1、先安装的工具
(一)、安装JDK1.8,多个服务器JDK环境不同可以通过 ln -s 当前jdk环境目录 需要映射的目录,统一JDK路径,JDK安装
(二)、安装Zookeeper
(三)、安装Mysql
所有的机器都需要执行
2、修改hosts文件
vim /etc/hosts
10.0.0.195 hdp02
10.0.0.196 hdp03
#hadoop master
10.0.0.198 hdp01
10.0.0.199 hdp04
10.0.0.193 hdp05
3、新增普通用户hadoop
#创建hadoop用户,并使用/bin/bash作为shell
sudo useradd -m hadoop -s /bin/bash
#为hadoop用户设置密码
sudo passwd hadoop
#为hadoop用户增加管理员权限
sudo adduser hadoop sudo
#切换当前用户为用户hadoop
su - hadoop
#更新hadoop用户
sudo apt-get update
4、新增SSH
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
5、复制所有的服务器的 /.ssh/id_rsa.pub到主服务器,之后把主服务器的/.ssh/authorized_keys覆盖所有的从服务器(注意权限需要相同:chmod 600 ./authorized_keys),可以使用 ssh 10.0.0.199测试是否免密登录,第一次需要输入yes记录公钥信息

下面在主服务器操作
6、下载hadoop到master服务
解压
tar -xvf hadoop-3.3.2.tar.gz
mv hadoop-3.3.2 ./hadoop
#把hadoop赋权给hadoop用户和hadoop用户组
chown -R hadoop:hadoop ./hadoop
#进入配置文件信息
cd ./hadoop/hadoop/etc/hadoop
vim mapred-env.sh
#新增公共的JDK路径,不同的路径使用ln -s 配置软链接
export JAVA_HOME=/opt/jdk1.8.0_101
vim yarn-env.sh
#新增公共的JDK路径,不同的路径使用ln -s 配置软链接
export JAVA_HOME=/opt/jdk1.8.0_101
vim hadoop-env.sh
#新增公共的JDK路径,不同的路径使用ln -s 配置软链接
export JAVA_HOME=/opt/jdk1.8.0_101
export JAVA_HOME=${JAVA_HOME}
