����Ŀ¼
һ���ع�C��C++���ļ�����
������
- C������������,��Ĭ�ϴ��������������
stdin->����
stdout->��ʾ��
stderr->��ʾ�� - ������������FILE* ���͵�,fopen����ֵ,�ļ�ָ������
����ʾ�������ӡ
#include<stdio.h>
int main()
{
const char * msg="you can see me!\n";
fputs(msg,stdout);
return 0;
}
�����ʾ:
C++�л��ṩ4����:cin cout cerr clog
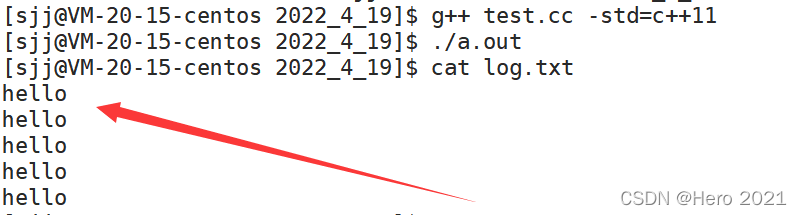
C++���ļ�����:
#include<iostream>
#include<fstream>
#include<string>
using namespace std;
int main()
{
//���ļ�
ofstream out ("./log.txt",ios::out | ios::binary);
if(!out.is_open())
{
cerr<<"open err"<<endl;
return 1;
}
int cnt=5;
while(cnt--)
{
string msg="hello\n";
out.write(msg.c_str(),msg.size());//�5��hello
}
//�ر��ļ�
out.close();
return 0;
}
���չʾ:
fputs������һ����ļ�����Ӳ���豸����д��!�ļ���Ӳ�̵ȶ���Ӳ��!�������ǿ��Եó�:һ�н��ļ�!
?��֮:���յ��ļ��������Ƿ���Ӳ��������ʾ�������̡�����
����ǰ��ѧϰ����֪��,����ϵͳ��Ӳ���Ĺ�����,���������϶��ڡ��ļ����IJ���,������ᴩ��������ϵͳ!!!���Ƿ��ʲ���ϵͳ����Ҫϵͳ���ýӿڵ�!
�������е�����(����װ��):fopen,fclose,fread,fputs�ȵײ�һ��Ҫʹ��OS�ṩ��ϵͳ����!
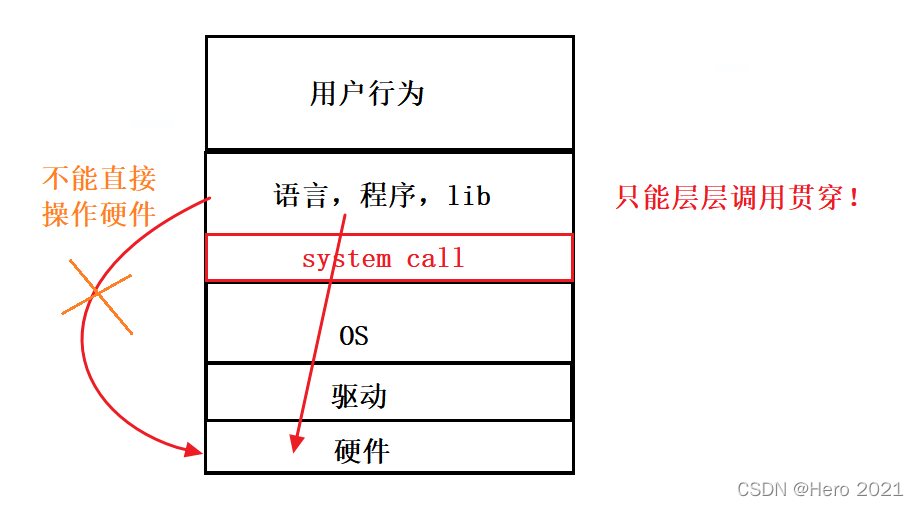
����ϵͳ�ļ�IO
open����
open�ӿڽ���
| �������� | open |
|---|---|
| �������� | ���ߴ����ļ� |
| ͷ�ļ� | #include<sys/types.h> #include<sys/stat.h> #include<fcntl.h> |
| ����ԭ�� | int open(const char *pathname, int flags); int open(const char *pathname, int flags, mode_t mode); |
| ���� | ������ |
| ����ֵ | ���ڵ���0������:�ɹ�(���ļ�������) -1:ʧ�� |
����˵��:
- pathname:Ҫ����Ҫ�����ĺ���·�����ļ���
- flags:�ļ�״̬��־,��ʾ���ļ��ķ�ʽ
1??����־:
?O_ RDONLY:��ֻ����ʽ���ļ�
?O_ WRONLY:��ֻд��ʽ���ļ�
?O_ RDWR:�Կɶ���д��ʽ���ļ�
��������������ָ��һ��,����ֻ����һ��
����־�ǻ����,ʹ������һ��������ʹ������һ�֡���������־����,���и���־�����������ʹ��,����־��ͬʱʹ�ö��,ʹ��ʱ������־����־֮����밴λ��(|)�������
2??����־:
?O_CREATE:���ļ�������,��������Ҫʹ��modeѡ��,��ָ�����ļ���Ȩ��
?O_APPEND:��д - mode:����ļ�������,ָ����Ȩ��(8����)
������:ϵͳ���õĵڶ�������flags
?���ķ���ֵ��int���͵�,�������һ���״���,����ʱ�����ǰ������������������,�����������,һ��ֻ�ܴ���1����־,����������־,����������ͨ��λ���������������,һ��flag��32������λ,һ������λ����һ����־,��ô������һ��flags���Դ���32�ֲ�ͬ�ı�־,ʵ���ϴ���flags��ÿһ��ѡ����ϵͳ���ж����Ժ�ķ�ʽ���ж����:
//����:
#define O_WRONLY 0x1
#define O_RDONLY 0x2
#define O_CREAT 0x4
��Щ�궼��ֻ��һ������λ��1������,���Ҳ��ظ�,��Ϊ1�ı���λ�Ǹ�����ͬ��
//ת��Ϊ��Ӧ�Ķ�����
#define O_WRONLY 0000 0001
#define O_RDONLY 0000 0010
#define O_CREAT 0000 0100
���ǾͿ�����ͨ�����������ñ�־λ:
//����
O_WRONLY | O_CREAT
�������������֮��͵ȼ��ڡ�w��,��ֻ���ķ�ʽ��
��������open�����ڲ��Ϳ���ͨ�����롱���������flag�Ƿ�������ijһѡ��:
int open()
{
//�������ж�:�Ƿ������˱�־λ
if(O_WRONLY&flag)
{
//������O_WRONLYѡ��
return ;
}
if(O_RDONLY&flag)
{
//������O_RDONLYѡ��
return ;
}
if(O_CREAT&flag)
{
//������O_CREATѡ��
return ;
}
}
//.......
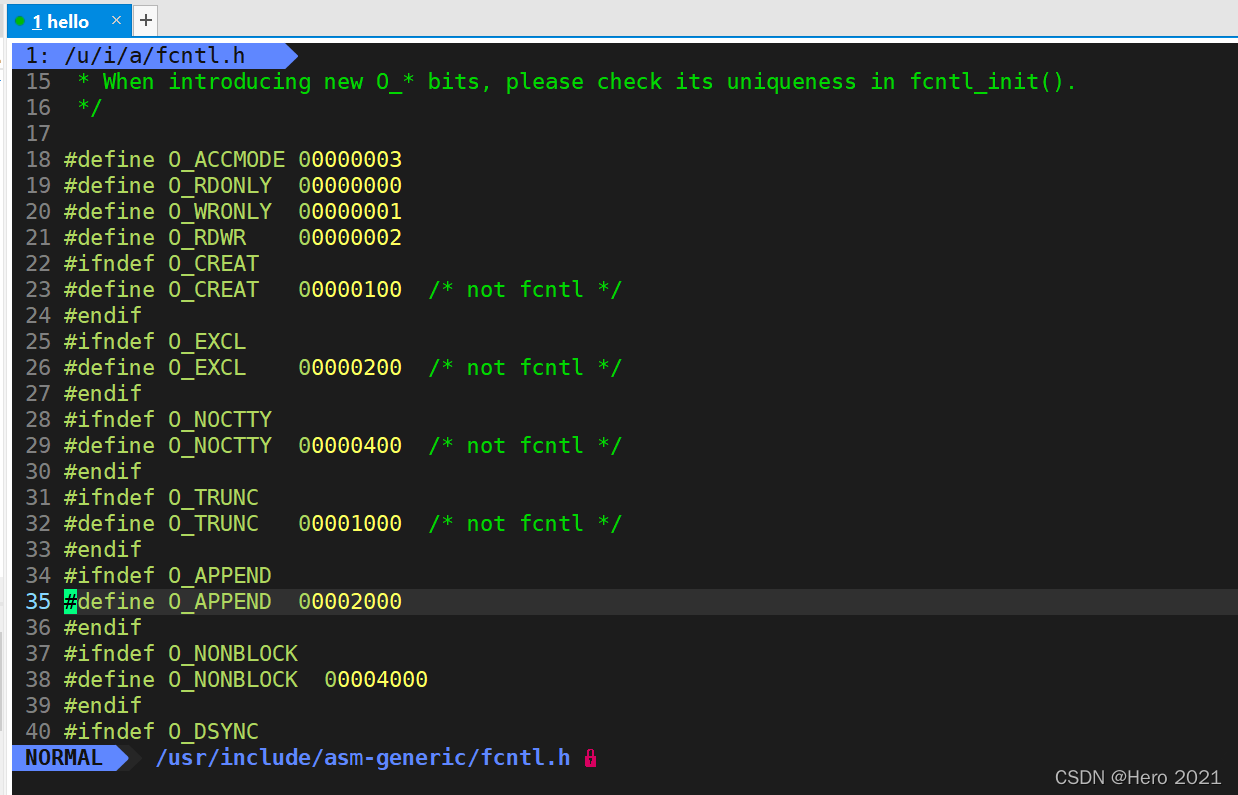
��fcntl.hͷ�ļ��۲����ϸ��:
����open����:
//��������������
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<unistd.h>
#include<fcntl.h>
int main()
{
int fd=open("./log.txt",O_WRONLY | O_CREAT);
if(fd<0)
{
perror("open");
return 1;
}
close(fd);
return 0;
}
���Ƿ����´�����log.txtȨ���ǻ��ҵ�:
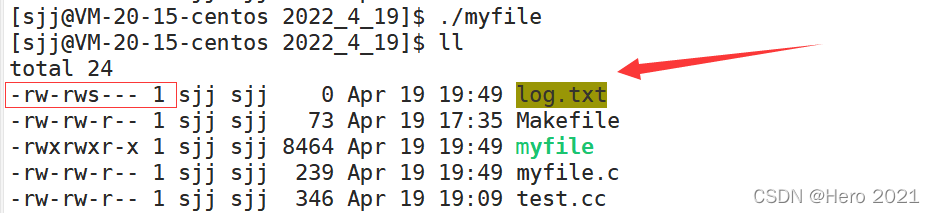
���Ǵ��ϵ���������,����ָ���ó�ʼȨ��:
int main()
{
int fd=open("./log.txt",O_WRONLY | O_CREAT,0644);//��ʼ��Ȩ��
if(fd<0)
{
perror("open");
return 1;
}
close(fd);
return 0;
}
ȷʵȨ�����ú���:
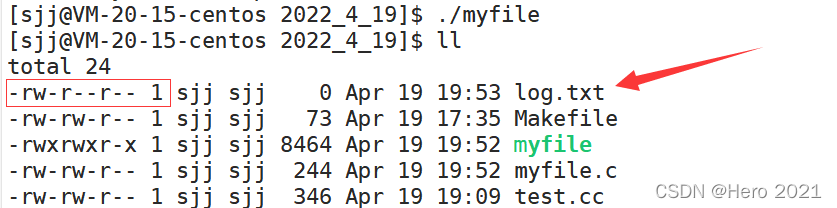
�������ڿ��ԶԱȲ���ϵͳ�����open��C���Բ����fopen��:

����C��������ϵͳ֮�ϵ�,�����������˷�װ,���ǾͲ����ٹ�����Щϸ���ˡ�
������¡�ؽ�������open�ķ���ֵ:
#include<stdio.h>
#include<fcntl.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<unistd.h>
int main()
{
int fd=open("./log.txt",O_WRONLY|O_CREAT,0644);
if(fd<0)
{
printf("open error!\n");
return 1;
}
printf("fd:%d\n",fd);
close(fd);
return 0;
}
��ӡ����:
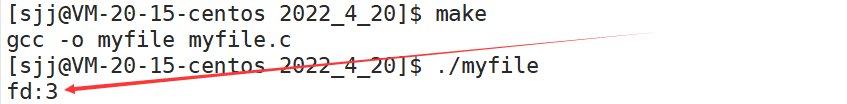
��������ٴ���һ���µ��ļ���?
