中断进入过程
本章采用的目标板子是三星的Exynos4412
使用的是4核的Cortex-A9,对应的中断控制器被称为GIC,相比于一般的中断控制器而言,其最主要的特点在于可以将一个特定的中断分发给一个特定的ARM核。但这并不是我们关注的重点,在后面的分析中,应该主要知道当中断发生后要如何调用驱动中的中断处理函数,以及在这个过程中所涉及的重要数据结构。整个过程中涉及较多的和体系结构相关的内容,主要体现在中断处理的前期阶段;
为了更方便读者理解这部分内容,在下面的讨论中会重新改写这部分代码。汇编阶段的主要相关代码如下:


vectors start 是异常向量表的起始地址,在内核的启动过程中会将异常向量表搬移到0xFFF000的位置,通过设置处理器的相关寄存器可以对异常向量表进行重映射。当IRQ中断发生后,程序将直接跳转到0xFFFF0018地址处,去执行“bvector_ irq" 这条指令,从而程序再次跳转,去执vector_ _irq 后的代码。
代码第7行至第10行
sub lr,lr,#4
stmia sp,{r0,lr}
mrs lr,spsr
str lr,{sp,#8}
调整了链接寄存器Ir中的中断返回地址的值,然后将r0、Ir、 spsr 的寄存器保存到IRQ模式下的栈(注意,此时的栈是向上生长的)。
代码第11行至第13行
mrs r0,cpsr
eor r0,r0,#(IRQ_MODE^SVC_MODE)
msr spsr_cxsf,r0
取出了cpsr 的值,并将模式位修改为SVC模式且保存到spsr寄存器中,这是为后面将模式由IRQ模式切换到SVC模式做准备。
代码第14行至第22行
and lr,lr,#0x0f
mov r0,sp
ldr lr,[pc,lr,lsl #2]
movs pc,lr
.long _irq_usr
long _irq_invalid
long _irq_invalid
long _irq_svc
将Ir的低4位(即spsr的低4位,这是在中断发生前的处理器模式的低4位)取出来,并根据其值来选择是调用_ irq _usr 还是调用_irq svc。
代码第16行ldr lr,[pc,lr,lsl #2]
利用pc寄存器来做间接寻址,pc的值是下两条指令的地址值,所以如果中断发生前是USER模式,那么将会把_irq_usr 的地址装载到Ir寄存器中,进而装载到pc寄存器中,从而跳转到_irq _usr 处执行代码。
相应的,如果之前是SVC模式,那么就会跳转到_irq_svc 处执行代码。这里分别对应了中断是打断了应用层的代码,还是内核层的代码。
irq_usr 调用了usr entry 和kuser_cmpxchg_check 两个宏分别进行了栈的准备,寄存器入栈和应用层的原子比较交换检查的相关操作,然后调用irq_ handler 宏进一步处理中断。_irq_sve 相对要简单一些, 只调用了svc_entry 宏进行了栈的准备,寄存器入栈的操作,最后也调用irq_handler 宏进一步 处理中断。
irq_ handler 宏获取了标号handle_ arch_ irq 内存中的内容,然后将sp的值复制到r0寄存器作为后面调用函数的第一一个参数,接下来将返回地址保存至Ir 寄存器,最后调用了handle_ arch_ irq内存中记录的函数,在Exynos4412处理器所对应的代码中,该函数是gic_handle_irq
irq handler 返回后,进行了一些现场恢复的操作。在_irq_ svc中还判断了是否配置了内核抢占来决定是否可以重新调度,从而抢占内核。而_jirq_usr 则不管内核抢占是否配置,都要检查是否需要重新调度,因为中断可能把具有高优先级的进程唤醒,那么应该立即调度这个被唤醒的进程。
得到中断IRQ号 和处理
gic_ handle_ irq 函数的关键代码如下:
/* drivers/irqchip/irq-gic.c*/
static asmlinkage void __exception_irq_entry gic_handle_irq(struct pt_regs *regs)
{
u32 irqstat, irqnr;
struct gic_chip_data *gic = &gic_data[0];
void __iomem *cpu_base = gic_data_cpu_base(gic);
do {
irqstat = readl_relaxed(cpu_base + GIC_CPU_INTACK);
irqnr = irqstat & ~0x1c00;
if (likely(irqnr > 15 && irqnr < 1021)) {
irqnr = irq_find_mapping(gic->domain, irqnr);
handle_IRQ(irqnr, regs);
continue;
}
if (irqnr < 16) {
writel_relaxed(irqstat, cpu_base + GIC_CPU_EOI);
#ifdef CONFIG_SMP
handle_IPI(irqnr, regs);
#endif
continue;
}
break;
} while (1);
}
代码第294行和第295行
irqstat = readl_relaxed(cpu_base + GIC_CPU_INTACK);
irqnr = irqstat & ~0x1c00;
得到硬件的中断线IRQ号
代码第298行
irqnr = irq_find_mapping(gic->domain, irqnr);
将硬件的IRQ号转换为Linux内核内部的IRQ号,然后调用handle_ IRQ来处理中断。
另外,gic 能够记录最高优先级的中断,所以handle_ IRQ 返回后,可以再次读取是否有新的中断产生,从而处理新的中断。
是否有新的中断可以通过中断号的值来判定。
在handle_IRQ函数中主要对内核抢占计数器的值进行了操作(这部分内容在后面讲解),然后调用了generic_ handle_irq 函数,generic_ handle_irq 函数的代码如下:
/* kernel/irq/irqdsc.c*/
int generic_handle_irq(unsigned int irq)
{
struct irq_desc *desc = irq_to_desc(irq);
if (!desc)
return -EINVAL;
generic_handle_irq_desc(irq, desc);
return 0;
}
EXPORT_SYMBOL_GPL(generic_handle_irq);
这里涉及一个结构类型struct irq_dese, 它是对系统中的单个中断的抽象,系统有多少个中断源就应该至少有多少个这样的对象。
这些对象可能是放在一个数组中的,也可能是放在一个基数树中的,并且是内核在启动过程中构建好的。
irq_to_desc 就是根据前面获得的Linux内部的IRQ号来从数组或基数树中得到这个对象,如果对象有效,那么将会调用generic_ handle_ irq_ desc 来进一步 处理中断。
在generic_ handle_ irq_ desc 函数中将会调用structirq_desc结构中的成员handle_irq函数指针所指向的函数,而根据中断的触发类型是边沿触发还是电平触发,被调用的函数又分为handle_edge_irq和handle_level_irq。 在这两个函数中都会检测同一个IRQ号所对应的中断处理函数是否正在执行,如果是则拒绝进一步执行,这也就防止了同一IRQ号的中断处理函数的嵌套执行。
这两个函数又都调用handle_irq_event 函数来处理中断,handle_ irq_event 函数又进一步调用了handle_ irq event_ percpu函数,相关的关键代码如下:
irqreturn_t
handle_irq_event_percpu(struct irq_desc *desc, struct irqaction *action)
{
.......
do {
.......
res = action->handler(irq, action->dev_id);
.......
action = action->next;
} while (action);
.......
