����ƪ
����Docker�ɲο��ò��͵�Docker��װ
��װDocker����������һЩ�����ɲο��ò��͵�Docker��װ����
��������
- windows : 10
- Docker : 4.7.0
- ��Ҫ��ȡ�ľ��� : centos 7.6.1810
1. ��װcentos 7.6����
1.1 ����centos 7.6����
docker search centos7
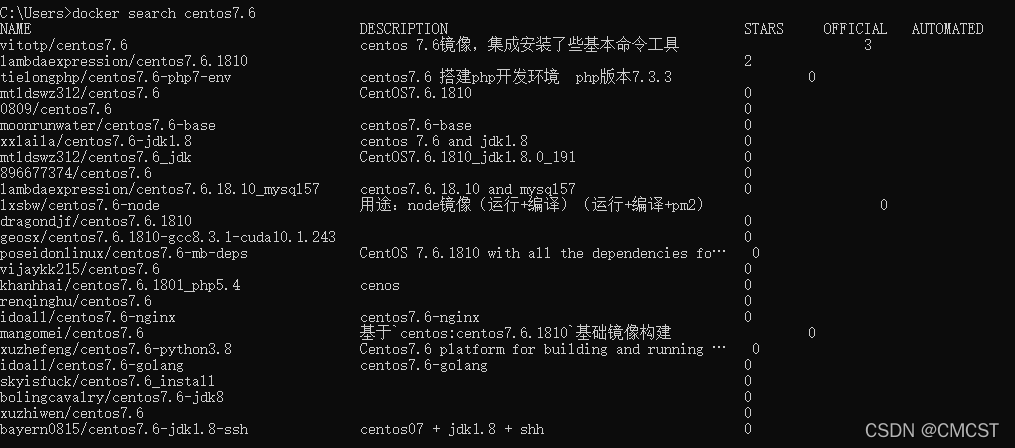
1.2 ��ȡ����
docker pull centos:7.6.1810
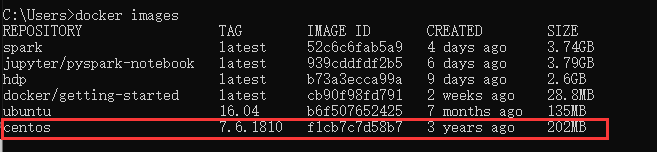
1.3 ��֤����װ�ɹ�
docker images
1.4 �����Ž�����(DockerĬ��ʹ���Ž�,�˴���ʹ���Ž�)
1.4.1 ��������������Ϊhadoop
docker network create -d bridge hadoop
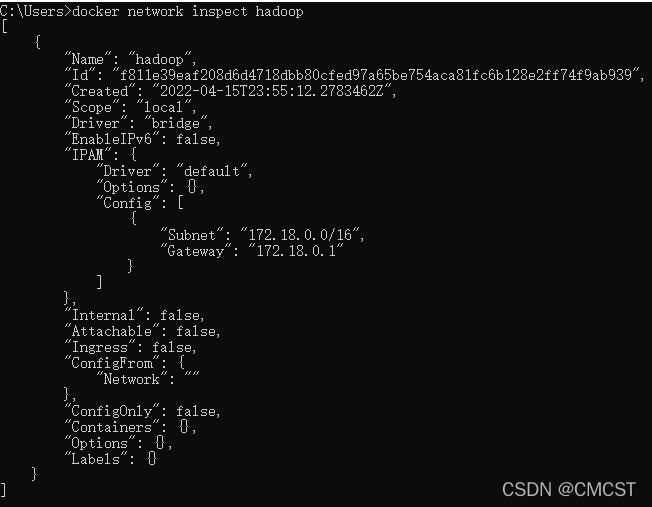
1.4.2 �鿴����hadoop
docker network inspect hadoop
1.5 ����������
# ������Ŀ¼A����������centos:7.6.1810,������Ȩģʽ�ں�̨��������(����Ϊcentos7)
docker run -v E:\COURSE\spark:/home -itd --privileged --name centos7 centos:7.6.1810 /usr/sbin/init