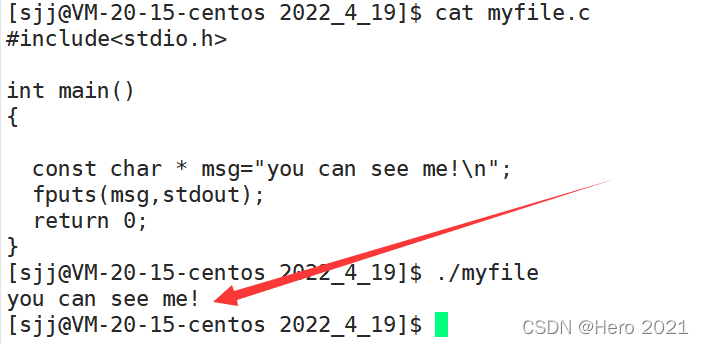
[sjj@VM-20-15-centos 2022_4_20]$ cat myfile.c
#include<stdio.h>
#include<fcntl.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<unistd.h>
int main()
{
int fd=open("./log.txt",O_WRONLY|O_CREAT,0644);
int fd1=open("./log1.txt",O_WRONLY|O_CREAT,0644);
int fd2=open("./log2.txt",O_WRONLY|O_CREAT,0644);
int fd3=open("./log3.txt",O_WRONLY|O_CREAT,0644);
int fd4=open("./log4.txt",O_WRONLY|O_CREAT,0644);
if(fd<0)
{
printf("open error!\n");
return 1;
}
printf("fd:%d\n",fd);
printf("fd1:%d\n",fd1);
printf("fd2:%d\n",fd2);
printf("fd3:%d\n",fd3);
printf("fd4:%d\n",fd4);
close(fd);
close(fd1);
close(fd2);
close(fd3);
close(fd4);
return 0;
}
[sjj@VM-20-15-centos 2022_4_20]$ ./myfile
fd:3
fd1:4
fd2:5
fd3:6
fd4:7
��ȻС��0��ʧ��,Ϊʲôû��0��1��2��?
�����0��1��2�ͷֱ��Ӧ���ǵ�:�����롢�������������
�����ǵij�����������֮��,�ͱ���˽���,Ĭ�������,OS��������ǵĽ��̴��������������!
- 0:������C>����
- 1:������C>��ʾ��
- 2:������C>��ʾ��
��Ȼ�Ա�����֮ǰC����ѧϰ���ļ�����,����֮�������һЩ��ϵ!
read����
//��������
ssize_t read(int fd, void *buf, size_t count);
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/stat.h>
#include<string.h>
#include<sys/types.h>
#include<fcntl.h>
int main()
{
//�
// int fd=open("./log.txt", O_WRONLY | O_CREAT,0644);
// if(fd<0)
// {
// perror("open");
// return 1;
// }
// int cnt=5;
// const char* msg="hello world\n";
// while(cnt--)
// {
// write(fd,msg,strlen(msg));
// }
// close(fd);
//��ȡ
int fd=open("./log.txt",O_RDONLY);
if(fd<0)
{
perror("open");
return 1;
}
char buf[1024]={0};
ssize_t s=read(fd,buf,sizeof(buf)-1);//-1����Ϊ����д���ļ���ʱ����Ҫ\0,���Ƕ���ʱ���ֶ�����\0,���俴���ַ���
//������,ÿ�����ַ���������\n��β��,����ֱ�ӽ������ַ�����������
if(s>0)//s>0˵�����Ƕ�������Ч������
{
buf[s]=0;//�ֶ�����\0
printf("%s\n",buf);
}
close(fd);
return 0;
}
�ļ������� fd
?ͨ������open������ѧϰ,����֪���ļ�����������open�����ķ���ֵ,������һ��С������open��һ��ϵͳ��εĵ���,��ζ����������±���OS�����ǵ�!
?���е��ļ�����,�����϶��ǽ���ִ�ж�Ӧ�ĺ���!�����̶��ļ��IJ����C>Ҫ�����ļ�����Ҫ�ȴ��ļ�!�C>���ļ���˼���ǽ��ļ��������Ϣ���ص��ڴ�֮��!
�C>���Dz���ϵͳ�д��ڴ����Ľ���,(����:�ļ�=1:n)�C>ϵͳ�д��ڿ��ܸ�������ļ�!�C>����ϵͳҪ�Ѵ��ļ����ڴ��й�������,��ô��ι���?
��������:������,����֯!
��չ:����ļ�û�б�����?��ô�������������?
�DZ�Ȼ�Ǵ��ڴ�������!
����֪��Linux����C����д��,��ô�������һ���ṹ��?
�Ǿ����ýṹ��struct!
������һ��struct file�ṹ��������һ�����ļ���������Ϣ:
struct file{
//�����˴��ļ������������Ϣ
//��������������
//......
