��ؽ�ģ��:һЩ�������̷������Զ�������С��
��ģ���������dz������ٵ�һ���������,���������������,ͨ��һЩ�������̷���,�ھ�������и������Ϣ,���ﵽ����ģ��Ч����Ŀ�ġ����Ա�ƪ���¾ͼ�������һЩ�������̵�˼·��������һЩ�ֳɵ���������python���߰�,�����һ��̽�֡�
һ������ƪ
���������������������̹������ǻ�������һ�ֻ���˼��,�����ݹ����س��������岻���,�����Ǻ������ֱ����ʱ�ձ���ʱ,���ֱ�����ḻ����Ϣ���������������ͬ����֮��Ӧ���ܹ�ͨ��ij���ض���ʽ���л���ϡ������ṩ�������������µ���Ч��Ϣ,���������������̹��������ij����㡣
1���������,����з������������ض���Ⱥ
��������,�������״̬����һ������,�����ǵ�ҵ���¿����Ľ��ͨ��������Ŀ�Ⱥ���ѻ�Ŀ�Ⱥ�Ļ���������һЩ,��Ҳû�����Բ��졣�����Ľ����˵������״̬��������Է���û�����ֶ�,������ģ��Ч��û�й�����?ʵ�ʲ������,�����ǰ�����ͻ���״̬����������Ϸ�������,30����������Ŀ�Ⱥ���ѻ�Ŀ�Ⱥ�����ʲ�û��ʲô���,��30�����¾�����Ŀ�Ⱥ������ȴ���Ը�����������״̬�������һ���Ƚ������ĸ������ݳ��������ӡ������ǵ���������״̬�������ʱ,�����ܻ�ȡ������Ϣ�dz�����,�ڷ������ֶ���Ҳ����������Ч��,�������Ǹ�����״̬�������������������,���Ǿͽ�һ����ȡ���˸����ε���Ϣ,30�겻��������,����ͨ������ά�ȵ��������,���ǾͿ�����һ���ƺ������ס������ء������������,���������Ȧ������Ⱥ�ڷ��ձ�������ȻҲ���ߡ�
�����������뷨,������Ƶĵ�һ���������̷����������б�������,��������,�ҵ����н���������Է�������������Ϸ�ʽ,������Щ���Ȧ������Ⱥ�Զ��ȱ���ķ�ʽ���,��Ϊ�µ�������������������:
from itertools import product
import multiprocessing
from tqdm import tqdm
def var_cross(df, res_col, target = 'if_overdue_30', bad_thresh=0.2, good_thresh=0.05, num_rate=0.02, lift_rate=1.5):
res = pd.DataFrame()
df_res = pd.DataFrame()
for group_col in res_col:
group_df = df[list(group_col)+[target]].copy()
for num_col in group_df.select_dtypes(include=[np.number]):
if group_df[num_col].value_counts().shape[0]>=10:
group_df[num_col] = pd.qcut(group_df[num_col],10,duplicates='drop').astype(str)
tmp = group_df.groupby(list(group_col) if isinstance(group_col,tuple) else group_col)[target].agg({'count','mean'})
for item in tmp.iterrows():
if (item[1]['count']>df.shape[0]*num_rate)&((item[1]['mean']>bad_thresh)|(item[1]['mean']<good_thresh)):
if len(group_col)==2:
br1 = group_df.loc[group_df[group_col[0]]==item[0][0],target].mean()
br2 = group_df.loc[group_df[group_col[1]]==item[0][1],target].mean()
if ( (item[1]['mean']>=br1*lift_rate)&(item[1]['mean']>=br2*lift_rate) )|( (item[1]['mean']*lift_rate<=br1)&(item[1]['mean']*lift_rate<=br2) ):
col_name = 'CROSS_'+str(group_col[0])+str(item[0][0])+str(group_col[1])+str(item[0][1])
col_name = col_name.replace(', ','_').replace('(','').replace(']','')
group_df[col_name]=0
group_df.loc[(group_df[group_col[0]]==item[0][0])&(group_df[group_col[1]]==item[0][1]),col_name]=1
df_tmp = pd.DataFrame({'var':str(group_col),'bin':str(item[0]),'count':item[1]['count'],
'bad_rate':item[1]['mean'],'var_bad_rate':str([br1,br2])},index=[0])
res = pd.concat([res,df_tmp])
df_res = pd.concat([df_res,group_df[col_name]],axis=1)
elif len(group_col)==3:
br1 = group_df.loc[group_df[group_col[0]]==item[0][0],target].mean()
br2 = group_df.loc[group_df[group_col[1]]==item[0][1],target].mean()
br3 = group_df.loc[group_df[group_col[2]]==item[0][2],target].mean()
if ( (item[1]['mean']>=br1*lift_rate)&(item[1]['mean']>=br2*lift_rate)&(item[1]['mean']>=br3*lift_rate) )|( (item[1]['mean']*lift_rate<=br1)&(item[1]['mean']*lift_rate<=br2)&(item[1]['mean']*lift_rate<=br3) ):