vim core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hdp01:9000</value>
</property>
<!-- Java代码通过用户名密码连接Hive-->
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hdp01:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hadoop/dfs/data</value>
</property>
<property>
#副本数量,默认3个
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hdp01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
vim slaves
#从服务器域名或IP
hdp02
hdp03
hdp04
hdp05
7、复制hadoop到别的从服务器
rsync -av /opt/hadoop hap02:/opt
rsync -av /opt/hadoop hap03:/opt
rsync -av /opt/hadoop hap04:/opt
rsync -av /opt/hadoop hap05:/opt
所有的机器都需要执行
8、新增文件夹目录并赋权给hadoop用户(root账号操作)
cd /data
mkdir hadoop
cd hadoop
mkdir tmp
mkdir var
mkdir dfs
cd dfs
mkdir name
mkdir data
chown -R hadoop:hadoop /data/hadoop
9、配置hadoop的环境变量
vim /etc/profile
#hadoop安装路径
export HADOOP_HOME=/opt/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#刷新配置文件
source /etc/profile
#校验是否安装完成
hadoop version

10、复制hadoop环境变量到hadoop用户下,否则用户执行hadoop格式化失败
su hadoop
cd ~
vim .bashrc
export HADOOP_HOME=/opt/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
11、格式化Master
source ~/.bashrc
hadoop namenode -format
