�ļ�ϵͳ(��)�������ڳ���ʲô��
�ļ�ϵͳ�Ѿ���չ���������,ͬʱ�ļ�ϵͳ�Ĵ���ҲԽ��Խ����,����ͨ��ǰ�����´���֪���˿������ȥ���һ���ļ�ϵͳ,���������б�Ҫȥ�˽�һ��linux�ļ�ϵͳ�������ڳ���ʲô����һ����,���ǿ���ͨ����������˽��ļ�ϵͳ���������,���Ӽ���������ļ�ϵͳ������ͻ�������;����һ�������ִ����ļ�ϵͳ���Ƚ��Ӵ�,����������,���ϵ��ļ�ϵͳ�ż�ǧ�д���,���������Ƚ����ס�
1 minix�ļ�ϵͳ
����дԭʼLinux�ں�,Linus Torvalds��Ҫһ���ļ�ϵͳ,���Dz��뿪�������������ʹ����Minix�ļ�ϵͳ,���� Andrew S. Tanenbaum������,������Tanenbaum ��Minix����ϵͳ��һ���֡�Minix����Unix����ϵͳ,Ϊ����ʹ�ö����������Ĵ��뿪��ʹ��,���Һ�������Ȩ��Torvalds,��������������Linux�ij����汾���������ǿ�����֪��Ext4�������ڵ�����˭,����֪��Linux����ϵͳ�Dzο�MINIX����ϵͳд�ġ�
minix�ļ�ϵͳ�����UNIX�ļ�ϵͳ������ͬ,����6���������,����һ��360K������,������ֵķֲ�����ͼ��ʾ
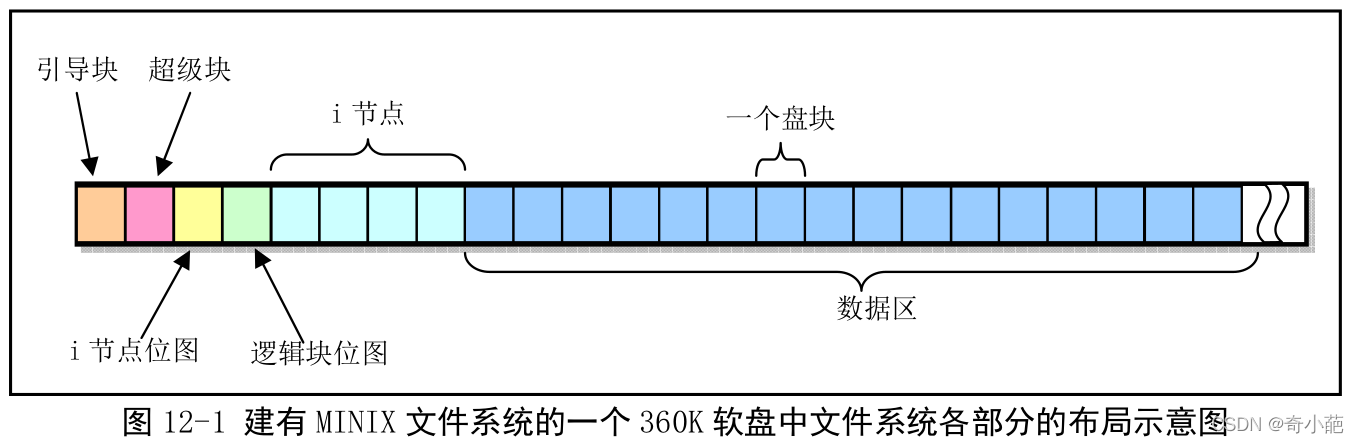
ͼ��,�������̿鱻����Ϊ��1KBΪ��λ�Ĵ��̿�,�����ͼ�й���360�����̿�,ÿ�������ʾһ�����̿顣
- ������: �Ǽ�����ӵ�����ʱ����ROM BOIS�Զ������ִ�д��������,�����������̶����������豸,���Զ��ڲ�������������Ƭ,��һ�̿��п��Բ������롣�����κ���Ƭ���뺬�������ռ�,�Ա���MINIX�ļ�ϵͳ�ĸ�ʽͳһ��
- ������: ���ڴ�����豸ʡ�ļ�ϵͳ�ṹ����Ϣ,��˵�������ֵĴ�С,�����ݽṹ����

ΪʲôҪ���ڴ�κʹ��̶���?
�����ļ�ϵͳ,��Ӧ�ô����д洢��Щ���ݽṹ����,���Dz���ϵͳΪ�˸�����õĹ����ļ�ϵͳ,���� �Կռ任ʱ��� ˼�����������ݡ�
�ӳ���������ݽṹ��,���ǿ��Կ���,����λͼ���ʹ��8�黺����(s_zmap[8]),��ÿ�黺������С��1024�ֽ�,ÿ���ر�ʾһ���̿��ռ��״̬,���һ���������ɴ���8192���̿顣8�����������ܹ��ɱ�ʾ65536���̿�,���MINIX�ļ�ϵͳ1.0����֧�ֵ������豸����64M��
-
����λͼ: ������������ÿ�������̿��ʹ�����,���˵�һ������λ(λ0)����,����λͼ��ÿ������λ���δ��������������е�һ�����顣
����λͼ�ı���λ1���������������еĵ�һ�������̿�,�������ϵĵ�һ�����̿�(������)����һ�������̿鱻ռ��ʱ,������λͼ����Ӧ�ı���λ����λ�����ڵ����д��������̿鶼��ռ��ʱ���ҿ����̿�ĺ����᷵��0ֵ,��������λͼ��ͱ���λ(λ0)���ò���,�����ڴ����ļ�ϵͳʱ,��Ԥ�Ƚ�������Ϊ1 -
inode�ڵ�λͼ: ����˵��i�ڵ��Ƿ�ʹ��,ͬ����ÿ������λ����һ��i�ڵ�,����1K��С����Ƭ��˵,һ����Ƭ�ɱ�ʾ8192��i�ڵ��ʹ��״����
������λͼ�������,���ڵ����е�i�ڵ㶼��ʹ��ʱ���ҿ��е�i�ڵ�ĺ����᷵��0ֵ,���i�ڵ�λͼ�ĵ�1���ֽڵ���ͱ���λ(λ0)�Ͷ�Ӧ��i�ڵ㶼���ò���,�����ڴ����ļ�ϵͳʱ,��Ԥ�Ƚ�i�ڵ�0��Ӧ����λͼ�еı���λ��Ϊ1,��˵�һ��i�ڵ�λͼ����ֻ�ܱ�ʾ8191��i�ڵ��״�� -
i�ڵ�: ������ļ�ϵͳ���ļ���Ŀ¼���������ڵ�,ÿ���ļ���Ŀ¼������һ��i�ڵ�,ÿ��i�ڵ�ṹ�д���Ŷ�Ӧ�ļ��������Ϣ��
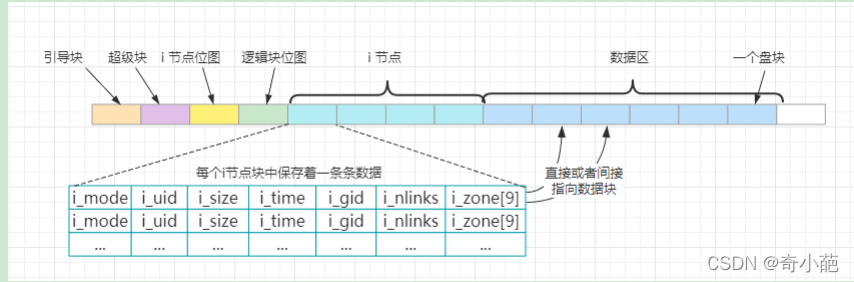

�ļ��е������Ƿ��ڴ��̿����������,��һ���ļ�����ͨ����Ӧ��i�ڵ�����Щ���ݴ��̿�����ϵ,��Щ�̿�ĺ���ʹ����i�ڵ��������i_zone[],����������ڴ��i�ڵ��Ӧ�ļ����̿�š�
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-T6rfoyEi-1649083982079)(%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F(%E4%B8%89)]%E2%80%94%E8%80%81%E7%A5%96%20b21f7/Untitled%202.png)](https://img-blog.csdnimg.cn/1aba4e243a024093accde15847b595c8.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5aWH5bCP6JGp,size_20,color_FFFFFF,t_70,g_se,x_16)
- i_zone[0]��i_zone[6]���ڴ���ļ���ʼ��7�����̿��,��Ϊֱ�ӿ顣����ļ�����С�ڵ���7K�ֽ�,�������i�ڵ���Ժܿ���ҵ�����ʹ�õ��̿顣
- ����ļ���һЩ,����Ҫ�õ�һ����ӿ�(i_zone[7]),����̿��д���Ÿ��ӵ��̿��,����MINIX�ļ�ϵͳ�����Դ��512���̿��,��˿���Ѱַ512���̿顣
- ����ļ���Ҫ��һЩ,����Ҫʹ�õ�������ӿ�(i_zone[8]),������ӿ����������һ������̿�,���ʹ�ÿ���Ѱַ512*512���̿�
���Զ���MINIX�ļ�ϵͳ��˵,һ���ļ������Ϊ(7+512+512*512) = 262,663KB
�����Ծ����������˵��һ��minix�ļ�ϵͳ��ϸ��:
- ����������ubuntuϵͳ���湹��һ��minix�ļ�ϵͳ�ľ���
dd if=/dev/zero of=minix.img bs=1K count=360
��¼��360+0 �Ķ���
��¼��360+0 ��д��
368640 bytes (369 kB, 360 KiB) copied, 0.00125697 s, 293 MB/s
mkfs.minix minix.img
128 �� inode
360 ����
��������=8 (8)
����С=1024
���ߴ�=268966912
���ǹ�����һ��minix.img�����ļ�,��������ļ���ʽ����minix�ļ�ϵͳ����СΪ360k,�������Ϣ����֪��,��Щ�����ڸ�ʽ��֮��,��ȷ������,����:
(1)�ܹ�128��i�ڵ�
(2)�ܹ�360����
(3)��һ�����������Ϊ8
(4)zone�Ĵ�С��1024�ֽ�
(5)�ļ����ߴ���268966912
- ������������ļ�,Ȼ����Ϊ����һЩ�ļ���Ŀ¼
mkdir mnt
sudo mount minix.img -o loop mnt
tree
.
������ bb.txt
������ mydir
������ aaa.txt
1 directory, 2 files
mnt$ cat bb.txt
bbb
mnt$ cat mydir/aaa.txt
aaa
- �鿴minix.img�������������,�������:
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-hAvYtCX8-1649083982081)(%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F(%E4%B8%89)]%E2%80%94%E8%80%81%E7%A5%96%20b21f7/Untitled%203.png)](https://img-blog.csdnimg.cn/9def7d38729045b8b196489058e40e48.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5aWH5bCP6JGp,size_20,color_FFFFFF,t_70,g_se,x_16)
- �Ա�������,���Ƿ������1K������������0,����û��ʹ��������,����
- �Աȳ�����,��Ӧ������Ľṹ����ֶ���������,�������������ļ�ϵͳ�����,�������inode���������ݿ�������zone��С�͵�һ��zone��λ�õȡ�
struct d_super_block {
unsigned short s_ninodes; //0x0080,ʮ����128,inode�ܹ�128��
unsigned short s_nzones; //0x0168,ʮ����360,�ܹ�360��zone
unsigned short s_imap_blocks; //0x0001,ʮ����1,inodeλͼռ1����
unsigned short s_zmap_blocks; //0x0001,ʮ����1,zoneλͼռ1����
unsigned short s_firstdatazone;//0x0008,ʮ����8,��һ�������������8
unsigned short s_log_zone_size;//0x0000,log��ʾ��һ�����ݴ�С,1kb
unsigned long s_max_size; //0x10081c00,ʮ����268966912,����ļ�����
unsigned short s_magic; //0x138f,minixħ��
};
���ϲŶ����ֽ�,�϶�������ȫռ��1k��,���ǹ涨��������,���㲻��ռ������1k�ռ�,Ҳ��������,�Ա���ʱ֮�衣���Կ���,û���õ�������ȫ��Ϊ0��
- �Ա�i�ڵ�λͼ, һ������λ0/1��ʾһ��i�ڵ��Ƿ�ʹ�á�
00000800 1f 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000810 fe ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
00000820 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
*
���ǿ���ǰ��16���ֽ�,��һ���ֽ���0x1f=0b00011111,����15���ֽڶ���0��16���ֽڸպõ���128λ,�ɳ������֪,�ܹ���128��i�ڵ㡣��һ��λͼ����,������Ϊ1,����һ��,�Dz�������һλ��,ֻ��127λ�����ǿ���������һ��0xfe,���ﻹ��һλ��0,����֮ǰ16�ֽ������127λ,�պ���128��λ��
- �Ա���������λͼ
00000c00 1f 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000c10 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000c20 00 00 00 00 00 00 00 00 00 00 00 00 fe ff ff ff |................|
00000c30 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
*
���ϴ�0x1f��0xfe,��ȥ��һλ����,�պ�352��λͼ�����Ӧ�������������λͼռ�ü�¼,����һ����������8��ʼ��
- �Ա�i�ڵ�����
minixʹ��32�ֽڵĽṹ��ʾһ��i�ڵ������,��ṹ������:
struct m_inode {
unsigned short i_mode; //0x41ed,040755, Ŀ¼�ļ�, rwxr-xr-x
unsigned short i_uid; //0x03e8, 1000
