在linux驱动开发过程中经常需要使用到连续大块物理内存,尤其是DMA设备。而实际在系统经过长时间的允许之后,物理内存会出现比较严重的碎片化现象,虽然通过内存规整,内存回收等手动可以清理出一段连续的物理内存,但是并不能保证一定能够申请较大连续物理块。最初连续申请较大块物理内存,一般都是只在DMA场景中使用,因此内核专门把物理内存划分出ZONE_DMA专门用于DMA内存申请(当然划分DMA_ZONE还有其他原因,在较早DMA中由于DMA寻址地址限制 只能将一定范围的物理内存),用于解决DMA申请连续物理内存问题。但是随着各种设备驱动出现,对连续物理内存需求也越来越大。因此将所有连续物理内存都做预留出来,很显然如果划分预留出较多内存专门给连续物理内存使用,对内存使用存在较为严重浪费情况,也支持长期发展需求。
Allocation of physically-contiguous memory buffers is required by many device drivers, but it cannot always be reliably done on long-running Linux systems. That leads to all kinds of unsatisfying workarounds in driver code.
A few years ago, when your editor was writing the camera driver for the original OLPC XO system, a problem turned up. The video acquisition hardware on the system was capable of copying video frames into memory via DMA operations, but only to physically contiguous buffers. There was, in other words, no scatter/gather DMA capability built into this (cheap) DMA engine. A choice was thus forced: either allocate memory