8大元素定位
tag_name:通过标签名称,找出来的元素太多了
name:用户输入input,不出意外总会有name属性
class_name
id:
1、同一个页面当中,某个id只能用一次,
2、如果元素有id,会优先使用id定位,
3、不好的消息,不是所有的元素都有id
link_text:连接的文本,只能用来定位连接
partial_link_text
css_selector
xpath:用的最多
//*[@id="s-top-left"]/a[3]: xpath表达式 相对路径: //开头
//*[@id="kw"]
/html/body/form/div/input[1] 绝对路径:/开头 必须从最开头的地方找
为什么叫路径?和操作系统的文件路径长的很像
xpath表达式的语法
用/还是//,测试行业,选择相对路径,几乎不会选择绝对路径
为什么?
1、因为绝对路径不稳定、
2、绝对路径更长,不好找
格式:
//找的标签名称[@属性名=‘属性值’]
以百度页面为例
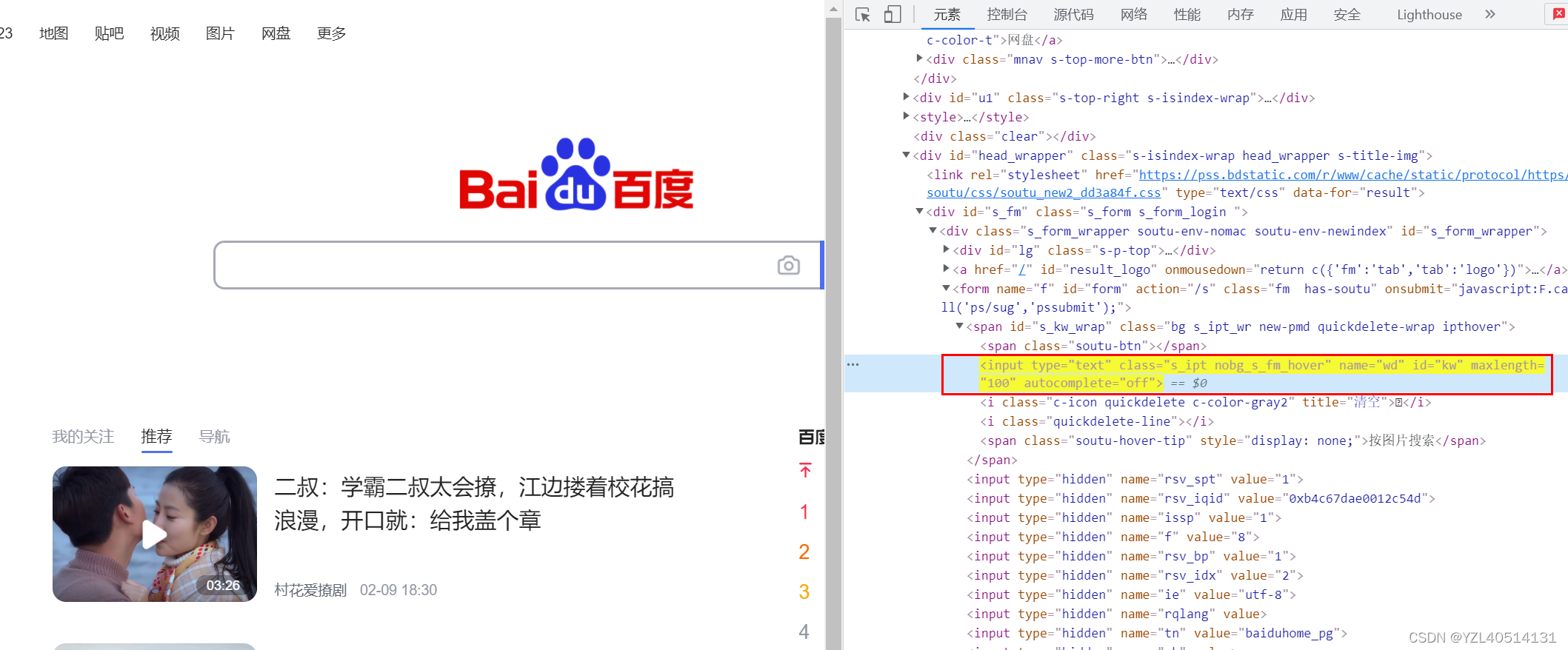
