Linux_������ظ���
��ŵ������ϵ
�������ڳ����ļ����,��ʼDZ�,���Dz�������,�������,���Ƕ���ѭ�ŷ�ŵ������ϵ
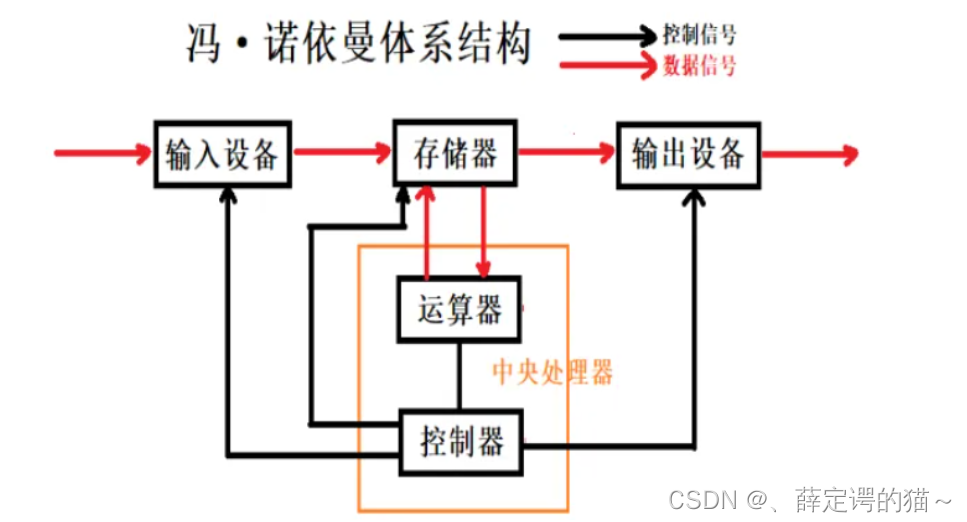
������ĿǰΪֹ,��������ʶ�������м����,������һ����Ӳ�����
- ���뵥Ԫ:��������,���,ɨ����,�ȵ�.
- ���봦����(cpu):�����������Ϳ�������
- �����Ԫ:��ʾ��,��ӡ����
���ڷ�ŵ��������Ҫע�
-
����Ĵ洢��ָ���ڴ�
-
�����ǻ���������,�����cpuֻ�ܶ��ڴ���ж�д,���ܷ�������
-
����Ҫ�����������,Ҳֻ��д���ڴ����ڴ��ж�ȡ
-
�ܶ���֮,���е��豸��ֻ�ܺ��ڴ�ֱ�Ӵ�
����ϵͳ
����
�κμ����ϵͳ������һ�������ij���,��Ϊ����ϵͳ(OS),��ͳ������,����ϵͳ����:
- �ں�(��������,�ڴ����,�ļ�����,��������)
- ��������(���纯����,shell����ȵ�)
��Ʋ���ϵͳ��Ŀ��
�������Ǵ����������������˽���Ʋ���ϵͳ��Ŀ��
1.����ϵͳ��ʲô
���������������ǵ�֪,OS����һ�������Ӳ����Դ������������������
2.ΪʲôҪ�в���ϵͳ
����ϵͳ����:��������Ӳ����Դ.����:������ͨ�û���˵,��Ϊ�û��ṩ�����õ����л���,�����ڳ���Ա��˵,Ϊ���ṩ�˸��ֻ�������
3.����ϵͳ��ι���
�ٸ�����:����ѧУ��У��Ҫͳ��ѧУ������,У������ֱ��ȥ����ȥ��ѧ��������,���ǻ��ټ���������Ա�ø���Աͳ�Ƹ����ѧ�������ܽ���У��
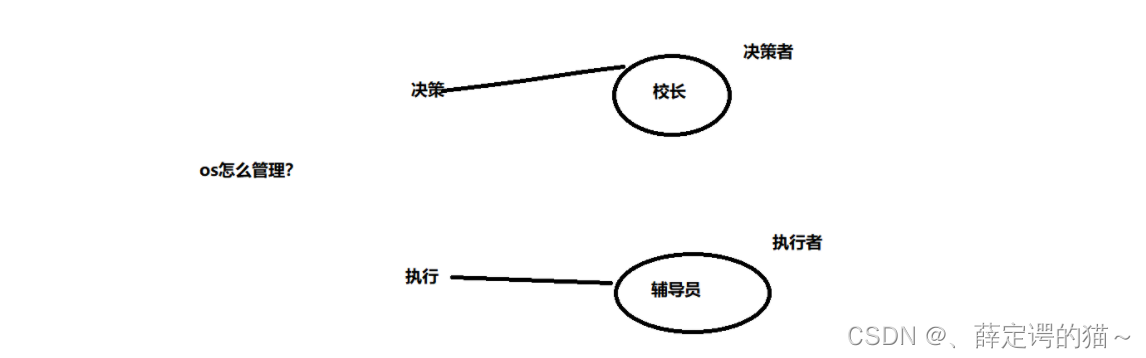
1.�����ߺͱ������߲�����ֱ�Ӵ�
2.��ι�������? �����������־���,������Ҫ�����ݵ�(�������)
3.�������뱻�����߲�����,��ôУ�������֪�����? ->����Ա
? �������뱻�����߲������C���ߵ�ִ����->����Ա
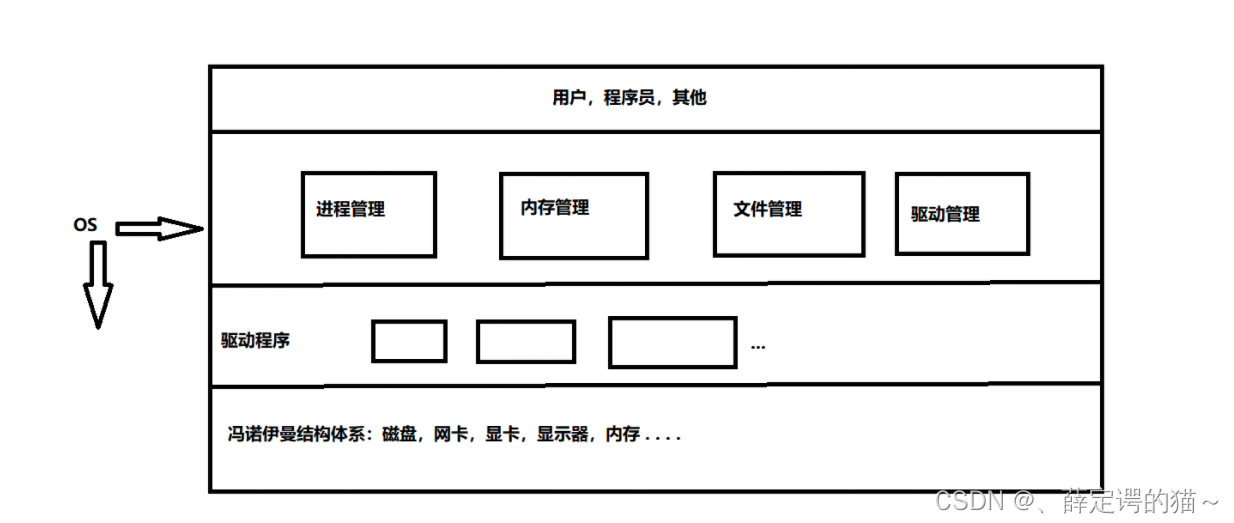
ϵͳ���úͿ⺯���ĸ���
- �ڿ����Ƕ�,����ϵͳ��������Ϊһ������,���ǻᱩ¶�Լ��IJ��ֽӿ�,���ϲ㿪��ʹ��,�ⲿ���ɲ���ϵͳ�Ľӿ�,����ϵͳ����
- ϵͳ������ʹ����,���ܱȽϻ���,���û���Ҫ��Ҳ�Ƚϸ�,����,���ĵĿ����߿��ԶԲ���ϵͳ���ý����ʵ��ķ�װ,�Ӷ��γ��˿�,���˿�,�ͺ������ڸ��ϲ���û�,���߿����߽��ж��ο���
����(�ص�)
��������
- �α�����:�����һ��ִ��ʵ��,����ִ�еij����
- �ں˹۵�:��������ϵͳ��Դ(cpuʱ��,�ڴ�)��ʵ��
���������Ĺ۵��������κβ���ϵͳ�Ľ�������,��Ҳ�Ƚ�Ƭ��.
��������һ������,����ϵͳ�пɲ����ܴ��ڴ����Ľ���? �ǿ��Ե�,��ô���̶����ɲ���ϵͳ��������? ��Ȼ,�DZ����
��ô����ϵͳ����ι������̵���? ������,����֯
����ϵͳ�������������?