}
irqreturn_t handle_irq_event(struct irq_desc *desc)
{
struct irqaction *action = desc->action;
......
ret = handle_irq_event_percpu(desc, action);
......
}
代码
struct irqaction *action = desc->action;
从前面得到的struct irq_desc 结构对象中得到action成员,该成员是一个指向struct irqaction结构的指针。
struct irqaction结构:
struct irqaction结构:
struct irqaction {
irq_handler_t handler;
void *dev_id;
void __percpu *percpu_dev_id;
struct irqaction *next;
irq_handler_t thread_fn;
struct task_struct *thread;
unsigned int irq;
unsigned int flags;
unsigned long thread_flags;
unsigned long thread_mask;
const char *name;
struct proc_dir_entry *dir;
} ____cacheline_internodealigned_in_smp;
其中关键的成员及其含义如下
- handler:指向驱动开发者编写的中断处理函数的指针。
- dev_ id: 区别共享中断中的不同设备的ID。
- next:将共享同一IRQ号的struct irqaction对象链接在一起的指针。
- irq: IRQ号。
- flags:以IRQF_开头的一组标志。
代码第191 行
ret = handle_irq_event_percpu(desc, action);
调用了handle_irq_event_ percpu, 并传入了刚才得到的action, 在handle_ irq_ event_ percpu 函数中的do… .while循环中,遍历了链表中的每一个 action,并调用了action中handler成员所指向的中断处理函数。
也就是说,经过这个漫长的过程后,驱动开发者编写的中断处理函数终于得到了调用。
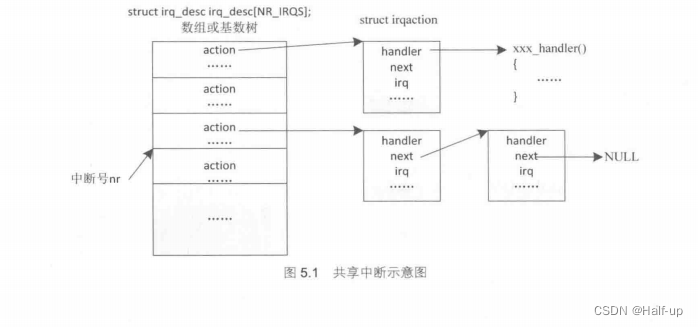
共享中断
上面提到了“共享中断”,那么什么是“共享中断”呢?接下来我们来讨论下。
由于中断控制器的管脚有限,所以在某些体系结构上有两个或两个以上的设备被接到了同一根中断线上,这样这两个设备中的任何一个设备产生了中断,都会触发中断,并且引发上述代码的执行过程,这就是共享中断。
Linux内核不能判断新产生的这个中断究竟属于哪个设备,于是将共用一根中断线的中断处理函数通过不同的struct irqaction结构包装起来,然后用链表链接起来。
内核得到IRQ号后,就遍历该链表上的每一个struct irqaction对象,然后调用handler成员所指向的中断处理函数。
而在中断处理函数中,驱动开发者应该判断该中断是否是自己所管理的设备产生的,如果是则进行相应的中断处理,如果不是则直接返回。自然地,dev_id 就成为了从链表中删除对应struct irqaction对象的一个重要信息(删除函数的参数只有IRQ号,没有struct irqaction结构对象的地址,这个我们将在后面的实例中看到)
通过上面的分析,我们不难得出如图5.1所示的示意图:
驱动中的中断处理
通过上一节的分析不难发现,要在驱动中支持中断,则需要构造一个struct irqaction的结构对象,并根据IRQ号加入到对应的链表中(因为irq _desc 已经在内核初始化时构建好了)。不过内核有相应的API接口,我们只需要调用就可以了。
注册中断处理函数
向内核注册一个中断处理函数的函数原型如下:
int request_irq(unsigned int irq, irq_handler_t handler,
unsigned long flags,const char* name,void *dev);
里面的参数:
-
各个形参说明如下。irq:设备上所用中断的IRQ号,这个号不是硬件手册上查到的号,而是内核中的IRQ号,这个号将会用于决定构造的struct irqaction 对象被插入到哪个链表,并用于初始化struct irqaction对象中的irq成员。
-
handler:指向中断处理函数的指针,类型定义如下:
irqreturn_t (*irq_handler_t)(int,void*)
中断发生后中断处理函数会被自动调用,第一个参数是IRQ号,第二个参数是对应的设备ID,也是struct irqaction结构中的dev_id 成员。
handler 用于初始化struct irqaction对象中handler成员。
中断处理函数的返回值是一个枚举类型irqreturn_t, 包含如下几个枚举值:
irqreturn_t:
IRQ_NONE:不是驱动所管理的设备产生的中断,用于共享中断。
IRQ HANDLED:中断被正常处理。
IRQ_ WAKE_ THREAD:需要唤醒一个内核线程。
flags:与中断相关的标志,用于初始化struct irqaction 对象中的flags 成员,常用的标志如下,这些标志可以用位或的方式来设置多个。
IRQF_ TRIGGER_RISING: 上升沿触发。
IRQF_TRIGGER_FALLING:下降沿触发。
IRQF_TRIGGER HIGH:高电平触发。
IRQF_TRIGGER_LOW:低电平触发。
IRQF_DISABLED: 中断函数执行期间禁止中断,将会被废弃。
IRQF_SHARED:共享中断必须设置的标志。
IRQF_TIMER:定时器专用中断标志。
name:该中断在/proc中的名字,用于初始化struct irqaction对象中的name成员。
dev:区别共享中断中的不同设备所对应的struct irqaction对象,在struct irqaction对象从链表中移除时需要,dev用于初始化struct irqaction对象中的dev_id 成员。
共享中断必须传递一个非NULL的实参,非共享中断可以传NULL。
中断发生后,调用中断处理函数时候,内核也会将该参数传给中断处理函数。
request_ irq 函数成功返回0,失败返回负值。
需要说明的是,request _irq 函数根据传入的参数构造好一个 struct irqaction对象,并加入到对应的链表后,还将对应的中断使能了。所以我们并不需要再使能中断。
注销中断处理函数
注销一个中断处理函数的函数原型如下:
void free_irq(unsigned int, void*);
其中,第一个参数是IRQ号,第二个参数是dev_id共享中断必须要传一个非NULL的实参,request_ inq 中的dev_id 保持一致。
其他函数
除了中断的注册和注销函数之外,还有一些关于中断使能和禁止的函数或宏,这些函数不常用到,简单罗列如下:
local_irq_enable(): 使能本地CPU的中断。
local_irq disable(): 禁止本地CPU的中断。
local_irq_save(flags): 使能本地CPU的中断,并将之前的中断使能状态保持存在flags中。
local_irq_restore(flags): 用flags中的中断使能状态恢复中断使能标志。
void enable_irq(unsigned int irq):使能irq指定的中断。
void disable_irq(unsigned int irq):同步禁止irq 指定的中断,即要等到irq上的所有中断处理程序执行完成后才能禁止中断。
//很显然,在中断处理函数中不能调用。
void disable_irq_nosync(unsigned int irq):
立即禁止irq指定的中断。
有了上面对中断API函数的认识,接下来就可以在我们的驱动中添加中断处理函数。
驱动添加中断处理函数例子
在下面的例子中,让虚拟串口和以太网卡共享中断,为了得到以太网卡的IRQ号,可以使用下面的命令来查询,其中eth0对应的167就是以太网卡使用的IRQ号:

查询FS4412使用的芯片是DM9000。是高电平触发。
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/cdev.h>
#include <linux/kfifo.h>
#include <linux/ioctl.h>
#include <linux/uaccess.h>
#include <linux/wait.h>
#include <linux/sched.h>
#include <linux/poll.h>
#include <linux/aio.h>
#include <linux/interrupt.h>
#include <linux/random.h>
#include "vser.h"
#define VSER_MAJOR 256
#define VSER_MINOR 0
#define VSER_DEV_CNT 1
#define VSER_DEV_NAME "vser"
struct vser_dev {
unsigned int baud;
struct option opt;
struct cdev cdev;
wait_queue_head_t rwqh;
wait_queue_head_t wwqh;
struct fasync_struct *fapp;
};
DEFINE_KFIFO(vsfifo, char, 32);
static struct vser_dev vsdev;
static int vser_fasync(int fd, struct file *filp, int on);
static int vser_open(struct inode *inode, struct file *filp)
{
return 0;
}
static int vser_release(struct inode *inode, struct file *filp)
{
vser_fasync(-1, filp, 0);
return 0;
}
static ssize_t vser_read(struct file *filp, char __user *buf, size_t count, loff_t *pos)