docker run����
- -v windows����Ŀ¼����������centos7��Ŀ¼��
- -itd ��̨����
- �Cprivileged ��Ȩģʽ
- �Cname ����������
# ���ӵ�ǰ��������,��ȡbash
docker exec -it centos7 /bin/bash
2. �hadoop����
2.1 ����centos����
2.1.1 ����
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
2.1.2 �����µ� CentOS-Base.repo �� /etc/yum.repos.d/
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
2.1.3 ���ɻ���
yum makecache
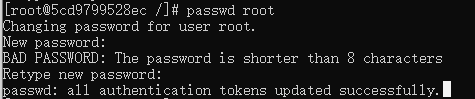
2.2 Ϊroot�û���������
yum -y install passwd
passwd root
2.3 ��װ����
�ɲ�ִ�и����
yum -y install vim passwd openssh-clients openssh-server net-tools
2.3.1 ��װvim
yum install -y vim
2.2.2 ��װopen-ssh
yum install -y openssh-server openssh-clients
ssh-keygen�����ѡ��:
- -t TYPE:ָ����Կ��������
- -P PASSWORD:ָ��˽Կ���ܵ�����,����Ϊ��
- -f FILENAME:ָ����Կ����λ��
- ����ssh���ܵ�¼
ssh-keygen -t rsa -P ""
- ����Կ�ӵ�authorized_keys �ļ���
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- �༭�ļ�
��PermitRootLogin yes��PubkeyAuthentication yes��ע��ȥ��
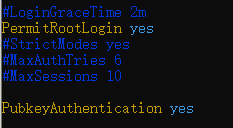
- ���� SSH ����������
systemctl enable sshd.service
- ���� SSH ����
systemctl start sshd.service
- ���ܵ�¼�Լ�(��֤ssh�Ƿ����óɹ�)
ssh 127.0.0.1

2.2.3 ��װJAVA
��ʽһ ʹ��yumԴ��װ
yum search java| grep jdk
yum install -y java-1.8.0-openjdk*
2.2.3.1. Ѱ��JAVA��װλ��
�ڶ����͵����������о���ls �ĸ�Ŀ¼, ����һ������������
which java
ls -lr /usr/bin/java
ls -lr /etc/alternatives/java

2.2.3.2 �ɢ�Ѱ��java��װĿ¼Ϊ/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64/jre/bin/java
2.2.3.3 �����й�java��������
vim /etc/profile
��ĩβ������������:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
2.2.3.4 ��֤
source /etc/profile
echo $JAVA_HOME

��ʽ�� ѹ����ʽ��װ
��һ�� : Oracle JDK����������(֮ǰ��������ʱ���ص�Ŀ¼A)
tar -zxvf /home/jdk-8u331-linux-x64.tar.gz -C /usr/local/
mv /usr/local/jdk-8u331-linux-x64 /usr/local/java
�ڶ��� : �����й�java��������
vim /etc/profile
��ĩβ������������:
export JAVA_HOME=/usr/local/java
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
������ : ��֤
source /etc/profile
echo $JAVA_HOME