for video acquisition at boot time, or attempt to allocate it on the fly when the camera is actually used. The former choice is reliable, but it has the disadvantage of leaving a significant chunk of memory idle (on a memory-constrained system) whenever the camera is not in use - most of the time on most systems. The latter choice does not waste memory, but is unreliable - large, contiguous allocations are increasingly hard to do as memory gets fragmented. In the OLPC case, the decision was to sacrifice the memory to ensure that the camera would always work.
CMA
为了解决上述问题,三星公司的Michal Nazarewicz 与2010年提出CMA(contiguous memory allocator)The Contiguous Memory Allocator [LWN.net],用于解决连续物理内存申请问题:
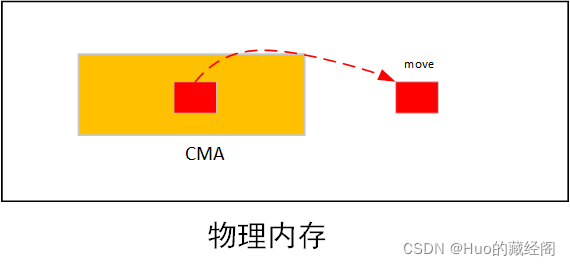
?CMA试图采用一个灵活的解决方案以满足不同的需求,CMA同样将物理内存中预留出连续物理内存区域(CMA),但是该区域的物理内存不仅仅局限于CMA内存申请,标记为MOVE可移动的内存申请也可以从CMA中申请内存,这样就不会造成内存浪费问题。同时如果CMA要求从CMA区域中申请连续物理内存时,发现CMA区域中内存已经被MOVE内存申请使用,则将被MOVE使用的物理页进行移动 ,将内存移到到非CMA区域,以为CMA申请腾出连续物理内存空间。
buddy为了方便标记CMA类型的内存,新增了MIGRATE_CMA migrate type用于对该类型内存管理:
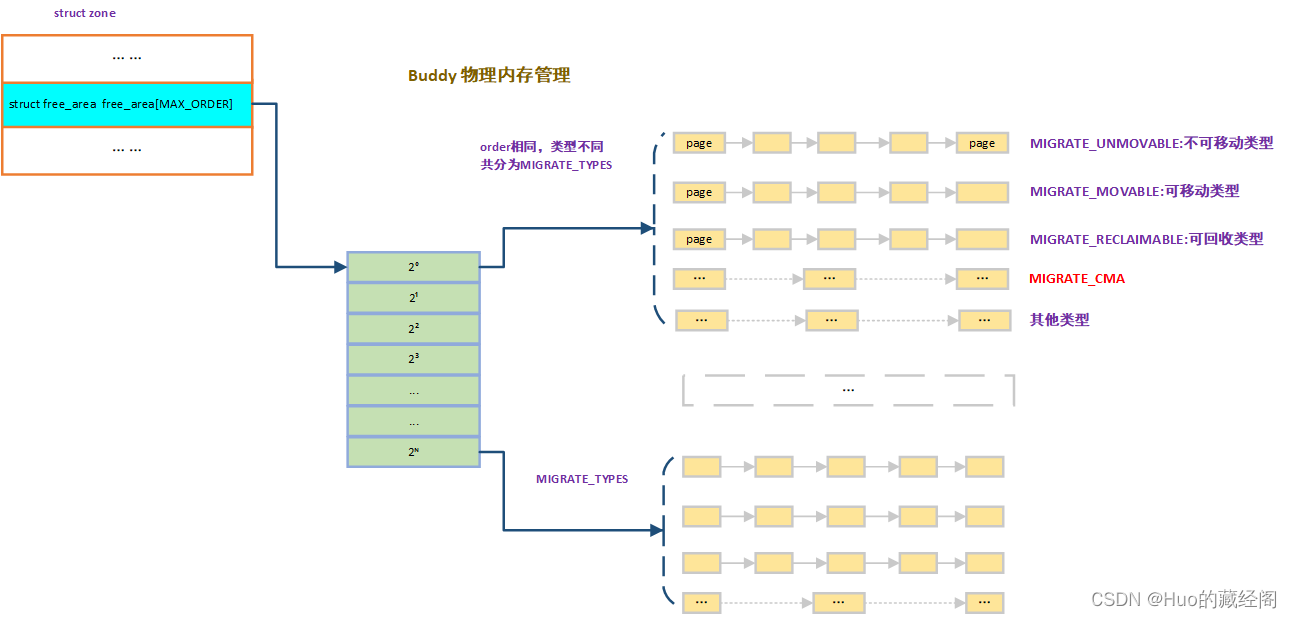
CMA也是一块特殊的保留内存,用于分配连续的大块物理内存。与一般保留内存不同的是,buddy将CMA区域可以用于分配MOVE类型内存申请。当DMA或者其他设备驱动使用时,将已经分配出去的页面迁移到CMA预留内存之外,以便腾出空间给连续物理内存分配使用。
CMA数据管理结构
CMA数据管理结构关系如下(来自于Linux 内存管理之CMA_mb6066e53e0c12a的技术博客_51CTO博客):
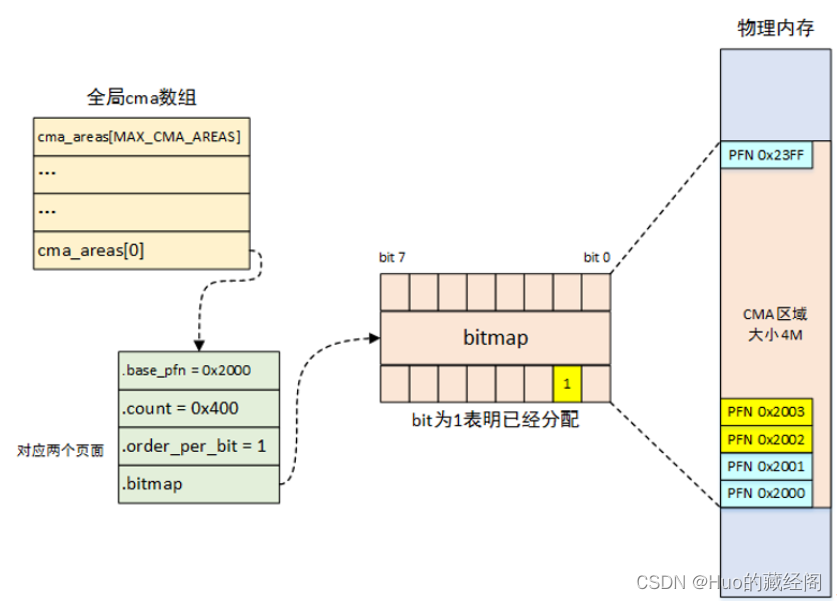
- ?内核使用一个struct cma cam_areas数组来管理所有cma区域,cma are最多支持MAX_CMA_AREAS个cma区域,可以根据实际需要进行配置。
- struct cma为管理每个cma区域数据结构,记录了每个cma区域实际内存多少,struct cma接轨成员如下:
struct cma { unsigned long base_pfn; unsigned long count; unsigned long *bitmap; unsigned int order_per_bit; /* Order of pages represented by one bit */ struct mutex lock; #ifdef CONFIG_CMA_DEBUGFS struct hlist_head mem_head; spinlock_t mem_head_lock; #endif const char *name; };
- bas_pfn: cma区域的起始物理地址页帧号。
- count: cma区域内多少个物理page。
- unsigned long *bitmap:使用bit 位方式代表每个单位page是否被使用(使用bit位便于节省内存),如果是1表示已经分配,0表示free。
- unsigned int order_per_bit: 代表每个bit 为表示多少个page,与buddy中order相同,如果为0,代表一个bit位一个物理页,如果为1,代表2个page占有一个bit位。因此可以计算出一个cma are占有的bit位数位:count>>order_per_bit,bitmap大小位BITS_TO_LONGS(count>>order_per_bit)。