col_name = 'CROSS_'+str(group_col[0])+str(item[0][0])+str(group_col[1])+str(item[0][1])+str(group_col[2])+str(item[0][2])
col_name = col_name.replace(', ','_').replace('(','').replace(']','')
group_df[col_name]=0
group_df.loc[(group_df[group_col[0]]==item[0][0])&(group_df[group_col[1]]==item[0][1])&(group_df[group_col[2]]==item[0][2]),col_name]=1
df_tmp = pd.DataFrame({'var':str(group_col),'bin':str(item[0]),'count':item[1]['count'],
'bad_rate':item[1]['mean'],'var_bad_rate':str([br1,br2,br3])},index=[0])
res = pd.concat([res,df_tmp])
df_res = pd.concat([df_res,group_df[col_name]],axis=1)
return df_res, res
�������һ��,����var_cross�����幦�ܾ���ʵ�ֱ����ķ��佻��,��������Ч��ϡ����е�һ������df���ǰ������б��������ݼ�;�ڶ�������res_col��ŵ���������Ҫ���н�����ϵı�����,������������������V1,V2,V3,Ҫ�����������,��res_col����[(V1,V2), (V1,v3), (V2,V3)];����������ָ����һ����Ŀ��y,�������������õ��Ƿ�����30��;�����ĸ����������Ƕ���ϵ���������,���������ҵ������Է��������������,���������Ķ������������Ȧ������ȺҪô�ܺ�,Ҫô�ܻ�,��������Ҫ��Ȼ����ij����ֵ,Ҫ��Ȼ����ij����ֵ,ͬʱ,Ϊ�˷�ֹ������ij�����䱾���ͺ���������,���ǻ�������һ��������,����Ϻ�,������Ҫ��һ�����ȵ������ű���������ѧ������,��������ѧ���������˿��ܾ���20%,��������ij��������ѧ������������һ����Ϻ�,����Ҫ�ﵽ30%�ŵ��Ա���������,���Ȧ������ȺҲҪ��֤һ������Ⱥ����,�������ٱ�֤2%���������������档�ɴ�,���ĸ�����ָ���˽��������Ҫ�߹�����ֵ,����ָ��Ϊ20%;���������ָ���˻���Ҫ���ڵ���ֵ;�������������˽�������С��������;���߸�����ָ���˽���������ı�����
���,��������������������ݼ�,��һ��df_res�������������������������ݼ����ڶ���res�����˽�����ϵ���ϸ��Ϣ,������ʾ:

��һ�б�ʾ��������������,������������Ա�;�ڶ��б�ʾÿ����������ȡֵ�Ƕ���,����������18-28��,�Ա���Ů,�����б�ʾ������������ǵ���Ⱥ��,������1170;�����б�ʾ������ϸ�����Ⱥ�Ļ�����,3%;���һ�г��ֵ�������������������Եķ������滵�����Ƕ���,���ڶԱ��ſ�������Ϻ����ʵ�������,��������18-28����Ⱥ������4.37%,�Ա�Ů�ԵĿͻ�������5.41%����˻�����һ�б���,������18-28��Ů�Կ�Ⱥ����Ϊ1,����Ϊ0,���������ı�������������������ϵı������ͷ���ȡֵ:CROSS_AGE18.0_28.0SEXŮ��
�����ǵ�����ά�Ƚ϶�,�����ϴ�ʱ,���ֱ���������Ͼͻ�dz���ʱ,����һ���õķ�������ʱ��,���ǿ���ͨ�����߳�ȥ��������ʱ������,����ͬʱ�������߳�ִ�����������Ĵ���:
def var_cross_multi(df, col:list, target = 'if_overdue_30', bad_thresh=0.15, good_thresh=0.05, num_rate=0.02, lift_rate=1.5):
if len(col)==1:
res_col = col[0]
else:
res_col = [list(x) for x in product(*col) if len(list(x))==len(set(x))]
res_col = set([tuple(set(sorted(x))) for x in res_col])
##����ָ��Ҫ�ü���������,�����Լ��Ļ����������
jobn = 60
row_s = pd.Series(range(0, len(res_col)), index=res_col)
jobn = min(jobn, len(row_s.index))
row_cut = pd.qcut(row_s, jobn, labels=range(0, jobn))
data_list = []
for i in range(0, jobn):
data_list.append(list(row_cut[row_cut == i].index))
mp = multiprocessing.Pool(jobn)
mplist = []
for i in range(0, jobn):
mplist.append(
mp.apply_async(
func=var_cross,
kwds={'df':df,'res_col':data_list[i],'target':target, 'bad_thresh':bad_thresh, 'good_thresh':good_thresh, 'num_rate':num_rate, 'lift_rate':lift_rate}))
mp.close()
mp.join()
res = pd.DataFrame()
df_res_list = []
for result in tqdm(mplist):
part_res = result.get()
if len(part_res)>1:
res = pd.concat([res,part_res[1]])
df_res_list.append(part_res[0])
df_res = pd.concat(df_res_list,axis=1)
print('FINISH!!')