}
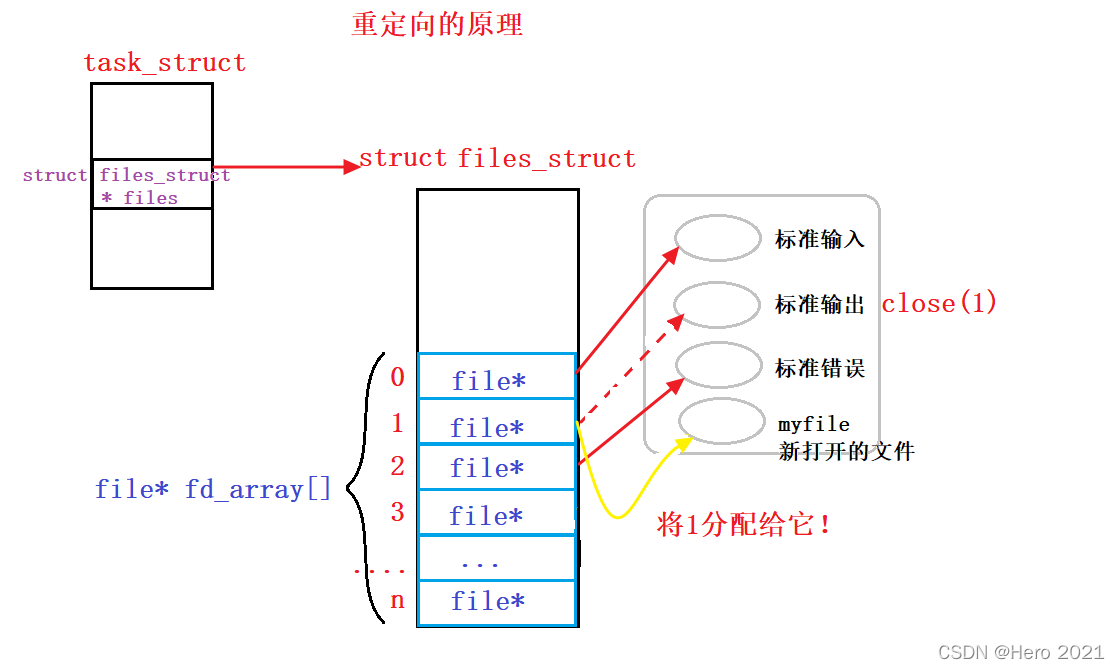
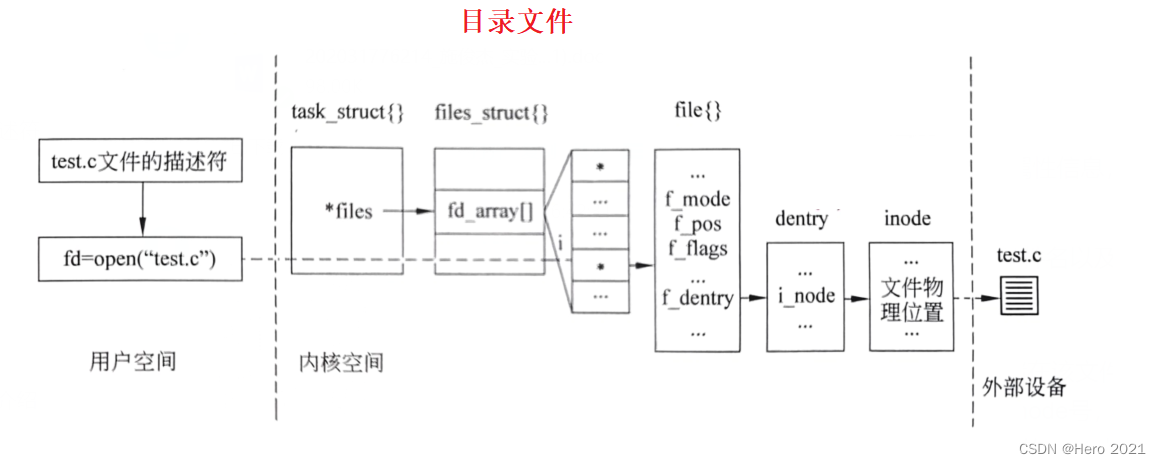
?����֪��,�ļ��������Ǵ�0��ʼ��С����,0��1��2��Ĭ�ϴ�ռ����,������Ҫ�����ļ�ʱ,OS���ڴ��д�����Ӧ�����ݽṹ�������ļ�,���Ǿ�����struct file�ṹ��,������ִ����Ӧ�ĺ�������(����open����),����Ҫ�ý��̺��ļ���������,�����ڽ��̵�task_struct����һ��struct files_struct* files�ĵ�ָ��,��ָ��һ��struct files_struct�Ľṹ���,�ýṹ���������Ҫ�����ļ��ܹ�������ϵ�ľ�����һ��struct file* fd_array[ ]��ָ������,ÿһ��Ԫ�ض���һ��ָ����ļ���ָ��,ͨ�������±�ķ������Ǿ��ܷ����ļ��������Ϣ,���Ƿ��ظ��ϲ�ľ���һ��һ�������֡�
?���Ա�����,�ļ����������Ǹ�������±�,ֻҪ�����ļ����������Ǿ����ҵ������ʡ��Ķ�Ӧ���ļ�!��write��read����OS�ϲ�ĺ���,ͨ���ļ��б��ҵ��ý��̴��ļ�,����fd�Ϳ�����������Ҫ�������ļ��ˡ�
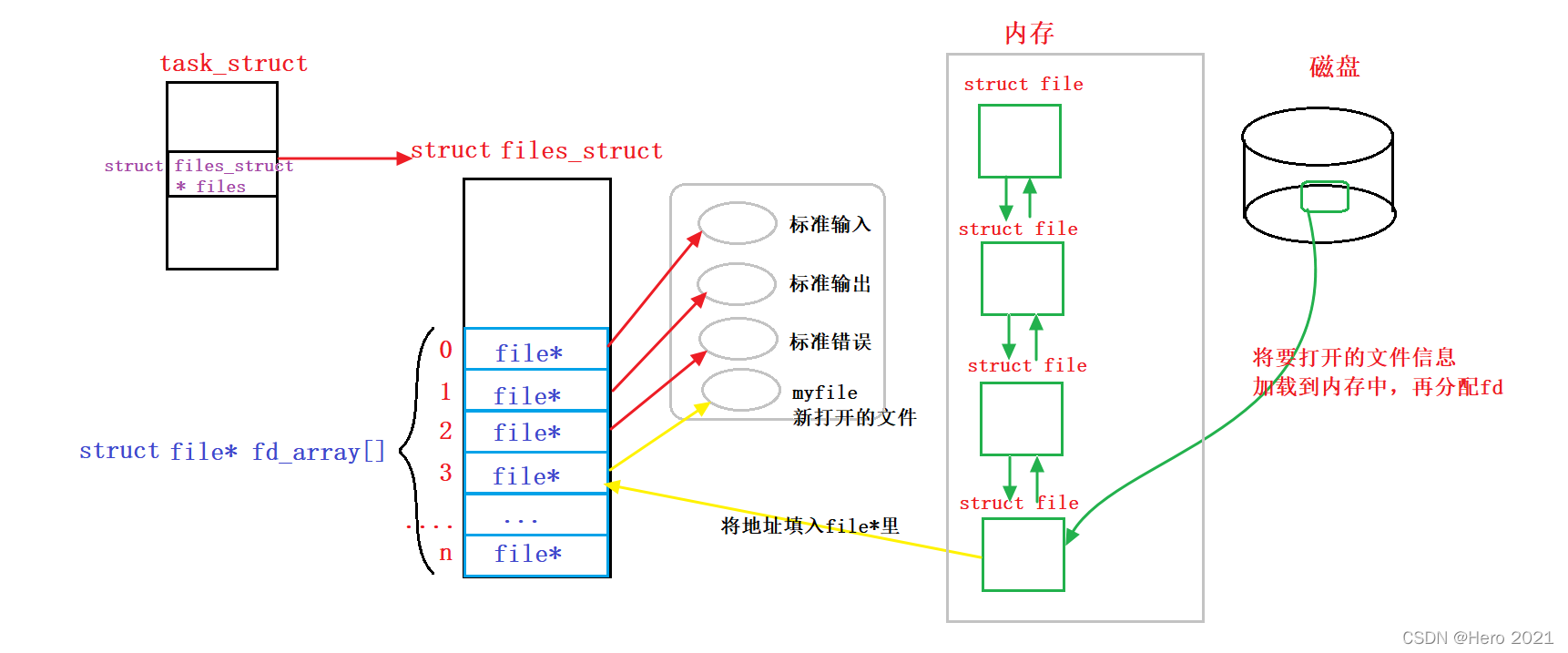
�������һ�н��ļ�
?����Ӳ���Ķ�д����һ���Dz�һ����,��ЩӲ������ֻ�ж�,��ЩӲ������ֻ��д,��ô��Linux�����������һ�н��ļ�����?�������ں�����һ��������װ�������VFS,������ͬ���ļ�ϵͳ���ϵ���һ��,�����ṩ��ͬһ��Ӧ�ó���ӿ�(API)���ϲ��Ӧ�ó���ʹ�á�
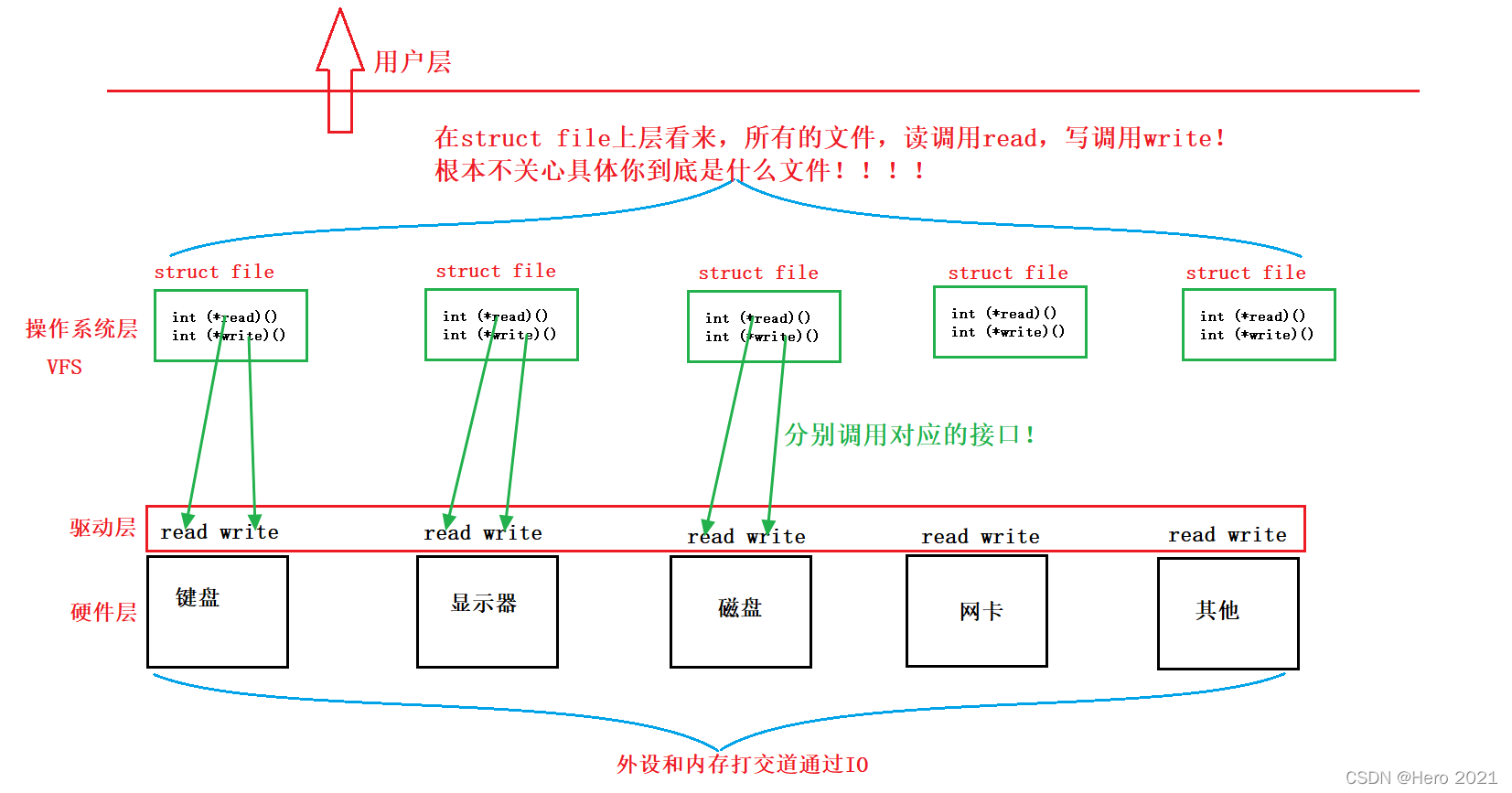
?����:��������Ҫ����̶�дʱ,�ϲ�ͳһʹ��read��write,���ǵײ�ȴ���ڴ��̶�Ӧ���ļ��е����ض���read��write����(�����õ��Ǻ���ָ��)!