- struct mutex ? ?lock: 位该cma 锁
- const char *name:cam 名称
- mem_head和mem_head_lock位CMA调试模式才能开启,需要配置CONFIG_CMA_DEBUGFS。
如何配置CMA are?
内核中提供了三种配置CMA are方式。
设备树
通过在设备树中添加配置cma节点,例如:
linux,cma { compatible = "shared-dma-pool"; reusable; size = <0 0x3c000000>; alloc-ranges = <0 0x96000000 0 0x3c000000>; linux,cma-default; };
- compatible:指明该节点CMA属性,为一段dma共享的内存吃。
- size:cam大小
- alloc_rangs:起始和结束地址。
kernel command
可以通过在启动kernel时传到kernel command参数,格式如下:
cma=nn[MG]@[start[MG][-end[MG]]]- ?nn[MG]: 为cma区域大小单位是M或者G,例如启动一个65M大小的CMA为:cma=64MB
- 如果需要指定特定物理地址范围,则后续需要跟@标识符
- @标识符后面start为起始物理地址
- end为结束物理地址,start和end都非必选项。?
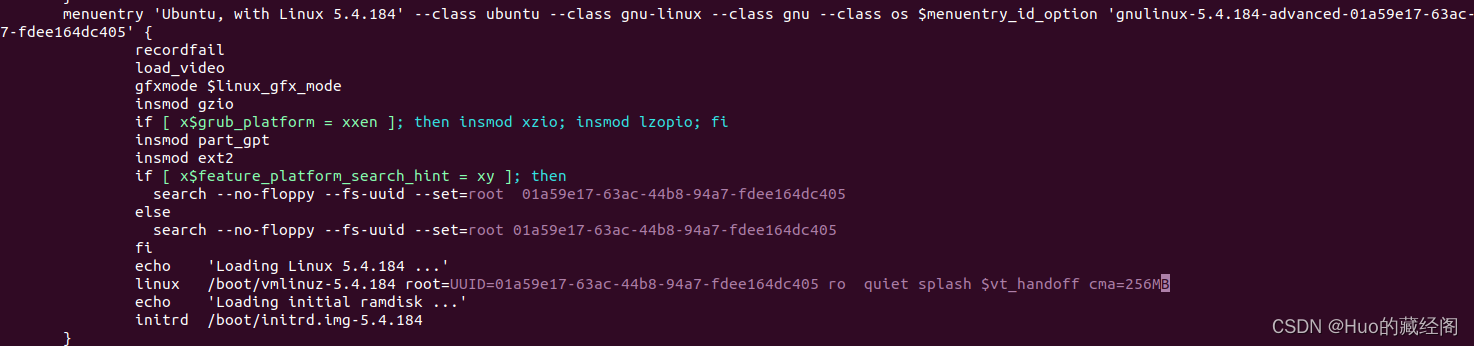
x86 ubuntu默认CMA是关闭的,如果要配置需要修改/boot/grub/grub.cfg文件,查找到对应启动内核版本在命令启动参数添加cma参数,设在cma are大小为256MB
kernel configuration
可以通过内核配置:
CONFIG_CMA_SIZE_MBYTES=960
CONFIG_CMA_SIZE_PERCENTAGE=25
# CONFIG_CMA_SIZE_SEL_MBYTES is not set
# CONFIG_CMA_SIZE_SEL_PERCENTAGE is not set
CONFIG_CMA_SIZE_SEL_MIN=y