hadoop datanode -format
12、启动所有服务
su hadoop
cd /opt/hadoop/sbin
./start-all.sh

13、查看日志启动日志信息(如果报格式化失败就重新执行hadoop namenode -format/hadoop datanode -format)
tail -f -n 300 /opt/hadoop/logs/hadoop-hadoop-namenode-ubuntu-198.log

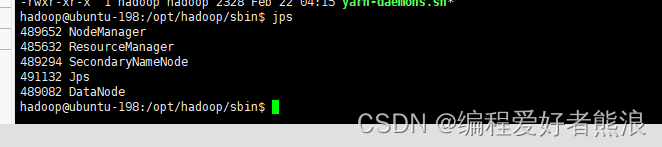
14、校验所有服务是否启动成功
jps
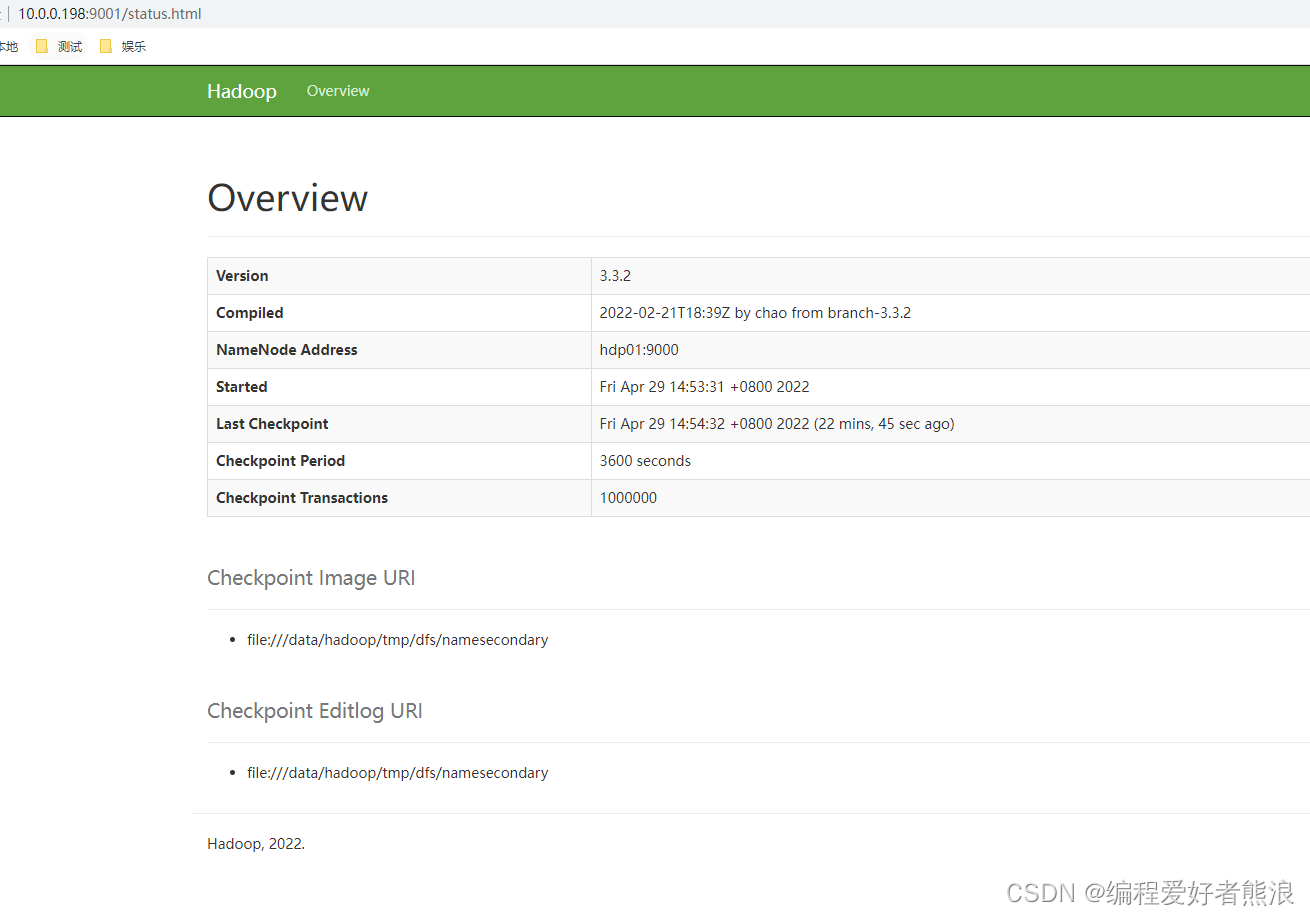
浏览器输入
http://10.0.0.198:9001/status.html
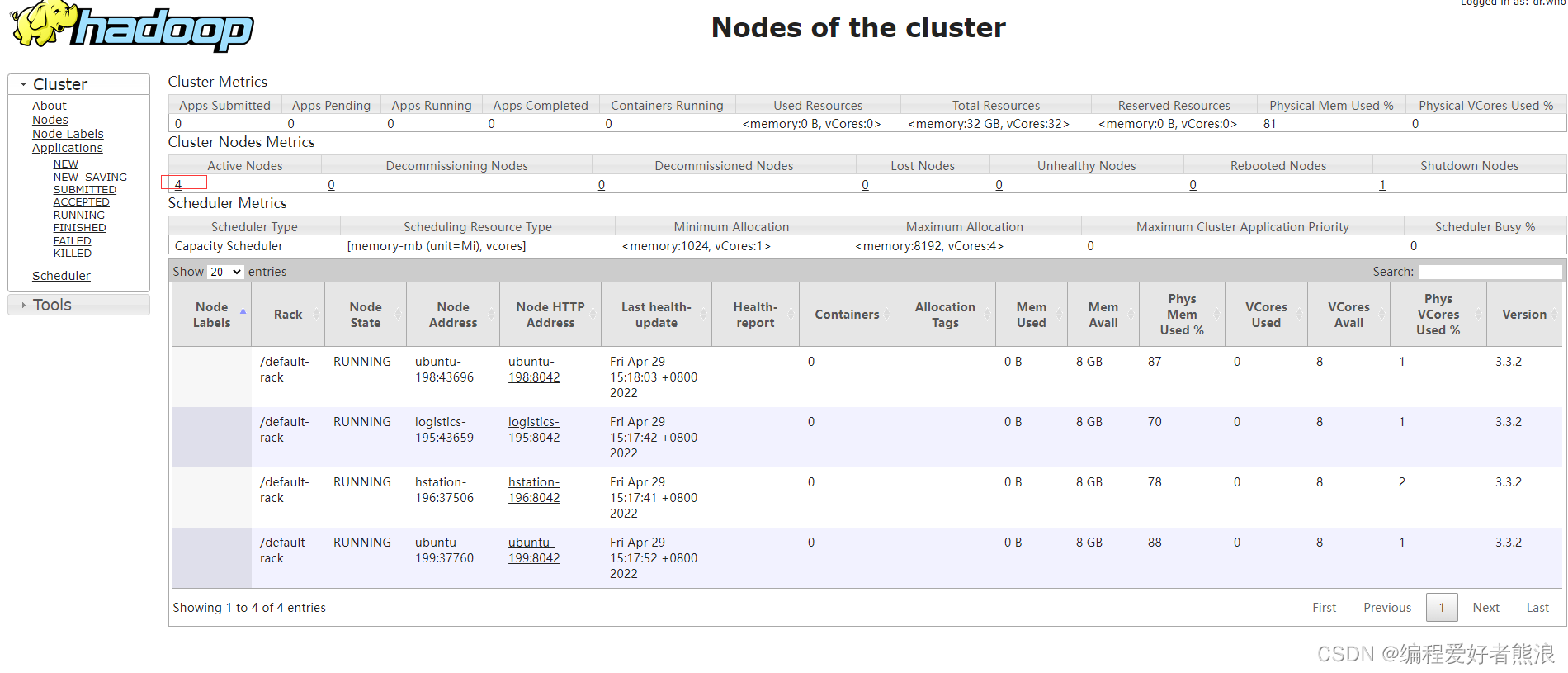
http://10.0.0.198:8088/cluster/nodes
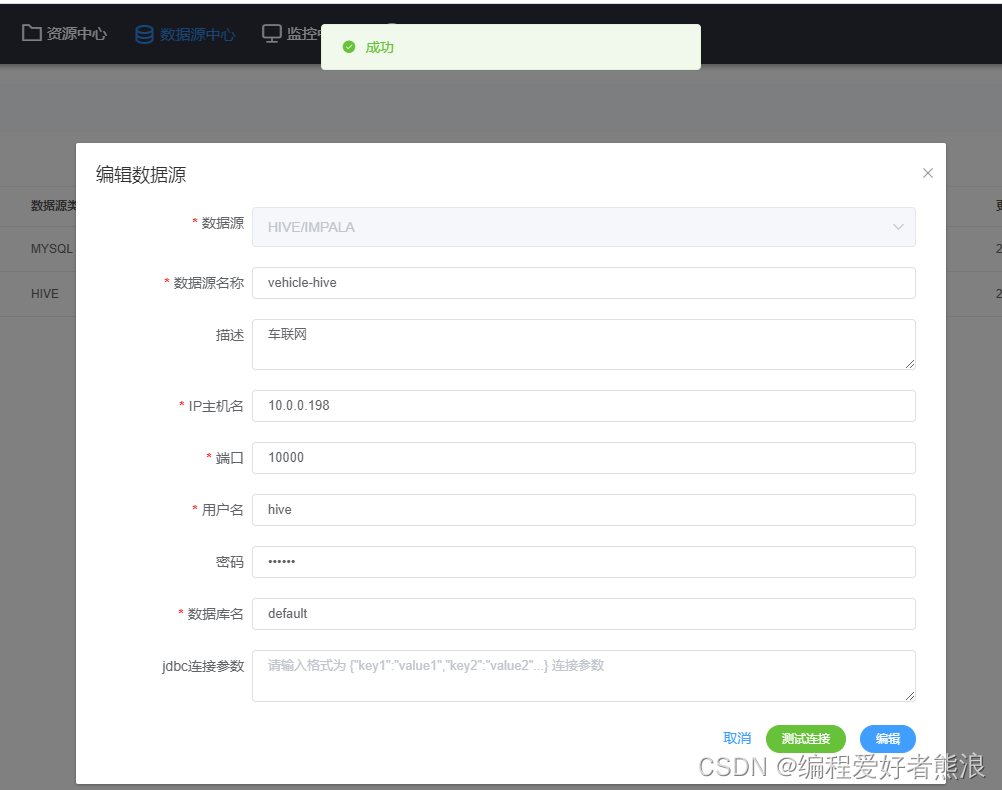
15、安装Hive
hive用户使用hadoop用户,权限相同,否则需要配置hive调用hadoop权限
下载Hive
注意Hadoop版本
下载路径,下载慢可以试下迅雷能不能下载快点
16、安装,配置环境变量
cd /opt
tar -xvf apache-hive-3.1.3-bin.tar.gz
mv apache-hive-3.1.3-bin/ ./hive
chmod -R hadoop:hadoop hive
su hadoop
cd ~
vim .bashrc
export HIVE_HOME=/opt/hive
export PATH=$PATH:$HIVE_HOME/bin
source .bashrc
cd conf
mv hive-env.sh.template ./hive-env.sh
mv hive-default.xml.template ./hive-site.xml
#hive.exec.local.scratchdir和hive.downloaded.resources.dir
#新建3个目录,是指本地目录(必须先手动建好)
#如果没有创建权限,可以先用root用户创建,之后通过 chmod -R hadoop:hadoop /data/hive赋权个hadoop
mkdir -p /data/hive/scratchdir
mkdir -p /data/hive/downloaded
mkdir -p /data/hive/logs
vim hive-env.sh
#JDK路径