�κν������γɵ�ʱ��,����ϵͳ��ҪΪ�䴴��PCB(���̿��ƿ�),OS����PCB����һ���ṹ��->struct PCB{//���̵���������!}
����Linux��,PCB->task_struct{//���̵���������!}
task_struct->PCB��һ��
- ��Linux���������̵Ľṹ�����task_struct��
- task_struct��Linux�ں˵�һ�����ݽṹ,���ᱻװ�ص�RAM(�ڴ�)�ﲢ�Ұ����Ž��̵���Ϣ��
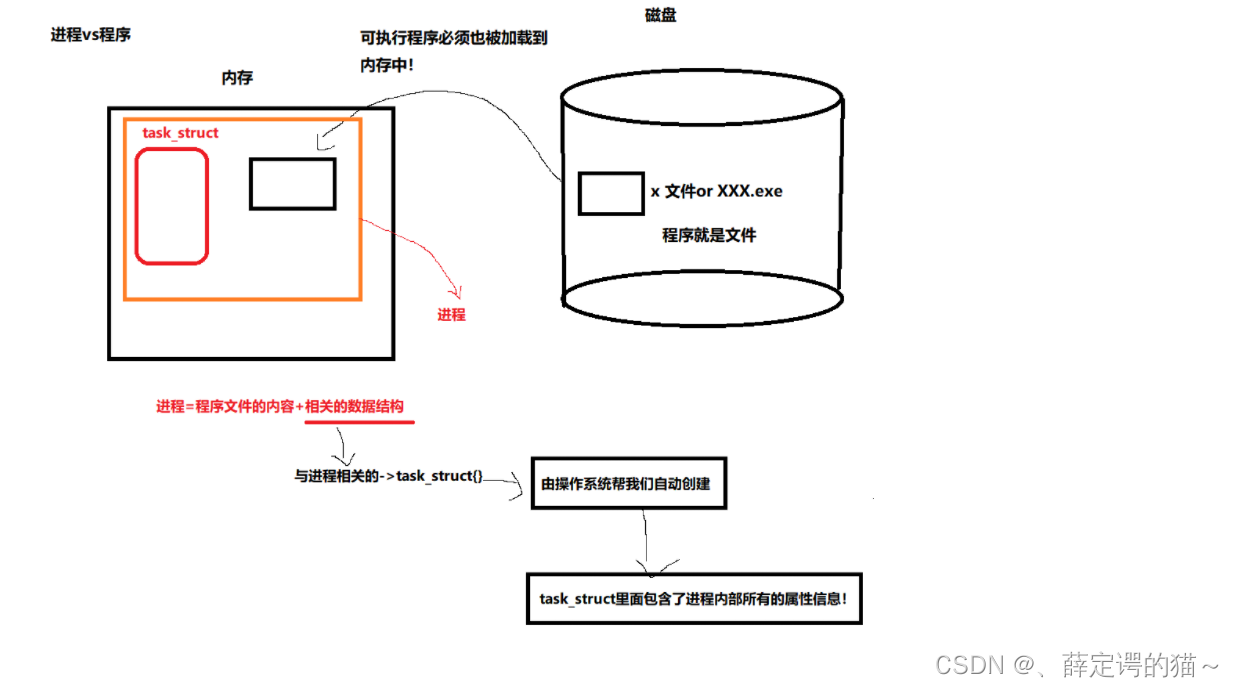
���� VS ����
�����������������г���,���ʶ�����ϵͳ���洴������
���˽��̿��ƿ�,���еĽ��̹�������,����̶�Ӧ�ij������ϵ!!!����̶�Ӧ���ں˴����ĸý��̵�PCBǿ���!
task_ struct���ݷ���
- ��ʾ��: ���������̵�Ψһ��ʾ��,����������������.
- ״̬: ����״̬,�˳�����,�˳��źŵȡ�
- ���ȼ�: ������������̵����ȼ���
- ���������: �����м�����ִ�е���һ��ָ��ĵ�ַ.
- �ڴ�ָ��: �����������ͽ���������ݵ�ָ��,���к��������̹������ڴ���ָ��.
- ����������: ����ִ��ʱ�������ļĴ����е�����.
- I/O״̬��Ϣ: ������ʾ��I/O����,��������̵�I/O�豸�ͱ�����ʹ�õ��ļ��б�.
- ������Ϣ: ���ܰ���������ʱ���ܺ�,ʹ�õ�ʱ�����ܺ�,ʱ������,���˺ŵ�.