return df_res,res
����ֵ��һ�����,�����ĵڶ�������col,��ֱ�Ӵ�����Ҫ������ϵı����б�,��������ָ��var_list1 = [V1,V2,V3],var_list2=[V4,V5,V6]��Ҫ���������б��еı���������Ͻ���,�����Ǿͽ�[var_list1, var_list2]����col�Ϳ�����,�������Զ����ɳ����в��ظ���������϶�,����var_cross�����������Ҫ�����������,ֻ��Ҫ��[var_list1, var_list2, var_list3]����col�Ϳ�����,Ŀǰ��������Ĺ���ֻ֧�����������������ϡ�
2����ֵ�����������ֶαȽ���Ϣ
��Щ��ֵ�ͱ���,��������Ⱥ����ȥ�Ƚ��Dz����ʵġ��������롣5000Ԫ���������Ǹ��ǵ���?���ڲ�ͬ�Ļ��������в�ͬ�ĺ���,������ڱ�������5000,�ǿ����֪,��������һ������,���������;������ں�����5000,��������˵,�㲻�÷���Ҳ���������ˡ����Զ����������������ı���,����ܹ����ֳ���ͬ�Ļ���,��ͬһ����������Թ�ƽ�ıȽ�����ʵ����Թ�ƽ�Ƚϵķ�ʽ������,һ�ǽ����ⲿ����Ϣ֪ʶ,�������ǿ��Ե�����ͳ�ƾ��ҵ�ÿ�����о����ƽ��������,��������Ҫ�����Ŀͻ��������ȥ�����ڳ��е�ƽ��������,�õ��������ڳ���ƽ�������ֵ������һ������;����ֱ�������ǵĿͻ�������ÿ�����е������ֵͳ��,�������ֵ������������������������Ҳ�е���,��Ϊ�����Ⱥ��������һ���Ϊ�������Ⱥ,ͬһ����ͬ���Ե���Ⱥ�Ƚ������ϸ�Ϊ��ƽ,��Ȼ,�����������������ʱ��,���������ȶ��Ի��һЩ��
�����������뷨,���Ǹ����ĵڶ������������������ǰ�������������ı����ŵ���ͬ������,�粻ͬ���С���ͬѧ������ְͬҵ����ͬ����εȵ�,ȥ�ó����µľ�ֵ�����ֵ����Сֵ���Ƚ�,ͬʱ�ڸó����½�������,��������:
def scene_feature_engineer(df,id_key,scene_features,value_features):
'''
create features such as: difference between personal salary and mean/max/min salary within a specific group
'''
for col in value_features:
if df[col].dtypes=='object':
raise ValueError('{} is not number value'.format(col))
columns = list(set(scene_features+value_features))+[id_key]
tmp = df[columns].copy()
for gp_feature in scene_features:
if (tmp[gp_feature].dtypes != object)&(tmp[gp_feature].value_counts().shape[0]>8):
tmp[gp_feature+'_bin'] = pd.qcut(tmp[gp_feature],8,duplicates='drop').astype(str)
else:
tmp[gp_feature+'_bin'] = tmp[gp_feature]
for v_feature in value_features:
if gp_feature == v_feature:
continue
gp_data = tmp.groupby(gp_feature+'_bin')[v_feature].agg({'mean','max','min'}).reset_index()
tmp = tmp.merge(gp_data, on=gp_feature+'_bin',how='left')
for agg in ['mean','max','min']:
tmp['GP_FEATURE_gpby_'+gp_feature+'_cntby_'+v_feature+'_'+ agg] = tmp[v_feature] - tmp[agg]
tmp.drop(['mean','max','min'],axis=1,inplace=True)
for i,gp_part in tmp.groupby(gp_feature+'_bin'):
gp_part['rankpercent'] = gp_part[v_feature].rank(pct=True)
tmp.loc[gp_part.index,'GP_RANK_gpby_'+gp_feature+'_sortby_'+v_feature] = gp_part['rankpercent']
return tmp[[id_key]+[x for x in tmp if (x.startswith('GP_FEATURE'))|(x.startswith('GP_RANK'))]]
���е�һ������df�ǰ������б��������ݼ�;����id_keyָ����һ��������,��������֤��,�������������ɺ��ԭ���ݼ���ƥ��;����scene_features��һ���б�,�������п���Ϊ�����ı���,������С�ʡ�ݡ�ְҵ�������;����value_featuresҲ��һ���б�,��ʽ����Ҫ����ͬ�������Ƚϵı���,�������롢��ծ�����Ѷ�ȵȡ�
�������ص���һ�����ݼ�,����������������������,��GP_FEATURE��ͷ�ı�����ӳ�����벻ͬ�����µľ�ֵ�����ֵ����Сֵ����;��GP_RANK��ͷ�ı�����ӳ�����ڲ�ͬ����������ķ�λ����
3�����������ָ�,�ҳ��������ֶ�
������һ���ó��������ı���ȥ˵������:
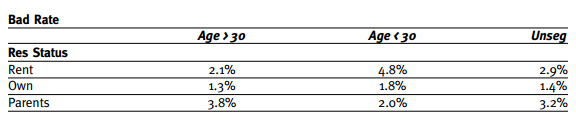
ס��״̬���������������,���ֶȷdz�һ��,�ⷿ������ס�����븸ĸͬס����ס��״̬����Ⱥ�����ʲ�����ԡ������������������������30��Ϊ����һ���ָ����,30��������Ⱥ����,����ס��״̬�Ļ����ʲ�������ֳ����ˡ������IVֵ���������ֶ�,���������ס��״̬���������IVֵһ��û��������30��ָ��,ֻ����30��������Ⱥס��״̬IVֵ�ߡ�˵��������������������ijЩ�������ָ��,���ھ������DZ�ص���Ϣ���ݴ�,��������ĵ������������̷�������ͨ������ָ�,�ھ����ЩDZ����Ϣ��
���巽������ͼ��ʾ,��������������A��BΪ��,���ȱ�������A��ÿһ������,����ÿһ��������B������IVֵ,�ͱ���B������IVֵ��Ƚϡ������佻�沿�ֱ���B��IVֵ����B�����IVֵ,���ⲿ��B�ı���ȡֵ��������,��Ϊһ���µ���������(�������AΪ����,BΪס��״̬,�ֱ����30������,30-40��,40�����Ͽ�Ⱥ��ס��״̬IVֵ,����и���������Ⱥס��״̬IVֵ��,������ȡֵ��Ϊ�µ���������)��Ȼ��֮,����B��ÿ������,����A��IVֵ��������A��B��ÿ�ַ����������ϡ������������:
from itertools import product
import multiprocessing
import numpy as np
from tqdm import tqdm
import warnings
warnings.filterwarnings('ignore')
def find_bins_cutpoint(data,col):
if if_continue_value(data,col):
_,bins = pd.qcut(data[col],5,duplicates='drop',retbins=True)
bins = zip([-np.inf]+list(bins),list(bins)+[np.inf])
else:
bins = data[col].value_counts().index.tolist()
return bins
def find_bins_dataframe(data,col_bin,bins,col_value):
if isinstance(bins,tuple):
return data.loc[(data[col_bin]>bins[0])&(data[col_bin]<=bins[1]),col_value]
else:
return data.loc[data[col_bin]==bins,col_value]
def create_new_df_vars(data,col_bin,bins,col_value,new_var_name):
data[new_var_name]=np.nan
if isinstance(bins,tuple):
data.loc[(data[col_bin]>bins[0])&(data[col_bin]<=bins[1]),new_var_name] = data.loc[(data[col_bin]>bins[0])&(data[col_bin]<=bins[1]),col_value]
else:
data.loc[data[col_bin]==bins,new_var_name] = data.loc[data[col_bin]==bins,col_value]
return data
def iv_value_compare(y,col_list,lift_rate=1.2,iv_threshold=0.02,num_threshold=0.03):
res = pd.DataFrame()
res_df = pd.DataFrame()
for col_1,col_2 in col_list:
if (not if_continue_value(df,col_1))&(not if_continue_value(df,col_2)):
continue
data = df[[col_1,col_2,y]].copy()
base_iv_value1 = calculate_iv(data,col_1,y)
base_iv_value2 = calculate_iv(data,col_2,y)
bins1 = find_bins_cutpoint(data,col_1)
bins2 = find_bins_cutpoint(data,col_2)
for col,bins,base_iv in [(col_1,bins1,base_iv_value2),(col_2,bins2,base_iv_value1)]:
for b in bins:
df_bin = find_bins_dataframe(data,col,b,[col_1,col_2,y])
if df_bin.shape[0]<df.shape[0]*num_threshold:
continue
bin_iv_value = calculate_iv(df_bin,[x for x in [col_1,col_2] if x!=col][0],y)
if (bin_iv_value>=base_iv*lift_rate)&(bin_iv_value>iv_threshold):
res_tmp = pd.DataFrame({'total_iv_value':base_iv,'col1_col2':str([col_1,col_2]),
'col':col,'bin':str(b),'bin_iv_value':bin_iv_value,'bin_num':df_bin.shape[0]},index=[0])
res = pd.concat([res,res_tmp])
var_name = 'CROSS_IV_'+col_1+col_2+col+'_'+str(b)
var_name = var_name.replace(', ','_').replace('(','').replace(']','').replace(')','')
df_tmp = create_new_df_vars(data.fillna(-9999),col,b,[x for x in [col_1,col_2] if x!=col][0],var_name)