例1:定义百度输入框,以下2种方法
第一种精确匹配
//input[@type=“text”]
第二种正则表达式匹配,*:代表正则表达式:通配符,表示匹配所有的标签名
//*[@type=“text”]
xpath组合条件
组合属性:可以缩短查询范围,当定位一个元素,用一个属性名=属性值不能精确定位时,可以用组合属性定位
例2:还是定位百度输入框
格式:
//标签名[@属性名=‘属性值’ and @属性名=‘属性值’]
//*[@type=“text” and @class=“s_ipt”]
嵌套匹配
组合通过父亲找儿子关系(先找到上一级,再定位本级)
//span[@id=“s_kw_wrap”]/input[@type=“text”]
组合通过祖先找儿子关系(只要是本级的上级就可以)
//form[@id=‘form’]//input[@name=‘wd’]
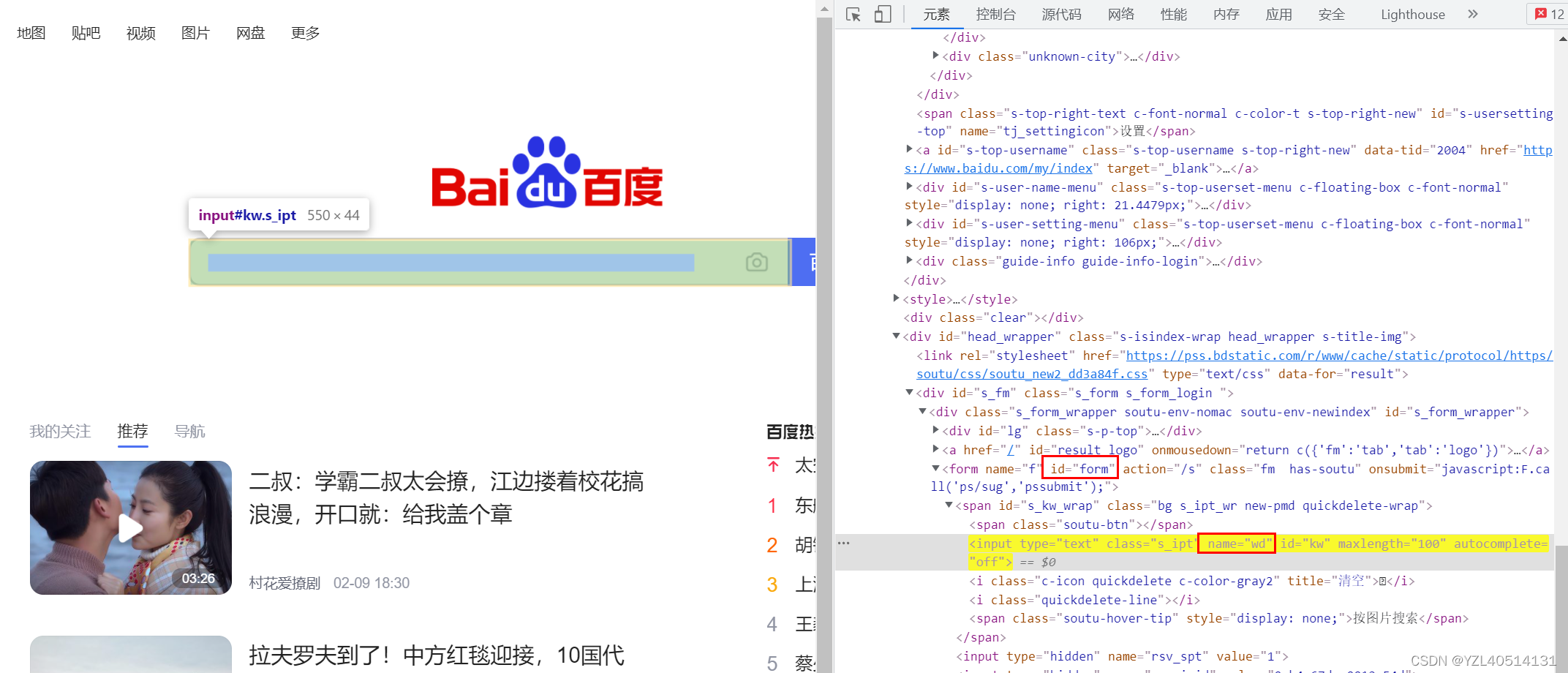
通过儿子找父亲
//input[@id='kw']/..