unsigned long i_size; //0x00000080, 128
unsigned long i_mtime; //0x5cb93ad2
unsigned char i_gid; //0xe8
unsigned char i_nlinks; //0x03
unsigned short i_zone[9]; //0x08,i_zone[0]=8,���ݿ��ڵ�8������
};
- �Ա�������: ��һ��������,ʵ�����Ǹ�Ŀ¼��������,��Ŀ¼�������������ŵ���Ŀ¼��,ÿ��Ŀ¼��,minix2.0��32λ,minix1.0��16λ��һ��Ŀ¼���ʾһ��Ŀ¼�����ļ�,����2�ֽڱ�ʾ���Ŀ¼�����ļ���inode�ڵ����,ʣ�µ��ֽ����ڴ���ļ����ַ��������е�һ��Ŀ¼���ʾ��.��,�ڶ�����ʾ����',��������ʾmydirĿ¼��Ҳ���������ͨ�ļ���������,��ֱ�Ӵ���ļ�����,������ʲô��������i�ڵ����ݱ�ʾ
2 �ļ�ϵͳĿ¼��ṹ
linux 0.11ϵͳ���õ���MINIX�ļ�ϵͳ1.0��,����Ŀ¼�ṹ��Ŀ¼��ṹ�봫ͳ��UNIX�ļ�Ŀ¼��ṹ��ͬ,������include/linux/fs.h��
#define NAME_LEN 14 // ���ֳ���ֵ��
#define ROOT_INO 1 // ��i �ڵ㡣
// �ļ�Ŀ¼��ṹ��
struct dir_entry
{
unsigned short inode; // i �ڵ㡣
char name[NAME_LEN]; // �ļ�����
};
ÿ��Ŀ¼��ֻ����һ������Ϊ14�ֽڵ��ļ����ַ������ļ�����Ӧ��2�ֽڵ�i�ڵ��,���һ�������̿���Դ��1024/16=64��Ŀ¼��й��ļ���������Ϣ�����ڸ�i�ڵ�ָ����i�ڵ�ṹ��,��Ҫ�����ļ��������ԡ����������ȡ����ʱ���ʱ���Լ����ڵĴ��̿����Ϣ��ÿ��i�ڵ�ŵ�i�ڵ㶼λ�ڴ����ϵĹ̶�λ�ô���
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-MZSsTIPg-1649083982082)(%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F(%E4%B8%89)]%E2%80%94%E8%80%81%E7%A5%96%20b21f7/Untitled%204.png)](https://img-blog.csdnimg.cn/126439e74d5b4d77ac0ec454a54c7e42.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5aWH5bCP6JGp,size_20,color_FFFFFF,t_70,g_se,x_16)
- �ڴ�һ���ļ�ʱ,�ļ�ϵͳ����ݸ������ļ����ҵ�i�ڵ��,�Ӷ�ͨ�����Ӧ��i�ڵ���Ϣ�ҵ��ļ�ϵͳ���ڵĴ��̿�λ��
- ����Ҫ�����ļ���/usr/bin/vi��i�ڵ��,�ļ�ϵͳ���Ȼ�Ӿ��й̶�i�ڵ��(1)�ĸ�Ŀ¼��ʼ����,����i�ڵ��1�����ݿ��в��ҵ���Ӧ��usrĿ¼��,�Ӷ��õ��ļ�/usr��i�ڵ��;���ݸ�i�ڵ���ļ�ϵͳ����˳��ȡ��Ŀ¼/usr,���������ҵ��ļ���bin��Ŀ¼��,����Ҳ��֪����/usr/bin��i�ڵ�,������ǿ���ֱ��Ŀ¼/usr/bin��Ŀ¼���ڵ�λ��,���ڸ�Ŀ¼���ҵ�vi�ļ���Ŀ¼��,���ջ�ȡ�ļ�·����Ϊ/usr/bin/vi��i�ڵ��,�Ӷ����ԴӴ����ϵõ���i�ڵ�ŵ�i�ڵ�ṹ��Ϣ��
�����һ���ļ��ڴ����ϵķֲ�����,����ij���ļ����ݿ���Ϣ��Ѱ�ҹ��̿�����ͼ��ʾ(���� δ���������顢�����顢i �ڵ������λͼ)��
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-agBfMk4u-1649083982084)(%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F(%E4%B8%89)]%E2%80%94%E8%80%81%E7%A5%96%20b21f7/Untitled%205.png)](https://img-blog.csdnimg.cn/39f60f33f8364aff97f7fb4c482101cd.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5aWH5bCP6JGp,size_20,color_FFFFFF,t_70,g_se,x_16)
�����������ڵ�ǰĿ¼�д���һ����Ϊmydir����Ŀ¼,��ô�ڵ�ǰĿ¼����Ŀ¼�е�����ʾ��ͼΪ
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-5LiMExXw-1649083982085)(%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F(%E4%B8%89)]%E2%80%94%E8%80%81%E7%A5%96%20b21f7/Untitled%206.png)](https://img-blog.csdnimg.cn/6e1664612a7c424ab02402ec894569fd.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5aWH5bCP6JGp,size_20,color_FFFFFF,t_70,g_se,x_16)
������ i �ڵ��Ϊ 56 ��Ŀ¼�н�����һ�� mydir ��Ŀ¼,����Ŀ¼�� i �ڵ���� 123��
�� mydir ��Ŀ¼�еġ�.��Ŀ¼��ָ���Լ��� i �ڵ� 123,���䡯��'Ŀ¼����ָ���丸Ŀ¼�� i �ڵ� 56���ɼ�,����һ��Ŀ¼��Ŀ¼������ǻ�����������,�������ٰ�����Ŀ¼,��ô��Ŀ¼�� i �ڵ��������͵��� 2+��Ŀ¼����
����,���ļ���a�´���һ���ļ���dir,����������:
- ������a��i_zone[]���е����ݿ��б���,������û�д�������Ϊdir��Ŀ¼��,�������,���ļ��Ѵ���,����;����������������һ��
- ��i�ڵ�λͼ�в���һ��bitλΪ0�Ŀ���λ,�ڶ�Ӧ��i�ڵ��д���һ��i�ڵ��¼,Ҳ����ͼi�ڵ���е�dir��i�ڵ��¼
- Ϊ�ļ���dir��i�ڵ㴴��һ�����ݿ�,���ݿ��б���2��Ŀ¼��,Ҳ����.�͡�Ŀ¼��,����.��Ŀ¼����inode�ڵ���ָ���Լ���Inode�ڵ�,����Ŀ¼����inode�ڵ�ָ���ʱa�Ľڵ��
- ������a��Ŀ¼��������һ���ļ���dir,�����a��Ŀ¼���ݿ�����һ��dir��Ŀ¼��,��Ȼdir��Ŀ¼����Inode��Ҳ�����Լ���inode��
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-DdtQ3kDv-1649083982086)(%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F(%E4%B8%89)]%E2%80%94%E8%80%81%E7%A5%96%20b21f7/Untitled%207.png)](https://img-blog.csdnimg.cn/adad3cb50a11446b871f1374ac0d2213.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5aWH5bCP6JGp,size_20,color_FFFFFF,t_70,g_se,x_16)
3 ���ٻ������
Ϊ�˷��ʿ��豸���ļ�ϵͳ�е�,�ں���Ҫÿ�ζ����ʿ��豸,���ж�д����������ÿ��I/O������ʱ�����ڴ��CPU�����ٶ�����Ƿdz�����,Ϊ�����ϵͳ������,�ں˾����ڴ��п�����һ���������ݻ�����(buffer Cache),���仮�ֳ�һ������������ݿ��С��ȵĻ������ʹ�ú���,�Լ�С���ʿ��豸�Ĵ�����
��linux�ں���,���ٻ�����λ���ں˴�������ڴ�֮��,����ͼ��ʾ,���ٻ������ڿ��豸���ں���������֮������һ���������á����˿��豸������������,�ں˳��������Ҫ���ʿ��豸�е�����,�Ͷ���Ҫ�������ٻ���������ӵز�����
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-TEaXGhWt-1649083982095)(%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F(%E4%B8%89)]%E2%80%94%E8%80%81%E7%A5%96%20b21f7/Untitled%208.png)](https://img-blog.csdnimg.cn/2e9e5957c09b4c08948134361315f1b3.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5aWH5bCP6JGp,size_20,color_FFFFFF,t_70,g_se,x_16)
���ٻ����д���������ʹ�ù� �ĸ������豸�е����ݿ�
- ����Ҫ�ӿ��豸�ж�ȡ����ʱ,�����������������Ȼ��ڸ��ٻ�������Ѱ��,�����Ӧ�����Ѿ��ڸ��ٻ�����,�������ٴӿ��豸�϶�,������ݲ��ڸ��ٻ�������,�ͷ��������豸������,�����ݶ������ٻ�������
- ����Ҫ������д�����豸ʱ,ϵͳ�ͻ��ڸ��ٻ�����������һ����еĻ��������ʱ�����Щ����,����ʲôʱ�����������д���豸��ȥ,����ͨ���豸����ͬ��ʵ��
3.1 ��ʼ��
�������ٻ����������ֳ�1024�ֽڴ�С�Ļ����,����������豸�ϵĴ��������С��ͬ�����ٻ������hash���Ͱ������л������������в�����������ʼ����������������������˿�ʼ,�ֱ�ͬʱ���û����ͷ�ṹ�ͻ��ֳ���Ӧ�Ļ����,��ͼ��ʾ
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-IPv0lAly-1649083982096)(%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F(%E4%B8%89)]%E2%80%94%E8%80%81%E7%A5%96%20b21f7/Untitled%209.png)](https://img-blog.csdnimg.cn/1fc21958d4e948fa8121f9cdb50fe6ff.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5aWH5bCP6JGp,size_20,color_FFFFFF,t_70,g_se,x_16)
�������ĸ߶˱����ֳ�һ����1024�ֽڵĻ����,�Ͷ���ֱ������Ӧ�������Ļ���ͷ�ṹbuffer_head,�ýṹ����������Ӧ����������,�����ڰ����л���ͷ���ӳ�����,���ֲ���һֱ��������������û���㹻���ڴ��ٻ��ֳ������Ϊֹ��
3.2 ���ٻ������ṹ������
���еĻ�����buffer_head������һ��˫�������ṹ,��Ϊ��������
// �ڳ����г���bh ����ʾbuffer_head ���͵���д��
struct buffer_head
{
char *b_data; //ָ�����������(1024�ֽ�)��ָ��
unsigned long b_blocknr; // ���/block number
unsigned short b_dev; // ����Դ���豸��(0 = free)
unsigned char b_uptodate; // ���±�־:��ʾ�����Ƿ��Ѹ��¡�
unsigned char b_dirt; //�ı�־:0 δ��,1 ����.