res_df = pd.concat([res_df,df_tmp[[var_name]]],axis=1)
for b1 in bins1:
df_bin = find_bins_dataframe(data,col_1,b1,[col_1,col_2,y])
for b2 in bins2:
df_bin = find_bins_dataframe(df_bin,col_2,b2,[col_1,col_2,y])
if df_bin.shape[0]<df.shape[0]*num_threshold:
continue
for col,base_iv in [(col_1,base_iv_value1),(col_2,base_iv_value2)]:
bin_iv = calculate_iv(df_bin,col,y)
if (bin_iv>=base_iv*lift_rate)&(bin_iv>iv_threshold):
res_tmp = pd.DataFrame({'total_iv_value':base_iv,'col1_col2':str([col_1,col_2]),
'col':col,'bin':str([b1,b2]),'bin_iv_value':bin_iv,'bin_num':df_bin.shape[0]},index=[0])
res = pd.concat([res,res_tmp])
var_name = 'CROSS_IV_'+col_1+col_2+str(b1)+str(b2)
var_name = var_name.replace(', ','_').replace('(','').replace(']','').replace(')','')
df_tmp = create_new_df_vars(data.fillna(-9999),col_1,b1,col,var_name+'tmp')
df_tmp = create_new_df_vars(df_tmp,col_2,b2,var_name+'tmp',var_name)
res_df = pd.concat([res_df,df_tmp[[var_name]]],axis=1)
return res_df,res
����iv_value_compare����Ϊʵ�ִ˹��ܵ�������,�������Ǹ����ԵĹ���С���������в���yָ����Ŀ��ֵ��;����col_list������Ҫ���н���ı�����,����������ҪV1,V2,V3����������������,ֻ��Ҫ���б�[(V1,V2),(V1,V3),(V2,V3)]����col_list;����lift_rateָ���˷��佻���IVֵҪ������IVֵ�������ٱ�,�ſ�����������,�������õ���1.2������;����iv_threshhold�趨��IVֵ����С��ֵ,����ָ���˱������佻����IVֵҪ���ٳ���0.02�Ž����±���������,����num_threshholdָ���˱�������������С���ǿ�Ⱥ��,����ָ���˷������������Ҫ�ﵽ�����Ⱥ��3%�ſ��ԡ�����������������ݼ�,���ݼ�res��¼�����б����������ϸ��Ϣ,���ݼ�res_df���������µ���������,����ͼ��ʾ:

res�е�һ����ʾ����������������,�����������˾����;�ڶ������б�ʾ���ĸ��������ĸ�����ȥ���и�,�������ù�˾����Ϊ������ҵȥ�и������������;��������ʾ�и����һ�����������IVֵ;���һ����ʾ�����еĿͻ������������ɵ��±����Ὣ��˾����Ϊ������ҵ������ԭʼֵ��������,����λ�����,������ΪCROSS_IV_INCOME_COMPANY_TYPE_COMPANY_TYPE������ҵ��
ͬ��,�����ϴ�ʱ,�����б����ı�����������ʱ�ϳ�,����ͬ���������̴߳����Ĵ���:
def iv_value_compare_multi(col,lift_rate=1.0,iv_threshold=0.02,num_threshold=0.03):
if len(col)==1:
res_col = col[0]
else:
res_col = [list(x) for x in product(*col) if len(list(x))==len(set(x))]
res_col = set([tuple(set(sorted(x))) for x in res_col])
##�����Լ������ĺ������и���
jobn = 60
row_s = pd.Series(range(0, len(res_col)), index=res_col)
jobn = min(jobn, len(row_s.index))
row_cut = pd.qcut(row_s, jobn, labels=range(0, jobn))
data_list = []
for i in range(0, jobn):
data_list.append(list(row_cut[row_cut == i].index))
print(jobn)
mp = multiprocessing.Pool(jobn)
mplist = []
for i in range(0, jobn):
mplist.append(
mp.apply_async(
func=iv_value_compare,
kwds={'y':'if_overdue_90','col_list':data_list[i],'lift_rate':lift_rate,'iv_threshold':iv_threshold,'num_threshold':num_threshold}))
mp.close()
mp.join()
res = pd.DataFrame()
df_res_list = []
for result in tqdm(mplist):
part_res = result.get()
if len(part_res)>1:
res = pd.concat([res,part_res[1]])
df_res_list.append(part_res[0])
df_res = pd.concat(df_res_list,axis=1)
print('FINISH!!!!')