# CONFIG_CMA_SIZE_SEL_MAX is not set可以通过?CONFIG_CMA_SIZE_MBYTE开启一个CMA are。
通过内核配置开启方法:
Memory Management options? ---->
????? --->Contiguous Memory Allocator
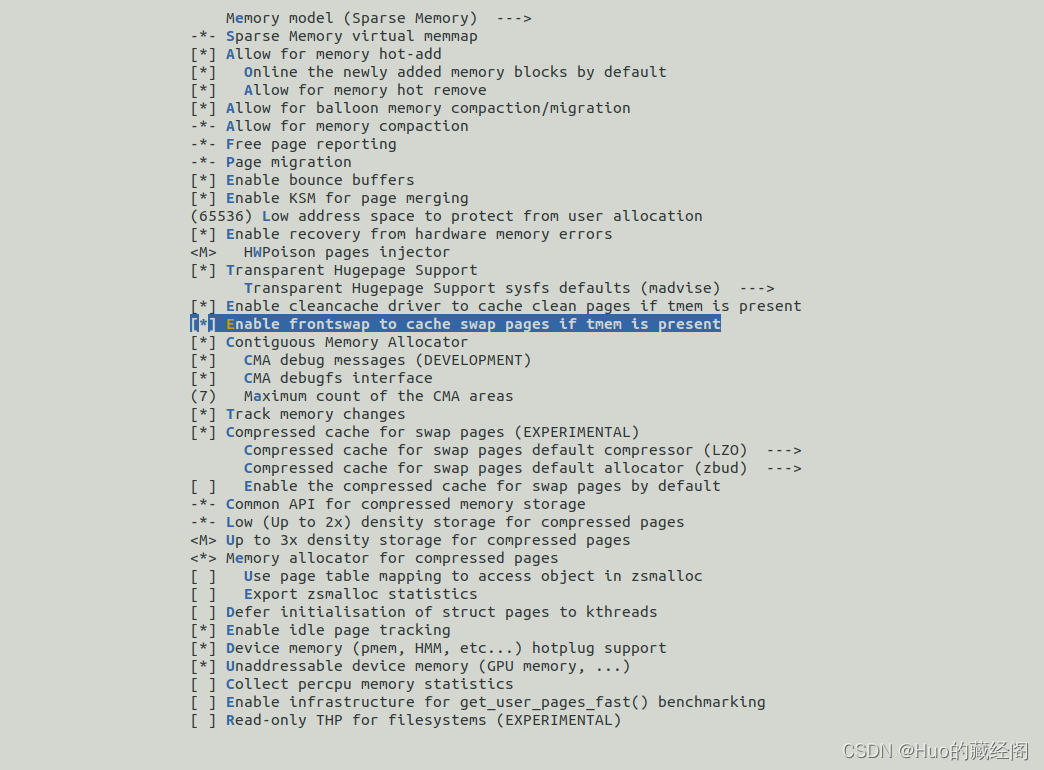
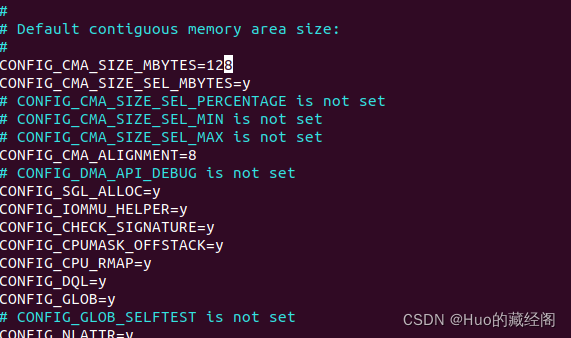
配置7个CMA are,打开config文件,同时将CMA debug打开。配置CONFIG_CMA_MBYTES为128M,
cma are生成过程
以cma command line说明cma are生成过程 以及如何加入到buddy系统中:
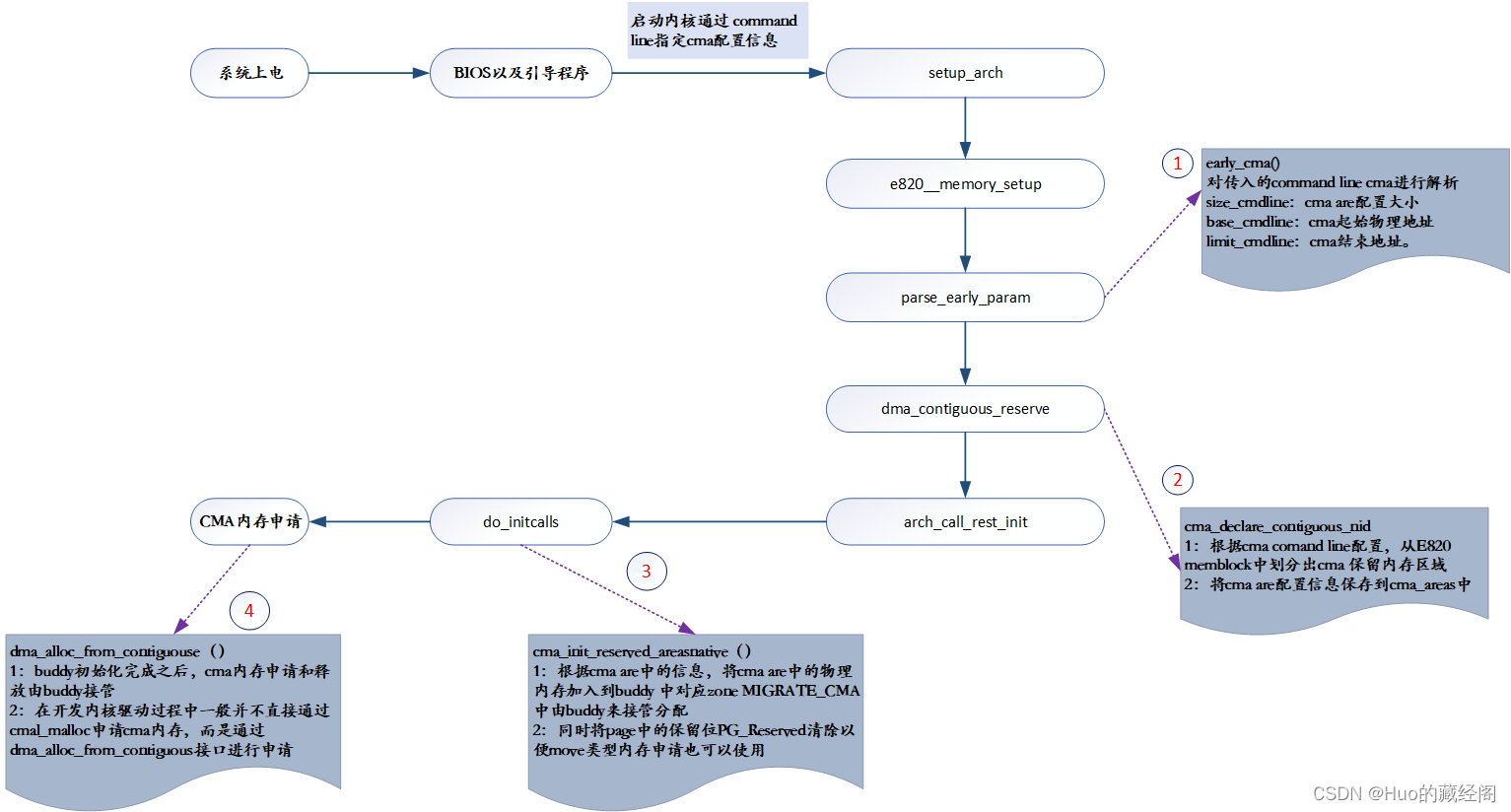
- early_cma:将传入的cma command line进行解析到size_cmdline等变了中。
- 之后根据解析出的cma 信息,cma_declare_contiguous_nid用于从E820 memblock中划分出满足要求的物理内存用于保留cma区域。
- 之后buddy初始化是,通过cma_init_reserved_areasnative将cma_are中的内存加入到MIGRATE_CMA migrate。
- 后续通过dma_alloc_from_contiguouse接口申请cma内存。
申请cma保留内存cma_declare_contiguous_nid
cma_declare_contiguous_nid用于根据需要从memblock中申请cma 保留内存,并初始化cma信息。
int __init cma_declare_contiguous_nid(phys_addr_t base,
phys_addr_t size, phys_addr_t limit,
phys_addr_t alignment, unsigned int order_per_bit,
bool fixed, const char *name, struct cma **res_cma,
int nid)
{
... ...