export JAVA_HOME=/opt/jdk1.8.0_101
#HIVE路径
export HIVE_HOME=/opt/hive
#hadoop路径
export HADOOP_HOME=/opt/hadoop
export HIVE_CONF_DIR=$HIVE_HOME/conf
export HIVE_AUX_JARS_PATH=$HIVE_HOME/lib/*
vim hive-site.xml
#根据property的name属性找到对应的位置,修改对应的值信息
#/user/hive/scratchdir
hive.exec.local.scratchdir
#/user/hive/downloaded
hive.downloaded.resources.dir
#Mysql url jdbc:mysql://ip:3306/hive?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true
#&符号非法
javax.jdo.option.ConnectionURL
#mysql驱动,根据数据库版本下载对应的驱动,5.7和8是不同的
javax.jdo.option.ConnectionDriverName
#mysql用户名
javax.jdo.option.ConnectionUserName
#mysql密码
javax.jdo.option.ConnectionPassword
#删除3215行的非法字符
#默认为NONE,改为CUSTOM,需要用户名密码
hive.server2.authentication
#存储验证用户名密码方法,此处的用法根据实际需求,我这里在hive数据库新建一张db_user表,只有用户名密码
#SELECT user_name,pass_word FROM hive.db_user
hive.server2.custom.authentication.class

模板(别的配置可以不要,用默认的,也可以只修改下面几个配置的name)
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://数据库域名(在/etc/hosts里面添加映射):3306/hive?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>suyun</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>suyun123</value>
</property>
<property>
<name>datanucleus.readOnlyDatastore</name>