{
int ret;
unsigned int copied = 0;
if (kfifo_is_empty(&vsfifo)) {
if (filp->f_flags & O_NONBLOCK)
return -EAGAIN;
if (wait_event_interruptible_exclusive(vsdev.rwqh, !kfifo_is_empty(&vsfifo)))
return -ERESTARTSYS;
}
ret = kfifo_to_user(&vsfifo, buf, count, &copied);
if (!kfifo_is_full(&vsfifo)) {
wake_up_interruptible(&vsdev.wwqh);
kill_fasync(&vsdev.fapp, SIGIO, POLL_OUT);
}
return ret == 0 ? copied : ret;
}
static ssize_t vser_write(struct file *filp, const char __user *buf, size_t count, loff_t *pos)
{
int ret;
unsigned int copied = 0;
if (kfifo_is_full(&vsfifo)) {
if (filp->f_flags & O_NONBLOCK)
return -EAGAIN;
if (wait_event_interruptible_exclusive(vsdev.wwqh, !kfifo_is_full(&vsfifo)))
return -ERESTARTSYS;
}
ret = kfifo_from_user(&vsfifo, buf, count, &copied);
if (!kfifo_is_empty(&vsfifo)) {
wake_up_interruptible(&vsdev.rwqh);
kill_fasync(&vsdev.fapp, SIGIO, POLL_IN);
}
return ret == 0 ? copied : ret;
}
static long vser_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
if (_IOC_TYPE(cmd) != VS_MAGIC)
return -ENOTTY;
switch (cmd) {
case VS_SET_BAUD:
vsdev.baud = arg;
break;
case VS_GET_BAUD:
arg = vsdev.baud;
break;
case VS_SET_FFMT:
if (copy_from_user(&vsdev.opt, (struct option __user *)arg, sizeof(struct option)))
return -EFAULT;
break;
case VS_GET_FFMT:
if (copy_to_user((struct option __user *)arg, &vsdev.opt, sizeof(struct option)))
return -EFAULT;
break;
default:
return -ENOTTY;
}
return 0;
}
static unsigned int vser_poll(struct file *filp, struct poll_table_struct *p)
{
int mask = 0;
poll_wait(filp, &vsdev.rwqh, p);
poll_wait(filp, &vsdev.wwqh, p);
if (!kfifo_is_empty(&vsfifo))
mask |= POLLIN | POLLRDNORM;
if (!kfifo_is_full(&vsfifo))
mask |= POLLOUT | POLLWRNORM;
return mask;
}
static ssize_t vser_aio_read(struct kiocb *iocb, const struct iovec *iov, unsigned long nr_segs, loff_t pos)
{
size_t read = 0;
unsigned long i;
ssize_t ret;
for (i = 0; i < nr_segs; i++) {
ret = vser_read(iocb->ki_filp, iov[i].iov_base, iov[i].iov_len, &pos);
if (ret < 0)
break;
read += ret;
}
return read ? read : -EFAULT;
}
static ssize_t vser_aio_write(struct kiocb *iocb, const struct iovec *iov, unsigned long nr_segs, loff_t pos)
{
size_t written = 0;
unsigned long i;
ssize_t ret;
for (i = 0; i < nr_segs; i++) {
ret = vser_write(iocb->ki_filp, iov[i].iov_base, iov[i].iov_len, &pos);
if (ret < 0)
break;
written += ret;
}
return written ? written : -EFAULT;
}
static int vser_fasync(int fd, struct file *filp, int on)
{
return fasync_helper(fd, filp, on, &vsdev.fapp);
}
static irqreturn_t vser_handler(int irq, void *dev_id)
{
char data;
get_random_bytes(&data, sizeof(data));
data %= 26;
data += 'A';
if (!kfifo_is_full(&vsfifo))
if(!kfifo_in(&vsfifo, &data, sizeof(data)))
printk(KERN_ERR "vser: kfifo_in failure\n");
if (!kfifo_is_empty(&vsfifo)) {
wake_up_interruptible(&vsdev.rwqh);
kill_fasync(&vsdev.fapp, SIGIO, POLL_IN);
}
return IRQ_HANDLED;
}
static struct file_operations vser_ops = {
.owner = THIS_MODULE,
.open = vser_open,
.release = vser_release,
.read = vser_read,
.write = vser_write,
.unlocked_ioctl = vser_ioctl,
.poll = vser_poll,
.aio_read = vser_aio_read,
.aio_write = vser_aio_write,
.fasync = vser_fasync,
};
static int __init vser_init(void)
{
int ret;
dev_t dev;
dev = MKDEV(VSER_MAJOR, VSER_MINOR);
ret = register_chrdev_region(dev, VSER_DEV_CNT, VSER_DEV_NAME);
if (ret)
goto reg_err;
cdev_init(&vsdev.cdev, &vser_ops);
vsdev.cdev.owner = THIS_MODULE;
vsdev.baud = 115200;
vsdev.opt.datab = 8;
vsdev.opt.parity = 0;
vsdev.opt.stopb = 1;
ret = cdev_add(&vsdev.cdev, dev, VSER_DEV_CNT);
if (ret)
goto add_err;
init_waitqueue_head(&vsdev.rwqh);
init_waitqueue_head(&vsdev.wwqh);
ret = request_irq(167, vser_handler, IRQF_TRIGGER_HIGH | IRQF_SHARED, "vser", &vsdev);
if (ret)
goto irq_err;
return 0;
irq_err:
cdev_del(&vsdev.cdev);
add_err:
unregister_chrdev_region(dev, VSER_DEV_CNT);
reg_err:
return ret;
}
static void __exit vser_exit(void)
{
dev_t dev;
dev = MKDEV(VSER_MAJOR, VSER_MINOR);
free_irq(167, &vsdev);
cdev_del(&vsdev.cdev);
unregister_chrdev_region(dev, VSER_DEV_CNT);
}
module_init(vser_init);
module_exit(vser_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Kevin Jiang <jiangxg@farsight.com.cn>");
MODULE_DESCRIPTION("A simple character device driver");
MODULE_ALIAS("virtual-serial");
上面是总代码,下面我们选些我们用的讲解:
代码
ret = request_irq(167, vser_handler, IRQF_TRIGGER_HIGH | IRQF_SHARED, "vser", &vsdev);
使用request_irq注册了中断处理函数vser_handler,因为是共享中断,所以flags参数设置为
IRQF_TRIGGER_HIGH | IRQF_SHARED
高电平和shared共享宏、
并且共享中断必须设置最后一个参数,通常设置设备的结构对象指针即可――vsdev
代码
static void __exit vser_exit(void)
{
....