return df_res,res
ͬ����һһ��,�������ָ��var_list1 = [V1,V2,V3],var_list2=[V4,V5,V6],��Ҫ���������б��еı���������Ͻ���,�����Ǿͽ�[var_list1, var_list2]��������col�Ϳ����ˡ�
�����Ҫ˵������,�����ᵽ���������̷���Ҳֻ�Ǹ���һЩ��ʶ����ҵ���������е�̽��,�ڲ�ͬ����������,Ч���β�,��������������ʱ��������Ϊ����ѧϰģ�ͽ����Ƕ����ֵļ����,����������ʱ�ձ���Ҳ���ǻ���ѧϰģ�͵�һ��ȱ��,�������������ܶ�����۵��ṩ����֧�š����������ǻ�û���ҵ���ȷ��������ʱ�ձ����ķ���,Ҳ����,������С���˻���ѧϰģ��,�����˽��������,�ܶ������������ɹ��ֵ��豦��Ϊ������ѧϰģ�ͽ����������������ȥȷʵ�ֱ�,����Ҳ����������������ʵ�����֮�䲩��ƽ������Ž⡣��Ȼ�������˴���������������ֶ�ȥȫ���˽�ͻ�,���ٴ������Ҳ����������,�������ݾ����벻�˸����۵��ӽ�,��Ϊ�������ǿ�������һ�������ڴ����ݵ��Ļ֮��,�����ڴ������ϱ��ֵ���ȫһ�µ���,����ı���Ҳ���ͽ�Ȼ����,����ֻƾ������,���Ǿ�ֻ���Ը����۵��ֶ�ȥ��֪����Ȼ���벻�˸�����,�ǻ���ѧϰģ�����һ���������ʵ�ȫ�����Ž�Ҳ����ͻ�Ʋ��˵�Ψһ�𰸡��ڲ���������Ϣ�������,ģ��Ч�������д����������Щ�������̲�������ģ��Ч�����鵤��ҩ,������DZ���ģ��Ч�������������Ŀ��,�����������ļ�ֵҲֻ����ǰ��֮��,�������ص�����;����Ϊ����ṩһЩ���,�����ܹ��ҵ�����Ч����������������
��������ƪ
1��Featuretools
Featuretools��һ��ʵ�����������Զ�����python��ܡ���Ҫ���ܾ��Ǹ���ʱ���͵ĺ�ϵ�͵����ݼ�,�Զ����ɰ���һϵ����������������������������ƾ����ڱ�����װ�˴�ԭʼ����,�����������Ĺ������,����ʡ����������ʱ��,���������Զ�������ѧϰ��
�������Ӧ��,ͨ���������İ���һ�۾Ϳ��Կ�����:

��Ӧ�Եij�����������,����һ�����׳���,��һ��custumer�����ݼ�����ÿ���ͻ��Ļ�����Ϣ,�ڶ���session�����ݼ�����ÿ�����׳�������Ϣ,һ���ͻ�һ���Ӧ������׳���,���ֻ��Ͻ��ס������Ͻ���,��ƽ���Ͻ��ס�������transaction���ݼ�����ÿ�ʽ�����Ϣ,һ���ͻ���һ�������¿����ж�ʽ���,��Ϣ�Ͷ��������
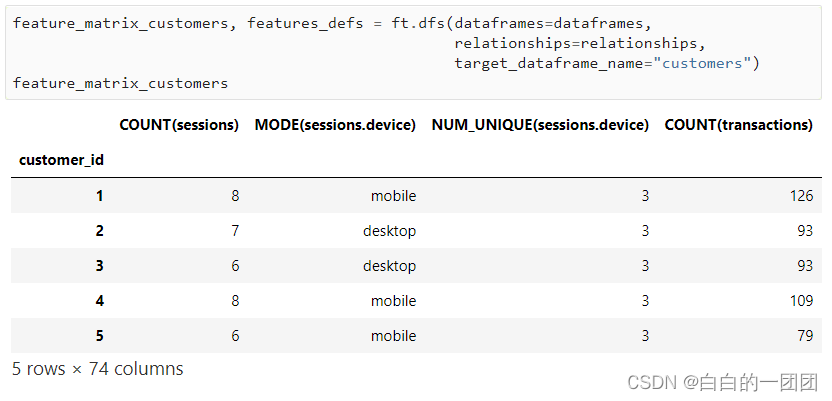
ָ���ò�����,ֻ��Ҫ��һ�����ĵ���,�Ϳ����Զ����ɸ��־ۺ��������ʱ�������,�ӱ�������Ҳ�ܺ�����ؿ�����������Щ����,����ۺ��������:һ���ͻ����н��ij�����������õ��豸���͡�ʹ�ù����豸�����������ױ����ȵ�;ʱ���������:�����ꡢ�¡��ա�ʱ�Ρ����һ���ÿ���ʱ��ȡ�����Featuretools��һ������Ӧ��,����������������һЩ�ĸ�����,����Ҳ����һ��:
1.1 ��������ϳ�
��������ϳɺ����ѧϰû��ʲô��ϵ,����˵���Ǽӹ�����ʱ,�����㼶����,һ�����ӾͿ��Լ�˵��:������ָ������Ȳ㼶Ϊ2��ʱ,���ͻ���������������������:
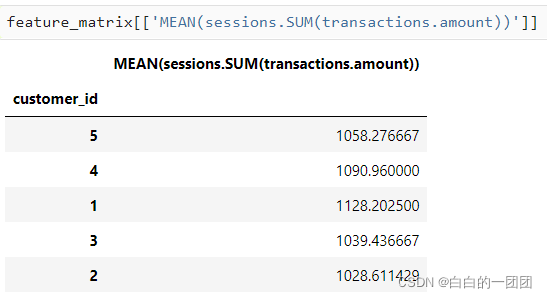
�����ȼ���ÿ�����׳��������н��Ľ���ܺ�,Ȼ������г����µĽ���ܺ���ƽ��ֵ����������Ϊ2�ĺ���,�������������㼶ȥ���ۺ�����������
1.2 ʱ�����д���
����ʱ������Ԥ��һ���dz���Ҫ�ĵ��������ʱ���з�,��ȷ���ֳ�ѵ������Ԥ�⼯��featuretools����ʱ�������������ʱ��Ϳ����Զ�ֻ�����зֵ�֮ǰ����Ϣ,��������ҪԤ��һ���ͻ��Ƿ����1��1��4������һ�컨��500��,������������������Ԥ���ʱ��,��Ҫ�ϸ����,���ܽ�1��1��4��֮�����Ϣ���������������ָ����cutoff_time����Ϊ1��1��4��֮��,featuretools���Զ���������4������Ϣ��
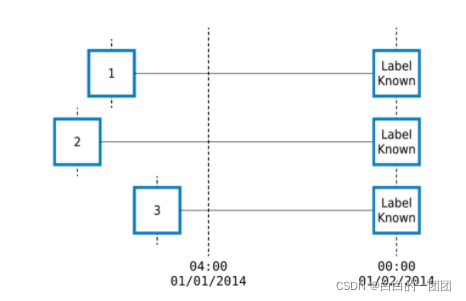
����֮��,���ǻ������Զ���һ��ʱ�䴰��,ÿ����¼����ͳһ��ʱ�䴰�����������㡣������ָ��ÿ��ʱ�䷢���Ŀ�ʼ�ͽ���ʱ��,�������ָ��ʱ�䴰�����ص����¼��ж��ٵȵȡ�
��������ֻ�Ǽ�Ҫ������Featuretools��Ӧ�ó�������Ҫ����,�����ʵ�ַ�����ϸ�ڵĹ��ܶ��������������ҵ���ϸ������������һ�����,��Ҫ����Ӧ��ʱ��ϸϸ�о�,�����֪Ч�ʡ�
2��Autofeat
Autofeat���װ���Զ��������������Զ�������ɸѡ��������,��Ҫ�����������������:���ӵĻ���ѧϰģ����������������ҵ��Ӧ�������Ź���ȱ��,һ�dz���̫���ѵ���;����������Ҫ���������;�����������ͳ����Ա����,�������Իع�������ҵ��Ӧ����ѡ,�������־�����������������,��Ҫ����Ϊ�������ܹ���ԭʼ������ѧϰ�������Եı���������(expressive representations)�����ڴ�,autofeat��Ҫ���ܾ���ͨ���˷����������Ӽ��˳���������������������,���Զ�ɸѡ���м�ֵ������������,autofeat�������������ܿ��Կ����Ƕ�featuretools���ܵĻ���,Ҳ���Կ����Ƕ�featuretools�Ĺ��ܽ���,featuretoolsʵ�ִ�ԭʼ���ݵ���������������,autofeat��ɴӻ��������������Ա�����������ɸѡ��
2.1 autofeat�ı���������
autofeat�ı������������ǡ�������ת��������������������ϡ�����������IJ��Ͻ���������������,��������ת����ָ���ǶԱ������� l o g ( x ) log(x) log(x)�� x \sqrt x x?