通过儿子找祖先(比较麻烦,不推荐)
//input[@id='kw']/../../..
通过兄弟姐妹找(比较麻烦)
//input[@id='kw']/../[@class='soutu-btn']
通过索引查找
xpath的索引是从1开始数的
xpath的计算索引的优先级很高
当通过//input[@type=“hidden”]可以定位多个元素的时候,加上索引
例:(//input[@type="hidden"])[3]
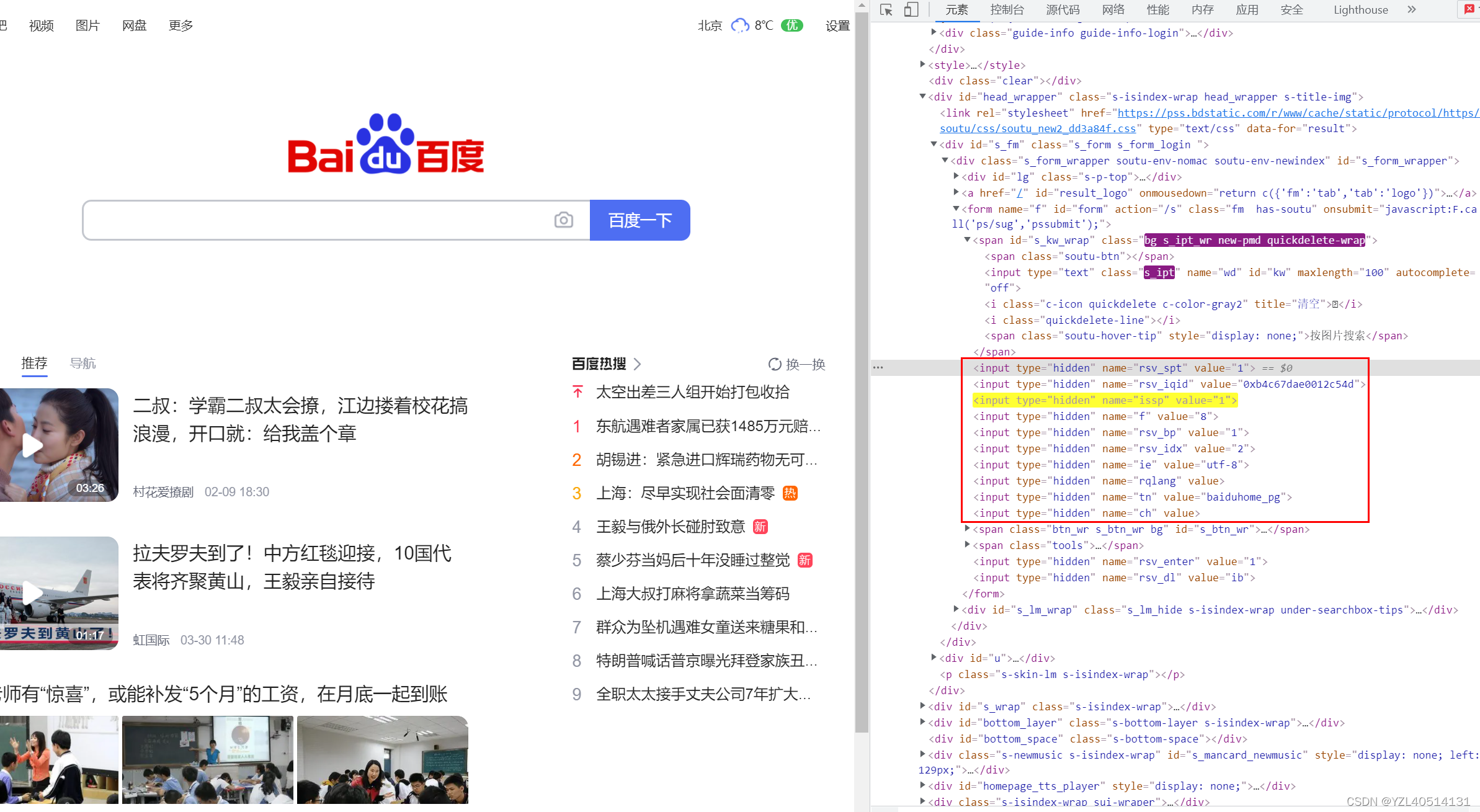
通过组合text文本
text不是用@符号,不是属性,是函数 text()
比对以下2种写法:
//a[text()=‘新闻’] text是方法名
//a[@text=‘师资团队’] text是属性名
例如:定位百度页面的图片超链接
//a[text()='图片']