<value>false</value>
</property>
<property>
<name>datanucleus.fixedDatastore</name>
<value>false</value>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoCreateTables</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoCreateColumns</name>
<value>true</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/data/hive/scratchdir</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/data/hive/downloaded</value>
</property>
<!--自定义远程连接用户名和密码-->
<property>
<name>hive.server2.authentication</name>
<!--默认为none,修改成CUSTOM-->
<value>CUSTOM</value>
</property>
<!--指定解析jar包-->
<property>
<name>hive.server2.custom.authentication.class</name>
<value>com.suyun.hive.CustomPasswdAuthenticator</value>
</property>
<!-- hive server2的使用端口,默认就是10000-->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
<description>Port number of HiveServer2 Thrift interface.Can be overridden by setting $HIVE_SERVER2_THRIFT_PORT</description>
</property>
<!-- hive server2绑定的主机名-->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>数据库域名(在/etc/hosts里面添加映射)</value>
<description>Bind host on which to run the HiveServer2 Thrift interface.Can be overridden by setting $HIVE_SERVER2_THRIFT_BIND_HOST</description>
</property>
</configuration>
17、创建log4j信息
cp hive-log4j2.properties.template ./hive-log4j2.properties
vim hive-log4j2.properties
property.hive.log.dir = /data/hive/logs

18、下载Mysql8.0.16版本驱动
下载Mysql驱动包
mysql-connector-java
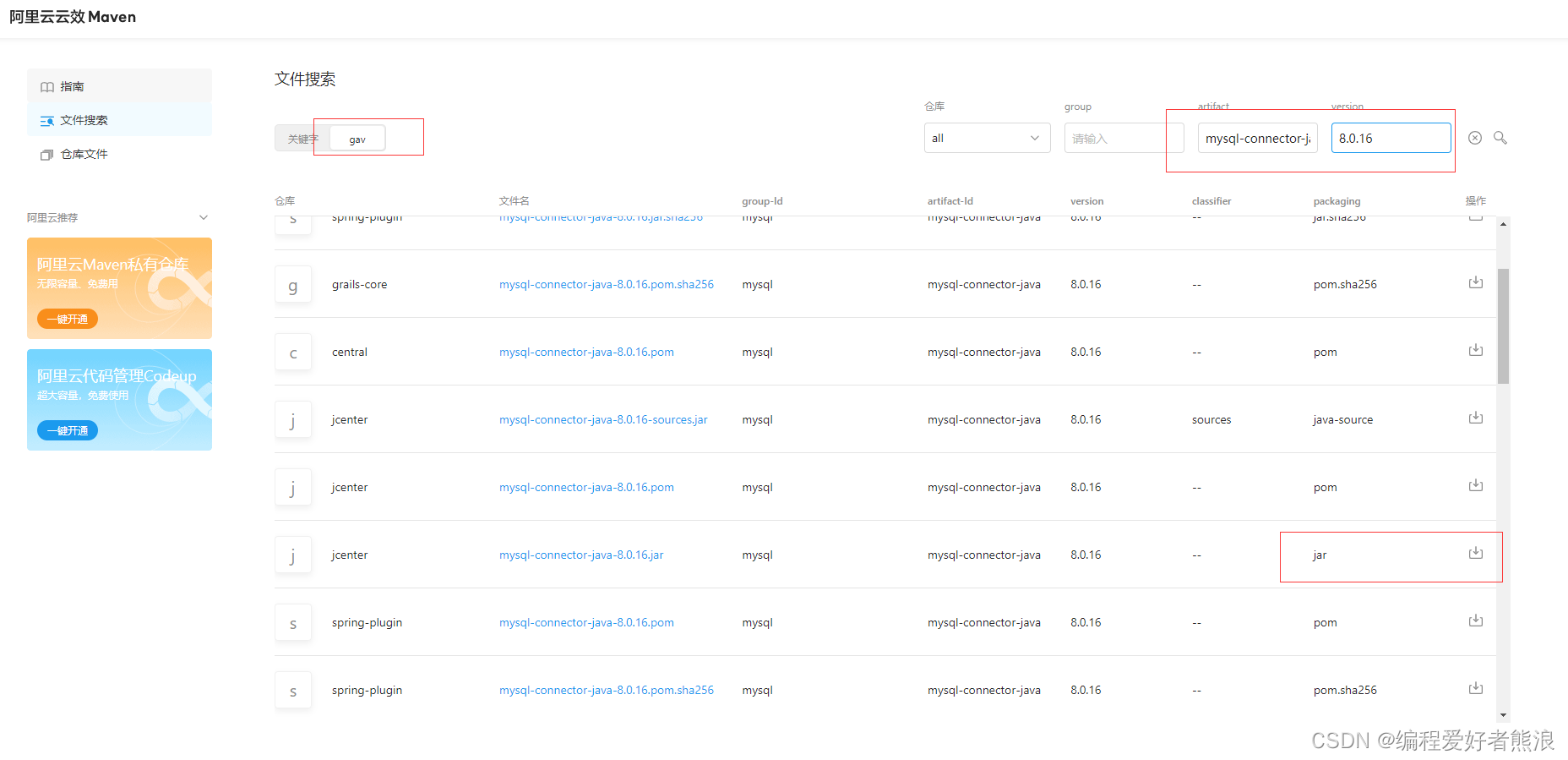
上传jar包到/opt/hive/lib下面

#初始化数据库
schematool -initSchema -dbType mysql -verbose

19、上传hive用户名密码jar
下载校验jar包
在hive数据库新增表db_user
-- ----------------------------
-- Table structure for db_user
-- ----------------------------
DROP TABLE IF EXISTS `db_user`;
CREATE TABLE `db_user` (
`user_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '登录用户名',
`pass_word` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '密码MD5加密',
PRIMARY KEY (`user_name`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of db_user 默认用户名:hive 密码:123456
-- ----------------------------
INSERT INTO `db_user` VALUES ('hive', 'e196a015eac49789e43b18c4ab565198');
上传jar包到/lib下面
20、启动hive(启动之前确定hadoop已经启动,没有启动,需要先启动hadoop)
nohup hive --service metastore &
nohup hive --service hiveserver2 &
#查看10000端口号是否启动成功
lsof -i:10000

JAVA代码测试获取连接
使用DolphinScheduler连接成功