- ������Ϣ
�鿴����
1.��Linux�����������鿴���̿���ͨ��/procϵͳ�ļ��鿴
������:������ȡPIDΪ1�Ľ�����Ϣ,��ֱ�Ӳ鿴/proc/1����ļ���

2. ������ͨ��ps�����û�����������ȡ
#include<iostream>
#include<unistd.h>
using namespace std;
int main()
{
while(1)
{
sleep(1);
}
return 0;
}
���ǽ���δ�����Linux������������,Ȼ����ps����ȡ��ν��̵���Ϣ
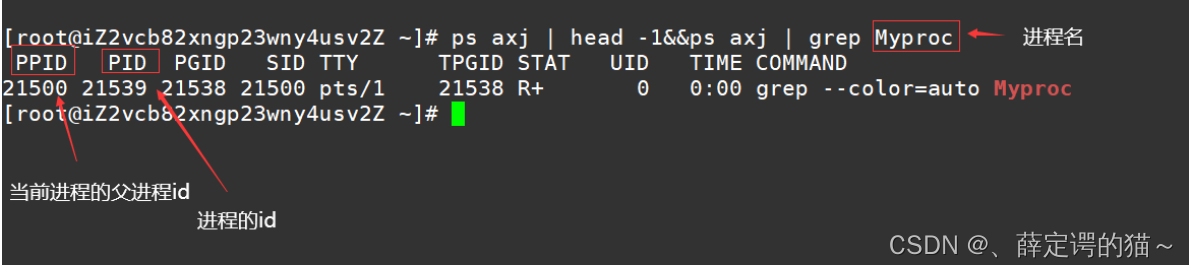
ͨ��ϵͳ���û�ȡ���̱�ʾ��
ͨ����ͼ���ǿ�֪:
-
����id(PID)
-
������(PPID)
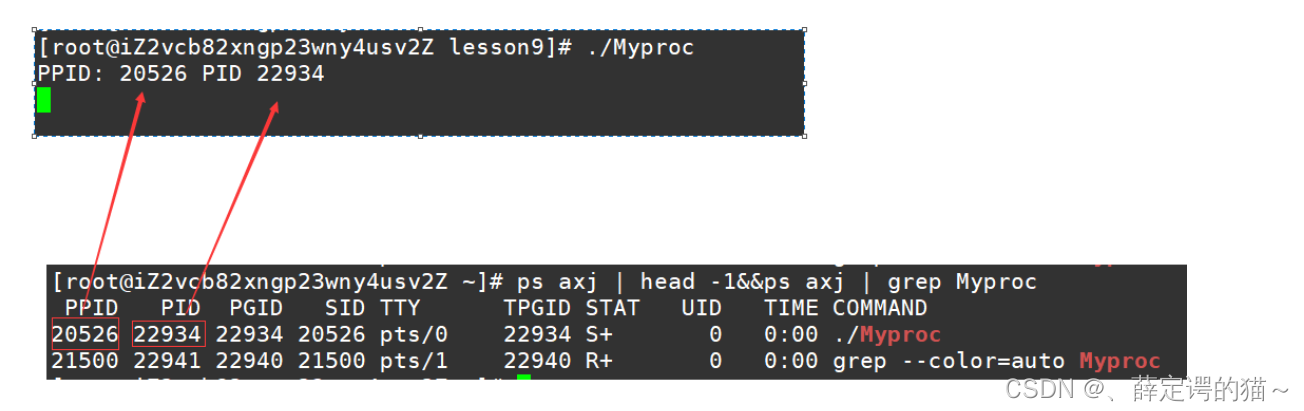
����ϵͳ�����ǿ⺯������ȥ��ȡ��ǰ���̵�PID��PPID
#include<iostream> #include<unistd.h> using namespace std; int main() { cout<<"PID: "<<getpid()<<endl; cout<<"PPID "<<getppid()<<endl; while(1) { sleep(1);//Ϊ���ó���һֱ����,���ڹ۲������Ϣ } return 0; }
ͨ��ϵͳ���ô�������-fork��ʶ
dz̸fork����
������һ�δ������˽�һ��fork
1 #include<iostream>
2 #include<unistd.h>
3 using namespace std;
4 int main()
5 {
6 fork();
7 cout<<"hello proc "<<getpid()<<"hello parent"<<getppid()<<endl;
8 sleep(1);
9 return 0;
10 }

���к����Ƿ���,����ִ��������ֻ��һ��,����ʾ����ȴ��ӡ������,��������ԭ��?
