数据科学中使用的数据集往往超过平常的存储和网络容量。 随着越来越多的人获取相同的数据,存储需求迅速扩大,从而产生重复数据(增加成本)。 并且在每个环境中都等待下载,浪费了大量宝贵的时间。
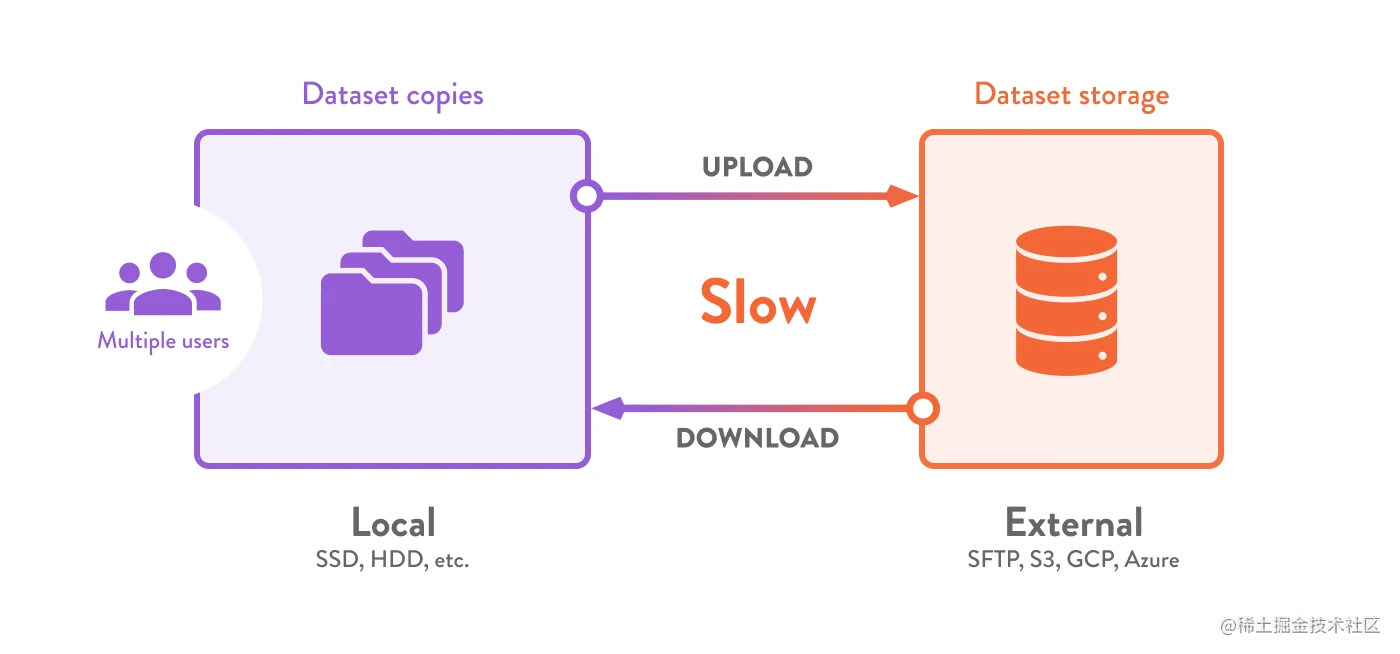
DVC 的内置数据缓存让您可以在全球范围内为整个团队实现一个简单高效的存储层。这种方法有助于:
- 加速从云上的海量对象存储中传输数据,或在不减慢速度的情况下跨多台机器共享数据。
- 只需为快速访问的常用数据付费(升级整个存储平台的成本很高)。
- 当多人处理相同的数据(例如,在共享的开发服务器上)时,避免再次下载数据和复制文件。
- 在用于机器学习实验的共享服务器上快速切换数据输入(无需重新下载)。
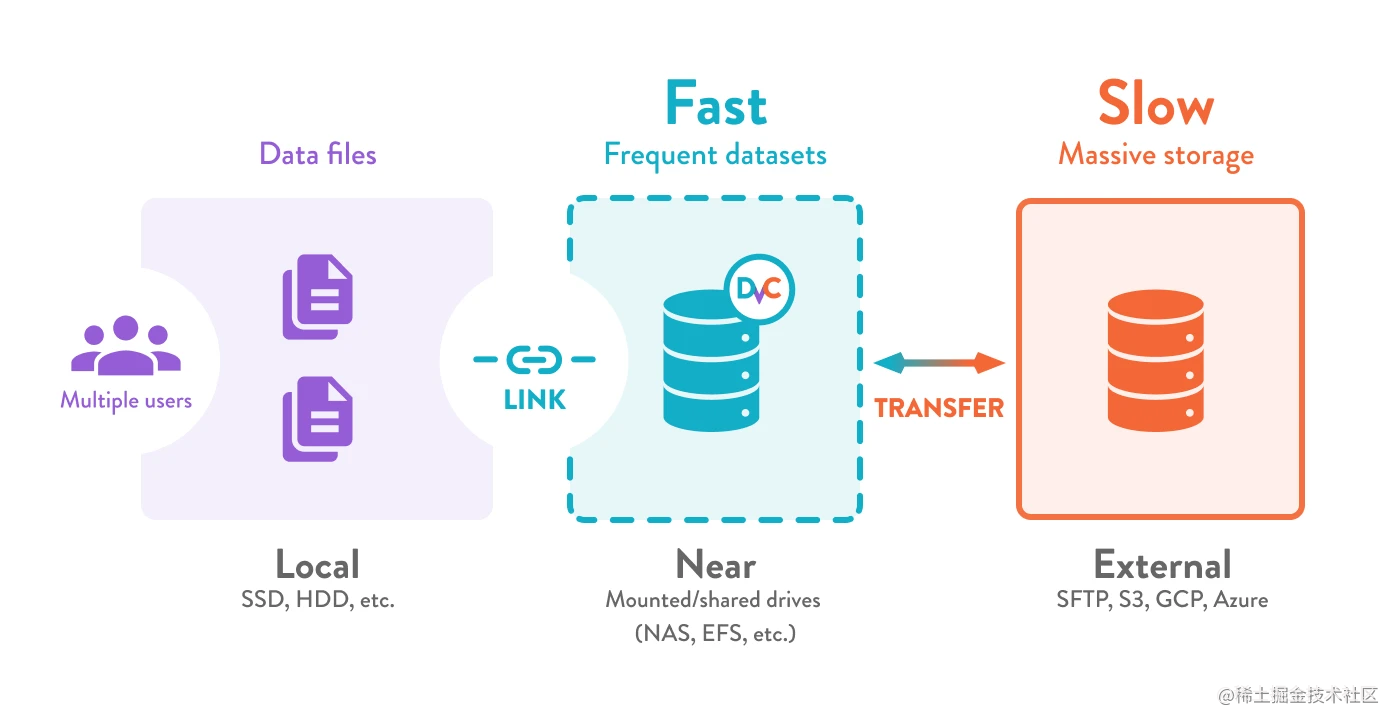
通过在附近的位置(网络、外部驱动等)设置共享 DVC 缓存,您可以为所有项目提供一个存储空间。 这可以跨数据集删除重复文件,并通过链接您的工作文件和目录来防止重复传输。 数据安全策略可以可靠地执行,因为数据永远不会离开中央存储。 DVC 还可以帮助您在外部/远程位置备份和共享数据和 ML 模型。