free_irq(167, &vsdev);
....
}
模块卸载时候 注销中断 .167是中断号即irqnr ,vsdev是设备结构对象指针
代码
static irqreturn_t vser_handler(int irq, void *dev_id)
{
char data;
get_random_bytes(&data, sizeof(data));
data %= 26;
data += 'A';
if (!kfifo_is_full(&vsfifo))
if(!kfifo_in(&vsfifo, &data, sizeof(data)))
printk(KERN_ERR "vser: kfifo_in failure\n");
if (!kfifo_is_empty(&vsfifo)) {
wake_up_interruptible(&vsdev.rwqh);
kill_fasync(&vsdev.fapp, SIGIO, POLL_IN);
}
return IRQ_HANDLED;
}
vser_handler中断处理函数实现
其中代码
get_random_bytes(&data, sizeof(data));
data %= 26;
data += 'A';
if (!kfifo_is_full(&vsfifo))
if(!kfifo_in(&vsfifo, &data, sizeof(data)))
printk(KERN_ERR "vser: kfifo_in failure\n");
random:随机
产生了一个随机的大写字母
写入FIFO中,
这里用到了get_random_bytes和kfifo_in和kfifo_full
・・随机,插入,不为空
代码
if (!kfifo_is_empty(&vsfifo)) {
wake_up_interruptible(&vsdev.rwqh);
kill_fasync(&vsdev.fapp, SIGIO, POLL_IN);
}
阻塞进程的唤醒和信号发送函数
然后最后返回的
return IRQ_HANDLED;
}
IRQ_HANDLED:表示中断处理正常
需要说明的是,对于共享中断的中断处理函数应该获取硬件的中断标志来判断该中断是否是本设备所产生的,如果不是则不应该进行相应的中断处理,并返回IRQ NONE。由于例子中是一个虚拟设备,没有相关的标志,所以没有做相关的处理。
最后,中断处理函数应该快速完成,不能消耗太长的时间。
因为在ARM处理器进入中断后,相应的中断被屏蔽(IRQ中断禁止IRQ中断,FIQ中断禁止IRQ中断和FIQ中断,内核没有使用FIQ中断),在之后的代码中又没有重新开启中断。所以在整个中断处理过程中中断是禁止的,如果中断处理函数执行时间过长,那么其他的中断将会被挂起,从而将会对其他中断的响应造成严重的影响。
必须记住的一条准则是,在中断处理函数中一定不能调用调度器,即一定不能调用可能会引起进程切换的函数(因为一旦中断处理程序被切换,将不能再次被调度),这是内核对中断处理函数的一个严格限制。
到目前为止,我们学过的可能会引起进程切换的函数有
kfifo_ to_ user.
kffo from. user.
copy from_ user、
copy_ to_ user.
wait event_ xxx。
后面遇到此类函数会再次指出。另外,在中断处理函数中如果调用disable__irq可能会死锁。
驱动的编译和测试命令如下: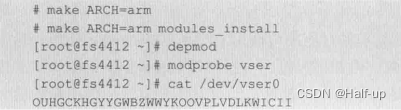
产生随机大写字母直到fifo为空
中断下部分
为了解决多个中断:
网卡为例,当网卡收到数据后会产生一个中断,在中断处理程序中需要将网卡收到的数据从网卡的缓存中复制出来,然后对数据包做严格的检查(是否有帧格式错误,是否有校验和错误等),检查完成后再根据协议对数据包进行拆包处理,最后将拆包后的数据包递交给上层。如果在这个过程中网卡又收到新的数据,从而再次产生中断,因为上一个中断正在处理的过程中,所以新的中断将会被挂起,新收到的数据就得不到及时处理。因为网卡的缓冲区大小有限,如果后面有更多的数据包到来,那么缓冲区最终会溢出,从而产生丢包。
为了解决这个问题,Linux 将中断分成了两部分:上半部(硬件中断)和下半部(耗时)
对于网卡来说,将数据从网卡的缓存复制到内存中就是紧急但可以快速完成的事情,需要放在上半部执行。
而对包进行校验和拆包则是不紧急但比较耗时的操作,可以放在下半部执行。下半部在执行的过程中,中断被重新使能,所以如果有新的硬件中断产生,将会停止执行下半部的程序,转为执行硬件中断的上半部。
软中断
下半部虽然可以推迟执行,但是还是希望它尽快执行。
什么时候试执行下半部呢?肯定是在上半部执行完成之后。
为了能更直观地了解这个过程,现在将这部分代码再次摘录如下:
/* arch/arm/kernel/irq.c*/
void handle_IRQ(unsigned int irq, struct pt_regs *regs)
{
struct pt_regs *old_regs = set_irq_regs(regs);
irq_enter();
/*
* Some hardware gives randomly wrong interrupts. Rather
* than crashing, do something sensible.