�� 1 / x 1/x 1/x�� x 2 x^2 x2�� x 3 x^3 x3�� �O x �O \left | x \right | �Ox�O�� e x p ( x ) exp(x) exp(x)�� 2 x 2^x 2x�� s i n ( x ) sin(x) sin(x)�� c o s ( x ) cos(x) cos(x)�ȷ�ʽ������;������������ϡ���ָ����������֮����мӼ��˵����㡣���ַ�ʽ�����ı��������ָ��������,��3��ԭʼ����Ϊ��,��һ��������20�����ҵı���,�ڶ���������750����������,�������ͻ���չ��4000����������,������ڴ��Ҫ��Ƚϴ�������������ǰ�����ȶ��������в���,ͨ��ִ��2-3�����㹻Ӧ�á�
2.2 autofeat�ı���ѡ����
��һ��,���Ӵ��������������ȥ����ԭʼ��������صı�����
�ڶ���,ѡ����������һ�����A:�����б���ѵ��һ��L1�������ع�ģ��,ѡ��ϵ������ֵ����һ�������
������,��һ��ѡ����Ч����:��ʣ�µı�������n��,ÿһ������ֱ��A����һ��ѵ��һ��ģ��,������ϵ����Сѡ�����Ч������
���IJ�,ѡ�������к�ѡ��������һ��ѵ��һ��ģ�Ͳ���������Ҫ�����ı�����
���岽,����2-4���ڶ�������Ӽ�����ִ��,ѡ�������ѡ������
������,�����ѡ��������һ��,ȥ������ر�����ѵ��һ��ģ��,ͨ��ϵ����С�������ձ���������
ֵ��һ�����,����ѡ��֮����Ҫ�����Ϸ�ʽһ��һ���ѡ,���ǵ�������ÿ�������Ĺ���(��IVֵ)����ѡ��,��Ҫ����Ϊ���������ı����Ϊ���,���������,��͵�����Щ���������ܴ���������Ϣ,����Щ��������������Ч��������,��������һЩ����һ����ģ�������ֳ�Ч����
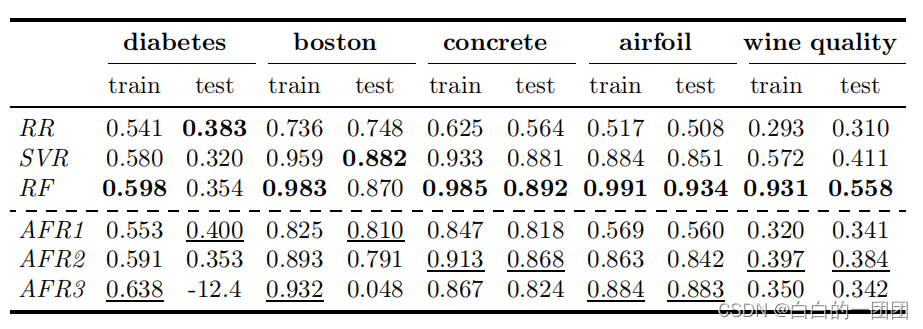
��һ�������մ�������ģ��Ч��������?Ҳ���ر��кܴ��Ԥ��,�ܵ���˵Ч����������,���ͻ���ѧϰģ����Ȼ��в��,���Կ������ǵ�������,����ͼ(����RR����ԭʼ����ѵ������ع���,SVR��֧���������ع���,RF�����ɭ�ֽ��,AFR123�ֱ����һ�ȡ����ȡ������������autofeat���)��ֻ��˵ʱ��ͼ����ڴ涼���õ�����¿�����һ�ԡ�
2.3 autofeatʹ�÷���
autofeat֧��pip��װ,���ṩ�˺�sklearnͬ����ʽ�ĵ��ýӿ�:
# ��ʼ��ģ��
model = AutoFeatRegressor()
# ѵ��ģ��,���õ�һ������ԭʼ�����������������������ݼ�df
df = model.fit_transform(X, y)
# Ԥ���µ�������
y_pred = model.predict(X_test)
# Ҳ����ͨ������transform��һ���µ��������ϵõ�������������
df_test = model.transform(X_test)
#����Ҳ���Ե���ʹ��2.2���ᵽ������ѡ��
FeatureSelector
���������ԭ�����������ѧϰ��
3��Tsfresh
tsfresh��Ҫ�����Ƕ�ʱ���������ݽ���������ȡ��ҵ���нӴ�����,�����ڴ�ֻ����Ҫ���ܡ�������������������������(ʱ�������������������ƽ���Ӻ�)�����ֲ�֡������ء��Իع�ϵ����������Եȵ�,��������������ϸ���Բ���������ϸ���ܡ