��ʵfork�Ǵ�����һ���ӽ���,�䷵��ֵ������,��һ�����ǵ���fork����֮��ͨ������if����
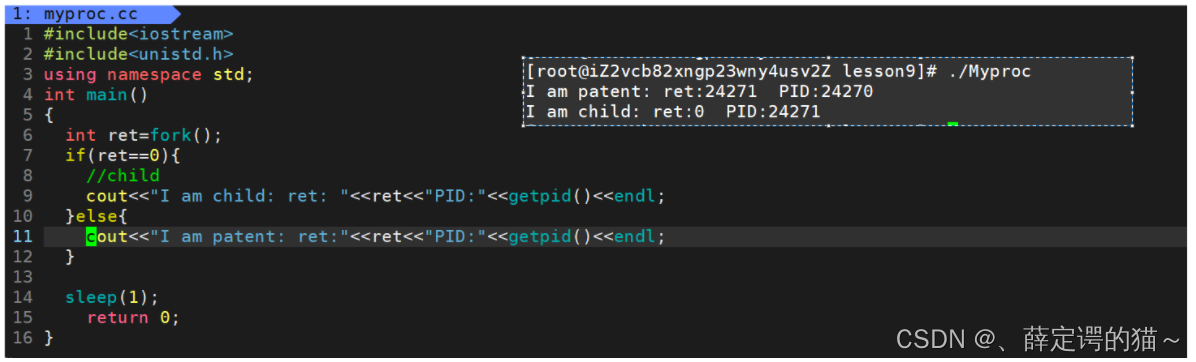
ͨ��������������֪��,fork��������������ֵ,����ֵΪ0ʱ˵�����ӽ���,������ֵ����0�Ǹ�����
�������fork�����ӽ���?
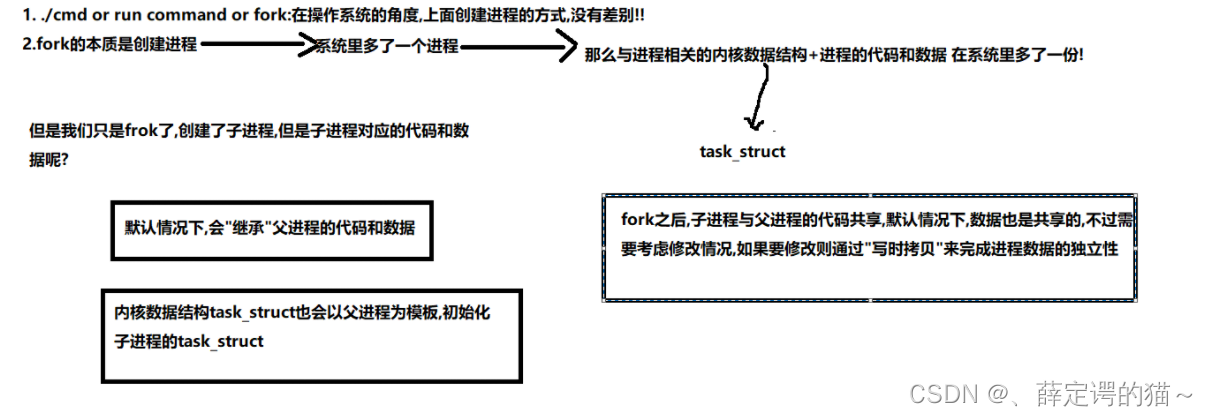
���Ǵ����ӽ���,����Ϊ�˺����̸�һ������?
����Ǹ�һ������,��ô��û�������,���������Ľ���,һ�㻹��Ҫͨ��if-else�������ø��ӽ�������ɲ�ͬ�Ĺ���
fork֮��,���ӽ���˭������?
