���紫���UDP/TCP
����
�ٶ˿ں�
�˿ںű�ʶһ�������Ͻ���ͨ�ŵIJ�ͬ����
��TCP/IPЭ����, �� ��ԴIP��, ��Դ�˿ںš�, ��Ŀ��IP��, ��Ŀ�Ķ˿ںš�, ��Э��š� ����һ����Ԫ������ʶһ��ͨ��
�ڶ˿ںŻ���
- 0 - 1023: ֪���˿ں�, HTTP, FTP, SSH����Щ��Ϊʹ�õ�Ӧ�ò�Э��, ���ǵĶ˿ںŶ��ǹ̶���
- 1024 - 65535: ����ϵͳ��̬����Ķ˿ں�. �ͻ��˳���Ķ˿ں�, �����ɲ���ϵͳ�������Χ�����
��֪���˿ں�
����:
- ssh������, ʹ��22�˿�
- ftp������, ʹ��21�˿�
- telnet������, ʹ��23�˿�
- http������, ʹ��80�˿�
- https������, ʹ��443
- sunproxyadmin: ʹ��8081�˿�
ִ������vim /etc/services���Բ鿴�˿ں�
��netstat��pidof��killall��ps�� awk��xargs????
netstat:
�: netstat [ѡ��]
����:�鿴����״̬
����ѡ��:
- -n �ܾ���ʾ����,����ʾ���ֵ�ȫ��ת��������
- -l ���г����� Listen (����) �ķ���״̬
- -p ��ʾ����������ӵij�����
- -t (tcp)����ʾtcp���ѡ��
- -u (udp)����ʾudp���ѡ��
- -a (all)��ʾ����ѡ��,Ĭ�ϲ���ʾLISTEN���
����tcp:

pidof ����������:�鿴���̵�pid

killall
����:kill��ps grep�ȵĽ����,����ʹ�ý���������ɱ������
����:
- -e:�Գ����ƽ��о�ȷƥ��;
- -l:���Դ�Сд�IJ�ͬ;
- -p:ɱ�����������Ľ�����;
- -i:����ʽɱ������,ɱ������ǰ��Ҫ����ȷ��;
- -l:��ӡ������֪�ź��б�;
- -q:���û�н��̱�ɱ����������κ���Ϣ;
- -r:ʹ���������ʽƥ��Ҫɱ���Ľ�������;
- -s:��ָ���Ľ��̺Ŵ���Ĭ���źš�SIGTERM��;
- -u:ɱ��ָ���û��Ľ���

ps axj | grep ����������:�鿴Ϊ���������������н���
ps axj | hread -nl && ps axj | grep ����������
ps axj | grep ����������| grep -v grep | awk ��{print $2}�� | xargs kill -p//�ڶ���
gawk �������
�����¼�е�ÿ���ֶζ�����ͨ����λ��������:$1��$2 �ȵȡ� $0 ��������¼���ֶβ���Ҫ����������: n = 5 print $n ��ӡ�����¼�еĵ�����ֶ�
xargs :Linux xargs ����
������Э����Ҫ�������������:
��Ҫ���:
- ��ν��Լ��ı�ͷ����Ч�غɷ��������
- �κ�Э�鶼������,Ҫ���Լ�����Ч�غɽ�����,�ϲ����һ��Э��
1)UDP
��UDPЭ��θ�ʽ
16λUDP����, ��ʾ�������ݱ�(UDP�ײ�+UDP����)�����;���У��ͳ���, �ͻ�ֱ�Ӷ���
����Э����Ҫ�������������(����UDP):
- ͨ��������ͷ
- 16λĿ�Ķ˿ں�
(1.Ϊʲôsocket����е�port��16λ����ΪЭ����16λ�� 2.ΪʲôserverҪ��,��Ϊ��Ҫ���ϲ�Э�齻��)
UDP����TCP�����ں�����,tcp/ ipЭ��ջ,����Ҳ��Linux�ں˵�һ����
����Linux�ں�����C����ʵ�ֵ�-->�ں���,���ǵı�ͷ��ʵ��λ��struct udp_header { uint32_t src_ port: 16 uint32_t dst_ port:16; uint32_t udp_ length: 16: uint32_t udp_ check: 16; }λ����һ������,���Զ������->���ٿռ�,��������->
��䱨ͷ�����Ͼ��Ǹ�λ�����Ͷ�Ӧ�ı�����ֵ

��UDP������
sendto, recvfrom,read,write,send, recv�ȱ��ʲ����ǰ����ݷ��͵�������,
���ǽ��û����ݿ�����udp/tcp�ķ��ͻ�����,���߽��ں˻������е�����,�������û�
OS�е������Э��������ʲôʱ��������,���Ͷ�������,�����˸ø���(UDP�����˲���)
UDP���н��ջ�����. ����������ջ��������ܱ�֤�յ���UDP����˳��ͷ���UDP����˳��һ��; �������������, �ٵ����UDP���ݾͻᱻ����;
UDP��socket��ͬʱ��д,ȫ˫��
��UDP�ص㼰ע������
UDP�������.