if (!addr) {
addr = memblock_alloc_range_nid(size, alignment, base,
limit, nid, true);
if (!addr) {
ret = -ENOMEM;
goto err;
}
}
... ...
ret = cma_init_reserved_mem(base, size, order_per_bit, name, res_cma);
... ...
}
- ?memblock_alloc_range_nid:从memblock中申请所需要的物理内存作为CMA 保留区域
- cma_init_reserved_mem:初始化cma are信息。
cma_init_reserved_mem
cma_init_reserved_mem初始化cma ares数组信息信息:
int __init cma_init_reserved_mem(phys_addr_t base, phys_addr_t size,
unsigned int order_per_bit,
const char *name,
struct cma **res_cma)
{
... ...
cma = &cma_areas[cma_area_count];
if (name) {
cma->name = name;
} else {
cma->name = kasprintf(GFP_KERNEL, "cma%d\n", cma_area_count);
if (!cma->name)
return -ENOMEM;
}
cma->base_pfn = PFN_DOWN(base);
cma->count = size >> PAGE_SHIFT;
cma->order_per_bit = order_per_bit;
*res_cma = cma;
cma_area_count++;
totalcma_pages += (size / PAGE_SIZE);
return 0;
}
?cma are加入到buddy系统中
将cma are加入到buddy系统中,需要遍历cma_area数组中所有cma内存,将其加入到MIGRATE_CMA内存,被buddy所接管,主要流程如下:
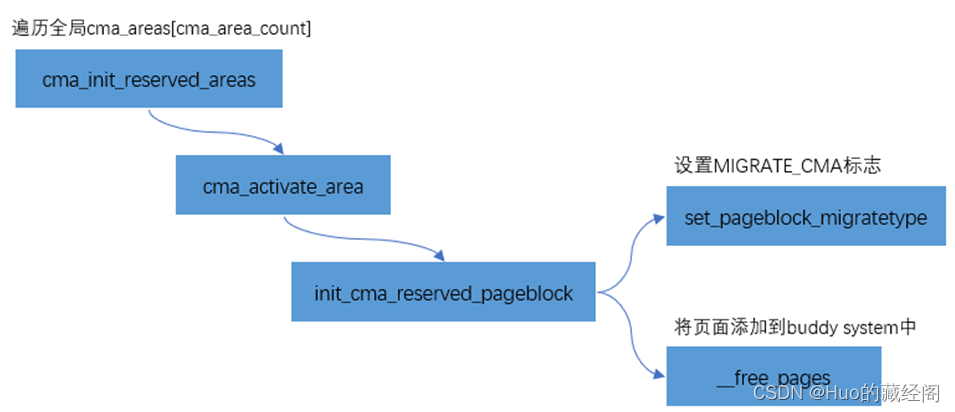
?最终通过init_cma_reserved_pageblock将其加入到buddy系统中
cma_activate_area
cma_activate_area用于激活一个cma are,并将其加入到buddy系统中:
static void __init cma_activate_area(struct cma *cma)
{
unsigned long base_pfn = cma->base_pfn, pfn = base_pfn;
unsigned i = cma->count >> pageblock_order;
struct zone *zone;
cma->bitmap = bitmap_zalloc(cma_bitmap_maxno(cma), GFP_KERNEL);
if (!cma->bitmap)
goto out_error;
WARN_ON_ONCE(!pfn_valid(pfn));
zone = page_zone(pfn_to_page(pfn));
do {
unsigned j;
base_pfn = pfn;
for (j = pageblock_nr_pages; j; --j, pfn++) {
WARN_ON_ONCE(!pfn_valid(pfn));
/*
* alloc_contig_range requires the pfn range
* specified to be in the same zone. Make this
* simple by forcing the entire CMA resv range
* to be in the same zone.