��һ��!,����Ҫȡ���ڵ�����,�ȵ���˭,��ʱ��������ִ��,��ʱ,�ӽ�����ִ��
���̵�״̬
�ȿ���Linux�ں�Դ����ô˵
-
Ϊ��Ū�����������еĽ�����ʲô��˼,������Ҫ֪�����̵IJ�ͬ״̬��һ�����̿����м���״̬(��Linux�ں���,������ʱ��Ҳ��������)
-
�����״̬��KernelԴ��Ķ���:
/* * The task state array is a strange "bitmap" of * reasons to sleep. Thus "running" is zero, and * you can test for combinations of others with * simple bit tests. */ static const char * const task_state_array[] = { "R (running)", /* 0 */ "S (sleeping)", /* 1 */ "D (disk sleep)", /* 2 */ "T (stopped)", /* 4 */ "t (tracing stop)", /* 8 */ "X (dead)", /* 16 */ "Z (zombie)", /* 32 */ };
���̵�״̬��Ϣ��������? ��������������task_struct(PCB)����
����״̬������:����OS�����жϽ���,����ض��Ĺ���,�������,��������һ�ַ���!
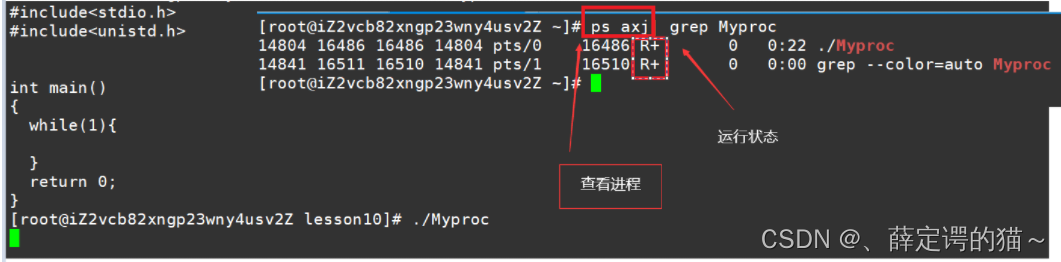
R״̬