- ������: ֪���Զ˵�IP�Ͷ˿ںž�ֱ�ӽ��д���, ����Ҫ��������;
- ���ɿ�: û��ȷ�ϻ���, û���ش�����; �����Ϊ������ϸö��������Է�, UDPЭ���Ҳ�����Ӧ�ò㷵���κδ�����Ϣ;(
ע�� ���ɿ��� ���Դ�)- �������ݱ�: ���ܹ����Ŀ��ƶ�д���ݵĴ���������
ע������:
- UDPЭ���ײ�����һ��16λ�����. Ҳ����˵һ��UDP�ܴ�������������64K(����UDP�ײ�).,Ȼ��64K�ڵ���Ļ�����������, ��һ���dz�С������.,���������Ҫ��������ݳ���64K, ����Ҫ��Ӧ�ò��ֶ��ķְ�, ��η���, ���ڽ��ն��ֶ�ƴװ
�ܻ���UDP��Э��
- NFS: �����ļ�ϵͳ
- TFTP: ���ļ�����Э��
- DHCP: ��̬��������Э��
- BOOTP: ����Э��(���������豸����)
- DNS: ����������
2)TCP
����
��ŵ������ϵ�ṹ��,(Ӳ����Ӳ��֮���ǻ��������)���������ͨ�����ߡ��������ݵĴ����� �������ڱ������ڲ�,�����豸�䶼Ҫ���Լ���Э��(����������,����SCSI HBA PCI ��)
ר�����TCP/IPЭ������Ϊͨ�ŵ��豸֮�䡰�߸�����,�����ľ����Զ��,���ݸ�����ʧ
- TCP�����������еĿɿ�������
- IP�����λ�豸����
����
����Կ�ϵͳ��,�Կ����绯
��TCPЭ��θ�ʽ
����:�κ�Э�鶼Ҫ�Ƚ������������:
- ������Ч�غ�
(λ�ײ�����,������ͷ+��������ͷ����4bit(����ѡ��) ���ֱ�ͷ����Ч�غ�)- ����Ч�غɴ�����һ��Э�� ( )
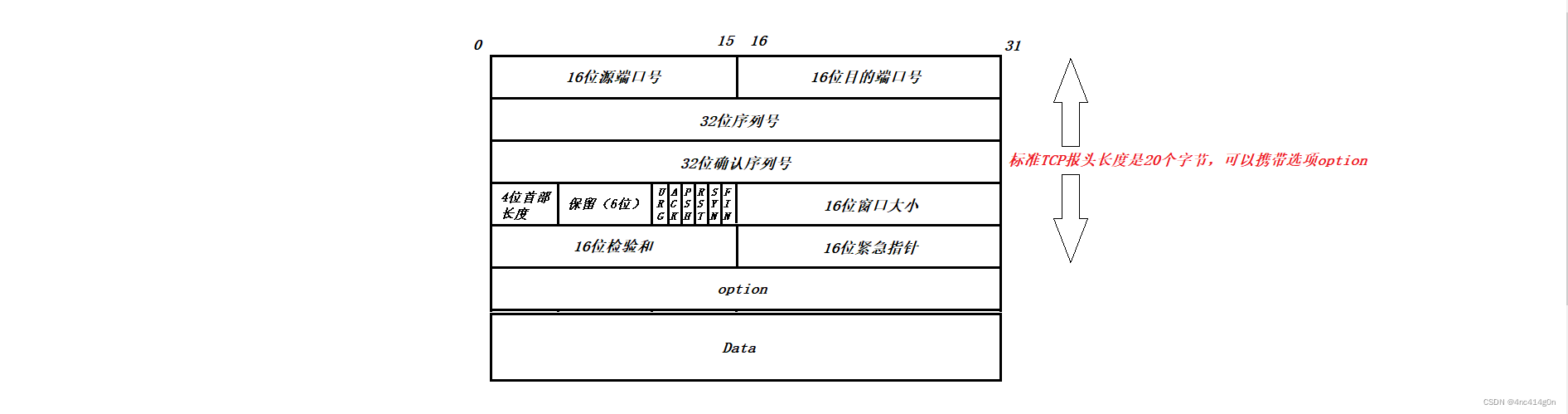
TCPЭ��θ�ʽ:
ע��:
�����4λ�ײ�����,��λ�����ֽ�,����:�����ͷ����20���ֽ�,4λ�ײ����Ⱦ���20/4=5 ������0101- ����TCP��ͷΪ20���ֽ����ͷ����Ϊ60�ֽ�(��Я��ѡ��40�ֽ�)(4λ�ײ�����-20�Ϳ��ж��Ƿ������ȡoption)
32λ��� �� 32λȷ�����
ȷ��Ӧ�����(ACK)��֤�˿ɿ���:
- ���Ƕ��������ݵĿɿ��Ա�֤ (�������ݿɿ��Բ��ܱ���֤,ֻ���յ�Ӧ��Ŵ�����������Ϣ���յ�,�ɿ�) ,����
����ʷ���ݵĿɿ��Խ��б�֤
TCP��ȫ˫����:
- ��Ҫ��֤˫��ɿ���,˫����Ҫȷ��Ӧ�����,������
host1��host2������Ϣ��һ���Ƿ�һ��,host2��һ��,�����Ƿ��Ͷ���,host2�ٻظ�����,�����������,ÿ�����Ŀ���ѡ���·��·�����Dz�ͬ��,��ͬ·����ͨ���̶�Ҳ��ͬ(���ɿ�)
- ����,��TCP�ı�ͷ�������,���ԶԱ��Ľ���˳������(��֤����)
������������Ӧ����:
- tcp���ݶ�:tcp����+��Ч�غ� (Ӧ�����û����Ч�غ�)
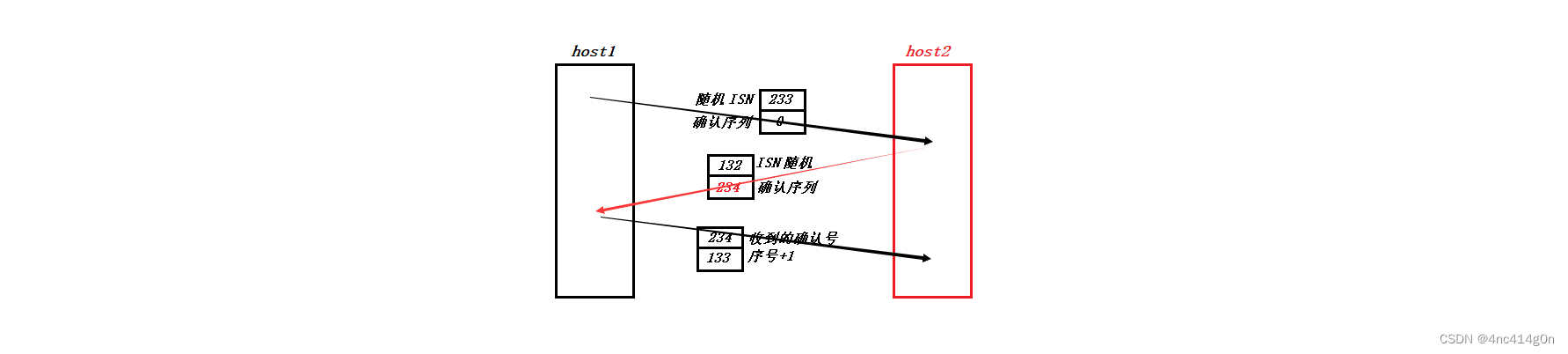
ΪʲôҪ��һ��32λ���?