*/
if (unlikely(irq >= nr_irqs)) {
if (printk_ratelimit())
printk(KERN_WARNING "Bad IRQ%u\n", irq);
ack_bad_irq(irq);
} else {
generic_handle_irq(irq);
}
irq_exit();
set_irq_regs(old_regs);
}
在前面的分析中我们知道,中断处理的过程中会调用上面列出的 handle_IRQ函数,该函数首先调用irq_enter函数将被中断进程中的抢占计数器 preempt_count加上了HARDIRQ_OFFSET这个值(主要是为了防止内核抢占,以及作为是否在硬中断中的一个判断条件)。当中断的上半部处理完,即generic_handle_irq函数返回后,又调用了irq_exit函数,代码如下:
void irq_exit(void)
{
.....
preempt_count_sub(HARDIRQ_OFFSET);
if(!in_interrupt()&&local_softirq_pending())
invoke_softirq();
.....
}
在这个函数中又将preempt_count减去了 HARDIRQ_OFFSET这个值,如果没有发生中断嵌套,那么preempt_count中关于硬件中断的计数值就为0,表示上半部已经执行完。
接下来代码
if(!in_interrupt()&&local_softirq_pending())
调用in_interrupt和 local_softirq _pending 函数来分别判断是否可以执行中断下半部,以及是否有中断下半部等待执行(in_interrupt函数主要是检测preempt_count中相关域的值,如果为0,表示具备执行中断下半部的条件)。如果条件满足就调用invoke_softirq来立即执行中断下半部。
由此可知,中断下半部的最早执行时间是中断上半部执行完成之后,但是中断还没有完全返回之前的时候。
在FS4412目标板对应的3.14.25版本的内核源码配置中,invoke_softirq函数调用了do_softirq_own_stack 函数,该函数又调用了do softirq函数,这是中断下半部的核心处理函数。
在了解这个函数之前,我们首先来认识一下softirq,即软中断。
softirq
中断下半部 由 softirq(软中断) 机制来实现的
在Linux内核中,有一个名为 softirq_vec 的数组,如下:
static struct softirq_action softirq_vec[32];
其类型为 softirq_action 结构,定义如下:
struct softirq_action
{
void (*action)(struct softirq_action *);
void *data;
};
内核共定义了NR_SOFTIRQS个(目前有10个) struct softirq_action对象,这些对象被放在softirq_vec的数组中.
对象在数组中的下标就是这个软中断的编号。内核中有一个全局整型变量来记录是否有相应的软中断需要执行,比如要执行编号为1的软中断,那么就需要把这个全局整型变量的比特1置位。当内核在相应的代码中检测到该比特位置1,就会用这个比特位的位数去索引softirq_vec这个数组,然后调用softirq_action对象中的action指针所指向的函数。
目前内核中定义的软中断编号:
enum
{
HI_SOFTIRQ=0,
TIMER_SOFTIRQ,
NET_TX_SOFTIRQ,
NET_RX_SOFTIRQ,
BLOCK_SOFTIRQ,
BLOCK_IOPOLL_SOFTIRQ,
TASKLET_SOFTIRQ,
SCHED_SOFTIRQ,
HRTIMER_SOFTIRQ,
RCU_SOFTIRQ, /* Preferable RCU should always be the last softirq */
NR_SOFTIRQS
};
比如,NET_RX_SOFTIRQ就代表网卡接收中断所对应的软中断编号,而这个编号所对应的软中断处理函数就是net_rx_action。
do_softirq
处理softirq是通过 do_softirq() 函数实现,代码如下:
/* kernel/softirq.c*/
asmlinkage void do_softirq(void)
{
......
pending = local_softirq_pending();
.......
local_irq_enable();
h = softirq_vec;
while ((softirq_bit = ffs(pending))) {
......
h += softirq_bit - 1;
.....
h->action(h);
......
h++;
.....
}
local_irq_disable();
......
}
pending = local_softirq_pending();
从上面的代码可以清楚地看到,_do_softirq首先用local_softirq_pending来获取记录所有挂起的软中断的全局整型变量的值pending
local_irq_enable();
然后调用local_irq_enable重新使能了中断(这就意味着软中断在执行过程中是可以响应新的硬件中断的)
接下来将softirq_vec数组首元素的地址赋值给h,在 while循环中,遍历被设置了的位,并索引得到对应softirq_action对象,再调用该对象的action成员所指向的函数。
虽然软中断可以实现中断的下半部,但是软中断基本上是内核开发者预定义好的,通常用在对性能要求特别高的场合,而且需要一些内核的编程技巧,不太适合于驱动开发者。
上面介绍的内容更多的是让读者清楚中断的下半部是怎样执行的,并且重点指出了在中断下半部执行的过程中,中断被重新使能了,所以可以响应新的硬件中断。
还需要说明的是,除了在中断返回前执行软中断,内核还为每个CPU创建了一个软中断内核线程,当需要在中断处理函数之外执行软中断时,可以唤醒该内核线程,该线程最终也会调用上面的_do_softirq函数。
最后需要注意的是,软中断也处于中断上下文中,因此对中断处理函数的限制同样适用于软中断,只是没有时间上的严格限定。
tasklet
虽然软中断通常是由内核开发者来设计的,但是内核开发者专门保留了一个软中断给驱动开发者,它就是TASKLET_SOFTIRQ,相应的软中断处理函数是tasklet_action,下面是相关的代码:
/* kernel/softirq.c*/
static void tasklet_action(struct softirq_action *a)
{
struct tasklet_struct *list;
local_irq_disable();
list = __this_cpu_read(tasklet_vec.head);
.....
while (list) {
struct tasklet_struct *t = list;
list = list->next;
......
t->func(t->data);
......
}
}
在软中断的处理过程中,如果 TASKLET_SOFTIRQ对应的比特位被设置了,则根据前面的分析tasklet_action函数将会被调用。
在代码
list = __this_cpu_read(tasklet_vec.head);
t->func(t->data);
首先得到了本CPU的一个struct tasklet_struct对象的链表,然后遍历该链表,调用其中 func成员所指向的函数,并将data成员作为参数传递过去。
struct tasklet_struct的类型定义如下:
struct tasklet_struct
{
struct tasklet_struct *next;
unsigned long state;
atomic_t count;
void (*func)(unsigned long);
unsigned long data;
};
其中
- next是构成链表的指针
- state是该tasklet被调度的状态(已经被调度还是已经在执行)
- count用于禁止 tasklet执行(非0时)
- func是 tasklet的下半部函数
- data是传递给下半部函数的参数。
从上面可知,驱动开发者要实现 tasklet的下半部,就要构造一个struct tasklet_struct结构对象,并初始化里面的成员,然后放入对应CPU的 tasklet链表中,最后设置软中断号TASKLET_SOFTIRQ所对应的比特位。
不过内核已经有封装好的宏和函数,大大地简化了这一操作。下面列出这些常用的宏和函数:
/*include/linux/interrupt.h*/
DECLARE_TASKLET(name, func, data)
DECLARE_TASKLET_DISABLED(name, func, data)
void tasklet_init(struct tasklet_struct *t,
void (*func)(unsigned long), unsigned long data);
void tasklet_schedule(struct tasklet_struct *t)
DECLARE_TASKLET(name, func, data)
其中,DECLARE_TASKLET 静态定义一个struct tasklet_struct 结构对象,名字为name,下半部函数为func,传递的参数为 data,该tasklet可以被执行。
DECLARE_TASKLET_DISABLED(name, func, data)
而 DECLARE_TASKLET_DISABLED和 DECLARE_TASKLET相似,只是count 成员的值被初始化为1,不能被执行,需要调用tasklet_enable来使能。
void tasklet_init(struct tasklet_struct *t,
void (*func)(unsigned long), unsigned long data);
tasklet_init通常用于初始化一个动态分配的struct tasklet_struct结构对象。
void tasklet_schedule(struct tasklet_struct *t)
tasklet_schedule将指定的struct tasklet_struct结构对象加入到对应CPU的 tasklet链表中,下半部函数将会在未来的某个时间被调度。
添加了tasklet 下半部的虚拟串口驱动的相关驱动代码如下:
挑选部分要用的:
static void vser_tsklet(unsigned long arg);
DECLARE_TASKLET(vstsklet, vser_tsklet, (unsigned long)&vsdev);
......