�������û���,��ͳһ���ӽ�,�������²��ļ�,����linux��һ�н��ļ�!
�ļ��������������
�۲�һ��:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
int fd = open("./log.txt", O_RDONLY);
if (fd < 0) {
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd);
return 0;
}
����fd:3
��������:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
close(0);
//close(2);
int fd = open("./log.txt", O_RDONLY);
if (fd < 0) {
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd);
return 0;
}
����fd:0����fd:2
�ļ��������ķ������:��files_struct���鵱��,�ҵ���ǰû�б�ʹ�õ���С��һ���±�,��Ϊ�µ��ļ�������
�ض���
������ǰ�1���ص�,��ô�����ʲô������?
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/stat.h>
#include<string.h>
#include<sys/types.h>
#include<fcntl.h>
int main()
{
close(1);
int fd = open("./log.txt", O_CREAT|O_WRONLY,0644);
if(fd < 0){
perror("open");
return 1;
}
printf("fd: %d\n", fd);
// close(fd);
return 0;
}

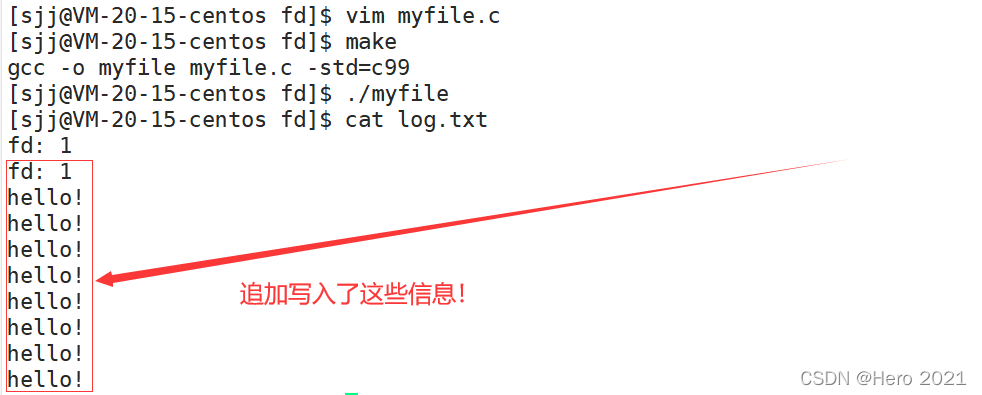
���ﱾ������ʾ���ϴ�ӡ��,����ȴ���ļ�����ʾ������!������ͽ�������ض���!
C������printf�Ĵ�ӡ,������������(stdout)��ӡ,stdout����FILE*���͵�,FLIE��һ���ṹ��,������ض���װ�˶�Ӧ�����ļ���fd��
���ض����ԭ��:
�ڴ��ļ�ʱ,�ٻ���һ��O_APPEND�Ϳ���ʵ���ˡ�
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/stat.h>
#include<string.h>
#include<sys/types.h>
#include<fcntl.h>
int main()
{
close(1);
int fd = open("./log.txt", O_CREAT|O_WRONLY|O_APPEND,0644); //O_APPEND��
if(fd < 0){
perror("open");
return 1;
}
printf("fd: %d\n", fd);
printf("hello!\n");
printf("hello!\n");
printf("hello!\n");
printf("hello!\n");
printf("hello!\n");
printf("hello!\n");
printf("hello!\n");
printf("hello!\n");
// close(fd);
return 0;
}
�����ض����ԭ��:
��������ض���ǡ���෴
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/stat.h>
#include<string.h>
#include<sys/types.h>
#include<fcntl.h>
int main()
{
close(0);
int fd=open("./log.txt",O_RDONLY);
//fd==0
if(fd < 0){
perror("open");
return 1;
}
printf("fd: %d\n", fd);
char line[128];
while(fgets(line,sizeof(line)-1,stdin))
{
printf("%s",line);
}
return 0;
}

ʹ��dup2ϵͳ����
| �������� | dup2 |
|---|---|
| �������� | ����һ���ļ������� |
| ͷ�ļ� | #include<unistd.h> |
| ����ԭ�� | int dup2(int oldfd,int newfd); |
| ���� | oldfd:�����Ƶ��ļ������� newfd:�µ��ļ������� |
| ����ֵ | >-1:���Ƴɹ�,�����µ��ļ������� -1:���� |
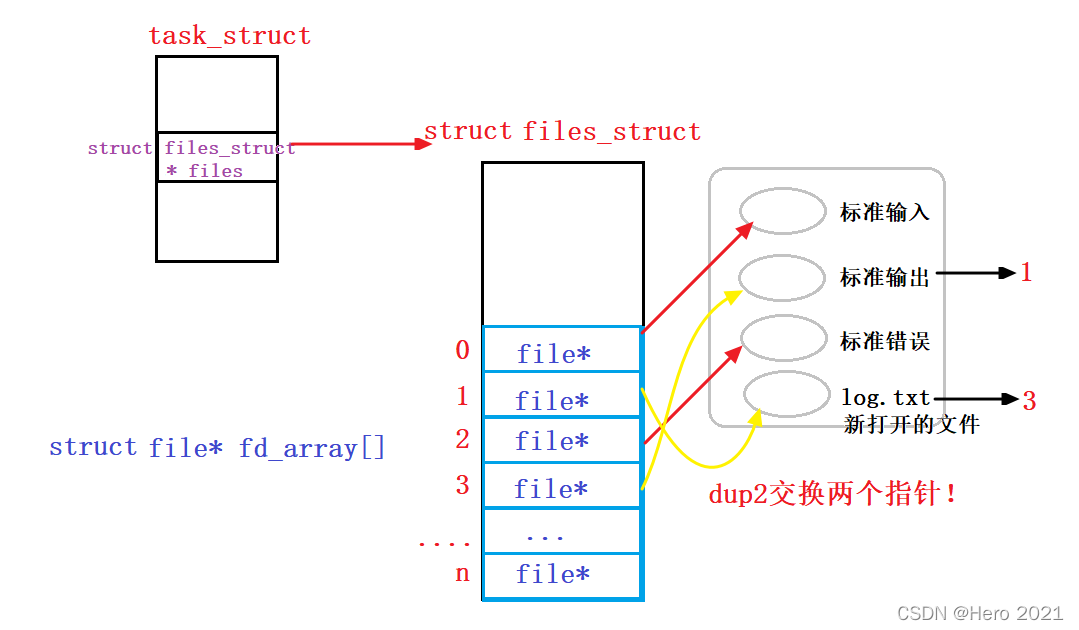
����֮ǰ�����о��Ķ���close(1)��close(0)�ر����ļ������������,����ʵ�ʲ�û����ô����!
����������ļ����������,����ض�����?
�����Ҫ�õ��������dup2������ʵ���ˡ�
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
int main()
{
int fd=open("./log.txt",O_CREAT|O_WRONLY,0644);
if(fd<0)
{
perror("open");
return 1;
}
dup2(fd,1);//��������ʾ���ϴ�ӡ��,����д�뵽���ļ���
printf("hello printf\n");
fprintf(stdout,"hello fprintf\n");
fputs("hello fputs\n",stdout);
}
���չʾ:
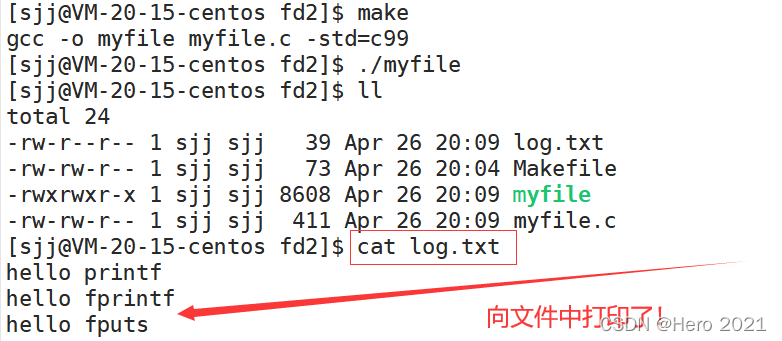
��������ʾ����ʾ���ϵ�����,����д�뵽���ļ���,�����൱����3ȥ���ǵ���1,�����ϲ�ȴֻ��ʶ�����±�1,�����ض���д�뵽���ļ��С�(stdoutҲ��ֻ�϶�1�±�)��
������
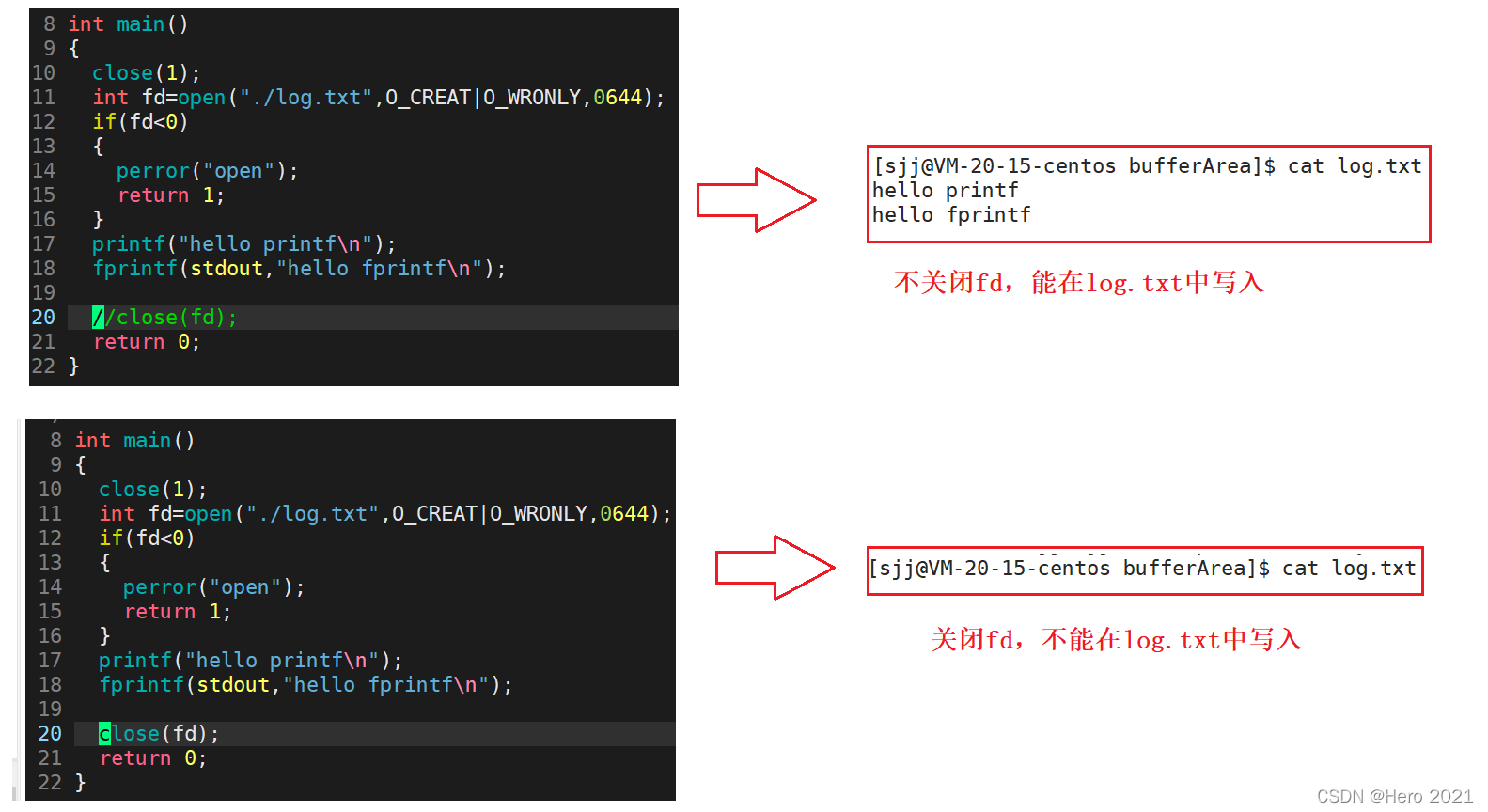
Ϊʲô���������������?