*/
if (page_zone(pfn_to_page(pfn)) != zone)
goto not_in_zone;
}
init_cma_reserved_pageblock(pfn_to_page(base_pfn));
} while (--i);
mutex_init(&cma->lock);
#ifdef CONFIG_CMA_DEBUGFS
INIT_HLIST_HEAD(&cma->mem_head);
spin_lock_init(&cma->mem_head_lock);
#endif
return;
not_in_zone:
bitmap_free(cma->bitmap);
out_error:
cma->count = 0;
pr_err("CMA area %s could not be activated\n", cma->name);
return;
}
- ?cma->bitmap:计算bitmap占用空间大小并为其分配物理内存,计算方法:BITS_TO_LONGS(count>>order_per_bit),同时将每个页对应bitmap都清零表示处于空闲状态。
- init_cma_reserved_pageblock:用于初始化cma are中每个物理页将其加入到buddy?MIGRATE_CMA类型中。
init_cma_reserved_pageblock
/* Free whole pageblock and set its migration type to MIGRATE_CMA. */
void __init init_cma_reserved_pageblock(struct page *page)
{
unsigned i = pageblock_nr_pages;
struct page *p = page;
do {
__ClearPageReserved(p);
set_page_count(p, 0);
} while (++p, --i);
set_pageblock_migratetype(page, MIGRATE_CMA);
if (pageblock_order >= MAX_ORDER) {
i = pageblock_nr_pages;
p = page;
do {
set_page_refcounted(p);
__free_pages(p, MAX_ORDER - 1);
p += MAX_ORDER_NR_PAGES;
} while (i -= MAX_ORDER_NR_PAGES);
} else {
set_page_refcounted(page);
__free_pages(page, pageblock_order);
}
adjust_managed_page_count(page, pageblock_nr_pages);
}
- 将cma 内存page 中的PG_Reserved清除,以便可以用于MOVE类型内存申请。
- ?set_pageblock_migratetype:将page block类型设置为MIGRATE_CMA。
- __free_pages 将page加入到buddy系统中。
CMA 内存申请
由于在使用CMA场景大部分都是使用在DMA场景中,因此并不会直接使用到cma_alloc接口,而是通过dma_alloc_contiguous接口进行CMA内存申请:
struct page *dma_alloc_contiguous(struct device *dev, size_t size, gfp_t gfp)参数:
- struct device *dev:cma内存所属device。
- size:申请CMA内存大小。
- gfp:申请内存所使用flag。
返回值:
- struct page*:申请CMA的起始物理页。
申请CMA内存过程中,如果当前CMA are中内存已经被MOVE申请使用,需要通过页迁移migrate_pages到CMA are之外,因此申请CMA操作属于比较重的操作,会比较耗时。整个过程大概如下?(图来自于Linux 内存管理之CMA_mb6066e53e0c12a的技术博客_51CTO博客):
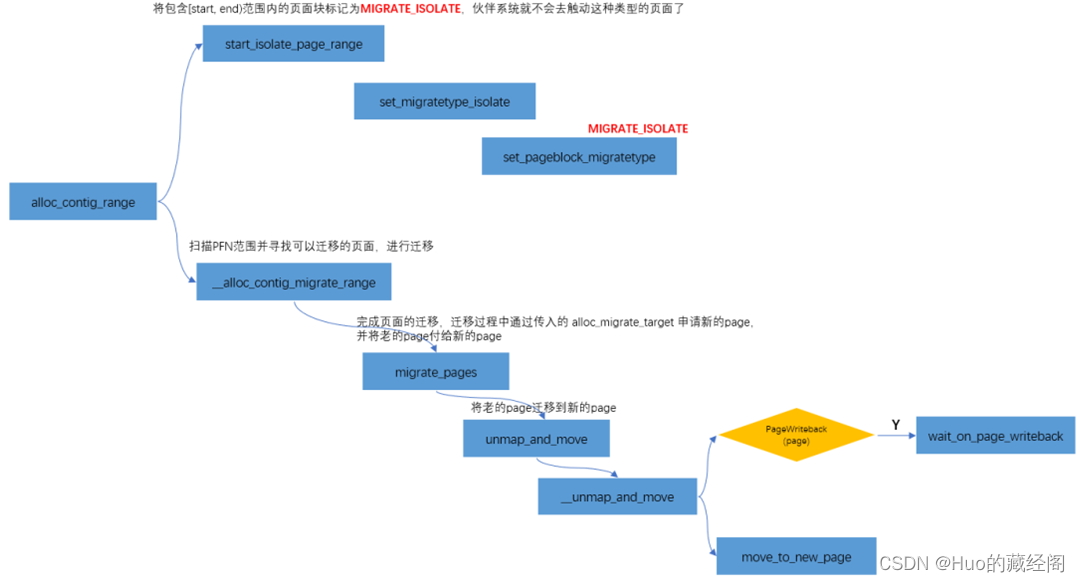
