在这一切开始之前,有几件重要的事情,一定要注意 attention
attention
attention
切记关闭防火墙,分区,而且Ubuntu和centos防火墙关闭方式不一样
systemctl stop firewalld #centos
systemctl disable firewalld
#ubuntu
sysemctl stop ufw
systemctl disable ufw
#关闭swap
vim /etc/fstab
将swapfile注释掉
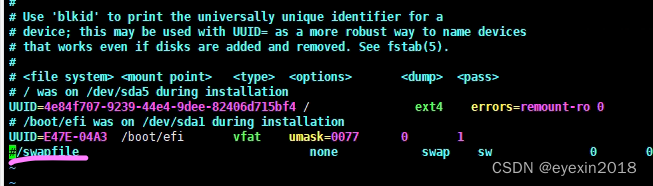
如果以上操作不做好,会付出巨大代价,遇到各种各样的问题,你意想不到。
docker
先安装docker
#step 1: 安装必要的一些系统工具
sudo apt-get update
sudo apt-get -y install apt-transport-https ca-certificates curl software-properties-common
#step 2: 安装GPG证书
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
#Step 3: 写入软件源信息
sudo add-apt-repository "deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
#Step 4: 更新并安装Docker-CE
sudo apt-get -y update
sudo apt-get -y install docker-ce
配置一下容器运行时
cat <<EOF | sudo tee /etc/modules-load.d/containerd.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
设置必需的 sysctl 参数,这些参数在重新启动后仍然存在。
cat <<EOF | sudo tee /etc/sysctl.d/99-kubernetes-cri.conf
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-ip6tables = 1
EOF
#应用 sysctl 参数而无需重新启动
sudo sysctl --system
配置 Docker 守护程序,尤其是使用 systemd 来管理容器的 cgroup。
cat <<EOF | sudo tee /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
重启docker
sudo systemctl enable docker
sudo systemctl daemon-reload
sudo systemctl restart docker
k8s
允许 iptables 检查桥接流量
确保 br_netfilter 模块被加载。这一操作可以通过运行 lsmod | grep br_netfilter 来完成。若要显式加载该模块,可执行 sudo modprobe br_netfilter。
为了让你的 Linux 节点上的 iptables 能够正确地查看桥接流量,你需要确保在你的 sysctl 配置中将 net.bridge.bridge-nf-call-iptables 设置为 1。例如:
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOF
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sudo sysctl --system
kubelet: k8s 的核心服务
kubeadm: 这个是用于快速安装 k8s 的一个集成工具,我们在master1和worker1上的 k8s 部署都将使用它来完成。
kubectl: k8s 的命令行工具,部署完成之后后续的操作都要用它来执行
使得 apt 支持 ssl 传输
apt-get update && apt-get install -y apt-transport-https
下载 gpg 密钥
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
添加 k8s 镜像源
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
更新
apt-get update
安装
apt-get install -y kubelet kubeadm kubectl
启动kubelet服务
systemctl start kubelet
systemctl enable kubelet
这个操作默认安装最新版本
Setting up kubectl (1.23.6-00) ...
Setting up kubernetes-cni (0.8.7-00) ...
Setting up kubelet (1.23.6-00) ...
Setting up kubeadm (1.23.6-00) ..