ԭ����C���Ը������ṩ�˻�����!
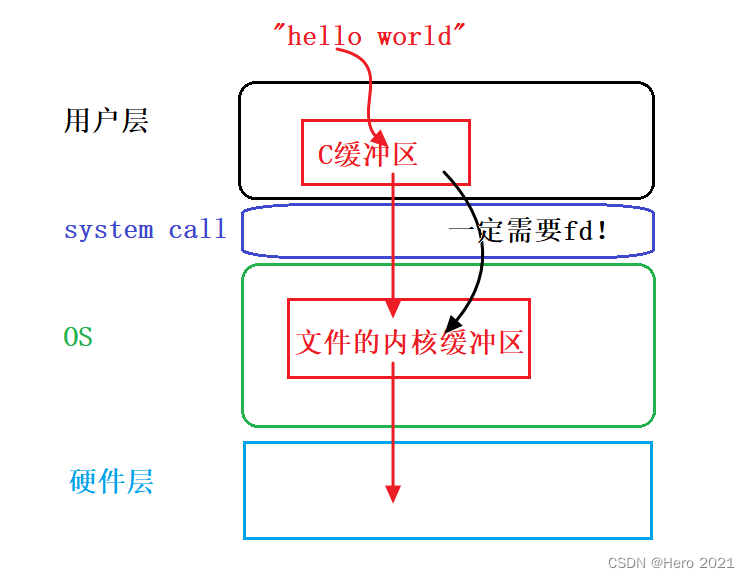
���û���C����C>OS�ں��ļ���������ˢ�²���:
1?? ����ˢ��(������)
2?? ��ˢ��(�л���\n)����:��ʾ����ӡ
3?? ����������ˢ��(ȫ����)����:�������ļ��ϴ�ӡ
4?? �����˳���ʱ��,��ˢ��FILE�ڲ������ݵ�OS������
��OS�ں��ļ��������C>Ӳ��,����ˢ�²���ͬ������!OS����ϵͳ�������ά��,���Dz��ع������е�ϸ�ڡ�
C���������������ˢ�µ�OS�ļ��ں˻�����?
��:һ����Ҫfd! ��Ϊ�м���һ��ϵͳ���õĽӿ�,����ƾ����fd�ļ�������,����ˢ�����ݵ�OS�ں˻�������!
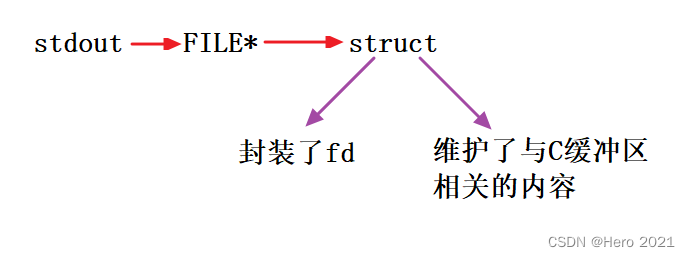
?�������Ǿ��ܽ���Ϊʲô����close(fd)֮��,������log.txt�ļ���д�������ˡ�
ԭ�����,ԭ����printf������ӡ����ʾ�������л����(��\n),�����ض������ļ�֮��,�����ȫ����,���ҹر���fd,C�����������ݾͲ���ˢ�µ�OS�ļ��ں˻�����,��������C���Ի��������ܲ�û�б�д��(��Ϊ���ȫ������),��ʹ�������˳�,OS�ں˻�����Ҳû�����ݱ�ˢ�µ��ļ��С�
���ǿ�����close(fd)֮ǰ,ʹ��fflush(stdout)ǿ��ˢ�����ݵ�OS�ں˻�����,���ܽ����������ˡ�
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<sys/types.h>
#include<fcntl.h>
#include<sys/stat.h>
int main()
{
close(1);
int fd=open("./log.txt",O_CREAT|O_WRONLY,0644);
if(fd<0)
{
perror("open");
return 1;
}
printf("hello printf\n");
fprintf(stdout,"hello fprintf\n");
const char* buf="hello write\n";
write(fd,buf,strlen(buf));
// fflush(stdout);
close(fd);
return 0;
}
Ч��չʾ:

��ϵͳ����ĺ���write,û�����Լ���Ļ�����,��write����ʱ,������ֱ��д���ں˻�������,��ʹclose(stdout)��,�������˳���ʱ��,Ҳ�ǻ�ˢ��OS�ں˻�����д�뵽�ļ�log.txt��
��������FILE�ṹ�������ϸ��:
// ��/usr/include/libio.h
typedef struct _IO_FILE FILE;
struct _IO_FILE {
int _flags;
#define _IO_file_flags _flags
//���������
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
char* _IO_write_ptr; /* Current put pointer. */
char* _IO_write_end; /* End of put area. */
char* _IO_buf_base; /* Start of reserve area. */
char* _IO_buf_end; /* End of reserve area. */
/* The following fields are used to support backing up and undo. */
char *_IO_save_base;
char *_IO_backup_base;
char *_IO_save_end;
struct _IO_marker *_markers;
struct _IO_FILE *_chain;
int _fileno; //��װ���ļ�������
#if 0
int _blksize;
#else
int _flags2;
#endif
_IO_off_t _old_offset; /* This used to be _offset but it's too small. */
#define __HAVE_COLUMN /* temporary */
/* 1+column number of pbase(); 0 is unknown. */
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
/* char* _save_gptr; char* _save_egptr; */
_IO_lock_t *_lock;
#ifdef _IO_USE_OLD_IO_FILE
};
��������fork֮������:
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<sys/types.h>
#include<fcntl.h>
#include<sys/stat.h>
int main()
{
// ϵͳ���ýӿ�
const char* msg1 = "hello �����\n";
write(1,msg1,strlen(msg1));
//C���Խӿ�
printf("hello printf\n");
fprintf(stdout,"hello fprintf\n");
fputs("hello fputs\n",stdout);
fork();
return 0;
}

Ϊʲô�⺯�������������,writeϵͳ����ֻ�����һ��?
�϶���fork�й�!
һ��C�⺯��д���ļ�ʱ��ȫ�����,��д����ʾ�����л��塣
printf/fwrite �⺯�����Դ�������,�������ض�����ͨ�ļ�ʱ,���ݵĻ��巽ʽ���л�������ȫ���塣 �����Ƿ��ڻ������е�����,�Ͳ��ᱻ����ˢ��,����fork֮�� ,���ǽ����˳�֮��,��ͳһˢ��,д���ļ����С�
����fork��ʱ��,�������ݻᷢ��дʱ����,���Ե��㸸������ˢ�µ�ʱ��,���������������Ҳ������,���ݴ��븸�Ӹ���һ��,�ӽ���Ҳ������ͬ����һ������,�漴�����������ݡ�
write û�б仯,˵��ϵͳ���ú���û����ν��C���Ի�����������ֱ����OS�ں˻�����д��,���ɲ���ϵͳˢ�µ��ļ�֮�С�
���������ļ�ϵͳ
�ļ�=�ļ�����+�ļ�����
���һ���ļ�û�б���,�������������?
