基于华为云沙箱实验室的Hyper Tuner性能调优测试学习笔记
实验目的:
- 使用鲲鹏性能分析工具Hyper Tuner创建系统性能分析以及函数分析任务。
- 使用鲲鹏的NEON指令来提升矩阵乘法执行效率。
实验内容:
-
准备环境
1.1 预置环境
1.2 登录华为云
1.3 登录裸金属服务器BMS -
工具安装
2.1 安装依赖的工具(・设置SSH超时断开时间、安装centos-release-scl、安装devtoolset、安装jdk 11版本)
2.2 安装系统性能分析工具Hyper Tuner(下载软件包“Hyper-Tuner-2.2.T3.tar.gz”、安装系统性能优化工具)
2.3 登录系统性能优化工具Hyper Tuner -
一维矩阵运算热点函数检测优化
3.1 编译运行“矩阵内存访问”代码(下载代码、编译程序、执行程序)
3.2 系统性能全景分析(创建工程、创建任务、查看采集分析结果)
3.3 进程/线程性能分析(创建任务、查看采集分析结果)
3.4 C/C++性能分析(创建任务、查看采集分析结果)
3.5 结束程序
3.6 NEON指令优化代码(编译程序)
3.7 C/C++性能分析(创建任务、对比优化前后采集分析结果)
3.8 结束程序 -
实验总结
实验过程:
1. 准备环境
1.1预置环境
1.2登录华为云

1.3登录裸金属服务器BMS
・登录成功后,会进入到华为云控制台页面,如下图所示:

・点击左上角“服务列表”再点击“裸金属服务器BMS”,进入裸金属服务器BMS管理列表。
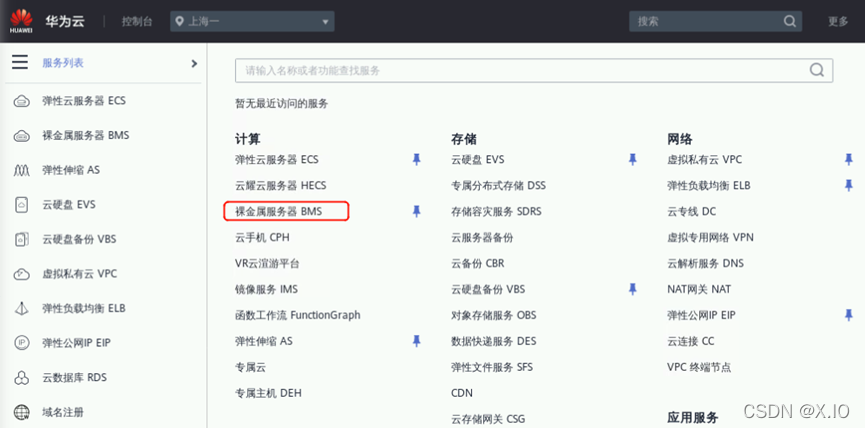
・在此可查看预置的裸金属服务器BMS的弹性公网IP(红框下方为裸金属服务器BMS的私有IP),如下图所示:
・打开Terminal(终端),执行如下命令(使用上图所示的弹性公网IP地址替换命令中的EIP),登录裸金属服务器BMS:
LANG=en_us.UTF-8 ssh root@EIP
示例如下:

・如下图所示,接受秘钥:输入“yes”回车;输入密码:aZ8lIuy-x@S01eR(输入密码时,命令行窗口不会显示密码,输完之后直接回车);
(这里我第一次密码输入错误,所以try again了)

2. 工具安装
2.1安装依赖的工具
・执行如下命令,设置SSH超时断开时间,防止服务器断连:
sed -i '112a ClientAliveInterval 600nClientAliveCountMax 10' /etc/ssh/sshd_config && systemctl restart sshd
示例如下:

(由于NEON intrinsic加速提升性能要求gcc版本7.3以上,gcc 4.8.5版本部分指令不兼容。执行如下命令,将gcc升级到7.3.1版本。)
・安装centos-release-scl:
yum install centos-release-scl -y
示例如下:

执行成功如下图所示:

・安装devtoolset:
yum install devtoolset-7-gcc* -y
示例如下:

执行成功如下图所示:
・激活对应的devtoolset:
scl enable devtoolset-7 bash
示例如下:

・执行如下命令,安装jdk 11版本并在home目录下重命名为jdk文件夹【需等待约3分钟】:
cd /home && wget https://mirrors.huaweicloud.com/kunpeng/archive/compiler/bisheng_jdk/bisheng-jdk-11.0.9-linux-aarch64.tar.gz && tar -zxvf bisheng-jdk-11.0.9-linux-aarch64.tar.gz && mv bisheng-jdk-11.0.9 jdk
示例如下:

执行成功如下图所示:

2.2安装系统性能分析工具Hyper Tuner
・执行如下命令,下载软件包“Hyper-Tuner-2.2.T3.tar.gz”安装在“/home”的根目录下,并解压安装包【需等待约5分钟】:
cd /home && wget https://mirrors.huaweicloud.com/kunpeng/archive/Tuning_kit/Packages/Hyper-Tuner-2.2.T3.tar.gz && tar -zxvf Hyper-Tuner-2.2.T3.tar.gz
示例如下:

执行成功如下图所示:
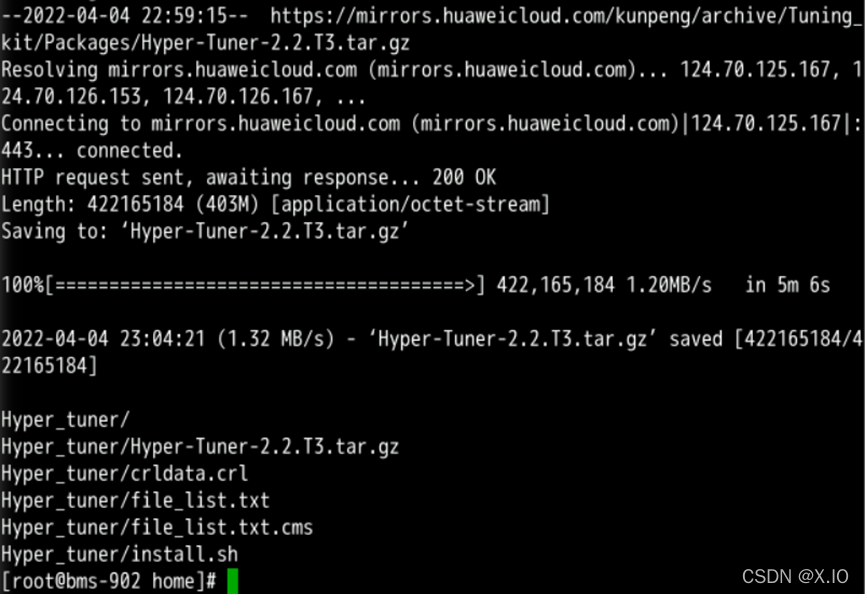
・执行如下命令(将命令中的“BMS IP”替换为裸金属服务器BMS的【私有】IP)安装系统性能优化工具,默认安装在“/opt”目录下【需等待约4分钟】:
【一定要注意,命令中的‘BMS IP’是需要改的】
cd /home/Hyper_tuner && tar -zxvf Hyper-Tuner-2.2.T3.tar.gz && cd /home/Hyper_tuner/Hyper_tuner && ./hyper_tuner_install.sh -a -i -ip=BMS IP -jh=/home/jdk
示例如下:

执行过程中,遇到Some risky components, such as binutils and strace, will be automatically installed with the Kunpeng Hyper Tuner, Do you allow automatic installation of these components? [Y/N],输入“Y”,然后单击键盘“回车”,执行结果如下图所示。

安装完成后,执行结果如下图所示:

2.3登录系统性能优化工具Hyper Tuner
・打开火狐浏览器新建标签页,访问地址 https://弹性公网IP:8086/user-management/#/login(例如:https:// 123.60.2.198:8086/user-management/#/login)浏览器提示连
【注意不要使用安装完成后给出的访问地址,此处所给出的ip地址为BMS私有IP,需要替换为BMS的弹性公网IP】。