2.2.4 ��hadoop3.2.2��ѹ��/usr/localĿ¼��
��ǰ��������ʱ,��Ŀ¼A(E:\COURSE\spark�ļ���)������������/home��
hadoop-3.2.3.tar.gz�廪����վ
tar -zxvf /home/hadoop-3.2.2.tar.gz -C /usr/local/
mv /usr/local/hadoop-3.2.2 /usr/local/hadoop
3. �hadoop��Ⱥ
3.1 ���ļ�
3.1.1 /etc/profile
vim /etc/profile
��ĩβ������������:
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_CONF_DIR=$HADOOP_HOME
export HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
export HADOOP_CONF_DIR=$HADOOP_PREFIX/etc/hadoop
export HDFS_DATANODE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_NAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
ʹ�ļ�/etc/profile��Ч:
source /etc/profile
3.1.2 $HADOOP_HOME/etc/hadoop/hadoop-env.sh
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
��ĩβ������������:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
3.1.3 $HADOOP_HOME/etc/hadoop/core-site.xml
vim $HADOOP_HOME/etc/hadoop/core-site.xml
��ԭ�ļ���<configuration></configuration>�滻Ϊ��������:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
</configuration>
3.1.4 $HADOOP_HOME/etc/hadoop/hdfs-site.xml
vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
��ԭ�ļ���<configuration></configuration>�滻Ϊ��������:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hdfs_name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hdfs_data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
3.1.5 $HADOOP_HOME/etc/hadoop/mapred-site.xml
vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
��ԭ�ļ���<configuration></configuration>�滻Ϊ��������:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01:19888</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/usr/local/hadoop/etc/hadoop,
/usr/local/hadoop/share/hadoop/common/*,
/usr/local/hadoop/share/hadoop/common/lib/*,
/usr/local/hadoop/share/hadoop/hdfs/*,
/usr/local/hadoop/share/hadoop/hdfs/lib/*,
/usr/local/hadoop/share/hadoop/mapreduce/*,
/usr/local/hadoop/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop/share/hadoop/yarn/*,
/usr/local/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
3.1.6 $HADOOP_HOME/etc/hadoop/yarn-site.xml
vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
��ԭ�ļ���<configuration></configuration>�滻Ϊ��������:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>node01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>node01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>node01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>node01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>node01:8088</value>
</property>
</configuration>
3.1.7 $HADOOP_HOME/etc/hadoop/workers
vim $HADOOP_HOME/etc/hadoop/workers
��ԭ�ļ����滻Ϊ��������:
node02
node03
3.2 �������б��澵��
# ��ǰ���� ��ʹ������ docker ps �鿴����ID
docker commit -m ��hadoop�� -a ��hadoop�� ��ǰ���� Ŀ�꾵��
���˴˴�����Ϊ
docker commit -m ��Deploy Hadoop based on centos�� -a ��CMCST�� centos7 hadoop_centos
docker commit :����������һ���µľ���
�
docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG]]
| OPTIONS˵�� | ˵�� |
|---|---|
| -a | �ύ�ľ�������; |
| -c | ʹ��Dockerfileָ������������; |
| -m | �ύʱ��˵������; |
| -p | ��commitʱ,��������ͣ |
3.3 ����hadoop
3.3.1 ����Master�ڵ�: node01
docker run -itd --privileged --network hadoop -h "node01" --name "node01" -p 9870:9870 -p 8088:8088 -p 50070:50070 -p 9001:9001 -p 8030:8030 -p 8031:8031 -p 8032:8032 hadoop_centos /usr/sbin/init
3.3.2 ����Worker�ڵ�: node02
docker run -itd --privileged --network hadoop -h "node02" --name "node02" hadoop_centos /usr/sbin/init
3.3.3 ����Worker�ڵ�: node03
docker run -itd --privileged --network hadoop -h "node03" --name "node03" hadoop_centos /usr/sbin/init
3.3.4 ���ļ�/etc/hosts
��ȡnode01��node02��node03��terminal
�ֱ������cmd����,�ֱ�ִ��
docker exec -it node01 /bin/bash
docker exec -it node02 /bin/bash
docker exec -it node03 /bin/bash
��ȡnode01��node02��node03��IP��ַ
docker network inspect ��������
docker network inspect hadoop
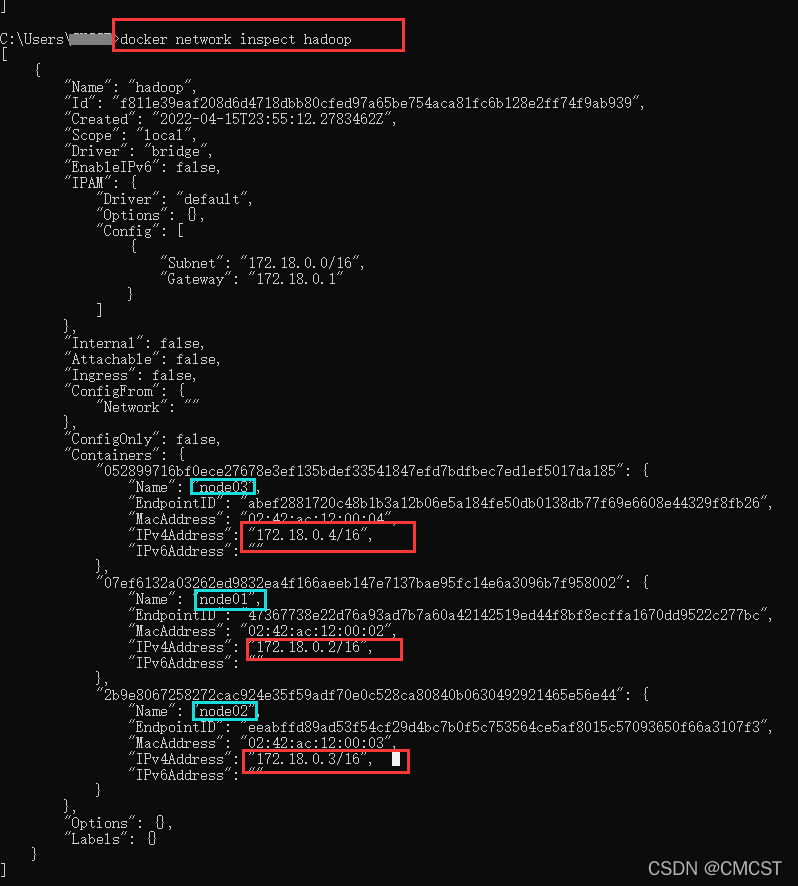
��node01��node02��node03�����ļ�/etc/hosts
vim /etc/hosts
���ļ��ײ�������������
172.18.0.2 node01
172.18.0.3 node02
172.18.0.4 node03
3.3.4 ��ʽ��[node1��]
/usr/local/hadoop/bin/hadoop namenode -format
3.3.5 ����hadoop��Ⱥ[node1��]
/usr/local/hadoop/sbin/start.all.sh