下载安装好了以后,就开始进行配置
先预检查系统是否符合要求,避免等会麻烦
通过kubeadm config images list命令查看所需要的镜像列表
k8s.gcr.io/kube-apiserver:v1.23.6
k8s.gcr.io/kube-controller-manager:v1.23.6
k8s.gcr.io/kube-scheduler:v1.23.6
k8s.gcr.io/kube-proxy:v1.23.6
k8s.gcr.io/pause:3.6
k8s.gcr.io/etcd:3.5.1-0
k8s.gcr.io/coredns/coredns:v1.8.6
先把所需镜像拉下来,其实如果在国外这个东西安装部署真的没那么复杂,只不过是我们无法访问谷歌造成了巨大的阻碍,因此先借助阿里巴巴镜像源将镜像拉下来
kubeadm config images pull --image-repository=registry.aliyuncs.com/google_containers
如果有cgroup不同所导致的问题,那就将两者修改一致,其实在上面的操作中已经完成了,因为k8s在其21版本后就默认采用systemd,而docker的cgroup只需在daemon守护进程中修改即可。
安装启动
解释一下,那个IP是pod所用的IP段,一定要记得添加镜像源的指定,否则无论如何都不成功的,这里我们用Calico,所以无需再加apiserver的参数。
kubeadm init --pod-network-cidr=192.168.0.0/16 --image-repository=registry.aliyuncs.com/google_containers
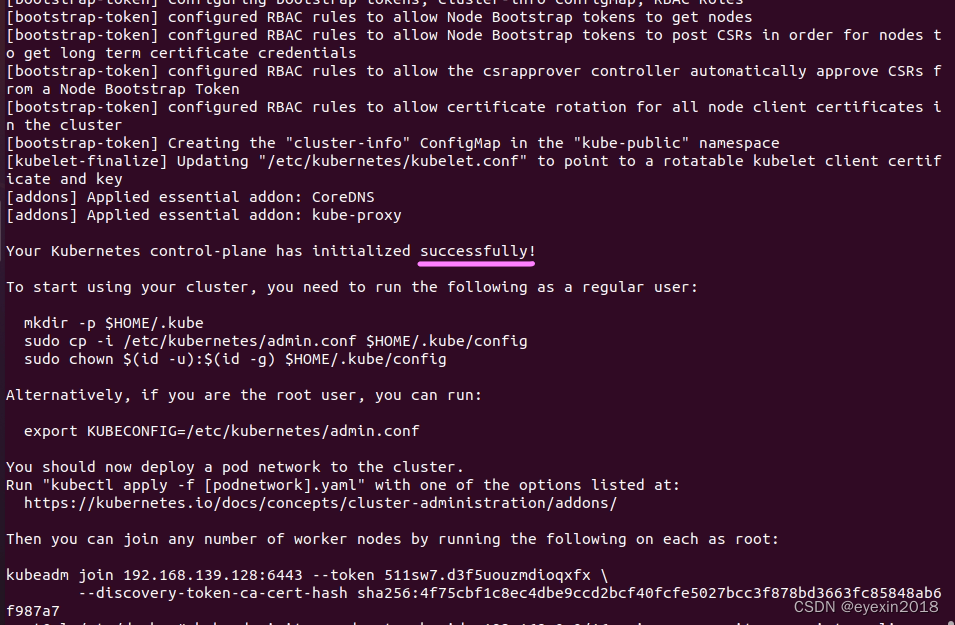
这就表示已经成功啦!以下是过程参数,
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local zl] and IPs [10.96.0.1 192.168.139.128]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost zl] and IPs [192.168.139.128 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost zl] and IPs [192.168.139.128 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 6.508068 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.23" in namespace kube-system with the configuration for the kubelets in the cluster
NOTE: The "kubelet-config-1.23" naming of the kubelet ConfigMap is deprecated. Once the UnversionedKubeletConfigMap feature gate graduates to Beta the default name will become just "kubelet-config". Kubeadm upgrade will handle this transition transparently.
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node zl as control-plane by adding the labels: [node-role.kubernetes.io/master(deprecated) node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node zl as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: 511sw7.d3f5uouzmdioqxfx
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.139.128:6443 --token 511sw7.d3f5uouzmdioqxfx \
--discovery-token-ca-cert-hash sha256:4f75cbf1c8ec4dbe9ccd2bcf40fcfe5027bcc3f878bd3663fc85848ab6f987a7
执行
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
安装calico
kubectl create -f https://projectcalico.docs.tigera.io/manifests/tigera-operator.yaml
这里会遇到一个问题,那就是该镜像被墙了,国内源又没有,所以只能想办法把它下载下来,再执行导入docker load …
docker load < apiserver.tar
root@zl:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
zl Ready control-plane,master 3d14h v1.23.6
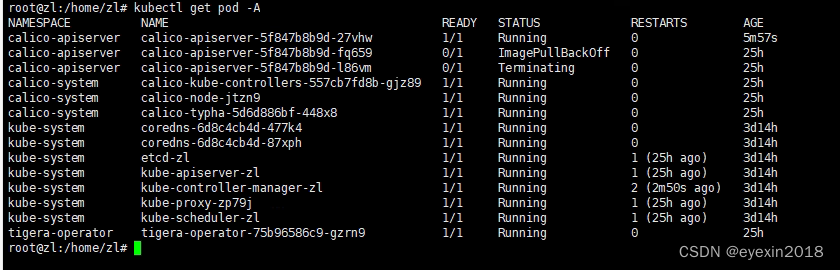
可以看见都运行正常了,那两个有问题的是因为墙的原因没成功留下的不影响。