static irqreturn_t vser_handler(int irq, void *dev_id)
{
tasklet_schedule(&vstsklet);
return IRQ_HANDLED;
}
static void vser_tsklet(unsigned long arg)
{
char data;
get_random_bytes(&data, sizeof(data));
data %= 26;
data += 'A';
if (!kfifo_is_full(&vsfifo))
if(!kfifo_in(&vsfifo, &data, sizeof(data)))
printk(KERN_ERR "vser: kfifo_in failure\n");
if (!kfifo_is_empty(&vsfifo)) {
wake_up_interruptible(&vsdev.rwqh);
kill_fasync(&vsdev.fapp, SIGIO, POLL_IN);
}
}
代码
DECLARE_TASKLET(vstsklet, vser_tsklet, (unsigned long)&vsdev);
静态定义了一个``struct tasklet_struct```结构对象,名字叫 vstsklet,执行的函数是vser_tsklet,传递的参数是&vsdev。
代码
tasklet_schedule(&vstsklet);
return IRQ_HANDLED;
}
直接调度tasklet,中断的上半部中没有做过多的其他操作,然后就返回了IRQ_HANDLED。
代码行
static void vser_tsklet(unsigned long arg)
{
char data;
get_random_bytes(&data, sizeof(data));
data %= 26;
data += 'A';
if (!kfifo_is_full(&vsfifo))
if(!kfifo_in(&vsfifo, &data, sizeof(data)))
printk(KERN_ERR "vser: kfifo_in failure\n");
if (!kfifo_is_empty(&vsfifo)) {
wake_up_interruptible(&vsdev.rwqh);
kill_fasync(&vsdev.fapp, SIGIO, POLL_IN);
}
}
是vser_tsklet函数的实现,它是以前的中断中上半部完成的事情。
这里是硬件随机大写字母
最后,对tasklet的主要特性进行一些总结。
- tasklet是一个特定的软中断,处于中断的上下文。
- tasklet_schedule函数被调用后,对应的下半部会保证被至少执行一次。
- 如果一个tasklet已经被调度,但是还没有被执行,那么新的调度将会被忽略。
工作队列
前面讲解的下半部机制不管是软中断还是 tasklet 都有一个限制,就是在中断上下文中执行不能直接或间接地调用调度器。
为了解决这个问题,内核又提供了另一种下半部机制,叫作工作队列
它的实现思想也比较简单,就是内核在启动的时候创建一个或多个(在多核的处理器上)内核工作线程,工作线程取出工作队列中的每一个工作,然后执行,当队列中没有工作时,工作线程休眠。当驱动想要延迟执行某一个工作时,构造一个工作队列节点对象,然后加入到相应的工作队列,并唤醒工作线程,工作线程又取出队列上的节点来完成工作,所有工作完成后又休眠。因为是运行在进程上下文中,所以工作可以调用调度器。工作队列提供了一种延迟执行的机制,很显然这种机制也适用于中断的下半部。另外,除了内核本身的工作队列之外,驱动开发者也可以使用内核的基础设施来创建自己的工作队列。下面是工作队列节点的结构类型定义:
/*include/linux/workqueue.h*/
struct work_struct{
atomic_long_t data;
struct list_head entry;
work_func_t func;
};
- data: 传递给工作的队列的参数,通常是整数,但更常用是指针。
- entry: 构成工作队列的链表节点对象
- func: 工作函数,工作线程取出工作队列节点后执行,data会作为调用该函数的参数。
常用的与工作队列有关的宏和函数如下:
/* include/linux/workqueue.h */
DECLARE_WORK(n, f)
DECLARE_DELAYED_WORK(n, f)
INIT_WORK(_work, _func)
bool schedule_work(struct work_struct *work)
bool schedule_delayed_work_on(struct delayed_work *dwork, unsigned long delay)
- DECLARE_WORK:静态定义一个工作队列节点,n是节点的名字,f是工作函数。
- DECLARE_DELAYED_WORK:静态定义一个延迟的工作队列节点。
- INIT_WORK:常用于动态分配的工作队列节点的初始化。
- schedule_work:将工作队列节点加入到内核定义的全局工作队列中。
- schedule_delayed_work:在 delay指定的时间后将一个延迟工作队列节点加入到全局的工作队列中。
下面是使用工作队列来实现中断下半部的相关代码:
static void vser_work(struct work_struct *work);
DECLARE_WORK(vswork, vser_work);
....