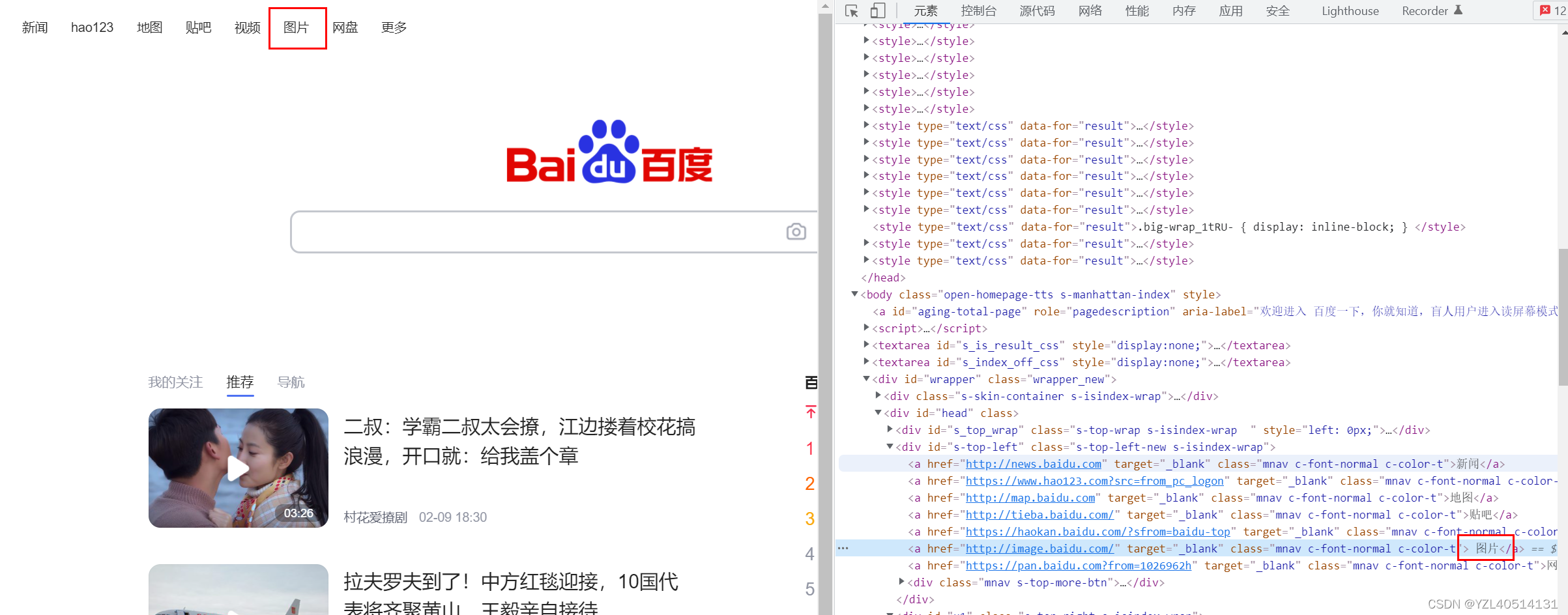
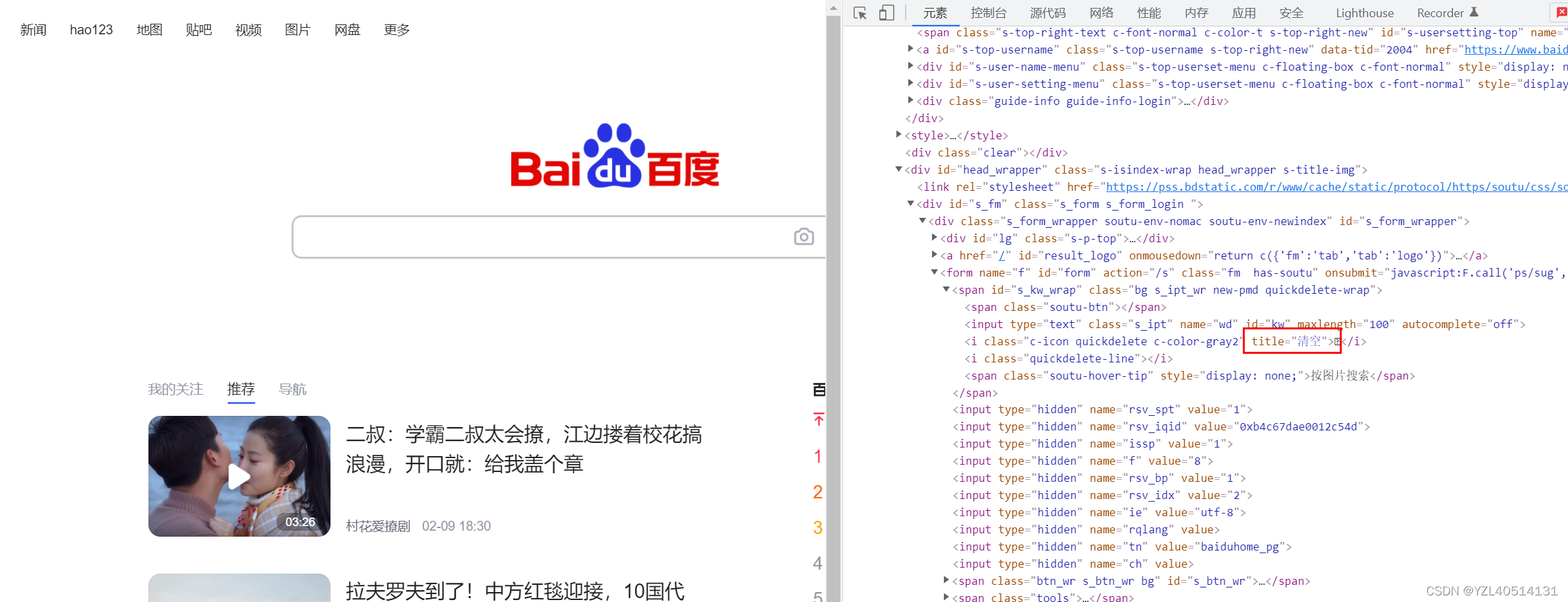
//i[@title="清空"]
通过函数组合contains(依据,值)
//a[contains(text(),'值')]模糊查找
//a[contains(@class,'值')]模糊查找