�𰸾����ڴ����������š�
���̻���

���̽���ͼ:
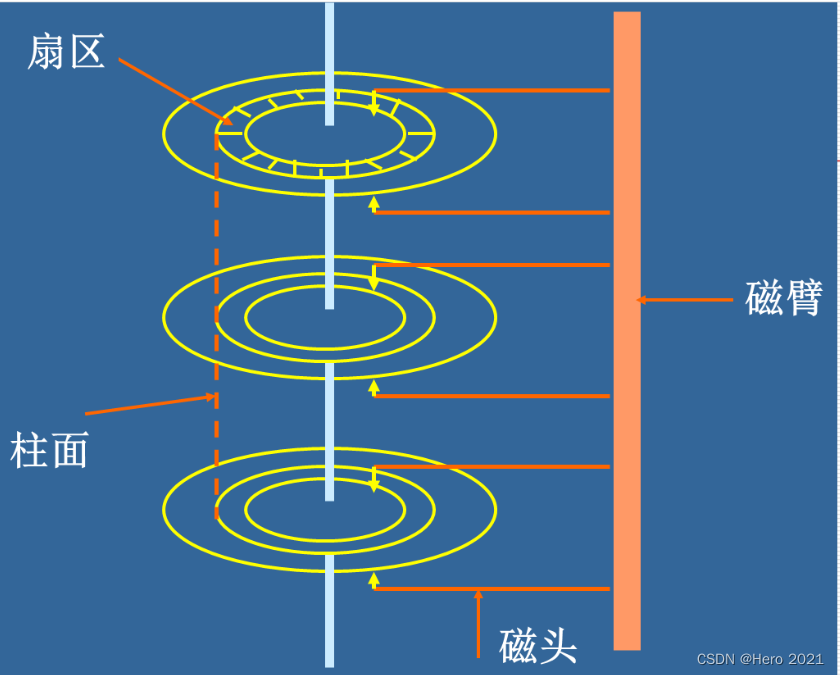
վ��OS�ĽǶ�,���ǿ��Խ�ƽʱ�Ĵ������Ի�����,��һȦһȦ�ı��һ���������㴦����
��Ӳ�̵Ĺ������ǿ���֪��,�����������̵���С��λ����λ��ij�������ϵ�ij���ŵ��ϵ�һ������,Ϊ�˴�ȡ���ݽ�����̻��ֳ�ΪС�ռ䲽��:
1����Ҫ����
2����ʽ��(д���ļ�ϵͳ)
�˽��ļ�ϵͳ:
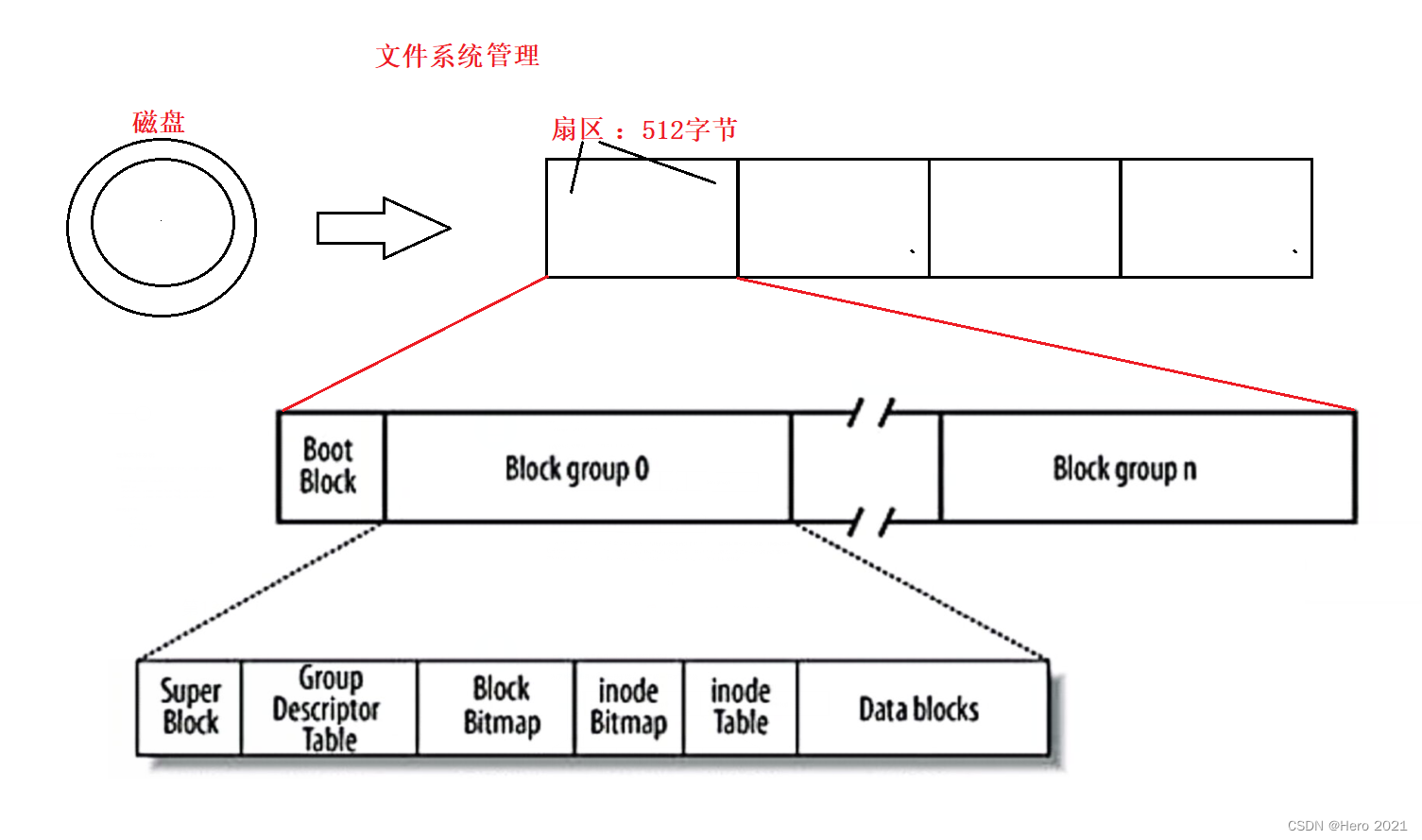
Linux ext2�ļ�ϵͳ,��ͼΪ�����ļ�ϵͳͼ(�ں��ڴ�ӳ��϶�������ͬ),�����ǵ��͵Ŀ��豸,Ӳ�̷���������Ϊһ������block��һ��block�Ĵ�С���ɸ�ʽ����ʱ��ȷ����,���Ҳ����Ը��ġ�����mke2fs��-bѡ������趨block��СΪ1024��2048��4096�ֽڡ�����ͼ��������(Boot Block)�Ĵ�С��ȷ����
Block Group(����):ext2�ļ�ϵͳ����ݷ����Ĵ�С����Ϊ����Block Group����ÿ��Block Group��������ͬ�Ľṹ��ɡ�������������������Super Block(������):����ļ�ϵͳ�����Ľṹ��Ϣ����¼����Ϣ��Ҫ��:bolck �� inode������,δʹ�õ�block��inode������,һ��block��inode�Ĵ�С,���һ�ι��ص�ʱ��,���һ��д�����ݵ�ʱ��,���һ�μ�����̵�ʱ��������ļ�ϵͳ�������Ϣ��Super Block����Ϣ���ƻ�,����˵�����ļ�ϵͳ�ṹ�ͱ��ƻ���Group Descriptor Table(����������):����������,��������������ϢBlock Bitmap(��λͼ):Block Bitmap�м�¼��Data Block���ĸ����ݿ��Ѿ���ռ��,�ĸ����ݿ�û�б�ռ��inode Bitmap(inodeλͼ):ÿ��bit��ʾһ��inode�Ƿ���п��á�inode Table(inode�ڵ��):����ļ��������ļ���С,������,�����ʱ���Date block(Data������):����ļ�����
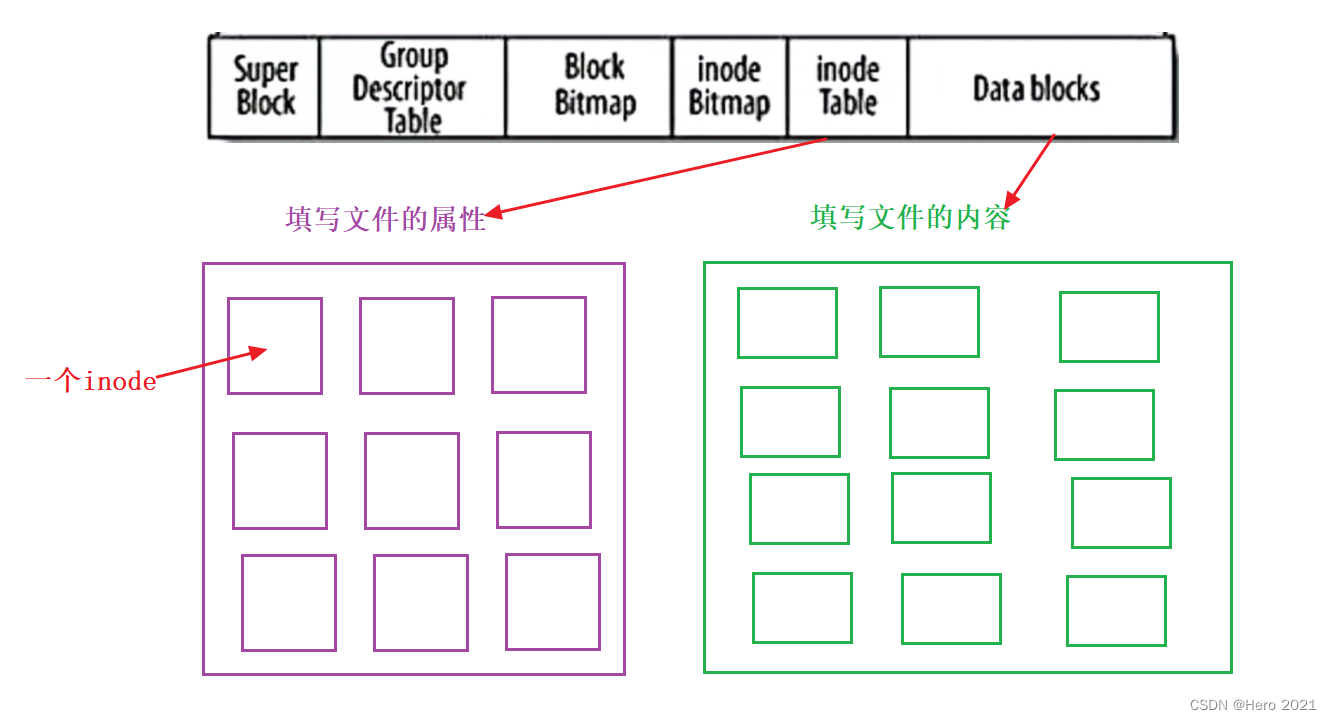
��Linux��,�ļ�����ϵͳ������û�������,�����ø��û�����,������ʶһ���ļ������ļ���inode���!һ�������,һ���ļ�һ��inode,һ��inode��Ӧһ��inode��š�
inode Table����һ���ṹ��:
struct inode{
//�ļ�����������
int inode_number; //inode���
int Data_blocks[NUM];//�����ݿ������,ͨ�������±���ܷ�������
}
ÿ������touch����һ���ļ�ʱ,����ϵͳ��inode Table��һ�����еĵط�,���������Ӧ�Ŀռ����ļ���������Ϣ,����Data blocksѰ��һ�����п�����,���������ļ���������Ϣ��
����Ҳ����������,��������Ҫ�´����ļ�ʱ,ϵͳ��ԭ�����кܶ��ļ�,inode Table ��Data blocks���ںܶ�,�ѵ�������Ҫ����һ����Ѱ���е����������ļ���������?