R״̬��������״̬,����������Ҫע�����,����״̬����һ��ռ����CPU,Ҳǧ��Ҫ��Ϊ,����ֻ��ȴ�CPU��Դ!!!
��ν�Ľ���,�����е�ʱ��,�п��ܻ���Ϊ������Ҫ,�����ڲ�ͬ�Ķ�����,�ڲ�ͬ�Ķ�����������״̬ʱ��һ����
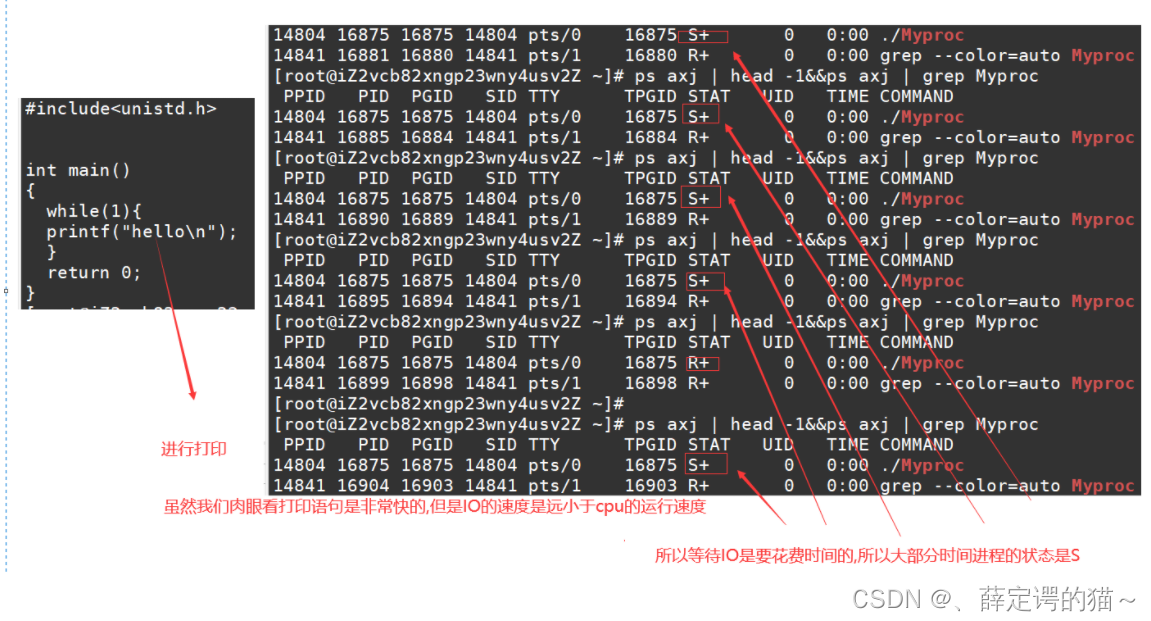
S/D״̬
S/D״̬�����Գ�֮Ϊ˯��״̬,ֻ�Ǵ���D״̬�Ľ����Dz��ɱ��жϵ�,��D״̬�н���һ���ȴ�IO�Ľ���
x״̬
X״̬��������״̬,���״ֻ̬��һ������״̬,�������������б�������״̬
ps:�������������ϵͳ����ս�����Դ,���ս�����Դ=������ص����ݽṹ+���������
�鿴����״̬
Z(zombie)-��ʬ����
- ��ʬ������һ���Ƚ������״̬.�������˳��Ҹ�����û�ж�ȡ���ӽ����˳��ķ��ش���ʱ,�ͻ������ʬ����
- ��ʬ���̻�ʼ�ձ����ڽ��̱���,���һ�һֱ�ȴ������̶�ȡ�˳��Ľ�����
- ����,ֻҪ�ӽ����˳�,�����̻�������,��������û�ж�ȡ���ӽ��̵�״̬,�ӽ��̻���뽩ʬ״̬
�ٸ�����:
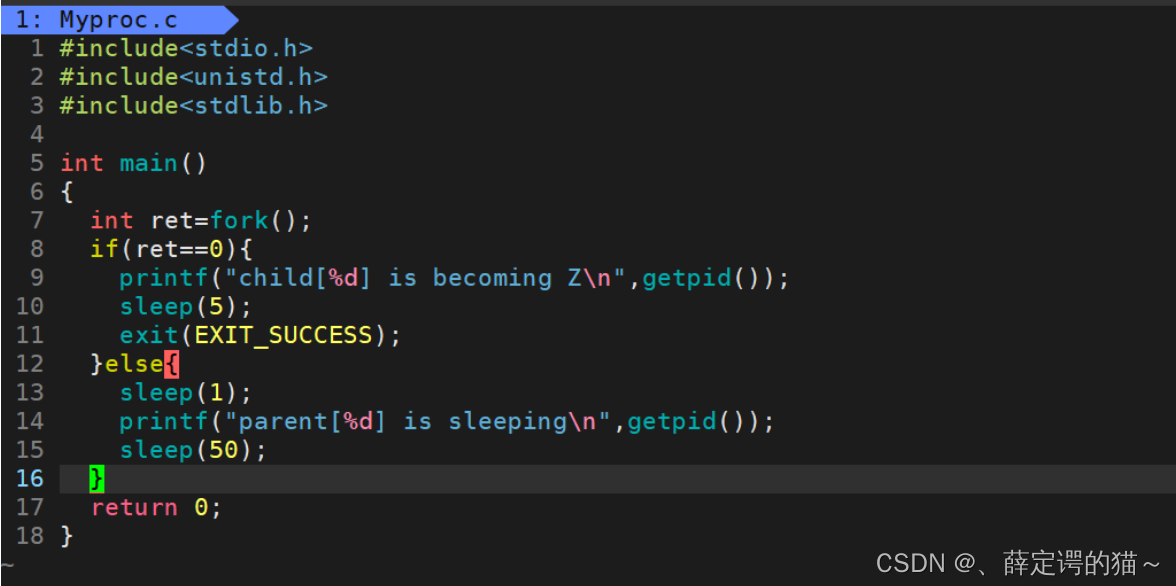
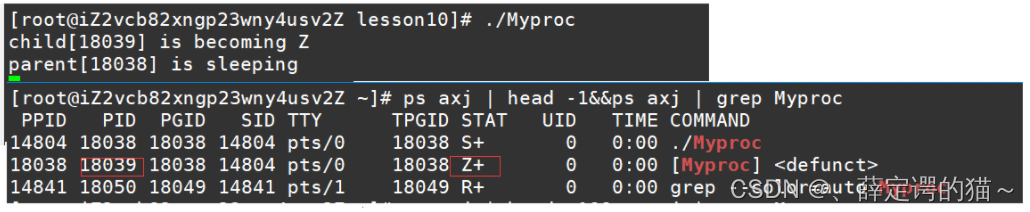
��ʬ���̵�Σ��
-
���̵��˳�״̬���뱻ά����ȥ,��Ϊ��Ҫ���߹������Ľ���(������),�㽻���ҵ�����,�Ұ����ô���ˡ��ɸ��������һֱ����ȡ,���ӽ��̾�һֱ����Z״̬?�ǵ�!