现在您的团队共享一个主存储,它可以作为您基础架构的一部分进行独立管理; 根据数据访问速度和成本要求进行配置。 您可以随时灵活地切换存储提供商,而无需更改项目的目录结构或代码。
示例:共享开发服务器
一些团队更喜欢使用一个共享机器来运行他们的实验。 这是一种提高资源利用率(快速传输、中央存储、GPU 访问等)的简单方法。 每个人仍然可以在一个单独的工作空间中工作(例如,在他们的用户主文件夹(/home/{username})中)。
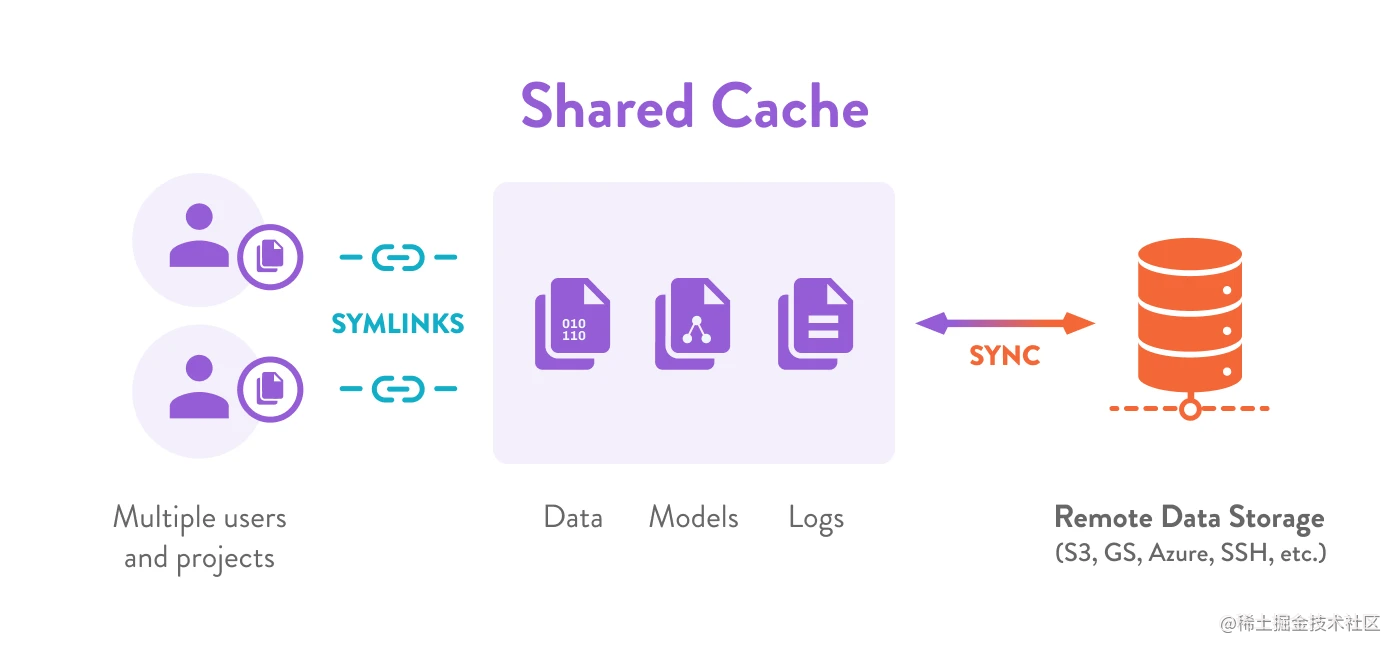
首先,配置 一个共享的 DVC 缓存 。当同事对项目进行更改时,您可以使用 dvc checkout 获得最新结果。 DVC 立即将数据文件和目录链接到您的工作区,因此永远不会移动或复制数据制品。
$ git pull
$ dvc checkout
A data/new
M data/labels