��������������ǵ�λʾͼ��,����ʾ��
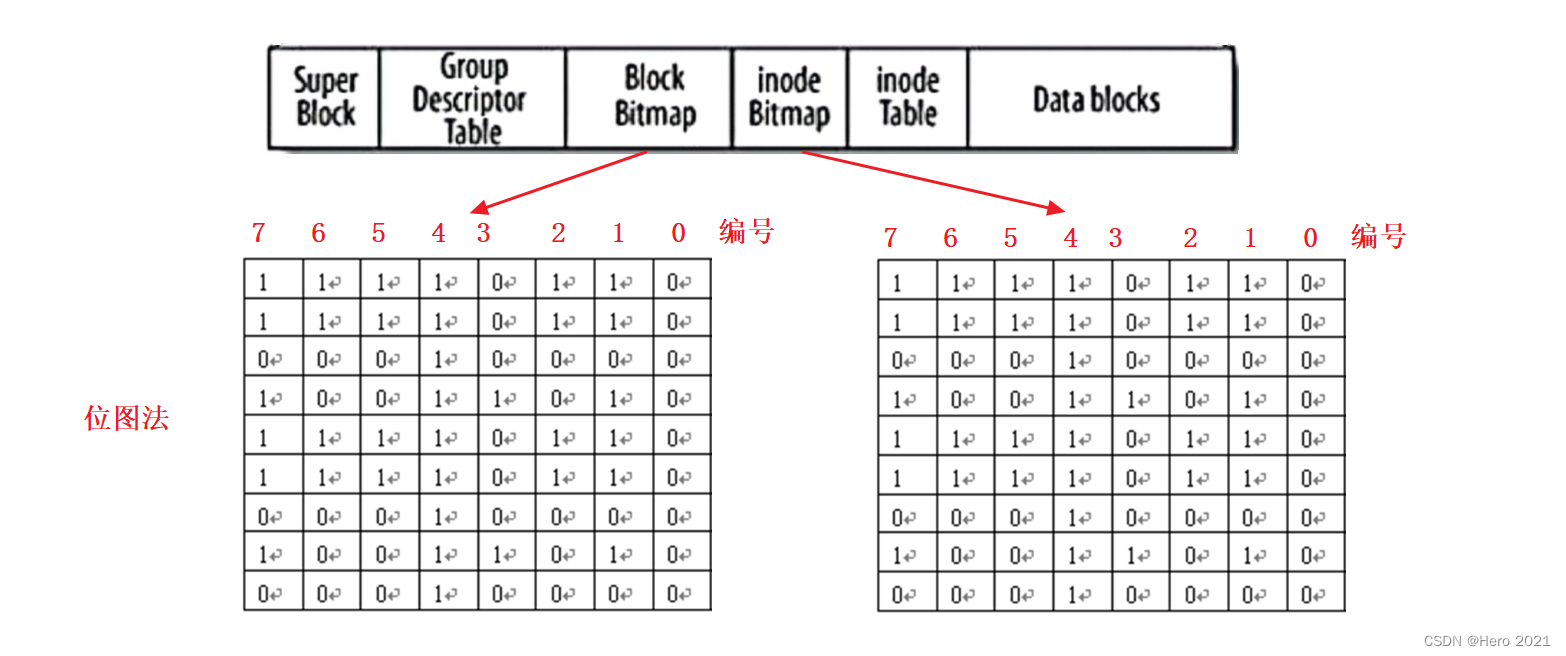
��������
����λ��λ�ú���: inode���
����λ�����ݺ���: �ض���inode�Ƿ�ռ��!
����Ϊ0����û�б�ռ��,1���DZ�ռ����
�������Dz����ٱ���inode Table ��Data blocks,ֻ��Ҫ����λͼ���ܺܿ���ҵ��ĸ��ռ�ʱ���е�,�õ�inode���!(����Ч�ʷdz���!)
Ŀ¼�ļ�
?ͬ��Ŀ¼Ҳ���ļ�,��Ҳ���Լ���inode,Ŀ¼����Ҳ�����ݿ��Ŵ�����ļ�����ӳ�䵽inode��ŵ��ļ�ָ��,�����û�����ʶ�����ļ���,��OS��ʶ����inode���,dentry�ṹ���д���˱�ʾ�ļ�inode����ŵij�Աi_node,����i_node,�ļ�ϵͳ�Ϳ����ڴ������ҵ����ļ���Ӧ��inode���,ͨ��inode�����,�ļ�����λ�þͿ��Է��ʵ��ļ��ڴ����ϵ�λ��,�����ļ�ϵͳ�Ϳ����ҵ���Ҫ�������ļ��ˡ�
?�������ǿ�������Ϊ,������һ���ַ���(�ļ���)��һ��inode���(����)֮���ӳ���ϵ
Ϊʲô�����ļ�ʱ��ȽϾ�һ��,��ɾ���ļ�ʱ�ܿ�Ϳ�ɾ��?
����ɾ��ֻ��Ҫ��inode bitmap��1��Ϊ0����,block bitmap��1��Ϊ0,���ǰ�һ���ļ��Ƿ���Ч����Ϣ��־��ɾ����,������Ҫɾ���������Ժ�������Ϣ��������Ҫ�ٴδ������ʱ,ֻ��Ҫ��ԭ�������ݸ����Ǽ��ɡ�
��Ӳ����
������
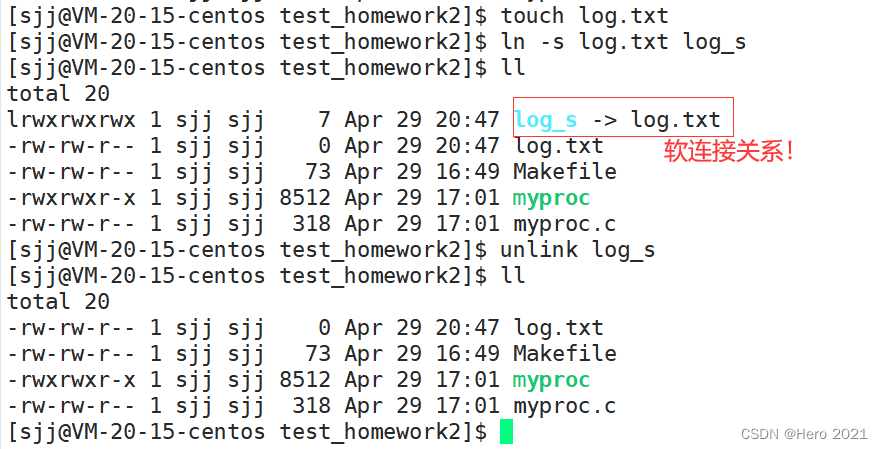
����:��������ͨ��������������һ���ļ�!
����ָ��:ln -s +Դ�ļ��� �������ļ���
ɾ������:unlink +�������ļ���
ʹ��������
�����˵Ľ���������,����һ����ݷ�ʽ,����Ϊ�˱���ִ�г���,��Ҫ�����߳���·��,���Դ���������
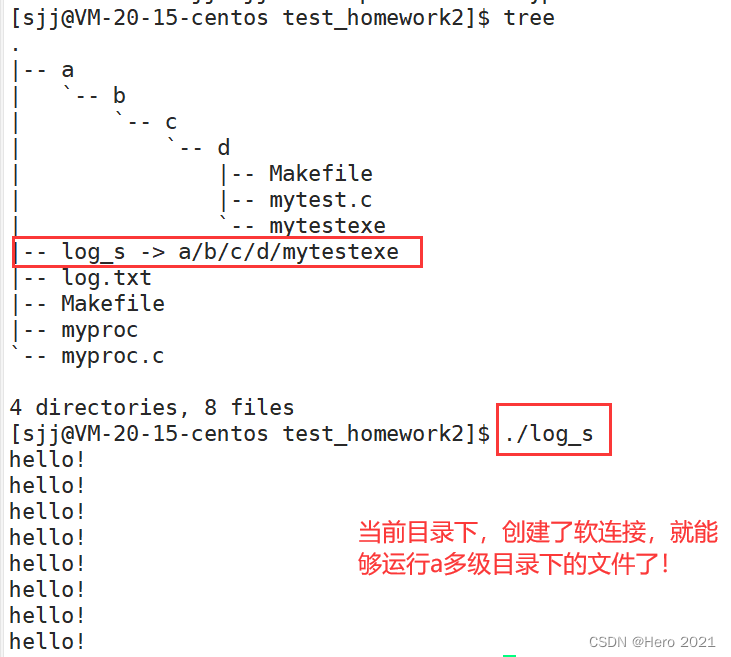
�������Windows�µĿ�ݷ�ʽ:

Ӳ����
����:Ӳ������ͨ��inode��������һ���ļ�!