static irqreturn_t vser_handler(int irq, void *dev_id)
{
schedule_work(&vswork);
return IRQ_HANDLED;
}
static void vser_work(struct work_struct *work)
{
char data;
get_random_bytes(&data, sizeof(data));
data %= 26;
data += 'A';
if (!kfifo_is_full(&vsfifo))
if(!kfifo_in(&vsfifo, &data, sizeof(data)))
printk(KERN_ERR "vser: kfifo_in failure\n");
if (!kfifo_is_empty(&vsfifo)) {
wake_up_interruptible(&vsdev.rwqh);
kill_fasync(&vsdev.fapp, SIGIO, POLL_IN);
}
}
代码
DECLARE_WORK(vswork, vser_work);
定义了一个工作队列节点,名字叫vswork,工作函数是vser_work。
和tasklet类似,中断上半部调度了工作然后返回了,以前中断上半部的事情交给下半部的工作函数处理
最后工作队列的总结:
- 工作队列的工作函数运行在进程上下文,可以调度调度器。
- 如果上一个工作还没有完成,有重新调度下一个工作,那么新的工作将不会被调度。
延时控制
在硬件的操作中经常要用到延时,比如要保持芯片的复位时间持续多久、芯片上电时序控制等。为此内核提供了一组延时操作函数。
内核在启动过程中会计算一个全局loops_per_jiffy的值,该变量反应了一段循环延时的代码要循环多少次才能延时一个jiffy的时间。根据jiffy这个值,就可以知道延时一微妙需要多少个循环,延时一毫秒需要多少个循环。于是内核就定义了一些靠循环来延时的宏或函数。比如:
void ndelay(unsigned long x); //纳秒级延时
udelay(n); //微秒级延时
mdelay(n); //毫秒级延时
ndelay和mdelay都是基于udelay的,将udelay的循环次数除以1000就是纳米延时(单位换算)
可想而知,如果udelay延时循环次数不到1000次,那么纳秒级延时也就是不准确的。
这些延时函数都是忙等待延时,是靠白白消耗CPU的时间来获得延时的,如果没有特殊的理由(如中断上下文中获取自旋锁的情况下)不推荐使用这些函数延迟较长的时间。
比较推荐使用休眠延迟,如下:
void msleep(unsigned int msecs); //休眠不可以被信号打断,只能等到休眠时间到了才会返回
long msleep_interuptible(unsigned int msecs); //休眠可以被信号打断
void ssleep(unsigned int seconds); //休眠不可以被信号打断,只能等到休眠时间到了才会返回
定时操作
有时候我们需要在设定的时间到时候自动执行一个操作,这就是定时。
定时有分为单次定时和循环定时两种
- 单次定时: 就是设定的时间到期之后,操作被执行了一次。
- 循环定时: 则是设定的时间到期之后操作被执行,然后再次启动定时器,下一次时间到期后操作被执行,然后再次启动定时器。如此循环反复。
目前Linux中有低分辨率定时器和高分辨率定时器。
低分辨率定时器
经典的定时器是基于一个硬件定时器的,该定时器周期性地产生中断,产生中断的次数可以进行配置,FS4412目标板上为200,内核源码中以HZ这个宏来代表这个配置值,也就是说,这个硬件定时器每秒钟会产生HZ次中断。该定时器自开机以来产生的中断次数会被记录在jiffies全局变量中(一般会偏移一个值),在32位的系统上jiffies被定义为32位,所以在一个可期待的时间之后就会溢出,于是内核又定义了一个jiffies_64的64位全局变量,这使得目前和可以预见的所有计算机系统都不会让该计数值溢出。
jiffies
内核通过链接器的帮助使jiffies和 jiffies_64共享4个字节,这使得这两个变量的操作更加方便。内核提供了一组围绕iiffies操作的函数和宏。
下面讲解下全局变量jiffies和jiffies_64:
u64 get_jiffies_64(void);
time_after(a,b)
time_before(a,b)
time_after_eq(a,b)
time_before_eq(a,b)
time_in_range(a,b,c)
time_after64(a,b)
time_before64(a,b)
time_after_eq64(a,b)
time_before_eq64(a,b)
time_in_range64(a,b,c)
unsigned int jiffies_to_msecs(const unsigned long j);
unsigned int jiffies_to_usecs(const unsigned long j);
u64 jiffies_to_nsecs(const unsigned long j);
unsigned long msecs_to_jiffies(const unsigned int m);
unsigned long usecs_to_jiffies(const unsigned int m);
- get_jiffies_64:获取jiffies_64的值。
- time_after:如果a在b之后则返回真,其他的宏可以以此类推,其后加“64”表示是64位值相比较,加“eq”则表示在相等的情况下也返回真。
- jiffies_to_msecs:将j转换为对应的毫秒值,其他的以此类推。
灵活使用time_after 或time_before也可以实现长延时,但前面已介绍了更方便的函数,所以在此就不多做介绍了。
了解了jiffies后,可以来查看内核中的低分辨率定时器。其定时器对象的结构类型定义如下:
定时器对象的结构类型time_list
struct timer_list{
...
struct list_head entry;
unsigned long expires;
struct tvec_base *base;
void (*function)(unsigned long)
unsigned long data;
...
}
@entry: 双向链表节点的对象,用于构成双向链表。
@ecpires: 定时器到期的jiffies值。
@function: 定时器到期后执行的函数
@data: 传递定时器函数的参数,通常传递一个指针
低分辨率定时器操作的相关函数如下:
inti_timer(timer); //初始化一个定时器
void add_timer(struct timer_list *timer);
//将定时器添加到内核中的定时器链表中。
int mod_timer(struct timer_list *timer,unsigned long expires);
//修改定时器的expires成员,而不考虑当前定时器的状态
int del_timer(struct timer_list *timer);
//从内核链表中删除该定时器,而不考虑当前定时器的状态
- inti_timer:初始化一个定时器
- add_timer:将定时器添加到内核中的定时器链表中
- mod_timer:修改定时器的expires成员,而不考虑当前定时器的状态
- del_timer:从内核链表中删除该定时器,而不考虑当前定时器的状态
要在驱动中实现一个定时器,需要经过下面几个步骤:
- 构造一个定时器对象,调用init_timer来初始化这个对象,并对expires、function和data成员赋值。
- 使用add_timer将定时器对象添加到内核的定时器链表中。
- 定时时间到了后,定时器函数自动被调用,如果需要周期定时,那么可以在定时函数中使用mod_timer来修饰expires。
- 在不需要定时器的时候,用del_timer来删除定时器。
内核是在定时器中断的软中断下半部来处理这些定时器的,内核将会遍历链表中的定时器,如果当前的jiffies 的值和定时器中的expires的值相等,那么定时器函数将会被执行,所以定时器函数是在中断上下文中执行的。
另外,内核为了高效管理这些定时器,会将这些定时器按照超时时间进行分组,所以内核只会遍历快要到期的定时器。
下面是添加了定时器的虚拟串口驱动代码:
struct vser_dev {
....
struct timer_list timer;
};
static void vser_timer(unsigned long arg)
{
char data;
struct vser_dev *dev = (struct vser_dev *)arg;
get_random_bytes(&data, sizeof(data));
data %= 26;
data += 'A';
if (!kfifo_is_full(&vsfifo))
if(!kfifo_in(&vsfifo, &data, sizeof(data)))
printk(KERN_ERR "vser: kfifo_in failure\n");
if (!kfifo_is_empty(&vsfifo)) {
wake_up_interruptible(&vsdev.rwqh);
kill_fasync(&vsdev.fapp, SIGIO, POLL_IN);
}
mod_timer(&dev->timer, get_jiffies_64() + msecs_to_jiffies(1000));
}
.....
init_timer(&vsdev.timer);
vsdev.timer.expires = get_jiffies_64() + msecs_to_jiffies(1000);
vsdev.timer.function = vser_timer;
vsdev.timer.data = (unsigned long)&vsdev;
add_timer(&vsdev.timer);
....
