可扩容)
epoll:
? 基于poll进行改进, 解决了剩下的2个问题
如何解决的:
- 只需要把fd数组从用户态拷贝到内核态一次, 而不用每次调用epoll都进行拷贝fd数组, 从而就不用频繁切换用户态和内核态了
- 事件通知机制中, 每次socket中有数据会主动通知内核, 并加入到就绪链表中, 便不需要遍历所有的socket, 而是只遍历就绪列表, 复杂度为O(1)
数据结构: 红黑树
实际应用:
windows上有select, 但没有epoll
Nginx和Redis都使用了Linux内核函数epoll来实现IO多路复用
Redis的IO多路复用:
用epoll函数来实现IO多路复用, 将连接信息和事件放到队列中, 事件分派器将队列中的事件分发给事件处理器(这一步是单线程的, 所以Redis核心是单线程模型)
Redis基于 多Reactor多线程 模式开发了网络(文件)事件处理器:

组成架构:
- 多个Socket套接字连接
- IO多路复用器(epoll)
- 事件分派器(Dispatcher) 分发过程是单线程的
- 事件处理器Handler
Reactor
Reactor模式组成架构:
- Reactor: 负责 监听是否有事件发生 和 分发事件
- Handler: 处理事件
Reactor的实现方案:
-
单Reactor-单线程
适用于处理占用时间不长的任务, 不适用于处理占用时间较长的任务
优点:
? 避免了切换上下文的开销
? 实现起来简单
缺点:
? 无法充分利用多核cpu, 某一任务执行时间占用太久会影响其他任务
-
单Reactor-多线程
只有?个 Reactor 对象来承担所有事件的监听和响应, 并发量低
-
多Reactor-多线程
主Reactor负责监听事件,从Reactor负责处理事件
Reactor 是「来了事件操作系统通知应用进程去处理」
Proactor (异步) 是「来了事件操作系统来处理,处理完再通知应用进程」
零拷贝
DMA:
内核缓冲区到用户缓冲区之间的拷贝要CPU
内核缓冲区到 Socket缓冲区之间的拷贝要CPU