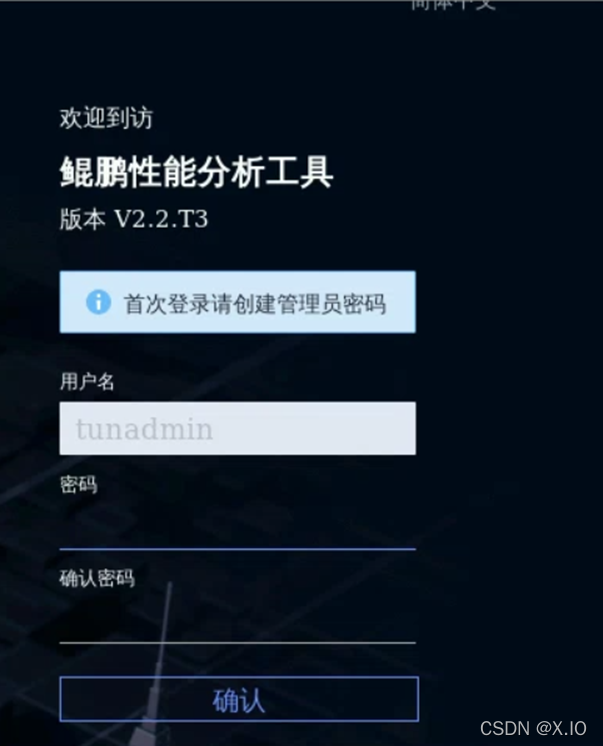
・之后将进入如下图所示页面。首次登录需要创建管理员密码,默认用户名为tunadmin,密码为tunadmin12#$
・管理员密码设置成功后,需要用管理员用户名和密码再次登录。


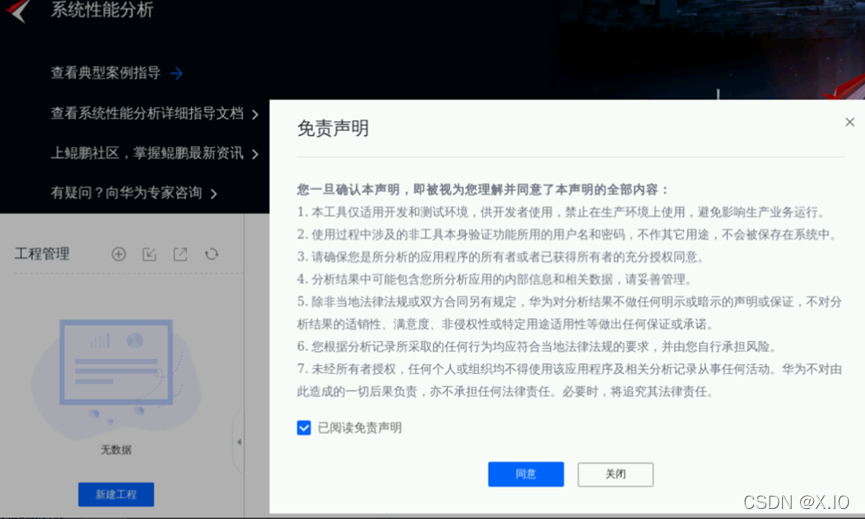
・登录成功后,单击“系统性能分析”,进入系统性能分析操作界面,仔细阅读免责声明后,勾选阅读并同意声明内容,即可进行下一步操作,
如下图所示:
3. 一维矩阵运算热点函数检测优化
此实验进行矩阵乘法计算,首先测试用普通for loop方式进行一维矩阵乘法计算的性能,然后考虑到矩阵乘法可以拆分并行计算,且并行计算分支相对独立,于是使用鲲鹏的NEON指令来进行计算,检测优化后的执行效率。
3.1 编译运行“矩阵内存访问”代码
・步骤1 下载代码
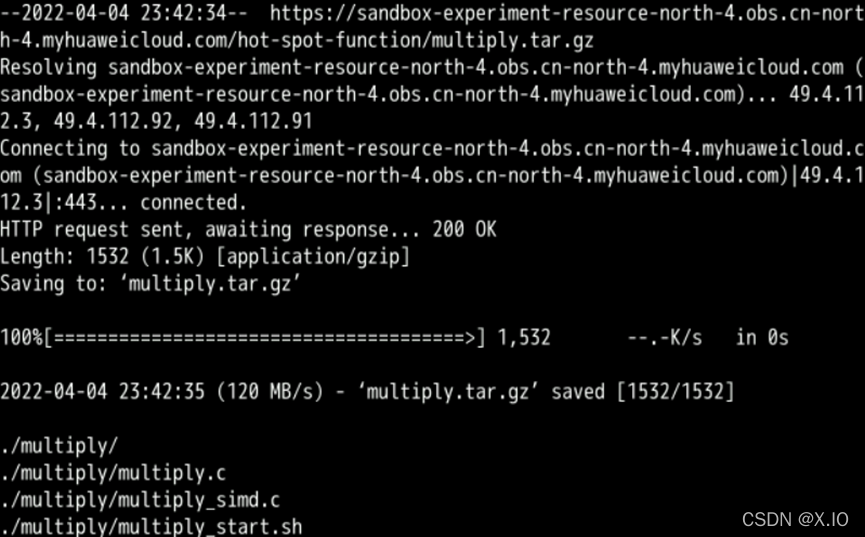
切换至1.3步骤登录的终端,执行如下命令,在裸金属服务器BMS上创建/home/testdemo目录,进入/home/testdemo目录并下载需要测试的程序:
mkdir /opt/testdemo && cd /opt/testdemo && wget https://sandbox-experiment-resource-north-4.obs.cn-north-4.myhuaweicloud.com/hot-spot-function/multiply.tar.gz && tar -zxvf multiply.tar.gz
示例如下:

执行成功如下图所示:
・步骤2 编译程序
执行如下命令,进入multiply文件夹,编译multiply.c并赋予执行文件所有用户只读、只写、可执行权限。
cd /opt/testdemo/multiply && gcc -g multiply.c -o multiply && chmod -R 777 /opt/testdemo/multiply
示例如下:

・步骤3 执行程序
执行如下命令,将multiply测试程序绑定CPU核启动(当前程序绑核到CPU 1,循环运行multiply程序200次),使用后台启动脚本,程序运行的输出(标准输出(1))将会保存到multiply.out文件,错误信息(2)会重定向到multiply.out文件:
cd /opt/testdemo/multiply && nohup bash multiply_start.sh >>multiply.out 2>&1 &
示例如下:

执行命令:jobs -l,如果当前进程是running状态,如下图所示,则说明程序在运行状态,可以进行下面的步骤。

【注:执行以下3.2、3.3章节的性能采集时,需要在此multiply程序运行过程中采集,若multiply程序运行结束,3.2和3.3章节操作将无法采集,此时可以重新执行cd /opt/testdemo/multiply && nohup bash multiply_start.sh >>multiply.out 2>&1 & 运行multiply程序,再执行3.2和3.3章节的性能采集。】
3.2 系统性能全景分析
・步骤1 创建工程
在程序运行的过程当中,我们利用工具分析当前程序。回到浏览器“系统性能分析”操作界面,根据提示,单击工程管理旁边“+”按钮创建工程,输入工程名称,如test,勾选节点,当前为此云服务器节点,单击“确认”创建工程,如下图所示:
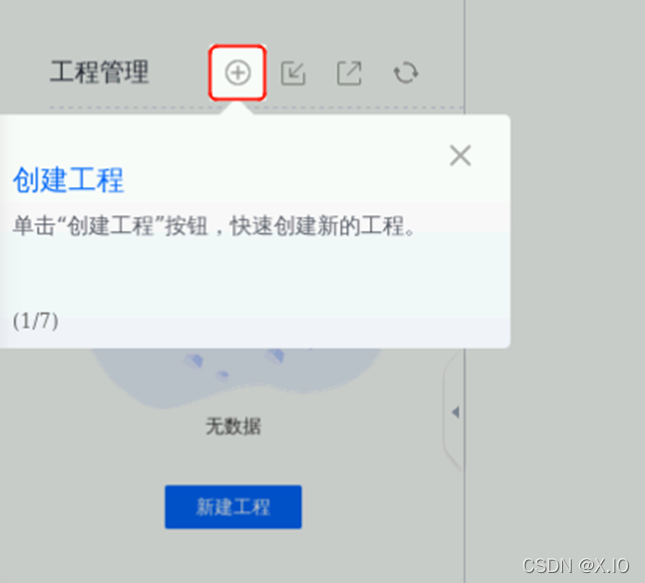


・步骤2 创建任务
将光标放到创建好的工程“test”上,会出现按钮,单击“+”创建任务,如下图所示:

弹出如下界面,填写如下:
① 任务名称:自定义工程名称multiply_quanjing,
② 选择分析对象:系统;
③ 分析类型:全景分析;
④ 采样时长:10秒;
⑤ 采样间隔:1秒,
点击“确认”执行

・步骤3 查看采集分析结果
执行完毕后,显示全景分析的结果,如下图所示。
①总览,点击“检测到CPU利用率高”显示优化建议;
②性能,在CPU利用率的图表中,可以看到top5的CPU核在采集时间内的利用率变化,点击右上角的按钮,可以看到在采集时间内的各项数据的平均值。由此可见,当前CPU核1的使用率(“性能”页签下%CPU的数值)接近100%,并且绝大部分消耗在用户态。说明该程序全部消耗在用户态计算,没有其他IO或中断操作。