}
....
static void __exit vser_exit(void)
{
....
del_timer(&vsdev.timer);
....
}
代码
struct timer_list timer;
添加一个低分变率定时器成员
代码
init_timer(&vsdev.timer);
vsdev.timer.expires = get_jiffies_64() + msecs_to_jiffies(1000);
vsdev.timer.function = vser_timer;
vsdev.timer.data = (unsigned long)&vsdev;
add_timer(&vsdev.timer);
初始化并向内核添加了这个定时器。
代码
static void vser_timer(unsigned long arg)
{
char data;
struct vser_dev *dev = (struct vser_dev *)arg;
get_random_bytes(&data, sizeof(data));
data %= 26;
data += 'A';
if (!kfifo_is_full(&vsfifo))
if(!kfifo_in(&vsfifo, &data, sizeof(data)))
printk(KERN_ERR "vser: kfifo_in failure\n");
if (!kfifo_is_empty(&vsfifo)) {
wake_up_interruptible(&vsdev.rwqh);
kill_fasync(&vsdev.fapp, SIGIO, POLL_IN);
}
mod_timer(&dev->timer, get_jiffies_64() + msecs_to_jiffies(1000));
}
是定时器函数的实现,其中
mod_timer(&dev->timer, get_jiffies_64() + msecs_to_jiffies(1000));
修改了定时器,就是get_jiffies_64得到的值加上msecs转换为jiffies,形成了一个循环定时器。
驱动将每过一秒向FIFO推入一个字符,编译和测试的命令和中断一样。
高分辨率定时器
因为低分辨率定时器以jiffies来定时,所以定时精度受系统的Hz影响,而通常这个值都不高。
如果Hz的值为200,那么一个jiffy的事件就是5ms,也就是说,定时器的精度就是5ms,对于像声卡一类需要高精度定时的设备,这种精度是不能满足需求的
ktime_t
高分辨率定时器是以ktime_t来定义时间的:
/*include/linux/ktime.h*/
union ktime{
s64 tv64;
#if BITS_PER_LONG != 64 && !defined(CONFIG_KTIME_SCALAR)
struct{
# ifdef __BIG_ENDIAN
S32 sec,nsec;
#else
s32 nsec,sec;
# endif
}tv;
#endif
};
typedef union ktime ktime_t;
ktime是一个共用体
- 如果是64位的系统,那么时间用tv64来表示就可以了,
- 如果是32位系统,那么时间分别用sec和nsec来表示秒和纳秒。
由此可以看到它是可以精确到纳秒的(nsec)。
初始化与结构定义
一般用ktime_set函数来初始化这个对象,常用方法如下:
ktime_t t = ktime_set(secs,nsecs);
分辨率定时器的结构类型定义如下:
struct hrtimer{
struct timerqueue_node node;
ktime_t _softexpires;
enum hrtimer_restart (*function)(struct hrtime *);
struct hrtimer_clock_base *base;
unsigned state;
...
};
//其中function为定时到期我们要执行的函数。
其中和驱动相关的成员就是function,它指向定时到期后执行的函数。
高分辨率定时器常用函数:
void hrtimer_init (struct hrtimer *timer,clockid_t clock_id, enum hrtimer_modemode);
int hrtimer_start(struct hrtimer *timer, ktime_t tim,const enum hrtimer_modemode);
static inline u64 hrtimer_forward_now(struct hrtimer *timer, ktime_t interval);
int hrtimercancel (struct hrtimer *timer);
- hrtimer_init:初始化 struct hrtimer结构对象clock_id是时钟的类型,种类很多,常用CLOCK_MONOTONIC表示自系统开机以来的单调递增时间。
- mode是时间的模式,可以是HRTIMER_MODE_ABS,表示绝对时间,也可以是 HRTIMER_MODE_REL,表示相对时间。
- hrtimer_start:启动定时器。tim是设定的到期时间,
- mode和 hrtimer_init 中的 mode参数含义相同。
- hrtimer_forward_now:修改到期时间为从现在开始之后的interval时间。
- hrtimer_cancel:取消定时器。
使用高分辨率定时器的虚拟串口驱动代码如下:
struct vser_dev {
.....
struct hrtimer timer;
};
static enum hrtimer_restart vser_timer(struct hrtimer *timer)
{
char data;
get_random_bytes(&data, sizeof(data));
data %= 26;
data += 'A';
if (!kfifo_is_full(&vsfifo))
if(!kfifo_in(&vsfifo, &data, sizeof(data)))
printk(KERN_ERR "vser: kfifo_in failure\n");
if (!kfifo_is_empty(&vsfifo)) {
wake_up_interruptible(&vsdev.rwqh);
kill_fasync(&vsdev.fapp, SIGIO, POLL_IN);
}
hrtimer_forward_now(timer, ktime_set(1, 1000));
return HRTIMER_RESTART;
}
static int __init vser_init(void)
{
.....
hrtimer_init(&vsdev.timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);
vsdev.timer.function = vser_timer;
hrtimer_start(&vsdev.timer, ktime_set(1, 1000), HRTIMER_MODE_REL);
....
}
static void __exit vser_exit(void)
{
....
hrtimer_cancel(&vsdev.timer);
......
}
代码
struct vser_dev {
.....
struct hrtimer timer;
};
在设备vser_dev结构中添加了一个高分辨率定时器成员。
代码
hrtimer_init(&vsdev.timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);
vsdev.timer.function = vser_timer;
hrtimer_start(&vsdev.timer, ktime_set(1, 1000), HRTIMER_MODE_REL);
初始化了高分辨率定时器timer,函数是vser_timer
并启动这个定时器hrtimer_start
ktime_sets说明32位系统,1秒,1000纳秒
代码
hrtimer_cancel(&vsdev.timer);
模块卸载时候取消定时器
代码
static enum hrtimer_restart vser_timer(struct hrtimer *timer)
{
char data;
get_random_bytes(&data, sizeof(data));
data %= 26;
data += 'A';
if (!kfifo_is_full(&vsfifo))
if(!kfifo_in(&vsfifo, &data, sizeof(data)))
printk(KERN_ERR "vser: kfifo_in failure\n");
if (!kfifo_is_empty(&vsfifo)) {
wake_up_interruptible(&vsdev.rwqh);
kill_fasync(&vsdev.fapp, SIGIO, POLL_IN);
}
hrtimer_forward_now(timer, ktime_set(1, 1000));
return HRTIMER_RESTART;
}
当定时时间到了之后,定时器函数vser_timer被调用,将随机产生的字符推入FIFO后
hrtimer_forward_now(timer, ktime_set(1, 1000));
给定时器重新设置了定时值ktime_t
return HRTIMER_RESTART;
然后返回HRTIMER_RESTART表示要重新启动定时器。
驱动实现的效果和低分辨率定时器的例子是一样的。