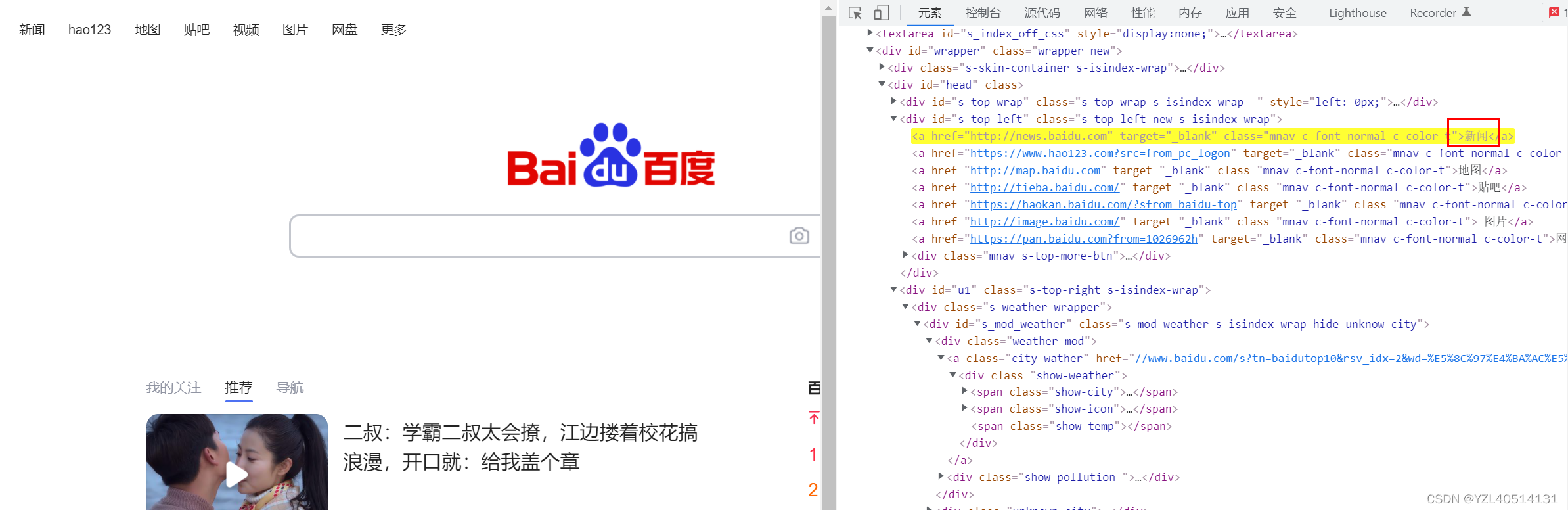
例:定位新闻超链接
通过text文本定位://a[contains(text(),'闻')]模糊查找
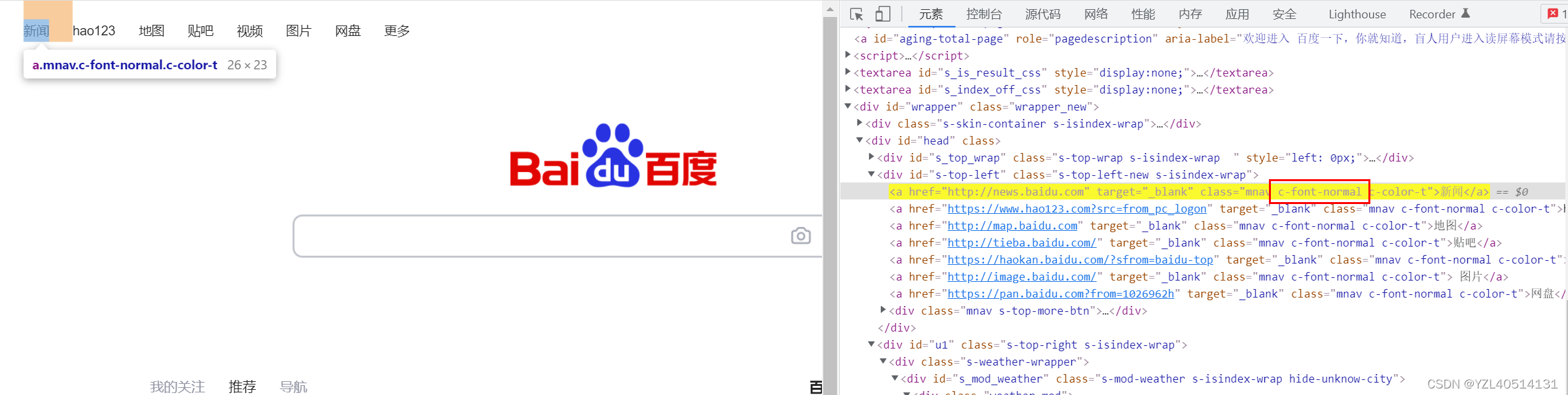
通过属性名定位://a[contains(@class,'c-font-normal')]
xpath定位,如何确定唯一性?