3.3 进程/线程性能分析
・步骤1 创建任务
参照3.2步骤2创建进程/线程性能分析任务,如下图所示。
①任务名称:multiply_process
②分析对象:系统
③分析类型:进程/线程性能分析
④ 采样时长:10秒
⑤ 采样间隔:1秒,
⑥ 采样类型:全部勾选
⑦采集线程信息:打开
点击“确认”执行。

・步骤2 查看采集分析结果
执行完毕后,显示进程/线程性能分析的结果,如下图所示。

默认排序是按照PID/TID升序排列,以此观察哪个进程造成了CPU消耗,点击CPU右侧降序排列按钮,得到如下图。可以看到multiply程序在消耗大量的CPU,同时全部消耗在用户态中,由此我们可以推测很可能是自身代码实现算法差或Cache Miss问题。

3.4 C/C++性能分析
・步骤1 创建任务
参照3.2步骤2创建C/C++性能分析任务,如下图所示。
①任务名称:multiply_c
②分析对象:应用(注意我们此时分析确定程序的热点函数,所以不需要在服务器上运行程序,而是直接在工具中选择需要运行的程序,当前是multiply程序)
③应用路径:/opt/testdemo/multiply/multiply(输入程序所在的绝对路径,注意:示例路径里面第一个multiply为文件夹,第二个multiply为可执行程序)
② 分析类型:C/C++性能分析
⑤采样范围:用户态(采样范围分用户态,内核态,所有。因为我们这里发现所有的CPU消耗都在用户态,所以只采集用户态的数据)
⑥二进制/符号文件路径:/opt/testdemo/multiply/multiply(用于采集过程当中,获取函数名和源文件代码)
⑦C/C++源文件路径:/opt/testdemo/multiply/multiply.c(用于采集过程当中,获取函数名和源文件代码)
点击“确认”执行

・步骤2 查看采集分析结果
执行完毕后,显示C/C++性能分析的结果,如下图所示。在“总览”显示采集运行时长、程序运行的时钟周期数和指令数。在右侧的Top 10 热点函数中,multiply程序中的multiply函数占用了40左右的时钟周期数。
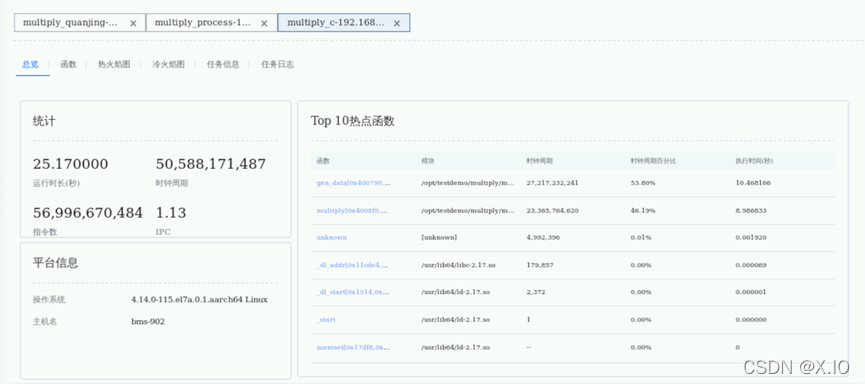
点击“函数”页签进入下图,可以看到所有函数的信息,包括执行时间,时钟周期,指令数等。

点击 “multiply” 进入函数模块,可以看到对应的源代码以及汇编代码,如下图。在“代码流”模块,显示不同Basic Block时钟周期的占比,颜色越深,占比越高。例如下图,单击Basic Block2,上方“汇编代码”和“源代码”浅蓝色突出显示占用时钟周期数高的代码行。

3.5 结束程序
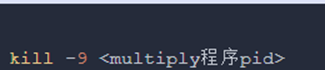
・切换至1.3步骤登录的终端,执行如下代码:
① 通过jobs -l查看multiply程序运行pid(如果程序尚未结束,可以看到后台运行的程序;如果没有输出,说明进程已经结束,不需要进行此步操作);

② 通过kill -9杀死进程,替换<multiply程序pid>为刚查到的multiply的pid。
(记得将’程序‘换掉)
3.6 NEON指令优化代码
考虑到矩阵乘法可以拆分并行计算,且并行计算分支相对独立,可以使用鲲鹏的NEON指令来提升执行效率。NEON指令通过将对单个数据的操作扩展为对寄存器,也即同一类型元素矢量的操作,从而大大减少了操作次数,以此来提升执行效率。
・步骤1 编译程序
在“Xfce终端”,执行如下代码,进入multiply文件夹,编译multiply_simd.c并赋予执行文件所有用户只读、只写、可执行权限。
cd /opt/testdemo/multiply && gcc -g multiply_simd.c -o multiply_simd && chmod -R 777 /opt/testdemo/multiply
示例如下:

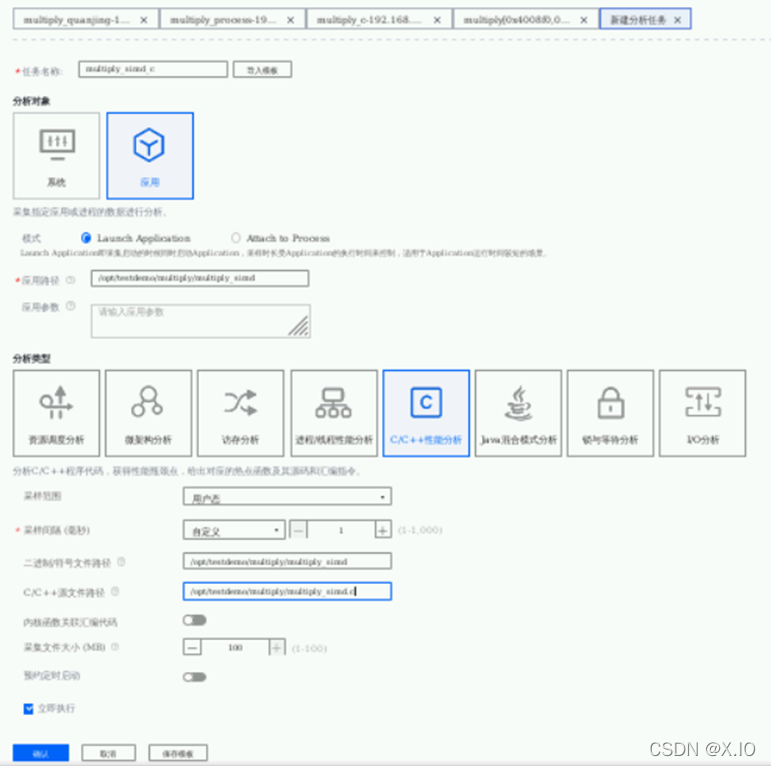
3.7 C/C++性能分析
・步骤1 创建任务
回到浏览器,参照3.4的步骤创建C/C++性能分析任务,如下图所示。
① 任务名称:multiply_simd_c
② 分析对象:应用
③ 应用路径:/opt/testdemo/multiply/multiply_simd(程序所在的绝对路径)
④ 分析类型:C/C++性能分析
⑤ 采样范围:用户态
⑥ 二进制/符号文件路径:/opt/testdemo/multiply/multiply_simd
⑦C/C++源文件路径: /opt/testdemo/multiply/multiply_simd.c
点击“确认”执行
・步骤2 查看采集分析结果
执行完毕后,显示C/C++性能分析的结果。对比multiply程序和multiply_simd程序的C/C++性能分析结果,如下图所示。在“总览”页签下,对比两者的指令数,可以发现优化后的multiply_simd程序指令数大幅减少。
下图为multiply程序C/C++性能分析结果:
 下图为multiply_simd程序C/C++性能分析结果:
下图为multiply_simd程序C/C++性能分析结果:

・点击进入函数“multiply_neon”,查看占有时钟周期数最长的Basic Block和相对应的源代码和汇编代码行,比较multiply和multiply_simd中占有时钟周期最大的代码行对应的“数量(占比)”数值。例如如下图所示:比较multiply程序C/C++性能分析结果的源代码60行,和multiply_simd程序分析结果的源代码71行,其数量(占比)有明显减少,说明优化有效。
下图为multiply程序C/C++性能分析结果:

下图为multiply_simd程序C/C++性能分析结果:

3.8 结束程序(同3.5)
切换至1.3步骤登录的终端,执行如下代码:
① 通过jobs -l查看multiply_simd程序运行pid(如果程序尚未结束,可以看到后台运行的程序;如果没有输出,说明进程已经结束,不需要进行此步操作)。

②通过kill -9杀死进程。替换<multiply_simd程序pid>为刚查到的multiply_simd的pid。
实验总结:
通过将矩阵乘法计算方式从for loop方式优化为使用鲲鹏的NEON指令来进行计算,函数指令数大幅减少,执行效率得到了提升。至此实验已全部完成。