����ָ��:ln (����-s)+�ļ���
ɾ��ָ��:unlink +Ӳ�����ļ���
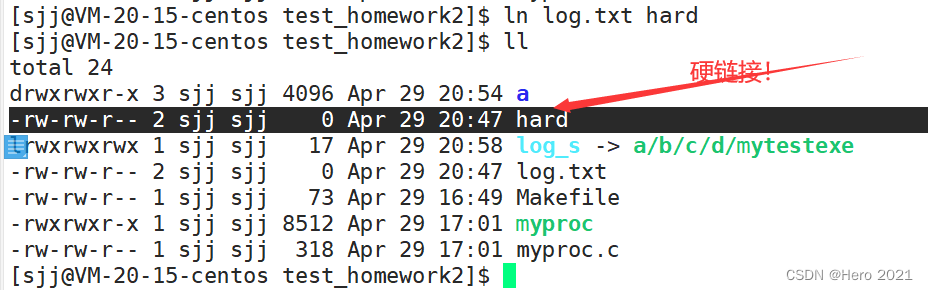
Ӳ���ӵ�ʹ��:
1??������
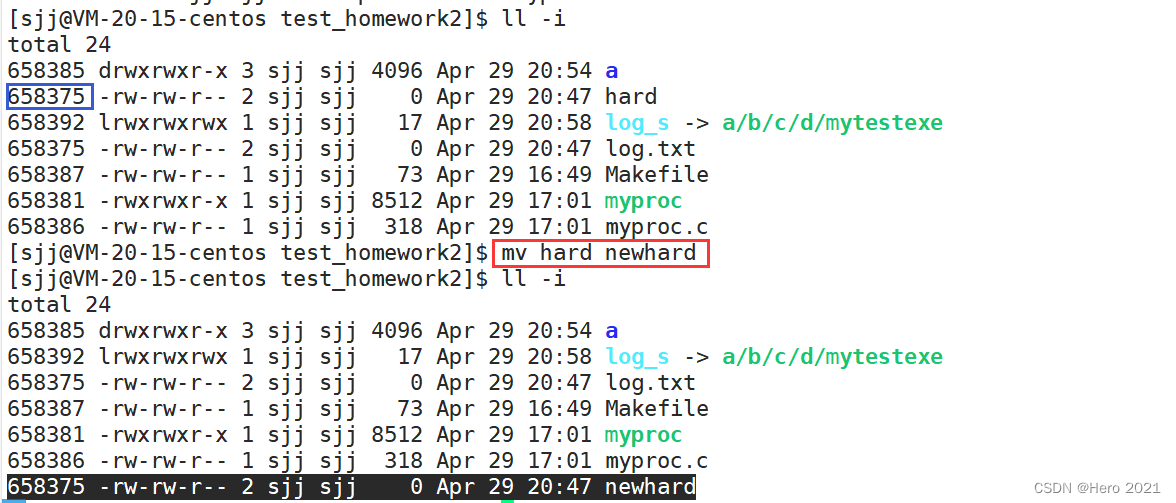
2??����ļ�ָ��ͬһ��inode
�۲�������

ȷʵ���Ƕ���ļ�ָ��ͬһ��inode
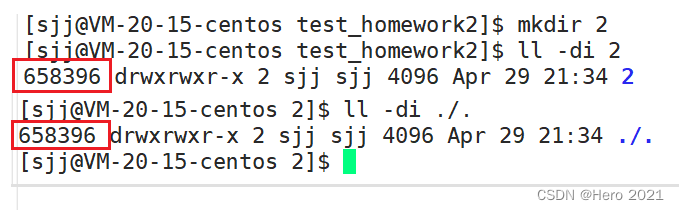
��Ҳͬʱӡ֤��Ϊʲôһ��Ŀ¼����ʱ,����������,������һ�����ص��ļ���.,ָ����ǵ�ǰĿ¼
�Ա���Ӳ����
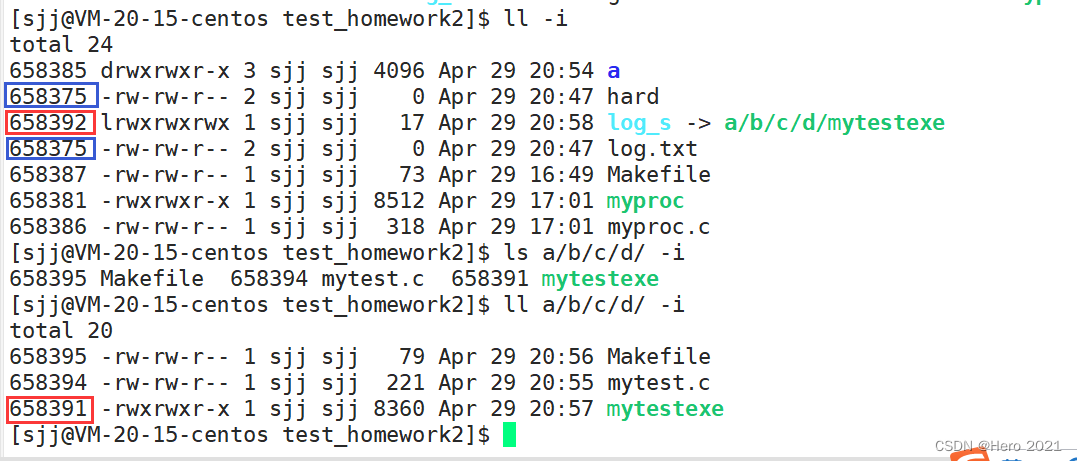
?�۲�inode���Ƿ���,�����������Լ�������inode��ŵ�,��Ӳ����û��,����ͬһ��inode��š�������������һ�������ļ�!�����Լ������Ժ����ݿ�!���ݿ��б�����������ӵ��ļ�·��+�ļ�����
Ӳ���ӱ����Ǹ����Ͳ���һ���������ļ�,����һ���ļ�����inode��ŵ�ӳ���ϵ,��Ϊ�Լ�û�ж�����inode���!
����ʱ��ACM
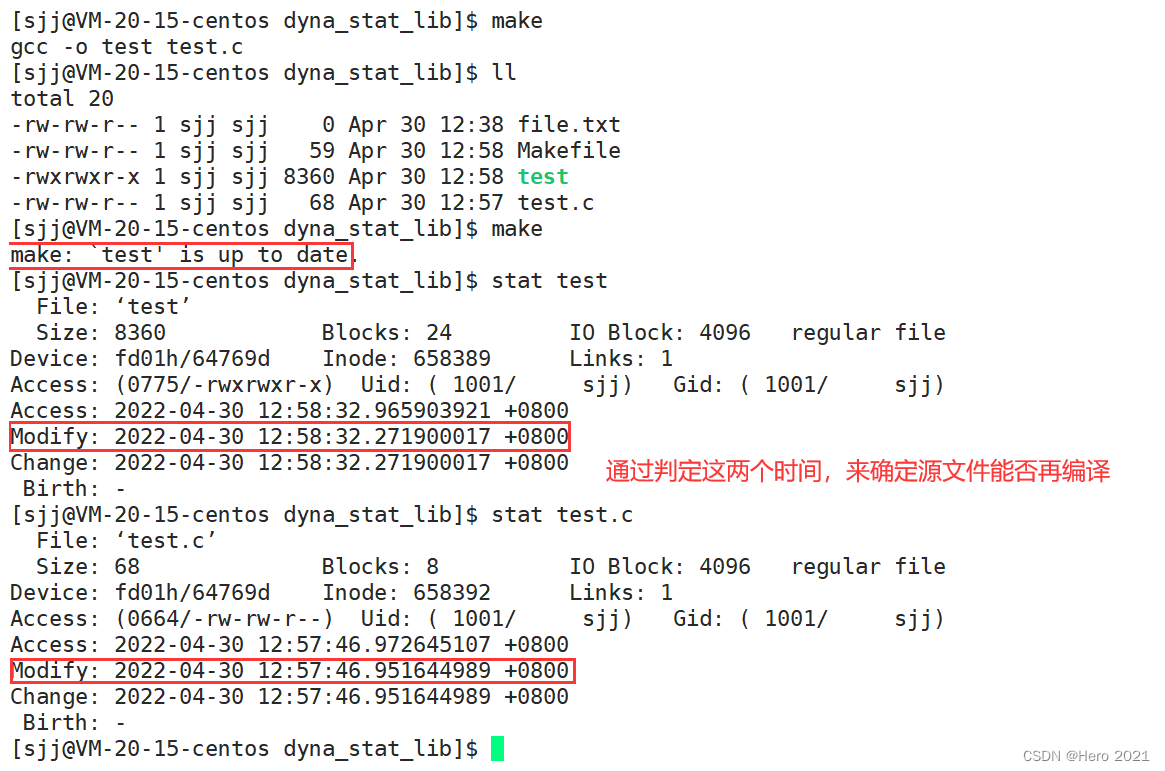
ָ��:stat �ļ��� ��ʾ�ļ����ļ�ϵͳ����ϸ��Ϣ
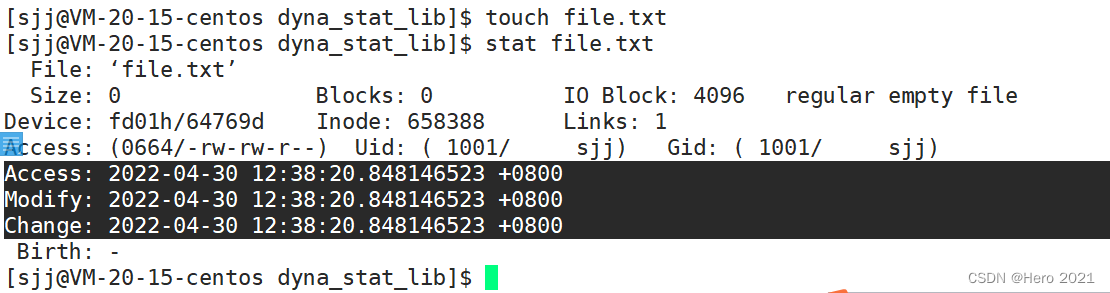
Access������ʱ��Modify�ļ����������ʱ��Change�ļ�����������ʱ��
Access ʱ�����ļ���������ʵ�ʱ��,���Ƿ���ʵ�ʲ�����,�ļ���ʱ��ò��û�б仯?
?������Ϊ�ڽ��µ�Linux�ں���,Accessʱ�䲻�ᱻ����ˢ��,������һ����ʱ����,OS�Ż��Զ�����Accessʱ�䡣Accessʱ����ʵ��Ҫˢ�µ����,��Ϊ������ʱ��ͣ�ķ��ʺ����ļ�������Ƶ��ˢ�¿��ܻᵼ��ϵͳ��ÿ���,Linux�����Ż�,��һ��ʱ������ˢ��Accessʱ�䡣
���������ļ�����ʱ,Ϊʲômodify��changeʱ����ʱ����ı�?
?������Ϊ�����������ݻ���ɾ����Ϣʱ,���ܻ�ı��ļ���������Ϣ,���硰�ļ���С�����ԡ�
����:Makefile��gcc�����Modifyʱ��,���ж�Դ�ļ��Ϳ�ִ�г���˭����,�Ӷ�ָ��ϵͳ��ЩԴ�ļ���Ҫ�����±���!
лл�ۿ�!