- �κ����������Ӧ��Ҳ���������ݷ���,����,��Ҫȷ�����,���ԶԷ��ı��Ľ���ȷ��,ͬʱҲ��Ҫ�������֤���ĵ��Է��İ���
ע��:ͼ��û�����ֳ����ֽ����ݵ����
32��:(�����ISN)
��ʼ���к�(ISN),�ǿͻ������������һ��ֵ,��ʼ���к�(ISN)��ʱ����仯��,���Ҳ�ͬ�IJ���ϵͳҲ���в�ͬ��ʵ�ַ�ʽ֮����ž��ǶԷ���ȷ�����32λȷ�����(
32��+1):
- ���߷�������һ�δ����↑ʼ��
ע��:ȷ�Ϻ��ǵ�һ�η��͵�ʱ����0֮���ǶԷ����������+1
(���緢�ͷ�������һ�����Ķ����Ϊ301��TCP��,�����Я����100�ֽ�����,����շ�Ӧ���ظ���ȷ�Ϻ���401)
16λ���ڴ�С
TCP���Լ��ķ��ͻ������ͽ��ܻ�����,��ϵ�֮ǰ��socket���
- write,send�������ǽ��û����ݿ�����TCP�ķ���
������- read,recv�������ǽ��ں˵�TCP
����������,�������û���������
�����͵����ݹ���,�Է�����������, 16λ����,�����Լ��Ľ�������(���ջ�������ʣ��Ŀռ��С)
վ��OS�ĽǶ�:
����ͨ������ͨ���Լ��Ľ�������(16λ���ڴ�С)���Է�,�Դﵽ���������ϵĴ����ٶȵĿ��ƽ�����������
ͬʱҲ���Կ�������������������������ߵ�Ӧ��
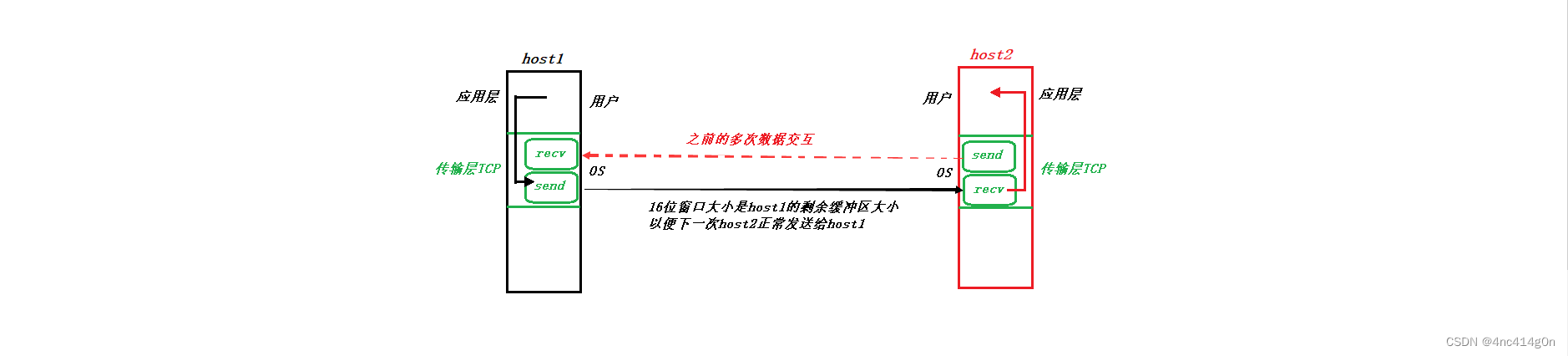
16λ����ָ��
��Ϊtcp�ǰ����, ����,������ú��������ݱ����ȶ�ȡ������,�Dz����ܵ�,����TCP�ṩ�����ȴ������ݵ�����,��������TCP�е�URG��־λ,�������ݱ�־λ,��Ͻ���ָ��ʹ��(
ֻ����һ�ֽڵĽ�������)
��socket�����send��recv��һ��flagѡ��:������дMSG_OOB�����ý������ݺ����ȴ�����������
sendrecv



6λ��־λ(16λ����ָ��)
��־λ(0 or 1) ���� URG(urgent) ����ָ���Ƿ���Ч ACK(acknowledgement) ȷ�Ϻ��Ƿ���Ч PSH(push) ��ʾ���ն�Ӧ�ó������̴�TCP�����������ݶ��� RST(reset) �Է�Ҫ�����½�������; ���ǰ�Я��RST��ʶ�ij�Ϊ ��λ���Ķ�SYN(synchronous) ����������; ���ǰ�Я��SYN��ʶ�ij�Ϊ ͬ�����Ķ�FIN(finish) ֪ͨ�Է�, ����Ҫ�ر���, ���dz�Я��FIN��ʶ��Ϊ �������Ķ�
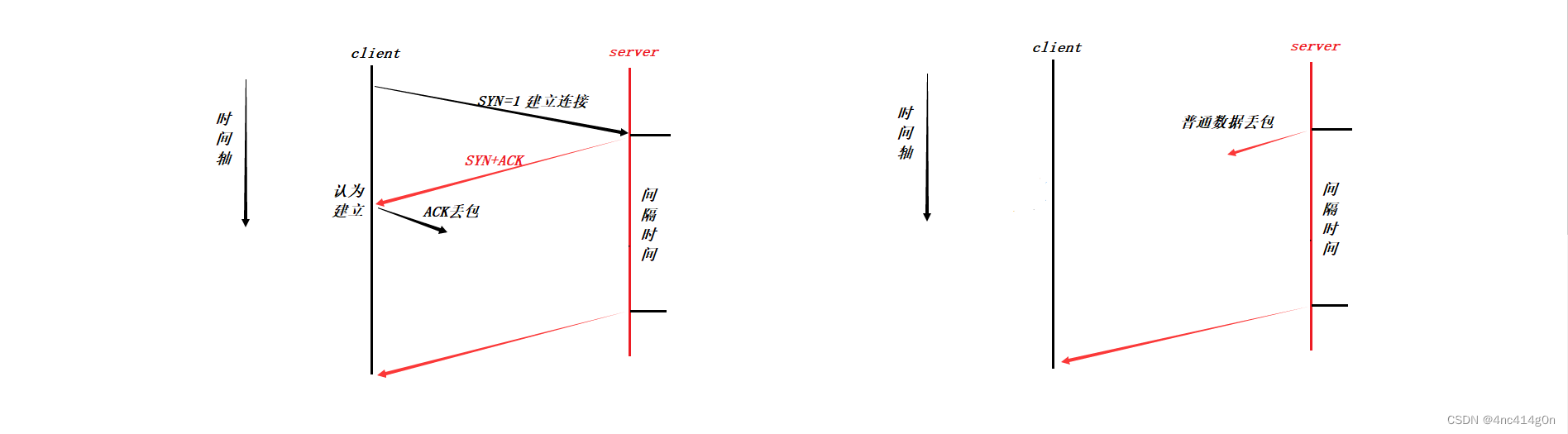
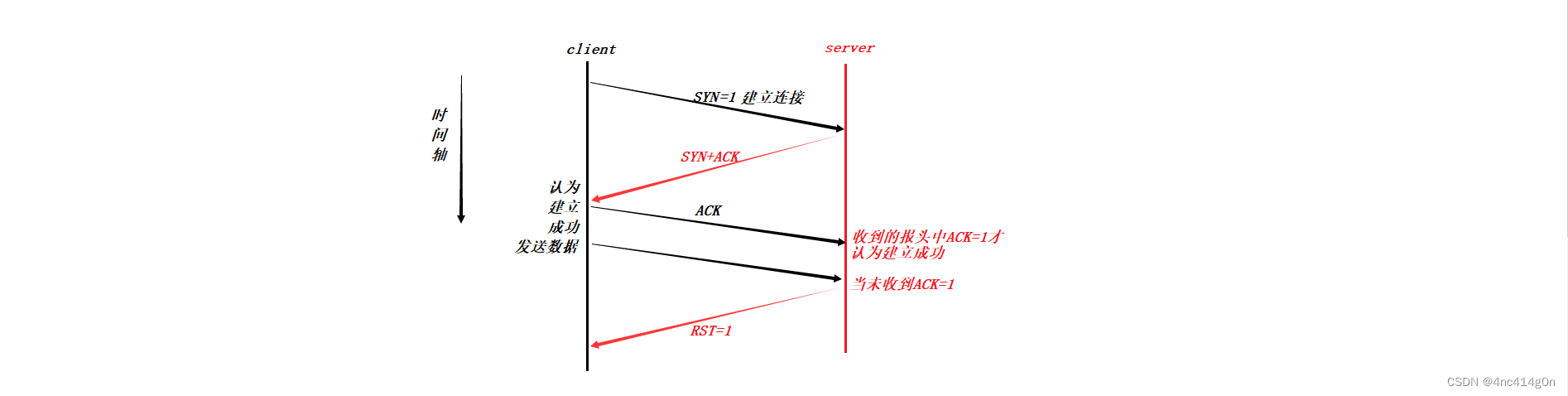
Ϊʲôһ��ҪSYN:
- �������յ�tcp���ĵ�ʱ��,һ������ͬһʱ���,�յ����ֱ���,Ϊ�˱�֤��������ͨ��,��ʱ���շ���ʹ��SYN�������, ��Щ������,��Щ�ǶϿ�����,��Щ�ǽ������ӵ�
����RST:
- ���������ֳ�����������һ��ACKʧ��,client����Ȼ��Ϊ�����dzɹ���(������û��Ӧ��),server����Ϊ��������ʧ��,����ʱ,��Ϊ�ɹ���client�ͻ���server��������,server�ڽ�������ʧ�ܵ�������յ����ݾͻ���client
����RST=1,Ҫ�����½�������
Ϊʲôһ������������:
- ����������4������,Ҳ���Ƕ���һ��ACK,���Ǹ���Ҫ����,
��Ϊ�������ӳɹ���һ����client��Ϊ��server
���ӿ��ܺܶ�,OS��Ҫ����,(ά��һ���������гɱ���(ʱ��+�ռ�), �ҽ������Ӳ����DZ���100%�����ɹ�,����ڿ���Ҫ����server,ֻ��Ҫ��server�����������������,���������һ��ʱ������server��ACK,����server��Ϊ�����ɹ�,���Ӵ���ά�����ӵijɱ�,����̱��,�������DZ���ʹ�������ε�����- TCP��
ȫ˫����,��ҪSYN - > SYN+ACK һ��һ��������֤�����ŵ���ͨ���̶�,���������dzɱ���͵�ѡ��
��ȷ��Ӧ��(ACK)����(Linux�ں� MARK)
TCP��ÿ���ֽڵ����ݶ������˱��. ��Ϊ32λ���к�(sequence number)
TCP��������ջ�����,���Լ�����Ϊ�ַ�����char send_buffer[MAXSIZE], char recv_buffer[MAXSIZE], �����±������Ȼ�����к�(����ϵͳ������������ʽʵ�ֵ�)
�۳�ʱ�ش�����
����������ᴥ����ʱ�ش�����:
1.ACK����
- ���ڼ��ʱ����client��server��������,�Իᴥ��RST
- �ش�SYN+ACK�ظ��Ľ������(TCP����ȥ������,ÿ�����Ķ������к�)
2.��ͨ����
���ʱ��:
- �������ʱ��ij���, �������绷���IJ�ͬ, ���в����.
- �����ʱʱ�����̫��, ��Ӱ��������ش�Ч��;
- �����ʱʱ�����̫��, �п��ܻ�Ƶ�������ظ��İ�
TCPΪ�˱�֤�������κλ����¶��ܱȽϸ����ܵ�ͨ��, ��˻ᶯ̬����������ʱʱ��.
- Linux��(BSD Unix��WindowsҲ�����), ��ʱ��500msΪһ����λ���п���, ÿ���ж���ʱ�ط��ij�ʱʱ�䶼��500ms��������.
- ����ط�һ��֮��, ��Ȼ�ò���Ӧ��, �ȴ� 2*500ms ���ٽ����ش�.
- �����Ȼ�ò���Ӧ��, �ȴ� 4*500ms �����ش�. ��������, ��ָ����ʽ����.
- �ۼƵ�һ�����ش�����, TCP��Ϊ������߶Զ����������쳣, ǿ�ƹر�����