unsigned char b_count; // ʹ�øÿ���û���
unsigned char b_lock; // �������Ƿ�����
struct task_struct *b_wait; // ָ��ȴ��û���������������
struct buffer_head *b_prev; // hash ������ǰһ��(���ĸ�ָ�����ڻ������Ĺ���)��
struct buffer_head *b_next; // hash ��������һ�顣
struct buffer_head *b_prev_free; // ���б���ǰһ�顣
struct buffer_head *b_next_free; // ���б�����һ�顣
};
- �ֶ�b_lock��������־,���������������ڶԸû�������ݽ�����,��˸û����������æ״̬�����������ñ�־�뻺����������־��,��Ҫ���� blk_drv/ll_rw_block.c �������ڸ��»������������Ϣʱ��������顣��Ϊ�ڸ��»����������ʱ,��ǰ���̻���Ըȥ˯�ߵȴ�,�Ӷ���Ľ��̾��л�����ʸû���顣���,��ʱΪ�˲�����������ʹ�����е����ݾ�һ��Ҫ��˯��֮ǰ���������
- �ֶ�b_count�ǻ����������bufferʹ�õļ���ֵ,��ʾ��Ӧ�����������������ʹ��(����)�Ĵ����������ü�����Ϊ0ʱ,��������������ͷ����õĻ���顣
- �ֶ�b_dirt�����־λ,˵������������Ƿ��ѱ��Ķ�����豸�ϵĶ�Ӧ���ݿ����ݲ�ͬ��
- �ֶ�b_uptodate�����ݸ���(��Ч)��־,˵��������������Ƿ���Ч,��ʼ�����ͷſ�ʱ,��������־λ������Ϊ0,����������ʱ��Ч��������д�뻺��鵫��û�б�д���豸ʱ,��b_dirt = 1,b_uptodate = 0;�����ݱ�д�뻺����մӿ��豸�ж��뻺��������ݱ����Ч,��b_uptodate=1;��������һ���豸�����ʱ,b_dirt��b_uptodate��Ϊ1,��ʾ�������������Ȼ����豸�ϵIJ�ͬ,����������Ȼ����Ч��(���µ�)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-L5TjRdLQ-1649083982097)(%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F(%E4%B8%89)]%E2%80%94%E8%80%81%E7%A5%96%20b21f7/Untitled%2010.png)](https://img-blog.csdnimg.cn/e867faa80f104567b24b5bd62d0b0ac9.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5aWH5bCP6JGp,size_20,color_FFFFFF,t_70,g_se,x_16)
- ͼ��free_listָ����������ͷָ��,ָ����п������е�һ����Ϊ���еĻ����,����������ʹ�õĻ����,���û����ķ���ָ��b_prev_free��ָ����е����һ�������,�����ʹ�õĻ���顣
- ͼ�л���ͷ�ṹ�������ֶΡ��������豸���������������,�������ֶ�Ψһȷ������������ݶ�Ӧ�Ŀ��豸�����ݿ�,����м�����־λ:������Ч��־���ı�־�����ݱ�ʹ�õĽ������ͱ���������Ƿ�����
�ں˳���ʹ�ø��ٻ������Ļ����,���ƶ��豸��(dev)����Ҫ�����豸���ݵ�����(block),ͨ�����û�����ȡ����bread()��bread_page()��breada()���в������⼸��������ʹ�û�����������������getblk()���������л������Ѱ��ƥ�����Ϊ���еĻ���顣������Щ��������ݴ�ȡ���������ĵ��ò�ι�ϵΪ
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-leSROacI-1649083982097)(%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F(%E4%B8%89)]%E2%80%94%E8%80%81%E7%A5%96%20b21f7/Untitled%2011.png)](https://img-blog.csdnimg.cn/ee2f93fe9b5a4fbf8dd69bcf56928558.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5aWH5bCP6JGp,size_20,color_FFFFFF,t_70,g_se,x_16)
3.3 ���ٻ������� Hash ��
Ϊ���ܹ����ٶ���Ч���ڻ�������Ѱ���жϳ���������ݿ��Ƿ��Ѿ������뵽��������,�ں�ʹ���˾���304��buffer_headָ�����hash������ṹ��hash��ʹ�õ�ɢ�к������豸�ź���������
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-U7joI687-1649083982098)(%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F(%E4%B8%89)]%E2%80%94%E8%80%81%E7%A5%96%20b21f7/Untitled%2012.png)](https://img-blog.csdnimg.cn/826d49d59e1c48c1af37f5ad31ccc19d.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5aWH5bCP6JGp,size_20,color_FFFFFF,t_70,g_se,x_16)
����free_listָ��ָ��Ļ���ͷ��������ָ��b_prev/b_next��������hash����ɢ����ͬһ�����϶��������˫������,����hash���������������ͬɢ��ֵ�Ļ����������ɢ������ͬһ�������ϡ�
- ˫����߱�ʾɢ����ͬһhash�����л����ͷ�ṹ֮���˫������ָ��
- ���߱�ʾ�����������л���������һ��˫������,��free_list�Ǹ�������Ϊ���еĻ�������ͷָ��,ʵ�������˫��������һ���������ʹ�õ�LRU����
���ڸ��ٻ�����,����Ҫ����getblk()��������,������ÿ�λ�ȡ�µĿ��л����ʱ,�ͻ�����Ƶ�free_listͷָ����ָ�����������,��Խ��������ĩ�˵Ļ���鱻ʹ�õ�ʱ���Խ��,������Hash����û���ҵ���Ӧ�����,�ͻ��������µĿ��л����ʱ��free_list����ͷ��ʼ,�ں�ȡ�û�����㷨ʹ�����µIJ���
- ���ָ���Ļ������hash����,��˵���Ѿ�ȡ�ÿ��û����,����ֱ�ӷ���
- �������Ҫ��������free_listͷָ�뿪ʼ����,���������ʹ�õĻ���鿪ʼ,�����������ҵ�һ����ȫ���еĻ����,��b_dirt��b_lock��־λ��Ϊ0�Ļ����;���������������������,��ô����Ҫ����b_dirt��b_lock�ı�־λ�����һ��ֵ,��Ϊ�豸����ͨ���ܺ�ʱ,�����ڼ���ʱ��Ӵ�b_dirt��Ȩ��,Ȼ�������ڼ�����ֵ��С�Ļ����ȴ�,���־λb_lockΪ0ʱ,��ʾ���ȴ��Ļ����ԭ�����Ѿ�д���豸��,�Ϳ��Ի��һ�������,������ʾ