?CMA特性在嵌入式设备特别是内存不是特别大时,长期运行无法申请到连续大块物理内存时经常使用到的特性。
__alloc_contig_migrate_range
__alloc_contig_migrate_range函数为触发页迁移接口函数:
/* [start, end) must belong to a single zone. */
static int __alloc_contig_migrate_range(struct compact_control *cc,
unsigned long start, unsigned long end)
{
/* This function is based on compact_zone() from compaction.c. */
unsigned int nr_reclaimed;
unsigned long pfn = start;
unsigned int tries = 0;
int ret = 0;
migrate_prep();
while (pfn < end || !list_empty(&cc->migratepages)) {
if (fatal_signal_pending(current)) {
ret = -EINTR;
break;
}
if (list_empty(&cc->migratepages)) {
cc->nr_migratepages = 0;
pfn = isolate_migratepages_range(cc, pfn, end);
if (!pfn) {
ret = -EINTR;
break;
}
tries = 0;
} else if (++tries == 5) {
ret = ret < 0 ? ret : -EBUSY;
break;
}
nr_reclaimed = reclaim_clean_pages_from_list(cc->zone,
&cc->migratepages);
cc->nr_migratepages -= nr_reclaimed;
ret = migrate_pages(&cc->migratepages, alloc_migrate_target,
NULL, 0, cc->mode, MR_CONTIG_RANGE);
}
if (ret < 0) {
putback_movable_pages(&cc->migratepages);
return ret;
}
return 0;
}
- 循环遍历cma中的每个page,将其迁移到指定的MIGRATE_CMA中,并且全部处于空闲状态,如果page不处于空闲状态,则migrate_pages将会触发页迁移将其内容转移到合适的CMA are之外。
cma debug
在开发内核过程中提供了cma debug功能用于对cma功能调试,但是需要开启CONFIG_CMA_DEBUG=y?CONFIG_CMA_DEBUGFS=y内核配置开关。
开启之后会在/sys/kernel/debug/cma目录:
# ls /sys/kernel/debug/cma/cma-0/
alloc base_pfn bitmap count free maxchunk order_per_bit used关于cma debug可以参考《cma debug》,这篇文章
参考资料
Contiguous memory allocation for drivers [LWN.net]
A reworked contiguous memory allocator [LWN.net]
The Contiguous Memory Allocator [LWN.net]
Linux 内存管理之CMA_mb6066e53e0c12a的技术博客_51CTO博客
Contiguous Memory Allocator - CMA (Linux)
The kernel’s command-line parameters ― The Linux Kernel documentation
Linux DebugFS 子目录也是用debugfs_create_dir来实现_此昵称已经存在吗的博客-CSDN博客_debugfs 目录