磁盘/网卡到内核缓冲区/Socket缓冲区要DMA, 不必占用CPU
IO过程:
-
用户进程调用 read( ), 向操作系统发出 I/O 请求,请求读取数据到
用户进程缓冲区中,进程进入阻塞状态 -
操作系统收到请求后,进?步将 I/O 请求发送
DMA,然后让CPU 执行其他任务 -
DMA 进?步将 I/O 请求发送给磁盘;
-
磁盘收到 DMA 的 I/O 请求,把数据从磁盘读取到磁盘控制器的缓冲区中,当磁盘控制器的缓冲区被读满后,向 DMA 发起中断信号,告知自己缓冲区已满
-
DMA 收到磁盘的信号, 将磁盘控制器缓冲区中的数据拷贝到内核缓冲区中
-
当 DMA 读取了足够多的数据,就会发送中断信号给 CPU
-
CPU 收到 DMA 的信号,知道数据已经准备好 于是将数据从内核拷贝到用户空间,系统调用返回;
CPU 在这个过程中也是必不可少的,因为传输什么数据 & 从哪里传输到哪里,都需要 CPU 来告诉 DMA 控制器。
PageCache:
功能:
-
缓存最近被访问的数据(时间局部性)
-
预读功能(空间局部性)
PageCache 不适合于大文件:
- PageCache 由于长时间被大文件占据,其他「热点」的小文件可能就无法充分使用到 PageCache
- DMA 将大文件拷贝到 PageCache 也很耗时, 如果要是没有被经常读取到 将很亏
解决方案: 直接I/O
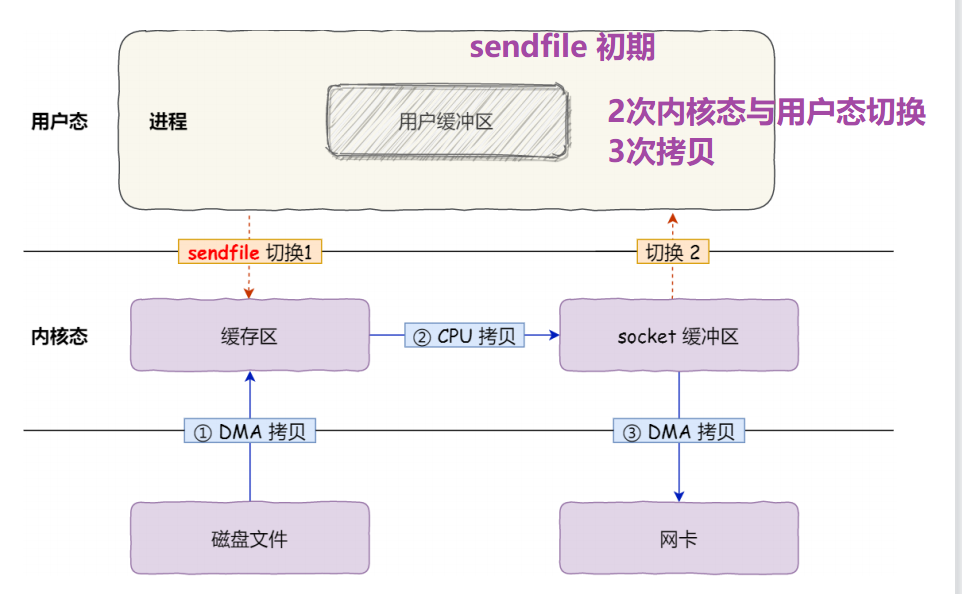
零拷贝:
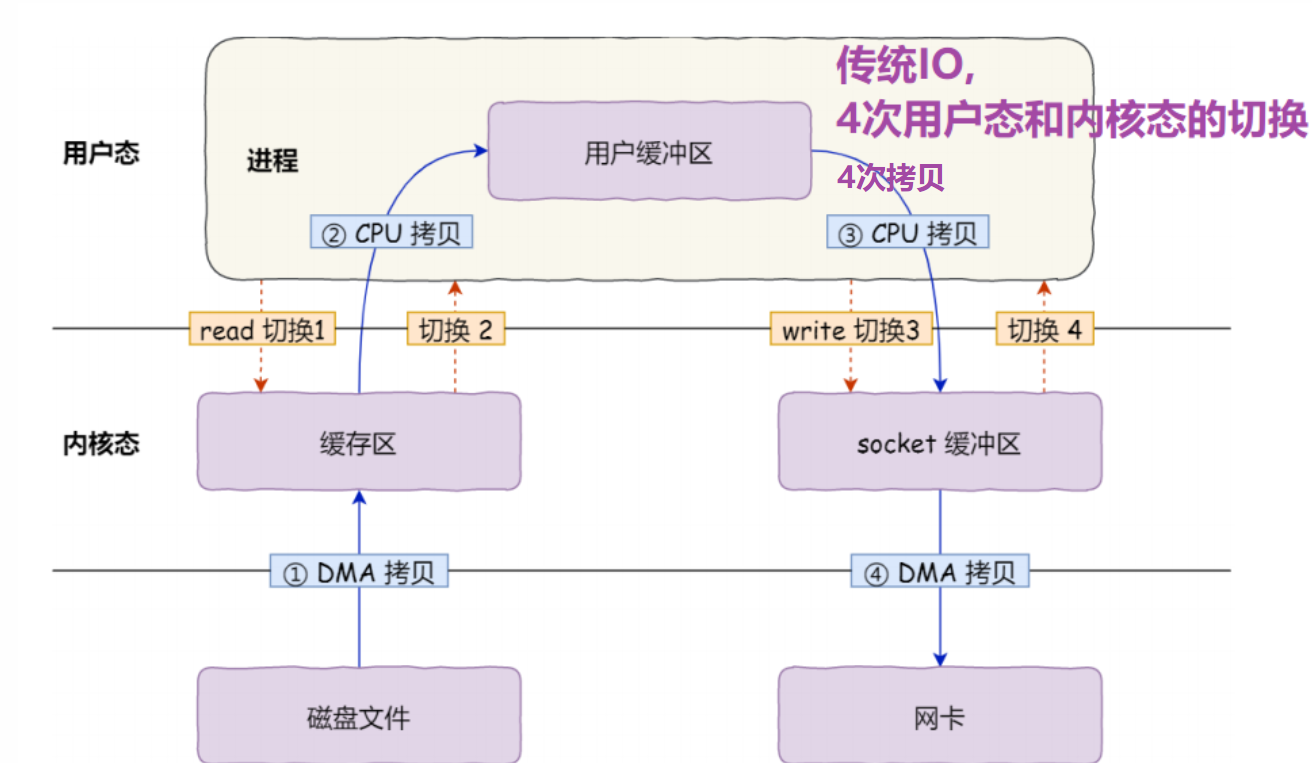
一次系统调用会发生2次用户态和内核态的切换
在文件传输的应用场景中,在用户空间我们并不会对数据「再加工」,所以数据实际上可以不必搬运到用户空间
1. 传统IO:
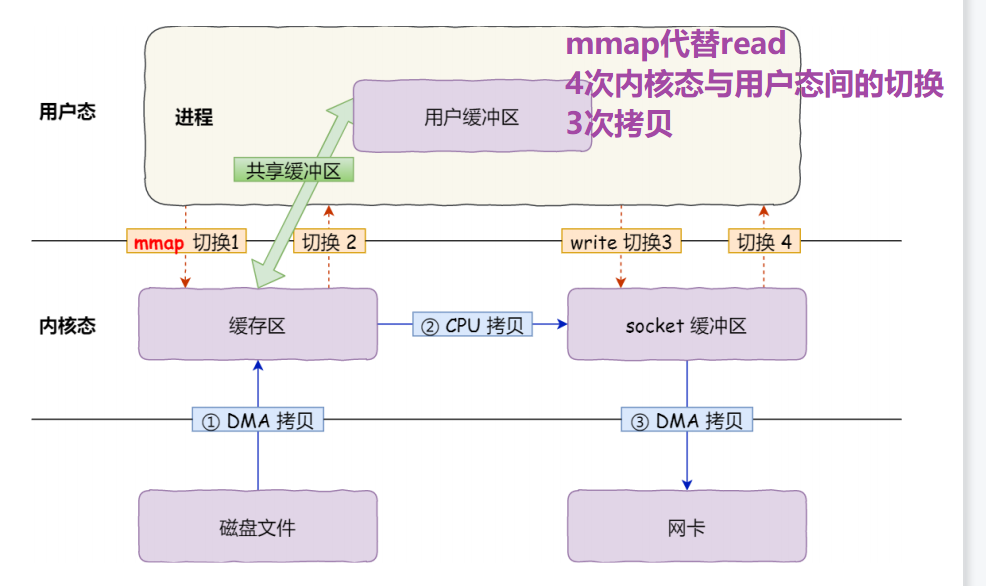
2. mmap代替read
3. sendfile代替 read+write [初期]
4. sendfile代替 read+write [后期]