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-w51BizDu-1649083982099)(%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F(%E4%B8%89)]%E2%80%94%E8%80%81%E7%A5%96%20b21f7/Untitled%2013.png)](https://img-blog.csdnimg.cn/ca998e83a8194607a313b85ca6a8bba1.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5aWH5bCP6JGp,size_20,color_FFFFFF,t_70,g_se,x_16)
���ڸ��ٻ�����ȡ����,����getblk()���صĻ���������һ���µĿ��п�,Ҳ���������Ǻ���������Ҫ���ݵĻ����,���Ѿ����ڸ��ٻ������С���˶��ڶ�ȡ���ݿ�,��ʱҪ�жϸû����ĸ��±�־,�������������Ƿ���Ч,�����Ч�Ϳ���ֱ�ӽ������ݿ鷵�ظ�����ij��������Ҫ�����豸�ĵײ���д����(ll_rw_block),��ͬʱ���Լ�����˯��״̬,�ȴ����ݱ����뻺��顣
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-xnIJnqFg-1649083982100)(%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F(%E4%B8%89)]%E2%80%94%E8%80%81%E7%A5%96%20b21f7/Untitled%2014.png)](https://img-blog.csdnimg.cn/55bafdad567845ef9b982716431b3eaa.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5aWH5bCP6JGp,size_20,color_FFFFFF,t_70,g_se,x_16)
3.4 ���ٻ��������ʹ��̺�ͬ������
������������,�ں��������ϲ����Կ��豸�Ķ�д��������Ҫ�������ٻ������������������ʵ�֡������ϲ�Ҫ���ʿ��豸����,ͨ��bread()����������������,�������������Ѿ��ڸ��ٻ�������,��������ͻὫ����ֱ�ӷ��ظ�����;��������������ʱ���ڻ�����,���������ͨ��ll_rw_block����豸������������,ͬʱ�ó����Ӧ�Ľ���˯�ߵȴ�,�ȴ����豸���������ָ�������ݷ�����ٻ�����,���ظ��ϲ�Ӧ��
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-jnEtaTm7-1649083982100)(%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F(%E4%B8%89)]%E2%80%94%E8%80%81%E7%A5%96%20b21f7/Untitled%2015.png)](https://img-blog.csdnimg.cn/8208b9694b2e47b2ba3790e33deab026.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5aWH5bCP6JGp,size_20,color_FFFFFF,t_70,g_se,x_16)
���ڸ��º�ͬ���IJ���,����Ҫ���������ڴ��е�һЩ�������������̵ȿ��豸�ϵ���Ϣһ�¡�
sync_inodes��Ҫ�ǰ�i�ڵ����inode_table�е�i�ڵ���Ϣ������ϵ�һ��������
4 �ײ��������
�ⲿ����Ҫ����5���ļ�,�ֱ���super.c��bitmap.c��truncate.c��inode.c��namei.c����
4.1 bitmap.c
bitmap������Ҫ�����ڸ����ļ�ϵͳ�������i�ڵ�ṹ��ʹ�����,������λͼ��i�ڵ�λͼ�ֱ���б���λ��ռ�ú��ͷ����ò�����
free_block�����ͷ�ָ���豸dev�ϵ�������������Block,��������Ǹ�λָ������block��Ӧ����λͼ�ı���λ,��ʵ�ֱȽϼ�
�ͷ��豸dev ���������е�����block��
// ��λָ������block ������λͼ����λ��
// ����:dev ���豸��,block �������(�̿��)��
void free_block(int dev, int block)
{
struct super_block * sb;
struct buffer_head * bh;
// ȡָ���豸dev �ij�����,���ָ���豸������,�����������
if (!(sb = get_super(dev)))
panic("trying to free block on nonexistent device");
// �������С��������Ż��ߴ����豸����������,�����,������
if (block < sb->s_firstdatazone || block >= sb->s_nzones)
panic("trying to free block not in datazone");
// ��hash ����Ѱ�Ҹÿ����ݡ����ҵ������ж�����Ч��,�������ĺ��±�־,�ͷŸ����ݿ顣
// �öδ������Ҫ��;����������鵱ǰ�����ڸ��ٻ�����,���ͷŶ�Ӧ�Ļ���顣
bh = get_hash_table(dev,block);
if (bh) {
if (bh->b_count != 1) {
printk("trying to free block (%04x:%d), count=%d\n",
dev,block,bh->b_count);
return;
}
bh->b_dirt=0; // ��λ��(����)��־λ��
bh->b_uptodate=0; // ��λ���±�־��
brelse(bh);
}
// ����block ����������ʼ��������������(��1 ��ʼ����)��Ȼ�������(����)λͼ���в���,
// ��λ��Ӧ�ı���λ������Ӧ����λԭ������0,�����,������
block -= sb->s_firstdatazone - 1 ;
if (clear_bit(block&8191,sb->s_zmap[block/8192]->b_data)) {
printk("block (%04x:%d) ",dev,block+sb->s_firstdatazone-1);
panic("free_block: bit already cleared");
}
// ����Ӧ����λͼ���ڻ��������ı�־��
sb->s_zmap[block/8192]->b_dirt = 1;
}
- ����,ȡ��ָ���豸dev�ij�����,�����ݳ���������豸����ķ�Χ,�ж������block����Ч��
- Ȼ���ٸ��ٻ������н��в���,����ָ���������ʱ�Ƿ����ڸ��ٻ������С������,��Ӧ�Ļ�����ͷŵ�
- ���ż���Block����������ʼ������ݿ��(��1��ʼ����),��������λͼ���в���,����λ��Ӧ��Bitλ,����ڰ�����Ӧ����λͼ�Ļ������,����������������ı���λ��־
new_block�������豸����һ������,���������,����λָ������block��Ӧ������λͼbitλ��
���豸dev ����һ������(�̿�,����)�����������(�̿��)��
// ��λָ������block ������λͼ����λ��
int new_block(int dev)
{
struct buffer_head * bh;
struct super_block * sb;
int i,j;
// ���豸dev ȡ������,���ָ���豸������,�����������
if (!(sb = get_super(dev)))
panic("trying to get new block from nonexistant device");
// ɨ������λͼ,Ѱ����0 ����λ,Ѱ�ҿ�������,��ȡ���ø�����Ŀ�š�
j = 8192;
for (i=0 ; i<8 ; i++)
if (bh=sb->s_zmap[i])
if ((j=find_first_zero(bh->b_data))<8192)
break;
// ���ȫ��ɨ���껹û�ҵ�(i>=8 ��j>=8192)����λͼ���ڵĻ������Ч(bh=NULL)��0,
// �˳�(û�п�������)��
if (i>=8 || !bh || j>=8192)
return 0;
// �����������Ӧ����λͼ�еı���λ,����Ӧ����λ�Ѿ���λ,�����,������
if (set_bit(j,bh->b_data))
panic("new_block: bit already set");
// �ö�Ӧ������������ı�־�������������ڸ��豸�ϵ���������,��˵��ָ��������
// ��Ӧ�豸�ϲ����ڡ�����ʧ��,����0,�˳���
bh->b_dirt = 1;
j += i*8192 + sb->s_firstdatazone-1;
if (j >= sb->s_nzones)
return 0;
// ��ȡ�豸�ϵĸ�����������(��֤)�����ʧ����������
if (!(bh=getblk(dev,j)))
panic("new_block: cannot get block");
// �¿�����ü���ӦΪ1������������
if (bh->b_count != 1)
panic("new block: count is != 1");
// ��������������,����λ���±�־�����ı�־��Ȼ���ͷŶ�Ӧ������,��������š�
clear_block(bh->b_data);
bh->b_uptodate = 1;
bh->b_dirt = 1;
brelse(bh);
return j;
}
- ����ȡָ���豸dev�ij�����,Ȼ�����������λͼ��������,Ѱ������0��bitλ,���û���ҵ�,��˵�����豸�ռ��Ѿ�����,����0;�����ҵ��ĵ�1��0ֵ��ӦBitλ��1,��ʾռ�ö�Ӧ����������,���������ñ���λ����λͼ���ڻ����������ı�־λ��λ
- ���������������̿��,���ڸ��ٻ�������������Ӧ�Ļ����,���Ѹû������0,Ȼ�����øû�����Ѹ��º�����,����ͷŸû����,�Ա���������ʹ��,�������̿��
����free_inode()�����ͷ�ָ����i �ڵ�,����λ��Ӧ��i �ڵ�λͼ����λ;new_inode()
����Ϊ�豸dev����һ����i �ڵ㡣���ظ���i �ڵ��ָ�롣��Ҫ�������������ڴ�i �ڵ��
�л�ȡһ������i �ڵ����,����i �ڵ�λͼ����һ������i �ڵ㡣�����������Ĵ�������
������������������,�������Ͳ���������
4.2 truncate.c
��������Ҫ�����ͷ�ָ��i�ڵ����豸��ռ�õ���������,����ֱ�ӿ顢һ�μ�ӿ�Ͷ��μ�ӿ�,�Ӷ����ļ��ڵ��Ӧ���ļ����Ƚ�Ϊ0,���ͷ�ռ�õ��豸�ռ䡣
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-dCM32rbk-1649083982101)(%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F(%E4%B8%89)]%E2%80%94%E8%80%81%E7%A5%96%20b21f7/Untitled%2016.png)](https://img-blog.csdnimg.cn/37851c4cf0764e43b6777896da270577.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5aWH5bCP6JGp,size_20,color_FFFFFF,t_70,g_se,x_16)
���ڵ��Ӧ���ļ����Ƚ�Ϊ0,���ͷ�ռ�õ��豸�ռ䡣
void
truncate (struct m_inode *inode)
{
int i;
// ������dz����ļ�������Ŀ¼�ļ�,�ء�
if (!(S_ISREG (inode->i_mode) || S_ISDIR (inode->i_mode)))
return;
// �ͷ�i �ڵ��7 ��ֱ������,������7 ��������ȫ���㡣
for (i = 0; i < 7; i++)
if (inode->i_zone[i])
{ // �����Ų�Ϊ0,���ͷ�֮��
free_block (inode->i_dev, inode->i_zone[i]);
inode->i_zone[i] = 0;
}
free_ind (inode->i_dev, inode->i_zone[7]); // �ͷ�һ�μ�ӿ顣
free_dind (inode->i_dev, inode->i_zone[8]); // �ͷŶ��μ�ӿ顣
inode->i_zone[7] = inode->i_zone[8] = 0; // ������7��8 ���㡣
inode->i_size = 0; // �ļ���С���㡣
inode->i_dirt = 1; // �ýڵ����ı�־��
inode->i_mtime = inode->i_ctime = CURRENT_TIME; // �����ļ��ͽڵ���ʱ��Ϊ��ǰʱ�䡣
}
i �ڵ��� i_zone[]�����д�����豸��������̿���롣�������ǰ 7 ��(i_zone[0]�Ci_zone[6])��
��ֱ�Ӵ��������ļ���ǰ 7 �����ݿ��̿�ĺ��롣i_zone[7]���һ�μ�ӿ���̿�š���Ϊ�����̿��СΪ 1024 �ֽ�,���ÿ���̿��п��Դ��(1024 / 2)= 512 ���̿��,Ҳ��һ�μ�ӿ��������Ѱַ 512 ���豸�̿顣��Ӧ��,���μ�ӿ�� i_zone[8]����Ѱַ(512 *512)= 261,144 ���̿�š�
4.3 inode.c
�ó�����Ҫ�������� i �ڵ�ĺ��� iget()��iput()�Ϳ�ӳ�亯�� bmap(),�Լ�����һЩ����������iget()��iput()�� bmap()������Ҫ���� namei.c �����ӳ�亯�� namei()��,�������ļ�·�������Ҷ�Ӧ i �ڵ㡣
-
iget(): �ú������ڴ��豸 dev �϶�ȡָ���ڵ�� nr �� i �ڵ�,���Ұѽڵ�����ü����ֶ�ֵ i_count �� 1
-
iput(): ����ɵĹ��������� iget()�෴������Ҫ���ڰ� i �ڵ����ü���ֵ�ݼ� 1,�������ǹܵ� i
�ڵ�,���ѵȴ��Ľ��̡� -
bmap(): ���ڰ�һ���ļ����ݿ�ӳ�䵽��Ӧ���̿���,����Ҫ�Ƕ�i�ڵ����������i_zone[]���д���,������i_zone�������õ����������������λͼ��ռ�������
- i_zone[0]�� i_zone[6]���ڴ�Ŷ�Ӧ�ļ���ֱ�������
- i_zone[7]���ڴ��һ�μ�������;
- i_zone[8]���ڴ�Ŷ��μ�������
- ���ļ���Сʱ(С�� 7K),�Ϳ��Խ��ļ���ʹ�õ��̿��ֱ�Ӵ���� i �ڵ�� 7 ��ֱ�ӿ�����;���ļ��Դ�һЩʱ(������ 7K+512K),��Ҫ�õ�һ�μ�ӿ��� i_zone[7];���ļ�����ʱ,����Ҫ�õ����μ�ӿ���i_zone[8]�ˡ����,�ļ��Ƚ�Сʱ,linux Ѱַ�̿���ٶȾͱȽϿ�һЩ��
4.4 super.c
���ļ������˶��ļ�ϵͳ�г���������ĺ���,��Щ���������ļ�ϵͳ�Ͳ㺯��,���ϲ���ļ�����Ŀ¼��������ʹ��,��Ҫ�� get_super()��put_super()�� read_super()������������й��ļ�ϵͳ����/ж�ص�ϵͳ���� sys_umount()�� sys_mount(),�Լ����ļ�ϵͳ���غ��� mount_root()������һЩ���������� buffer.c �еĸ����������������ơ�
- get_super()����������ָ���豸��������,���ڴ泬����������������Ӧ�ij�����,��������Ӧ�������ָ�롣���,�ڵ��øú���ʱ,����Ӧ���ļ�ϵͳ�����Ѿ�����(mount),��������ó������Ѿ�ռ���˳����������е�һ��,���� NULL��
- put_super()�����ͷ�ָ���豸�ij����顣���Ѹó������Ӧ���ļ�ϵͳ�� i �ڵ�λͼ������λͼ��ռ�õĻ���鶼�ͷŵ�,���ͷų������(����)super_block[]�ж�Ӧ�IJ�������ڵ��� umount()ж��һ���ļ�ϵͳ���߸�������ʱ������øú�����
- read_super()���ڰ�ָ���豸���ļ�ϵͳ�ij�������뵽��������,���Ǽǵ����������,ͬʱҲ���ļ�ϵͳ�� i �ڵ�λͼ������λͼ�����ڴ泬����ṹ����Ӧ�����С���ظó�����ṹ��ָ�롣
- sys_umount()ϵͳ��������ж��һ��ָ���豸�ļ������ļ�ϵͳ,�� sys_mount()��������һ��Ŀ¼���ϼ���һ���ļ�ϵͳ�����������һ������ mount_root()���ڰ�װϵͳ�ĸ��ļ�ϵͳ,������ϵͳ��ʼ��ʱ������
- mount_root()��������ϵͳִ�г�ʼ������ main.c ��,�ڽ��� 0 �����˵�һ���ӽ���(���� 1)���õ�,����ϵͳ�������������һ�Ρ�����ĵ���λ�����ڳ�ʼ������ init()�� setup()������
5 �ļ����ݵķ��ʲ���
����ѧϰ�˵ײ�Ľӿں�����ԭ��,��Ҫ��Ϊ���ṩ�ϲ�Ӧ�õĽӿ�,����linux0.11��û�������ļ�ϵͳ�ĸ���,����Ҫ��ͨ�����¿��
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-qdCTpy26-1649083982101)(%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F(%E4%B8%89)]%E2%80%94%E8%80%81%E7%A5%96%20b21f7/Untitled%2017.png)](https://img-blog.csdnimg.cn/0457967f5e7e41ea9f4fdf4ac962423f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5aWH5bCP6JGp,size_20,color_FFFFFF,t_70,g_se,x_16)
�����ļ������ݵķ��ʲ���,��Ҫ�漰5���ļ�:blk_dev.c,file_dev.c,char_dev.c,pipe.c��read_write.c��ǰ�ĸ�������Ϊ�ǿ��豸����ͨ�ļ����ַ��豸���ܵ��豸���ļ���дϵͳ���õĽӿڳ���, ���ǹ�ͬʵ����read_write.c �е�read()��write()ϵͳ���á� ͨ���Ա������ļ����Ե��ж�,������ϵͳ���û�ֱ������Щ�ļ��е���ش����������в�����
-
block_dev.c �еĺ��� block_read()��block_write()�����ڶ�д���豸�����ļ��е�����,ʹ�õIJ���ָ���� Ҫ���ʵ��豸�š���д����ʼλ�úͳ��ȡ�
-
file_dev.c �е�file_read()��file_write()��������������һ��������ļ�,ͨ���ļ�����ȡ��Ӧ��i�ڵ�ź��ļ���Ϣ,�Ӷ����ж�д������
-
pipe.c �ܵ���Ҫ�����ڽ���֮�䰴���Ƚ��ȳ��ķ�ʽ��������,Ҳ��������ʹ����ͬ��ִ�С�
-
�����ܵ�,��ʹ���ļ�ϵͳ��open���ý�����
-
�����ܵ�,ʹ��ϵͳ���� pipe()������
-
char_dev.c �ַ��豸��������̨�ն�(tty),�����ն�(ttyx)���ڴ��ַ��豸,�����ַ��豸�ļ�,ϵͳ����read()��write()�����char_dev.c�е� rw_char() ����������
������sys_writeΪ��,���ܺܿ� ��������,�������δ���
int sys_write (unsigned int fd, char *buf, int count) { struct file *file; struct m_inode *inode; // ����ļ����ֵ���ڳ��������ļ���NR_OPEN,������Ҫд����ֽڼ���С��0,���߸þ�� // ���ļ��ṹָ��Ϊ��,�س����벢�˳��� if (fd >= NR_OPEN || count < 0 || !(file = current->filp[fd])) return -EINVAL; // �����ȡ���ֽ���count ����0,��0,�˳� if (!count) return 0; // ȡ�ļ���Ӧ��i �ڵ㡣���ǹܵ��ļ�,������д�ܵ��ļ�ģʽ,�����д�ܵ�����,���ɹ��� // д����ֽ���,���س�����,�˳��� inode = file->f_inode; if (inode->i_pipe) return (file->f_mode & 2) ? write_pipe (inode, buf, count) : -EIO; // ������ַ����ļ�,�����д�ַ��豸����,����д����ַ���,�˳��� if (S_ISCHR (inode->i_mode)) return rw_char (WRITE, inode->i_zone[0], buf, count, &file->f_pos); // ����ǿ��豸�ļ�,����п��豸д����,������д����ֽ���,�˳��� if (S_ISBLK (inode->i_mode)) return block_write (inode->i_zone[0], &file->f_pos, buf, count); // ���dz����ļ�,��ִ���ļ�д����,������д����ֽ���,�˳��� if (S_ISREG (inode->i_mode)) return file_write (inode, file, buf, count); // ����,��ʾ��Ӧ�ڵ���ļ�ģʽ,���س�����,�˳��� printk ("(Write)inode->i_mode=%06o\n\r", inode->i_mode); return -EINVAL; }
5 �ܽ�
ͨ��linux0.11�Ĵ����ԭ��,���ǽ�һ����Ϥ����ôȥ�Լ�ʵ��һ���ļ�ϵͳ,����ṩ���ϲ�ӿڡ