-
ά���˳�״̬��������Ҫ������ά��,Ҳ���ڽ��̻�����Ϣ,���Ա�����task_struct(PCB)��,���仰˵,Z״̬һֱ���˳�,PCBһֱ��Ҫά��?�ǵ�!
-
��һ�������̴����˺ܶ��ӽ���,���Dz�����,�Dz��Ǿͻ�����ڴ���Դ���˷�?�ǵ�!��Ϊ���ݽṹ��������Ҫռ���ڴ�,����C�ж���һ���ṹ�����(����),��Ҫ���ڴ��ij��λ�ý��п��ٿռ�
�¶�����
- ���������˳�,�ӽ��̾ͳ�֮Ϊ���¶�����
- �¶����̱�1��init��������,��ȻҪ��init���̻���ඡ�
�������ȼ�
��������
-
cpu��Դ������Ⱥ�˳��,����ָ���̵�����Ȩ(priority)
-
����Ȩ�ߵĽ���������ִ��Ȩ�������ý�������Ȩ�Զ�������linux������,���Ը���ϵͳ���ܡ�
-
�����ѽ������е�ָ����CPU��,����һ��,�Ѳ���Ҫ�Ľ��̰��ŵ�ij��CPU,���Դ�����ϵͳ��������
Ϊʲô�������ȼ�? ��Դ̫����! �����Ƿ�����Դ��һ�ַ�ʽ!
�鿴���ȼ�
��Linux/Unix�в鿴���ȼ�һ����ps -l�������������¼�������:

���Ǻ�����ע����м�����Ҫ��Ϣ,����:
- UID:����ִ��������
- PID:����������̵Ĵ���
- PPID:����������������ĸ����̷�չ����������,�༴�����̵Ĵ���
- PRI:����������̿ɱ�ִ�е����ȼ�,��ֵԽСԽ�类ִ��
- NI:����������̵�niceֵ
PRI and NI
- PRIҲ���DZȽϺ������,�����̵����ȼ�,����ͨ��˵���dz���CPUִ�е��Ⱥ�˳��,��ֵԽС���̵����ȼ���Խ��
- ��NI��?����������Ҫ˵��niceֵ��,���ʾ���̿ɱ�ִ�е����ȼ���������ֵ
- PRIֵԽСԽ�챻ִ��,��ô����niceֵ��,����ʹ��PRI��Ϊ:PRI(new)=PRI(old)+nice
- ����,��niceֵΪ��ֵ��ʱ��,��ô�ó������ȼ�ֵ����С,�������ȼ�����,����Խ�챻ִ��
- ����,�����������ȼ�,��Linux��,���ǵ�������niceֵ
- nice��ȡֵ��Χ��-20��19,һ��40������
PRI VS NI
-
��Ҫǿ��һ�����,���̵�niceֵ���ǽ��̵����ȼ�,���Dz���һ������,���ǽ���niceֵ��Ӱ�쵽���̵����ȼ��仯
-
��������niceֵ�ǽ������ȼ���������������
����:niceֵΪʲô��һ����Խ�С�ķ�Χ��?
���ȼ�����ô����,Ҳֻ����һ����Ե����ȼ�,���ܳ��־��Ե����ȼ�,����ͻ���ֺ����صĽ��̡��������⡱
���Ҵӵ������ĽǶȳ���,������Ҫ��Ϊ�������ÿ���������ܵ�CPU��Դ
=PRI(old)+nice**
- ����,��niceֵΪ��ֵ��ʱ��,��ô�ó������ȼ�ֵ����С,�������ȼ�����,����Խ�챻ִ��
- ����,�����������ȼ�,��Linux��,���ǵ�������niceֵ
- nice��ȡֵ��Χ��-20��19,һ��40������
PRI VS NI
-
��Ҫǿ��һ�����,���̵�niceֵ���ǽ��̵����ȼ�,���Dz���һ������,���ǽ���niceֵ��Ӱ�쵽���̵����ȼ��仯
-
��������niceֵ�ǽ������ȼ���������������
����:niceֵΪʲô��һ����Խ�С�ķ�Χ��?
���ȼ�����ô����,Ҳֻ����һ����Ե����ȼ�,���ܳ��־��Ե����ȼ�,����ͻ���ֺ����صĽ��̡��������⡱
���Ҵӵ������ĽǶȳ���,������Ҫ��Ϊ�������ÿ���������ܵ�CPU��Դ