在源代码中ctrl+f,粘贴 查找
xpath:轴定位,轴运算
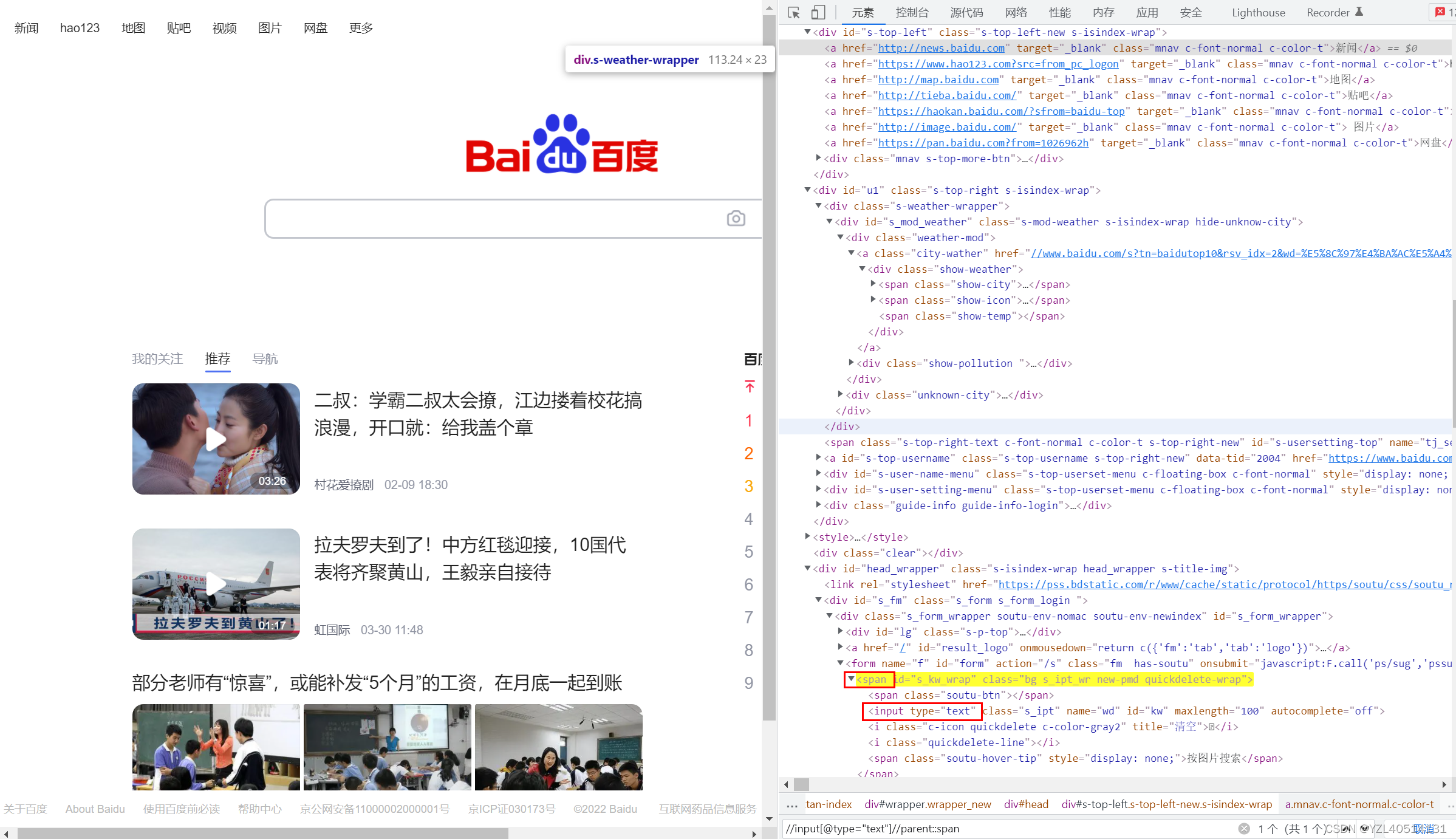
获取父亲://input[@type="text"]//parent::span
获取祖先://input[@type="text"]//ancestor::form

后面还可以加条件 //input[@type="text"]//ancestor::form[@id='form']
同级查找,该元素(input)上方的,哥哥/姐姐
//input[@type="text"]/following-sibling::span
如果有多个哥哥就需要索引查找了
同级查找,该元素(input)下方的,妹妹/弟弟
//input[@type="text"]/preceding-sibling::span
如果有多个妹妹就需要索引查找了